

ABSTRACT
Similar to the role of Markov decision processes in reinforcement learning, Markov games (also called stochastic games) lay down the foundation for the study of multi-agent reinforcement learning and sequential agent interactions. We introduce approximate Markov perfect equilibrium as a solution to the computational problem of finite-state stochastic games repeated in the infinite horizon and prove its PPAD-completeness. This solution concept preserves the Markov perfect property and opens up the possibility for the success of multi-agent reinforcement learning algorithms on static two-player games to be extended to multi-agent dynamic games, expanding the reign of the PPAD-complete class.
Keywords: Markov game, multi-agent reinforcement learning, Markov perfect equilibrium, PPAD-completeness, stochastic game
We proved that solving Markov perfect equilibria of general-sum stochastic games is PPAD-complete, which lays down the foundation of algorithmic complexity for multi-agent reinforcement learning methodology.
INTRODUCTION
Shapley [1] introduced stochastic games (SGs) to study the dynamic non-cooperative multi-player game, where each player simultaneously and independently chooses an action at each round for a reward. According to their current state and the chosen actions, the next state is determined by a probability distribution specified a priori. Shapley’s work includes the first proof of the existence of a stationary strategy profile under which no agent has an incentive to deviate, in two-player zero-sum SGs. Next, the existence of equilibrium in stationary strategies was extended to multi-player general-sum SGs by Fink [2]. Such a solution concept (known as Markov perfect equilibrium (MPE) [3]) captures the dynamics of multi-player games.
Because of its generality, the framework of SGs has enlightened a sequence of studies [4] on a wide range of real-world applications ranging from advertising and pricing [5], species interaction game modeling in fisheries [6], traveling inspection [7] and gaming AIs [8]. As a result, developing algorithms to compute MPE in SGs has become one of the key subjects in this extremely rich research domain, using approaches from applied mathematics, economics, operations research, computer science and artificial intelligence (see, e.g., [9]).
The concept of the SG underpins many AI and machine learning studies. The optimal policy making of Markov decision processes (MDPs) captures the central problem of a single agent interacting with its environment, according to Sutton and Barto [10]. In multi-agent reinforcement learning (MARL) [11,12], SG extends to incorporate the dynamic nature in multi-agent strategic interactions, to study optimal decision making and subsequently equilibria in multi-player games [13,14].
For two-player zero-sum (discounted) SGs, the game-theoretical equilibrium is closely related to the optimization problem in MDPs as the opponent is purely adversarial [15,16]. On the other hand, solving general-sum SGs has been possible only under strong assumptions [2,17]. Zinkevich et al. [18] demonstrated that, for the entire class of value iteration methods, it is difficult to find stationary Nash equilibrium (NE) policies in general-sum SGs. This has led to few existing MARL algorithms to general-sum SGs. Known approaches have either studied special cases of SGs [19,20] or ignored the dynamic nature to limit the study to the weaker notion of Nash equilibrium [21].
Recently, Solan and Vieille [22] reconfirmed the importance of the existence of a stationary strategy profile as having several philosophical implications. First, it is conceptually straightforward. Second, past play affects the players’ future behavior only through the current state. Third, subsequently and most importantly, equilibrium behavior does not involve non-credible threats, a property that is stronger than the equilibrium property, and viewed as highly desirable [23].
Surprisingly, the complexity of finding an MPE in an SG remains an open problem, although an SG was proposed more than sixty years ago and despite its importance. While fruitful studies have been conducted on zero-sum SGs, we still know little about the complexity of solving general-sum SGs. It is clear that solving MPE in (infinite-horizon) SGs is at least PPAD-hard, since solving a two-player NE in one-shot SGs is already complete in this computational class [24,25] defined by Papadimitriou [26]. This suggests that it is unlikely to have polynomial-time algorithms in general-sum stochastic games for two players. Yet, with complications involved in the general-sum and dynamic settings, the unresolved challenge has been: Can solving MPE in general-sum SGs be anywhere complete in computational complexity classes?
We answer the above question in the positive, proving the computation of an approximate MPE in SGs equivalent to that of a Nash equilibrium in a single state setting, and subsequently showing its PPAD-completeness. It opens up the possibility to develop MARL algorithms to work for the general-sum SGs in the same way as for an ordinary Nash equilibrium computation.
Intuitions and a sketch of our main ideas
Computational studies on problem solving build understanding on various types of reduction. After all, computations carried out on computers are eventually reduced to AND/OR/NOT gates on electronic circuits.
To prove that a problem is PPAD-complete, we need to prove that it is in the class, and that it can be used as a base to solve any other problem in this class (for its hardness). More formally, the reduction needs to be carried out in polynomial (with respect to the input size) time. Nash equilibrium computation of two-player normal-form games [27] is arguably the most prominent PPAD-complete problem [24,25]. When one stochastic game has only one state and the discount factor γ = 0, then finding an MPE is equivalent to finding a Nash equilibrium in the corresponding normal-form game. The PPAD-hardness of finding an MPE follows immediately. Our main result is to prove the PPAD membership property of computing an approximate MPE (Lemma 2 below).
Firstly, we construct a function f on the strategy profile space, such that each strategy profile is a fixed point of f if and only if it is an MPE of the stochastic game (Theorem 2 below). Furthermore, we prove that the function f is continuous (λ-Lipschitz by Lemma 3 below), so that fixed points are guaranteed to exist by the Brouwer fixed point theorem.
Secondly, we prove that the function f has some ‘good’ approximation
properties. Let 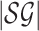 be the input size of a
stochastic game. If we can find a
be the input size of a
stochastic game. If we can find a 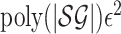 -approximate
fixed point π of f, i.e.
-approximate
fixed point π of f, i.e. 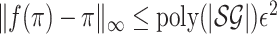 ,
where π is a strategy profile, then π is an ε-approximate MPE for the stochastic game
(combining Lemma 5 and Lemma 6 below). So our goal converts to finding an
approximate fixed point of a Lipschitz function.
,
where π is a strategy profile, then π is an ε-approximate MPE for the stochastic game
(combining Lemma 5 and Lemma 6 below). So our goal converts to finding an
approximate fixed point of a Lipschitz function.
Finally, our PPAD membership follows from the theorem that computation of the approximate Brouwer fixed point of a Lipschitz function is PPAD-complete, as shown in the seminal paper by Papadimitriou [26].
Related work
In practice, MARL methods are most often applied to compute the MPE of an SG based on the interactions between agents and the environment. Their uses can be classified in two different settings: online and offline. In the offline setting (also known as the batch setting [21]), the learning algorithm controls all players in a centralized way, hoping that the learning dynamics can eventually lead to an MPE by using a limited number of interaction samples. In the online setting, the learner controls only one of the players to play with an arbitrary group of opponents in the game, assuming unlimited access to the game environment. The central focus is often on the regret: the difference between the learner’s total reward during learning versus that of a benchmark measure in hindsight.
