

Abstract
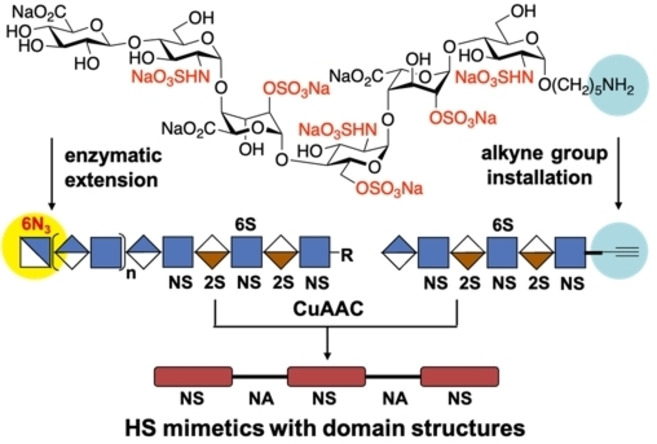
Heparan sulfate (HS) has a domain structure in which regions that are modified by epimerization and sulfonation (NS domains) are interspersed by unmodified fragments (NA domains). There is data to support that domain organization of HS can regulate binding of proteins, however, such model has been difficult to probe. Here, we report a chemoenzymatic methodology that can provide HS oligosaccharides composed of two or more NS domains separated by NA domains of different length. It is based on the chemical synthesis of a HS oligosaccharide that enzymatically was extended by various GlcA‐GlcNAc units and terminated in GlcNAc having an azido moiety at C‐6 position. HS oligosaccharides having an azide and alkyne moiety could be assembled by copper catalyzed alkyne‐azide cycloaddition to give compounds having various NS domains separated by unsulfonated regions. Competition binding studies showed that the length of an NA domain modulates the binding of the chemokines CCL5 and CXCL8.
Keywords: Carbohydrates, Chemokine, Enzyme Catalysis, Glycomimetic, Glycosylation
Well‐defined heparan sulfate mimetics having a domain structure were synthesized by copper catalyzed alkyne‐azide cycloaddition of HS oligosaccharide having a terminal alkyne or azide moiety. Competition binding experiments demonstrated that the length of NA domains modulates the binding of the chemokines CCL5 and CXCL8.
Introduction
Heparan sulfate (HS) are highly O‐ and N‐sulfonated carbohydrates that reside on the cell surface and in the extracellular matrix (ECM) of virtually all mammalian cell types where they can interact with a multitude of proteins. [1] The interaction between HS and proteins mediates biological processes such as cell‐cell and cell‐matrix interactions, cell migration and proliferation, growth factor sequestration, chemokine and cytokine activation, and tissue morphogenesis. Alteration in HS expression has been associated with diseases such as cancer, inflammation, neurological disorders, cardiovascular and infectious diseases. [2]
HS is biosynthesized on core proteins by the formation of a polymer composed of 1,4‐linked repeating disaccharides of D‐glucuronic acid (GlcA) and N‐acetyl‐D‐glucosamine (GlcNAc) [1f] that is modified by a series of enzymatic transformations including N‐deacetylation, N‐sulfonation, epimerization of GlcA to L‐iduronic acid (IdoA), and sulfonation of the C‐2 hydroxyl of IdoA and the C‐6 hydroxyl of GlcNAc moieties. Occasional sulfonation of the C‐3 position of GlcN also occurs. The epimerization and sulfonation proceed only partially resulting in substantial structural diversity. This diversity is not random and cells have an ability to create specific HS‐epitopes by regulating the expression of specific isoforms of HS biosynthetic enzymes.[ 1d , 3 ] The premise of the “HS sulfate code hypothesis” is that such epitopes can recruit specific HS‐binding proteins, thereby influencing multiple biological and disease processes.
Additional structural complexity in HS arises from domain formation in which highly sulfonated (N‐sulfonated, NS) regions are interspersed with regions that have undergone no‐ or very limited modifications (N‐acetylated, NA) and consist mainly of GlcA‐GlcNAc repeating units (Figure 1).[ 1a , 1g ] It has been proposed that the spacing of NS domains can regulate proteins binding.[ 1g , 4 ] For example, proteins such as CXC motif chemokine ligand 5 (CXCL5), CC chemokine ligand 8 (CCL8), interferon (IFN)‐γ, platelet factor 4 (PF4, also called CXCL4), and CCL3, occur at physiological concentrations as dimers or higher oligomers,[ 1c , 1f , 4a , 4c , 5 ] and a binding model has been proposed in which each monomer binds to a distinct NS domain resulting in di‐ or multivalent binding interactions.[ 4a , 4b , 4c ] Analysis of HS‐saccharides obtained by affinity purification using several different chemokines indicate they require NA domains of defined length for optimal binding.[ 4a , 4b , 4c , 4e ] Domain organization of HS impacts biological processes, and for example, inactivation of 2‐OST changed the domain structure of endothelial HS, which led to a substantial increase in the number of binding sites for CXCL8, which in turn led to acute inflammatory responses in mice.[ 4d , 6 ]
Figure 1.

