

Abstract
Automated liver segmentation from radiology scans (CT, MRI) can improve surgery and therapy planning and follow-up assessment in addition to conventional use for diagnosis and prognosis. Although convolutional neural networks (CNNs) have became the standard image segmentation tasks, more recently this has started to change towards Transformers based architectures because Transformers are taking advantage of capturing long range dependence modeling capability in signals, so called attention mechanism. In this study, we propose a new segmentation approach using a hybrid approach combining the Transformer(s) with the Generative Adversarial Network (GAN) approach. The premise behind this choice is that the self-attention mechanism of the Transformers allows the network to aggregate the high dimensional feature and provide global information modeling. This mechanism provides better segmentation performance compared with traditional methods. Furthermore, we encode this generator into the GAN based architecture so that the discriminator network in the GAN can classify the credibility of the generated segmentation masks compared with the real masks coming from human (expert) annotations. This allows us to extract the high dimensional topology information in the mask for biomedical image segmentation and provide more reliable segmentation results. Our model achieved a high dice coefficient of 0.9433, recall of 0.9515, and precision of 0.9376 and outperformed other Transformer based approaches. The implementation details of the proposed architecture can be found at https://github.com/UgurDemir/tranformer_liver_segmentation.
Keywords: Liver segmentation, Transformer, Generative adversarial network
1. Introduction
Liver cancer is among the leading causes of cancer-related deaths, accounting for 8.3% of cancer mortality [14]. The high variability in shape, size, appearance, and local orientations makes liver (and liver diseases such as tumors, fibrosis) challenging to analyze from radiology scans for which the image segmentation is often necessary [3]. An accurate organ and lesion segmentation could facilitate reliable diagnosis and therapy planning including prognosis [5].
As a solution to biomedical image segmentation, the literature is vast and rich. The self-attention mechanism is nowadays widely used in the biomedical image segmentation field where long-range dependencies and context dependent features are essential. By capturing such information, transformer based segmentation architectures (for example, SwinUNet [2]) have achieved promising performance on many vision tasks including biomedical image segmentation [7, 15].
In parallel to the all advances in Transformers, generative methods have achieved remarkable progresses in almost all fields of computer vision too [4]. For example, Generative Adversarial Networks (GAN) [6] is a widely used tool for generating one target image from one source image. GAN has been applied to the image segmentation framework to distinguish the credibility of the generated masks like previous studies [11, 9]. The high dimensional topology information is an important feature for pixel levell classification, thus segmentation. For example, the segmented mask should recognize the object location, orientation, and scale prior to delineation procedure, but most current segmentation engines are likely to provide false positives outside the target region or conversely false negatives within the target region due to an inappropriate recognition of the target regions. By introducing the discriminator architecture (as a part of GAN) to distinguish whether the segmentation mask is high quality or not, we could proactively screen poor predictions from the segmentation model. Furthermore, this strategy can also allow us to take advantage of many unpaired segmentation masks which can be easily acquired or even simulated in the segmentation targets. To this end, in this paper, we propose a Transformer based GAN architecture as well as a Transformer based CycleGAN architecture for automatic liver segmentation, a very improtant clinical precursor for liver diseases. By combining two strong algorithms, we aim to achieve both good recognition (localization) of the target region and high quality delineations.
2. Proposed method
We first investigated the transformer architecture to solve the liver segmentation problem from radiology scans, CT in particular due to its widespread use and being the first choice in most liver disease quantification. The self-attention mechanism of the Transformers has been demonstrated to be very effective approach when finding long range dependencies as stated before. This can be quite beneficial for the liver segmentation problem especially because the object of interest (liver) is large and pixels constituting the same object are far from each other. We also utilized an adversarial training approach to boost the segmentation model performance. For this, we have devised a conditional image generator in a vanilla-GAN that learns a mapping between the CT slices and the segmentation maps (i.e., surrogate of the truths or reference standard). The adversarial training forces the generator model to predict more realistic segmentation outcomes. In addition to vanilla-GAN, we have also utilized the CycleGAN [17], [13] approach to investigate the effect of cycle consistency constraint on the segmentation task. Figure 1 demonstrates the general overview of the proposed method.