In the offline setting, two-player zero-sum (discounted) SGs have been extensively studied. Since the opponent is purely adversarial in zero-sum SGs, the process of seeking the worst-case optimality for each player can be thought of as solving MDPs. As a result, (approximate) dynamic programming methods [28,29] such as least-squares policy iteration [30] and fitted value iteration [31] or neural fitted Q iteration [32] can be adopted to solve SGs [33–36]. Under this setting, policy-based methods [37,38] can also be applied. However, directly applying existing MDP solvers on general-sum SGs is problematic. Since solving two-player NE in general-sum normal-form games (i.e. one-shot SGs) is well known to be PPAD-complete [24,25], the complexity of MPE in general-sum SGs is expected to be at least PPAD-hard. Although early attempts such as Nash-Q learning [39], correlated-Q learning [40], friend-or-foe Q-learning [41] have been made to solve general-sum SGs under strong assumptions, Zinkevich et al. [18] demonstrated that none in the entire class of value iteration methods can find stationary NE policies in general-sum SGs. The difficulties on both the complexity side and the algorithmic side have led to few existing MARL algorithms for general-sum SGs. Successful approaches either assume knowing the complete information of the SG such that solving MPE can be turned into an optimization problem [42], or prove the convergence of batch RL methods to a weaker notion of NE [21].
In the online setting, agents aim to minimize their regret by trial and error. One of the most well-known online algorithms is R-MAX [43], which studies (average-reward) zero-sum SGs and provides a polynomial (in game size and error parameter) regret bound while competing against an arbitrary opponent. Following the same regret definition, UCSG [44] improved R-MAX and achieved a sublinear regret, but still in the two-player zero-sum SG setting. When it comes to MARL solutions, Littman [13] proposed a practical solution named Minimax-Q that replaces the max operator with the minimax operator. Asymptotic convergence results of Minimax-Q were developed in both tabular cases [45] and value function approximations [46]. To avoid the overly pessimism property by playing the minimax value for general-sum SGs, WoLF [47] was proposed to take variable steps to exploit an opponent’s suboptimal policy for a higher reward on a variety of stochastic games. AWESOME [48] further generalized WoLF and achieved NE convergence in multi-player general-sum repeated games. However, outside the scope of zero-sum SGs, the question [43] of whether a polynomial time no-regret (near-optimal) MARL algorithm exists for general-sum SGs remains open.
Some recent works studied the sample complexity issue in RL and MARL algorithms, most of which considered a finite horizon. Jin et al. [49] proved that a variant of Q-learning with upper confidence bound exploration can achieve a near-optimal sample efficiency under episodic MDP setting. Zhang et al. [50] proposed a learning algorithm for episodic MDP with a regret bound close to the information theoretic lower bound. Li et al. [51] proposed a probably approximately correct learning algorithm for episodic RL with a sample complexity independent of the planning horizon. For general-sum MARL, Chen et al. [52] proved an exponential lower bound on the sample complexity of approximate Nash equilibrium even in n-player normal-form games. In the same direction, Song et al. [53] showed that correlated equilibrium (CE) and coarse correlated equilibrium (CCE) can be learned within a sample complexity polynomial in the maximum size of the action set of a player, rather than the size of the joint action space. Jin et al. [54] developed a decentralized MARL algorithm with polynomial sample complexity to learn CE and CCE.
DEFINITIONS AND THE MAIN THEOREM
Definition 1 (Stochastic game). A stochastic game is defined by a tuple of six elements
.
By n we denote the number of agents.
By
 we denote the set of finite
environmental states. Let
we denote the set of finite
environmental states. Let  .
.By
 we denote the action space
of agent i. Note that each agent i can choose
different actions under different states. Without loss of generality, we assume that,
for each agent i, the action space
we denote the action space
of agent i. Note that each agent i can choose
different actions under different states. Without loss of generality, we assume that,
for each agent i, the action space  under each state is the same. Here
under each state is the same. Here 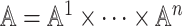 is the set of agents’ joint action vector. Let
is the set of agents’ joint action vector. Let 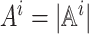 and
Amax = max i ∈
[n]Ai.
and
Amax = max i ∈
[n]Ai.By
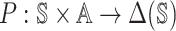 we denote the transition probability, that is, at each time step, given the agents’
joint action vector
we denote the transition probability, that is, at each time step, given the agents’
joint action vector 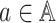 , then the transition
probability from state s to state s′ in the next time
step is P(s′|s, a).
, then the transition
probability from state s to state s′ in the next time
step is P(s′|s, a).By
 we denote the reward function, that is, when agents are at state s and
play the joint action vector a, then agent i will get
reward ri(s, a). We assume
that the rewards are bounded by rmax .
we denote the reward function, that is, when agents are at state s and
play the joint action vector a, then agent i will get
reward ri(s, a). We assume
that the rewards are bounded by rmax .By γ ∈ [0, 1) we denote the discount factor that specifies the degree to which the agent’s rewards are discounted over time.
Each agent aims to find a behavioral strategy with Markovian property, which is conditioned on the current state of the game.
The pure strategy space of agent i is 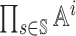 , which
means that agent i needs to select an action at each state. Note that the
size of the pure strategy space of each agent is
, which
means that agent i needs to select an action at each state. Note that the
size of the pure strategy space of each agent is 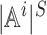 , which is
already exponential in the number of states. More generally, we define the mixed behavioral
strategy as follows.
, which is
already exponential in the number of states. More generally, we define the mixed behavioral
strategy as follows.
Definition 2 (Behavioral strategy). A behavioral strategy of agent i is
. For all
, πi(s) is a probability distribution on
.
In the rest of the paper, we focus on behavioral strategy and refer to it simply as a strategy for convenience. A strategy profile π is the Cartesian product of all agents’ strategies, i.e. π = π1 × ⋅⋅⋅ × πn. We denote the probability of agent i using action ai at state s by πi(s, ai). The strategy profile of all the agents other than agent i is denoted by π−i. We use πi, π−i to represent π, and ai, a−i to represent a.
Given π, the transition probability and the reward function depend only on the current
state  . Let
ri, π(s) denote
. Let
ri, π(s) denote
 and
Pπ(s′|s) denote
and
Pπ(s′|s) denote
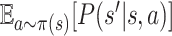 .
Fix π−i; the transition probability and the reward function
depend only on the current state
.
Fix π−i; the transition probability and the reward function
depend only on the current state 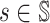 and player
i’s action ai. Let
and player
i’s action ai. Let
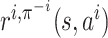 denote
denote
 and
and 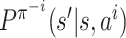 denote
denote
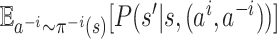 .
.
For any positive integer m, let 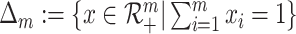 .
Define
.
Define 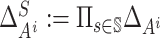 .
Then, for all
.
Then, for all 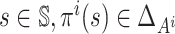 ,
,
 and
and
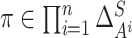 .
.
Definition 3 (Value function). A value function for agent i under strategy profile π,
, gives the expected sum of its discounted rewards when the starting state is s:
Here, s0, s1, … is the Markov chain such that the transition matrix is Pπ, that is,
for all k = 0, 1, …. Equivalently, the value function can be defined recursively via the Bellman policy equation
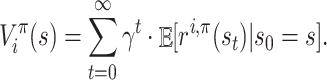

Definition 4 (Markov perfect equilibrium). A behavioral strategy profile π is called a Markov perfect equilibrium if, for all
, all i ∈ [n] and all
,
where
is the value function of i when its strategy deviates to
while the strategy profile of other agents is π−i.

