

Abstract
针对临床上重症疾病样本数量少容易导致预后模型过拟合、预测误差大、不稳定的问题,本文提出迁移长短时程记忆算法(transLSTM)。该算法基于迁移学习思想,利用疾病间的相关性实现不同疾病预后模型的信息迁移,借助相关疾病的大数据辅助构建小样本目标病种有效模型,提升模型预测性能,降低对目标训练样本量的要求。transLSTM 算法先利用相关疾病数据预训练部分模型参数,再用目标训练样本进一步调整整个网络。基于 MIMIC-Ⅲ数据库的测试结果显示,相比传统的 LSTM 分类算法,transLSTM 算法的 AUROC 指标高出 0.02~0.07,AUPRC 指标超过 0.05~0.14,训练迭代次数仅为传统算法的 39%~64%。应用于脓毒症疾病的结果显示,仅 100 个训练样本的 transLSTM 模型死亡率预测性能与 250 个训练样本的传统模型相当。在小样本情况下,transLSTM 算法预测精度更高、训练速度更快,具有显著优势。它实现了迁移学习在小样本重症疾病预后模型中的应用。
Keywords: 重症疾病, 预后模型, 小样本, 长短时程记忆, 迁移学习
Abstract
Aiming at the problem that the small samples of critical disease in clinic may lead to prognostic models with poor performance of overfitting, large prediction error and instability, the long short-term memory transferring algorithm (transLSTM) was proposed. Based on the idea of transfer learning, the algorithm leverages the correlation between diseases to transfer information of different disease prognostic models, constructs the effictive model of target disease of small samples with the aid of large data of related diseases, hence improves the prediction performance and reduces the requirement for target training sample quantity. The transLSTM algorithm firstly uses the related disease samples to pretrain partial model parameters, and then further adjusts the whole network with the target training samples. The testing results on MIMIC-Ⅲ database showed that compared with traditional LSTM classification algorithm, the transLSTM algorithm had 0.02-0.07 higher AUROC and 0.05-0.14 larger AUPRC, while its number of training iterations was only 39%-64% of the traditional algorithm. The results of application on sepsis revealed that the transLSTM model of only 100 training samples had comparable mortality prediction performance to the traditional model of 250 training samples. In small sample situations, the transLSTM algorithm has significant advantages with higher prediciton accuracy and faster training speed. It realizes the application of transfer learning in the prognostic model of critical disease with small samples.
Keywords: critical disease, prognostic model, small samples, long short-term memory, transfer learning
引言
随着信息技术的高速发展和医院信息系统的日益普及,大量临床资料得以电子化存储和高效使用。基于患者临床数据利用机器学习技术建立的临床预测模型,能够为医生评估病情和确定治疗管理方案提供决策支持。对于持续监测的患者生理指标构成的临床时间序列数据,长短时程记忆(long short-term memory,LSTM)算法[1]能够捕捉其中的变化趋势信息,近年来在医学上的研究和应用进展迅速[2-12]。Lipton 等[3]基于 10 401 份儿童病例,建立了 128 种疾病诊断的 LSTM 模型,能够判断患者是否患急性呼吸窘迫、充血性心力衰竭和肾衰竭等疾病。Harutyunyan 等[6]利用 42 276 份病例的时间序列数据,设计了基于 LSTM 的多目标学习模型,实现了多个临床最终事件的预测功能。Baytas 等[9]提出能适应不规则采样时间间隔的 LSTM 网络,以提取患者特性,实现了患者的聚类分组。Reddy 等[12]针对狼疮患者构建了 LSTM 模型,以准确预测其 30 天再入院概率。
大部分医学领域的 LSTM 应用都是基于大量临床样本,但对于单病种,尤其是重症疾病,其样本量往往比较少。样本量不足会导致 LSTM 模型过拟合、预测误差大、不稳定,甚至难以构建多层复杂 LSTM 模型。因此,目前 LSTM 算法在单病种、少样本量临床预测模型的应用中受到了严重制约。
大样本临床数据所获得的知识能解决小样本量疾病应用中数据稀缺的问题,而迁移学习为疾病间的信息迁移提供了一种技术框架。传统机器学习是基于目标领域数据训练出目标模型,它要求目标领域有足够数量的样本才能保证模型的准确性和可靠性;而迁移学习是利用多个领域间的相关性,将源领域数据中学习到的知识迁移至目标领域以辅助目标模型的训练,通过源领域知识和目标领域数据相结合的方式,降低模型对目标领域样本量的需求[13-16]。目前,迁移学习在计算机视觉、自然语言、推荐系统等领域的应用都取得了显著进展[13-22]。计算机视觉领域,迁移学习被广泛应用于目标识别、图像分类和人体动作识别等场景;自然语言领域,迁移学习成功应用于情感分类、垃圾邮件检测和多语言文本分类等任务;迁移学习还应用于推荐系统,例如新上映电影的个性化推送。
