


Abstract
LitCovid (https://www.ncbi.nlm.nih.gov/research/coronavirus/)—first launched in February 2020—is a first-of-its-kind literature hub for tracking up-to-date published research on COVID-19. The number of articles in LitCovid has increased from 55 000 to ∼300 000 over the past 2.5 years, with a consistent growth rate of ∼10 000 articles per month. In addition to the rapid literature growth, the COVID-19 pandemic has evolved dramatically. For instance, the Omicron variant has now accounted for over 98% of new infections in the United States. In response to the continuing evolution of the COVID-19 pandemic, this article describes significant updates to LitCovid over the last 2 years. First, we introduced the long Covid collection consisting of the articles on COVID-19 survivors experiencing ongoing multisystemic symptoms, including respiratory issues, cardiovascular disease, cognitive impairment, and profound fatigue. Second, we provided new annotations on the latest COVID-19 strains and vaccines mentioned in the literature. Third, we improved several existing features with more accurate machine learning algorithms for annotating topics and classifying articles relevant to COVID-19. LitCovid has been widely used with millions of accesses by users worldwide on various information needs and continues to play a critical role in collecting, curating and standardizing the latest knowledge on the COVID-19 literature.
INTRODUCTION
The COVID-19 pandemic has resulted in over 605 million confirmed cases and 6 million deaths globally as of September 2022 (https://covid19.who.int/). Over the past 2 years, scientists and healthcare professionals worldwide have made significant progress toward understanding its disease mechanisms, prevention and treatments. Meanwhile, the number of new scholarly articles on COVID-19 has been increasing steadily—∼10 000 per month since May 2020—and has accounted for ∼9% of new articles in the entire PubMed (1). This creates significant information overload to keep up with the latest SARS-CoV-2, the virus that causes COVID-19, and COVID-19 research.
In early 2020, we launched LitCovid (https://www.ncbi.nlm.nih.gov/research/coronavirus/), the first-of-its-kind literature hub for tracking up-to-date published research on COVID-19 (2,3). Over the course of the pandemic, LitCovid has been widely used with tens of millions of accesses by users from ∼200 countries, as well as by computer programs. LitCovid is updated daily with a combination of machine learning assisted annotation and manual review. When first published in 2020, LitCovid tracked 55 000 relevant articles (3). As of September 2022, not only has the number of COVID-19 articles grown by more than four times, but the COVID-19 pandemic itself has also evolved substantially. Our understanding of the virus is significantly different compared with 2 years ago. One particular instance is the long-term symptoms experienced by a significant percentage of COVID-19 survivors, a condition named long COVID by the patients affected (4). Some survivors of acute COVID-19 began reporting symptoms lasting much longer than the amount of time then reported for clinical recovery. Long COVID has caused skepticisms and slow responses, and to date, there is no effective treatment (5). In contrast, there is now substantial evidence that a significant percentage of COVID-19 survivors experiencing ongoing multisystemic symptoms (6–8), including respiratory issues (9), cardiovascular disease (10), cognitive impairment (11) and profound fatigue (12). Another significant difference compared with 2020 is the rapid evolution of COVID-19 variants and the deployment of COVID-19 vaccines. Prominent variants such as Alpha, Delta, and more recently Omicron have changed the virus properties and may affect the performance of diagnostic tools and vaccines. According to the report on 3 September 2022 by the Centers for Disease Control and Prevention (CDC) in the United States (US), the Omicron B4.5 variant accounts for over 88% of COVID-19 infections in the United States (https://covid.cdc.gov/covid-data-tracker/#variant-proportions). Amid the evolution of COVID-19 variants, over 700 clinical trials have been dedicated to COVID-19 vaccine candidate development and validation (https://covid19.trackvaccines.org/). To date, World Health Organization (WHO) has 12 COVID-19 vaccines for emergency use (https://covid19.trackvaccines.org/agency/who/); CDC recommended the first updated COVID-19 booster specifically designed to combat Omicron variants on 1 September 2022 (https://www.cdc.gov/media/releases/2022/s0901-covid-19-booster.html). Therefore, tracking COVID-19 variants and vaccines is critical for the ongoing response to the COVID-19 pandemic.
