

Abstract
To study a core component of human intelligence—our ability to combine the meaning of words—neuroscientists have looked to linguistics. However, linguistic theories are insufficient to account for all brain responses reflecting linguistic composition. In contrast, we adopt a data-driven approach to study the composed meaning of words beyond their individual meaning, which we term ‘supra-word meaning’. We construct a computational representation for supra-word meaning and study its brain basis through brain recordings from two complementary imaging modalities. Using functional magnetic resonance imaging, we reveal that hubs that are thought to process lexical meaning also maintain supra-word meaning, suggesting a common substrate for lexical and combinatorial semantics. Surprisingly, we cannot detect supra-word meaning in magnetoencephalography, which suggests that composed meaning might be maintained through a different neural mechanism than the synchronized firing of pyramidal cells. This sensitivity difference has implications for past neuroimaging results and future wearable neurotechnology.
Understanding language in the real world requires us to compose the meaning of individual words in a way that makes the final composed product more meaningful than the string of isolated words. For example, we understand the statement that ‘Mary finished the apple’ to mean that Mary finished eating the apple, even though ‘eating’ is not explicitly specified1. This supra-word meaning, or the product of meaning composition beyond the meaning of individual words, is at the core of language comprehension, and its neurobiological bases and processing mechanisms must be specified in the pursuit of a complete theory of language processing in the brain.
Different types of supra-word meaning exist. In addition to coercion, such as ‘finished eating’ in ‘Mary finished the apple’1, other examples of supra-word meaning include a specific contextualized meaning of a word or phrase (for example, ‘green banana’ evokes the meaning of an unripe, rather than simply green-coloured, banana) that can also distinguish between different senses of the same word (for example, ‘play a game’ versus ‘theatre play’), and the different meaning of two events that can be described with the same words but reversed semantic roles (for example, ‘John gives Mary an apple’ and ‘Mary gives John an apple’). Previous works have focused on specific types of supra-word meaning in carefully controlled experiments2–6. However, much is left to know about the brain processing of supra-word meaning in naturalistic language. For instance, to understand how meaning is processed and composed and how the brain makes sense of language, knowing where the supra-word meaning is maintained is an essential requirement. One proposed hypothesis is that the ventro-medial prefrontal cortex represents the product of meaning composition1.
How can we find the regions that represent supra-word meaning? One approach is to focus on every type of supra-word meaning and design a controlled experiment to study it. This approach is not without challenges because it would require many experimental conditions, and carefully balancing the condition of interest and the control condition for all types of supra-word meaning might be challenging. One alternative is to use a complex natural text that readily contains various types of supra-word meaning and build representations that characterize this set of supra-word meanings. Deep neural network language models are currently the most powerful tools for building such representations7–9. Though these natural language processing (NLP) systems are not specifically designed to mimic the processing of language in the brain, representations of language extracted from these NLP systems have been shown to predict the brain activity of a person comprehending language better than ever before10–15.
After being trained to predict a word in a specific position from its context on extremely large corpora of text, neural network language models achieve unprecedented performance on various NLP tasks7–9. One can use these networks to extract representations for the meaning of stimulus text. While these representations are often difficult to interpret (we do not know what the dimensions of the representational space correspond to, what processes are being computed or what type of composition is happening at a given time), they can still help us achieve our goal of identifying the regions that represent supra-word meaning. This is because the neural network representations could be assumed to contain at least some of the aspects of supra-word meaning (otherwise, they would fail at many of the NLP tasks16,17). If we can isolate the information in the neural network representations of a sequence of words that is not contained in the individual words themselves, then we would be isolating some aspects of supra-word meaning. We can then identify brain regions that are well predicted by this isolated supra-word meaning.
We thus build a computational object for supra-word meaning using neural network representations, which we call a supra-word embedding. Specifically, we construct the following computational representation of supra-word meaning: a ‘supra-word embedding’ is the part of a contextualized word embedding extracted from the NLP system that is orthogonal to the individual word meanings that make up the adjacent context. This computational object acts as a set that includes some types of supra-word meaning and that enables us to identify regions that encode supra-word meaning. The current work relies on deep learning models because of their expressivity and ability to predict brain activity in naturalistic contexts, which at the moment is not matched by methods that are tied to linguistic theory. Linguistic theory has traditionally focused on a different set of problems than the problem of predicting words and word sequences with high accuracy across a large variety of contexts, and is well equipped to shed light on more systematic features of language18. While our analysis relies on deep learning models, it does not exclude future analyses that are more closely tied to linguistic theory. Future work could indeed focus on constructing representations for specific types of supra-word meaning, or on interpreting the contents of supra-word embeddings to identify which types of supra-word meaning they contain.
We study the neural bases of supra-word meaning by using its computational representation ‘supra-word embedding’ and data from naturalistic reading in two neuroimaging modalities. We find that the supra-word embedding predicts functional magnetic resonance imaging (fMRI) activity in the anterior and posterior temporal cortices, suggesting that these areas represent composed meaning. The posterior temporal cortex is considered to be primarily a site for lexical (that is word-level) semantics19,20, so our finding that it also maintains supra-word meaning suggests a common substrate for lexical and combinatorial semantics. Furthermore, we find clusters of voxels in both the posterior and anterior temporal lobe that share a common representation of supra-word meaning, suggesting that these two areas may be working together to maintain the supra-word meaning. We replicate these findings in an independent fMRI data set recorded from a different experimental paradigm and a different set of participants.
The second neuroimaging modality that we utilize to investigate the neural bases of supra-word meaning is magnetoencephalography (MEG). While MEG and fMRI are both thought to be primarily driven by post-synaptic cellular processes and many traditional localization studies have found similar location of activations in fMRI and MEG for the same task, the relationship between these two modalities is complex and still not fully understood21. For example, some discordances have been observed in the primary cortex, where MEG has sensitivity to spatial frequency22,23 and colour24 while fMRI does not22–24. At the same time, fMRI–MEG fusion, a method that relates the representations of the same stimuli in both modalities, has identified regions that are sensitive to the properties of written individual words when measured in fMRI but without a significant correspondence in MEG25. We also find a mismatch between our MEG and fMRI results. We find that it is very difficult to detect the representation of supra-word meaning in MEG activity. MEG has been shown to reveal signatures of the computations involved in incorporating a word into a sentence26,27, which are themselves a function of the composed meaning of the words seen so far. However, our results suggest that the sustained representation of the composed meaning may rely on neural mechanisms that do not lead to reliable MEG activity. This hypothesis calls for a more nuanced understanding of the body of literature on meaning composition and has important implications for the future of brain–computer interfaces.
Results
Computational controls of natural text
We built on recent progress in NLP that has resulted in algorithms that can capture the meaning of words in a particular context. One such algorithm is ELMo7, a powerful language model with a bi-directional long short-term memory (LSTM) architecture. ELMo estimates a contextualized embedding for a word by combining a non-contextualized fixed input vector for that word with the internal state of a forward LSTM (containing information from previous words) and a backward LSTM (containing information from future words). To capture information about word t, we used the non-contextualized input vector wt for word t. To capture information about the context preceding word t, we used the internal state of the forward LSTM computed at word t − 1 (Fig. 1b), which we term ct−1. We did not include information from the backward LSTM, since it contains future words which have not yet been seen at time t. Note that ELMo’s forward and backward LSTMs are trained independently and do not influence one another7. We have also experimented with GPT-2 (ref.28), which is a more complex language model with a transformer-based architecture and 12 internal layers, and observed that our findings from ELMo replicate (Results). We choose to focus on ELMo because of its good performance at language tasks and at predicting brain recordings12, and yet relative simplicity with respect to other recent language models.
Fig. 1 |. Approach.
