

Abstract
Universal compilation is a training process that compiles a trainable unitary into a target unitary. It has vast potential applications from depth-circuit compressing to device benchmarking and quantum error mitigation. Here we propose a universal compilation algorithm for quantum state tomography in low-depth quantum circuits. We apply the Fubini-Study distance as a trainable cost function and employ various gradient-based optimizations. We evaluate the performance of various trainable unitary topologies and the trainability of different optimizers for getting high efficiency and reveal the crucial role of the circuit depth in robust fidelity. The results are comparable with the shadow tomography method, a similar fashion in the field. Our work expresses the adequate capability of the universal compilation algorithm to maximize the efficiency in the quantum state tomography. Further, it promises applications in quantum metrology and sensing and is applicable in the near-term quantum computers for various quantum computing tasks.
Subject terms: Quantum mechanics, Quantum metrology, Qubits
Introduction
Quantum computers promise an excellent computational capacity that is intractable for classical computers to solve challenging problems, including materials science1–3, information science4,5, computer science6,7, mathematical science8–10, and others. However, there are two major challenges to bringing quantum computers to materialize2: (1) it is difficult to access full information from entangled systems because of the state collapse upon measurements, and (2) it is difficult to build, control, and measure quantum states with arbitrarily high accuracy. In this regard, even though the current state-of-the-art quantum computers rely on the noisy intermediate-scale (NISQ devices,) which usually prevent high efficiency11, various hybrid quantum-classical algorithms were proposed and actively studied recently12, and that could be promising for quantum speedup in the regime of NISQ devices. Massive applications including variational quantum eigensolvers13–17, quantum approximate optimization algorithms18, new frontiers in quantum foundations19–22, and others, were reported.
Beyond the actively studied VQAs, the universal compilation has drawn tremendous interest recently. Its core idea relies on a training process to transform a trainable unitary into a target unitary23,24. It was demonstrated in different applications from gate optimization23, to quantum-assisted compiling process24, continuous-variable quantum learning25, and robust quantum compilation26. The future of universal quantum compiling could be circuits depth-compression, black-box compiling, error mitigation, gate-fidelity benchmarking, and efficient gate synthesis.
In another aspect, quantum state tomography (QST) is a measurement process performed on numerous identical copies of a system to extract its state’s information27. In general, for a given unknown quantum state in a complex Hilbert space of d-dimension, it requires an exponentially growing measurements on different bases to completely reproduce the state, which is intractable for large systems. Numerous methods were proposed for improving the standard QST in terms of efficiency28–31, methodology32–38, quantum dynamic39–41, and so on. Recently, the quantum circuits-based QST has attracted significant attention owing to the incredible advantages of the quantum device42–44, which allows to efficiently prepare quantum states with high confidence, fully control the Hamiltonian for the state evolution, and directly access the measurement results. A variational approach45 and single-shot measurements46,47 to name a few, were investigated.
Despite recent achievements on the QST, it is still challenging to implement in the NISQ devices. In this work, we introduce a promising application of the universal compilation on the QST. Our main idea is to use a trainable unitary acting upon a known fiducial state to reconstruct an unknown state, which is created by using a Haar random target unitary acting upon the fiducial state. The advantage of this method is that it requires low-depth trainable unitaries and few measurements to realize the target state, which significantly reduces the complexity and allows for tractability of large systems. Furthermore, the flexibility of the trainable unitaries is more elevated than that of the target unitaries, resulting in a better fault-tolerant capacity and thus allowing high efficiency for the trainable quantum circuits.
Concretely, we first introduce the general framework of the universal compilation-based quantum state tomography (UC-QST) We also introduce several gradient-based optimizers, including the standard gradient descent (SGD), the Adam, and the quantum natural gradient descent (QNG). We discuss the numerical experiment results for a representative case of single-qubit tomography, and then evaluate the reconstructing efficiency of unknown Haar random states via various popular circuit ansatzes. We find that the circuit depth plays a crucial role in the robust fidelity, i.e., by choosing a proper circuit depth via the number of layers in the quantum circuit, we get high fidelity at any qubit numbers. We finally compare the results with the shadow tomography method48,49, a similar fashion in the field.
