

Abstract
Detrended Fluctuation Analysis (DFA) is the most popular fractal analytical technique used to evaluate the strength of long-range correlations in empirical time series in terms of the Hurst exponent, H. Specifically, DFA quantifies the linear regression slope in log-log coordinates representing the relationship between the time series’ variability and the number of timescales over which this variability is computed. We compared the performance of two methods of fractal analysis—the current gold standard, DFA, and a Bayesian method that is not currently well-known in behavioral sciences: the Hurst-Kolmogorov (HK) method—in estimating the Hurst exponent of synthetic and empirical time series. Simulations demonstrate that the HK method consistently outperforms DFA in three important ways. The HK method: (i) accurately assesses long-range correlations when the measurement time series is short, (ii) shows minimal dispersion about the central tendency, and (iii) yields a point estimate that does not depend on the length of the measurement time series or its underlying Hurst exponent. Comparing the two methods using empirical time series from multiple settings further supports these findings. We conclude that applying DFA to synthetic time series and empirical time series during brief trials is unreliable and encourage the systematic application of the HK method to assess the Hurst exponent of empirical time series in behavioral sciences.
Keywords: detrended fluctuation analysis, fractal fluctuations, fractional, human movement, long-range correlation, physiology, variability
1. Introduction
Behavior in humans is fluid. Repetitions of gross movements, such as walking, and fine movements, such as tapping a finger, vary from one cycle to the next. Even the most basic behavioral measurement—the reaction time—ebbs and flows around a typical value, the arithmetic Mean. The standard deviation, SD, measures the average distance of each point from that Mean and carries the assumption that deviations from the Mean are errors surrounding an intended stride or a tapping response. Decades of research refute this assumption in the serial measurement of human behavior. The “variability is error” assumption means that behavioral measurements should be independent of one observation to the next. However, an inspection of temporal sequences of measurements reveals that behaviors correlate with one another over time. Long steps tend to follow long steps; fast responses tend to follow fast responses. The closer in time, the closer the resemblance. Conversely, correlation decays with greater separation in time. The quantification of these long-range relationships is, therefore, of critical importance in behavioral sciences. However, long-range correlations are not amenable to measurement by descriptive statistics such as SD, coefficient of variation (CoV), and root mean square (RMS).
A robust approach to assessing how long-range correlations between measurements decline over longer time intervals is to use the Hurst exponent, H [1]. The Hurst exponent, H, was named by Mandelbrot [2] in honor of pioneering work by Edwin Hurst in the field of hydrology, the “fractal” flood characteristics of the Nile River delta [1]. According to Mandelbrot, H measures the presence of long-run statistical persistence in a time series, as well as its intensity [2, 3]. H describes how the measurements’ SD-like variations grow across progressively longer timescales, indicating the rate at which correlation among sequential measurements decay across subsequent separations in time (Fig. 1). More precisely, the Hurst exponent describes a single fractal-scaling estimate of power-law decay in the autocorrelation ρ for lag k as ρk = |k + 1|2H − 2|k|2H + |k − 1|2H, for which H reveals the presence and degree of persistent correlations (0.5 < H < 1.0, wherein large values are typically followed by large values and vice versa) or anti-persistent correlations (0 < H < 0.5), wherein small values typically follow large values and vice versa. An empirical time series with H → 0.5 implies a random process where subsequent observations are uncorrelated.
Fig. 1. Schematic portrayal of the measure of fractality, H, yielded by the DFA.

H relates how the SD-like variation grows across many timescales, statistically encoding how the correlation among sequential measurements might decay slowly across longer separations in time. We use detrending of these variations over progressively longer timescales to remove the mean drift across each of these timescales.
Detrended fluctuation analysis (DFA) is the most used technique to uncover long-range correlations in diverse research fields, such as material science [4], meteorology [5–7], economics [8–12], ethology [13, 14], bioinformatics [15–17], and physiology [18–21]. The Hurst exponent estimated using DFA has also proved to be extremely powerful in its capacity to uncover system dynamics, such as feedforward and forward processes in postural control [22–24], system-wide coordination in motor control [25, 26], cognition [27–31], and perception-action [32–34]. The Hurst exponent estimated using DFA also helps identify different states of the same system according to its different scaling behaviors, for instance, the H values for heart interbeat intervals between healthy individuals and those with disease [35–37]. Likewise, the H values for stride intervals during walking are different for healthy adults and individuals with movement deficits due to aging and pathology [38–43]. The Hurst exponent, typically estimated using DFA, also serves as a critical benchmark for developing interventions [44–46] and quantifying their effects [47–49]. In short, DFA has become central to quantifying the Hurst exponent across diverse research fields, including behavioral sciences.
The most significant advantage of DFA over other methods of assessing the strength of long-range correlations in empirical time series is that it is suitable for nonstationary time series, thereby preventing erroneous detection of long-range correlations that are a side effect of non-stationarity. However, the Hurst exponent yielded by the DFA becomes unstable because of the nonlinear filtering characteristics associated with detrending [50]. Therefore, DFA has been modified by introducing different detrending techniques, such as the centered moving average (CMA) method [51], detrended moving average (DMA) method [52], the modified detrended fluctuation analysis (MDFA) [53], and orthogonal detrended fluctuation analysis [54]. Different detrending methods show various advantages and limitations, depending on the presence of long-range trends [55, 56]. For instance, CMA is slightly superior to the original DFA algorithm in terms of straighter fluctuation curves [57], and DFA based on empirical mode decomposition (EMD) is superior to the traditional DFA when the time series is strongly anticorrelated [58]. DMA method is superior to the traditional DFA for time series with 0.2 < H < 0.8, while traditional DFA performs better when H > 0.8 [59]. Numerical analysis shows the traditional DFA still confers several advantages, mainly when the data trend’s functional form is not known a priori [60, 61].
Nonetheless, DFA has several shortcomings beyond the detrending procedure. For instance, numerous authors have pointed out that DFA does not accurately assess long-range correlations when the empirical time series is short [62–64], producing a positive bias in its central tendency in addition to a large dispersion [65–70]. Often an empirical time series with more than 500 samples is required to use DFA with reasonable accuracy. This requirement is a significant limitation, especially when it is impractical to collect a long measurement time series due to time constraints and financial or clinical reasons [67]. In addition, many cognitive and psychological phenomena are fleeting and ephemeral such as moments of insight [71, 72]. As it stands, the outcome yielded by many other methods of assessing the strength of long-range correlations in measurement time series is precariously sensitive to the length of the measurement time series. However, DFA generally performs best [66, 73]. Therefore, there is an urgent need in behavioral sciences for an analytical method that: (i) accurately assesses long-range correlations when the measurement time series is short, (ii) shows minimal dispersion about the central tendency, and (iii) yields a point estimate that does not depend on the length of the measurement time series or its underlying Hurst exponent. No such methods are currently widely used, thus limiting our ability to make strong inferences in those many limiting domains noted above.
In this paper, we present a simulation study comparing two methods of fractal analysis, the current gold standard, DFA [74, 75], and a Bayesian method that is not well-known in behavioral sciences—the Hurst-Kolmogorov (HK) methodology [76]. We use these simulation results to inform four empirical human behavioral time series analyses. Those studies capture a broad swath of common behavioral measurements—gait, sensorimotor synchronization, and reaction times—derived from tasks typically conceived as purely motor and those considered more purely cognitive. Using synthetic and empirical time series, we show that the HK method outperforms DFA in all three benchmarks described above.
2. Two methods of estimating the Hurst exponent
2.1. Estimating the Hurst exponent using the HK method
Tyralis and Koutsoyiannis [76] developed a Bayesian method for estimating H. As we will show, this method offers a viable solution to several issues with DFA outlined above. As a preview, we show that the HK method outperforms DFA across a broad range of H, especially when time series are short. In the remainder of this section, we overview the HK method. Additional details, including mathematical proofs, can be found in Tyralis and Koutsoyiannis [76]. In this description, we generally follow their notation.
Koutsoyiannis [77] report that the autocorrelation function for the so-called Hurst-Kolmogorov (HK) process is given by:
| (1) |
where H is the Hurst exponent, k is the time lag, and ρk is the autocorrelation for a given k. When H = 0.5, ρk is zero for all k > 0 but 1 when k = 0. When 0 < H < 0.5, ρk is negative at lag 1 but damps towards zero for k > 1; when 0.5 < H < 1, ρk is positive at lag 1 but slowly decays to zero; and as H → 1, ρk approaches 0 asymptotically.
Tyralis and Koutsoyiannis [76] employ a Bayesian technique for estimating the Hurst exponent. In that work, they derive a method to sample from the posterior distribution of H that takes the following form:
| (2) |
and its natural logarithm is then:
| (3) |
where Rn is the autocorrelation matrix with elements ri,j where i, j = 1, 2, 3, …, n, en = (1, 1, 1, …, 1)T is a vector of ones with n elements, |…| indicates a determinant, the superscript in indicates a matrix inverse, and the superscript T indicates a matrix transpose. The matrix products on the right-hand side of Eq. 3 are built from the quadratic forms for the inverse of a symmetric, positive definite autocorrelation matrix which can be obtained using the Levinson algorithm (Algorithm 4.7.2, Golub & Van Loan [78], p. 235) for a given xtρk.
Accept-reject algorithms are standard, powerful tools for sampling from complex distributions and follow a simple set of steps [79]. Suppose a probability density function (PDF) exists, f(x), from which it is difficult to sample. We refer to f(x) as the target distribution. One can use the Monte Carlo method to sample from f(x). The algorithm is as follows. First, one samples from a simpler proposal distribution from which it is easy to sample, Mg(x), where g(x) has the same domain as f(x) and M is a constant large enough such that g(x) ≥ f(x). The proposal PDFs can take many forms, such as uniform or truncated Gaussian distributions. Computational efficiency is gained if the overall shape of g(x) is similar to f(x). Second, one evaluates f(x) at the value proposed by sampling from g(x). Third, one draws a sample from the U(x) ~ Uniform(0, Mg(x)). If U(x) ≤ f(x), then we accept the proposed value from g(x) as a valid sample. Otherwise, we reject the proposal from g(x). This process is repeated for n samples, where n is the number of samples we wish to draw from the posterior distribution.
In the present case, we used the accept-reject algorithm to sample from the posterior distribution of H (Algorithm A.5, Robert & Casella [79], p. 49). The target distribution, f(x) is Eq. 3 and g(x) ~ Uniform(0, 1). The choice of g(x) makes sense in this case because g(x) shares the same domain of H and hence Eq. 3, namely (0, 1) [76]. M is chosen using a numerical optimization routine that finds the maximum of Eq. 3 as a function of H. Finally, from the sampled posterior distribution of H, we take the median of the distribution as a point estimate of H. Time series were submitted to the HK method using R [80] using the function inferH() from the package “HKprocess” [81]. The function inferH() has two inputs : the time series, xN, and the size of the simulated sample from the posterior distribution of H, n. We set the n to 500.
2.2. Estimating the Hurst exponent using DFA
We used DFA—as described by Peng et al. [74, 75]—to access the strength of long-range correlations in synthetic time series of different a priori known values of H and empirical human behavioral time series. DFA computes the Hurst exponent, H, using the first-order integration of time series xt of length N, where :
| (4) |
where 〈x232a is the grand mean of the time series. It computes root mean square (RMS; that is, averaging the residuals) for each linear trend Yt fit to non-overlapping n-length bins to build fluctuation function:
| (5) |
for n < N/4. f(n) is a power law:
| (6) |
where H is the Hurst exponent estimable using logarithmic transformation:
| (7) |
A bin size range of [4, N/2] was used for the DFA in the present study, which is standard practice while using DFA [82–86]. Time series were submitted to the DFA in R [80] using the function dfa() from the package “fractalRegression” [87].
The computational details of the two methods are relatively distinct, with the HK method having its foundations in the Bayes theorem, whereas DFA computes the Hurst exponent directly from the time series data.
3. Simulations
3.1. Methods
We used the Davies-Harte algorithm [88] to generate synthetic time series of varying lengths (N = 32, 64, 128, 256, 512, 1024) and varying values of the Hurst exponent (H = 0.1, 0.2, …, 0.9). This algorithm generates fractional Gaussian noise (fGn), which has been proposed as a model to understand the long-range correlations postulated to occur in various behavioral systems [25–29, 31, 89–91]. We generated 1, 000 synthetic time series for each combination of N and H in R [80] using the function fgn_sim() from the package “fractalRegression” [87] and submitted them to the HK method and DFA.
3.2. Results
Figs. 2 & 3 provide a summary visualization of the simulation results for each combination of the time series lengths (N = 32, 64, …, 1024), and the a priori known values of the Hurst exponent (H = 0.1, 0.2, …, 0.9). As a general preview, in all one but the shortest time series, N = 32, where neither method was useful, the HK method outperforms DFA in estimating Ĥ (Fig. 2). For the shortest time series, N = 32, both methods produce unreasonable errors (Mean |ΔĤ| > 0.05; Fig. 3, top left), although the HK method is still somewhat unbiased in its central tendency, producing Mean Ĥ close to the a priori known values of H (Fig. 2, top right).
Fig. 2. The HK method estimates the Hurst exponent, Ĥ, with consistently better accuracy than DFA, which overestimates Ĥ, specifically for short time series and small values of H.
