

Abstract
Data-independent acquisition (DIA) methods have become increasingly popular in mass spectrometry–based proteomics because they enable continuous acquisition of fragment spectra for all precursors simultaneously. However, these advantages come with the challenge of correctly reconstructing the precursor–fragment relationships in these highly convoluted spectra for reliable identification and quantification. Here, we introduce a scan mode for the combination of trapped ion mobility spectrometry with parallel accumulation—serial fragmentation (PASEF) that seamlessly and continuously follows the natural shape of the ion cloud in ion mobility and peptide precursor mass dimensions. Termed synchro-PASEF, it increases the detected fragment ion current several-fold at sub-second cycle times. Consecutive quadrupole selection windows move synchronously through the mass and ion mobility range. In this process, the quadrupole slices through the peptide precursors, which separates fragment ion signals of each precursor into adjacent synchro-PASEF scans. This precisely defines precursor–fragment relationships in ion mobility and mass dimensions and effectively deconvolutes the DIA fragment space. Importantly, the partitioned parts of the fragment ion transitions provide a further dimension of specificity via a lock-and-key mechanism. This is also advantageous for quantification, where signals from interfering precursors in the DIA selection window do not affect all partitions of the fragment ion, allowing to retain only the specific parts for quantification. Overall, we establish the defining features of synchro-PASEF and explore its potential for proteomic analyses.
Keywords: TIMS, TOF, PASEF, data-independent acquisition, scan mode
Abbreviations: ADH, alcohol dehydrogenase; BSA, bovine serum albumin; DAC, digital analog converter; DC, direct current; DDA, data-dependent acquisition; DIA, data-independent acquisition; FPGA, field programmable gate array; PASEF, parallel accumulation – serial fragmentation; SPD, samples per day; TIMS, trapped ion mobility spectrometry
Graphical Abstract
Highlights
-
•
Synchro-PASEF is a highly efficient scan mode for MS-based proteomics.
-
•
It allows very fast cycle times, amplifying the fragment signal three-fold.
-
•
Fragments are directly linked to precursors via precursor slicing.
-
•
Precursor slicing enables deconvolution to pure fragmentation spectra.
-
•
Synchro-PASEF unites the benefits of data-dependent and data-independent acquisition.
In Brief
The novel scan mode synchro-PASEF efficiently follows the natural shape of the precursor cloud in the m/z and the trapped ion mobility space. This manifests in short cycle times and high sampling frequency of the eluting peptides and fragment signal amplification. Additionally, the seamlessly movement of the quadrupole nearly universally slices the precursor in the ion mobility dimension. The slicing position adds tremendous specificity, allowing deconvolution of the fragment space to ‘pure fragmentation spectra’ reminiscent of data-dependent acquisition spectra.
Data-independent acquisition (DIA) has shown enormous promise in recent years because of its signature advantage that every precursor is guaranteed to be fragmented once within every DIA acquisition cycle (1). Although this does not guarantee that every peptide is identified and quantified in every run, it goes a long way to make datasets more reproducible. Importantly, the fragment ions in DIA have elution profiles just like precursors, which dramatically improves to the quality of the fragment peaks. Frequently used software tools such as DIA-NN (2, 3) or Spectronaut (4) match peptides from a library into each of the DIA runs. These libraries were traditionally acquired experimentally with deep data-dependent acquisition (DDA)-based measurements of the proteome of interest but are now often generated directly from the DIA data (5) or in silico from the entire proteome using deep learning (6, 7, 8, 9, 10, 11). Given these advantages, very deep and quantitatively accurate datasets can now routinely be generated by DIA.
Despite these rapid developments, many researchers still prefer DDA—often because only a single precursor is targeted for fragmentation, leading to simpler fragmentation spectra and more straightforward peptide identifications that may appear more trustworthy.
Following the original implementation of the SWATH acquisition scheme on the Sciex platform by Aebersold et al. (1, 12) and then on the Orbitrap instruments, where DIA first demonstrated in-depth proteome coverage (4), we have recently combined DIA with the Bruker timsTOF (13). In this instrument, peptides are confined in a trapped ion mobility spectrometry (TIMS) device by the opposing forces of a gas flow and an electric field and then released from the trap by lowering the electric field strength. Collisional cross-sections and molecular weights of charged peptides are highly correlated, which is the basis of the ‘parallel accumulation—serial fragmentation’ (PASEF) principle, which boosts fragmentation rates in DDA more than 10-fold at no loss of sensitivity (14, 15). For the DIA mode, we very recently described a refined acquisition scheme that simultaneously optimizes the ion mobility and mass ranges for best precursor coverage (16). However, in these schemes, the quadrupole selection window remains fixed for each segment of the acquisition cycle.
We reasoned that a synchronous movement of the quadrupole selection window with the ion mobility scan would better utilize the trapped ion cloud. Furthermore, the rapidly advancing quadrupole window across the mass and ion mobility ranges could lead to much more defined precursor–fragment relationships. Although this scan mode is reminiscent of the one-dimensional movement of the quadrupole in techniques such as SONAR (17, 18) and Scanning SWATH (19), there are important conceptional differences. Simply scanning the m/z range in a timsTOF would imply very wide selection windows to cover the extent of the ion cloud in the mass dimension and would fail to capture most precursors if it was not synchronized with the release of the ions from the TIMS device.
We therefore set out to develop a synchronized PASEF scan mode with very high speed, so as to cover the entire precursor mass range of interest ideally in a single TIMS ramp. We first investigate the analytical properties of ‘synchro-PASEF’ on simple protein mixtures. Our results demonstrate that it makes efficient use of the ion population for fragmentation, even with very short acquisition cycles. We also find that peptide precursors are nearly universally ‘sliced’ in the ion mobility dimension by adjacent synchro-PASEF scans and describe how this enables the extraction of pure fragmentation spectra and mitigates interference for quantification.
Experimental Procedures
Development of an Extremely Fast and Synchronized Scan Capability
Previously in dda- and dia-PASEF, the analytical quadrupole was operated statically, i.e., stepped through a defined number of isolation windows per TIMS ramp. While the quadrupole changed its position, the signal was not recorded, limiting the number of quadrupole steps. In synchro-PASEF, the quadrupole selection window changes incrementally and is constantly synchronized to the TIMS elution. To acquire the complete signal, we routed the digital analog converters (DACs) of the quadrupole radio frequency-amplitude, bias-direct current (DC), and resolution-DC to the same field programmable gate array (FPGA) of the instrument controller that controls the TIMS device. We also implemented the mass-to-set-value calculations based on the quadrupole calibration in the FPGA. Translation of the setpoint isolation masses and widths to the DAC values is implemented on the firmware level.
Together, this results in a more accurate correlation of the quadrupole with the TIMS ramp and when the quadrupole changes the mass position, the MS data are recorded simultaneously. However, these simultaneous events in synchro-PASEF bring their own challenges since there are several delays between triggering the programmed isolation position and recording the fragment spectra: First, the time constant of the electronics and thus the rise time of the actual values that are applied to the quadrupole rods need to be adapted to each other; second, the ions' mass and mobility-dependent transition time from the quadrupole to the time of flight (TOF) detector need to be accounted for. Both result in an apparent isolation mass shift of the quadrupole. Moreover, the transition time of ions through the quadrupole reduces the effective isolation width, given the very high scanning speed. To correct for this, we quantified the combined effects in terms of isolation mass and width offsets for scan rates up to 36,000 Th/s (see below) and determined linear correction functions to calibrate the quadrupole isolation mass and width in alignment with the synchronous movement.
