

Abstract
皮肤恶性黑色素瘤是一种常见的恶性肿瘤,针对病灶区域进行准确的分割对于该病的早期诊断非常重要。为了实现对皮肤病灶区域进行更有效、准确的分割,本文提出了一种基于变换器(Transformer)的并联网络结构。该网络由两条并联支路构成:前者为本文新构建的多重残差频域通道注意网络(MFC),后者为视觉变换网络(ViT)。首先,在MFC网络支路中,本文将多重残差模块和频域通道注意力模块(FCA)进行融合,在提高网络鲁棒性的同时加强对图像细节特征的提取;其次,在ViT网络支路中采用Transformer中的多头自注意机制(MSA)使图像的全局特征得以保留;最后,通过并联的方式将两条支路提取的特征信息结合起来,更有效地实现对图像的分割。为了验证本文算法,本文在国际皮肤成像合作组织(ISIC)2018年所公开的皮肤镜图像数据集上进行实验,结果表明本文算法的分割结果中交并比(IoU)和戴斯(Dice)系数分别达到了90.15%和94.82%,相比于最新的皮肤黑色素瘤分割网络均有较好的提升。因此,本文提出的网络能够更好地对病灶区域进行分割,为皮肤科医生提供更准确的病灶数据。
Keywords: 深度学习, 皮肤分割, 变换器, 计算机视觉
Abstract
Cutaneous malignant melanoma is a common malignant tumor. Accurate segmentation of the lesion area is extremely important for early diagnosis of the disease. In order to achieve more effective and accurate segmentation of skin lesions, a parallel network architecture based on Transformer is proposed in this paper. This network is composed of two parallel branches: the former is the newly constructed multiple residual frequency channel attention network (MFC), and the latter is the visual transformer network (ViT). First, in the MFC network branch, the multiple residual module and the frequency channel attention module (FCA) module are fused to improve the robustness of the network and enhance the capability of extracting image detailed features. Second, in the ViT network branch, multiple head self-attention (MSA) in Transformer is used to preserve the global features of the image. Finally, the feature information extracted from the two branches are combined in parallel to realize image segmentation more effectively. To verify the proposed algorithm, we conducted experiments on the dermoscopy image dataset published by the International Skin Imaging Collaboration (ISIC) in 2018. The results show that the intersection-over-union (IoU) and Dice coefficients of the proposed algorithm achieve 90.15% and 94.82%, respectively, which are better than the latest skin melanoma segmentation networks. Therefore, the proposed network can better segment the lesion area and provide dermatologists with more accurate lesion data.
Keywords: Deep learning, Skin segmentation, Transformer, Computer vision
引言
皮肤癌中的黑色素瘤是目前世界上发病率增长最快的癌症之一[1]。研究表明,如果早期能及时发现黑色素瘤并对病灶区域进行精准判断,便可通过手术进行切除治疗,从而提高患者生存率。然而,当医生通过肉眼来观察皮肤镜图像中的病症区域时,要求医生具有高水平的专业知识和丰富的经验。因此在实际的临床中,在皮肤镜图像上对各种皮肤病变区域进行分割是一项具有挑战性的任务。