Fig. 1:
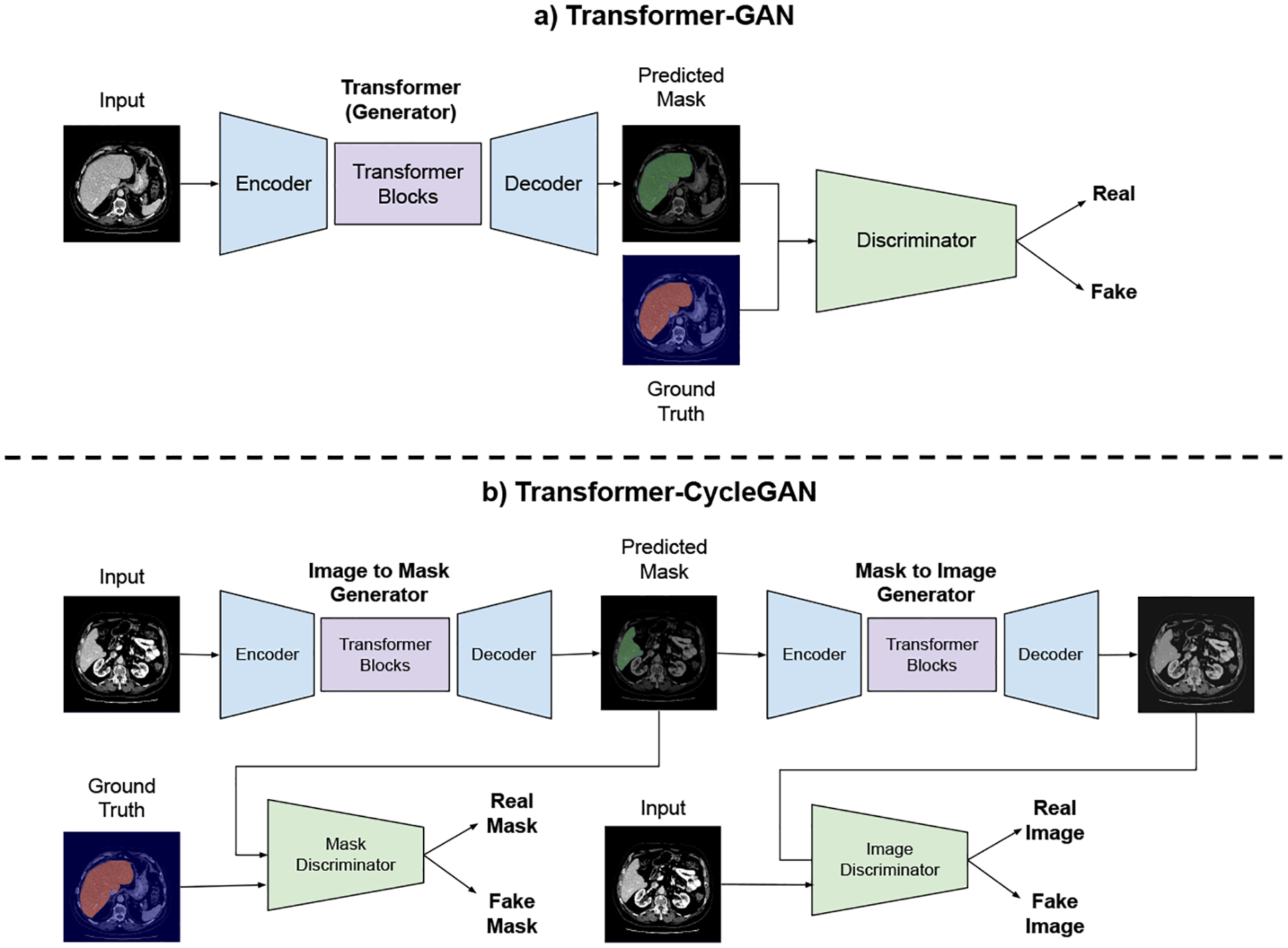
Block diagram of the Transformer GAN. (a) Vanilla GAN and (b) Cycle-GAN with Transformer generator architectures.
