

Abstract
针对自动检测医学图像中指定目标时存在的问题,提出了一种基于深度学习自动检测目标位置和估计对象姿态的算法。该算法基于区域深度卷积神经网络和目标结构的先验知识,采用区域生成候选框网络、感兴趣区域池化策略,引入包括分类损失、边框位置回归定位损失和像平面内朝向损失的多任务损失函数,近似优化一个端到端的有监督定位网络,能快速地对医学图像中目标自动定位,有效地为下一步的分割和参数自动提取提供定位结果。并在超声心动图左心室检测中提出利用检测额外标记点(二尖瓣环、心内膜垫和心尖),能高效地对左心室朝向姿态进行估计。为了验证算法的鲁棒性和有效性,实验数据选取经食管超声心动图和核磁共振图像。实验结果表明算法是快速、精确和有效的。
Keywords: 计算机辅助检测, 核磁共振图像, 超声心动图, 物体检测, 区域卷积神经网络
Abstract
This paper performs a comprehensive study on the computer-aided detection for the medical diagnosis with deep learning. Based on the region convolution neural network and the prior knowledge of target, this algorithm uses the region proposal network, the region of interest pooling strategy, introduces the multi-task loss function: classification loss, bounding box localization loss and object rotation loss, and optimizes it by end-to-end. For medical image it locates the target automatically, and provides the localization result for the next stage task of segmentation. For the detection of left ventricular in echocardiography, proposed additional landmarks such as mitral annulus, endocardial pad and apical position, were used to estimate the left ventricular posture effectively. In order to verify the robustness and effectiveness of the algorithm, the experimental data of ultrasonic and nuclear magnetic resonance images are selected. Experimental results show that the algorithm is fast, accurate and effective.
Keywords: computer-aided detection, magnetic resonance image, echocardiogram, object detection, region convolutional neural network
引言
计算机辅助检测(computer-aided detection,CAD)是医学影像诊断过程中的一项重要任务,是进行相关结构功能测量的前提条件。其中,二维图像的目标组织结构自动检测是 CAD 技术的核心基础。在临床实践中,医生需整合不同模态、不同位置方向且以不同比例显示的图像信息,目前的研究主要关注如何使检测过程快速自动化。由于医学影像自身的特殊性,比如缺乏大量高质量标注数据,大多数医学目标组织结构存在非刚性形变,以及图像背景前景的区分不明显等,导致组织结构自动定位比较困难。现有大多数 CAD 系统在临床实际应用中表现不佳,检测结果的敏感性和特异性都较低,诊断效能较低[1]。
