

Abstract
Recent comparative genomic studies have identified many human accelerated elements (HARs) with elevated substitution rates in the human lineage. However, it remains unknown to what extent transcription factor binding sites (TFBSs) are under accelerated evolution in humans and other primates. Here, we introduce two pooling-based phylogenetic methods with dramatically enhanced sensitivity to examine accelerated evolution in TFBSs. Using these new methods, we show that more than 6000 TFBSs annotated in the human genome have experienced accelerated evolution in Hominini, apes, and Old World monkeys. Although these TFBSs individually show relatively weak signals of accelerated evolution, they collectively are more abundant than HARs. Also, we show that accelerated evolution in Pol III binding sites may be driven by lineage-specific positive selection, whereas accelerated evolution in other TFBSs might be driven by nonadaptive evolutionary forces. Finally, the accelerated TFBSs are enriched around developmental genes, suggesting that accelerated evolution in TFBSs may drive the divergence of developmental processes between primates.
Subject terms: Molecular evolution, Statistical methods, Evolutionary genetics
Characterizing genomic elements under accelerated evolution is crucial for understanding the genomic basis of human evolution and disease. Here, Zhang et al. introduce GroupAcc, a collection of two pooling-based phylogenetic methods with enhanced sensitivity to examine accelerated evolution in transcription factor binding sites.
Introduction
During the course of evolution, a subset of genes and regulatory elements may be subject to different pressures of natural selection in distinct species. These genomic elements often have varying substitution rates across species, which may be identified by phylogenetic models with lineage-specific substitution rates1–10. Notably, previous studies have revealed a few thousand human accelerated regions (HARs) with dramatically elevated substitution rates in the human lineage compared to other vertebrates7–15. A large proportion of HARs are neural enhancers14–20 and frequently subject to strong positive selection in the human lineage9–11,21, suggesting that they may contribute to the adaptive evolution of human brain. Also, recent studies show that deleterious mutations in HARs may be associated with neurodevelopmental disorders22–26, highlighting the key role of HARs in maintaining the integrity of the central nervous system. Thus, characterizing genomic elements under accelerated evolution is of great importance for understanding the genomic basis of human evolution and disease.
While numerous studies have been conducted to examine accelerated evolution in humans and other species7–15,27–29, the existing studies may suffer from two critical limitations. First, most of the previous studies have focused on conserved noncoding elements under accelerated evolution. Because a large proportion of noncoding regulatory elements may be subject to frequent evolutionary turnover30–34, these studies may not be able to characterize accelerated evolution in non-conserved regulatory elements. Second, the previous studies have focused on identifying individual HARs with a genome-wide level of significance. Because of the small amount of alignment data in a single genomic element and the high burden of multiple testing correction associated with a genome-wide scan, these studies may have limited statistical power to detect weakly accelerated evolution driven by relaxed purifying selection or weak positive selection. Altogether, it remains unknown to what extent non-conserved genomic elements are subject to weakly accelerated evolution.
Substitutions in transcription factor binding sites (TFBSs) are a main driver of phenotype diversity between species35–37, implying that TFBSs may also be subject to accelerated evolution. However, to the best of our knowledge, accelerated evolution in TFBSs has not been systematically explored in previous studies, possibly because the majority of TFBSs are not highly conserved across vertebrates30–33,38,39. Also, TFBSs might be subject to weaker acceleration compared to conserved elements because the phenotypic effects of mutations are weaker in TFBSs than in conserved elements40. Therefore, previous phylogenetic methods dedicated to infer strong signals of accelerated evolution may be underpowered to detect TFBSs under weakly accelerated evolution.
Here, we introduce two novel phylogenetic methods for exploring TFBSs under accelerated evolution. Unlike previous methods that analyze individual elements separately7–15, our new approaches pool thousands of TFBSs with similar functions together to boost the statistical power to detect weak signals of accelerated evolution. These new methods allow us to rigorously test whether a group of TFBSs as a whole is significantly enriched with accelerated elements, despite that we may lack statistical power to identity individual TFBSs under accelerated evolution due to limited alignment data in a single TFBS. Using these methods, we show that TFBSs of numerous transcription factors are likely to be under accelerated evolution in Hominini, apes, and Old World monkeys. Compared to previously identified HARs, these TFBSs show weaker acceleration but are more abundant genome-wide. Among these accelerated TFBSs, binding sites of DNA-directed RNA polymerase III (Pol III) show the strongest signal of acceleration, which might be driven by strong lineage-specific positive selection on par with HARs. Taken together, accelerated evolution may be a common characteristic of TFBSs in Hominini, apes, and Old World monkeys.
Results
Pooling-based phylogenetic inference of accelerated evolution
In the current study, we introduce a novel software application, GroupAcc, which includes two pooling-based phylogenetic approaches with improved statistical power to infer weakly accelerated evolution. The key idea of GroupAcc is to group TFBSs by the bound transcription factor and then examine whether each TFBS group as a whole shows an elevated substitution rate in a lineage of interest. In this study, TFBSs refer to peaks in Chromatin immunoprecipitation-sequencing(ChIP-seq)41. By pooling alignment data from a large number of TFBSs, our new methods have significantly higher statistical power to detect weakly accelerated evolution at the group level even if the signals of acceleration are statistically insignificant at the level of individual TFBSs.
In the first method, we utilize a group-level likelihood ratio test (LRT) to infer whether a TFBS group as a whole shows an elevated substitution rate in a predefined foreground lineage compared to the other lineage (background lineage) (Fig. 1). To this end, we first fit a reference phylogenetic model to the concatenated alignment of all TFBSs, where we estimate the branch lengths of a phylogenetic tree, the gamma shape parameter for rate variation among nucleotide sites42, and the parameters of the general time reversible substitution model43. Assuming that the majority of TFBSs may not be under accelerated evolution, the reference phylogenetic model may represent the overall pattern of sequence evolution in TFBSs when accelerated evolution is absent. Given the reference phylogenetic tree, we then fit the group-level LRT to the concatenated alignment of a TFBS group, where we estimate two scaling factors, r1 and r2, for the foreground and the background branches, respectively. We interpret r1 and r2 as the relative substitution rates of the TFBS group in the foreground and background lineages throughout this study. We assume that r1 = r2 in the null model (H0), indicating that the TFBS group has evolved at a constant rate across all lineages. Conversely, we assume that r1 ≠ r2 in the alternative model (Ha), indicating that the TFBS group has evolved at different substitution rates between the foreground and background lineages. Because the TFBS group may consist of hundreds of TFBSs, we assume that the likelihood ratio statistic of the group-level LRT asymptotically follows a chi-square distribution with one degree of freedom. If the null model is rejected in the group-level LRT and r1 > r2, we consider that the TFBS group as a whole may be subject to accelerated evolution.
Fig. 1. Pooling-based phylogenetic methods for inferring accelerated evolution in TFBSs.

In the first method, we fit the group-level LRT to the concatenated alignment of TFBSs bound by the same transcription factor, which allows us to examine whether the group of TFBSs as a whole evolved at an elevated substitution rate in the foreground lineage compared to the background lineage. In the second method, we fit the element-level LRT to the alignment of each individual TFBS, which provides an element-level p-value. Then, we fit a beta-uniform mixture model to the distribution of p-values in each TFBS group to estimate the proportion of accelerated TFBSs. Colored rectangles and hexagons represent TFBSs and transcription factors, respectively. r1 and r2 represent relative substitution rates in the foreground and background lineages, respectively.
In the second method, we use a phylogenetics-based mixture model to estimate the proportion of accelerated TFBSs in a TFBS group (Fig. 1). To this end, we first perform an element-level LRT to infer evidence for accelerated evolution in individual TFBSs given that H0 is rejected in the group-level LRT. The element-level LRT is similar to the group-level LRT but is applied to the alignments of individual TFBSs rather than to the concatenated alignment of the TFBS group. Given the likelihood ratio statistics from the element-level LRT, we then calculate empirical p-values for individual TFBSs using parametric bootstrapping. Unlike the chi-square distribution in the group-level LRT, the parametric bootstrapping procedure provides accurate p-values even when there is a small amount of alignment data per test9. Finally, we estimate the proportion of accelerated TFBSs in the TFBS group by fitting a beta-uniform mixture model to the distribution of p-values44. The beta-uniform mixture model allows us to estimate an upper bound of the proportion of TFBSs generated from H0 (). We consider as a conservative estimate (lower bound) of the proportion of accelerated TFBSs.
GroupAcc is able to identify weakly accelerated evolution in synthetic data
To verify the power of GroupAcc to infer weakly accelerated evolution in TFBS groups, we conducted simulations under various lineage-specific evolutionary dynamics. In the first scenario, we assumed that all the binding sites in one group are under accelerated evolution in a specific lineage. The second scenario considered the heterogeneity of evolutionary patterns in each single binding site: only parts of each binding site (for example, motif) undergo accelerated evolution in a specific lineage. The third scenario considered the heterogeneity of evolutionary dynamics in groups of binding sites: only certain numbers of binding sites in one group undergo accelerated evolution in a specific lineage, while the other binding sites do not undergo accelerated evolution. Under each scenario, we verified the ability of the group-level LRT method to detect accelerated evolution in a specific lineage and estimate the fold of increase in substitution rate (r1/r2). We also compared the performance of the phylogenetics-based mixture model and traditional element-level LRT in estimating the number of elements under accelerated evolution in a given lineage.