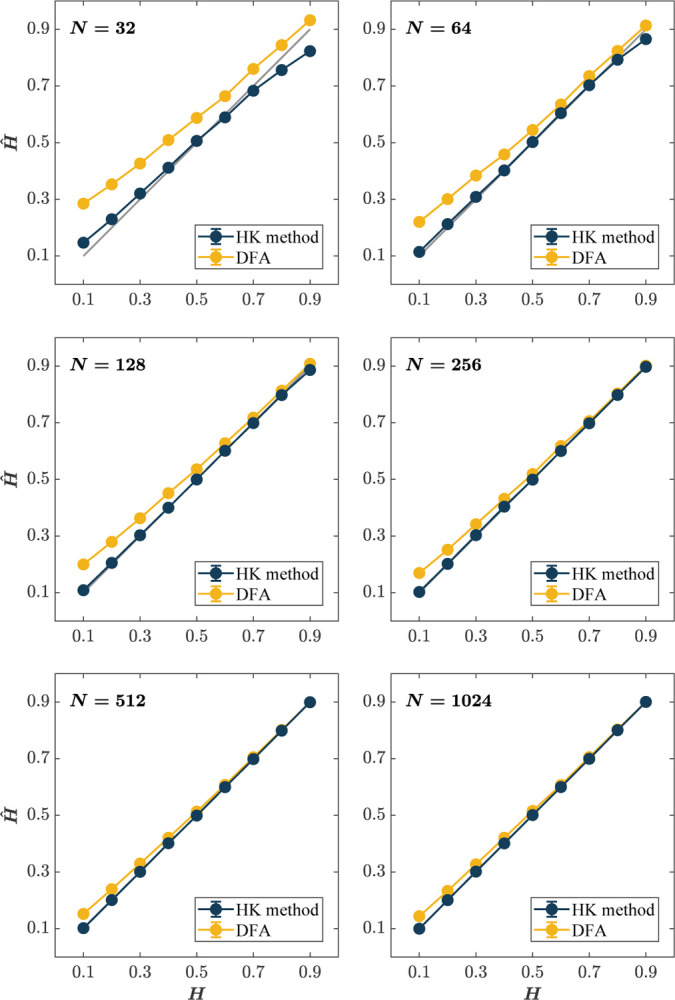
Each panel plots the Mean estimated values of Ĥ for 1, 000 synthetic time series of length N = 32, 64, 128, 256, 512, 1024 with a priori known values of H. The grey line indicates the ideal case where the estimated value is the same as the actual value, i.e., Ĥ = H. Error bars indicate 95% CI across 1000 simulations.
Fig. 3. Although DFA estimates the Hurst exponent, Ĥ, reasonably accurately for long time series (|ΔĤ| ~ 0.05 for N > 512), the HK method estimates H with consistently better accuracy than DFA.
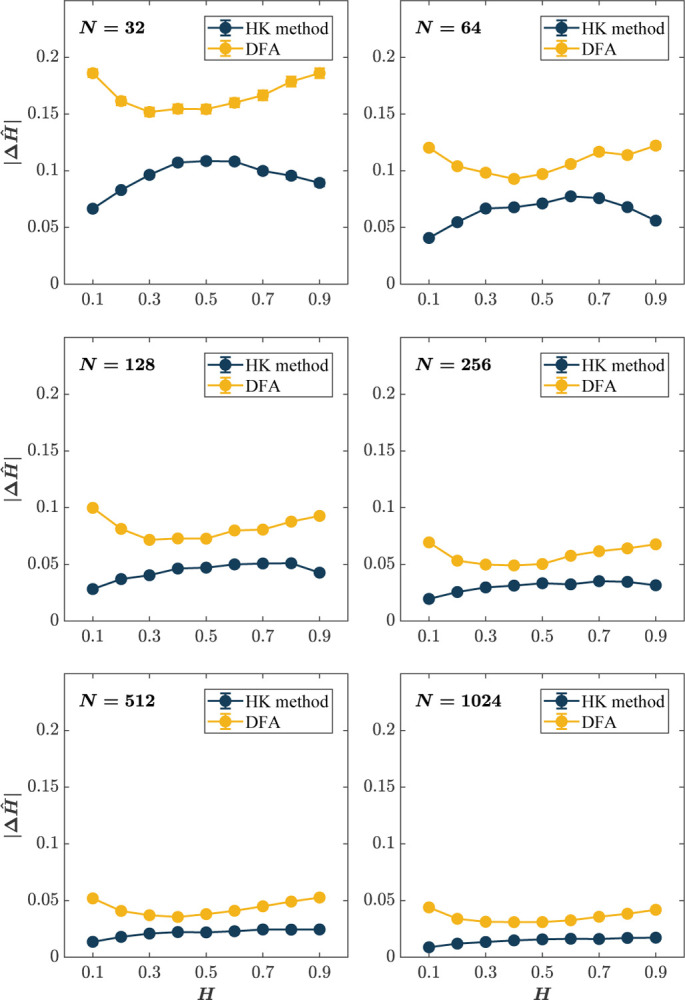
Each panel plots the Mean absolute error in the estimation of Ĥ, |ΔĤ|, for 1, 000 synthetic time series of length N = 32, 64, 128, 256, 512, 1024 with a priori known values of H. Error bars indicate 95% CI across 1000 simulations.
When N = 64, a very short time series compared to the DFA standard of > 500, the HK method and DFA show considerable differences in performance. First, the Mean Ĥ estimated by the HK method closely approximates the a priori known values of H, while DFA produces substantially and uniformly positive bias in mean Ĥ across the entire range of H (Fig. 2, top right). Second, the HK method produces substantially smaller Mean absolute errors, specifically |ΔĤ| falling within a range that could be used, with caution, in analyzing short time series (Fig. 3, top left). When N = 128, Mean Ĥ are virtually indistinguishable from nominal values, while DFA remains positively biased (Fig. 2, middle left). |ΔĤ| for the HK method drop below 0.05 for all H with the exception of extreme values (i.e., H = 0.1, 0.9; Fig. 2, middle right, respectively). The same general trend is observed for longer time series (N = 256, 512, 1024; Figs. 2 & 3, middle right, bottom left, and bottom right). While |ΔĤ| for DFA drops to reasonable levels for these time series lengths, DFA still tends to be positively biased for H = 0.1, 0.2, …, 0.6. In contrast, the HK method produces unbiased estimates across the entire range of H. In brief, across all N and H, the HK method outperforms DFA in that it (i) accurately assesses long-range correlations when the measurement time series is short and (ii) shows minimal dispersion about the central tendency.
Although the DFA estimates Ĥ with reasonable accuracy for long time series (Mean |ΔĤ| ~ 0.05 for N > 512; Fig. 3, bottom left and bottom right), the HK method estimates Ĥ with consistently better accuracy than DFA (Fig. 3). A noteworthy trend is that both methods have a curvilinear error profile, albeit with different forms. The error profile for DFA is concaveup, implying that DFA will be most error-prone when Ĥ is at both extreme antipersistence and extreme persistence. In contrast, the error profile of the HK method is concave-down, implying that peak error will be in the middle when the time series resembles a wGn. A caveat for that last observation is that as N → 512, the error in the estimation of Ĥ using the HK method is smallest as H → 0.1 and tends to plateau as H → 0.9 (Fig. 3, bottom left and bottom right). Thus, practitioners should keep these trends when the estimated Ĥ values fall within these regions.
4. Empirical results
The above results demonstrate the superiority of DFA in estimating the Hurst exponent on synthetic data when underlying dynamics are known. What remains to be learned is the relative performance of the HK method and DFA on human behavioral data. In the following subsections, we present four case studies that demonstrate the superior performance of the HK method in a diverse range of contexts.
4.1. Context 1: Stride interval time series in a locomotion task
Healthy and highly adaptable systems—such as the human movement system—display an optimal temporal structure of variability. This ideal structure is described by persistence in stride-to-stride variations indicated by the Hurst exponent, H, close to 1. It implies a temporal structure in consecutive strides that is ordered and stable but also variable and adaptable. DFA has been used in multiple studies to estimate H in stride-to-stride variations in walking [92–98] and running [84, 99–105] under various manipulations of task constraints both on treadmill [84, 92–100, 102–106] and overground [92, 101]. These studies have consistently reported H values close to 1, at least for young and healthy adults. Furthermore, stride-to-stride variations show a reduction in H in older adults and pathological populations [39, 40, 43, 107]. This reduction of persistence in stride-to-stride variations is linked with increased fall risk [41, 108–111]. In short, the Hurst exponent of stride-to-stride variations reflects both the constraints on the movement system due to the task and the physiological health of the movement system. Hence, stride-to-stride variations (e.g., in the stride interval time series) offer an empirical test case to compare downstream performance differences between the HK method and DFA.
4.1.1. Methods
Stride interval time series were reanalyzed from a published study on walking and running dynamics on the treadmill and an overground surface [112]. Eight adults (5 women and three men; Mean ± 1s.d. age: 30.5 ± 11.5 years) participated in exchange for monetary compensation after providing informed consent approved by the University of Nebraska Medical College’s Institutional Review Board. All participants met the following criteria: (i) they could give their informed consent; (ii) they could walk without the aid of a cane or other device; and (iii) they had not been diagnosed with any neurological disease or lower limb disability, injury, or illness.
Participants used a Bodyguard Commercial 312C Treadmill with a top speed of 12.0 mph and increases/reduction in speed by 0.1 mph housed in the Balance and Strength Lab at The University of Nebraska at Omaha to do treadmill walking and treadmill running. In addition, participants engaged in overground walking and overground running on the University of Nebraska at Omaha’s indoor track, which extends 200 meters and has inner, middle, and outer lanes. Participants donned a Trigno™ 4 Contact FSR (Force Sensitive Resistor) sensor (Delsys Inc., Boston, MA) under each foot. The first and second channels registered relative pressure at the heel and midfoot. A Trigno™ Personal Monitor (TPM) datalogger attached to the participant’s body stored the relative pressure data registered FSR sensors.
Participants performed four 20-min trials across two days. The first day consisted of walking and running either on the treadmill or the indoor track. The second day, separated by at least two but less than seven days, consisted of locomoting on the second surface. On the treadmill locomotion day, two familiarization trials were conducted to estimate the participant’s preferred walking and running speeds based on a previously established protocol [113]. Then the participant walked at that speed for 20 mins. After 5–10 min rest, the participant’s preferred running speed was estimated using the same protocol [113], following which the participant ran at that speed for 20 mins.
Heel strikes were determined based on the timing associated with the peak pressure of each foot strike from the FSRs. The peak of the ith heel strike of the left foot was subtracted from the peak of the (i − 1)th heel strike of the same foot to determine the stride intervals. The trials produced stride interval time series of various lengths, with the minimum length of N = 983. Therefore, all stride interval time series were cropped at N = 983 for further analyses. Segments of the original and shuffled stride interval time series of lengths N = 32, 64, 128, 256, 512, 983 were submitted to the HK method and DFA. Stride interval time series of all six lengths were shuffled to preserve the probability distribution but destroyed any temporal correlations and submitted to the HK method and DFA. As opposed to the original time series expected to yield Ĥ > 0.5. these shuffled time series were expected to yield an Ĥ value of 0.5, indicating an absence of long-range correlations.
We utilized linear mixed-effects (LME) models using Satterthwaite’s approximation to examine the effects of locomotion Mode (Walking vs. Running) and Surface (Treadmill vs. Overground) on Ĥ estimated using the HK method and DFA. Locomotion Mode (Walking vs. Running) and Surface (Treadmill vs. Overground), along with their interactions, served as three fixed effects, and Participant identity served as the random effect (i.e., we allowed the intercept to vary across participants). All mixed-modeling was performed in R [80] using the function lmer() from the package “nlme” [114] and the function anova() from the package “lmertest” [115]. Statistical significance was set at the Type I error rate of 5%.
4.1.2. Results
The central tendencies—Mean and Median—of Ĥ for stride interval time series estimated using the HK method, as well as the distribution of Ĥ, do not depend on the time series length N, except for N = 32 for which the HK method yields marginally smaller Ĥ (Fig. 4, top). In contrast, while the Mean and Median Ĥ for stride interval time series estimated using DFA do not appear to differ between N = 32 and N = 64, they show a consistent and linear increase with N after that. Furthermore, while the Ĥ values estimated using the HK method lie within the tight bounds of [0, 1], the Ĥ values estimated using DFA often exceed the upper bound of 1 (Fig. 4, bottom). Another notable distinction is a narrower range of Ĥ for the shuffled stride interval time series estimated using the HK method compared to DFA. Overall, the HK method estimates Ĥ that show smaller dispersion about the central tendency and lesser dependence on the length of the stride interval time series.
Fig. 4. The Hurst exponent, Ĥ, for stride interval time series estimated using the HK method do not depend on the time series length N, but Ĥ estimated using DFA show a strong dependence on N, resulting in larger Ĥ for larger N.

The right and the left violin plots represent the distribution of Ĥ for the original and shuffled stride interval time series, respectively, estimated using the HK method (top) and DFA (bottom). Vertical lines represent the interquartile range of the original Ĥ values, white circles represent the median value of Ĥ, and horizontal lines represent the Mean value of Ĥ for the original stride interval time series. Horizontal dash-dotted green and red lines indicate Ĥ = 0.5 and Ĥ = 1, respectively.
To investigate the sensitivity of both methods to task constraints, we analyzed the influence of locomotion Mode and Surface on Ĥ values estimated using both methods. We submitted the Ĥ values estimated using both methods to linear mixed-effects modeling with Satterthwaite’s approximation for finite sample size [116]. We performed this modeling separately for each time series length N = 32, 64, 128, 256, 512, 1024. Tables 1 & 2 describe the model outcomes.
Table 1.