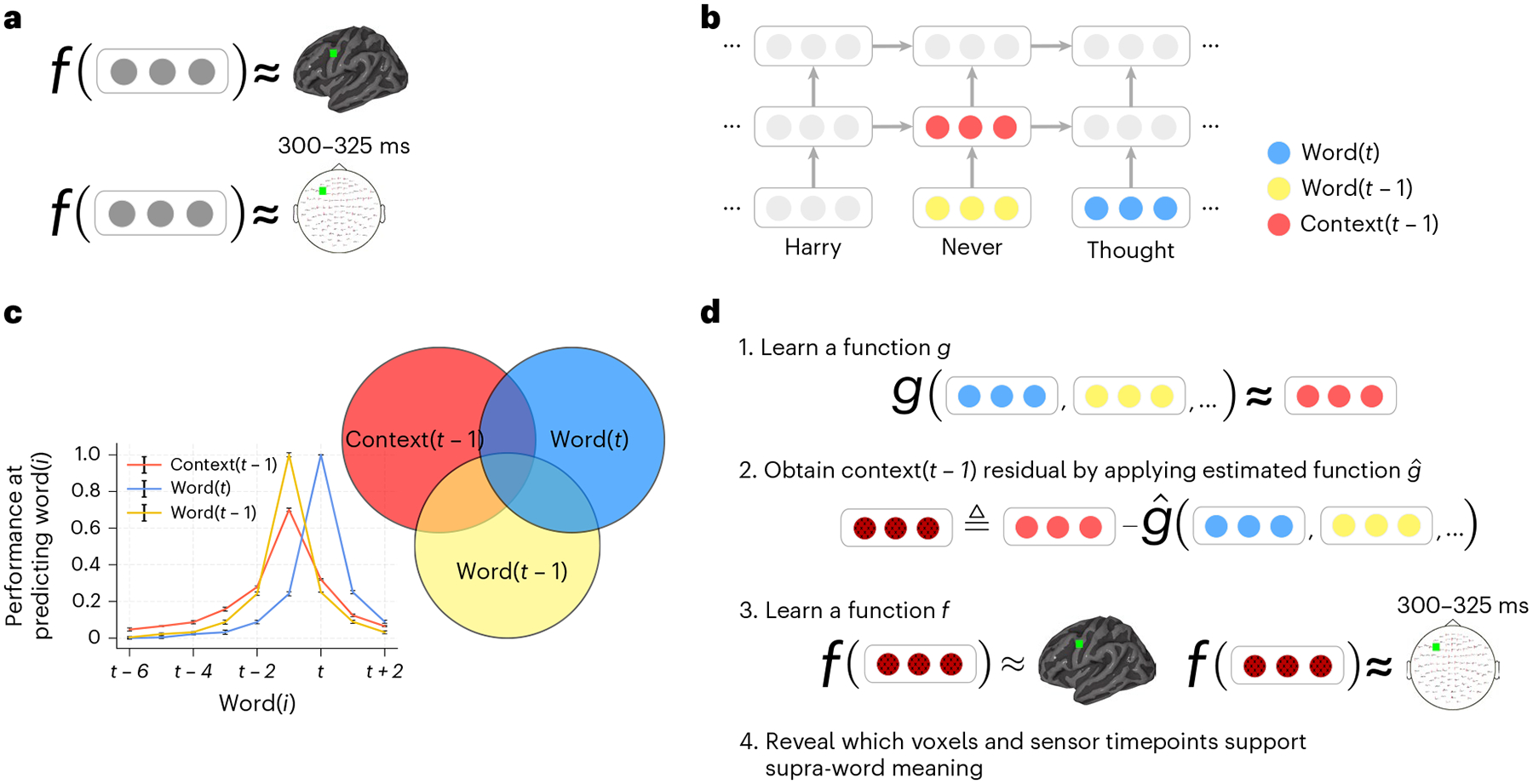
a, An encoding model f learns to predict a brain recording as a function of representations of the text read by a participant during the experiment. A different function is learned for each voxel in fMRI (top) and each sensor timepoint in MEG (bottom). b, Stimulus representations are obtained from an NLP model that has captured language statistics from millions of documents. This model represents words using context-free embeddings (yellow and blue) and context embeddings (red). Context embeddings are obtained by continuously integrating each new word’s context-free embedding with the most recent context embedding. c, Context and word embeddings share information. The performance of the context and word embeddings at predicting the words at surrounding positions is plotted for different positions (the s.e.m. across test instances is shown, n = 5,156). The context embedding contains information about up to six past words, and the word embedding contains information about embeddings of surrounding words. To isolate the representation of supra-word meaning, it is necessary to account for this shared information. d, Supra-word meaning is modelled by obtaining the residual information in the context embeddings after removing information related to the word embeddings. We refer to this residual as the ‘supra-word embedding’ or ‘residual context embedding’. The supra-word embedding is used as an input to an encoding model f, revealing which fMRI voxels and MEG sensor timepoints are modulated by supra-word meaning.
To study supra-word meaning, the meaning that results from the composition of words should be isolated from the individual word meaning. ELMo’s context embeddings ct−1 contain information about individual words (for example, ‘finished’, ‘the’ and ‘apple’ in the context ‘finished the apple’) in addition to the implied supra-word meaning (for example, eating) (Fig. 1c). In fact, ELMo’s context embedding ct−1 of word t is strongly linearly related to the non-contextualized embeddings of the next word wt+1, the current word wt and the previous word wt−1 (Supplementary Fig. 1). We post-processed the context embeddings ct−1 produced by ELMo to remove the contribution due to the context-independent meanings of individual words (captured by the non-contextualized embeddings wt… wt−24). We constructed an embedding for the ‘residual context’ by removing the shared information between the context embedding ct−1 and the individual word embeddings wt to wt−24 (Fig. 1d and Supplementary Fig. 1). We defined g to be a linear function that relates the context embedding ct−1 to the non-contextualized embeddings of the 25 most recent words (wt, wt−1, wt−2, …, wt−24). After estimating , we expressed the residual context as
| (1) |
To investigate the brain substrate of supra-word meaning, we trained encoding models to predict the brain recordings of nine fMRI participants and eight MEG participants as they read a chapter of a popular book in rapid serial visual presentation. The encoding models predict each fMRI voxel and MEG sensor timepoint, as a function of the constructed residual context embedding of the text read by the participant up to that time point (Fig. 1a). The prediction performance of these models was tested by computing the correlation between the model predictions and the true held-out brain recordings. Hypothesis tests were used to identify fMRI voxels and MEG sensor timepoints that were significantly predicted (Methods).
Detecting regions that are predicted by supra-word meaning
To identify brain areas representing supra-word meaning, we focus on the fMRI portion of the experiment. We find that much of the areas previously implicated in language-specific processing29,30 and word semantics31 is significantly predicted by the full context embeddings across subjects (voxel-level permutation test, Benjamini–Hochberg false discovery rate (FDR) control at 0.01 (ref.32)). These areas include the bilateral posterior temporal lobe (PTL) and anterior temporal lobe (ATL), angular gyri, inferior frontal gyri, posterior cingulate and dorsomedial prefrontal cortex (Fig. 2a and Supplementary Figs. 2 and 3). A subset of these areas is also significantly predicted by residual context embeddings. To quantify these observations, we select regions of interest (ROIs) based on refs.29,31, using ROI masks that are entirely independent of our analyses and data (Methods). Full context embeddings predict a significant proportion of the voxels within each ROI across all nine participants (Fig. 2b; ROI-level Wilcoxon signed-rank test, P < 0.05, Holm–Bonferroni correction33). In contrast, residual context embeddings predict a significant proportion of only the PTL and ATL. These results are not specific to word representations obtained from ELMo. Using a different language model (GPT-2) to obtain the full and residual context embeddings replicates the results obtained using ELMo (Methods), showing that all bilateral language ROIs are predicted significantly by the full context embedding, and that the bilateral ATL and PTL are predicted significantly by the residual context embedding (Supplementary Fig. 4).
Fig. 2 |. fMRI results.
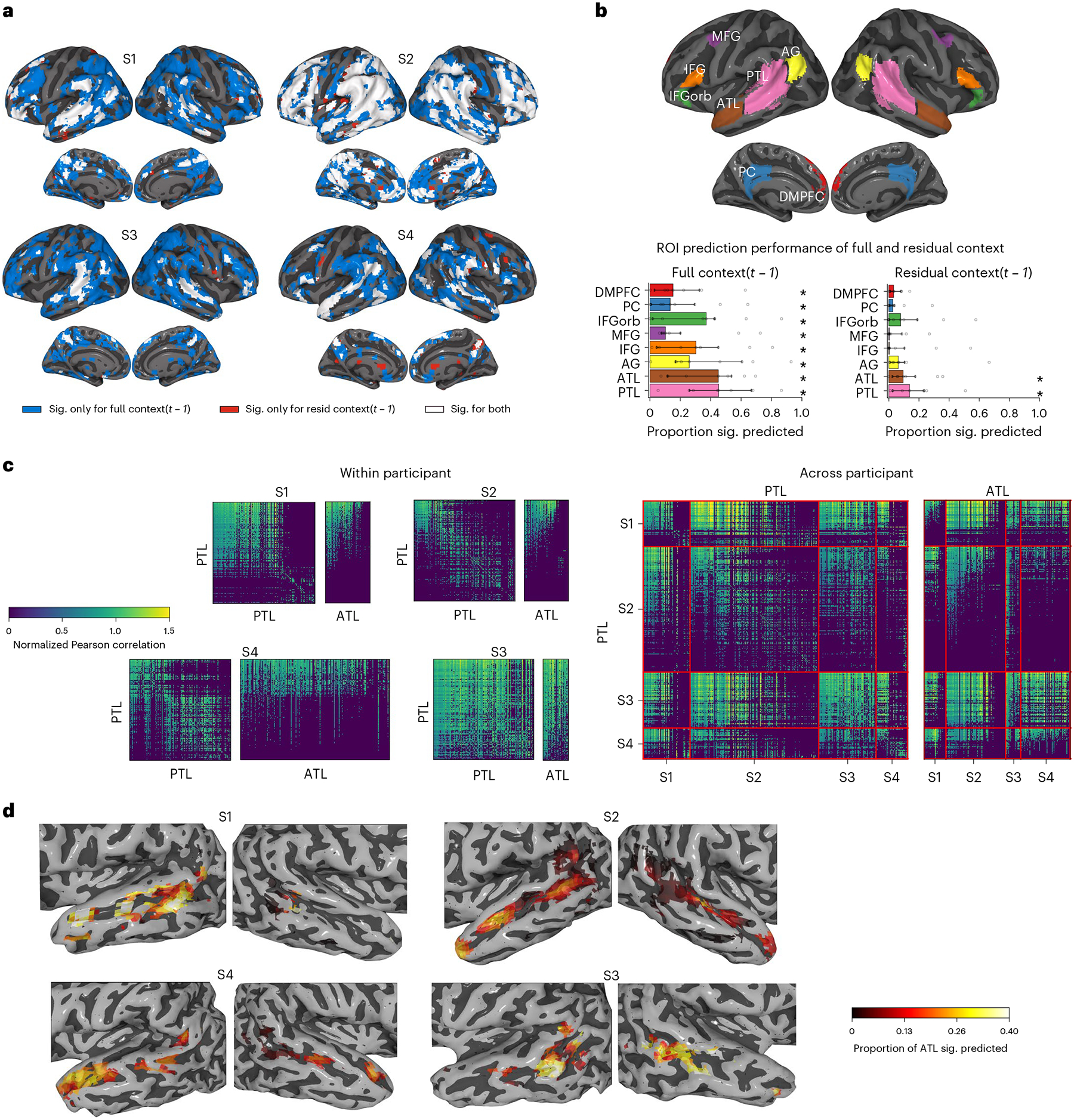
Visualizations for four (S1–S4) of the nine participants, with the remainder available in Supplementary Figs. 3–5. Voxel-level significance is FDR corrected at level 0.01. a, Voxels significantly (sig.) predicted by full-context embeddings (blue), residual-context embeddings (red) or both (white), visualized in Montreal Neurological Institute space. Most of the temporal cortex and inferior frontal gyri are predicted by full context embeddings, with residual context embeddings mostly predicting a subset of those areas. b, ROI-level results. Top: language system ROIs29 and two semantic ROIs31. Bottom: proportion of ROI voxels significantly predicted by full context (left) and residual context (right) embeddings. The investigated ROI correspond to the bilateral dorsomedial prefrontal cortex (DMPFC), posterior cingulate cortex (PC), inferior frontal gyrus pars orbitalis (IFGorb), middle frontal gyrus (MFG), inferior frontal gyrus (IFG), angular gyrus (AG), anterior temporal lobe (ATL) and posterior temporal lobe (PTL). Displayed are the median proportions across all nine participants and the 95% confidence interval on the median. Full context predicts all ROIs (ROI-level Holm–Bonferroni correction, P < 0.05), while residual context predicts only bilateral ATL and PTL (significant predictions indicated by an asterisk). c, Spatial generalization matrices. Models trained to predict PTL voxels are used to predict PTL and ATL voxels, within participant (left) and across participants (right). PTL cross-voxel correlations form two clusters: models that predict activity for voxels in one cluster can also predict activities of other voxels in the same cluster, but not activities for voxels in the other cluster. Across participants, only one of these clusters has voxels that predict ATL voxels. d, Performance of models trained on ATL and PTL voxels at predicting other participants’ ATL. All participants show a cluster of predictive voxels in the pSTS.