In each scenario, eight cases were generated in which different lineages of primates were under accelerated evolution: (1) only human, (2) subtree of Hominini (human, chimp), (3) subtree of human, chimp, and gorilla, (4) subtree of Great apes (chimp, gorilla, orangutan) and human, (5) only chimp, (6) only gorilla, (7) only orangutan, (8) only macaque. For each case, we simulated alignments of 10,000 binding sites, each at the length of 200 bp based on the reference model plus those assumptions. We also simulated alignments of different numbers of binding sites (1000) and different lengths of each alignment (100 bp) to test the performance of the model in different settings. Both weak and strong accelerated evolution were taken into consideration: the fold of increase in substitution rate in foreground lineage (r1/r2) varied from 1.2 to 5.
Under the first scenario, all the 200 bp binding sites in one group were assumed to be under accelerated evolution in a defined lineage as each case (1–8) showed, for example, in case 1, all the 200 bp binding sites would be under accelerated evolution in only human. With foreground lineage matching with the accelerated lineage in each case, the group-level LRT method was able to tell the presence of accelerated evolution at the group level and accurately estimate the fold of increase in substitution rate in foreground lineages (r1/r2), even given weak accelerated evolution when the fold of increase in substitution rates is only slightly larger than 1 (Fig. 2a). The GroupAcc model performed better than element-level LRT in estimating the number of elements under accelerated evolution (Fig. 2b). We also tested if the model could detect accelerated evolution in a tip if a subtree containing the tip is under accelerated evolution (Fig. 3). In cases (1), (2), (3) and (4), when accelerated evolution happened in lineages such as human or subtrees containing human, taking human as foreground lineage, GroupAcc methods were able to identify the presence of accelerated evolution in human and estimate the number of elements under accelerated evolution in human with higher accuracy compared to traditional element-level LRT method (Fig. 3). In cases (5), (6), (7) and (8), when accelerated evolution occurred in lineages other than human, the GroupAcc methods were able to identify the fact that human is not undergoing accelerated evolution (Fig. 3).
Fig. 2. Simulation results of scenario 1 with foreground lineage matching the accelerated lineage in each case (1–8).

a X-axis shows the scaling factor of foreground lineage branch length in simulation setting, which is the real fold of increase in the substitution rate of the foreground lineage. Y-axis shows the fold of increase in the substitution rate of the foreground lineage estimated from group-level LRT. b Comparison of accuracy estimating the number of elements under accelerated evolution between GroupAcc and element-level LRT method. Blue curves are the accuracy of GroupAcc. Red curves are the accuracy of element-level LRT.
Fig. 3. Simulation results of scenario 1 using human as foreground lineage.

a X-axis shows the scaling factor of accelerated lineage branch length in simulation setting, which is the real fold of increase in the substitution rate of the accelerated lineage. Y-axis shows the fold of increase in the substitution rate of human estimated from group-level LRT. b Comparison of the estimated number of elements under accelerated evolution in human between GroupAcc and element-level LRT method. Blue curves are the estimates of GroupAcc. Red curves are the estimates of element-level LRT.
We validated the ability of our methods to identify lineage-specific acceleration when only part of the TFBS is under accelerated evolution from simulation scenario 2. We generated 10,000 200 bp alignments standing for elements. Each alignment was composed of 200 × L bp generated with a scaled tree (with substitution rate increase) and 200(1 − L) bp generated from an unscaled tree (without substitution rate increase). Given that L = 0.1, 0.2, 0.5, 0.8. the group-level LRT was able to identify the presence of accelerated evolution, even under weak acceleration when the fold of substitution rate increase in foreground lineage was only 1.2 (Fig. 4a). The GroupAcc method outperformed the element-level LRT method in estimating the number of elements under accelerated evolution (Fig. 4b). Therefore, under situations with the heterogeneity of evolutionary patterns in each single binding site, our pooling based methods were able to identify lineage-specific accelerated evolution with a uniform scaling of substitution rates on the foreground lineages across the whole binding sites.
Fig. 4. Simulation results of scenario 2.

a Accuracy of GroupAcc in estimating the fold of increase in the substitution rate of foreground lineage given different portions of each binding site under accelerated evolution. X-axis shows the scaling factor of accelerated lineage branch length in simulation setting, which is the real fold of increase in the substitution rate of accelerated lineage. Y-axis shows the accuracy of estimating the fold of increase in the substitution rate of the accelerated lineage. The weighted estimate of the fold of increase in the substitution rate of foreground lineage across the whole group of binding sites is calculated by (). The accuracy of estimating the fold of increase is calculated as . b Comparison of performance estimating the number of elements under accelerated evolution between GroupAcc and element-level LRT method. Blue curves are the estimated numbers of GroupAcc. Red curves are the estimated numbers of element-level LRT.
Under the third scenario, a specific proportion M of binding sites (M = 0.1, 0.2, 0.5, 0.8) in a group were under accelerated evolution. This scenario considered the heterogeneity of evolutionary dynamics in multiple binding sites of one transcription factor. We found group-level LRT method was able to tell the presence of accelerated evolution at the group level and estimate the fold of increase in the substitution rate of foreground lineages, even when the fold of increase in substitution rates of foreground lineage was slightly larger than 1 (Fig. 5). The GroupAcc model performed better than element-level LRT in estimating the number of elements under accelerated evolution (Fig. 5).
Fig. 5. Simulation results of scenario 3.

a Accuracy of GroupAcc in estimating the fold of increase in the substitution rate of foreground lineage given different portions of elements in a group under accelerated evolution. X-axis shows the scaling factor of accelerated lineage branch length in simulation setting, which is the real fold of increase in the substitution rate of accelerated lineage. Y-axis shows the accuracy of estimating the fold of increase in the substitution rate of the accelerated lineage. The weighted estimate of the fold of increase in the substitution rate of foreground lineage across the whole group of binding sites is calculated by (). The accuracy of estimating the fold of increase is calculated as . b Comparison of performance estimating the number of elements under accelerated evolution between GroupAcc and element-level LRT method. Blue curves are the estimated numbers of GroupAcc. Red curves are the estimated numbers of element-level LRT.
Numerous TFBS groups show evidence for accelerated evolution
Using the group-level LRT, we examined accelerated evolution in 4,380,444 TFBSs of 161 transcription factors identified by ChIP-seq experiments in the ENCODE Project45. We tested whether each group of TFBSs bound by the same transcription factor had an elevated substitution rate in the human lineage. We used Multiz genome alignments of ten primate species46 and defined the human lineage after the divergence of chimpanzees and humans as the foreground lineage. Unlike previous studies of HARs7–15, we did not include non-primate vertebrates to mitigate the impact of the evolutionary turnover of TFBSs on our analysis30–33,38,39. After Bonferroni correction, we observed that 15 TFBS groups had significantly different substitution rates between the foreground and background lineages (Supplementary Data 1), which all showed elevated substitution rates in humans compared to other primates (r1 > r2).
TFBS groups with elevated substitution rates in humans could be either directly under accelerated evolution or merely overlapping with other accelerated TFBS groups. To identify TFBS groups directly under accelerated evolution, we sought to partition the binding sites of the 15 TFBS groups with elevated substitution rates into non-overlapping, biologically interpretable TFBS groups. Because BDP1, BRF1, and POLR3G are components of the Pol III transcription machinery47, we defined a new TFBS group, Pol III binding, consisting of genomic regions bound by at least two of the three transcription factors. Similarly, since POU5F1 and NANOG can interact with each other to form a protein complex48,49, we defined another TFBS group, POU5F1-NANOG binding, consisting of genomic regions bound by both of the two transcription factors.
Then, we removed all binding sites overlapping more than one TFBS group, resulting in 17 non-overlapping TFBS groups. We applied the group-level LRT again to these non-overlapping TFBS groups. After Bonferroni correction, seven non-overlapping TFBS groups showed significantly elevated substitution rates in the human lineage (Fig. 6; Supplementary Table 1). These non-overlapping TFBS groups included Pol III binding, POU5F1-NANOG binding, BDP1, FOXP2, POU5F1, NANOG, and NRF1. Compared to previously identified HARs, the seven non-overlapping TFBS groups showed weaker acceleration as evidenced by their smaller increases in substitution rates in the human lineage (Fig. 6). We focused on the seven non-overlapping TFBS groups with evidence for weakly accelerated evolution in downstream analysis.
Fig. 6. Non-overlapping TFBS groups under accelerated evolution in the human genome.
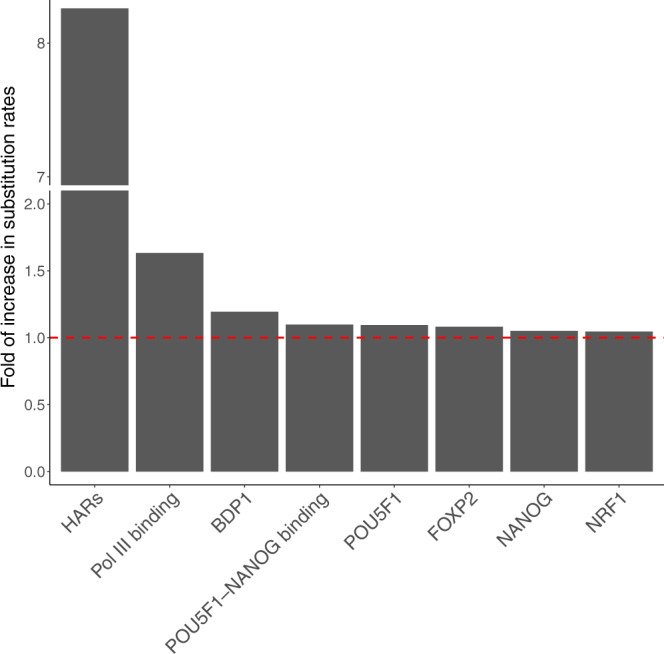
The fold of increase in substitution rate is defined as r1/r2, where r1 and r2 are the relative substitution rates of a TFBS group in the human lineage and in other primates, respectively.