迁移学习可利用大样本量所获得的知识解决小样本量应用中数据稀缺、知识稀缺等瓶颈问题[23],在目标领域样本采集困难而相关领域样本数量大的情况下具有显著优势,因此可应用于小样本的重症疾病预后模型。但目前相关研究较为缺乏,一系列关键技术还有待探索。
本文提出基于迁移学习框架的迁移长短时程记忆算法(long short-term memory transferring algorithm,transLSTM),利用不同疾病之间的相关性,通过多病种重症监护室(intensive care unit,ICU)大数据集的信息迁移辅助有限样本特定疾病预后模型的构建。该算法采取基于模型的迁移策略,运用微调[24]技术以实现预后模型间的信息迁移。首先基于源领域疾病的数据集建立预后模型原型,再传递模型框架及部分模型参数,最后用目标疾病的数据集对所有模型参数进行调整以转换成目标疾病预后模型。
1. 迁移长短时程记忆算法
本文选用 ICU 中多病种的时序数据集为源领域,某种重症疾病为目标领域。源任务与目标任务是预测患者进入 ICU 第 28 天的生存状态,以评价疾病严重程度。transLSTM 算法首先基于相关疾病数据集(记为 sourceData)训练出预后模型的原型,再根据原型对目标疾病预后模型的部分参数进行初始化,最后用目标疾病数据集(记为 targetData)对模型参数进行细微调整,从而得到目标模型。
假设 sourceData 中有 N1 个样本,第 i 个样本为
 。其中 Ai 包含该样本 T 个时刻 D 个临床指标的数值,可表示为
。其中 Ai 包含该样本 T 个时刻 D 个临床指标的数值,可表示为

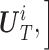 。
。
 包含 D 个临床指标的数值,可表示为
包含 D 个临床指标的数值,可表示为
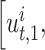
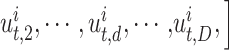 。第 i 个样本的目标标签
。第 i 个样本的目标标签
 ,取值 0 代表 28 天生存,取值 1 则代表 28 天内死亡。假设 targetData 中有 N2 个训练样本,第 i 个样本为
,取值 0 代表 28 天生存,取值 1 则代表 28 天内死亡。假设 targetData 中有 N2 个训练样本,第 i 个样本为
 。其中 Bi 的数据结构与 sourceData 中的 Ai 相同,包含该样本 T 个时刻 D 个临床指标的数值,可表示为
。其中 Bi 的数据结构与 sourceData 中的 Ai 相同,包含该样本 T 个时刻 D 个临床指标的数值,可表示为

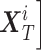 。
。
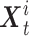 可表示为
可表示为
 。与 sourceData 中的 yi 含义一样,zi 代表该样本的 28 天生存状况,取值 0 是生存,取值 1 则是死亡。
。与 sourceData 中的 yi 含义一样,zi 代表该样本的 28 天生存状况,取值 0 是生存,取值 1 则是死亡。
transLSTM 算法的训练过程包括两个环节:
(1)基于 sourceData 构建预后模型的原型:预后模型的结构由 LSTM 隐藏层和 Sigmoid 输出层两个部分构成。LSTM 模块的结构如图1 所示,预后模型的结构如图2 所示。
图 1.

Structure diagram of LSTM block
LSTM 模块结构示意图
图 2.

Structure diagram of the prognosis model
预后模型结构示意图
LSTM 模块的输入为 Ut,即第 t 个时刻的 sourceData。通过式(1)~(4)依次计算遗忘门 ft、输入门 it、输出门 ot 以及当下时刻的细胞记忆值 Ct。
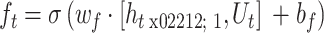 |
1 |
 |
2 |
 |
3 |
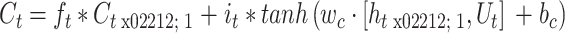 |
4 |
式(1)~(4)中,权重 wf、wi、wo、wc 和偏置 bf、bi、bo、bc 是可训练的模型参数,ht − 1 是上一个时刻的隐藏层状态。式(4)中,Ct − 1 代表上一个时刻的细胞记忆值。符号 σ 代表 Sigmoid 函数,符号 tanh 代表 hyperbolic tangent 函数。符号·代表矩阵乘法(matrix multiplication),而符号 * 代表元素积(element-wise product)。
再根据式 (5) 计算第 t 个时刻的隐藏层状态 ht。
 |
5 |
Sigmoid 输出层对 LSTM 模块最后时刻的隐藏层状态 hT 进行处理以输出二分类结果
 。
。
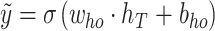 |
6 |
式中,who 和 bho 是基于 sourceData 预训练模型时输出层的权重和偏置参数。
损失函数是真实标签 y 与预测值
 的交叉熵。随机初始化所有参数,并以最小化损失函数为优化目标对所有参数进行调整。通过多次迭代优化,得到最小的损失值及相应参数值。
的交叉熵。随机初始化所有参数,并以最小化损失函数为优化目标对所有参数进行调整。通过多次迭代优化,得到最小的损失值及相应参数值。
(2)基于 targetData 转换成目标疾病预后模型:该环节中,LSTM 模块的输入是 targetData 第 t 个时刻的数据 Xt。通过式 (7)~(11) 计算第 t 个时刻的隐藏层状态
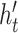 。
。
 |
7 |
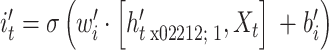 |
8 |
 |
9 |
 |
10 |
 |
11 |
式(7)~(10)中,权重
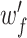 、
、
 、
、
 、
、
 和偏置
和偏置
 、
、
 、
、
 、
、
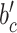 是可训练的模型参数。
是可训练的模型参数。
接着对 LSTM 模块最后一个时刻的隐藏层状态
 进行处理,得到目标模型的预测值
进行处理,得到目标模型的预测值
 。
。
 |
12 |
式中,
 和
和
 是 targetData 训练目标模型时输出层的权重和偏置参数。
是 targetData 训练目标模型时输出层的权重和偏置参数。
损失函数是真实标签 z 与预测值
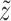 的交叉熵。根据预后模型原型对 LSTM 模块参数进行初始化,同时随机初始化 Sigmoid 输出层,再以最小化损失函数为优化目标调整所有参数。通过多次迭代优化,得到最小损失值及最优目标模型参数值。
的交叉熵。根据预后模型原型对 LSTM 模块参数进行初始化,同时随机初始化 Sigmoid 输出层,再以最小化损失函数为优化目标调整所有参数。通过多次迭代优化,得到最小损失值及最优目标模型参数值。
图3 给出了 transLSTM 算法的完整训练过程。
图 3.

