

Rates of sharing of genome-wide association studies (GWAS) summary statistics are historically low, limiting potential for scientific discovery. Here we show, using GWAS Catalog data, that GWAS papers that share data get on average 81.8% more citations, an effect that is sustained over time.
Subject terms: Genetics, Research data
A review of citation rates from genomic studies in the GWAS Catalog suggests that sharing summary statistics results, on average, in ~81.8% more citations, highlighting a benefit of publicly sharing GWAS summary statistics.
In recent years, we have witnessed an increasing and solid push toward open science in the form of incentives for open-access publishing and data sharing across scientific fields, exemplified by Plan S (https://www.coalition-s.org/) and the rise of the FAIR (Findable, Accessible, Interoperable, and Reusable) principles, created as guidance for good data sharing practice to support data reusability1. This effort comes from recognising that the accessibility and reuse of research data have a huge potential to boost scientific progress, especially given the vast amounts of data generated in genomics and biomedical fields2.
Human genomics pioneered the establishment of norms for data sharing, starting with the Human Genome Project, reflected in the Bermuda principles (https://web.ornl.gov/sci/techresources/Human_Genome/research/bermuda.shtml) and later expanded by the Fort Lauderdale agreement3, which promoted the publication, sharing and maintenance of a community resource of genetic data, paving the way for successful multinational collaborative work.
Genome-wide association studies (GWAS) have been the workhorse of genomics for over a decade and are an example of reproducible science principles in practice due to the sharing of results and data4. GWAS typical output, summary statistics (i.e. plain text files with the results of the per-SNP tests), are especially suited for sharing, as they are easily stored, alleviate privacy concerns posed by sharing individual data, and can be exploited by many bioinformatic techniques (eg. meta-analysis5, Mendelian randomisation6, linkage disequilibrium score regression7, colocalisation8, polygenic risk scores)9, thus enabling the reuse of existing data to explore new questions.
The NHGRI-EBI GWAS Catalog10 is a publicly available and manually curated resource of human GWAS, which not only provides the most significant results and metadata of published GWAS but also offers structured and harmonised GWAS summary statistics associated with each study when available. However, there is still no agreement on GWAS summary statistic format, although efforts to develop one are being made11 or sharing policy, and recent work shows that most authors do not share their GWAS data12.
Lack of data sharing is a common phenomenon across fields, and factors influencing data sharing have been investigated elsewhere (eg.13,14). Within GWAS, one particular challenge is participant privacy since individual-level genetic data is theoretically identifiable15,16, and some possibility of identifiability exists even in summary statistics17, although either would require someone to hold the genetic data on an individual already to identify them within a published study. Despite these concerns, in 2018, after considering all the risks and benefits, NIH supported the open sharing of summary-level GWAS data (https://grants.nih.gov/grants/guide/notice-files/NOT-OD-19-023.html).
There is still no definitive answer to which incentives would act to increase data sharing18. We hypothesised that data sharing might benefit authors regarding citations upon data reuse. If this were so, it would provide an additional incentive, beyond good citizenship, for data sharing. We, therefore, used data from the GWAS Catalog10 to explore the current sharing landscape of human GWAS summary statistics and to analyse the relationship between sharing and potential citations.
Results
We collected sharing and citation information from 5756 studies with results published in the GWAS Catalog (Supplementary Data 1)10. Roughly one in ten (604, 10.5%) had summary statistics available for download. The proportion of summary statistics-sharing studies has increased over the years, especially since 2015, but even in 2021, only 121 out of 578 studies (~21%) shared their summary statistics. (Fig. 1). Although we considered the GWAS Catalog as the prime source of GWAS summary statistics, some datasets might be available elsewhere (e.g. authors’ or consortium’s websites or alternative repositories), making studies be mislabeled as non-sharers. To verify that our measure of sharing—whether the summary statistics were available in the GWAS Catalog—was valid, we manually inspected a random sample of 353 manuscripts (out of 629) from two journals with high levels of GWAS publications, PLoS Genetics and Nature Genetics, and for which GWAS Catalog did not hold summary statistics. We found that 324 (91.7%) did not provide full summary statistics or data was controlled-access, 5 (1.4%) claimed to provide access, but links were either broken or contained no data, and only 24 (6.8%) linked to full summary statistics in non-GWAS catalog websites (Supplementary Data 2).
