

Abstract
Prediction is critical for decision-making under uncertainty and lends validity to statistical inference. With targeted prediction, the goal is to optimize predictions for specific decision tasks of interest, which we represent via functionals. Although classical decision analysis extracts predictions from a Bayesian model, these predictions are often difficult to interpret and slow to compute. Instead, we design a class of parametrized actions for Bayesian decision analysis that produce optimal, scalable, and simple targeted predictions. For a wide variety of action parametrizations and loss functions—including linear actions with sparsity constraints for targeted variable selection—we derive a convenient representation of the optimal targeted prediction that yields efficient and interpretable solutions. Customized out-of-sample predictive metrics are developed to evaluate and compare among targeted predictors. Through careful use of the posterior predictive distribution, we introduce a procedure that identifies a set of near-optimal, or acceptable targeted predictors, which provide unique insights into the features and level of complexity needed for accurate targeted prediction. Simulations demonstrate excellent prediction, estimation, and variable selection capabilities. Targeted predictions are constructed for physical activity data from the National Health and Nutrition Examination Survey (NHANES) to better predict and understand the characteristics of intraday physical activity.
Keywords: Bayesian statistics, functional data, physical activity, variable selection
1. Introduction
Prediction is a cornerstone of statistical analysis: it is essential for decision-making under uncertainty and provides validation for inference (Geisser, 1993). Predictive evaluations are crucial for model comparisons and selections (Gelfand et al., 1992) and offer diagnostic capabilities for detecting model misspecification (Gelman et al., 1996). More subtly, predictions provide an access point for model interpretability: namely, via identification of the model characteristics or variables which matter most for accuracy. However, the demands of many datasets—which can be high-dimensional, high-resolution, and multi-faceted—often necessitate sophisticated and complex models. Even when such models predict well, they can be cumbersome to deploy and difficult to summarize or interpret.
Our focus is targeted prediction, where predictions are customized for the decision tasks of interest. The translation of models into actionable decisions requires predictive quantities in the form of functionals of future or unobserved data. Predictions should be optimized for these decision tasks—and targeted to the relevant functionals. The target is fundamental for defining the correct (predictive) likelihood (Bjornstad, 1990). Absent specific functionals of interest, targeted prediction offers a path for interpretable statistical learning: the functionals probe the data-generating process to uncover the predictability of distinct attributes.
To illustrate these points, we display wearable device data from the National Health and Nutrition Examination Survey (NHANES) in Figure 1. Physical activity (PA) trajectories are modeled as functional data and accompanied by subject-specific covariates; descriptions of the data and the model are in Section 5. Scientific interest does not reside exclusively with these intraday profiles: we are also interested in functionals of the trajectories. Figure 1 shows several such functionals: the average activity (avg), the peak activity level (max), and the time of peak activity (argmax). These functionals summarize daily PA and describe clear sources of variability in PA among the individuals. Other features are discernible, such as sedentary behavior and periods of absolute inactivity, and are investigated in Section 5. However, Bayesian model-based point predictions alone do not explain what drives the variability among individuals and can be slow to compute out-of-sample.
Fig. 1.

Intraday physical activity (gray line) and fitted values (blue line) for two subjects under model in (6)-(8). The lines denote the empirical (solid gray) and predictive expected value (dashed blue) of avg (lower horizontal), max (upper horizontal), and argmax (vertical).
Our goal is construct targeted predictions that improve accuracy, streamline decision making, and highlight the model attributes and covariates that matter most for prediction—which notably may differ among functionals. Building upon classical decision analysis, we introduce parametrized actions that extract optimal, simple, and fast predictions under any Bayesian model . The parameterizations exploit familiar model structures, such as linear, tree, and additive forms, while the actions minimize a posterior predictive expected loss that is customized for each functional. For a broad class of parametrized actions and loss functions, we derive a convenient representation of the optimal targeted prediction that yields efficient and interpretable solutions. These solutions can be computed using existing software packages for penalized regression, which allows for widespread and immediate deployment of the proposed techniques. The targeted predictions are constructed simultaneously for multiple functionals based on a single , which avoids the need to re-fit a Bayesian model for each functional. While intrinsically useful for prediction, the elicitation of multiple targeted predictors is also informative for understanding and summarizing the model posterior.
A key feature of our approach is the use of the model predictive distribution to provide uncertainty quantification for out-of-sample predictive evaluation. We design a procedure to identify not only the most accurate targeted predictor, but also any predictor that performs nearly as well with some nonnegligible predictive probability. This strategy emerges as a Bayesian representation of the Rashomon effect, which observes that there often exists a multitude of acceptably accurate predictors (Breiman, 2001). The set of acceptable predictors is informative: it describes the shared characteristics and level of complexity needed for near-optimal targeted prediction. We do not require any re-fitting of and instead design an efficient algorithm to approximate the relevant out-of-sample predictive quantities for each functional. The proposed methods are applied to both simulated and real data and demonstrate excellent prediction, estimation, and selection capabilities.
There is a rich literature on the use of decision analysis to extract information from a Bayesian model. Bernardo and Smith (2009) provide foundational elements, while Vehtari and Ojanen (2012) give a prediction-centric survey. MacEachern (2001) and Gutiérrez-Peña and Walker (2006) use decision analysis to summarize Bayesian nonparametric models. The proposed methods expand upon a line of research for posterior summarization, most commonly for Bayesian variable selection, advocated by Lindley (1968) and rekindled by Hahn and Carvalho (2015). These techniques have been adapted for seemingly unrelated regressions (Puelz et al., 2017), graphical models (Bashir et al., 2019), nonlinear regressions (Woody et al., 2020), functional regression (Kowal and Bourgeois, 2020), and time-varying parameter models (Huber et al., 2020). Alternative approaches combine linear variable selection with Kullback-Leibler distributional approximations (Goutis and Robert, 1998; Nott and Leng, 2010; Tran et al., 2012; Crawford et al., 2019; Piironen et al., 2020). In general, these methods focus on global summarizations of a particular model posterior distribution. By comparison, our emphasis on predictive functionals adds specificity and a direct link to the observables, which provides a solid foundation for (out-of-sample) predictive evaluations and broadens applicability among Bayesian models with different parameterizations.
