

Abstract
Dynamic (or varying) covariate effects often manifest meaningful physiological mechanisms underlying chronic diseases. However, a static view of covariate effects is typically adopted by standard approaches to evaluating disease prognostic factors, which can result in depreciation of some important disease markers. To address this issue, in this work, we take the perspective of globally concerned quantile regression, and propose a flexible testing framework suited to assess either constant or dynamic covariate effects. We study the powerful Kolmogorov-Smirnov (K-S) and Cramér-Von Mises (C-V) type test statistics and develop a simple resampling procedure to tackle their complicated limit distributions. We provide rigorous theoretical results, including the limit null distributions and consistency under a general class of alternative hypotheses of the proposed tests, as well as the justifications for the presented resampling procedure. Extensive simulation studies and a real data example demonstrate the utility of the new testing procedures and their advantages over existing approaches in assessing dynamic covariate effects.
Keywords: Hypothesis testing, Globally concerned quantile regression, Testing consistency, Resampling
1. Introduction
Identifying useful prognostic factors is often of critical interests in chronic disease studies. When the disease outcome is captured by a time-to-event, a commonly used approach is to model the mechanism of a prognostic factor influencing the time-to-event outcome via a standard survival regression model and then test the corresponding covariate effects (see a review in Kleinbaum and Klein (2010) and Cox and Oakes (2018)). The standard survival regression models, such as the Cox proportional hazard (PH) regression model and the accelerated failure time (AFT) model, impose assumptions like the proportional hazards and the location-shift effects, which implicitly confine the prognostic factor of interest to be a static portent of disease progression.
There has been growing awareness that a prognostic factor may follow a dynamic association with a time-to-event disease outcome. Many reports in literature (Dickson et al., 1989; Thorogood et al., 1990; Verweij and van Houwelingen, 1995; Bellera et al., 2010, for example) have suggested that postulating constant covariate effects, sometimes, is not adequate to reflect underlying physiological disease mechanisms, leading to distorted assessment of the prognostic factor. For example, an analysis of a dialysis dataset reported by Peng and Huang (2008) suggested that the severity of restless leg syndrome (RLS) symptoms may be prognostic of mortality for short-term dialysis survivors but not for long-term dialysis survivors. The standard tests based on the Cox PH model and the AFT model failed to detect such a dynamic effect.
Quantile regression (Koenker and Bassett, 1978), which directly formulates covariate effects on quantile(s) of a response, confers a seminal venue to characterize a dynamic effect of a prognostic factor. Specifically, given a time-to-event outcome T and a covariate (which represents the prognostic factor of interest), a linear quantile regression model may assume,
| (1) |
where denotes the τ-th conditional quantile of T given , is an unknown coefficient vector, and Δ ⊆ (0, 1) is a pre-specified set including the quantile levels of interest. The coefficient represents the effect of on the τ-th conditional quantile of T, and is allowed to change with τ. This implicates that the prognostic factor is permitted to have different effects across different segments of the distribution of the time-to event outcome.
Many authors have studied linear quantile regression with a time-to-event outcome (Powell, 1986; Ying et al., 1995; Portnoy, 2003; Zhou, 2006; Peng and Huang, 2008; Wang and Wang, 2009; Huang, 2010, for example). Most of the existing methods concern covariate effects on a single or multiple pre-specified quantile levels (e.g. Δ is a singleton set {0.5}), and, following the terminology of Zheng et al. (2015), are locally concerned. As discussed in Zheng et al. (2015), locally concerned quantile regression cannot inform of the covariate effect on quantiles other than the specifically targeted ones (e.g. median), and thus may miss important prognostic factors. Adopting the perspective of globally concerned quantile regression, one can simultaneously examine covariate effects over a continuum of quantile levels (e.g. Δ is an interval [0.1, 0.9]), and thus confer a more comprehensive assessment of a prognostic factor. However, powerful tests tailored to evaluate covariate effects under the perspective of globally concerned quantile regression have not been formally studied, partly owing to the associated inferential complexity.
In this work, we develop a new framework for evaluating a survival prognostic factor following the spirit of globally concerned quantile regression. As a proof of concept, we shall confine the scope of this work to the standard survival setting where the time-to-event outcome T is subject to random censoring. Specifically, our proposal is to simultaneously assess the influence of the prognostic factor on a range of quantiles of T, indexed by a τ-interval, [τL, τU] ⊂ (0, 1). As the key rationale, a significant prognostic factor is allowed to have a dynamic τ-varying effect, which may be non-zero throughout the whole τ-interval (i.e. full effect), or only over a part of the τ-interval (i.e. partial effect). Under this view, when model (1) with Δ = [τL, τU] holds, the task of identifying a prognostic factor reduces to testing the null hypothesis,
Moreover, without assuming any models, we may consider the null hypothesis formulated as,
where QT(τ) = inf{t : Pr(T ≤ t) ≥ τ}, denoting the τ-th unconditional (or marginal) quantile of T. The null hypothesis corresponds to the setting where has no influence on the conditional quantile of T at any quantile level between τL and τU.
It is remarkable that under mild regularity conditions, implies that model (1) holds with Δ = [τL, τU] and for τ ∈ [τL, τU]; on the other hand, model (1) with Δ = [τL, τU] and for τ ∈ [τL, τU] implies for τ ∈ [τL, τU]; see Lemma 1 in the Appendix A. This finding sheds an important insight that a model-based test developed for H0 may be used towards testing the model-free null hypothesis . From an alternative view, this result suggests that the globally concerned quantile regression model (1) with Δ = [τL, τU] can be used as a working model to test , which adopts the view that the effect of a prognostic factor can be assessed through contrasting the conditional versus unconditional quantiles of T.
Regarding , we study two “omnibus” test statistics constructed based on the estimator of θ0(τ) obtained under the working model (1) with Δ = [τL, τU]. One test is a Kolmogorov-Smirnov (K-S) type test statistic defined upon the maximum “signal” strength (i.e. covariate effect) over τ’s in [τL, τU]. The other one is a CramérVon-Mises (C-V) type test statistics based on the average “signal” strength over τ’s in [τL, τU]. These two types of test statistics are known to be very sensitive to detect any departure from the null hypothesis H0 under model (1). However, the analytic form of their limit null distributions are generally complex and sometimes intractable. This challenge is more intense in the quantile regression setting, where coefficient estimates do not have a closed form, and the corresponding asymptotic variance matrix involves unknown density functions (Koenker, 2005). To overcome these difficulties, we propose to approximate the limit null distributions through a resampling procedure that perturbs the influence function associated with the adopted coefficient estimator under the working model (1), following similar strategies of Lin et al. (1993) and Li and Peng (2014). We derive a sample-based procedure to estimate the influence function without requiring the correct specification of model (1), thereby circumvents directly evaluating the unknown density function via smoothing. The proposed resampling procedure is easy to implement and is shown to perform well even with realistic sample sizes. Moreover, we provide rigorous theoretical justifications for the proposed resampling procedure.
The rest of this paper is organized as follows. In Section 2, we first briefly review some existing results about the estimation of model (1), which we use as a working model for testing . We then present the proposed test statistics along with their theoretical properties. A resampling procedure is developed to carry out inference regarding H0 or based on the proposed test statistics. We also discuss some computational strategies to help simplify or improve the implementation of the proposed method. In Section 3, we report extensive simulation studies conducted to evaluate the finite-sample performance of the proposed testing procedures. Our simulation results show that the proposed tests have accurate empirical sizes and can be much more powerful than benchmark methods when assessing a covariate with a dynamic effect. In Section 4, we further demonstrate the usefulness of the proposed testing procedures with a real data example. Concluding remarks and discussions are provided in Section 5.