Heparan sulfate domain architectures. HS has a domain structure in which sulfonated fragments (NS) are interspersed with unmodified fragments (NA).
Progress in chemical, [7] enzymatic [8] and chemoenzymatic synthesis [9] of HS oligosaccharides has provided collection of compounds that makes it possible to probe the importance of sulfonation patterns of NS domains for protein binding. Well‐defined synthetic oligosaccharides have also been displayed on dendrimers, polymers and nanoparticles to recapitulate biological activities of heparin. [10] Although these materials demonstrate the importance of multivalent display of HS epitopes for binding and biological activity, they do not recapitulate the NS‐NA domain organization of natural heparan sulfate and cannot probe the importance of spacing of NS domains for binding and biological activity. To examine the importance of spacing between two NS domains, a sulfonated hexasaccharide having an allyl ether at the anomeric center was chemically synthesized and dimerized by an ultraviolet‐promoted thiol‐ene reaction with α,ω,‐bis‐(thio)oligo(ethyleneglycol) spacers of different length. [11] The resulting compounds inhibited the binding of IFN‐γ/heparin in a length dependent manner. To better mimic NA domains of HS, an oligosaccharide was enzymatically assembled composed of regions with GlcNAc and trifluoracetyl glucosamine (GlcNTFA) using the glycosyl transferases KfiA (N‐acetyl glycosaminyl transferase of E. coli K5 strain) and Pasteurella multocida heparosan synthase (PmHS2) in combination with UDP‐GlcNTFA or UDP‐GlcNAc and UDP‐GlcA. [12] The TFA moieties could selectively be removed and the resulting amines enzymatically sulfonated to give a well‐defined oligomer having GlcNAc and GlcNS moieties. Further epimerizations and O‐sulfonations resulted, however, in the formation of complex mixtures of products. Thus, the preparation of panels of well‐defined HS‐oligosaccharides having domain structures is still an unresolved goal.
Here, we report a chemoenzymatic methodology that can give HS mimetics composed of two or more well‐defined sulfonated domains separated by NA domains of defined length (Figure 2). Competition binding studies by surface plasmon resonance (SPR) showed that the length of an NA domain can modulate the bind of the chemokines CCL5 and CXCL8. The binding data was rationalized based on structural models of CCL5 and CXCL8. The chemoenzymatic approach is based on the modular chemical synthesis[ 7c , 7l ] of a hexasaccharide that terminates in a GlcA moiety (e.g. 1, Figure 2A), which is an appropriate primer for enzymatic extension by the bi‐functional glycosyl transferases PmHS2[ 9b , 13 ] that can act both as α1,4‐N‐acetylglucosaminyltransferase and β1,4‐glucuronyltransferase by using UDP‐GlcNAc and UDP‐GlcA, respectively. Repetitive use of this enzyme module was expected to provide compounds having NA domains of different length. The final enzymatic step exploited the finding that PmHS2 tolerates a GlcNAc moiety having an azido group at the C‐6 position [9b] to give compounds such as 3–8 (n=0–5) (Figure 2B). Compound 1 is equipped with an anomeric aminopentyl linker which provided a chemical handle to install an alkyne moiety to afford compound 2 (Figure 2A). It was envisaged that compounds such as 2 and 3–8 could be coupled in a controlled manner by copper catalyzed alkyne‐azide cycloaddition (CuAAC) [14] reaction to give derivatives such as 9–14 in which sulfonated domains are separated by an NA domain of defined length (Figure 2C). Repeating the process of enzymatic elongation and installation of an azido‐containing GlcNAc moiety followed by CuAAC with 2 should then give HS mimetics having multiple NA‐ and NS‐domains.
Figure 2.

Synthetic strategy for the preparation of HS mimetics having well‐defined NA and NS domains. A) Hexasaccharide 1 that terminates in a GlcA moiety, which is a primer for PmHS2 enzymatic extension. Compound 2 is equipped with an alkyne moiety at the reducing end of 1. B) Enzymatically extended compounds 3, 4, 5, 6, 7, and 8 that terminate in a GlcNAc‐6N3 moiety and repeated GlcA‐GlcNAc moiety. C) CuAAC click reaction products 9, 10, 11, 12, 13, and 14 in which NS domains are separated by an NA domain of defined length. Symbol nomenclature for HS backbone monosaccharides, structure of azide modified GlcNAc, and inter‐domain triazole linkage is presented. 2S 2‐O‐sulfate, 6S 6‐O‐sulfate and NS N‐sulfate.