Experimental Design and Statistical Rationale
We performed the experiments with tryptic HeLa cell lysate digest obtained from HeLa S3 cells (American Tissue Culture Collection, ATCC) to illustrate the behavior of synchro-PASEF in a complex sample type and with a simple tryptic protein digest mixture consisting of bovine serum albumin (BSA, P02769), yeast alcohol dehydrogenase (ADH, P00330), yeast enolase (P00924), and rabbit phosphorylase b (P00489) for detailed analyses. This simple protein mixture was obtained from Waters GmbH.
The complete dataset consisted of 13 raw files of single runs for this proof-of-principle study. For experiments involving a complex proteome mixture, 200 ng HeLa digest was used; for experiments involving the simple protein mixture, 200 fmol was injected for LC gradients of 3.2 min [300 samples per day (SPD) on the Evosep system] and 5.6 min (200 SPD) and 400 fmol for LC gradients of 11 min (100 SPD) and 21 min (60 SPD). To analyze simple protein digests in a complex background, we spiked 200 fmol protein mixture into 100 ng HeLa. The figure legends contain additional experimental design and statistical rationale for the respective experiments.
Sample Preparation
The complex proteome mixture used in our experiments was composed of HeLa S3 cells (ATCC). Cells were cultured in Dulbecco’s modified Eagle’s medium (Life Technologies Ltd) supplemented with 20 mM glutamine, 10% fetal bovine serum, and 1% penicillin-streptomycin. The sample preparation was performed following the in-StageTip protocol (20). After washing the cells in PBS and cell lysis, the proteins were reduced, alkylated, and digested by trypsin (Sigma-Aldrich) and LysC (WAKO) (1:100, enzyme/protein, w/w) in one step. The peptides were dried, resuspended in 0.1% TFA/2% acetonitrile (ACN), and 200 ng digest was loaded onto Evotips (Evosep). The Evotips were prepared by activation with 1-propanol, washed with 0.1% formic acid (FA)/99.9% ACN, and equilibrated with 0.1% FA. After loading the samples, tips were washed once with 0.1% FA.
The simple proteome mixture was composed in equal amounts of the purified and predigested tryptic standard proteins enolase, phosphorylase b, ADH, and BSA. The peptides were reconstituted in 0.1% FA, and either 200 or 400 fmol (see above) were loaded onto Evotips.
LC Analysis
The Evosep One liquid chromatography system separated peptide mixtures at various throughputs using standardized gradients with 0.1% FA and 0.1% FA/99.9% ACN as the mobile phases. The 60 and 100 SPD runs were measured with an 8 cm × 150 μm reverse-phase column packed with 1.5 μm C18-beads (Bruker Daltonics) connected to a fused silica 10 μm ID emitter (Bruker Daltonics). For measuring 200 and 300 SPD, we connected the same emitter to a 3 cm × 150 μm reverse-phase column packed with 1.9 μm C18-beads (Bruker Daltonics). In both cases, the emitter was operated inside a nanoelectrospray ion source (Captive spray source, Bruker Daltonics).
MS Analysis
The Evosep LC system was coupled with a modified timsTOF Pro 2 mass spectrometer (Bruker Daltonics) to acquire data in synchro-PASEF mode and for comparison in dda- and dia-PASEF mode.
We acquired dda-PASEF with four PASEF scans per top-N acquisition cycle, an intensity threshold of 2500 arbitrary units (a.u.) as indicated by the Bruker acquisition software and a target value of 20,000 a.u. for precursor selection. Precursors that reached this target value were excluded for 0.4 min, which still permitted resequencing in simple mixtures, as shown in section two. Singly charged precursors were filtered out based on their m/z-ion mobility position, and precursors with a mass below 700 Da were isolated with a quadrupole selection window of 2 Th and otherwise with 3 Th.
For dia-PASEF, we used a method generated with our python tool py_diAID (16). That method covered an m/z-range from 350 to 1200 in 12 dia-PASEF scans with two isolation windows per dia-PASEF scan resulting in a cycle time of 1.4 s.
Additionally, we optimized three synchro-PASEF methods based on the tryptic HeLa reference library introduced in our optimal dia-PASEF study (16). The first method consists of four 25 Th isolation windows with a cycle time of 0.56 s and a second method of seven 15 Th windows (0.9 s cycle time). The third method had one 35 Th, two 25 Th, and one 50 Th isolation window (cycle time 0.56 s). The calculated precursor coverages and kernel density plots depicting a precursor ion cloud in the figures was based on this reference library, too.
If not stated otherwise, we used 100 ms to accumulate and elute ions in the TIMS tunnel. The m/z-range was acquired from 100 to 1700, and the ion mobility range from 1.3 to 0.7 V cm−2 calibrated with Agilent ESI Tuning Mix ions (m/z, 1/K0: 622.02, 0.98 V cm−2, 922.01, 1.19 V cm−2, 1221.99, 1.38 V cm−2). Experiments described to be ‘with minimal collision energy’ were measured at a constant collision energy of 10 eV (because the software does not allow setting this value to zero), which is not sufficient to cause peptide fragmentation. For experiments with collision energy, the energy was linearly decreased from 59 eV at ion mobility of 1.6 Vs cm−2 to 20 eV at 0.6 V cm−2.
Raw Data Analysis
Data were analyzed by manual and visual inspection with the help of our publicly available Python tools AlphaTims (21) and AlphaViz (22). The MaxQuant evidence output table (Version 1.6.17.0) (23, 24) from a single HeLa dda-PASEF run was the basis for calculating the percentage of precursor slicing. We used the reviewed human proteome (UniProt, Nov 2021, 20,360 entries without isoforms) and default settings for the analyses. This comprised a false discovery rate of 1%, two missed cleavages, the cleavage pattern for trypsin, cysteine carbamidomethylation as fixed modification, and methionine oxidation and protein N-terminal acetylation as variable modifications. The mass tolerance was set to 10 ppm for the main search, and known contaminants were excluded from the dataset.
Statistical Analysis
The raw data were analyzed and visualized with Python (3.8, Jupyter notebook) and the packages pandas (1.2.4), AlphaTims (1.0.4) and numpy (1.20.3, (25)) for data accession and py_diAID (0.0.16), AlphaViz (1.1.15), matplotlib (3.4.2), and astropy (5.1) for visualization.
Results
Synchronizing Quadrupole Movement With Trapped Ion Mobility Separation
The timsTOF principle adds a combined trapping and separation device to the regular liquid chromatography quadrupole TOF set up (26, 27, 28) (Fig. 1A). The TIMS tunnel has two segments, the first of which accumulates the ions for typically 100 ms, while the second releases the ions from the tunnel in high to low order, with the ions that have the largest cross-sections (and typically mass) first. Although the TIMS device is capable of an ion mobility resolution of greater than 100, in complex mixtures, the ion mobility peaks are typically several ms wide.