2.1. Transformer based GAN
Like other GAN architectures [10], Transformer based GAN architecture is composed of two related sub-architectures: the generator and the discriminator. The generator part could generate the segmentation mask from the raw image (i.e., segmentation task itself), while the discriminator tries to distinguish predictions from the human annotated ground truth. GAN provides a better way to distinguish the high-dimensional morphology information. The discriminator can provide the similarity between the predicted masks and the ground truth (i.e., surrogate truth) masks. Vanilla GAN considers the whole segmentation to decide whether it is fake or not.
2.2. Transformer based CycleGAN
One alternative extension to the standard GAN approach is to use transformer based segmentation model within the CycleGAN setup. Unlike a standard GAN, CycleGAN consists of two generators and two discriminator networks. While the first generator accepts the raw images as input and predicts the segmentation masks, the second generator takes the predicted segmentation maps as input and maps them back to the input image. The first discriminator classifies the segmentation masks as either real or fake, and the second discriminator distinguishes the real and the reconstructed image. Figure 1 illustrates this procedure with liver segmentation from CT scans.
To embed transformers within the CycleGAN, we utilized the encoder-decoder style convolutional transformer model [13]. The premise behind this idea was that the encoder module takes the input image and decreases the spatial dimensions while extracting features with convolution layers. This allowed processing of large-scale images. The core transformer module consisted of several stacked linear layers and self-attention blocks. The decoder part increased the spatial dimension of the intermediate features and makes the final prediction. For the discriminator network, we tried three convolutional architectures. The vanilla-GAN discriminator evaluates the input image as a whole. Alternatively, we have adopted PatchGAN discriminator architecture [8] to focus on small mask patches to decide the realness of each region. It splits the input masks into NxN regions and asses their quality individually. When we set the patch size to a pixel, PatchGAN can be considered as pixel level discriminator. W have observed that the pixel level discriminator tends to surpass other architecture for segmentation. Figure 1 demonstrates the network overview. In all of the experiments, the segmentation model uses the same convolutional transformer and pixel level discriminator architectures.
3. Experimental setup
We have used Liver Tumor Segmentation Challenge (LiTS)[1] dataset. LiTS consists of 131 CT scans. This dataset is publicly available under segmentation challenge website and approved IRB by the challenge organizers. More information about the dataset and challenge can be found here1.
All our models were trained on NVIDIA RTX A6000 GPU after implemented using the PyTorch [12] framework. We have used 95 samples for training and 36 samples for testing. All models are trained on the same hyperparameters configuration with a learning rate of 2e−4, and Adam optimizer with beta1 being 0.5 and beta2 being 0.999. All of the discriminators use the pixel level discriminator in both GAN and CycleGAN experiments. We have used recall, precision, and dice coefficient for quantitative evaluations of the segmentation. Further, segmentation results were qualitatively evaluated by the participating physicians. Our algorithms are available for public use.
4. Results
We presented the evaluation results in Table 1. Our best performing method was Transformer based GAN architecture, achieved a highest dice coefficient of 0.9433 and recall rate of 0.9515. Similarly, our transformer based CycleGAN architecture has the highest precision, 0.9539. With Transformer based GAN, we achieved 0.9% improvement in recall and 0.01% improvement in dice coefficient with respect to the vanilla Transformers. It is to be noted that we have used also post-processing technique which boosts the performance for ”all” the baselines to avoid biases one from each other.
Table 1:
Performance of Transformer based methods on the LITS dataset. [1]
Figure 2 shows our qualitative results for the liver segmentation. We have examined all the liver segmentation results one-by-one and no failure were identified by the participating physicians. Hence, visual results agreed with the quantitative results as described in Table 1.