Outcomes of linear mixed-effects modeling with Satterthwaite’s approximation for small sample size, examining the influence of locomotion Mode and Surface on the Hurst exponent, Ĥ, estimated using the HK method for stride interval time series of length N = 32, 64, 128, 256, 512, 983.
| Mean Sq | Sum Sq | DF | F | P * | |
|---|---|---|---|---|---|
| N = 32 | |||||
| Mode | 0.199 | 0.199 | 1,32 | 8.277 | 0.007 |
| Surface | 0.346 | 0.346 | 1,32 | 14.397 | < 0.001 |
| Mode × Surface | 0.105 | 0.105 | 1,32 | 4.388 | 0.044 |
| N = 64 | |||||
| Mode | 0.217 | 0.217 | 1,24 | 12.662 | 0.002 |
| Surface | 0.174 | 0.174 | 1,24 | 10.132 | 0.004 |
| Mode × Surface | 0.028 | 0.028 | 1,24 | 1.642 | 0.212 |
| N = 128 | |||||
| Mode | 0.187 | 0.187 | 1,32 | 15.056 | < 0.001 |
| Surface | 0.124 | 0.124 | 1,32 | 10.004 | 0.003 |
| Mode × Surface | 0.022 | 0.022 | 1,32 | 1.789 | 0.191 |
| N = 256 | |||||
| Mode | 0.127 | 0.127 | 1,24 | 9.389 | 0.005 |
| Surface | 0.112 | 0.112 | 1,24 | 8.229 | 0.008 |
| Mode × Surface | 0.003 | 0.003 | 1,24 | 0.227 | 0.638 |
| N = 512 | |||||
| Mode | 0.152 | 0.152 | 1,24 | 13.093 | 0.001 |
| Surface | 0.150 | 0.150 | 1,24 | 12.930 | 0.001 |
| Mode × Surface | 0.000 | 0.000 | 1,24 | 0.043 | 0.838 |
| N = 983 | |||||
| Mode | 0.128 | 0.128 | 1,24 | 14.794 | < 0.001 |
| Surface | 0.119 | 0.119 | 1,24 | 13.759 | 0.001 |
| Mode × Surface | 0.000 | 0.000 | 1,24 | 0.097 | 0.758 |
Boldfaced values indicate significant differences at the two-tailed alpha of 0.05.
Table 2.
Outcomes of linear mixed-effects modeling with Satterthwaite’s approximation for small sample size, examining the influence of locomotion Mode and Surface on the Hurst exponent, Ĥ, estimated using DFA for stride interval time series of length N = 32, 64, 128, 256, 512, 983.
| Mean Sq | Sum Sq | DF | F | P * | |
|---|---|---|---|---|---|
| N = 32 | |||||
| Mode | 0.144 | 0.144 | 1,32 | 3.960 | 0.055 |
| Surface | 0.276 | 0.276 | 1,32 | 7.584 | 0.009 |
| Mode × Surface | 0.148 | 0.148 | 1,32 | 4.053 | 0.053 |
| N = 64 | |||||
| Mode | 0.284 | 0.284 | 1,24 | 11.346 | 0.003 |
| Surface | 0.254 | 0.254 | 1,24 | 10.140 | 0.004 |
| Mode × Surface | 0.111 | 0.111 | 1,24 | 4.447 | 0.046 |
| N = 128 | |||||
| Mode | 0.200 | 0.200 | 1,24 | 9.280 | 0.006 |
| Surface | 0.159 | 0.159 | 1,24 | 7.385 | 0.012 |
| Mode × Surface | 0.091 | 0.091 | 1,24 | 4.230 | 0.051 |
| N = 256 | |||||
| Mode | 0.060 | 0.060 | 1,24 | 1.958 | 0.174 |
| Surface | 0.127 | 0.127 | 1,24 | 4.129 | 0.053 |
| Mode × Surface | 0.002 | 0.002 | 1,24 | 0.077 | 0.784 |
| N = 512 | |||||
| Mode | 0.148 | 0.148 | 1,32 | 6.754 | 0.014 |
| Surface | 0.076 | 0.076 | 1,32 | 3.442 | 0.073 |
| Mode × Surface | 0.017 | 0.017 | 1,32 | 0.758 | 0.391 |
| N = 983 | |||||
| Mode | 0.161 | 0.161 | 1,24 | 12.951 | 0.001 |
| Surface | 0.062 | 0.062 | 1,24 | 4.960 | 0.036 |
| Mode × Surface | 0.009 | 0.009 | 1,24 | 0.714 | 0.406 |
Boldfaced values indicate significant differences at the two-tailed alpha of 0.05.
Linear-mixed effects modeling of Ĥ estimated using the HK method revealed that Running is associated with greater Ĥ (i.e., stronger long-range correlations in stride-to-stride variations) compared to Walking, and Overground locomotion is associated with greater Ĥ compared to Treadmill locomotion (Fig. 5; Table 1). These results are supported by previous studies that have reported similar effects of locomotion Mode and Surface on the long-range correlations in stride-to-stride fluctuations [92, 112]. These results also remain consistent across all values of N (32, 64, 128, 256, 512, 1024), suggesting that the HK method is sensitive to task constraints for stride interval time series as short as 32 strides. Lastly, it is noteworthy from a movement science perspective that locomotion Mode and Surface exert their influence independently. However, this effect must be replicated, given the relatively small sample size.
Fig. 5. The effects of locomotion mode and surface on the Hurst exponent, Ĥ, estimated using the HK method do not depend o such as uniform or truncated Gaussian distributions, etc. the stride interval time series length (see Table 1 for the outcomes of the statistical tests).
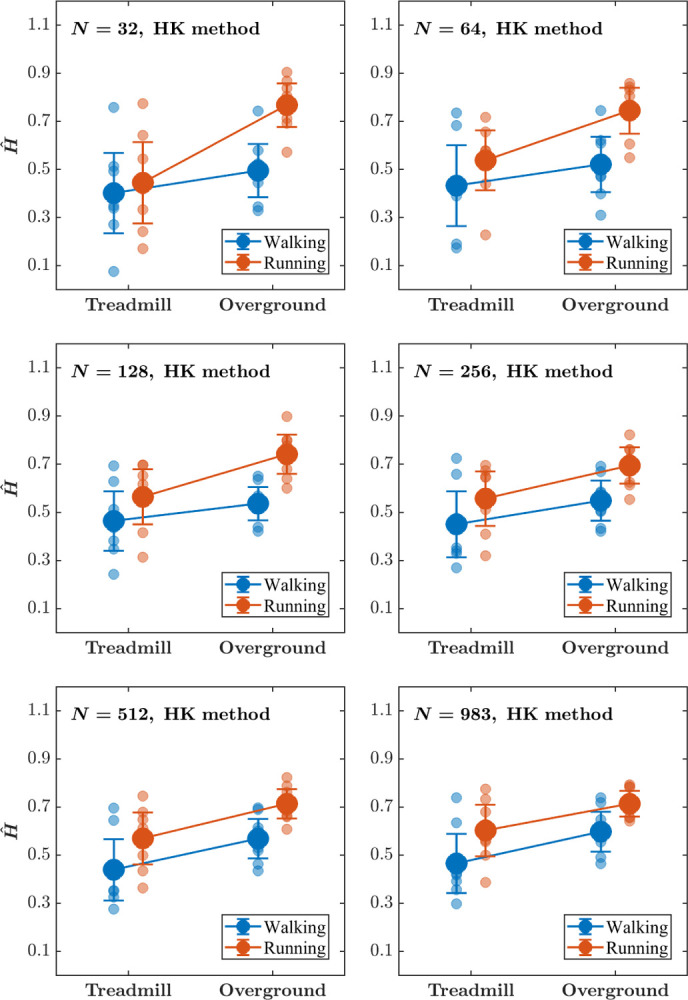
Each panel plots the Mean values of Ĥ, estimated using the HK method for stride interval time series of length N = 32, 64, 128, 256, 512, 983. Light blue and light red circles indicate Ĥ values for individual participants in the respective conditions. Error bars indicate 95% CI across 8 participants.
In contrast to the HK method, the results for the linear-mixed effects modeling of Ĥ estimated using DFA wax and wane depending on the stride interval time series length (Fig. 6; Table 2). For N = 32, Overground locomotion seems to produce greater Ĥ values than Treadmill locomotion. However, for N = 64, Running is associated with greater Ĥ than Walking, and the interaction effect of locomotion Mode and Surface appears. Both factors show an effect for N = 128, but then the effects of both factors disappear for N = 256. Then again, for N = 512—the typical recommendation for the application of DFA in gait analysis [117], Running is associated with greater Ĥ compared to Walking, and for N = 983, the effect of locomotion surface meets conventional levels of statistical significance.
Fig. 6. The effects of locomotion mode and surface on the Hurst exponent, Ĥ, estimated using DFA wax and wane depending on the stride interval time series length (see Table 2 for the outcomes of the statistical tests).

Each panel plots the Mean values of Ĥ, estimated using DFA for stride interval time series of length N = 32, 64, 128, 256, 512, 983. Light blue and light red circles indicate Ĥ values for individual participants in the respective conditions. Error bars indicate 95% CI across 8 participants.
These results suggest that DFA, when used with short empirical time series, increases the likelihood of the Type II error because we failed to find consistent effects that are present when the time series is long. Therefore, DFA should be reasonably accurate based on our simulations. This is problematic from the perspective of accumulating knowledge in movement science (and other fields) because such findings do not meet conventional levels of statistical significance still pervasive in scientific literature irrespective of relentless criticism [118–122]. We argue that this phenomenon may be more prevalent than previously thought in studies using the Hurst exponent as a dependent variable, which could have severe theoretical consequences. The above-described results on stride interval time series strongly support the idea that adopting the HK method in favor of DFA could drastically reduce the likelihood of Type II errors in behavioral sciences where H is a critical dependent variable. On a more substantive level, we recognize that the HK method produces lower H values than are typically observed in the gait literature. Whether these specific results generalize to other contexts is a matter of extensive replication.
4.2. Context 2: Intertap interval time series in a syncopation task
It has now been well established that the series of time intervals produced in repetitive tapping also show persistence or long-range correlations in sample-to-sample variations [123–126]. Instead of being a universally prevalent generic property of sensory time series, these long-range correlations in taping interval time series constitute a constant and recognizable characteristic of individuals performing a specific tapping activity, e.g., synchronizing with pacing signals of different fractal properties [30, 123, 126–128]. Tapping interval time series thus offer another empirical test case to compare the performance of the HK method and DFA.
4.2.1. Methods
Intertap interval time series were collected. Intertap intervals were recorded as participants pressed the letter “M” on their keyboard at a pace they could maintain for 1 minute. Participants performed tapping for 8 min in four conditions: three paced conditions: “Persistent,” “Random,” and “Periodic,” and one without pacing,” “Free.” In paced conditions, participants synchronized their finger taps to the metronome by pressing the letter “M.” In the Persistent condition, participants synchronized their tapping to a variable and structured metronome with interbeat interval time series exhibiting a Hurst’s exponent, H, of 1.0. In the Random condition, participants synchronized their tapping to a non-correlated metronome with interbeat interval time series exhibiting H of 0.5. In the Periodic condition, participants synchronized their taps to an invariant metronome (i.e., traditional metronome). Finally, in the Free condition, participants pressed the letter “M” at a self-selected pace. The Mean and SDs of Persistent and Random signals were set equal to each participant’s preferred tapping characteristics. The Periodic signal period was set equal to each Participant’s preferred tapping interval. The order of the four conditions was randomized for each participant.
The tapping trial was successful if the number of taps in the pacing condition was within 10% of the self-paced condition. Nineteen participants who fulfilled this criterion in all three pacing conditions were included for further analysis. Intertap interval time series of lengths N = 32, 64, 128, 256 were submitted to the HK method and DFA. Intertap interval time series of all four lengths were shuffled to preserve the probability distribution but destroyed any temporal correlations and submitted to the HK method and DFA. As opposed to the original time series expected to yield Ĥ > 0.5. these shuffled time series were expected to yield an Ĥ value of 0.5, indicating an absence of long-range correlations.
We utilized LME models using Satterthwaite’s approximation to examine the effects of the Pacing condition on Ĥ values for the tapping interval time series estimated using the HK method and DFA. Pacing condition served as the fixed effect, and Participant identity was included as a random effect. All mixed-modeling was performed in R [80] using the function lmer() from the package “nlme” [114] and the function anova() from the package “lmertest” [115]. Statistical significance was set at the Type I error rate of 5%.
4.2.2. Results
The central tendencies—Mean and Median—of Ĥ for the tapping interval time series estimated using the HK method, as well as the distribution of Ĥ, do not depend on the time series length N, except for N = 32 for which the HK method yields marginally larger Ĥ (Fig. 7, top). In contrast, while the Mean and Median Ĥ for tapping interval time series estimated using DFA do not appear to depend on the time series length N, the Ĥ values show a larger dispersion around the Mean compared to the counterparts estimates using the HK method (Fig. 7, bottom). While the Ĥ values estimated using the HK method lie with the tight bounds of [0, 1], the Ĥ values estimated using DFA often exceed the upper bound of 1. Another notable distinction is a narrower range of Ĥ for the shuffled tapping interval time series estimated using the HK method compared to DFA. Overall, Ĥ of tapping interval time series estimated using the HK method estimates show smaller dispersion about the central tendency and are more consistent with the theory of the Hurst exponent.
Fig. 7. The Hurst exponent, Ĥ, for the finger tapping interval time series estimated using the HK method do not depend on the time series length N, but Ĥ estimated using DFA show a strong dependence on N, resulting in larger Ĥ for smaller and larger N.

The right and the left violin plots represent the distribution of Ĥ for the original and shuffled tapping interval time series, respectively, estimated using the HK method (top) and DFA (bottom). Vertical lines represent the interquartile range of the original Ĥ values, white circles represent the median value of Ĥ, and horizontal lines represent the Mean value of Ĥ for the original stride interval time series. Horizontal dash-dotted green and red lines indicate Ĥ = 0.5 and Ĥ = 1, respectively.
