

Abstract
High-dimensional neural recordings across multiple brain regions can be used to establish functional connectivity with good spatial and temporal resolution. We designed and implemented a novel method, Latent Dynamic Factor Analysis of High-dimensional time series (LDFA-H), which combines (a) a new approach to estimating the covariance structure among high-dimensional time series (for the observed variables) and (b) a new extension of probabilistic CCA to dynamic time series (for the latent variables). Our interest is in the cross-correlations among the latent variables which, in neural recordings, may capture the flow of information from one brain region to another. Simulations show that LDFA-H outperforms existing methods in the sense that it captures target factors even when within-region correlation due to noise dominates cross-region correlation. We applied our method to local field potential (LFP) recordings from 192 electrodes in Prefrontal Cortex (PFC) and visual area V4 during a memory-guided saccade task. The results capture time-varying lead-lag dependencies between PFC and V4, and display the associated spatial distribution of the signals.
1. Introduction
New electrode arrays for recording electrical activity generated by large networks of neurons have created great opportunities, but also great challenges for statistical machine learning (e.g., Steinmetz et al., 2018). For example, Local Field Potentials (LFPs) are signals that represent the bulk activity in relatively small volumes of tissue (Buzsáki et al., 2012; Einevoll et al., 2013), and they have been shown to correlate substantially with the BOLD fMRI brain imaging signal (Logothetis et al., 2001; Magri et al., 2012). Typical LFP data sets may have dozens to hundreds of time series in each of two or more brain regions, recorded simultaneously across many experimental trials. A motivating example in this paper is LFP recordings from a prefrontal cortex (PFC) and visual area V4 during a visual working memory task. V4 has been reported to retain higher-order information (e.g., color and shape) and attention in visual processing (Fries et al., 2001; Orban, 2008), while PFC is considered to exert cognitive control in working memory (Miller and Cohen, 2001). Despite their spatial distance and functional difference, these regions have been presumed to cooperate during visual working memory tasks. Various approaches have been used to track the interaction among brain regions Adhikari et al. (2010); Buesing et al. (2014); Gallagher et al. (2017); Hultman et al. (2018); Jiang et al. (2015). In particular, delay-specific theta synchrony led by PFC has been discovered during visual memory tasks (Liebe et al., 2012; Sarnthein et al., 1998).
Because many functional interactions among brain regions are transient, it is highly desirable to have methods that accommodate non-stationary behavior in the multivariate time series recorded in each region. We report here an extension of Gaussian process factor analysis (GPFA, Yu et al., 2009) to two or more groups of time series, where the main interest is non-stationary cross-group interaction; furthermore, the multivariate noise within groups can have both spatial covariation and non-stationary temporal covariation. Here, spatial covariation refers to dependence among the time series and, in the neural context, this results from the spatial arrangement of the electrodes, each of which records one of the time series. Our approach uses probabilistic CCA, but the framework allows rich spatiotemporal dependencies. These generalizations come at a cost: we now have a high-dimensional time series problem within each brain region together with a high-dimensional covariance structure. We solve these high-dimensional problems by imposing sparsity of the dominant effects, building on Bong et al. (2020), which treats the high-dimensional covariance structure in the context of observational white noise, and by incorporating banded covariance structure as in Bickel and Levina (2008). We thus call our method Latent Dynamic Factor Analysis of High-dimensional time series, LDFA-H.
In a simulation study, based on realistic synthetic time series, we verify the recovery of cross-region structure even when some of our assumptions are violated, and even in the presence of high noise. We then apply the method to 192 LFP time series recorded simultaneously from both Prefrontal Cortex (PFC) and visual area V4, during a memory task, and find time-varying cross-region dependencies.
2. Latent Dynamic Factor Analysis of High-dimensional time series
We treat the case of two groups of time series observed, repeatedly, N times. Let and be p1 and p2 recordings at time t in each of the two groups, for t = 1, …, T. As in Yu et al. (2009), we assume that a q-dimensional latent factor drives each group, here, each brain region, according to the linear relationship
| (1) |
for brain region k = 1, 2, where are mean vectors, are matrices of constant factor loadings, and are errors centered at zero (independently of the latent vectors Z). We are interested in the pairwise cross-group dependencies of the latent vectors and , for f = 1, …, q. As in (Bong et al., 2020), we assume that the time series of these latent vectors follows a multivariate normal distribution
| (2) |
where Σf describes all of their simultaneous and lagged dependencies, both within and between the two vectors. We assume the N sets of random vectors (ϵ, Z) are independent and identically distributed. Fig. 1a illustrates the dependence structure of this model. We let Pf be the correlation matrix corresponding to Σf, and write its inverse as
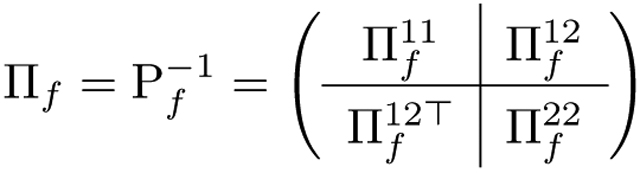 |
(3) |
where and are the scaled auto-precision matrices and is the scaled cross-precision matrix. We now assume finite-range partial auto-correlation and cross-correlation for , so that , and in Equation (3) have a banded structure. Specifically, for k, l = 1, 2, we assume there is a value such that is a -diagonal matrix. Because our goal is to address the cross-region connectivity and lead-lag relationship, we are particularly interested in the estimation of for each latent factor f = 1, …, q. Note that the non-zero elements , depicted as the red star in the expanded display within Fig. 1b, determine associations between the latent pair and , which are simultaneous when t = s and lagged when t ≠ s.
Figure 1: LDFA-H model.