The remainder of the paper is organized as follows. Section 2 introduces predictive decision analysis for optimal targeted prediction. Section 3 develops the methods and algorithms for predictive evaluations and comparisons. A simulation study is in Section 4. The PA data are analyzed in Section 5. Section 6 concludes. Online supplementary material includes methodological generalizations and further examples, computational details, additional results for the simulated and PA data, proofs, and R code to reproduce the analyses.
2. Targeted point prediction
Consider the paired data with p-dimensional covariates xi and m-dimensional response yi. The response variables yi may be univariate (m = 1), multivariate (m > 1), or functional data with yi =(yi(τ1,),…,yi(τm))′ observed on a domain . Suppose we have a satisfactory Bayesian model parametrized by θ with posterior . The requisite notion of “satisfactory” is made clear below, but fundamentally should encapsulate the modeler’s beliefs about the data-generating process and demonstrate empirically the ability to capture the essential features of the data. Although these criteria are standard for Bayesian modeling, they often demand highly complex and computationally intensive models. There is broad interest in extracting simple, accurate, and computationally efficient representations or summaries of , especially for prediction.
Our approach builds upon Bayesian decision analysis. First, we target the predictive functionals , where each hj is a functional of interest and is the predictive distribution of unobserved data at covariate value and conditional on observed data. Each hj reflects a prediction task: often the data (x, y) are an input to a system hj, which inherits predictive uncertainty when y has not yet been observed. Alternatively, the functionals {hj} can be selected to provide distinct summaries of the model . Next, we introduce a parametrized action , which is a point prediction of at with unknown parameters δ. The role of g is to produce interpretable, fast, and accurate predictions targeted to h. Examples include linear, tree, and additive forms, but g is not required to match the structure of . The targeted predictions are not burdened by the complexity required to capture the global distributional features of —which may be mostly irrelevant for predicting any particular —yet use the full posterior distribution under to incorporate all available data. Lastly, we leverage the model predictive distribution to quantify and compare the out-of-sample predictive accuracy of each parametrized action. Using this information, we assemble a collection of near-optimal, or acceptable targeted predictors, which offers unique insights into the predictability of .
For any functional hj = h, predictive accuracy is measured by a loss function , which determines the loss from predicting when is realized. To incorporate multiple covariate values , we introduce an aggregate loss function
where each is the predictive variable at under model . The choice of can be distinct from the original covariates , for example to customize predictions for specific designs or subpopulations of interest, yet still leverages the full posterior distribution under model . We augment the aggregate loss with a complexity penalty on the unknown parameters δ:
where λ ≥ 0 indexes a path of parameterized actions and determines the tradeoff between predictive accuracy and complexity .
Since depends on a random quantities , Bayesian decision analysis proceeds by optimizing for δ over the joint posterior predictive distribution :
| (1) |
This operation averages the predictive loss over the joint distribution of future or unobserved values at under model , and then selects parameters that minimize this quantity. We define the parametrized action as a triple consisting of the targeted predictor g, the complexity penalty , and the complexity parameter λ. Since we typically compare among parametrized actions for the same functional h, design points , and Bayesian model , we suppress notational dependence on these terms.
The challenge is to produce optimal point prediction parameters for distinct parametrized actions , and subsequently to evaluate and compare the resulting point predictions. A schematic is presented in Figure 2: given data , a Bayesian model is constructed; for each functional h, one or more parametrized actions are optimized for prediction; point predictions are computed for at . The optimal parameters offer a summary of the posterior (predictive) distribution of model —akin to posterior expectations, standard deviations, and credible intervals—but specifically targeted to h.
Fig. 2.
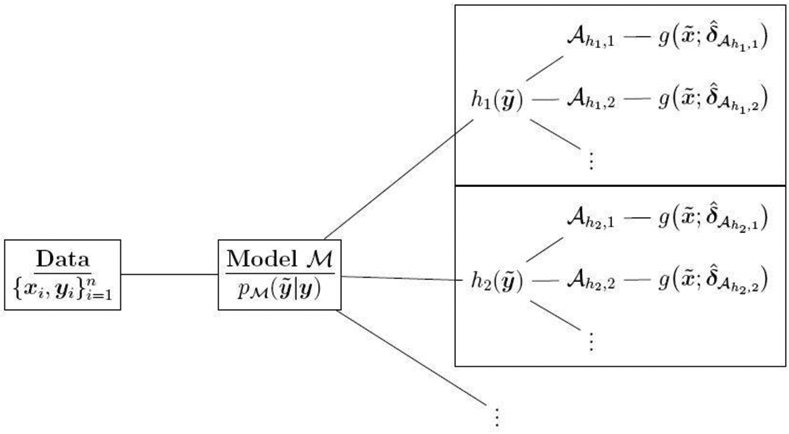
Given data , a Bayesian model is constructed. For each functional and using model , multiple parametrized actions are optimized, evaluated, and compared. The optimal parameters are used to compute point predictions of at .
By design, the optimal parameters depend on the loss function . Generality of is desirable, but tractability is essential for practical use. A natural starting point is squared error loss with generalizations considered below. In this setting, we identify a representation of the requisite optimization problem (1) that admits fast and interpretable solutions for a broad class of parametrized actions:
Theorem 1. When at each , the optimal point prediction parameters in (1) under squared error loss are
| (2) |
where is the posterior predictive expectation of at under model .
Theorem 1 establishes an equivalence between the solution to the posterior predictive expected loss (1) and a penalized least squares criterion, with important computational implications. First, estimation of is a standard Bayesian exercise, for example using posterior predictive samples: for at . Most commonly, posterior predictive samples are generated by iteratively drawing from the posterior and from the sampling distribution. Second, the penalized least squares representation in (2) implies that the optimal point prediction parameters can be computed easily and efficiently for many choices of using existing algorithms and software. Third, the optimal parametrized actions produce fast out-of-sample targeted predictions: the prediction of at any is , which is quick to compute for many choices of g. Lastly, the optimal parameters from (2) can be computed simultaneously for many parametrized actions and distinct functionals h—all based on a single Bayesian model .
Remark. Certain choices of h, such as binary functionals , are incompatible with squared error loss. In the supplementary material, we discuss generalizations to deviance-based loss functions. Importantly, the core attributes of the proposed approach are maintained: computational speed, ease of implementation, and interpretability.
We illustrate the utility of this framework with the following examples; an additional example with is presented in the supplementary material.