The Markov perfect equilibrium is a solution concept within SGs in which the players’ strategies depend only on the current state but not on the game history.
Definition 5 (ε-approximate MPE). Given ε > 0, a behavioral strategy profile π is called an ε-approximate MPE if, for all
, all i ∈ [n] and all
,
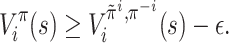
We use Approximate MPE to denote the computational problem of finding an
approximate Markov perfect equilibrium in stochastic games, where the inputs and outputs are
as follows. The input instance of problem Approximate MPE is a pair
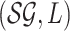 , where
, where
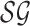 is a stochastic game and
L is a positive integer. The output of problem Approximate MPE
is a strategy profile
is a stochastic game and
L is a positive integer. The output of problem Approximate MPE
is a strategy profile  , also
dependent only at the current state but not on its history, such that π is a
1/L-approximate MPE of
, also
dependent only at the current state but not on its history, such that π is a
1/L-approximate MPE of 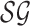 . We use the
notation
. We use the
notation 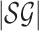 to denote the input size of
the stochastic game
to denote the input size of
the stochastic game  .
.
Theorem 1 (Main theorem). Approximate MPEis PPAD-complete.
We note that, when |S| = 1 and γ = 0, a stochastic game degenerates to an n-player normal-form game. At this time, any MPE of this stochastic game is a Nash equilibrium for the corresponding normal-form game. So we have the following hardness result immediately.
Lemma 1. Approximate MPE is PPAD-hard.
To derive Theorem 1, we focus on the proof of PPAD membership of Approximate MPE in the rest of the paper.
Lemma 2. Approximate MPE is in PPAD.
ON THE EXISTENCE OF MPE
The original proof of the existence of MPE is from [2] and based on Kakutani’s fixed point theorem. Unfortunately, proofs that are based on Kakutani’s fixed point theorem in general cannot be turned into PPAD-membership results. We develop a proof that uses Brouwer’s fixed point theorem, based on which we also prove the PPAD membership of Approximate MPE.
Inspired by the continuous transformation defined by Nash to prove the existence of the
equilibrium point [27], we define an updating
function  to adjust the strategy profile of agents in a stochastic game to establish the existence of
MPE.
to adjust the strategy profile of agents in a stochastic game to establish the existence of
MPE.
Let  be the
behavioral strategy profile under discussion.
be the
behavioral strategy profile under discussion.
Let  denote the
expected sum of discounted rewards of agent i if agent i
uses pure action ai at state s
at the first step, and then follows πi after that, but every
other agent j maintains its strategy πj.
Formally,
denote the
expected sum of discounted rewards of agent i if agent i
uses pure action ai at state s
at the first step, and then follows πi after that, but every
other agent j maintains its strategy πj.
Formally,
 |
For each player i ∈
[n] with each action  at each
state
at each
state 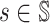 , we define a policy update
function of πi(s,
ai) as
, we define a policy update
function of πi(s,
ai) as
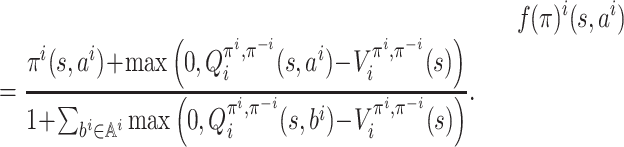 |
We consider the infinite norm distance of two strategy profiles π1 and
π2, denoted by ‖π1 − π2‖∞:
 .
.
We first prove that the function f satisfies a continuity property,
namely, is λ-Lipschitz for λ equal to  .
.
Lemma 3. The function f is λ-Lipschitz, i.e. for every
such that ‖π1 − π2‖∞ ≤ δ, we have
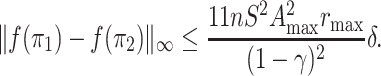
Proof. At any
, pick any player i ∈ [n]. For an action
, let M1(ai) denote
and
. From the next claim (proof in the Appendix),
Claim 1. For any x, x′, y, y′, z, z′ ≥ 0 such that (x + y)/(1 + z) ≤ 1 and (x′ + y′)/(1 + z′) ≤ 1, it holds that
Take δ = ‖π1 − π2‖∞; then
for any
. Next, for any
, we estimate
We should first derive an upper bound on
.
Claim 2. It holds that
This follows from the following claim (proof in the Appendix).
Claim 3. It holds that
Similarly, we have the following claim.
Claim 4. It holds that
To bound
for every
, we denote by
the column vector
, and by ri, π the column vector
and by Pπ the matrix
. By the Bellman policy equation (Definition 3), we have
which means that
We prove in Lemma 7 below that
for all
.
Now we are ready to give an upper bound on
for any
. We have
where the forth line follows from
, in Lemma 7 below.
Similarly, we establish a bound for
:
For any
, we have
Thus, for any
and any
, we obtain
This completes the proof of Lemma 3.□
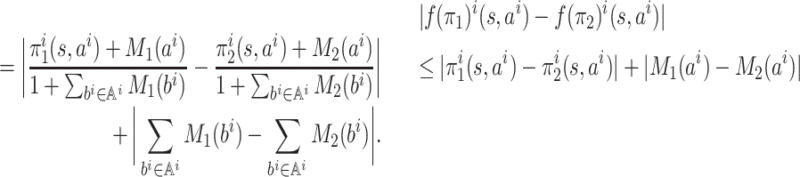

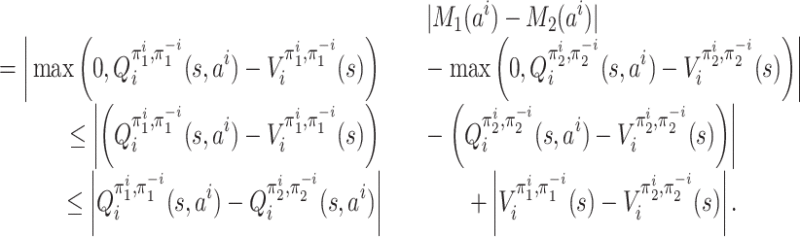
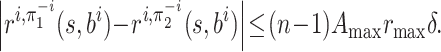
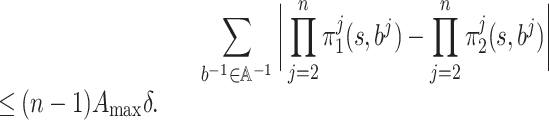