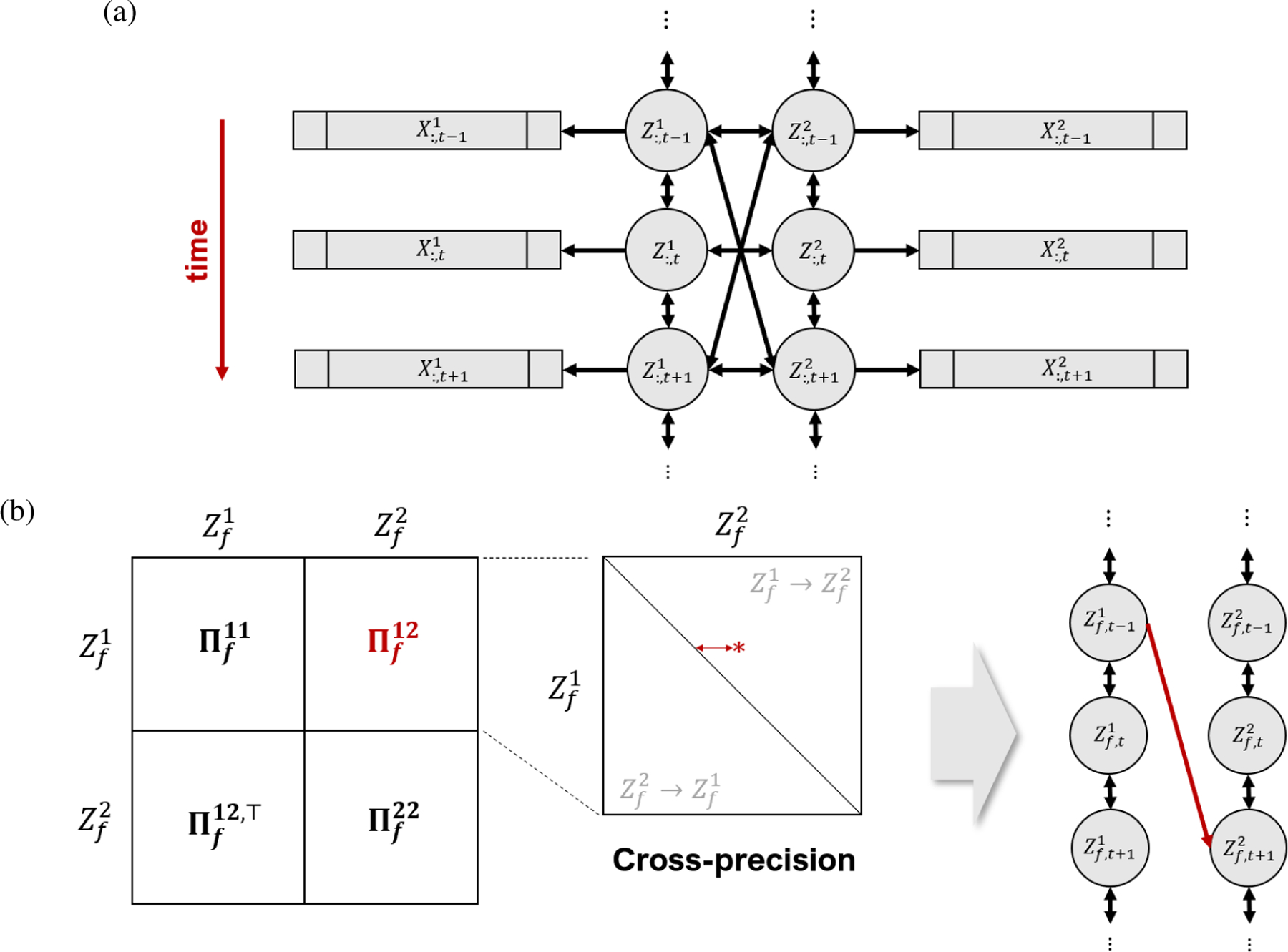
(a) Dynamic associations between vectors and are summarized by the dynamic associations between their associated 1D latent variables and . (b) When a significant cross-precision entry is identified, e.g., the red star in the expanded view of , its coordinates and distance from the diagonal indicate at what time in the experiment connectivity between two brain areas occurs, and at what lead or lag. Here the red star is in the upper diagonal of , which means that, at this particular time, region 1 leads region 2, or in short (a non-zero entry in the lower diagonal would mean ). We represent this association by the red arrow on the right-most plot, with a lag of two units of time for illustration.
Finally, we model the noise in Eq. (1) as a Gaussian random vector
| (4) |
where we allow Φk to have non-zero off-diagonal elements to account for within-group spatiotemporal dependence. We assume Φk can be written in Kronecker product form
| (5) |
where and are the temporal and spatial components of Φk, as is often assumed for spatiotemporal matrix-normal distributions, e.g., (Dawid, 1981). Although this is a strong assumption, implying, for instance, that the auto-correlation of every is proportional to , we regard Φk as a nuisance parameter: our primary interest is Σf in Eq. (2). We also assume an auto-regressive order at most , so that is a -diagonal matrix. In our simulation we show that we can recover Σf accurately even when the Kronecker product and bandedness assumptions fail to hold.
The model in Equations (1)–(5) generalizes other known models. First, when q = 1, and Z1 = Z2 remains constant over time, in the noiseless case (ϵk = 0), it reduces to the probabilistic CCA model of Bach and Jordan (2005); see Theorem 2.2 of Bong et al. (2020) Thus, model (1)–(5) can be viewed as a denoising, multi-level and dynamic version of probabilistic CCA. Second, when k = 1, the Gaussian processes are stationary, and the ϵ vectors are white noise, (1)–(5) reduces to GPFA (Yu et al., 2009). Thus, (1)–(5) is a two-group, nonstationary extension of GPFA that allows for within-group spatio-temporal dependence.
Identifiability and sparsity constraints
Despite the structure imposed on Φk in Eq. (5), parameter identifiability issues remain. Our model in Eqs. (1), (2) and (4) induces the marginal distribution of the observed data (X1, X2):
| (6) |
where S is the marginal covariance matrix given by:
| (7) |
The family of parameters
| (8) |
where , induce the same marginal distribution in Eq. (6), for all α1, (notice that is the original parameter). Preliminary analysis of LFP data indicated that strong cross-region dependence occurs relatively rarely. We therefore resolve this lack of identifiability by choosing the solution given by maximizing the likelihood with an L1 penalty, under the assumption that the inverse cross-correlation matrix is a sparse -diagonal matrix.
Latent Dynamic Factor Analysis of High-dimensional time series (LDFA-H)
Given N simultaneously recorded pairs of neural time series {X1[n], X2[n]}n=1, …, N, the maximum penalized likelihood estimator (MPLE) of the inverse correlation matrix of the latent variables solves
| (9) |
where the log-likelihood is
| (10) |
with S defined in Eq. (7), and the constraints are
| (11) |
for factor f = 1, …, q and brain region k = 1, 2. The first constraint forces the corresponding to zero and thus imposes a banded structure for , and the second assigns the same sparsity constraint λf on the off-diagonal elements of . Finally, to make calibration of tuning parameters computationally feasible, we set the bandwidth for the latent precisions and the noise precisions within each region to a single value hauto, we set the bandwidth for the latent precisions across regions to a value hcross, and we set the sparsity parameters to a value λcross, i.e.,
for each factor f = 1, …, q and region k = 1, 2. The bandwidths are chosen using domain knowledge and preliminary data analyses. We determine the remaining parameters λcross and q by 5-fold cross-validation (CV).
Solving Eq. (9) requires S−1. Because it is not available analytically and a numerical approximation is computationally prohibitive, we solve Eq. (9) using an EM algorithm (Dempster et al., 1977). Let θ(r) be the parameter estimate at the r-th iteration. We consider the data {X1[n], X2[n]}n=1, …, N to be incomplete observations of {X1[n], Z1[n], X2[n], Z2[n]}n=1, …, N. In the E-step, we estimate the conditional mean and covariance matrix of each {Z1[n], Z2[n]} with respect to {X1[n], X2[n]} and θ(r). Given these sufficient statistics, the problem of computing the MPLE decomposes into two separate minimizations of
the negative log-likelihood of Σf, w.r.t. the latent factor model (Eq. (2)) and
the negative log-likelihood of , , , , β1, β2, μ1, μ2 w.r.t. the observation model (Eqs. (1) and (4)).
With the noise correlation and latent factor correlation disentangled, the M-step reduces to easy sub-problems. For example, the minimization with respect to Σf is a graphical Lasso problem (Friedman et al., 2007) and the minimization with respect to and is a maximum likelihood estimation of a matrix-variate distribution (Dawid, 1981). We thus obtain an affordable M-step, and alternating E and M-steps produces a solution to the MPLE problem.
We derive the full formulations in Appendix A. Its computational cost is inexpensive: a single iteration of E and M-steps on our cluster server (with 11 Intel(R) Xeon(R) CPU 2.90GHz processors) took in average less than 45 seconds, applied to the experimental data in Section 3.2. A single fit on the same data took 42 iterations for around 30 minutes until P and {β1, β2} converged under threshold 1e-3 and 1e-5, respectively. The code is provided at https://github.com/HeejongBong/ldfa.
