

Abstract
This paper proposes a solution to a long-standing problem concerning the joint distribution of allelic identity by descent between two individuals at two linked loci. Such distributions have important applications across various fields of genetics, and detailed formulas for selected relationships appear scattered throughout the literature. However, these results were obtained essentially by brute force, with no efficient method available for general pedigrees. The recursive algorithm described in this paper, and its implementation in R, allow efficient calculation of two-locus identity coefficients in any pedigree. As a result, many existing procedures and techniques may, for the first time, be applied to complex and inbred relationships. Two such applications are discussed, concerning the expected likelihood ratio in forensic kinship testing, and variances in realized relatedness.
Keywords: pairwise relatedness, identity-by-descent, identity coefficients, kinship, pedigree analysis, two-locus coefficients, expected likelihood ratio, realized relatedness, linkage
Introduction
The study of genetic relatedness centers around various coefficients of relatedness, each defined as the probability that certain alleles are identical by descent (IBD), i.e. that they originate from the same ancestral allele within the given pedigree. For the alleles of two individuals at a single locus, common coefficients range in complexity from the simple kinship and inbreeding coefficients (Wright 1922) to the detailed identity coefficients which characterize the distribution of IBD states for any pairwise relationship (Jacquard 1974).
The generalization of IBD probabilities to multiple linked loci was pioneered by Haldane (1949), who defined two-locus kinship and inbreeding coefficients and derived explicit formulas in special cases. Seeking a general procedure, he admitted defeat in the case of individuals with related common ancestors. (In fact, the problems Haldane faced here are unsolvable in his formulation, as we demonstrate in Section “Examples.”) Weir and Cockerham (1969) outlined a more general method, but their approach is impractical except in small pedigrees. Finally, Thompson (1988) proposed an efficient, recursive algorithm for two-locus kinship coefficients, elucidated and popularized by Weeks and Lange (1992). This algorithm is implemented in the MORGAN software (https://sites.stat.washington.edu/thompson/Genepi/MORGAN/Morgan.shtml) and also included in the R package ribd featured in the present paper. The latter has the advantage of supporting selfing and pedigrees with inbred founders (Vigeland 2020).
Just as in the single-locus case, the two-locus kinship coefficient is only the simplest in a range of two-locus coefficients. For noninbred pairs, the 9 two-locus IBD coefficients , for , are defined as the probabilities of sharing exactly i alleles IBD at the first locus and j at the second, where ρ denotes the recombination fraction. These coefficients, and their extension to inbred relationships, are the focus of the present article.
Two-locus IBD coefficients have played central roles in a variety of applications over the years. For example, they were important in the development of medical linkage analysis (Bishop and Williamson 1990) and quantitative-trait linkage analysis (Almasy and Blangero 1998). Applications in forensic genetics include match probabilities (Buckleton and Triggs 2006; Bright et al. 2013), kinship testing (Egeland and Sheehan 2008; Egeland and Slooten 2016) and mixture analysis (Dørum et al. 2015) among others. Furthermore, two-locus coefficients encode key information about distributions of realized (or actual, or genomic) relatedness, which is sometimes more relevant than the pedigree-based expectation (Speed and Balding 2015). A considerable body of literature is devoted to estimating variances in realized IBD sharing by integrating suitable two-locus IBD coefficients (Guo 1995, 1996; Hill and Weir 2011, 2012; Thompson 2013).
Despite the enduring interest in two-locus IBD coefficients, no efficient algorithm for their calculation has hitherto been described in the literature. Formulas for in special cases were given by Denniston (1975) using a path-counting approach, and subsequent authors have used similar, direct methods to analyze certain classes relationships. Nevertheless, previous works involving two-locus IBD coefficients (or closely related probabilities) have been invariably limited to simple, noninbred relationships.
In this paper, we propose and implement a method for computing pairwise joint two-locus IBD probabilities in any pedigree. This includes the 9 coefficients for noninbred pairs, and also the 81 two-locus condensed identity coefficients for general pairs. The key ingredient is a recursive algorithm for generalized two-locus kinship coefficients, inspired by previous works on single-locus identity coefficients (Weeks and Lange 1988; Lange and Sinsheimer 1992). Using this method, and its implementation in the R package ribd (Vigeland 2020), several existing applications may be extended to general pedigrees, including inbred relationships. Two such applications are explored in the Discussion; one in forensic kinship testing and one in the study of variances in realized relatedness.
Background
In this section, we review the basics of relatedness coefficients and settle our notation.
A pairwise relationship is a triple , where is a finite, connected pedigree, and a and b are (not necessarily distinct) members of . We will usually assume that the relationship is nontrivial, i.e. that a and b are connected with at least one path in , although most of the results also hold in the trivial case. Homologous alleles of a and b are IBD if they descend from the same allele carried by a common ancestor of a and b within . We often suppress in our notation, but emphasize that any calculations or concepts based on IBD only make sense in the context of an explicit pedigree. We restrict our attention to diploid species.
Single-locus coefficients
The kinship coefficient between a and b is the probability that a random allele from a is IBD with a random allele from b at the same autosomal locus. The inbreeding coefficient of a child c between a and b is defined by . We say that c is inbred if , and completely inbred if . Pedigree founders are usually assumed to be noninbred, but this may be relaxed in some applications (Vigeland 2020).
Note about notation: Relatedness coefficients are conventionally written with the individuals as subscripts rather than superscripts. We use superscripts in this paper, reserving subscripts for other indices. When the context is clear, we may drop the superscripts and simply write φ or f.
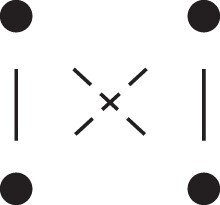
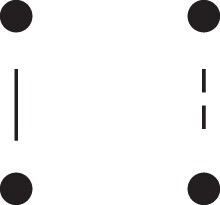
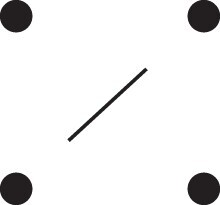
Figure 1a shows all possible patterns of IBD between the four alleles carried by two individuals at a single autosomal locus. The 15 patterns are called the (single-locus) detailed identity states. The expected relative frequencies of these states in a given relationship are denoted , and referred to as the detailed identity coefficients of a and b.
Fig. 1.