Traning procedure of transLSTM algorithm
transLSTM 算法的训练过程
transLSTM 算法训练具体操作流程如下:
1)参照图2 设置 LSTM 预后分类模型的结构。
2)初始化模型参数。权重参数采用 Glorot 均匀初始化方法,LSTM 遗忘门的偏置参数初始值设为 1[25],其余偏置参数初始值均设置为 0。
3)用 sourceData 训练出模型的原型。
for j=1:max_epochs
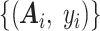 输入模型计算损失函数值 loss
输入模型计算损失函数值 loss
通过 BPTT 更新一次模型参数
if (j < max_epochs) and (loss 没有持续下降)
break;# 跳出循环,即 early stopping
end
end
4)再次初始化模型参数。复制步骤 3)训练完毕得到的参数终值作为 LSTM 隐藏层参数初始值,Sigmoid 输出层的权重参数采用 Glorot 均匀初始化,偏置参数初始值设为 0。
5)用 targetData 样本微调模型。
for j=1:max_epochs
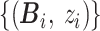 输入模型计算损失函数值 loss
输入模型计算损失函数值 loss
通过 BPTT 更新一次模型参数
if (j < max_epochs) and (loss 没有持续下降)
break;# 跳出循环,即 early stopping
end
end
2. 算法验证
2.1. 实验方案
为了评估 transLSTM 算法的性能,本文开展了两个阶段的测试:第一阶段基于公开的 ICU 数据库 MIMIC-Ⅲ[26]进行多个疾病组的测试;第二阶段将其应用于常见的重症疾病——脓毒症,验证算法的实际效果。
第一阶段,transLSTM 模型的目标是通过患者入院后连续 7 天的 50 个常用临床指标数值,判断患者是否生存超过 28 天。首先提取 MIMIC-Ⅲ数据库中住院不少于 7 天的 28 743 份病例,再根据病例的第一诊断疾病的国际疾病分类(International Classification of Diseases,ICD)[27]编码,将病例归类成若干疾病组。为了保证模型的可靠性,本研究选择 28 天生存病例数量和非生存病例数量都大于 50 的疾病组作为目标领域,相应疾病组的病例作为 targetData,而数据库中其他病例组合成为 sourceData。符合条件的共有 7 个疾病组,其基本情况见表1。这些疾病组依次作为目标领域,形成 7 个目标领域,由此构成 7 组不同的数据组织和模型测试方案:第 1 组测试中,非 A 组病例作为 sourceData 训练出模型原型,接着 A 组病例作为 targetData 对参数进行微调以确定 A 疾病的预后模型;第 2 组测试中,作为 sourceData 的非 B 组病例训练得到模型原型,作为 targetData 的 B 组病例再确定 B 疾病的预后模型;以此类推。采用 20 次重复实验。每次实验从 targetData 中随机抽取 90% 作为训练集,剩下 10% 作为测试集。
表 1. Overview of disease groups.
各疾病组情况概览
| 组别 | ICD-9 编码 | 疾病类型 | 生存组病例数量 | 非生存组病例数量 |
| A | 001~139 | 传染病和寄生虫疾病(Infectious and Parasitic Diseases) | 2 107 | 538 |
| B | 140~239 | 赘生物(Neoplasms) | 2 173 | 371 |
| C | 390~459 | 循环系统疾病(Circulatory System) | 9 404 | 787 |
| D | 460~519 | 呼吸系统疾病(Respiratory System) | 2 300 | 486 |
| E | 520~579 | 消化系统疾病(Digestive System) | 2 711 | 334 |
| F | 580~629 | 泌尿生殖系统疾病(Genitourinary System) | 470 | 84 |
| G | 800~999 | 受伤及中毒(Injury and Poisoning) | 4 110 | 427 |