3. Results
One major novelty of our method is its accounting for auto-correlated noise in neural time series to better estimate cross-region associations in CCA type analysis. This is illustrated in Section 3.1 based on simulated data. In Section 3.2, we apply LDFA-H to experimental data to examine the lead-lag relationships across two brain areas and the spatial distribution of factor loadings.
3.1. LDFA-H retrieves cross-correlations even when noise auto-correlations dominate
We simulated N = 1000 i.i.d. neural time series Xk of duration T = 50 from Eq. (1) for brain regions k = 1, 2. The latent time series Zk were generated from Eq. (2) with q = 1 pair of factors and correlation matrix P1 depicted in Fig. 2a. The noise ϵk was taken to be the N = 1000 trials of the experimental data analyzed in Section 3.2, first permuted to remove cross-region correlations, then contaminated with white noise to modulate the strength of noise correlation relative to cross-region correlations. The resulting temporal noise correlation matrices, found by averaging correlations over all pairs of simulated time series, are shown in Fig. 2b, for four levels of white noise contamination. The magnitudes of cross-region correlation and within-region noise auto-correlation are quantified by the determinant of each matrix, known as the generalized variance (Wilks, 1932); their logarithms are provided atop the panels in Fig. 2a and Fig. 2b. Generalized variance ranges from 0 (identical signals) to 1 (independent signals). Thus, larger negative values indicate stronger within-region noise correlation (see B). Other simulation details are in B.
Figure 2: Simulation settings.
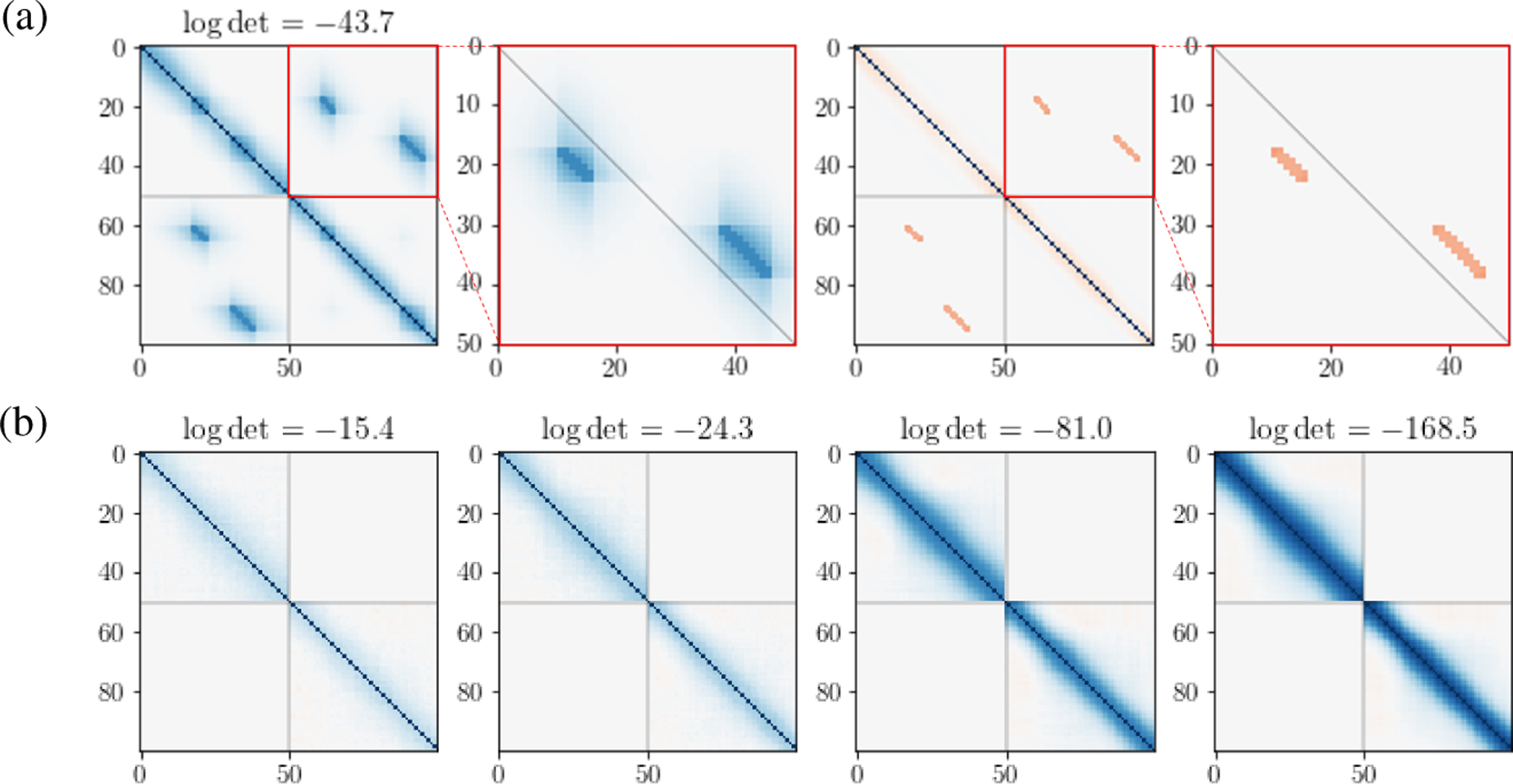
(a) (Left to right panels) True correlation matrix P1 for latent factors and from model in Eq. (2); close-up of the cross-correlation matrix; corresponding precision matrix ; and close-up of cross-precision matrix (Eq. (3)). Matrix axes represent the duration, T = 50 ms, of the time series. Factors Z1 and Z2 are associated in two epochs: Z2 precedes Z1 by 7ms from t = 13 to 19ms, and Z1 precedes Z2 by 7ms from t = 33 to 42ms. (b) Noise auto-correlation matrices (Eq. (5)) for pairs of simulated time series at four strength levels. log det in (a) and (b) measure correlation strengths.
We note that the simulation does not satisfy some of the model assumptions in Section 2. The noise vectors ϵk are not matrix-variate distributed as in Eqs. (4) and (5) and the derived does not satisfy a banded structure as in Eq. (9). Also, the latent partial auto-correlations (Fig. 2) are not banded as assumed in Eq. (9).
We applied LDFA-H with q = 1 factor, hcross = 10, hauto equal to the maximum order of the auto-correlations in the 2000 observed simulated time series, and λcross determined by 5-fold CV. Fig. 3 shows LDFA-H cross-precision matrix estimates corresponding to the four level of noise correlation shown in Fig. 2b. They closely match the true shown in the right most panel of Fig. 2a.
Figure 3: Simulation results: LDFA-H cross-precision matrix estimates.