Fig. 1.

The principle of synchro-PASEF precursor isolation.A, the timsTOF ion path: Ions enter the mass spectrometer after electrospray, accumulate and separate in the TIMS tunnel, and are then isolated by a mass-selective quadrupole. A collision cell fragments these precursor ions and a reflector TOF analyzer determines the mass spectrum every 110 us. B, top panel, simulations of dda-PASEF, dia-PASEF, and synchro-PASEF. The background ion cloud in m/z and ion mobility dimensions shows a kernel density distribution of a reference library from tryptic HeLa (see Experimental Procedures). Bottom panel, precursor signal of each scan mode from 200 ng tryptic HeLa digest acquired with minimal collision energy for a 21 min gradient (60 samples per day). dda-PASEF selects the top-N most intense precursors with an isolation width of 2 to 3 Th. Each TIMS ramp isolates different precursors, and the 5656th TIMS ramp is visualized above (left panel). dia-PASEF isolates the precursor cloud in vertical stripes with variable isolation widths. A 20 Th isolation in the sixth dia-PASEF scan at frame 5649 is shown (middle panel). Synchro-PASEF follows the precursor cloud naturally and selects many more precursors per isolation window as the previous dia-PASEF schemes. The third synchro scan, frame 5654, is shown (right panel). C, visualization of the synchro-PASEF quadrupole movement in m/z in Th, inverse ion mobility (1/K0), and TIMS ramp time dimensions in ms. The quadrupole control steps 0.9 Th (later referred to as quadrupole step size) to lower m/z values for every 110 μs TOF trigger, corresponding to a 0.0007 V cm−2 downwards step in the inverted ion mobility direction. DDA, data-dependent acquisition; DIA, data-independent acquisition; PASEF, parallel accumulation—serial fragmentation; TIMS, trapped ion mobility spectrometry; TOF, time of flight.
The downstream quadrupole sets the molecular mass per charge (m/z or Th) isolation range of interest, and the selected precursors are subjected to fragmentation, with all fragment ions appearing at the same ion mobility value as their precursors. The PASEF principle utilizes the speed of the TOF analyzer and the correlation between ion mobility and molecular weight to subject more than one precursor per accumulation cycle for fragmentation. This implies a selection in two dimensions since all peptide precursors require isolation based on molecular weight and ion mobility (13, 15). Note that the selection in m/z dimension is performed explicitly by the quadrupole whereas the selection in ion mobility dimension happens implicitly by the timing of the quadrupole selection in relation to the release of ions from the TIMS device.
In DDA mode, PASEF allows the selection of more than ten precursors per TIMS ramp, which involves rapid placement of the selection window to the precursor positions in a zig-zag pattern (Fig. 1B, left panel). In our previous implementation of DIA, the quadrupole is instead stationary with an appropriate selection window for a part of the TIMS ramp and then jumps the next mass range (Fig. 1B, middle panel). Although highly efficient (16), neither scan mode naturally follows the ‘banana-shaped’ ion cloud in the m/z versus ion mobility plane.
We reasoned that a continuous and synchronized movement of the quadrupole could slice the ion cloud into several, equally complex TIMS ramps (Fig. 1B, right panel). To enable such a synchro-PASEF scan, we built upon the FPGA already present in the instrument that previously controlled among others the TIMS scan. In addition, the DACs of the quadrupole radio frequency-amplitude, the bias-DC, and the resolution-DC are all routed through this FPGA (Experimental Procedures). This allows the quadrupole to move continuously and extremely fast, covering about 8000 Th/s while being aligned with the TIMS release (Fig. 1C).
In this particular implementation, the mass spectrometer executes 927 TOF pulses during the 100 ms TIMS ramp, where each TOF acquisition takes 110 μs. The leading edge (lower m/z) of the quadrupole selection window of 25 Th starts at m/z 1170 and moves down to 335 in our method (Fig. 1C). Thus, the quadrupole control changes its position every 0.11 ms with a step size of 0.9 Th. In comparison, Scanning SWATH (19) moves the selection window every 2 ms with a step size of 2 Th. Given a width of the ion cloud of about 100 Th of the doubly charged precursors (Fig. 1B, top right panel), we found that four TIMS ramps with our 25 Th isolation width adequately cover these precursors. Beyond this, the window size can be adjusted to any desired value. Based on the reference library, this acquisition scheme leads to a precursor coverage of 76% (see Experimental Procedures). Adding one MS1 level TIMS ramp to measure precursors and transfer time, the total cycle time is only 0.56 s (supplemental Table S1), much faster than our previously optimized dia-PASEF method for short gradients (1.4 s, Experimental Procedures). Those methods were designed for comprehensive coverage, but only contain 8% of precursors per isolation window, in contrast to 19% for synchro-PASEF. The underlying reason for this advantage is that slicing the banana-shaped ion cloud vertically as we had done before requires many more steps than slicing it diagonally along its length while keeping the same width. Thus synchro-PASEF is better adapted to the ion cloud, thereby increasing precursor sampling and making it very fast and efficient.
Synchro-PASEF Combines Continuous Fragmentation With Short Cycle Times
Having established the feasibility and parameters of synchro-PASEF scans on unfragmented precursor selection, we next investigated their benefits for the fragment spectra compared to dda- and dia-PASEF.
As mentioned above, dda-PASEF selects single precursors leading to a striped pattern of fragment ions in the ion mobility (Fig. 2A, left panel). Only a small proportion of precursors is covered in each TIMS ramp, but for these, the precursor-fragment and the fragment-fragment relationships are clearly defined. These fragmentation spectra can still be composed of more than one co-eluting precursor in the same precursor isolation window, but the ion mobility selection makes this less likely.
Fig. 2.

Fragmentation behavior for dda-, dia- and synchro-PASEF.A, comparing fragment signals of dda-, dia- and synchro-PASEF. A tryptic digest of HeLa cells was measured in a 21 min gradient. The same frame numbers as in Figure 1B are shown but collision energy was applied. Left panel, fragmentation spectra of 15 precursors marked with their isolation windows in dda-PASEF. Middle panel, isolation windows and continuous fragment acquisition in dia-PASEF. There are no fragments at the transition point and at the precursor low mobility regions. Right panel, the isolation window of the third synchro-PASEF scan is shown. Note the uniform fragment distribution in the entire m/z – ion mobility plane. B, conversion efficiency to fragments for the three scan modes illustrated with the fragment intensities of GLAGVENVTELK (phosphorylase b) and SISIVGSYVGNR (ADH) co-eluting at a retention time of 10.35 to 10.55 min and an ion mobility of 0.93 to 0.955 V cm−2. In DDA mode, the eluting peptides were fragmented three times in this low complexity mixture. Synchro-PASEF sampled the peptide many more times than dia-PASEF due to shorter cycle times. C, summed intensities for the fragment signals of the two peptides in (B). ADH, alcohol dehydrogenase; DDA, data-dependent acquisition; DIA, data-independent acquisition; PASEF, parallel accumulation—serial fragmentation.