This article describes our continuous efforts to enhance LitCovid in response to these recent developments. First, we created the long COVID collection in LitCovid to identify biomedical research articles useful for researchers, clinicians, and patients via a human-in-the-loop machine learning approach. Second, we began annotating the latest COVID-19 strains and vaccines mentioned in the literature based on WHO and other authenticated resources. Third, several existing features have also been improved with more accurate and competition-winning deep learning algorithms for annotating topics and identifying COVID-19 relevant articles, respectively. Finally, a new web interface has been developed to improve the user experience.
MATERIALS AND METHODS
The main curation workflow of LitCovid is described in its initial publication in 2020 (3). Every day, new articles from PubMed are classified first regarding their relevance to COVID-19. Then, we annotate relevant COVID-19 topics (e.g. treatment) and extract key entities (e.g. vaccine names) mentioned in the literature. Machine learning models have been developed, evaluated and incrementally updated to relieve the burden of manual review (13). Herein, we describe significant updates in the past 2o years.
Classifying articles on long COVID
A significant update is the annotation of long COVID articles. Compared with the initial LitCovid publication in early 2020, we now know that a significant percentage of COVID-19 survivors experience ongoing multisystemic symptoms that often affect daily living, a condition known as long COVID or post-acute-sequelae of SARS-CoV-2 infection (6,8). Identifying long COVID articles is challenging because this is still a topic under research; studies use a variety of less common terms to describe the condition and most articles do not refer to the condition by name. We developed an iterative human-in-the-loop machine learning framework to efficiently use manually curated labels and also prioritize the documents that need manual review (14,15). For each iteration of the loop, the framework takes eight input signals including the output from a long COVID mention recognizer, predictions from LitSuggest machine learning models (16), entity annotations from PubTator (17), and other resources and provides final predictions for manual review. We refer interested readers to (15) for more details on this approach. The related data and documentation are publicly available via https://ftp.ncbi.nlm.nih.gov/pub/lu/LongCovid/.
Annotating COVID-19 variants and vaccines
We manually annotated a benchmark dataset of 500 articles in LitCovid with a total of 2456 COVID-19 variant (e.g. Beta, B.1.351) and vaccine mentions (e.g. mRNA-1273) and subsequently developed and evaluated automatic named entity recognition (NER) methods. A team of five annotated three entity types: COVID-19 virus strains (e.g. Beta, B.1.351), vaccines (e.g. mRNA-1273), and vaccine funders (e.g. Moderna) (the companies or the affiliations providing the vaccines) and normalized them into the corresponding concepts. For example, we link the vaccine mRNA-1273 to its vaccine funder (i.e. Moderna). All five curators annotated the first 100 samples and achieved an inter-annotator agreement of 80.5% (the ratio of exact matches (text span, entity type and normalized concepts) out of the total number of entities). The remaining documents were further annotated in batches (two annotators per article) and the conflicts were addressed by a third annotator.
The benchmark set enables the development and validation of our NER methods on COVID-19 variants and vaccines. Our NER method consists of two components: entity recognition (identifying whether a text mention is an entity of interests) and entity normalization (normalizing entities into corresponding concepts). For recognition, we applied regular expressions and rule-based methods to identify entities. For normalization, we developed a dictionary-lookup approach using the lexicon collected by multiple resources (e.g. MeSH and CDC). The method will also be incrementally updated with the manual annotations on new articles in LitCovid.
