

Abstract
Human bulk tissue samples comprise multiple cell types with diverse roles in disease etiology. Conventional transcriptome-wide association study approaches predict genetically regulated gene expression at the tissue level, without considering cell-type heterogeneity, and test associations of predicted tissue-level expression with disease. Here we develop MiXcan, a cell-type-aware transcriptome-wide association study approach that predicts cell-type-level expression, identifies disease-associated genes via combination of cell-type-level association signals for multiple cell types, and provides insight into the disease-critical cell type. As a proof of concept, we conducted cell-type-aware analyses of breast cancer in 58,648 women and identified 12 transcriptome-wide significant genes using MiXcan compared with only eight genes using conventional approaches. Importantly, MiXcan identified genes with distinct associations in mammary epithelial versus stromal cells, including three new breast cancer susceptibility genes. These findings demonstrate that cell-type-aware transcriptome-wide analyses can reveal new insights into the genetic and cellular etiology of breast cancer and other diseases.
Subject terms: Statistical methods, Gene expression, Breast cancer, Cancer genetics
Conventional transcriptome-wide association study (TWAS) approaches predict genetically regulated gene expression at the tissue level. Here, the authors develop a framework for cell-type-aware TWAS that predicts cell-type level expression from genotype data and identifies disease-associated genes with cell-type-specific effects.
Introduction
Transcriptome-wide association studies (TWAS) aim to identify genes that are associated with disease through their genetically regulated gene expression (GReX) levels1,2. Conventional TWAS approaches such as PrediXcan1 predict tissue-level GReX using models trained on transcriptomic and genomic data from bulk tissue samples, and test associations between the predicted tissue-level GReX and disease. By reducing the multiple testing burden from millions of variants to thousands of genes, TWAS can improve the power of genome-wide association studies (GWAS) while providing biological insights into the genes and regulatory mechanisms underlying disease. However, conventional TWAS approaches do not account for cell-type heterogeneity of bulk tissue samples, which can reduce the accuracy of GReX prediction models and obscure disease associations, particularly when the most mechanistically relevant cell type for the disease is a minor cell type in the tissue3.
Breast carcinoma is a common and highly heritable cancer that arises from epithelial cells, which line the ducts and lobules that produce milk during lactation4,5. Human mammary tissue has highly variable cell composition. Visualized on mammography, breast composition can range from extremely dense (light), reflecting a high proportion of fibroglandular tissue, to almost entirely fatty (dark), reflecting a high proportion of adipose tissue6,7. Whereas higher mammographic density is associated with increased risk of breast cancer, a higher amount of nondense fatty tissue is associated with decreased risk, indicating disparate roles of the different cellular components of mammary tissue in carcinogenesis8–10. Breast cancer susceptibility loci identified by prior GWAS11–13 and TWAS14–16 approaches that do not account for cell-type heterogeneity explain only a fraction of the familial relative risk. Disentangling the distinct effects of gene expression in mammary epithelial cells from other cell types through cell-type-aware analysis could lead to new gene discoveries and biological insights.
To our knowledge, no statistical methods currently exist for conducting cell-type-aware TWAS using GWAS data. Single-cell sorting and transcriptome profiling are costly, and large reference panels with both single-cell transcriptomic and genomic data are not yet widely available for training robust GReX prediction models. Recent studies of bulk tissue transcriptomic data have used computational estimates of cell-type enrichment, which are correlated with their proportions, to evaluate cell-type-specific effects. The Genotype-Tissue Expression (GTEx17) consortium estimated cell-type enrichment scores in bulk tissue samples using xCell18 and tested for interactions between genotype and xCell scores in linear regression models of gene expression to identify interaction expression quantitative trait loci (ieQTL)19. The breast was among the human tissues with the most ieQTLs, specifically involving mammary epithelial cells and adipocytes19, highlighting the potential for new methods that harness cell-type-specific genetic regulation of expression to improve the power of breast cancer TWAS. Methods that integrate bulk tissue data with single-cell reference profiles to estimate cell-type-level gene expression have also been proposed to study cell-type-specific disease associations20,21. However, these methods all require transcriptomic data from the disease-relevant tissue and cannot be applied to existing GWAS datasets to perform TWAS in large populations.
Here we present MiXcan, a new statistical framework for conducting cell-type-aware TWAS using GWAS data. MiXcan builds cell-type-level GReX prediction models through decomposition of bulk tissue data, identifies disease-associated genes via combination of signals from cell-type-level association analyses of multiple cell types, and provides insight into the cell type responsible for the disease association. We show that MiXcan improves the tissue-level GReX prediction accuracy compared with conventional approaches in an independent bulk-tissue validation set, and reliably predicts epithelial cell GReX in a single-nucleus RNA sequencing (snRNAseq) dataset. Simulation studies show that MiXcan controls the type I error, and provides higher power than conventional TWAS approaches when disease associations are driven by a minor cell type (e.g. mammary epithelial cells) rather than the predominant cell type in a tissue, or have opposite directions in different cell types. We apply MiXcan to conduct the first cell-type-aware TWAS of breast cancer risk in 31,716 cases and 26,932 controls, and report three new susceptibility genes (ZNF703, TMEM245, and PSG4) with evidence of distinct associations in mammary epithelial versus stromal cells that were not detected by prior TWAS nor GWAS. These findings provide a proof a concept that cell-type-aware TWAS can reveal new insights into the genetic and cellular etiology of breast cancer and other diseases.
Results
MiXcan framework
We developed the MiXcan framework for conducting cell-type-aware TWAS (Fig. 1). To build GReX prediction models, MiXcan requires specification of the cell type of interest and a prior estimate of its proportion in bulk tissue training samples with transcriptomic and genomic data. The cell type of interest for a given disease may be selected based on prior biologic knowledge, and its proportion estimated from the transcriptomic data using existing deconvolution methods and reference panels21–23. For cell types without large reference panels or direct proportion estimates, a cell-type enrichment score can be estimated from the bulk tissue transcriptomic data using xCell18. MiXcan can utilize xCell or other enrichment scores as a prior to estimate the cell-type proportion (see “Methods”). MiXcan then decomposes the bulk tissue gene expression level into its cell-type levels and uses joint penalized regression to model the association of genetic variants (SNPs) with gene expression for each cell type. The regression coefficients (SNP weights) are compared to determine whether the GReX prediction models for each gene are cell-type-specific (different weights in different cell types) or nonspecific (sames weights across cell types). Simulation studies (below) show that MiXcan prediction models are robust to misspecification of the cell-type proportion, which can result from inaccurate estimates24–26.
Fig. 1. MiXcan framework.

MiXcan estimates cell-type composition using transcriptomic data, builds cell-type-specific and nonspecific GReX prediction models, identifies disease-associated genes in any cell types, and provides insight into the cell type responsible for the disease association.
To conduct cell-type-aware TWAS, MiXcan uses the predicted GReX to test the following composite null and alternative hypotheses:
H0: There is no association between the predicted GReX and the disease in any cell type.
HA: There is an association between the predicted GReX and disease in at least one cell type.
Genes with cell-type-specific GReX prediction models are first associated with disease within each cell type, and then the signals are combined across cell types using the Cauchy-based p-value combination method27. Genes with nonspecific GReX prediction models are tested for their association with disease in one step. Significant associations are identified using an appropriate threshold to control the family-wise error rate (FWER) or false discovery rate (FDR). For significant genes with cell-type-specific GReX models, the cell-type-level results are compared to provide further insight into the cell type(s) likely to be responsible for the disease association.
While the MiXcan framework is general, its performance depends on the cell types under consideration and the available training data. As the number of cell types increases, the number of parameters increases and the accuracy of the model decreases. At present, given the limited sample sizes of transcriptomic and genomic datasets available for most human tissues through public repositories such as GTEx, it is practical to consider only two categories of cells using MiXcan and to focus on the cell type of greatest interest for the disease under investigation versus the other cell types. As breast carcinoma is known to arise from epithelial cells, we developed MiXcan epithelial and stromal (nonepithelial) cell models using bulk mammary tissue transcriptomic and genomic data available for 125 European ancestry (EA) women in GTEx v8.
Prediction performance
The accuracy of MiXcan and PrediXcan GReX prediction models trained using GTEx v8 data for 125 mammary tissue samples from EA women was initially evaluated in an independent dataset of 103 tumor-adjacent normal mammary tissue samples from EA women in The Cancer Genome Atlas (TCGA). MiXcan estimates of the epithelial cell proportions were highly correlated with the xCell18 epithelial cell enrichment scores (used as a prior), with Pearson correlations (r) of 0.90 and 0.89 in normal mammary tissue samples from EA women in GTEx (N = 125) and TCGA (N = 103), respectively (Supplementary Fig. 1). However, MiXcan estimates of the epithelial cell proportion were more highly correlated with the expression levels of 126 genes included in the xCell epithelial cell gene signature (median r of 0.54 in GTEx and 0.60 in TCGA samples) than were the xCell enrichment scores themselves (median r of 0.36 in GTEx and 0.39 in TCGA samples) indicating that MiXcan can improve cell proportion estimation from its prior (Supplementary Fig. 1).
MiXcan estimated cell-type-specific prediction models for 5473 (84.7%) and nonspecific prediction models for 988 (15.3%) of 6461 genes that had mammary tissue-level prediction models available in PredictDB28 (Fig. 2). The tissue-level GReX was computed using MiXcan estimates of the cell-type proportion and predicted cell-type-level GReX values. The median correlation of predicted GReX and measured mammary tissue expression levels for the 6461 genes in the TCGA validation set was significantly higher for MiXcan compared with PrediXcan (median r of 0.41 vs. 0.10; p value < 2.2 × 10−16) models trained using the same dataset of 125 GTEx EA women. The prediction accuracy for the 5473 genes with cell-type-specific models in MiXcan was significantly better than PrediXcan (median r of 0.43 vs. 0.12; p < 2.2 × 10−16), whereas the prediction accuracy for the remaining 988 genes with nonspecific models in MiXcan was the same as PrediXcan (median r of 0.08 vs. 0.08; p value=1). These results indicate that allowing for cell-type-level GReX prediction models increases the prediction accuracy for genes with evidence of cell-specific genetic regulation, and does not decrease the prediction accuracy for other genes compared with standard approaches for predicting tissue-level GReX.
Fig. 2. Validation of tissue-level GReX predictions in an independent bulk mammary tissue dataset.

The correlation of tissue-level GReX predictions using MiXcan or PrediXcan with measured gene expression levels in adjacent normal mammary tissue samples from 103 European ancestry women with breast cancer in TCGA were computed for (a) all 6461 genes with MiXcan and PrediXcan models trained using mammary tissue samples from 125 European ancestry women in GTEx, (b) 5473 genes with cell-type-specific MiXcan models, and (c) 988 genes with nonspecific MiXcan models. Differences between the correlations for MiXcan and PrediXcan were compared using the two-sided Wilcoxon signed-rank test. Boxplot bounds show the lower, median, and upper quartiles; whisker lengths are 1.5 times the interquartile range; and points beyond the whiskers are outliers. Source data are provided as a Source Data file.