The study reveals that the accuracy mainly relies on (1) the ansatz topologies with the optimal circuit depth and (2) the significant impact of different optimizers. Our study can further promise applications in quantum metrology and sensing, and new frontier foundation aspects. Moreover, it is possible to implement the algorithm on near-term quantum computers, and thus it could be a valuable technique for verifying the fidelity of quantum circuits and studying various quantum computing tasks. These are also benefits that overcome the standard QST, which requires the set-up of traditional experiments, consumes heavy post-processing calculations to reproduce the quantum state, and the accuracy depends on the estimators, such as the Maximum-Likelihood and Least-Squares27.
Results
We introduce a universal compilation scheme23–26 to translate a given state into another one and apply it to quantum state tomography.
Universal compilation-based quantum state tomography (UC-QST)
A universal compilation scheme consists of a quantum part and a classical part, as shown in Fig. 1a. The quantum part is a circuit with parameterizable ansatzes. Let is a fixed target unitary and is a trainable unitary ansatz (sets of quantum gates with some parameters ) that act sequentially onto the circuit and transform an initial state into a final state as
| 1 |
The transition probability yields
| 2 |
Figure 1.

Universal compilation-based quantum state tomography. (a) A universal compilation algorithm consists of a quantum part and a classical part. In the quantum part, a final state is created by applying a set of quantum gates followed by onto the initial circuit and then be measured. In the classical part, we compute the appropriate cost function, use an optimizer to compute new parameters, and update the scheme until it converges. (b) Structures of the target and trainable unitaries used in the QST. The unitary is a Haar random generator while is parameterized into and broken out into entangled gates and local rotation gates with several structures as shown in the figure. (c) A sketch of some quantum gates used in (b). Other notations: N the number of qubits, L the number of layers, the rotation gate around the j axis.
Our task is to maximize the transition probability , such that a state is compiled to . The maximization of the transition probability, i.e., , implies , which can be applied to the QST as we will describe below.
Concretely for the QST, let , where N is the number of qubits, we transform it into a random (unknown) quantum state via a Haar random unitary 50. To reconstruct this state, we apply a trainable unitary evolution that can learn the role of , i.e., a reconstructed state resembles to the unknown state , where can be adaptively updated during a training process, M is the number of trainable parameters. There is no free lunch for the choice of 25. However, it can break out into a sequence of single-qubit and multi-qubit gates as
| 3 |
as shown in Fig. 1b, wherein includes the chain, alternating, and all-to-all structures51 as shown in Fig. 1c. We emphasize that the entangled gates consist of two-qubit controlled y-rotation gates, which differs from previous works51. We refer to these gates as parameter-dependent entanglement gate. They are useful for preparing variational states metrology21 and rapid entangled circuits52, for testing of the expressibility and entangling capability53, and so on.
To qualify how closed the two states are, we consider the Fubini-Study distance as54
| 4 |
where is the probability for getting the outcome . In the quantum circuit, we apply a sequence of followed by onto the initial state to get the final state and then measure a projective operator , which yields the probability .
The variational (reconstructed) state becomes the target (unknown) state if the distance reaches zero. In the classical part, we thus use the Fubini-Study distance as a cost function that needs to minimize, i.e., , such that
| 5 |
By training the variational circuit until it converges, we obtain the optimal and the reconstructed state yields . This is a normalized pure state because is a unitary ansatz, i.e., .
For the training process, we apply gradient-based optimizations to iteratively update the parameters and minimize the cost function. We first compute the derivative for all and then compute new parameters via various appropriate optimizers, including the Standard gradient descent (SGD), Adam gradient descent55, and Quantum natural gradient (QNG)56. See “Methods” section for details.
Numerical results
Single-qubit QST
We first consider reconstructing an abstract single-qubit state encodes in a quantum circuit as shown in the inset Fig. 2. We randomly generate an unknown quantum state , where
| 6 |
where we set random with Haar measure , , and . To reconstruct , we set the unitary . Indeed, a single-qubit rotation is and is a Pauli matrix applied on the qubit. We train the scheme with 100 iterations using various optimizers and show the cost function versus iteration in the main (Fig. 2). Here, the QNG optimizer gives the best optimization. In the inset figure, we show the trajectory in the Bloch sphere of the reconstructed state under the updated of for two cases of SGD and QNG optimizers. The former needs around 60 iterations for the reconstructed state to reach the true state, while the latter only requires around 6 iterations to reach the same accuracy.