Do the parts of the ATL and PTL that are predicted by supra-word meaning process the same information? Inspired by temporal generalization matrices34, we introduce spatial generalization matrices that estimate the pairwise similarity of voxel representations (Methods). The spatial generalization matrices reveal that the PTL can be divided into two main clusters such that the models of voxels in one cluster can also predict other voxels in that cluster but not in the other cluster (Fig. 2c and Supplementary Fig. 5; voxel-level permutation test, Benjamini–Hochberg FDR controlled at level 0.01). Furthermore, the models of voxels within one of the PTL clusters significantly predict voxels in the ATL, while those in the other PTL cluster do not. This division of the PTL can be observed within (Fig. 2c, left), and across participants (Fig. 2c, right). In contrast, the ATL voxels show only one cluster of voxels that are predictive both of other ATL voxels and also of PTL voxels (Supplementary Fig. 5). This pattern indicates that the organization of information in the ATL and parts of the PTL is shared and consistent across participants. To localize this shared representation, we visualize how well each ATL and PTL voxel predicts the other participants’ ATLs (Fig. 2d and Supplementary Fig. 6). ATL voxels are predictive of significant proportions of the ATL across participants, reinforcing the single cluster of ATL voxels observed in the spatial generalization matrices. Much of the left PTL predicts a significant proportion of the ATL across participants, whereas much of the right PTL does not (ROI-level Wilcoxon signed-rank test, P < 0.05, Holm–Bonferroni correction). The left PTL appears further subdivided, with a cluster of voxels in the posterior superior temporal sulcus (pSTS) being more predictive. This suggests that the ATL and the left pSTS process a similar facet of supra-word meaning.
To test whether the findings that the ATL and PTL support supra-word meaning are specific to our data set or experimental paradigm, we conducted a replication analysis using a second fMRI experiment acquired by the Courtois NeuroMod Group using a completely different paradigm (participants viewed a full-length popular movie), different sensory modalities (reading versus listening) and different participant population. The computational representation of supra-word meaning (that is, the residual context embedding) was computed based on the speech in the movie. Our ATL and PTL results are repeated with this data set (see Supplementary Fig. 7 for ROI-level results, Supplementary Fig. 8 for group-level voxel-wise significance masks, Supplementary Fig. 9 for individual voxel-wise significance masks and Supplementary Figs. 10 and 11 for the spatial generalization results).
The processing of supra-word meaning is invisible in MEG
To study the temporal dynamics of supra-word meaning, we turn to the MEG portion of the experiment (Fig. 3). We computed the proportion of sensors significantly predicted at different spatial granularity: the whole brain (Fig. 3a), by lobe subdivisions (Supplementary Fig. 12) and at each sensor neighbourhood location (Fig. 3b; sensor timepoint-level permutation test, Benjamini–Hochberg FDR control at level 0.01; see Supplementary Fig. 13 for sensor-level results for individual participants). The full context embedding is significantly predictive of the recordings across all lobes (Fig. 3a, performance visualized in lighter colours; timepoint-level Wilcoxon signed-rank test, P < 0.05, Benjamini–Hochberg FDR correction). Surprisingly, we find that the residual context does not significantly predict any timepoint in the MEG recordings at any spatial granularity. This surprising finding leads to two conclusions. First, supra-word meaning is invisible in MEG. Second, what is instead salient in MEG recordings is information that is shared between the context and the individual words. These results are not specific to word representations obtained from ELMo. Using embeddings obtained from GPT-2 replicates the results (Methods and Supplementary Fig. 14).
Fig. 3 |. MEG prediction results at different spatial granularity.
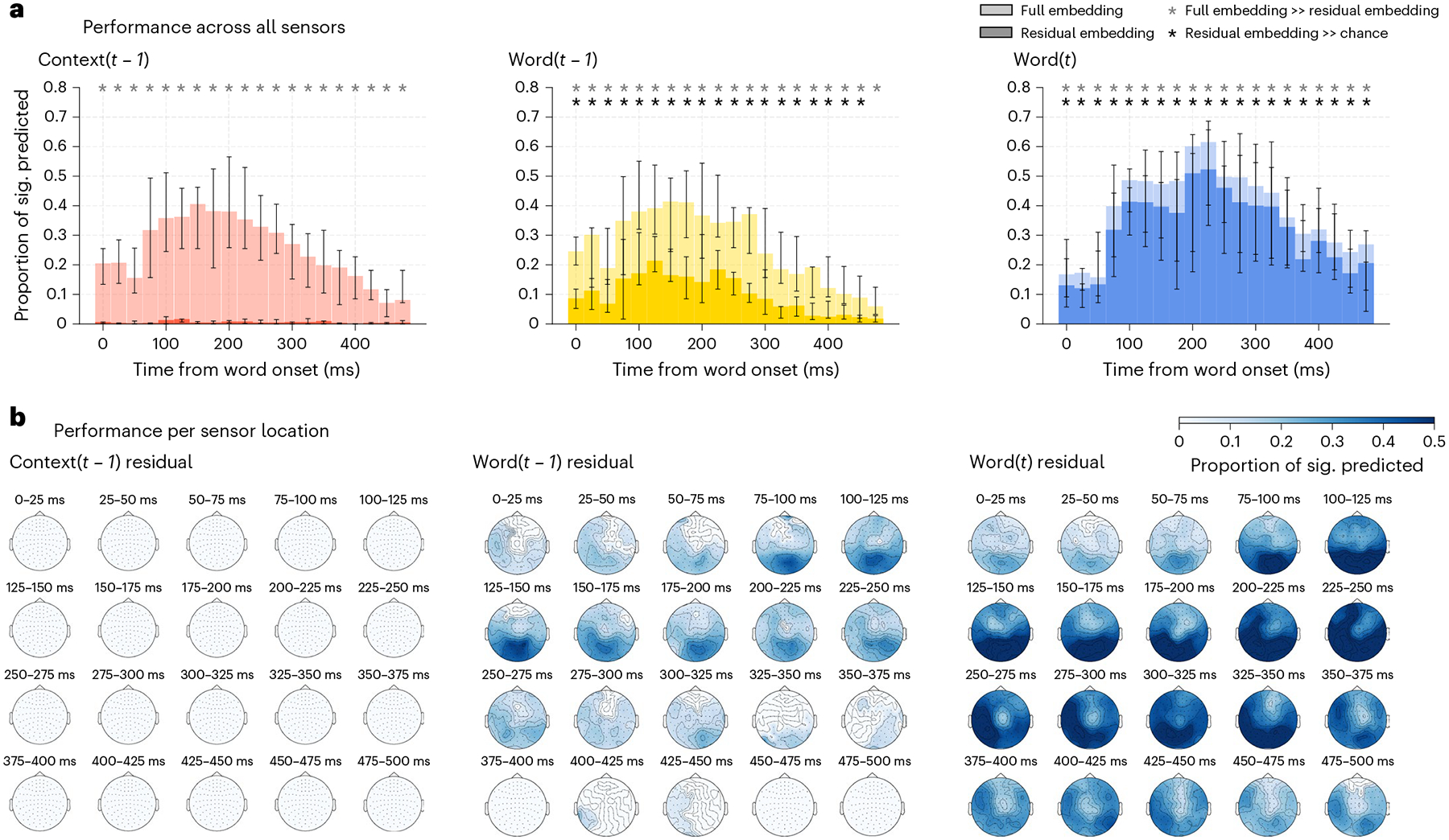
All subplots present the median across all eight participants, and error bars show the 95% confidence interval on the median. a, Proportion of sensors for each timepoint significantly predicted by the full (lighter colours) and residual (darker colours) embeddings. Significant predictions are indicated with an asterisk. Removing the shared information among the full current word, the previous word and the context embeddings results in a significant decrease in performance for all embeddings and lobes (one-sided Wilcoxon signed-rank test, P < 0.05, Benjamini–Hochberg FDR correction). The decrease in performance for the context embedding (left column) is the most drastic, with no time windows being significantly different from chance for the residual context embedding. b, Proportions of sensor neighbourhoods significantly predicted by each residual embedding. Only the significant proportions are displayed (FDR corrected, P < 0.05). Context residuals do not predict any sensor timepoint neighbourhood, while both the previous and the current residual word embedding predict a large subset of sensor timepoints, with performance peaks in occipital and temporal lobes.