Fig. 2:
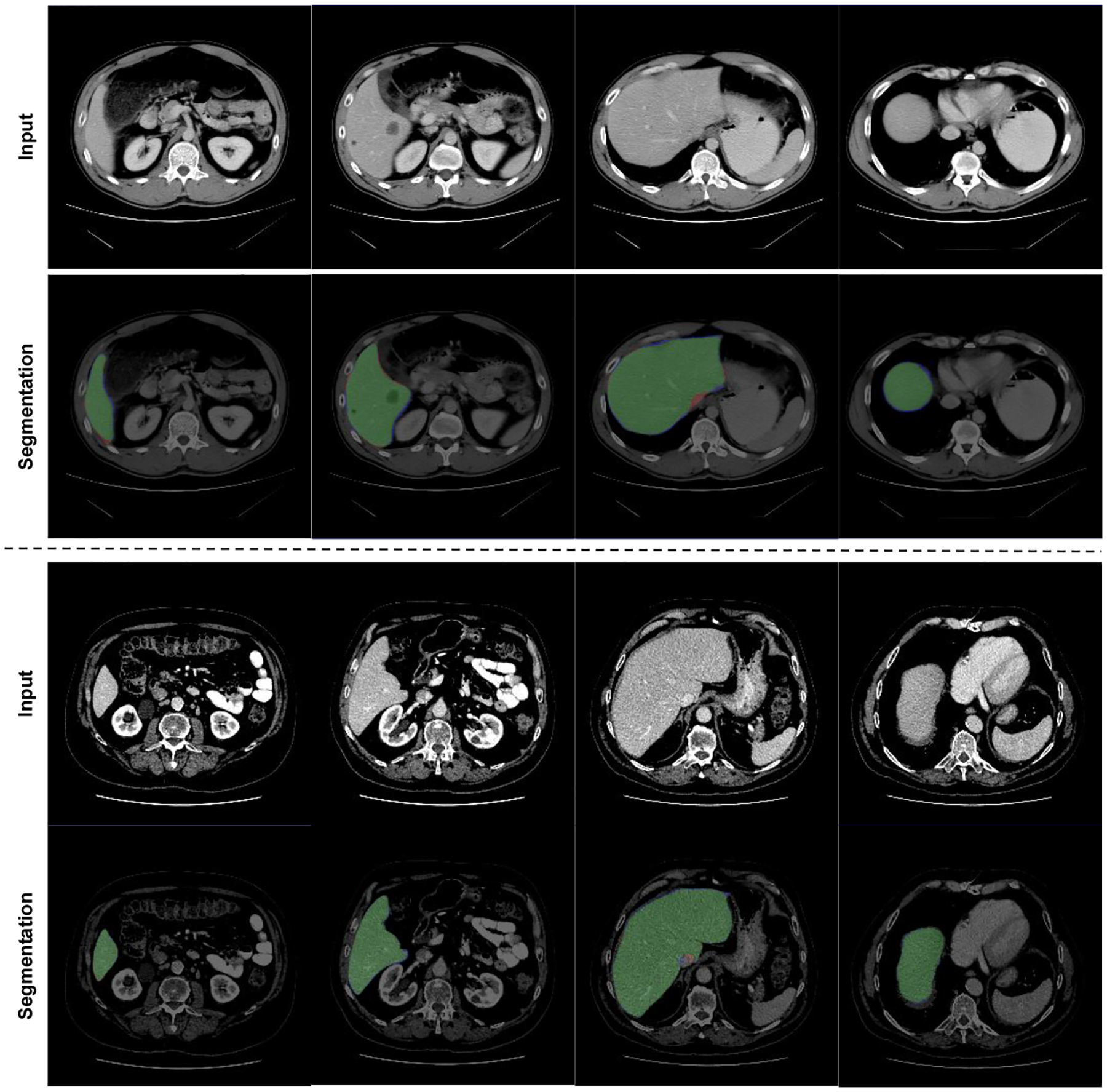
Transformer based GAN liver segmentation results. Green: True positive, Red: False Positive, Blue: False Negative.
5. Conclusion
In this study, we explored the use of transformer-based GAN architectures for medical image segmentation. Specifically, we used a self-attention mechanism and designed a discriminator for classifying the credibility of generated segmentation masks. Our experimental result showed that the proposed new segmentation architectures could provide accurate and reliable segmentation performance as compared to the baseline Transfomers. Although we have shown our results in an important clinical problem for liver diseases where image-based quantification is vital, the proposed hybrid architecture (i.e., combination of GAN and Transformers) can potentially be applied to various medical image segmentation tasks beyond liver CTs as the algorithms are generic, reproducible, and carries similarities with the other segmentation tasks in biomedical imaging field. We anticipate that our architecture can also be applied to medical scans within the semi-supervised learning, planned as a future work.
