

Abstract
We investigated the imaging performance of a fast convergent ordered-subsets algorithm with subiteration-dependent preconditioners (SDPs) for positron emission tomography (PET) image reconstruction. In particular, we considered the use of SDP with the block sequential regularized expectation maximization (BSREM) approach with the relative difference prior (RDP) regularizer due to its prior clinical adaptation by vendors. Because the RDP regularization promotes smoothness in the reconstructed image, the directions of the gradients in smooth areas more accurately point toward the objective function’s minimizer than those in variable areas. Motivated by this observation, two SDPs have been designed to increase iteration step-sizes in the smooth areas and reduce iteration step-sizes in the variable areas relative to a conventional expectation maximization preconditioner. The momentum technique used for convergence acceleration can be viewed as a special case of SDP. We have proved the global convergence of SDP-BSREM algorithms by assuming certain characteristics of the preconditioner. By means of numerical experiments using both simulated and clinical PET data, we have shown that the SDP-BSREM algorithms substantially improve the convergence rate, as compared to conventional BSREM and a vendor’s implementation as Q.Clear. Specifically, SDP-BSREM algorithms converge 35%−50% faster in reaching the same objective function value than conventional BSREM and commercial Q.Clear algorithms. Moreover, we showed in phantoms with hot, cold and background regions that the SDP-BSREM algorithms approached the values of a highly converged reference image faster than conventional BSREM and commercial Q.Clear algorithms.
Index Terms—: Image reconstruction, ordered-subsets, positron emission tomography, preconditioner, relative difference prior
Introduction
Positron emission tomography (PET) data are inherently count limited due to health consideration, basic physical processes, and patient tolerance. Moreover, these data must be reconstructed into images within a few minutes of acquisition. This creates a challenging situation in which vendors strive to produce high quality images in a clinically viable time frame. In this study, we introduce a method for accelerating the reconstruction of high quality PET images.
Over last 20 years, the non-penalized maximum-likelihood (ML) statistical approaches have become a preferred model for the reconstruction of PET [1], [2]. However, when iterated to full convergence, ML methods produce extremely noisy images, and are sensitive to small statistical perturbations in the data. Hence, these methods are seldom run to full convergence and iterations are stopped before fitting noise becomes unacceptable at the expense of excessive blur in the reconstructed images. It has been demonstrated that applications of penalized likelihood (PL) models that include a data fidelity term (Kullback-Leibler divergence) and a regularization term leads to improved quantification and better noise suppression, as compared to non-penalized reconstructions [3]. To reduce the computational expense, ordered-subsets expectation maximization (OSEM) algorithms proposed by Hudson and Larkin are widely used in unregularized PET image reconstruction [4]. However, OSEM is unsuitable for regularized image reconstruction leading to the development of relaxation [5], [6] and the block sequential regularized expectation maximization (BSREM) algorithm [7].
Initially, quadratic penalties were explored [8], [9], but they had resulted in over-smoothed edges and loss of details in the reconstructed images. Later, a number of other penalties were developed to address these problems but they often had undesirable properties including nonsmooth [10], [11], non-covex [12], or requiring additional hyper-parameters [13]. An example of such an approach is the total variation penalty that is able to preserve sharp boundaries between low-variability regions [10], [14]. Thus, ability to deal with non-smooth priors became an urgent issue, However, only a few reconstruction algorithms have been able to combine the Poisson noise model and non-smooth priors [15]–[17].
In an alternative approach, Nuyts et al. [18] introduced the relative difference prior (RDP) that preserved high spatial frequencies in reconstructed images while still being smooth and convex. This RDP was adopted by General Electric (GE) Healthcare as the penalty term in their PL PET reconstruction model. The penalty term is controlled by a single user-defined parameter called beta. The GE Healthcare introduced a modified BSREM algorithm [8] to solve the PL model in their commercial clinical software, called Q.Clear, that is currently available on GE PET/CT scanners [3]. Other interesting methods, suitable for optimization with smooth penalties, include the optimization transfer descent algorithm (OTDA) [19], [20] and the preconditioned limited-memory Broyden-Fletcher-Goldfarb-Shanno with boundary constraints algorithm (L-BFGS-B-PC) [9]. While these algorithms converge very rapidly, they represent a substantial departure from the BSREM algorithm complicating their implementation.
The choice of preconditioners in the algorithm is well known to strongly affect the convergence rate [9], [16], [21], [22]. The widely used preconditioners have been designed based on the EM matrix [16], [21]–[23] or the Hessian matrix [9]. As part of the BSREM convergence proof, Ahn and Fessler [8] presented the subiteration-independent preconditioner, which can be viewed as a uniform operator of the image for all subiteration. However, a subiteration-independent preconditioner is overly restrictive and may result in a slower convergence rate. We believe that a well-designed subiteration-dependent preconditioner (SDP) will accelerate the algorithm convergence.
In the present study, we propose a subiteration-dependent preconditioned BSREM (SDP-BSREM) for the RDP regularized PET image reconstruction. We prove that it is convergent under certain assumptions imposed on the preconditioner. According to the smoothness-promoting property of the RDP regularization in the reconstructed image, the directions of the gradients in smooth areas more accurately point toward the objective function’s minimizer than those in variable areas. Inspired by this observation, we propose two SDPs satisfying the assumptions needed for the convergence proof. We note that the momentum technique is a special case of SDP. We have used the numerical gradient of the image to measure its smoothness. These two SDPs achieve larger step-sizes in the smooth areas of the image and smaller step-sizes in the variable areas of the image. The proposed algorithms have been compared with BSREM for simulations and with the Q.Clear method with data acquired from a GE PET/CT. In simulations, two numerical phantoms were used. In the clinical comparisons, data from a whole-body PET patient and an American College of Radiology (ACR) quality assurance phantom (Esser Flangeless PET phantom) were used both with and without time-of-flight data.
This paper is organized in five sections. In section II, we first describe the RDP regularized PET image reconstruction model and the modified BSREM algorithm and then develop our new SDP-BSREM algorithm. In section III, proofs for convergence of SDP-BSREM are provided with and without an interior assumption and four SDPs satisfying the convergence conditions are presented as well. Comprehensive comparisons of the results obtained for simulated and clinical data obtained by means of our proposed SDP-BSREM methods versus BSREM and Q.Clear are provided in section IV. The conclusions are presented in section V. Two appendices with additional details are also provided.
II. Methodology
In this section, we develop the SDP-BSREM algorithm for solving the RDP regularized PET image reconstruction model.
A. RDP Regularized PET Image Reconstruction Model
We denote by the set of all nonnegative real numbers, by the set of all positive real numbers, by the set of positive integers, and by . For , we let denote the PET system matrix whose entries are the probability of detection of the positron annihilation gamma photon pairs emitted from a particular voxel containing PET radiotracer, and let denote the mean value of the background events produced by random and scatter coincidences. The relation of the radiotracer distribution within a patient with the projection data acquired by a PET scanner is described by the Poisson model
| (1) |
where Poisson(x) denotes a Poisson-distributed random vector with mean x.
Model (1) may be solved by minimizing the fidelity term
| (2) |
where denotes the vector with all components 1, ln is the logarithmic function at a vector and xi is the i-th component of x, and denotes the inner product of . It is well-known that model (2) is ill-posed [24] and its solutions may result in over-fitting in reconstructed images. Regularization is often used to avoid the over-fitting problem. A commonly used regularized PET image reconstruction model has the following form:
| (3) |
where
| (4) |
with being the regularization parameter and R(f) representing the regularization term. In this study, we will consider the RDP [18] regularization term that is given by
| (5) |
where controls the degree of edge preservation, and Nj is the neighborhood of pixel j.
In model (5), a small constant ϵ > 0 is added to the denominator to avoid singularities when both fj and fk are equal to zero. By its definition, RDP is a function of both differences of neighboring pixels and their sums. The inclusion of the sums term makes RDP differ from conventional regularization terms and causes the regularizer to be activity-dependent. We note that the function Φ(f) is twice differentiable since both F (f) and R(f) are twice differentiable [16], [18]. The inclusion of a small constant ϵ in the denominator of RDP provides the objective function Φ with two useful properties (the proofs are provided in appendix A): (i) it is strictly convex under an assumption that is a nonzero vector; and (ii) it has a Lipschitz continuous gradient on .
B. Modified BSREM Algorithm
A modified BSREM [8] was adopted by GE Healthcare as the optimizer in the Q.Clear method [3] for solving the model (3). Here we describe and review the modified BSREM.
Minimization problem (3) is often solved by the gradient descent method. However, computing the whole gradient ∇Φ is computationally expensive. To alleviate this issue, the ordered-subsets (OS) algorithm was developed to accelerate its convergence [4]–[7]. For , let . For , let be a collection of disjoint subsets of such that . The partition is chosen as in [8]. According to the partition , we partition the system matrix A into M row sub-matrices Ai, and g and γ into M sub-vectors gi and γi, respectively, for . We use |Ω| to denote the cardinality of set Ω. For , we define
| (6) |
It follows that . An OS algorithm computes only one ∇Φi at each subiteration step.
A subiteration-independent preconditioned OS algorithm was proposed in [8]. The preconditioner is designed by using an upper bound of the solution set of minimization problem (3). It was proved in [8] that for any projection data g, there exists a constant U > 0 such that the solution set of minimization problem (3) is contained in the bounded set
| (7) |
That is, . For , a subiteration-independent diagonal preconditioner S(f) is defined as
| (8) |
where pj are defined by
| (9) |
Note that the preconditioner S is uniform for all iterations.
For a small t ∈ (0, U) and , an operator is defined by
| (10) |
Using operator Pt, the modified BSREM algorithm [8] may be described as for , ,
| (11) |
with , where λk > 0 is the relaxation parameter. For simplicity of notation, we will refer to the modified form of BSREM simply as BSREM.
C. BSREM with Subiteration-Dependent Preconditioners
In this subsection we propose subiteration-dependent preconditioners (SDPs). To motivate them, we review the momentum approach. The momentum is an acceleration technique widely used in optimization [25]–[27]. The Nesterov momentum [25] has been combined with OS by Kim et al. [28] for CT image reconstruction. Recently, Lin et al. [22] successfully applied a different form of momentum to PET image reconstruction. However, no explicit convergence proof has been provided for the OS combined momentum methods. Instead, Kim et al. proved that the expectation of the successive steps converged, while Lin et al. proved convergence for the non-OS method. The momentum technique used in [22] can be described as follows: for , ,
| (12) |
where 𝜶k,i > 1 is the momentum sequence. Under an assumption that are non-negative, one can obtain
| (13) |
By letting Sk,i(f) := 𝜶k,iS(f), we may reinterpret Sk,i as an SDP and (13) as a BSREM algorithm with Sk,i. Inspired by this, we introduce SDPs by setting Sk,i(f) := diag(𝜶k,i)S(f), where 𝜶k,i is a positive vector sequence and diag(y) denotes the diagonal matrix with the diagonal entries being the components of the vector y. Using the same notation as for BSREM above, we have arrived at the SDP-BSREM algorithm for solving model (3) given in Table I.