Results and Discussion
To establish the methodology, hexasaccharide primer 1 was assembled employing modular disaccharide building blocks 15–17 (Scheme 1).[ 7j , 7l ] Thus, triflic acid (TfOH)‐mediated coupling of 16 with 17 gave a tetrasaccharide that was converted into an acceptor by selective removal of the 9‐fluorenylmethyl carbonate (Fmoc) followed by further glycosylation with glycosyl donor 15 to give hexasaccharide 18 in an overall yield of 30 % (Scheme S1). Standard procedures were employed to replace the Fmoc protecting group of 18 by an acetyl ester to give compound 19, which was treated with hydrazine acetate to remove the levulinoyl esters (Lev) and the resulting hydroxyls were sulfonated with sulfur trioxide‐pyridine complex (SO3⋅Py) in N,N‐dimethylformamide (DMF) to give 20. The latter compound was treated with lithium hydroxide and hydrogen peroxide (LiOH/H2O2) to remove the acetyl and methyl ester (→21), which was followed by reduction of the azido moieties using trimethyl phosphine in tetrahydrofuran (THF) and H2O to give free amines that were subjected to selective N‐sulfonation employing SO3⋅Py complex in methanol and triethylamine (MeOH/Et3N) in the presence of sodium hydroxide (NaOH) (pH≈11) to afford 22. The target hexasaccharide primer 1 was obtained by hydrogenolysis of 22 over palladium hydroxide on carbon (Pd(OH)2/C) in a mixture of tert‐butanol/H2O (1/1, v/v).
Scheme 1.

Chemical synthesis of hexasaccharide 1. Reagents and conditions: a) DCM/Et3N (4/1), 2 h; Ac2O, Py., 3 h; b) NH2NH2⋅AcOH, Toluene/EtOH (1/2), 2 h; SO3⋅Py, DMF, 2 h; c) 1.0 M LiOH, 30 % H2O2, THF/H2O (1/1); 51 % over five steps; d) 1.0 M PMe3 in THF, 0.1 N NaOH, 2 h; e) SO3⋅Py, MeOH, Et3N, 0.1 N NaOH; 50 % over two steps; f) Pd(OH)2/C, H2 (atm.), t‐BuOH/H2O (1/1), 48 h; 85 %.
Next, attention was focused on the enzymatic extension of 1 to give derivatives 23–27 having NA domains of different length (Scheme 2A). Thus, hexasaccharide 1 was converted into octasaccharide 23 (n=1), first by exposure to UDP‐GlcNAc in the presence of the bifunctional enzyme PmHS2 to install a GlcNAc moiety. Upon completion of the reaction as indicated by electrospray ionization mass spectrometry (ESI‐MS), the compound was purified by size exclusion chromatography (SEC) over a P6 Biogel column and then re‐exposed to PmHS2 in the presence of UDP‐GlcA and purification over P6 Biogel was repeated. Intermediate purification was important to remove sugar nucleotides to prevent polymerization. The enzyme module and purification were repeated several times to give compounds 24, 25, 26 and 27. As anticipated, compounds 1, 23–27 could readily be converted into derivatives 3–8 having a terminal 6‐azido‐GlcNAc moiety upon treatment with UDP‐GlcNAc‐6N3 in the presence of PmHS2. [9b] In parallel, the aminopentyl linker of hexasaccharide 1 was functionalized with an alkyne moiety for CuAAC chemistry by treatment of N‐hydroxysuccinamide (NHS)‐activated 4‐pentynoic acid in a mixture of 0.3 M NaHCO3/acetonitrile/MeOH to give 2 (Scheme 2B).
Scheme 2.

Chemoenzymatic synthesis of HS mimetics having two NS domains separated by an NA domain of different length. A) Compound 1 was transformed to 23–27 by repeated enzymatic extension using PmHS2 in combination with UDP‐GlcNAc and UDP‐GlcA step by step, resulting compounds 23–27 and unmodified 1 were capped with GlcNAc‐N3 to obtain 3–8. B) Compound 1 was functionalized with an alkyne moiety by treatment of N‐hydroxysuccinamide (NHS)‐activated 4‐pentynoic acid in a mixture of 0.3 M NaHCO3/acetonitrile/MeOH (5/5/1) to give 2. C) Compounds 9–14 with two NS domains separated by an NA domain of defined length were obtained by CuAAC click reaction of 2 with 3–8, respectively.
Various reaction conditions were explored to link compound 2 with 3 by CuAAC to give HS mimetic 9 (Scheme 2C). The reactions were carried out in 0.1 M ammonium bicarbonate buffer (pH 8) to ensure that sensitive sulfate moieties stayed intact. CuAAC exploiting sodium ascorbate and CuSO4 led to by‐product formation probably because the initial oxidation product, dehydroascorbate, can hydrolyze to form reactive aldehydes such as 2,3‐diketogulonate and glyoxal that can react with the free amino group of the anomeric linker.[ 14a , 15 ] Previously, it was reported that such side reactions can be avoided by employing aminoguanidine and tris(3‐hydroxypropyltriazolylmethyl)amine (THPTA) as stabilizing agents for CuI and sacrificial reductant to protect the biomolecules from oxidation. [14a] When the CuAAC reaction was performed in the presence of these stabilizing agents at room temperature for 1 h, no degradation was observed, however only a trace amount of 9 was formed and mainly starting material was recovered. When the reaction was performed at a higher temperature (37 °C) for an extended period (24 h), it proceeded readily and desired compound 9 was isolated in an isolated yield of 61 % after purification by SEC over P6 Biogel and sodium exchange using Dowex® 50×8Na+ resin. In a similar way, HS mimetics 10–14 were synthesized by CuAAC of 2 with 4–8, respectively.