第二阶段,transLSTM 模型的目标是通过脓毒症患者入院后连续 7 天的若干预后指标数值,预测脓毒症患者入院后是否生存超过 28 天。脓毒症是感染引起的全身炎症反应综合征,具有病情凶险、死亡率高的特点,是 ICU 中常见的一种重症疾病[28]。其预后指标包括体温、心率、呼吸频率、收缩压、平均动脉压(mean arterial pressure,MAP)、空腹血糖、谷草转氨酶(aspartate aminotransferase,AST)、谷丙转氨酶(alanine aminotransferase,ALT)、总胆红素、白蛋白、血尿素氮(blood urea nitrogen,BUN)、肌酐(creatinine,Cr)、K+、Na+、Cl−、白细胞、血红蛋白、血细胞比容、Plt、pH、PaCO2、PaO2、BE、动脉 FiO2、PaO2/FiO2 和血乳酸。临床上,脓毒症多由循环系统、呼吸系统、消化系统和泌尿生殖系统的感染引起,而且身患脓毒症时,代表循环系统的心率增加、MAP 下降,代表呼吸系统的呼吸频率增加、PaO2/FiO2 下降,代表消化系统的胆红素增加、AST 和 ALT 升高,而代表泌尿生殖系统的 BUN 和 Cr 升高、尿量减少。综上所述,循环系统、呼吸系统、消化系统和泌尿生殖系统都与脓毒症存在相关性,可作为该阶段 transLSTM 模型的源领域。
“严重脓毒症/脓毒性休克早期预警体系研究”项目纳入 2013 年 10 月至 2015 年 9 月浙江医院 ICU 严重脓毒症/脓毒性休克的成年患者( ≥ 18 岁),共 497 例。脓毒症诊断符合 2012“拯救脓毒症运动”(Surviving Sepsis Campaign,SSC)指南的脓毒症诊断标准[29]。该项目通过医院的医学伦理委员会审核,得到所有患者的知情同意。为了验证模型的临床应用效果,以上述 497 份脓毒症病例样本集为 targetData,并将 MIMIC-Ⅲ数据库中住院至少 7 天且第一诊断疾病属于脓毒症相关系统疾病的 16 576 份病例作为 sourceData。采用 20 次重复实验。为了评估训练样本数量对算法的影响,每次实验从 497 份脓毒症病例中选取 40% 样本作为测试集,从其余样本中随机选取 50、100、150、200、250 个样本作为训练集。
此外,为了分析更大数量目标训练样本对算法的影响,本研究从 MIMIC-Ⅲ数据库中提取住院至少 7 天的病例,其中 4 442 份脓毒症(ICD-9 编码前三位为“038”)病例作为 targetData,非脓毒症而第一诊断疾病属于脓毒症相关系统疾病的病例作为 sourceData,进行实验。从这 4 442 份脓毒症样本中选取 30% 样本作为测试集,其余样本中选取 200、400、600、800、1 000、1 500、2 000、2 500、3 000 个样本作为训练集。
2.2. 评估设置
本文提出的 transLSTM 算法与传统 LSTM 算法(仅用 targetData 训练 LSTM 模型的方法,记为 targetLSTM)进行比较。为了评估算法的预测精度,根据测试集的预测结果计算并比较两种算法的 ROC 曲线下面积(area under ROC curve,AUROC)、precision-recall 曲线下面积(area under precision-recall curve,AUPRC)、灵敏度、特异度及正确率指标。同时,通过迭代次数评估算法的计算效率。
算法超参数设置为:LSTM 模块的神经元个数为 64,学习率为 0.001,最大迭代次数为 100,采用 AdamOptimizer 优化器。
所有实验在配置为 NVIDIA GeForce GTX 1080Ti GPU 以及 i7-6700 CPU、8G RAM 的计算机上用 Python 3.6 编程实现。在 Tensorflow1.7 平台上设计模型网络结构并实现迭代优化。
3. 测试结果
3.1. 基于 MIMIC-Ⅲ数据库的测试结果
基于 MIMIC-Ⅲ数据库所有疾病组的测试结果列于表2 中。A~G 组测试中,transLSTM 的 AUROC 值比 targetLSTM 分别高 0.03、0.04、0.02、0.04、0.03、0.07、0.03,其 AUPRC 值比 targetLSTM 分别高 0.05、0.06、0.05、0.07、0.06、0.14、0.08。transLSTM 算法在 C 组、D 组、E 组、F 组、G 组测试中的灵敏度、特异度、正确率都明显优于 targetLSTM 算法;而 A 组测试中,相比 targetLSTM 算法,transLSTM 的灵敏度更高,特异度、正确率与之接近;B 组测试中,transLSTM 算法的灵敏度、正确率高于 targetLSTM,两个算法的特异度相近。采用 LSTM 流行变体——门控循环单元(gated recurrent unit,GRU)[30]为预后模型隐藏层模块时,非迁移算法 targetLSTM(G) 和迁移算法 transLSTM(G) 比较具有类似的结果。所有疾病组测试中,相比非迁移的 targetLSTM(G) 模型,迁移模型 transLSTM(G) 均取得更高的 AUROC 值和 AUPRC 值。
表 2. Testing results based on MIMIC-Ⅲ cases.