Example 1 (Linear contrasts). Consider a (multivariate) regression model for yi = (yi,1,…, yi,m)′. The linear contrast is often of interest: the matrix C can extract specific components of , evaluate differences between components of , and apply a linear weighting scheme to . For functional data with yi,j = yi(τj), the linear contrast can target subdomains for and evaluate derivatives of . In this setting, the predictive target simplifies to the posterior expectation . Given an estimate of the posterior expectation of the regression function at , the response variable needed for (2) is easily computable for many choices of C. Notably, the predictive expected contrast is distinct from the empirical contrast h(yi) = Cyi: the former can incorporate shrinkage, smoothness, and other regularization of the regression function fθ under . From a single Bayesian model , multiple parametrized actions can be optimized for each contrast C.
Example 2 (Functional data summaries). Suppose h is a scalar summary of a curve , such as the maximum or the point at which the maximum occurs , and let be a Bayesian functional data model (Section 5 provides a detailed example). To select variables for optimal linear prediction of , we apply Theorem 1 with and an ℓ1-penalty, :
| (3) |
for example using the observed covariates . The optimal parameters are readily computable using existing software, such as glmnet in R (Friedman et al., 2010).
In practice, we apply an adaptive variant of the ℓ1-penalty. Motivated by the adaptive lasso (Zou, 2006), Kowal et al. (2020) introduce the penalty , where ωj =∣ βj ∣−1 and βj are the regression coefficients in a Gaussian linear model . For nonlinear or non-Gaussian models and targeted predictions, we use the generalized weights , where is the ℓ2-projection of the predictive variables onto the predictor g. Bayesian decision analysis requires integration over the unknown θ, so the requisite penalty in (2) becomes the posterior expectation for , which is estimable using posterior predictive samples.
The parameterized and targeted decision analysis from (1) features connections with classical decision analysis. Targeted prediction arises in classical decision analysis through the Bayes estimator , which is obtained from Theorem 1 as a special case:
Corollary 1. Let denote an unrestricted and unpenalized action. The optimal point predictor parameters are .
However, action parametrization and penalization are valuable tools: they lend interpretability to the targeted prediction, highlight the balance between accuracy and simplicity, and often produce faster—and more accurate—out-of-sample predictions via .
In some cases, the optimal actions can be linked to the underlying model parameters θ, such as when the parameterization matches the form of and both are linear:
Corollary 2. Let denote a linear and unpenalized action. For a model with and using the observed design points , the optimal point predictor parameters are .
Corollary 2 is most familiar when is a linear model and h is the identity. By further allowing λ > 0 with a sparsity penalty , we recover the decoupling shrinkage and selection approach for Bayesian linear variable selection (Hahn and Carvalho, 2015). Similar links to Woody et al. (2020) can be established for nonlinear regression.
Despite the potential connections to θ in certain cases, the parametrized actions are not bound by the parametrization of model . The full benefits of Theorem 1 are realized by the simultaneous generality of the model , the functionals h, and the parametrized actions . Of course, we can shift the emphasis from prediction toward posterior summarization by replacing the predictive functional with a posterior functional h(θ), such as . However, we prefer the predictive functionals: they correspond to concrete observables that are comparable across Bayesian models (Geisser, 1993).
3. Predictive inference for model determination
Decision analysis extracts an optimal by minimizing a posterior (predictive) expected loss function. However, this optimality is obtained only for a given parametrized action . The key implication of Theorem 1 is that optimal point predictions can be computed easily and efficiently for many (see Figure 2). To fully exploit these benefits, additional tools are needed to evaluate, compare, and select among the parametrized actions.
We proceed to evaluate predictive performance out-of-sample, which best encapsulates the task of predicting new data. The Bayesian model provides predictive uncertainty quantification for all evaluations and comparisons. These out-of-sample predictive comparisons serve to identify not only the best targeted predictor, but also those targeted predictors that achieve an acceptable level of accuracy for out-of-sample prediction. The collection of acceptable targeted predictors illuminates the shared characteristics of near-optimal models, such as the important covariates, the forms of g and , and the level of complexity needed for accurate prediction of . This approach only requires a Bayesian model , an evaluative loss function L, and the design points at which to evaluate the predictions under some g.
3.1. Predictive model evaluation
The path toward model comparisons and selection begins with evaluation of a single targeted predictor. We proceed nominally using , but note that any point predictor of at can be used. Let denote the loss associated with a prediction when z has occurred. We consider both empirical and predictive versions of the loss: the former uses empirical functionals z = h(y) and relies exclusively on the observed data, while the latter uses predictive functionals and inherits a predictive distribution under .
Out-of-sample evaluation necessitates a division of the data into training and validation sets: model-fitting and optimization are restricted to the training data, while predictive evaluations are conducted on the validation data. Dependence on any particular data split is reduced by repeating this procedure for K randomly-selected splits akin to K-fold cross-validation; we use K = 10. Let denote the kth validation set, where each data point appears in (at least) one validation set, . We prefer validation sets that are equally-sized, mutually exclusive, and selected randomly from (1,…, n}, although other designs are compatible. Importantly, we do not require re-fitting of the Bayesian model on each training set, and instead use computationally efficient approximation techniques based on a single fit of to the full data (see Section 3.3).
For each data split k, the out-of-sample empirical and predictive losses are
| (4) |
respectively, where is optimized only using the training data , and similarly is the predictive variate at xi conditional only on the training data. Although in-sample versions are available, there is an important distinction between the out-of-sample predictive distribution, , and the in-sample predictive distribution, . The in-sample version conditions on both the training data and the validation data , which overstates the accuracy and understates the uncertainty for a validation point . The out-of-sample version avoids these issues and more closely resembles most practical prediction problems.
Evaluation of is based on the averages of (4) across all data splits,
The K-fold aggregation averages over two sources of variability in (4): variability in the training sets , each of which results in a distinct estimate of the coefficients , and variability in the validation sets , which evaluates predictions only at the validation design points . The contrast between and is important: is a point estimate of the risk under predictions from , while provides the distribution of out-of-sample loss under different realizations of the predictive variables . Specifically, each h(yi) for represents one possible realization of the out-of-sample target variable at xi; the predictive variable for expresses the distribution of possible realizations according to . The predictive loss incorporates this distributional information for out-of-sample predictive uncertainty quantification.