TABLE I.
SDP-BSREM Algorithm
Bearing in mind the momentum concept defined in [22], it is clear that the iteration sequence provided in (13) is a special case of our proposed SDP-BSREM algorithm with 𝜶k,i := 𝜶k,i1q. For this reason, we expect that our proposed SDP-BSREM algorithm setting will allow us to choose an SDP to yield the convergence acceleration. We will evaluate its performance by means of numerical experiments to be presented in section IV.
III. Convergence of SDP-BSREM algorithm
In this section we present convergence properties of the SDP-BSREM algorithm. We also describe four specific SDPs that satisfy the convergence condition. To this end, we assume that the objective function Φ satisfies the hypothesis:
-
i
Φ has a unique minimizer on ;
-
ii
Φ is convex and twice differentiable on ;
-
iii
∇Φi are Lipschitz continuous on for all .
The use of SDPs results in scaled subset gradients with their sum inconsistent with the scaled full gradient. It complicates the convergence proof and requires additional assumptions on the preconditioner to make the inconsistencies asymptotically approach zero. For a general SDP, our proposed SDP-BSREM algorithm may not converge [8]. Nevertheless, by imposing certain assumptions on Sk,i, convergence to the desired optimum point can be ensured. For a SDP Sk,i(f) = diag(𝜶k,i)S(f) with S(f) defined in (8), the required additional assumptions are as follows:
-
iv
The relaxation sequence satisfies and ;
-
v
There exists a positive vector 𝜶 such that for all ;
-
vi
The vector series converge for all .
Note that condition (iv) was imposed in [8], [29] for convergence proofs for relaxed OS algorithms. Conditions (v) and (vi) were imposed to overcome difficulties caused by the use of different preconditioners in different subiterations.
We now state a lemma regarding the Lipschitz continuity properties of SDPs. The proof is included in Appendix B.
Lemma 1: If conditions (iii) and (v) are satisfied, then are uniformly bounded and Lipschitz continuous on with Lipschitz constants bounded above by a uniform constant, for all , .
The inclusion of the operator Pt in the SDP-BSREM algorithm complicates the convergence proof. Here, we present our approach in dealing with this difficulty. Let denote the interior of . We prove the convergence of SDP-BSREM in two steps. We first prove it with the interior assumption for all , , and then prove it by showing that the interior assumption holds true under certain conditions.
We now proceed the first step. If for all , , then and the iteration scheme can be formulated as
| (14) |
We first establish a technical lemma.
Lemma 2: Suppose conditions (iii) and (v) are satisfied. If , and , for all , , then , for all .
Proof: By Lemma 1, , , , are uniformly bounded on . This combined with and (14) yields the desired result. ■
Let , . We state a technical lemma whose proof is included in Appendix B.
Lemma 3: Suppose conditions (iii)-(vi) are satisfied and for all , . If for all , then
| (15) |
If for all , then
| (16) |
We recall that a cluster point of a sequence fk is defined as the limit of a convergent subsequence of fk and state a lemma whose proof is included in Appendix B.
Lemma 4: If conditions (i)-(vi) are satisfied and for all , , then (a) converges in , (b) there exists a cluster point f∗ of fk with S(f∗)∇Φ(f∗) = 0, and (c) such a cluster point f∗ described in (b) is a global minimizer of Φ over .
We are ready to prove convergence of fk and fk,i with the interior assumption.
Proposition 5: If conditions (i)-(vi) are satisfied and for all , , then both fk and fk,i converge to the global minimizer of Φ on .
Proof: According to Lemma 4 (c), f∗ is a global minimizer of Φ over . Suppose there exists another cluster point f∗∗ ≠ f∗. By Lemma 4 (a), Φ(fk) converges in , which implies that Φ(f∗) = Φ(f∗∗). Then f∗∗ is also a minimizer of Φ(f), which is a contradiction since Φ(f) has a unique minimizer on . Then we obtain . The convergence of fk,i follows from Lemma 2 and the convergence of fk. ■
We have shown that condition for all , is sufficient for the convergence of SDP-BSREM algorithm. Next, we prove the convergence of SDP-BSREM without the interior assumption. The proof of convergence is completed by proving for all and k > K for some K > 0. We now state a lemma to prove it.
Lemma 6: Suppose condition (iii) is satisfied. If 𝜶k,i is bounded and , then for all and k > K for some K > 0.
Proof: It suffices to prove that for all , , k > K, for some K > 0. By condition (iii), is bounded over for all , . Combining this with the boundedness of 𝜶k,i, there exists c1 > 0 such that , for all , , , and all . Because , there exists K > 0 such that for all k > K, so that . Hence, for k > K, , if , the preconditioner gives rise to , from which we can show that . Likewise, if , the preconditioner gives that , from which we can show that . ■
We now arrive at the following theorem for the convergence of SDP-BSREM algorithm without an interior assumption.
Theorem 7: If conditions (i)-(vi) are satisfied, then fk,i converges to the global minimizer of Φ on .
Proof: We have that and 𝜶k,i is bounded from conditions (iv) and (v) respectively. Thus, by Lemma 6, there exists K > 0 such that for all k > K, . Then the proof follows from Proposition 5. ■
We next propose four specific SDPs which satisfy the convergence conditions (iv)-(vi). For Sk,i(f) = diag(𝜶k,i)S(f), let , where 𝜶k,i is a scalar sequence and νk,i is a vector sequence to be determined. Other, potentially better, choices of 𝜶k,i are left as future work.
In this case, inspired by momentum techniques [22], [25], we consider the following two choices of 𝜶k,i. This first one is derived from Nesterov momentum [25]:
| (17) |
Where , and , , . The second one has the following form:
| (18) |
for , , where , δ1 and δ2 are positive parameters. We notice that this 𝜶k,i is an extension of the momentum proposed in [22].
The motivation for the design of νk,i is presented as follows. The use of different step-sizes for different regions in the image can accelerate the convergence of the algorithm. The diagonal nonnegative definite preconditioner plays an important role in rescaling the step-sizes of the algorithm. Hence, a good preconditioner can significantly accelerate the convergence of the algorithm. We propose a type of preconditioner that is related to the regularization term that promotes smoothness in the reconstructed image. Our goal is to find the minimizer of the objective function which consists of the fidelity term and the regularization term. The fidelity term estimates the fitting quality of the reconstructed image to the data and the regularization term defined in (5) promotes smoothness in the reconstructed image. Smaller fidelity term makes the reconstructed image more consistent with the data and smaller regularization term leads to a smoother reconstructed image.
Suppose f∗ is a minimizer of the objective function Φ and the iteration scheme of the algorithm converges to f∗. Let Is and Iv be the smooth and variable areas of f∗, respectively. Suppose and are the subsets of defined in the areas Is and Iv, respectively. Then for the smooth areas Is, the descent directions of the fidelity term and the regularization term are consistent whereas for the variable areas Iv, the descent directions of the fidelity term and the regularization term are inconsistent. Thus the direction of more accurately points toward the minimizer than the direction of . Therefore, we conclude that the directions of and are more consistent than the directions of and . We illustrate this conjecture (the subset gradient is used in practice) via numerical experiments (see Fig. 2). The preconditioner is designed to achieve larger iteration step-sizes in the smooth areas Is and smaller iteration step-sizes in the variable areas Iv. The numerical gradient (the gradient function in Matlab) of f∗ is applied to measure the smoothness degree of the image f∗. Then larger and smaller step-sizes will be used in the areas having smaller and larger numerical gradients, respectively.
Fig. 2.
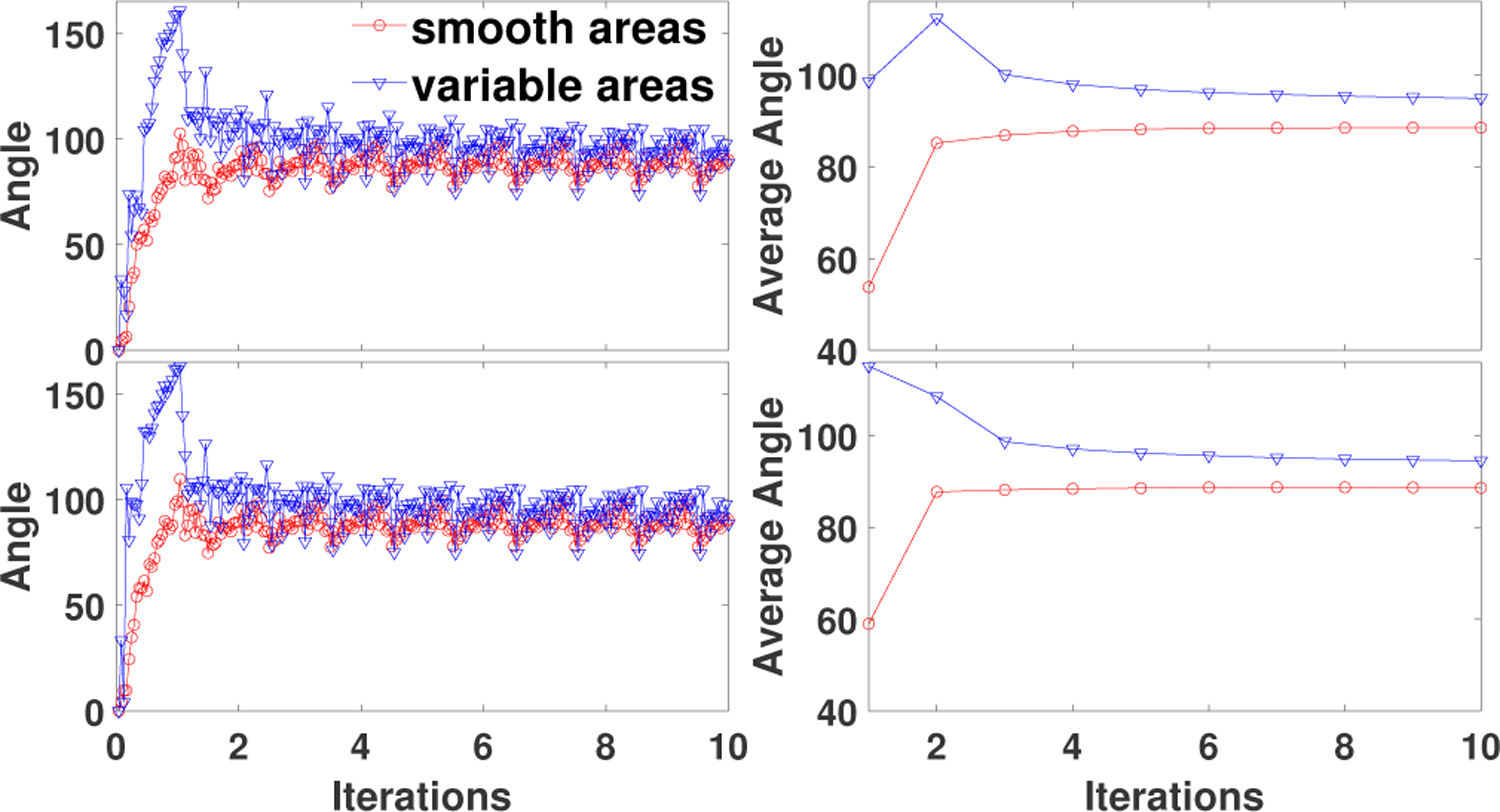
Angle (left) and average angle (right) between the gradients of the successive subiterations vs. iterations projected in the smooth areas and variable areas in the reconstructed images, respectively, for the brain phantom with high count data. Top row: SDP-P1 (24). Bottom row: SDP-P2(24).