High data completeness is inherent to DIA modes since a broad mass range is recorded deterministically. Furthermore, DIA samples the precursor and fragments multiple times over an elution peak in the retention time and—in the case of dia-PASEF—in the ion mobility dimension. This sampling over the elution peaks in principle enables the reconstruction of the relationship between the precursor and its fragments based on the alignment of the elution profiles. However, the broad isolation windows of DIA lead to highly chimeric fragment spectra since multiple precursors are selected at once, which in practice limits a precise reconstruction of these relationships even in dia-PASEF (Fig. 2A, middle panel).
Synchro-PASEF maintains the principle of DIA—fragmenting multiple precursors at once—resulting in complex spectra. However, in contrast to our previous dia-PASEF methods, the fragmentation spectrum is continuous in the m/z and ion mobility dimension, filling nearly the entire m/z versus ion mobility plane. Furthermore, there are no artifactual borders due to the quadrupole jumping to different mass ranges (Fig. 2A, right panel).
To directly measure the increase in fragmentation yield in synchro-PASEF, we analyzed a low complexity mixture (Experimental Procedures). Taking the co-eluting phosphorylase b peptide GLAGVENVTELK and ADH peptide SISIVGSYVGNR measured with 21 min gradients (60 SPD on the Evosep system) as an example, we only observed a few fragmentation events across the elution peak in DDA (caused by ‘resequencing events’ in this low complexity mixture) (Fig. 2B, left panel). In contrast, our recently reported optimal dia-PASEF method (16) had five fragmentation data points per peak at a cycle time of 1.4 s (Fig. 2B, middle panel). As outlined above, the diagonal quadrupole movement of synchro-PASEF leads to much more rapid sampling of the eluting peaks, in this case multiplying the number of fragmentation data points compared to dia-PASEF (Fig. 2B, right panel). Importantly, the increased sampling also amplifies the integrated signal for each fragment. For these peptides, synchro-PASEF acquired three-fold more fragment signal than our previous dia-PASEF method, as expected from the nearly three-fold faster sampling (Fig. 2C).
Extensions of Synchro-PASEF
So far, we have elucidated the features of synchro-PASEF with an acquisition method that had a constant isolation width of 25 Th, four synchro scans, a ramp time of 100 ms, and a quadrupole step size of 0.9 Th. This is, however, just a reference method and can be adjusted depending on the use case, for example to increase proteome coverage. Next, we explored three acquisition schemes that achieve different balances between quadrupole isolation width, cycle time, precursor coverage, and now also quadrupole step size (Fig. 3A).
Fig. 3.

Parametrization of synchro-PASEF scan modes.A, acquisition schemes for synchro scan methods with different quadrupole selection window widths. B, cycle times of the methods in (A). C, precursor coverage of methods in (A) calculated with the HeLa reference library. D, quadrupole step size in dependence on the TIMS ramp time. E, precursor elution profiles and sampled data points in the retention time dimension at a throughput of 60 SPD (21 min), 100 (11 min), 200 (5.6 min), and 300 (3.2 min) for the peptide GLAGVENVTELK. PASEF, parallel accumulation—serial fragmentation; SPD, samples per day; TIMS, trapped ion mobility spectrometry.
The first one is the method predominantly used in this paper, the second one has seven 15 Th synchro scans, and the third method has four synchro scans with different window sizes adapted to the precursor cloud density but kept constant throughout each individual synchro scan. Since the second method has seven synchro scans, it also has the longest cycle time (899 ms instead of 561 ms, Fig. 3B and supplemental Table S1). Method 3 has the widest isolation windows and covers 86% of the precursor cloud, which is 10% more than the coverage of method 1 and 2, while having a short cycle time of 561 ms (Fig. 3C).
A TOF trigger, which is the duration of one TOF acquisition, takes 107.87 μs (for simplicity rounded to 110 μs above). At a TIMS ramp time of 100 ms, the TOF executes 927 triggers in the standard methods (100 ms TIMS ramp time/107.87 μs = 927 TOF trigger) (Fig. 1C), whereas doubling the ramp time to 200 ms also doubles the number of TOF triggers to 1854. In the case of a quadrupole selection window of 25 Th moving from 1170 to 335 Th, a 200 ms ramp time leads to a step size of 0.45 Th ((1170 Th − 335 Th)/1854 TOF trigger = 0.45 Th quadrupole step size) (Fig. 3D). Thus, the quadrupole step size can be made even smaller for longer TIMS ramps.
A TIMS ramp of 50 ms implies a step size of 1.8 Th (Fig. 3D) and a quadrupole scanning speed of about 16,000 Th/s. We characterized the isolation performance at these very fast scan rates to evaluate the implications for method optimization. Note that the electronics trigger the programmed mass position earlier than the actual recording of the fragment spectrum (Experimental Procedures). We quantified the isolation mass and width effects for scan rates up to 36,000 Th/s and determined linear calibration functions to correct for the synchronously moving quadrupole (supplemental Fig. S1A). After calibration, the mass deviation of the center of the 25 Th isolation window at a scan speed of 16,000 Th/s was less than ±0.4 Th for the relevant mass-to-charge range. Deviation of total isolation width was less than ±0.5 Th (supplemental Fig. S1B). Note that this is not the accuracy of the leading and trailing edges of the isolation window (see below).
Motivated by this quadrupole precision even at very high scan rates, we wished to investigate how much LC gradients could be shortened while retaining many data points per peak. We acquired our simple protein mixture with the standard method (four times 25 Th synchro scans) with progressively higher throughput (Fig. 3E). Taking the same peptide GLAGVENVTELK for illustration, we achieve high peak sampling for all gradients, including the ones with FWHM peak widths around 1 s. Remarkably, even at a throughput of 300 SPD corresponding to an LC gradient of 3.2 min, we still obtained eight data points per peak with a cycle time of 0.56 ms. This suggests that synchro-PASEF is suitable for high throughput, quantitative DIA applications.
Precursor Slicing by Synchro-PASEF Deconvolutes DIA Spectra
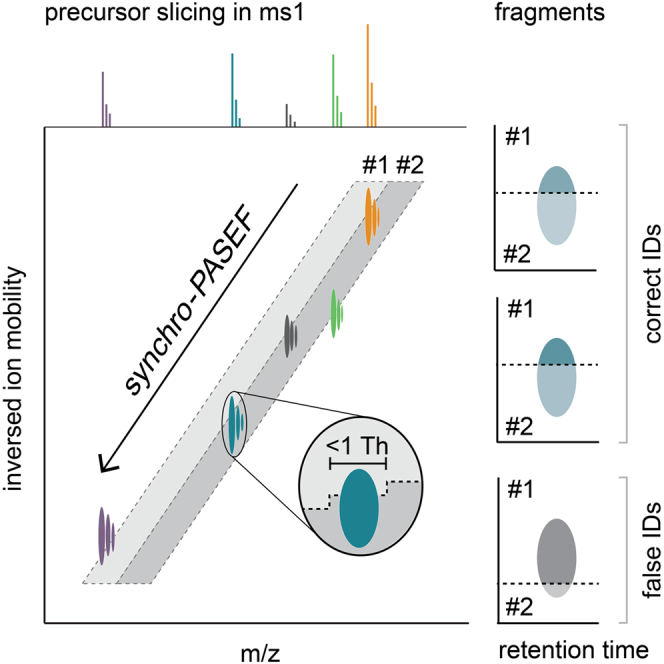
Our results up to this point establish superior precursor sampling efficiency and speed for synchro-PASEF compared to previous scanning modes. However, when analyzing the data, we noticed that the diagonal synchro scans frequently intersected or ‘sliced’ precursors in the m/z and ion mobility plane. In fact, this was the rule rather than the exception and is caused by the fact that scan lines are closer together than the ion mobility peak widths (see below). We also noticed that precursor slicing divides the fragment signals into adjacent synchro scans.