不同模态的医学图像中,如超声、计算机断层扫描(computed tomography,CT)和核磁共振(magnetic resonance imaging,MRI)等,都存在目标身体器官自动定位的问题。以左心室(left ventricle,LV)检测为例,大多数 LV 定位方法主要依据位置、时间和形状的假设。基于位置的方法仅假设心室在图像的中心,该方法并不对不同患者心室位置的差异性以及图像的尺寸变化进行考虑,效果较差。基于时间的方法,假设 LV 是图像中唯一的运动对象,然而这种方法假阳性率高,除心室的运动伪影之外,还存在其他运动的器官。Schöllhuber[2] 针对 MRI 短轴使用时空信息并消除运动伪影,由分层模式匹配算法定位包含 LV 的感兴趣区域,其通过使用互信息图像配准使运动伪影最小化,随后估计时间—特征强度曲线进行像素分类和边界的提取,得到最终分割结果。基于形状的方法将 LV 视为圆(短轴)、椭圆(长轴),然而该方法通常针对异常形状的 LV 容错性差。Lu 等[3]使用大津阈值度量圆形程度,然后进行霍夫变换定位 LV 位置。也可搜索每个切片的质心,并用三维最小二乘拟合去除异常值,得到分割结果[4]。
不依据具体的强先验假设,机器学习算法可通过区分前景目标对象和背景来解决目标结构自动检测的问题。Kellman 等[5]提出了一种使用概率集成提升树来估计 LV 姿态和用空间间隔学习 LV 短轴边界的方法。Zhou 等[6]在超声心动图中通过规一化集成提升回归学习非线性映射以定位 LV,其团队后来提出针对多个器官的特异性置信最大化分类器,整合更高的自由度以改善回归定位任务的精度。She 等[7]通过利用基于子模块函数优化理论的多标记搜索策略来进行标记点的检测。Zheng 等[8]在实现器官定位的同时,通过组合优化置信度来估计目标器官的位置、缩放及朝向等参数值。前述机器学习算法都基于弱先验知识,启发式设计相关特征,结合滑动窗口策略,选择分类器分类判断窗口中内容以估计相应位置。
近来通用物体检测领域取得巨大进展,主要得益于深度学习能利用大量标注数据,从原始像素出发,逐层分级学习中高层抽象语义特征[9]。区域卷积神经网络[10]在大规模自然图像数据集(如 ImageNet[11])上,识别性能远超传统方法[10, 12]。当前实践中由于深度学习需要大量的训练数据,所以仅在少数医学任务中取得有限的成功应用。深度学习方法用在定位检测问题时可分为两个阶段[13]:候选框位置选取和窗口内容类别分类。例如,利用深度卷积网络进行显微镜图像中细胞检测[14]、结合深度全卷积网络的 MRI 心室检测与分割[15-16]和超声图像解剖结构的检测[17]。这些方法大都关注特定目标结构的检测分割,而本文专门针对目前 CAD 普遍存在的检测定位问题,基于改进的生成候选框的快速区域深度卷积神经网络[18]方法,提出一种医学目标结构检测框架,包括:① 在区域生成网络的基础上引入空间变换损失使得候选框生成网络能捕捉目标的空间变换参数;② 采用在线困难样例挖掘策略,加快训练收敛过程,提高检测小目标的准确度;③ 基于目标先验知识,针对 LV 提出利用检测二尖瓣环、心内膜垫和心尖位置,高效估计 LV 姿态参数。为验证该算法的鲁棒性和有效性,分别针对两个具体 CAD 应用进行实验分析。
1. 区域卷积神经网络概览
1.1. 物体检测形式化定义
若用 r 来表示图像中的矩形窗口区域,令 R 表示由对象检测系统提供的所有候选窗口的集合,将有效定位标记定义为 R 的子集,使得标记位置中内容“不重叠”,令 Y 来表示所有有效标记位置的集合。并合并常用的非最大值抑制(non-maximum suppression,NMS)过程,给定图像 x 和窗口评分函数 f,物体检测算法流程可定义为:
算法 1 物体检测
Input: 图像 x,窗口得分函数 f
1: D: = 所有候选框 r ∈ R 使得 f(x,r)>0
2: 按 f 排序 D 使得 D
1 ≥ D
2 ≥ D
3 ≥
 ≥ Dn
≥ Dn
3: y∗: = {}
4: for i = 1 to n do
5: 若 Di 和 y∗中任意候选框不重叠
6: y∗: = y∗∪{ Di }
7: end for
8: Return: 物体的目标位置 y∗
形式化定义物体检测过程见式(1),式中参数定义请参考算法 1。
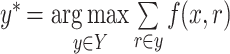 |
1 |
通常式(1)可通过贪心搜索的方法来完成,算法将联合最小化在算法 1 中产生假阳例的数量和最大化检测窗口评分函数,即寻找具有最大得分但同时不重叠的滑动窗口位置集合。
1.2. 区域卷积神经网络的演进