Suppose is a 2D image with size q1 × q2. Let be the matrix form of f. Using the gradient function in Matlab, we compute the gradients of mat(f) along the x and y directions, namely, and . Let , where the square and square root operations are element-wise. For PET patients data, the minimizer f∗ is unknown and we use fk,i to approximate f∗. Based on the consideration that areas with larger numerical gradients should have smaller step-sizes, we first let , where is used to normalize the fk,i. Instead of directly letting νk,i be the 1/µk,i, we define a projection operator to avoid too large or too small step-sizes. For two positive numbers νm < νM, and , a projection operator is defined by .
Let , , . For , and , the is determined by
| (19) |
For the first J0 subiterations, the νk,i is set to the identity vector since the approximation of fk,i to f∗ is poor. The approximation becomes better as the iteration continues, hence different step-sizes for different regions of the image are used for J0 < Jk,i ≤ J1. After J1-th subiteration νk,i is then fixed due to improved approximation. The preconditioners Sk,i(f) = S(f)diag(𝜶k,iνk,i) are denoted by P1 and P2 depending on 𝜶k,i defined in (17) and (18) respectively. The momentum-like preconditioners Sk,i(f) = S(f)diag(𝜶k,i1q) are denoted by M1 and M2 depending on 𝜶k,i defined in (17) and (18) respectively. Then we have the following theorem. The proof can be found in the appendix B.
Theorem 8: The SDP-BSREM algorithm with Φ defined in (4), and with relaxation , λ0, a > 0, and preconditioner P1, P2, M1, or M2 is convergent.
IV. Numerical results
In this section, we present results of evaluations of the SDP-BSREM algorithms performance obtained by means of numerical experiments using both simulated and clinical PET data, in comparison with BSREM and with the clinical version of BSREM (Q.Clear, GE).
A. Simulation Setup
The algorithms were implemented using a 2D PET simulation model developed in the Matlab environment [22], [30]. The projection matrix, based on a single detector ring of a GE D710 PET/CT, was built using a ray-driven model with 32 parallel rays per detector pair. Cylindrical detector ring, consisting of 576 detectors whose width are 4 mm, was applied. The field of view (FOV) was set to 300 mm and 288 projection angles were used to reconstruct a 256×256 image with pixel size 1.17 mm×1.17mm. The true count projection data were obtained by forward projecting the phantom convolved in image space with an idealized point spread function (PSF). The PSF was a shift-invariant Gaussian function with full width at half maximum (FWHM) equal to 6.59 mm [31]. Uniform water attenuation, with attenuation coefficient 0.096 cm−1, was simulated using the PET image as support. Scatter was simulated by adding highly smoothed and scaled projection of the phantom to the attenuated image sinograms. The scaling factor was equal to the estimated scatter fraction SF := S/(T + S), where T and S are true and scatter counts respectively [32]. Random counts were simulated by adding a uniform distribution to the true and scatter count distributions scaled by a random fraction RF := R/(T +S +R), where R is the random count [32]. The total count was defined as TC := T +S+R. In the simulations, it was TC = 6.8×106 for high count data and TC = 6.8×105 for low count data. In both cases SF = RF = 0.25. The individual noise realizations were generated by adding the Poisson noise to the total count distribution. The same system matrix was used to simulate the data and to reconstruct them.
To investigate the convergence acceleration and its impact on reconstructed images fidelity, two figures-of-merit were computed: the objective function and the normalized root mean square difference (NRMSD). The region of interest (ROI) based NRMSD is defined by , where is the converged image at 1000 iterations by BSREM algorithm with 24 subsets in simulations, and Ω is the ROI. In the simulations the global NRMSD is obtained by setting the ROI as the whole image.
Two 256×256 numerical 2D phantoms shown in Fig. 1 were used in simulations. The brain phantom [30] was obtained from a high quality clinical PET image. The uniform phantom consists of 4 uniform hot spheres and 2 uniform cold spheres with distinct radii: 4, 6, 8 (cold), 10 (cold), 12, 14 pixels. The contrast ratio for the cold and hot spheres are 0 : 1 and 1 : 10, respectively. All simulations were performed in a 64-bit Windows 10 OS laptop with Intel Core i7–8550U Processor at 1.80 GHz, 16 GB of DDR4 memory and 512 GB SATA SSD.
Fig. 1.
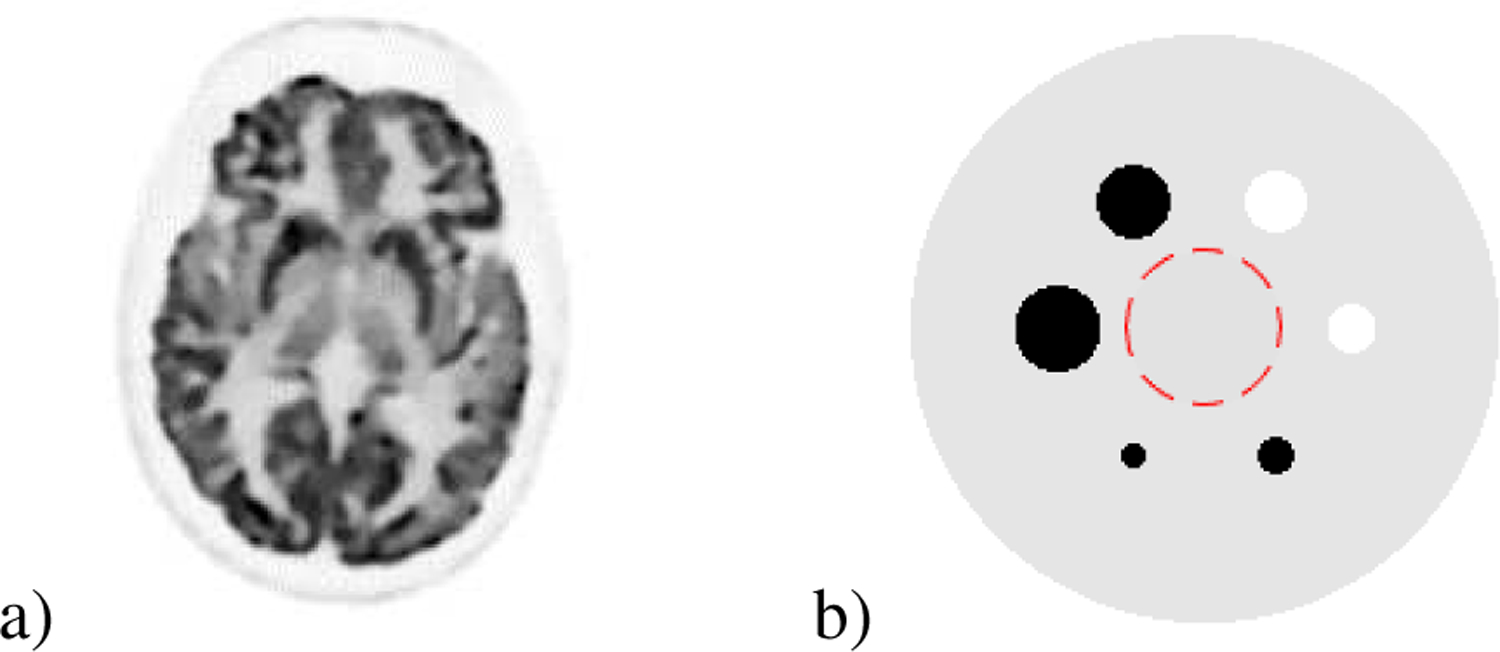
Numerical phantom used in simulations. a) Brain phantom. b) Uniform phantom: uniform background (1 ROI with radius 25 pixels is shown) with 6 uniform spheres of different radii (2 cold spheres and 4 hot spheres).
The parameter t in Pt was set to 10−4. The constant ϵ was set to 10−12. The regularization parameter β in model (3) was set to 0.1 and 0.8 for high and low count data respectively. In RDP regularization term, the parameter γR was set to 2 and 8-point neighborhood was considered. The initialization f0 was set to 1q to examine the setting of νk,i. We used the relaxation sequence defined by , a > 0. In all simulation experiments, for simplicity, we empirically set λ0 = 1, J0 = 3, J2 = 1000 and δ1 = δ2. Other parameter values, shown in Table II, were chosen based on the performance of objective function value.
TABLE II.
Algorithmic parameters for 2D simulation reconstruction
| Parameters | Brain phantom | Uniform phantom |
|---|---|---|
| BSREM(12) | high count: a =
1/400 low count: a = 1/18 |
- |
| SDP-P1(12) | high count: a =
1/13, ν1 = 1.6, ν2 = 2.4 low count: a = 0.5, ν1 = 1.6, ν2 = 2.4 |
- |
| SDP-P2(12) | high count: a = 1/5,
ϱ =
5, δ1 = 5, ν1 = 0.8, ν2 = 2.2 low count: a = 1.3, ϱ = 7.5, δ1 = 5, ν1 = 1.3, ν2 = 2.1 |
- |
| BSREM(24) | high count: a =
1/35 low count: a = 1/5 |
high count: a = 1/35 |
| SDP-P1(24) | high count: a =
0.35, ν1 = 1.6, ν2 = 2.4 low count: a = 1.3, ν1 = 1.4, ν2 = 2.5 |
high count: a =
0.5, ν1 = 1.8, ν2 = 2.5 |
| SDP-P2(24) | high count: a = 0.45,
ϱ =
4, δ1 = 3, ν1 = 0.8, ν2 = 1.8 low count: a = 1.4, ϱ = 2.2, δ1 = 1, ν1 = 1.3, ν2 = 2.4 |
high count: a = 0.7, ϱ = 3, δ1 = 7, ν1 = 1.4, ν2 = 2.3 |
B. Simulation Results
1). Comparison of Gradient Consistency:
To measure the directional consistency of two vectors, we computed the angle between them. The angle between vectors v1 and v2 is defined as . We define the smooth areas sequence by , and the variable areas sequence by . In order to estimate the consistency of and , we computed the angle between them. For smooth areas, we define the angle sequence by , and the average angle in each iteration by , where . Similarly, for variable areas, we computed and . In Fig. 2, we observed that for SDP-P1 and SDP-P2, the angle and average angle in smooth areas were smaller than those in the areas with more variability. This is consistent with our conjecture that the directions of gradients in the smooth areas more accurately point toward the minimizer than those in the variable areas. Hence, larger step-sizes in the smooth areas and smaller step-sizes in the variable areas are reasonable.