This principle is depicted schematically in Figure 4A. When the quadrupole moves from high to low m/z values and from high to low inversed ion mobility values, the trailing edge of the quadrupole selection window (synchro scan #1) moves through the orange precursor and the top parts of all fragments for this precursor are recorded. The leading edge of the next synchro scan slices the precursor at the same position, this time recording the bottom parts of all fragments. Importantly, adding the top and bottom parts reconstitutes the total fragment signal with the same two-dimensional peak shape as the precursor signal.
Fig. 4.

Principle of precursor slicing in synchro-PASEF.A, two synchro scans and five precursors are schematically depicted (left panel). As the trailing edge of synchro scan #1 moves through the orange precursor, the top parts of all fragments appear at the same time, followed by the bottom part in scan #2 (middle and right panels, respectively). The slicing position is known for each precursor, and all pieces with the same slicing position belong together. This specifies the precursor–fragment and fragment–fragment relationships. B, slicing of the quadrupole of the yeast ADH peptide SIPETQK. For illustration, minimal collision energy was applied. The precursor peak can be quantitatively reconstructed from the sliced parts in two subsequent synchro scans. C, same as (B) but applying collision energy and focusing on the y5 ion. The traces in adjacent synchro scans add up to the full trace for this transition (left panel). The fragment is sliced in exactly the same way as the precursor in (B) (right three panels). ADH, alcohol dehydrogenase; PASEF, parallel accumulation—serial fragmentation.
To analyze how frequent such slicing events occur, we note that at each quadrupole position, the isolation window is 25 Th wide, and the scan diagonal of one synchro-PASEF scan is 3.2 ms high in the ion mobility dimension (supplemental Fig. S2A). With our dda-PASEF HeLa run from Figure 2A, we determined that the average ion mobility peak width was 4.3 ms (supplemental Fig. S2B). A total of 79% of the precursor peaks have an ion mobility profile wider than the synchro scan height. Altogether, 97.4% of the precursors that are within the area covered by the synchro scans are sliced at least once, making precursor slicing a nearly universal phenomenon (supplemental Fig. S2C). The percentage for each synchro-PASEF scan varies from 65% to 27% depending on the position of the acquisition scheme and the precursor density in the m/z and ion mobility plane (supplemental Fig. S2D). The percentage of precursors that are sliced depends on the height of the synchro scans in ion mobility direction, which in turn varies with the quadrupole selection window width and the TIMS ramp time. Referring back to the three synchro-PASEF methods in Figure 3A, the wider isolation windows of method 3 reduce the percentage of sliced precursors to 90.1%. Method 2 with the smallest isolation width (15 Th) also has the smallest height of the diagonal, resulting in 99.7% of precursors being sliced (supplemental Fig. S2C).
To experimentally demonstrate precursor slicing, we measured our simple protein mixture, focusing in detail on the doubly charged yeast alcohol dehydrogenase peptide SIPETQK (modified sequence: acetylated protein N-term-SIPETQK, m/z 422.7). Acquiring this peptide with minimal collision energy in MS1 mode defines the peak shape in retention time and ion mobility space (Fig. 4B, leftmost panel). Given the known precursor m/z and ion mobility, it is straightforward to calculate the intersection point of the synchro scan that slices this precursor (dashed line in the figure). Applying synchro scans with minimal collision energy, the top part of the precursor appears in one synchro scan with the edge at the expected slicing position. The next synchro scan contains the remainder of the peak and both parts together reconstitute the full precursor peak (Fig. 4B, rightmost panel). This peak reconstitution can also be seen when signal intensities of the two synchro scans are separately plotted as a function of m/z, retention time or ion mobility (supplemental Fig. S3A).
Next, we examined how precisely the quadrupole slices. Inspection of the ion cloud after synchro scan isolation but with minimal fragmentation showed good overall alignment between the programmed isolation window and actually transmitted ions, with the leading edge of the quadrupole ejecting lower mass ions somewhat sharper than the trailing edge ejecting higher mass ions (supplemental Fig. S3, B and C). This is the expected behavior because the stability to instability transition of a quadrupole is steeper for the low mass ejection than the one for high mass ejection (29). When applying collision energy, we observe the slicing behavior for all fragments (shown for y5 in Fig. 4C).
Synchro-PASEF inherits the PASEF dimensions retention time, ion mobility, m/z, and intensity from dia-PASEF. However, precursor-fragment or fragment-fragment relationships are defined by the phenomenon of precursor slicing. As illustrated in our simple mixture and in more detail below, two-dimensional precursor slicing conceptually ‘deconvolutes’ the unprocessed DIA spectra because it establishes precursor–fragment relationships similar to DDA spectra. In the next section, we refine this concept and apply it to qualitatively and quantitatively disentangle individual peptides from the complex background of a cellular proteome.
Precise Identification and Quantification Via a Lock-and-Key Mechanism
As described above, synchro-PASEF slices precursors and forms complementary fragment parts in adjacent synchro scans. When put back together at the known slicing position of the precursor, these parts should reconstitute its shape. We found these criteria to be exquisitely specific (see below), reminiscent of a ‘lock-and-key mechanism’.
To illustrate, we first depict a precursor and the slicing plane in the m/z, retention time, and ion mobility dimensions (Fig. 5A). A number of fragment ions have roughly similar retention times and ion mobilities and could therefore potentially belong to the precursor (Fig. 5B). From the calculated slicing position of the precursor, the potential fragments can be verified based on their experimental slicing pattern (Fig. 5C). Investigating these peaks more closely, fragments 1, 3, and 4 have the same shape and slicing position as the precursor and are correct identifications. Fragment 2 co-elutes in retention time and ion mobility but is sliced at a different position then calculated for the precursor mass. Fragment 5 has a different shape in the ion mobility dimension and therefore cannot be fragments for this precursor.
Fig. 5.

Precursor slicing makes identification and quantification more precise.A, the quadrupole slices precursors into at least two parts. B, all features with the same retention time and ion mobility distribution as the precursor are potential fragments of the precursor. C, precise identification enabled by slicing: fragment 2 is sliced at the wrong position, and fragment 5 does not align in the retention time and ion mobility dimension; hence these fragments do not belong to this precursor. D, slicing improves the confidence for correct quantification since both sliced parts should add up to 100% normalized intensity. E, a particular precursor in the HeLa digest and its calculated slicing position indicated by a dashed line. F, fragment m/z spectrum extracted at the precursor's ion mobility and retention time position. G, pure fragmentation spectrum after inspecting the single fragments for correct precursor slicing and the mirrored spectrum predicted by AlphaPeptDeep (6). H, fragment signal from (F) in detail. m/z positions: (1) fragment y5: 662.33, (2) fragment y6: 777.35, (3) fragment y7: 876.42, (4) 887.46. IM, ion mobility; RT, retention time.