Figure 2.
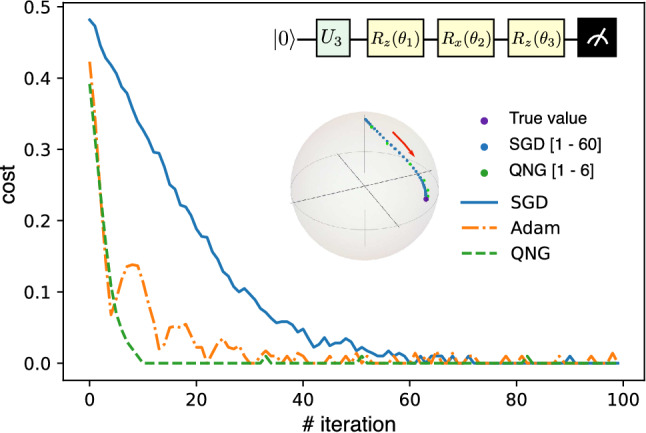
Single-qubit tomography. Cost function versus the number of iterations for difference optimizers: SGD (blue), Adam (orange), and QNG (green). Inset 1: quantum circuit for a single-qubit tomography where an unknown qubit state is generated by a random unitary , and is made up of , , and gates. Inset 2: Bloch sphere represents the qubit states: violet circle: the true state, blue circle: the trajectory of the reconstructed state under the SGD optimizer for the iterations run from 1 to 60, green circle: the trajectory under the QNG optimizer for the iteration runs from 1 to 6.
Haar random state QST
Now, we focus on a general random Haar state i.e., , as shown in Fig. 1b. To reconstruct the state, we use several ansatzes for the entangled gate in , including the , and structures. Refer Fig. 1c for the detailes of these structures, where we used the parameter-dependent controlled y-rotation gates to construct them. The circuit’s depth for these structures are and , respectively. The trainable parameters are , and , respectively, which are grown linearly with N. This is suitable for NISQ devices even for the large number of qubits.
The results are shown in Fig. 3. Let us consider the fidelity between the true Haar state and the reconstructed state as
| 7 |
which is the overlap between these two states. In Fig. 3a–c, we show the fidelities for different structures of . For each case, we fix and examine the three optimizers SGD (blue circle), Adam (yellow square), and QNG (green triangle). We first observe that the SGD optimizer is not good for all structures and needs to choose an appropriate learning rate. The fidelities reduce with the increasing N and nearly vanish at . In contrast, the Adam optimizer exhibit high fidelities up to for (a), for (c), and gradually reduces from for (b). Even though it is not stable near the optimal point, the Adam is remarkable for achieving high accuracy in the QST. Furthermore, the QNG optimizer also allows for getting such high accuracy up to for (a) and even better than the Adam for (b), while it gradually reduces for (c). This observation can be explained by these own structures: the contains the most number of parameters via the controlled y-rotation gates compared to the others, which results in the low accuracy. It is apparent that the QNG optimizer is sensitive to the controlled y-rotation gates, where the more controlled y-rotation gates, the less efficient QNG optimizer.
Figure 3.

Numerical results for quantum state tomography. (a–c) Plot of the fidelity between an unknown Haar random state and its reconstructed state for different structures: (a), (b), and (c). For each case, we show the results for different optimizers: SGD, Adam, and QNG. Here we fixed . (d–f) Plot of the fidelity similar as above for different L as shown in the colored parentheses (blue star, yellow dagger, green double dagger). Here, blue star is the optimal number of layers for the SGD, yellow dagger is the optimal number of layers for the Adam, and green double dagger is the optimal number of layers for the QNG. We choose the appropriate (blue star, yellow dagger, green double dagger) for each N and each structure so that the fidelity gets its (possible) highest accuracy.