Fig. 1. GWAS summary statistics sharing patterns by year (2007–2021).
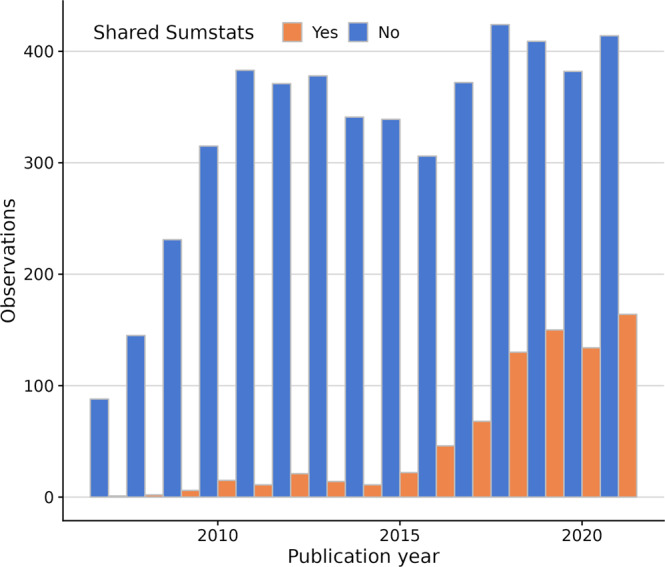
Despite increased sharing from 2015 onwards, most GWAS studies do not share their summary statistics.
Most mislabeled articles (ie. classified as non-sharers in GWAS Catalog but sharing data elsewhere) in our sample appeared after 2017, indicating that sharing elsewhere also increased over time. We next downloaded the full text of 3317/5152 non-sharer articles in our dataset that were available from PubMed central and developed a custom search strategy to identify articles sharing data outside GWAS Catalog (see Methods). We found 217 additional sharers, raising the total proportion of data-sharing articles to 14.26% (Fig. 1, Supplementary Data 3).
Satisfied that this was a valid measure, we used logistic regression to study which factors influence sharing. According to the Bayesian Information Criterion (BIC), the optimal model included the year of publication and log-journal impact factor. Both year (OR = 1.4911 [1.4373–1.5469]) and journal impact factor (log(SJR) OR = 2.6896[2.4118–2.9993]) have positive effects on sharing, suggesting that sharing has increased over time, and tends to be more frequent in journals with higher reported impact factors (Supplementary Data 4).
We decided to investigate the impact of sharing on a paper’s citations using the relative citation ratio (RCR), which compares the number of citations an article has to the average citation rates of the journals in its co-citation network19. In the early years of GWAS, such articles appeared to outperform their co-citation network before a gradual decrease in the median score (towards RCR = 1), except for the most recent complete year, 2021. This bump may reflect incomplete data or a sudden behaviour change (Fig. 2a). As a broad pattern, studies that shared their summary statistics in the GWAS Catalog had consistently higher RCR over the years than their non-sharing counterparts (Fig. 2b). Again, the data from 2021 appeared anomalous, with sharing papers showing only a weak advantage over non-sharing papers.
Fig. 2. Citation patterns over time (2006–2021), measured in log relative citation ratio.

a All GWAS. b Split by summary statistics sharing status. Sharing studies are consistently more cited than non-sharing studies. Lower and upper box hinges represent the 25th and 75th percentiles, respectively. The whiskers extend for 1.5 * IQR from each hinge, and the horizontal line within the boxes represents the median.