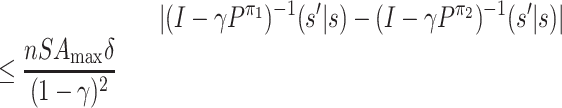
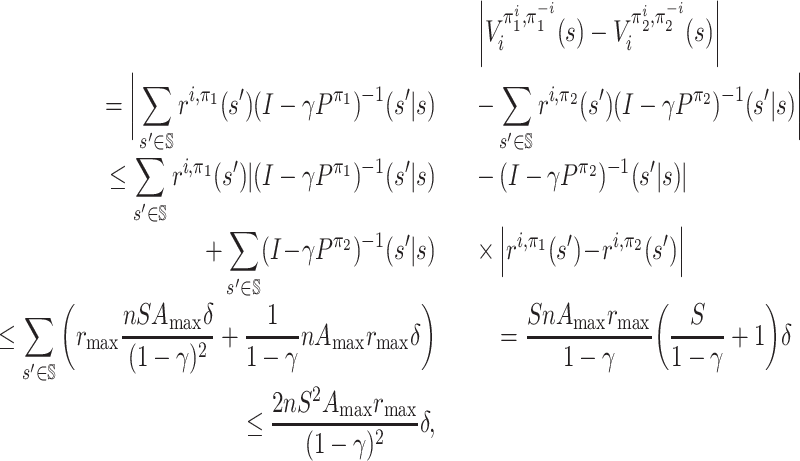



Now we can establish the existence of MPE by the Brouwer fixed point theorem.
Theorem 2. For any stochastic game
, a strategy profile π is an MPE if and only if it is a fixed point of the function f, i.e. f(π) = π. Furthermore, the function f has at least one fixed point.
Proof. We first show that the function f has at least one fixed point. Brouwer’s fixed point theorem states that, for any continuous function mapping a compact convex set to itself, there is a fixed point. Note that f is a function mapping a compact convex set to itself. Also, f is continuous by Lemma 3. Therefore, the function f has at least one fixed point.
We then prove that a strategy profile π is an MPE if and only if it is a fixed point of f.
⇒: For the necessity, suppose that π is an MPE; then, by Definition 4, we have, for each player i ∈ [n], each state
and each policy
,
. By Lemma 4 to be proven next, we have, for any action
,
, which implies that
. Then, for each player i ∈ [n], each state
and each action
, (f(π))i(s, ai) = πi(s, ai). It follows that π is a fixed point of f.
⇐: For the proof of the sufficiency part, let π be a fixed point of f. Then, for each player i ∈ [n], each state
and each action
,
We first provide the following claim given the condition that π is a fixed point.
Claim 5. For any
,
.
Proof of Claim 5. Suppose for contradiction that there exists i ∈ [n] and
such that
. The above fixed point equation implies that πi(s, di) > 0.
Let
; then
. Note that, by the recursive definition of
, we have
Since
, there must exist some
such that
, because otherwise we have
for all
, which, com-bined with
, implies that
, a contradiction to the above equation. With some further calculation, we can have the equation
The above strict inequality follows because
as well as πi(s, ci) > 0.
This contradicts with the assumption that π is a fixed point of f. Therefore, it holds for any
that
.□
Combining Claim 5 and Lemma 4 (to be proven next), we find that, for any
and any
,
. Thus, π is an MPE by definition. This completes the proof of Theorem 2.□

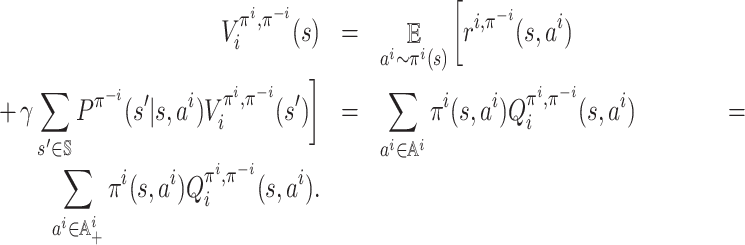

Lemma 4. For any player i ∈ [n], given π−i, for any
, the following two statements are equivalent:
for all
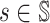 and all
and all
 ,
,
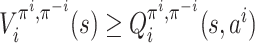 ;
;for all
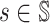 and all
and all
 ,
,
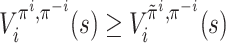 .
.
Proof. Let
denote the space of value functions
, and define the l∞ norm for any
as
.
Pick any player i ∈ [n] and keep π−i fixed. Define the Bellman operator
such that, for any
and any
,
Note that, for all
,
, since
.
We first prove the equivalence between statements 1 and 2, based on Claim 6 below, which will be proved next for completeness.
2⇒1: From statement 2, for all
,
, which is the fixed point of Φi by Claim 6 below. That is, for all
,
, by definition of the Bellman operator Φi. Statement 1 holds.
1⇒2: If statement 1 holds, we have, for all
,
. Since
by Claim 6 below, we get
.
, implying that
is a fixed point of Φi. By Claim 6, the unique fixed point of Φi is
. Therefore, for all
,
: statement 2 holds.