Precursor slicing has also implications for quantification based on the requirement that fragment parts added together should reconstitute the shape of the precursor peak. The fraction of the precursor intensity in each synchro scan has fixed ratios given by the slicing position (Fig. 5D). If the top and bottom parts of a sliced fragment do not add up to the intensity distribution of the precursor, this typically indicates an interference of another precursor at this fragment mass.
We demonstrate the specificity of this principle on a precursor, which we calculate to be sliced at an ion mobility position of 0.895 V cm−2 based on a precursor m/z of 563.786 (Fig. 5E). The fragmentation spectrum for this precursor is complex even after filtering for concordance in retention time and ion mobility (Fig. 5F) but this can be disentangled by inspecting the individual peaks in detail (Fig. 5G). The prominent peaks labeled signals 1 and 2 have a similar shape and slicing position as the precursor. Additionally, their intensity ratios (35% and 65%) correspond to the calculated precursor slicing (Fig. 5H). Fragment 3 has the correct slicing position, but the fragment part from synchro scan two is overlayed with another signal, changing the intensity ratios. Fragment 4 is sliced at a different position and has a different shape. As a result, only fragments 1 and 2 are valid. Note that only one part of fragment 3 has an interference; therefore, the second part could still be used for identification and quantification.
Going through all fragment signals leads to an extracted spectrum as simple or even simpler than a DDA spectrum (Fig. 5G) (see explanation in supplementary Figs. S4 and S5). The precursor and fragment masses extracted in this way excellently fit the doubly charged peptide LHVDPENFR (P02081) of hemoglobin fetal subunit beta that is present in the HeLa growth medium. Fragment 1 is the y5 ion, fragment 2 the y6, and fragment 3 the y7 ion.
To demonstrate the extraction of DDA-like spectra more objectively, we assigned precursors of the simple protein mixture spiked into a complex HeLa mixture. As before, we filtered spectra for co-elution in retention time and ion mobility and, in a second step, extracted peaks that conform to the constraints imposed by the additional precursor slicing dimension. Because virtually all fragments in the extracted spectra belong to only one precursor (unlike in DDA spectra), we term them ‘pure fragmentation spectra’. To computationally handle the slicing of the precursors, we calculated a correlation score between the in-silico sliced precursor and the measured fragment partitions. We found that a correlation threshold of at least 0.2 efficiently rejected unrelated peaks. Additionally, we required the intensity ratios for the summed intensities between the upper and lower part of the in-silico sliced precursor and the fragment partitions to deviate on an absolute log2 scale less than 3. We found these values to be an optimal balance for generating pure fragmentation spectra while retaining annotated fragments (supplemental Fig. S4). Although we used fixed cutoffs, we believe that future algorithms would benefit most from handling these scores as dynamic features. As a result of our analysis, the ion current in the 29 pure spectra easily explainable by the expected fragmentation spectrum is 58.2% on average, whereas this was only 11.4% without considering precursor slicing (supplemental Fig. S5). To further validate the quality of the peptide-spectrum matches, we calculated the cross-correlation between the theoretical fragmentation pattern and the acquired spectrum. We used the XCorr score that is a standard score in DDA search algorithms (30, 31). Reassuringly, spectra filtered for precursor slicing showed a higher score compared to spectra without precursor slicing (supplemental Fig. S6), as expected by reducing the impact of background signal on the score. Inspecting these spectra manually, we found that eight of the 29 peptides showed interference in one of the fragment partitions (similar to fragment 3 in Fig. 5H), demonstrating that the lock-and-key mechanism can assist in preventing misassignment. For 21 peptides, we found at least one slicing position that did not agree with the expected one for this precursor (similar to fragment 4 in Fig. 5H); thus, the slicing position could assist in sorting out wrong precursor–fragment associations (supplemental Table S2).
Discussion
In this paper, we have developed and characterized a novel scanning method termed synchro-PASEF. A defining feature is that the quadrupole selection window moves diagonally through the m/z - ion mobility plane and synchronously to the ion mobility elution. In this sense, it is the two-dimensional extension of methods such as SONAR or Scanning SWATH. Compared to our previous DDA- or DIA-based PASEF methods, this movement samples the precursor cloud more efficiently, covering up to 19% of all precursors per isolation window. Additionally, it allows short cycle times which is reflected in up to three-fold higher fragment intensities and much higher peak sampling rates compared to our previous standard method. This implies adequate sampling even for very short LC gradients, in turn opening up for high throughput. The fragment signal amplification and higher sampling rate should also be beneficial for quantitative precision.
Another key and unanticipated feature of synchro-PASEF is the fact that precursors are sliced in m/z and ion mobility space by the fast-moving quadrupole selection window. Nearly all precursors are sliced, and their fragments are thereby separated into adjacent synchro scans with high precision and reproducibility. The slicing position deterministically depends on the precursor mass and establishes precursor–fragment and fragment–fragment relationships. We found that the separated fragment parts can be recombined quantitatively with very high specificity. This lock-and-key mechanism can serve as a highly specific criterium for identification and quantification, in effect deconvoluting the unprocessed DIA spectra to the simplicity of DDA spectra or perhaps even better. We plan to use this additional information to eliminate false identifications, pinpoint signals with interference and even correct them by retrieving only the interference-free part of the transition.
Taken together, synchro-PASEF adds another dimension to the already five-dimensional data cube in timsTOF—consisting of retention time, ion mobility, quadrupole selection, m/z, and intensity (28). It offers all the advantages of DIA, including a comprehensive picture of precursor and fragments over the elution profiles, as well as high data completeness resulting from a high ion beam usage with short cycle times. This is combined with the specificity of DDA owing to a defined precursor–fragment and fragment–fragment relationship established by two-dimensional precursor slicing. Clearly, both library-free and library-based analysis could benefit from this principle. In this sense, synchro-PASEF promises to combine the advantages of DDA and DIA.
Here, we only established these defining features and potential of synchro-PASEF but did not actually evaluate proteome coverage or quantitative accuracy in complex proteome mixtures at a global scale. This is due to the current absence of tools that can handle the data structures generated by synchro scans. Once the appropriate algorithms and software are available, it will be interesting to see how the principal advantages of synchro-PASEF translate to increases in proteome depth, coverage, and quantitation. This will also be a good point to optimize and extend the method parameters, similar to what we reported for dia-PASEF to design optimal methods (16). For instance, synchro scan borders could be chosen somewhat wider (as in method 3 in Fig. 3A) to cover more of the precursors. Likewise, the borders of the quadrupole selection windows could be offset between adjacent scans to ensure that all precursors are sliced.
Once the downstream informatic infrastructure is in place, synchro-PASEF may be particularly promising for proteome types that are traditionally challenging for DIA. We speculate that the additional confidence in fragment identity would be useful for studying posttranslational modifications, where each additional fragment can be crucial in pinpointing the modification site. Likewise, synchro-PASEF may help disentangle the very complex spectra generated by multiplex DIA approaches (32, 33, 34). Since precursor slicing is directly dependent on the precursor mass, it could link fragments to labeled precursors that are co-eluting and are co-isolated for fragmentation.