We emphasize that this null result is accompanied by two strongly significant results which, when taken together, should alleviate some concerns about the quality of the MEG data and the quality of the supra-word meaning embedding. First, the MEG data are indeed strongly predicted by representations of both individual words and context (Fig. 3), and second, the supra-word meaning embedding predicts significant proportions of the fMRI recordings (Fig. 2). There is a null result only when the supra-word meaning embeddings are used to predict the MEG data. Given these results, we are confident that removing the individual word information from the adjacent context eliminates much of the information that is useful to predict the MEG recordings. Further, these results repeated in data from one subject listening to 70 min of spoken stories (totalling 15,030 words) from ref.35 (Supplementary Fig. 15). A similar analysis with this data revealed that, while the full context embedding is well predictive of many sensor timepoint combinations, the residual context is not predictive at any sensor or timepoint.
To understand the source of this salience, we investigated the relationship between the MEG recordings and the word embeddings for the currently read and previously read words. One approach is to train an encoding model as a function of the word embedding11,12. However, the word embedding of word t is correlated with the surrounding word embeddings (Fig. 1c). To isolate processing that is exclusively related to an individual word, we constructed ‘residual word embeddings’, following the approach of constructing the residual context embeddings. Namely we estimate a linear function that relates a word’s embedding to the previous context embedding and the embedding of recent words, and we compute the residuals between the word embedding and this linear estimate (Methods). We observe that the residual word embeddings for the current and previous words lead to significantly worse predictions of the MEG recordings, when compared with their corresponding full embeddings (Fig. 3a, middle and right panels; timepoint-level Wilcoxon signed-rank test, P < 0.05, Benjamini–Hochberg FDR correction). This indicates that a significant proportion of the activity predicted by the current and previous word embeddings is due to the shared information with surrounding word embeddings. Nonetheless, we find that the residual current word embedding is still significantly predictive of brain activity everywhere the full embedding was predictive. This indicates that properties unique to the current word are well predictive of MEG recordings at all spatial granularity. The residual previous word embedding predicts fewer time windows, particularly 350–500 ms post word t onset. This indicates that the activity in the first 350 ms when a word is on the screen is predicted by properties that are unique to the previous word. Taken together, these results suggest that the properties of recent words are the elements that are predictive of MEG recordings, and that MEG recordings do not reflect the supra-word meaning beyond these recent words.
Lastly, we directly compared how well each imaging modality can be predicted by each meaning embedding (Fig. 4). Residual embeddings predict fMRI and MEG with significantly different accuracy (Fig. 4a), with fMRI being significantly better predicted than MEG by the residual context, and MEG being significantly better predicted by the residual of the previous and current words (Wilcoxon rank-sum test, P < 0.05, Holm–Bonferroni correction). In contrast, the full context embeddings do not show a significant difference in predicting fMRI and MEG recordings (Fig. 4b). We further observe that the residual embeddings lead to an opposite pattern of prediction in the two modalities (Fig. 4c). While the residual context predicts fMRI the best out of the three residual embeddings, it performs the worst out of the three at predicting MEG (Wilcoxon signed-rank test, P < 0.05, Holm–Bonferroni correction). In contrast, the full context and previous word embeddings do not show a significant difference in MEG prediction (Fig. 4d), suggesting that it is the removal of individual word information from the context embedding that leads to a significantly worse MEG prediction. These findings further suggest that fMRI and MEG reflect different aspects of language processing: while MEG recordings reflect processing related to the recent context, fMRI recordings capture the contextual meaning that is beyond the meaning of individual words.
Fig. 4 |. Direct comparisons of prediction performance of different meaning embeddings.
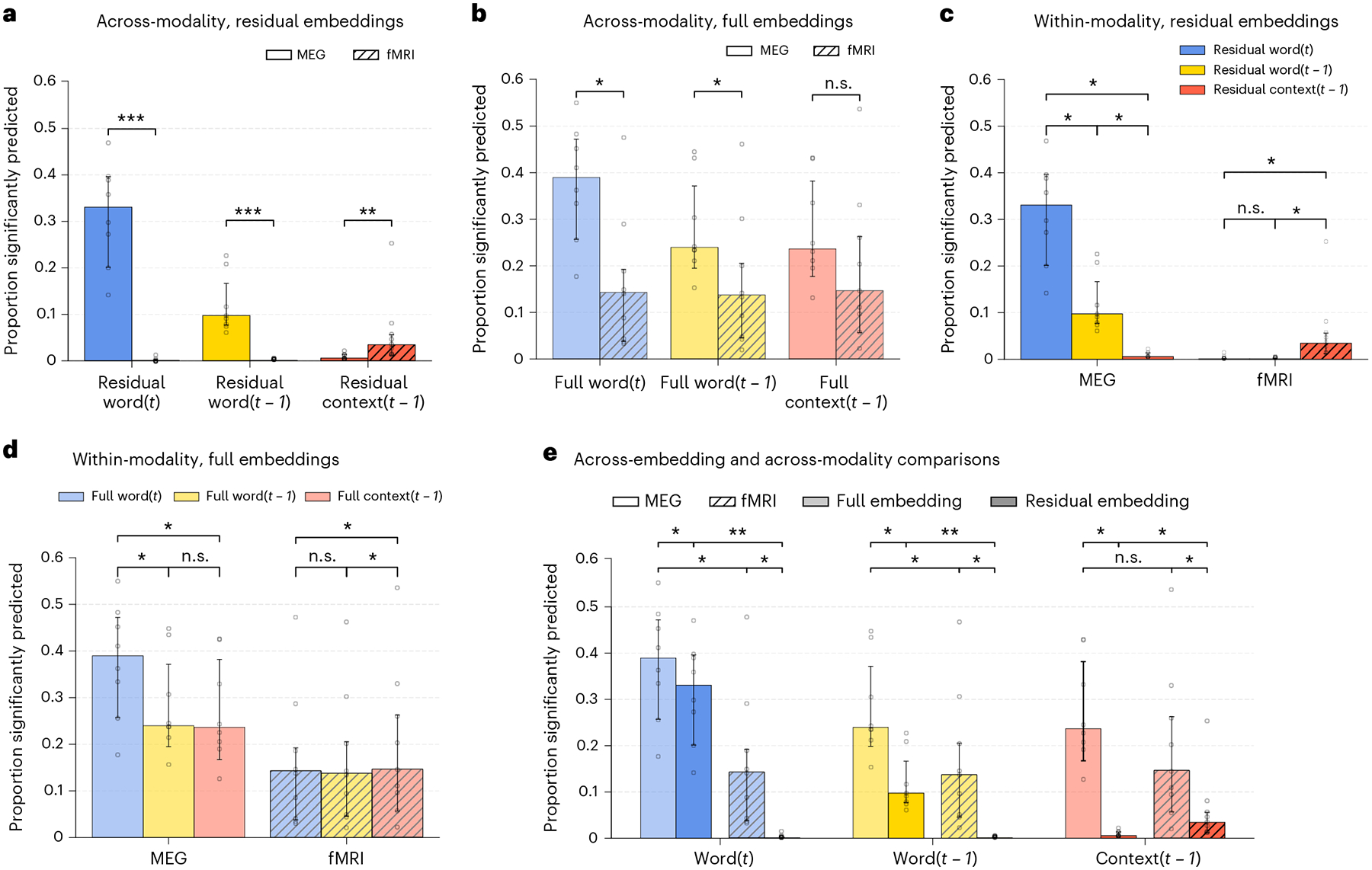
Median proportions across participants and the 95% confidence intervals on the median (nfMRI = 9, nMEG = 8). The proportions for individual participants are marked with open circles. Differences between modalities are tested for significance using a one-sided Wilcoxon rank-sum test. Differences within modality are tested using a one-sided Wilcoxon signed-rank test. All P values are adjusted for multiple comparisons with the Holm–Bonferroni procedure at level 0.05. Significant differences are indicated with asterisks according to their P value (***P < 0.001, **P < 0.01, *P < 0.05). a, Residual previous word, context and current word embeddings predict fMRI and MEG with significant differences. b, Full context embeddings do not predict fMRI and MEG with significant differences, while the full current word and previous word embeddings predict MEG significantly better than fMRI. c, MEG and fMRI display a contrasting pattern of prediction by the residual embeddings. The current residual word embedding best predicts MEG activity, significantly better than the previous residual word embedding, which in turns predicts MEG significantly more than the residual context. In contrast, the residual context significantly predicts fMRI activity better than the previous and current residual word embedding. d, Full previous word and context embeddings do not predict MEG significantly differently. e, All full embeddings predict both fMRI and MEG significantly better than the corresponding residual embeddings.