Girshick 等[10]在 2014 年首次提出区域卷积神经网络(region-based convolutional neural network,RCNN),对每一候选框窗口都进行一次前向传播,这将导致冗余计算,时间复杂度高。为解决这一问题,He 等[19]和 Girshick 等[13]提出 SPP-net 和 Fast RCNN 加以改进,不再把每一候选窗口均送入网络,而是仅对图像特征提取一次,把原图中候选区域投影到卷积特征图上,然后对投影后的区域特征图进行空间感兴趣区域池化得到固定长度的特征向量。其中 Fast RCNN 中的感兴趣区域池化是 SPP-Net 中多尺度空间金字塔池化的特例,仅用单一尺度的金字塔池化操作。RCNN 及其改进的 Fast RCNN 都依赖于人为设计的候选框生成方法,如选择性搜索等。为减少生成候选框的计算时间,Faster RCNN[18]中利用区域生成网络(region proposal networks,RPN)和检测网络共享提取特征的卷积层,仅提取几百个或者更少的高质量预选窗口,且召回率较高(导致更少的假阳例)。但现有的通用物体检测算法均是假设候选框为矩形,不能解决旋转朝向问题。
2. 候选区域生成网络及其改进
本节将分别从候选区域生成网络模型的结构、仿射变换候选框区域的生成、空间变换损失函数的设计、模型训练方法等方面介绍本文所提出框架,并结合 Faster RCNN 模型提出端到端的目标检测方法。
2.1. 候选区域生成网络模型结构
候选区域生成网络将一图像(任意大小)作为输入,输出目标候选框的集合和每个候选框内有无目标的概率估计,如图 1b 所示,RPN 在卷积层后接两个全卷积层完成候选区域生成功能,以实现增加滑动窗口操作。该模型使用全卷积网络[20]处理任意大小的图片输入,为了和目标检测网络[13]共享计算,在特征提取的过程中同时计算目标检测所需的感兴趣区域的初始估计,在最后一个共享卷积层输出的特征映射图上滑动小网络,卷积特征映射图上 n × n 大小空间窗口作为该网络全连接的输入,本文 n 取 3。每个滑动窗口映射到一个低维向量上(如图 1a 上方 256-d),该向量输出给两个全连接层:候选框位置定位回归层和候选框类别分类层。原文中采用类别无关分类损失,即仅区分该候选框内是否包含物体(前/背景),本文将其扩展为类别相关的分类损失。
图 1.
The architecture of proposed detection network model framework
提出的检测网络模型框架示意图
a. anchor mechanism of invariance of space(top)and spatial transformation network(down);b. architecture of Faster RCNN with affine transformation
a. 引入空间不变性的 anchor 机制(上)和空间变换网络(下);b. Faster RCNN 带仿射变换的检测模型框架

为引入空间尺度不变性,采用多尺度和多纵横比的“锚点”(anchor)框(图 1a 上所示),该机制可看作是金字塔型参考框的回归,避免了枚举多尺度、多纵横比的图像或卷积核。在每一个滑动窗口的位置,同时预测 k 个参考区域,回归层有 4 k 个输出,即 k 个候选区域位置的坐标编码,多元逻辑回归分类层输出(c + 1)× k 个(物体类别数 c 加背景类的)概率估计。候选框由相应的 k 个 anchor 的参数化表示,每个 anchor 以当前滑动窗口中心为中心,并对应一种尺度和长宽比,我们使用 3 种尺度和 3 种长宽比,在每一个滑动位置就有 k = 9 个 anchor。对于大小为 w × h 的卷积特征映射,总共有 w × h × k 个 anchor。
2.2. 仿射变换候选框
为检测物体的姿态,结合空间变换网络[21](见图 1a 下),提出带仿射变换的候选框生成算法。之前的候选框生成方法仅考虑固定尺度和宽高比的矩形框,并未考虑物体的旋转朝向,二维空间仿射变换可表示为:
 |
2 |
式中
 为输入特征图中目标坐标系下的网格点,
为输入特征图中目标坐标系下的网格点,
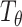 为变换矩阵,
为变换矩阵,
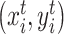 输出特征图中目标坐标系下的采样网格点。其中由于图像的坐标不是中心坐标系,宽高坐标需归一化表示,如