To try and understand the 2021 data, which had the shortest follow-up time by definition, we analysed the citation patterns of sharing and non-sharing studies over time by year of publication (Fig. 3). On average, GWAS citations rise quickly and stabilise around 2 years after publication. Then citations either stay stable or slowly decrease throughout the following years. However, summary statistics-sharing GWAS citation counts grow faster (Fig. 3a) and sustain higher mean citation counts, regardless of the year of publication (Fig. 3b). Given the citation advantage of sharing papers to non-sharing takes two or more years to accumulate, we decided to exclude the anomalous data points from 2021 because there had not been sufficient time for them to stabilise.
Fig. 3. Mean citation count evolution after publication, by year of publication (2010–2018).

Sharing studies get more citations from early on, then stabilising circa 2 years after publication. a Mean citation count ratio (shared/unshared). b Sharing (orange) and non-sharing (blue) mean citation count. Text in squares indicates the number of studies in each category.
To analyse the effect of sharing on citations, we first built an optimal linear model of log(RCR) using all considered covariates (ie. year of publication, SJR, publication in one of the top 20 GWAS journals by number of publications, and NLM score) except sharing status according to the BIC. The selected model included the year of publication, log-journal impact factor, and the National Library of Medicine’s (NLM) “molecular/cellular” score. The molecular/cellular score represents the proportion of molecular/cellular MeSH terms in the articles’ text, used to predict the translation potential of the research20. By adding a binary variable describing sharing practice, we concluded that sharing summary statistics has a positive effect on the RCR, providing ~81.8% more citations on average than non-sharing articles (RCR ratio = 1.8177 [1.6798–1.967], P < 2e-16, Supplementary Data 5).
We recognised that our custom search was likely to be imperfect, not least because only 70% of papers had full text available. We estimated the same quantity using GWAS Catalog inferred sharing status, and found the estimated effect of sharing to be very similar (RCR ratio = 1.8438 [1.6858–2.0166]), providing reassurance that our result is robust to remaining mislabelling.
Discussion
Data sharing in the life sciences remains a controversial topic. We showed that overall summary statistics sharing rates are low, although we see a remarkable increase in the past 5 years. Many factors not included in this work but analysed elsewhere21, such as changes in scientific culture towards sharing, growing incentives from public and private funders, and varying privacy regulations across countries, along with technical difficulties, may influence sharing of GWAS summary statistics and other datasets. This may be further complicated by the multifactorial nature of data in many cases, the lack of clear definitions of what constitutes shared data, and the challenge of verifying the completeness of any dataset. Funders like Wellcome Trust, the NIH, the MRC and the ERC have mandated open-access publishing for articles, but strong mandates on data sharing are still generally lacking, and existing journal policies on data are not consistently enforced22. Thus, while data sharing remains reliant on the goodwill and diligence of researchers, both the inertia to changing practice and the effort required may outweigh the limited incentives, leaving data unshared.
Citations are imperfect yet crucial metrics for evaluating research impact, which affects hiring decisions and career prospects. We hypothesised that sharing GWAS summary statistics may positively affect citations by allowing other scientists to conduct research using shared data and, in turn, cite the original research. Indeed, we observed a consistent pattern of increased citation rates over time, and by using linear models, we estimated that sharing increased citation rates by 81.8% on average, an estimate slightly higher than the 68% increase in citations found in a study of microarray data sharing >15 years ago23, and much higher than the 25% increase predicted in papers linking to more general biological data repositories24.
Our analysis of 353 GWAS papers that did not use the GWAS Catalog revealed that most studies did not share data at all or shared either restricted access and/or incomplete data (e.g. only top significant hits), which hampers reuse. Only 24 articles shared full summary statistics without controlled access or request requirements using alternative repositories, and five provided links that did not work anymore. An additional, broader analysis including all 3317 non-sharing papers for which full text was available provided 217 mislabeled sharers, although the estimated effect of sharing was similar to that using GWAS Catalog sharing only. These results highlight that the GWAS Catalog has become the de facto standard for unrestricted summary statistic sharing as well as a reliable, future-proof data storage platform. Therefore, we encourage authors to use standard repositories like GWAS Catalog whenever possible.