To examine potential sources of the gain in prediction accuracy, three additional approaches were compared with MiXcan and PrediXcan (Supplementary Fig. 2). The median correlation of predicted GReX with measured mammary tissue-level expression for all 6461 genes in the TCGA validation set was slightly higher for PredictDB (r = 0.12) elastic-net models trained using 337 GTEx EA men and women on the entire genome compared with PrediXcan (r = 0.10) trained using 125 EA women indicating modest gains from the inclusion of 212 EA men in the training dataset. Accounting for cell composition using penalized regression models including interactions of SNPs with the xCell epithelial cell score (xCell Interaction; r = 0.20) or MiXcan cell proportion (MiXcan0; r = 0.38) led to substantial gains in prediction accuracy. Symmetric estimation of cell-type-level prediction models employed in MiXcan (r = 0.41) further improved performance compared with standard interaction models that employ asymmetric penalization for the two cell types. Importantly, whereas standard interaction models require estimates of cell-type composition, which often are unavailable for the tissue of interest in GWAS of human diseases, MiXcan prediction models can be applied directly to GWAS genotype data to perform cell-type-aware TWAS.
Finally, to evaluate the prediction accuracy of MiXcan at the cell-type level, we compared the predicted epithelial cell GReX with measured mammary epithelial cell snRNAseq data available for three GTEx women of European, Asian, and African ancestry29. We found that genes (n=100) predicted to have the largest GReX differences based on the SNP genotypes in each pair of women also had significantly different measured snRNAseq levels in their mammary epithelial cells (p value range: 0.01 to 3.3 × 10−7), as expected (Fig. 3). The observed snRNAseq differences were significant despite the potentially poorer prediction accuracy of MiXcan models in women of Asian and African ancestry who were not represented in the training dataset. These snRNAseq results support the robustness of the cell-type level GReX predictions obtained using the MiXcan approach.
Fig. 3. Validation of MiXcan epithelial cell GReX predictions using mammary epithelial cell snRNAseq data.

Measured mammary epithelial cell snRNAseq levels for three GTEx women of White, Asian, and African-American (AA) ancestry were compared for six sets of 100 genes predicted to have the largest GReX differences in each pair of women. Distributions of the observed differences in the measured snRNAseq levels are shown for the 100 genes predicted to have the largest positive (blue) and negative (yellow) GReX differences for the (a) White − Asian, (b) White − AA, and (c) AA − Asian women. Dashed lines show the median of each distribution, and departures from zero were evaluated using the one-sided Wilcoxon signed-rank test. Source data are provided as a Source Data file.
Simulation studies
Type I error and power
To evaluate type I error and power of MiXcan association tests, datasets were simulated (see “Methods”) under a broad range of realistic settings for the associations of genetic variants with gene expression (SNP-Exp) and gene expression with disease (Exp-Disease). MiXcan predicted GReX with higher accuracy than PrediXcan in the presence of cell-type heterogeneity of SNP-Exp associations, while maintaining comparable accuracy in the absence of cell-specific effects (Supplementary Fig. 3), consistent with results in the independent TCGA validation dataset (Fig. 2).
The type I error was well controlled for MiXcan and PrediXcan under all simulated data scenarios (Fig. 4 col. 1). When SNP-Exp associations were homogeneous in the two cell types (Fig. 4a), the power was similar for MiXcan and PrediXcan whether the Exp-Disease associations were homogeneous or heterogeneous across cell types. Differences in the mean gene expression level between the two cell types that were not determined by SNP-Exp associations (Fig. 4a, b) did not impact the power of MiXcan and PrediXcan indicating robustness to differential expression that is not regulated by genetic variants.
Fig. 4. Simulation studies to evaluate the type I error and power of MiXcan and PrediXcan to detect associations of GReX with disease at the tissue level.

Bulk tissue samples (N = 300) for training GReX prediction models and independent studies (N = 3000) for testing disease associations were simulated under a range of realistic data scenarios. Gene expression levels were modeled by u = b0 + b1x + eu in the minor cell type, v = b2x + ev in the major cell type, and y = πu + (1 − π)v at the tissue level, where π denotes the minor cell-type proportion, b0 denotes the mean difference of the gene expression levels in the two cell types, and b1 and b2 denote the weights for the association of SNPs X with gene expression levels in the minor and major cell types, respectively. The disease D was modeled by logit P(D = 1) = η0 + η1u + η2v where η1 and η2 denote the associations of the gene expression levels with disease in the two cell types, respectively. (a) Homogeneous SNP-Exp associations (b1 = b2) in the two cell types, varying the mean difference in gene expression levels between the two cell types (b0). Heterogeneous SNP-Exp associations (b1 ≠ b2) in the two cell types, varying the: (b) mean difference in gene expression levels between the two cell types (b0); (c) magnitude of the SNP-Exp association in the minor cell type (b1); and (d) magnitude of the SNP-Exp association in the major cell type (b2). Source data are provided as a Source Data file.
When SNP-Exp associations were heterogeneous in the two cell types (Fig. 4b–d), the relative power of MiXcan and PrediXcan depended on the mechanisms of the Exp-Disease and SNP-Exp associations. PrediXcan was generally more powerful than MiXcan when the Exp-Disease association was either homogeneous across cell types (Fig. 4 col. 2) or present only in the major cell type (Fig. 4 col. 3). However, MiXcan was generally more powerful than PrediXcan when the Exp-Disease association was present only in the minor cell type (Fig. 4 col. 4) or had opposite directions in the two cell types (Fig. 4 col. 5).
As the strength of the SNP-Exp association increased in the same cell type as the Exp-Disease association, the power increased for both PrediXcan and MiXcan (Fig. 4c col. 4; Fig. 4d col. 3). However, as the strength of the SNP-Exp association increased in a different cell type from the Exp-Disease association, the power decreased for PrediXcan but not MiXcan (Fig. 4c col. 3; Fig. 4d col. 4). When the Exp-Disease association had opposite directions in the two cell types, the power was U-shaped for PrediXcan but increased for MiXcan as the strength of the SNP-Exp association increased in either cell type (Fig. 4c-d col. 5). Similar patterns were observed when type I error and power were evaluated in relation to the expression heritability in the two cell types instead of the strength of SNP-Exp associations (Supplementary Fig. 4). These patterns show that different association signals in the two cell types can cancel each other out in PrediXcan, which averages their effects, but are aggregated across cell types in MiXcan thereby preserving power to detect associations due to the minor cell type or that differ across cell types.
In addition to providing valid tissue-level association tests, MiXcan provides information for each cell type separately. Simulation studies showed that the type I error was well controlled for MiXcan cell-type-level tests when no Exp-Disease association was present in any cell type (Supplementary Fig. 5 col. 1). When SNP-Exp associations were homogeneous across cell types (Supplementary Fig. 5a), MiXcan generally estimated nonspecific GReX prediction models which yield the same disease-association test results for all cell types. Thus, cell-type-level inferences can only be made in the heterogeneous SNP-Exp setting (Supplementary Fig. 5b–d), when MiXcan estimates cell-type-specific GReX prediction models. When the Exp-Disease association was present in both cell types in the same or opposite directions (Supplementary Fig. 5 cols. 2 & 5), the power of the cell-type-level tests was similar when the SNP-Exp associations had similar magnitude (regardless of direction) and increased as the magnitude of the SNP-Exp association increased. When the Exp-Disease association was present in only one cell type (Supplementary Fig. 5 cols. 3-4), the power was always highest in this cell type, but the association signal was shared to some degree with the uninvolved cell type. This correlation of the cell-type-level results arises from the joint estimation of the SNP weights for the cell-type-level GReX prediction models in MiXcan. Therefore, we recommend using the combined p-value for all cell types to make inferences regarding whether GReX is significantly associated with disease in any cell type in the tissue, and the cell-type-level results to compare the evidence that different cell types are involved for significant genes.
Finally, we evaluated the impact of the sample size of the training dataset on the type I error and power of MiXcan association tests in simulation studies (Supplementary Fig. 6). As the training dataset increased from 100 to 300 samples, the power of association studies with 3000 samples increased while the type I error remained well controlled. Prediction models trained using only 100-150 samples provided reasonable power for gene identification.
Performance under model misspecification
MiXcan decomposes bulk tissue expression levels into two components using an estimate of the cell-type proportion for the cell of interest. First, we evaluated the performance of MiXcan under misspecification of (Fig. 5a). In simulation studies using a broad range of biased and noisy estimates of , the type I error was consistently well controlled. The power of MiXcan also was generally maintained when was misspecified, and compared favorably with PrediXcan when the Exp-Disease association was in the minor cell type or had opposite directions in the two cell types. Second, we evaluated the performance of MiXcan when a latent third cell type was present that had different SNP-Exp associations from the other cell types (Fig. 5b). We simulated a tissue with three cell types comprising 40%, 50% and 10% of the tissue, respectively, and assumed that MiXcan decomposed the tissue into cell type 1 versus a mixture of cell types 2 and 3. The type I error was consistently well controlled in the presence of a latent third cell type, and the power of MiXcan remained higher than PrediXcan when the Exp-Disease association was in cell type 1 (corresponding to the minor cell type in correctly specified models) or in opposite directions in cell types 1 vs. 2 and 3. The latent third cell type reduced the power of both PrediXcan and MiXcan when the Exp-Disease association was present in the most common cell type or homogeneous across all cell types. Third, we evaluated the impact of Exp-Disease associations in a latent third cell type on study power (Fig. 5c). Similar to the performance under correctly specified models, PrediXcan was more powerful mostly when Exp-Disease associations exist in cell type 2 (the most common cell type), and MiXcan was more powerful mostly when Exp-Disease associations exist in cell type 1 (the minor cell type of interest) or in opposite directions in cell types 1 and 2.
Fig. 5. Simulation studies to assess the performance of MiXcan under model misspecification.

a Type I error (column 1) and power (columns 2-5) when the estimated cell-type proportion used by MiXcan equals: the true π of 0.4; 0.8π biasing the mean to 0.32 and changing the scale from (0, 1) to (0, 0.8) (mean/scale change 1); 0.7π + 0.2 biasing the mean to 0.48 and changing the scale to (0.2, 1) (mean/scale change 2); Beta(50π, 50(1 − π)) reducing the correlation with π to 0.9 (reduced correlation 1); and Beta(5.5π, 5.5(1 − π)) reducing the correlation with π to 0.6 (reduced correlation 2). b Type I error (column 1) and power (columns 2–5) when a latent third cell type contributes to SNP-Exp associations. MiXcan was assumed to decompose the tissue into two components, cell type 1 (π1 = 40%) vs. a mixture of cell types 2 (π2 = 50%) and 3 (π3 = 10%). In Setting 1, the SNP-Exp associations were the same in cell types 3 and 2 and different in cell type 1 (b3 = b2 ≠ b1). In Setting 2, all three cell types had different SNP-Exp associations (b3 ≠ b2 ≠ b1). c Study power for a tissue with a latent third cell type that contributes to Exp-Disease associations under three heterogeneous Exp-Disease settings where η1 ≠ η2 and η3 varied from –0.2 to 0.2. Source data are provided as a Source Data file.