Single-locus identity states. Each diagram depicts the four homologous alleles carried by a and b at an autosomal locus, where IBD alleles are connected with a line segment. a) Detailed states, with paternal alleles to the left and maternal alleles to the right. b) Condensed states ignoring the paternal/maternal ordering.
If the allele ordering (i.e. the paternal/maternal origin) within each individual is ignored, the 15 states are reduced to 9 condensed identity states (Fig. 1b), with expected relative frequencies . The notation and ordering follow Jacquard (1974).
Noninbred relationships
We say that a relationship is noninbred if neither a nor b is inbred in . Note, however, that other members of may be inbred. For noninbred relationships, only may be nonzero—the probabilities that a and b share, respectively, 0, 1, and 2 alleles IBD. Following Thompson (1975), we denote these by . We refer to them as IBD coefficients, to distinguish them from the previously defined identity coefficients.
A noninbred relationship is called unilineal if , and bilineal if (Cotterman 1940). Furthermore, is direct if a is a direct descendant of b or vice versa, and collateral otherwise. The following simple fact will be used in later proofs:
Lemma 1
Let be a noninbred relationship with . Then the following implications hold: .
Proof.
For the first implication, suppose for a contradiction that is bilineal and that a is an ancestor of b. If are the parents of b, we can then assume w.l.o.g. that a is an ancestor of (or equal to) f. In order for to be nonzero, a must be related to m as well. But then m and f are related, contradicting the assumption that b is noninbred. The same argument applies if b is an ancestor of a, hence we conclude that cannot be direct.
The second implication follows from the fact that if a is a founder of , the only relatives of a in are the descendants of a. ȃ□
Finally, we recall the close connection between φ and κ at a single locus. The following well-known facts, which we include for easy reference, are straightforward from the definitions (see also Thompson 2000).
Proposition 1
Let be noninbred, with kinship coefficient φ and IBD coefficients .
For any , φ is determined by κ, by the formula .
If is unilineal, then κ is determined by φ, by the formula .
(1)
Two-locus coefficients
All of the single-locus coefficients described above can be generalized to multiple loci by considering the joint IBD probabilities at the loci. Crucially, such multilocus coefficients are functions of the recombination rates between the loci. In the present paper, we restrict our attention to two autosomal loci, and , with recombination rate , which we assume to be the same for males and females.
The two-locus kinship coefficient is the probability that a random gamete from a and a random gamete from b contain IBD alleles at both and . If a and b are clear from the context, we will write this coefficient as , or simply , with the understanding that it is always a function of ρ. As first observed by Haldane (1949), we have and for any relationship.
If both a and b are noninbred, we define the two-locus IBD coefficient, for , to be the probability that a and b share exactly i IBD alleles at and exactly j IBD alleles at . As with , we may drop a, b and ρ from the notation and simply write . Clearly, so the coefficients form a symmetric matrix:
If , the absence of recombination implies that any pedigree path between a and b yields IBD alleles either at both or none of the loci. Hence for and if . At the other extreme, , the two loci segregate independently of each other, thus for all .
Another important observation is that for any ρ, the row and column sums of are κ:
| (2) |
Indeed, this is a simple consequence of the law of total probability applied to the first locus (row sums) and the second locus (column sums).
The relations (2) are especially powerful for unilineal relationships, where . Then also for , and we obtain after simplification,
| (3) |
Since , it follows that in the unilineal case, the entire matrix K is uniquely determined by .
Finally, we generalize to the case where a and b may be inbred. For we define the two-locus identity coefficient as the probability that the condensed identity states at and are and , respectively. For any fixed ρ these coefficients form a symmetric matrix:
| (4) |
As in the noninbred case, the row sums, and also the column sums, of D are the single-locus coefficients .
Examples
The purpose of this section is to illustrate some of the complications that arise with linked loci.
In light of Proposition 1, it is natural to wonder if there exists a direct relationship between the two-locus coefficients and K. Especially for unilineal relationships, where the one-locus situation boils down to the formula , one might hope for a similar identity relating and . Unfortunately, as the following two examples demonstrate, no such formula can exist.
The first well-known example (e.g. Section 4.5 of Thompson 2000) shows that two relationships may have different , but the same . An interpretation of this is that the relationships are theoretically distinguishable given genetic data from the two individuals, but not with data from their child alone.
Example 1 (Different , same ). —
The relationships of grandparent–grandchild (G) and half-siblings (H) have different two-locus IBD functions,
(5) where , but identical two-locus kinship, . These functions are easily verifiable by direct calculation.
Next, we show that the opposite situation is also possible. This particular example appears to be original, although it seems likely that the effect it illustrates has been known to previous authors.
Example 2 (Same , different ). —
Consider an outbred parent-offspring relationship (PO), and compare it with half-sibs whose shared parent is completely inbred (H-i). It is easy to see that both of these satisfy for all ρ; in other words, they have a constant IBD matrix
(6) In the H-i case, the IBD alleles are always in cis, i.e. on the same haplotype, since they come from the same parent. For PO, on the other hand, the alleles are in cis in the child, but not necessarily in the parent. This difference leads to distinct functions (see Example 4 for calculations):
(7)
A remarkable consequence of Example 2 is that PO and H-i cannot be distinguished by means of (unphased) genetic data from the two individuals themselves, but can be so given data from their child alone.
For our final example, we return to Haldane’s problem mentioned in the introduction. In our notation this amounts to the following: Given a relationship where a and b have two different common ancestors in , find a formula for expressed by the single-locus coefficient and the two-locus coefficient between the ancestors. Failing to do so, Haldane remarked:
It is possible that [these coefficients] do not give all the needful information.
As it turns out, Haldane’s intuition was correct: In general, depends not only on and , but also on the two-locus IBD matrix . Here is an illustration:
Example 3 —
Suppose a and b are full siblings whose parents P and Q are unilineally related. Then the two-locus kinship of a and b is given by
(8) In particular, cannot be expressed solely by and .
The formula (8) is obtained as follows. The first two terms cover the cases where the emitted gametes are nonrecombinant, either originating from the same parent (probability ) or one from each (). The middle term is the probability of IBD at both loci when one gamete is recombinant and the other not. Finally, when both gametes are recombinant, the alleles may come from the same parent at each locus, i.e. paternal alleles at and maternal at , or vice versa (total probability ), or one from each parent at each locus (). Altogether, this gives the claimed formula.
For an explicit example, consider the case of siblings whose parents are half-siblings. Inserting the expressions for and from Example 1 into (8), we obtain after simplification:
Phased components of two-locus coefficients
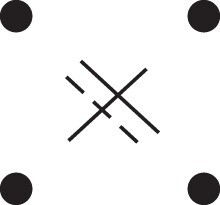
Denniston (1975) introduced a refinement of the coefficients, taking into account the phase of the IBD alleles. He found efficient formulas for some of these extended coefficients, but had to resort to tedious path tracing for the remaining ones. One contribution of the current paper is to enable recursive calculation of all of these phased coefficients, which in turn provide the ’s.
Starting with the coefficient , this naturally splits into four phased components:
The superscripts signify if the IBD alleles are in cis or in trans in a and respectively. The underlying IBD patterns are shown in the top row of Fig. 2.
Fig. 2.

