

Abstract
针对糖尿病视网膜病变(DR)分级任务中不同种类之间差异性微小特点,提出一种基于跨层双线性池化(CHBP)的视网膜病变分级算法。首先根据霍夫圆变换(HCT)对输入图像进行裁剪,再使用预处理方法提升图像对比度;然后以挤压激励分组残差网络(SEResNeXt)作为模型的主干,引入跨层双线性池化模块进行分类;最后在训练过程中引入随机拼图生成器进行渐进训练,并采用中心损失(CL)和焦点损失(FL)方法进一步提升最终分类效果。实验结果显示,本文方法在印度糖尿病视网膜病变图像数据集(IDRiD)中二次加权卡帕系数(QWK)为90.84%,在梅西多数据集(Messidor-2)中受试者工作特征曲线下的面积(AUC)为88.54%。实验证明,本文提出的算法在糖尿病视网膜病变分级领域具有一定应用价值。
Keywords: 跨层双线性池化, 视网膜病变分级, 随机拼图生成器, 渐进训练, 中心损失
Abstract
Considering the small differences between different types in the diabetic retinopathy (DR) grading task, a retinopathy grading algorithm based on cross-layer bilinear pooling is proposed. Firstly, the input image is cropped according to the Hough circle transform (HCT), and then the image contrast is improved by the preprocessing method; then the squeeze excitation group residual network (SEResNeXt) is used as the backbone of the model, and a cross-layer bilinear pooling module is introduced for classification. Finally, a random puzzle generator is introduced in the training process for progressive training, and the center loss (CL) and focal loss (FL) methods are used to further improve the effect of the final classification. The quadratic weighted Kappa (QWK) is 90.84% in the Indian Diabetic Retinopathy Image Dataset (IDRiD), and the area under the receiver operating characteristic curve (AUC) in the Messidor-2 dataset (Messidor-2) is 88.54%. Experiments show that the algorithm proposed in this paper has a certain application value in the field of diabetic retina grading.
Keywords: Cross-layer bilinear pooling, Retinopathy grade, Random puzzle generator, Progressive training, Center loss
引言
糖尿病视网膜病变(diabetic retinopathy,DR)是由糖尿病引起视网膜微血管病变的眼部疾病,近期研究表明它可能是导致多数糖尿病患者失明的主要原因[1],而微动脉瘤、硬渗出物等疾病都与DR密切相关[2]。根据近年相关治疗结果分析,对DR开展早期治疗能够有效地预防视力障碍并大幅度减小失明的风险。在临床实践中,DR诊断需要眼科医生对患者进行详细的眼底检查,其诊断过程是一项非常耗时的任务。因此利用计算机辅助诊断DR从而提高诊断效率,这一需求显得越来越迫切[3]。
随着深度学习技术的发展,已证实卷积神经网络(convolutional neural network,CNN)能够有效地学习不同DR分级特征,是计算机辅助诊断的有力工具之一。相对于传统图像识别领域以手工设计分类特征(如颜色、形状、黄斑和血管等)的分级方法,基于CNN的方法能够显著地提升DR分类的性能[4-5]。例如,Zhou等[6]采用分类和回归损失的方法,提出一种多网格多任务视网膜分级框架。该框架采用多个网格结构逐步提高图像分辨率和网络的深度,同时引入均方差损失函数最小化标签值和预测值的差异,在加速训练的同时提高预测精度。而后Ren等[7]提出一种以矢量量化半监督学习方法用于糖尿病黄斑水肿分级,对疑似眼底渗出区域进行分割并矢量化,再通过半监督学习及图形分类器复判,最终对渗出物的位置及黄斑判断病变分级严重程度。文献[8-9]的研究中,先利用CNN进行血管分割,再从血管结构中提取鉴别信息,最后根据鉴别信息对糖尿病视网膜进行病变分级。以上这些针对视网膜病变分级的方法虽采用不同深度的网络结构及分级策略,但要实现准确诊断的目的,依然存在以下几点局限:① 与粗粒度分类(coarse-grained classification,CGC)不同,DR分级是细粒度分类(fine-grained classification,FGC)任务,具有较大的类内方差;② 医学领域带图像标注的DR分级开源数据集稀少且标注信息有限;③ 医学领域公开数据集内的数据种类分布极度不均衡。