The HS derivatives 1, 9–14 were analyzed by ESI‐MS and nuclear magnetic resonance spectroscopy (NMR). 1H NMR spectra were fully assigned by one‐dimensional (1D) and 2D NMR spectroscopy including 1H‐1H correlation spectroscopy (COSY), 1H‐13C heteronuclear single quantum coherence spectroscopy (HSQC), 1H‐13C heteronuclear multiple bond correlation spectroscopy (HMBC), 1H‐1H total correlation spectroscopy (TOCSY), and 1H‐1H nuclear overhauser effect spectroscopy (NOESY). The anomeric configuration was confirmed by 1 J C1,H1 coupling constants (1 J C1,H1≈175 Hz for α linkage) and 13C chemical shifts of C1 (<100 ppm for α linkage). The 1H NMR spectra confirmed the formation of a 1,2,3‐triazole ring, and for example a unique aromatic proton at ≈7.85 ppm was observed arising from the triazole ring (Figure 3A and D). Further support came from downfield shift of H6 and H5 (Figure 3C, D, H6 from ≈3.6 to ≈4.7 ppm, H5 from ≈3.9 to 4.1 ppm) and upfield shift of H4 and H1 (Figure 3C, D, H4 from ≈3.5 to ≈2.8 ppm, H1 from 5.44 to 5.35 ppm) of sugar protons connected to the triazole. In addition, the disappearance of alkyne proton and downfield shift of CH2 protons that are linked to the triazole (Figure 3B and D and Figure S1, S2) confirm product formation.
Figure 3.
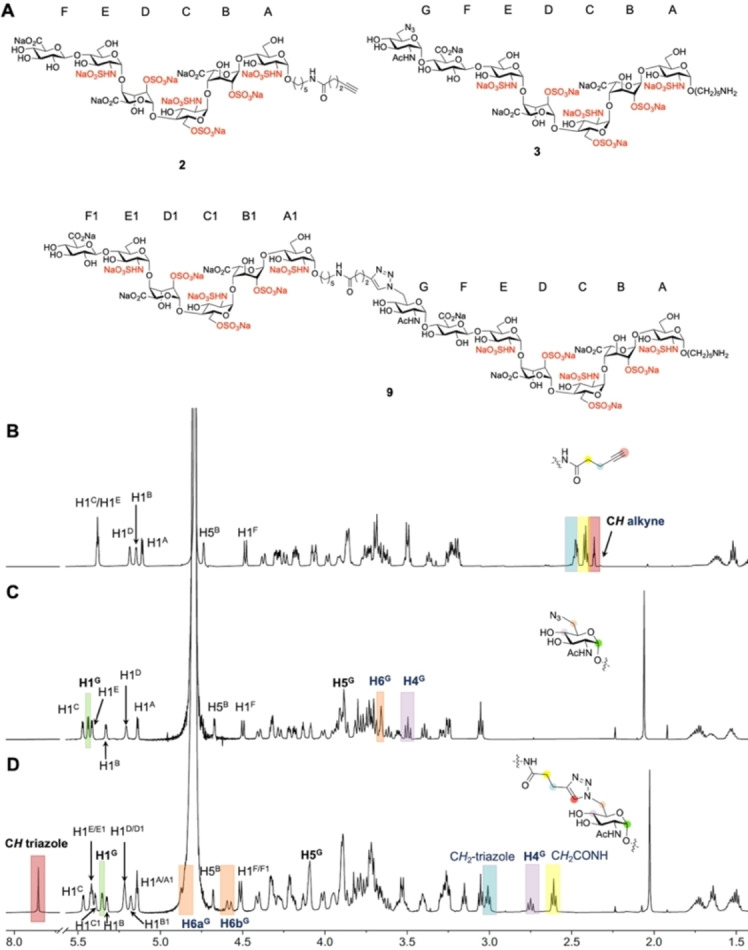
Analysis of synthetic compounds by NMR spectroscopy. 1H NMR stacked plots and structures of compounds 2, 3, and their CuAAC product 9. A) Structures of compounds 2, 3, and 9, sugar rings are labelled alphabetically, starting from reducing to non‐reducing end. B) 1H NMR of hexasaccharide 2 where anomeric linker is extended with alkyne functionality; characteristic protons are annotated. C) 1H NMR of compound 3 with terminal GlcNAc‐6N3; characteristic protons are annotated. D) 1H NMR of CuAAC product of 2 and 3, HS mimetic 9. Blue highlighted area, presence of CH2 that is attached to alkyne of compound 2 (B) and presence of CH2 that is attached to triazole of compound 9 (D). Yellow highlighted area, presence of CH2 that is highlighted in the structure (B and D). Red highlighted area, presence of CH alkyne of compound 2 (B) and presence of CH triazole of compound 9 (D). Orange highlighted area, presence of H6 of GlcNAc‐6N3 of compound 3 (C) and presence of H6 of sugar with triazole of compound 9 (D). Purple highlighted area, presence of H4 of GlcNAc‐6N3 of compound 3 (C) and presence of H4 of sugar with triazole of compound 9 (D). Green highlighted area, presence of H1 of GlcNAc‐6N3 of compound 3 (C) and presence of H1 of sugar with triazole of compound 9 (D).