输出特征图中目标坐标系下的采样网格点。其中由于图像的坐标不是中心坐标系,宽高坐标需归一化表示,如
 ,且采用图形学中齐次坐标表示。式(2)能用六个参数定义对输入特征图的裁剪、平移、旋转和缩放等变换。该公式进一步简化为只考虑旋转变换:
,且采用图形学中齐次坐标表示。式(2)能用六个参数定义对输入特征图的裁剪、平移、旋转和缩放等变换。该公式进一步简化为只考虑旋转变换:
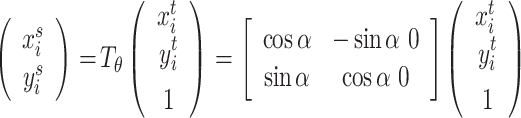 |
3 |
其中 α 表示绕图像中心顺时针旋转角度,通常变换后的像素并不是在相应网格的整数值,常用双线性插值进行近似,变换后的候选框送入感兴趣区域池化层,后接多任务损失函数。实质是把空间变换层嵌入到 RPN 网络中,并且引入有监督的损失以指导空间变换。
2.3. 朝向回归损失函数
旋转朝向的周期性会导致两个问题:① 一般的损失函数并不能处理周期性损失,简单地将模运算应用于网络的输出会导致不可靠的损失梯度,不能再被鲁棒地优化。② 由大多数参数模型中执行的矩阵向量积产生的回归输出是固定的线性运算。为此提出旋转朝向回归损失
 ,第一个问题可以通过采用 Von Mise 分布[22]来解决损失函数不连续性,其近似服从于单位圆上的正态分布:
,第一个问题可以通过采用 Von Mise 分布[22]来解决损失函数不连续性,其近似服从于单位圆上的正态分布:
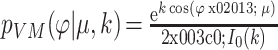 |
4 |
其中 p 指相应的概率密度函数,
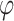 指角度,
指角度,
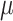 是分布的平均角度,
是分布的平均角度,
 与近似高斯方差成反比,而
与近似高斯方差成反比,而
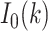 是阶数为 0 的修正贝塞尔函数,利用余弦函数来避免不连续性,可以得出以下损失函数:
是阶数为 0 的修正贝塞尔函数,利用余弦函数来避免不连续性,可以得出以下损失函数:
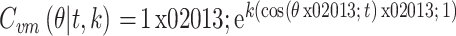 |
5 |
式中
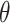 为预测旋转角度大小,t 为真实旋转角度大小,称 t 为目标值,k 为控制损失函数尾部的简单超参数。由角度
为预测旋转角度大小,t 为真实旋转角度大小,称 t 为目标值,k 为控制损失函数尾部的简单超参数。由角度
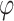 正余弦组成的二维向量 y 替代表示,利用自然语言处理文献中广泛使用的余弦代价函数来解决使用线性操作预测周期值的问题:
正余弦组成的二维向量 y 替代表示,利用自然语言处理文献中广泛使用的余弦代价函数来解决使用线性操作预测周期值的问题:
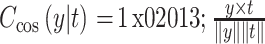 |
6 |
在神经网络框架中的实现是相对简单的,因为所需要的是全连接层和归一化层,前向传播公式如下所示:
 |
7 |
式中
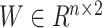 和
和
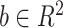 是来自全连接层的可学习参数,然后反向传播归一化损失的导数为:
是来自全连接层的可学习参数,然后反向传播归一化损失的导数为:
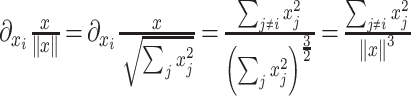 |
8 |
式中归一化确保输出值被联合学习,通过比较 CVM 和 Ccos,最终朝向回归损失函数为
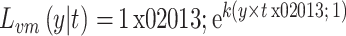 |
9 |
式(9)与式(6)相似,主要区别在于存在 e,它将目标值附近的错误“下推”,实际上是较小地惩罚小错误。
2.4. 带朝向的多任务损失函数
多任务损失分别存在于 RPN 及检测网络中,图 2 中显示的是所提出的检测网络结构示意图。每一个候选框均送入感兴趣池化层,后接两层的全连接层和多元逻辑回归分类损失(图 2 中 Softmax loss)、候选区域回归定位损失(图 2 中 Bbox.reg loss)和旋转朝向回归损失(图 2 中 Rotation loss):
图 2.