3.2. Predictive model selection
The out-of-sample empirical and predictive losses, and , respectively, provide the ingredients needed to compare and select among targeted predictors. Predictive quantities have proven useful for Bayesian model selection; see Vehtari and Ojanen (2012) for a thorough review. Our goal is not only to identify the most accurate predictor, but also to gather those targeted predictors that achieve an acceptable level of accuracy. In doing so, we introduce a Bayesian representation of the Rashomon effect, which observes that for many practical applications, many approaches can achieve adequate predictive accuracy (Breiman, 2001).
The proposed notion of “acceptable” accuracy is defined relative to the most accurate targeted predictor, , which minimizes out-of-sample empirical loss as in classical K-fold cross-validation. The set may include different forms for g and and usually will include a path of λ values for each (g, ) pair. We prefer relative rather than absolute accuracy because it directly references an empirically attainable accuracy level.
For any two actions , let be the percent increase in out-of-sample predictive loss from to . We seek all parametrized actions that perform within a margin η ≥ 0% of the best model, , with probability at least ε ∈[0,1]. The margin η acknowledges that near-optimal performance—especially for simple models—is often sufficient, while the probability level Ɛ incorporates predictive uncertainty. In concert, η and Ɛ provide domain-specific and model-informed leniency for admission into a set of acceptable predictors. We formally define the set of acceptable predictors as follows:
Definition 1. The set of acceptable predictors is
The probability is estimated using out-of-sample predictive draws under model (see Section 3.3). Each set Λη,ε is nonempty, since for all η, ε, and nested: Λη,ε ⊆ Λη′,ε′, for any η′ ≥ η or ε′ ≤ ε, so increasing η or decreasing Ɛ can expand the set of acceptable predictors. The special case of sparse Bayesian linear regression was considered in Kowal et al. (2020). With similar intentions, Tulabandhula and Rudin (2013) and Semenova and Rudin (2019) define a Rashomon set of predictors for which the in-sample empirical loss is within a margin η of the best predictor. By comparison, Λη,ε uses out-of-sample criteria for evaluation and incorporates predictive uncertainty via the Bayesian model .
The set of acceptable predictors also can be constructed using prediction intervals:
Lemma 1. A predictor is acceptable, , if and only if there exists a lower (1 − ε) posterior prediction interval for that includes η.
Viewed another way, is not acceptable if the lower 1 − ε predictive interval for excludes η. From this perspective, unacceptable predictors are those for which there is insufficient predictive probability (under ) that the out-of-sample accuracy of is within a certain margin of the best predictor. This definition is similar to the confidence sets of Lei (2019), which exclude any for which the null hypothesis that produces best predictive risk is rejected. Lei (2019) relies on a customized bootstrap procedure, which adds substantial computational burden to the model-fitting and cross-validation procedures. By comparison, acceptable predictor sets are derived entirely from the predictive distribution of and accompanied by fast and accurate approximation algorithms (see Section 3.3).
Among acceptable predictors, we highlight the simplest one. For fixed (g, ), the simplest predictor has the largest complexity penalty: . When is a sparsity penalty such as (3), the simplest acceptable predictor contains the smallest set of covariates needed to (nearly) match the predictive accuracy of the best predictor—which may itself be . Selection based on λη,ε resembles the one-standard-error rule (e.g., Hastie et al., 2009), which selects the simplest predictor for which the out-of-sample empirical loss is within one standard error of the best predictor. Instead, λη,ε uses the out-of-sample predictive loss with posterior uncertainty quantification inherited from .
3.3. Fast approximations for out-of-sample predictive evaluation
The primary hurdle for out-of-sample predictive evaluations is computational: they require computing and sampling for each data split k = 1,…, K. Re-fitting on each training set is impractical and in many cases computationally infeasible. To address these challenges, we develop efficient approximations that require only a single fit of the Bayesian model to the data—which is already necessary for standard posterior inference. Specifically, we use a sampling-importance resampling (SIR) algorithm with the full posterior predictive distribution as a proposal for the relevant out-of-sample predictive distributions. The subsequent results focus on squared error loss, but adaptations to other loss functions are straightforward.
To obtain , we equivalently represent the optimal action as in Theorem 1:
| (5) |
where is the out-of-sample point prediction at xj. As such, (5) is easily solvable for many choices of : all that is required is an estimate of for each in the training set. We estimate this quantity using importance sampling. Proposals are generated from the full predictive distribution by sampling from the full posterior and from the likelihood. The full data posterior serves as a proposal for the training data posterior with importance weights , with further factorization under conditional independence. The target can be estimated using or based on SIR sampling. In some cases, it is beneficial to regularize the importance weights (Ionides, 2008; Vehtari et al., 2015), but our empirical results remain unchanged with or without regularization. Successful variants of this approach exist for Bayesian model selection (Gelfand et al., 1992) and evaluating prediction distributions (Vehtari and Ojanen, 2012).
SIR provides a mechanism for sampling using the importance weights , which in turn provides out-of-sample predictive draws of and , for any actions . The idea is to obtain the proposal samples from the full posterior distribution and then subsample from without replacement based on the corresponding importance weights . The full SIR algorithm details are provided in the supplementary material.
4. Simulation study
We evaluate the selection capabilities and predictive accuracy of the proposed techniques using synthetic data. For targeted prediction, these evaluations must be directed toward a particular functional of the response variable. Specifically, we generate functional data such that the argmax of each function, , is linearly associated with a subset of covariates, . The covariates are correlated and mixed continuous and discrete: we draw xi,j from marginal standard normal distributions with Cor(xi,j,xi,j′) = (0.75)∣j−j′∣ and binarize half of these p variables, . The continuous covariates are centered and scaled to sample standard deviation 0.5. For the true coefficients , we randomly select 5% for , 5% for , and leave the remaining values at zero with the exception of the intercept, . The coefficients are rescaled such that to ensure that the argmax occurs away from the boundary; see the supplementary material. The true functions are computed as , where , and . By construction, is piecewise linear and concave with a single breakpoint, , and therefore . Finally, the observed data yi are generated by adding Gaussian noise to at m equally-spaced points with a root signal-to-noise ratio of 5. Example figures are provided in the supplementary material.