To synthesize HS mimetics having three NS domains (Scheme 3), compounds 9, 10, and 11 were transformed into alkyne linker containing derivatives 28, 29, and 30, respectively by treatment with NHS‐activated 4‐pentynoic acid (Scheme 3A). CuAAC of 3 with 28, 4 with 29, and 5 with 30 gave HS mimetics 31, 32, and 33, respectively having three NS domains separated by two NA domains (Scheme 3B, C). The HS mimetics were purified by SEC over P6 Biogel, converted into their sodium salts by treatment with Dowex® 50×8Na+ resin and fully characterized by NMR and ESI‐MS.
Scheme 3.

Chemoenzymatic synthesis of HS mimetics bearing three NS domains separated by well‐defined NA domains. A) Preparation of alkyne modified compounds 28, 29, and 30 with two NS domains separated by a NA domain of defined length. B) Structure of acceptors 3, 4, and 5 with terminal azide group. C) Assembly of 31–33 having three NS domains separated by two NA domains via CuAAC click reaction.
A surface plasmon resonance (SPR) assay [16] was employed to examine the binding of compounds 1, 9–14, and 31–33 with the chemokines CXCL8 and CCL5 (Figure 4). Thus, biotinylated heparin was immobilized to a streptavidin‐coated sensor chip and the binding of proteins of interest was inhibited by using the synthetic compounds. First, binding experiments were performed using CXCL8 and CCL5 as analyte at different concentrations (Figure 4B–D). CXCL8 exhibited fast binding kinetics and therefore the equilibrium dissociation constant (K D) was determined by non‐linear regression analysis of the steady‐state binding responses at different protein concentrations, which gave a moderate affinity of 240 nM (Figure 4C). CCL5 exhibited much slower binding kinetics and in this case fitting of the binding curves to a 1 : 1 Langmuir binding model gave a K D of 14.7 nM (Figure 4D). The measured K D values are in agreement with previously reported data. [17] Next, SPR inhibition experiments were performed by premixing 20 μM of mono‐valent 1, bi‐valent 9–14, and trivalent 31–33 with CCL5 or CXCL8 followed flow of the mixtures over the heparin modified sensor chip and monitoring of the response units (Figure 4A, B). Compounds that exhibited at least 50 % inhibition were further evaluated at various concentrations to determine IC50. In the case of CXCL8, only compound 9 having two NS domains separated by a very short NA domain, and derivatives 31 and 32 having three NS domains showed substantially more potent inhibition compared to hexasaccharide 1 (Figure 4E). Compounds 10 and 11 with one or two additional GlcA‐GlcNAc units in the unsulfonated domain, gave lower inhibitory activities than compound 9 while compound 12 and 13 exhibited a further decrease in inhibition. However, compound 14, having two NS domains bridged by the longest NA domain had a slight increase in inhibition potential. CXCL8 is an 8 kDa proinflammatory chemokine that is produced by immune and non‐immune cells to establish chemotactic gradients at infected or damaged endothelia. [18] It is biologically active as a monomer but readily forms dimers in which the two binding sites are arranged in an anti‐parallel manner. Affinity purification has indicated that the smallest heparin fragment that can bind in solution with appreciable affinity is an 18‐mer, and a model was proposed in which two NS domains separated by an NA domain of sufficient length can engage with the two binding sites of the dimeric protein in horseshoe fashion over two antiparallel‐oriented helical regions on the dimeric protein (Figure 4F).[ 4c , 18 ] Compounds 14, 31 and 32 are expected to be sufficiently long to establish such a binding interaction. More recent NMR and molecular dynamic simulations have indicated that the binding interface of CXCL8 is structurally plastic and additional perpendicular binding modes were identified that require shorter HS oligosaccharides for high avidity binding (Figure 4F). [5a] It is conceivable that a compound such as 9, having a very short spacer between the two sulfonated domains, can bind in such a mode. Compounds in which sulfonated domains are not appropriately spaced are expected to bind in a monovalent manner resulting in lower affinities. (Figure 4F). HS can promote oligomerization of CXCL8 to form chemotactic gradients and therefore it is conceivable that HS can also promote the bind to two or more dimers. [17]
Figure 4.