Claim 6. We have the following important properties.
It holds that Φiis a γ-contraction mapping with respect to the l∞norm, and has a unique fixed point.
For any
 and any
and any
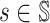 ,
, 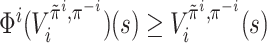 .
.Let
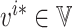 denote the fixed point of Φi; then
vi* is the optimal value function, i.e.
for any
denote the fixed point of Φi; then
vi* is the optimal value function, i.e.
for any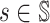 ,
,
 .
.
Proof of Claim 6. Define
We have
for all
and
.
We first prove that Φi is a γ-contraction mapping with respect to the l∞ norm. For all
, let
. We show that ‖Φi(v1) − Φi(v2)‖∞ ≤ γδ.
For all
and all
, observe that
so
.
Without loss of generality, one can suppose that Φi(v1)(s) ≥ Φi(v2)(s). Taking arbitrary
, we have
thus, |Φi(v1)(s) − Φi(v2)(s)| ≤ γδ. By symmetry, the claim holds for the case in which Φi(v1)(s) ≤ Φi(v2)(s). Therefore, it holds that ‖Φi(v1) − Φi(v2)‖∞ ≤ γδ. Thus, Φi is a γ-contraction mapping.
By the Banach fixed point theorem, we know that
has a unique fixed point
. Moreover, for any
, the point sequence v, Φi(v), Φi(Φi(v)), … converges to vi*, i.e. for all
, limk → ∞(Φi)(k)(v)(s) = vi*(s), where (Φi)(k) = Φi
(Φi)(k − 1) is defined recursively with (Φi)(1) = Φi.
Next, for all
and all
,
, since
by definition.
Finally we prove that, for any
,
. For any
, define the operator
, such that, for any
and any
,
Note that, for any
,
is also a γ-contraction mapping. This is because, for any
such that ‖v1 − v2‖∞ = δ, we have shown that, for any
and any
,
, so
and then
.
For any
, we can observe that
by definition. By the Banach fixed point theorem, we know that
has a unique fixed point in
, so
is exactly the unique fixed point of
.
Now we arbitrarily take a policy
such that, for all
,
. It can be seen that, for any
,
It follows that
, so vki* is a fixed point of
. Since the unique fixed point of
is
, we have
. Thus, for any
,
.
To show that, for any
,
, we observe that, given
, if for all
, then, for any
and any
,
. Therefore,
. As we have, for all
and all
,
, we have, for any
and any
,
by induction. It follows that
. Let k → ∞; then we get
. Thus,
.
The claim that, for all
,
follows.

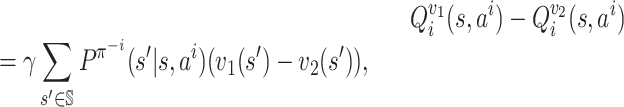
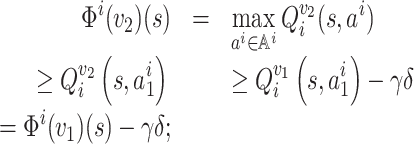
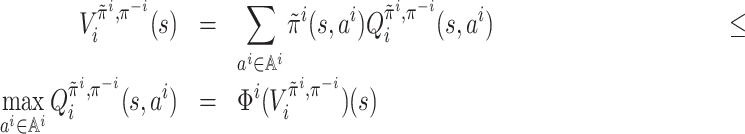

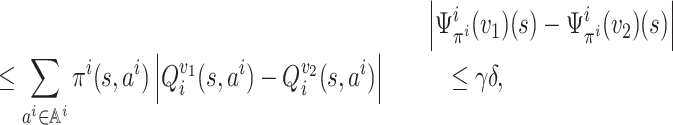

THE APPROXIMATION GUARANTEE
Theorem 2 states that π is a fixed point of
f if and only if π is an MPE for the stochastic game. Now we prove that
f has some good approximation properties: if we find an ε-approximate
fixed point π of f then it is also a 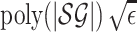 -approximate
MPE for the stochastic game (combining the following Lemma 5 and Lemma 6). This
implies the PPAD-membership of Approximate MPE.
-approximate
MPE for the stochastic game (combining the following Lemma 5 and Lemma 6). This
implies the PPAD-membership of Approximate MPE.
Lemma 5. Let ε > 0 and π be a strategy profile. If ‖f(π) − π‖∞ ≤ ε then, for each player i ∈ [n] and each state
, we have
where
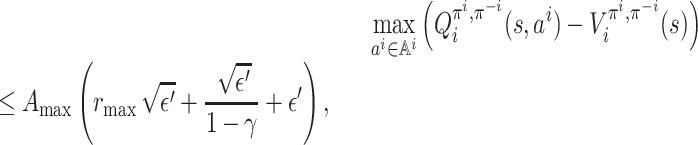

Proof. Pick any player i ∈ [n] and any state
. For simplicity, for any
, define
and
.
First we give an upper bound on M(ai). For any
, it can be easily seen that
By the condition ‖f(π) − π‖∞ ≤ ε , for any
, we have
Set ε′ = (1 + Amax rmax /(1 − γ))ε; then we have the crucial inequality
(1) Let
denote
or, equivalently,
. Let
.
Case 1:
. By inequality (1) we have
Case 2:
. By inequality (1) we have
(2) As
and, for all
,
,
Therefore,
Moreover, observe that
. Substituting these into inequality (2), we get
It follows that
.
In conclusion, combining the two cases, we get
Thus, for each
, we have
which completes the proof.□

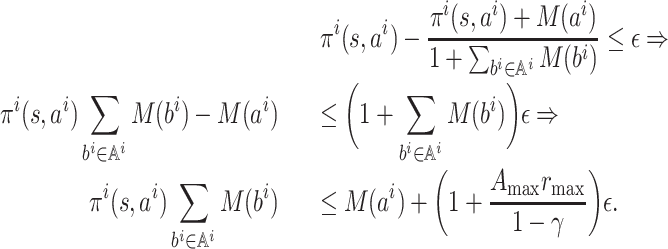
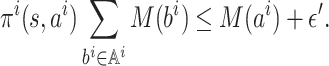


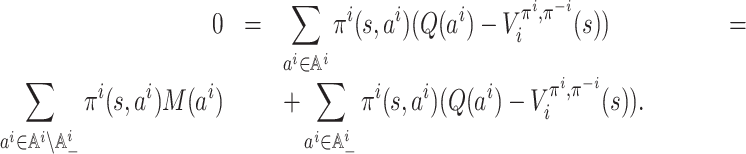
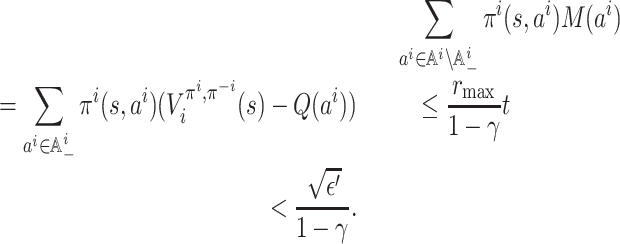
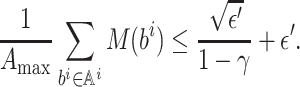


Lemma 6. Let ε > 0 and π be a strategy profile. If, for each player i ∈ [n] and each state
,
then π is an ε/(1 − γ)-approximate MPE.
Proof. Recall the mapping
, defined as the Bellman operator, from the proof of Lemma 4. Let
be the unique fixed point of Φi and recall that, for all
,
.
Pick any player i ∈ [n]; by assumption, for each state
, we have
. On the other hand,
, so we have
, i.e.
.
Since Φi is a γ-contraction mapping,
In addition, by the triangle inequality we have
so it follows that
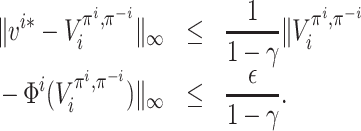
Thus, we have
It follows that, for any
and any
,
By definition, it follows that π is an ε/(1 − γ)-approximate MPE.□