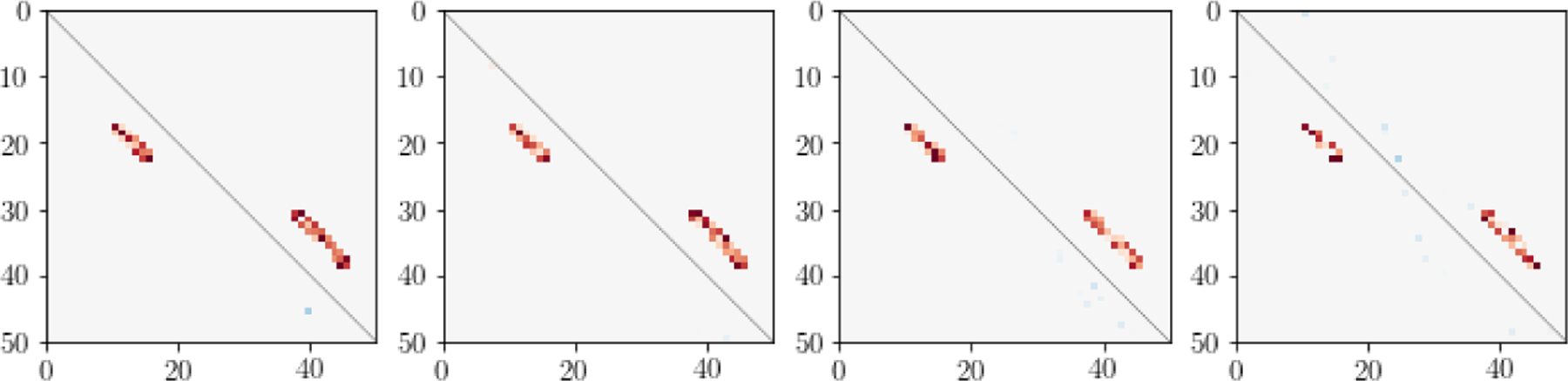
Estimates of , shown in the right-most panel of Fig. 2a, using LDFA-H, for the four noise auto-correlation strengths shown in Fig. 2b. LDFA-H identified the true cross-area connections at all noise strengths.
We also applied five other methods to estimate cross-region connections in the simulated data. They include the popular averaged pairwise correlation (APC); correlation of averaged signals (CAS); and CCA (Hotelling, 1936), applied to the NT observed pairs of multivariate random vectors to estimate the cross-correlation matrix between the canonical variables; as well as DKCCA (Rodu et al., 2018) and LaDynS (Bong et al. (2020)). The first four methods do not explicitly provide cross-precision matrix estimates, so we display their cross-correlation matrix estimates in Fig. 4, along with LDFA-H cross-correlation estimates in the last row. It is clear that only LDFA-H successfully recovered the true cross-correlations shown in the second panel of Fig. 2a, at all auto-correlated noise levels.
Figure 4: Simulation results: cross-correlation matrix estimates.
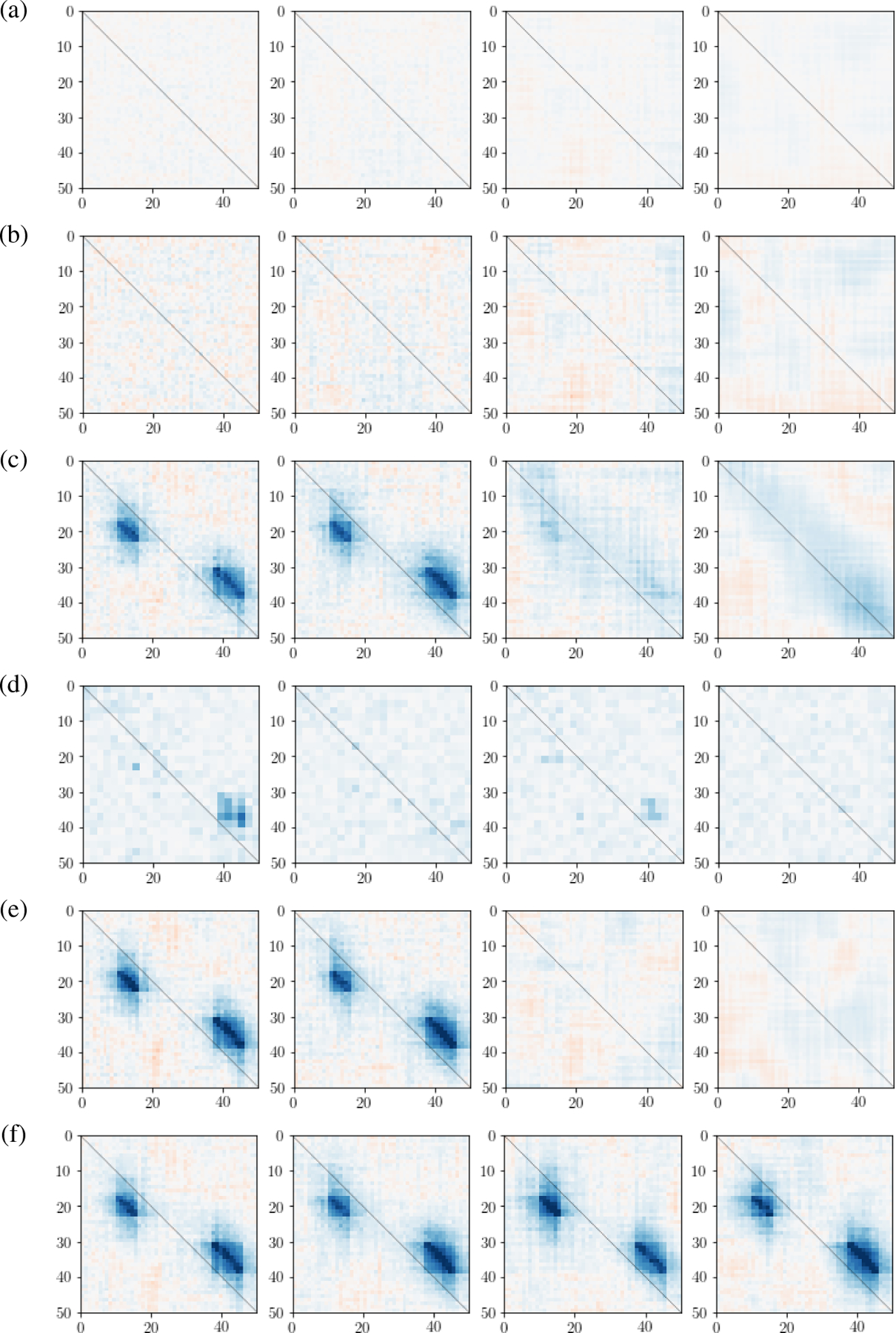
Estimates of under four noise correlation levels using (a) averaged pairwise correlation (APC), (b) correlation of averaged signal (CAS), (c) canonical correlation analysis (CCA, Hotelling (1936)), (d) dynamic kernel CCA (DKCCA, Rodu et al. (2018)), (e) LaDynS (Bong et al. (2020)), and (f) LDFA-H. Only LDFA-H successfully recovered the true cross-correlation at all noise auto-correlation strengths.
3.2. Experimental Data Analysis from Memory-Guided Saccade Task
We now report the analysis of LFP data in areas PFC and V4 of a monkey during a saccade task, provided by Khanna et al. (2020). One trial of the experiment consisted of four stages: (i) fixation: the animal fixated at the center of the screen; (ii) cue: a cue appeared on the screen randomly at one of eight locations; (iii) delay: the animal had to remember the cue location while maintaining eye fixation; (iv) choice: the monkey made a saccade to the remembered cue location. We focused our analysis on the 500 ms delay period, when the animal both processed cue information and prepared a saccade. LFP data were recorded for N = 1000 trials by two 96-electrode Utah arrays implanted in PFC and V4, β band-passed filtered, down-sampled from 1 kHz to 100 Hz.