A network model architecture diagram for predicting the orientation of an object
考虑物体朝向的区域生成网络模型结构示意图
Conv:convoluted layer;pool:pooling layer;FC:fully connected layer;Softmax class loss:the loss of classification in multitask loss;Bbox.reg loss:candidate locator loss of localization;Rotation loss:loss of Von Mise for transform parameter θ
Conv:卷积层;pool:池化层;FC:全连接层;Softmax class loss:多任务损失中的分类损失;Bbox.reg loss:候选框回归定位损失;Rotation loss:文中针对变换参数 θ 的 Von Mise 损失

 |
10 |
式中,p 、 t 和 o 分别代表预测类别分类概率、候选框偏移量和感兴趣区域内物体的朝向大小;
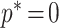 表示标记类别为背景,[p
*>0]表示框内是否有目标的指示函数,
表示标记类别为背景,[p
*>0]表示框内是否有目标的指示函数,
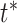 、
、
 分别表示物体的候选框标记和真实朝向。
分别表示物体的候选框标记和真实朝向。
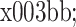 、
、
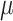 为两个损失的相应平衡权重大小,详细形式如下:
为两个损失的相应平衡权重大小,详细形式如下:
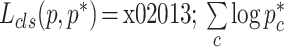 |
11 |
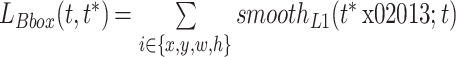 |
12 |
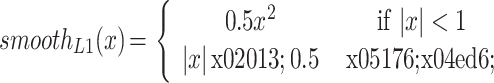 |
13 |
 和
和
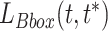 是式(4)中的分类损失和相应的平滑 L 1 损失,c 代表类别数。
是式(4)中的分类损失和相应的平滑 L 1 损失,c 代表类别数。
2.5. 困难样例挖掘
由于医学数据样本标注困难,数量相对较少,一般假设与目标位置矩形框有重叠的候选框有较大概率是难以区分的,结果也可能是次优的,因为在其他位置可能存在更难区分的样本,导致模型收敛变慢,误警率高。在每次迭代训练过程中采用在线困难样例挖掘方法(Online Hard Example Mining,OHEM)[23],对所有候选框的损失进行排序,由于相似候选框重叠区域的损失很接近,可采用非极大值抑制策略限制候选框的数目,选择前 m 个最大损失作为困难样例,反向传播其相应的梯度,其他候选框的梯度不进行回传,即不更新模型权重。
3. 实验结果和分析
为验证提出的自动检测算法的有效性和正确性,本节将分别采用一个公开可用的 MRI 数据集,以及我们收集的来源于四川大学华西医院麻醉科的经食管超声心动图数据集(不包含患者信息)进行实验。相关实验代码请参考 https://github.com/taopanpan/echodetection。
3.1. 检测 MRI 中 LV 短轴
纽约大学提供的公用数据集[24]包含 33 名患者的心脏 MRI 体数据,以及 LV 心内膜和心外膜的手动分割结果。该数据集中的大多数切片为包含心脏疾病的切片。该数据集使用 GE Genesis Signa MRI 扫描仪,采取 FIESTA 方案扫描获得。每个患者的 20 个序列帧包含 8~15 个短轴切片,大小为 256 × 256,厚度为 6~13 mm,像素分辨率为 0.93~1.64 mm。为了检验所提出方法的定位性能,取 14 个体数据形成 1 176 个切片作为训练集,其余作为测试集。本实验中不使用旋转朝向损失,评价指标采用文献[15]中定量评估计算 LV 短轴定位的准确度、敏感性和特异性。
为评价不同深度模型对检测效果的影响,实验的检测模型选取 VGG16[25] 和 ResNet101[26],训练方法采取端到端的近似联合优化,OHEM 表明训练过程中采用困难样例挖掘方法,即在训练中只选择损失占前 70% 的样本进行反向传播。训练参数及实现与文献[18]中一致,迭代次数为 1 000,以文献[18]方法作为基准检测模型(表 1 中 Baseline),评价指标采用通用的定位精度、敏感性和特异性,结果如表 1 所示,在测试集上最优检测准确度为 99.49%,敏感性为 83.12%,特异性为 99.40%,与基准检测模型相比精度提高超过 3%,同时特异性提高约 1.5%。
表 1. Comparison of detection result of different models.