近年来,运用计算机辅助诊断技术对皮肤的病灶区进行分割,有效地减轻了皮肤科医生的工作时间和工作强度[2-5]。其中,深度学习技术是计算机辅助诊断中最受关注的方法,随着此技术的发展,其算法的结构及功能都取得了较大的进展[6-7]。在结构上,早期的卷积神经网络(convolutional neural networks,CNN)采用的是逐层处理、单一路径的网络结构,通过逐层地对图像进行卷积、激活和池化达到对其特征的学习。Long等[8]提出的全卷积神经网络(full convolutional neural networks,FCN),采用反卷积层对最后一层的特征图进行上采样,使它恢复到与输入图像相同的尺寸,从而实现图像分割的任务。然而,由于该网络使用的单路径结构对图像特征的提取不够充分,因此Szegedy等[9]提出了谷歌网络(google network,GoogleNet),采用并联结构增加网络的宽度使其能学习到更多的特征,增强了网络的表达能力。随后,Ronneberger等[10]提出了一种“U”型网络(U-Net)并将其用于医学图像分割,它由编码器和解码器组成,通过增加跳跃连接使网络的细节特征得到保留,有效地解决了高层语义特征丢失问题。近来,Valanarasu等[11]提出的复合型并联结构,在总体上采用类似于GoogleNet模型的并联结构,将网络分为两个并联的分支,但其分支不再是简单的卷积操作而是由功能完善的网络模型构成。
与其他机器学习方法相比,深度学习具有显著的模块化特点。近年来,随着各种新的功能模块的提出[12-15],深度学习算法的性能更加完善。如He等[16]提出的残差模块能较好地解决深层次网络中梯度消失的问题从而提高网络对特征的捕获能力。Ibtehaz等[17]在其基础上提出多重残差模块,在不受网络深度影响的前提下利用多重卷积提取了更多的特征。Qin等[18]提出的频域通道注意力(frequency channel attention,FCA)模块从频域方面入手,进一步提升了CNN提取图像特征的能力,但并没有解决其提取全局特征信息能力较差的问题。Vaswani等[19]提出了变换器(Transformer)的概念,其中包含的多头自注意机制(multiple head self-attention,MSA)因能够较好地解决上述问题而受到广泛关注。随后Dosovitskiy等[20]将Transformer引入计算机视觉领域中,提出了视觉变换网络(vision transformer network,ViT)并取得了较好的效果。该网络能够较好地提取全局特征信息,但在细节特征信息的提取方面却不如CNN。
基于神经网络在结构及功能上的进展,本文提出了一种能够更好地提取图像信息的新算法:多重残差FCA(multiple residual frequency channel attention,MFC)-ViT(MFC-ViT),并将它应用于皮肤黑色素瘤的分割研究。该算法采用并联结构,通过两个分支从不同的角度提取图像特征:首先,MFC网络分支用于提取图像的细节特征,该网络在U-Net结构的基础上结合了多重残差模块和FCA模块,能够有效提高网络的鲁棒性以及图像特征的提取能力;其次,ViT网络分支用于提取图像的全局特征,该分支采用Transformer中的多头自注意机制使图像的全局特征信息得以保留;最后,本文将两个分支所得到的特征信息结合起来,实现对皮肤病变区域进行更准确地分割,以期该算法能有效解决皮肤黑色素瘤分割精度低、难度大等问题,为医生更好地对黑色素瘤进行诊断提供准确的病灶区域奠定理论基础。
1. 算法理论
1.1. 算法结构
皮肤的病变区域由于存在易受毛发遮挡、病变区边缘模糊等问题,而难以对这些区域实现精准分割。针对这些问题,本文提出了MFC-ViT算法,该算法采用双支路的并联结构,分别提取图像的细节特征和全局特征,并将它们进行结合以达到对皮肤病变区域的精准分割,具体结构如图1所示。
图 1.

MFC-ViT network diagram
MFC-ViT网络模型示意图
由图1可知,此模型由两个并联分支组成,分别为MFC网络分支和ViT网络分支。这两个分支的输入都是从一个初始的卷积块中提取特征向量,然后将其送入各分支中进行训练。其中MFC网络分支用于提取图像的细节特征,ViT网络分支用于提取图像的全局特征。最后将两个分支提取到的特征结合并对其进行降维,得到最终的分割图像。各分支结构及功能如下文所述。
1.2. MFC网络分支
本文所提出的MFC网络分支在U-Net结构的基础上,在其编码块和解码块中分别引入多重残差模块和FCA模块,提高网络的鲁棒性及其图像特征的提取能力,并通过上采样、反卷积等操作对图像尺寸进行恢复,达到分割要求,其具体结构如图2所示。
图 2.

MFC branch diagram
MFC网络分支示意图
图2中,MFC网络分支分为编码阶段和解码阶段。在编码阶段,每一级都运用多重残差模块,通过对输入图像进行多次堆叠,并与初始图像拼接,通过数量的累积达到类似于大卷积核的效果。同时运用残差结构提高网络的鲁棒性,有效防止了由于网络深度而引起的梯度消失问题。在解码阶段引入了FCA模块提取频域信息,使得到的拼接图像不仅完成浅层特征与深层特征的交互,还包含相关的频域特征,有效地提升了细节特征的提取能力。
1.2.1. 多重残差模块
根据上文所述,本文在MFC网络分支中采用多重残差模块,具体结构如图3所示。
图 3.