针对上述问题,本文提出一种基于跨层双线性池化(cross-layer hierarchical bilinear pooling,CHBP)的DR-FGC算法。由于临床中DR严重程度的分级依据主要取决于小病变区域,如微动脉瘤、出血等,因此采用CHBP模块互补输出,能最大限度减少特征丢失并突出小区域细节特征;同时引入渐进训练策略,配合随机拼图技术逐阶段优化网络各个部分参数,引导网络从细粒度逐步到粗粒度学习特征。为了进一步提升DR分级效果,本文还融合中心损失(center loss,CL)函数和焦点损失(focal loss,FL)函数分别缓解数据集类内方差大和数据类别分布极度不均衡等问题。相对其他现有算法,通过在两个公开数据集中对本文算法进行验证,以期实现在临床诊断中对DR快速筛查的目的。
1. 数据来源及预处理
1.1. 数据来源
本文算法使用2018年国际生物医学成像技术研讨会(international symposium on biomedical imaging,ISBI)上印度DR图像挑战赛开源数据集(Indian DR image dataset,IDRiD)(网址为:https://idrid.grand-challenge.org/)[10]进行仿真,同时为了验证模型在其他同类数据集中的泛化性表现,实验引入额外的开源DR分级数据集-梅西多数据集(Messidor-2)(网址为:https://www.adcis.net/en/third-party/messidor2/)[11]。其中,IDRiD数据集包含五类共516张视网膜眼底图像,其分辨率为4 288 × 2 848。根据国际临床DR严重程度量表[12],DR共分为5级:健康(DR:0)、轻度非增殖性DR(mild non-proliferative DR,mild-NPDR)(DR:1)、中度非增殖性DR(moderate non-proliferative DR,moderate-NPDR)(DR:2)、重度非增殖性DR(severe non-proliferative DR,severe-NPDR)(DR:3)和增殖性DR(proliferative DR,PDR)(DR:4),如图1所示。
图 1.

Diagrams of different severity levels of DR
不同严重等级的DR图
IDRiD数据集中训练集图像共413张,其中健康图像134张、轻度非增殖性图像20张、中度非增殖性图像136张、重度非增殖性图像74张、增殖性图像49张。测试集图像共103张,其中健康图像34张、轻度非增殖性图像5张、中度非增殖性图像32张、重度非增殖性图像19张、增殖性图像13张。Messidor-2数据集由来自于三个眼科部门的1 200张眼底彩色图像组成,其分辨率分别为1 440 × 960,2 240 × 1 488和2 304 × 1 536。
DR根据微动脉瘤数量(μA)、出血次数(H)、新生血管(NV=1)和无新生血管(NV=0)情况,将上述图像分为4级,其中第0级健康图像(μA=0和H=0)共546张、第1级图像(0<μA≤5和H=0)共254张、第2级图像(5<μA≤15或0<H<5和NV=0)共247张、第3级图像(μA≥15或H≥5和NV=1)共153张,对比IDRiD数据集并未出现严重类别不均衡现象。在DR筛查过程中,第0级健康图像和第1级图像是计算机辅助设计系统和临床专家最难区分的任务。Sánchez等[13]将第0级健康图像和第1级图像作为可参考图像分为一组,把第2级和第3级图像作为不可参考分为另一组。这两类设定已经广泛应用在现有DR筛选中,因此本文将Messidor-2数据集作为二分类任务[14]。
1.2. 数据预处理算法原理
针对DR数据集中存在大量黑色背景问题,首先使用霍夫圆变换(hough circle transform,HCT)定位图像中眼球位置并裁剪多余的黑色背景区域及部分眼球边缘区域像素,再将图像分辨率全部调整到448 × 448。同时为了突出视网膜中小病变区域特征,对图像I进行高斯滤波操作以平滑中小病变区域,得到的高斯模糊图作为眼球平均背景图像,然后将加权的原始图像减去加权高斯模糊图即可获得眼球特征图,最后为了避免产生负值引入常数γ,如式(1)~式(2)所示:
 |
1 |
 |
2 |
式中,α、β和γ分别代表线性加权值,其值分别取4、−4和128;*表示滤波操作;x、y分别代表图像单个像素点x轴和y轴坐标,σ为标准差值,e为自然常数,Gσ为二维高斯核, 为经过加权融合后的图像,如图2所示。
为经过加权融合后的图像,如图2所示。
图 2.

