

Abstract
Colonoscopy is a gold standard procedure but is highly operator-dependent. Automated polyp segmentation, a precancerous precursor, can minimize missed rates and timely treatment of colon cancer at an early stage. Even though there are deep learning methods developed for this task, variability in polyp size can impact model training, thereby limiting it to the size attribute of the majority of samples in the training dataset that may provide sub-optimal results to differently sized polyps. In this work, we exploit size-related and polyp number-related features in the form of text attention during training. We introduce an auxiliary classification task to weight the text-based embedding that allows network to learn additional feature representations that can distinctly adapt to differently sized polyps and can adapt to cases with multiple polyps. Our experimental results demonstrate that these added text embeddings improve the overall performance of the model compared to state-of-the-art segmentation methods. We explore four different datasets and provide insights for size-specific improvements. Our proposed text-guided attention network (TGANet) can generalize well to variable-sized polyps in different datasets. Codes are available at https://github.com/nikhilroxtomar/TGANet.
Keywords: Label embedding, polyp, multi-scale features, attention
1. Introduction
Colorectal cancer (CRC) is one of the leading causes of cancer-related deaths [16] worldwide. However, high operator-dependence and subjectivity during gold standard colonoscopic procedures remain high. This is also due to the complex topology of organ, severe artefacts, constant deformation of organ, debris and stool etc. Even though cleansing of the bowel is done to improve detection rates of cancer and cancer precursor lesions such as polyps, the missed rate is still high that accounts for 26.8% for polyps located on the right colon and 21.4% to polyps on the left colon [10,12]. In addition, the missed rate for flat or sessile polyps (diminutive polyps) is grim (nearly 32.7%). An automated system is thus clearly needed to minimize the operator subjectivity and missed rate. Semantic segmentation can classify each pixel into a class category, allowing the opportunity to learn meaningful semantic representations of polyps and their complex surroundings. Several methods do exist in the literature [3,7,14] but most them focus on exploiting only localized spatial context. However, the nature and occurrence of polyps in colonic mucosa can be confused with colonic folds. Exploiting associated attributes such as size and occurrence (one or a few) could be used to infer and improve segmentation for hard samples.
Encoder-decoder networks has been widely used for polyp segmentation using various modifications to boost network performance [3,7,14]. PraNet [3] applied area and boundary cues in reverse attention to focus on the polyp boundary regions. The high-level feature aggregation and boundary attention blocks in the network help to calibrate some of the misaligned predictions and improve the segmentation accuracy. Similarly, HRENet [14] designed an informative context enhancement (ICE) technique and adaptive feature aggregation (AFA) module and trained the model on their edge and structure consistency aware loss (ESCLoss), and obtained superior performance. Other works such as PolypSeg [18] and MSRFNet [15] uses modules incorporating multiple-scale information. An adaptive scale context module (ASCM) and semantic global context module (SGCM) was used in PolypSeg [18]. The ASCM tackles the size variations among the polyp and improves the better feature representation capability, while SGCM enhances the feature fusion between the high-level and low-level features and remove noise in the low-level features to improve the segmentation accuracy. Similarly, MSRFNet [15] integrated cross-scale fusion modules to propagate both high resolution and low-resolution features and an added shape stream network to prune polyp boundaries.
Most of these works in the literature [3,14,15] focuses on size variation, boundary curves, background regions, dense skip connections and dense residual scale fusions that can boost performance. However, these adjustments are made using additional layers and explicit extensions of networks and their connections. This adds to the complexity of the model that can adversely affect the generalization of test samples coming from a similar distribution and require a large dataset. In addition, it can also affect images with underrepresented polyp sizes. In this work, we propose incorporating a text guided attention mechanism using a simple byte-pair encoding for the attributes comprising polyp number and its size. In addition, we use the same encoder layer of the network to provide weights for each of these attributes.