Improvements in document triage and topic annotation
Document triage
Document triage identifies whether a new PubMed article is related to COVID-19; if so, the document will be added to LitCovid and annotated further. We have observed an increasing number of articles that mention such keywords as COVID-19 but are not about COVID-19 research. For instance, a study mentions COVID-19 only as a background description and is actually on tuberculosis (‘Tuberculosis is caused by the bacterium Mycobacterium tuberculosis (Mtb) and is ranked as the second killer infectious disease after COVID-19’ (18)). Such cases not only increase the curation workflow but also bring inconsistencies to downstream users. We categorized these articles mentioning COVID-19 but are not related to COVID-19 into three primary categories: (i) the results or findings are not related to COVID-19 (e.g. a study mentions its analysis was completed before the COVID-19 pandemic (19)), (ii) studies only introduce COVID-19 as a background without stating or quantifying the impacts of COVID-19 (e.g. the Tuberculosis example (18)) and (iii) studies mention COVID-19 in other fields rather than the main text (e.g. COVID-19 is mentioned in the funding statement (20)). We have been manually identifying hundreds of such cases and included them into our training data for calibrating automated triage method.
Topic annotation
Topic annotation assigns a set of possible topics (e.g. Treatment and Diagnosis) to an article in LitCovid. Previously we used binary classification models where each model predicts a single topic. In contrast, we have employed LITMC-BERT, a transformer-based multi-label classification method (21). Compared with the previous topic annotation model deployed in LitCovid, it better captures the correlations between topics and provides all the topic predictions simultaneously via multi-task learning.
RESULTS
Literature growth
Compared with the initial LitCovid publication in October 2020, the number of articles in LitCovid has increased by over five times—from 55 000 to over 280 000. Figure 1 illustrates the overall growth of LitCovid by July 2022. The number of articles has been growing rapidly and consistently with ∼10 000 new articles every month for over 2 years (Figure 1A). Since the second quarter of 2020, the number of LitCovid articles has accounted for ∼9% of the new articles in the entire PubMed (Figure 1B). The articles in LitCovid are annotated with up to eight broad topics when applicable, including the new topic Long COVID, which will be detailed later. Figure 2 demonstrates the overall growth of these topics by July 2022. Treatment and Prevention have been the two largest topics, each with over 60 000 articles; in addition, the number of articles with the long COVID topic has increased more rapidly since March 2021 (Figure 2A). More than half of the articles in LitCovid have been annotated with one or two topics (Figure 2B). The new long COVID topic has frequently co-occurred with Diagnosis (e.g. representative symptoms of long COVID (22)), Treatment (e.g. therapies for long COVID treatment (23)) and Case Report (e.g. specific long COVID patient cases (24)) (Figure 2C).
Figure 1.
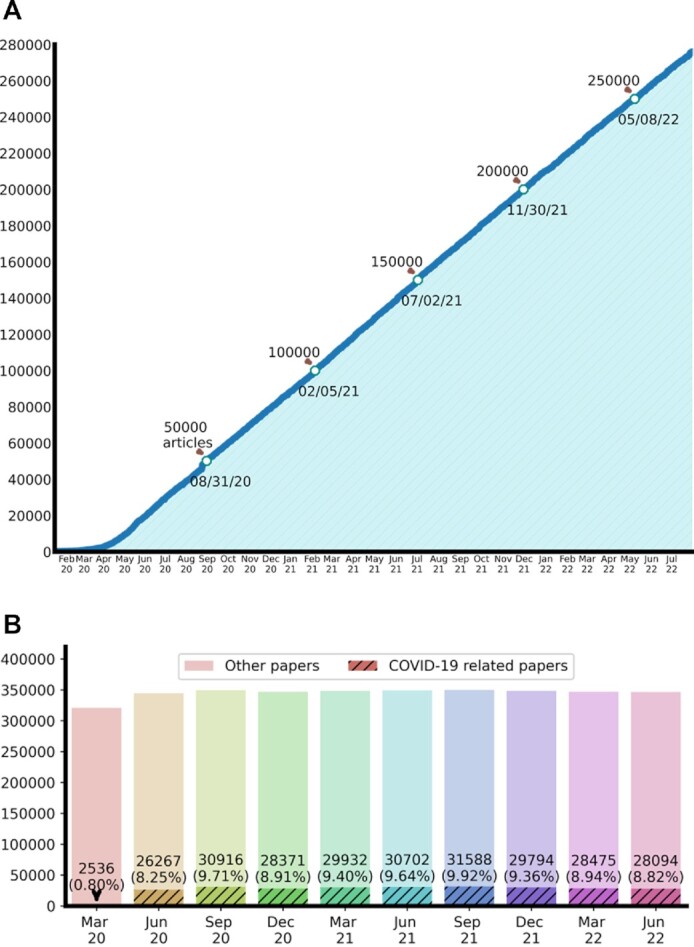
The overall growth of LitCovid by July 2022. (A) The accumulated daily literature growth; (B) the quarterly ratio of LitCovid articles compared with entire PubMed articles.