One of the most significant challenges of DIA is the data complexity, especially with increasing isolation window width and decreasing gradient length. Synchro-PASEF has several unique advantages that address these issues. The diagonal movement of the quadrupole allows for very short cycle times (sub-second) even when using standard isolation widths such as 25 Th. This sufficiently samples peptides and their transitions even for very short gradients, in turn increasing throughput. While the gradient time strongly influences the peak capacity in retention time, the separation in the m/z and ion mobility dimension are independent of this (35). Synchro-PASEF retains all the advantages of traditional DIA window schemes, but additionally disentangles data complexity by introducing precursor slicing, which establishes a clear precursor–fragment relationship even if there would only be a single timepoint sampled across the elution profile. Since this feature only depends on the precursor mass and the position in the ion mobility dimension, we hypothesize that synchro-PASEF is much less affected by interference in extremely short gradients or in multiplexed DIA.
Data Availability
All method parameter files required for the acquisition and mass spectrometry raw files have been deposited with the ProteomeXchange Consortium via the PRIDE partner (36) repository with the dataset identifier PXD037766 and with MassIVE with the identifier MSV000090925. Homo sapiens (taxon identifier: 9606) proteome database and the sequence of BSA (P02769), ADH (P00330), enolase (P00924), and phosphorylase b (P00489) were downloaded from https://www.uniprot.org.
Supplemental data
This article contains supplemental data (6, 23).
Conflict of interest
M. M. is an indirect investor in Evosep Biosystems. F. K., M. L., S. W. and O. R. are employees of Bruker Daltonics. All other authors declare that they have no conflict of interest with the contents of this article.
Acknowledgments
We thank our colleagues at the department of proteomics and signal transduction as well as at Bruker Daltonics for discussions and help. We are grateful for the input from Igor Paron, Bianca Splettstoesser and Fabian Opitz. Maximilian Strauss suggested using the cross correlation for retrieving fragments.
Funding and additional information
This study was supported by the Max-Planck Society for Advancement of Science, the Deutsche Forschungsgemeinschaft project “Chemical proteomics inside us” (grant no.: 412136960), European Union’s Horizon 2020 research and innovation program under grant agreement No 874839 ISLET and by the Bavarian State Ministry of Health and Care through the research project DigiMed Bayern (www.digimed-bayern.de).
Author contributions
P. S., S. W., O. R., and M. M. conceptualization; P. S., S. W., M. M., F. K., M. L., and O. R. methodology; P. S., G. W., M. W., E. C. M. I., P. K., and F. M. investigation; P. S., F. K., G. W., P. K., M. T., F. M., S. W., and M. M. formal analysis; P. S. and M. M. witing-original draft.
Contributor Information
Sander Willems, Email: sander.willems@bruker.com.
Oliver Raether, Email: oliver.raether@bruker.com.
Matthias Mann, Email: mmann@biochem.mpg.de.
Supplemental Data
References
- 1.Ludwig C., Gillet L., Rosenberger G., Amon S., Collins B.C., Aebersold R. Data-independent acquisition-based SWATH - MS for quantitative proteomics: a tutorial. Mol. Syst. Biol. 2018;14:1–23. doi: 10.15252/msb.20178126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Demichev V., Messner C.B., Vernardis S.I., Lilley K.S., Ralser M. DIA-NN: neural networks and interference correction enable deep proteome coverage in high throughput. Nat. Methods. 2020;17:41–44. doi: 10.1038/s41592-019-0638-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Demichev V., Szyrwiel L., Yu F., Teo G.C., Rosenberger G., Niewienda A., et al. dia-PASEF data analysis using FragPipe and DIA-NN for deep proteomics of low sample amounts. Nat. Commun. 2022;13:3944. doi: 10.1038/s41467-022-31492-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Bruderer R., Bernhardt O.M., Gandhi T., Miladinović S.M., Cheng L.Y., Messner S., et al. Extending the limits of quantitative proteome profiling with data-independent acquisition and application to acetaminophen-treated three-dimensional liver microtissues. Mol. Cell. Proteomics. 2015;14:1400–1410. doi: 10.1074/mcp.M114.044305. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Tsou C.C., Avtonomov D., Larsen B., Tucholska M., Choi H., Gingras A.C., et al. DIA-Umpire: comprehensive computational framework for data-independent acquisition proteomics. Nat. Methods. 2015;12:258–264. doi: 10.1038/nmeth.3255. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Zeng W.-F., Zhou X.-X., Willems S., Ammar C., Wahle M., Bludau I., et al. AlphaPeptDeep: a modular deep learning framework to predict peptide properties for proteomics. Nat. Commun. 2022;13:7238. doi: 10.1038/s41467-022-34904-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Mann M., Kumar C., Zeng W.-F., Strauss M.T. Artificial intelligence for proteomics and biomarker discovery. Cell Syst. 2021;12:759–770. doi: 10.1016/j.cels.2021.06.006. [DOI] [PubMed] [Google Scholar]
- 8.Gessulat S., Schmidt T., Zolg D.P., Samaras P., Schnatbaum K., Zerweck J., et al. Prosit: proteome-wide prediction of peptide tandem mass spectra by deep learning. Nat. Methods. 2019;16:509–518. doi: 10.1038/s41592-019-0426-7. [DOI] [PubMed] [Google Scholar]
- 9.Tiwary S., Levy R., Gutenbrunner P., Salinas Soto F., Palaniappan K.K., Deming L., et al. High-quality MS/MS spectrum prediction for data-dependent and data-independent acquisition data analysis. Nat. Methods. 2019;16:519–525. doi: 10.1038/s41592-019-0427-6. [DOI] [PubMed] [Google Scholar]
- 10.Ma C., Ren Y., Yang J., Ren Z., Yang H., Liu S. Improved peptide retention time prediction in liquid chromatography through deep learning. Anal. Chem. 2018;90:10881–10888. doi: 10.1021/acs.analchem.8b02386. [DOI] [PubMed] [Google Scholar]
- 11.Zeng W.-F., Zhou X.-X., Zhou W.-J., Chi H., Zhan J., He S.-M. MS/MS spectrum prediction for modified peptides using pDeep2 trained by transfer learning. Anal. Chem. 2019;91:9724–9731. doi: 10.1021/acs.analchem.9b01262. [DOI] [PubMed] [Google Scholar]
- 12.Gillet L.C., Navarro P., Tate S., Röst H., Selevsek N., Reiter L., et al. Targeted data extraction of the MS/MS spectra generated by data-independent acquisition: a new concept for consistent and accurate proteome analysis. Mol. Cell. Proteomics. 2012;11 doi: 10.1074/mcp.O111.016717. O111.016717. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Meier F., Brunner A.D., Frank M., Ha A., Bludau I., Voytik E., et al. diaPASEF: parallel accumulation–serial fragmentation combined with data-independent acquisition. Nat. Methods. 2020;17:1229–1236. doi: 10.1038/s41592-020-00998-0. [DOI] [PubMed] [Google Scholar]