Image preprocessing
图像预处理
2. 网络体系结构
2.1. 主干网络原理
对比其他图像分类任务,DR分级由于各类图像特征差异小、数据集样本量少和类别分布不均匀等问题变得更具挑战性。相比以残差网络(residual network,ResNet)作为主干网络,挤压激励分组ResNet(squeeze-and-excitation grouping ResNet,SEResNeXt)不但融合了通道注意力机制还增大了网络的基数,使模型辨别能力到达一个更高的水平[15-16]。在SEResNeXt瓶颈结构中,继承ResNet经典的堆砌结构同时,运用分组卷积将原有的3 × 3卷积操作拆分成数个部分。具体而言,上述操作分为拆分、转换和聚合三部分:首先设定需要拆分的向量个数D,将向量x拆分成D个低维向量  ,然后将多个低维度向量经不同的卷积
,然后将多个低维度向量经不同的卷积 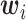 提取特征得到
提取特征得到 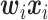 ,最后把多个低维度向量特征按通道方向连接,并由1 × 1卷积
,最后把多个低维度向量特征按通道方向连接,并由1 × 1卷积  将各个低维向量融合形成
将各个低维向量融合形成 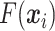 ,如式(3)所示:
,如式(3)所示:
 |
3 |
相比于ResNet的瓶颈结构,SEResNeXt在大幅度精简网络参数量的同时显著提升网络识别的准确率。而挤压激励通道注意力模块(squeeze-and-excitation channel attention module,SECAM)通过提取特征通道之间的相互依赖关系,允许网络对通道特征进行重新校准,通过全局信息来加强有用的特征并抑制不太重要的特征。给定特征输入矩阵为u,将其进行全局平均池化操作获取全局特征信息向量,如式(4)所示:
 |
4 |
式中,i和j分别代表特征输入u中对应坐标点的像素值,H和W代表特征输入矩阵的长和宽,c代表特征输入对应的通道维度,最终特征输出为包含通道信息的 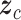 。为了提取通道中的依赖关系,使用两层全连接层对通道特征
。为了提取通道中的依赖关系,使用两层全连接层对通道特征  进行学习,最后用S型生长曲线(sigmoid)激活函数作为门控机制,如式(5)所示:
进行学习,最后用S型生长曲线(sigmoid)激活函数作为门控机制,如式(5)所示:
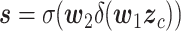 |
5 |
式中,δ代表线性整流激活函数(linear rectification function,ReLU), 和
和  分别为全连接层学习参数矩阵,同时为了限制模型复杂度将输入的向量维度c减少至r倍,并由第二个全连接层恢复至c个通道维度,σ代表sigmoid激活函数,最终得到归一化后的通道注意力特征矩阵s。将通道注意力特征矩阵s与特征u逐通道相乘,获得最终调整通道后的特征图。网络瓶颈层结构图如图3所示。
分别为全连接层学习参数矩阵,同时为了限制模型复杂度将输入的向量维度c减少至r倍,并由第二个全连接层恢复至c个通道维度,σ代表sigmoid激活函数,最终得到归一化后的通道注意力特征矩阵s。将通道注意力特征矩阵s与特征u逐通道相乘,获得最终调整通道后的特征图。网络瓶颈层结构图如图3所示。
图 3.

Structure of SEResNeXt backbone network bottleneck layer
SEResNeXt主干网络瓶颈层结构图
2.2. 跨层双线性池化模块
以往的分类CNN通常在主干网络后面再添加全局平均池化层降维并通过全连接层直接对特征进行分类,而作为小样本细粒度的DR分级任务显然不适用。首先,仅将最后一层卷积的激活值作为图像的特征表示并采用池化层对特征进行缩减,会导致特征大量丢失,不足以描述对象细粒度的各种语义表征;其次,它忽略了层间部分特征交互关系和细粒度特征学习的相互关联性。中间层卷积激活的语义信息可以通过互补的方式形成更具判别的特征,这部分信息对于细粒度视觉识别具有重要意义。因此本文采用一种CHBP方法来捕获层间部分特征关系,这与其他分类方法相比具有更优的性能[17]。
为了最大限度地减少细粒度识别信息的损失,CHBP框架集成了多个跨层双线性特征,以增强它们的表示能力。由于来自不同卷积层的特征具有互补性,充分利用中间卷积层的激活特征值有助于鉴别特征学习,因此所有交互层的双线性特征在最终分类之前被级联。三条不同的特征通过独立的线性映射,并在层间相互交互,强化相同位置的共有特征并抑制无关特征,形成自我注意力机制。本文所提出的网络受益于层间特征交互和细粒度特征学习之间的相互增强。
跨层双线性模块融合SEResNext网络最后三个瓶颈层的激活函数特征,其中双线性向量的输出连接如式(6)所示:
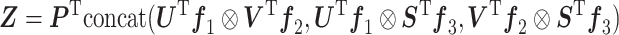 |
6 |
式中,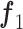 、
、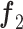 、
、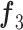 分别代表输入的特征图;V、U、S是将特征映射成双线性向量的投影矩阵;P是分类参数矩阵;