2). Comparison of Preconditioners:
In order to reveal the improvement due to the application of a preconditioner, as compared to the use of a momentum, we compared SDP-BSREM algorithm with four different preconditioners: P1, P2, M1, and M2, where M1 and M2 are surrogates of momenta. The parameter a in SDP-M1(12) and SDP-M1(24) was set to 1/50 and 1/6, respectively. And the parameters a, ϱ, δ1 in SDP-M2(12) and SDP-M2(24) were set to 1/15, 3, 1 and 1/5, 2.6, 0.5, respectively. In Fig. 3, one can observe that SDP-P1 and SDP-P2 outperform SDP-M1 and SDP-M2, in reaching the same objective function value, by 25–30% and 25%, respectively.
Fig. 3.
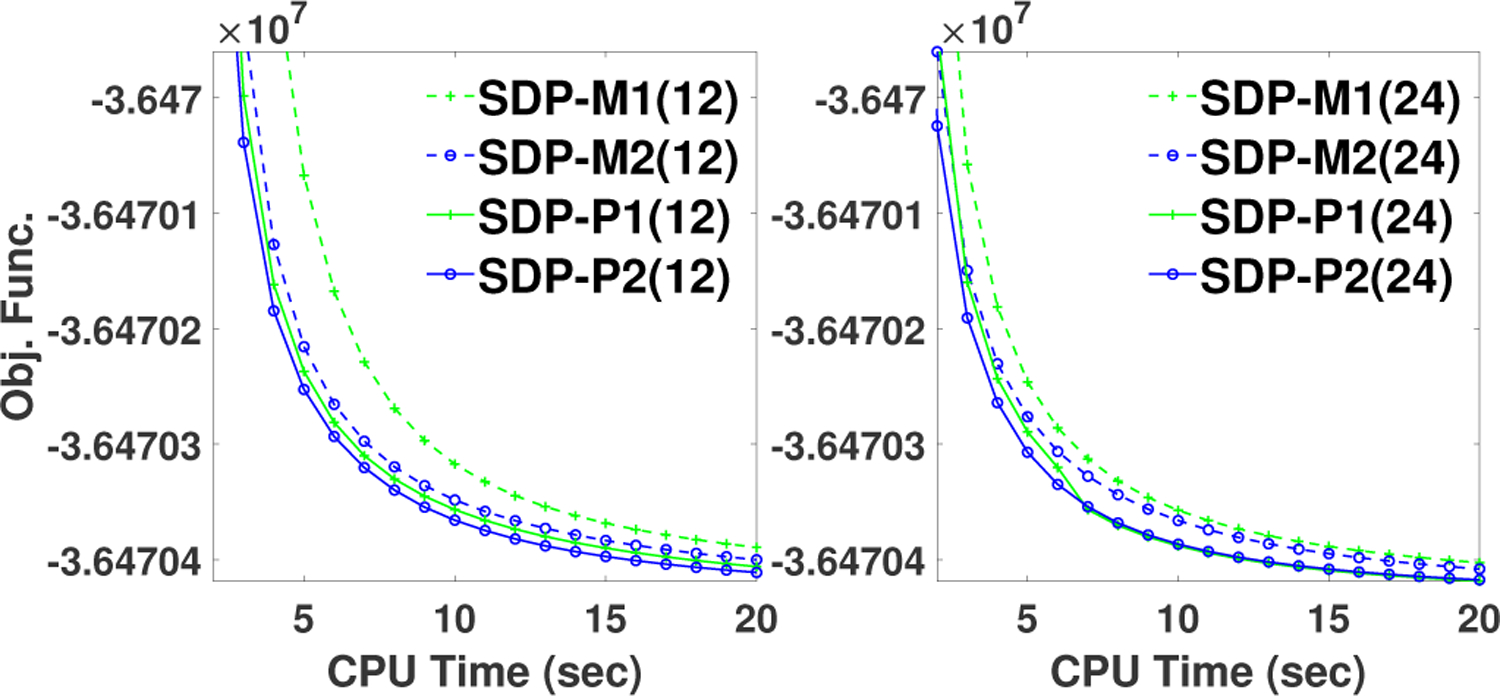
Comparison of performance of preconditioners investigated in this study. Objective function vs. elapsed CPU time in reconstructions performed with SDP-BSREM algorithm with four preconditioners: M1, M2, P1, and P2, and with 12 subsets (left) and 24 subsets (right), respectively, for the brain phantom with high count data. Preconditioners P1 and P2 were generalized from M1 and M2, respectively.
3). Comparison of SDP-BSREM with BSREM:
In this sub-section, we analyzed the performance of SDP-BSREM algorithms compared to the BSREM algorithm. First, we showed the global NRMSD for all the algorithms, with 12 and 24 subsets, in Fig. 4, using the brain phantom. It showed that all algorithms converged to the same solution for both low and high count data. Further, this figure showed that SDP-P1 and SDP-P2 outperformed BSREM with respect to global NRMSD. To analyze convergence acceleration, we showed the objective function values of each algorithm in Fig. 5. In this figure, one can observe that both proposed algorithms, SDP-P1 and SDP-P2, outperform the BSREM algorithm, in reaching the same objective function value, by roughly a factor of two for all cases: 12 and 24 subsets for both low and high count data using the brain phantom.
Fig. 4.
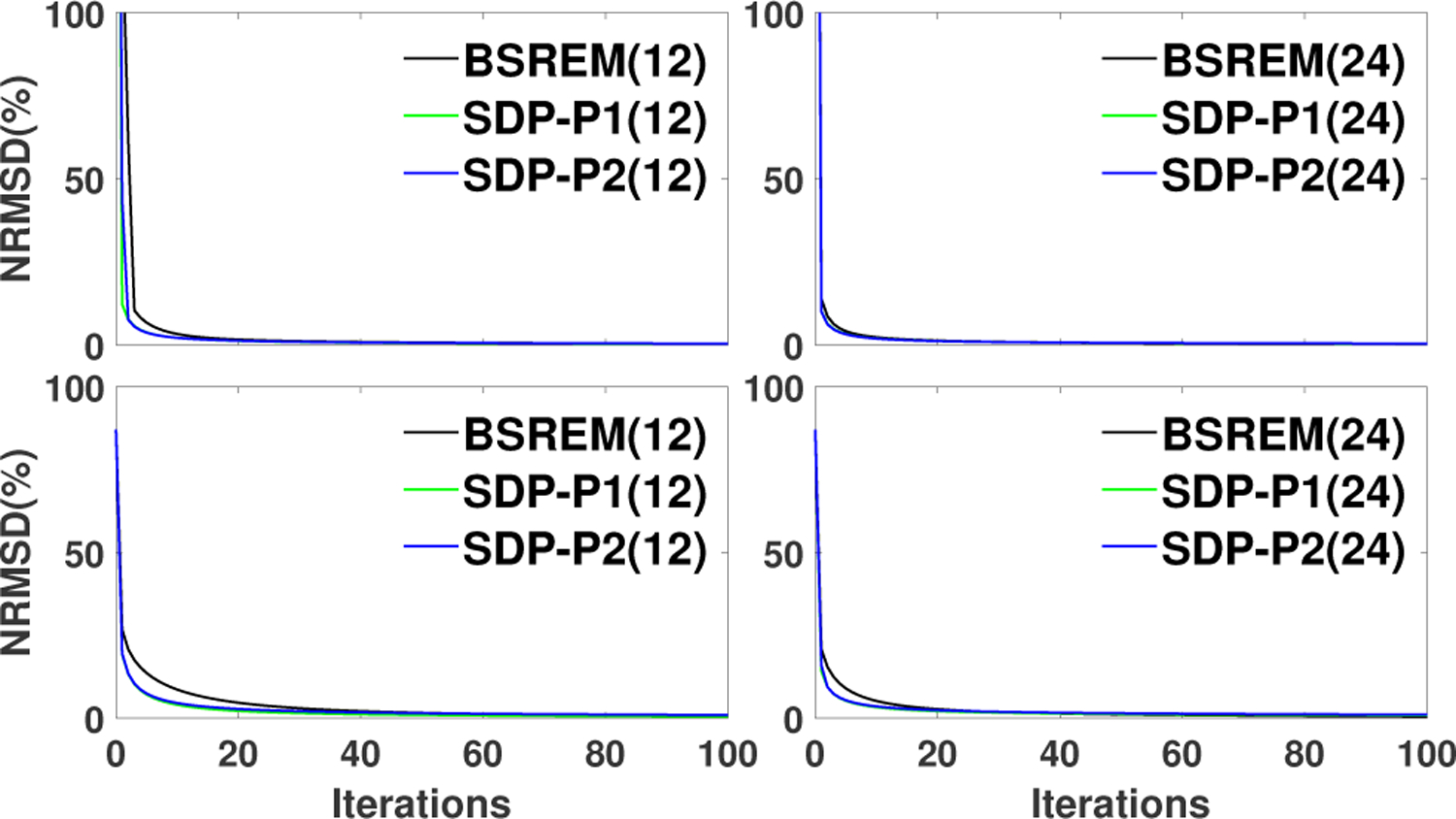
Global NRMSD vs. Iterations in reconstructions performed with different algorithms: BSREM(12), SDP-P1(12), SDP-P2(12), BSREM(24), SDP-P1(24), SDP-P2(24) for the brain phantom with low (top row) and high (bottom row) count data, respectively.
Fig. 5.