Phased IBD patterns underlying the coefficients , , and . Each diagram shows phased (but unordered) haplotypes of a and b at two loci. Equal symbols represent IBD alleles, except for the tiny dots, which are not IBD with any other. Mnemonic superscripts: c (cis), t (trans), h (haplotype), and r (recombination). Top row: The four possible cis/trans combinations when a and b share exactly one IBD allele at each locus. Middle row: Configurations with two IBD alleles at one locus and one at the other. Bottom row: Configurations with two IBD alleles at each locus.
Turning to bilineal relationships, the coefficients , and have similar decompositions:
| (9) |
where the superscripts indicate whether the IBD alleles form the same haplotype(s) in a and b, or if a recombination has happened. See Fig. 2 (rows 2 and 3) for illustrations. Our notation differs slightly from that of Denniston (1975).
For each pattern in Fig. 2, it is straightforward to find the probability that a and b emit gametes with IBD alleles at both loci. For instance, in the diagram corresponding to (top-left), this amounts to , since both individuals must emit the same haplotype unrecombined. With similar calculations for the other patterns in the top row, we finally obtain a two-locus analogue of the single-locus formula (Proposition 1b) for unilineal relationships:
| (10) |
For bilineal relationships, we must include all the patterns in Fig. 2, producing the formula
| (11) |
where . Exploiting the symmetries and , the expression can be compactified to
| (12) |
Example 4
Analyzing the phase elucidates the differences between PO and H-i in Example 2. The point is that although both relationships have , the phased components are different. In the PO case, we have , while the same coefficients are for H-i. Inserting these values into equation (10) produces the formulas for given in (7).
Generalized kinship coefficients
A key idea introduced by Karigl (1981), was to express identity coefficients in terms of generalized kinship coefficients. Recursive formulas for such coefficients were given by Karigl and further developed by other authors, allowing efficient computation of identity coefficients.
Passing to the two-locus situation, it is natural to seek a similar generalization of two-locus kinship coefficients. Thompson (1988) used special cases of this to compute , but to the best of our knowledge no general treatment has been given. Indeed, this will prove to be the main ingredient in computing the two-locus coefficients K and D.
We begin by reviewing the single-locus case.
Generalized single-locus kinship coefficients
The pairwise kinship coefficient φ generalizes naturally to three or more individuals. For example, Karigl (1981) used the notation to denote the probability that homologous alleles drawn from individuals a, and c are all IBD. We will adopt a more flexible notation, close to that of Weeks and Lange (1988), writing the above three-person coefficient as . A crucial idea of Weeks and Lange (1988) was to consider multiple groups of IBD alleles simultaneously. For example, the coefficient denotes the probability that if one allele is sampled at random from each of a, b, and d, then the alleles from a and b are IBD, and the ones from c and d are IBD, but different from those in the first group. More generally, a generalized kinship pattern is a finite collection of blocks of pedigree members,
| (13) |
The associated generalized kinship coefficient is the probability that if one allele is sampled from each individual (with replacement if the individual is repeated), then the alleles within each block are all IBD, while alleles from different blocks are not IBD.
A few simple properties of generalized kinship coefficients are worth noticing. Firstly, is invariant under permutations of the blocks, and also under permutations of the individuals within a block. If any block of contains two different founders, or indeed any unrelated individuals, then . Moreover, if any individual occurs in more than two blocks, this also implies .
Generalized two-locus kinship coefficients
Let and be fixed autosomal loci with recombination rate ρ. If and are generalized single-locus kinship patterns, we write for the simultaneous occurrence of and at loci and respectively. The corresponding generalized two-locus kinship coefficient is the probability
| (14) |
As with all the previous two-locus coefficients, this probability is a function of ρ.
Whenever a kinship pattern involves multiple alleles from the same individual, we must specify whether or not these belong to the same gamete. To this end, we add a segregation index superscript to each allele (Thompson 1988; Lange and Sinsheimer 1992). Note that the indices themselves are irrelevant; only equality between indices matters, and only if attached to the same individual. For example, the previously defined two-locus kinship can be expressed as , but also as, e.g. .
Even though the segregation index carries no inherent meaning, the following convention is useful. If the involved gamete is a transmission from a parent x to a child y, we may use y as a segregation index and write . This notation is particularly efficient in implementations and is used extensively in the recursion formulas in Appendix A. It has, however, one notable shortcoming that seems to have gone unnoticed by previous authors. If y is the result of selfing of x, there are two different gametes segregating from x to y. Since these require different labels, the notation must be augmented in this case, e.g. and . We note that the software MORGAN, which implements the algorithm of Thompson (1988), does not support pedigrees with selfing.
A recursive algorithm for computing for any in any pedigree, is given in Appendix A.
Two-locus identity coefficients
In this section, we show how the generalized two-locus kinship coefficients allow us to calculate two-locus identity coefficients. We split the presentation into three steps, in increasing order of pedigree complexity, which have different computational demands. We start with the unilineal case, where a simple trick provides efficient calculation of the matrix K.
Unilineal relationships
Let be a unilineal relationship, and its matrix of two-locus IBD coefficients. Recall from equation (3) that K is uniquely determined by .
As evident from Example 1, we cannot generally compute directly from . Moreover, equation (10) shows why: the phased components of contribute unequally to . However, it turns out that we can recover by considering a slightly more complex, generalized kinship coefficient, constructed to balance the contributions.
Theorem 1
For any unilineal relationship , the coefficient satisfies
(15) where is the two-locus IBD pattern in Fig. 3.
Fig. 3.