Finally, the field of GWAS has been focused on studies of white European subjects conducted by authors based in North American or European institutions, reflecting both early concerns of ancestry or admixture confounding and concentration of scientific funding in these regions25–27. This has led to a well-documented understudy of diverse populations (see https://gwasdiversitymonitor.com/ for a visual approach to the issue), and the data that is now accruing demonstrates the value of studying the whole human population to have better coverage of all human variation as well as to enable equitable benefits as GWAS findings begin to have clinical impacts28. The data we use reflect this history, and thus cannot be considered to reflect the impact of data sharing on citations of studies of under-represented populations, although we do expect the direction of the effect would also be positive.
Whilst our work shows that there can be a direct benefit to the authors for sharing data, further work is needed to properly understand the other barriers to sharing, and to allow that these barriers may be different in studies of under-represented populations, to more fully support wider sharing of GWAS data for the benefit of all.
While appreciating the issue’s complexity, we support the implementation of more data-sharing mandates and recognition-based incentives, such as alternative metrics to promote data-sharing work, independent of journal of publication, as well as the inclusion of data generation and stewardship on researchers’ CVs29,30. We also agree with other authors that the nature of increasingly large and more complex datasets will require improved training on data stewardship13.
We consider that the strongest incentive for scientists to share data is good citizenship because data sharing increases the ability of all of us to make discoveries through meta-analysis or integrative studies, thus accelerating scientific knowledge. However, and despite the observed recent trend changes, that incentive alone is clearly insufficient because papers sharing data remain a minority. We hope the robust evidence here that data sharing can increase citations independent of the journal of publication will provide further incentives and that we will see sharing of summary statistics continue to increase in the coming years.
Methods
Analyses
The GWAS Catalog10 is an established and high-quality repository of curated human GWAS results, providing easy access to summary statistics made public by authors (via curator inclusion or author submission). Its large coverage (400,000+ associations from 5690 publications as of May 2022) and its easy-to-access statistics make it an ideal reference database for our analyses. Hence, we downloaded the full list of studies and available summary statistics in GWAS Catalog on 26th May 2022.
We fetched citation information for each study from NIH’s database using iCiteR v0.2.131, a wrapper for NIH’s iCite API32. To quantify citations, here we focused on relative citation ratio (RCR), an improved metric to quantify the influence of a research article by using co-citation networks to field-normalise the number of citations19. We also used iCiteR to retrieve the number of citations each study received each year.
Despite not being an appropriate indicator for the individual quality of a given paper, journal impact factor can affect citations via journal visibility and prestige. We retrieved 2021 SJR (SCimago Journal Rank) scores to assess overall journal prestige33,34. There were 723 journals in our dataset, from which 691 had SJR data available for at least 1 year. Those 27 without SJR data were either too new to have scores (eg. Nature Aging, EISSN: 2662-8465) or changed names (eg. BMC Genomic Data, ISSN: 2730-6844, previously known as BMC Genetics), or contained 2022 articles only (eg. PLoS Biology, ISSN:1545-7885), for which we did not collect SJR data. We additionally considered factors for the 20 journals with the most published GWAS to allow for additional variation between journals, pooling the rest as a reference category. The top 20 journals are Am J Hum Genet, Am J Med Genet B Neuropsychiatr Genet, Ann Rheum Dis, BMC Med Genet, Circ Cardiovasc Genet, Diabetes, Eur J Hum Genet, Front Genet, Hum Genet, Hum Mol Genet, J Allergy Clin Immunol, J Hum Genet, Mol Psychiatry, Nat Commun, Nat Genet, Nature, PLoS Genet, PLoS One, Sci Rep, and Transl Psychiatry (Supplementary Data 6).
We used the glm function in R 4.1.235 to fit (1) a set of logistic models to explore the effects of time, journal of publication and other available factors on sharing, and (2) a set of linear models to explore the effect of sharing and other available factors on RCR. We chose to include all datasets published between 2007 and 2021 only, with 2007 being the first year with a shared summary statistics dataset and 2021 the last complete calendar year.
iCite tool uses Medical Subject Headings (MeSH) terms in articles’ text to predict the potential for translation of research20. The tool provides scores that represent the proportion of terms that can be classified within three overarching branches of the MeSH ontology: Human, Animal, and Molecular/Cellular.