Cell-type-aware TWAS of breast cancer
As a proof of concept, we applied MiXcan to conduct the first cell-type-aware TWAS of breast cancer in a publicly available dataset of 58,648 EA women (31,716 cases and 26,932 controls) from the DRIVE GWAS (Discovery, Biology, and Risk of Inherited Variants in Breast Cancer) who were genotyped using the OncoArray30. Transcriptome-wide significance was determined using the Bonferroni-corrected threshold of 7.7 × 10−6 to account for the 6461 genes tested, and suggestive associations were determined using the Benjamini-Hochberg false discovery rate (FDR) of 0.10. MiXcan identified 12 significant genes (p value < 7.7 × 10−6) (Table 1, Fig. 6) and 82 suggestive genes (FDR < 0.10) (Supplementary Data 1) whose predicted GReX in mammary tissue were associated with breast cancer risk. In comparison, PrediXcan (trained using the same 125 EA female mammary tissue samples as MiXcan) identified only 8 significant genes (p value < 7.7 × 10−6), and 31 suggestive genes (FDR < 0.10). The inflation factor obtained using the BACON v1.26 Bayesian method to estimate the empirical null distribution was 1.01 for MiXcan and 1.03 for PrediXcan, indicating well-controlled type I error31.
Table 1.
Genes significantly associated with breast cancer risk using the MiXcan or PrediXcan approaches in 58,648 women, and the corresponding S-PrediXcan and GWAS results in a larger sample of 228,951 women of European ancestry
| Gene Name | Cytoband | MiXcana | PrediXcanb | S-PrediXcanc | GWASd SNPs within 500 kb | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Epithelial | Stromal | Combined | |||||||||||||
| Effect | SE | P value | Effect | SE | P value | P value | Effect | SE | P value | Effect | SE | P value | |||
| Genes identified by both MiXcan and PrediXcan | |||||||||||||||
| CH17-437K3.1• | 1p11.2 | –1.62 | 0.28 | 7.3E–09 | –1.62 | 0.28 | 7.3E–09 | 7.3E–09 | –1.62 | 0.28 | 7.3E–09 | –0.56 | 0.05 | 3.1E–28*** | rs11249433 |
| SLC4A7• | 3p24.1 | 2.30 | 0.27 | 2.0E–17 | 2.30 | 0.27 | 2.0E–17 | 2.0E–17 | 2.30 | 0.27 | 2.0E–17 | 1.11 | 0.09 | 3.5E–38*** | rs4973768 |
| L3MBTL3• | 6q23.1 | –0.12 | 0.02 | 1.4E–08 | –0.12 | 0.02 | 1.4E–08 | 1.4E–08 | –0.12 | 0.02 | 1.4E–08 | –0.11 | 0.02 | 2.1E–11*** | rs6569648 |
| RCCD1• | 15q26.1 | –0.16 | 0.03 | 4.2E–07 | –0.16 | 0.03 | 4.2E–07 | 4.2E–07 | –0.16 | 0.03 | 4.2E–07 | –0.16 | 0.02 | 3.5E–11*** | rs2290203 |
| Genes identified by MiXcan only | |||||||||||||||
| MRPS30 | 5p12 | 3.00 | 0.67 | 6.8E–06 | –4.82 | 0.75 | 1.8E–10 | 3.5E–10 | –0.08 | 0.31 | 8.1E–01 | 0.50 | 0.04 | 3.3E–30*** | rs10941679 |
| SETD9 | 5q11.2 | 0.15 | 0.04 | 5.2E–04 | –0.57 | 0.10 | 4.2E–09 | 8.4E–09 | –0.07 | 0.02 | 1.8E–03 | –0.10 | 0.02 | 1.9E–08*** | rs62355902 |
| ADGRV1 | 5q14.3 | –0.27 | 0.05 | 3.6E–07 | 0.27 | 0.05 | 3.6E–07 | 3.6E–07 | NA | NA | NA | –0.09 | 0.15 | 5.5E–01 | rs10474352 |
| ZNF703 | 8p11.23 | –1.96 | 0.38 | 2.7E–07 | 1.59 | 0.27 | 2.4E–09 | 4.8E–09 | 0.07 | 0.08 | 3.9E–01 | 0.17 | 0.06 | 4.3E–03* | – |
| TMEM245 | 9q31.3 | –0.64 | 0.12 | 7.0E–08 | –0.30 | 0.10 | 2.2E–03 | 1.4E–07 | –0.42 | 0.14 | 3.4E–03 | 0.04 | 0.07 | 5.4E–01 | – |
| PRR33 | 11p15.5 | –1.41 | 0.28 | 5.2E–07 | 1.41 | 0.28 | 5.2E–07 | 5.2E–07 | NA | NA | NA | –1.39 | 0.14 | 1.4E–23*** | rs3817198 |
| CDYL2 | 16q23.2 | –0.13 | 0.03 | 9.1E–07 | –0.08 | 0.03 | 1.0E–03 | 1.8E–06 | –2.67 | 0.85 | 1.7E–03 | –0.10 | 0.04 | 3.7E–03* | rs13329835 |
| PSG4 | 19q13.31 | –0.16 | 0.04 | 3.0E–06 | 0.14 | 0.04 | 1.1E–04 | 5.9E–06 | 0.00 | 0.03 | 9.5E–01 | 0.01 | 0.01 | 5.3E–01 | – |
| Genes identified by PrediXcan only | |||||||||||||||
| SRGAP2C | 1p11.2 | –0.19 | 0.25 | 4.3E–01 | –0.58 | 0.28 | 4.1E–02 | 7.8E–02 | –0.65 | 0.11 | 1.8E–09 | –0.56 | 0.05 | 1.2E–28*** | rs11249433 |
| CASP8 | 2q33.1 | –0.65 | 0.30 | 2.7E–02 | 0.43 | 0.27 | 1.1E–01 | 4.4E–02 | –0.13 | 0.03 | 3.1E–06 | –0.11 | 0.02 | 3.1E–11*** | rs1830298 |
| ALS2CR12 | 2q33.1 | –0.10 | 0.12 | 4.0E–01 | 0.40 | 0.22 | 7.0E–02 | 1.3E–01 | 0.18 | 0.04 | 2.6E–06 | 0.15 | 0.02 | 4.2E–12*** | rs1830298 |
| STXBP4 | 17q22 | –0.06 | 0.07 | 4.1E–01 | 0.18 | 0.05 | 2.1E–04 | 4.2E–04 | 0.16 | 0.03 | 4.5E–06 | 0.32 | 0.03 | 3.4E–23*** | rs2787486 |
aGenes with a MiXcan combined p value < 7.7 × 10−6 (0.05/6461 genes tested) aggregating across epithelial and stromal (non-epithelial) cell types were considered statistically significant. • denotes same model for epithelial and stromal cell types in MiXcan.
bElastic net models were built using GTEx v8 mammary tissue data for 125 European ancestry women and all SNPs in the PredictDB database https://predictdb.org/. NA indicates that none of the SNPs evaluated were selected as predictors in the elastic net models for ADGRV1 and PRR33. Genes with a PrediXcan p value < 7.7 × 10−6 were considered statistically significant.
cS-PrediXcan33 was used to test associations of predicted GReX with breast cancer risk using GWAS summary statistics for 122,977 cases and 105,974 controls11. *** denotes p value < 7.7 × 10−6 and * denotes p value < 0.05.
dBreast cancer SNPs reported in a GWAS of 122,977 breast cancer cases and 105,974 controls11.
Fig. 6. Transcriptome-wide association studies of breast cancer.
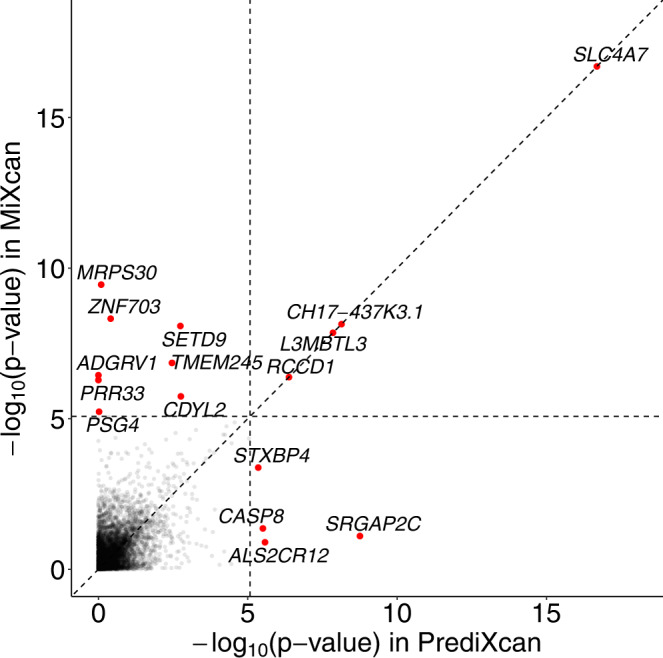
MiXcan identified 12 genes and PrediXcan identified 8 genes that were significantly associated with breast cancer risk at p value < 7.7 × 10−6, applying a Bonferroni correction for the 6461 genes tested in 31,716 breast cancer cases and 26,932 controls of European ancestry from the DRIVE study. Source data are provided as a Source Data file.
Four significant genes (CH17-437K3.1, SLC4A7, L3MBTL3, and RCCD1) were identified by both MiXcan and PrediXcan (Table 1). MiXcan estimated nonspecific prediction models for these genes, yielding the same results as PrediXcan. All four genes were near (<500 kb) breast cancer SNPs previously identified by GWAS11, and two genes (L3MBTL3 and RCCD1) also were reported by prior breast cancer TWAS (Supplementary Data 1)14,15,32. Follow-up analyses in a larger sample of 228,951 EA women (122,977 cases and 105,974 controls) in the Breast Cancer Association Consortium (BCAC) and DRIVE studies using GWAS summary statistics11 and S-PrediXcan33 models for mammary tissue confirmed that the tissue-level GReX for all four genes were significantly (p value < 7.7 × 10−6) associated with breast cancer risk.
Eight genes were identified by MiXcan but not PrediXcan (Table 1). MiXcan estimated cell-type-specific GReX prediction models for all eight of these genes (Supplementary Data 2). Six of these genes (MRPS30, SETD9, ADGRV1, ZNF703, PRR33, and PSG4) showed different directions of association with breast cancer in epithelial vs. stromal (nonepithelial) cells. In MiXcan the signals from the two cell types were aggregated, whereas in PrediXcan they canceled each other out reducing the tissue-level signal. Notably, for ADGRV1 and PRR33, no SNPs in the training dataset were predictive of tissue-level GReX because of the mixture of the different cell-type effects, and consequently the PrediXcan association analysis could not be performed. Two genes (TMEM245 and CDYL2) showed the same directions of association, with stronger effects in epithelial vs. stromal cells. These results indicate that MiXcan may be more powerful than PrediXcan in the presence of cell-type heterogeneity of GReX and when the disease association is present in a minor cell type, e.g. mammary epithelial cells, rather than the predominant cell type in the tissue.