The synthetic data-generating process is repeated 100 times for p = 50 covariates, m = 200 observation points, and varying sample sizes n ∈{75, 100, 500}. For each simulated dataset , we compute the posterior and predictive distributions under the Bayesian function-on-scalars regression model of Kowal and Bourgeois (2020), which models a linear association between the functional data response and the scalar covariates. We emphasize that this model does not reflect the true data-generating process, yet our targeted predictions are derived from the predictive distribution under . We consider linear actions with the adaptive ℓ1-penalty from Example 2 and computed using glmnet in R (Friedman et al., 2010). In this case, the set of parametrized actions is determined by the path of λ values, which control the sparsity of the linear action δ. For benchmark comparisons, we use the adaptive lasso (Zou, 2006) and projection predictive feature selection (Piironen et al., 2020) on the empirical functionals . Model sizes were selected using 10-fold cross-validation. Implementation of Piironen et al. (2020) uses the projpred package in R; for the requisite Bayesian linear model, we assume double exponential priors for the linear coefficients, but results are unchanged for Gaussian and t-priors.
To validate the proposed definition of acceptable predictor sets, we investigate a simple yet important question: does the true model belong to Λη,ε ? Specifically, we determine whether the true set of active variables matches the set of active variables for any acceptable predictor . This task is challenging: we do not assume knowledge of the active variables, so the true model only belongs to Λη,ε when it is both correctly identified along the λ path and correctly evaluated by . Correct identification is only satisfied when all and only the true active variables are nonzero according to .
For this task, we compute , which is the maximum probability level for which the true model is acceptable. The margin η corresponds to the percent increase in loss relative to . By design, , remains acceptable for any smaller probability level ε′ ≤ εmax(η). Most important, we set εmax(η) = 0 if is not on the λ path. For each simulated dataset, we compute εmax(η) for a grid of η% values. The results averaged across 100 simulations are in Figure 3. Naturally, εmax(η) uniformly increases with the sample size for each value of η. When η = 0, the average maximum probability levels are εmax(0) ∈{0.21, 0.39, 0.54} for n ∈{75, 100, 500}, respectively, which suggests that a cutoff of ε = 0.1 is capable of capturing the true model even when zero margin is allowed. Notably, εmax(η) does not converge to one as η increases for the smaller sample sizes n ∈{75, 100}. The reason is simple: if is not discovered along the λ path, then εmax(η) = 0 by definition—regardless of the choice of η. This result demonstrates the importance of the set of predictors under consideration , which here is determined entirely by the selected variables in the glmnet solution path.
Fig. 3.

The maximum probability level εmax(η) for which the true model is acceptable, , across values of η. For any smaller probability level , the true model remains acceptable: . The horizontal gray line is ε = 0.1.
Next, we evaluate point predictions of and estimates of β* using root mean squared errors (RMSEs). The parametrized actions and point predictions are computed for multiple choices of λ: the simplest acceptable predictor λ = λη,ε with η = 0 and ε = 0.1 (proposed(out)); the analogous choice of λ based on in-sample evaluations (proposed(in)); and the unpenalized linear action with λ = 0 (proposed(full)). For comparisons, we include the aforementioned adaptive lasso and projpred, the point predictions under model (h_bar; see Corollary 1), and the empirical functionals h(yi) (h(y)). The results are in Figure 4. In summary, clear improvements in targeted prediction are obtained by (i) fitting to rather than h(yi), (ii) including covariate information, (iii) incorporating penalization or variable selection, and (iv) selecting the complexity λ based on out-of-sample criteria. The targeted actions vastly outperform the model predictions—even though each is based entirely on the predictive distribution from . Lastly, the accurate estimation of the linear coefficients is important: the estimates describe the partial linear effects of each xj on targeted prediction of .
Fig. 4.
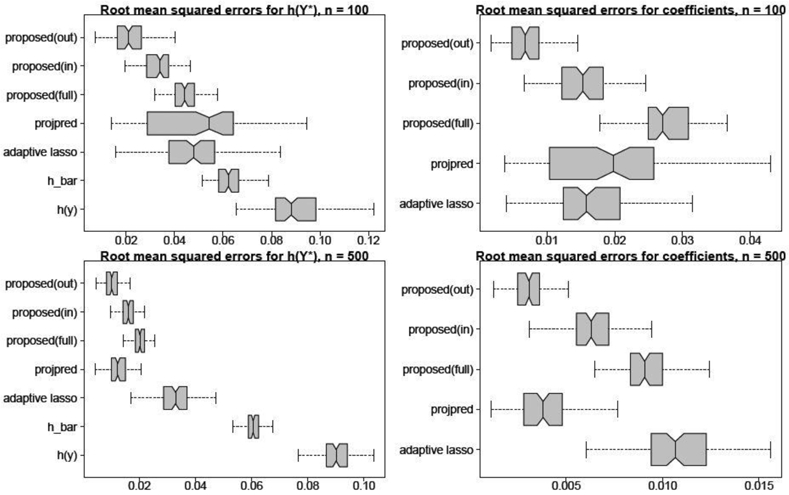
RMSEs for the true functionals h(Y*) (left) and the true regression coefficients β* (right) for n = 100 (top) and n = 500 (bottom) across 100 simulated datasets. Non-overlapping notches indicate significant differences between medians. The parametrized actions with out-of-sample selection are most accurate for prediction and estimation.
The supplementary material includes additional comparisons. Marginal variable selection is evaluated based on true positive and negative rates, with proposed(out) offering the best performance among these methods. Results for high dimensional data with p > n(n = 200, p = 500 and n = 100, p = 200) confirm the prediction and estimation advantages of the proposed approach. Sensitivity to ε ∈{0.05, 0.10, 0.20, 0.50} is also studied for prediction, estimation, and selection. Lastly, we evaluate the robustness in predictive accuracy among these methods. Specifically, we consider the setting in which the distribution of the covariates differs significantly between the training and validation datasets. The parametrized actions offer superior targeted predictions, especially for small to moderate sample sizes.
5. Physical activity data analysis
We apply targeted prediction to study physical activity (PA) data from the National Health and Nutrition Examination Survey (NHANES). NHANES is a large survey conducted by the Centers for Disease Control to study the health and wellness of the U.S. population. We analyze data from the 2005-2006 cohort, which features minute-by-minute PA data measured by hip-worn accelerometers (see Figure 1). To date, the 2005-2006 cohort is the most recent publicly available NHANES PA data. These data are high-resolution and empirical measurements of PA, and offer an opportunity to study intraday activity profiles.