Figure 2.

The overall growth of LitCovid topics by July 2022. (A) The accumulated topic growth; (B) the distributions of topics assigned per LitCovid article; (C) topic co-occurrences.
Evaluation performance of automated methods in curation assistance
We evaluated all the automated methods described above before their first use and have improved them continuously. Table 1 summarizes the current performance; all the evaluation datasets and documentation are also publicly available via https://ftp.ncbi.nlm.nih.gov/pub/lu/LitCovid/LitCovid2/litcovid_evaluation/.
Table 1.
Training and testing datasets and evaluation results of automation tools
| Modules | Train/test | Precision/recall/ F1-score |
|---|---|---|
| Vaccines recognition and normalization | NA/500 | 97.2/96.0/96.3 |
| Strains recognition and normalization | NA/500 | 98.8/96.5/97.1 |
| Long COVID | 5733/1911 | 77.0/87.7/82.0 |
| Topic annotations | 31 199/2500 | 93.7/91.5/92.1 |
| Document triage (overall) | 39 975/10 025 | 99.5/95.4/97.4 |
Long COVID collection
As demonstrated in Table 1, the method achieved an F1-score of 0.82 for identifying articles pertinent to long COVID. The annotation of long COVID articles has been deployed in LitCovid and has been continuously updated. LitCovid has so far accumulated almost 10 000 long COVID articles (https://www.ncbi.nlm.nih.gov/research/coronavirus/docsum?filters=e_condition.LongCovid) and nearly 70% of them do not mention long COVID by name in the title or abstract. We have further collected over 800 synonymous terms for long COVID and shared with the community. We further compared the long COVID topic coverage between LitCovid and PubMed Clinical Queries (25) up to July 2022. PubMed Clinical Queries used the eight topic names in LitCovid but is based on keyword matching (25). Figure 3 shows the long COVID topic coverage comparison results. LitCovid tracks four times more articles on long COVID (9084 versus 2261) and ∼90% of long COVID articles in Clinical Queries are already in LitCovid. The articles that are unique in Clinical Queries are either preprints—which are not tracked by LitCovid (3)—or false positives. That is, they contain long COVID-related keywords but do not discuss long COVID, e.g. the article (26) mentions ‘Long-Term COVID-19’ in the context of ‘Short-Term and Long-Term COVID-19 Pandemic Forecasting’.
Figure 3.
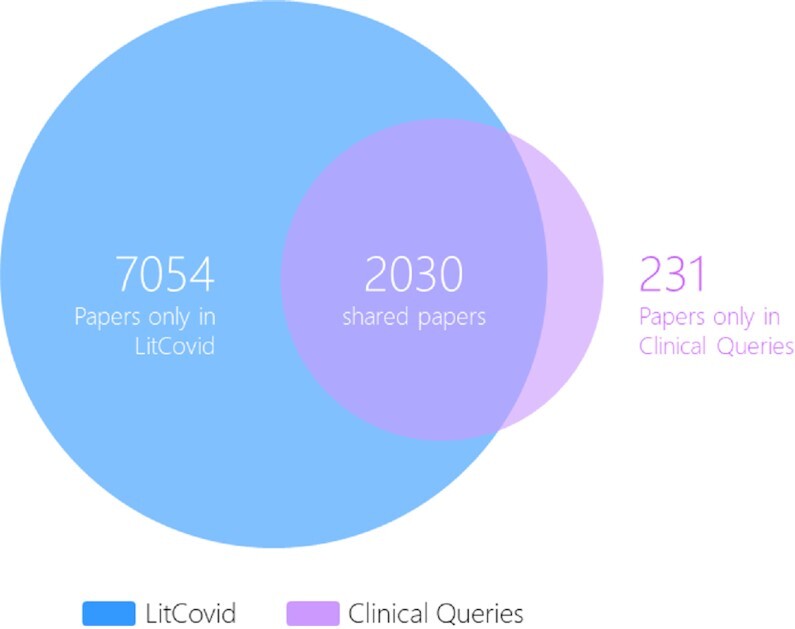
Comparative analysis of the long COVID topic coverage between LitCovid and Clinical Queries.