分别代表输入的特征图;V、U、S是将特征映射成双线性向量的投影矩阵;P是分类参数矩阵;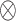 为哈达玛积;concat(·)代表特征图按照通道维度连接操作;Z为跨层双线性模块最终输出结果。
为哈达玛积;concat(·)代表特征图按照通道维度连接操作;Z为跨层双线性模块最终输出结果。
2.3. 损失函数
在深度学习损失函数选择方面,由于DR数据集自身存在严重的数据类别不均衡问题,同时每类DR图像之间特征差异性小且类别粒度相对于其他分类任务更为精细,使得传统交叉熵损失函数训练的网络难以区分DR每一种类别。为了解决上述问题,本文提出一种新的组合损失函数,即CL函数和FL函数。CL函数是为了提高CNN判别特征空间的鉴别能力而提出的[18]。具体来说,CL函数能够同时学习每个类深度特征中心,并惩罚深度特征中心与其对应的类中心的距离。从而迫使不同类的深度特征保持分离,进而扩大类间特征的差异性,并将类内样本之间的距离拉近,使得网络学习特征的鉴别能力能够高度增强,如式(7)所示:
 |
7 |
式中,m对应分类任务类别总数,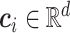 代表种类为i的深层特征的类别中心,用于表征类内变化,
代表种类为i的深层特征的类别中心,用于表征类内变化,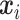 代表CNN预测对应种类i的类别中心,
代表CNN预测对应种类i的类别中心,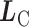 为CL值。
为CL值。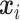 在网络优化过程中,
在网络优化过程中,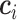 随着深度特征的变化而更新,但由于类中心
随着深度特征的变化而更新,但由于类中心 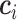 代表所有样本特征的平均值,理论上无法直接获取,因此在每个批次中计算当前数据与中心的距离,然后以梯度的形式加到中心上,类似于梯度下降的参数修正,同时再增加一个标量α用于避免小批量数据带来剧烈抖动,x代表网络总体预测值,
代表所有样本特征的平均值,理论上无法直接获取,因此在每个批次中计算当前数据与中心的距离,然后以梯度的形式加到中心上,类似于梯度下降的参数修正,同时再增加一个标量α用于避免小批量数据带来剧烈抖动,x代表网络总体预测值,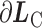 为
为 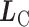 求偏导,
求偏导,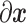 为x求偏导,如式(8)所示:
为x求偏导,如式(8)所示:
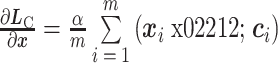 |
8 |
由于数据集中存在严重数据类别不均衡问题,FL损失函数通过加权误差调制指数来重塑交叉熵,以减轻不均衡所带来的干扰[19],如式(9)所示:
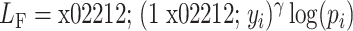 |
9 |
式中,γ代表加权误差调制系数, 代表对应类别的标签,
代表对应类别的标签,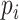 代表CNN的预测值,
代表CNN的预测值,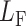 为FL损失函数结果。
为FL损失函数结果。
最终损失函数是度量CL函数和FL函数的加权组合,引入超参数λ以均衡两个损失函数的值,如式(10)所示:
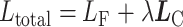 |
10 |
式中,Ltotal为最终的融合损失,超参数设置值λ为0.001。
2.4. 渐进训练策略
由于DR分级是一个渐进的过程,不同种类之间存在微妙的变化关系,而同属一类的眼球图像在形态也有很大差异。作为FGC任务,近年研究主要集中在定位更具判别性、互补和各种尺寸的特征上。相比于首先定位差异性特征的方式,本文算法侧重发掘图像中分布的大尺度结构,并将注意转移到越来越小的尺寸信息中,引导网络从细粒度逐步到粗粒度学习特征。
渐进训练策略最早运用于生成对抗网络,从低阶段网络开始训练,然后通过添加卷积层逐步训练更高阶段网络,相比以往的训练方式能够通过中间监督简化网络中信息传递[20]。由于低阶段网络的感受野和表达能力有限,网络被迫从局部细节中寻找可利用的差异性信息,这种渐进训练策略允许模型将鉴别信息从局部细节定位到全局结构中。渐进训练策略将整个训练过程分为4个阶段,具体流程如图4所示。阶段1首先训练步骤1中的低层次卷积层,其中两层卷积堆叠的卷积块(convolution block,CB)用于通道特征融合和降维,然后使用全局最大池化层和全连接层分类器对步骤1的网络参数训练更新;然后按照上述操作依次训练步骤2和步骤3中的卷积层并同步更新权重,损失函数1、损失函数2和损失函数3均为交叉熵损失;最后训练阶段4中步骤4所对应的卷积层参数,包含整个主干网络和双线性池化分类器,最终损失包含FL和CL的组合损失函数。在整个训练过程中为了进一步提升效果,引入随机拼图生成模块,迫使模型在每个训练阶段学习特定粒度的信息。
图 4.