The main contributions of the presented work include - 1) text guided attention to learn different features in the context of the number of polyps presence (one or many) and size (small, medium and large), 2) feature enhancement module to strengthen the features of the encoder and pass them to the decoder, and 3) multi-scale feature aggregation to capture features learned by different decoder blocks. We have evaluated our TGANet on four publicly available polyp datasets and compared it with five SOTA medical image segmentation methods.
2. Method
The proposed TGANet is a polyp segmentation architecture with text guided attention that enables to enhance feature representations such that the polyps present in images are segmented optimally independent of their size variability and occurrence. Our TGANet architecture consists of various components that are shown in Figure 1 and elaborated below.
Fig.1:
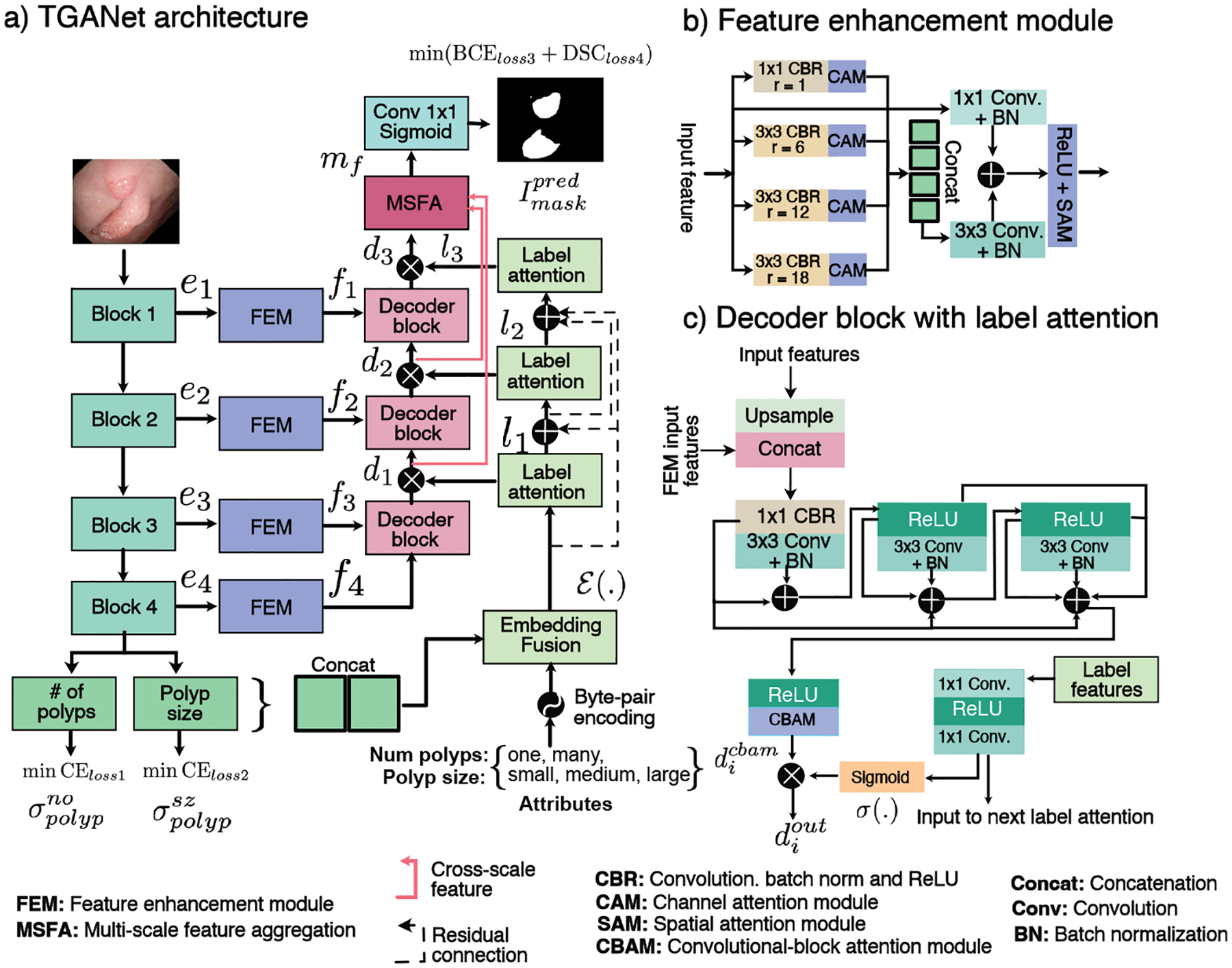
Block diagram of the proposed TGANet
2.1. Encoder module
TGANet is built upon a pre-trained ResNet50 [4] as backbone encoder network for which we use its four different encoding blocks, ei, i ∈ 1 2 3, 4. These blocks are consecutively used for our auxiliary attribute classification task and for main polyp segmentation task. For the text-attribute classification, we use the output from the fourth encoder block as two classification task modules separately, i.e., number of polyps (one or many) and their size (small, medium and large). Here, softmax probabilities and are predicted. For the main segmentation task, we take the output from each ResNet50 block and passes them through the feature enhancement module (FEM, fi, i ∈ 1, 2, 3, 4) that is responsible for strengthening the features by applying multiple dilated convolutions and an attention mechanism.
2.2. Feature enhancement module
Feature enhancement module (FEM) (see Figure 1 (b)) begins with four parallel dilated convolutions Conv with a dilation rate r = {1, 6, 12, 18}. Each dilation is followed by a batch normalization BN and a rectified linear unit ReLU which we refer as CBR. The output features are passed through a channel-attention module CAM [17] to capture the explicit relationship between the feature channels. The highlighted features from these four dilated convolutions are then concatenated and passed through a Conv3×3 followed by BN layer and added with the original input features through a Conv1×1. The resulting features are then followed by a ReLU activation function, and a spatial attention mechanism SAM [17] is applied to suppress the irrelevant regions.
2.3. Label attention