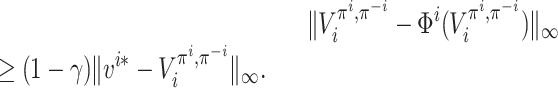
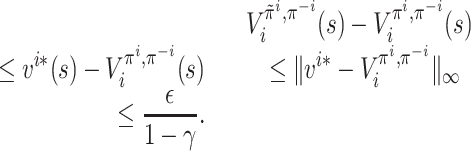
To conclude, Lemma 2 is proven by combining Lemma 5 and Lemma 6, which completes the proof of Lemma 1.
CONCLUSION
Solving an MPE in general-sum SGs has long expected to be at least PPAD-hard. In this paper, we prove that computing an MPE in a finite-state infinite horizon discounted SG is PPAD-complete. Our completeness result also immediately implies the PPAD-completeness of computing an MPE in action-free SGs and single-controller SGs. We hope that our results can encourage MARL researchers to study solving an MPE in general-sum SGs, proposing a sample-efficient MARL solution, which leads to more prosperous algorithmic developments than those currently on zero-sum SGs.
ACKNOWLEDGEMENT
We would like to thank Yuhao Li for his early work, when he was an undergraduate student at Peking University.
APPENDIX
Proof of Claim 1
We have
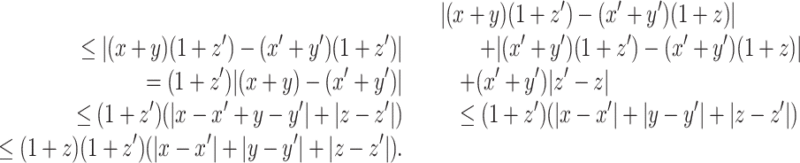 |
The first and third inequalities follow by the triangle inequality, the second inequality holds because x′ + y′ ≤ 1 + z′ and the last inequality follows because 1 + z ≥ 1. It immediately follows that
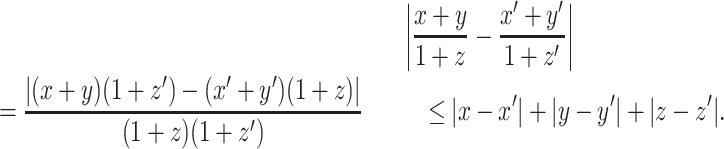 |
Proof of Claim 2
We have
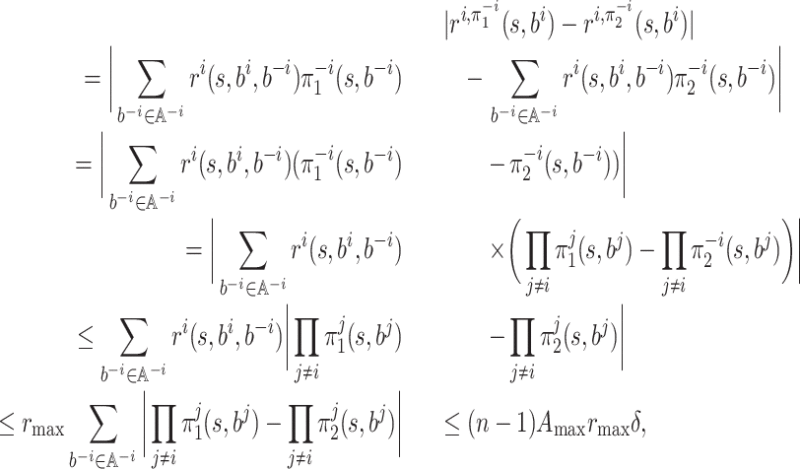 |
where the last inequality follows from the next claim.
Proof of Claim 3
We have
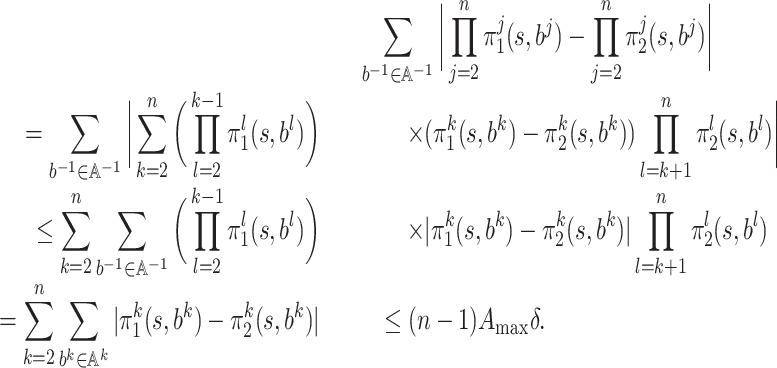 |
Proof of Claim 4
We have
 |
Lemma 7 and its proof
Lemma 7. For every
such that ‖π1 − π2‖∞ ≤ δ, we have
for any
.
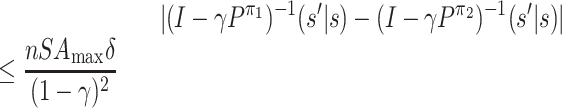
Proof. We first give an upper bound on
for any
:
Now we view Pπ as an S × S matrix. For any two S × S matrices M1, M2, we use ‖M1 − M2‖max to denote max i, j|M1(i, j) − M2(i, j)|, i.e. the max norm. Then we have
.
Let
and
. (Note that the inverse of (I − γPπ) must exist because γ < 1.)
By definition, we have
and
. Then
where the sixth line follows the following facts:
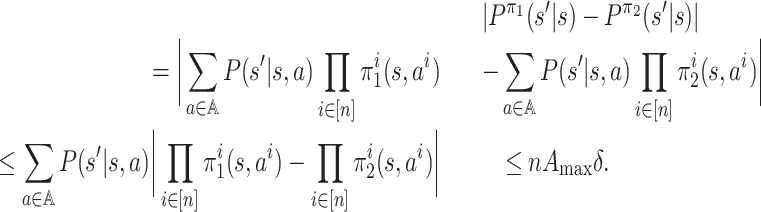
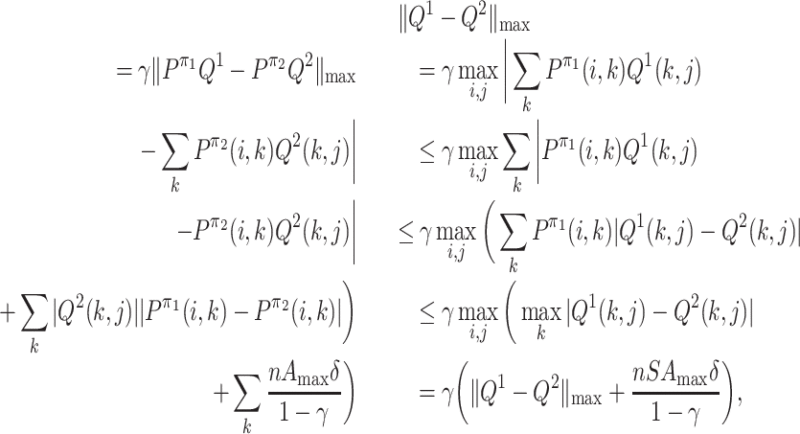
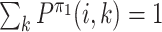 ;
;|Q1(k, j) − Q2(k, j)| ≤ max k|Q1(k, j) − Q2(k, j)|;
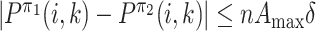 ;
; .
.
Note that  . Since the
1-norm is submultiplicative, we have
. Since the
1-norm is submultiplicative, we have
 |
which leads to the fourth fact. So we have
 |
This completes the proof.
Contributor Information
Xiaotie Deng, Center on Frontiers of Computing Studies, School of Computer Science, Peking University, Beijing 100091, China; Center for Multi-Agent Research, Institute for AI, Peking University, Beijing 100091, China.
Ningyuan Li, Center on Frontiers of Computing Studies, School of Computer Science, Peking University, Beijing 100091, China.
David Mguni, Huawei UK, London WC1E 6BT, UK.
Jun Wang, Computer Science, University College London, London WC1E 6BT, UK.
Yaodong Yang, Center for Multi-Agent Research, Institute for AI, Peking University, Beijing 100091, China.
FUNDING
This work was partially supported by the Science and Technology Innovation 2030—‘New Generation of Artificial Intelligence’ Major Project (2018AAA0100901).
AUTHOR CONTRIBUTIONS
X.D., D.M. and J.W. designed the research; X.D. and D.M. identified the research problem; X.D. and N.L. performed the research; D.M. and Y.Y. coordinated the team; X.D., N.L. and Y.Y. wrote the paper.
Conflict of interest statement. None declared.
REFERENCES
- 1. Shapley LS. Stochastic games. Proc Natl Acad Sci USA 1953; 39: 1095–100. 10.1073/pnas.39.10.1095 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Fink AM. Equilibrium in a stochastic n-person game. J Sci Hiroshima Univ Ser A-I Math 1964; 28: 89–93. 10.32917/hmj/1206139508 [DOI] [Google Scholar]
- 3. Maskin E, Tirole J. Markov perfect equilibrium: I. observable actions. J Econ Theory 2001; 100: 191–219. 10.1006/jeth.2000.2785 [DOI] [Google Scholar]
- 4. Neyman A, Sorin S. Stochastic Games and Applications, vol. 570. New York: Springer Science and Business Media, 2003. 10.1007/978-94-010-0189-2 [DOI] [Google Scholar]
- 5. Albright SC, Winston W. A birth-death model of advertising and pricing. Adv Appl Probab 1979; 11: 134–52. 10.2307/1426772 [DOI] [Google Scholar]
- 6. Sobel MJ. Myopic solutions of Markov decision processes and stochastic games. Oper Res 1981; 29: 995–1009. 10.1287/opre.29.5.995 [DOI] [Google Scholar]
- 7. Filar J. Player aggregation in the traveling inspector model. IEEE Trans Automat Contr 1985; 30: 723–9. 10.1109/TAC.1985.1104060 [DOI] [Google Scholar]
- 8. Perez-Nieves N, Yang Y, Slumbers Oet al. Modelling behavioural diversity for learning in open-ended games. In: Meila M, Zhang T (eds). Proceedings of the 38th International Conference on Machine Learning, vol. 139. Cambridge, MA: PMLR, 2021, 8514–24. [Google Scholar]