COVID-19 variant and vaccine annotations
Both named entity recognition and normalization modules achieved robust performance with F1-scores over 0.98. We will continue to monitor and update the method for new variants and vaccines. They are now used as filters in the interface to improve the search experience, which we will describe below.
Document triage and topic annotations
The document classification method achieved an F1-score of 0.96 for classifying whether an article is on COVID-19. In addition, the topic annotation method achieved an F1-score of 0.92. It had a better overall performance than the results reported by the LitCovid challenge overview from 80 system submissions worldwide (27,28) and only required ∼20% of the inference time of the previous topic annotation model in the LitCovid production environment.
Improvements in the user interface and other search functions
We further improved the LitCovid interface to maximize the user experience. Figure 4 demonstrates the latest interface (screenshot on 10 September 2020). First, we added the newly annotated ‘Long Covid’ topic (A) to the toolbar at the top for more convenient access. Second, we added a brief overview widget (B) to the homepage to present the main statistics of our database content: number of publications, journals, and topics. Third, we updated the growth of publications histogram (C) by monthly to track a longer period of the COVID-19 pandemic. Finally, we further presented a more informative ‘Trending Publications’ widget (D), allowing users to quickly grasp the current state of COVID19 research. The trending articles are generated by filtering publications trending in PubMed by their presence in the LitCovid database.
Figure 4.

The updated LitCovid interface (screenshot in 10 September 2022).
In addition, we enhanced the document summary page to improve the search experience. First, we added two new filters, vaccines (E) and variants (F), reflecting the latest change in tracking COVID-19 vaccines and variants as mentioned above. Second, we replaced the ‘chemical’ filter by a more specific ‘drugs’ filter (G). Users can search articles across multiple filters. For instance, the bottom part of the figure shows an example of the articles co-mentioning the Omicron variant and Pfizer vaccine. For each publication, we also added the functions to share and cite the publication (H).
CONCLUSION
LitCovid has continued its central role in accumulating the latest knowledge on the COVID-19 literature. In this article, we describe the continuing efforts on improving LitCovid over the past two years in response to the latest status of the COVID-19 pandemic, such as tracking long COVID-related articles and annotating the latest variants and vaccines. LitCovid has been updated daily for over 2 years and the entire data collection is freely available to the community. Possible research directions for LitCovid development include further development of COVID-19-specific language models for downstream curation tasks and text mining applications, as well as large-scale topic analyses (29). We also look forward to user feedback to guide further enhancements in a similar fashion as PubMed (30).
DATA AVAILABILITY
LitCovid is free and open to all users and there is no login requirement. LitCovid can be accessed via https://www.ncbi.nlm.nih.gov/research/coronavirus/.
Contributor Information
Qingyu Chen, National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, MD, USA.
Alexis Allot, National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, MD, USA.
Robert Leaman, National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, MD, USA.
Chih-Hsuan Wei, National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, MD, USA.
Elaheh Aghaarabi, National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, MD, USA; Towson University, Towson, MD, USA.
John J Guerrerio, National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, MD, USA; Dartmouth College, Hanover, NH, USA.
Lilly Xu, National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, MD, USA; Land O’ Lakes High School, FL, USA.
Zhiyong Lu, National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, MD, USA.