Next, to achieve high accuracy for any qubit numbers N, we increase the number of layers L, while paying attention to the barren plateau57–61, i.e., the accuracy of the training process reduces when increasing the parameters space. Figure 3d–f plot the fidelities versus N, where for each N, the corresponding L is shown in the colored parenthesis (blue star, yellow dagger, green double dagger), for the SGD, Adam, and QNG, respectively. The number of layers shown in the parenthesis is the smallest (optimal) L required for achieving such high accuracy before it goes down due to the barren plateau. As can be seen from the figure, the Adam method allows for reaching the maximum fidelity (results are shown up to for all structures) with a suitable L as shown in the middle position of the parenthesis. Similarly, we can reach high accuracy with the QNG optimizer up to when choosing an appropriate L as shown in the last position of the parenthesis. For the SGD, it is intractable for achieving high accuracy, such as for . Even though the relation between N and the required L is not clear, interestingly, we can see from the results up to , the required L is also around 5 (more L is redundancy or may reduce the accuracy due to the barren plateau, see details in “Methods” section).
We only simulate up to . However, for larger N, the scheme still works well. Evidently, in Fig. 3d–f, we enhance high fidelity with an appropriate optimizer for every N up to 5. Following the procedure in “Methods” section, we can entirely expand to a larger N while still maintaining high fidelity.
Compare to the shadow tomography protocol
Finally, we address the merit of our UC-QST approach and the shadow tomography protocol48,49, a recent promising method in this regime. A shadow tomography protocol is given as follows49: (1) initially prepare a random unknown quantum state , and the task ahead is to predict a target function underlying the state from its shadow, (2) randomly pick up a unitary in a T-tuple , i.e., then apply it to the initial state to transform , (3) measure the evolved state in the computational basis . Steps (2) and (3) are repeated for a certain number of measurements. For each measurement, we get a random classical snapshot
| 8 |
We then define an invertible channel matrix
| 9 |
where is the average over , with a corresponding pick-up probability. Let exists, and let is the probability of picking up a unitary , then we can reconstruct a (non-normalized) state as
| 10 |
which is the classical shadow of the original unknown state . For the transformation belongs to a family of the global Clifford gates, i.e., , refer to Random Clifford measurements, the reconstructed state explicitly yields49
| 11 |
For the transformation belongs to the random Pauli gates, such as , refer to Random Pauli measurements, it straightforwardly yields49
| 12 |
for .
For comparing the shadow tomography with the UC-QST scheme, we apply the Random Pauli measurements and consider the prediction of a linear function as a figure of merit for the accuracy. A global observable , gives the predicted (linear) expectation value as
| 13 |
The fluctuation (distribution around the true expectation value) of the predicted expectation value is given by the variance Var as
| 14 |
In Fig. 4a, we show the variance Var as a function of the number of measurements for the shadow tomography. The variance slightly decreases when increasing the number of measurements from to . See the inset figure for the detailed zoom-in. The result is compared with the standard quantum limit (SQL), i.e., SQL = 1/ #measurement, and the Heisenberg limit (HL), i.e., HL = 1/ (#measurement). Here, the variance does not beat the SQL nor HL.
Figure 4.
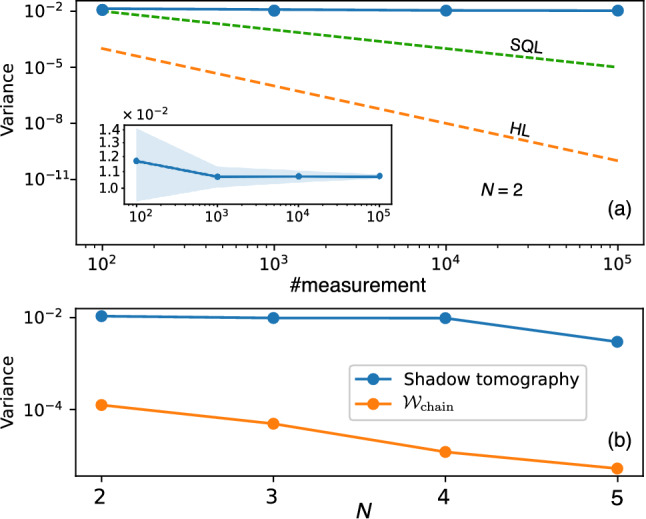
Comparison between the UC-QST approach and the shadow tomography method. (a) Log–log plot of the variance Var versus the number of repeated measurements (#measurement) using the shadow tomography. The standard quantum limit (SQL) and Heisenberg limit (HL) are shown for comparison purposes. The number of qubits is fixed at . Inset: Zoom-in the variance, where the blue area is the standard deviation after talking ten runs. (b) Plot of variance for the shadow tomography (blue) and UC-QST (orange). For the shadow tomography, we fix #measurement , and for the UC-QST, we use the structure of and the Adam optimizer, the number of shots is .