Label attention module is designed to provide learned text-based attention to the output features of the decoder blocks in our TGANet. Here, we use three label attention modules, li, i ∈ 1, 2, 3, as soft channel-wise attention to the three decoder outputs that enables larger weights to the representative features and suppress the redundant ones. The first label attention module uses the output of the embedding fusion ℰ(.) obtained by element-wise dot product between the softmax probability concatenation {σone, σmany, σsmall, σmedium, σlarge} with the encoded text embedding. Say, 𝒜 = {one, many, small, medium, large} be the attributes that are encoded using byte-pair encoding [5] and denoted by 𝒜encode with as vector embedding for each attribute j of length |k|, then ℰ(.) that is given by:
| (1) |
The output of the label attention module is referred to as label features lf in this paper.
2.4. Decoder
The decoder in the proposed TGANet is comprised of three different decoder blocks di, i ∈ 1, 2, 3, of which each takes the input features to upsample it and pass it through some convolutional layers to produce the output. This output is refined using the label attention module li and passed to the subsequent decoder blocks di (see Figure 1 (c)). The first decoder block takes the output of the fourth FEM f4 to upsample it using bilinear interpolation by a factor of two, and then it is concatenated with the output features from the third FEM f3. The resulting concatenated feature is passed through a Conv1×1-BN-ReLU referred as CBR followed by a sequence of three Conv3×3-BN, further accompanied by their multiple residual connections and a ReLU activation function with subsequent convolutional block attention module represented as . An element-wise multiplication is done to allow additional soft-attention from the computed label features lf using a sigmoid function for each decoder block output , i ∈ 1, 2, 3 given by:
| (2) |
2.5. Multi-scale feature aggregation
Multi-scale feature aggregation (MSFA) module (see supplementary Figure 1) is used to fuse multi-scale feature representations at various decoder outputs , i ∈ 1, 2, 3 that allows to capture learned features. We take the first two features and pass them through a bilinear upsampling to ensure that all three features have the exact spatial dimensions followed by linear 1 × 1 convolution layers, BN and ReLU activation before concatenation. To boost the capture of non-linear features we further apply a series of convolutional layers, BN and ReLU together with multiple residual connections for improved flow of information. The output is represented as mf which is responsible for our predicted segmentation map given by: .