Progressive training strategy process
渐进训练策略流程
2.5. 随机拼图生成模块
图像拼图处理最早运用于不同渐进训练方式的自监督任务[21]。Chen等[22]在精细图像分类任务中采用破坏全局结构的图像切片操作,虽取得了较好的分类效果,但在训练过程中切片操作意味着很难获取多种尺度的区域特征。为了避免上述情况,本文在渐进训练过程中引入随机拼图生成器,用于限制网络学习特定区域信息并加强局部细节特征和图像重建,以学习局部区域之间的语义相关性。首先,随机拼图生成器将输入图像分割成数个小块用于训练模型底层网络,然后逐步减小拼图分割数量并开始对应高层网络训练,其目的是通过不同粒度区域迫使模型在每个训练步骤中学习特定粒度的信息。具体操作如下:给定一张输入图像,将其按照长宽方向平均分割,形成多个相同大小的小块,然后将每个小块的位置进行随机洗牌合并成一个全新图像。关于每个阶段小块数量选择遵守下面两个条件:① 切块的大小应小于相应阶段的感受野,否则会降低拼图生成器性能。② 切片大小应随各阶段感受野的增加而同比例增加。通常每个阶段感受野大概是上一阶段的两倍,故设定数量分别为16、4、1。
在推理阶段网络中不再使用拼图生成和渐进学习策略,直接通过主干网络和双线性分类器输出最终结果。
2.6. 跨层双线性池化的糖尿病视网膜病变分级网络
本文提出的CHBP网络由两部分组成:SEResNeXt主干网络和CHBP分类器。其中SEResNeXt主干网络采用免费公开的图像网络数据集(ImageNet dataset)(网址为:https://image-net.org/index.php)大规模训练的权重作为模型初始化参数,其目的为:一方面模型迁移能够有效地避免由于训练数据少而造成的过拟合问题;另一方面也能大幅加快网络训练速度。CHBP分类器以主干网络最后三个SEResNeXt瓶颈块末端ReLU层的输出作为输入,利用层间交互形成自注意机制,抑制无关特征并强化共有特征,同时三个分支互补输出。最终采用CL度量损失和FL梯度优化,其中CL用于扩大类间差异以解决DR中每一类差异度小而难以区分的问题,而FL用来抑制数据集中各类样本数据严重分布不均匀问题。本文主干网络大体结构如图5所示。
图 5.