- 9. Filar J, Vrieze K.Competitive Markov Decision Processes. New York: Springer Science and Business Media, 2012. [Google Scholar]
- 10. Sutton RS, Barto AG. Reinforcement Learning: An Introduction. Cambridge, MA: MIT Press, 2018. [Google Scholar]
- 11. Busoniu L, Babuska R, De Schutter B. A comprehensive survey of multiagent reinforcement learning. IEEE Trans Syst Man Cybern C Appl Rev 2008; 38: 156–72. 10.1109/TSMCC.2007.913919 [DOI] [Google Scholar]
- 12. Yang Y, Wang J. An overview of multi-agent reinforcement learning from game theoretical perspective. arXiv: 2011.00583. [Google Scholar]
- 13. Littman ML. Markov games as a framework for multi-agent reinforcement learning. In: Cohen WW, Hirsh H (eds). Proceedings of the 11th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann Publishers, 1994, 157–63, 10.1016/B978-1-55860-335-6.50027-1 [DOI] [Google Scholar]
- 14. Hu J, Wellman MP. Multiagent reinforcement learning: theoretical framework and an algorithm. In: Proceedings of the 15th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann Publishers, 1998, 242–50, [Google Scholar]
- 15. Cesa-Bianchi N, Lugosi G. Prediction, Learning, and Games. Cambridge: Cambridge University Press, 2006. [Google Scholar]
- 16. Bubeck S, Cesa-Bianchi N. Regret Analysis Of Stochastic and Nonstochastic Multi-Armed Bandit Problems. Delft: Now Publishers Inc, 2012. 10.1561/9781601986276 [DOI] [Google Scholar]
- 17. Takahashi M. Stochastic games with infinitely many strategies. J Sci Hiroshima Univ Ser A-I Math 1962; 26: 123–34. 10.32917/hmj/1206139732 [DOI] [Google Scholar]
- 18. Zinkevich M, Greenwald A, Littman M. Cyclic equilibria in Markov games. In: Proceedings of the 18th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2005, 1641–8. [Google Scholar]
- 19. Yang Y, Luo R, Li Met al. Mean field multi-agent reinforcement learning. In: Proceedings of the 35th International Conference on Machine Learning, vol. 80. Cambridge, MA: PMLR, 2018, 5571–80. [Google Scholar]
- 20. Guo X, Hu A, Xu Ret al. Learning mean-field games. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems, vol. 80. Red Hook, NY: Curran Associates, 2019, 4966–76. [Google Scholar]
- 21. Pérolat J, Strub F, Piot Bet al. Learning nash equilibrium for general-sum Markov games from batch data. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, vol. 54. Cambridge, MA: PMLR, 2017, 232–41. [Google Scholar]
- 22. Solan E, Vieille N. Stochastic games. Proc Natl Acad Sci USA 2015; 112: 13743–6. 10.1073/pnas.1513508112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Selten R. Reexamination of the perfectness concept for equilibrium points in extensive games. Internat J Game Theory 1975; 4: 25–55. 10.1007/BF01766400 [DOI] [Google Scholar]
- 24. Daskalakis C, Goldberg PW, Papadimitriou CH. The complexity of computing a Nash equilibrium. SIAM J Comput 2009; 39: 195–259. 10.1137/070699652 [DOI] [Google Scholar]
- 25. Chen X, Deng X, Teng SH. Settling the complexity of computing two-player nash equilibria. J ACM 2009; 56: 1–57. 10.1145/1516512.1516516 [DOI] [Google Scholar]
- 26. Papadimitriou CH. On the complexity of the parity argument and other inefficient proofs of existence. J Comput Syst Sci 1994; 48: 498–532. 10.1016/S0022-0000(05)80063-7 [DOI] [Google Scholar]
- 27. Nash J. Non-cooperative games. Ann Math 1951; 54: 286–95. 10.2307/1969529 [DOI] [Google Scholar]
- 28. Bertsekas DP. Approximate dynamic programming. In: Sammut C, Webb GI (eds). Encyclopedia of Machine Learning. Boston, MA: Springer, 2010, 39. [Google Scholar]
- 29. Szepesvári C, Littman ML. Generalized Markov decision processes: dynamic-programming and reinforcement-learning algorithms. Technical Report. Brown University, 1997. [Google Scholar]
- 30. Lagoudakis MG, Parr R. Least-squares policy iteration. J Mach Learn Res 2003; 4: 1107–49. [Google Scholar]
- 31. Munos R, Szepesvári C. Finite-time bounds for fitted value iteration. J Mach Learn Res 2008; 9: 815–57. [Google Scholar]
- 32. Riedmiller M. Neural fitted Q iteration - first experiences with a data efficient neural reinforcement learning method. In: Gama J, Camacho R, Brazdil PB. et al (eds). Machine Learning: ECML 2005, vol. 3720. Berlin: Springer, 2005, 317–28. 10.1007/11564096_32 [DOI] [Google Scholar]
- 33. Pérolat J, Piot B, Geist Met al. Softened approximate policy iteration for Markov games. In: Proceedings of The 33rd International Conference on Machine Learning, vol. 48. Cambridge, MA: PMLR, 2016, 1860–8. [Google Scholar]