PA has been linked to all-cause mortality not only in total daily activity (Schmid et al., 2015) but also via other functionals that describe activity behaviors (Fishman et al., 2016; Smirnova et al., 2019). Our goal is to construct targeted predictions that more accurately predict and explain the defining characteristics of PA. Specifically, we consider the following functionals for intraday PA at times-of-day τ1,…, τm:
where avg captures average daily activity, tlac is the total log activity count and measures moderate activity (Wolff-Hughes et al., 2018), sd targets the intraday variability in PA, sedentary computes the amount of time below a low activity threshold, max is the peak activity level, and argmax is the time of peak activity. In addition, we include a binary indicator of absolute inactivity during sleeping hours: for all τ ∈[1am,5am]}. Individuals with zeros(1am-5am) = 1 likely removed the accelerometer during sleep in accordance with the NHANES instructions. Since we omit subjects with insufficient accelerometer wear time (< 10 hours), individuals with zeros(1am-5am) = 1 are active at other times of the day.
The PA data are accompanied by demographic variables (age, gender, body mass index (BMI), race, and education level), behavioral attributes (smoking status and alcohol consumption), self-reported comorbidity factors (diabetes, coronary heart disease (CHD), congestive heart failure, cancer, and stroke), and lab measurements (total cholesterol, HDL cholesterol, systolic blood pressure). Data pre-processing generally follows Leroux et al. (2019) using the R package rnhanesdata. We consider individuals aged 50-85 without mobility problems and without missing covariates. The continuous covariates are centered and scaled to sample standard deviation 0.5.
In accordance with the schematic in Figure 2, targeted predictive decision analysis begins with a Bayesian model . Since the PA data are intraday activity counts, we use a count-valued functional regression model based on the simultaneous transformation and rounding (STAR) framework of Kowal and Canale (2020). STAR formalizes the popular approach of transforming count data prior to applying Gaussian models, but includes a latent rounding layer to produce a valid count-valued data-generating process. STAR models can capture zero-inflation, over- and under-dispersion, and boundedness or censoring, and provide a path for adapting continuous data models and algorithms to the count data setting.
For each individual, we aggregate PA across all available days (at least three and at most seven days per subject) in five-minute bins. Let yi,j and and denote the average and total PA, respectively, for subject i at time τj, where i = 1,…, n = 1012 and j = 1,…, m = 288. Total PA is count-valued and will serve as the input for the STAR model, while all subsequent functionals and predictive distributions use average PA. Model is the following:
| (6) |
| (7) |
| (8) |
with and . In (6), round maps the latent continuous data to {0,1,…, ∞}, while transform maps to for continuous data modeling. We use round(t) = ⌊t⌋ for t > 0 and round(t) = 0 for t ≤ 0, so whenever , and set in the Box-Cox family. In the functional regression levels (7)-(8), b is a vector of spline basis functions with basis coefficients θi for subject i and aℓ is the vector of regression coefficients for each basis coefficient ℓ. The spline basis is reparametrized to orthogonalize b and diagonalize the prior variance of the basis coefficients, which justifies the assumption of independence across basis coefficients in (8). Heavy-tailed innovations (v = 3) are introduced to model large spikes in PA.
Posterior inference is conducted based on 5000 samples from a Gibbs sampler after discarding a burn-in of 5000 iterations; the algorithm is detailed in the supplementary material. Posterior predictive diagnostics (see the supplementary material) demonstrate adequacy of for the functionals of interest. These results are insensitive to v, but alternative choices of transform (e.g., logt) or b (e.g., wavelets) produce inferior results.
Targeted predictions for each functional were constructed using a linear action with an adaptive ℓ1-penalty (see Example 2). Trees were also considered but were not competitive. The set of parametrized actions is given by the path of λ values computed using glmnet in R (Friedman et al., 2010): we highlight the simplest acceptable action λ = λ0,0.1 (proposed(out)) and the unpenalized linear action λ = 0 (proposed(full)). For comparison, we fit an adaptive lasso to for each h. Squared error loss is used for all but zeros(1am-5am) which uses cross-entropy. In the supplementary material, we consider quadratic effects for age and BMI and pairwise interactions for each of age and BMI with race, gender, the behavioral attributes, and the self-reported comorbidity factors.
The targeted predictions are evaluated out-of-sample using the approximations from Section 3.3. For each functional h and complexity λ—which indexes the number of nonzero elements in —Figure 5 presents the percent increase in predictive and empirical loss relative to the best predictor . The measures of vigorous PA (avg, sd, and max) produce nearly identical results, so we only include max here; avg and sd are in the supplement. The predictive expectations align closely with the empirical values, which suggests that model is adequate for these predictive metrics.
Fig. 5.

Approximate out-of-sample squared error loss for sparse linear actions targeted to each functional. Results are presented for each size as a percent increase in loss relative to . The predictive expectations (triangles) and 80% intervals (gray bars) are included with the empirical relative loss for each model size (x-marks) and the adaptive lasso (red lines). The horizontal black lines denote the choices of η and the vertical lines denote λη,0.1 (solid) and (dashed).
For each functional, we obtain optimal or near-optimal predictions with only about 10 covariates with better accuracy than the adaptive lasso. Many of the selected covariates are shared among functionals: age, BMI, gender, race, HDL cholesterol, and CHD are selected for all but argmax, while smoking status (avg, sd, max), diabetes (avg, sd, sedentary, max), and total cholesterol (tlac, sedentary) appear as well. The functionals measuring vigorous PA agree on the selected variables, including negative effects for diabetes and smoking. Most distinct is argmax: while includes 11 covariates, the predictive uncertainty quantification from indicates that linear predictors with as few as one covariate (race) are acceptable. These covariates are simply not linearly predictive of argmax: the difference between and any other is less than 1%. Details on the selected covariates and the direction of the estimated effects are provided in the supplement.
Robustness to the choice of η is also illustrated in Figure 5. We select η = 0% for max and argmax and η = 1% for tlac and sedentary, which highlights the purpose of η: by allowing η > 0, we can obtain targeted predictors with fewer covariates. By comparison, increasing the margin to η = 1% for max and argmax does not change the smallest acceptable predictor.
To validate the approximations in Figure 5, we augment the analysis with a truly out-of-sample prediction evaluation. For each of 20 training/validation splits, model and the adaptive lasso are fit to the training data and sparse linear actions are targeted to each h. We emphasize that this exercise is computationally intensive: the MCMC for model requires about 30 minutes per 10000 iterations (using R on a MacBook Pro, 2.8 GHz Intel Core i7), so repeating the model-fitting process 20 times is extremely slow. Comparatively, the approximations used for Figure 5 compute in under two seconds.