2. The Proposed Testing Procedures
2.1. Estimation of θ0(τ) under model (1)
As explained in Section 1, we propose to use globally concerned quantile regression as a vehicle to address the testing problem regarding the general null hypothesis . The first step is to obtain an estimator of θ0(τ) (and thus ) from fitting the working model (1) to the observed data. Here and hereafter, we shall set the Δ in model (1) as Δ = [τL, τU], which is a pre-specified interval within (0, 1). Let C denote time to censoring, X = min(T, C), and δ = I(T ≤ C). The observed data include n i.i.d. replicates of (X, δ, Z), denoted by .
To estimate θ0(τ) under model (1), we choose to adapt the existing results of Peng and Fine (2009) developed for competing risks data to the setting with randomly censored data. Compared to the other available estimators developed by Portnoy (2003) and Peng and Huang (2008), which require τL = 0, the estimator derived from Peng and Fine (2009) is more robust to any realistic violation of the global linearity assumed by model (1) (Peng, 2021). The influence function associated with Peng and Fine (2009)’s estimator also has a simpler form that can facilitate the development of the corresponding testing procedures.
The estimator of θ0(τ) adapted from Peng and Fine (2009)’s work, denoted by , is obtained as the solution to the following estimating equation:
| (2) |
where is a reasonable estimator of G(x|Z) ≡ Pr(C ≥ x|Z). For simplicity of illustration, in sequel, we shall assume C is independent of and thus take as the Kaplan-Meier estimator of the marginal survival function of C, . As noted by Peng and Fine (2009), solving (2) can be formulated as a L1-type minimization problem of the following convex objective function:
Here M is a sufficiently large number. This L1-type minimization problem can be easily solved using the rq() function in the R package quantreg by Koenker (2022).
By the results of Peng and Fine (2009), the estimator enjoys desirable asymptotic properties. Specifically, under certain regularity conditions, we have (i) ; and (ii) converge weakly to a mean zero Gaussian process for τ ∈ [τL, τU] with covariance function Φ(τ′, τ) = E{ξ1(τ′)ξ1(τ)⊤}. Here ξi(τ) (i = 1, …, n) are defined as
where G(x) = Pr(C > x), A(b) = E[ZZ⊤f(Z⊤b|Z)] with f(t|Z) denoting the conditional density of X given Z, w(b, t) = E[ZY (t)I(X ≤ exp{Z⊤b})I(δ = 1)G(X)−1], and with , Yi(t) = I(Xi ≥ t), y(t) = Pr(X ≥ t), λG(t) = limΔ→0 P(C ∈ (t, t + Δ)|C ≥ t)/Δ, and . In addition, , where ≈ indicate asymptotical equivalence uniformly in τ ∈ [τL, τU]. Consequently, ξi(τ) is referred to as the influence function of .
Note that the variance estimation for is complicated by the involvement of the unknown density f(t|Z) in the asymptotic covariance matrix Φ(τ′, τ). As justified by Peng and Fine (2009), a sample-based procedure that avoids smoothing-based density estimation can be used for variance estimation and is outlined below:
-
(1.a)Compute an consistent variance estimate for Sn(θ0(τ), τ) given by
where for a vector a, a⊗2 = aa⊤.
-
(1.b)
Find a symmetric and nonsingular matrix En(τ) ≡ {en,0(τ), en,1(τ)} such that .
-
(1.c)
Calculate , where is the solution to the perturbed estimating equation Sn(b, τ) = e(τ).
-
(1.d)
Obtain an estimate for the asymptotic variance of as .
Here En(τ) can be computed with the eigenvalue eigenvector decomposition of using the R function eigen(). As another important remark, the above procedure ensures that the perturbation terms, en,j(τ), j = 1, 2, have the desired asymptotic order. As a result, this procedure remains valid when en,j(τ) in step (1.c) is replaced by u · en,j(τ) for some constant u. Based on our numerical experiences, incorporating some constant u can help stabilize variance estimation when sample size is small or τ is close to 0 or 1. Variance estimation based on the above procedure is found to have satisfactory finite sample performance based on some unreported simulation studies.
2.2. The proposed test statistics and theoretical properties
Express and let denote the square root of the second diagonal element of Vn(τ), which corresponds to the variance estimate for under . We propose to construct two “omnibus” test statistics based on and :
and
These two test statistics mimic the classic Kolmogorov-Smirnov (K-S) test statistic and CramérVon-Mises (C-V) test statistic for two-sample distribution comparisons (Darling, 1957). Under model (1), and capture the maximum and average magnitude of the covariate effect over τ ∈ [τL, τU] respectively. By this design, both test statistics are sensitive to any type of departures from the null hypothesis H0 and can be used to construct powerful tests for H0.
Without assuming model (1), we can also show that and provide valid tests for and have power approaching one under a general class of alternative hypotheses as specified in Theorem 2. The key insight is that even when model (1) does not hold, may still converge in probability to a deterministic function that is the solution to μ(b, τ) ≡ E[Z{I(log T ≤ Z⊤b) − τ}] = 0. It is easy to see that under model (1). By Lemma 1, it follows that under , for τ ∈ [τL, τU]. As detailed in Theorems A1–A2 in Appendix A, under certain regularity conditions, we further have , and converge weakly to a mean zero Gaussian process for τ ∈ [τL, τU] with covariance function , where are defined as
A useful by-product from the proof of Theorem A2 is that
| (3) |
We can prove these results by adapting the arguments of Peng and Fine (2009) which utilize model assumption (1) only through using its implication μ(θ0, τ) = 0 for τ ∈ [τL, τU]. This provides the critical justification for why can be used to test even when model (1) does not hold. The sample-based procedure reviewed in Section 2.1 is still applicable to estimate the asymptotic covariance matrix .
In Theorems 1 and 2, we establish useful asymptotic properties of and without assuming model (1). Specifically, in Theorem 1, we provide the limit distributions of the proposed test statistics under the null hypothesis :
Theorem 1 Assuming the regularity conditions (C1)–(C5) in the Appendix hold, under the null hypothesis H0 or , we have
where 𝒳(1)(τ) is a mean zero Gaussian process defined in Appendix C.
We also investigate the asymptotic behavior of the proposed test statistics under a general class of alternative hypotheses. The findings are stated in Theorem 2.
Theorem 2 Assuming the regularity conditions (C1)–(C5) in the Appendix hold,
- is consistent against the alternative hypothesis
is consistent against the alternative hypothesis:
The results of Theorem 2 indicate that the test statistics have power approaching to 1 (as n goes to ∞) under alternative cases subject to very mild constraints. Given the smoothness of , a general scenario that ensures the consistency of both and can be described as
This suggests that the proposed tests are powerful to identify a significant prognostic factor even when it only influences a segment of the outcome distribution, not necessarily the whole outcome distribution. This feature is conceptually appealing for handling a dynamic covariate effect, which may not have similar effect strength across different quantiles. The detailed proofs for Theorems 1 and 2 can be found in Appendix C.
2.3. The proposed resampling procedure to obtain p values
The results in Theorem 1 suggest that and , like the classic K-S test statistic and C-V test statistic, have complex, non-standard limit null distributions. This motivates us to develop a resampling-based procedure to approximate their limit null distributions and obtain the corresponding p values for testing .
Our key strategy is to approximate the distribution of , which reduces to under H0, through perturbing the influence function , which is the second component of . Similarly ideas were used by other authors, for example, Lin et al. (1993) and Li and Peng (2014). The core justification of our proposal is provided by equation (3), which suggests that may be used to approximate , where are i.i.d. standard normal variates.