To investigate the sensitivity of both methods to task constraints, we analyzed the influence of the Pacing condition on Ĥ values for the tapping interval estimated using both methods. We performed this modeling separately for each time series length N = 32, 64, 128, 256. Tables 3 & 4 describe the model outcomes.
Table 3.
Outcomes of linear mixed-effects modeling with Satterthwaite’s approximation for small sample size, examining the influence of the Pacing condition on the Hurst exponent, Ĥ, estimated using the HK method for the tapping interval time series of length N = 32, 64, 128, 256.
| Mean Sq | Sum Sq | DF | F | P * | |
|---|---|---|---|---|---|
| N = 32 | |||||
| Pacing condition | 0.170 | 0.057 | 3,57 | 1.8591 | 0.147 |
| N = 64 | |||||
| Pacing condition | 0.763 | 0.254 | 3,76 | 10.727 | < 0.001 |
| AT = 128 | |||||
| Pacing condition | 0.763 | 0.254 | 3,76 | 19.113 | < 0.001 |
| N = 256 | |||||
| Pacing condition | 0.532 | 0.177 | 3,57 | 14.787 | < 0.001 |
Boldfaced values indicate significant differences at the two-tailed alpha of 0.05.
Table 4.
Outcomes of linear mixed-effects modeling with Satterthwaite’s approximation for small sample size, examining the influence of the Pacing condition on the Hurst exponent, Ĥ, estimated using DFA for the tapping interval time series of length N = 32, 64, 128, 256.
| Mean Sq | Sum Sq | DF | F | P * | |
|---|---|---|---|---|---|
| N = 32 | |||||
| Pacing condition | 0.763 | 0.254 | 3,76 | 10.727 | < 0.001 |
| N = 64 | |||||
| Pacing condition | 0.519 | 0.173 | 3,76 | 2.567 | 0.061 |
| N = 128 | |||||
| Pacing condition | 1.355 | 0.451 | 3,76 | 18.774 | < 0.001 |
| N = 256 | |||||
| Pacing condition | 1.560 | 0.520 | 3,76 | 22.876 | < 0.001 |
Boldfaced values indicate significant differences at the two-tailed alpha of 0.05.
The Ĥ values estimated using the HK method differed across the Pacing conditions for the tapping interval time series of length N = 64, 128, 256 but not for N = 32 (Fig. 8; Table 3). In other words, the Ĥ values estimated using the HK method are sensitive to the pacing condition for the tapping interval time series comprising at least 64 intervals, and this sensitivity is consistent across progressively longer time series. In contrast, the effect of the Pacing condition on the Ĥ values estimated using DFA wax and wane depending on the tapping interval time series length, appearing for N = 32 but disappearing for N = 64 (Fig. 9; Table 4). Hence, the HK method yields more consistent effects of the different temporal structures of the pacing signal on the Hurst exponent of tapping intervals in a syncopation task. These results align with the above results on stride interval time series and strengthen the argument that DFA increases the likelihood of Type II error and makes an even more compelling case for adopting the HK method over the age-old DFA for estimating the Hurst exponent in behavioral sciences.
Fig. 8. The effects of pacing conditions on the Hurst exponent, Ĥ, estimated using the HK method do not depend on the tapping interval time series length (see Table 2 for the outcomes of the statistical tests).

Each panel plots the Mean values of Ĥ, estimated using the HK method for the tapping interval time series of length N = 32, 64, 128, 256, 512, 983. Light blue circles indicate Ĥ values for individual participants. Error bars indicate 95% CI across 19 participants.
Fig. 9. The effects of pacing condition on the Hurst exponent, Ĥ, estimated using DFA wax and wane depending on the tapping interval time series length (see Table 4 for the outcomes of the statistical tests).

Each panel plots the Mean values of Ĥ, estimated using DFA for the tapping interval time series of length N = 32, 64, 128, 256, 512, 983. Light blue circles indicate Ĥ values for individual participants. Error bars indicate 95% CI across 19 participants.
4.3. Context 3: Reaction time (RT) time series in simple and choice RT tasks
Reaction time (RT) is a workhorse of cognitive science and many other areas of psychological science. Often, RTs are collected from many (sometimes hundreds or thousands) of trials under the assumption that for a given experimental task, there exists a “true” RT that can be extracted from repeated sampling. The key to that assumption is that variation in RTs reflects independent white noise. However, persistence in sample-to-sample variations or 0.5 < H < 1 is not limited to predominantly movement tasks—such as walking, running, or finger tapping, but tasks involving spatial or temporal interval estimation also seem to show 1/fα noise unambiguously [129–131]. Simple RT tasks and choice RT tasks, such as lexical decision-making, also seem to provide unambiguous information about the state of the physiological system in that the RT time series in these tasks also yields 0.5 < H < 1 [28, 31, 131–133]. Therefore, we also compare the performance of the HK method and DFA using RTs from three tasks (a simple RT, a forced-choice RT, and time estimation task), all conducted in a similar experimental format.
4.3.1. Methods
RT time series were reanalyzed from a published study [131]. Six healthy adults responded to the Arabic digits 1, 2, 3, 4, 6, 7, 8, and 9 displayed on a computer screen. The experimental phase consisted of 1024 stimuli after 24 practice stimuli, with each stimulus appearing equally frequently in a randomized order for each task and participant. Each participant completed three tasks: (i) simple RT, in which they pressed the “?/” key with their right index finger immediately after detecting the stimulus. In addition to instructing participants to avoid anticipations, feedback “TOO FAST” was presented for two seconds following responses < 100 ms to prevent anticipatory responding (e.g., [134]). (ii) Choice RT, in which they pressed the “?/” key with their right index finger in response to an even number and pressed the “z” key in response to an odd number, “as fast as possible without making errors.” (iii) one second time interval estimation, in which participants pressed the “?/” key with their right index finger to mark an estimated time interval of one second after each stimulus was presented. The task order was counterbalanced across participants.
Each task (i.e., Simple RT, Choice RT, and time interval Generation) was performed with a relatively short response-stimulus interval (RSI) and a Long RSI, yielding a total of 3 tasks × 2 RSI = six sessions conducted on different days. One set of RSIs was randomly drawn from a uniform distribution that extended from 200 ms to 600 ms, and the set of long RSIs was obtained by adding a constant 600 ms to the set of short RSIs, and hence the long RSIs varied between 800 ms and 1200 ms. The order of the RSIs was randomized for each task and participant. The experiment—aimed at collecting RT time series of length N = 1024—yielded RT time series with a minimum length N = 1020. RT time series of lengths N = 32, 64, 128, 256, 512, 1020 were submitted to the HK method and DFA. RT time series of all four lengths were shuffled to preserve the probability distribution but destroyed any temporal correlations and submitted to the HK method and DFA. As opposed to the original time series expected to yield Ĥ > 0.5. these shuffled time series were expected to yield an Ĥ value of 0.5, indicating an absence of long-range correlations.
We utilized LME models using Satterthwaite’s approximation to examine the effects of Task and RSI on Ĥ values estimated using both methods. Pacing condition served as the fixed effect, and Participant identity served as the random effect. Task (Simple RT vs. Choice RT vs. Generation) and RSI (Short vs. Long), along with their interactions, served as three fixed effects, and Participant identity served as the random effect. All mixed-modeling was performed in R [80] using the function lmer() from the package “nlme” [114] and the function anova() from the package “lmertest” [115]. Statistical significance was set at the Type I error rate of 5%.
4.3.2. Results
The central tendencies—Mean and Median—of Ĥ for RT time series estimated using the HK method, as well as the distribution of Ĥ, do not depend on the time series length N, showing only marginal dependence of the distribution of Ĥ on N (Fig. 10, top). In contrast, while the Mean and Median Ĥ for the RT time series estimated using DFA do not differ among N = 64, 128, 512, 1024, the values are visibly greater for N = 32 and smaller for N = 256 (Fig. 10, bottom). Furthermore, while the Ĥ values estimated using the HK method lie with the tight bounds of [0, 1], the Ĥ values estimated using the DFA frequently exceed the upper bound of 1, especially for short time series. Another notable distinction is a narrower range of Ĥ for the shuffled RT time series estimated using the HK method compared to the DFA. Overall, and similar to the results above, the HK method estimates Ĥ that show smaller dispersion about the central tendency and lesser dependence on the length of the RT time series.
Fig. 10. The Hurst exponent, Ĥ, for the response-stimulus interval time series estimated using the HK method do not depend on the time series length N, but Ĥ estimated using DFA show a strong dependence on N, resulting in larger Ĥ for smaller and larger N.

The right and the left violin plots represent the distribution of Ĥ for the original and shuffled response-stimulus interval time series, respectively, estimated using the HK method (top) and DFA (bottom). Vertical lines represent the interquartile range of the original Ĥ values, white circles represent the median value of Ĥ, and horizontal lines represent the Mean value of Ĥ for the original stride interval time series. Horizontal dash-dotted green and red lines indicate Ĥ = 0.5 and Ĥ = 1, respectively.
To investigate the sensitivity of both methods to task constraints, we analyzed the influence of the Task and RSI on Ĥ on Ĥ values for the tapping interval estimated using both methods. We performed this modeling separately for each time series length N = 32, 64, 128, 256. Tables 5 & 6 describe the model outcomes.
Table 5.
Outcomes of linear mixed-effects modeling with Satterthwaite’s approximation for small sample size, examining the influence of Task and RSI on the Hurst exponent, Ĥ, estimated using the HK method for the RT time series of length N = 32, 64, 128, 256, 512, 983.
| Mean Sq | Sum Sq | DF | F | P * | |
|---|---|---|---|---|---|
| N = 32 | |||||
| Task | 0.228 | 0.114 | 2,36 | 11.634 | < 0.001 |
| RSI | 0.031 | 0.031 | 1,36 | 3.202 | 0.082 |
| Task × RSI | 0.232 | 0.116 | 2,36 | 11.840 | < 0.001 |
| N = 64 | |||||
| Task | 0.226 | 0.113 | 2,36 | 11.913 | < 0.001 |
| RSI | 0.005 | 0.005 | 1,36 | 0.554 | 0.462 |
| Task × RSI | 0.257 | 0.128 | 2,36 | 13.501 | < 0.001 |
| N = 128 | |||||
| Task | 0.145 | 0.073 | 2,36 | 9.826 | < 0.001 |
| RSI | 0.022 | 0.022 | 1,36 | 3.039 | 0.090 |
| Task × RSI | 0.318 | 0.159 | 2,36 | 21.538 | < 0.001 |
| N = 256 | |||||
| Task | 0.061 | 0.030 | 2,36 | 5.985 | 0.006 |
| RSI | 0.012 | 0.012 | 1,36 | 2.342 | 0.135 |
| Task × RSI | 0.258 | 0.129 | 2,36 | 25.337 | < 0.001 |
| N = 512 | |||||
| Task | 0.088 | 0.044 | 2,30 | 10.154 | < 0.001 |
| RSI | 0.002 | 0.002 | 1,30 | 0.470 | 0.498 |
| Task × | 0.181 | 0.091 | 2,30 | 20.990 | < 0.001 |
| N = 1020 | |||||
| Task | 0.088 | 0.044 | 2,36 | 14.371 | < 0.001 |
| RSI | 0.001 | 0.001 | 1,36 | 0.414 | 0.5241 |
| Task × RSI | 0.164 | 0.082 | 2,36 | 26.747 | < 0.001 |
Boldfaced values indicate significant differences at the two-tailed alpha of 0.05.
Table 6.
Outcomes of linear mixed-effects modeling with Satterthwaite’s approximation for small sample size, examining the influence of Task and RSI on the Hurst exponent, Ĥ, estimated using DFA for the RT time series of length N = 32, 64, 128, 256, 512, 983.
| Mean Sq | Sum Sq | DF | F | P * | |
|---|---|---|---|---|---|
| N = 32 | |||||
| Task | 0.282 | 0.141 | 2,36 | 2.287 | 0.116 |
| RSI | 0.028 | 0.028 | 1,36 | 0.451 | 0.506 |
| Task × RSI | 0.390 | 0.195 | 2,36 | 3.169 | 0.054 |
| N = 64 | |||||
| Task | 0.388 | 0.194 | 2,36 | 9.529 | < 0.001 |
| RSI | 0.028 | 0.028 | 1,36 | 1.384 | 0.247 |
| Task × RSI | 0.226 | 0.113 | 2,36 | 5.549 | 0.008 |
| N = 128 | |||||
| Task | 0.125 | 0.062 | 2,36 | 3.189 | 0.053 |
| RSI | 0.041 | 0.041 | 1,36 | 2.103 | 0.156 |
| Task × RSI | 0.321 | 0.160 | 2,36 | 8.205 | 0.001 |
| N = 256 | |||||
| Task | 0.157 | 0.079 | 2,36 | 5.538 | 0.008 |
| RSI | 0.003 | 0.003 | 1,36 | 0.243 | 0.625 |
| Task × RSI | 0.249 | 0.124 | 2,36 | 8.752 | 0.001 |
| N = 512 | |||||
| Task | 0.194 | 0.097 | 2,36 | 6.628 | 0.004 |
| RSI | 0.035 | 0.035 | 1,36 | 2.398 | 0.130 |
| Task × RSI | 0.131 | 0.065 | 2,36 | 4.465 | 0.019 |
| N = 1020 | |||||
| Task | 0.159 | 0.080 | 2,30 | 5.618 | 0.008 |
| RSI | 0.044 | 0.044 | 1,30 | 3.113 | 0.088 |
| Task × RSI | 0.208 | 0.104 | 2,30 | 7.354 | 0.003 |
Boldfaced values indicate significant differences at the two-tailed alpha of 0.05.