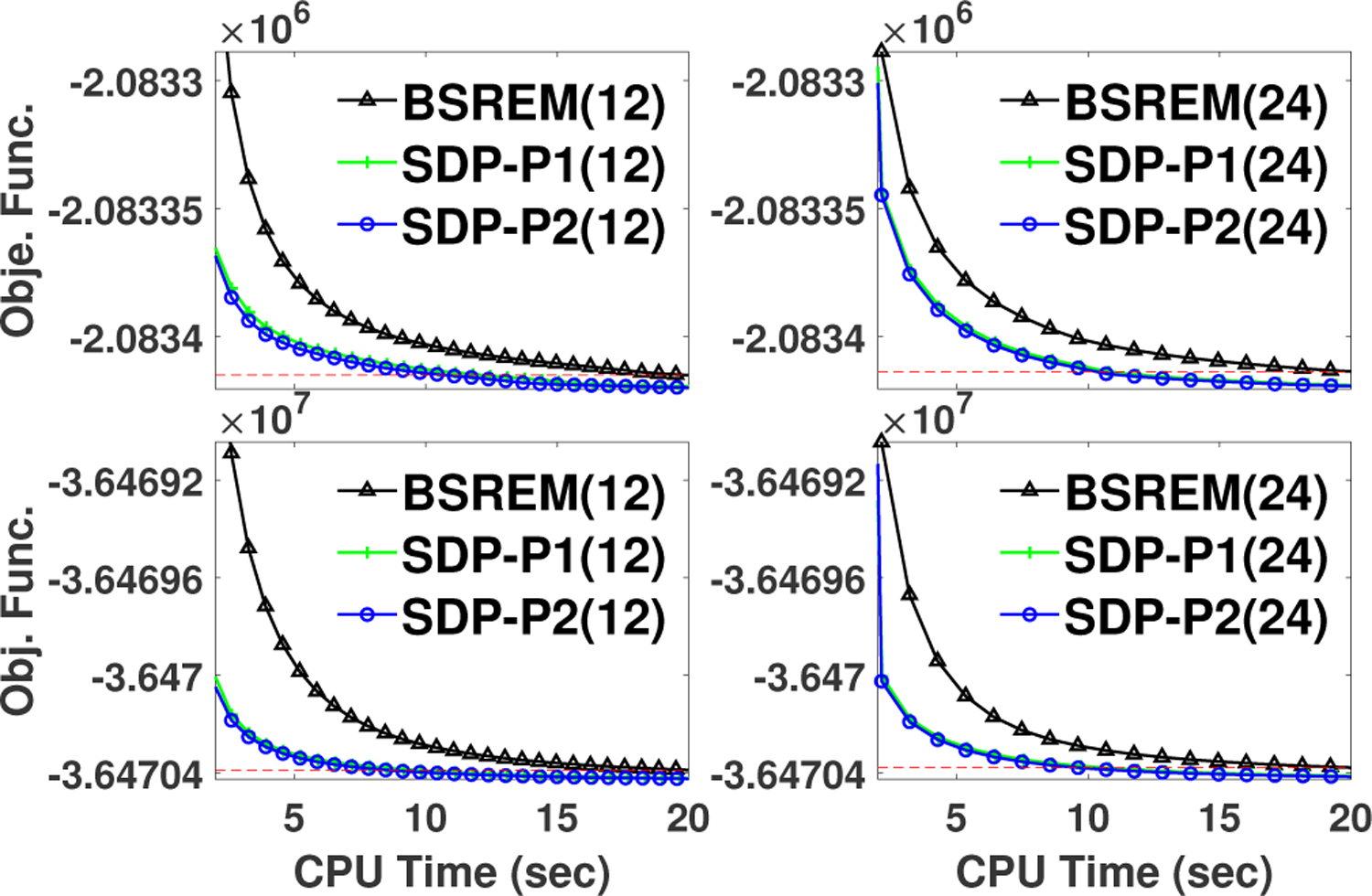
Comparison of performance of SDP-BSREM vs. BSREM algorithm. Objective function vs. elapsed CPU time in reconstructions performed with BSREM, SDP-P1, and SDP-P2, with 12 (left) and 24 (right) subsets for the brain phantom with low (top row) and high (bottom low) count data, respectively. The dash lines represent the objective function values of BSREM at 20 seconds CPU time.
Next, we examined the local convergence performance of SDP-BSREM algorithms by ROI based NRMSD in 8 different ROIs with different contrast ratios in the reconstructions of the uniform phantom. High count data and 24 subset were used in this experiments. In Fig. 6, we observed that the proposed SDP-P1 and SDP-P2 algorithms converged fast than BSREM algorithm in all 8 ROIs.
Fig. 6.
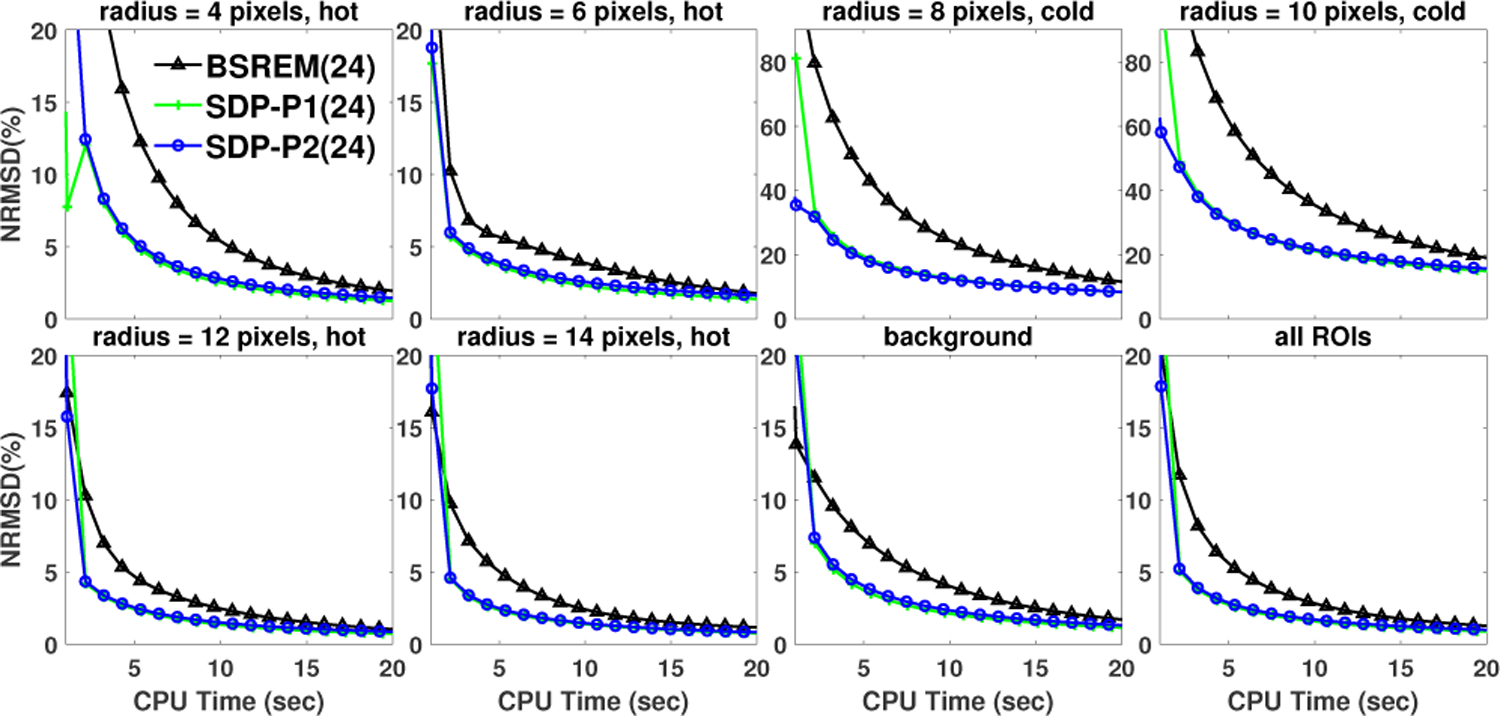
Comparison of local convergence performance of SDP-BSREM vs. BSREM algorithms for the uniform phantom with high count data. ROI based normalized root mean square difference (NRMSD) vs. iterations is shown. The eight ROIs are the 4 hot spheres, 2 cold spheres, 1 background spheres, and the region consisting of all the former 7 ROIs, named “all ROIs”.
C. Clinical Results
The reconstructions were performed with our SDP-BSREM algorithm with P2 preconditioner and with commercial Q.Clear by means of the GE toolbox [33] with the penalty weight (β) set to the default value of 350. Because the 2D-projectors used in the simulations and 3D-projectors used in clinical data reconstructions were scaled differently, the penalty values used in respective reconstructions differed substantially.
To mimic the GE’s clinical implementation of Q.Clear, 25 and 8 iterations were used for non-TOF and TOF data, respectively, with 24 subsets in the experiments. For the same reason we initialized both the non-TOF and TOF reconstructions using OSEM with 2 iterations and 24 subsets. The reconstructions with TOF data were further initialized using 3 iterations with 24 subsets of non-TOF algorithm. This gives a more clinically realistic view of the performance, but at the cost of being able to isolate TOF performance.
The parameter values are shown in Table III. For simplicity, since good initializations were used, we set J0 = 0 and J1 = 1000. The other algorithmic parameters were found via an iterative golden search procedure using a single bed position (centered on the Derenzo region) from an ACR PET phantom [35] with similar count characteristics as the patient’s data. Using this phantom each parameter was sequentially optimized with 5% tolerance and then used in search for the next parameter until parameter values ceased to change (∼3 iterations).
TABLE III.
Algorithmic parameters for 3D patient reconstruction
| Algorithm | Parameters |
|---|---|
| Q.Clear(nonTOF) | λ0 = 2, a = 1/5 |
| Q.Clear(TOF) | λ0 = 1.2, a = 1/5 |
| SDP-P2(nonTOF) |
λ0 =
1.6, a = 1/4, ϱ =
2.2, δ1 = 0.1, δ2 = 1.6, ν1 = 0.6, ν2 = 1.25 |
| SDP-P2(TOF) |
λ0 =
1.1, a = 1/3, ϱ =
2.4, δ1 = 0.6, δ2 = 1.6, ν1 = 0.6, ν2 = 1.25 |
In Fig. 8 we show convergence, via the objective function value as a function of iteration for non-TOF/TOF data, for an 18F-FDG whole-body PET clinical patient (shown in Fig. 7a). This data was obtained from 8 bed positions acquired on a GE D710 PET/CT. The nominal administered activity and post-administration acquisition were 444 MBq and 1-hour, respectively, with 3-minute dwell times and 25% overlap, resulting in [4.1/3.4/4.2/4.5/4.6/3.8/3.1/2.6] × 107 total counts, where the bolded numbers are from the bed positions 4 and 6 shown in Fig. 8.
Fig. 8.