The two-locus IBD pattern used to compute for unilineal relationships. Two gametes are emitted from each of a and b. At the first locus, all four alleles are IBD. At the second locus, exactly one gamete of a is IBD with exactly one gamete of b.
Proof
The crucial point is that has the same probability under each of the four cis/trans combinations underlying , shown in the top row of Fig. 2. To see this, note that if the IBD alleles in a are in cis, the two gametes from a dictated by (cf. Fig. 3) occur with probability and , respectively. On the other hand, if the alleles are in trans, these probabilities are simply switched. Hence the total probability of a’s gametes is always . Clearly, the same holds for b, and it follows that as claimed. ȃ□
Theorem 1 enables efficient calculation of , and thereby the entire matrix , for any . The endpoint is trivial, as previously explained.
The four phased coefficients can also be computed using a similar technique as that in Theorem 1. The idea is to find four different generalized IBD patterns whose coefficients are linear expressions in . By choosing such that the resulting system of linear equations has full rank, this can then be solved for the phased coefficients. Details are given in Appendix B.
Bilineal relationships
Moving on to bilineal relationships, we now assume (by Lemma 1) that a and b are nonfounders of . Let denote the parents of a, and the parents of b, with the understanding that some of these may coincide. To simplify matters we assume that , noting that if , then K is trivially determined by for all ρ.
Before continuing, it is worth noting why Theorem 1 no longer holds in the bilineal case. When one or both loci may share 2 alleles IBD, the expression for given in the proof of that theorem, gains several additional terms which obstruct an explicit solution for .
Our approach for computing K, and also the two-locus identity matrix D in the next section, is inspired by the method used by Lange and Sinsheimer (1992) to calculate the single-locus coefficients . They noted that, for example, the detailed identity state corresponds to (in our notation) the generalized kinship pattern . Hence we have , which by means of a recursive algorithm enabled Lange and Sinsheimer to compute in any pedigree.
In the same fashion one may define generalized IBD patterns corresponding to all detailed states in which a and b are noninbred (cf. Fig. 1a):
| (16) |
(We will complete this list in the next section by including patterns corresponding to .)
Let , be the partition of indices according to the number of IBD alleles in each of the detailed states:
| (17) |
With these definitions the single-locus IBD coefficients could be obtained by the formula
| (18) |
Switching to the two-locus situation, our aim is to give a two-locus version of (18). To compute a two-locus IBD coefficient, say , we might proceed as follows: is the probability that a and b share 0 alleles IBD at both loci, i.e. that both loci are in state . In other words, . Similarly, is the probability that the state at is either or (the states where a and b share 2 alleles), while is in state , thus . By this reasoning, we obtain the following general result:
Theorem 2
Suppose a and b are nonfounders in , and let be the IBD patterns defined in (16). The two-locus IBD coefficients , for are then given by.
(19)
A complete overview of the detailed two-locus states and their corresponding patterns , is given in Table 1. This table also shows how to obtain the phased versions by further partitioning the sums given in Theorem 2. For example, equation (19) dictates that
| (20) |
Inspecting the corresponding states (top two rows of Table 1) it is evident that the first and fourth terms of (20) contribute to , while the other two belong to .
Table 1.
Formulas for the phased two-locus IBD coefficients in bilineal relationships.
| Detailed two-locus IBD states | Formula | |||
|---|---|---|---|---|