Multiple residual block diagram
多重残差模块示意图
图3中,多重残差模块由卷积操作、归一化处理和激活函数组成[17]。不同于其他的功能模块,该模块秉承了一种双向优化的原则:一方面,通过堆叠多个3 × 3的小卷积核以达到与大卷积核相似的感受野,提取不同尺度的特征信息;另一方面,这些3 × 3和1 × 1卷积核在避免参数过大以及内存过载问题的同时,也便于融合多层次的特征信息,提升分割效果。
1.2.2. FCA模块
注意力机制是一种能够强化重要信息抑制非重要信息的方法,本文采用FCA模块,通过融合多个频域分量提升网络的特征提取能力,具体流程如图4所示。
图 4.

FCA block diagram
FCA模块示意图
由图4可知,FCA模块在Hu等[21]提出的压缩激励(squeeze-excitation,SE)模块的基础上,从频域出发,使用离散余弦变换(discrete cosine transform,DCT)(以符号DCT表示)对相关频域进行处理,通过融合多个频域分量加强对特征的提取。具体操作流程为:首先将输入 按其通道维度划分为n部分
按其通道维度划分为n部分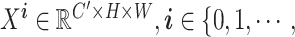
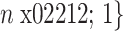 ,C′ = C/n,H、W为原始图像的分辨率,C为通道数。为每个部分分配相应的二维(two dimensional,2D)(以符号2D表示)离散余弦变换频域分量,如式(1)所示:
,C′ = C/n,H、W为原始图像的分辨率,C为通道数。为每个部分分配相应的二维(two dimensional,2D)(以符号2D表示)离散余弦变换频域分量,如式(1)所示:
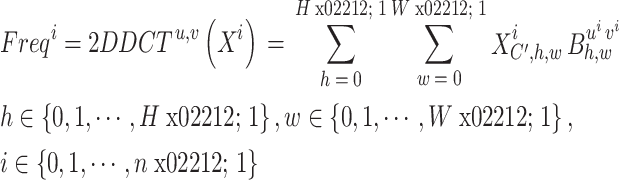 |
1 |
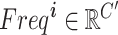 即为Xi对应的第i个频域分量。其中,B为Xi经过DCT变换所得的频域特征图。[ui, vi]为相应的频域分量指标。对于这两个超参数u和v,本文采用Qin等[18]经过实验后的最优参数进行计算。
即为Xi对应的第i个频域分量。其中,B为Xi经过DCT变换所得的频域特征图。[ui, vi]为相应的频域分量指标。对于这两个超参数u和v,本文采用Qin等[18]经过实验后的最优参数进行计算。
接着计算各频域分量的权重系数并将其进行拼接(concatenation,cat),如式(2)和式(3)所示:
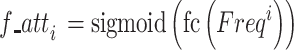 |
2 |
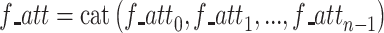 |
3 |
其中,f_atti为Freqi对应的权重系数,f_att是将所有权重系数拼接后的组合。cat为拼接操作,fc是全连接层,S型生长曲线(sigmoid)为常用激活函数。
最后,将计算出的每个频域分量的权重系数与通道逐个进行加权,完成对之前特征向量的重构,得到新的特征图 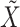 ,如式(4)所示:
,如式(4)所示:
 |
4 |
其中,X为最初的输入图像,Xi是将X按照通道维度划分后的第i个分量。Fscale(·)为逐通道加权操作。
1.3. ViT网络分支
ViT网络分支结构如图1所示,由编码块和解码块组成。编码块中采用Transformer编码结构,通过“把图像看作文本,像素块看成单词”的方式,使ViT网络分支能够更好地提取图像的全局信息,弥补了MFC网络分支在此方面的不足。解码块中运用卷积块操作减少计算负荷并恢复图像的尺寸。Transformer编码结构如图5所示。
图 5.