不同模型检测精度的比较
| 方法 | 准确度 | 敏感性 | 特异性 |
| Baseline | 95.06% | 73.91% | 97.56% |
| VGG16 | 96.35% | 74.68% | 99.26% |
| ResNet101 | 98.66% | 76.81% | 99.16% |
| VGG16_OHEM | 96.56% | 79.42% | 99.07% |
| ResNet101_OHEM | 99.49% | 83.12% | 99.40% |
另一方面,敏感性是最容易提高的指标,最优模型超基准模型约 8%,模型不能正确定位为大尺寸的心脏,导致检测较小的 LV 切片时具有较高的假阳性,降低了整体系统性能。而困难样例挖掘的方法没有显著提高特异性,因为真阴性和假阳性的概率都降低了。考虑到心脏存在异常时会导致心脏形状的大变异性,所提出的算法均能成功定位 LV 短轴,当检测出心室短轴时,可大致确定心室中心点(如图 3a 所示),利用二腔心(two-chamber heart,2CH)和四腔心(four-chamber heart,4CH)切面均垂直于短轴切面的先验,找到与短轴的 2CH 和 4CH 交集在短轴平面上的投影,然后得到投影线在二维图像上相交的位置,即为 LV 的三维位置(如图 3b 所示)。
图 3.
Results of the left ventricular, mitral annulus, endocardial pad and apical position and rotation angle
左心室、二尖瓣环、心内膜垫和心尖位置及旋转角度的检测结果
a. the results of the left ventricular of different MRI images; b. the measurement of ventricular volume; c. the left ventricular, mitral annulus, endocardial pad and apical position and rotation angle of the ME4C section of echocardiography
a. MRI 中左心室检测结果;b. 心室体积测量;c. 超声心动图 ME4C 切面的左心室、二尖瓣环、心内膜垫和心尖位置及旋转角度的检测结果

3.2. 检测 LV 及其朝向
在 MRI 中检测 LV 短轴,由于组织结构相对简单且噪声少,所以较容易检测到心室位置。为验证所提出算法的通用性,针对超声图像 LV 长轴切面检测心室、二尖瓣环、心内膜垫和心尖位置,并估计 LV 朝向。主要包含单扇形和多普勒成像的双扇形两种由专业医师标注食管中段四腔心(mid-esophageal four-chamber heart,ME4C)的标准切面视频构成,视频中包含 2~3 个心动周期,依据医师建议从视频中截取 5 帧,并经医师检验手工筛选后得到 900 张 ME4C 切面,对切面内 LV、二尖瓣环、心内膜垫和心尖位置进行人工标注作为“金标准”。其中随机选取 100 张作为测试集,其余作为训练集。
训练时采用提出的联合多任务损失,以 VGG16 网络作为检测的预训练的模型为例,在 RPN 中添加空间变换网络实现了各个候选框的空间变换,并施加旋转朝向损失。VGG16 网络特征提取器包括 13 个卷积层,并输出 512 个卷积特征图,空间变换网络包括具有两个同样卷积池化层组成的定位网络,其由 20 个卷积核大小为 5、步长为 1 和核大小为 2 的池化层构成,两层全连接层回归得出 6 个仿射变换参数,其中,全连接层的激活函数需选择为双曲正切函数,权重高斯初始化,而变换参数初始化为[1 0 0 0 1 0]T。其他跟 Faster RCNN 中设置一致,其中
 、
、
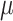 分别取 0.1 和 0.001;训练方法采取端到端的近似联合优化,迭代轮数为 50 000。
分别取 0.1 和 0.001;训练方法采取端到端的近似联合优化,迭代轮数为 50 000。
评价指标采用平均检测精度(mean average precision,mAP),是指多个类别平均检测精度的平均值。表 2 显示使用所提出方法分别在 VGG16 模型和 ResNet101 模型上,结合困难样例挖掘训练方法得出的测试结果,其中 OHEM 表示相应模型结合在线困难样例挖掘方法的检测结果,STN 表示结合提出带朝向损失的空间变换网络的检测结果,在测试集上,针对 LV 的检测精度最优可达 99.1%,结果表明所提出算法在不同基础模型上均可提高检测精度。
表 2. Comparison of detection accuracy of different models.