Specifically, we take the following steps:
-
(2.a)
Generate B independent sets of , where are independent random variables from a standard normal distribution and b = 1, 2, …, B.
-
(2.b)Compute the estimates for the influence function as the second component of
where .
-
(2.c)For b = 1, …, B, calculate
where is the second component of .
-
(2.d)
The p values based on and are calculated respectively as
The resampling procedure presented above is easy to implement without involving smoothing. The rigorous theoretical justification for the presented resampling procedure is provided in Appendix D.
2.4. Some Computational Considerations
Note that and are piecewise constant; thus an exact calculation of the supremum or integration involved in and is possible. Alternatively, we may follow the recommendation of Zheng et al. (2015) to compute and based on a simpler piecewise-constant approximation of on a pre-determined fine τ-grid, , with the grid size . In this case, the proposed test statistics can be calculated as
| (4) |
When n is not large, the sample-based variance estimation (i.e. the computation of ) sometimes is not stable. Our remedy is to replace the en,j(τ) in step (1.c) (see Section 2.1) with u · en,j(τ), where u is a pre-specified constant. We develop the following algorithm to determine a good choice of the adjusting constant u among a set of candidate values, 𝒰 = {1, 2, …, U}.
-
(3.a)
For each u ∈ 𝒰, calculate for τ ∈ 𝒢, where is the computed with the adjusting constant u.
-
(3.b)
For each u ∈ 𝒰, calculate and .
-
(3.c)
For each u ∈ 𝒰, calculate , where Vn(τ; u) is Vn(τ) computed with the adjusting constant u. Here, for a matrix A, max(A) (or min(A)) denotes the largest (or the smallest) component of the matrix A.
-
(3.d)Assign a large positive value to A[0] and B[0], say 105. Set k = 1 and u[0] = U + 1.
- If and , then let , , and u[k] = k. Otherwise, let A[k] = A[k−1], B[k] = B[k−1] and u[k] = u[k−1].
- Increase k by 1 and go back to (i) until k > U.
-
(3.e)
If u[U] < U + 1, then choose u as u[U]. Otherwise, no appropriate u can be selected from 𝒰.
By this algorithm, we provide an empirical strategy to select u based on two estimation instability measures: (A) , which reflects the spread of over τ given u = k; (B) , which measures the maximum fluctuation of the estimated variance matrices across τ given u = k. It is clear that both measures would be large when unstable variance estimation occurs. Our algorithm first compares them with pre-specified initial values, A[0] and B[0], to rule out the occurrence of obviously outlying estimates of or . Once these two measures are found to meet the stability criteria set by the initial values with some u ∈ 𝒰, the algorithm will proceed to check if other u’s can yield smaller values of the instability measures. The output from this algorithm is either the value of u that produces the smallest instability measures, or an error message indicating that none of the constants in 𝒰 can lead to stable estimation required by the proposed testing procedure. Based on our numerical experiences, setting 𝒰 = {1, 2, …, 6}, which corresponds to U = 6, works well for small sample sizes such as 200 or 400. In a rare case where this algorithm fails to identify an appropriate u, we recommend adaptively increasing the value of U until an appropriate u can be identified. Our extensive numerical experiences suggest that incorporating the adjusting constant u selected by this algorithm results in good and stable numerical performance of the proposed tests. The algorithm can be easily generalized to allow 𝒰 to include non-integer values.
3. Simulation Studies
We conduct extensive simulation studies to investigate the finite-sample performance of the proposed resampling-based testing procedures. To simulate randomly censored data, we consider six setups where T and follow different relationships. In all setups, we generate from Uniform(0, 1) and generate censoring time C from Uniform(UL, UU), where UL and UU are properly specified to produce 15% or 30% censoring. Let Φ(·) denote the cumulative distribution function of the standard normal distribution. The six simulation set-ups are described as follows.
Setup I: Generate T such that Qτ{log(T)} = Φ−1(τ). Set (UL, UU) = (2, 3.8) to produce 15% censoring, and set (UL, UU) = (1, 2.5) to produce 30% censoring.
Setup II: Generate T such that Qτ{log(T)} = 0.2X +Φ−1(τ). Set (UL, UU) = (2.5, 3.9) to produce 15% censoring and set (UL, UU) = (1.2, 2.8) to produce 30% censoring.
Setup III: Generate T such that Qτ{log(T)} = 0.5X + Φ−1(τ). Set (UL, UU) = (2.7, 4.9) to produce 15% censoring, and set (UL, UU) = (1.5, 3) to produce 30% censoring.
Setup IV: Generate T such that Qτ{log(T)} = l4(τ)X + Φ−1(τ), where l4(τ) is as plotted in Figure 1. Set (UL, UU) = (2, 3.9) to produce 15% censoring, and set (UL, UU) = (1, 2.5) to produce 30% censoring.
Setup V: Generate T such that Qτ{log(T)} = l5(τ)X + Φ−1(τ), where l5(τ) is as plotted in Figure 1. Set (UL, UU) = (5.2, 6.5) to produce 15% censoring, and set (UL, UU) = (1.5, 3.5) to produce 30% censoring.
Setup VI: Generate T such that Qτ{log(T)} = l6(τ)X + Φ−1(τ), where l6(τ) is as plotted in Figure 1. Set (UL, UU) = (3.5, 5.5) to produce 15% censoring, and set (UL, UU) = (1.1, 3.5) to produce 30% censoring.
Fig. 1.
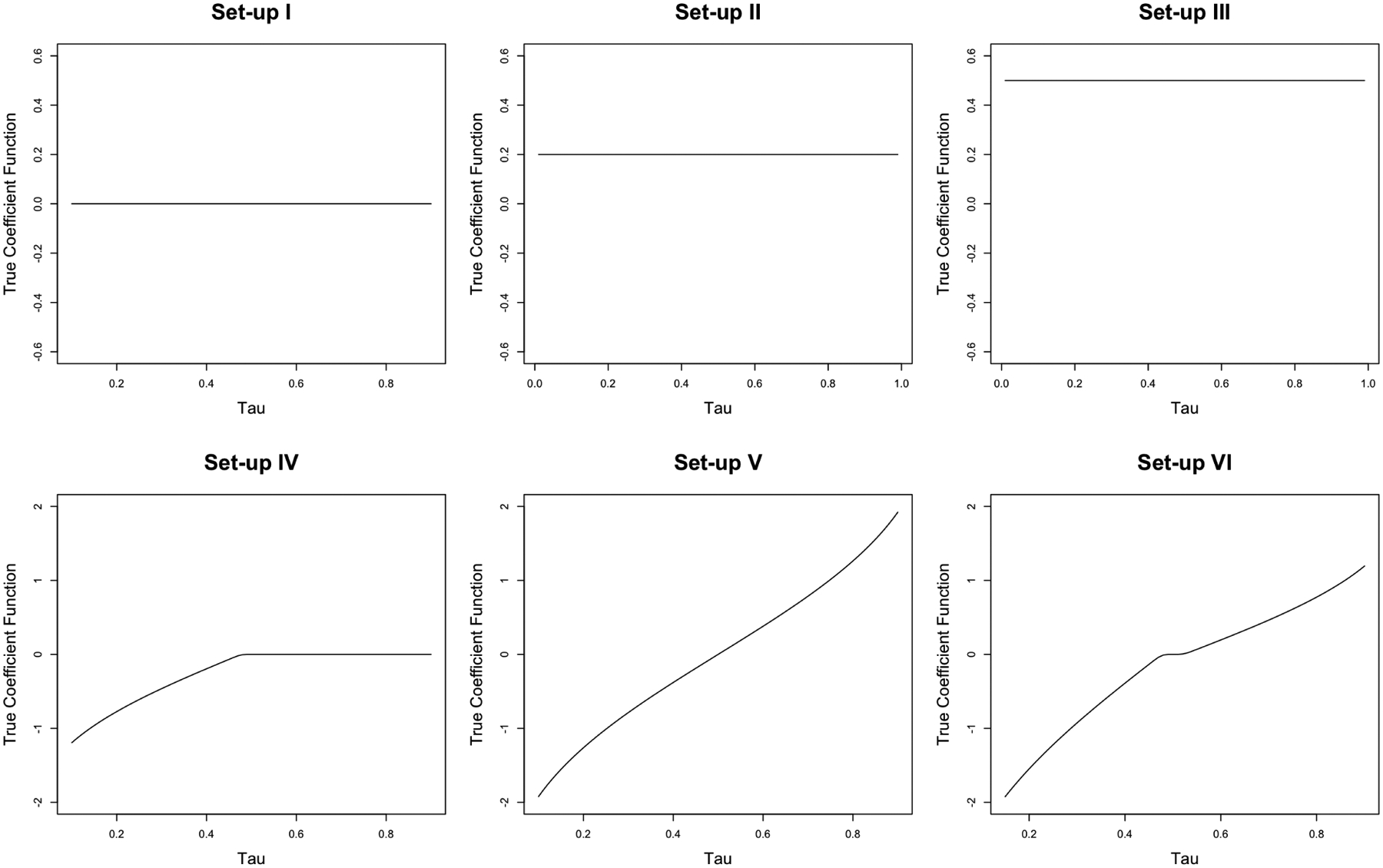
The true coefficient function for all simulation set-ups.