FUNDING
Intramural Research Program of the National Library of Medicine, National Institutes of Health; [1K99LM014024-01], National Library of Medicine, National Institutes of Health. Funding for open access charge: Intramural Research Program of the National Library of Medicine, National Institutes of Health.
Conflict of interest statement. None declared.
REFERENCES
- 1. Chen Q., Leaman R., Allot A., Luo L., Wei C.-H., Yan S., Lu Z.. Artificial intelligence in action: addressing the COVID-19 pandemic with natural language processing. Annu. Rev. Biomed. Data Sci. 2021; 4:313–339. [DOI] [PubMed] [Google Scholar]
- 2. Chen Q., Allot A., Lu Z.. Keep up with the latest coronavirus research. Nature. 2020; 579:193–193. [DOI] [PubMed] [Google Scholar]
- 3. Chen Q., Allot A., Lu Z.. LitCovid: an open database of COVID-19 literature. Nucleic Acids Res. 2021; 49:D1534–D1540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Callard F., Perego E.. How and why patients made long covid. Soc. Sci. Med. 2021; 268:113426. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Bergmans R.S., Chambers-Peeple K., Aboul-Hassan D., Dell’Imperio S., Martin A., Wegryn-Jones R., Xiao L.Z., Yu C., Williams D.A., Clauw D.J.. Opportunities to improve long COVID care: implications from semi-structured interviews with black patients. Patient. 2022; 15:715–728. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Nalbandian A., Sehgal K., Gupta A., Madhavan M.V., McGroder C., Stevens J.S., Cook J.R., Nordvig A.S., Shalev D., Sehrawat T.S.. Post-acute COVID-19 syndrome. Nat. Med. 2021; 27:601–615. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Taquet M., Dercon Q., Luciano S., Geddes J.R., Husain M., Harrison P.J.. Incidence, co-occurrence, and evolution of long-COVID features: a 6-month retrospective cohort study of 273,618 survivors of COVID-19. PLoS Med. 2021; 18:e1003773. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Davis H.E., Assaf G.S., McCorkell L., Wei H., Low R.J., Re’em Y., Redfield S., Austin J.P., Akrami A.. Characterizing long COVID in an international cohort: 7 months of symptoms and their impact. EClinicalMedicine. 2021; 38:101019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Hayes L.D., Ingram J., Sculthorpe N.F.. More than 100 persistent symptoms of SARS-CoV-2 (Long COVID): a scoping review. Front Med. (Lausanne). 2021; 8:750378. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Xie Y., Xu E., Bowe B., Al-Aly Z.. Long-term cardiovascular outcomes of COVID-19. Nat. Med. 2022; 28:583–590. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Douaud G., Lee S., Alfaro-Almagro F., Arthofer C., Wang C., McCarthy P., Lange F., Andersson J.L.R., Griffanti L., Duff E.et al.. SARS-CoV-2 is associated with changes in brain structure in UK biobank. Nature. 2022; 604:697–707. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Gemelli Against COVID-19 Post-Acute Care Study Group Carfì A., Bernabei R., Landi F.. Persistent symptoms in patients after acute COVID-19. JAMA. 2020; 324:603. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. International Society for Biocuration Biocuration: distilling data into knowledge. PLoS Biol. 2018; 16:e2002846. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Leaman R., Chen Q., Allot A., Islamaj R., Lu Z.. Proceedings of the BioCreative VII Challenge Evaluation Workshop. 2021; 353–355. [Google Scholar]
- 15. Leaman R., Islamaj R., Allot A., Chen Q., Wilbur W.J., Lu Z.. Comprehensive identification of long Covid articles with human-in-the-loop machine learning. 2022; arXiv doi:16 September 2022, preprint: not peer reviewedhttps://arxiv.org/abs/2209.08124. [DOI] [PMC free article] [PubMed]