Transformer encoding framework
Transformer编码结构
根据图5可知,Transformer编码结构主要包括三个组成部分:补丁嵌入、多头自注意机制和多层感知机(multiple layer perceptron,MLP)。输入图像首先通过补丁嵌入操作,将图像分为大小相同的图像块并对其位置信息进行嵌入,随后输入到由多头自注意机制和多层感知机组成的编码块中进行训练。
首先,对输入图像进行补丁嵌入。将大小为H × W × C的输入图像转变为N个P × P × C的图像块。其中(H,W)为原始图像的分辨率,C为通道数,(P,P)为每个图像块的分辨率,N = H × W/P × P为生成的图像块数,也作为Transformer的输入序列长度。出于对内存空间和实验数据的考虑,在此本文将P的大小设置为32 × 32分辨率,通过较小的图像块学习细微的特征表示。由于Transformer在其所有层中都使用维度为D的向量,因此对图像块进行压缩,并通过一个可迭代的线性投影映射到D维空间中。同时为了对图像块的序列信息进行编码,在图像块中嵌入特定的位置信息,如式(5)所示:
 |
5 |
其中,Z0为补丁嵌入后的第0层特征信息。E ∈ 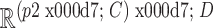 为图像块的嵌入投影,Xip为输入图像划分后的第i个图像块,位置编码Epos ∈
为图像块的嵌入投影,Xip为输入图像划分后的第i个图像块,位置编码Epos ∈ 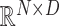 是在正态分布中随机选取的一个可学习的变量,在输出时可通过其选择正确的通道位置。
是在正态分布中随机选取的一个可学习的变量,在输出时可通过其选择正确的通道位置。
然后,将通过补丁嵌入处理后的数据序列输入编码块中。其结构如图5所示,由多头自注意机制和多层感知机交替组成,在每个模块前进行特征逐层归一化(layer-norm,LN)并通过残差结构连接。这种结构设计能让注意力机制去优化每个序列的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让特征拥有更多元的表达。第N层的输出可以写成如式(6)、式(7)所示:
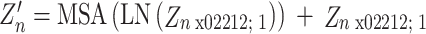 |
6 |
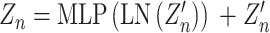 |
7 |
其中,Zn为编码后的特征信息,Zn’为多头自注意机制所提取的特征信息,Zn-1为第n-1层所输出的特征信息,MSA(·)和MLP(·)为多头自注意机制和多层感知机的相关操作,LN(·)为逐层归一化操作。最后,在解码阶段通过卷积对输出图像的尺寸进行恢复,达到分割要求。
2. 实验
本文的实验工具为Python 3.8 (Centrum Wiskunde&Informatica,荷兰)中的PyTorch 1.5,编译环境搭建在64位Windows 10操作系统上,图形处理器(graphics processing unit,GPU)为2 060,内存6 GB。PyTorch (Facebook Inc.,美国)是一个高度开源的深度学习库,它可以利用诸如GPU等并行结构优化深度学习模型,本文使用端对端开源机器学习平台PyTorch (Facebook Inc.,美国)作后端搭建模型。
2.1. 数据集和实验设置
为了验证模型的适用性,本文将国际皮肤成像合作组织( International Skin Imaging Collaboration,ISIC)中2016年(ISIC 2016)和2018年(ISIC 2018)的皮肤病变分割数据集(网址:https://www.isic-archive.com/#!/onlyHeaderTop/gallery)作为数据来源进行实验。这些数据集的收集来自各种不同的医疗中心,由该组织所制作。其中,ISIC 2018包含2 594张和900张的皮肤境图像作为训练集和测试集;ISIC 2016包括1000张和379张的图像作为训练集和测试集。数据集中的每张图片是在专业医生的监督下对拥有黑色素瘤的病灶区进行了手动分割,并形成了二值图像的金标准。由于图像大小不一且灰度范围不一致,出于对内存空间和训练速度等问题的考虑,本文将数据集中的图像裁剪成224 × 224的像素大小,并进行灰度归一化等预处理。
本文采用随机梯度下降(stochastic gradient descent,SGD)优化器更新参数,学习率为0.01,并采用二分类交叉熵(binary cross entropy,BCE)作为损失函数,训练50次,训练批次大小(batchsize)为8。
2.2. 评价指标
本文采用准确率(accuracy)、交并比(intersection-over-union,IoU)、敏感度(sensitivity)和戴斯(Dice)系数来对皮肤病灶区的分割结果进行评估,其计算公式如式(8)~式(11)所示:
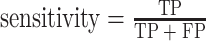 |
8 |
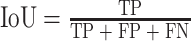 |
9 |
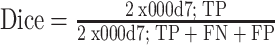 |
10 |
 |
11 |
其中,真阳性(true positive,TP)表示分割算法将医生手工标注的病灶区域正确分割,假阴性(false negative,FN)表示分割算法将医生手工标注的病灶区域错误分割为非病灶区域,真阴性(true negative,TN)表示分割算法将非病灶区域正确分割为非病灶区域,假阳性(false positive,FP)表示分割算法将非病灶区域错误分割为医生手工标注的病灶区域。
2.3. 实验结果
2.3.1. ISIC 2018数据集结果
为了验证本文提出算法的性能,本文在ISIC 2018数据集上,分别将本文算法与常用的医学图像分割算法[10, 13, 22]以及目前最新的图像分割算法[11, 23-25]进行对比,并以算法分割结果和金标准之间的Dice系数、IoU和accuracy作为评价指标,结果如表1所示。
表 1. Test results of the proposed algorithm and other algorithms on ISIC 2018.