|

|
|||
|

|
|||

|

|
|

|
|

|

|

|

|
|

|

|

|

|
|

|

|

|

|
|

|

|
|||

|

|
|||

|

|

|

|
|

|

|

|

|
|

|

|

|

|
|
|

|

|

|
|

|

|

|
|
|

|

|

|

|
|

|
||||
To the left of each formula are shown the corresponding detailed IBD states, where solid (resp. dashed) lines indicate IBD at the first (resp., second) locus. The diagrams otherwise follow the conventions of Fig. 1a. Definitions of the single-locus patterns are given in the main text.
General relationships
The method of the previous section generalizes immediately to the full-blown matrix D of 81 two-locus identity coefficients between a and b, which we now allow to be inbred. The main challenge is the volume of cases, as there are now detailed two-locus states to consider, each corresponding to a generalized two-locus kinship coefficient of the form , .
First of all, we complete the list (16) by adding the patterns corresponding to the states for inbred a and/or b:
| (21) |
In the same manner as (17), we define subsets as the indices corresponding to the condensed states, i.e. so that .
| (22) |
We can then give the most general result of this paper, providing an implementation-friendly formula for the 81 two-locus identity coefficients of any pairwise relationship .
Theorem 3
For any nonfounders their two-locus condensed identity coefficients , are given by
(23) where are the generalized IBD patterns defined in (16) and (21).
The assumption that are nonfounders can easily be circumvented by extending the pedigree before applying the theorem. For example, if a is a founder of , let be the pedigree resulting from adding both of a’s parents, as unrelated founders. Theorem 3 can then be applied to .
Implementation
The algorithms described in this paper are implemented in the R package ribd (Vigeland 2020), which is part of the ped suite collection of packages for pedigree analysis in R (Vigeland 2021). Detailed explanations and many examples are included in the documentation of the functions twoLocusKinship, twoLocusIBD and twoLocusIdentity.
In light of the extensive recursions needed to calculate generalized two-locus kinship coefficients, care should be taken to alleviate the computational burden. A naive application of Theorem 3 requires the calculation of generalized two-locus kinship coefficients to obtain the complete matrix D. However, this number can be almost halved by exploiting linear dependencies. Let be the number of terms in equation (23), i.e.
| (24) |
Since the coefficients in row 8 and column 8 are the most expensive (numbers shown in bold), it is most profitable to obtain these by other means. First, using the rows sums of D, we have , for each . Then, by the columns sums, , for all j (including 8). This procedure eliminates 104 of the 225 terms, leaving only 121 (53%) generalized coefficients requiring recursive calculation.
For unilineal relationships, the computation of two-locus IBD coefficients can be performed very quickly using Theorem 1. On a standard laptop computer (Intel core i5 CPU @ 1.60GHz, 16 Gb RAM, Windows 10, 64-bit R), ribd computes in 0.01 s for 5th cousins, and in 0.1 s for 50th cousins. Bilinear and, in particular, inbred relationships are more computer intensive, even with the trick described in the preceding paragraph. For example, the current implementation takes 0.5 s to compute the complete matrix D for a pair of siblings resulting from brother-sister mating, and about 30 s after 5 generations of brother-sister mating.
A particular feature of the ped suite is the support of founder inbreeding, i.e. the assignment of nonzero inbreeding coefficients to any pedigree founders. As shown in Vigeland (2020, Section 6.2), such founder inbreeding generally leads to ill-defined multilocus IBD coefficients, except in cases of complete inbreeding. All two-locus functions in ribd support completely inbred founders (and give an error if encountering partially inbred founders). For example, the H-i pedigree featured in Example 2 can be analyzed as follows, after loading the ribd package in R:
# Half siblings with completely inbred parent
x = halfSibPed()
founderInbreeding(x, ids = 2) = 1
# A two-locus kinship coefficient
twoLocusKinship(x, ids = 4:5, rho = 0.25)
[1] 0.140625
# The two-locus IBD matrix (same for any rho)
twoLocusIBD(x, ids = 4:5, rho = 0.25)
The output of the last command (not shown) is the matrix K in equation (6).
If either of the two individuals, say a, is a founder, then the algorithm described in Section “General relationships” requires that we extend the pedigree by adding the parents of a before applying Theorem 3. However, this cannot be done adequately if a is completely inbred; hence in this particular case founder inbreeding is not supported in the current implementation.
In order to check the implementation, numerical validation was performed against a wide variety of previously published two-locus probability formulas. Details and source code for these efforts can be found in the documentation of ribd, including examples from Weir and Cockerham (1969), Denniston (1975), Donnelly (1983), Thompson (1988), Bishop and Williamson (1990), Almasy and Blangero (1998), Egeland and Slooten (2016), and Vigeland (2021).
Of particular interest is the work of Almasy and Blangero (1998) (AB98 in the following), which provides extensive tables of formulas for in unilineal relationships, and IBD correlation formulas (which are simple functions of the ’s) for many bilineal cases. Some mistakes in these formulas were discovered as a result of the comparison. Given the high impact of AB98 we briefly record these here: In Table 4 of AB98, the correlation coefficient of “Double second cousins (type A)” should be (they use θ to denote the recombination fraction). Furthermore, Table 6 has a misprint in the entry for “First cousin and second cousin,” where the coefficient of should be 8,240, not 8,420.
Discussion
Considering the enduring interest in two-locus IBD probabilities, the lack of general algorithms may seem surprising. One explanation may be that for simple relationships explicit formulas can be obtained by direct calculation. Below we briefly discuss two applications of two-locus coefficients which, with the methods of the present paper, can now be extended to larger classes of pedigrees.
In forensic kinship testing, a hypothesized relationship between two individuals is typically tested by evaluating the likelihood ratio , where G denotes the genotypes at a predetermined set of markers. Egeland and Slooten discovered that if G is interpreted as a random variable, the expectation is independent of allele frequencies, and can be expressed by a remarkably simple formula (Egeland and Slooten 2016). In the case of two markers, let be the matrix
| (25) |
where is the number of alleles at the first marker, and define similarly for the second marker. For convenience, we use 0-indexing for the entries of these matrices, e.g. . Now, suppose are the two-locus IBD coefficients of , where ρ is the recombination fraction between the markers. Furthermore, suppose that are the coefficients of the true relationship , which may be different from . (We assume that both and are noninbred.) The expected likelihood ratio is then the following sum (Egeland and Slooten 2016, eq. 2.18),
| (26) |
In Fig. 4, we reproduce and expand a result of Egeland and Slooten (2016, Example 3.4). Here, is shown as a function of ρ for various relationships (assuming ) with two markers of 10 and 15 equally frequent alleles. The three lowest curves, corresponding to grandparent–grandchild, half-siblings and uncle-nephew relationships, agree with the lower part of Fig. 2 in Egeland and Slooten (2016). Two further relationships have been added, namely quadruple half-first cousins (QHFC) and simultaneous half-siblings and half-second cousins (HS+HSC). These were chosen because they are genetically close to the first three, and also to illustrate the utility of the algorithm presented in this paper, since exact formulas for are not available (and nontrivial to work out) for these relationships. An interesting observation from Fig. 4 is that the ranking of the relationships according to depends on the distance between the markers.
Fig. 4.