Accelerated evolution in TFBSs may not be human specific
A recent study showed that many HARs may also undergo accelerated evolution in other apes15. Based on the simulation of scenario 1 (Fig. 3), we found that the GroupAcc methods were able to tell the presence of accelerated evolution in human lineage at the group level when accelerated evolution occurred in any subtrees containing human. To characterize when acceleration occurred during the evolution of TFBSs, we employed a model comparison approach to search for lineages with elevated substitution rates. Specifically, we evaluated the goodness-of-fit of seven phylogenetic models with different foreground lineages, denoted as M1 to M7 (Fig. 7a). All these models were based on Ha in the group-level LRT (Fig. 1), and the foreground lineages associated with these models corresponded to all the monophyletic clades that included the human lineage (Fig. 7a). These models effectively assumed that the change of substitution rate occurred at most once during the evolution of a TFBS group, which was designed to explore the most parsimonious explanations of accelerated evolution and to limit the number of tested foreground lineages. We used the Bayesian information criterion (BIC) as a measure of goodness-of-fit of these models.
Fig. 7. Lineages associated with accelerated evolution in TFBS groups.

a The seven foreground lineages examined in the model comparison analysis. b Model fit with different foreground lineages. The black bars indicate the best-fit foreground lineages.
Although the seven accelerated TFBS groups were originally detected using humans as the foreground lineage, our model comparison analysis showed that accelerated evolution may not be human specific (Fig. 7b and Supplementary Table 2). Specifically, for binding sites of Pol III, BDP1, and NRF1, a model with both apes and Old World monkeys as the foreground lineage (M5) showed the best goodness-of-fit. Similarly, for binding sites of FOXP2 and NANOG, a model with apes as the foreground (M4) showed the best goodness-of-fit. Moreover, for POU5F1-NANOG and POU5F1 binding sites, a model with Hominini as the foreground (M2) showed the best goodness-of-fit. Altogether, the acceleration of TFBS evolution might be driven by changes of selection pressure in Hominini, apes, and Old World monkey and, thus, might contribute to phenotypic differences between these species and other primates.
More than 6000 TFBSs may be under accelerated evolution
In this section, we sought to infer the total number of TFBSs under accelerated evolution. While the group-level LRT can examine whether a TFBS group as a whole was under accelerated evolution, it could not estimate the number of accelerated TFBSs in the TFBS group. Also, because the signal of acceleration might be weak in TFBSs (Fig. 6), previous phylogenetic models could not be used to estimate this number either7–15. To address this problem, we utilized the phylogenetics-based mixture method to estimate the proportion of accelerated TFBSs from the distribution of p-values associated with individual TFBSs in the same group (Fig. 1).
We observed that 78% of Pol III binding sites were under accelerated evolution (Table 1 and Supplementary Table 3), which translates to approximately 222 accelerated Pol III binding sites. Also, 20 and 25% of binding sites of BDP1 and NRF1 were under accelerated evolution in Old World monkeys and apes, which translates to approximately 90 and 466 accelerated TFBSs, respectively. Approximately 25% of TFBSs of FOXP2 and NANOG were under accelerated evolution in apes, suggesting about 5000 binding sites in these TFBS groups were accelerated elements. Furthermore, approximately 8% of TFBSs of POU5F1 and POU5F1-NANOG were under accelerated evolution in Hominini, indicating that about 300 binding sites of the two groups were accelerated in the clade consisting of humans and chimpanzees. In total, more than 6000 TFBSs spanning 1573kb were under accelerated evolution in Hominini, apes, and Old World monkeys (Table 1), which is more than the 3098 known HARs spanning 720 kb (see “Methods”).
Table 1.
Numbers of accelerated TFBSs estimated by the phylogenetic mixture model
| TFBS group | Proportion of accelerated elements () | Number of elements | Number of accelerated elements | Lineage with accelerated evolution | Selection coefficient ρ | Gene conversion disparity B |
|---|---|---|---|---|---|---|
| Pol III binding | 0.78 | 286 | 222.30 | OWM & ape (M5) | 0.03 | 0.21 |
| BDP1 | 0.20 | 439 | 89.75 | OWM & ape (M5) | 0.02 | 0.24 |
| POU5F1-NANOG binding | 0.08 | 1341 | 109.90 | Hominini (M2) | 0.19 | 0.06 |
| POU5F1 | 0.10 | 2040 | 204 | Hominini (M2) | 0.09 | 0 |
| FOXP2 | 0.27 | 15881 | 4264.92 | Ape (M4) | 0.20 | 0 |
| NANOG | 0.26 | 2952 | 771.21 | Ape (M4) | 0.23 | 0 |
| NRF1 | 0.25 | 1856 | 466.34 | OWM & ape (M5) | 0.07 | 2.0 |
Positive selection may drive accelerated evolution in Pol III binding sites
The acceleration of TFBS evolution could be due to either positive selection or relaxed purifying selection in the foreground lineage. To examine whether positive selection is a driver of accelerated evolution in TFBSs and estimate the selection pressure in TFBSs, we employed the INSIGHT model50–52 to infer the strength of positive selection and selection pressure on the seven accelerated TFBS groups in the human lineage. Similar to the McDonald-Kreitman test53,54, INSIGHT incorporates divergence and polymorphism data to infer positive selection on a set of predefined genomic elements. We fit the INSIGHT model to the binding sites of each TFBS group, which provided an estimate of Dp, that is, the expected number of adaptive substitutions per kilobase in the human lineage, as well as an estimate of ρ which is the fraction of sites under selection within functional elements.
We observed that Pol III binding sites were subject to strong positive selection in the human lineage, because Dp of Pol III binding sites was significantly higher than 0 and was comparable to that of previously identified HARs (Fig. 8; Supplementary Table 4). By downsampling the 286 Pol III binding sites to 200 or 240 binding sites, we verified that the positive selection could still be detected in Pol III binding sites. In other TFBS groups, Dp was not significantly different from 0, indicating that positive selection might not be the driving force of accelerated evolution in these TFBS groups. Each of the seven TFBS groups were inferred to have a smaller fraction of sites under selection in human ρ (Table 1) than the collection of 161 TFBS groups (ρ = 0.76). The reduced values of ρ implied weaker selection constraints in the seven TFBS groups. Applying phastBias55 to the seven TFBS groups, we observed GC-biased gene conversion in NRF1 binding sites (Table 1).
Fig. 8. Positive selection on accelerated TFBS groups in the human lineage.
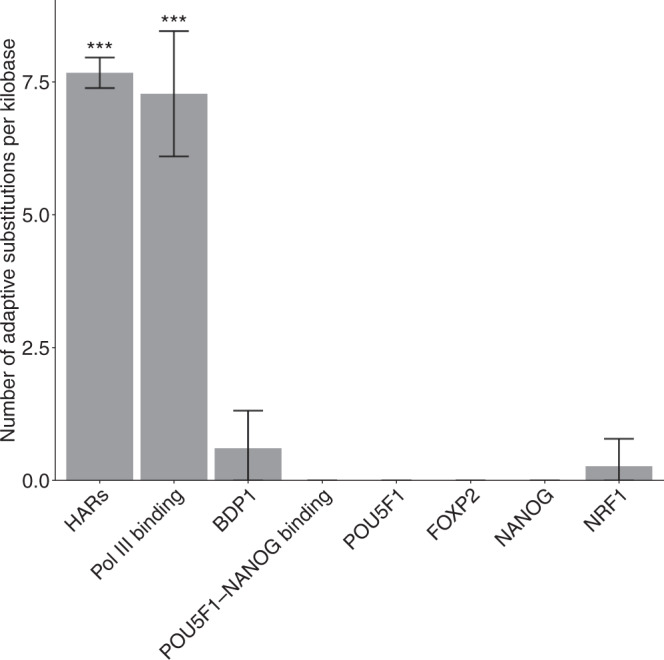
The numbers of adaptive substitutions per kilobase Dp and the standard errors SE(Dp) are estimated by INSIGHT50–52 (Supplementary Table 3). Error bars are centered at the MLE of Dp estimates and indicate two-fold standard errors in each direction. Total number of genetic elements: n = 27,893 (HARs: n = 3098, Pol III binding: n = 286, BDP1 binding sites: n = 439, POU5F1-NANOG binding: n = 1341, POU5F1 binding sites: n = 2040, FOXP2 binding sites: n = 15,881, NANOG binding sites: n = 2952, NRF1 binding sites: n = 1856). P-values were estimated from the one-sided Wald test to compare if Dp is greater than 0. Estimates of Dp found to be significantly greater than 0 are highlighted with stars, ***p < 0.001.
The accelerated TFBSs are enriched around developmental genes
To identify the major functions represented by the top accelerated binding sites in the seven TFBS groups, we utilized Genomic Regions Enrichment of Annotations Tool (GREAT) to first find the potential target genes by predicting both proximal and distal binding events, and then analyzed the functional significance of those top accelerated binding sites by applying GO enrichment test and pathway enrichment analysis to their potential target genes with background gene lists composed of all the genes associated with the whole TFBS group56–58.