Time interval generation is associated with greater Ĥ (i.e., stronger long-range correlations in sample-to-sample variations) compared to simple RT and choice RT, and RSI shows significant interaction with the task (Fig. 13). Furthermore, these effects of Task and Task × RSI interaction remain consistent across all values of N (32, 64, 128, 256, 512, 1020; Table 5), suggesting that the HK method is sensitive to task constraints for RT time series as short as 32 RTs. This result dovetails with what we found in the stride interval time series and tapping interval time series reported above.
Fig. 13. The Hurst exponent, Ĥ, for reaction time series estimated using the HK method do not depend on the time series length N, but Ĥ estimated using DFA show a strong dependence on N, resulting in larger Ĥ for smaller and larger N.

The right and the left violin plots represent the distribution of Ĥ for the original and shuffled stride interval time series, respectively, estimated using the HK method (top) and DFA (bottom). Vertical lines represent the interquartile range of the original Ĥ values, white circles represent the median value of Ĥ, and horizontal lines represent the Mean value of Ĥ for the original stride interval time series. Horizontal dash-dotted green and red lines indicate Ĥ = 0.5 and Ĥ = 1, respectively.
In contrast to the HK method, the effects of task constraints Ĥ estimated using the DFA again vary as a function of RT time series length (Fig. 14; Table 6). For N = 32, the Ĥ values neither varied with Task nor with RSI. For N = 128, neither Task nor RSI affects the Ĥ values estimated using the DFA, but the two factors show a significant interaction effect. For N = 64, 256, 512, 1020, the Ĥ values estimated using DFA show similar sensitivity to the task constraints as do the Ĥ values estimated using the HK method.
Fig. 14. The effect of the speaker—human vs. text-to-speech (TTS) synthesizer—on the Hurst exponent, Ĥ, estimated using the HK method and DFA does not depend on the reaction time series length.

Each panel plots the Mean values of Ĥ, estimated using the HK method and DFA for reaction time series of length N = 32, 64, 128, 256, 512, 983. Light blue and light red circles indicate Ĥ values for individual participants in the respective conditions. Error bars indicate 95% CI across 10 participants.
These results further support our proposition that adopting the HK method might reduce the likelihood of the Type II error in not being able to find an actual effect of task constraints on the Hurst exponent when it exists—irrespective of whether the task is predominantly motor (e.g., walking, running) or predominantly cognitive (e.g., simple RT, complex RT).
4.4. Context 4: RT time series in a listening task
The above examples of stride interval time series, tapping interval time series, and RT time series illustrate that the HK method reduces the likelihood of Type II error when comparing the Hurst exponent across task constraints from multiple measurement modalities and settings, ranging from gross and fine motor tasks to classic cognitive/psychologicalexperiments. However, other things equal, Types I and II errors are inversely related [135–138], raising the possibility that the HK method might increase the likelihood of Type I error, i.e., increasing the likelihood of finding the effect of an independent factor when it does not exist. To investigate whether this is the case, we analyzed an RT time series dataset in which the H values estimated using DFA did not differ as a function of task constraints.
4.4.1. Methods
RT time series were reanalyzed from a published study [139]. Data was collected on twenty adults (nine men and eleven women, M ± SD age = 20.10 ± 1.29 years) after obtaining informed consent. Participants were randomly assigned to hear the voice of either an adult woman or Acapela’s U.S. English text-to-speech female voice “Sharon” (Acapela Inc., Mons, Belgium), using the iPad app “Voice Dream.” They both produced speech recordings of 2,027 words from The Atlantic article “Torching the Modern-Day Library of Alexandria.” Also, they both produced words interspersed with pauses to allow parsing.
E-Prime software (Psychology Software Tools Inc., Pittsburgh, PA) presented audio recordings of each word in its original sequence through headphones. Participants sat at an E-Prime-ready computer and were instructed: “Listen to the audio stimuli and press the spacebar after you feel as though you have understood the word you just heard. Try to pay attention to the passage because comprehension and word-memory questions will be asked at the end of the experiment. However, if you miss a word, do not worry and continue to move on because you cannot go back.” When the spacebar was released, a word recording played. The following word may be heard by pressing the spacebar once more, either during or after the recording playback, allowing participants to skip the entire word in favor of the subsequent one. E-Prime measured the RT in ms from the beginning of each word until the succeeding button press. The experiment yielded RT time series of lengths N = 2027 and 2025 in human speech and text-to-speech conditions, respectively. RT time series of lengths N = 32, 64, 128, 256, 512, 1024 were submitted to the HK method and DFA. Intertap interval time series of all six lengths were shuffled to preserve the probability distribution but destroyed any temporal correlations and submitted to the HK method and DFA. As opposed to the original time series expected to yield Ĥ > 0.5. these shuffled time series were expected to yield an Ĥ value of 0.5, indicating an absence of long-range correlations.
We utilized independent samples t-tests to examine the effects of Speech (Human speaker vs. Text-to-speech synthesizer) on Ĥ values estimated using both methods. All tests were performed in R [80] using the function t.test(). Statistical significance was set at the Type I error rate of 5%.
4.4.2. Results
The central tendencies—Mean and Median—of Ĥ for RT time series in the listening task estimated using the HK method, as well as the width of the distribution of Ĥ, show a marginal reduction with the time series length N (Fig. 13, top). In contrast, the Mean and Median Ĥ for RT time series estimated using DFA show a strong dependence on N, resulting in larger Ĥ for smaller and larger N (Fig. 13, bottom). Furthermore, while the Ĥ values estimated using the HK method lie with the tight bounds of [0, 1], the Ĥ values estimated using the DFA frequently exceed the upper bound of 1, especially for short time series. Another notable distinction is a visibly narrower range of Ĥ for the shuffled RT time series estimated using the HK method compared to DFA. As we observed in the above-discussed examples, the HK method estimates Ĥ that show smaller dispersion about the central tendency and lesser dependence on the length of the RT time series.
To investigate whether the high task sensitivity of the Hurst exponent estimated using the HK method—as shown in the above-described examples—can result in a Type I error, we next analyzed examine the effects of Speech on Ĥ values estimated using both the HK method and DFA. We submitted the Ĥ values estimated using both methods to independent samples t-tests. We performed these tests separately for each time series length N = 32, 64, 128, 256, 512, 1024.
For each time series length, the H values measuring the strength of persistence in RT time series in the listening task do not differ between participants listening to the Human speaker and the Text-to-speech synthesizer, irrespective of whether these were estimated using the HK method (t9 = −0.728, −0.941, −0.649, −0.518, −0.434, −0.425, p = 0.485, 0.371, 0.533, 0.617, 0.675, 0.681 for N = 32, 64, 128, 256, 512, 1024, respectively) or the DFA (t9 = 0.580, −1.124, −1.765, −1.640, −1.486, −0.967, p = 0.576, 0.290, 0.111, 0.135, 0.171, 0.359 for N = 32, 64, 128, 256, 512, 1024, respectively; Fig. 14). These results suggest that the HK method balances Type I and Type II errors. Furthermore, the method reduces the likelihood of the Type II error by not missing an effect of an independent factor when it exists—as illustrated by our results on stride interval time series and RT series in simple and choice RT tasks, without increasing the likelihood of the Type I error by finding an effect of an independent factor when it does not exist—as illustrated by this example.
5. Discussion
We compared the performance of two methods of fractal analysis—the current gold standard, DFA, and a Bayesian approach that is not well-known in behavioral sciences : the Hurst-Kolmogorov (HK) method—in estimating the Hurst exponent of synthetic and multiple empirical time series. Simulations demonstrate that the HK method consistently outperforms the DFA in three critical ways : the HK method (i) accurately assesses long-range correlations when the measurement time series is short, (ii) shows minimal dispersion about the central tendency, and (iii) yields a point estimate that does not depend on the length of the measurement time series or its underlying Hurst exponent. Comparing the two methods using empirical time series from multiple settings further supports those findings.
The practical limitations of DFA (e.g., N ≥ 500) is a significant drawback across the board in basic, applied, and clinical areas of science [67]. From a fundamental science perspective, experiments are often constructed to obtain long sequences of measurements (e.g., RTs, stride intervals, heartbeats). Those experimental designs are slow to collect, create physical and cognitive burdens for participants, and potentially confound with fatigue. Additionally, assessing the immediate influence of experimentally induced perturbations is often desirable. However, a requirement for long time series makes it difficult to determine whether observed dynamics result from immediate reaction or longer-term learning. These concerns amplify in applied and clinical domains concerned with real-time monitoring and quick clinical assessments. We show that the HK method might help bypass these limitations because the method estimates the Hurst exponent with reasonable accuracy for time series as short as 64 samples. Specifically, we found that the Hurst exponent yielded by the HK method closely matches the a priori known Hurst exponent of synthetic time series as short as 64 samples. In contrast, DFA consistently overestimates the Hurst exponent for short time series and for time series with large actual Hurst exponent. Furthermore, while the difference in performance tends to shrink with increasing time series length, the HK method consistently outperformed DFA, producing a notably smaller error in estimating the Hurst exponent even for time series as long as 1052 samples.
Numerous authors have noted that DFA produces a large dispersion around the Mean estimate of the Hurst exponent and that this dispersion increases with the actual Hurst exponent and decreases with the time series length [65–70], factors that may severely limit the reproducibility of research findings. Alterations to the DFA algorithm, for instance, the evenly spacing algorithm used in our simulations and subsequent analyses, reduce the dispersion around the Mean by as much as 36% [65]. Our simulations show that the HK method can estimate H with almost no dispersion around the Mean estimate for time series as short as 64 samples. Even for time series of just 32 samples, the dispersion is negligible, as opposed to considerable dispersion in the Hurst exponent estimated by DFA. Hence, the HK method confers substantial benefits over the traditional DFA by increasing estimates’ consistency—a critical feature when using the Hurst exponent as a biomarker in clinical applications wherein the objective is to differentiate between groups (e.g., healthy vs. Pathological individuals).
Finally, the present results provide irrefutable evidence that while DFA is precariously sensitive to the time series length—as has been known for long [66, 73], the HK method yields consistent values of the Hurst exponent irrespective of the time series length. For instance, in one study [67], the Hurst exponent derived from the first 150 strides of the 15-min walking experiment did not match the Hurst exponent from the entire 15-min trial. We also found comparable trends with the Hurst exponent estimated by DFA for empirical data on stride-to-stride variations for walking and running both on the treadmill and the overground surface, but the Hurst exponent estimated by the HK method remained consistent across different lengths taken from the empirical time series.
Empirical data poses several issues that might influence the accuracy and dispersion in the estimation of the Hurst exponent, such as trends [56, 140, 141], nonstationarity [140, 142], nonlinearity [55], and the Hurst exponent being larger than one [60, 143–145]. Therefore, multiple efforts have been made to tailor the DFA algorithm to make it more suitable for empirical data showing one or more of these issues [58, 146–151]. Future studies could investigate how the HK method is sensitive to the presence of either one or a combination of strong trends, nonstationarity, nonlinearity, and larger-than-one H. Our research team is currently involved in all those aspects.
6. Conclusion
The purpose of the work presented above was to compare the HK method and DFA in several contexts relevant to behavioral scientists interested in time series analysis. Without variation, simulation results showed that the HK method bypasses many of the known limitations of DFA; it (i) accurately assesses long-range correlations when the measurement time series is short, (ii) shows minimal dispersion about the central tendency, and (iii) yields a point estimate that does not depend on the length of the measurement time series or its underlying Hurst exponent. In contrast, our results also show that the DFA results applied to brief measurement time series (N ≤ 500 should be interpreted with caution. As a general conclusion, the HK method outperforms DFA in many ways, encouraging its systematic application to assess the strength of long-range correlations in empirical time series in behavioral sciences.
Fig. 11. The effects of Task and RSI on the Hurst exponent, Ĥ, estimated using the HK method do not depend on the response-stimulus interval time series length (see Table 5 for the outcomes of the statistical tests).

Each panel plots the Mean values of Ĥ, estimated using the HK method for the response-stimulus interval time series of length N = 32, 64, 128, 256, 512, 1020. Light blue and light red circles indicate Ĥ values for individual participants in the respective conditions. Error bars indicate 95% CI across 6 participants.
Fig. 12. The effects of Task and RSI on the Hurst exponent, Ĥ, estimated using DFA wax and wane depending on the response-stimulus interval time series length (see Table 6 for the outcomes of the statistical tests).

Each panel plots the Mean values of Ĥ, estimated using DFA for the response-stimulus interval time series of length N = 32, 64, 128, 256, 512, 1020. Light blue and light red circles indicate Ĥ values for individual participants in the respective conditions. Error bars indicate 95% CI across 6 participants.
Acknowledgments.
This work was supported by the NSF award 212491, the University of Nebraska Collaboration Initiative, the Center for Research in Human Movement Variability at the University of Nebraska at Omaha, the NIH awards P20GM109090 and R01NS114282, the NASA EPSCoR mechanism, and the IARPA WatchID award.
Footnotes
Declarations. The authors declare no competing financial interests.