Expected LR with two markers with 10 and 15 alleles, for various relationships. QHFC = Quadruple half-first cousins. HS + HSC = Simultaneous half-siblings and half-second cousins.
Another powerful application of two-locus coefficients is in the study of realized relatedness, i.e. the actual IBD segments shared by a pair of related individuals. Guo (1995, 1996) showed that for noninbred individuals, the variance in proportion of genome-shared IBD can be expressed as a double integral involving two-locus IBD probabilities, and used this to compute the said variance in special cases. The same technique can be used to compute other similar variances. For instance, for a given pair of noninbred relatives, let be the actual proportions of their genomes where they share 0,1,2 alleles IBD, respectively. For each we have . For a chromosome of length L, we can write , where is an indicator variable and is the number of IBD alleles (0, 1 or 2) at locus x. The variance formula then gives:
| (27) |
Here, is the recombination rate between loci x and y. Assuming a Poisson crossover process, Haldane’s map function entails , where is the genetic distance (in Morgan) between x and y. Hill and Weir (2011) used an approach resembling (27) to compute the variances of and other measures of realized relatedness. However, only special cases of noninbred relationships were considered, in which the required two-locus IBD probabilities could be obtained by direct, but tedious calculations. In contrast, the algorithm and implementation presented here allow these variances to be also obtained in complex pedigrees. This includes inbred relationships, where variances in the realized proportions in states may be defined analogously to (27). Further details and examples, including numerical validations of Hill and Weir (2011) are given in the documentation of the ribd package.
Conclusion
This paper presents an algorithm for computing joint IBD probabilities at two linked loci, called two-locus identity coefficients, in any pedigree. Previous work in this area have focused on simple cases of noninbred relationships, where explicit formulas can be obtained by brute force. In contrast, the method described here applies to any pairwise relationship, both noninbred and inbred. The inbred case requires as many as 81 two-locus coefficients, which may seem like a daunting task. However, they can all be expressed in terms of generalized two-locus kinship coefficients, for which a recursive algorithm is given. All methods, including numerous examples, are implemented in the R package ribd, which runs on all common platforms and is freely available from CRAN. As a result, a variety of methods and applications, previously restricted to simple, special cases, may now be applied and explored in general pedigrees.
Acknowledgments
I thank Thore Egeland for the connection to forensic kinship testing, and for many constructive comments on the manuscript.
Appendix A: A recursive algorithm for generalized two-locus kinship coefficients
We will here describe a recursive algorithm for computing any generalized two-locus kinship coefficient, including the terms used in Theorems 2 and 3 to obtain two-locus identity coefficients. The algorithm is similar in spirit to that of Weeks and Lange (1988) (referred to as WL88 below) and Lange and Sinsheimer (1992), although some additional care is required to account for linkage between the loci.
To compute the probability of any two-locus IBD pattern , we start by writing it in the form
| (A1) |
where a is not an ancestor of any individual present in , and the target sets (some of which may be empty) contain the segregation indices of the alleles emitted from a in each block:
| (A2) |
The assumption that a is present in at most two blocks at each locus follows from diploidy; clearly, otherwise. By permuting blocks and loci if necessary, we may assume w.l.o.g. that , that , and that the first locus has at least as many nonempty target sets as the second. Calling the ’s sets is justified since duplicates within any block of can be removed without changing . On the other hand, duplicates across blocks at the same locus gives , since the same gamete cannot have multiple alleles at the same locus. Thus, we may assume .
The following integers are used in the recursion formulas:
| (A3) |
Note that ν is the total number of distinct gametes emitted from a, of which contain specified alleles from a at both loci. Importantly, both ν and the (unordered) set are invariant under permutations of blocks and loci of .
Recursion formulas
The recursion proceeds upwards through the pedigree, in each step replacing a child a with its parents f and m, until only founders are left. For notational convenience, we denote parent-to-child transmissions using the child’s label as segregation index, as in . As mentioned previously, this does not work with selfing, but such cases can be easily handled in the implementation.
Case 1: , —