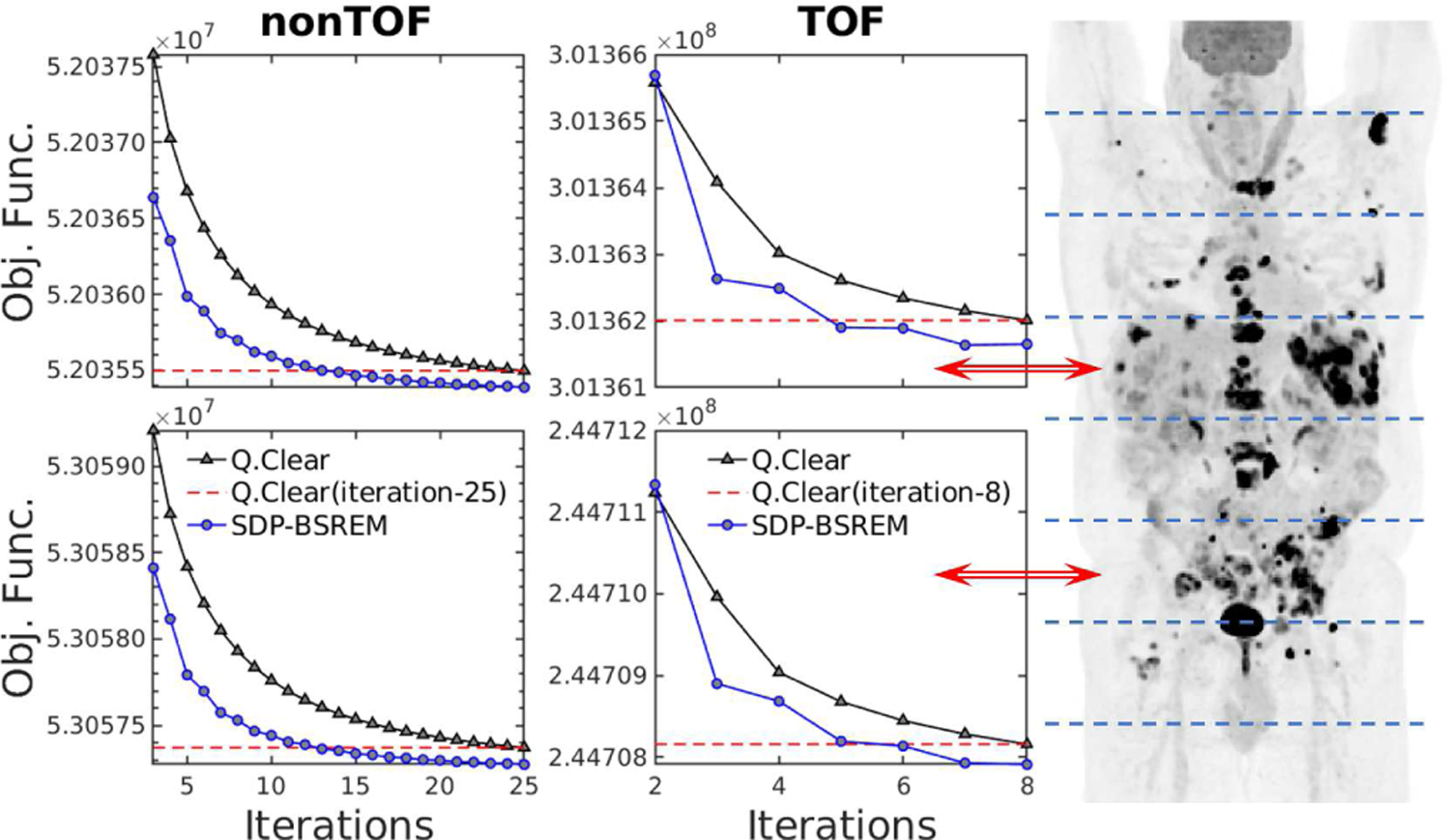
Comparison of performance of SDP-BSREM vs. Q.Clear (β = 350) algorithms. A whole-body 18F-FDG clinical PET patient scan was used. Eight patient bed positions separated by dashed lines are shown in the coronal maximum intensity projection (MIP) image. The objective function vs. iterations is shown for PET scanner patient bed positions 4 and 6 (red arrows) for nonTOF (left) and TOF data (right). The dashed lines represent the objective function values at the final Q.Clear iterations.
Fig. 7.
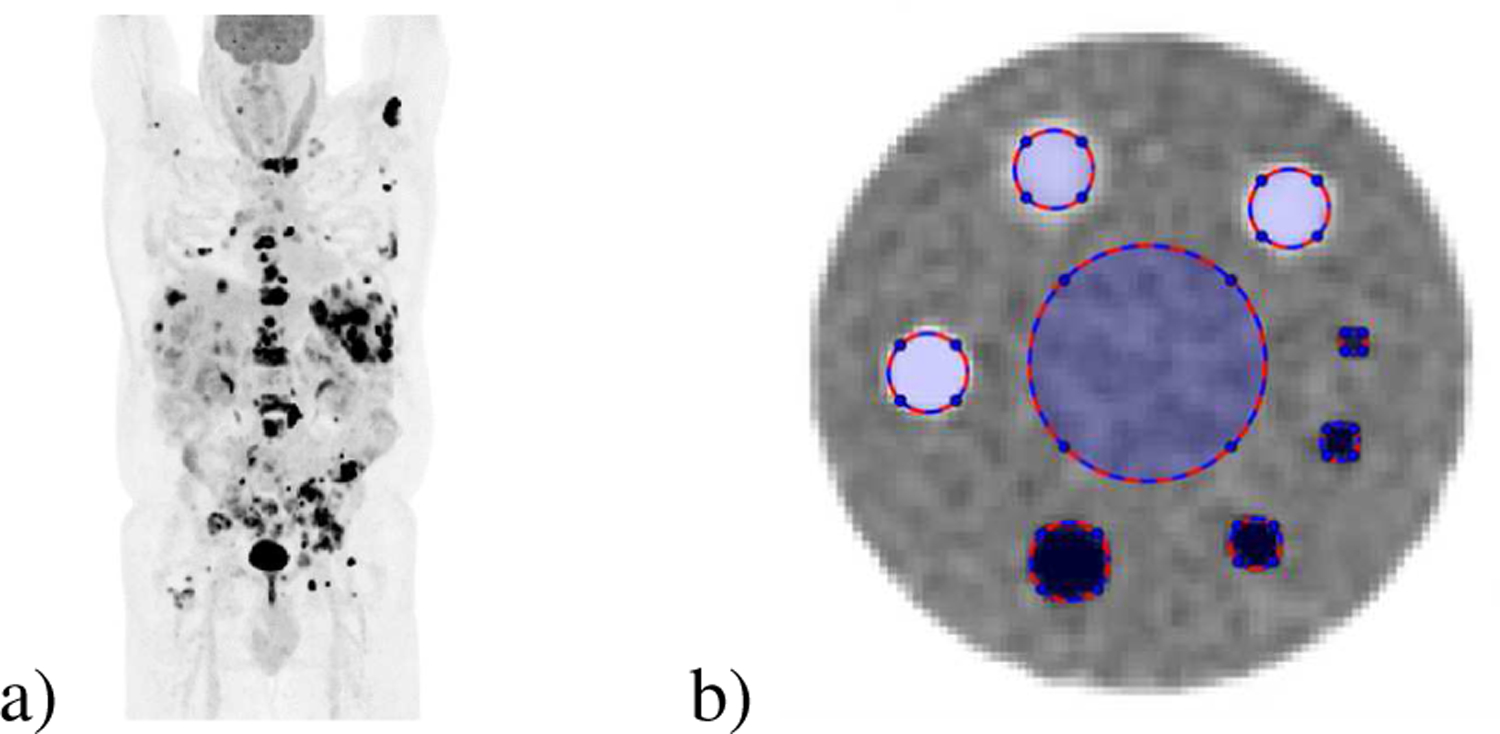
Clinical PET patient and ACR phantom. a) Clinical PET patient: Coronal maximum intensity projection (MIP) of a clinical whole-body 18F-FDG PET patient image acquired on a GE D710 PET/CT and reconstructed using the Q.Clear clinical method [3]. b) Clinical ACR quality assurance phantom showing the regions of interest for cold/hot cylinders, 0:1 and 2.5:1 activity concentration ratios, respectively, and background [34].
We observed that our SDP-BSREM method outperformed the Q.Clear algorithm, in reaching the same objective function value, by 40–50% and 35–50% for non-TOF and TOF data, respectively. We note that both the clinical 3D projection and penalty operator have much greater computational complexity than the convergence acceleration scheme described in section III. Hence, the increased computational cost required for the use of the SDP is negligible.
To evaluate the local convergence, TOF data from a quarterly ACR quality assurance test was used. Following ACR guidelines [34] the activity corresponded to a nominal 444 MBq (12 mCi) of 18F-FDG administration used at MSKCC. The upper proton of this phantom contains 8 regions (3 cold, 4 hot, and background) with nominal contrast ratios of 0:1 and 2.5:1 for the cold and hot cylinders, respectively. ROI were defined using the cylinder boundaries from registered CT images. Using the methodology described by Kim et al. [36], for each ROI we measured the NRMSD, where thef∞ in NRMSD is the converged image at 300 iterations by Q.Clear without subsets. These reconstructions used the same parameters as those used in the whole body patient reconstructions (i.e., J0 = 0, J1 = 1000 and Table III). The results are shown in Fig. 9. For each ROI, the SDP-BSREM method converged to f∞ faster than Q.Clear.
Fig. 9.
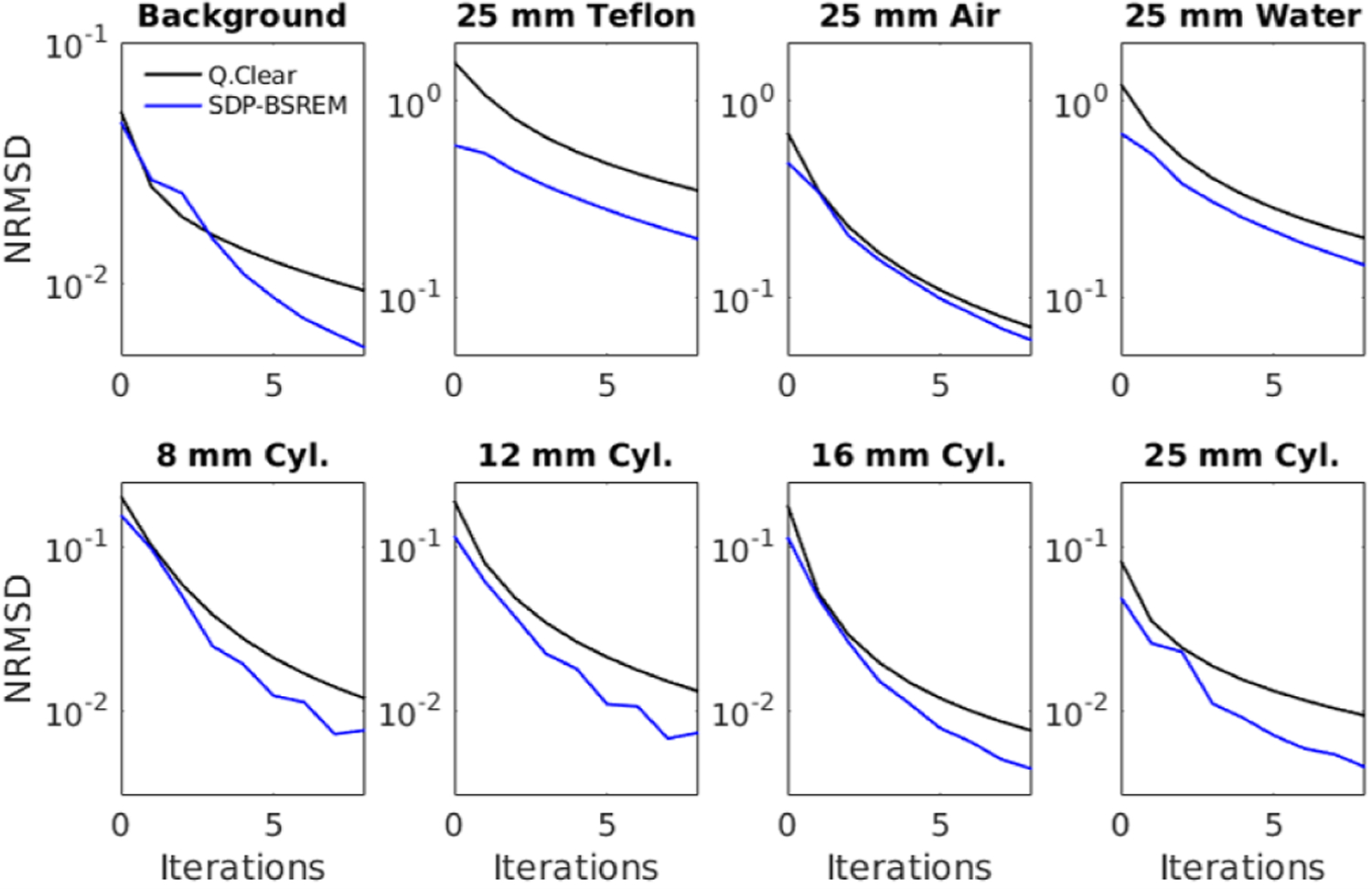
Local convergence is assessed using the 8 regions of interest from an ACR quality assurance test with TOF data [34]. These regions of interest can be seen in Fig. 7b. Each subplot represents one of the eight regions, which are from left to right and top to bottom: background, cold Teflon/air/water, and hot 8/12/16/25 mm cylinders, respectively.