Surface Plasmon Resonance (SPR) binding assay and SPR competition inhibition assay. A) Symbol structures of HS domain compounds employed in SPR competition inhibition assay, where R=O(CH2)5NH2. B) Binding assay using a streptavidin‐coated sensor chip on which biotinylated heparin was immobilized, CXCL8 or CCL5 as analyte at different concentrations. Competition assay was performed by premixing HS mimetics with CXCL8 or CCL5 followed by flowing the mixtures over the heparin modified sensor chip and monitoring the response units. C) and D) SPR sensorgrams representing the concentration‐dependent kinetic analysis of the binding of immobilized heparin with CXCL8 (C) and CCL5 (D). Data were analyzed using Biacore T100 evaluation software. For steady state affinity analysis, fitting curves and detailed binding parameters see Supporting Information Figures S3 and S4. E) SPR‐based competition assay. Maximum inhibition observed (at 20 μM) and half‐maximal inhibitory concentration (IC50) values of domain structures for CXCL8 and CCL5 binding to heparin functionalized surfaces. For individual inhibition curve see Supporting Information Figures S5 and S6. Data are presented as mean ±SEM (n=3), all experiments were performed three times at the minimum. n.d.: not determined. F) Different binding modes of CXCL8.
CCL5 is a proinflammatory chemokine that activates leukocytes through binding to the receptor CCR5. Although the monomeric form of CCL5 can induce cell migration in vitro, oligomerization is critical for in vivo activity. Oligomerization is promoted by interactions with glycosaminoglycans (GAGs), and mutants that cannot interact with GAGs are limited to induce cell migration in vitro but not in vivo. [19] As can been seen in Figure 4E, compound 9 which has two sulfonated domains separated by a short unsulfonated fragment inhibited the binding of CCL5 to the heparin chip more potently than hexasaccharide 1. Compounds 10 and 11, which have one or two additional GlcA‐GlcNAc units in the unsulfonated domain, had slightly lower activities compared to 9 whereas compounds 12 and 13 showed a further reduction in inhibitory activity and had similar responses compared to monovalent compound 1. Compound 14, which has the longest NA domain, showed a substantial increased inhibitor potential. Thus, HS mimetics with the shortest and longest NA domain were the most potent inhibitors of CCL5 indicating that the interaction of these chemokines with HS is complex involving different binding modes. Structural analyses of CCL5 oligomers in complex with synthetic heparin indicated that heparin substantially increases the propensity of CCL5 to form high‐molecular weight aggregates. [20] Thus, it is feasible that HS can bind to two or more dimers of CCL5.
Conclusion
A chemoenzymatic methodology is described that can provide well‐defined HS mimetics that have multiple NS domains separated by NA domains of different length. It is based on the chemical synthesis of a sulfonated HS oligosaccharide that is designed that it can be enzymatically extended by additional GlcA‐GlcNAc moieties. In the last step of enzymatic synthesis, UDP‐GlcNAc‐6N3 is employed as glycosyl donor to install a terminal GlcNAc‐6N3 moiety. The reducing end of compound 1 is equipped with an anomeric aminopentyl linker that made it possible to introduce an alkyne moiety and the resulting compound could be linked by CuAAC chemistry to the GlcNAc‐6N3 moiety of the afore described oligosaccharides to give compounds having two sulfonated domains separated by an unsulfonated domain. The process of enzymatic NA introduction and click reaction could be repeated to give mimetics having three sulfonated domains. The newly synthesized compounds represent the longest well‐defined HS analogs prepared having various sulfonated domains separated by unsulfonated fragments. SPR inhibition studies showed that the length of NA domain influences protein binding in complex manners in agreement with different binding modes of chemokines. It is to be expected that the synthetic methodology presented here in combination with various biophysical, computational, and biological studies will offer opportunities to examine the importance of HS domain structure for biological activity.
Supporting Information
Supporting Information for this article is available with synthetic protocols, compound characterization, detailed SPR data, and NMR and ESI‐MS spectra (PDF).
Conflict of interest
The authors declare no conflict of interest.
1.
Supporting information
As a service to our authors and readers, this journal provides supporting information supplied by the authors. Such materials are peer reviewed and may be re‐organized for online delivery, but are not copy‐edited or typeset. Technical support issues arising from supporting information (other than missing files) should be addressed to the authors.
Supporting Information
Acknowledgements
This research was supported by the European Union's Horizon 2020 Research and Innovation Programme (grant number 899687 (HS‐SEQ) to G.‐J.B.) and the Chinese Scholarship Council (to L.S.).
L. Sun, P. Chopra, G.-J. Boons, Angew. Chem. Int. Ed. 2022, 61, e202211112; Angew. Chem. 2022, 134, e202211112.
A previous version of this manuscript has been deposited on a preprint server (https://doi.org/10.1101/2022.07.27.501676).
Data Availability Statement
The data that support the findings of this study are available in the Supporting Information of this article.
References
- 1.