Acknowledgement
This study is partially supported by NIH NCI grants R01-CA246704 and R01-R01-CA240639.
Footnotes
References
- 1.Bilic P, Christ PF, Vorontsov E, Chlebus G, Chen H, Dou Q, Fu CW, Han X, Heng PA, Hesser J, et al. : The liver tumor segmentation benchmark (lits). arXiv preprint arXiv:1901.04056 (2019) [Google Scholar]
- 2.Cao H, Wang Y, Chen J, Jiang D, Zhang X, Tian Q, Wang M: Swinunet: Unet-like pure transformer for medical image segmentation. arXiv preprint arXiv:2105.05537 (2021) [Google Scholar]
- 3.Chlebus G, Schenk A, Moltz JH, van Ginneken B, Hahn HK, Meine H: Automatic liver tumor segmentation in ct with fully convolutional neural networks and object-based postprocessing. Scientific reports 8(1), 1–7 (2018) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Chuquicusma MJ, Hussein S, Burt J, Bagci U: How to fool radiologists with generative adversarial networks? a visual turing test for lung cancer diagnosis. In: 2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018). pp. 240–244. IEEE (2018) [Google Scholar]
- 5.Cornelis F, Martin M, Saut O, Buy X, Kind M, Palussiere J, Colin T: Precision of manual two-dimensional segmentations of lung and liver metastases and its impact on tumour response assessment using recist 1.1. European radiology experimental 1(1), 1–7 (2017) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y: Generative adversarial nets. Advances in neural information processing systems 27 (2014) [Google Scholar]
- 7.Huang X, Deng Z, Li D, Yuan X: Missformer: An effective medical image segmentation transformer. arXiv preprint arXiv:2109.07162 (2021) [DOI] [PubMed] [Google Scholar]
- 8.Isola P, Zhu JY, Zhou T, Efros AA: Image-to-image translation with conditional adversarial networks. CVPR (2017) [Google Scholar]
- 9.Khosravan N, Mortazi A, Wallace M, Bagci U: PAN: Projective Adversarial Network for Medical Image Segmentation. In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2019 – 22nd International Conference, Proceedings (2019) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Liu Y, Khosravan N, Liu Y, Stember J, Shoag J, Bagci U, Jambawalikar S: Cross-modality knowledge transfer for prostate segmentation from ct scans. In: Domain adaptation and representation transfer and medical image learning with less labels and imperfect data, pp. 63–71. Springer; (2019) [Google Scholar]
- 11.Luc P, Couprie C, Chintala S, Verbeek J: Semantic Segmentation using Adversarial Networks. In: NIPS Workshop on Adversarial Training. Barcelona, Spain: (Dec 2016), https://hal.inria.fr/hal-01398049 [Google Scholar]
- 12.Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, Antiga L, et al. : Pytorch: An imperative style, highperformance deep learning library. Advances in neural information processing systems 32 (2019) [Google Scholar]
- 13.Ristea NC, Miron AI, Savencu O, Georgescu MI, Verga N, Khan FS, Ionescu RT: Cytran: Cycle-consistent transformers for non-contrast to contrast ct translation. arXiv preprint arXiv:2110.06400 (2021) [Google Scholar]
- 14.Sung H, Ferlay J, Siegel RL, Laversanne M, Soerjomataram I, Jemal A, Bray F: Global cancer statistics 2020: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: a cancer journal for clinicians 71(3), 209–249 (2021) [DOI] [PubMed] [Google Scholar]
- 15.Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I: Attention is all you need. Advances in neural information processing systems 30 (2017) [Google Scholar]
- 16.Wu H, Xiao B, Codella N, Liu M, Dai X, Yuan L, Zhang L: Cvt: Introducing convolutions to vision transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22–31 (October 2021) [Google Scholar]
- 17.Zhu JY, Park T, Isola P, Efros AA: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE international conference on computer vision. pp. 2223–2232 (2017) [Google Scholar]