We applied LDFA-H using hauto = hcross = 10, corresponding to 100 ms (at 100 Hz); the LFP β-power envelopes have frequencies between 12.5Hz to 30Hz, and hauto = 10 enables the slowest filtered signal to complete one full oscillation period. The other tuning parameters were determined by 5-fold CV over λcross ∈ {0.0002, 0.002, 0.02, 0.2} and q ∈ {5, 10, 15, 20, 25, 30}, yielding optimal values λcross = 0.02 and q = 10. We also regularize the diagonal elements, due to the otherwise excessively smooth β-power envelopes (see our code or Bong et al. (2020) for details). The fitted factors were ranked based on the Frobenius norms of their covariance matrices ; norms are plotted versus f in decreasing order in Fig. C.1, and of the top three factors are provided above each panel in Fig. 5a. The estimated cross-precison matrices between two brain regions corresponding to the top three factors are shown in Fig. 5a. Note that a positive entry in the precision matrix represents negative association between two regions. We also summarized, for each factor f, the temporal information flow at time t from V4 to PFC and to V4 from PFC with and , respectively, where is the inverse correlation matrix estimate in Eq. (9). Fig. 5d displays smoothed If,PFC→V4(t) and If,V4→PFC(t) as functions of t for the top three factors. Lead-lag relationships between V4 and PFC change dynamically over time, and the information flow tends to peak either early in the delay period, when the animal must remember the cue, or later, when it must make a saccade decision. The dominant first factor captures a flow from V4 to PFC centered around 200 milliseconds into the task and a flow from PFC to V4 centered around 320 milliseconds. Factor loadings (subsampled over space) for the 96 V4 and PFC electrodes are shown in Fig. 5b and Fig. 5c, respectively, for the top three factors (first three columns of the estimate of βk in Eq. (9), with area k = 1 being V4 and k = 2 being PFC), arranged spatially according to electrode positions on the Utah array. The factors have different spatial modes over the physical space of the Utah array. Confirmation of these patterns would require additional data and analyses.
Figure 5: Experimental data results for the top 3 factors.
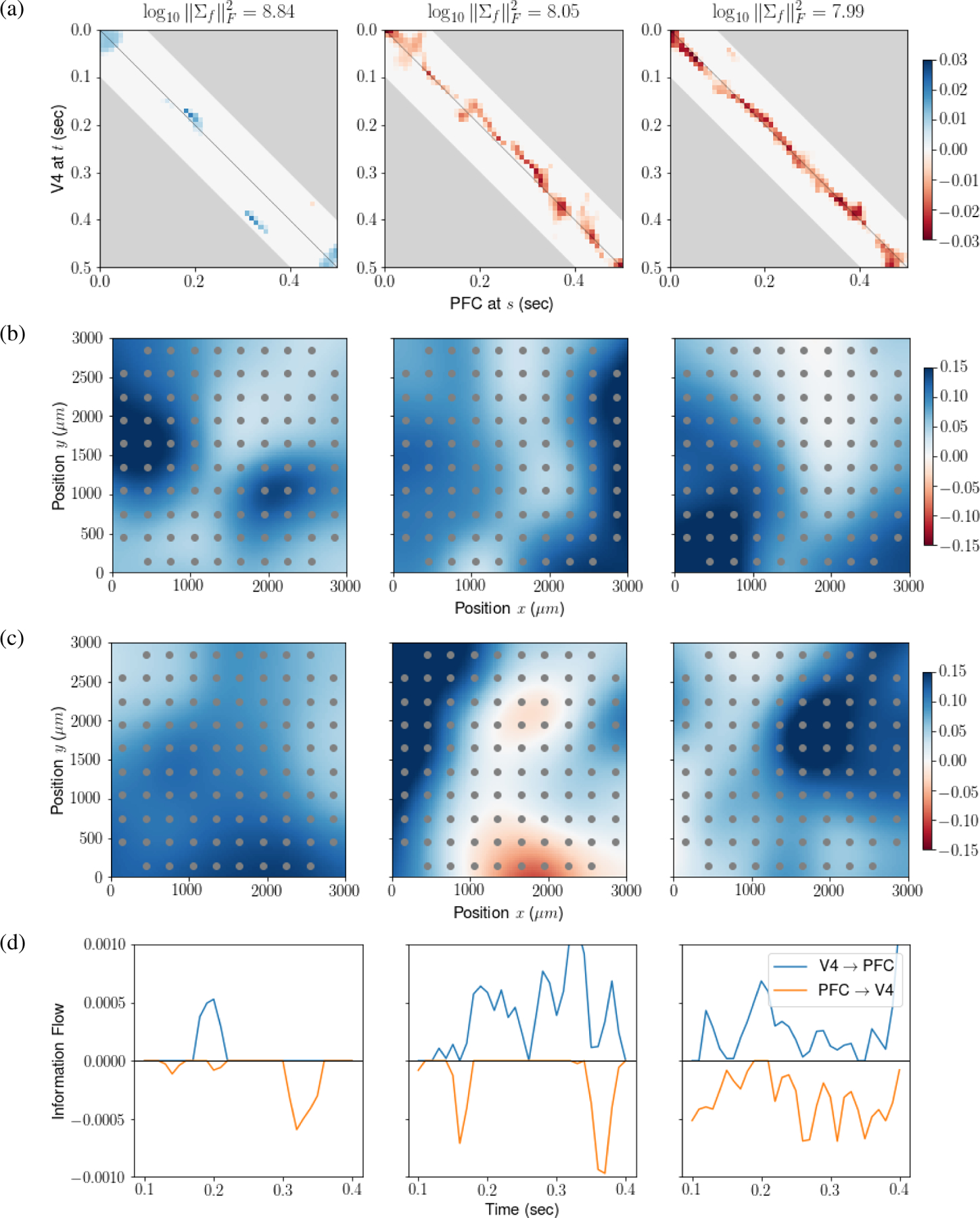
(a) Cross-precision matrices. Blue represents positive precision matrix entries, corresponding to negative association. Factors have different connectivity patterns over the experimental trials. , written atop the panels, measures the strength of each factor. The first factor is more than 6 times larger than the second and third, and displays activity in V4 leading PFC centered around 200 milliseconds and activity in PFC leading V4 centered around 320 milliseconds post cue disappearance. This is also shown in panel (d). (b,c) Factor loadings, smoothed and color coded, plotted on the electrode coordinates (μm). Here, positivity is arbitrary, due to identifiability. Panels (b) and (c) display loadings for the V4 and PFC arrays, respectively. The first factor has activity in V4 centered in two distinct subregions of the array, while activity in PFC is more broadly distributed. (d) Dynamic information flow in the directions V4 → PFC (blue) and PFC → V4 (orange).
4. Conclusion
To identify dynamic interactions across brain regions we have developed LDFA-H, a nonstationary, multi-group extension of GPFA that allows for within-group spatio-temporal dependence among high-dimensional neural recordings. We applied the method to data during a memory task and found interesting, intuitive results. Although we treated the two-group case, and applied it to interactions across two brain regions, several groups can be handled with straightforward modifications. The approach could, in principle, be applied to many different types of time series, but it has some special features: first, like all methods based on sparsity, it assumes a small number of large effects are of primary interest; second, it uses repetitions, here, repeated trials, to identify time-varying dependence; third, because the within-group spatio-temporal structure is not of interest, the method can remain useful even with some modest within-group model misspecification.