不同模型检测精度对比
| 方法 | mAP | 左心室 | 心尖 | 二尖瓣环 | 心内膜垫 |
| VGG16_OHEM | 80.1% | 90.1% | 65.4% | 81.2% | 83.5% |
| VGG16_OHEM_STN | 82.0% | 90.9% | 66.5% | 86.1% | 84.4% |
| ResNet101_OHEM | 83.0% | 95.7% | 66.3% | 85.2% | 84.8% |
| ResNet101_OHEM_STN | 85.5% | 99.1% | 67.8% | 87.6% | 87.4% |
为验证所提出算法在检测 LV 位置的同时可以回归学习 LV 的姿态参数、预测 LV 的朝向变换,超参数 k 跟文献[22]一致,交叠比大于 0.5 时估计姿态参数,人为标定心室朝向存在较大偏差,但可以根据二尖瓣环、心内膜垫和心尖位置估算出心室朝向角度作为对照。由于 ME4C 切面中心室的大概朝向的分布范围在[–45°,45°]之间,通过手工构建训练集,训练样本旋转以 15° 为间隔的指定角度。通过分析相关检测精度的估算值和预测值,可以发现二者具有很大的一致性。LV 检测旋转朝向的检测性能见表 3,检测结果如图 3c 所示,更多实验结果请参考给定开源地址。
表 3. Comparison of detection performance with different rotation angles.
不同旋转角度分类检测精度比较
| 方法 | – 45° | – 30° | – 15° | + 15° | + 30° | + 45° | 平均 |
| 估算值 | 66.6% | 78.0% | 87.3% | 85.5% | 75.8% | 62.3% | 75.9% |
| 预测值 | 73.0% | 81.7% | 81.7% | 89.5% | 80.4% | 70.3% | 80.7% |
为了更详细地评估模型性能,使用检测分析工具[27]分析了心尖位置的检测结果,如图 4 显示模型可以准确(白色区域)检测到心尖位置,召回率在 84%~87%。针对心尖位置的定位精确度较低,这是因为医师在标定心尖位置时有很大的随意性,且目标尺寸较小,与类似对象类别容易混淆。
图 4.
Visualization of performance for our model on apical location
心尖位置检测结果分析图
a. the cumulative fraction of detections:correct (Cor), false positive due to poor localization (Loc), confusion with similar categories (Sim), others (Oth), or background (BG). The solid red line reflects the change of recall with “strong” criteria (0.5 overlap) as the number of detections increases; the dashed red line is for the “weak” criteria (0.1 overlap). b. the distribution of top-ranked false positive types
a. 显示心尖检测精度的累积分布:正确的(Cor),定位不准确(Loc)的假阳性,与之混淆的类似类别(Sim),其他类别(Oth),以及背景(BG)。红色实线使用“强”标准(大于 0.5 交叠比)反映精确度随检测增加而变化;红色虚线则为“弱”标准(大于 0.1 交叠比)。b. 显示排名靠前的假阳性类型的分布

4. 结语
本文利用深度学习来解决医学图像计算机辅助检测问题,设计并验证了自动检测 MRI 中 LV 短轴和超声心动图中 LV 长轴切面的方法,在通用物体检测 Faster RCNN 框架的基础上,针对 RPN 引入空间变换,结合带朝向损失的多任务损失,探索解决图像平面内物体旋转角度检测的问题,并利用困难样例挖掘策略加快迭代训练。在公共 MRI 数据集和自主收集的超声心动图数据上进行详尽的实验验证,在多个评估指标方面提供了较传统方法更好的测试结果。但该方法仍耗费较多的标注数据,因此探索需要更少标注数据的检测算法是将来的工作目标。
Funding Statement
四川省科技支撑计划基金项目(2016JZ0035)
References
- 1.Cheng J Z, Ni D, Chou Y H, et al Computer-aided diagnosis with deep learning architecture: applications to breast lesions in US images and pulmonary nodules in CT scans. Sci Rep. 2016;6:24454. doi: 10.1038/srep24454. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Schöllhuber A Fully automatic segmentation of the myocardium in cardiac perfusion MRI. Eng Med. 2008;14(7):1250–1280. [Google Scholar]
- 3.Lu Y, Radau P, Connelly K, et al. Segmentation of left ventricle in cardiac cine MRI: an automatic image-driven method//Ayache N, Delingette H, Sermesant M. Functional Imaging and Modeling of the Heart. FIMH 2009. Lecture Notes in Computer Science, vol 5528. Berlin, Heidelberg: Springer, 5528: 339-347
- 4.Petitjean C, Dacher J N A review of segmentation methods in short axis cardiac MR images. Med Image Anal. 2011;15(2):169–184. doi: 10.1016/j.media.2010.12.004. [DOI] [PubMed] [Google Scholar]
- 5.Kellman P, Lu Xiaoguang, Jolly M P, et al Automatic LV localization and view planning for cardiac MRI acquisition. Journal of Cardiovascular Magnetic Resonance. 2011;13(S1):33–39. [Google Scholar]
- 6.Zhou S K, Georgescu B, Zhou X S, et al. Image based regression using boosting method//Proceedings of the IEEE International Conference on Computer Vision. Beijing: IEEE, 2005: 541-548
- 7.She Y, Liu D C. An interactive editing tool from arbitrary slices in 3D ultrasound volume data//Proceedings of the World Congress on Medical Physics and Biomedical Engineering. Berlin, Heidelberg: Springer, 2007, 14: 2447-2451