基于 MIMIC-Ⅲ病例的测试结果
| 组别 | AUROC
(mean ± std) |
AUPRC
(mean ± std) |
灵敏度
(mean ± std) |
特异度
(mean ± std) |
正确率
(mean ± std) |
| 注:targetLSTM 和 transLSTM 算法采用经典 LSTM 结构,targetLSTM(G) 和 transLSTM(G) 算法采用 LSTM 的流行变体 GRU | |||||
| A 组 | |||||
| targetLSTM 算法 | 0.806 8 ± 0.029 6 | 0.559 4 ± 0.065 0 | 0.697 6 ± 0.060 2 | 0.777 6 ± 0.029 6 | 0.760 6 ± 0.022 3 |
| transLSTM 算法 | 0.834 3 ± 0.025 9 | 0.604 7 ± 0.049 1 | 0.753 0 ± 0.056 3 | 0.762 0 ± 0.029 6 | 0.760 2 ± 0.025 0 |
| targetLSTM(G) 算法 | 0.815 4 ± 0.030 0 | 0.569 8 ± 0.066 5 | 0.713 0 ± 0.063 6 | 0.777 6 ± 0.033 6 | 0.763 8 ± 0.027 3 |
| transLSTM(G) 算法 | 0.838 7 ± 0.026 0 | 0.609 6 ± 0.060 4 | 0.778 3 ± 0.052 0 | 0.766 1 ± 0.037 8 | 0.768 9 ± 0.031 0 |
| B 组 | |||||
| targetLSTM 算法 | 0.805 7 ± 0.036 8 | 0.470 7 ± 0.065 7 | 0.663 0 ± 0.060 2 | 0.785 5 ± 0.032 9 | 0.766 7 ± 0.028 0 |
| transLSTM 算法 | 0.842 9 ± 0.033 1 | 0.531 0 ± 0.072 3 | 0.720 9 ± 0.090 1 | 0.785 1 ± 0.030 4 | 0.774 9 ± 0.026 0 |
| targetLSTM(G) 算法 | 0.822 4 ± 0.042 4 | 0.484 1 ± 0.080 4 | 0.699 0 ± 0.077 2 | 0.774 0 ± 0.037 8 | 0.762 4 ± 0.028 5 |
| transLSTM(G) 算法 | 0.842 5 ± 0.034 4 | 0.526 3 ± 0.087 8 | 0.741 1 ± 0.080 5 | 0.775 1 ± 0.033 1 | 0.769 6 ± 0.028 5 |
| C 组 | |||||
| targetLSTM 算法 | 0.845 0 ± 0.015 9 | 0.365 1 ± 0.051 5 | 0.717 8 ± 0.043 7 | 0.797 8 ± 0.019 9 | 0.791 6 ± 0.017 2 |
| transLSTM 算法 | 0.860 9 ± 0.019 3 | 0.412 8 ± 0.061 4 | 0.759 3 ± 0.052 8 | 0.801 4 ± 0.016 9 | 0.798 2 ± 0.014 9 |
| targetLSTM(G) 算法 | 0.852 8 ± 0.017 4 | 0.380 8 ± 0.053 4 | 0.721 5 ± 0.059 9 | 0.804 9 ± 0.023 2 | 0.798 4 ± 0.018 6 |
| transLSTM(G) 算法 | 0.865 0 ± 0.019 7 | 0.424 5 ± 0.056 8 | 0.760 5 ± 0.059 7 | 0.806 0 ± 0.019 2 | 0.802 5 ± 0.016 0 |
| D 组 | |||||
| targetLSTM 算法 | 0.755 0 ± 0.030 2 | 0.422 2 ± 0.070 0 | 0.629 3 ± 0.055 6 | 0.740 6 ± 0.033 7 | 0.721 0 ± 0.028 7 |
| transLSTM 算法 | 0.793 6 ± 0.034 5 | 0.494 3 ± 0.057 8 | 0.692 2 ± 0.080 6 | 0.742 5 ± 0.037 8 | 0.733 2 ± 0.030 9 |
| targetLSTM(G) 算法 | 0.772 4 ± 0.032 9 | 0.436 5 ± 0.058 5 | 0.666 8 ± 0.080 9 | 0.743 9 ± 0.027 8 | 0.730 3 ± 0.022 8 |
| transLSTM(G) 算法 | 0.793 6 ± 0.036 5 | 0.493 1 ± 0.062 7 | 0.698 3 ± 0.071 6 | 0.742 3 ± 0.030 5 | 0.734 4 ± 0.025 4 |
| E 组 | |||||
| targetLSTM 算法 | 0.820 6 ± 0.037 9 | 0.444 7 ± 0.090 5 | 0.676 6 ± 0.085 3 | 0.813 0 ± 0.029 6 | 0.799 2 ± 0.025 2 |
| transLSTM 算法 | 0.850 6 ± 0.032 1 | 0.504 2 ± 0.092 8 | 0.722 0 ± 0.091 5 | 0.822 8 ± 0.034 3 | 0.812 3 ± 0.025 1 |
| targetLSTM(G) 算法 | 0.826 9 ± 0.036 7 | 0.444 2 ± 0.087 5 | 0.675 3 ± 0.088 2 | 0.812 9 ± 0.035 3 | 0.798 7 ± 0.028 2 |
| transLSTM(G) 算法 | 0.851 5 ± 0.032 4 | 0.509 0 ± 0.095 6 | 0.729 3 ± 0.077 3 | 0.815 5 ± 0.035 5 | 0.806 4 ± 0.027 5 |
| F 组 | |||||
| targetLSTM 算法 | 0.756 9 ± 0.120 6 | 0.438 9 ± 0.170 0 | 0.556 0 ± 0.195 9 | 0.786 9 ± 0.083 5 | 0.750 9 ± 0.078 5 |
| transLSTM 算法 | 0.824 4 ± 0.070 4 | 0.579 1 ± 0.168 4 | 0.646 7 ± 0.190 9 | 0.829 9 ± 0.065 9 | 0.801 8 ± 0.047 2 |
| targetLSTM(G) 算法 | 0.776 2 ± 0.109 7 | 0.463 2 ± 0.153 9 | 0.618 2 ± 0.131 1 | 0.792 6 ± 0.097 6 | 0.767 0 ± 0.091 5 |
| transLSTM(G) 算法 | 0.841 3 ± 0.060 2 | 0.598 3 ± 0.174 4 | 0.709 2 ± 0.162 5 | 0.814 8 ± 0.060 5 | 0.799 1 ± 0.047 5 |
| G 组 | |||||
| targetLSTM 算法 | 0.829 8 ± 0.018 0 | 0.393 5 ± 0.070 2 | 0.699 1 ± 0.052 2 | 0.800 8 ± 0.025 8 | 0.790 6 ± 0.020 8 |
| transLSTM 算法 | 0.861 7 ± 0.018 9 | 0.468 7 ± 0.073 2 | 0.747 5 ± 0.059 3 | 0.807 9 ± 0.022 6 | 0.801 5 ± 0.016 9 |
| targetLSTM(G) 算法 | 0.838 8 ± 0.022 6 | 0.397 0 ± 0.070 5 | 0.734 0 ± 0.059 4 | 0.803 8 ± 0.026 9 | 0.796 8 ± 0.021 8 |
| transLSTM(G) 算法 | 0.866 8 ± 0.017 1 | 0.473 1 ± 0.054 3 | 0.766 3 ± 0.054 2 | 0.806 6 ± 0.021 5 | 0.802 6 ± 0.015 9 |
A~G 组的多次重复实验平均迭代次数列于表3 中。从表中看到,A~G 组测试中,transLSTM 的迭代次数都比 targetLSTM 少,分别是 targetLSTM 迭代次数的 48%、47%、56%、45%、56%、64%、39%。采用 GRU 为预后模型隐藏层模块的 targetLSTM(G) 和 transLSTM(G) 算法的迭代次数呈现出类似的差异。所有疾病组测试中,相比非迁移的 targetLSTM(G) 模型,迁移模型 transLSTM(G) 均具有更少的迭代次数。
表 3. Number of model iterations for different disease groups.