Under all setups, model (1) holds for τ ∈ (0, 1) and thus for τ ∈ [0.1, 0.6], a pre-specified τ-interval of interest [τL, τU]. In Figure 1, we plot the true coefficient function for each setup. It is easy to see that setup (I) represents a null case, where has no effect on any quantile of T. Setup (II) and (III) are two setups where has nonzero constant effects over all τ ∈ [0.1, 0.6]. The constant effect in setup (II) has a magnitude of 0.2, which is smaller than that in setup (III), which is 0.5. In setups (IV), (V), and (VII), has a dynamic effect varying across different τ’s. More specifically, has a partial effect over the τ-interval [0.1, 0.49] in setup (IV). In setup (V), the magnitude of ’s effect is symmetric around 0.5, while the sign of the effect is opposite for τ < 0.5 and for τ > 0.5, and the effect equals 0 at τ = 0.5. In setup (VI), the τ-varying effect pattern of is similar to that in setup (V) except that there is a small interval around 0.5 where has no effect in setup(VI).
We compare the proposed method with the Wald test based on the Cox PH model, denoted by “CPH (Wald)”, as well as the Wald test based on the locally concerned quantile regression that focuses on τ = 0.4, 0.5, or 0.6, denoted by “CQR (Wald)”. To implement CQR (Wald), we adopt Peng and Huang (2008)’s estimates with variance estimated by bootstrapping. The resampling size used for both CQR (Wald) and the proposed testing procedures is set as 2500. In the sequel, we shall refer the testing procedures based on and respectively to as GST and GIT. For all the methods, we consider sample sizes 200, 400, and 800. We set 𝒰 = {1, …, 6} when implementing the algorithm for selecting the constant u.
In Table 1, we report the empirical rejection rates based on 1000 simulations. The results in setup I show that the proposed GIT, and the existing tests, CQR (Wald) and CPH (Wald), have empirical sizes quite close to the nominal level 0.05. The proposed GST yields relatively larger empirical type I errors as compared to the other tests. The empirical size of GST equals 0.1 when the sample size is 200 but decreases to 0.077 when the sample size increases to 800. Such an anti-conservative behavior of GST is not surprising because the K-S type test statistic is defined based on the largest value of over τ ∈ [0.1, 0.6], which is more sensitive to a possible outlying value of at some τ.
Table 1.
Empirical rejection rate based on 1000 simulations.
| Set-up | n | Proposed Test | CQR (Wald) | CPH (Wald) | |||
|---|---|---|---|---|---|---|---|
| GST | GIT | τ = 0.4 | τ = 0.5 | τ = 0.6 | |||
| 15% censoring | |||||||
| I | 200 | 0.100 | 0.073 | 0.066 | 0.062 | 0.057 | 0.049 |
| 400 | 0.091 | 0.078 | 0.072 | 0.072 | 0.066 | 0.051 | |
| 800 | 0.077 | 0.055 | 0.064 | 0.063 | 0.059 | 0.061 | |
| II | 200 | 0.234 | 0.167 | 0.117 | 0.131 | 0.117 | 0.115 |
| 400 | 0.275 | 0.214 | 0.155 | 0.153 | 0.150 | 0.178 | |
| 800 | 0.410 | 0.362 | 0.277 | 0.265 | 0.247 | 0.322 | |
| III | 200 | 0.566 | 0.485 | 0.359 | 0.401 | 0.360 | 0.450 |
| 400 | 0.786 | 0.772 | 0.585 | 0.592 | 0.576 | 0.722 | |
| 800 | 0.957 | 0.957 | 0.873 | 0.887 | 0.865 | 0.960 | |
| IV | 200 | 0.377 | 0.254 | 0.097 | 0.060 | 0.053 | 0.063 |
| 400 | 0.652 | 0.478 | 0.116 | 0.065 | 0.063 | 0.067 | |
| 800 | 0.939 | 0.816 | 0.148 | 0.047 | 0.058 | 0.090 | |
| V | 200 | 0.653 | 0.464 | 0.143 | 0.070 | 0.118 | 0.260 |
| 400 | 0.937 | 0.827 | 0.208 | 0.071 | 0.153 | 0.458 | |
| 800 | 0.999 | 0.993 | 0.291 | 0.053 | 0.279 | 0.757 | |
| VI | 200 | 0.731 | 0.552 | 0.149 | 0.062 | 0.086 | 0.125 |
| 400 | 0.971 | 0.896 | 0.198 | 0.055 | 0.095 | 0.201 | |
| 800 | 1.000 | 0.995 | 0.260 | 0.033 | 0.142 | 0.364 | |
| 30% censoring | |||||||
| I | 200 | 0.171 | 0.095 | 0.062 | 0.060 | 0.048 | 0.047 |
| 400 | 0.110 | 0.085 | 0.069 | 0.074 | 0.065 | 0.056 | |
| 800 | 0.066 | 0.052 | 0.063 | 0.059 | 0.050 | 0.038 | |
| II | 200 | 0.302 | 0.186 | 0.115 | 0.122 | 0.105 | 0.122 |
| 400 | 0.305 | 0.221 | 0.152 | 0.156 | 0.138 | 0.188 | |
| 800 | 0.411 | 0.359 | 0.277 | 0.259 | 0.245 | 0.298 | |
| III | 200 | 0.681 | 0.539 | 0.360 | 0.393 | 0.322 | 0.432 |
| 400 | 0.828 | 0.791 | 0.585 | 0.590 | 0.534 | 0.703 | |
| 800 | 0.959 | 0.957 | 0.874 | 0.877 | 0.855 | 0.952 | |
| IV | 200 | 0.440 | 0.271 | 0.101 | 0.061 | 0.044 | 0.056 |
| 400 | 0.668 | 0.480 | 0.115 | 0.065 | 0.062 | 0.085 | |
| 800 | 0.947 | 0.804 | 0.150 | 0.048 | 0.046 | 0.089 | |
| V | 200 | 0.799 | 0.573 | 0.135 | 0.069 | 0.103 | 0.092 |
| 400 | 0.960 | 0.846 | 0.206 | 0.068 | 0.135 | 0.140 | |
| 800 | 1.000 | 0.993 | 0.292 | 0.054 | 0.282 | 0.211 | |
| VI | 200 | 0.803 | 0.587 | 0.148 | 0.063 | 0.077 | 0.053 |
| 400 | 0.978 | 0.903 | 0.199 | 0.052 | 0.082 | 0.064 | |
| 800 | 1.000 | 0.995 | 0.263 | 0.033 | 0.141 | 0.083 | |
When the quantile effect of is constant over τ (i.e. setups (II) and (III)), we note that in setup (II) where the effect size (i.e. magnitude of the constant effect) is relatively small, CPH (Wald) has lower empirical power as compared to the proposed GIT and GST, and the power improvement associated with the proposed GIT and GST is more evident with the smaller sample size 200. In setup (III), where the effect size is larger, CPH (Wald) still generally has lower empirical power compared to the proposed tests but its empirical power becomes comparable to that of GIT when the sample size is large (i.e. n = 800). These observations suggest that even in the trivial constant effect cases, the proposed tests can outperform the traditional Cox regression based tests in data scenarios with small effect sizes or sample sizes. In both setups (II) and (III), the locally concerned CQR (Wald) consistently yields lower empirical power than the proposed globally concerned GIT and GST. This reflects the power benefit resulted from integrating information on covariate effects on different quantiles as in GST and GIT, rather than focusing on the covariate effect on a single quantile as in CQR (Wald).