In Fig. 4b, we compare the variances obtained from the shadow tomography and the UC-QST for the different number of qubits N. For the shadow tomography, we fix #measurement . For the UC-QST, we consider the structure with the Adam optimizer as an example. The number of shots is fixed at . It can be seen that the UC-QST offers a better result over 100 times than the resulting shadow tomography.
Discussion
We discuss some features of the UC-QST and shadow tomography in the previous section. The shadow tomography only allows predicting target functions, such as expectation values, entanglement entropies, correlation functions, and so on49, while maintaining the precision. Whereas the UC-QST allows for reconstructing the entire quantum state up to a phase shift. Both schemes allow for predicting properties of quantum states or quantum states with fewer measurements compared to standard quantum tomography. Another remarkable feature is that the efficiency of the shadow tomography protocol depends on the random choice of the unitaries in an ensemble , while the efficiency of the UC-QST scheme relies on the choice of different ansatzes and optimizes. Finally, we emphasize that the comparison in this section only provides a very first glance about the two approaches. We need to further characterize these features in future works for more concrete evaluation.
Furthermore, the idea of UC-QST resembles the self-guided quantum tomography (SGQT)62 and single-shot measurement (SSM)46,47. These previous approaches also iteratively search the estimated state to converge to the true state. However, the trainable unitary topologies and optimization algorithms are different. The SGQT uses a simultaneous perturbation stochastic approximation63 to optimize the cost function, while the SSM trains a learning unitary to be a fiducial (known) state that converges to the true state. Here, we apply the universal compilation technique to train a learning unitary to be the target unitary.
Finally, we emphasize that the current method is suitable only for pure-state tomography and not for general mixed-state tomography.
Methods
Training process
The training process is a hybrid protocol as illustrated in Fig. 1a: a set of unitary gates followed by are applied onto the circuit and the final state is measured afterwards. The results are sent to the classical counterpart to compute the corresponding cost function and then update new parameters using a suitable optimizer protocol until it reaches convergence.
We use gradient-based optimizations to iteratively update the parameters and minimize the cost function. To do that, we need to calculate the derivative w.r.t in the jth gate for every . We compute two cases as follows. First, if the jth gate is a single-qubit rotation gate, i.e., , then using the standard (two-term) parameter-shift rule64,65, we have
| 15 |
where s denotes an arbitrary shift, and is the jth unit vector, or in other words, we only add s to . Second, if the jth gate is a controlled rotation gate, i.e., , then using the four-term parameter-shift rule66, we partially compute
| 16 |
where . Then, we get .
To compute new parameters, we use several optimizers in all experiments: Standard gradient descent (SGD), Adam gradient descent55, and Quantum natural gradient (QNG)56.
The formula for SGD reads
| 17 |
where for M training parameters, and is the learning rate. In comparison, Adam is a non-local averaging optimizer that allows adapting the learning rate but requires more steps than the SGD
| 18 |
where with the hyper-parameters are chosen as and . Finally, the QNG is defined by
| 19 |
where is the pseudo-inverse of a Fubini-Study metric tensor g67. Assume that we can group into layers, i.e., , so that in each layer , any two of unitaries satisfy . Then, the metric tensor g gives68
| 20 |
where an element of reads
| 21 |
where is the quantum state at the th layer. For unitary , e.g., a rotation gate, such that , then is recast as68
| 22 |
See a detailed example of computing a tensor metric g below.
Each optimizer has its own pros and cons: (1) the SGD is simple but low coverage, one must choose a proper learning rate to achieve the best result, (2) the Adam allows to automatically adapt the learning rate and fast coverage but it is noisy near the optimal point, and (3) the QNG is better than other optimizers but also requires more computational cost regards to quantum circuits. While the SGD and Adam do not depend on quantum states and work for any classical data types, including the probabilities, the QNG optimizes the parameters towards the geometry of evolved quantum states and is thus expected to offer better and faster optimization. We conduct these optimizers based on their advantages and disadvantages and compare the results. They also serve as a test bed and reference for future works.