Joint loss optimization:
We jointly minimize loss for both the auxiliary classification tasks (cross-entropy losses, CEloss1, CEloss2) and the segmentation task (binary cross entropy, BCEloss3 and dice loss, DSCloss4) with equal weights.
3. Experiments and results
3.1. Datasets
To evaluate the performance of our TGANet, we have used four publicly available polyp segmentation benchmark datasets including Kvasir-SEG [9], CVC-ClinicDB [1], BKAI[11], and Kvasir-Sessile [8] (details are presented in supplementary Table 1). Relevant to our experiment, Kvasir-Sessile [8] contains 196 small, diminutive, sessile and flat polyps that are less than 10 mm in size.
3.2. Implementation Details
All models are trained on NVIDIA GeForce RTX 3090 GPU, and images are resized to 256 × 256 pixels with 80:10:10 training, validation, and testing splits except for Kvasir-SEG, where we adopted the official split of 880/120 for training and testing. Simple data augmentation strategy including random rotation, vertical flipping, horizontal flipping, and coarse dropout are used. All models are trained on a similar hyperparameters configuration with a learning rate of 1e−4, batch size of 16, and optimized with Adam optimizer. An early stopping mechanism and ReduceLROnPlateau is used to prevent models from overfitting.
Standard medical image segmentation metrics such as mean intersection over union (mIoU), mean Sørensen–dice coefficient (mDSC), recall, precision, F2-score and frame per second (FPS) are used.
3.3. Results
We have compared our results with five SOTA methods that include UNet [13], HarDNet-MSEG [6], ColonSegNet [7], DeepLabv3+ [2], and PraNet [3]. These algorithms are widely used baselines in both polyp segmentation and general medical image segmentation. The quantitative results are presented in Table 1.
Table 1:
Quantitative results on the experimented polyp datasets.
| Method | Backbone | mloU | mDSC | Recall | Precision | F2 |
|---|---|---|---|---|---|---|
| Dataset: Kvasir-SEG [9] | ||||||
| U-Net [13] | - | 0.7472 | 0.8264 | 0.8504 | 0.8703 | 0.8353 |
| HarDNet-MSEG [6] | HardNet68 | 0.7459 | 0.8260 | 0.8485 | 0.8652 | 0.8358 |
| ColonSegNet [7] | - | 0.6980 | 0.7920 | 0.8193 | 0.8432 | 0.7999 |
| DeepLabV3+ [2] | ResNet50 | 0.8172 | 0.8837 | 0.9014 | 0.9028 | 0.8904 |
| PraNet [3] | Res2Net | 0.8296 | 0.8942 | 0.9060 | 0.9126 | 0.8976 |
| TGANet (Ours) | ResNet50 | 0.8330 | 0.8982 | 0.9132 | 0.9123 | 0.9029 |
| Dataset: CVC-ClinicDB [1] | ||||||
| U-Net [13] | - | 0.8428 | 0.8978 | 0.9001 | 0.9209 | 0.8981 |
| HarDNet-MSEG [6] | HardNet68 | 0.8388 | 0.8967 | 0.8929 | 0.9216 | 0.8938 |
| ColonSegNet [7] | - | 0.8248 | 0.8862 | 0.8828 | 0.9017 | 0.8826 |
| DeepLabV3+ [6] | ResNet50 | 0.8973 | 0.9391 | 0.9441 | 0.9442 | 0.9389 |