In setups (IV), (V), and (VI), the effect of is τ-varying, reflecting its dynamic association with T. In these cases, CPH (Wald), which assumes a constant covariate effect, can have poor power to detect the dynamic effect of (e.g. 8.3% empirical power in setup (VI) with n = 800 in the presence of 30% censoring), while the proposed GST and GIT may yield much higher power (e.g. >99% power in setup (VI) with n = 800 in the presence of 30% censoring). The locally concerned CQR (Wald) can have higher power than CPH (Wald) when the targeted quantile level is within the τ-region where is non-zero. When the targeted quantile level is outside the τ-region with non-zero effect, such as τ = 0.6 in setup (IV) or τ = 0.5 in setups (V) and (VI), the CQR (Wald) has even poorer power compared to CPH (Wald). This is well expected because these cases may serve as the null cases for the locally concerned CQR (Wald). This confirms that CQR (Wald) is inadequate to capture the meaningful effect of that is manifested at non-targeted quantiles.
We compare the simulation results across settings that are only differed by the censoring distribution. For each relationship between and T specified by setups (I)-(VI), we consider three different censoring distributions to yield 0%, 15%, and 30% censoring. The results for settings with 15% and 30% censoring are presented in Table 1 and the results based on uncensored data are presented in Table A.1 in Appendix E. From our comparisons, we find that quantile regression based tests, including GST, GIT and CQR (Wald), demonstrate small variations in empirical powers as the censoring rate (or distribution) changes. In cases with a constant covariate effect, the Cox regression based test, CPH (Wald), also has similar performance among settings with different censoring rates. However, in setup (V), where the covariate effect is not constant over τ, CPH (Wald) has reasonably good power when there is no censoring or only 15% censoring, but its performance deteriorates considerably when the censoring rate is increased to 30%. We have a similar observation for CPH (Wald) in setup (VI). A reasonable interpretation of these observations is that the capacity to detect a dynamic effect can be weakened by incorrectly assuming a constant proportional hazard effect and can be further attenuated by the missing data from censoring.
We also investigate whether the proposed tests are sensitive to the choice of 𝒰. We conduct additional simulation studies with 𝒰 set as {1, …, 3}, {1, …, 6}, and {1, …, 12} for the six set-ups with 15% censoring. The results are summarized in Table A.2. in the Appendix. From this table, we note that GIT is quite robust to the change in 𝒰, while GST demonstrates more variations across different choices of 𝒰. Another observation is that GIT becomes less sensitive to the change in 𝒰 when the sample size becomes larger. A possible explanation for these results is similar to that for the observed anti-conservative behavior of GST. That is, GST, by its construction, is sensitive to any outlying value of with τ ∈ [τL, τU], which is more likely to occur when the sample size is not large.
Aligning with the definitions of the proposed tests, the simulation results suggest that GST, as compared to GIT, is more sensitive to detect a departure from the null hypothesis, yielding higher power. This observation is also consistent with the anti-conservative behavior of GST observed in the null cases, which is reflected by empirical sizes notably greater than 0.05. With a smaller sample size, such as n = 200, GST can produce quite elevated type I errors, while GIT yields more reasonable empirical sizes. Therefore, in practice, one may need to exercise caution for applying GST to a small dataset, for which we recommend using GIT instead. In summary, our simulation results demonstrate the proposed testing procedures have robust satisfactory performance for detecting a covariate of either a constant or dynamic effect. The new tests tend to exhibit greater advantages over benchmark approaches when the covariate presents a dynamic effect, or the covariate has a constant effect but of a small magnitude.
4. Real Data Analysis
To illustrate the utility of the proposed testing framework, we apply our method to investigate the prognostic factors for dialysis survival based on a dataset collected from a cohort of 191 incident dialysis patients (Kutner et al., 2002). In this dataset, time to death is censored in about 35% of dialysis patients due to either renal transplantation or end of the study as of December 31, 2005. In our analysis, we consider six potential prognostic factors (or covariates), which include age in years (AGE), indicator of reporting fish consumption over the first year of dialysis (FISHH), the indicator for baseline HD dialysis modality (BHDPD); whether the patient has severe symptoms of restless leg syndrome or not (BLEGS); whether or not education level is equal or higher than college (HIEDU); and the indicator of being in the black race group (BLACK). In our analyses, we standardize AGE by subtracting the sample mean and then dividing the resulting quantity by the sample standard deviation.
As a part of exploratory analyses, we check the proportional hazard assumption for each covariate based on Grambsch and Therneau (1994)’s method, using the R function cox.zph() in the R package survival. The p-values corresponding to AGE, FISHH, BHDPD, BLEGS, HIEDU and BLACK are 0.43, 0.63, 0.55, 0.0006, 0.047 and 0.0004, respectively. These results suggest that the proportional hazard assumption may be violated for BLEGS, HIEDU and BLACK.
We fit model (1) for time to death (i.e. T) with each covariate separately. We set [τL, τU] as [0.1, 0.6] for FISHH, BLGES, HIEDU, and BLACK, but set [τL, τU] as [0.1, 0.54] and [0.1, 0.49] respectively for AGE and BHDPD. This is because the estimation of based on Peng and Fine (2009) does not converge for some τ’s larger than 0.54 and 0.49 when is AGE or BHDPD. Figure 2 presents the estimated coefficients with the pointwise 95% confidence interval across τ ∈ [τL, τU]. It is suggested by Figure 2 that AGE and BLACK have strong and persistent effects across all or most quantiles of time to death, implying an apparent survival advantage for younger or black patients. For each of the rest covariates, FISHH, BHDPD, BLEGS, or HIEDU, we note a partial effect pattern. For example, FISHH and BLEGS may only impact some lower quantiles of the survival time. BHDPD and HIEDU may only have quantile effects in the τ-intervals, [0.15, 0.3] and [0.3, 0.4], respectively. These observations suggest the presence of dynamic covariate effects as well as the need to appropriately accommodate such dynamic covariate effects.