In this case, a is present only in the first block of the first locus. This is covered by Recursion rules 1 and 2 of WL88, giving
(A4) where , and if , and 0 otherwise.
Case 2: , —
Again, a is present only in the first locus, and we may apply Recurrence rule 3 of WL88:
(A5) where .
Case 3: , —
This is the most complicated case, with up to 9-fold recursion:
(A6) The coefficients are as follows, where . (Note that and .)
(A7) The first two terms of (A6) cover the possibilities where the alleles emitted from a, all originate from the father f, or all from the mother m. The next two terms consider the situations when all of come from f and all of from m, or vice versa. The terms account for the cases where the set includes alleles from both f and m (implying that a is inbred), while the alleles in originate either all from f or all from m. The terms are similar, but with the loci switched. The last term covers the remaining cases when both sets and contain alleles from both f and m.
Case 4: , —
Here, we have
(A8) where, as before, the coefficients are found by considering the origins (f or m) of the alleles:
(A9)
Case 5: —
In the final case, we have the following recursion formula:
(A10) where and .
Boundary formulas
Since each step replaces a child with its parents, the recursion will eventually reach a pattern involving only founders. The following boundary conditions, adapted from WL88, then apply to each locus individually:
Boundary condition 1
If a founder (or in fact any person) occurs in more than two blocks of , then .
Boundary condition 2
If two different founders occur in the same block of , then .
Finally, we have a single boundary rule where and are considered together.
Boundary condition 3
If all individuals in are founders, and none of the above boundary rules applies, then where the product is over all distinct founders appearing in , and the factors are computed as follows.
After a suitable permutation of the blocks, we can write , where each block of involves the alleles of a single founder (otherwise Boundary condition 2 would apply). With ν, μ and σ as in (A3), we claim that the ν gametes emitted from a contain either exactly μ nonrecombinants and σ recombinants, or vice versa. Indeed, this follows from the observation that, since a is noninbred, the gametes corresponding to and are either all nonrecombinant or all recombinant, and similarly, but oppositely, for and . Hence, the contribution of a to is
(A11)
Note that if and are empty, i.e. if a occurs only in , then reduces to . From this, it follows that if is empty, then , where is the total number of gametes and the number of distinct individuals, in agreement with Boundary condition 3 of WL88.
Appendix B: Phased two-locus coefficients of unilineal relationships
The purpose of this appendix is to derive a formula for the phased coefficients , , and in the unilineal case. Recall that in this case we cannot assume that a and b are nonfounders, so we cannot rely on the generalized patterns .
The approach is similar to the computation of in Theorem 1. We start off by defining the following generalized two-locus IBD patterns:
| (B1) |
Theorem 4
For a unilineal relationship , the phased coefficients are determined as follows:
(B2)
Proof
(a) Like we did for in the proof of Theorem 1, we can express each as a linear combination of . In matrix form, the equations work out to be
(B3) The matrix on the right-hand side is invertible for , yielding the stated solution.
(b) Suppose first that a is an ancestor of b, and that a and b share one IBD allele at each locus. Since b is noninbred, a can only be related to one of b’s parents, from which b must inherit both alleles. Thus b’s alleles are in cis, implying that . In a, on the other hand, cis/trans are equally likely since the loci are independent (). In other words, . The result, when a is an ancestor of b, then follows since the phased coefficients sum to , which for any relationship equals .
The same argument applies in the case where is collateral and both parents of a are related to b. By symmetry, the cases where b is an ancestor of a, or is collateral and both parents of b are related to a, are treated similarly. The only remaining case is when is collateral and exactly one parent of a is related to exactly one parent of b. This clearly enforces that the IBD alleles are in cis in both individuals, so that is the only nonzero contribution. The result follows. ȃ□
Data availability
All source code is available on GitHub at https://github.com/magnusdv/ribd.
Funding
This work has been supported by the Norwegian Research Council (project no. 321043).
Communicating editor: A. Kern
Literature cited
- Almasy L, Blangero J. Multipoint quantitative-trait linkage analysis in general pedigrees. Am J Hum Genet. 1998;62:1198–1211. doi: 10.1086/301844 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bishop DT, Williamson JA. The power of identity-by-state methods for linkage analysis. Am J Hum Genet. 1990;46:254–265. [PMC free article] [PubMed] [Google Scholar]