We extracted the significant binding sites in each of the seven groups from the phylogenetics-based mixture model and defined them as the top accelerated binding sites. GREAT identified 2611 potential target genes for the top accelerated binding sites of FOXP2, 662 genes for the top accelerated binding sites of NANOG, 390 genes for the top accelerated binding sites of NRF1, 222 genes for the top accelerated binding sites of POU5F1, 163 genes for the top accelerated binding sites shared by POU5F1 and NANOG, 104 genes for the top accelerated binding sites of BDP1 and 143 genes for the top accelerated binding sites shared by Pol III TFs. Using default settings in GREAT, we built seven background gene lists for seven TFBS groups, respectively containing 9896 potential target genes for FOXP2 binding sites, 3745 genes for NANOG binding sites, 2931 genes for NRF1 binding sites, 1976 genes for POU5F1-NANOG binding sites and 478 potential target genes for POU5F1 binding sites.
After removing the redundant GO terms with high semantic similarity (0.7) and performing Bonferroni correction on the GO enrichment results, we found FOXP2 top accelerated TFBSs were associated with genes functioning in artery development and regulation of transforming growth factor signaling pathway. The concatenation of top accelerated binding sites in seven TFBS groups were associated with genes playing roles in development and cell proliferation processes (Fig. 9; Supplementary Data 2).
Fig. 9. Gene ontology analysis of the genes associated with top accelerated binding sites.

The dot plots show the significant GO terms after Bonferroni correction for biological process of (a) genes associated with top accelerated binding sites of FOXP2 (b) genes associated with top accelerated binding sites of all seven TFBS groups. The size of circle represents the number of genes associated with top accelerated binding sites affiliated with the specific GO terms. The color of circle represents the Bonferroni-corrected p-values.
In the genes associated with other accelerated TFBS groups, no pathways or biological terms were found to be significant after correction. Benjamini–Hochberg correction has been applied to the GO enrichment results. After Benjamini–Hochberg correction, developmental process terms were also enriched for the genes nearby the top accelerated binding sites among the seven groups (Supplementary Data 2).
Accelerated evolution in primates’ ChIP-seq peaks
To investigate the accelerated evolution in primates, we applied the GroupAcc method to datasets that were not human-centric, including non-human primates’ ChIP-seq peaks. Vermunt et al.59 identified histone H3 lysine 27 acetylation (H3K27ac) enriched regions in human, chimpanzee and rhesus macaque brain. The H3K27ac enriched regions were predicted to be active cis-regulatory elements(CREs), We applied the group-level LRT method to the predicted CREs in human, chimpanzee and rhesus macaque brain. Results revealed a slight increase in substitution rates of human and chimpanzee lineage in CREs of human and chimpanzee brain, compared to the fold of increase in substitution rate of rhesus macaque lineage in CREs of rhesus macaque brain.
Villar et al.60 identified trimethylated lysine 4 of histone H3 (H3K4me3) enriched regions and H3K27ac enriched regions in liver of 20 mammals including human and rhesus macaque. The regions were classified into active gene promoters and enhancers. Enhancers were identified by regions only enriched for H3K27ac, while promoters defined as regions containing both H3K27ac and H3K4me3. We applied the group-LRT method to the promoters and enhancers in human and rhesus macaque. Results showed that enhancers tended to evolve faster than promoters in both species.
To identify accelerated evolution in tissue-specific genetic regulatory elements, we applied the GroupAcc method to the most abundant TFBS group: CTCF binding sites. We included 80074 CTCF binding sites across 29 tissues or cell types61. We found lower leg skin and tibial nerve CTCF binding sites undergo weak accelerated evolution in human.
Discussion
In the current study, we present two pooling-based methods to infer genomic elements under accelerated evolution. Unlike previous methods that focus on analyzing individual elements7–15, our new methods group hundreds of genomic elements with similar biological functions to increase the sample size per test and reduce the multiple testing burden. Thus, our methods may have higher sensitivity to detect weak signals of accelerated evolution. To the best of our knowledge, our methods are the first statistical framework dedicated to inferring weakly accelerated evolution in non-coding regions.
Using the group-level LRT, we identify seven groups of non-overlapping TFBSs with significant evidence for accelerated evolution (Fig. 6). The model comparison analysis suggests that these TFBS groups may be under accelerated evolution not only in humans but also in other primate species (Fig. 7). In agreement with our finding, a recent study of HARs has shown that many HARs may also be subject to accelerated evolution in other ape species15. Therefore, accelerated evolution of regulatory elements may be a shared characteristic of primates rather than specific to the human lineage.
Among the seven groups of accelerated TFBSs, we show that Pol III binding sites may be subject to positive selection in the human lineage but find no evidence for positive selection in other accelerated TFBS groups (Fig. 8). In contrast, more than half of HARs may be subject to positive selection in the human lineage21, suggesting that positive selection may be the main driving force of accelerated evolution in HARs. Because previous studies of HARs have focused on identifying individual genomic elements with extremely high substitution rates in the human lineage, the higher frequency of detecting positive selection in HARs could partially reflect the lower power of previous methods in discovering weakly accelerated elements driven by evolutionary forces other than positive selection.
Although accelerated evolution is much weaker in Pol III binding sites than in HARs (Fig. 6), Pol III binding sites are subject to strong positive selection in the human lineage, on par with HARs (Fig. 8). Because HARs are highly conserved across species, they may have very low substitution rates in non-human primates, which in turn enhances the signals of accelerated evolution. In contrast, Pol III binding sites may not be highly conserved across species, resulting in a weaker signal of accelerated evolution despite strong positive selection in the foreground lineage. Taken together, weak signals of accelerated evolution may not always imply weak positive selection in the foreground lineage.
Other than lineage-specific positive selection, we find that nonadaptive evolutionary forces, such as relaxed purifying selection and GC-biased gene conversion, may drive the accelerated evolution of TFBSs21,55. GC-biased gene conversion has been found in NRF1 binding sites but not in other accelerated TFBS groups. The seven groups of accelerated TFBSs have reduced values of the fraction of sites under selection ρ in human comparing to the collection of 161 groups of TFBSs. Overall, the seven groups of TFBSs are under weaker selection constraints than other TFBSs. The widespread nonadaptive evolutionary forces do not indicate the lack of functional importance of those accelerated regions.
Notably, the seven groups of accelerated TFBSs may play key roles in developmental processes. First, recent studies suggest that disruptive mutations in subunits of Pol III, such as POLR3A, POLR3B and BRF1, may be associated with neurodevelopmental disorders62–64. Therefore, accelerated evolution in Pol III binding sites might be associated with the adaptive evolution of the central nervous system in apes and Old World monkeys (Fig. 7). Second, POU5F1 and NANOG are transcription factors necessary to the pluripotency and self-renewal of embryonic stem cells65–67. The colocalization of POU5F1 and NANOG in regulatory elements, referred to as POU5F1-NANOG binding in the current study, might trigger zygotic gene activation in vertebrates48,68–71. Third, FOXP2 is a highly conserved vertebrate protein with high expression in the central nervous systems during embryogenesis, and detrimental mutations in the FOXP2 gene may cause impaired speech development in humans72–74. Also, previous studies have shown that the protein sequence and expression of FOXP2 could be subject to accelerated evolution in humans75–77, echolocating bats78, and vocal learning birds79. Finally, NRF1 has been found to regulate the expression of GABRB1, a gene associated with neurological and neuropsychiatric disorders80,81. To summarize, the collection of seven TFBS groups may be functionally related to developmental processes. Specifically, when compared with a background gene list containing all the genes associated with the collection of seven TFBS groups, developmental process terms were enriched for the genes nearby the top accelerated binding sites among the seven groups (Fig. 9). Therefore, among the collection, the binding sites with strongest signals of accelerated evolution might be more crucial to the developmental processes. Together with the fact that a large proportion of HARs are neural enhancers and subject to accelerated evolution in humans and other primates19–21, we conclude that regulatory sequences of neurodevelopmental genes may be the main target of accelerated evolution in primates.
Due to the scarcity of ChIP-seq data in non-human primates, we have used human-based TFBS annotations to infer accelerated evolution. It may limit our ability to detect accelerated evolution present in non-human primates but not in humans. Thus, our estimate of the number of accelerated TFBSs is likely to be conservative (Table 1). In future studies, it is of great interest to investigate accelerated evolution in TFBSs identified in non-human primates, highlighting the urgent need to perform high-throughput functional genomic experiments in our close relatives.
Compared to conserved genomic elements explored in previous studies of HARs, TFBSs may have a higher evolutionary turnover rate30–33,38,39. To alleviate the impact of evolutionary turnover on our analysis, we have only included primate genomes in the current study and filtered out low-quality alignments. Nevertheless, a small proportion of TFBSs identified in the human genome may still be subject to evolutionary turnover in other primates39. We expect that the evolutionary turnover of TFBSs in non-human primates may not lead to false positive results in our analysis. Indeed, conditional on the presence of a TFBS in the human genome, the evolutionary turnover of the TFBS in non-human primates is more likely to increase the substitution rate in the background lineage and hence makes our analysis conservative. Moreover, conditional on the loss of an old binding site in the human genome, the sequences would not be annotated as TFBSs in the human genome. Given that we used human genome annotation, those regions functional in background lineages but not in humans were not included in our analysis. Once ChIP-seq data become available in multiple non-human primates in the future, the conservativeness of our analysis may be alleviated by including only species where the TFBS of interest is detected.