- 16. Allot A., Lee K., Chen Q., Luo L., Lu Z.. LitSuggest: a web-based system for literature recommendation and curation using machine learning. Nucleic Acids Res. 2021; 49:W352–W358. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Wei C.-H., Allot A., Leaman R., Lu Z.. PubTator central: automated concept annotation for biomedical full text articles. Nucleic Acids Res. 2019; 47:W587–W593. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Li C., Liu S., Dong B., Li C., Jian L., He J., Zeng J., Zhou Q., Jia D., Luo Y.. Discovery and mechanistic study of mycobacterium tuberculosis PafA inhibitors. J. Med. Chem. 2022; 65:11058–11065. [DOI] [PubMed] [Google Scholar]
- 19. Touray M.M., Cohen D.R., Williams S.R.P., Alam M.F., Groves S., Longo M., Gage H.. Overweight/obesity and time preference: evidence from a survey among adults in the UK. Obes. Facts. 2022; 15:428–441. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Peñafiel Vicuña A.K., Yamazaki Nakashimada M., León Lara X., Mendieta Flores E., Nuñez Núñez M.E., Lona-Reyes J.C., Hernández Nieto L., Ramírez Vázquez M.G., Barroso Santos J., López Iñiguez Á.. Mendelian susceptibility to mycobacterial disease: retrospective clinical and genetic study in Mexico. J. Clin. Immunol. 2022; 10.1007/s10875-022-01357-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Chen Q., Du J., Allot A., Lu Z.. LitMC-BERT: transformer-based multi-label classification of biomedical literature with an application on COVID-19 literature curation. IEEE/ACM Trans. Comput. Biol. Bioinf. (2022); 19:2584–2595. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Choudhury A., Tariq R., Jena A., Vesely E.K., Singh S., Khanna S., Sharma V.. Gastrointestinal manifestations of long COVID: a systematic review and meta-analysis. Therap Adv. Gastroenterol. 2022; 15:17562848221118403. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Imai K., Yamano T., Nishi S., Nishi R., Nishi T., Tanaka H., Tsunoda T., Yoshimoto S., Tanaka A., Hiromatsu K.. Epipharyngeal abrasive therapy (EAT) has potential as a novel method for long COVID treatment. Viruses. 2022; 14:907. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Nirenberg M.S., Requena L., Santonja C., Smith G.T., McClain S.A.. Histopathology of persistent long COVID toe: a case report. J. Cutan. Pathol. 2022; 49:791–794. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Sayers E.W., Beck J., Bolton E.E., Bourexis D., Brister J.R., Canese K., Comeau D.C., Funk K., Kim S., Klimke W.. Database resources of the national center for biotechnology information. Nucleic Acids Res. 2021; 49:D10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Hussein T., Hammad M.H., Surakhi O., AlKhanafseh M., Fung P.L., Zaidan M.A., Wraith D., Ershaidat N.. Short-Term and long-term COVID-19 pandemic forecasting revisited with the emergence of OMICRON variant in jordan. Vaccines. 2022; 10:569. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Chen Q., Allot A., Leaman R., Islamaj R., Du J., Fang L., Wang K., Xu S., Zhang Y., Bagherzadeh P.. Multi-label classification for biomedical literature: an overview of the biocreative VII litcovid track for COVID-19 literature topic annotations. Database. 2022; 2022:baac069. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Chen Q., Allot A., Leaman R., Doğan R.I., Lu Z.. Proceedings of the seventh BioCreative challenge evaluation workshop. 2021; [Google Scholar]
- 29. Yeganova L., Islamaj R., Chen Q., Leaman R., Allot A., Wei C.-H., Comeau D.C., Kim W., Peng Y., Wilbur W.J.. Navigating the landscape of COVID-19 research through literature analysis: a bird's eye view. 2020; arXiv doi:11 September 2020, preprint: not peer reviewedhttps://arxiv.org/abs/2008.03397.
- 30. Fiorini N., Lipman D.J., Lu Z.. Cutting edge: towards pubmed 2.0. Elife. 2017; 6:e28801. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
LitCovid is free and open to all users and there is no login requirement. LitCovid can be accessed via https://www.ncbi.nlm.nih.gov/research/coronavirus/.