本文算法与其他算法在ISIC 2018数据上的测试结果
从表1可以得出,本文改进的算法在accuracy、sensitivity、IoU、Dice上的评估结果分别为 94.82%、94.81%、90.15%、94.82%均高于其他对比的算法。其中,IoU和Dice系数常用来评价模型的分割性能,相比于Wang等[24]提出的对皮肤黑色素瘤分割的边界感知Transformer(boundary-aware Transformer,BA-Transformer),本文算法的评价指标占比更高。相较于Wang等[23]提出的“U-Net”型通道变换网络(U-Net channel transformer network,UCTransNet)也有提升。此外,本文算法的sensitivity相比于运用注意力U-Net(Attention U-Net)也更高,这表明本文算法预测的结果中假阳性更少,其在抑制噪声预测方面比其他算法更有优势。
为了更进一步说明本文算法在病灶区分割上的优势,本研究随机选取了4个样本,并分析这些样本在不同算法上的分割结果,如图6所示。
图 6.

Compare of segmentation results
分割结果对比图
根据图6所示,各行图像分别为样本1~样本4,各列图像从左至右分别为:原始图像、金标准、本文算法MFC-ViT、Attention U-Net、U-Net、巢穴U-Net(U-Net++)[22]和UCTransNet的分割结果。为了更明显地比较分割结果中差异较大的区域,本文通过红色方框进行标注,红色方框中的图像为分割结果中与金标准图像差异较大的区域。对比这些方框区域可知,仅运用CNN的U-Net、Attention U-Net和U-net++对于皮肤黑色素瘤区域的分割更容易出现欠分割或者过分割现象。例如在样本1中,Attention U-Net对右边方框中的病灶区域有一些过分割,而U-Net对其欠分割;在样本2中,U-Net对上方病灶区的预测出现了过分割现象,而Attention U-Net和U-Net++则对其有着欠分割现象。与此同时,将Transformer和CNN结合后的网络模型,如UCTransNet,在进行分割时较前几种方法有了较大的改善,但其分割结果仍与本文算法存在差距。
曲线下面积(area under the curve,AUC)定义为受试者工作特征(receiver operating characteristic,ROC)的AUC,其值可以有效衡量算法的性能,通常AUC值越大,模型的性能就越好,故本文使用AUC值来进一步验证各算法性能好坏,如图7所示。
图 7.

ROC curve
ROC曲线
2.3.2. ISIC 2016数据集结果
为了进一步验证本文方法可以在不同皮肤图像上对病灶区进行有效分割,本文在ISIC 2016数据集上重新训练所提出的模型,并在测试集中对其进行评估,实验及参数设置与上文相同,实验结果如表2所示。
表 2. Test results of the segmentation index of each algorithm on ISIC 2016 dataset.