Our pooling-based methods have a potential to be extended in future studies. For instance, if multiple TFBSs overlap with each other, our current methods cannot distinguish between TFBSs directly under accelerated evolution from those overlapping other accelerated TFBSs. To address this problem, we have used a heuristic method to remove overlapping TFBSs in the current study, which may reduce the number of TFBSs in our analysis. In the future, it is of great interest to develop a rigorous method for inferring accelerated evolution in overlapping TFBSs. Motivated by the recent success of evolution-based regression models34,82–84, we propose that unifying our pooling-based methods and generalized linear models may be a promising direction to disentangle causal from correlational relationships in the analysis of accelerated evolution.
Methods
Genome alignment and TFBS annotation
We obtained the Multiz alignment of 46 vertebrate genomes from the UCSC Genome Browser46. Then, we extracted a subset of alignments for ten primate species from the 46-way Multiz alignment. The ten primate species and their genome assemblies included Homo Sapiens (hg19), Pan troglodytes (panTro2), Gorilla gorilla (gorGor1), Pongo abelii (ponAbe2), Macaca mulatta (rheMac2), Papio hamadryas (papHam1), Callithrix jacchus (calJac1), Tarsius syrichta (tarSyr1), Microcebus murinus (micMur1), and Otolemur garnettii (otoGar1). Also, we downloaded 4,380,444 TFBSs for 161 transcription factors from the UCSC Genome Browser. These TFBSs were identified by ChIP-seq experiments in the ENCODE Project45. We extracted alignments of TFBSs across ten primate species using PHAST85. We removed the TFBSs overlapping with UTRs, CDSs, and previously identified HARs. To filter out low-quality alignments, we obtained informative alignment sites where unambiguous bases were found in at least five out of ten primate species in the Multiz alignment. We retained TFBSs with at least 50 informative alignment sites for downstream analysis.
Previously defined HARs collection
We obtained a comprehensive list of previously defined HARs from https://docpollard.org/research/. We first combined the following genetic elements: Merged list of 2649 HARs(a set of HARs in noncoding regions built by Capra et al.17), 284 human accelerated elements in mammal conserved regions with adjusted p-value <0.05 (mapped to hg19 using the LiftOver tools on the UCSC genome browser), and 760 human accelerated elements in primate conserved regions with adjusted p-value <0.05 (mapped to hg19 using the LiftOver tools on the UCSC genome browser). Then we sorted and merged the bed file using bedtools/2.27.1.
Group-level LRT for inferring accelerated evolution
We built a reference phylogenetic model using the alignment of ten primate genomes, assuming that the majority of TFBSs may not be subject to accelerated evolution. We first concatenated alignments of all TFBSs. We then fit a phylogenetic model to the concatenated alignment using the phangorn library in R86. In the phylogenetic model, we used the generalized time-reversible (GTR) substitution model to describe nucleotide sequence evolution and the discrete Gamma distribution with four rate categories to model substitution rate variation among nucleotide sites42. Also, we fixed the tree topology of the reference phylogenetic model to the one used from the UCSC Genome Browser (http://hgdownload.cse.ucsc.edu/goldenPath/hg19/multiz46way/46way.nh). We estimated model parameters, including branch lengths, the shape parameter of the discrete Gamma distribution, and parameters of the GTR substitution model, using the optim.pml function in phangorn.
Given the reference phylogenetic model, we used a customized R program based on phangorn to perform the group-level LRT. First, we concatenated alignments for each TFBS group separately. Then, we fit two group-level phylogenetic models to the concatenated alignment of each TFBS group. In the null model (H0), we inferred a global scaling factor of branch lengths with maximum likelihood estimation and fixed all other model parameters to the ones in the reference phylogenetic model. We interpreted the estimated scaling factor as the relative substitution rate of TFBS sequences in both the foreground and the background lineage. In the alternative model (Ha), we estimated two scaling factors of branch lengths, r1 and r2, for the foreground and background lineages, respectively. The two scaling factors were interpreted as the relative substitution rates in the foreground and background lineages in the alternative model. For each TFBS group, we calculated a likelihood ratio statistic defined as the two-fold difference in the log likelihood between Ha and H0. Given the likelihood ratio statistic, we obtained a p-value for each TFBS group using a chi-square test with one degree of freedom. Finally, we calculated adjusted p-values using the Bonferroni correction.
From the group-level LRT, we found that TFBSs of 15 transcription factors showed elevated substitution rates in the human lineage. We further partitioned the TFBSs of the 15 transcription factors into 17 non-overlapping TFBS groups. These non-overlapping TFBS groups included genomic regions exclusively bound by one of the 15 transcription factors and two new TFBS groups: Pol III binding and POU5F1-NANOG binding. The Pol III binding group consisted of TFBSs bound by at least two of BDP1, BRF1, and POLR3G. Similarly, the group of POU5F1-NANOG binding consisted of TFBSs bound by both POU5F1 and NANOG. Then, we applied the group-level LRT again to the 17 non-overlapping TFBS groups and calculated adjusted p-values using the Bonferroni correction.
Estimation of the number of TFBSs under accelerated evolution
We utilized the R program for the group-level LRT to perform the element-level LRT. To this end, we applied the phangorn package in R language86,87 to the alignment of each individual TFBS separately, after filtering out TFBSs with less than 50 informative alignment sites. Then, we performed parametric bootstrapping at the group level to calculate a p-value for each TFBS. Specifically, we first fit the H0 in the group-level LRT to the concatenated alignment of each TFBS group, which provided a global scaling factor to calibrate the branch lengths of the reference phylogenetic model. Second, we randomly sampled 10,000 TFBSs with replacement from each TFBS group and used the calibrated phylogenetic model to generate 10,000 simulated alignments of matched length. Third, we fit the element-level LRT to the simulated TFBS alignments from the same group, which provided an empirical null distribution of the likelihood ratio statistic for each TFBS group. Fourth, we compared the observed likelihood ratio statistic to the empirical null distribution to calculate a p-value for each TFBS. Finally, we fit a beta-uniform mixture model with probability density function (PDF)
| 1 |
to p-values from each TFBS group44. We considered a statistic, , from the beta-uniform mixture model as the upper bound of proportion or binding site without acceleration and, accordingly, as the lower bound of proportion of accelerated TFBSs.
| 2 |
To build 95% confidence interval for , we first searched for all values of λ⋆ and a⋆, such that
| 3 |
The 95% confidence interval for was calculated by combinations of λ⋆ and a⋆ which fell into the confidence interval.
| 4 |
Simulations
We generated eight cases in which different lineages of primates were under accelerated evolution: (1) only human, (2) subtree of all the hominini(human, chimp), (3) subtree of human, chimp, gorilla, (4) subtree of all the apes(human, chimp, gorilla, orangutan), (5) only chimp, (6) only groilla, (7) only orangutan, (8) only macaque. For each case, folds of increase in substitution rates of accelerated lineage span from 1.2 to 5. We generated 10,000 ten-sequence alignments based on the reference model plus those assumptions. Each alignment is 200 bp long, which is the median length in TFBS data. We then compared the performance of our GroupAcc methods and traditional element-level LRT methods in detecting lineage-specific acceleration. Group-level LRT method and Phylogenetics-based mixture model were described in the former two sections. Traditional element-level LRT was implemented via the R program for the group-level LRT followed with Bonferroni correction to the p-values.
In scenario 1, we generated 10,000 200 bp alignments upon reference model and a scaled tree with increased branch length in lineages of each case. First, we applied the group-level LRT and phylogenetics-based mixture model to the simulated alignments, taking the accelerated lineage listed in each case (1–8) as foreground lineage, respectively. We compared the estimated fold of increase in substitution rate in foreground lineage with the scaling factor of the phylogenetic tree in simulation setting. We also compared the estimated number of elements under accelerated evolution from phylogenetics-based mixture model and element-level LRT methods. Second, the same methods were used with human as foreground lineage for all the cases. Cases 1–4 were designed to test the sensitivity of the methods to identify accelerated evolution when the foreground lineage (human) is truly under accelerated evolution. Cases 5–8 were designed to test the specificity of the methods when the foreground lineage (human) is mis-specified and not under accelerated evolution. We then compared the estimated fold of increase in substitution rate in foreground lineage with the scaling factor of phylogenetic tree in simulation setting. We also compared the estimated number of elements under accelerated evolution from phylogenetics-based mixture model and element-level LRT methods.
The second scenario considered heterogeneity of evolutionary dynamics in each binding site: only parts of each binding site (L: portion of each binding site under accelerated evolution) were under accelerated evolution. We simulated 10,000 ten-sequence alignments representing 10,000 binding sites in one group, each binding site is 200 bp long (200 × L bp generated from a scaled tree with X-fold increase in branch length of the lineage shown in the cases, 200 − 200 × L bp generated from unscaled tree). We analyzed the data with our mixture model to see if our method could estimate the proportion of binding sites with accelerated evolution accurately. In addition, we tested with group-level LRT method to see if our methods could detect group-level signals and estimate the fold of increase in substitution rates when the acceleration only happens in specific positions or motifs.
The third scenario considered heterogeneity in groups of binding sites: only certain numbers of binding sites (M: proportion of binding sites in a group under accelerated evolution) in one group have accelerated evolution in a specific lineage, while the other binding sites do not have accelerated evolution. We simulated 10,000 elements in a group, 10,000 × M elements from a scaled tree, while 10,000 − 10,000 × M from unscaled tree. Each element is 200 bp long. We analyzed the data with our mixture model to see if our method can estimate the number of binding sites with accelerated evolution accurately. In addition, we tested with group-level LRT method to see if our methods can detect group-level signals and estimate the fold of increase in substitution rates when the acceleration only happens in parts of the binding sites in a group.