不同疾病组的模型迭代次数
| 组别 | targetLSTM | transLSTM | targetLSTM(G) | transLSTM(G) |
| A 组 | 46.3 ± 10.0 | 22.4 ± 8.5 | 51.9 ± 12.4 | 20.2 ± 9.6 |
| B 组 | 43.1 ± 10.8 | 20.4 ± 5.9 | 53.1 ± 9.9 | 19.8 ± 7.5 |
| C 组 | 57.1 ± 7.7 | 32.2 ± 8.1 | 64.6 ± 7.8 | 33.5 ± 13.5 |
| D 组 | 40.2 ± 8.7 | 17.9 ± 7.9 | 49.4 ± 10.7 | 16.4 ± 9.9 |
| E 组 | 43.4 ± 8.5 | 24.5 ± 8.6 | 51.9 ± 9.5 | 24.0 ± 9.8 |
| F 组 | 27.7 ± 12.4 | 17.7 ± 9.5 | 29.8 ± 13.7 | 17.7 ± 9.0 |
| G 组 | 45.8 ± 11.3 | 18.0 ± 8.6 | 50.8 ± 10.6 | 18.4 ± 9.1 |
3.2. 应用于脓毒症疾病的死亡率预测结果
从图4 看到,以脓毒症项目的脓毒症样本集为目标数据集时,随着目标训练样本数量的增加,targetLSTM 算法和 transLSTM 算法预测脓毒症患者 28 天生存状态的 AUROC 值都不断上升。50~250 个目标训练样本时,transLSTM 算法的 AUROC 始终高于 targetLSTM。50 个目标样本得到的 transLSTM 模型的 AUROC 指标优于 200 个目标样本训练出的 targetLSTM 模型;采用 100 个目标样本的 transLSTM 算法可达到 250 个目标样本 targetLSTM 模型的分类效果。同时,targetLSTM(G) 算法和 transLSTM(G) 算法的对比结果与上述结果类似。
图 4.

AUROC values of the two algorithms with different sample numbers (sepsis sample source: sepsis project)
两种算法不同样本数量的 AUROC(脓毒症样本来源: 脓毒症项目)
从图5 看到,以 MIMIC-Ⅲ数据库脓毒症样本集为目标数据集时,随着目标训练样本数量的增加,targetLSTM 和 transLSTM 算法的 AUROC 都不断上升。200~2 000 个训练样本时,transLSTM 算法的 AUROC 值大幅超过 targetLSTM:200 个目标样本得到的 transLSTM 模型的 AUROC 值可达到 800 个目标样本训练出的 targetLSTM 模型的水平;transLSTM 模型仅需 600 个目标样本即可达到 2 000 个目标样本 targetLSTM 模型的分类效果。而目标训练样本数量上升至 2 500 个及以上时,两个模型的 AUROC 值十分接近。同时,targetLSTM(G) 算法和 transLSTM(G) 算法的对比结果与上述结果类似。
图 5.

AUROC values of the two algorithms with different sample numbers (sepsis sample source: MIMIC-Ⅲ)
两种算法不同样本数量的 AUROC(脓毒症样本来源: MIMIC-Ⅲ)
为了进一步分析 transLSTM 算法的有效性,本文还观察了图5 对应的模型训练过程中的参数变化范围。对于 targetLSTM 算法和 transLSTM 算法,其迭代过程中 LSTM 层参数初始值与终值之差的绝对值记为 target_range 和 trans_range。将 target_range 减去 trans_range,取均值得到 mean_delta_range。由图6 看到,目标训练样本数量为 200~3 000 时,mean_delta_range 都为正值,即 target_range > trans_range。说明不管目标训练样本数量多少,相比 targetLSTM 模型,迁移模型 transLSTM 的模型参数调整范围总是更小。这与 transLSTM 算法中微调方式设计的初衷完全相符。
图 6.