在ISIC2016数据上各算法分割指标的测试结果
从表2 中可以看出本文算法的IoU、Dice系数等指标均优于所对比算法[4-5, 10, 13, 22, 24, 26],进一步说明了本文算法在皮肤黑色素瘤分割方面有很好的性能和更强的泛化能力。
2.3.3. 消融实验
为了验证本文算法中各个模块的效果,分别在上述两个数据集中进行消融实验,结果如表3所示。在分别去掉ViT和MFC网络分支后本文所提出的网络在各项指标中均有所下降,该实验证明上述两个分支在皮肤病灶区的分割任务中起着至关重要的作用。同时,本文分别将FCA模块和Attention U-Net中的注意门(attention gates,AG)模块放入MFC网络分支中进行训练,结果表明运用FCA模块所得的accuracy比AG模块高,证明在黑色素瘤的分割任务中FCA模块可以提取更多有效的特征信息。
表 3. Results of the ablation module experiment on ISIC 2018 and 2016 datasets.
消融实验在ISIC 2018和2016数据上的结果
| 模型 | ISIC 2018 | ISIC 2016 | |||
| IoU (%) | Dice (%) | IoU (%) | Dice (%) | ||
| MFC(AG) | 81.81 | 90.45 | 85.41 | 92.14 | |
| MFC(FCA) | 85.12 | 91.95 | 87.67 | 93.43 | |
| ViT | 84.11 | 91.37 | 87.69 | 93.44 | |
| 本文 | 90.15 | 94.82 | 90.39 | 94.94 | |
3. 结论
本文提出了一种基于Transformer的并联结构网络模型,并将其运用到皮肤黑色素瘤的分割中。该算法采用并联的方式将MFC网络分支和ViT网络分支进行连接,前者在U-Net结构的基础上结合了多重残差模块和FCA模块,从而更好地提取图像的细节特征;后者通过Transformer中的多头自注意机制对长范围特征信息进行编码,更好地提取图像全局特征;最终将两者的信息结合起来达到对特征图像的精确分割。实验表明,以accuracy、IoU、Dice系数、AUC等作为评价指标,本文所提出算法在ISIC 2018和ISIC 2016数据集上取得了良好的分割结果,相比于最新的皮肤黑色素瘤分割网络均有一定程度的提升。因此,使用本文算法对皮肤黑色素瘤区域进行分割时可得到更准确的病灶区域。
重要声明
利益冲突声明:本文全体作者均声明不存在利益冲突。
作者贡献声明:易三莉作者对论文进行撰写,张罡作者对数据进行收集和实验,贺建峰作者为论文提供了资助和支持。
Funding Statement
国家自然科学基金地区科学基金资助项目(82160347)
National Natural Area Science Foundation of China
References
- 1.Al-Masni M A, Kim D H, Kim T S Multiple skin lesions diagnostics via integrated deep convolutional networks for segmentation and classification. Comput Methods Programs Biomed. 2020;190:105351. doi: 10.1016/j.cmpb.2020.105351. [DOI] [PubMed] [Google Scholar]
- 2.Jaisakthi S, Mirunalini P, Aravindan C Automated skin lesion segmentation of dermoscopic images using GrabCut and k-means algorithms. IET Comput Vis. 2018;12(8):1088–1095. doi: 10.1049/iet-cvi.2018.5289. [DOI] [Google Scholar]
- 3.蒋新辉, 李喆 基于U型结构上下文编码解码网络的皮肤病变分割研究. 激光与光电子学进展. 2021;58(12):122–129. [Google Scholar]
- 4.Hasan M, Roy S, Mondal C, et al Dermo-DOCTOR: a framework for concurrent skin lesion detection and recognition using a deep convolutional neural network with end-to-end dual encoders. Biomedical Signal Processing and Control. 2021;68:102661. doi: 10.1016/j.bspc.2021.102661. [DOI] [Google Scholar]
- 5.杨国亮, 赖振东, 喻丁玲 一种改进UNet++网络用于检测黑色素瘤皮肤病变. 中国医学影像技术. 2020;36(12):1877–1881. doi: 10.13929/j.issn.1003-3289.2020.12.025. [DOI] [Google Scholar]
- 6.Badrinarayanan V, Kendall A, Cipolla R SegNet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell. 2017;39(12):2481–2495. doi: 10.1109/TPAMI.2016.2644615. [DOI] [PubMed] [Google Scholar]
- 7.易三莉, 王天伟, 杨雪莲, 等 基于改进U-Net的肺野分割算法. 激光与光电子学进展. 2022;59(2):175–183. [Google Scholar]
- 8.Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. IEEE T Pattern Anal. 2015, 39(4): 640-651.