Discussion
The finding that our devised supra-word meaning representation consistently predicts fMRI recordings in the ATL and PTL supports some current hypotheses of language composition in the literature. Specifically, our results provide additional evidence that the ATL processes composed meaning beyond simple concrete concepts, supporting the hypothesis that the ATL is a semantic integration hub1,36,37. Our results may also align with the hypothesis that the pSTS (part of the PTL) is involved in building a type of supra-word meaning, by integrating information about the verb and its arguments with other syntactic information38–40. Further, our findings pose questions for the theory that posits left PTL as primarily a site of lexical (that is, word-level) semantics. It also poses questions for the theory that combinatorial semantics is processed in the ATL while lexical semantics is processed in more posterior regions20. Our findings suggest that the PTL acts as a common substrate for lexical and combinatorial semantics. Lastly, the finding that clusters of voxels in the PTL and ATL share a common representation of composed meaning suggests that these two areas may be working together to maintain the supra-word meaning.
The findings that the same supra-word embeddings failed to significantly predict any MEG sensor-timepoint across participants suggest a difference in the underlying brain processes that fMRI and MEG capture. Our results suggest that fMRI recordings are sensitive to supra-word meaning, while MEG recordings reflect instantaneous processes related to both the current word being read and the previously read word. A likely candidate for the instantaneous process reflected in MEG is the process of integrating the current word with the previous context. The sensitivity to the previously read word has many possible explanations. One explanation is that words take longer to process and integrate into the composed meaning than their duration on the screen. Another explanation is that a word may constrain the processing of the word that follows it, highlighting its relevant properties and aiding with composition. The hypothesis that MEG recordings reflect the process of composition aligns well with a vast number of previous findings characterizing transient responses evoked by a stimulus that is difficult to integrate with the preceding context41–44. Indeed, our results are not in disagreement with this literature: they do not show that MEG activity does not reveal word integration processes that depend on previous context.
Instead, our results suggest that the maintenance of composed meaning does not rely on neural mechanisms that generate MEG signal (such as synchronized current flow in pyramidal cell dendrites21) but on other mechanisms that do not lead to MEG responses distinguishable from noise (for example, unsynchronized neural firing) but that have enough metabolic demands to generate an fMRI response. Since the MEG signal is thought to be most related to synchronized firing of pyramidal cells, one hypothesis is that it best reflects the representation of language processes supported by these cells. For example, the N400 and other event-related potentials related to composition operations are measurable in both MEG and electroencephalography, and thus are likely to recruit pyramidal cells. Working memory processes have also been shown to involve pyramidal cell firing45. While both the N400 and working memory are thought to reflect short-term transient processing46,47, maintaining the supra-word meaning may depend on longer-term memory processes, which different cell types or mechanisms may support. Another hypothesis is that our MEG data set presented a false negative due to particularities of the experimental paradigm, or statistical variability due to noise. The replication in one additional subject with a natural speech listening paradigm, while encouraging, will need to be followed by future work that considers a larger number of subjects with a comparable number of data per subject (more than 1 h per subject), both of which are important for evaluating the significance of the results48. Our results, if replicated in other studies, will call for a more nuanced understanding of previous MEG work that aims to study meaning composition (as well as other electrophysiology modalities such as electroencephalography and electrocorticography). Our results suggest that observed increases in activity measured by such modalities during sentence reading49,50 and the improved fit by a model constrained by very recent context27 may be due to instantaneous integration processes rather than the maintenance of sentence-level meaning. Future work is needed to understand whether and how these imaging modalities can be used to study sentence-level meaning.
Pinpointing what linguistic information relates to the significant brain predictions we observe using the supra-word embeddings is an important question for future work. However, we want to emphasize that, even if we understand that information X, Y and Z is contained in the supra-word embeddings, that would not answer this question. The reason is that the supra-word embedding contains X, Y and Z, and possibly other information W, that we have not measured, and any one of these may be the information that is predictive of brain activity. For example, as our work shows, the MEG recordings are predicted by the full context embedding but not by the information in the full context embedding that is orthogonal to the individual word embeddings (that is, supra-word embeddings). Therefore, knowing only that (1) full context embeddings predict MEG and (2) some supra-word information is contained in the full context embeddings is insufficient to reveal what information in the full context embeddings is predictive of the MEG recordings, and suggesting that it may be because of the supra-word information would be misleading. Similarly, linguistic information X, Y and Z may be contained in the supra-word embedding but may not be necessary for predicting brain activity. We believe that it is critical to make this point as it is becoming increasingly popular to relate brain recordings to neural network embeddings that contain multiple sources of information51. Here, we show that one solution is to use computational controls. If linguistic information X, Y and Z are shown to be contained in the supra-word embedding, one could regress this information from the supra-word embedding and observe how the prediction of fMRI recordings changes. These analyses would require the stimulus data set to be annotated with various linguistic and psychological labels, some of which may require expert linguists who might even disagree among themselves. We believe that this will be an important undertaking that would increase our control over the scientific inferences we can make through computational modelling.
Our analysis depends on the degree to which the chosen neural network can represent composed meaning. Based on ELMo’s competitive performance on downstream tasks7 and its ability to capture complex linguistic structure52, we believe that ELMo can extract some aspects of composed meaning. In addition, we showed that using a different network (GPT-2) also leads to significant predictions in the ATL and PTL, as well as the angular gyrus (AG) and posterior cingulate (PC). This added predictive power may be due to factors that we cannot control without training a model from scratch: GPT-2 has larger embeddings (768 versus 512 for the forward LSTM in ELMo), has more hidden layers (12 versus 2 in ELMo), was pre-trained on more data (40 GB of text data versus 11 GB of text data for ELMo) and has an all-together different architecture (transformer based versus recurrence based for ELMo). Overall, evaluating the ability of different architectures to encode supra-word meaning is an interesting question that should be approached with care owing to these many differences. Another point is that our residual approach accounts only for the linear dependence between individual word embeddings and context embeddings. By construction, the internal state of the LSTM in ELMo contains non-linear dependences on the input word vector and the previous LSTM state. It is possible that some dimensions of the internal state of the ELMo LSTM correspond to non-linear operations on the dimensions of the input vector alone (see Methods for the LSTM equations). This non-linear transformations might not be removed by our residual procedure, and whether it aligns with processing of individual words in the brain is a question for future research.
The surprising finding that supra-word meaning is difficult to capture using MEG has implications for future neuroimaging research and applications where natural language is decoded from the brain. While high temporal imaging resolution is key to reaching a mechanistic level of understanding of language processing, our findings suggest that a modality other than MEG may be necessary to detect long-range contextual information. Further, the fact that an aspect of meaning can be predictive in one imaging modality but invisible in another calls for caution when interpreting findings about the brain from one modality alone, as some parts of the puzzle are systematically hidden. Our results also suggest that the imaging modality may impact the ability to decode the contextualized meaning of words, which is central to brain–computer interfaces that aim to decode attempted speech. Recent success in decoding speech from electrocorticography recordings53 is promising, but needs to be evaluated carefully with more diverse and naturalistic stimuli. It is yet to be determined whether word-level information conveyed by electrophysiology will be sufficient to decode a person’s intent, or if the lack of supra-word meaning should be compensated in other ways.
Methods
Our research complies with all relevant ethical regulations specified by the Carnegie Mellon University and the University of Pittsburgh Institutional Review Boards, which have approved and overseen the data collection related to this study. No statistical methods were used to pre-determine sample sizes, but our sample sizes are similar to those reported in previous publications11,12,35,54,55. We do not make assumptions about the underlying data distribution, and we use non-parametric statistical tests.
fMRI data and preprocessing: reading a chapter of a book
We use fMRI data from nine participants (five female, four male; age 18–40 years) reading chapter 9 of Harry Potter and the Sorcerer’s Stone56, collected and made available online by Wehbe et al.54. Written informed consent was obtained from all participants, and participants were compensated for their time. Words were presented one at a time at a rate of 0.5 s each using Psychtoolbox-3 for MATLAB. fMRI data were acquired at a rate of 2 s per image, that is, with a repetition time (TR) of 2 s. The images were composed of 3 × 3 × 3 mm3 voxels. The data for each participant was slice-time and motion corrected using SPM-8 (ref.55), then detrended and smoothed with a kernel having a full-width at half-maximum of 3 mm. The brain surface of each participant was reconstructed using Freesurfer57, and a grey matter mask was obtained. The Pycortex software58 was used to handle and plot the data. For each participant, 25,000–31,000 cortical voxels were kept.
fMRI data and preprocessing: watching a full-length movie
We replicated our fMRI findings in a second fMRI data set, which is provided by the Courtois NeuroMod Group (data release cneuromod-2020). In this data set, six healthy participants view the movie Hidden Figures in English. In total, approximately 120 min of data were recorded per participant during 12 scans of roughly equal length. The fMRI sampling rate (TR) was 1.49 s. The data were prepossessed using fMRIPrep 20.1.0 (ref.59). Three participants are native French speakers, and three are native English speakers. All participants are fluent in English and report regularly watching movies in English. These data are available on request at https://docs.cneuromod.ca/en/latest/ACCESS.html.
MEG data and preprocessing
The same paradigm was recorded for nine participants (five female, four male; age 18–40 years) using MEG by the authors of ref.10 and shared upon our request. Written informed consent was obtained from all participants, and participants were compensated for their time. One subject’s data were discarded due to noise. The data were recorded from 306 sensors organized in 102 locations around the head. MEG records the changes in the magnetic field due to neuronal activity, and the data we used were sampled at 1 kHz then preprocessed using the signal space separation (SSS) method60 and its temporal extension (tSSS)61. The signal from each sensor was down-sampled into 25 ms non-overlapping time bins. For each of the 5,176 words in the chapter, we therefore obtained a recording from 306 sensors at 20 time points after word onset (since each word was presented for 500 ms).