Several restrictive assumptions of LDFA-H, as defined, were helpful here but could be modified for other applications. One is the Kronecker-product form of the noise process. In our simulation study, using a realistic scenario, we showed that LDFA-H can be effective even when the Kronecker-product assumption is violated, but in other cases it may be problematic. In some problems, space and/or time can be decomposed into windows within which the assumption is more reasonable (see Leng and Tang, 2012; Zhou, 2014). Another potentially bothersome assumption is independence between latent factors. It would be possible to include covariance matrix parameters between the factors, but then the model will get computationally prohibitive even with a moderate factor size. State-space models (Buesing et al., 2014; Linderman et al., 2019; Yang et al., 2016) have potential but, to be comparable to LDFA-H, they would have to accommodate nonstationary lead-lag behavior. Computationally efficient methods for identifying time-varying relationships is a vital goal in the analysis of neural data from multiple brain regions.
We applied LDFA-H to LFP data. In contrast, GPFA has been applied mainly to neural spike count data, and it is of course possible to apply LDFA-H to spike counts, as well. However, we have been struck by the strong attenuation of effects due to Poisson-like noise, as discussed in Vinci et al. (2018) and references therein. A version of LDFA-H built for Poisson-like counts, or for point processes, could be the subject of additional research. It may also be advantageous to model spatial dependence explicitly, perhaps based on physical distance between electrodes, analogously to what was done in Vinci et al. (2018), and there may be, in addition, important simplifications available in the temporal structure. It would also be helpful to have additional statistical inference procedures for assessing effects. In the future, we hope to pursue these possible directions, and refine the application of this promising approach to the analysis of high-dimensional neural data.
Broader Impact
While progress in understanding the brain is improving life through research, especially in mental health and addiction, in no case is any brain disorder well understood mechanistically. Faced with the reality that each promising discovery inevitably reveals new subtleties, one reasonable goal is to be able to change behavior in desirable ways by modifying specific brain circuits and, in animals, technologies exist for circuit disruptions that are precise in both space and time. However, to determine the best location and time for such disruptions to occur, with minimal off-target effects, will require far greater knowledge of circuits than currently exists: we need good characterizations of interactions among brain regions, including their timing relative to behavior. The over-arching aim of our research is to provide methods for describing the flow of information, based on evolving neural activity, among multiple regions of the brain during behavioral tasks. Such methods can lead to major advances in experimental design and, ultimately, to far better treatments than currently exist.
Acknowledgments and Disclosure of Funding
Bong, Liu, Ventura, and Kass are supported in part by NIMH grant R01 MH064537. Smith is supported in part by NIMH grant R01 MH118929. Ren is supported in part by NSF grant DMS 1812030.
A EM-algorithm to fit LDFA-H (Section 2)
Initialization
Let be the initial parameter value. Since the MPLE objective function for LDFA-H given in Eq. (9) is not guaranteed convex, an EM-algorithm may find a local minimum according to a choice of the initial value. Hence a good initialization is crucial to a successful estimation. Here we suggest an initialization by a canonical correlation analysis (CCA).
Let {X1[n], X2[n]}n=1, …, N be N simultaneously recorded pairs of neural time series. We can view them as NT recorded pairs of multivariate random vectors . We obtain and by CCA as follows:
| (A.1) |
where
| (A.2) |
According to the equivalence between CCA and probablistic CCA shown by A. Anonymous, it gives an estimate of the first latent factors
| (A.3) |
for n = 1, …, N and k = 1, 2. The initial second latent factors and the corresponding factor loading is similarly set by the second pair of canonical variables, and so on. Then we assign the empirical covariance matrix of to the initial latent covariance matrix for f = 1, …, q and the matrix-variate normal estimate (Zhou, 2014) on to and for k = 1, 2. Along , the above parameters comprises the initial parameter set .
However, we cannot run an E-step on the above parameter set because is not invertible. We instead pick one of its unidentifiable parameter sets , defined in Eq. (8), with all ’s and ’s invertible. Specifically, we take
| (A.4) |
for f = 1, …, q and k = 1, 2 where λmin(A) is the smallest eigenvalue of symmetric matrix A. Henceforth, we notate by . For t = 1, 2, …, we iterate the following E-step and M-step until convergence.
Another promising initialization is by finding time (t, s) on which the canonical correlation between and maximizes. i.e., we initialize and by
| (A.5) |
where
| (A.6) |
for (t, s) ∈ [T] × [T]. Then the other parameters are initialized as above. We can even take an ensemble approach in which we fit LDFA-H on different initialized values and pick the estimate with the minimum cost function (Eq. (9)).
Now, for r = 1, 2, …, we alternate an E-step and an M-step until the target parameter Πf convergences.
E-step
Given from the previous iteration, the conditional distribution of latent factors Z1[n] and Z2[n] with respect to observed data X1[n] and X2[n] on trial n = 1, …, N follows
| (A.7) |
where
| (A.8) |
and
| (A.9) |
given
| (A.10) |
for f, g = 1, …, q.
M-step
We find which maximize the conditional expectation of the penalized likelihood under the same constraints in Eq. (9), i.e.
| (A.11) |
where p is the probability density function of our model in Eqs. (1), (4) and (5) and the expectation follows the conditional distribution in Eq. (A.7). Taking a block coordinate descent approach, we solve the optimization problem by alternating M1 – M4.
- M1: With respect to latent precision matrices Ωf, Eq. (A.11) reduces to a graphical Lasso problem,
for each f = 1, …, q where . The graphical Lasso problem is solved by the P-GLASSO algorithm by Mazumder et al. (2010).(A.12) - M2: With respect to Γk, Eq. (A.11) reduces to an estimation of matrix-variate normal model (Zhou, 2014). The estimation problem can be formulated as
and(A.13)
for each k = 1, 2 where and is the empirical mean of a random matrix A. The estimation of under the bandedness constraint is tractable with modified Cholesky factor decomposition approach with bandwidth using the procedure by Bickel and Levina (2008).(A.14) - M3: With respect to βk, Eq. (A.11) reduces to a quadratic program
where is the (t, s) entry in and is the empirical covariance matrix between random vectors A and B. The analytic form of the solution is given by(A.15) (A.16) - M4: With resepct to μk, it is straight-forward that Eq. (A.11) yields
B Simulation details (Section 3)
We simulated realistic data with known cross-region connectivity as follows. Simulating q = 1 pair of latent time-series Zk from Equation (2), we introduced an exact ground-truth for the inverse cross-correlation matrix by setting:
| (B.1) |
where D1 and D2 are diagonal matrices with elements and , which ensures that the matrix on the right hand side is positive definite. The matrix on the left hand side contains the auto-precision matrices of the two latent time series, with elements simulated from the squared exponential function:
| (B.2) |
with c1 = 0.105 and c2 = 0.142, chosen to match the observed LFPs auto-correlations in the experimental dataset (Section 3.2). We added the regularizer λIT, λ = 1, to render Pkk invertible.
We designed the true inverse cross-correlation matrix Π12 to induce lead-lag relationship between Z1 and Z2 in two epochs as depicted in the right-most panel of Fig. 2a. Specifically, the elements of Π12 were set:
| (B.3) |
where the association intensity r = 0.6 was chosen to match our cross-correlation estimate in the experimental data (Section 3.2). Finally, we rescaled to have diagonal elements equal to one. The corresponding factor loading vector was randomly generated from standard multivariate normal distribution and then scaled to have .