General structure of the network
网络大体结构
3. 实验内容与结果分析
3.1. 评价指标
为了准确地评估本文所提方法在IDRiD和Messidor-2数据集上的表现,同时方便与之前的方法对比,本文对上述两个数据集进行5折交叉验证。针对不同数据集评判指标的差异性,IDRiD数据集利用二次加权卡帕系数(quadratic weighted Kappa,QWK)进行一致性检验评估,其范围在–1~1之间。通过其衡量两个评级之间的一致性,值越大,一致性越高,如式(11)~式(12)所示:
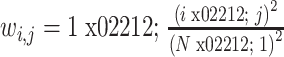 |
11 |
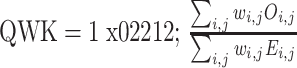 |
12 |
式中,N代表分类的总类数,i和j代表预测类别和标签类别, 代表每一对(i, j)的惩罚权重,
代表每一对(i, j)的惩罚权重,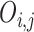 代表第i类判别为j类的个数,
代表第i类判别为j类的个数,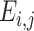 代表i类总数乘以j类总数再除以总个数。
代表i类总数乘以j类总数再除以总个数。
同时在Messidor-2数据集上评估时采用灵敏度(sensitivity,Sen)、特异性(specificity,Spe)、真阳性率(true positive rate,TPR)、假阳性率(false positive rate,FPR)和受试者工作特征曲线(receiver operating characteristic curve,ROC)下的面积(area under curve,AUC)值作为指标评价分类性能,对模型进行评判。如式(13)~式(15)所示:
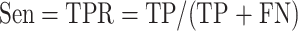 |
13 |
 |
14 |
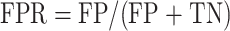 |
15 |
式中,真阳性(true positive,TP)代表正样本被正确分类的个数,真阴性(true negative,TN)代表负样本被正确分类的个数,假阳性(false positive,FP)代表正样本被错误分类的个数,假阴性(false negative,FN)代表负样本被错误分类的个数。通过以TPR为纵轴,以FPR为横轴绘制得到ROC曲线,求出ROC曲线下面积获得AUC值。
3.2. 训练细节
针对数据集中图像分辨率大小不一致的问题,为了方便训练和测试,本文将其统一调整分辨率为448×448。同时在训练过程中使用数据增强的手段,包括:随机调整大小裁剪、随机仿射、随机水平翻转、随机垂直翻转和高斯模糊等。本文所有的实验均在操作系统Ubuntu 16.04(Canonical Inc.,美国)进行;建模基于深度学习架构Pytorch 1.5(Facebook Inc.,美国)和计算统一设备架构CUDA 10.1(Nvidia Inc.,美国)。计算机具体配置:显卡(Nvidia GeFore GTX2070 GPU,Nvidia Inc.,美国)、中央处理器(Intel Core TM i7-6700H CPU, Inter Inc.,美国)。所有骨干网络均在ImageNet dataset数据集上进行预先训练。对于优化器采用自适应矩估计(adaptive moment estimation,Adam),动量(momentum,Mom)设置为0.9。批量大小和轮次分别设置为4和200。学习率初始值为0.01,并采用循环学习率训练策略[23]。
3.3. 实验结果分析
为了更直观地分析CHBP算法中不同模块对分级性能的贡献,本文设计了四组对照实验:① 仅仅保留CHBP算法主干网络(实验1);② 将CHBP算法的组合损失函数改成交叉熵损失函数,并去掉渐进训练方法(实验2);③ 只去掉CHBP算法的渐进训练方法(实验3);④ 本文所提完整的CHBP算法(实验4)。分别对四种不同的对照实验进行仿真,结果如表1所示。
表 1. Five-fold cross-validation performance of control experiment in the IDRiD dataset.
对照实验在IDRiD数据集中5折交叉验证表现
| 模型 | QWK |
| 实验1 | 0.883 1 |
| 实验2 | 0.902 0 |
| 实验3 | 0.906 0 |
| 实验4 | 0.908 4 |
表1反映了CHBP算法中不同模块在IDRiD数据集上性能贡献情况,其中由实验1和实验2可知双线性池化层能够使QWK提升1.89%,在所有模块中提升最明显。而根据实验2和实验3可以看出FL函数和CL函数能够有效地提升DR性能。最后引入渐进训练方式引导网络学习,对于最终的结果也有一定的贡献。
3.4. 对比分析
为了充分说明本文算法对于DR分级性能,表2和表3分别给出本文模型与其他模型在IDRiD和Messidor-2数据集上实验结果对比。
表 2. Five-fold cross-validation performance of different models in the IDRiD dataset.
不同模型在IDRiD数据集中5折交叉验证表现
表 3. Performance of different models in the Messidor-2 dataset.
不同模型在Messidor-2数据集中的表现
如表2所示,本文在IDRiD数据集上对比现有主流FGC算法和最新DR分级算法的分类结果,其QWK均低于本文所提出的算法。文献[17]提出双线性池化模块对网络输出特征进行融合,但由于自身主干网络特征提取能力有限,而与本文算法性能差异最大。文献[24]提出一种利用局部信息和全局外观信息的非对称多分支结构并引入弱监督增强学习能力,但是无法将类间特征分离且无弱监督能力,虽然有较大进步但实验结果相比于本文算法下降了0.028 0。文献[25]提出渐进训练方法引导网络学习,但特征融合时层间特征差距过大且部分特征未经充分提取也使得最终精度受到影响。文献[26]采用多主干模型增强分类效果,最终结果依然弱于本文所提算法。文献[27]融合多种FGC策略并通过度量学习获得更具鉴别力的特征以帮助最终分类。对比上述研究,由分类结果可知,本文方法在IDRiD数据集中取得更有竞争力的性能结果。5折交叉验证(交叉验证-1~交叉验证-5)训练图及学习率变化趋势,如图6所示。
图 6.