V. Conclusion
In this paper, we have presented the SDP-BSREM algorithms with two SDPs and their global convergence theorems. The two SDPs were designed based on the smoothness-promoting property in the reconstructed images of the regularization term. We tested these algorithms using both simulated and clinical PET data. Using two simulated phantoms, our numerical studies showed that, for solving the RDP regularized PET image reconstruction model, our proposed algorithms converged more quickly than BSREM. Similarly, when using clinical patient and phantom PET data, our proposed algorithm SDP-P2 outperformed Q.Clear. We plan to test the SDP-BSREM algorithm on more varied data sets acquired under a wide range of conditions seen in the clinic
Acknowledgments
J. Guo is supported by the Special Project on High-performance Computing under the National Key R&D Program (No. 2016YFB0200602) and by the National Natural Science Foundation of China under grant 11771464; C. R. Schmidtlein is partially supported by the Memorial Sloan Kettering Cancer Center’s support grant from the National Cancer Institute (P30 CA008748); C. R. Schmidtlein, A. Krol and Y. Xu are partially supported by the National Cancer Institute of the National Institutes of Health under Award Number R21CA263876; S. Li is supported by the Natural Science Foundation of Guangdong Province under grant 2022A1515012379, by the Opening Project of Guangdong Province Key Laboratory of Computational Science at Sun Yat-sen University under grant 2021007 and by the National Natural Science Foundation of China under grant 11771464; Y. Lin is supported by Guangdong Basic and Applied Basic Research Foundation under grant 2021A1515110541, by the Fundamental Research Funds for the Central Universities of China under grant 21620352 and by the Opening Project of Guangdong Province Key Laboratory of Computational Science at Sun Yat-sen University under grant 2021006; Y. Xu is supported by the US National Science Foundation under grant DMS-1912958. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Appendix A
This appendix includes the proof of strict convexity and Lipschitz continuous gradient of the objective function Φ.
Proposition 9: If , then the objective function Φ(f) in (4) is strictly convex on .
Proof: From (2), the gradient of fidelity term F is given by . Then the Hessian matrix of F can be computed as follows:
| (20) |
with G a diagonal matrix and G = diag(g/(Af + γ)2). The first-order partial derivative of the RDP term R(f) is given by
| (21) |
Then we have the second-order partial derivative of R as follows:
| (22) |
For any , ignoring the zero entries of ∇2R, we obtain
| (23) |
| (24) |
We can see that and for any , if and only if there exists a nonzero constant c, such that x = c(2f + ϵ). For any x = c(2f + ϵ) ≠ 0, we have , thus by using . Since , one can obtain that for all x ≠ 0. Then Φ is strictly convex on . ■
Proposition 10: The objective function Φ(f) in (4) has a Lipschitz continuous gradient on .
Proof: From (20), one can obtain that where γmin > 0 is the minimum entry of γ. For any with and , let . From (24), we know that h(f) is continuous on and . Thus there exists C1 > 0 such that for any x with . Then we have which, when combined with the boundedness of , implies that . Using Lemma 1.2.2 in [37], one can obtain that ∇Φ(f) is Lipschitz continuous with constant on . ■
Appendix B
This appendix includes proofs of Lemma 1, Lemma 3, Lemma 4, and Theorem 7. Here is the proof of Lemma 1.
Proof: We present only a proof of the Lipschitz continuity and the uniform boundedness can be shown in a similar manner. For any f, , we consider the quantities , and .
By the triangle inequality and the Cauchy–Schwarz inequality, we have that
| (25) |
According to condition (v), 𝜶k,i is bounded. This together with the definition of S(f) implies that Sk,i(f) := diag(𝜶k,i)S(f) is bounded for all , and . By condition (iii), there exists c2 > 0 such that for all ,
| (26) |
We next prove that Sk,i(f) are Lipschitz continuous on with Lipschitz constants bounded above by a constant. For any f, , if both are in [0, U/2) or in [U/2, U ], then . If fj and are not in the same interval, without lose of generality, assuming , , then . Therefore, one can get . Thus, , where . Since 𝜶k,i and are bounded and there exists a constant such that for all , ,
| (27) |
Let L := c2 + c3. It follows from (25), (26) and (27) that . That is, are Lipschitz continuous with Lipschitz constants bounded above by L for all , . ■
The proof of Lemma 3 is presented as follows.
Proof: Let for , . For , , we have that . By assumption, . The definition of fk,i yields , which implies . By the boundedness of , we have . We next estimate . By definition, . To estimate the first term of the last equation, we write , where . It follows that . By condition (iii), there exists c4 > 0 such that . Since by (14) and Lemma 1, there exists a constant c5 > 0 such that
| (28) |
Hence and this gives that . Moreover, by condition (iii), we have that . Therefore, . Thus we obtain (15).
Equation (16) may be shown in a similar manner. Indeed, for , , we have that . The definition of fk,i yields that . This equation with similar arguments leads to (16). ■
The proof of Lemma 4 is presented as follows.
Proof: We first prove part (a). Let H(f) denote the Hessian matrix of Φ(f), ‘’ denote the component-wise multiplication of two vectors, and . By the Taylor expansion, we have that
| (29) |
where , for some vector with for all . We now estimate Rk. By condition (iii), ∇Φ(f) is Lipschitz continuous. Hence H(f) is bounded on . Then we have . We next evaluate the term hk. For notation simplicity, we let , and . By Lemma 1, we have . This combined with (28) implies that , and thus . By assumption, , from (14), we obtain that
| (30) |
Let , and . Then by condition (v) and Lemma 1, and Jk ⩾ 0 by the positive semi-definiteness of diag(𝜶)S(fk). Since Sk,i(fk) = diag(𝜶 − δk,i)S(fk), then we have
| (31) |
Combining this with (30), we have
| (32) |
By the boundedness of diag(𝜶)S(f)∇Φ(f) and the norm of ek and dk, we have and hence, . This combined with (29), (32) and the boundedness of yields that
| (33) |
For , summing both sides of (33) for k from 0 to s, we obtain that
| (34) |
We now prove the convergence of the right hand side of (34). By condition (vi), is convergent, and hence is convergent. Notice the facts we have in hand: (i) (by condition (iv)); (ii) the convergence of , it remains to show that is convergent. In view of the facts (i), (ii) and the boundedness of Φ (f) on , the partial sum is bounded, which combined with its monotonicity implies its convergence.
We next prove part (b). Since for each k, Jk ≥ 0, there exists a subsequence such that . In fact, assume to the contrary that there exists ϵ0 > 0 and such that , for all k > K0. Because , by condition (iv), and λk > 0, we would have , as , a contradiction. Moreover, since is bounded, there exists a convergent subsequence having the limit . Thus, . Letting and , the last equation yields . Since and 𝜶j > 0, we have for all that , which implies that for all . That is, .
Finally, we show part (c). According to [38, Page 203], it suffices to prove that for each , (i) if , then ; (ii) if then ; and if , then . Case (i) clearly follows from part (b), from which we have sjrj = 0 for all . By the definition (8) of S(f), sj > 0 for , and thus, rj = 0.
It remains to prove case (ii). To this end, we Let , , and show . Assume to the contrary that . Then, either or . Assume , then for any , since ∇Φ(f) is continuous at f∗, there exists δ ∈ (0, U/4) such that for all , there holds . By Lemma 2, there exists such that for k > K1, . Then for k > K1, if , we have , and hence, for all , . In this case, for all , and hence Lemma 3 ensures that (15) holds. Since for and , as , then there exists K2 > K1 such that if k > K2 and , we have for any . Therefore, for k > K2, if , then we have , for any . Similarly, if , for any , there exists K3 > K2 such that for k > K3, if , then (16) ensures that .
Since , there exists K4 > K3 such that if , Suppose for some n0. Let . If for some n, for all , set tn := K4, and hence . Clearly, we have if . Moreover, tn is a monotone increasing sequence. Then, either (a), (b). If it is the case (a), then for all k > t0. Thus, for m > l > t0 that for . This contradicts the fact that for . Hence, it must be the case (b). Since for , we have that for and for . It follows that for and for . Then, Lemma 2 ensures that for and for . Thus, we can find a convergent subsequence of such that with for and for . Since , we observe that , which ensures that . By part (a), is convergent, which implies that . Let . Thus, . It can be verified for any that . By [38, Page 203], f∗ is a minimizer of Φ over . Hence, Φ has two different minimizers f∗ and f∗∗ over the convex set . This contradicts the assumption that Φ has a unique minimizer on . Thus, we have that . ■
Here is the proof of Theorem 8.
Proof: From Proposition 9 and Proposition 10, we have that Φ satisfies conditions (i)-(iii). One can directly obtain that the relaxation sequence λk satisfies condition (iv).
By Theorem 7, to prove the convergence of SDP-BSREM algorithm with λk and Sk,i, it is sufficient to show that λk and Sk,i satisfy conditions (v) and (vi). To do this, for the subiteration-dependent preconditioner , one need to show that for all ,and converges for all since νk,i is a positive vector sequence and for k > k1 and .