ELMo details
At each layer, for each word, ELMo combines the internal representations of two independent LSTMs: a forward LSTM (containing information from previous words) and a backward LSTM (containing information from future words). We extracted context embeddings only from the forward LSTM in order to more closely match the participants, who have not seen the future words. For a word token t, the forward LSTM generates the hidden representation in layer l using the following update equations:
where bc and wc represent the learned bias and weight, and ft, ot and it represent the forget, output and input gates. The states of the gates are computed according to the following equations:
where σ(x) represents the sigmoid function and bx and wx represent the learned bias and weight of the corresponding gate. The learned parameters are trained to predict the identity of a word given a series of preceding words, in a large text corpus. We use a pretrained version of ELMo with two hidden LSTM layers provided by Gardner et al.62. This model was pretrained on the 1 Billion Word Benchmark63, which contains approximately 800 million tokens of news crawl data from the Workshop on Statistical Machine Translation 2011.
GPT-2 details
GPT-2 (ref.28) is a transformer-based model. The pretrained GPT-2 model that we used (‘GPT-2 small’) consists of 12 stacked transformer decoders. Unlike BERT8, GPT-2 is a causal language model that only takes the past as input to predict the future (as opposed to both the past and the future). GPT-2 was pretrained on 8 million web pages, which were scraped using Reddit.
Obtaining full stimulus representations
We obtain a full ELMo word embedding (as opposed to a residual word embedding) for word wn by passing word wn through the pretrained ELMo model and obtaining the token-level embeddings (that is, from layer 0) for wn. If word wn contains multiple tokens, we average the corresponding token-level embeddings and use this average as the final full word embedding. We obtain a full ELMo context embedding for word wn by passing the most recent 25 words (wn−24, …, wn) through the pretrained ELMo model and obtaining the embeddings from the first hidden layer (that is, from layer 1) of the forward LSTM for wn. If word wn contains multiple tokens, we average the corresponding layer 1 embeddings and use this mean as the final full context embedding for word wn. We use 25 words to extract the context embedding because it has been previously shown that ELMo and other LSTMs appear to reduce the amount of information they maintain beyond 20–25 words in the past12,64.
We follow the same technique to obtain full stimulus representations from GPT-2. We extract the word representations from the penultimate hidden layer in the network (layer 11 of 12).
Obtaining residual stimulus representations
We obtain three types of residual embeddings for each word at position t in the stimulus set: (1) residual context(t − 1) embedding, (2) residual word(t − 1) embedding and (3) residual word(t) embedding. We compute all three types using the same general approach of training a regularized linear regression, but with inputs xt and outputs yt that change depending on the type of residual embedding. The steps to the general approach are the following, given an input xt and output yt:
Step 1: Learn a linear function g that predicts each dimension of yt as a linear combination of xt. We follow the same steps outlined in the training of function f in the encoding model. Namely, we model g as a linear function, regularized by the ridge penalty. The model is trained via four-fold cross-validation, and the regularization parameter is chosen via nested cross-validation.
Step 2: Obtain the residual , using the estimate of the g function learned above. This is the final residual stimulus representation.
For the residual context(t − 1) embedding, the input xt is the concatenation of the full word embeddings for the 25 consecutive words wt−24, …, wt, and the output yt is the full context(t − 1) embedding. For the residual word(t − 1) embeddings, the input xt is the concatenation of the full context(t − 1) embedding and the full word embeddings for the 24 consecutive words wt−24, …, wt that exclude the full word embedding for word(t − 1) and the output yt is the full word(t − 1) embedding. For the residual word(t) embeddings, the input xt is the the concatenation of the full context(t − 1) embedding and the full word embeddings for the 24 consecutive words wt−24, …, wt−1 and the output yt is the full word(t) embedding.
We also performed experiments with the residual context(t − 1) obtained from the second hidden layer of ELMo. We did not find any significant differences in the proportion of language regions that are predicted significantly by the supra-word meaning obtained from the first hidden layer versus the supra-word meaning obtained from the second hidden layer.
According to our definition, every sentence has some supra-word meaning. Mathematically, we know that the supra-word meaning embedding (that is, the embedding calculated by context(t − 1) − g(word(t), word(t − 1), …, word(t − n)) contains information because context(t − 1) is a non-linear function of word(t − 1), …, word(t − n), whereas g(word(t), word(t − 1), …, word(t − n)) is a linear function. Whether that supra-word meaning is brain relevant is not known, and this is what we test in the current work. Our results show that the supra-word meaning embedding indeed contains brain-relevant information, because the supra-word meaning embedding predicts significant proportions of several language regions (Fig. 2b). In addition, we show that the supra-word meaning embedding contains multiple facets of brain-relevant meaning: one facet that is predictive of the bilateral ATL and the left pSTS, and the other of the right PTL. We further show that, while the full context embedding from the first hidden layer of ELMo evaluated at word t is strongly linearly related to the next word t + 1, the current word t and the previous word t − 1, the supra-word embedding for word t does not strongly depend on any individual word, as it was designed to limit contributions of individual words (Supplementary Fig. 1). The presence of the strong linear relationship between the full context representation and the closely adjacent words means that any linear prediction of brain recordings may be overwhelmingly related to these adjacent words.
Encoding model evaluation
We evaluate the predictions of each encoding model by computing the Pearson correlation between the held-out brain recordings and the corresponding predictions in the four-fold cross-validation setting. We compute one correlation value for each of the four cross-validation folds and report the average value as the final encoding model performance.
General encoding model training
For each type of embedding et, we estimate an encoding model that takes et as input and predicts the brain recording associated with reading the same words that were used to derive et. We estimate a function f, such that f(et) = b, where b is the brain activity recorded with either MEG or fMRI. We follow previous work10,35,54,65,66 and model f as a linear function, regularized by the ridge penalty.
The fMRI and MEG Harry Potter data are collected in four runs. To estimate all encoding models using these data, we perform four-fold cross-validation and the regularization parameter is chosen via nested cross-validation. Each fold holds out data corresponding to one run that we use to test the generalization of the estimated models. The edges of each run are removed during preprocessing (data corresponding to 20 TRs from the beginning and 15 TRs from the end of each run), and we further remove data corresponding to an additional 5 TRs between the training and test data. We follow the same procedures for the movie fMRI data, with the exception that we perform 12-fold cross validation because this data set was recorded in 12 runs.
fMRI encoding models
Ridge regularization is used to estimate the parameters of a linear model that predicts the brain activity yi in every fMRI voxel i as a linear combination of a particular NLP embedding x. For each output dimension (voxel), the ridge regularization parameter is chosen independently by nested cross-validation. We use ridge regression because of its computational efficiency and because of the results of Wehbe et al.67 showing that, for fMRI data, as long as proper regularization is used and the regularization parameter is chosen by cross-validation for each voxel independently, different regularization techniques lead to similar results. Indeed, ridge regression is a common regularization technique used for building predictive fMRI35,54,66,68.
For every voxel i, a model is fitted to predict the signals , where n is the number of time points, as a function of the NLP embedding. The words presented to the participants are first grouped by the TR interval in which they were presented. Then, the NLP embeddings of the words in every group are averaged to form a sequence of features x = [x1, x2, …, xn] which are aligned with the brain signals. The models are trained to predict the signal at time t, yt, using the concatenated vector zt formed of [xt−1, xt−2, xt−3, xt−4]. The features of the words presented in the previous volumes are included to account for the lag in the haemodynamic response that fMRI records. Indeed, the response measured by fMRI is an indirect consequence of brain activity that peaks about 6 s after stimulus onset, and the approach of expressing brain activity as a function of the features of the preceding time points is a common solution for building predictive models35,54,66. The reason for doing this is that different voxels may exhibit different haemodynamic response functions (HRFs), so this approach allows for a data-driven estimation of the HRF instead of using the canonical HRF for all voxels.
For each given participant and each NLP embedding, we perform a cross-validation procedure to estimate how predictive that NLP embedding is of brain activity in each voxel i. For each fold:
The fMRI data Y and feature matrix Z = z1, z2, …zn are split into corresponding training and validation matrices. These matrices are individually normalized (mean of 0 and s.d. of 1 for each voxel across time), ending with training matrices YR and ZR and validation matrices YV and ZV.
- Using the training fold, a model wi is estimated as
A ten-fold nested cross-validation procedure is first used to identify the best λi for every voxel i that minimizes the nested cross-validation error. wi is then estimated by using λi on the entire training fold.
The predictions for each voxel on the validation fold are obtained as p = ZVwi.
The above steps are repeated for each of the four cross-validation folds, and the average correlation is obtained for each voxel i, NLP embedding and participant.
MEG encoding models
MEG data are sampled faster than the rate of word presentation, so for each word, we have 20 times points recorded at 306 sensors. Ridge regularization is similarly used to estimate the parameters of a linear model that predicts the brain activity yi,τ at every MEG sensor i, at time τ after word onset. For each output dimension (sensor/time tuple i, τ), the ridge regularization parameter is chosen independently by nested cross-validation.
For every tuple i, τ, a model is fitted to predict the signals , where n is the number of words in the story, as a function of NLP embeddings. We use as input the word vector x but without the delays we used in fMRI because the MEG recordings capture instantaneous consequences of brain activity (changes in magnetic field). The models are trained to predict the signal at word t, , using the vector xt.
For each participant and NLP embedding, we perform a cross-validation procedure to estimate how predictive that NLP embedding is of brain activity in each sensor timepoint i. For each fold:
The MEG data Y and feature matrix X = x1, x2, …xn are split into corresponding training and validation matrices, and these matrices are individually normalized (to get a mean of 0 and s.d. of 1 for each voxel across time), ending with training matrices YR and XR and validation matrices YV and ZV.