| PraNet [3] | Res2Net | 0.8866 | 0.9318 | 0.9347 | 0.9479 | 0.9333 |
| TGANet (Ours) | ResNet50 | 0.8990 | 0.9457 | 0.9437 | 0.9519 | 0.9439 |
| Dataset: BKAI [11] | ||||||
| U-Net [13] | - | 0.7599 | 0.8286 | 0.8295 | 0.8999 | 0.8264 |
| HarDNet-MSEG | HardNet68 | 0.6734 | 0.7627 | 0.7532 | 0.8344 | 0.7528 |
| ColonSegNet [7] | - | 0.6881 | 0.7748 | 0.7852 | 0.8711 | 0.7746 |
| DeepLabV3+ [2] | ResNet50 | 0.8314 | 0.8937 | 0.8870 | 0.9333 | 0.8882 |
| PraNet [3] | Res2Net | 0.8264 | 0.8904 | 0.8901 | 0.9247 | 0.8885 |
| TGANet (Ours) | ResNet50 | 0.8409 | 0.9023 | 0.9026 | 0.9208 | 0.9002 |
| Dataset: Kvasir-Sessile [8] | ||||||
| U-Net [13] | - | 0.2472 | 0.3688 | 0.7237 | 0.3264 | 0.4635 |
| HarDNet-MSEG | HardNet68 | 0.1565 | 0.2558 | 0.5403 | 0.2236 | 0.3298 |
| ColonSegNet [7] | - | 0.2113 | 0.3278 | 0.5234 | 0.3336 | 0.3868 |
| DeepLabV3+ [2] | ResNet50 | 0.5927 | 0.7078 | 0.7085 | 0.8225 | 0.7009 |
| PraNet [3] | Res2Net | 0.6671 | 0.7736 | 0.8069 | 0.8244 | 0.7871 |
| TGANet (Ours) | ResNet50 | 0.6910 | 0.7980 | 0.7925 | 0.8588 | 0.7879 |
| Training dataset: Kvasir-SEG – Test dataset: CVC-ClinicDB | ||||||
| U-Net [13] | - | 0.5433 | 0.6336 | 0.6982 | 0.7891 | 0.6563 |
| HarDNet-MSEG [6] | HardNet68 | 0.6058 | 0.6960 | 0.7173 | 0.8528 | 0.7010 |
| ColonSegNet [7] | - | 0.5090 | 0.6126 | 0.6564 | 0.7521 | 0.6246 |
| DeepLabV3+ [2] | ResNet50 | 0.7388 | 0.8142 | 0.8331 | 0.8735 | 0.8198 |
| PraNet [3] | Res2Net | 0.7286 | 0.8046 | 0.8188 | 0.8968 | 0.8077 |
| TGANet (Ours) | ResNet50 | 0.7444 | 0.8196 | 0.8290 | 0.8879 | 0.8207 |
Results on Kvasir-SEG:
Table 1 shows that TGANet outperforms all the SOTA methods with a mIoU of 0.8330 and mDSC of 0.8982. Our TGANet outperforms most competitive PraNet [3] by 1.58% in mIoU and 1.45% mDSC.
Results on CVC-ClinicDB:
For CVC-ClinicDB dataset, TGANet outper-forms all SOTA methods reporting the highest mIoU and mDSC of 0.8990 and 0.9457, respectively. Our method outperformed the most competitive DeepLabV3+ [2] with a mIoU of 0.17% and mDSC of 0.66%.
Results on BKAI:
Table 1 shows the comparison of the result on the BKAI dataset that show that our proposed TGANet obtains mIoU of 0.8409 and mDSC of 0.9023 and outperforms the best performing DeepLabV3+ [2] by 0.95% on mIoU and 0.86% on mDSC.
Results on Kvasir-Sessile:
Kvasir-Sessile dataset is clinically most relevant as it has flat and sessile polyps. On this dataset, it can be observed (see Table 1) that our TGANet surpasses all the other methods in all the evaluation metrics. It outperforms the best performing PraNet [3] by a large margin of 2.39% on mIoU and 2.44% on mDSC. Similarly, almost 10% improvement is observed compared to the DeepLabV3+ [2] in this case which is a significant improvement.