For 𝜶k,i defined in (17), the sequence tk,i is increasing. By induction, we have that . Further, it can be shown that , and thus for all . Then we can obtain . By computing , we have that . Thus the series converges since . Therefore, for preconditioners P1 or M1 and relaxation λk, conditions (v) and (vi) are satisfied.
For 𝜶k,i defined in (18), we have that 𝜶k,i is monotone and . It can be shown that . Hence for precondition P2 or M2 and relaxation λk, conditions (v) and (vi) are satisfied. ■
Contributor Information
Jianfeng Guo, School of Computer Science and Engineering, Sun Yat-sen University, Guangzhou, 510275, China.
C. Ross Schmidtlein, Department of Medical Physics, Memorial Sloan Kettering Cancer Center, New York, NY 10065, USA.
Andrzej Krol, Departments of Radiology and Pharmacology, SUNY Upstate Medical University, 750 East Adams Street, Syracuse NY 13210, USA.
Si Li, School of Computer Science and Technology, Guangdong University of Technology, Guangzhou 510006, China.
Yizun Lin, Department of Mathematics, College of Information Science and Technology, Jinan University, Guangzhou 510632, China.
Sangtae Ahn, GE Research, Niskayuna, NY 12309, USA.
Charles Stearns, GE Healthcare, Waukesha, WI 53188, USA.
Yuesheng Xu, Department of Mathematics and Statistics, Old Dominion University, Norfolk, VA 23529, USA.
References
- [1].Shepp LA and Vardi Y, “Maximum likelihood reconstruction for emission tomography,” IEEE Trans. Med. Imag, vol. 1, no. 2, pp. 113–122, Oct. 1982. [DOI] [PubMed] [Google Scholar]
- [2].Lange K and Carson R, “EM reconstruction algorithms for emission and transmission tomography,” J. Comput. Assist. Tomogr, vol. 8, no. 2, pp. 306–316, 1984. [PubMed] [Google Scholar]
- [3].Ahn S, Ross SG, Asma E, Miao J, Jin X, Lishui Cheng SDW, and Manjeshwar1 RM, “Quantitative comparison of OSEM and penalized likelihood image reconstruction using relative difference penalties for clinical PET,” Phys. Med. Biol, vol. 60, no. 15, pp. 5733–5751, 2015. [DOI] [PubMed] [Google Scholar]
- [4].Hudson HM and Larkin RS, “Accelerated image reconstruction using ordered subsets of projection data,” IEEE Trans. Med. Imag, vol. 13, no. 4, pp. 601–609, Dec. 1994. [DOI] [PubMed] [Google Scholar]
- [5].Browne J and De Pierro AR, “A row-action alternative to the EM algorithm for maximizing likelihood in emission tomography,” IEEE Trans. Med. Imag, vol. 15, no. 5, pp. 687–699, Oct. 1996. [DOI] [PubMed] [Google Scholar]
- [6].Bertsekas DP, “A new class of incremental gradient methods for least squares problems,” SIAM J. Optim, vol. 7, no. 4, pp. 913–926, 1997. [Google Scholar]
- [7].De Pierro AR and Yamagishi MEB, “Fast EM-like methods for maximum” a posteriori” estimates in emission tomography,” IEEE Trans. Med. Imag, vol. 20, no. 4, pp. 280–288, Apr. 2001. [DOI] [PubMed] [Google Scholar]
- [8].Ahn S and Fessler JA, “Globally convergent image reconstruction for emission tomography using relaxed ordered subsets algorithms,” IEEE Trans. Med. Imag, vol. 22, no. 5, pp. 613–626, May 2003. [DOI] [PubMed] [Google Scholar]
- [9].Tsai Y-J, Bousse A, Ehrhardt MJ, Stearns CW, Ahn S, Hutton BF, Arridge S, and Thielemans K, “Fast quasi-Newton algorithms for penalized reconstruction in emission tomography and further improvements via preconditioning,” IEEE Trans. Med. Imag, vol. 37, no. 4, pp. 1000–1010, Apr. 2018. [DOI] [PubMed] [Google Scholar]
- [10].Rudin LI, Osher S, and Fatemi E, “Nonlinear total variation based noise removal algorithms,” Phys. D, vol. 60, no. 1–4, pp. 259–268, 1992. [Google Scholar]
- [11].Bredies K, Kunisch K, and Pock T, “Total generalized variation,” SIAM J. Imag. Sci, vol. 3, no. 3, pp. 492–526, 2010. [Google Scholar]
- [12].Geman S and McClure DE, “Statistical methods for tomographic image reconstruction,” Bull. Int. Statist. Inst, vol. 52, no. 4, pp. 5–21, 1987. [Google Scholar]
- [13].Mumcuoglu EÜ, Leahy RM, and Cherry SR, “Bayesian reconstruction of PET images: methodology and performance analysis,” Phys. Med. Biol, vol. 41, no. 9, pp. 1777–1807, 1996. [DOI] [PubMed] [Google Scholar]
- [14].Zhang Z, Ye J, Chen B, Perkins AE, Rose S, Sidky EY, Kao C-M, Xia D, Tung C-H, and Pan X, “Investigation of optimizationbased reconstruction with an image-total-variation constraint in PET,” Phys. Med. Biol, vol. 61, no. 16, pp. 6055–6084, Aug. 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Chambolle A and Pock T, “A first-order primal-dual algorithm for convex problems with applications to imaging,” J. Math. Imag. Vis, vol. 40, no. 1, pp. 120–145, 2011. [Google Scholar]
- [16].Krol A, Li S, Shen L, and Xu Y, “Preconditioned alternating projection algorithms for maximum a posteriori ECT reconstruction,” Inverse Problems, vol. 28, no. 11, p. 115005, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Li S, Zhang J, Krol A, Schmidtlein CR, Vogelsang L, Shen L, Lipson E, Feiglin D, and Xu Y, “Effective noise-suppressed and artifact-reduced reconstruction of SPECT data using a preconditioned alternating projection algorithm,” Med. Phys, vol. 42, no. 8, pp. 4872–4887, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Nuyts J, Bequé D, Dupont P, and Mortelmans L, “A concave prior penalizing relative differences for maximum-a-posteriori reconstruction in emission tomography,” IEEE Trans. Nucl. Sci, vol. 49, no. 1, pp. 56–60, Feb. 2002. [Google Scholar]
- [19].Wang G and Qi J, “Penalized likelihood PET image reconstruction using patch-based edge-preserving regularization,” IEEE Trans. Med. Imag, vol. 31, no. 12, pp. 2194–2204, Dec. 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].——, “Edge-preserving PET image reconstruction using trust optimization transfer,” IEEE Trans. Med. Imag, vol. 34, no. 4, pp. 930–939, Apr. 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Mumcuoglu EÜ, Leahy R, Cherry SR, and Zhou Z, “Fast gradient-based methods for bayesian reconstruction of transmission and emission PET images,” IEEE Trans. Med. Imag, vol. 13, no. 4, pp. 687–701, Dec. 1994. [DOI] [PubMed] [Google Scholar]
- [22].Lin Y, Schmidtlein CR, Li Q, Li S, and Xu Y, “A krasnoselskiimann algorithm with an improved EM preconditioner for PET image reconstruction,” IEEE Trans. Med. Imag, vol. 38, no. 9, pp. 2114–2126, Sep. 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Ehrhardt MJ, Markiewicz P, and Sch C-Bönlieb, “Faster PET reconstruction with non-smooth priors by randomization and preconditioning,” Phys. Med. Biol, vol. 64, no. 22, p. 225019, Nov. 2019. [DOI] [PubMed] [Google Scholar]
- [24].Yu DF and Fessler JA, “Edge-preserving tomographic reconstruction with nonlocal regularization,” IEEE Trans. Med. Imag, vol. 21, no. 2, pp. 159–173, Feb. 2002. [DOI] [PubMed] [Google Scholar]
- [25].Nesterov YE, “A method of solving a convex programming problem with convergence rate O(1/k2),” Sov. Math. Dokl, vol. 27, no. 2, pp. 372–376, 1983. [Google Scholar]
- [26].Beck A and Teboulle M, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM J. Imag. Sci, vol. 2, no. 1, pp. 183–202, 2009. [Google Scholar]
- [27].Zeng X, Shen L, and Xu Y, “A convergent fixed-point proximity algorithm accelerated by FISTA for the l0 sparse recovery problem,” in Imaging, Vision and Learning Based on Optimization and PDEs, Tai X-C, Bae E, and Lysaker M, Eds. Cham, Switzerland: Springer Int. Publishing, 2018, pp. 27–45. [Google Scholar]
- [28].Kim D, Ramani S, and Fessler JA, “Combining ordered subsets and momentum for accelerated X-ray CT image reconstruction,” IEEE Trans. Med. Imag, vol. 34, no. 1, pp. 167–178, Jan. 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Li Q, Asma E, Ahn S, and Leahy RM, “A fast fully 4-D incremental gradient reconstruction algorithm for list mode PET data,” IEEE Trans. Med. Imag, vol. 26, no. 1, pp. 58–67, Jan. 2007. [DOI] [PubMed] [Google Scholar]
- [30].Schmidtlein CR, Lin Y, Li S, Krol A, Beattie BJ, Humm JL, and Xu Y, “Relaxed ordered subset preconditioned alternating projection algorithm for PET reconstruction with automated penalty weight selection,” Med. Phys, vol. 44, no. 8, pp. 4083–4097, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Moses WW, “Fundamental limits of spatial resolution in PET,” Nucl. Instrum. Methods Phys. Res. A, Accel. Spectrom. Detect. Assoc. Equip, vol. 648, pp. S236–S240, Aug. 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Berthon B, Häggström I, Apte A, Beattie BJ, Kirov AS, Humm JL, Marshall C, Spezi E, Larsson A, and Schmidtlein CR, “PETSTEP: generation of synthetic PET lesions for fast evaluation of segmentation methods,” Phys. Med, vol. 31, no. 8, pp. 969–980, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].Ross S and Thielemans K, General Electric PET Toolbox Release 5.0, 2011–2019.
- [34].A. A. of Physicists in Medicine et al. , PET phantom instructions for evaluation of PET image quality, 2012.
- [35].MacFarlane CR, “Acr accreditation of nuclear medicine and PET imaging departments,” J. Nucl. Med. Technol, vol. 34, no. 1, pp. 18–24, Mar. 2006. [PubMed] [Google Scholar]
- [36].Kim K, Kim D, Yang J, El Fakhri G, Seo Y, Fessler JA, and Li Q, “Time of flight pet reconstruction using nonuniform update for regional recovery uniformity,” Med. Phys, vol. 46, no. 2, pp. 649–664, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Nesterov YE, Introductory Lectures on Convex Optimization: A Basic Course New York: Kluwer, 2004. [Google Scholar]
- [38].Polyak BT, Introduction to optimization New York, NY, USA: Optim. Softw., 1987. [Google Scholar]