Reduction of redundancy in the 15 TFBS groups
From Group-level LRT, we found 15 groups of TFBSs with accelerated evolution in human. However, there is redundancy among the data possibly because the transcription factors share a considerable proportion of binding sites.
Some of the groups have similar biological functions, for example, BDP1, BRF1 and POLR3G are key factors in the Pol III transcription machinery; POU5F1 and NANOG are necessary regulators in ES cell pluripotency and self-renewal. To identify the evolutionary forces in the colocalization of transcription factors, we defined two new TFBS groups. The Pol III binding sites, were defined as the binding sites occupied by at least two out of the three transcription factors related to Pol III (BDP1, BRF1 and POLR3G). To define the POU5F1-NANOG binding, we obtained the intersecting regions of POU5F1 and NANOG binding sites.
To remove redundancy in overlapping binding sites, we then got the non-overlapping regions bound by merely BDP1, BRF1 or POLR3G. For each of the other 12 TFBS groups with accelerated evolution in human, we obtained the entries that don’t overlap with any of BDP1, BRF1, POLR3G or the rest 11 TFBS groups. Then we ran the group-level LRT again for the 15 non-overlapping TFBS groups and 2 newly-defined TFBS groups.
Inference of lineages with accelerated evolution
We utilized the alternative model (Ha) in the group-level LRT to search for lineages associated with accelerated evolution. To this end, we fit the group-level Ha with seven different foreground lineages to the concatenated alignment of each TFBS group (Fig. 7). The seven foreground lineages corresponded to all monophyletic clades that included humans. For each TFBS group and foreground lineage, we used the BIC as a measure of goodness-of-fit,
| 5 |
where l is the log likelihood of the group-level Ha, k is the number of model parameters, and n is the sample size. Because the group-level Ha included two parameters (r1 and r2), we set k to 2. Also, we assumed that n could be approximated by the total number of bases in the concatenated alignment of each TFBS group. For each TFBS group, we considered the foreground lineage with the highest BIC to be the best-fit lineage.
Detection of selection pressure and GC-biased gene conversion
To investigate if accelerated evolution in TFBSs was driven by positive selection, we used the INSIGHT model to infer positive selection on the seven accelerated, non-overlapping TFBS groups in the human lineage50–52. We obtained INSIGHT2, a highly efficient implementation of the INSIGHT model, from https://github.com/CshlSiepelLab/FitCons2. Then, we applied INSIGHT2 to each TFBS group under accelerated evolution and the collection of all TFBSs from ENCODE. INSIGHT2 provided Dp and SE[Dp], that is, the expected number of adaptive substitutions per kilobase and its standard error, as well as ρ and SE[ρ] which quantified the fraction of sites under selection within functional elements and its standard error. We performed the Wald test to examine if Dp was significantly different from 0 for each TFBS group. Under the null hypothesis of Dp = 0, we assumed that the z-statistic, , asymptotically followed a 50:50 mixture of a point probability mass at 0 and a half standard normal distribution88. We conducted comparisons of ρ among the seven accelerated TFBS groups and the collection of all TFBSs from ENCODE (Supplementary Table 2). To identify the role of GC-biased gene conversion in the accelerated evolution of the seven TFBS groups, we used the phastBias model to infer gene conversion disparity B in the lineage where accelerated evolution occurred, identical to the best-fit lineage found in model comparison (Fig. 7).
Functional enrichment analysis of accelerated TFBS associated genes
To investigate specific functions of the accelerated binding sites in each group, we performed functional enrichment analysis of the accelerated TFBS-associated genes. We first extracted the TFBSs with significant results in the phylogenetics-based mixture model and referred them to the top accelerated TFBSs. Then we identified the potential target genes of the seven TFBS groups as well as top accelerated bindings sites among the seven groups using GREAT with default settings. For each of the seven groups, we performed GO enrichment analysis using clusterProfiler on the genes associated with top accelerated binding sites, with the genes associated with the TFBS group, respectively, as background. Besides, we performed GO enrichment analysis on the genes associated with the concatenation of all the top accelerated binding sites across seven groups, with genes associated with all TFBSs as background, With the clusterProfiler package, the significance of enrichment test for GO terms under biology process subontology was estimated by hypergeometric distribution and then adjusted by Bonferroni correction. The redundant GO terms were trimmed by applying the simplify function to remove terms among which semantic similarities were higher than 0.7. Significant terms after Bonferroni correction were shown in the Fig. 9, while the complete list of significant GO biological process terms with corrected p-value <0.05 are available in the Supplementary Data 2. Benjamini–Hochberg correction was also used in to the GO results and the significant results are listed in Supplementary Data 2.
Primate ChIP-seq data
We obtained a list of histone H3 lysine 27 acetylation (H3K27ac) enriched regions in human, chimpanzee and rhesus macaque brain59 from NCBI GEO Series GSE67978. The H3K27ac enriched regions were predicted to be active cis-regulatory elements (CREs). Since hg19 has been the reference genome in Multiz alignment, the annotated regions were first mapped to hg19 using the LiftOver tools on the UCSC genome browser and then processed using bedtools/2.27.1. We extracted the alignments of those annotated regions from the Multiz alignment. We applied the group-level LRT method to the CREs in human brain with human as the foreground lineage, to the CREs in chimpanzee brain with chimpanzee as the foreground lineage and to the CREs in rhesus macaque brain with rhesus macaque as the foreground lineage.
We also obtained a list of trimethylated lysine 4 of histone H3 (H3K4me3) enriched regions and H3K27ac enriched regions in liver of 20 mammals including human and rhesus macaque60 (Accession E-MTAB-2633). The annotation of regions was first mapped to hg19 using the LiftOver tools on the UCSC genome browser. Then we sorted and merged the bed file using bedtools/2.27.1. The regions were classified into active gene promoters and enhancers. Enhancers were identified by regions only enriched for H3K27ac, while promoters defined as regions containing both H3K27ac and H3K4me3. We obtained the bed files of promoters and enhancers using intersect function in bedtools/2.27.1.
We obtained a list of CTCF tissue-specific binding sites61 and downloaded the annotated files from ENCODE.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Supplementary information
Description of Additional Supplementary Files
Acknowledgements
The authors thank Adam Siepel, Ilan Gronau, Zhihan Liu and Ritika Ramani for useful discussions. Research reported in this publication was supported by the National Institute of General Medical Sciences of the National Institutes of Health under Award Number R35GM142560 (to Y.H.), the Pennsylvania State University (to X.Z. and Y.H.) and a postdoctoral fellowship from the Harvard University (to B.F.). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Author contributions
Y.H. conceived of and supervised the project. X.Z. conducted all analyses with contributions from Y.H. and B.F. X.Z. and Y.H. wrote the manuscript. B.F. contributed to simulation analyses and visualization. All authors provided comments and revisions on drafts and approved the final paper.
Peer review
Peer review information
Nature Communications thanks Marc Robinson-Rechavi and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Data availability
Human TFBS annotation were downloaded from Txn Factor ChIP Track on UCSC genome browser. Primate alignments were extracted from Multiz alignment of 46 vertebrate genomes from the UCSC Genome Browser (http://hgdownload.cse.ucsc.edu/goldenPath/hg19/multiz46way/). Reference model built with concatenated alignments of all TFBSs was uploaded to https://github.com/May-BG/GroupAcc89. TFBS groups with accelerated evolution in primates were uploaded to the Github page. Previously defined HARs collection were downloaded from https://docpollard.org/research/. ChIP-seq data of primates’ brains were downloaded from NCBI GEO Series GSE67978 and Accession E-MTAB-2633. Human tissue-specific CTCF binding sites information were downloaded from ENCODE with the accession numbers from Supplementary Data 3.
Code availability
GroupAcc and companion data are available at https://github.com/May-BG/GroupAcc89.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Xinru Zhang, Email: xmz5176@psu.edu.
Yi-Fei Huang, Email: yuh371@psu.edu.
Supplementary information
The online version contains supplementary material available at 10.1038/s41467-023-36421-3.