- Using the training fold, a model w(i, τ) is estimated as
A ten-fold nested cross-validation procedure is first used to identify the best λ(i, τ) for every sensor–timepoint tuple (i, τ) that minimizes the nested cross-validation error. w(i, τ)ℓ is then estimated using λ(i, τ) on the entire training fold.
The predictions for each sensor–timepoint tuple (i, τ) on the validation fold are obtained as p = XVw(i, τ).
The above steps are repeated for each of the four cross-validation folds, and an average correlation is obtained for each sensor location–timepoint tuple (s, τ), each NLP embedding and each participant.
Spatial generalization matrices
We introduce the concept of spatial generalization matrices, which tests whether an encoding model trained to predict a particular voxel can generalize to predicting other voxels. This approach can be applied to voxels within the same participant or in other participants. The purpose of this method is to test whether two voxels relate to a specific representation of the input (for example, NLP embedding) in a similar way. If an encoding model for a particular voxel is able to significantly predict a different voxel’s activity, we conclude that the two voxels process similar information with respect to the input of the encoding model.
For each pair of voxels (i, j), we first follow our general approach of training an encoding model to predict voxel i as a function of a specific stimulus representation, described above, and test how well the predictions of the encoding model correlate with the activity of voxel j. We do this for all pairs of voxels in the PTL and ATL across all nine participants. Finally, we normalize the resulting performance at predicting voxel j by dividing it by the performance at predicting test data from voxel i that was held out during the training process. The significance of the performance of the encoding model on voxel j is evaluated using a permutation test, described in the next subsection.
Since we are interested in semantic representation, we can formalize the tuning differences of two voxels as sensitivity to a different part of the semantic space. We can assume that there exists a global, large semantic space that encodes semantic information, with the understanding that which semantic dimensions are encoded by each region, and the way in which they are encoded, can differ. We use as an approximation of the semantic space, the supra-word embedding, and the way that a brain region encodes the dimensions in that space corresponds to the estimated weights of the encoding model. It is most likely that a brain region will be encoding information using a different semantic basis than our neural network-derived embedding, and two brain regions might not be using the same basis. Note that the spatial generalization takes into consideration only regions that are already significantly predicted by the supra-word embedding. Since the two hypothetical regions are predicted by the encoding model using the supra-word embedding, we can assume that the supra-word embedding captures some of the dimensions spanned by their bases, up to a transformation. The difference between the bases of the two regions could manifest as some difference in the weights of the learned encoding models for the two regions. Therefore spatial generalization allows us to test how similar the semantic sensitivity of two regions are by measuring how well the estimated encoding of one voxel transfers to another voxel. Note that this is similar to methods that directly compare the encoding model weights estimated for two voxels35,69,70, but spatial generations looks not only at how much the weights are different, but also at how much this difference affects the ability to predict held-out data. It could be considered a more stringent method, ignoring small differences in weights that do not affect generalization performance.
Permutation tests
Significance of the degree to which a single voxel or a sensor timepoint is predicted is evaluated based on a standard permutation test. To conduct the permutation test, we block-permute the predictions of a specific encoding model within each of the four cross-validation runs and compute the correlation between the block-permuted predictions and the corresponding true values of the voxel/sensor timepoint. We use blocks of 5 TRs in fMRI (corresponding to 20 presented words) and 20 words in MEG in order to retain some of the auto-regressive structure in the permuted brain recordings. We used a heuristic to set the block size to 5 TRs: because our TR is 2 s, we set the block size such that it would include most of a canonical haemodynamic response, which peaks around 6 s and falls back to baseline over the next few seconds. We conduct 1,000 permutations and calculate the number of times the resulting mean correlation across the four cross-validation folds of the permuted predictions is higher than the mean correlation from the original unpermuted predictions. The resulting P values for all voxels/sensor timepoints/time windows are FDR corrected for multiple comparisons using the Benjamini–Hochberg procedure32.
Chance proportions of ROI/time windows predicted significantly
To establish whether a significant proportion of an ROI/time window is predicted by a specific encoding model, we contrast the proportion of the ROI/time window that is significantly explained by the encoding model with a proportion of the ROI/time window that is significantly explained by chance. We do this for all proportions of the same ROI/time window across participants, using a Wilcoxon signed-rank test. We compute the proportion of an ROI/time window that is significantly predicted by chance using the permutation tests described above. For each permutation k, we compute the P value of each voxel in this permutation according to its performance with respect to the other permutations. Next for each ROI/time window, we compute the proportion of this ROI/time window with P values of <0.01 after FDR correction, for each permutation. The final chance proportion of an ROI/time window for a specific encoding model and participant is the average chance proportion across permutations.
Confidence intervals
We use an open-source package71 to compute the 95% bias-corrected confidence intervals of the median proportions across participants. We use bias-corrected confidence intervals72 to account for any possible bias in the sample median due to a small sample size or skewed distribution73.
Experiments revealing shared information among NLP embeddings
For each of the three NLP embedding types (that is, context(t − 1) embedding, word(t − 1) embedding and word(t)), we train an encoding model taking as input each NLP embedding and predicting as output the word embedding for word(i), where i ∈ [t − 6, t + 2]. We evaluate the predictions of the encoding models using Pearson correlation, and obtain an average correlation over the four cross-validation folds.
Supplementary Material
Acknowledgements
We thank E. Laing and D. Howarth for help with data collection and preprocessing, and M.J. Tarr for helpful feedback on the manuscript. Research reported in this publication was partially supported by the National Institute on Deafness and other Communication Disorders of the National Institutes of Health under award no. R01DC020088. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. This research was also supported in part by a Google Faculty Research Award and the Air Force Office of Scientific Research through research grants FA95501710218 and FA95502010118.
Footnotes
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Code availability
All custom scripts are available without restrictions at https://github.com/brainML/supraword74.
Competing interests
The authors declare no competing interests.
Supplementary information The online version contains supplementary material available at https://doi.org/10.1038/s43588-022-00354-6.
Data availability
Two of the three data sets analysed during this study can be found at http://www.cs.cmu.edu/~fmri/plosone/ for the fMRI data set and at https://kilthub.cmu.edu/articles/dataset/RSVP_reading_of_book_chapter_in_MEG/20465898 for the MEG data set. The remaining data set is available from the Courtois Neuromod group at https://docs.cneuromod.ca/en/latest/ACCESS.html. Source data for Figs. 2–4 is available with this manuscript.
References
- 1.Pylkkänen L Neural basis of basic composition: what we have learned from the red-boat studies and their extensions. Philos. Trans. R. Soc. B 375, 20190299 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Pylkkänen L & McElree B An MEG study of silent meaning. J. Cogn. Neurosci 19, 1905–1921 (2007). [DOI] [PubMed] [Google Scholar]
- 3.Baggio G, Choma T, Van Lambalgen M & Hagoort P Coercion and compositionality. J. Cogn. Neurosci 22, 2131–2140 (2010). [DOI] [PubMed] [Google Scholar]
- 4.Bemis DK & Pylkkänen L Simple composition: a magnetoencephalography investigation into the comprehension of minimal linguistic phrases. J. Neurosci 31, 2801–2814 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Brooks TL & de Garcia DC Evidence for morphological composition in compound words using MEG. Front. Hum. Neurosci 9, 215 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Kim S & Pylkkänen L Composition of event concepts: evidence for distinct roles for the left and right anterior temporal lobes. Brain Lang. 188, 18–27 (2019). [DOI] [PubMed] [Google Scholar]
- 7.Peters ME et al. Deep contextualized word representations. In Proceedings of NAACL-HLT, pp 2227–2237 (2018). [Google Scholar]
- 8.Devlin J, Chang M-W, Lee K, & Toutanova K. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp 4171–4186 (2019). [Google Scholar]
- 9.Brown T et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst 33, 1877–1901 (2020). [Google Scholar]
- 10.Wehbe L, Vaswani A, Knight K, & Mitchell T. Aligning context-based statistical models of language with brain activity during reading. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2014). [Google Scholar]
- 11.Jain S & Huth A Incorporating context into language encoding models for fmri. In Advances in Neural Information Processing Systems, pp 6628–6637 (2018). [Google Scholar]
- 12.Toneva M & Wehbe L Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain). In Advances in Neural Information Processing Systems, pp 14928–14938 (2019). [Google Scholar]
- 13.Schrimpf M et al. The neural architecture of language: integrative modeling converges on predictive processing. Proc. Natl Acad. Sci. USA 118, 45 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Caucheteux C & King J-R Brains and algorithms partially converge in natural language processing. Commun. Biol 5, 1–10 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Goldstein A et al. Shared computational principles for language processing in humans and deep language models. Nat. Neurosci 25, 369–380 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Levesque H, Davis E & Morgenstern L The winograd schema challenge. In Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning. Citeseer; (2012). [Google Scholar]
- 17.Marvin R & Linzen T Targeted syntactic evaluation of language models. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp 1192–1202 (Association for Computational Linguistics, 2018). [Google Scholar]
- 18.Baroni M On the proper role of linguistically-oriented deep net analysis in linguistic theorizing. Preprint at https://arxiv.org/abs/2106.08694 (2021).