Fig. 2.
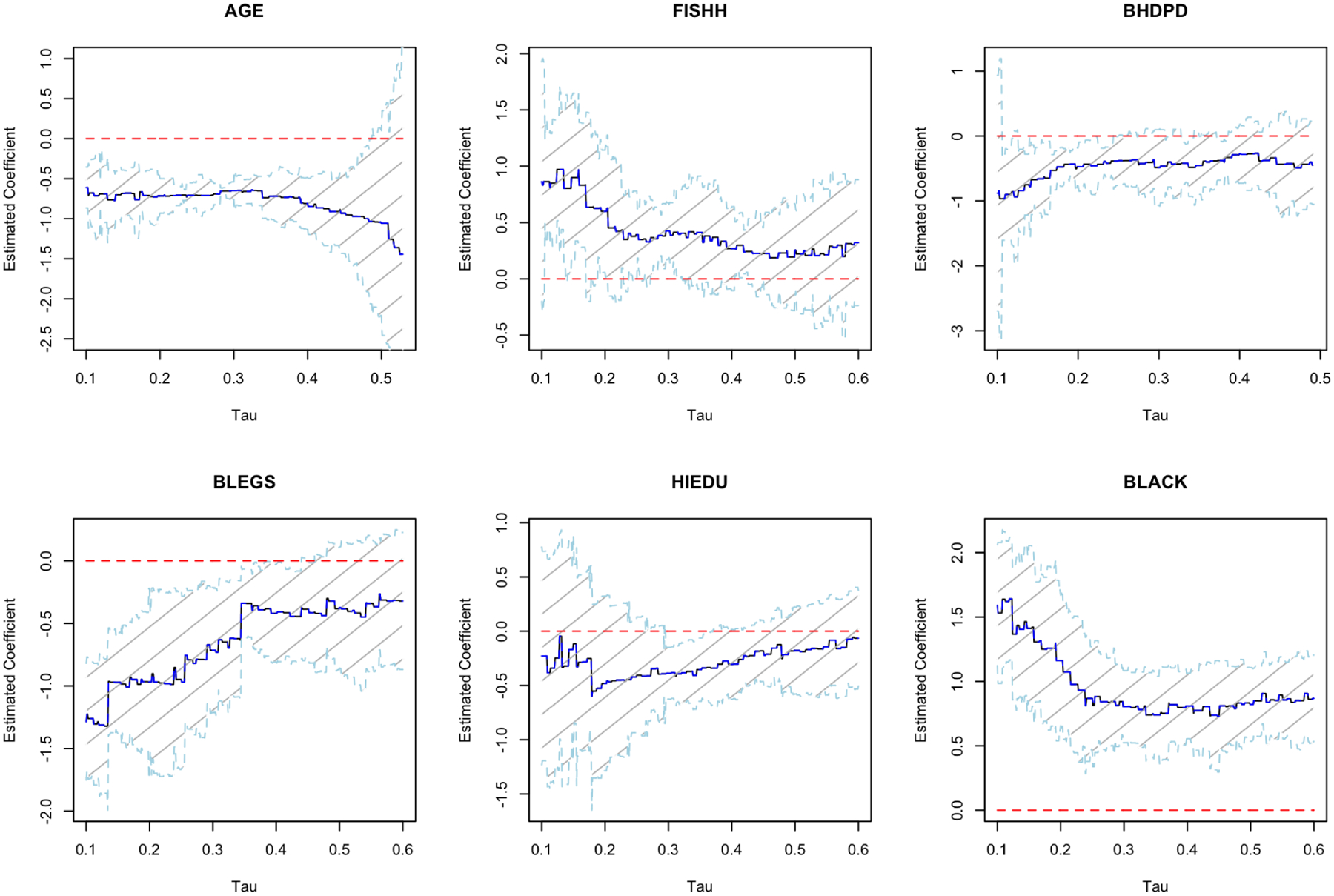
The estimated coefficient with the 95% confidence interval for the covariates based on the censored quantile regression model on the dialysis data.
To evaluate each potential prognostic factor considered, we apply the proposed testing procedures, GST and GIT, along with the benchmark methods, CPH (Wald) and CQR (Wald), as described in Section 3. Table 2 summarizes the p values obtained from different methods for evaluating each covariate. We note that all tests consistently suggest a strong effect of AGE or BLACK on the survival time. The locally concerned quantile regression tests, CQR (Wald), reveal τ-varying effects of FISHH, BHDPD, BLEGS, and HIEDU. For example, BLEGS may significantly influence the 10th and 20th quantiles of the survival time but not the 30th, 40th, 50th, 60th of quantiles. HIEDU may also have a partial effect, influencing some quantiles, such as the 30th and 40th quantiles, but not the other quantiles. The classic Cox regression based test, CPH (Wald), however, fails to capture the partial effects of BLEGS and HIEDU. The p values for testing the effect of BLEGS and HIEDU based on CPH (Wald) are 0.35 and 0.25 respectively. This is possibly caused by imposing a restrictive static view on how a covariate can influence the survival time. In contrast, the proposed GIT and GST, through simultaneously examining covariate effects at quantile levels [τL, τU], are able to detect the partial effect of BLEGS, with small p values ≤ 0.001 and to suggest a trend toward the association between HIEDU and the survival time, with marginal p values 0.01 and 0.09. The proposed GIT and GST also provide some evidence for the dynamic prognostic value of FISHH and BHDPD for dialysis survival. For example, as suggested by CQR (Wald), fish consumption in the first year may benefit dialysis patients with shorter survival time but may manifest little effect on the long-term survival. In general, our analysis results are consistent with the analyses of Peng and Huang (2008) based on multivariate censored quantile regression model. This example demonstrates the good practical utility of the proposed methods when varying covariate effects are present.
Table 2.
A summary of p-values for each covariates with different methods.
| Covariate | Proposed Test | CQR (Wald) | CPH (Wald) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| GST | GIT | τ = 0.1 | τ = 0.2 | τ = 0.3 | τ = 0.4 | τ = 0.5 | τ = 0.6 | ||
| AGE | <0.001 | <0.001 | 0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 |
| FISHH | <0.001 | 0.018 | 0.037 | 0.055 | 0.036 | 0.214 | 0.473 | 0.316 | 0.026 |
| BHDPD | <0.001 | 0.005 | 0.090 | 0.021 | 0.152 | 0.228 | 0.229 | 0.030 | 0.008 |
| BLEGS | <0.001 | 0.001 | <0.001 | 0.001 | 0.062 | 0.082 | 0.091 | 0.507 | 0.349 |
| HIEDU | 0.013 | 0.093 | 0.596 | 0.137 | 0.003 | 0.032 | 0.068 | 0.241 | 0.245 |
| BLACK | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 |
5. Discussion
In this paper, we develop a new testing framework for evaluating a survival prognostic factor. The main thrust of the new framework lies in its flexibility of accommodating a dynamic covariate effect, which is achieved through adapting the spirit of globally concerned quantile regression. Our testing procedures are conveniently developed based on existing results on fitting a working quantile regression model with randomly censored data. It is important to note that the validity of the testing procedures does not require that the working model is the true model. Moreover, the proposed methods can be readily extended to handle more complex survival outcomes, such as time to event subject to competing risks.