Learning rate change and model cross-validation QWK value change trend
学习率变化图及模型交叉验证QWK值变化趋势图
如表3所示,现有FGC算法和最新的DR分级算法在Messidor-2数据集中,本文Sen对比文献[28]和文献[29]分别提高0.108 0和0.202 3。但是特异性低于文献[29],AUC均高于其他两种算法,分别增长0.032 4和0.006 7。这也表明本文算法在Messidor-2数据集上依然具有一定的泛化能力。
4. 结束语
本文提出了一个新的CHBP的DR-FGC模型,其整体结构由主干网络(SEResNeXt)和CHBP分类器组成,并引入CL函数和FL函数缓解数据不均衡和种类差异度小的问题,同时利用渐进训练方法提升精度。实验结果证明,CHBP算法能够有效地根据DR不同种类之间微小差异判断DR等级。由于本文网络整体参数量大,部分网络还有精减的空间,而且引入渐进训练方法大幅度增加了训练时间,因此下一步研究重心将集中在精简网络和加快推理上。本文模型不但提高了DR分级的效率,而且不会出现医生由于主观原因而导致误判,在DR分级领域具有很大的前景。
重要声明
利益冲突声明:本文全体作者均声明不存在利益冲突。
作者贡献声明:梁礼明主要负责项目主持、平台搭建、算法程序设计、协调沟通以及计划安排,彭仁杰主要负责实验流程、数据记录与分析、论文编写以及算法程序设计;冯骏和尹江主要负责提供实验指导,数据分析指导,论文审阅修订。
Funding Statement
国家自然科学基金(51365017,61463018);江西省自然科学基金面上项目(20192BAB205084);江西省教育厅科学技术研究重点项目(GJJ170491)
National Natural Science Foundation of China; National Natural Science Foundation of Jiangxi Province; Science and Technology Research Key Project of Educational Commission of Jiangxi Province
References
- 1.Cho N H, Shaw J E, Karuranga S, et al IDF diabetes atlas: global estimates of diabetes prevalence for 2017 and projections for 2045. Diabetes Res Clin Pract. 2018;138:271–281. doi: 10.1016/j.diabres.2018.02.023. [DOI] [PubMed] [Google Scholar]
- 2.Haneda S, Yamashita H International clinical diabetic retinopathy disease severity scale. Nihon rinsho. Japanese Journal of Clinical Medicine. 2010;68:228–235. [PubMed] [Google Scholar]
- 3.Cunha L P, Figueiredo E A, Araújo H P, et al Non-mydriatic fundus retinography in screening for diabetic retinopathy: agreement between family physicians, general ophthalmologists, and a retinal specialist. Frontiers in endocrinology. 2018;9:251. doi: 10.3389/fendo.2018.00251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Gulshan V, Peng L, Coram M, et al Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA. 2016;316(22):2402–2410. doi: 10.1001/jama.2016.17216. [DOI] [PubMed] [Google Scholar]
- 5.Pratt H, Coenen F, Broadbent D M, et al Convolutional neural networks for diabetic retinopathy. Procedia computer science. 2016;90:200–205. doi: 10.1016/j.procs.2016.07.014. [DOI] [Google Scholar]
- 6.Zhou K, Gu Z, Liu W, et al Multi-cell multi-task convolutional neural networks for diabetic retinopathy grading//The 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) IEEE. 2018:2724–2727. doi: 10.1109/EMBC.2018.8512828. [DOI] [PubMed] [Google Scholar]
- 7.Ren F, Cao P, Zhao D, et al Diabetic macular edema grading in retinal images using vector quantization and semi-supervised learning. Technol Health Care. 2018;26(S1):389–397. doi: 10.3233/THC-174704. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Girard F, Kavalec C, Cheriet F Joint segmentation and classification of retinal arteries/veins from fundus images. Artif Intell Med. 2019;94:96–109. doi: 10.1016/j.artmed.2019.02.004. [DOI] [PubMed] [Google Scholar]
- 9.Mahiba C, Jayachandran A Severity analysis of diabetic retinopathy in retinal images using hybrid structure descriptor and modified CNNs. Measurement. 2019;135:762–767. doi: 10.1016/j.measurement.2018.12.032. [DOI] [Google Scholar]
- 10.Porwal P, Pachade S, Kamble R, et al Indian diabetic retinopathy image dataset (IDRiD): a database for diabetic retinopathy screening research. Data. 2018;3(3):25. doi: 10.3390/data3030025. [DOI] [Google Scholar]
- 11.Decencière E, Zhang X, Cazuguel G, et al Feedback on a publicly distributed image database: the Messidor database. Image Analysis & Stereology. 2014;33(3):231–234. [Google Scholar]
- 12.Wilkinson C P, Ferris F L, Klein R E, et al Proposed international clinical diabetic retinopathy and diabetic macular edema disease severity scales. Ophthalmology. 2003;110(9):1677–1682. doi: 10.1016/S0161-6420(03)00475-5. [DOI] [PubMed] [Google Scholar]