Importantly, MiXcan uniquely identified three novel breast cancer susceptibility genes (ZNF703, TMEM245, and PSG4) that were not previously implicated by breast cancer GWAS11–13 nor TWAS14–16,32 (Table 1). For ZNF703, GReX was associated with increased breast cancer risk in stromal cells (p value=2.4 × 10−9) and decreased risk in epithelial cells (p value=2.7 × 10−7). Because adipocytes are the predominant stromal cell type in mammary tissue, we also performed follow-up analyses using the S-PrediXcan subcutaneous fat model and discovered a highly significant (p value=2.1 × 10−20) association of ZNF703 with increased breast cancer risk in the four-fold larger BCAC/DRIVE dataset, consistent with the MiXcan stromal cell results in the DRIVE data only. For TMEM245 and PSG4 the signal was stronger in epithelial cells, which are a minor cell type in mammary tissue and may explain why their tissue-level GReX was not significantly associated with breast cancer risk. MiXcan also identified two breast cancer genes (ADGRV1 and CDYL2) at previously reported GWAS loci11 that had different associations in epithelial and stromal cells and were not detected in prior TWAS.
Four genes (SRGAP2C, CASP8, ALS2CR12, and STXBP4) were identified by PrediXcan but not MiXcan (Table 1). There was high correlation between the predicted tissue-level GReX of CH17-437K3.1 (also identified by MiXcan) and SRGAP2C at 1p11.2 (r = 0.95) and CASP8 and ALS2CR12 at 2q33.1 (r = –0.97) indicating that these associations may represent only two independent loci. All four genes identified by PrediXcan only were located near breast cancer SNPs previously identified by GWAS11, and three genes (CASP8, ALS2CR12, and STXBP4) also were reported by prior breast cancer TWAS (Supplementary Data 1)15,32. Associations of the mammary tissue-level GReX with breast cancer risk were found for all four genes in S-PrediXcan analyses of the BCAC/DRIVE data, as expected. MiXcan estimated cell-type-specific GReX prediction models for these four genes (Supplementary Data 2), and different associations with breast cancer risk in epithelial and stromal cells that did not reach statistical significance in part because of the larger number of model parameters compared with PrediXcan. However, the cell-type-specific MiXcan results for STXBP4 suggest that stromal cells (estimated effect=0.18; p value = 2.1 × 10−4) may play a more important role than epithelial cells (estimated effect = –0.06; p value=0.41) in driving the positive association of tissue-level GReX with breast cancer risk.
Finally, we compared the TWAS results using MiXcan and PrediXcan with publicly available PredictDB28 elastic-net models trained using GTEx mammary tissue data for 212 EA men in addition to 125 EA women (Supplementary Fig. 7). There was substantial overlap of the genes detected by PrediXcan and PredictDB as expected, although PredictDB detected a larger number of genes perhaps because the larger training dataset enabled more accurate prediction models for genes that have similar expression patterns in male and female mammary tissue. However, the etiology and pathobiology of male breast cancer is distinct from female breast cancer34. Thus, prior TWAS of breast cancer in EA women15,32 also trained PrediXcan models using mammary tissue samples (n=67) from EA women only, as we did here using a larger number of EA women from GTEx. Cell-type-specific TWAS using MiXcan identified five genes (ADGRV1, ZNF703, TMEM245, CDYL2, and PSG4), including three novel breast cancer susceptibility genes, that were not identified by either PrediXcan or PredictDB.
Discussion
MiXcan is a new statistical framework for conducting cell-type-aware TWAS using GWAS data. In contrast to standard TWAS methods, MiXcan builds cell-type-level prediction models for the genetically regulated component of gene expression and performs association tests taking into consideration the signals from multiple cell types. We have shown that MiXcan improves the prediction accuracy of GReX at both the tissue and cellular levels in independent validation datasets, and improves the power to detect disease associations that are driven by a minor cell type or are heterogeneous between cell types compared with standard approaches. We applied MiXcan to perform the first cell-type-aware TWAS of breast cancer risk and identified three new susceptibility genes (ZNF703, TMEM245, and PSG4) with evidence of distinct associations in mammary epithelial versus stromal cells that were not detected by prior GWAS11–13 nor TWAS14–16,32. These findings provide a proof of concept that cell-type-aware TWAS can reveal novel insights into the genetic and cellular etiology of human diseases.
Several recent studies have explored context-specific TWAS35–37. Li et al. proposed a tissue-specificity-aware TWAS framework that uses prior knowledge of trait-related tissue types for accurate detection of single-tissue and cross-tissue TWAS35. Feng et al. proposed to derive cross-tissue expression features using sparse canonical correlation analysis, and then combine expression-outcome associations across single- and cross-tissue features for powerful detection36. Thompson et al. proposed CONTENT to go one step further and model both shared and tissue-specific components of gene expression in bulk multi-tissue data for model construction37. This approach can also be used for modeling shared and cell-type-specific components in single-cell RNAseq data37. These recently developed TWAS methods model associations at the same resolution of the data, such as modeling tissue-level associations for bulk profiling data and cell-type-level associations for single-cell data, and thus do not provide higher-resolution (single cell) understanding of disease using lower-resolution (bulk tissue) data as does MiXcan.
Recent studies have also explored methods for performing cell-type-level association analyses when the tissue-level data are available for all study participants19,38–42. Luo et al. evaluated cell-type-specific associations between DNA methylation and traits40, but this method did not involve prediction models and methylation data are required for all subjects. Liu et al. built tissue-level GReX prediction models, inferred cell types from the predicted GReX, and looked for associations of the inferred cell-type proportions with disease rather than constructing a TWAS framework for identifying genes42. In this study, MiXcan enables cell-type-aware TWAS in large populations using existing GWAS datasets that do not have transcriptomic and cell composition data from the disease-relevant tissue. MiXcan evaluates the composite null hypothesis that there is no association between the GReX in any cell type with the disease, which tolerates decomposition uncertainty to provide robust cell-type-aware analysis using bulk tissue samples. By carefully modeling cell-type-level expression, MiXcan is more powerful than PrediXcan when disease associations are driven by a minor cell type or have opposite directions in different cell types. However, when the association of GReX with disease is similar in all cell types or driven by the major cell type, then conventional TWAS approaches using more parsimonious tissue-level GReX prediction models that assume cell-type homogeneity can be more powerful. Thus, these two TWAS approaches are complementary, and additional cell-type-aware analyses are especially valuable for diseases where cell-type heterogeneity and a minor cell of origin are hypothesized, as for breast carcinoma and many other human diseases.
To construct cell-type-level GReX prediction models, MiXcan uses a scaled xCell18 cell-type enrichment score in the training data as prior information. While estimates from other approaches20,21,23,43–45 can also be used as priors, xCell is among the most widely used. Building upon the priors, MiXcan fits mixture models for the expression levels of the epithelial cell signature genes in the training data to improve estimation of the cell-type proportion. By incorporating better estimates of the cell-type proportion, and penalizing all cell types equally, MiXcan improves the accuracy of the GReX prediction models, as well as the power and type I error of the downstream association tests. Compared with standard interaction models that include interaction effects between cell-type enrichment scores and genetic variants19, an important advantage of MiXcan is that the predicted values correspond to the cell-type-specific GReX, which are directly interpretable and biologically meaningful. Moreover, standard interaction models require cell composition information, which is often unavailable for the tissue of interest, whereas MiXcan prediction models can be applied directly to GWAS data without transcriptomic or cell composition data to interrogate genetic associations within the disease-relevant tissue and cell type context.
MiXcan has several limitations. First, although the MiXcan framework is generalizable, the model building procedure requires hypotheses regarding the disease-related cell types and tissue. The prediction models for this cell-type-aware TWAS of breast cancer were developed specifically for human mammary tissue with a focus on distinguishing epithelial and stromal (nonepithelial) cells, which have distinct roles in breast carcinogenesis8–10. Second, the current MiXcan framework decomposes a tissue into two cell-type components only. The MiXcan framework can be extended naturally to model more than two cell types. However, given limited sample sizes of the available training datasets, the model performance becomes quite variable with additional cell types due to the rapidly increasing dimension of the parameter space and complexity of the numerical optimization. As larger training sets with bulk tissue transcriptomic and genomic data become available, a careful evaluation of its analytical performance can be performed for additional less common cell types. Third, paired single-cell RNAseq and genomic datasets are presently very limited, and the validation of MiXcan epithelial cell predictions was performed for a small set of genes using epithelial cell snRNAseq data available for only three women in GTEx. Human single-cell transcriptome profiling efforts46,47 are currently underway, and will enable further evaluation of the performance of MiXcan in larger datasets. Future studies can also investigate integrating single-cell transcriptome profiles into MiXcan, for example to improve estimation of cell composition in bulk tissue samples23,45 or to provide an initial estimate of SNP weights, which could be used to tune separate penalty terms for different SNPs in adaptive elastic-net models48.
Human mammary tissue has variable cell composition and numerous eQTLs with distinct effects in epithelial cells and adipocytes, which are a major stromal cell type in the breast19. Cell-type-aware TWAS using MiXcan mammary tissue models applied to publicly available GWAS data identified three new breast cancer susceptibility genes that were associated with disease risk through their GReX in normal mammary epithelial or stromal cells. ZNF703 (zinc finger protein 703) is an oncogene that is commonly amplified in luminal B breast tumors, and has been shown to regulate genes involved in proliferation, invasion, and an altered balance of progenitor stem cells49–51. To our knowledge, common germline variants in ZNF703 have not previously been implicated in breast cancer risk. Our finding that genetic upregulation of ZNF703 in normal mammary stromal cells (predominantly adipocytes) was associated with increased breast cancer risk in 58,648 women was confirmed by a highly significant (p-value=2.1 × 10−20) association of tissue-level GReX predicted using S-PrediXcan subcutaneous fat models in 228,951 EA women, which has not previously been reported to our knowledge. Notably, the mammary tissue-level results for ZNF703 did not reach transcriptome-wide significance, underscoring the importance of accounting for cell-type heterogeneity to elucidate disease etiology. TMEM245 (transmembrane protein 245) is the host gene for microRNA 32, which has been shown to promote proliferation and suppress apoptosis of breast cancer cells52. Relatively little is known about PSG4 (pregnancy specific beta-1-glycoprotein 4), a member of the carcinoembryonic antigen gene family that may play a role in regulation of the innate immune system53. Future studies are needed to provide experimental validation of the breast cancer genes identified in this study and better understand the cellular mechanisms underlying the associations.