- 1a. Kreuger J., Spillmann D., Li J. P., Lindahl U., J. Cell Biol. 2006, 174, 323–327; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 1b. Lortat-Jacob H., Curr. Opin. Struct. Biol. 2009, 19, 543–548; [DOI] [PubMed] [Google Scholar]
- 1c. Salanga C. L., Handel T. M., Exp. Cell Res. 2011, 317, 590–601; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 1d. Kreuger J., Kjellen L., J. Histochem. Cytochem. 2012, 60, 898–907; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 1e. Li L., Ly M., Linhardt R. J., Mol. BioSyst. 2012, 8, 1613–1625; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 1f. Xu D., Esko J. D., Annu. Rev. Biochem. 2014, 83, 129–157; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 1g. Gallagher J., Int. J. Exp. Pathol. 2015, 96, 203–231. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Lindahl U., Kjellen L., J. Intern. Med. 2013, 273, 555–571. [DOI] [PubMed] [Google Scholar]
- 3. Annaval T., Wild R., Cretinon Y., Sadir R., Vives R. R., Lortat-Jacob H., Molecules 2020, 25, 4215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.
- 4a. Lortat-Jacob H., Turnbull J. E., Grimaud J. A., Biochem. J. 1995, 310(Pt2), 497–505; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4b. Stringer S. E., Gallagher J. T., J. Biol. Chem. 1997, 272, 20508–20514; [DOI] [PubMed] [Google Scholar]
- 4c. Spillmann D., Witt D., Lindahl U., J. Biol. Chem. 1998, 273, 15487–15493; [DOI] [PubMed] [Google Scholar]
- 4d. Stringer S. E., Forster M. J., Mulloy B., Bishop C. R., Graham G. J., Gallagher J. T., Blood 2002, 100, 1543–1550; [PubMed] [Google Scholar]
- 4e. Robinson C. J., Mulloy B., Gallagher J. T., Stringer S. E., J. Biol. Chem. 2006, 281, 1731–1740. [DOI] [PubMed] [Google Scholar]
- 5.
- 5a. Joseph P. R., Mosier P. D., Desai U. R., Rajarathnam K., Biochem. J. 2015, 472, 121–133; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5b. Sepuru K. M., Nagarajan B., Desai U. R., Rajarathnam K., J. Biol. Chem. 2016, 291, 20539–20550. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Axelsson J., Xu D., Kang B. N., Nussbacher J. K., Handel T. M., Ley K., Sriramarao P., Esko J. D., Blood 2012, 120, 1742–1751. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.
- 7a. Poletti L., Lay L., Eur. J. Org. Chem. 2003, 2999–3024; [Google Scholar]
- 7b. Noti C., de Paz J. L., Polito L., Seeberger P. H., Chem. Eur. J. 2006, 12, 8664–8686; [DOI] [PubMed] [Google Scholar]
- 7c. Arungundram S., Al-Mafraji K., Asong J., F. E. Leach III , Amster I. J., Venot A., Turnbull J. E., Boons G. J., J. Am. Chem. Soc. 2009, 131, 17394–17405; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7d. Baleux F., Loureiro-Morais L., Hersant Y., Clayette P., Arenzana-Seisdedos F., Bonnaffe D., Lortat-Jacob H., Nat. Chem. Biol. 2009, 5, 743–748; [DOI] [PubMed] [Google Scholar]
- 7e. Hu Y. P., Lin S. Y., Huang C. Y., Zulueta M. M. L., Liu J. Y., Chang W., Hung S. C., Nat. Chem. 2011, 3, 557–563; [DOI] [PubMed] [Google Scholar]
- 7f. Dulaney S. B., Huang X. F., Adv. Carbohydr. Chem. Biochem. 2012, 67, 95–136; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7g. Hansen S. U., Miller G. J., Cole C., Rushton G., Avizienyte E., Jayson G. C., Gardiner J. M., Nat. Commun. 2013, 4, 2016; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7h. Dulaney S. B., Xu Y. M., Wang P., Tiruchinapally G., Wang Z., Kathawa J., El-Dakdouki M. H., Yang B., Liu J., Huang X. F., J. Org. Chem. 2015, 80, 12265–12279; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7i. Mende M., Bednarek C., Wawryszyn M., Sauter P., Biskup M. B., Schepers U., Brase S., Chem. Rev. 2016, 116, 8193–8255; [DOI] [PubMed] [Google Scholar]
- 7j. Zong C., Venot A., Li X., Lu W., Xiao W., Wilkes J. L., Salanga C. L., Handel T. M., Wang L., Wolfert M. A., Boons G. J., J. Am. Chem. Soc. 2017, 139, 9534–9543; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7k. Dey S., Lo H. J., Wong C. H., J. Am. Chem. Soc. 2019, 141, 10309–10314; [DOI] [PubMed] [Google Scholar]
- 7l. Sun L., Chopra P., Boons G. J., J. Org. Chem. 2020, 85, 16082–16098; [DOI] [PubMed] [Google Scholar]
- 7m. Chopra P., Joshi A., Wu J., Lu W., Yadavalli T., Wolfert M. A., Shukla D., Zaia J., Boons G. J., Proc. Natl. Acad. Sci. USA 2021, 118, e2012935118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Chen J., Avci F. Y., Munoz E. M., McDowell L. M., Chen M., Pedersen L. C., Zhang L., Linhardt R. J., Liu J., J. Biol. Chem. 2005, 280, 42817–42825. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.