Point predictions were generated for the validation data using under (h_bar), the adaptive lasso, and sparse linear actions with λ = λ0,0.1 (proposed(out)), λ = 0 (proposed(full)), and . Since is also the unique acceptable predictor when ε = 1, η = 0, it provides information about robustness to Ɛ and η. The point predictions under are highly inaccurate—and so excluded from Figure 6—and slow to compute: we draw at each validation point and then average over these draws. The targeted actions simply evaluate , which is faster, simpler, less susceptible to Monte Carlo error, and empirically more accurate. Predictions were evaluated on the empirical functionals h(yi) in the validation data using mean squared prediction error.
Fig. 6.
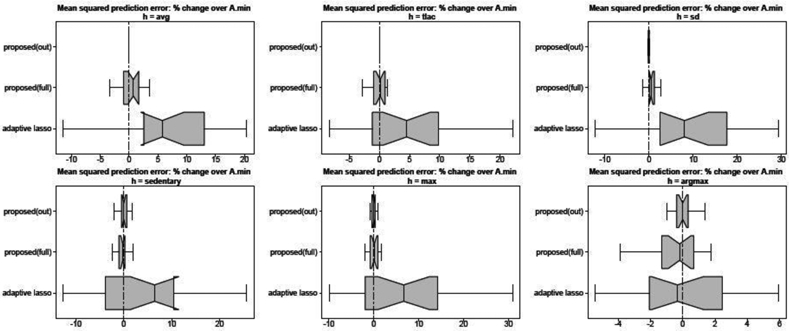
Mean squared prediction error for each functional across 20 training/validation splits. Results are presented as a percent increase relative to ; values below zero (vertical line) indicate improvement over . Non-overlapping notches indicate significant differences between medians. Point predictions from (h_bar) are noncompetitive and omitted. Both proposed(out) proposed(full) improve upon adaptive lasso and h_bar, while proposed(out) is most accurate and performs almost identical to despite using fewer covariates.
The results from the out-of-sample prediction exercise are in Figure 6. The smallest acceptable predictor proposed(out) performs almost identical to the best predictor despite using fewer covariates—which is precisely the goal of the acceptable predictor sets and the out-of-sample approximations in Figure 5. Both proposed(out) and proposed(full) outperform the adaptive lasso, in some cases by a large margin. The strength of this result is remarkable: the predictions are evaluated on the empirical functionals h(yi), which are used for training the adaptive lasso but not for the proposed methods. Instead, the parametrized actions are trained using —which is itself a poor out-of-sample predictor. However, the targeted actions only rely on the in-sample adequacy of and, unlike models trained to the empirical functionals, leverage both the model-based regularization and the uncertainty quantification provided by . In summary, the targeted predictors improve upon both the empirical predictor and the model-based predictor from which they were derived. Lastly, we note that the performance comparisons in Figure 6 confirm those in Figure 5, which validates the accuracy of the out-of-sample approximations from Section 3.3.
Since NHANES data are collected using a stratified multistage probability sampling design, it is natural to question the absence of survey weights from this analysis. Although it is straightforward to incorporate the survey weights into an aggregate loss function to mimic a design-based approach (e.g., Rao, 2011), the unweighted approach has its merits. By design, NHANES oversamples certain subpopulations to ensure representation in the dataset. So although our out-of-sample predictions are not evaluated on a representative sample of the U.S. population, they are evaluated on a carefully-curated sample that includes key demographic, income, and age groups within the U.S. population.
6. Discussion
Using predictive decision analysis, we constructed optimal, simple, and efficient predictions from Bayesian models. These predictions were targeted to specific functionals and provide new avenues for model summarization. Out-of-sample predictive evaluations were computed using fast approximation algorithms and accompanied by predictive uncertainty quantification. Simulation studies demonstrated the prediction, estimation, and model selection capabilities of the proposed approach. The methods were applied to a large physical activity dataset, for which we built a count-valued functional regression model. Using targeted prediction with sparse linear actions, we identified 10 covariates that provide near-optimal out-of-sample predictions for important and descriptive PA functionals, with substantial gains in accuracy over both Bayesian and non-Bayesian predictors.
A core attribute of the proposed approach is that only a single Bayesian model is required. The model is used to construct, evaluate, and compare among targeted predictors for each functional h, and is the vessel for all subsequent uncertainty quantification. Although it is practically impossible for to be adequate for every functional, many well-designed models are capable of describing multiple functionals. We only require that provides a sufficiently accurate predictive distribution for each , which is empirically verifiable through standard posterior predictive diagnostics (Gelman et al., 1996). When the predictive distribution of is intractable or computationally prohibitive, the proposed methods remain compatible with any approximation algorithm for .
Future work will establish uncertainty quantification for the optimal point prediction parameters . This task is nontrivial: frequentist uncertainty estimates for penalized regression are generally not valid, since the data have already been used to obtain the posterior (predictive) distribution under model . A promising alternative is to project the predictive targets onto , which induces a predictive distribution for the resulting parameter δ. Similar posterior projections have proven useful for linear variable selection (Woody et al., 2020) with growing theoretical justification (Patra and Dunson, 2018).
Supplementary Material
Acknowledgements
Research was sponsored by the Army Research Office (W911NF-20-1-0184) and the National Institute of Environmental Health Sciences of the National Institutes of Health (R01ES028819). The content, views, and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Office, the National Institutes of Health, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.