- 13.Sánchez C I, Niemeijer M, Dumitrescu A V, et al Evaluation of a computer-aided diagnosis system for diabetic retinopathy screening on public data. Invest Ophthalmol Vis Sci. 2011;52(7):4866–4871. doi: 10.1167/iovs.10-6633. [DOI] [PubMed] [Google Scholar]
- 14.Wang Z, Yin Y, Shi J, et al. Zoom-in-net: deep mining lesions for diabetic retinopathy detection//International Conference on Medical Image Computing and Computer-Assisted Intervention, Cham: Springer, 2017: 267-275.
- 15.Hu J, Shen L, Sun G Squeeze-and-excitation networks//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Utah: IEEE. 2018:7132–7141. [Google Scholar]
- 16.Xie S, Girshick R, Dollár P, et al Aggregated residual transformations for deep neural networks//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE. 2017:1492–1500. [Google Scholar]
- 17.Yu C, Zhao X, Zheng Q, et al. Hierarchical bilinear pooling for fine-grained visual recognition//Proceedings of the European Conference on Computer Vision (ECCV), München: Springer, 2018: 574-589.
- 18.Qian Q, Shang L, Sun B, et al. Softtriple loss: deep metric learning without triplet sampling//Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul: IEEE, 2019: 6450-6458.
- 19.Lin T Y, Goyal P, Girshick R, et al Focal loss for dense object detection long//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE. 2017:2980–2988. [Google Scholar]
- 20.Karras T, Aila T, Laine S, et al. Progressive growing of gans for improved quality, stability, and variation. arXiv: 1710.10196, 2017. https://doi.org/10.48550/arXiv.1710.10196
- 21.Wei C, Xie L, Ren X, et al. Iterative reorganization with weak spatial constraints: solving arbitrary jigsaw puzzles for unsupervised representation learning//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach: IEEE, 2019: 1910-1919.
- 22.Chen Y, Bai Y, Zhang W, et al. Destruction and construction learning for fine-grained image recognition//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach: IEEE, 2019: 5157-5166.
- 23.Smith L N. Cyclical learning rates for training neural networks//2017 IEEE winter conference on applications of computer vision (WACV), Nevada: IEEE, 2017: 464-472.
- 24.Wang Y, Morariu V I, Davis L S. Learning a discriminative filter bank within a CNN for fine-grained recognition//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Utah: IEEE, 2018: 4148-4157.
- 25.Du R , Chang D , Bhunia A K , et al. Fine-grained visual classification via progressive multi-granularity training of jigsaw patches//European Conference on Computer Vision (ECCV 2020), Glasgow: ECCV, 2020.
- 26.Porwal P, Pachade S, Kokare M, et al IDRiD: diabetic retinopathy-segmentation and grading challenge. Med Image Anal. 2020;59:101561. doi: 10.1016/j.media.2019.101561. [DOI] [PubMed] [Google Scholar]
- 27.Tian L, Ma L, Wen Z, et al. Learning discriminative representations for fine-grained diabetic retinopathy grading//2021 International Joint Conference on Neural Networks (IJCNN), Padua: IEEE, 2021: 1-8.
- 28.Voets M, Møllersen K, Bongo L A Reproduction study using public data of: development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. PLoS One. 2019;14(6):e0217541. doi: 10.1371/journal.pone.0217541. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Toledo-Cortés S, de la Pava M, Perdómo O, et al Hybrid deep learning gaussian process for diabetic retinopathy diagnosis and uncertainty quantification// 7th International Workshop on Ophthalmic Medical Image Analysis (OMIA 2020) Lima, Peru: OMIA and MICCAI. 2020:206–215. [Google Scholar]