For each set of models, we sequentially added and removed predictors, using the BIC to choose the optimal model. For (1), this procedure selected the logistic model:
| 1 |
where pSS stands for public summary statistics dataset available, encoded as [0, 1], year is the year of online publication [2007–2020], and lSJR is the logarithm of the SJR score, log(SJR).
For (2), we selected covariates excluding pSS which produced the baseline linear model
| 2 |
where molcel corresponds to the NLM molecular/cellular score, which showed to contribute to model fit, which we compared to
| 3 |
to quantify the effect of sharing on log(RCR). In this case, modelling year as a factor, rather than a continuous variable, improved model fit.
While we expect manually curated GWAS Catalog to contain most publicly available summary statistics datasets, authors can choose to share their data on a different platform (eg. their own or consortium’s website, Dryad, or GWAS archive), posing a potential bias in our analysis. To explore this scenario, we selected random 50% of studies labelled as non-sharers in two of the journals with most published GWAS (PLoS Genetics (100 studies) and Nature Genetics (253 studies)) and manually checked whether their summary statistics were listed in the manuscript as freely available elsewhere and whether the statistics still resided at any such URL. We noted that most mislabeled articles in our sample appeared after 2017. We broadened our analysis by checking for full-text availability on PubMed Central for 5152 non-sharer articles (Supplementary Data 3) and downloading the full text for 3317 where it was available. We developed a custom search strategy to identify sharing articles, matching phrases such as “available for download”, “available at figshare” and more complex patterns. Where the text search suggested data was available via dbGaP, we confirmed that data was freely available (ie not via data access committee) by confirming the dbGaP identifier contained files in the “analyses” subdirectory according to index file https://ftp.ncbi.nlm.nih.gov/dbgap/studies/Ftp_Table_of_Contents.zip downloaded on 25 October 2022. Full code for performing this search is at https://github.com/chr1swallace/data-sharing-search.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Supplementary information
Description of Additional Supplementary Files
Acknowledgements
C.W. and G.R. are funded by the Wellcome Trust (WT220788). CW is funded by the Medical Research Council (MRC; MC UU 00002/4) and supported by the NIHR Cambridge BRC (BRC-1215-20014). The views expressed are those of the author(s) and not necessarily those of the NHS, the NIHR or the Department of Health and Social Care. The authors thank all GWAS researchers who proactively share their full summary statistics on GWAS Catalog or elsewhere. This research was funded in whole, or in part, by the Wellcome Trust WT220788. For the purpose of Open Access, the author has applied a CC BY public copyright licence to any Author Accepted Manuscript version arising from this submission.
Author contributions
C.W. and G.R. conceived the study. G.R. collected data. C.W. and G.R. performed the analyses and wrote and reviewed the manuscript.
Peer review
Peer review information
Communications Biology thanks Yoichiro Kamatani and Palwende Boua for their contribution to the peer review of this work. Primary Handling Editor: George Inglis.
Data availability
All source and generated data underlying figures in this study are available in two Zenodo repositories, one containing the main data analysis (10.5281/zenodo.7516613)36 and another containing the extended search for sharing outside GWAS Catalog (10.5281/zenodo.7516708)37. These repositories contain links and information about how the source data was obtained. GWAS Catalog accessions and PubMed Identifiers for all GWAS Catalog studies included in our analysis are available in Supplementary Data 1.
Code availability
All code used in this work is publicly available without restriction in two Zenodo repositories,, one containing the main data analysis (10.5281/zenodo.7516613)36 and another containing the extended search for sharing outside GWAS Catalog (10.5281/zenodo.7516708)37. These repositories contain the scripts and datasets used to generate all figures, results, and supplementary tables.
Competing interests
C.W. receives research funding from GSK and MSD and is a part-time employee of GSK. Neither company had any influence on this work or its publication. All other authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
The online version contains supplementary material available at 10.1038/s42003-023-04497-8.