As suggested by one referee, we would like to point out that for τ ∈ (0, 1) implies the statistical independence between T and . Nevertheless, in this work, we confine our attention to with τU less than 1. This is because right censoring typically precludes the information on the upper tail of the distribution of T, and thus QT(τ) or can become non-identifiable as τ approaches 1. The null hypothesis entails a weaker version of the independence between T and that can be better assessed with right censored data. Rejecting can provide evidence for the dependence between T and , while accepting may not sufficiently indicate the independence between T and .
Another commendable extension of this work is to generalize the current null hypothesis and testing procedures to permit evaluating multiple prognostic factors simultaneously. This work also lays a key foundation for developing a nonparametric screening method for helping identify useful prognostic factors among a large number of candidates. These extensions will be reported in separate work.
Appendix
Appendix A: Lemma 1 and its proof
Lemma 1 Suppose the conditional distribution function of T given is continuous and strictly monotone for all possible values of . Then for τ ∈ [τL, τU] is equivalent to model (1) holds with Δ = [τL, τU] and for τ ∈ [τL, τU].
Proof for Lemma 1. Suppose we have for τ ∈ [τL, τU]. It is clear that for τ ∈ [τL, τU], we can write with θ0(τ) = (logQT(τ), 0)⊤. This means that model (1) holds with Δ ∈ [τL, τU] and for τ ∈ [τL, τU].
Suppose model (1) holds with Δ = [τL, τU] and for τ ∈ [τL, τU]. This means, for τ ∈ [τL, τU]. Given that the conditional distribution function of T given is continuous and strictly monotone, it follows from the definition of that for τ ∈ [τL, τU]. Taking expectation on both sides of this equality with respect to , we then get for τ ∈ [τL, τU]. Given the continuity and strict monotonicity of the distribution function of T, which is implied by the continuity and strict monotonicity of the conditional distribution function of T given , this implies that . Thus, for τ ∈ [τL, τU]. This completes the proof of Lemma 1.
Appendix B: Asymptotic properties of without assuming model (1)
We assume the following regularity conditions:
-
(C1)
There exist a constant v such that P(C = v) > 0 and P(C > v) = 0.
-
(C2)
is uniformly bounded, i.e. .
-
(C3)
(i) is Lipschitz continuous for τ ∈ [τL, τU]; (ii) f(y|z) is bounded above uniformly in y and z, where f(y|z) denotes the conditional density of X given Z = z.
-
(C4)
For some ρ0 > 0 and c0 > 0, eigminA(b) ≥ c0, where and A(b) = E[ZZ⊤f(Z⊤b|Z)]. Here ∥ · ∥ is the Euclidean norm and eigminA(b) represents the minimal eigenvalue of A(b).
Condition (C1) is adopted to simplify the theoretical arguments to ensure that is consistent for G(·). This condition is usually satisfied in studies subject to administrative censoring. Condition (C2) imposes covariate boundedness. Condition (C3) assumes that the limit coefficient process is smooth and the conditional density distribution is bounded and smooth. Condition (C4) requires that the asymptotic limit of Un(b, τ) is strictly convex in a neighborhood of for τ ∈ [τL, τU], implying the uniqueness of the solution to μ(b, τ) ≡ E{ZI(log T ≤ Z⊤b) − τ)} = 0. This plays a critical role in establishing the uniform convergence of to .
Theorem A1 Under regularity conditions (C1)–(C4), we have
Theorem A2 Under regularity conditions (C1)–(C4), we have converge weakly to a mean zero Gaussian process for τ ∈ [τL, τU] with covariance
The proofs of Theorems A1 and A2 closely resemble the proofs in Peng and Fine (2009) and thus are omitted.
Appendix C: Proofs of Theorem 1 and 2
We assume one additional regularity condition:
-
(C5)
, where {σ(1)(τ)}2 is the second diagonal element of .
Proof of Theorem 1
Following the lines of Peng and Fine (2009), we can show that the sample-based variance estimation procedure presented in Section 2.1 provides consistent variance estimation, which implies .
Note that under the null hypothesis , we have and consequently,
| (5) |
By Theorem A2, converges weakly to a mean zero Gaussian process 𝒳(1)(τ) with covariance process
where denotes the element in the second row and the second column of . In addition, condition (C5) and imply . Applying the result of Theorem A2 and the Slutsky’s Theorem (line 11 of Example 1.4.7 in Boucheron et al. (2013)) to (5), we then get in l∞(ℱT), where l∞(S) is the collection of all bounded functions f: S → R for any index set S and . Then, by the extended continuous mapping theorem (Theorem 1.11.1 in van der Vaart et al. (1996)), we can establish the limiting null distribution for and as
This completes the proof of Theorem 1.
Proof for Theorem 2
We first investigate the asymptotic limit of under the alternative hypothesis Ha,1. Simple algebra shows that
By the extended continuous mapping theorem, we can show that the converges in distribution to and thus is Op(1). At the same time, given , under condition (C5), we get , where .
Under the alternative hypothesis Ha,1 and condition (C5), we have ν0 > 0, and hence as n → ∞. Furthermore, for any a > 0, we have , which implies as n → ∞. Note that
It then follows that as n → ∞ under the alternative hypothesis Ha,1. This immediately implies that is a consistent test against Ha,1 because as n → ∞ given Ha,1 holds, where Csup,α denotes the α-level critical value determined upon the limit null distribution of , which is greater than 0.
Next, we consider under the alternative hypothesis Ha,2. Write as
By the continuous mapping theorem, combined with and condition (C5), we get , where , and
and thus Op(1). By condition (C5), the alternative hypothesis Ha,2 implies . Then following the same arguments for showing for any a > 0 based on the results that and , we can prove that as n → ∞ for any a > 0 under Ha,2. This implies that as n → ∞ for any a > 0 under Ha,2. Therefore, is a consistent test against the alternative hypothesis Ha,2.
Appendix D: Justification for the proposed resampling procedure
Given the observed data denoted by , since are i.i.d. standard normal random variables, we have
By the arguments of Lin et al. (1993), the distribution of converges weakly to 𝒳(1)(τ), the same limit as that of , for almost all realizations of . Applying the extended continuous mapping theorem as in the proof of Theorem 2, we have that under , the conditional distribution of (or ) given the observed data is asymptotically equivalent to the unconditional distributions of (or ). This justifies using the resampling procedure in Section 2.3 to obtain the p values of the proposed tests.
Appendix E: Additional simulation results
Table A.1.
Empirical rejection rate for the uncensored case based on 1000 simulations.
| Set-up | n | Proposed Test | CQR (Wald) | CPH (Wald) | |||
|---|---|---|---|---|---|---|---|
| GST | GIT | τ = 0.4 | τ = 0.5 | τ = 0.6 | |||
| I | 200 | 0.098 | 0.070 | 0.055 | 0.052 | 0.056 | 0.048 |
| 400 | 0.093 | 0.075 | 0.069 | 0.064 | 0.060 | 0.047 | |
| 800 | 0.076 | 0.058 | 0.053 | 0.053 | 0.048 | 0.061 | |
| II | 200 | 0.215 | 0.156 | 0.104 | 0.108 | 0.108 | 0.121 |
| 400 | 0.275 | 0.216 | 0.162 | 0.156 | 0.139 | 0.183 | |
| 800 | 0.420 | 0.372 | 0.276 | 0.265 | 0.238 | 0.328 | |
| III | 200 | 0.541 | 0.478 | 0.344 | 0.374 | 0.337 | 0.456 |
| 400 | 0.790 | 0.771 | 0.589 | 0.595 | 0.590 | 0.745 | |
| 800 | 0.958 | 0.961 | 0.883 | 0.886 | 0.873 | 0.963 | |
| IV | 200 | 0.378 | 0.250 | 0.074 | 0.045 | 0.049 | 0.060 |
| 400 | 0.656 | 0.476 | 0.101 | 0.056 | 0.055 | 0.049 | |
| 800 | 0.935 | 0.808 | 0.118 | 0.034 | 0.045 | 0.085 | |
| V | 200 | 0.618 | 0.452 | 0.106 | 0.057 | 0.121 | 0.428 |
| 400 | 0.939 | 0.828 | 0.169 | 0.071 | 0.165 | 0.737 | |
| 800 | 1.000 | 0.994 | 0.255 | 0.041 | 0.313 | 0.968 | |
| VI | 200 | 0.729 | 0.543 | 0.095 | 0.047 | 0.088 | 0.228 |
| 400 | 0.971 | 0.898 | 0.154 | 0.048 | 0.097 | 0.446 | |
| 800 | 1.000 | 0.995 | 0.243 | 0.020 | 0.154 | 0.756 | |
Table A.2.