We generated the noise ϵk from the N = 1000 trials of the experimental data analyzed in Section 3.2. First, we permuted the trials in one region to remove cross-region correlations. Let {Y1[n], Y2[n]}n=1, …, N be the permuted dataset. Then we contaminated the dataset with white noise to modulate the strength of noise correlation relative to cross-region correlations. i.e.
| (B.4) |
where and wer the empirical mean and covariance matrix of , respectively, for k = 1, 2, t = 1, …, T. The noise auto-correlation level was modulated by λϵ ∈ {2.78, 1.78, 0.44, 0.11}. We also obtained Σ1 by scaling P1 so that . Putting all the pieces together, we generated observed time series by Eq. (1).
C Experimental data analysis details (Section 3.2)
The strength of each factor, which is characterized by Σf, is shown in Fig. C.1.
We also examined an alternative definition of information flow, using non-stationary regresssion in the spirit of Granger causality. For the latent factor f in V4 at time t, we use partial R2, effectively comparing the full regression model using the full history of latent variables in both area,
with the reduced model using history of latent variables in V4 only,
The partial R2 for on given summarizes the contribution of PFC history to V4, after taking account of the autocorrelation in V4, and thus can be viewed as information flow from V4 to PFC at time t. Dynamic information flow from V4 to PFC is defined similarly. The results shown in Fig. C.2 are consistent with those in Fig. 5d.
Figure C.1:
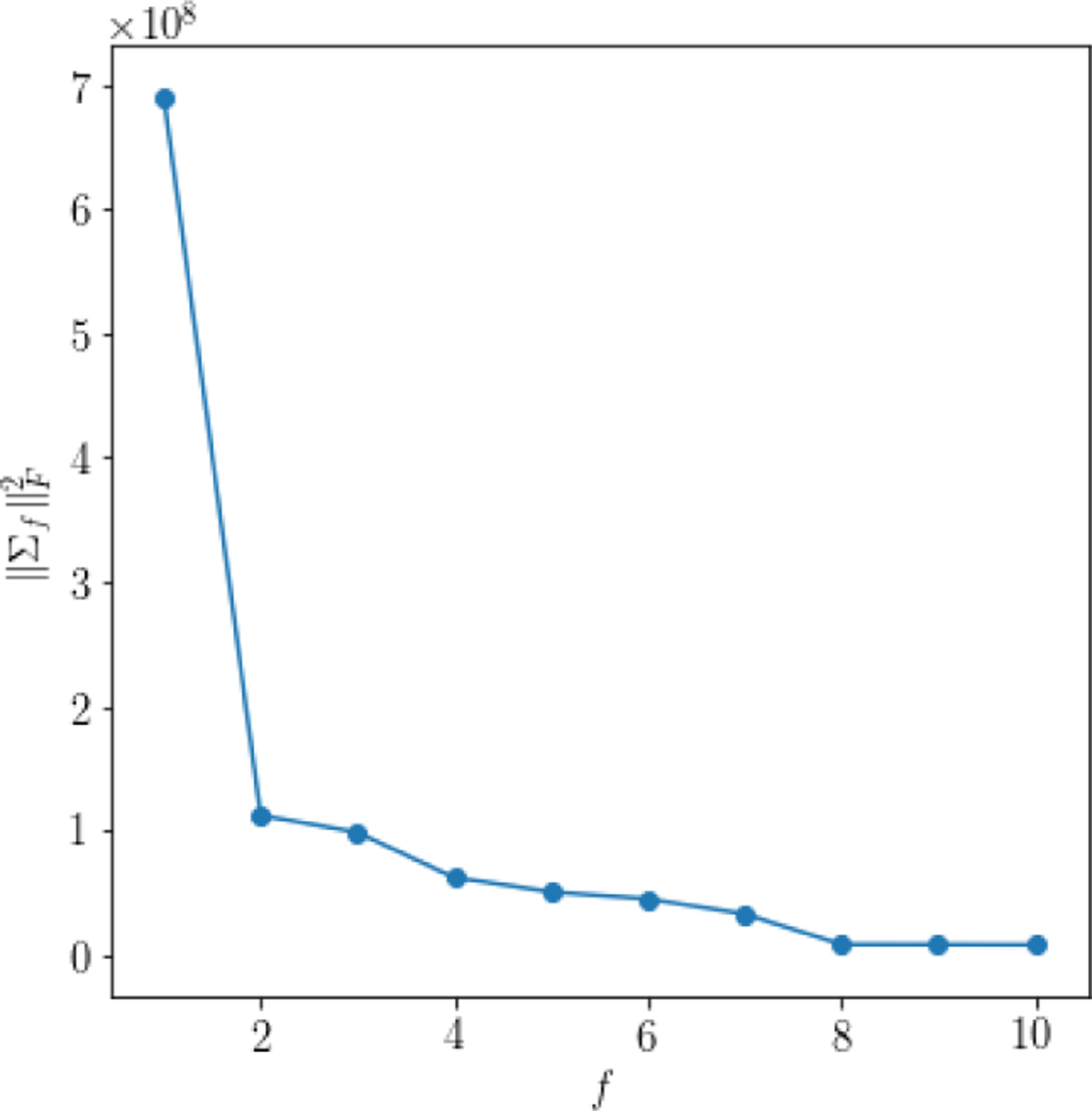
Squared Frobenius norms of covariance matrix estimates, , for all factors f = 1, …, 10. Notice that the amplitudes of the top four factors dominate the others.
Figure C.2: Information flow by partial R2 for the top three factors.
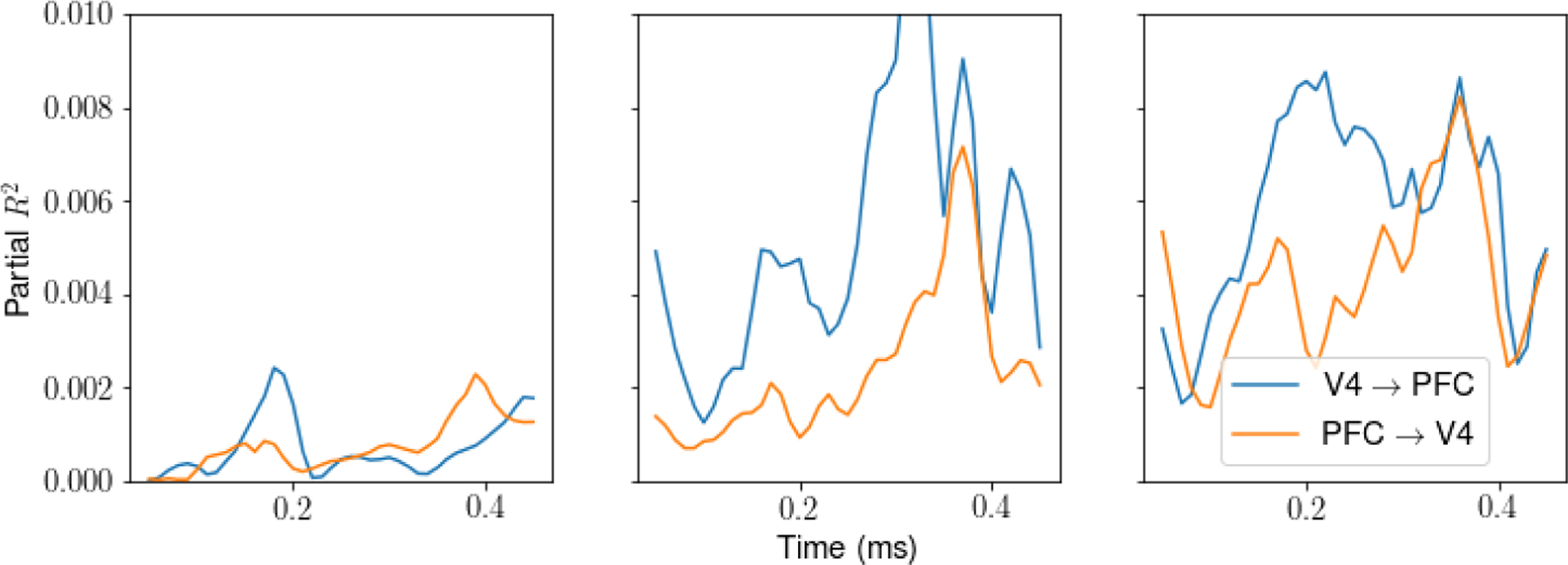
In this figure, we characterize dynamic information flow in terms of partial R2. We show dynamic information flow from V4 → PFC (blue) and PFC → V4 (orange). The results in the first panel are consistent with those in the first panel of Fig. 5d.