- 8.Zheng Y, Comaniciu D. Marginal space learning for medical image analysis. New York: Springer New York, 2014
- 9.Razavian A S, Azizpour H, Sullivan J, et al. CNN features off-the-shelf: An astounding baseline for recognition//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Columbus: IEEE, 2014: 512-519
- 10.Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580-587
- 11.Russakovsky O, Deng Jia, Su Hao, et al ImageNet large scale visual recognition challenge. Int J Comput Vis. 2015;115(3):211–252. [Google Scholar]
- 12.Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks//Proceedings of the Advances in Neural Information Processing Systems 25. New York: Curran Associates, Inc, 2012, 60(2): 1-9
- 13.Girshick R. Fast R-CNN//Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1440-1448
- 14.Akram S U, Kannala J, Eklund L, et al Cell segmentation proposal network for microscopy image analysis. Deep Learning and Data Labeling for Medical Applications. 2016:21–29. [Google Scholar]
- 15.Emad O, Yassine I A, Fahmy A S. Automatic localization of the left ventricle in cardiac MRI images using deep learning//Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Milan: IEEE, 2015: 683-686
- 16.Tran P V A fully convolutional neural network for cardiac segmentation in short-axis MRI. arXiv preprint. 2016:1–21. [Google Scholar]
- 17.Chen H, Zheng Y, Park J H, et al Iterative multi-domain regularized deep learning for anatomical structure detection and segmentation from ultrasound images. Medical Image Computing and Computer-Assisted Intervention. 2016:487–495. [Google Scholar]
- 18.Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks//Proceedings of the Advances in Neural Information Processing Systems 25. Montreal: Curran Associates, Inc, 2015: 1021-1029
- 19.He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell. 2015;37(9):1904–1916. doi: 10.1109/TPAMI.2015.2389824. [DOI] [PubMed] [Google Scholar]
- 20.Shelhamer E, Long J, Darrell T Fully convolutional networks for semantic segmentation. IEEE Trans Pattern Anal Mach Intell. 2017;39(4):640–651. doi: 10.1109/TPAMI.2016.2572683. [DOI] [PubMed] [Google Scholar]
- 21.Jaderberg M, Simonyan K, Zisserman A, et al. Spatial transformer networks//Advances in Neural Information Processing Systems 28: 29th Annual Conference on Neural Information Processing Systems 2015. Montreal: Curran Associates, Inc, 2015: 2017-2025
- 22.Beyer L, Hermans A, Leibe B Biternion nets: continuous head pose regression from discrete training labels. Lecture Notes in Computer Science. 2015;9358:157–168. [Google Scholar]
- 23.Shrivastava A, Gupta A, Girshick R. Training region-based object detectors with online hard example mining//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1063-1069
- 24.Andreopoulos A, Tsotsos J K Efficient and generalizable statistical models of shape and appearance for analysis of cardiac MRI. Med Image Anal. 2008;12(3):335–357. doi: 10.1016/j.media.2007.12.003. [DOI] [PubMed] [Google Scholar]
- 25.Chatfield K, Simonyan K, Vedaldi A, et al. Return of the devil in the details: delving deep into convolutional nets//Proceedings of the British Machine Vision Conference. Lodon: BMVC, 2014: 1-11
- 26.He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2015, 7(3): 171-180
- 27.Hoiem D, Chodpathumwan Y, Dai Q Diagnosing error in object detectors. Lecture Notes in Computer Science. 2012;7574:340–353. [Google Scholar]