This work implements the numerical experiments using various configurations described above to train the variational models and compare them together. The numerical results are executed by Qiskit open-source package, version 0.24.0, which is available to run on all platforms. For each experiment, to get the probability we execute shots using the qasm simulator backend. The number of iterations for every training process is fixed at 400, except for others shown in the text. It is sufficient for the cost function to converge for all data shown in the text. The experiments are then scaled up to 6 qubits for quantum state tomography to demonstrate the scalability. Furthermore, after the training process, we can reproduce the unknown state by applying into the initial state , and use it for further applications and other statistical computations.
Complexity
In terms of complexity, to execute the parameter-shift rule in Eq. (15), the quantum circuit executes times, one M times to compute , one M times to compute , and one time to compute . Furthermore, a single evaluation requires executing the circuit for a constant number of shots to reach a certain precision, and each execution involves around G gate operations. So, the complexity of each iteration is . Similarly, the complexity for an iteration with four-term parameter-shift rule is .
Ideally, after each step, the cost function will decrease with a linear or logarithmic speed regarding the number of iterations. However, the variational circuit always offers a lower bound of the cost function during the training process. In particular, this bound increases by the number of qubits N, which means the problem will be harder according to the size of the system
| 23 |
The complexity of the ansatz is another challenge. Its current structure is fixed into the chain, alternating, and all-to-all. However, the structure also needs to optimize in future works, e.g., using Genetic Algorithms for generating a compressed ansatz that can work well on the current NISQ devices for the large number of qubits.
Fubini-Study tensor metric
We provide a practical example of how to compute a Fubini-Study tensor metric. Let us consider a concrete circuit as shown in Fig. 5. It consists of , , and . Since (because they act on different qubits), we can group them into one layer (layer 1), with , and put into another layer (layer 2), with . The tensor metric g explicitly yields
| 24 |
Figure 5.
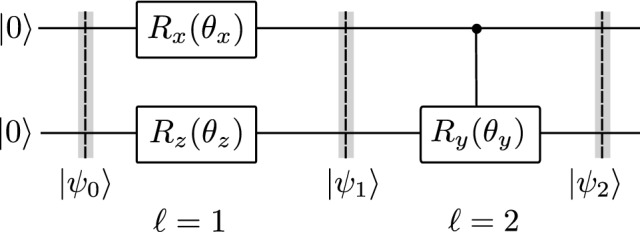
An example quantum circuit for evaluating the Fubini-Study tensor metric. The circuit starts with the initial state and evolves under a set of gates in layer 1, and in layer 2. Detailed of the Fubini-Study tensor metric evaluation for this circuit is provided in the text.
The quantum states are explicitly expressed as
| 25 |
| 26 |
| 27 |
The elements is given through Eq. (22) as
where and .
Next, we calculate . Starting from Eq. (21) in the main text, we derive
| 28 |
Then, we get
| 29 |
where . To derive expectation values in Eq. (29), we prepare as in Fig. 5, then measure and . Finally, we obtain the tensor metric g
| 30 |
Supported data for QST
We discuss more data supporting the results in Fig. 3d–f in the main text. As we discussed above, the accuracy can be improved when increasing the number of layers L. However, we cannot increase L arbitrarily large and need to stop at an optimal point. We define the optimal L as the smallest number of layers that, at the next layer, the accuracy saturates or starts to reduce. In Fig. 6 below, we discuss the optimal L for various cases, where we mark the optimal L with colored arrows. See also Table 1 below.
Figure 6.

Plot of fidelity as a function of L for different structures and different optimizers. (a) (, SGD), (b) (, Adam), (c) (, QNG), (d) (, SGD), (e) (, Adam), (f) (, QNG), (g) (, SGD), (h) (, Adam), (i) (, QNG).
Table 1.
Number of optimal layers L taking from Fig. 6.
 )
) )
) )
) )
) )
) )
)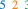 )
) )
)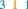 )
)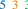 )
) )
) )
)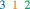 )
)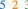 )
)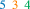 )
) )
)From the results here, we trace out the optimal L as shown in Fig. 3 in the main text.