- 19.Hagoort P The meaning-making mechanism(s) behind the eyes and between the ears. Phil. Trans. R. Soc. B 375, 20190301 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hickok G & Poeppel D The cortical organization of speech processing. Nat. Rev. Neurosci 8, 393–402 (2007). [DOI] [PubMed] [Google Scholar]
- 21.Hall EL, Robson SE, Morris PG & Brookes MJ The relationship between MEG and fMRI. NeuroImage 102, 80–91 (2014). [DOI] [PubMed] [Google Scholar]
- 22.Muthukumaraswamy SD & Singh KD Spatiotemporal frequency tuning of bold and gamma band MEG responses compared in primary visual cortex. NeuroImage 40, 1552–1560 (2008). [DOI] [PubMed] [Google Scholar]
- 23.Muthukumaraswamy SD & Singh KD Functional decoupling of BOLD and gamma-band amplitudes in human primary visual cortex. Hum. Brain Mapp 30, 2000–2007 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Swettenham JB, Muthukumaraswamy SD & Singh KD BOLD responses in human primary visual cortex are insensitive to substantial changes in neural activity. Front. Hum. Neurosci 7, 76 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Leonardelli E & Fairhall SL Similarity-based fMRI–MEG fusion reveals hierarchical organisation within the brainas semantic system. NeuroImage 259, 119405 (2022). [DOI] [PubMed] [Google Scholar]
- 26.Halgren E et al. N400-like magnetoencephalography responses modulated by semantic context, word frequency, and lexical class in sentences. NeuroImage 17, 1101–1116 (2002). [DOI] [PubMed] [Google Scholar]
- 27.Lyu B et al. Neural dynamics of semantic composition. Proc. Natl Acad. Sci. USA 116, 21318–21327 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Radford A et al. Language models are unsupervised multitask learners. OpenAI blog 1, 9 (2019). [Google Scholar]
- 29.Fedorenko E, Hsieh P-J, Nieto-Castanon A, Whitfield-Gabrieli S & Kanwisher N New method for fMRI investigations of language: defining ROIs functionally in individual subjects. J. Neurophysiol 104, 1177–1194 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Fedorenko E & Thompson-Schill SL Reworking the language network. Trends Cogn. Sci 18, 120–126 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Binder JR, Desai RH, Graves WW & Conant LL Where is the semantic system? A critical review and meta-analysis of 120 functional neuroimaging studies. Cerebral Cortex 19, 2767–2796 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Benjamini Y & Hochberg Y Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. B 57, 289–300 (1995). [Google Scholar]
- 33.Holm S A simple sequentially rejective multiple test procedure. Scand. J. Stat 6, 65–70 (1979). [Google Scholar]
- 34.King J-R & Dehaene S Characterizing the dynamics of mental representations: the temporal generalization method. Trends Cogn. Sci 18, 203–210 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Huth AG et al. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature 532, 453–458 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Visser M, Jefferies E & Ralph MAL Semantic processing in the anterior temporal lobes: a meta-analysis of the functional neuroimaging literature. J. Cogn. Neurosci 22, 1083–1094 (2010). [DOI] [PubMed] [Google Scholar]
- 37.Pallier C, Devauchelle A-D & Dehaene S Cortical representation of the constituent structure of sentences. Proc. Natl Acad. Sci 108, 2522–2527 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Friederici AD The brain basis of language processing: from structure to function. Physiol. Rev 91, 1357–1392 (2011). [DOI] [PubMed] [Google Scholar]
- 39.Frankland SM & Greene JD An architecture for encoding sentence meaning in left mid-superior temporal cortex. Proc. Natl Acad. Sci 112, 11732–11737 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Skeide MA & Friederici AD The ontogeny of the cortical language network. Nat. Rev. Neurosci 17, 323–332 (2016). [DOI] [PubMed] [Google Scholar]
- 41.Kutas M & Federmeier KD Thirty years and counting: finding meaning in the N400 component of the event-related brain potential (ERP). Annu. Ref. Psychol 62, 621–647 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Kuperberg GR et al. Distinct patterns of neural modulation during the processing of conceptual and syntactic anomalies. J. Cogn. Neurosci 15, 272–293 (2003). [DOI] [PubMed] [Google Scholar]
- 43.Kuperberg GR Neural mechanisms of language comprehension: challenges to syntax. Brain Res. 1146, 23–49 (2007). [DOI] [PubMed] [Google Scholar]
- 44.Rabovsky M, Hansen SS & McClelland JL Modelling the N400 brain potential as change in a probabilistic representation of meaning. Nat. Hum. Behav 2, 693–705 (2018). [DOI] [PubMed] [Google Scholar]
- 45.Goldman-Rakic PS Regional and cellular fractionation of working memory. Proc. Natl Acad. Sci 93, 13473–13480 (1996). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Luck SJ, Vogel EK & Shapiro KL Word meanings can be accessed but not reported during the attentional blink. Nature 383, 616–618 (1996). [DOI] [PubMed] [Google Scholar]
- 47.Courtney SM, Ungerleider LG, Keil K & Haxby JV Transient and sustained activity in a distributed neural system for human working memory. Nature 386, 608–611 (1997). [DOI] [PubMed] [Google Scholar]
- 48.Chen G et al. Hyperbolic trade-off: the importance of balancing trial and subject sample sizes in neuroimaging. NeuroImage 247, 118786 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Fedorenko E et al. Neural correlate of the construction of sentence meaning. Proc. Natl Acad. Sci 113, E6256–E6262 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Hultén A, Schoffelen J-M, Uddén J, Lam NHL & Hagoort P How the brain makes sense beyond the processing of single words-an meg study. NeuroImage 186, 586–594 (2019). [DOI] [PubMed] [Google Scholar]
- 51.Toneva M, Williams J, Bollu A, Dann C & Wehbe L Same cause; different effects in the brain. In First Conference on Causal Learning and Reasoning (2021). [Google Scholar]
- 52.Tenney I et al. What do you learn from context? probing for sentence structure in contextualized word representations. In 7th International Conference on Learning Representations (2019). [Google Scholar]
- 53.Makin JG, Moses DA & Chang EF Machine Translation of Cortical Activity to Text with an Encoder–Decoder Framework (Nature Publishing Group, 2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Wehbe L et al. Simultaneously uncovering the patterns of brain regions involved in different story reading subprocesses. PloS ONE 9, e112575 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Kay KN, Naselaris T, Prenger RJ & Gallant JL Identifying natural images from human brain activity. Nature 452, 352 (2008). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Rowling JK Harry Potter and the Sorcerer’s Stone (Pottermore Limited, 2012). [Google Scholar]
- 57.Fischl B Freesurfer. NeuroImage 62, 774–781 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Gao JS, Huth AG, Lescroart MD & Gallant JL Pycortex: an interactive surface visualizer for fMRI. Front. Neuroinform 9, 23 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Esteban O et al. fmriprep software. Zenodo 10.5281/zenodo.852659 (2018). [DOI] [Google Scholar]
- 60.Taulu S, Kajola M & Simola J Suppression of interference and artifacts by the signal space separation method. Brain Topogr. 16, 269–275 (2004). [DOI] [PubMed] [Google Scholar]
- 61.Taulu S & Simola J Spatiotemporal signal space separation method for rejecting nearby interference in MEG measurements. Phys. Med. Biol 51, 1759–1768 (2006). [DOI] [PubMed] [Google Scholar]
- 62.Gardner M et al. Allennlp: a deep semantic natural language processing platform. In Proceedings of Workshop for NLP Open Source Software (NLP-OSS), pp 1–6 (2018). [Google Scholar]
- 63.Chelba C et al. One billion word benchmark for measuring progress in statistical language modeling. Preprint at https://arxiv.org/abs/1312.3005 (2013).
- 64.Khandelwal U, He H, Qi P & Jurafsky D Sharp nearby, fuzzy far away: How neural language models use context. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp 284–294 (2018). [Google Scholar]
- 65.Sudre G et al. Tracking neural coding of perceptual and semantic features of concrete nouns. NeuroImage 62, 451–463 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Nishimoto S et al. Reconstructing visual experiences from brain activity evoked by natural movies. Curr. Biol 21, 1641–1646 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Wehbe L, Ramdas A, Steorts RC & Shalizi CR Regularized brain reading with shrinkage and smoothing. Ann. Appl. Stat 9, 1997–2022 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Mitchell TM et al. Predicting human brain activity associated with the meanings of nouns. Science 320, 1191–1195 (2008). [DOI] [PubMed] [Google Scholar]
- 69.Çukur T, Nishimoto S, Huth AG & Gallant JL Attention during natural vision warps semantic representation across the human brain. Nat. Neurosci 16, 763–770 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Deniz F, Nunez-Elizalde AO, Huth AG & Gallant JL The representation of semantic information across human cerebral cortex during listening versus reading is invariant to stimulus modality. J. Neurosci 39, 7722–7736 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Sheppard K et al. Xavier RENE-CORAIL, and syncoding. bashtage/arch: release 4.15, June 2020. Zenodo 10.5281/zenodo.3906869 (2020). [DOI] [Google Scholar]
- 72.Efron B & Tibshirani RJ An Introduction to the Bootstrap (CRC, 1994). [Google Scholar]
- 73.Miller J A warning about median reaction time. J. Exp. Psychol. Hum. Percept. Perform 14, 539–543 (1988). [DOI] [PubMed] [Google Scholar]
- 74.Toneva M & Wehbe L brainml/supraword: version 1, October 2022. Zenodo 10.5281/zenodo.7178795 (2022). [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Two of the three data sets analysed during this study can be found at http://www.cs.cmu.edu/~fmri/plosone/ for the fMRI data set and at https://kilthub.cmu.edu/articles/dataset/RSVP_reading_of_book_chapter_in_MEG/20465898 for the MEG data set. The remaining data set is available from the Courtois Neuromod group at https://docs.cneuromod.ca/en/latest/ACCESS.html. Source data for Figs. 2–4 is available with this manuscript.