Results on cross dataset:
To explore the generalization capability of our proposed TGSNet, we train the model on Kvasir-SEG and test it on the CVC-ClinicDB. The cross-dataset test (Table 1) also suggested improvements compared to all SOTA methods and obtained an increment of 0.56% on mIoU and 0.54% on mDSC compared to the SOTA DeepLabv3+ [2].
Results on size and number-based sampled polyps:
To show the effectiveness of our proposed TGANet, we evaluated test samples of Kvasir-SEG-based on the attributes used in training. It can be observed in Table 2 that our model outperforms the best SOTA methods for almost all cases. For the ‘small’, ‘medium’ and ‘many cases’, the improvement ranges from nearly 1–2%.
Table 2:
mDSC for different sizes and polyp counts on Kvasir-SEG
Our qualitative results (see Figure 2) demonstrate a clear improvement of our text-based attention method for different sizes and number polyp samples. It is evident that both PraNet [3] and DeepLabV3+ [2] failed to capture sample with two polyps (4th row) and also provided over segmentation for the small (1st row) and medium polyps (2nd row). Additionally, we have provided the total number of parameters, flops and FPS in supplementary material Table 2.
Fig.2:
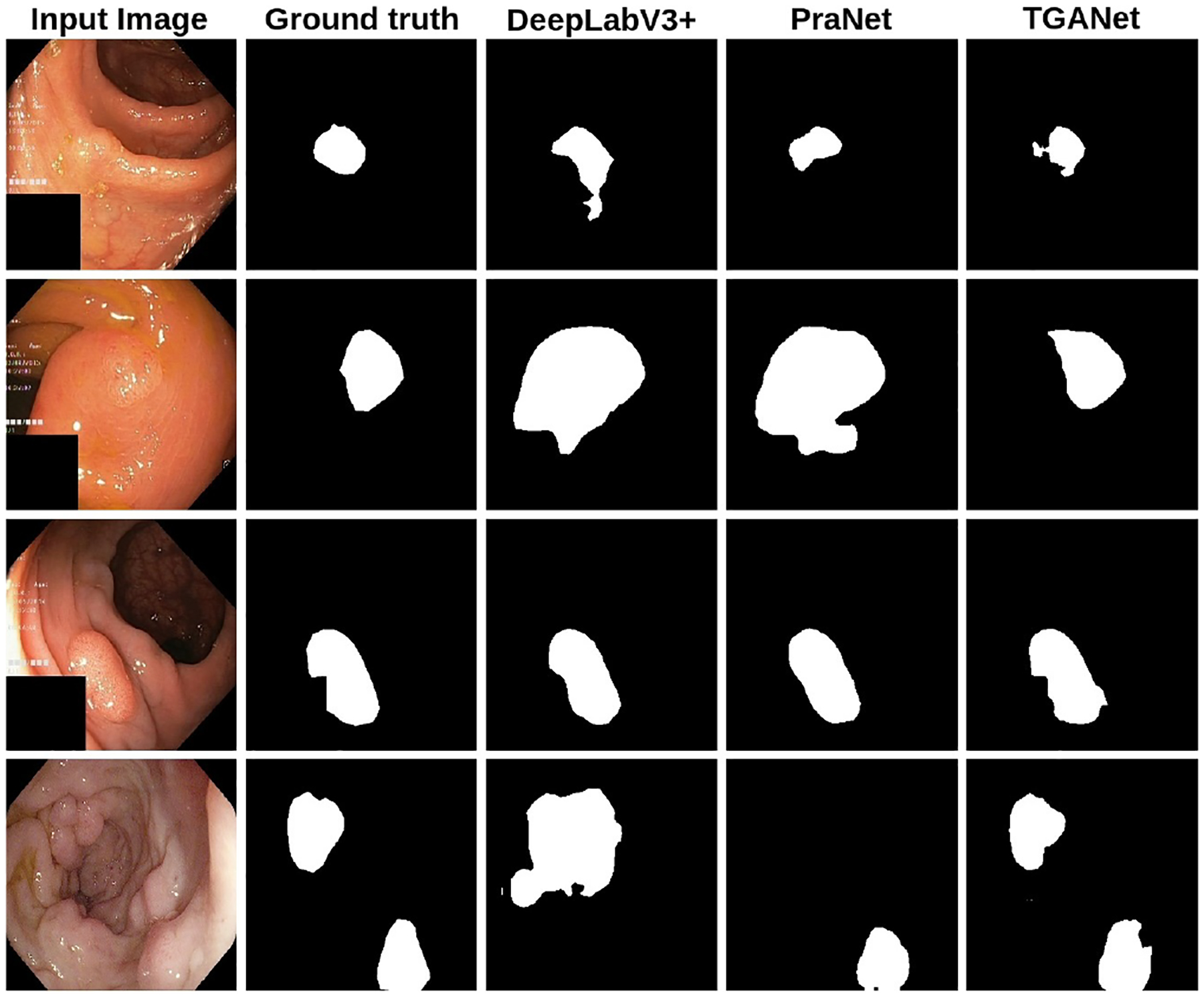
Qualitative results comparison on the Kvasir-SEG dataset.
3.4. Ablation study