In conclusion, the MiXcan framework enables cell-type-aware TWAS using prediction models that allow for differences across cell types in the disease-relevant tissue. MiXcan mammary tissue models are available at https://github.com/songxiaoyu/MiXcan54 and can be applied to GWAS genotype data to identify genes associated with complex traits through their GReX in epithelial or stromal cells. MiXcan software is also freely available to facilitate training prediction models for other tissues and cell types, and conducting cell-type-aware TWAS. MiXcan prediction models had excellent performance in independent validation datasets, and identified new breast cancer susceptibility genes in the first cell-type-aware TWAS of breast cancer. These findings provide a proof of concept that cell-type-aware TWAS are feasible using existing bulk tissue training datasets and GWAS data, and can lead to the discovery of new disease genes and cellular mechanisms. Future research is needed to develop MiXcan models for other human tissues and cell types, extend the MiXcan framework to GWAS summary statistics, and explore alternative modeling and inference strategies2,55,56. These research directions will enable the broad application of cell-type-aware TWAS to improve our understanding of the genetic and cellular mechanisms underlying human diseases.
Methods
MiXcan framework
We first summarize PrediXcan1, an established tissue-level TWAS framework, and then present the MiXcan cell-type-aware TWAS framework. Let yi denote the measured expression level of a gene in the bulk tissue sample i ∈ (1, . . . , N), xi denote the genetic variants (e.g. SNPs) used in model training, and zi denote the non-genetic covariates (e.g. age).
PrediXcan tissue-level TWAS framework
PrediXcan uses a linear additive model to characterize the gene expression level:
| 1 |
where ei ~ N(0, σ2) is the model error, is the genetically determined component of gene expression, and is the non-genetically determined component. This model can be estimated with the elastic-net method57, which maximizes the following penalized log-likelihood function:
| 2 |
where is the elastic-net penalty function with the mixing parameter α ∈ (0, 1). In PrediXcan, α is set at 0.5 and λ is selected via 10-fold cross validation.(CV)58 The estimated SNP weights can be used to predict the GReX by where denotes the SNP genotypes of the GWAS subject j ∈ (1, . . . , M). Then, the association of with the phenotype (e.g. disease status) dj can be evaluated using a generalized linear model , where g(. ) is a link function. The null and alternative hypotheses, H0: η1 = 0 vs. HA: η1 ≠ 0, test whether the GReX at the tissue level is associated with the phenotype.
MiXcan cell-type-level GReX prediction model
MiXcan extends upon PrediXcan to enable cell-type-aware TWAS. In this section, we build the prediction models for the cell-type-level GReX. In the next section, we develop strategies for applying these prediction models in disease-association studies.
Human bulk tissue samples from solid tissue (e.g. mammary tissue) comprise a mixture of cells of different types. Let πi and 1 − πi be the proportions of the cell type of interest (e.g. epithelial cells) and all other cell types (e.g. stromal cells) in the ith tissue sample, respectively. We assume the observed bulk tissue expression level of a given gene yi is a linear combination of expression levels in the cell types. Introducing two latent variables ui and vi to denote the unobserved average gene expression levels in the epithelial and stromal cells, respectively, we have:
| 3 |
We model both ui and vi using the linear additive models:
| 4 |
where and are the model errors. In Eq. (4), the intercepts au and av and genetic parameters bu and bv differ between cell types, allowing for different mean expression levels and cell-type-specific effects of genetic variants on gene expression. A shared parameter c is used for the non-genetic component zi to simplify the model as the non-genetic variables are not necessarily used in downstream analyses.
The proportion of epithelial cells π = {π1, . . . , πN} is a feature of the tissue samples, which can be jointly estimated using multiple genes, whereas are features of each gene for investigation. Therefore, we present a step-wise procedure to first estimate π using multiple epithelial signature genes, and then estimate the cell-type-level effects Θ for each gene.
Estimation of π. The notation in the sections above focuses on individual genes, and here we introduce additional notation to describe the joint modeling of multiple genes. Let be the observed expression of G epithelial signature genes in N tissue samples; and and be the unobserved gene expression levels in epithelial and stromal cells, respectively. Similarly as in Eq. (3), we have:
| 5 |
Leveraging primarily the mean differences of signature genes in epithelial and stromal cells for estimating π, we model the marginal distributions of individual genes and omit the complex gene-gene correlations for computationally efficient estimation, as supported by our previous work59. Specifically, we assume:
Across all G genes, the parameters include , where .
In parallel, we also take advantage of a prior cell-type proportion estimate hi based on existing tools (i.e. rescaled xCell18 enrichment scores). We link the prior estimates hi to the true πi using a Beta distribution such that hi ~ Beta(πiδ, (1 − πi)δ) for some positive parameter δ. We have E(hi) = πi and var(hi) = πi(1 − πi)/(δ + 1) such that hi is an unbiased estimator of the true πi with variation.
We then join these two models for parameter estimation and solve the following maximization problem:
| 6 |
where and l(πi, δ∣hi) are the log-likelihood of the observed gene expression profile and cell proportion estimate of the ith sample, respectively. This optimization problem is solved using an Expectation-Maximization (EM) algorithm similar to that in Petralia et al.59
To enhance the robustness of the estimation, we implement a bagging strategy to estimate the parameters with randomly selected bootstrap samples, and aggregate multiple estimates by calculating a tail truncated mean. This bagging strategy further stabilizes the estimates, and may also be used to investigate the consistency of π estimation.
Estimation ofbuandbv. Given , we next estimate bu and bv in Eq. (4). Since ui and vi are unobserved, we integrate Eqs. (3) and (4) to have:
| 7 |
This equation can be rearranged as:
| 8 |
where . A simple strategy for estimating bu and bv is to apply elastic-net regression to Eq. (8). Specifically, the elastic-net regularization is put on (bv, bu − bv, c)—the dependence of expression levels on genetic variants and covariates—but not on (av, au − av) —the mean expression levels in the two cell types. We refer to this strategy as MiXcan0.
One issue with MiXcan0 is that the two cell components in the mixture model are not treated in a symmetric manner. In other words, the penalization on bu and bv differs: bv is shrunk towards zero, while bu is shrunk towards bv. This asymmetric penalization results in different models if the order of the two components is switched. To address this issue, we introduce and rewrite Eq. (8) as:
| 9 |
When fitting elastic-net regression to Eq. (9), we include penalties on , which impose the same degree of regularization on bu and bv: the penalty on regularizes the overall sparsity of the genetic effects, while the penalty on bu − bv encourages similarities between the two components. We refer to this strategy as MiXcan.
Note, when fitting elastic-net regressions in MiXcan0 and MiXcan, we do not consider the varying variances of ϵi as takes different values. This is because the residual variance structure has limited impact on the coefficient estimates, especially for regularized regression. In a trade-off between extensive computational costs (allowing varying residual variances) and minimal sacrifice of estimation accuracy (assuming constant variance), we chose the latter and take advantage of the fast implementation of elastic-net regression in the glmnet package.
Model Aggregation. In the prediction models, the term is of particular importance: a non-zero value suggests that the dependence structure between genetic variants and expression levels is cell-type-specific. Therefore, it is critical to know the selection robustness of . We employ a procedure similar to stability selection60 for its evaluation. Specifically, for models that select non-zero , we generate B bootstrap samples (e.g. B = 200), perform ordinary least square analysis on the pre-selected variables, and record for b = 1, . . . , B. Only when the 95% confidence interval (CI) for excludes 0 do we employ cell-type-specific prediction models (inferred using the complete data set). Otherwise, nonspecific models that have the same prediction weights for the two cell types will be used, as in Eq. (2) of PrediXcan.
Association analysis with cell-type-level prediction models
The model building procedure in MiXcan selects cell-type-specific prediction models for some genes and nonspecific models for other genes. Cell-type-specific prediction models estimate different SNP weights in the two cell types () resulting in different predicted GReX from the same genotype data (j ∈ (1, ..., M)), such that and . These cell-type-specific GReX levels cannot be combined into tissue levels in GWAS datasets that lack cell-type proportion estimates, requiring a novel statistical framework for association analysis. One natural idea is to infer cell-type-specific associations by directly associating the phenotype dj with and , either separately, such that and , or jointly, such that . As and are predicted from the same genotype data with prediction weights jointly learned using the bulk tissue data in MiXcan, they may capture leaked information from each other. As a result, if an association exists in one cell type, analysis in the other cell type may also capture this association, resulting in an inflated type I error for inferring associations in each cell type. To avoid this inflation, we propose a composite hypothesis test to test whether association exists in any cell types in the tissue:
H0: There is no association in any cell type in the tissue vs.
HA: There is an association in at least one cell type in the tissue.
This composite null is robust against information leakage, as the leaked values under the null are not associated with the phenotype. To perform the test, we first associate dj with and , separately if the are highly correlated (e.g. r = ±1), or jointly otherwise. Then, we propose to aggregate the resulting p values pu and pv for and using Cauchy combination27. The Cauchy combination provides valid test for correlated p-values, and in this setting the test statistic can be written as:
| 10 |
where pi is the mathematical constant approximately equal to 3.14159. The combined p-value for the tissue is approximated by:
| 11 |
The ptissue tests whether association exists in any cell type in the tissue. Unlike PrediXcan that tests associations averaged across all cell types, the ptissue in MiXcan accumulates signals from different cell types. Note that pu and pv are building blocks of TCauchy and the resulting ptissue is between pu and pv. After the tissue-level hypothesis test, pu and pv can provide information on the cell type(s) driving the association. For example, pu << pv indicates that a significant ptissue is primarily driven by epithelial cells.
Some genes have nonspecific models with the same estimated SNP weights and predicted GReX in the two cell types (). While association analyses can follow the same strategy described above for cell-type-specific models, it is equivalent to performing a single tissue-level association analysis as in PrediXcan. Finally, in transcriptome-wide studies, ptissue from genes with cell-type-specific prediction models and p-values from genes with nonspecific models can be jointly used to adjust for multiple testing, and infer transcriptome-wide significant discoveries.
Build MiXcan prediction models using GTEx mammary tissue data
MiXcan gene expression prediction models were developed using the GTEx v8 genotype and gene expression data for mammary tissue samples from 125 European ancestry women (dbGaP accession number phs000424.v8.p2 <https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs000424.v8.p2>). PredictDB (http://predictdb.org) provides tissue-level expression prediction models trained on 337 men and women of European ancestry with mammary tissue data available in GTEx v8. PredictDB included mammary tissue elastic-net models for a total of 6461 genes that were well predicted by genetic variants (176,983 SNPs). An additional 1,715 SNPs were included in PredictDB mammary tissue MASHR models61. For the purpose of comparison to PrediXcan as a proof of concept, we developed cell-type-level prediction models for these 6461 genes using all 178,698 SNPs in the PredictDB mammary tissue database. MiXcan cell-type-level prediction models were developed for mammary epithelial cells, the cell of origin for breast carcinoma, and stromal (non-epithelial) cells.