- 14.Meier F., Beck S., Grassl N., Lubeck M., Park M.A., Raether O., et al. Parallel accumulation-serial fragmentation (PASEF): multiplying sequencing speed and sensitivity by synchronized scans in a trapped ion mobility device. J. Proteome Res. 2015;14:5378–5387. doi: 10.1021/acs.jproteome.5b00932. [DOI] [PubMed] [Google Scholar]
- 15.Meier F., Brunner A.D., Koch S., Koch H., Lubeck M., Krause M., et al. Online parallel accumulation–serial fragmentation (PASEF) with a novel trapped ion mobility mass spectrometer. Mol. Cell. Proteomics. 2018;17:2534–2545. doi: 10.1074/mcp.TIR118.000900. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Skowronek P., Thielert M., Voytik E., Tanzer M.C., Hansen F.M., Willems S., et al. Rapid and in-depth coverage of the (phospho-)proteome with deep libraries and optimal window design for dia-PASEF. Mol. Cell. Proteomics. 2022;21:100279. doi: 10.1016/j.mcpro.2022.100279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Juvvadi P.R., Moseley M.A., Hughes C.J., Soderblom E.J., Lennon S., Perkins S.R., et al. Scanning quadrupole data-independent acquisition, part B: application to the analysis of the calcineurin-interacting proteins during treatment of Aspergillus fumigatus with Azole and Echinocandin antifungal drugs. J. Proteome Res. 2018;17:780–793. doi: 10.1021/acs.jproteome.7b00499. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Moseley M.A., Hughes C.J., Juvvadi P.R., Soderblom E.J., Lennon S., Perkins S.R., et al. Scanning quadrupole data-independent acquisition, part A: qualitative and quantitative characterization. J. Proteome Res. 2018;17:770–779. doi: 10.1021/acs.jproteome.7b00464. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Messner C.B., Demichev V., Bloomfield N., Yu J.S.L., White M., Kreidl M., et al. Ultra-fast proteomics with scanning SWATH. Nat. Biotechnol. 2021;39:846–854. doi: 10.1038/s41587-021-00860-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Kulak N.A., Pichler G., Paron I., Nagaraj N., Mann M. Minimal, encapsulated proteomic-sample processing applied to copy-number estimation in eukaryotic cells. Nat. Methods. 2014;11:319–324. doi: 10.1038/nmeth.2834. [DOI] [PubMed] [Google Scholar]
- 21.Willems S., Voytik E., Skowronek P., Strauss M.T., Mann M. AlphaTims: indexing trapped ion mobility spectrometry-TOF data for fast and easy accession and visualization. Mol. Cell. Proteomics. 2021;20:100149. doi: 10.1016/j.mcpro.2021.100149. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Voytik E., Skowronek P., Zeng W.-F., Tanzer M.C., Brunner A.-D., Thielert M., et al. AlphaViz: visualization and validation of critical proteomics data directly at the raw data level. bioRxiv. 2022 doi: 10.1101/2022.07.12.499676. [preprint] [DOI] [Google Scholar]
- 23.Prianichnikov N., Koch H., Koch S., Lubeck M., Heilig R., Brehmer S., et al. Maxquant software for ion mobility enhanced shotgun proteomics. Mol. Cell. Proteomics. 2020;19:1058–1069. doi: 10.1074/mcp.TIR119.001720. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Cox J., Mann M. MaxQuant enables high peptide identification rates, individualized p.p.b.-range mass accuracies and proteome-wide protein quantification. Nat. Biotechnol. 2008;26:1367–1372. doi: 10.1038/nbt.1511. [DOI] [PubMed] [Google Scholar]
- 25.Harris C.R., Millman K.J., van der Walt S.J., Gommers R., Virtanen P., Cournapeau D., et al. Array programming with NumPy. Nature. 2020;585:357–362. doi: 10.1038/s41586-020-2649-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Ridgeway M.E., Lubeck M., Jordens J., Mann M., Park M.A. Trapped ion mobility spectrometry: a short review. Int. J. Mass Spectrom. 2018;425:22–35. [Google Scholar]
- 27.Fernandez-Lima F., Kaplan D.A., Suetering J., Park M.A. Gas-phase separation using a trapped ion mobility spectrometer. Int. J. Ion Mobil. Spectrom. 2011;14:93–98. doi: 10.1007/s12127-011-0067-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Meier F., Park M.A., Mann M. Trapped ion mobility spectrometry and parallel accumulation–serial fragmentation in proteomics. Mol. Cell. Proteomics. 2021;20:100138. doi: 10.1016/j.mcpro.2021.100138. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Paul W., Steinwedel H. Notizen: Ein neues Massenspektrometer ohne Magnetfeld. Z. Naturforsch. 1953;8:448–450. [Google Scholar]
- 30.Eng J.K., McCormack A.L., Yates J.R. An approach to correlate tandem mass spectral data of peptides with amino acid sequences in a protein database. J. Am. Soc. Mass Spectrom. 1994;5:976–989. doi: 10.1016/1044-0305(94)80016-2. [DOI] [PubMed] [Google Scholar]
- 31.Eng J.K., Hoopmann M.R., Jahan T.A., Egertson J.D., Noble W.S., MacCoss M.J. A deeper look into comet—implementation and features. J. Am. Soc. Mass Spectrom. 2015;26:1865–1874. doi: 10.1007/s13361-015-1179-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Derks J., Leduc A., Wallmann G., Huffman R.G., Willetts M., Khan S., et al. Increasing the throughput of sensitive proteomics by plexDIA. Nat. Biotechnol. 2022 doi: 10.1038/s41587-022-01389-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Pino L.K., Baeza J., Lauman R., Schilling B., Garcia B.A. Improved SILAC quantification with data-independent acquisition to investigate bortezomib-induced protein degradation. J. Proteome Res. 2021;20:1918–1927. doi: 10.1021/acs.jproteome.0c00938. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Griffiths J.R., Chicooree N., Connolly Y., Neffling M., Lane C.S., Knapman T., et al. Mass spectral enhanced detection of Ubls using SWATH acquisition: MEDUSA—simultaneous quantification of SUMO and ubiquitin-derived isopeptides. J. Am. Soc. Mass Spectrom. 2014;25:767–777. doi: 10.1007/s13361-014-0835-x. [DOI] [PubMed] [Google Scholar]
- 35.Oliinyk D., Meier F. Ion mobility-resolved phosphoproteomics with dia-PASEF and short gradients. Proteomics. 2022 doi: 10.1002/pmic.202200032. [DOI] [PubMed] [Google Scholar]
- 36.Perez-Riverol Y., Bai J., Bandla C., García-Seisdedos D., Hewapathirana S., Kamatchinathan S., et al. The PRIDE database resources in 2022: a hub for mass spectrometry-based proteomics evidences. Nucleic Acids Res. 2022;50:D543–D552. doi: 10.1093/nar/gkab1038. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
All method parameter files required for the acquisition and mass spectrometry raw files have been deposited with the ProteomeXchange Consortium via the PRIDE partner (36) repository with the dataset identifier PXD037766 and with MassIVE with the identifier MSV000090925. Homo sapiens (taxon identifier: 9606) proteome database and the sequence of BSA (P02769), ADH (P00330), enolase (P00924), and phosphorylase b (P00489) were downloaded from https://www.uniprot.org.