To validate the effectiveness and importance of the core components used in the network, we compare TGANet with its five variants, which is presented in Table 3. The results suggest that the introduction of the text guided attention along with the label boosts the performance of the network. The results show that TGANet improves the baseline without the label and classifier (#1) by 2.26% on mIoU and 1.96% on mDSC.
Table 3:
Ablation study of TGANet on Kvasir-SEG
| No | Method | mIoU | mDSC | Recall | Precision | F2 |
|---|---|---|---|---|---|---|
| #1 | TGANet w/o label and classifier | 0.8104 | 0.8786 | 0.8987 | 0.8970 | 0.8850 |
| #2 | TGANet w/o MSFA | 0.8151 | 0.8832 | 0.9061 | 0.8999 | 0.8907 |
| #3 | TGANet w/o FEM TGANet w/o (label+classifier+ | 0.8084 | 0.8766 | 0.8968 | 0.9010 | 0.8838 |
| #4 | MSFA+FEM) | 0.8063 | 0.8747 | 0.8963 | 0.8971 | 0.8798 |
| #5 | TGANet (Ours) | 0.8330 | 0.8982 | 0.9132 | 0.9123 | 0.9029 |
4. Conclusion
We proposed a text-guided attention architecture (TGANet) to tackle polyps’ variable size and number for robust polyp segmentation. We have used multiple feature enhancement modules connected with different encoder blocks to achieve this. An auxiliary task is learned together with the main task to compliment both the size-based and number-based feature representations and used as label attentions in the decoder blocks. Additionally, the multi-scale fusion of the features at the decoder enabled our network to deal with these attribute changes. Our experimental results demonstrated the effectiveness of our TGANet outperformed and provided higher segmentation performance on flat and sessile polyps that are clinically important.