References
- 1.Haygood R, Fedrigo O, Hanson B, Yokoyama K-D, Wray GA. Promoter regions of many neural- and nutrition-related genes have experienced positive selection during human evolution. Nat. Genet. 2007;39:1140. doi: 10.1038/ng2104. [DOI] [PubMed] [Google Scholar]
- 2.Kosiol C, et al. Patterns of positive selection in six mammalian genomes. PLoS Genet. 2008;4:e1000144. doi: 10.1371/journal.pgen.1000144. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Sackton TB, et al. Convergent regulatory evolution and loss of flight in paleognathous birds. Science. 2019;364:74–78. doi: 10.1126/science.aat7244. [DOI] [PubMed] [Google Scholar]
- 4.Zhao S, et al. Identifying lineage-specific targets of natural selection by a bayesian analysis of genomic polymorphisms and divergence from multiple species. Mol. Biol. Evol. 2019;36:1302–1315. doi: 10.1093/molbev/msz046. [DOI] [PubMed] [Google Scholar]
- 5.Clark AG, et al. Inferring nonneutral evolution from human-chimp-mouse orthologous gene trios. Science. 2003;302:1960–1963. doi: 10.1126/science.1088821. [DOI] [PubMed] [Google Scholar]
- 6.Dorus S, et al. Accelerated evolution of nervous system genes in the origin of Homo sapiens. Cell. 2004;119:1027–1040. doi: 10.1016/j.cell.2004.11.040. [DOI] [PubMed] [Google Scholar]
- 7.Prabhakar S, Noonan JP, Pääbo S, Rubin EM. Accelerated evolution of conserved noncoding sequences in humans. Science. 2006;314:786–786. doi: 10.1126/science.1130738. [DOI] [PubMed] [Google Scholar]
- 8.Pollard KS, et al. An RNA gene expressed during cortical development evolved rapidly in humans. Nature. 2006;443:167–172. doi: 10.1038/nature05113. [DOI] [PubMed] [Google Scholar]
- 9.Pollard KS, et al. Forces shaping the fastest evolving regions in the human genome. PLoS Genet. 2006;2:e168. doi: 10.1371/journal.pgen.0020168. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Kim SY, Pritchard JK. Adaptive evolution of conserved noncoding elements in mammals. PLoS Genet. 2007;3:e147. doi: 10.1371/journal.pgen.0030147. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Bird CP, et al. Fast-evolving noncoding sequences in the human genome. Genome Biol. 2007;8:R118. doi: 10.1186/gb-2007-8-6-r118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Bush EC, Lahn BT. A genome-wide screen for noncoding elements important in primate evolution. BMC Evol. Biol. 2008;8:17. doi: 10.1186/1471-2148-8-17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Lindblad-Toh K, et al. A high-resolution map of human evolutionary constraint using 29 mammals. Nature. 2011;478:476–482. doi: 10.1038/nature10530. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Gittelman RM, et al. Comprehensive identification and analysis of human accelerated regulatory DNA. Genome Res. 2015;25:1245–1255. doi: 10.1101/gr.192591.115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Kostka D, Holloway AK, Pollard KS. Developmental loci harbor clusters of accelerated regions that evolved independently in ape lineages. Mol. Biol. Evol. 2018;35:2034–2045. doi: 10.1093/molbev/msy109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Prabhakar S, et al. Human-specific gain of function in a developmental enhancer. Science. 2008;321:1346–1350. doi: 10.1126/science.1159974. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Capra JA, Erwin GD, Gabriel M, Rubenstein JLR, Pollard KS. Many human accelerated regions are developmental enhancers. Phil. Trans. Royal Soc. B: Biol. Sci. 2013;368:20130025. doi: 10.1098/rstb.2013.0025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Kamm GB, Pisciottano F, Kliger R, Franchini LF. The developmental brain gene npas3 contains the largest number of accelerated regulatory sequences in the human genome. Mol. Biol. Evol. 2013;30:1088–1102. doi: 10.1093/molbev/mst023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Whalen, S. et al. Machine learning dissection of human accelerated regions in primate neurodevelopment. Neuron. 10.1016/j.neuron.2022.12.026 (2023). [DOI] [PMC free article] [PubMed]
- 20.Uebbing S, et al. Massively parallel discovery of human-specific substitutions that alter enhancer activity. Proc. Natl Acad. Sci. USA. 2021;118:e2007049118. doi: 10.1073/pnas.2007049118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Kostka D, Hubisz MJ, Siepel A, Pollard KS. The role of GC-biased gene conversion in shaping the fastest evolving regions of the human genome. Mol. Biol. Evol. 2012;29:1047–1057. doi: 10.1093/molbev/msr279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Xu K, Schadt EE, Pollard KS, Roussos P, Dudley JT. Genomic and network patterns of schizophrenia genetic variation in human evolutionary accelerated regions. Mol. Biol. Evol. 2015;32:1148–1160. doi: 10.1093/molbev/msv031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Doan RN, et al. Mutations in human accelerated regions disrupt cognition and social behavior. Cell. 2016;167:341–354. doi: 10.1016/j.cell.2016.08.071. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Levchenko A, Kanapin A, Samsonova A, Gainetdinov RR. Human accelerated regions and other human-specific sequence variations in the context of evolution and their relevance for brain development. Genome Biol. Evol. 2018;10:166–188. doi: 10.1093/gbe/evx240. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Wei Y, et al. Genetic mapping and evolutionary analysis of human-expanded cognitive networks. Nat. Commun. 2019;10:4839. doi: 10.1038/s41467-019-12764-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Castelijns B, et al. Hominin-specific regulatory elements selectively emerged in oligodendrocytes and are disrupted in autism patients. Nat. Commun. 2020;11:301. doi: 10.1038/s41467-019-14269-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Booker BM, et al. Bat accelerated regions identify a bat forelimb specific enhancer in the hoxd locus. PLoS Genet. 2016;12:1–21. doi: 10.1371/journal.pgen.1005738. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Eckalbar WL, et al. Transcriptomic and epigenomic characterization of the developing bat wing. Nat. Genet. 2016;48:528–536. doi: 10.1038/ng.3537. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Tollis M, et al. Elephant genomes reveal accelerated evolution in mechanisms underlying disease defenses. Mol. Biol.Evol. 2021;38:3606–3620. doi: 10.1093/molbev/msab127. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Dermitzakis ET, Clark AG. Evolution of transcription factor binding sites in mammalian gene regulatory regions: conservation and turnover. Mol. Biol. Evol. 2002;19:1114–1121. doi: 10.1093/oxfordjournals.molbev.a004169. [DOI] [PubMed] [Google Scholar]
- 31.Moses AM, et al. Large-scale turnover of functional transcription factor binding sites in drosophila. PLoS Comput. Biol. 2006;2:e130. doi: 10.1371/journal.pcbi.0020130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Doniger SW, Fay JC. Frequent gain and loss of functional transcription factor binding sites. PLoS Comput. Biol. 2007;3:e99. doi: 10.1371/journal.pcbi.0030099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Schmidt D, et al. Five-vertebrate ChIP-seq reveals the evolutionary dynamics of transcription factor binding. Science. 2010;328:1036–1040. doi: 10.1126/science.1186176. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Dukler N, Huang Y-F, Siepel A. Phylogenetic modeling of regulatory element turnover based on epigenomic data. Mol. Biol. Evol. 2020;37:2137–2152. doi: 10.1093/molbev/msaa073. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Wittkopp PJ, Kalay G. Cis-regulatory elements: molecular mechanisms and evolutionary processes underlying divergence. Nat. Rev. Genet. 2012;13:59–69. doi: 10.1038/nrg3095. [DOI] [PubMed] [Google Scholar]
- 36.Siepel A, Arbiza L. Cis-regulatory elements and human evolution. Curr. Opin. Genet. Dev. 2014;29:81–89. doi: 10.1016/j.gde.2014.08.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Villar D, Flicek P, Odom DT. Evolution of transcription factor binding in metazoans: mechanisms and functional implications. Nat. Rev. Genet. 2014;15:221–233. doi: 10.1038/nrg3481. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Rands CM, Meader S, Ponting CP, Lunter G. 8.2% of the human genome is constrained: variation in rates of turnover across functional element classes in the human lineage. PLoS Genet. 2014;10:e1004525. doi: 10.1371/journal.pgen.1004525. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Yokoyama KD, Zhang Y, Ma J. Tracing the evolution of lineage-specific transcription factor binding sites in a birth-death framework. PLoS Comput. Biol. 2014;10:e1003771. doi: 10.1371/journal.pcbi.1003771. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Finucane HK, et al. Partitioning heritability by functional annotation using genome-wide association summary statistics. Nat. Genet. 2015;47:1228–1235. doi: 10.1038/ng.3404. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Johnson DS, Mortazavi A, Myers RM, Wold B. Genome-wide mapping of in vivo protein-DNA interactions. Science. 2007;316:1497–1502. doi: 10.1126/science.1141319. [DOI] [PubMed] [Google Scholar]
- 42.Yang Z. Maximum likelihood phylogenetic estimation from DNA sequences with variable rates over sites: approximate methods. J. Mol. Evol. 1994;39:306–314. doi: 10.1007/BF00160154. [DOI] [PubMed] [Google Scholar]
- 43.Tavaré S. Some probabilistic and statistical problems in the analysis of dna sequences. Lectures Math. Life Sci. 1986;17:57–86. [Google Scholar]
- 44.Pounds S, Morris SW. Estimating the occurrence of false positives and false negatives in microarray studies by approximating and partitioning the empirical distribution of p-values. Bioinformatics. 2003;19:1236–1242. doi: 10.1093/bioinformatics/btg148. [DOI] [PubMed] [Google Scholar]
- 45.ENCODE Project Consortium. An integrated encyclopedia of DNA elements in the human genome. Nature. 2012;489:57–74. doi: 10.1038/nature11247. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Navarro Gonzalez J, et al. The UCSC Genome Browser database: 2021 update. Nucleic Acids Res. 2021;49:D1046–D1057. doi: 10.1093/nar/gkaa1070. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.White RJ. Transcription by RNA polymerase III: more complex than we thought. Nat. Rev. Genet. 2011;12:459–463. doi: 10.1038/nrg3001. [DOI] [PubMed] [Google Scholar]