- 9a. Xu Y., Masuko S., Takieddin M., Xu H., Liu R., Jing J., Mousa S. A., Linhardt R. J., Liu J., Science 2011, 334, 498–501; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9b. Chen Y., Li Y., Yu H., Sugiarto G., Thon V., Hwang J., Ding L., Hie L., Chen X., Angew. Chem. Int. Ed. 2013, 52, 11852–11856; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2013, 125, 12068–12072; [Google Scholar]
- 9c. Liu J., Linhardt R. J., Nat. Prod. Rep. 2014, 31, 1676–1685; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9d. Wang Z., Hsieh P. H., Xu Y., Thieker D., Chai E. J., Xie S., Cooley B., Woods R. J., Chi L., Liu J., J. Am. Chem. Soc. 2017, 139, 5249–5256; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9e. Lu W., Zong C., Chopra P., Pepi L. E., Xu Y., Amster I. J., Liu J., Boons G. J., Angew. Chem. Int. Ed. 2018, 57, 5340–5344; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2018, 130, 5438–5442; [Google Scholar]
- 9f. Zhang X., Lin L., Huang H., Linhardt R. J., Acc. Chem. Res. 2020, 53, 335–346. [DOI] [PubMed] [Google Scholar]
- 10.
- 10a. Oh Y. I., Sheng G. J., Chang S. K., Hsieh-Wilson L. C., Angew. Chem. Int. Ed. 2013, 52, 11796–11799; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2013, 125, 12012–12015; [Google Scholar]
- 10b. Sheng G. J., Oh Y. I., Chang S. K., Hsieh-Wilson L. C., J. Am. Chem. Soc. 2013, 135, 10898–10901; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10c. Huang M. L., Smith R. A., Trieger G. W., Godula K., J. Am. Chem. Soc. 2014, 136, 10565–10568; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10d. Loka R. S., Yu F., Sletten E. T., Nguyen H. M., Chem. Commun. 2017, 53, 9163–9166; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10e. Naticchia M. R., Laubach L. K., Tota E. M., Lucas T. M., Huang M. L., Godula K., ACS Chem. Biol. 2018, 13, 2880–2887; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10f. Li J., Cai C., Wang L., Yang C., Jiang H., Li M., Xu D., Li G., Li C., Yu G., ACS Macro Lett. 2019, 8, 1570–1574. [DOI] [PubMed] [Google Scholar]
- 11. Lubineau A., Lortat-Jacob H., Gavard O., Sarrazin S., Bonnaffe D., Chem. Eur. J. 2004, 10, 4265–4282. [DOI] [PubMed] [Google Scholar]
- 12. Xu Y., Pempe E. H., Liu J., J. Biol. Chem. 2012, 287, 29054–29061. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Chavaroche A. A., Springer J., Kooy F., Boeriu C., Eggink G., Appl. Microbiol. Biotechnol. 2010, 85, 1881–1891. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.
- 14a. Hong V., Presolski S. I., Ma C., Finn M. G., Angew. Chem. Int. Ed. 2009, 48, 9879–9883; [DOI] [PMC free article] [PubMed] [Google Scholar]; Angew. Chem. 2009, 121, 10063–10067; [Google Scholar]
- 14b. Tiwari V. K., Mishra B. B., Mishra K. B., Mishra N., Singh A. S., Chen X., Chem. Rev. 2016, 116, 3086–3240. [DOI] [PubMed] [Google Scholar]
- 15. Shangari N., Chan T. S., Chan K., Huai Wu S., O'Brien P. J., Mol. Nutr. Food Res. 2007, 51, 445–455. [DOI] [PubMed] [Google Scholar]
- 16. Zhang F., McLellan J. S., Ayala A. M., Leahy D. J., Linhardt R. J., Biochemistry 2007, 46, 3933–3941. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Dyer D. P., Salanga C. L., Volkman B. F., Kawamura T., Handel T. M., Glycobiology 2016, 26, 312–326. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Krieger E., Geretti E., Brandner B., Goger B., Wells T. N., Kungl A. J., Proteins Struct. Funct. Bioinf. 2004, 54, 768–775. [DOI] [PubMed] [Google Scholar]
- 19. Proudfoot A. E., Handel T. M., Johnson Z., Lau E. K., LiWang P., Clark-Lewis I., Borlat F., Wells T. N., Kosco-Vilbois M. H., Proc. Natl. Acad. Sci. USA 2003, 100, 1885–1890. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Liang W. G., Triandafillou C. G., Huang T. Y., Zulueta M. M., Banerjee S., Dinner A. R., Hung S. C., Tang W. J., Proc. Natl. Acad. Sci. USA 2016, 113, 5000–5005. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
As a service to our authors and readers, this journal provides supporting information supplied by the authors. Such materials are peer reviewed and may be re‐organized for online delivery, but are not copy‐edited or typeset. Technical support issues arising from supporting information (other than missing files) should be addressed to the authors.
Supporting Information
Data Availability Statement
The data that support the findings of this study are available in the Supporting Information of this article.