References
- [1].Hurst H.E.: Long-term storage capacity of reservoirs. Transactions of the American Society of Civil Engineers 116(1), 770–799 (1951). 10.1061/TACEAT.0006518 [DOI] [Google Scholar]
- [2].Mandelbrot B.B., Wallis J.R.: Computer experiments with fractional Gaussian noises: Part 1, averages and variances. Water Resources Research 5(1), 228–241 (1969). 10.1029/WR005i001p00228 [DOI] [Google Scholar]
- [3].Beran J., Terrin N.: Estimation of the long-memory parameter, based on a multivariate central limit theorem. Journal of Time Series Analysis 15(3), 269–278 (1994). 10.1111/j.1467-9892.1994.tb00192.x [DOI] [Google Scholar]
- [4].Kantelhardt J.W., Berkovits R., Havlin S., Bunde A.: Are the phases in the Anderson model long-range correlated? Physica A: Statistical Mechanics and its Applications 266(1–4), 461–464 (1999). 10.1016/S0378-4371(98)00631-1 [DOI] [Google Scholar]
- [5].Efstathiou M., Varotsos C.: On the altitude dependence of the temperature scaling behaviour at the global troposphere. International Journal of Remote Sensing 31(2), 343–349 (2010). 10.1080/01431160902882702 [DOI] [Google Scholar]
- [6].Ivanova K., Ausloos M.: Application of the detrended fluctuation analysis (DFA) method for describing cloud breaking. Physica A: Statistical Mechanics and its Applications 274(1–2), 349–354 (1999). 10.1016/S0378-4371(99)00312-X [DOI] [Google Scholar]
- [7].Tatli H., Dalfes H.N.: Long-time memory in drought via detrended fluctuation analysis. Water Resources Management 34(3), 1199–1212(2020). 10.1007/s11269-020-02493-9 [DOI] [Google Scholar]
- [8].Alvarez-Ramirez J., Alvarez J., Rodriguez E.: Short-term predictability of crude oil markets: A detrended fluctuation analysis approach. Energy Economics 30 (5), 2645–2656 (2008). 10.1016/j.eneco.2008.05.006 [DOI] [Google Scholar]
- [9].Grau-Carles P.: Empirical evidence of long-range correlations in stock returns. Physica A: Statistical Mechanics and its Applications 287(3–4), 396–404 (2000). 10.1016/S0378-4371(00)00378-2 [DOI] [Google Scholar]
- [10].Ivanov P.C., Yuen A., Podobnik B., Lee Y.: Common scaling patterns in intertrade times of US stocks. Physical Review E 69(5), 056107 (2004). 10.1103/PhysRevE.69.056107 [DOI] [PubMed] [Google Scholar]
- [11].Liu Y., Cizeau P., Meyer M., Peng C.-K., Stanley H.E.: Correlations in economic time series. Physica A: Statistical Mechanics and its Applications 245(3–4), 437–440 (1997). 10.1016/S0378-4371(97)00368-3 [DOI] [Google Scholar]
- [12].Liu Y., Gopikrishnan P., Stanley H.E., et al. : Statistical properties of the volatility of price fluctuations. Physical Review E 60(2), 1390 (1999). 10.1103/PhysRevE.60.1390 [DOI] [PubMed] [Google Scholar]
- [13].Alados C.L., Huffman M.A.: Fractal long-range correlations in behavioural sequences of wild chimpanzees: A non-invasive analytical tool for the evaluation of health. Ethology 106(2), 105–116 (2000). 10.1046/j.1439-0310.2000.00497.x [DOI] [Google Scholar]
- [14].Bee M.A., Kozich C.E., Blackwell K.J., Gerhardt H.C.: Individual variation in advertisement calls of territorial male green frogs, Rana clamitans: Implications for individual discrimination. Ethology 107(1), 65–84 (2001). 10.1046/j.1439-0310.2001.00640.x [DOI] [Google Scholar]
- [15].Buldyrev S., Dokholyan N., Goldberger A., Havlin S., Peng C.-K., Stanley H., Viswanathan G.: Analysis of DNA sequences using methods of statistical physics. Physica A: Statistical Mechanics and its Applications 249(1–4), 430–438 (1998). 10.1016/S0378-4371(97)00503-7 [DOI] [Google Scholar]
- [16].Mantegna R.N., Buldyrev S.V., Goldberger A.L., Havlin S., Peng C.-K., Simons M., Stanley H.E.: Linguistic features of noncoding DNA sequences. Physical Review Letters 73(23), 3169 (1994). 10.1103/PhysRevLett.73.3169 [DOI] [PubMed] [Google Scholar]
- [17].Peng C.-K., Buldyrev S., Goldberger A., Havlin S., Simons M., Stanley H.: Finite-size effects on long-range correlations: Implications for analyzing DNA sequences. Physical Review E 47(5), 3730 (1993). 10.1103/PhysRevE.47.3730 [DOI] [PubMed] [Google Scholar]
- [18].Castiglioni P., Faini A.: A fast DFA algorithm for multifractal multiscale analysis of physiological time series. Frontiers in Physiology 10, 115 (2019). 10.3389/fphys.2019.00115 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Goldberger A.L., Amaral L.A., Hausdorff J.M., Ivanov P.C., Peng C.-K., Stanley H.E.: Fractal dynamics in physiology: Alterations with disease and aging. Proceedings of the National Academy of Sciences 99(suppl 1), 2466–2472 (2002). 10.1073/pnas.012579499 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Hardstone R., Poil S.-S., Schiavone G., Jansen R., Nikulin V.V., Mansvelder H.D., Linkenkaer-Hansen K.: Detrended fluctuation analysis: A scale-free view on neuronal oscillations. Frontiers in Physiology 3, 450 (2012). 10.3389/fphys.2012.00450 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Peng C.-K., Mietus J., Hausdorff J., Havlin S., Stanley H.E., Goldberger A.L.: Long-range anticorrelations and non-Gaussian behavior of the heartbeat. Physical Review Letters 70(9), 1343 (1993). 10.1103/PhysRevLett.70.1343 [DOI] [PubMed] [Google Scholar]
- [22].Delignières D., Torre K., Bernard P.-L.: Transition from persistent to anti-persistent correlations in postural sway indicates velocity-based control. PLoS Computational Biology 7(2), 1001089 (2011). 10.1371/journal.pcbi.1001089 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Duarte M., Sternad D.: Complexity of human postural control in young and older adults during prolonged standing. Experimental Brain Research 191 (3), 10.1007/s00221-008-1521-7 265–276 (2008). [DOI] [PubMed] [Google Scholar]
- [24].Lin D., Seol H., Nussbaum M. A., Madigan M.L.: Reliability of COP-based postural sway measures and age-related differences. Gait & Posture 28(2), 337–342 (2008). 10.1016/j.gaitpost.2008.01.005 [DOI] [PubMed] [Google Scholar]
- [25].Chen Y., Ding M., Kelso J.S.: Long memory processes (1/fα type) in human coordination. Physical Review Letters 79(22), 4501 (1997). 10.1103/PhysRevLett.79.4501 [DOI] [Google Scholar]
- [26].Diniz A., Wijnants M.L., Torre K., Barreiros J., Crato N., Bosman A.M., Hasselman F., Cox R.F., Van Orden G.C., Delignières D.: Contemporary theories of 1/f noise in motor control. Human Movement Science 30(5), 889–905 (2011). 10.1016/j.humov.2010.07.006 [DOI] [PubMed] [Google Scholar]
- [27].Allegrini P., Menicucci D., Bedini R., Fronzoni L., Gemignani A., Grigolini P., West B.J., Paradisi P.: Spontaneous brain activity as a source of ideal 1/f noise. Physical Review E 80(6), 061914 (2009). 10.1103/PhysRevE.80.061914 [DOI] [PubMed] [Google Scholar]
- [28].Gilden D.L., Thornton T., Mallon M.W.: 1/f noise in human cognition. Science 267(5205), 1837–1839 (1995). 10.1126/science.7892611 [DOI] [PubMed] [Google Scholar]
- [29].Kello C.T., Brown G.D., Ferrer-i-Cancho R., Holden J.G., Linkenkaer-Hansen K., Rhodes T., Van Orden G.C.: Scaling laws in cognitive sciences. Trends in Cognitive Sciences 14(5), 223–232 (2010). 10.1016/j.tics.2010.02.005 [DOI] [PubMed] [Google Scholar]
- [30].Stephen D.G., Stepp N., Dixon J.A., Turvey M.: Strong anticipation: Sensitivity to long-range correlations in synchronization behavior. Physica A: Statistical Mechanics and its Applications 387(21), 5271–5278 (2008). 10.1016/j.physa.2008.05.015 [DOI] [Google Scholar]
- [31].Van Orden G.C., Holden J.G., Turvey M.T.: Self-organization of cognitive performance. Journal of Experimental Psychology: General 132(3), 331–350 (2003). 10.1037/0096-3445.132.3.331 [DOI] [PubMed] [Google Scholar]
- [32].Mangalam M., Conners J.D., Kelty-Stephen D.G., Singh T.: Fractal fluctuations in muscular activity contribute to judgments of length but not heaviness via dynamic touch. Experimental Brain Research 237(5), 1213–1226 (2019). 10.1007/s00221-019-05505-2 [DOI] [PubMed] [Google Scholar]
- [33].Mangalam M., Chen R., McHugh T.R., Singh T., Kelty-Stephen D.G.: Bodywide fluctuations support manual exploration: Fractal fluctuations in posture predict perception of heaviness and length via effortful touch by the hand. Human Movement Science 69, 102543 (2020). 10.1016/j.humov.2019.102543 [DOI] [PubMed] [Google Scholar]
- [34].Mangalam M., Carver N.S., Kelty-Stephen D.G.: Global broadcasting of local fractal fluctuations in a bodywide distributed system supports perception via effortful touch. Chaos, Solitons & Fractals 135, 109740 (2020). 10.1016/j.chaos.2020.109740 [DOI] [Google Scholar]
- [35].Ashkenazy Y., Lewkowicz M., Levitan J., Havlin S., Saermark K., Moelgaard H., Thomsen P.B.: Discrimination between healthy and sick cardiac autonomic nervous system by detrended heart rate variability analysis. Fractals 7(1), 85–91 (1999). 10.1142/S0218348X99000104 [DOI] [Google Scholar]
- [36].Ho K.K., Moody G.B., Peng C.-K., Mietus J.E., Larson M.G., Levy D., Goldberger A.L.: Predicting survival in heart failure case and control subjects by use of fully automated methods for deriving nonlinear and conventional indices of heart rate dynamics. Circulation 96(3), 842–848 (1997). 10.1161/01.CIR.96.3.842 [DOI] [PubMed] [Google Scholar]
- [37].Peng C.-K., Havlin S., Hausdorff J., Mietus J., Stanley H., Goldberger A.: Fractal mechanisms and heart rate dynamics: Long-range correlations and their breakdown with disease. Journal of Electrocardiology 28, 59–65 (1995). 10.1016/S0022-0736(95)80017-4 [DOI] [PubMed] [Google Scholar]
- [38].Bartsch R., Plotnik M., Kantelhardt J.W., Havlin S., Giladi N., Hausdorff J.M.: Fluctuation and synchronization of gait intervals and gait force profiles distinguish stages of Parkinson’s disease. Physica A: Statistical Mechanics and its Applications 383(2), 455–465 (2007). 10.1016/j.physa.2007.04.120 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Hausdorff J.M., Mitchell S.L., Firtion R., Peng C.-K., Cudkowicz M.E., Wei J.Y., Goldberger A.L.: Altered fractal dynamics of gait: Reduced stride-interval correlations with aging and Huntington’s disease. Journal of Applied Physiology 82(1), 262–269 (1997). 10.1152/jappl.1997.82.1.262 [DOI] [PubMed] [Google Scholar]
- [40].Hausdorff J.M., Ashkenazy Y., Peng C.-K., Ivanov P.C., Stanley H.E., Goldberger A.L.: When human walking becomes random walking: Fractal analysis and modeling of gait rhythm fluctuations. Physica A: Statistical Mechanics and its Applications 302(1–4), 138–147 (2001). 10.1016/S0378-4371(01)00460-5 [DOI] [PubMed] [Google Scholar]
- [41].Hausdorff J.M.: Gait dynamics, fractals and falls: Finding meaning in the stride-to-stride fluctuations of human walking. Human Movement Science 26 (4), 555–589 (2007). 10.1016/j.humov.2007.05.003 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [42].Herman T., Giladi N., Gurevich T., Hausdorff J.: Gait instability and fractal dynamics of older adults with a “cautious” gait: Why do certain older adults walk fearfully? Gait & Posture 21(2), 178–185 (2005). 10.1016/j.gaitpost.2004.01.014 [DOI] [PubMed] [Google Scholar]
- [43].Kobsar D., Olson C., Paranjape R., Hadjistavropoulos T., Barden J.M.: Evaluation of age-related differences in the stride-to-stride fluctuations, regularity and symmetry of gait using a waistmounted tri-axial accelerometer. Gait & Posture 39(1), 553–557 (2014). 10.1016/j.gaitpost.2013.09.008 [DOI] [PubMed] [Google Scholar]
- [44].Mangalam M., Skiadopoulos A., Siu K.-C., Mukherjee M., Likens A., Stergiou N.: Leveraging a virtual alley with continuously varying width modulates step width variability during self-paced treadmill walking. Neuroscience Letters 793, 136966 (2022). 10.1016/j.neulet.2022.136966 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [45].Raffalt P.C., Stergiou N., Sommerfeld J.H., Likens A.D.: The temporal pattern and the probability distribution of visual cueing can alter the structure of stride-to-stride variability. Neuroscience Letters 763, 136193 (2021). 10.1016/j.neulet.2021.136193 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [46].Raffalt P.C., Sommerfeld J.H., Stergiou N., Likens A.D.: Stride-to-stride time intervals are independently affected by the temporal pattern and probability distribution of visual cues. Neuroscience Letters 792, 136909 (2023). 10.1016/j.neulet.2022.136909 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [47].Kaipust J.P., McGrath D., Mukherjee M., Stergiou N.: Gait variability is altered in older adults when listening to auditory stimuli with differing temporal structures. Annals of Biomedical Engineering 41(8), 1595–1603 (2013). 10.1007/s10439-012-0654-9 [DOI] [PubMed] [Google Scholar]