- 48.Boyer LA, et al. Core transcriptional regulatory circuitry in human embryonic stem cells. Cell. 2005;122:947–956. doi: 10.1016/j.cell.2005.08.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Liang J, et al. Nanog and Oct4 associate with unique transcriptional repression complexes in embryonic stem cells. Nat. Cell Biol. 2008;10:731–739. doi: 10.1038/ncb1736. [DOI] [PubMed] [Google Scholar]
- 50.Arbiza L, et al. Genome-wide inference of natural selection on human transcription factor binding sites. Nat. Genet. 2013;45:723–729. doi: 10.1038/ng.2658. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Gronau I, Arbiza L, Mohammed J, Siepel A. Inference of natural selection from interspersed genomic elements based on polymorphism and divergence. Mol. Biol. Evol. 2013;30:1159–1171. doi: 10.1093/molbev/mst019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Gulko B, Siepel A. An evolutionary framework for measuring epigenomic information and estimating cell-type-specific fitness consequences. Nat. Genet. 2019;51:335–342. doi: 10.1038/s41588-018-0300-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.McDonald JH, Kreitman M. Adaptive protein evolution at the Adh locus in drosophila. Nature. 1991;351:652–654. doi: 10.1038/351652a0. [DOI] [PubMed] [Google Scholar]
- 54.Smith NGC, Eyre-Walker A. Adaptive protein evolution in Drosophila. Nature. 2002;415:1022–1024. doi: 10.1038/4151022a. [DOI] [PubMed] [Google Scholar]
- 55.Capra JA, Hubisz MJ, Kostka D, Pollard KS, Siepel A. A model-based analysis of GC-biased gene conversion in the human and chimpanzee genomes. PLoS Genet. 2013;9:e1003684. doi: 10.1371/journal.pgen.1003684. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.McLean CY, et al. Human-specific loss of regulatory DNA and the evolution of human-specific traits. Nature. 2011;471:216. doi: 10.1038/nature09774. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Yu G, Wang L-G, Han Y, He Q-Y. clusterprofiler: an r package for comparing biological themes among gene clusters. Omics: J. Integrative Biol. 2012;16:284–287. doi: 10.1089/omi.2011.0118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Yu G, He Q-Y. Reactomepa: an r/bioconductor package for reactome pathway analysis and visualization. Mol. BioSystems. 2016;12:477–479. doi: 10.1039/C5MB00663E. [DOI] [PubMed] [Google Scholar]
- 59.Vermunt MW, et al. Epigenomic annotation of gene regulatory alterations during evolution of the primate brain. Nat. Neurosci. 2016;19:494–503. doi: 10.1038/nn.4229. [DOI] [PubMed] [Google Scholar]
- 60.Villar D, et al. Enhancer evolution across 20 mammalian species. Cell. 2015;160:554–566. doi: 10.1016/j.cell.2015.01.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Liu J, Robinson-Rechavi M. Robust inference of positive selection on regulatory sequences in the human brain. Sci. Adv. 2020;6:eabc9863. doi: 10.1126/sciadv.abc9863. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Bernard G, et al. Mutations of POLR3A encoding a catalytic subunit of rna polymerase pol iii cause a recessive hypomyelinating leukodystrophy. Am. J. Human Genet. 2011;89:415–423. doi: 10.1016/j.ajhg.2011.07.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Saitsu H, et al. Mutations in POLR3A and POLR3B encoding rna polymerase iii subunits cause an autosomal-recessive hypomyelinating leukoencephalopathy. Am. J. Human Genet. 2011;89:644–651. doi: 10.1016/j.ajhg.2011.10.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Borck G, et al. BRF1 mutations alter RNA polymerase III-dependent transcription and cause neurodevelopmental anomalies. Genome Res. 2015;25:155–66. doi: 10.1101/gr.176925.114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Chew J-L, et al. Reciprocal transcriptional regulation of Pou5f1 and Sox2 via the Oct4/Sox2 complex in embryonic stem cells. Mol. Cell. Biol. 2005;25:6031–6046. doi: 10.1128/MCB.25.14.6031-6046.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Loh Y-H, et al. The Oct4 and Nanog transcription network regulates pluripotency in mouse embryonic stem cells. Nat. Genet. 2006;38:431–440. doi: 10.1038/ng1760. [DOI] [PubMed] [Google Scholar]
- 67.Lee MT, et al. Nanog, Pou5f1 and SoxB1 activate zygotic gene expression during the maternal-to-zygotic transition. Nature. 2013;503:360–364. doi: 10.1038/nature12632. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Sharov AA, et al. Identification of Pou5f1, Sox2, and Nanog downstream target genes with statistical confidence by applying a novel algorithm to time course microarray and genome-wide chromatin immunoprecipitation data. BMC Genom. 2008;9:269. doi: 10.1186/1471-2164-9-269. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Leichsenring M, Maes J, Mössner R, Driever W, Onichtchouk D. Pou5f1 transcription factor controls zygotic gene activation in vertebrates. Science. 2013;341:1005–1009. doi: 10.1126/science.1242527. [DOI] [PubMed] [Google Scholar]
- 70.Wang J, et al. A protein interaction network for pluripotency of embryonic stem cells. Nature. 2006;444:364–368. doi: 10.1038/nature05284. [DOI] [PubMed] [Google Scholar]
- 71.Rodda DJ, et al. Transcriptional regulation of Nanog by OCT4 and SOX2. J. Biol. Chem. 2005;280:24731–24737. doi: 10.1074/jbc.M502573200. [DOI] [PubMed] [Google Scholar]
- 72.Lai CS, Fisher SE, Hurst JA, Vargha-Khadem F, Monaco AP. A forkhead-domain gene is mutated in a severe speech and language disorder. Nature. 2001;413:519–523. doi: 10.1038/35097076. [DOI] [PubMed] [Google Scholar]
- 73.Fisher SE, Scharff C. FOXP2 as a molecular window into speech and language. Trends Genet. 2009;25:166–177. doi: 10.1016/j.tig.2009.03.002. [DOI] [PubMed] [Google Scholar]
- 74.Vernes SC, et al. Foxp2 regulates gene networks implicated in neurite outgrowth in the developing brain. PLoS Genet. 2011;7:e1002145. doi: 10.1371/journal.pgen.1002145. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Zhang J, Webb DM, Podlaha O. Accelerated protein evolution and origins of human-specific features: Foxp2 as an example. Genetics. 2002;162:1825–1835. doi: 10.1093/genetics/162.4.1825. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Enard W, et al. Molecular evolution of FOXP2, a gene involved in speech and language. Nature. 2002;418:869–872. doi: 10.1038/nature01025. [DOI] [PubMed] [Google Scholar]
- 77.Atkinson EG, et al. No evidence for recent selection at FOXP2 among diverse human populations. Cell. 2018;174:1424–1435.e15. doi: 10.1016/j.cell.2018.06.048. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Li G, Wang J, Rossiter SJ, Jones G, Zhang S. Accelerated FoxP2 evolution in echolocating bats. PLoS One. 2007;2:1–10. doi: 10.1371/journal.pone.0000900. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Cahill JA, et al. Positive selection in noncoding genomic regions of vocal learning birds is associated with genes implicated in vocal learning and speech functions in humans. Genome Res. 2021;31:2035–2049. doi: 10.1101/gr.275989.121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Li Z, Cogswell M, Hixson K, Brooks-Kayal AR, Russek SJ. Nuclear respiratory factor 1 (NRF-1) controls the activity dependent transcription of the GABA-a receptor beta 1 subunit gene in neurons. Front. Mol. Neurosci. 2018;11:285. doi: 10.3389/fnmol.2018.00285. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Biswas M, Chan JY. Role of Nrf1 in antioxidant response element-mediated gene expression and beyond. Toxicol. Appl. Pharmacol. 2010;244:16–20. doi: 10.1016/j.taap.2009.07.034. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Meyer AG, Wilke CO. Integrating sequence variation and protein structure to identify sites under selection. Mol. Biol. Evol. 2013;30:36–44. doi: 10.1093/molbev/mss217. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Meyer AG, Dawson ET, Wilke CO. Cross-species comparison of site-specific evolutionary-rate variation in influenza haemagglutinin. Phil. Trans. R. Soc. B: Biol. Sci. 2013;368:20120334. doi: 10.1098/rstb.2012.0334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Huang Y-F. Dissecting genomic determinants of positive selection with an evolution-guided regression model. Mol. Biol. Evol. 2022;39:msab291. doi: 10.1093/molbev/msab291. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Hubisz MJ, Pollard KS, Siepel A. PHAST and RPHAST: phylogenetic analysis with space/time models. Brief. Bioinformat. 2011;12:41–51. doi: 10.1093/bib/bbq072. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Schliep KP. phangorn: phylogenetic analysis in R. Bioinformatics. 2011;27:592–593. doi: 10.1093/bioinformatics/btq706. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/ (2022).
- 88.Cheng, R. Non-Standard Parametric Statistical Inference (Oxford University Press, 2017).
- 89.Xinru, Z. & Yifei, H. Transcription factor binding sites are frequently under accelerated evolution in primates. 10.5281/zenodo.7535878. May-BG/GroupAcc: v1.0.0. (2023). [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Description of Additional Supplementary Files
Data Availability Statement
Human TFBS annotation were downloaded from Txn Factor ChIP Track on UCSC genome browser. Primate alignments were extracted from Multiz alignment of 46 vertebrate genomes from the UCSC Genome Browser (http://hgdownload.cse.ucsc.edu/goldenPath/hg19/multiz46way/). Reference model built with concatenated alignments of all TFBSs was uploaded to https://github.com/May-BG/GroupAcc89. TFBS groups with accelerated evolution in primates were uploaded to the Github page. Previously defined HARs collection were downloaded from https://docpollard.org/research/. ChIP-seq data of primates’ brains were downloaded from NCBI GEO Series GSE67978 and Accession E-MTAB-2633. Human tissue-specific CTCF binding sites information were downloaded from ENCODE with the accession numbers from Supplementary Data 3.
GroupAcc and companion data are available at https://github.com/May-BG/GroupAcc89.