Empirical rejection rate for the proposed test with different choices of 𝒰 on the six set-ups subject to 15% censoring based on 1000 simulations.
| Set-up | n | 𝒰 = {1,…, 3} | 𝒰 = {1,…, 6} | 𝒰 = {1,…, 12} | |||
|---|---|---|---|---|---|---|---|
| GST | GIT | GST | GIT | GST | GIT | ||
| I | 200 | 0.128 | 0.074 | 0.091 | 0.067 | 0.092 | 0.065 |
| 400 | 0.126 | 0.079 | 0.086 | 0.067 | 0.081 | 0.063 | |
| 800 | 0.112 | 0.060 | 0.080 | 0.059 | 0.072 | 0.058 | |
| II | 200 | 0.287 | 0.178 | 0.228 | 0.161 | 0.225 | 0.158 |
| 400 | 0.359 | 0.231 | 0.283 | 0.218 | 0.256 | 0.206 | |
| 800 | 0.472 | 0.379 | 0.415 | 0.369 | 0.376 | 0.361 | |
| III | 200 | 0.666 | 0.549 | 0.593 | 0.510 | 0.585 | 0.513 |
| 400 | 0.841 | 0.789 | 0.779 | 0.773 | 0.761 | 0.757 | |
| 800 | 0.975 | 0.964 | 0.956 | 0.956 | 0.940 | 0.957 | |
| IV | 200 | 0.427 | 0.257 | 0.364 | 0.242 | 0.362 | 0.243 |
| 400 | 0.702 | 0.490 | 0.666 | 0.470 | 0.649 | 0.471 | |
| 800 | 0.952 | 0.808 | 0.942 | 0.811 | 0.936 | 0.808 | |
| V | 200 | 0.695 | 0.478 | 0.649 | 0.452 | 0.649 | 0.446 |
| 400 | 0.962 | 0.850 | 0.948 | 0.831 | 0.944 | 0.827 | |
| 800 | 1.000 | 0.994 | 1.000 | 0.991 | 1.000 | 0.993 | |
| VI | 200 | 0.768 | 0.558 | 0.723 | 0.534 | 0.726 | 0.535 |
| 400 | 0.981 | 0.902 | 0.971 | 0.894 | 0.970 | 0.892 | |
| 800 | 1.000 | 0.997 | 1.000 | 0.997 | 1.000 | 0.998 | |
References
- Bellera CA, MacGrogan G, Debled M, de Lara CT, Brouste V, and Mathoulin-Pélissier S (2010), “Variables with time-varying effects and the Cox model: some statistical concepts illustrated with a prognostic factor study in breast cancer,” BMC medical research methodology, 10, 1–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boucheron S, Lugosi G, and Massart P (2013), Concentration inequalities: A nonasymptotic theory of independence, Oxford university press. [Google Scholar]
- Cox DR and Oakes D (2018), Analysis of survival data, Chapman and Hall/CRC. [Google Scholar]
- Darling DA (1957), “The kolmogorov-smirnov, cramer-von mises tests,” The Annals of Mathematical Statistics, 28, 823–838. [Google Scholar]
- Dickson ER, Grambsch PM, Fleming TR, Fisher LD, and Langworthy A (1989), “Prognosis in primary biliary cirrhosis: model for decision making,” Hepatology, 10, 1–7. [DOI] [PubMed] [Google Scholar]
- Grambsch PM and Therneau TM (1994), “Proportional hazards tests and diagnostics based on weighted residuals,” Biometrika, 81, 515–526. [Google Scholar]
- Huang Y (2010), “Quantile calculus and censored regression,” The Annals of Statistics, 38, 1607–1637. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kleinbaum DG and Klein M (2010), Survival analysis, vol. 3, Springer. [Google Scholar]
- Koenker R (2005), Quantile regression, vol. 38, Cambridge Univ Pr. [Google Scholar]
- — (2022), “quantreg: Quantile Regression,” R package version 5.87 [Google Scholar]
- Koenker R and Bassett G (1978), “Regression quantiles,” Econometrica: journal of the Econometric Society, 33–50. [Google Scholar]
- Kutner NG, Clow PW, Zhang R, and Aviles X (2002), “Association of fish intake and survival in a cohort of incident dialysis patients,” American journal of kidney diseases, 39, 1018–1024. [DOI] [PubMed] [Google Scholar]
- Li R and Peng L (2014), “Varying coefficient subdistribution regression for left-truncated semi-competing risks data,” Journal of multivariate analysis, 131, 65–78. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin DY, Wei L-J, and Ying Z (1993), “Checking the Cox model with cumulative sums of martingale-based residuals,” Biometrika, 80, 557–572. [Google Scholar]
- Peng L (2021), “Quantile Regression for Survival Data,” Annual review of statistics and its application, 8, 413–437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peng L and Fine JP (2009), “Competing risks quantile regression,” Journal of the American Statistical Association, 104, 1440–1453. [Google Scholar]
- Peng L and Huang Y (2008), “Survival analysis with quantile regression models,” Journal of the American Statistical Association, 103, 637–649. [Google Scholar]
- Portnoy S (2003), “Censored quantile regression,” Journal of American Statistical Association, 98, 1001–1012. [Google Scholar]
- Powell JL (1986), “Censored regression quantiles,” Journal of econometrics, 32, 143–155. [Google Scholar]
- Thorogood J, Persijn G, Schreuder GM, D’amaro J, Zantvoort F, Van Houwelingen J, and Van Rood J (1990), “The effect of HLA matching on kidney graft survival in separate posttransplantation intervals.” Transplantation, 50, 146–150. [DOI] [PubMed] [Google Scholar]
- van der Vaart A, van der Vaart A, van der Vaart A, and Wellner J (1996), Weak Convergence and Empirical Processes: With Applications to Statistics, Springer Series in Statistics, Springer. [Google Scholar]
- Verweij PJ and van Houwelingen HC (1995), “Time-dependent effects of fixed covariates in Cox regression,” Biometrics, 1550–1556. [PubMed] [Google Scholar]
- Wang H and Wang L (2009), “Locally weighted censored quantile regression,” Journal of the American Statistical Association, 104, 1117–1128. [Google Scholar]
- Ying Z, Jung S, and Wei L (1995), “Survival analysis with median regression models,” Journal of the American Statistical Association, 90, 178–184. [Google Scholar]
- Zheng Q, Peng L, and He X (2015), “Globally adaptive quantile regression with ultra-high dimensional data,” Annals of statistics, 43, 2225. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou L (2006), “A simple censored median regression estimator,” Statistica Sinica, 16, 1043–1058. [Google Scholar]