- [48].Marmelat V., Duncan A., Meltz S., Meidinger R.L., Hellman A.M.: Fractal auditory stimulation has greater benefit for people with Parkinson’s disease showing more random gait pattern. Gait & Posture 80, 234–239 (2020). 10.1016/j.gaitpost.2020.05.021 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [49].Vaz J.R., Knarr B.A., Stergiou N.: Gait complexity is acutely restored in older adults when walking to a fractal-like visual stimulus. Human Movement Science 74, 102677 (2020). 10.1016/j.humov.2020.102677 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [50].Kiyono K., Tsujimoto Y.: Nonlinear filtering properties of detrended fluctuation analysis. Physica A: Statistical Mechanics and its Applications 462, 807–815 (2016). 10.1016/j.physa.2016.06.129 [DOI] [Google Scholar]
- [51].Alvarez-Ramirez J., Rodriguez E., Echeverría J.C.: Detrending fluctuation analysis based on moving average filtering. Physica A: Statistical Mechanics and its Applications 354, 199–219 (2005). 10.1016/j.physa.2005.02.020 [DOI] [Google Scholar]
- [52].Arianos S., Carbone A.: Detrending moving average algorithm: A closed-form approximation of the scaling law. Physica A: Statistical Mechanics and its Applications 382(1), 9–15 (2007). 10.1016/j.physa.2007.02.074 [DOI] [Google Scholar]
- [53].Höll M., Kiyono K., Kantz H.: Theoretical foundation of detrending methods for fluctuation analysis such as detrended fluctuation analysis and detrending moving average. Physical Review E 99(3), 033305 (2019). 10.1103/PhysRevE.99.033305 [DOI] [PubMed] [Google Scholar]
- [54].Govindan R.: Detrended fluctuation analysis using orthogonal polynomials. Physical Review E 101(1), 010201 (2020). 10.1103/PhysRevE.101.010201 [DOI] [PubMed] [Google Scholar]
- [55].Chen Z., Hu K., Carpena P., Bernaola-Galvan P., Stanley H.E., Ivanov P.C.: Effect of nonlinear filters on detrended fluctuation analysis. Physical Review E 71(1), 011104 (2005). 10.1103/PhysRevE.71.011104 [DOI] [PubMed] [Google Scholar]
- [56].Hu K., Ivanov P.C., Chen Z., Carpena P., Stanley H.E.: Effect of trends on detrended fluctuation analysis. Physical Review E 64(1), 011114 (2001). 10.1103/PhysRevE.64.011114 [DOI] [PubMed] [Google Scholar]
- [57].Shao Y.-H., Gu G.-F., Jiang Z.-Q., Zhou W.-X., Sornette D.: Comparing the performance of FA, DFA and DMA using different synthetic long-range correlated time series. Scientific Reports 2, 835 (2012). 10.1038/srep00835 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [58].Qian X.-Y., Gu G.-F., Zhou W.-X.: Modified detrended fluctuation analysis based on empirical mode decomposition for the characterization of anti-persistent processes. Physica A: Statistical Mechanics and its Applications 390(23–24), 4388–4395 (2011). 10.1016/j.physa.2011.07.008 [DOI] [Google Scholar]
- [59].Xu L., Ivanov P.C., Hu K., Chen Z., Carbone A., Stanley H.E.: Quantifying signals with power-law correlations: A comparative study of detrended fluctuation analysis and detrended moving average techniques. Physical Review E 71(5), 051101 (2005). 10.1103/PhysRevE.71.051101 [DOI] [PubMed] [Google Scholar]
- [60].Bashan A., Bartsch R., Kantelhardt J.W., Havlin S.: Comparison of detrending methods for fluctuation analysis. Physica A: Statistical Mechanics and its Applications 387(21), 5080–5090 (2008). 10.1016/j.physa.2008.04.023 [DOI] [Google Scholar]
- [61].Grech D., Mazur Z.: Statistical properties of old and new techniques in detrended analysis of time series. Acta Physica Polonica Series B 36(8), 2403 (2005) [Google Scholar]
- [62].Dlask M., Kukal J.: Hurst exponent estimation from short time series. Signal, Image and Video Processing 13(2), 263–269 (2019). 10.1007/s11760-018-1353-2 [DOI] [Google Scholar]
- [63].Katsev S., L’Heureux I.: Are Hurst exponents estimated from short or irregular time series meaningful? Computers & Geosciences 29(9), 1085–1089 (2003). 10.1016/S0098-3004(03)00105-5 [DOI] [Google Scholar]
- [64].Schaefer A., Brach J.S., Perera S., Sejdić E.: A comparative analysis of spectral exponent estimation techniques for 1/fβ processes with applications to the analysis of stride interval time series. Journal of Neuroscience Methods 222, 118–130 (2014). 10.1016/j.jneumeth.2013.10.017 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [65].Almurad Z.M., Delignières D.: Evenly spacing in detrended fluctuation analysis. Physica A: Statistical Mechanics and its Applications 451, 63–69 (2016). 10.1016/j.physa.2015.12.155 [DOI] [Google Scholar]
- [66].Delignieres D., Ramdani S., Lemoine L., Torre K., Fortes M., Ninot G.: Fractal analyses for ‘short’ time series: A re-assessment of classical methods. Journal of Mathematical Psychology 50(6), 525–544 (2006). 10.1016/j.jmp.2006.07.004 [DOI] [Google Scholar]
- [67].Marmelat V., Meidinger R.L.: Fractal analysis of gait in people with Parkinson’s disease: Three minutes is not enough. Gait & Posture 70, 229–234 (2019). 10.1016/j.gaitpost.2019.02.023 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [68].Ravi D.K., Marmelat V., Taylor W.R., Newell K.M., Stergiou N., Singh N.B.: Assessing the temporal organization of walking variability: A systematic review and consensus guidelines on detrended fluctuation analysis. Frontiers in Physiology 11, 562 (2020). 10.3389/fphys.2020.00562 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [69].Roume C., Ezzina S., Blain H., Delignières D.: Biases in the simulation and analysis of fractal processes. Computational and Mathematical Methods in Medicine 2019, 4025305 (2019). 10.1155/2019/4025305 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [70].Yuan Q., Gu C., Weng T., Yang H.: Unbiased detrended fluctuation analysis: Long-range correlations in very short time series. Physica A: Statistical Mechanics and its Applications 505, 179–189 (2018). 10.1016/j.physa.2018.03.043 [DOI] [Google Scholar]
- [71].Stephen D.G., Boncoddo R.A., Magnuson J.S., Dixon J.A.: The dynamics of insight: Mathematical discovery as a phase transition. Memory & Cognition 37(8), 1132–1149 (2009). 10.3758/MC.37.8.1132 [DOI] [PubMed] [Google Scholar]
- [72].Stephen D.G., Anastas J.R., Dixon J.A.: Scaling in cognitive performance reflects multiplicative multifractal cascade dynamics. Frontiers in Physiology, 102 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]; Scalingincognitiveperformancereflectsmultiplicativemultifractalcascadedynamics
- [73].Stroe-Kunold E., Stadnytska T., Werner J., Braun S.: Estimating long-range dependence in time series: An evaluation of estimators implemented in R. Behavior Research Methods 41(3), 909–923 (2009). 10.3758/BRM.41.3.909 [DOI] [PubMed] [Google Scholar]
- [74].Peng C.-K., Buldyrev S.V., Havlin S., Simons M., Stanley H.E., Goldberger A.L.: Mosaic organization of DNA nucleotides. Physical Review E 49(2), 1685 (1994). 10.1103/PhysRevE.49.1685 [DOI] [PubMed] [Google Scholar]
- [75].Peng C.-K., Havlin S., Stanley H.E., Goldberger A.L.: Quantification of scaling exponents and crossover phenomena in nonstationary heartbeat time series. Chaos 5(1), 82–87 (1995). 10.1063/1.166141 [DOI] [PubMed] [Google Scholar]
- [76].Tyralis H., Koutsoyiannis D.: A Bayesian statistical model for deriving the predictive distribution of hydroclimatic variables. Climate Dynamics 42(11), 2867–2883 (2014). 10.1007/s00382-013-1804-y [DOI] [Google Scholar]
- [77].Koutsoyiannis D.: Climate change, the Hurst phenomenon, and hydrological statistics. Hydrological Sciences Journal 48(1), 3–24 (2003). 10.1623/hysj.48.1.3.43481 [DOI] [Google Scholar]
- [78].Golub G.H., Van Loan C.F.: Matrix Computations. John Hopkins University Press, Baltimore, MD: (2013) [Google Scholar]
- [79].Robert C.P., Casella G., Casella G.: Monte Carlo Statistical Methods vol. 2. Springer, New York, NY: (1999) [Google Scholar]
- [80].R Core Team: R: A language and environment for statistical computing (2013). https://www.R-project.org/
- [81].Tyralis H.: Package ‘hkprocess’. R Package Version 0.1–1 (2022). https://cran.r-project.org/package=HKprocess [Google Scholar]
- [82].Damouras S., Chang M.D., Sejdić E., Chau T.: An empirical examination of detrended fluctuation analysis for gait data. Gait & Posture 31(3), 336–340 (2010). 10.1016/j.gaitpost.2009.12.002 [DOI] [PubMed] [Google Scholar]
- [83].Farag A.F., El-Metwally S.M., Morsy A.A.A.: Automated sleep staging using detrended fluctuation analysis of sleep EEG. In: Soft Computing Applications, pp. 501–510. Springer, New York, NY: (2013). 10.1007/978-3-642-33941-744 [DOI] [Google Scholar]
- [84].Jordan K., Challis J.H., Newell K.M.: Long range correlations in the stride interval of running. Gait & Posture 24(1), 120–125 (2006). 10.1016/j.gaitpost.2005.08.003 [DOI] [PubMed] [Google Scholar]
- [85].Likens A.D., Fine J.M., Amazeen E.L., Amazeen P.G.: Experimental control of scaling behavior: What is not fractal? Experimental Brain Research 233(10), 2813–2821 (2015). 10.1007/s00221-015-4351-4 [DOI] [PubMed] [Google Scholar]
- [86].Likens A.D., Stergiou N.: A tutorial on fractal analysis of human movements. In: Stergiou N. (ed.) Biomechanics and Gait Analysis, pp. 313–344. Academic Press, Cambridge, MA: (2020) [Google Scholar]
- [87].Likens A., Wiltshire T.: fractalRegression: An R package for fractal analyses and regression (2021). https://github.com/aaronlikens/fractalRegression
- [88].Davies R.B., Harte D.: Tests for Hurst effect. Biometrika 74(1), 95–101 (1987). 10.1093/biomet/74.1.95 [DOI] [Google Scholar]
- [89].Gilden D.L.: Cognitive emissions of 1/f noise. Psychological Review 108(1), 33–56 (2001). 10.1037/0033-295X.108.1.33 [DOI] [PubMed] [Google Scholar]
- [90].Grigolini P., Aquino G., Bologna M., Luković M., West B.J.: A theory of 1/f noise in human cognition. Physica A: Statistical Mechanics and its Applications 388(19), 4192–4204 (2009). 10.1016/j.physa.2009.06.024 [DOI] [Google Scholar]
- [91].Van Orden G.C., Holden J.G., Turvey M.T.: Human cognition and 1/f scaling. Journal of Experimental Psychology: General 134(1), 117–123 (2005). 10.1037/0096-3445.134.1.117 [DOI] [PubMed] [Google Scholar]
- [92].Bollens B., Crevecoeur F., Nguyen V., Detrembleur C., Lejeune T.: Does human gait exhibit comparable and reproducible long-range auto-correlations on level ground and on treadmill? Gait & Posture 32(3), 369–373 (2010). 10.1016/j.gaitpost.2010.06.011 [DOI] [PubMed] [Google Scholar]
- [93].Ducharme S.W., Liddy J.J., Haddad J.M., Busa M.A., Claxton L.J., van Emmerik R.E.: Association between stride time fractality and gait adaptability during unperturbed and asymmetric walking. Human Movement Science 58, 248–259 (2018). 10.1016/j.humov.2018.02.011 [DOI] [PubMed] [Google Scholar]
- [94].Fairley J.A., Sejdić E., Chau T.: The effect of treadmill walking on the stride interval dynamics of children. Human Movement Science 29(6), 987–998 (2010). 10.1016/j.humov.2010.07.015 [DOI] [PubMed] [Google Scholar]
- [95].Hausdorff J.M., Peng C.-K., Ladin Z., Wei J.Y., Goldberger A.L.: Is walking a random walk? Evidence for long-range correlations in stride interval of human gait. Journal of Applied Physiology 78(1), 349–358 (1995). 10.1152/jappl.1995.78.1.349 [DOI] [PubMed] [Google Scholar]
- [96].Hausdorff J.M., Purdon P.L., Peng C.-K., Ladin Z., Wei J.Y., Goldberger A.L.: Fractal dynamics of human gait: Stability of long-range correlations in stride interval fluctuations. Journal of Applied Physiology 80(5), 1448–1457 (1996). 10.1152/jappl.1996.80.5.1448 [DOI] [PubMed] [Google Scholar]
- [97].Jordan K., Challis J.H., Cusumano J.P., Newell K.M.: Stability and the time-dependent structure of gait variability in walking and running. Human Movement Science 28(1), 113–128 (2009). 10.1016/j.humov.2008.09.001 [DOI] [PubMed] [Google Scholar]
- [98].Terrier P., Dériaz O.: Kinematic variability, fractal dynamics and local dynamic stability of treadmill walking. Journal of Neuroengineering and Rehabilitation 8(1), 12 (2011). 10.1186/1743-0003-8-12 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [99].Agresta C.E., Goulet G.C., Peacock J., Housner J., Zernicke R.F., Zendler J.D.: Years of running experience influences stride-to-stride fluctuations and adaptive response during step frequency perturbations in healthy distance runners. Gait & Posture 70, 376–382 (2019). 10.1016/j.gaitpost.2019.02.034 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [100].Bellenger C.R., Arnold J.B., Buckley J.D., Thewlis D., Fuller J.T.: Detrended fluctuation analysis detects altered coordination of running gait in athletes following a heavy period of training. Journal of Science and Medicine in Sport 22(3), 294–299 (2019). 10.1016/j.jsams.2018.09.002 [DOI] [PubMed] [Google Scholar]