Values of mean_delta_range with various numbers of target training samples
不同数量目标训练样本的 mean_delta_range
4. 讨论
由表2 可知,在 MIMIC-Ⅲ数据库 A~G 组的测试中,transLSTM 算法的 AUROC、AUPRC 指标均优于 targetLSTM,其 AUROC 指标比 targetLSTM 算法高出 0.02~0.07,其 AUPRC 指标超过 targetLSTM 算法 0.05~0.14。以上数据表明 transLSTM 算法的泛化性好,该算法在 ICU 临床预后方面具有性能优势,能够为治疗管理决策提供更有效的辅助工具。通过表3 可知,在 A~G 组测试中,transLSTM 算法的迭代次数仅为 targetLSTM 迭代次数的 39%~64%,说明其训练速度更快。在脓毒症疾病的应用中,仅 100 个训练样本的 transLSTM 模型预测精度与 250 个训练样本的 targetLSTM 模型相当(见图4),600 个训练样本的 transLSTM 模型预测精度与 2 000 个训练样本的 targetLSTM 相当(见图5)。为了获取相同的预测性能,transLSTM 所需要的脓毒症样本数量远小于 targetLSTM,说明 transLSTM 算法能够降低对目标样本数量的要求。综上所述,相比传统的 targetLSTM 算法,基于迁移学习框架的 transLSTM 算法具有预测精度更高和训练速度更快的优点,且对目标样本数量的要求更低。
transLSTM 模型的优势可从两方面进行理解:① 源领域疾病与目标领域疾病虽是样本概率分布不同的两类疾病,但同属 ICU 疾病,其临床指标的数值高低和变化趋势与患者身体状况的对应关系是一致的,说明源领域与目标领域之间具有相关性,因此能够保证迁移学习的有效性;② transLSTM 算法通过源领域数据为目标模型的训练提供了一个比随机初始化更合理的起始点,所以能够以更少的迭代次数(见表3)和更小的模型参数调整范围(见图6)逼近最优值。
VC 维是用于评价算法复杂度的指标[31],样本量/VC 维 < 20 代表样本量不足 [32-34]。根据实践规律,算法 VC 维与算法中能够自由变动的参数数量大约相等,因此本文预后模型的 VC 维≈预后模型的参数数量 > LSTM 层参数数量 = ((64 + 26)*64 + 64)*4 = 23 296。若仅靠脓毒症项目中的 497 个脓毒症样本建立预后模型,则样本量/VC 维 < 497/23 296 = 0.021,远小于 20,说明样本量是严重不足的。若采用迁移学习框架的 transLSTM 模型,则模型中随机初始化的参数数量为 65。因 497/65 = 7.65,比 0.021 有大幅提高,所以 transLSTM 能够解决单病种样本量少导致模型过拟合、预测误差大的问题。
5. 结语
本文针对重症疾病样本数量少容易导致预后模型过拟合的问题,提出了基于迁移学习框架的迁移长短时程记忆算法 transLSTM。目前缺乏迁移学习应用于小样本重症疾病预测的相关研究。transLSTM 算法采用微调技术实现不同疾病预后模型的信息迁移,借助相关疾病大数据辅助构建小样本目标病种有效模型。它利用相关疾病样本预训练部分模型参数,再用目标疾病样本进一步调整网络以转换成目标模型。基于 MIMIC-Ⅲ数据库测试以及应用于脓毒症疾病的结果表明,相比传统的 targetLSTM 模型,基于迁移框架的 transLSTM 模型具有更高的预测精度和更快的训练速度,取得相同预测性能所需的样本量更少。迁移模型 transLSTM 为构建有限样本的临床预测模型提供了一种行之有效的思路,有望推动今后小样本疾病预测模型的技术发展和应用拓展。
利益冲突声明:本文全体作者均声明不存在利益冲突。
Funding Statement
国家自然科学基金(81871454,31870938)
References
- 1.Hochreiter S, Schmidhuber J Long short-term memory. Neural Comput. 1997;9(8):1735–1780. doi: 10.1162/neco.1997.9.8.1735. [DOI] [PubMed] [Google Scholar]
- 2.Miotto R, Wang Fei, Wang Shuang, et al Deep learning for healthcare: review, opportunities and challenges. Brief Bioinform. 2018;19(6):1236–1246. doi: 10.1093/bib/bbx044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Lipton Z C, Kale D C, Elkan C, et al. Learning to diagnose with LSTM recurrent neural networks. arXiv: 1511.03677.
- 4.Che Z, Purushotham S, Khemani R, et al. Interpretable deep models for ICU outcome prediction//AMIA Annual Symposium Proceedings. Chicago: American Medical Informatics Association, 2016: 371-380.
- 5.Jo Y, Lee L, Palaskar S. Combining LSTM and latent topic modeling for mortality prediction. arXiv: 1709.02842.
- 6.Harutyunyan H, Khachatrian H, Kale D C, et al. Multitask learning and benchmarking with clinical time series data. arXiv: 1703.07771.
- 7.Purushotham S, Meng C, Che Zhengping, et al. Benchmark of deep learning models on large healthcare MIMIC datasets. arXiv: 1710.08531.
- 8.Pham T, Tran T, Phung D, et al. Deepcare: A deep dynamic memory model for predictive medicine//Bailey J, Khan L, Washio T, et al. Advances in knowledge discovery and data mining. PAKDD 2016. Cham: Springer, 2016, 9652: 30-41.
- 9.Baytas I M, Xiao Cao, Zhang Xi, et al. Patient subtyping via time-aware LSTM networks//Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Canada: ACM, 2017: 65-74.