π estimation. The epithelial cell proportion πi was estimated using 126 epithelial cell signature genes18 available in the training dataset of 125 GTEx female mammary tissue samples. We first computed xCell gene set enrichment scores for epithelial cells and 63 other cell types using the curated set of cell signature genes for each cell type18 and the bulk tissue transcriptomic data for each sample. We then re-scaled the xCell epithelial cell enrichment score to range from 0 to 1 for use as a prior estimate of the cell-type proportion in MiXcan. The πi estimation was performed using 100 bootstrap samples (80% random draw with replacement). The final estimate was computed by excluding the most extreme 5% of bootstrap estimates in each of the two tails and averaging the remaining estimates.
Prediction model. Using , we modeled the cell-type-level expression levels for each of the 6461 genes using MiXcan with tuning parameter λ selected by tenfold CV. We adjusted for covariates that were used in GTEx eQTL analyses including age, platform, PCR, genomic principal components (PC) 1-5, and PEER factors 1–1562. For genes with , we performed ordinary least squares regression on the pre-selected variables for 200 bootstrap samples, and calculated the 95% bootstrap CI of . If the 95% CI excluded 0, we used cell-type-specific models with parameters estimated using the full data; otherwise, we used nonspecific models that were the same as PrediXcan. The average computation time for training models for 1000 genes using 125 samples on a single CPU core was 11 min (standard deviation, 2.8 minutes).
Evaluate MiXcan prediction accuracy in independent TCGA data
We evaluated the prediction performance of MiXcan in an independent dataset of 103 European ancestry female breast cancer patients with adjacent normal tissue samples from TCGA63,64. To minimize the study effect, we re-processed the TCGA gene expression data using methods analogous to those used to process the GTEx expression data (https://gtexportal.org/home/documentationPage). Briefly, we required genes to have Transcripts Per Kilobase Million (TPM) >0.1 in at least 20% of samples, and at least six reads in at least 20% of samples, resulting in a set of 25,702 out of 25,849 total genes that met these quality control (QC) requirements. Expression data were then normalized using the trimmed mean of M values method (TMM)65 as implemented in the R package edgeR v3.16.566, and the results were quantile-normalized to a standard normal distribution with mean=0 and variance = 1. Comparison of these normalized gene expression levels showed no systematic differences between the GTEx and TCGA data (Supplementary Fig. 7). To process the genotype data, we removed all indels, monomorphisms, and ambiguous pairs (e.g. A/T, C/G). SNPs with >5% missing genotypes or Hardy-Weinberg equilibrium (HWE) test p value < 1e–05 were also removed. The remaining SNPs were aligned to build 37 coordinates, and imputation was performed on the TOPMed imputation server67. A total of 97% (54,663 out of 56,531) and 97% (52,031 out 53,876) SNPs used in MiXcan and PrediXcan prediction models, respectively, were available for analysis.
We estimated the epithelial cell proportion in the TCGA samples as described above, and used this estimate to combine the predicted cell-type-level GReX from epithelial and stromal components into the tissue level. To evaluate predication accuracy, we computed the Pearson correlation between the predicted and observed tissue-level gene expression, and compared the results with the predicted tissue-level expression using PrediXcan. The observed bulk tissue expression levels showed significantly higher correlation with the tissue-level GReX predicted by MiXcan compared with PrediXcan. To investigate the sources of the improved performance, we compared five approaches for predicting tissue-level GReX:
Existing PredictDB elastic-net models (PredictDB)
PrediXcan trained on the same dataset as MiXcan (PrediXcan)
Prediction model including interactions between SNPs and the xCell enrichment score (xCell interaction)
Prediction model including interactions between SNPs and the MiXcan cell-type proportion (MiXcan0)
Cell-type-level prediction models with symmetric penalization (MiXcan).
These comparisons evaluated incorporating cell-type composition, use of the MiXcan cell-type proportion estimate, and symmetric penalization of the two cell types in prediction models, as well as use of a larger training set including both men and women in PredictDB. It is worth noting that “MiXcan0" and “xCell interaction" models are not applicable to GWAS datasets that lack cell-type composition information for the tissue of interest, and are included here only for the purpose of understanding the sources of improved prediction performance for MiXcan.
Evaluate MiXcan epithelial cell prediction accuracy in snRNAseq data
We evaluated the performance of MiXcan epithelial cell prediction models using snRNAseq data for normal mammary epithelial cells and paired genomic data available for three women of European, Asian and African ancestry from GTEx v929. Details of the snRNAseq data generation and processing were provided in29. The preprocessed log count expression profiles for a total of 5990, 2324 and 1456 nuclei, including 2292 (38%), 2180 (94%) and 1327 (91%) epithelial cell nuclei, from the European, Asian and African ancestry woman, respectively, were downloaded from https://gtexportal.org/home/datasets. Mammary epithelial cell snRNAseq data were available in all three women for 4751 genes with MiXcan prediction models. To enable comparisons between women, the snRNAseq levels were averaged for each gene and quantile normalized to a standard normal distribution within each woman to reduce the impact of noise, skewness and outliers.
To evaluate prediction accuracy, MiXcan epithelial cell prediction models were applied to the genotype data for each woman, and the between-woman difference in the predicted GReX for each gene was computed to identify the two sets of 100 genes predicted to have the largest positive or negative differences in mammary epithelial cell expression in each pair of women. The Wilcoxon signed-rank test was used to test whether the observed snRNAseq differences for genes predicted to have the largest GReX differences between women were significantly different from zero, as expected.
Simulation studies
To evaluate the type I error and power of MiXcan association tests, we performed extensive simulation studies under a broad range of realistic models for the associations of genetic variants with gene expression (SNP-Exp) and gene expression with disease (Exp-Disease). Mimicking real data, in each simulation, we generated a training dataset for building the GReX prediction models, and a GWAS dataset for testing the associations of GReX with disease. Without loss of generality, non-genetic covariates were excluded from simulations to allow direct evaluation of the predicted GReX.
For the training dataset, we simulated 300 bulk tissue samples with observed SNP genotypes and tissue-level gene expression. We assumed each tissue i ∈ (1, . . . , 300) was a mixture of two cell types and that the minor cell type (cell type 1) comprised an average of 40% of the tissue, with proportion πi ~ Beta(α = 2, β = 3). We further simulated the genotypes of 50 neighboring SNPs xi = {x1i, . . . , x50i} using the genome simulator R package sim1000G, with its default reference genome region (chromosome 4) and minor allele frequency (MAF) range 0.05–0.50. For the expression levels in the two cell types ui and vi, we considered a linear additive model such that ui = b0 + b1xi + eui and vi = b2xi + evi where eui, evi ~ N(0, 1). The parameter b0 determined the mean expression difference in the two cell types under xi = 0, and b1 and b2 determined the association patterns between the SNPs X and gene expression level Y in the minor and major cell types, respectively. Then, the tissue-level gene expression was a weighted average of the expression levels in the two cell types: yi = πiui + (1 − πi)vi.
We considered two SNP-Exp settings: Homogeneous SNP-Exp Association (b1 = b2) and Heterogeneous SNP-Exp Association (b1 ≠ b2). Under the Homogeneous SNP-Exp setting, we randomly selected one genetic variant p to be associated with expression levels in the two cell types and let b1p = b2p = 1 or -1 with equal chance, corresponding to a median heritability of 0.27 and interquartile range (IQR) of 0.10. We varied b0 from -2 to 2 to evaluate the impact of the intercept (mean expression difference in two cell types under xi = 0) on TWAS. Under the Heterogeneous SNP-Exp setting, we randomly selected two SNPs p1 ≠ p2 ∈ (1, . . . , 50) with SNPs p1 and p2 associated with expression levels in the minor and major cell types, respectively, corresponding to the same heritability in both cell types (median 0.27; IQR 0.10). Similar to the Homogeneous SNP-Exp setting, we first evaluated the impact of the intercept by varying b0 from -2 to 2 while fixing at 1 or -1 and at 1 or -1 with equal chance. Second, we varied the magnitude of b1p from 0 to 2 (median heritability 0 to 0.59) with equal chance of a positive or negative sign, while fixing b0 at 1 and b2p = ± 1 to understand the impact of the SNP-Exp association strength in the minor cell type. Third, we varied the magnitude of b2p from 0 to 2 (allowing a random sign with equal chance), while fixing b0 at 1 and b1p = ± 1 to understand the impact of the SNP-Exp association strength in the major cell type. Finally, to evaluate the impact of the training data sample size, we assessed sample sizes ranging from 100 to 300, while fixing b0 at 1 and the magnitude of non-zero components of b1, b2 at 1.
For the GWAS dataset, we simulated a case-control study of 3000 participants with observed genotypes and disease status. We assumed the unobserved cell-type composition and cell-type-level gene expression in this dataset followed the same distributions as in the training dataset. Disease risk was simulated using a logistic model, such that logitP(dj = 1) = η0 + η1uj + η2vj for j ∈ (1, . . . , 3000). The intercept η0 was set to reflect a 1:1 ratio of cases and controls. We considered five different settings for η1, η2 to capture the dynamic relationship between gene expression levels in the two cell types and disease risk:
No Exp-Disease Association: η1 = η2 = 0, i.e. disease is not associated with the gene expression in either cell type.
Homogeneous Exp-Disease Association: η1 = η2 = 0.2, i.e. disease is associated with the gene expression in both cell types in the same way.
Exp-Disease Association in Major Cell: η1 = 0 and η2 = 0.2, i.e. disease is associated with the gene expression in the major cell type (cell type 2).
Exp-Disease Association in Minor Cell: η1 = 0.2 and η2 = 0, i.e. disease is associated with the gene expression in the minor cell type (cell type 1).
Exp-Disease Association in Opposite Directions: η1 = − 0.2 and η2 = 0.2, i.e. disease is associated with the gene expression in the two cell types in opposite directions.
We compared the prediction accuracy, type I error, and power of MiXcan with PrediXcan, which ignores cell-type heterogeneity in 500 Monte Carlo simulations.
MiXcan performance under misspecified models. MiXcan decomposes tissues into two cell-type components. To evaluate the robustness of MiXcan to misspecification of the cell-type proportion, where a noisy estimate of is used instead of the true π, we simulated: (a) to shift the mean from 0.4 to 0.32 and scale from (0–1) to (0–0.8); (b) to shift the mean from 0.4 to 0.48 and scale from (0-1) to (0.2-1); (c) to reduce the correlation with the true value to 0.9; and (d) to further reduce to 0.6. We compared the performance of MiXcan using the misspecified with MiXcan using the true π and PrediXcan.