- 34. Lagoudakis MG, Parr R. Value function approximation in zero-sum Markov games. In: Proceedings of the 18th Conference on Uncertainty in Artificial Intelligence. San Francisco, CA: Morgan Kaufmann Publishers, 2002, 283–92. [Google Scholar]
- 35. Pérolat J, Scherrer B, Piot Bet al. Approximate dynamic programming for two-player zero-sum Markov games. In: Proceedings of the 32nd International Conference on Machine Learning, Vol. 37. Cambridge, MA: PMLR, 2015, 1321–9. [Google Scholar]
- 36. Sidford A, Wang M, Yang Let al. Solving discounted stochastic two-player games with near-optimal time and sample complexity. In: Chiappa S, Calandra R (eds). Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics, vol. 108. Cambridge, MA: PMLR, 2020, 2992–3002. [Google Scholar]
- 37. Daskalakis C, Foster DJ, Golowich N. Independent policy gradient methods for competitive reinforcement learning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates, 2020, 5527–40. [Google Scholar]
- 38. Hansen TD, Miltersen PB, Zwick U. Strategy iteration is strongly polynomial for 2-player turn-based stochastic games with a constant discount factor. J ACM 2013; 60: 1–16. 10.1145/2432622.2432623 [DOI] [Google Scholar]
- 39. Hu J, Wellman MP. Nash Q-learning for general-sum stochastic games. J Mach Learn Res 2003; 4: 1039–69. [Google Scholar]
- 40. Greenwald A, Hall K. Correlated-Q learning. In: Proceedings of the 20th International Conference on International Conference on Machine Learning. Washington, DC: AAAI Press, 2003, 242–49. [Google Scholar]
- 41. Littman ML. Friend-or-foe Q-learning in general-sum games. In: Proceedings of the 18th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann Publishers, 2001, 322–8. [Google Scholar]
- 42. Prasad H, LA P, Bhatnagar S. Two-timescale algorithms for learning nash equilibria in general-sum stochastic games. In: Proceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems. Richland, SC: International Foundation for Autonomous Agents and Multiagent Systems, 2015, 1371–9. [Google Scholar]
- 43. Brafman RI, Tennenholtz M. R-MAX – A general polynomial time algorithm for near-optimal reinforcement learning. J Mach Learn Res 2002; 3: 213–31. [Google Scholar]
- 44. Wei CY, Hong YT, Lu CJ. Online reinforcement learning in stochastic games. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates, 2017, 4994–5004. [Google Scholar]
- 45. Littman ML, Szepesvári C. A generalized reinforcement-learning model: convergence and applications. In: Proceedings of the 13th International Conference on International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann Publishers, 1996, 310–8. [Google Scholar]
- 46. Fan J, Wang Z, Xie Yet al. A theoretical analysis of deep Q-learning. In: Proceedings of the 2nd Conference on Learning for Dynamics and Control, vol. 120. Cambridge, MA: PMLR, 2020, 486–9. [Google Scholar]
- 47. Bowling M, Veloso M. Rational and convergent learning in stochastic games. In: Proceedings of the 17th International Joint Conference on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann Publishers, 2001, 1021–6. [Google Scholar]
- 48. Conitzer V, Sandholm T. Awesome: a general multiagent learning algorithm that converges in self-play and learns a best response against stationary opponents. Mach Learn 2007; 67: 23–43. 10.1007/s10994-006-0143-1 [DOI] [Google Scholar]
- 49. Jin C, Allen-Zhu Z, Bubeck Set al. Is Q-learning provably efficient? In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates, 2018, 4868–78. [Google Scholar]
- 50. Zhang Z, Zhou Y, Ji X. Almost optimal model-free reinforcement learning via reference-advantage decomposition. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates, 2020, 15198–207. [Google Scholar]
- 51. Li Y, Wang R, Yang LF. Settling the horizon-dependence of sample complexity in reinforcement learning. In: 2021 IEEE 62nd Annual Symposium on Foundations of Computer Science (FOCS). Piscataway, NJ: IEEE Press, 2022, 965–76. 10.1109/FOCS52979.2021.00097 [DOI] [Google Scholar]
- 52. Chen X, Cheng Y, Tang B. Well-supported versus approximate Nash equilibria: query complexity of large games. In: Proceedings of the 2017 ACM Conference on Innovations in Theoretical Computer Science. New York, NY: Association for Computing Machinery, 2017, 57. [Google Scholar]
- 53. Song Z, Mei S, Bai Y. When can we learn general-sum Markov games with a large number of players sample-efficiently? In: International Conference on Learning Representations. La Jolla, CA: OpenReview, 2022. [Google Scholar]
- 54. Jin C, Liu Q, Wang Yet al. V-learning – a simple, efficient, decentralized algorithm for multiagent RL. arXiv: 2110.14555. [Google Scholar]