Supplementary Material
References
- 1.Bernal J, Sánchez FJ, Fernández-Esparrach G, Gil D, Rodríguez C, Vilariño F: WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Computerized Medical Imaging and Graphics 43, 99–111 (2015) [DOI] [PubMed] [Google Scholar]
- 2.Chen LC, Zhu Y, Papandreou G, Schroff F, Adam H: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European conference on computer vision (ECCV). pp. 801–818 (2018) [Google Scholar]
- 3.Fan DP, Ji GP, Zhou T, Chen G, Fu H, Shen J, Shao L: Pranet: Parallel reverse attention network for polyp segmentation. In: Proceedings of the International conference on medical image computing and computer-assisted intervention (MICCAI). pp. 263–273 (2020) [Google Scholar]
- 4.He K, Zhang X, Ren S, Sun J: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). pp. 770–778 (2016) [Google Scholar]
- 5.Heinzerling B, Strube M: BPEmb: Tokenization-free Pre-trained Subword Embeddings in 275 Languages. In: Proceedings of the International Conference on Language Resources and Evaluation (LREC 2018) (2018) [Google Scholar]
- 6.Huang CH, Wu HY, Lin YL: HarDNet-MSEG A Simple Encoder-Decoder Polyp Segmentation Neural Network that Achieves over 0.9 Mean Dice and 86 FPS. arXiv preprint arXiv:2101.07172 (2021) [Google Scholar]
- 7.Jha D, Ali S, Tomar NK, Johansen HD, Johansen D, Rittscher J, Riegler MA, Halvorsen P: Real-time polyp detection, localization and segmentation in colonoscopy using deep learning. IEEE Access 9, 40496–40510 (2021) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Jha D, Smedsrud PH, Johansen D, de Lange T, Johansen HD, Halvorsen P, Riegler MA: A comprehensive study on Colorectal Polyp Segmentation With ResUNet++, Conditional Random Field and Test-Time Augmentation. IEEE journal of Biomedical and Health Informatics 25(6), 2029–2040 (2021) [DOI] [PubMed] [Google Scholar]
- 9.Jha D, Smedsrud PH, Riegler MA, Halvorsen P, Lange T.d., Johansen D, Johansen HD: Kvasir-SEG: a segmented polyp dataset. In: Proceedings of the International Conference on Multimedia Modeling (MMM). pp. 451–462 (2020) [Google Scholar]
- 10.Kim NH, Jung YS, Jeong WS, Yang HJ, Park SK, Choi K, Park DI: Miss rate of colorectal neoplastic polyps and risk factors for missed polyps in consecutive colonoscopies. Intestinal research 15(3), 411 (2017) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lan PN, An NS, Hang DV, Van Long D, Trung TQ, Thuy NT, Sang DV: NeoUNet: towards accurate colon polyp segmentation and neoplasm detection. arXiv preprint arXiv:2107.05023 (2021) [Google Scholar]
- 12.Rex DK, Cutler CS, Lemmel GT, Rahmani EY, Clark DW, Helper DJ, Lehman GA, Mark DG: Colonoscopic miss rates of adenomas determined by back-to-back colonoscopies. Gastroenterology 112(1), 24–28 (1997) [DOI] [PubMed] [Google Scholar]
- 13.Ronneberger O, Fischer P, Brox T: U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Proceedings of the International Conference on Medical image computing and computer-assisted intervention (MICCAI). pp. 234–241 (2015) [Google Scholar]
- 14.Shen Y, Jia X, Meng MQH: Hrenet: A hard region enhancement network for polyp segmentation. In: Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI). pp. 559–568 (2021) [Google Scholar]
- 15.Srivastava A, Jha D, Chanda S, Pal U, Johansen HD, Johansen D, Riegler MA, Ali S, Halvorsen P: MSRF-Net: A Multi-scale Residual Fusion Network for Biomedical Image Segmentation. IEEE Journal of biomedical imaging and health informatics (2021) [DOI] [PubMed] [Google Scholar]
- 16.Sung H, Ferlay J, Siegel RL, Laversanne M, Soerjomataram I, Jemal A, Bray F: Global cancer statistics 2020: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: a cancer journal for clinicians 71(3), 209–249 (2021) [DOI] [PubMed] [Google Scholar]
- 17.Woo S, Park J, Lee JY, Kweon IS: Cbam: Convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018) [Google Scholar]
- 18.Zhong J, Wang W, Wu H, Wen Z, Qin J: Polypseg: An efficient context-aware network for polyp segmentation from colonoscopy videos. In: Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI). pp. 285–294 (2020) [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.