We also evaluated the robustness of MiXcan to the presence of a latent third cell type. We simulated a tissue with three cell types that have different SNP-Exp or Exp-Disease associations, and evaluated the performance of MiXcan by decomposing the tissue into cell type 1 vs. a mixture of cell types 2 and 3. Specifically, we simulated 300 bulk tissue samples comprised of three cell types with proportions π1i = 40%, π2i = 50% and π3i = 10%. As in the simulations above, gene expression levels in three cell types were linearly dependent on 50 neighboring SNPs as determined by b1, b2 and b3, and logit transformed disease risk was linearly dependent on the expression levels in the three cell types as determined by η1, η2 and η3. To evaluate the impact of a latent third cell type contributing to the SNP-Exp association, we compared the performance of MiXcan and PrediXcan for b2 = b3 vs. b2 ≠ b3 assuming η2 = η3 under the Heterogeneous SNP-Exp Association (b1 ≠ b2) setting. In detail, we randomly selected three different SNPs p1, p2, p3 ∈ (1, . . . , 50) to be associated with expression levels in the three cell types, respectively, and fixed the magnitude of these non-zero b () at 1, with equal chance of a positive or negative sign. We evaluated type I error and power in simulated GWAS datasets (N = 3000) under five Exp-Disease patterns as described for η1, η2 above. As we observed that type I error was well controlled under various SNP-Exp associations in a latent third cell type, we next evaluated the impact of a latent third cell type contributing to the Exp-Disease association on the study power of MiXcan. In this simulation, we fixed b3 = b2 but simulated η3 ≠ η2 with η3 values ranging from -0.2 to 0.2.
Apply MiXcan to perform cell-type-aware TWAS of breast cancer
Cell-type-aware TWAS of breast cancer
We performed cell-type-aware TWAS of breast cancer risk using GWAS data from the Discovery, Biology, and Risk of Inherited Variants in Breast Cancer (DRIVE) study. Genotype data for 60,014 women (32,438 cases and 27,576 controls) assayed using the Oncoarray30, which includes >500,000 variants and provides excellent coverage of most common variants, were downloaded from dbGaP (phs001265.v1.p1 <https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs001265.v1.p1>). After imputation (as described above for TCGA data), 95% (53,528 out of 56,531) and 95% (51,049 out of 53,876) SNPs used in MiXcan and PrediXcan prediction models, respectively, were available for analysis.
Principle component analysis (PCA) was performed using 20,629 SNPs, after excluding SNPs with a missing rate above 0.01% and selecting SNPs in approximate linkage equilibrium using PLINK v1.90 (indep-pairwise option with window size=50kb, step size=5, r2 threshold=0.05)68. EIGENSOFT v6.1.4 was used to compute PCs with the fast mode option enabled, which implements the FastPCA approximation69. The first PC separated individuals of African (e.g. from Nigeria, Uganda and Cameroon) vs. European (e.g. from Australia) ancestry. In total, 58,648 women (31,716 cases and 26,932 controls) of European ancestry determined by PCs were included in TWAS analyses.
MiXcan, PrediXcan and PredictDB elastic-net mammary tissue models were applied to the individual-level genotype data to perform cell-type-aware or tissue-level TWAS, as described above. All three models were adjusted for the same covariates, including age, country of origin and the top 10 PCs15.
Evaluation of TWAS findings
We evaluated significant TWAS genes identified by MiXcan and PrediXcan in a substantially larger study of 228,951 European ancestry women (122,977 cases and 105,974 controls) from the combined DRIVE and Breast Cancer Association Consortium (BCAC) GWAS meta-analysis of breast cancer11. The summary statistics for the “Combined Oncoarray, iCOGS GWAS meta analysis" were downloaded from https://bcac.ccge.medschl.cam.ac.uk/bcacdata/oncoarray/oncoarray-and-combined-summary-result/gwas-summary-results-breast-cancer-risk-2017/. Associations of predicted tissue-level GReX with breast cancer risk were evaluated using S-PrediXcan33 with PredictDB28 elastic-net models derived from GTEx v8 mammary tissue data for 337 men and women of European ancestry. We also determined whether TWAS genes identified by MiXcan and PrediXcan were located within 500 kb of 214 previously reported genome-wide significant breast cancer susceptibility loci11–13.
MiXcan software
We developed a computationally efficient R package MiXcan to facilitate estimation of cell-type-level GReX prediction models in the two cell components of bulk tissue data, and to perform cell-type-aware TWAS. The MiXcan R package, and pre-trained models for the epithelial and stromal (non-epithelial) cell components of mammary tissue derived from 125 European ancestry women in GTEx v8 are freely available at https://github.com/songxiaoyu/MiXcan54.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Supplementary information
Description of Additional Supplementary Files
Acknowledgements
This study was supported by the National Institutes of Health R01CA237541 (W.S., L.A.H., P.W.), R01CA244948 (R.J.K.), R01CA264987 (W.S., L.A.H.), R03AG075567 (X.S.), U24CA210993 (P.W.), U24CA271114 (P.W.), and P30CA196521 (X.S.). The authors acknowledge the computational resources and staff expertise provided by Scientific Computing at the Icahn School of Medicine at Mount Sinai. The BCAC breast cancer genome-wide association analyses were supported by the Government of Canada through Genome Canada and the Canadian Institutes of Health Research, the ‘Ministère de l’Économie, de la Science et de l’Innovation du Québec’ through Genome Québec and grant PSR-SIIRI-701, the National Institutes of Health (U19CA148065, X01HG007492), Cancer Research UK (C1287/A10118, C1287/A16563, C1287/A10710) and the European Union (HEALTH-F2-2009-223175 and H2020 633784 and 634935); all studies and funders are listed11. The GTEx Project was supported by the Common Fund of the Office of the Director of the National Institutes of Health, and by NCI, NHGRI, NHLBI, NIDA, NIMH, and NINDS. The results published here are in whole or part based upon data generated by the TCGA Research Network.
Source data
Author contributions
Study conception and design (X.S., J.H.R., R.J.K., L.A.H., P.W., W.S.); data curation and processing (J.H.R., R.J.K., W.S.); software development (X.S., J.J.); statistical analysis (X.S., J.J., J.H.R., R.J.K., P.W., W.S.); interpretation of results and critical review of the manuscript (X.S., J.J., J.H.R., S.E.A., L.C.S., A.S., N.A., E.J., A.S.W., R.J.K., L.A.H., P.W., W.S.).
Peer review
Peer review information
Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work.
Data availability
The data used in this study are publicly available from the following sources: GTEx v8 (dbGaP accession number phs000424.v8.p2 <https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs000424.v8.p2>); GTEx v9 (https://gtexportal.org/home/datasets); TCGA (dbGaP accession number phs000178.v8.p7 <https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs000178.v8.p7>); Discovery, Biology, and Risk of Inherited Variants in Breast Cancer (DRIVE) (dbGaP accession number phs001265.v1.p1 <https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs001265.v1.p1>); PredictDB (http://predictdb.org); and the Breast Cancer Association Consortium (BCAC) (https://bcac.ccge.medschl.cam.ac.uk/bcacdata/). Source data are provided with this paper.
Code availability
The MiXcan R package is publicly available at https://github.com/songxiaoyu/MiXcan54.
Competing interests
E.J. is an employee at Regeneron. The remaining authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
These authors jointly supervised this work: Pei Wang, Weiva Sieh.
Contributor Information
Xiaoyu Song, Email: xiaoyu.song@mountsinai.org.
Pei Wang, Email: pei.wang@mssm.edu.
Weiva Sieh, Email: weiva.sieh@mssm.edu.
Supplementary information
The online version contains supplementary material available at 10.1038/s41467-023-35888-4.
References
- 1.Gamazon ER, et al. A gene-based association method for mapping traits using reference transcriptome data. Nat. Genet. 2015;47:1091. doi: 10.1038/ng.3367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Gusev A, et al. Integrative approaches for large-scale transcriptome-wide association studies. Nat. Genet. 2016;48:245–252. doi: 10.1038/ng.3506. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Wainberg M, et al. Opportunities and challenges for transcriptome-wide association studies. Nat. Genet. 2019;51:592–599. doi: 10.1038/s41588-019-0385-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.National Cancer Institute. SEER Cancer Statistics Factsheets. Breast Cancer. http://seer.cancer.gov/statfacts/html/breast.html.
- 5.Mucci LA, et al. Familial risk and heritability of cancer among twins in Nordic countries. J. Am. Med. Assoc. 2016;315:68–76. doi: 10.1001/jama.2015.17703. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Boyd NF, et al. Mammographic breast density as an intermediate phenotype for breast cancer. Lancet Oncology. 2005;6:798–808. doi: 10.1016/S1470-2045(05)70390-9. [DOI] [PubMed] [Google Scholar]
- 7.Sickles, E. A. et al. ACR BI-RADS Mammography. In ACR BI-RADS Atlas, Breast Imaging Reporting and Data System (American College of Radiology, Reston, VA, 2013).
- 8.Pettersson A, et al. Mammographic density phenotypes and risk of breast cancer: a meta-analysis. J. Natl. Cancer Inst. 2014;106:dju078. doi: 10.1093/jnci/dju078. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Arendt LM, Rudnick JA, Keller PJ, Kuperwasser C. Stroma in breast development and disease. Seminars Cell Dev. Biol. 2010;21:11–18. doi: 10.1016/j.semcdb.2009.10.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Sieh W, et al. Identification of 31 loci for mammographic density phenotypes and their associations with breast cancer risk. Nat. Commun. 2020;11:5116. doi: 10.1038/s41467-020-18883-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Michailidou K, et al. Association analysis identifies 65 new breast cancer risk loci. Nature. 2017;551:92–94. doi: 10.1038/nature24284. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Milne RL, et al. Identification of ten variants associated with risk of estrogen-receptor-negative breast cancer. Nat. Genet. 2017;49:1767–1778. doi: 10.1038/ng.3785. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Zhang, H. et al. Genome-wide association study identifies 32 novel breast cancer susceptibility loci from overall and subtype-specific analyses. Nat. Genet.52, 572–581 (2020). [DOI] [PMC free article] [PubMed]
- 14.Hoffman JD, et al. Cis-eQTL-based trans-ethnic meta-analysis reveals novel genes associated with breast cancer risk. PLoS Genet. 2017;13:e1006690. doi: 10.1371/journal.pgen.1006690. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Wu L, et al. A transcriptome-wide association study of 229,000 women identifies new candidate susceptibility genes for breast cancer. Nat. Genet. 2018;50:968–978. doi: 10.1038/s41588-018-0132-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Bhattacharya A, et al. A framework for transcriptome-wide association studies in breast cancer in diverse study populations. Genome Biology. 2020;21:1–18. doi: 10.1186/s13059-020-1942-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.GTEx Consortium. The Genotype-Tissue Expression (GTEx) project. Nat. Genet. 2013;45:580–585. doi: 10.1038/ng.2653. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Aran D, Hu Z, Butte AJ. xCell: digitally portraying the tissue cellular heterogeneity landscape. Genome Biology. 2017;18:1–14. doi: 10.1186/s13059-017-1349-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.GTEx Consortium. The GTEx Consortium atlas of genetic regulatory effects across human tissues. Science. 2020;369:1318–1330. doi: 10.1126/science.aaz1776. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Wang J, Roeder K, Devlin B. Bayesian estimation of cell type-specific gene expression with prior derived from single-cell data. Genome Res. 2021;31:1807–1818. doi: 10.1101/gr.268722.120. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Newman AM, et al. Determining cell type abundance and expression from bulk tissues with digital cytometry. Nat. Biotechnol. 2019;37:773–782. doi: 10.1038/s41587-019-0114-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Hunt GJ, Freytag S, Bahlo M, Gagnon-Bartsch JA. dtangle: accurate and robust cell type deconvolution. Bioinformatics. 2019;35:2093–2099. doi: 10.1093/bioinformatics/bty926. [DOI] [PubMed] [Google Scholar]
- 23.Wang X, Park J, Susztak K, Zhang NR, Li M. Bulk tissue cell type deconvolution with multi-subject single-cell expression reference. Nat. Commun. 2019;10:380. doi: 10.1038/s41467-018-08023-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Sturm G, et al. Comprehensive evaluation of transcriptome-based cell-type quantification methods for immuno-oncology. Bioinformatics. 2019;35:i436–i445. doi: 10.1093/bioinformatics/btz363. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Avila Cobos F, Alquicira-Hernandez J, Powell JE, Mestdagh P, De Preter K. Benchmarking of cell type deconvolution pipelines for transcriptomics data. Nat. Commun. 2020;11:1–14. doi: 10.1038/s41467-020-19015-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Sutton GJ, et al. Comprehensive evaluation of deconvolution methods for human brain gene expression. Nat. Commun. 2022;13:1–18. doi: 10.1038/s41467-022-28655-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Liu Y, Xie J. Cauchy combination test: a powerful test with analytic p value calculation under arbitrary dependency structures. J. Am. Stati. Assoc. 2020;115:393–402. doi: 10.1080/01621459.2018.1554485. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.PredictDB Data Repository—GTEx V8 Model Release (2019). https://predictdb.org/.