- 10.Van Steenkiste T, Ruyssinck J, De Baets L, et al Accurate prediction of blood culture outcome in the intensive care unit using long short-term memory neural networks. Artif Intell Med. 2019;97:38–43. doi: 10.1016/j.artmed.2018.10.008. [DOI] [PubMed] [Google Scholar]
- 11.Suresh H, Gong J J, Guttag J V. Learning tasks for multitask learning: Heterogenous patient populations in the ICU// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. London: ACM, 2018: 802-810.
- 12.Reddy B K, Delen D Predicting hospital readmission for lupus patients: An RNN-LSTM-based deep-learning methodology. Comput Biol Med. 2018;101:199–209. doi: 10.1016/j.compbiomed.2018.08.029. [DOI] [PubMed] [Google Scholar]
- 13.Pan S J, Yang Qiang A survey on transfer learning. IEEE Trans Knowl Data Eng. 2010;22(10):1345–1359. doi: 10.1109/TKDE.2009.191. [DOI] [Google Scholar]
- 14.Weiss K, Khoshgoftaar T M, Wang D A survey of transfer learning. J Big Data. 2016;3(1):9. doi: 10.1186/s40537-016-0043-6. [DOI] [Google Scholar]
- 15.庄福振. 迁移学习中文本分类算法研究. 北京: 中国科学院大学, 2011.
- 16.戴文渊. 基于实例和特征的迁移学习算法研究. 上海: 上海交通大学, 2009.
- 17.Shao Ling, Zhu Fan, Li Xuelong Transfer learning for visual categorization: a survey. IEEE Trans Neural Netw Learn Syst. 2015;26(5):1019–1034. doi: 10.1109/TNNLS.2014.2330900. [DOI] [PubMed] [Google Scholar]
- 18.Cheplygina V, Pena I P, Pedersen J H, et al Transfer learning for multi-center classification of chronic obstructive pulmonary disease. IEEE J Biomed Health Inform. 2018;22(5):1486–1496. doi: 10.1109/JBHI.2017.2769800. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Paul R, Hawkins S H, Balagurunathan Y, et al Deep feature transfer learning in combination with traditional features predicts survival among patients with lung adenocarcinoma. Tomography. 2016;2(4):388–395. doi: 10.18383/j.tom.2016.00211. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Pan Weike A survey of transfer learning for collaborative recommendation with auxiliary data. Neurocomputing. 2016;177:447–453. doi: 10.1016/j.neucom.2015.11.059. [DOI] [Google Scholar]
- 21.Bianchi A, Raimondo Vendra M, Protopapas P, et al. Improving image classification robustness through selective CNN-filters fine-tuning. arXiv: 1904.03949.
- 22.Zhu Y, Zhuang F, Yang J, et al. Adaptively transfer category-classifier for handwritten chinese character recognition//Advances in Knowledge Discovery and Data Mining. Cham: Springer International Publishing, 2019: 110-122.
- 23.龙明盛. 迁移学习问题与方法研究. 北京: 清华大学, 2014.
- 24.Yosinski J, Clune J, Bengio Y, et al. How transferable are features in deep neural networks?//Ghahramani Z, Welling profile M, Cortes C, et al. Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014, 2: 3320-3328.
- 25.Jozefowicz R, Zaremba W, Sutskever I An empirical exploration of recurrent network architectures. Proceedings of Machine Learning Research. 2015;37:2342–2350. [Google Scholar]
- 26.Johnson A E W, Pollard T J, Shen Lu, et al MIMIC-Ⅲ, a freely accessible critical care database. Scientific Data. 2016;3:160035. doi: 10.1038/sdata.2016.35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.World Health Organization. ICD-10: International Statistical Classification of Diseases and Related Health Problems. Geneva: World Health Organization, 2004, 1.
- 28.Zhou Jianfang, Qian Chuanyun, Zhao Mingyan, et al Epidemiology and outcome of severe sepsis and septic shock in intensive care units in mainland China. PLoS One. 2014;9(9):e107181. doi: 10.1371/journal.pone.0107181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Dellinger R P, Levy M M, Rhodes A, et al Surviving sepsis campaign: international guidelines for management of severe sepsis and septic shock: 2012. Crit Care Med. 2013;41(2):580–637. doi: 10.1097/CCM.0b013e31827e83af. [DOI] [PubMed] [Google Scholar]
- 30.Cho K, Van Merrienboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv: 1406.1078.
- 31.Burges C C A tutorial on support vector machines for pattern recognition. Data Min Knowl Discov. 1998;2(2):121–167. doi: 10.1023/A:1009715923555. [DOI] [Google Scholar]
- 32.Lateh M A, Kamilah Muda A, Yusof Z I M, et al Handling a small dataset problem in prediction model by employ artificial data generation approach: A review. Journal of Physics: Conference Series. 2017;892(1):1–10. [Google Scholar]
- 33.Chao G Y, Tsai T I, Lu T J, et al A new approach to prediction of radiotherapy of bladder cancer cells in small dataset analysis. Expert Syst Appl. 2011;38(7):7963–7969. doi: 10.1016/j.eswa.2010.12.035. [DOI] [Google Scholar]
- 34.辛宪会, 叶秋果, 滕惠忠, 等 小样本机器学习算法的特性分析与应用. 海洋测绘. 2007;27(3):16–19. doi: 10.3969/j.issn.1671-3044.2007.03.005. [DOI] [Google Scholar]