References
- Bashir A, Carvalho CM, Hahn PR, and Jones MB (2019). Post-processing posteriors over precision matrices to produce sparse graph estimates. Bayesian Analysis, 14(4): 1075–1090. [Google Scholar]
- Bernardo JM and Smith AFM (2009). Bayesian theory, volume 405. John Wiley & Sons. [Google Scholar]
- Bjornstad JF (1990). Predictive likelihood: A review. Statistical Science, pages 242–254. [Google Scholar]
- Breiman L (2001). Statistical Modeling: The Two Cultures (with comments and a rejoinder by the author). Statistical Science, 16(3):199–231. [Google Scholar]
- Crawford L, Flaxman SR, Runcie DE, and West M (2019). Variable prioritization in nonlinear black box methods: A genetic association case study. Ann. Appl. Stat, 13(2):958–989. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fishman EI, Steeves JA, Zipunnikov V, Koster A, Berrigan D, Harris TA, and Murphy R (2016). Association between Objectively Measured Physical Activity and Mortality in Nhanes. Medicine and Science in Sports and Exercise, 48(7):1303–1311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friedman J, Hastie T, and Tibshirani R (2010). Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software, 33(1):1–22. [PMC free article] [PubMed] [Google Scholar]
- Geisser S (1993). Predictive inference, volume 55. CRC press. [Google Scholar]
- Gelfand AE, Dey DK, and Chang H (1992). Model determination using predictive distributions, with implementation via sampling-based methods (with discussion). Bayesian Statistics 4, 4:147–167. [Google Scholar]
- Gelman A, Meng XL, and Stern H (1996). Posterior predictive assessment of model fitness via realized discrepancies. Statistica Sinica, 6(4):733–807. [Google Scholar]
- Goutis C and Robert CP (1998). Model choice in generalised linear models: A Bayesian approach via Kullback-Leibler projections. Biometrika, 85(1):29–37. [Google Scholar]
- Gutiérrez-Peña E and Walker SG (2006). Statistical Decision Problems and Bayesian Nonparametric Methods. International Statistical Review, 73(3) :309–330. [Google Scholar]
- Hahn PR and Carvalho CM (2015). Decoupling shrinkage and selection in bayesian linear models: A posterior summary perspective. Journal of the American Statistical Association, 110(509):435–448. [Google Scholar]
- Hastie T, Tibshirani R, and Friedman J (2009). The elements of statistical learning: data mining, inference, and prediction. Springer Science & Business Media. [Google Scholar]
- Huber F, Koop G, and Onorante L (2020). Inducing Sparsity and Shrinkage in Time-Varying Parameter Models. Journal of Business and Economic Statistics, pages 1–48. [Google Scholar]
- Ionides EL (2008). Truncated importance sampling. Journal of Computational and Graphical Statistics, 17(2):295–311. [Google Scholar]
- Kowal DR and Bourgeois DC (2020). Bayesian Function-on-Scalars Regression for High-Dimensional Data. Journal of Computational and Graphical Statistics, pages 1–10.33013150 [Google Scholar]
- Kowal DR, Bravo M, Leong H, Griffin RJ, Ensor KB, and Miranda ML (2020). Bayesian Variable Selection for Understanding Mixtures in Environmental Exposures. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kowal DR and Canale A (2020). Simultaneous Transformation and Rounding (STAR) Models for Integer-Valued Data. Electronic Journal of Statistics, 14(1):1744–1772. [Google Scholar]
- Lei J (2019). Cross-Validation With Confidence. Journal of the American Statistical Association, 0(0):1–53. [Google Scholar]
- Leroux A, Di J, Smirnova E, Mcguffey EJ, Cao Q, Bayatmokhtari E, Tabacu L, Zipunnikov V, Urbanek JK, and Crainiceanu C (2019). Organizing and Analyzing the Activity Data in NHANES. Statistics in Biosciences, 11(2):262–287. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lindley DV (1968). The Choice of Variables in Multiple Regression. Journal of the Royal Statistical Society: Series B (Methodological), 30(1):31–53. [Google Scholar]
- MacEachern SN (2001). Decision theoretic aspects of dependent nonparametric processes. In Bayesian Methods with Applications to Science, Policy, and Official Statistics, pages 551–560. [Google Scholar]
- Nott DJ and Leng C (2010). Bayesian projection approaches to variable selection in generalized linear models. Computational Statistics and Data Analysis, 54(12):3227–3241. [Google Scholar]
- Patra S and Dunson DB (2018). Constrained Bayesian Inference through Posterior Projections. arXiv preprint arXiv:1812.05741 [Google Scholar]
- Piironen J, Paasiniemi M, and Vehtari A (2020). Projective inference in high-dimensional problems: Prediction and feature selection. Electronic Journal of Statistics, 14(1):2155–2197. [Google Scholar]
- Puelz D, Hahn PR, and Carvalho CM (2017). Variable selection in seemingly unrelated regressions with random predictors. Bayesian Analysis, 12(4):969–989. [Google Scholar]
- Rao JNK (2011). Impact of frequentist and Bayesian methods on survey sampling practice: a selective appraisal. Statistical Science, 26(2):240–256. [Google Scholar]
- Schmid D, Ricci C, and Leitzmann MF (2015). Associations of objectively assessed physical activity and sedentary time with all-cause mortality in US adults: The NHANES study. PLoS ONE, 10(3). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Semenova L and Rudin C (2019). A study in Rashomon curves and volumes: A new perspective on generalization and model simplicity in machine learning. arXiv preprint arXiv: 1908.01755 [Google Scholar]
- Smirnova E, Leroux A, Cao Q, Tabacu L, Zipunnikov V, Crainiceanu C, and Urbanek JK (2019). The Predictive Performance of Objective Measures of Physical Activity Derived From Accelerometry Data for 5-Year All-Cause Mortality in Older Adults: National Health and Nutritional Examination Survey 2003–2006. The Journals of Gerontology: Series A. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tran MN, Nott DJ, and Leng C (2012). The predictive Lasso. Statistics and Computing, 22(5):1069–1084. [Google Scholar]
- Tulabandhula T and Rudin C (2013). Machine learning with operational costs. Journal of Machine Learning Research, 14(1):1989–2028. [Google Scholar]
- Vehtari A and Ojanen J (2012). A survey of Bayesian predictive methods for model assessment, selection and comparison. Statistics Surveys, 6(1):142–228. [Google Scholar]
- Vehtari A, Simpson D, Gelman A, Yao Y, and Gabry J (2015). Pareto Smoothed Importance Sampling. arXiv preprint arXiv:1507.02646 [Google Scholar]
- Wolff-Hughes DL, Bassett DR, and White T (2018). In response to: Re-evaluating the effect of age on physical activity over the lifespan. Preventive Medicine, 106:231–232. [DOI] [PubMed] [Google Scholar]
- Woody S, Carvalho CM, and Murray JS (2020). Model interpretation through lower-dimensional posterior summarization. Journal of Computational and Graphical Statistics, pages 1–9.33013150 [Google Scholar]
- Zou H (2006). The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101 (476):1418–1429. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.