- 9.Szegedy C, Liu W, Jia Y, et al Going deeper with convolutions// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Boston: IEEE. 2015:1–9. [Google Scholar]
- 10.Ronneberger O, Fischer P, Brox T U-Net: convolutional networks for biomedical image segmentation// 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) Munich: Springer. 2015:234–241. [Google Scholar]
- 11.Valanarasu J M J, Oza P, Hacihalilu I, et al. Medical transformer: gated axial-attention for medical image segmentation// Medical Image Computing and Computer Assisted Intervention (MICCAI 2021), Strasbourg: MICCAI, 2021. https://doi.org/10.48550/arXiv.2102.10662.
- 12.Schlemper J, Oktay O, Schaap M, et al Attention gated networks: learning to leverage salient regions in medical images. Med Image Anal. 2019;53:197–207. doi: 10.1016/j.media.2019.01.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Oktay O, Schlemper J, Folgoc L, et al. Attention U-Net: learning where to look for the pancreas// Medical Imaging with Deep Learning (MIDL). Amsterdam: Academic Press. 2018. https: //doi.org/10.48550/arXiv.1804.03999.
- 14.Thomas E, Pawan SJ, Kumar S, et al Multi-res-attention UNet: a CNN model for the segmentation of focal cortical dysplasia lesions from magnetic resonance images. IEEE J Biomed Health Inform. 2021;25(5):1724–1734. doi: 10.1109/JBHI.2020.3024188. [DOI] [PubMed] [Google Scholar]
- 15.Chen L, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation// Proceedings of the European Conference on Computer Vision (ECCV). Munich: Springer. 2018: 801-818.
- 16.He K, Zhang X, Ren S, et al. Deep residual learning for image recognition// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas: IEEE, 2016: 770–778.
- 17.Ibtehaz N, Rahman M S MultiResUNet : rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020;121:74–87. doi: 10.1016/j.neunet.2019.08.025. [DOI] [PubMed] [Google Scholar]
- 18.Qin Zequn, Zhang Pengyi, Wu Fei, et al. FcaNet: frequency channel attention networks// 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal: IEEE, 2021: 763-772.
- 19.Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need// 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach: NIPS, 2017: 6000-6010.
- 20.Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: transformers for image recognition at scale// International Conference on Learning Representations (ICLR 2022), 2021: 2010.11929v2. https: //doi.org/10.48550/arXiv.2010.11929.
- 21.Hu Jie, Shen Li, Albanie S, et al Squeeze-and-excitation networks. IEEE Trans Pattern Anal Mach Intell. 2020;42(8):2011–2023. doi: 10.1109/TPAMI.2019.2913372. [DOI] [PubMed] [Google Scholar]
- 22.Zhou Z, Siddiquee M, Tajbakhsh N, et al UNet++: a nested U-Net architecture for medical image segmentation// 2018 International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) Granada: Springer. 2018;11045:3–11. doi: 10.1007/978-3-030-00889-5_1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Wang Haonan, Cao Peng, Wang Jiaqi, et al. UCTransNet: rethinking the skip connections in U-Net from a channel-wise perspective with transformer// AAAI Conference on Artificial Intelligence (AAAI 2022), AAAI, 2022. https://doi.org/10.48550/arXiv.2109.04335.
- 24.Wang J, Wei L, Wang L, et al. Boundary-aware transformers for skin lesion segmentation// 2018 International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Strasbourg: Springer, 2021: 206-216.
- 25.Gu Z, Cheng J, Fu H, et al CE-Net: context encoder network for 2D medical image segmentation. IEEE Trans Med Imaging. 2019;38(10):2281–2292. doi: 10.1109/TMI.2019.2903562. [DOI] [PubMed] [Google Scholar]
- 26.Lee H, Kim J, Lee S, et al. Structure boundary preserving segmentation for medical image with ambiguous boundary// 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle: IEEE, 2020: 4816–4825.