References
- 1.Wilkinson MD, et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data. 2016;3:160018. doi: 10.1038/sdata.2016.18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Bonomi L, Huang Y, Ohno-Machado L. Privacy challenges and research opportunities for genomic data sharing. Nat. Genet. 2020;52:646–654. doi: 10.1038/s41588-020-0651-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Wellcome Trust. Sharing Data From Large-Scale Biological Research Projects: A System of Tripartite Responsibility.https://docplayer.net/14942178-Sharing-data-from-large-scale-biological-research-projects-a-system-of-tripartite-responsibility.html (2003).
- 4.Burt C, Munafò M. Has GWAS lost its status as a paragon of open science? PLoS Biol. 2021;19:e3001242. doi: 10.1371/journal.pbio.3001242. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Willer CJ, Li Y, Abecasis GR. METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics. 2010;26:2190–2191. doi: 10.1093/bioinformatics/btq340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Zhu Z, et al. Causal associations between risk factors and common diseases inferred from GWAS summary data. Nat. Commun. 2018;9:224. doi: 10.1038/s41467-017-02317-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Bulik-Sullivan BK, et al. LD Score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat. Genet. 2015;47:291–295. doi: 10.1038/ng.3211. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Wallace C. A more accurate method for colocalisation analysis allowing for multiple causal variants. PLoS Genet. 2021;17:e1009440. doi: 10.1371/journal.pgen.1009440. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Privé, F., Arbel, J. & Vilhjálmsson, B. J. LDpred2: better, faster, stronger. Bioinformatics10.1093/bioinformatics/btaa1029 (2020). [DOI] [PMC free article] [PubMed]
- 10.Buniello A, et al. The NHGRI-EBI GWAS Catalog of published genome-wide association studies, targeted arrays and summary statistics 2019. Nucleic Acids Res. 2019;47:D1005–D1012. doi: 10.1093/nar/gky1120. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Hayhurst, J. et al. A community driven GWAS summary statistics standard. biorXiv10.1101/2022.07.15.500230 (2022).
- 12.Thelwall M, et al. Is useful research data usually shared? An investigation of genome-wide association study summary statistics. PLoS One. 2020;15:e0229578. doi: 10.1371/journal.pone.0229578. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Fecher B, Friesike S, Hebing M. What drives academic data sharing? PLoS One. 2015;10:e0118053. doi: 10.1371/journal.pone.0118053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Sayogo DS, Pardo TA. Exploring the determinants of scientific data sharing: understanding the motivation to publish research data. Gov. Inf. Q. 2013;30:S19–S31. doi: 10.1016/j.giq.2012.06.011. [DOI] [Google Scholar]
- 15.Heeney C, Hawkins N, Vries J, de, Boddington P, Kaye J. Assessing the privacy risks of data sharing in genomics. Public Health Genom. 2011;14:17–25. doi: 10.1159/000294150. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Shabani, M. & Marelli, L. Re-identifiability of genomic data and the GDPR. EMBO Rep. 20, e48316 (2019). [DOI] [PMC free article] [PubMed]
- 17.Homer N, et al. Resolving individuals contributing trace amounts of DNA to highly complex mixtures using high-density SNP genotyping microarrays. PLoS Genet. 2008;4:e1000167. doi: 10.1371/journal.pgen.1000167. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Mongeon P, Robinson-Garcia N, Jeng W, Costas R. Incorporating data sharing to the reward system of science: linking DataCite records to authors in the Web of science. Aslib J. Inf. Manag. 2017;69:545–556. doi: 10.1108/AJIM-01-2017-0024. [DOI] [Google Scholar]