- 29.Eraslan G, et al. Single-nucleus cross-tissue molecular reference maps toward understanding disease gene function. Science. 2022;376:eabl4290. doi: 10.1126/science.abl4290. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Amos CI, et al. The OncoArray consortium: a network for understanding the genetic architecture of common cancers. Cancer Epidemiol. Biomarkers Prevent. 2017;26:126–135. doi: 10.1158/1055-9965.EPI-16-0106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.van Iterson M, van Zwet EW, Heijmans BT. Controlling bias and inflation in epigenome-and transcriptome-wide association studies using the empirical null distribution. Genome Biology. 2017;18:1–13. doi: 10.1186/s13059-016-1131-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Feng H, et al. Transcriptome-wide association study of breast cancer risk by estrogen-receptor status. Genet. Epidemiol. 2020;44:442–468. doi: 10.1002/gepi.22288. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Barbeira AN, et al. Exploring the phenotypic consequences of tissue specific gene expression variation inferred from GWAS summary statistics. Nature Communications. 2018;9:1–20. doi: 10.1038/s41467-018-03621-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Gucalp A, et al. Male breast cancer: a disease distinct from female breast cancer. Breast Cancer Res. Treat. 2019;173:37–48. doi: 10.1007/s10549-018-4921-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Li B, et al. Tissue specificity-aware TWAS (TSA-TWAS) framework identifies novel associations with metabolic, immunologic, and virologic traits in hiv-positive adults. PLoS Genet. 2021;17:e1009464. doi: 10.1371/journal.pgen.1009464. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Feng H, et al. Leveraging expression from multiple tissues using sparse canonical correlation analysis and aggregate tests improves the power of transcriptome-wide association studies. PLoS Genet. 2021;17:e1008973. doi: 10.1371/journal.pgen.1008973. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Thompson, M. et al. Multi-context genetic modeling of transcriptional regulation resolves novel disease loci. Nat. Commun.13, 5704 (2022). [DOI] [PMC free article] [PubMed]
- 38.Donovan MK, D’Antonio-Chronowska A, D’Antonio M, Frazer KA. Cellular deconvolution of GTEx tissues powers discovery of disease and cell-type associated regulatory variants. Nat. Commun. 2020;11:1–14. doi: 10.1038/s41467-020-14561-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Chen J, et al. Fast and robust adjustment of cell mixtures in epigenome-wide association studies with SmartSVA. BMC Genomics. 2017;18:413. doi: 10.1186/s12864-017-3808-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Luo X, Yang C, Wei Y. Detection of cell-type-specific risk-CpG sites in epigenome-wide association studies. Nat. Commun. 2019;10:3113. doi: 10.1038/s41467-019-10864-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Rahmani E, et al. Cell-type-specific resolution epigenetics without the need for cell sorting or single-cell biology. Nat. Commun. 2019;10:3417. doi: 10.1038/s41467-019-11052-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Liu, W. et al. A statistical framework to identify cell types whose genetically regulated proportions are associated with complex diseases. medRxiv (2021). [DOI] [PMC free article] [PubMed]
- 43.Newman AM, et al. Robust enumeration of cell subsets from tissue expression profiles. Nat. Methods. 2015;12:453–457. doi: 10.1038/nmeth.3337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Yoshihara K, et al. Inferring tumour purity and stromal and immune cell admixture from expression data. Nat. Commun. 2013;4:2612. doi: 10.1038/ncomms3612. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Tsoucas D, et al. Accurate estimation of cell-type composition from gene expression data. Nat. Commun. 2019;10:2975. doi: 10.1038/s41467-019-10802-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Nguyen QH, et al. Profiling human breast epithelial cells using single cell RNA sequencing identifies cell diversity. Nat. Commun. 2018;9:2028. doi: 10.1038/s41467-018-04334-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Han X, et al. Construction of a human cell landscape at single-cell level. Nature. 2020;581:303–309. doi: 10.1038/s41586-020-2157-4. [DOI] [PubMed] [Google Scholar]
- 48.Zou H, Zhang HH. On the adaptive elastic-net with a diverging number of parameters. Ann. Stat. 2009;37:1733. doi: 10.1214/08-AOS625. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Holland DG, et al. ZNF703 is a common Luminal B breast cancer oncogene that differentially regulates luminal and basal progenitors in human mammary epithelium. EMBO Mol. Med. 2011;3:167–180. doi: 10.1002/emmm.201100122. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Sircoulomb F, et al. ZNF703 gene amplification at 8p12 specifies luminal B breast cancer. EMBO Mol. Med. 2011;3:153–166. doi: 10.1002/emmm.201100121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Slorach EM, Chou J, Werb Z. Zeppo1 is a novel metastasis promoter that represses E-cadherin expression and regulates p120-catenin isoform expression and localization. Genes Dev. 2011;25:471–484. doi: 10.1101/gad.1998111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Xia W, et al. MicroRNA-32 promotes cell proliferation, migration and suppresses apoptosis in breast cancer cells by targeting FBXW7. Cancer Cell Int. 2017;17:14. doi: 10.1186/s12935-017-0383-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Gene [Internet]. Bethesda (MD): National Library of Medicine (US), National Center for Biotechnology Information (2021). https://www.ncbi.nlm.nih.gov/gene/.
- 54.Song, X. et al. MiXcan: a framework for cell-type-aware transcriptome-wide association studies with an application to breast cancer. Zenodo (2022). 10.5281/zenodo.7350463. [DOI] [PMC free article] [PubMed]
- 55.Nagpal S, et al. TIGAR: an improved bayesian tool for transcriptomic data imputation enhances gene mapping of complex traits. Am. J. Hum. Genet. 2019;105:258–266. doi: 10.1016/j.ajhg.2019.05.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Mancuso N, et al. Probabilistic fine-mapping of transcriptome-wide association studies. Nat. Genet. 2019;51:675–682. doi: 10.1038/s41588-019-0367-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Friedman, J., Hastie, T. & Tibshirani, R. The Elements of Statistical Learning, vol. 1 (Springer series in statistics New York, 2001).
- 58.Friedman J, Hastie T, Tibshirani R. Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 2010;33:1. doi: 10.18637/jss.v033.i01. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Petralia F, et al. A new method for constructing tumor specific gene co-expression networks based on samples with tumor purity heterogeneity. Bioinformatics. 2018;34:i528–i536. doi: 10.1093/bioinformatics/bty280. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Meinshausen N, Bühlmann P. Stability selection. J. R. Stat. Soc.: Series B (Stat. Methodol.) 2010;72:417–473. doi: 10.1111/j.1467-9868.2010.00740.x. [DOI] [Google Scholar]
- 61.Urbut SM, Wang G, Carbonetto P, Stephens M. Flexible statistical methods for estimating and testing effects in genomic studies with multiple conditions. Nat. Genet. 2019;51:187–195. doi: 10.1038/s41588-018-0268-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Stegle O, Parts L, Piipari M, Winn J, Durbin R. Using probabilistic estimation of expression residuals (peer) to obtain increased power and interpretability of gene expression analyses. Nat. Protoc. 2012;7:500–507. doi: 10.1038/nprot.2011.457. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Network TCGA. Comprehensive molecular portraits of human breast tumours. Nature. 2012;490:61–70. doi: 10.1038/nature11412. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Grossman RL, et al. Toward a shared vision for cancer genomic data. N. Engl. J. Med. 2016;375:1109–1112. doi: 10.1056/NEJMp1607591. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Robinson MD, Oshlack A. A scaling normalization method for differential expression analysis of RNA-seq data. Genome Biology. 2010;11:1–9. doi: 10.1186/gb-2010-11-3-r25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Robinson MD, McCarthy DJ, Smyth GK. edgeR: a Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics. 2010;26:139–140. doi: 10.1093/bioinformatics/btp616. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Das S, et al. Next-generation genotype imputation service and methods. Nat. Genet. 2016;48:1284–1287. doi: 10.1038/ng.3656. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Purcell S, et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 2007;81:559–575. doi: 10.1086/519795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Galinsky KJ, et al. Fast principal-component analysis reveals convergent evolution of ADH1B in Europe and East Asia. Am. J. Hum. Genet. 2016;98:456–472. doi: 10.1016/j.ajhg.2015.12.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Description of Additional Supplementary Files
Data Availability Statement
The data used in this study are publicly available from the following sources: GTEx v8 (dbGaP accession number phs000424.v8.p2 <https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs000424.v8.p2>); GTEx v9 (https://gtexportal.org/home/datasets); TCGA (dbGaP accession number phs000178.v8.p7 <https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs000178.v8.p7>); Discovery, Biology, and Risk of Inherited Variants in Breast Cancer (DRIVE) (dbGaP accession number phs001265.v1.p1 <https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs001265.v1.p1>); PredictDB (http://predictdb.org); and the Breast Cancer Association Consortium (BCAC) (https://bcac.ccge.medschl.cam.ac.uk/bcacdata/). Source data are provided with this paper.
The MiXcan R package is publicly available at https://github.com/songxiaoyu/MiXcan54.