- Bright JA, Curran JM, Buckleton JS. Relatedness calculations for linked loci incorporating subpopulation effects. Forensic Sci Int Genet. 2013;7:380–383. doi: 10.1016/j.fsigen.2013.03.002 [DOI] [PubMed] [Google Scholar]
- Buckleton J, Triggs C. The effect of linkage on the calculation of DNA match probabilities for siblings and half siblings. Forensic Sci Int. 2006;160:193–199. doi: 10.1016/j.forsciint.2005.10.004 [DOI] [PubMed] [Google Scholar]
- Cotterman CW. A calculus for statistico-genetics [PhD thesis]. The Ohio State University; 1940.
- Denniston C. Probability and genetic relationship: two loci. Ann Hum Genet. 1975;39(1):89–104. doi: 10.1111/j.1469-1809.1975.tb00110.x [DOI] [PubMed] [Google Scholar]
- Donnelly KP. The probability that related individuals share some section of genome identical by descent. Theor Popul Biol. 1983;23(1):34–63. doi: 10.1016/0040-5809(83)90004-7 [DOI] [PubMed] [Google Scholar]
- Dørum G, Kling D, Tillmar A, Vigeland MD, Egeland T. Mixtures with relatives and linked markers. Int J Legal Med. 2015;130(3):621–634. doi: 10.1007/s00414-015-1288-x [DOI] [PubMed] [Google Scholar]
- Egeland T, Sheehan N. On identification problems requiring linked autosomal markers. Forensic Sci Int Genet. 2008;2:219–225. doi: 10.1016/j.fsigen.2008.02.006 [DOI] [PubMed] [Google Scholar]
- Egeland T, Slooten K. The likelihood ratio as a random variable for linked markers in kinship analysis. Int J Legal Med. 2016;130(6):1445–1456. doi: 10.1007/s00414-016-1416-2 [DOI] [PubMed] [Google Scholar]
- Guo S-W. Proportion of genome shared identical by descent by relatives: concept, computation, and applications. Am J Hum Genet. 1995;56(6):1468–1476. [PMC free article] [PubMed] [Google Scholar]
- Guo S-W. Variation in genetic identity among relatives. Hum Hered. 1996;46:61–70. doi: 10.1159/000154328 [DOI] [PubMed] [Google Scholar]
- Haldane JBS. The association of characters as a result of inbreeding and linkage. Ann Eugen. 1949;15(1):15–23. doi: 10.1111/j.1469-1809.1949.tb02418.x [DOI] [PubMed] [Google Scholar]
- Hill WG, Weir BS. Variation in actual relationship as a consequence of mendelian sampling and linkage. Genet Res. 2011;93(1):47–64. doi: 10.1017/S0016672310000480 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hill WG, Weir BS. Variation in actual relationship among descendants of inbred individuals. Genet Res (Camb). 2012;94:267–274. doi: 10.1017/S0016672312000468 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jacquard A. The Genetic Structure of Populations. Berlin, Heidelberg, New York: Springer-Verlag; 1974. [Google Scholar]
- Karigl G. A recursive algorithm for the calculation of identity coefficients. Ann Hum Genet. 1981;45(3):299–305. doi: 10.1111/j.1469-1809.1981.tb00341.x [DOI] [PubMed] [Google Scholar]
- Lange K, Sinsheimer JS. Calculation of genetic identity coefficients. Ann Hum Genet. 1992;56(4):339–346. doi: 10.1111/j.1469-1809.1992.tb01162.x [DOI] [PubMed] [Google Scholar]
- Speed D, Balding DJ. Relatedness in the post-genomic era: is it still useful? Nat Rev Genet. 2015;16(1):33–44.doi: 10.1038/nrg3821 [DOI] [PubMed] [Google Scholar]
- Thompson EA. The estimation of pairwise relationships. Ann Hum Genet. 1975;39(2):173–188. doi: 10.1111/j.1469-1809.1975.tb00120.x [DOI] [PubMed] [Google Scholar]
- Thompson EA. Two-locus and three-locus gene identity by descent in pedigrees. IMA J Math Appl Med Biol. 1988;5(4):261–279. doi: 10.1093/imammb/5.4.261 [DOI] [PubMed] [Google Scholar]
- Thompson EA. Statistical Inference from Genetic Data on Pedigrees. Institute of Mathematical Statistics; 2000(NSF-CBMS regional conference series in probability and statistics). [Google Scholar]
- Thompson EA. Identity by descent: variation in meiosis, across genomes, and in populations. Genetics. 2013;194(2):301–326.doi: 10.1534/genetics.112.148825 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vigeland MD. Relatedness coefficients in pedigrees with inbred founders. J Math Biol. 2020;81:185–207. doi: 10.1007/s00285-020-01505-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vigeland MD. Pedigree Analysis in R. Academic Press; 2021. [Google Scholar]
- Weeks DE, Lange K. The affected-pedigree-member method of linkage analysis. Am J Hum Genet. 1988;42(2):315–326. [PMC free article] [PubMed] [Google Scholar]
- Weeks DE, Lange K. A multilocus extension of the affected-pedigree-member method of linkage analysis. Am J Hum Genet. 1992;50(4):859–868. [PMC free article] [PubMed] [Google Scholar]
- Weir BS, Cockerham CC. Pedigree mating with two linked loci. Genetics. 1969;61:923–940. doi: 10.1093/genetics/61.4.923 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wright S. Coefficients of inbreeding and relationship. Am Nat. 1922;56(645):330–338. doi: 10.1086/279872 [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All source code is available on GitHub at https://github.com/magnusdv/ribd.