Footnotes
34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada.
References
- Adhikari A, Sigurdsson T, Topiwala MA, and Gordon JA (2010). Cross-correlation of instantaneous amplitudes of field potential oscillations: a straightforward method to estimate the directionality and lag between brain areas. Journal of neuroscience methods, 191:191–200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bach FR and Jordan MI (2005). A probabilistic interpretation of canonical correlation analysis. Technical Report 688, Department of Statistics, University of California, Berkeley, Berkeley, CA. [Google Scholar]
- Bickel PJ and Levina E (2008). Regularized estimation of large covariance matrices. Ann. Statist, 36:199–227. [Google Scholar]
- Bong H, Ventura V, Smith M, and Kass R (2020). Latent cross-population dynamic time-series analysis of high-dimensional neural recordings. Manuscript submitted for publication. [PMC free article] [PubMed]
- Buesing L, Machado TA, Cunningham JP, and Paninski L (2014). Clustered factor analysis of multineuronal spike data. In Advances in Neural Information Processing Systems, pages 3500–3508. [Google Scholar]
- Buzsáki G, Anastassiou CA, and Koch C (2012). The origin of extracellular fields and currents — EEG, ECoG, LFP and spikes. Nature Reviews Neuroscience, 13:407–420. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dawid AP (1981). Some matrix-variate distribution theory: notational considerations and a Bayesian application. Biometrika, 68:265–274. [Google Scholar]
- Dempster AP, Laird NM, and Rubin DB (1977). Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39:1–22. [Google Scholar]
- Einevoll GT, Kayser C, Logothetis NK, and Panzeri S (2013). Modelling and analysis of local field potentials for studying the function of cortical circuits. Nature Reviews Neuroscience, 14:770–785. [DOI] [PubMed] [Google Scholar]
- Friedman J, Hastie T, and Tibshirani R (2007). Sparse inverse covariance estimation with the graphical lasso. Biostatistics, 9:432–441. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fries P, Reynolds JH, Rorie AE, and Desimone R (2001). Modulation of oscillatory neuronal synchronization by selective visual attention. Science, 291:1560–1563. [DOI] [PubMed] [Google Scholar]
- Gallagher N, Ulrich KR, Talbot A, Dzirasa K, Carin L, and Carlson DE (2017). Cross-spectral factor analysis. In Advances in Neural Information Processing Systems, pages 6842–6852. [Google Scholar]
- Hotelling H (1936). Relations between two sets of variates. Biometrika, 28:321–377. [Google Scholar]
- Hultman R, Ulrich K, Sachs BD, Blount C, Carlson DE, Ndubuizu N, Bagot RC, Parise EM, Vu M-AT, Gallagher NM, et al. (2018). Brain-wide electrical spatiotemporal dynamics encode depression vulnerability. Cell, 173:166–180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jiang H, Bahramisharif A, van Gerven MA, and Jensen O (2015). Measuring directionality between neuronal oscillations of different frequencies. Neuroimage, 118:359–367. [DOI] [PubMed] [Google Scholar]
- Khanna SB, Scott JA, and Smith MA (2020). Dynamic shifts of visual and saccadic signals in prefrontal cortical regions 8Ar and FEF. Journal of Neurophysiology. In press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Leng C and Tang CY (2012). Sparse matrix graphical models. Journal of the American Statistical Association, 107:1187–1200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liebe S, Hoerzer GM, Logothetis NK, and Rainer G (2012). Theta coupling between v4 and prefrontal cortex predicts visual short-term memory performance. Nature neuroscience, 15:456. [DOI] [PubMed] [Google Scholar]
- Linderman S, Nichols A, Blei D, Zimmer M, and Paninski L (2019). Hierarchical recurrent state space models reveal discrete and continuous dynamics of neural activity in c. elegans. bioRxiv, page 621540. [Google Scholar]
- Logothetis NK, Pauls J, Augath M, Trinath T, and Oeltermann A (2001). Neurophysiological investigation of the basis of the fMRI signal. Nature, 412:150–157. [DOI] [PubMed] [Google Scholar]
- Magri C, Schridde U, Murayama Y, Panzeri S, and Logothetis NK (2012). The amplitude and timing of the bold signal reflects the relationship between local field potential power at different frequencies. Journal of Neuroscience, 32:1395–1407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mazumder R, Hastie T, and Tibshirani R (2010). Spectral regularization algorithms for learning large incomplete matrices. Journal of Machine Learning Research, 11:2287–2322. [PMC free article] [PubMed] [Google Scholar]
- Miller EK and Cohen JD (2001). An integrative theory of prefrontal cortex function. Annual review of neuroscience, 24:167–202. [DOI] [PubMed] [Google Scholar]
- Orban GA (2008). Higher order visual processing in macaque extrastriate cortex. Physiological reviews, 88:59–89. [DOI] [PubMed] [Google Scholar]
- Rodu J, Klein N, Brincat SL, Miller EK, and Kass RE (2018). Detecting multivariate cross-correlation between brain regions. Journal of Neurophysiology, 120:1962–1972. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sarnthein J, Petsche H, Rappelsberger P, Shaw G, and Von Stein A (1998). Synchronization between prefrontal and posterior association cortex during human working memory. Proceedings of the National Academy of Sciences, 95:7092–7096. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steinmetz NA, Koch C, Harris KD, and Carandini M (2018). Challenges and opportunities for large-scale electrophysiology with neuropixels probes. Current opinion in neurobiology, 50:92–100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vinci G, Ventura V, Smith MA, and Kass RE (2018). Adjusted regularization of cortical covariance. Journal of Computational Neuroscience, 45:83–101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilks SS (1932). Certain generalizations in the analysis of variance. Biometrika, pages 471–494. [Google Scholar]
- Yang Y, Aminoff E, Tarr M, and Robert KE (2016). A state-space model of cross-region dynamic connectivity in meg/eeg. In Lee DD, Sugiyama M, Luxburg UV, Guyon I, and Garnett R, editors, Advances in Neural Information Processing Systems 29, pages 1234–1242. Curran Associates, Inc. [Google Scholar]
- Yu BM, Cunningham JP, Santhanam G, Ryu SI, Shenoy KV, and Sahani M (2009). Gaussian-process factor analysis for low-dimensional single-trial analysis of neural population activity. Journal of Neurophysiology, 102:614–635. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou S (2014). Gemini: Graph estimation with matrix variate normal instances. Ann. Statist, 42:532–562. [Google Scholar]