- 19.Hutchins BI, Yuan X, Anderson JM, Santangelo GM. Relative Citation Ratio (RCR): a new metric that uses citation rates to measure influence at the article level. PLoS Biol. 2016;14:e1002541. doi: 10.1371/journal.pbio.1002541. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hutchins BI, Davis MT, Meseroll RA, Santangelo GM. Predicting translational progress in biomedical research. PLoS Biol. 2019;17:e3000416. doi: 10.1371/journal.pbio.3000416. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.MacArthur JAL, et al. Workshop proceedings: GWAS summary statistics standards and sharing. Cell Genom. 2021;1:100004. doi: 10.1016/j.xgen.2021.100004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Christensen G, Dafoe A, Miguel E, Moore DA, Rose AK. A study of the impact of data sharing on article citations using journal policies as a natural experiment. PLoS One. 2019;14:e0225883. doi: 10.1371/journal.pone.0225883. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Piwowar HA, Day RS, Fridsma DB. Sharing detailed research data is associated with increased citation rate. PLoS One. 2007;2:e308. doi: 10.1371/journal.pone.0000308. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Colavizza G, Hrynaszkiewicz I, Staden I, Whitaker K, McGillivray B. The citation advantage of linking publications to research data. PLoS One. 2020;15:e0230416. doi: 10.1371/journal.pone.0230416. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Martin AR, et al. Clinical use of current polygenic risk scores may exacerbate health disparities. Nat. Genet. 2019;51:584–591. doi: 10.1038/s41588-019-0379-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Popejoy AB, Fullerton SM. Genomics is failing on diversity. Nature. 2016;538:161–164. doi: 10.1038/538161a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Petrovski S, Goldstein DB. Unequal representation of genetic variation across ancestry groups creates healthcare inequality in the application of precision medicine. Genome Biol. 2016;17:157. doi: 10.1186/s13059-016-1016-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Fatumo S, et al. A roadmap to increase diversity in genomic studies. Nat. Med. 2022;28:243–250. doi: 10.1038/s41591-021-01672-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Kidwell MC, et al. Badges to acknowledge open practices: a simple, low-cost, effective method for increasing transparency. PLoS Biol. 2016;14:e1002456. doi: 10.1371/journal.pbio.1002456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Piwowar H. Value all research products. Nature. 2013;493:159–159. doi: 10.1038/493159a. [DOI] [PubMed] [Google Scholar]
- 31.Riddle, T. iCiteR: A Minimal Wrapper Around NIH’s ‘iCite’ API (API, 2019).
- 32.ICite, Hutchins, B. Ian & Santangelo, G. iCite Database Snapshots (NIH Open Citation Collection). 10.35092/YHJC.C.4586573 (2022).
- 33.Guerrero-Bote VP, Moya-Anegón F. A further step forward in measuring journals’ scientific prestige: The SJR2 indicator. J. Informetr. 2012;6:674–688. doi: 10.1016/j.joi.2012.07.001. [DOI] [Google Scholar]
- 34.Scimago Lab. Scimago Journal & Country Rankhttps://www.scimagojr.com/ (2022).
- 35.R Core Team. R: A Language and Environment for Statistical Computing (R Core Team, 2021).
- 36.Reales, G & Wallace, C. Sharing GWAS summary statistics results in more citations. Zenodo10.5281/ZENODO.7516613 (2023). [DOI] [PMC free article] [PubMed]
- 37.Reales, G & Wallace, C. Sharing GWAS summary statistics results in more citations—extended search code. Zenodo10.5281/ZENODO.7516708 (2023). [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Description of Additional Supplementary Files
Data Availability Statement
All source and generated data underlying figures in this study are available in two Zenodo repositories, one containing the main data analysis (10.5281/zenodo.7516613)36 and another containing the extended search for sharing outside GWAS Catalog (10.5281/zenodo.7516708)37. These repositories contain links and information about how the source data was obtained. GWAS Catalog accessions and PubMed Identifiers for all GWAS Catalog studies included in our analysis are available in Supplementary Data 1.
All code used in this work is publicly available without restriction in two Zenodo repositories,, one containing the main data analysis (10.5281/zenodo.7516613)36 and another containing the extended search for sharing outside GWAS Catalog (10.5281/zenodo.7516708)37. These repositories contain the scripts and datasets used to generate all figures, results, and supplementary tables.