- [101].Brahms C.M., Zhao Y., Gerhard D., Barden J.M.: Long-range correlations and stride pattern variability in recreational and elite distance runners during a prolonged run. Gait & Posture 92, 487–492 (2020). 10.1016/j.gaitpost.2020.08.107 [DOI] [PubMed] [Google Scholar]
- [102].Fuller J.T., Amado A., van Emmerik R.E., Hamill J., Buckley J.D., Tsiros M.D., Thewlis D.: The effect of footwear and footfall pattern on running stride interval long-range correlations and distributional variability. Gait & Posture 44, 137–142 (2016). 10.1016/j.gaitpost.2015.12.006 [DOI] [PubMed] [Google Scholar]
- [103].Fuller J.T., Bellenger C.R., Thewlis D., Arnold J., Thomson R.L., Tsiros M.D., Robertson E.Y., Buckley J.D.: Tracking performance changes with running-stride variability when athletes are functionally overreached. International Journal of Sports Physiology and Performance 12(3), 357–363 (2017). 10.1123/ijspp.2015-0618 [DOI] [PubMed] [Google Scholar]
- [104].Lindsay T.R., Noakes T.D., McGregor S.J.: Effect of treadmill versus overground running on the structure of variability of stride timing. Perceptual and Motor Skills 118(2), 331–346 (2014). 10.2466/30.26.PMS.118k18w8 [DOI] [PubMed] [Google Scholar]
- [105].Nakayama Y., Kudo K., Ohtsuki T.: Variability and fluctuation in running gait cycle of trained runners and non-runners. Gait & Posture 31(3), 331–335 (2010). 10.1016/j.gaitpost.2009.12.003 [DOI] [PubMed] [Google Scholar]
- [106].Jordan K., Challis J.H., Newell K.M.: Speed influences on the scaling behavior of gait cycle fluctuations during treadmill running. Human Movement Science 26(1), 87–102 (2007). 10.1016/j.humov.2006.10.001 [DOI] [PubMed] [Google Scholar]
- [107].Hausdorff J.M.: Gait dynamics in Parkinson’s disease: Common and distinct behavior among stride length, gait variability, and fractal-like scaling. Chaos: An Interdisciplinary Journal of Nonlinear Science 19(2), 026113 (2009). 10.1063/1.3147408 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [108].Hausdorff J.M., Rios D.A., Edelberg H.K.: Gait variability and fall risk in community-living older adults: A 1-year prospective study. Archives of Physical Medicine and Rehabilitation 82(8), 1050–1056 (2001). 10.1053/apmr.2001.24893 [DOI] [PubMed] [Google Scholar]
- [109].Johansson J., Nordström A., Nordström P.: Greater fall risk in elderly women than in men is associated with increased gait variability during multitasking. Journal of the American Medical Directors Association 17(6), 535–540 (2016). 10.1016/j.jamda.2016.02.009 [DOI] [PubMed] [Google Scholar]
- [110].Paterson K., Hill K., Lythgo N.: Stride dynamics, gait variability and prospective falls risk in active community dwelling older women. Gait & Posture 33(2), 251–255 (2011). 10.1016/j.gaitpost.2010.11.014 [DOI] [PubMed] [Google Scholar]
- [111].Toebes M.J., Hoozemans M.J., Furrer R., Dekker J., van Dieën J.H.: Local dynamic stability and variability of gait are associated with fall history in elderly subjects. Gait & Posture 36(3), 527–531 (2012). 10.1016/j.gaitpost.2012.05.016 [DOI] [PubMed] [Google Scholar]
- [112].Wilson T., Mangalam M., Stergiou N., Likens A.: Multifractality in stride-to-stride variations reveals that walking entails tuning and adjusting movements more than running Under review (2023) [DOI] [PMC free article] [PubMed]
- [113].Martin P.E., Rothstein D.E., Larish D.D.: Effects of age and physical activity status on the speed-aerobic demand relationship of walking. Journal of Applied Physiology 73(1), 200–206 (1992). 10.1152/jappl.1992.73.1.200 [DOI] [PubMed] [Google Scholar]
- [114].Pinheiro J., Bates D., DebRoy S., Sarkar D., Team R.C.: Linear and nonlinear mixed effects models. R Package Version 3.1–96 (2007). https://cran.r-project.org/package=nlme [Google Scholar]
- [115].Kuznetsova A., Brockhoff P.B., Christensen R.H.B., et al. : Package ‘lmertest’. R package version 3.1–3 (2015). http://cran.r-project.org/package=multcomp [Google Scholar]
- [116].Luke S.G.: Evaluating significance in linear mixed-effects models in R. Behavior Research Methods 49(4), 1494–1502 (2017). 10.3758/s13428-016-0809-y [DOI] [PubMed] [Google Scholar]
- [117].Kuznetsov N.A., Rhea C.K.: Power considerations for the application of detrended fluctuation analysis in gait variability studies. PLoS One 12(3), 0174144 (2017). 10.1371/journal.pone.0174144 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [118].Amrhein V., Greenland S., McShane B.: Scientists rise up against statistical significance 567, 305–307 (2019). 10.1038/d41586-019-00857-9 [DOI] [PubMed] [Google Scholar]
- [119].Berger J.O., Sellke T.: Testing a point null hypothesis: The irreconcilability of P values and evidence. Journal of the American statistical Association 82(397), 112–122 (1987). 10.1080/01621459.1987.10478397 [DOI] [Google Scholar]
- [120].Halsey L.G.: The reign of the p-value is over: What alternative analyses could we employ to fill the power vacuum? Biology Letters 15(5), 20190174 (2019). 10.1098/rsbl.2019.0174 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [121].Ioannidis J.P.: What have we (not) learnt from millions of scientific papers with P values? The American Statistician 73(sup1), 20–25 (2019). 10.1080/00031305.2018.1447512 [DOI] [Google Scholar]
- [122].Lieberman M.D., Cunningham W.A.: Type I and type II error concerns in fMRI research: Re-balancing the scale. Social Cognitive and Affective Neuroscience 4(4), 423–428 (2009). 10.1093/scan/nsp052 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [123].Delignières D., Torre K., Lemoine L.: Long-range correlation in synchronization and syncopation tapping: A linear phase correction model. PloS One 4(11), 7822 (2009). 10.1371/journal.pone.0007822 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [124].Lemoine L., Torre K., Delignières D.: Testing for the presence of 1/f noise in continuation tapping data. Canadian Journal of Experimental Psychology 60(4), 247–257 (2006). 10.1037/cjep2006023 [DOI] [PubMed] [Google Scholar]
- [125].Torre K., Delignières D.: Unraveling the finding of 1/fβ noise in self-paced and synchronized tapping: A unifying mechanistic model. Biological Cybernetics 99(2), 159–170 (2008). 10.1007/s00422-008-0247-8 [DOI] [PubMed] [Google Scholar]
- [126].Torre K., Balasubramaniam R., Rheaume N., Lemoine L., Zelaznik H.N.: Long-range correlation properties in motor timing are individual and task specific. Psychonomic Bulletin & Review 18(2), 339–346 (2011). 10.3758/s13423-011-0049-1 [DOI] [PubMed] [Google Scholar]
- [127].Coey C.A., Hassebrock J., Kloos H., Richardson M.J.: The complexities of keeping the beat: Dynamical structure in the nested behaviors of finger tapping. Attention, Perception, & Psychophysics 77(4), 1423–1439 (2015). 10.3758/s13414-015-0842-4 [DOI] [PubMed] [Google Scholar]
- [128].Delignières D., Marmelat V.: Strong anticipation and long-range cross-correlation: Application of detrended cross-correlation analysis to human behavioral data. Physica A: Statistical Mechanics and its Applications 394, 47–60 (2014). 10.1016/j.physa.2013.09.037 [DOI] [Google Scholar]
- [129].Holden J.G., Van Orden G.C., Turvey M.T.: Dispersion of response times reveals cognitive dynamics. Psychological Review 116(2), 318–342 (2009). 10.1037/a0014849 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [130].Kuznetsov N.A., Wallot S.: Effects of accuracy feedback on fractal characteristics of time estimation. Frontiers in Integrative Neuroscience 5, 62 (2011). 10.3389/fnint.2011.00062 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [131].Wagenmakers E.-J., Farrell S., Ratcliff R.: Estimation and interpretation of 1/fα noise in human cognition. Psychonomic Bulletin & Review 11(4), 579–615 (2004). 10.3758/BF03196615 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [132].Irrmischer M., van der Wal C.N., Mansvelder H.D., Linkenkaer-Hansen K.: Negative mood and mind wandering increase long-range temporal correlations in attention fluctuations. PloS One 13(5), 0196907 (2018). 10.1371/journal.pone.0196907 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [133].Malone M., Castillo R.D., Kloos H., Holden J.G., Richardson M.J.: Dynamic structure of joint-action stimulus-response activity. PLoS One 9(2), 89032 (2014). 10.1371/journal.pone.0089032 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [134].Snodgrass J.G., Luce R.D., Galanter E.: Some experiments on simple and choice reaction time. Journal of experimental psychology 75(1), 1–17 (1967). 10.1037/h0021280 [DOI] [PubMed] [Google Scholar]
- [135].Cohen P.: To be or not to be: Control and balancing of type I and type II errors. Evaluation and Program Planning 5(3), 247–253 (1982). 10.1016/0149-7189(82)90076-3 [DOI] [Google Scholar]
- [136].DeGroot M.H., Schervish M.J.: Probability and Statistics. Pearson Education, ??? (2012). London, UK [Google Scholar]
- [137].Harrison H.B., Saenz-Agudelo P., Planes S., Jones G.P., Berumen M.L.: On minimizing assignment errors and the trade-off between false positives and negatives in parentage analysis. Wiley Online Library. 10.1111/mec.12527 (2013) [DOI] [PubMed] [Google Scholar]
- [138].Walley R.J., Grieve A.P.: Optimising the trade-off between type I and II error rates in the Bayesian context. Pharmaceutical Statistics 20(4), 710–720 (2021). 10.1002/pst.2102 [DOI] [PubMed] [Google Scholar]
- [139].Bloomfield L., Lane E., Mangalam M., Kelty-Stephen D.G.: Perceiving and remembering speech depend on multifractal nonlinearity in movements producing and exploring speech. Journal of the Royal Society Interface 18(181), 20210272 (2021). 10.1098/rsif.2021.0272 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [140].Bryce R., Sprague K.: Revisiting detrended fluctuation analysis. Scientific Reports 2, 315 (2012). 10.1038/srep00315 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [141].Horvatic D., Stanley H.E., Podobnik B.: Detrended cross-correlation analysis for non-stationary time series with periodic trends. Europhysics Letters 94(1), 18007 (2011). 10.1209/0295-5075/94/18007 [DOI] [Google Scholar]
- [142].Chen Z., Ivanov P.C., Hu K., Stanley H.E.: Effect of nonstationarities on detrended fluctuation analysis. Physical Review E 65(4), 041107 (2002). 10.1103/PhysRevE.65.041107 [DOI] [PubMed] [Google Scholar]
- [143].Carpena P., Gómez-Extremera M., Bernaola-Galván P.A.: On the validity of detrended fluctuation analysis at short scales. Entropy 24(1), 61 (2021). 10.3390/e24010061 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [144].Gao J., Hu J., Mao X., Perc M.: Culturomics meets random fractal theory: Insights into long-range correlations of social and natural phenomena over the past two centuries. Journal of The Royal Society Interface 9(73), 1956–1964 (2012). 10.1098/rsif.2011.0846 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [145].Telesca L., Lovallo M.: Long-range dependence in tree-ring width time series of Austrocedrus Chilensis revealed by means of the detrended fluctuation analysis. Physica A: Statistical Mechanics and its Applications 389(19), 4096–4104 (2010). 10.1016/j.physa.2010.05.031 [DOI] [Google Scholar]
- [146].Gao J., Hu J., Tung W. w.: Facilitating joint chaos and fractal analysis of biosignals through nonlinear adaptive filtering. PloS One 6(9), 24331 (2011). 10.1371/journal.pone.0024331 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [147].Shang P., Lin A., Liu L.: Chaotic svd method for minimizing the effect of exponential trends in detrended fluctuation analysis. Physica A: Statistical Mechanics and its Applications 388(5), 720–726 (2009). 10.1016/j.physa.2008.10.044 [DOI] [Google Scholar]
- [148].Nagarajan R., Kavasseri R.G.: Minimizing the effect of trends on detrended fluctuation analysis of long-range correlated noise. Physica A: Statistical Mechanics and its Applications 354, 182–198 (2005). 10.1016/j.physa.2005.01.041 [DOI] [Google Scholar]
- [149].Nagarajan R., Kavasseri R.G.: Minimizing the effect of sinusoidal trends in detrended fluctuation analysis. International Journal of Bifurcation and Chaos 15(05), 1767–1773 (2005). 10.1142/S021812740501279X [DOI] [Google Scholar]
- [150].Nagarajan R., Kavasseri R.G.: Minimizing the effect of periodic and quasi-periodic trends in detrended fluctuation analysis. Chaos, Solitons & Fractals 26(3), 777–784 (2005). 10.1016/j.chaos.2005.01.036 [DOI] [Google Scholar]
- [151].Xu N., Shang P., Kamae S.: Minimizing the effect of exponential trends in detrended fluctuation analysis. Chaos, Solitons & Fractals 41(1), 311–316 (2009). 10.1016/j.chaos.2007.12.006 [DOI] [Google Scholar]