Acknowledgements
This work is supported by the VNUHCM-University of Information Technology’s Scientific Research Support Fund.
Author contributions
V.T.H. implemented the algorithms and performed numerical analysis. L.B.H. derived the theoretical framework. All authors wrote the manuscript.
Data availability
Data are available from the corresponding authors upon reasonable request.
Code availability
All codes used to produce the findings of this study are available at: https://github.com/vutuanhai237/UC-VQA.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.de Leon NP, et al. Materials challenges and opportunities for quantum computing hardware. Science. 2021;372:eabb2823. doi: 10.1126/science.abb2823. [DOI] [PubMed] [Google Scholar]
- 2.Alexeev Y, et al. Quantum computer systems for scientific discovery. PRX Quantum. 2021;2:017001. doi: 10.1103/PRXQuantum.2.017001. [DOI] [Google Scholar]
- 3.Ebadi S, et al. Quantum phases of matter on a 256-atom programmable quantum simulator. Nature. 2021;595:227–232. doi: 10.1038/s41586-021-03582-4. [DOI] [PubMed] [Google Scholar]
- 4.Pirandola S, Eisert J, Weedbrook C, Furusawa A, Braunstein SL. Advances in quantum teleportation. Nat. Photon. 2015;9:641–652. doi: 10.1038/nphoton.2015.154. [DOI] [Google Scholar]
- 5.Spiller TP. Quantum information technology. Mater. Today. 2003;6:30–36. doi: 10.1016/S1369-7021(03)00130-5. [DOI] [Google Scholar]
- 6.Shor, P. Algorithms for quantum computation: Discrete logarithms and factoring. In Proceedings 35th Annual Symposium on Foundations of Computer Science, 124–134. 10.1109/SFCS.1994.365700 (1994).
- 7.Grover, L. K. A fast quantum mechanical algorithm for database search. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, 212–219 (1996).
- 8.Harrow AW, Hassidim A, Lloyd S. Quantum algorithm for linear systems of equations. Phys. Rev. Lett. 2009;103:150502. doi: 10.1103/PhysRevLett.103.150502. [DOI] [PubMed] [Google Scholar]
- 9.Xu X, Benjamin SC, Yuan X. Variational circuit compiler for quantum error correction. Phys. Rev. Appl. 2021;15:034068. doi: 10.1103/PhysRevApplied.15.034068. [DOI] [Google Scholar]
- 10.Lubasch M, Joo J, Moinier P, Kiffner M, Jaksch D. Variational quantum algorithms for nonlinear problems. Phys. Rev. A. 2020;101:010301. doi: 10.1103/PhysRevA.101.010301. [DOI] [Google Scholar]
- 11.Preskill J. Quantum computing in the NISQ era and beyond. Quantum. 2018;2:79. doi: 10.22331/q-2018-08-06-79. [DOI] [Google Scholar]
- 12.Cerezo M, et al. Variational quantum algorithms. Nat. Rev. Phys. 2021;3:625–644. doi: 10.1038/s42254-021-00348-9. [DOI] [Google Scholar]
- 13.Peruzzo A, et al. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 2014;5:4213. doi: 10.1038/ncomms5213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Nakanishi KM, Mitarai K, Fujii K. Subspace-search variational quantum eigensolver for excited states. Phys. Rev. Res. 2019;1:033062. doi: 10.1103/PhysRevResearch.1.033062. [DOI] [Google Scholar]
- 15.Kirby WM, Tranter A, Love PJ. Contextual subspace variational quantum eigensolver. Quantum. 2021;5:456. doi: 10.22331/q-2021-05-14-456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Gard BT, et al. Efficient symmetry-preserving state preparation circuits for the variational quantum eigensolver algorithm. NPJ Quantum Inf. 2020;6:10. doi: 10.1038/s41534-019-0240-1. [DOI] [Google Scholar]
- 17.Tkachenko NV, et al. Correlation-informed permutation of qubits for reducing ansatz depth in the variational quantum eigensolver. PRX Quantum. 2021;2:020337. doi: 10.1103/PRXQuantum.2.020337. [DOI] [Google Scholar]
- 18.Zhou L, Wang S-T, Choi S, Pichler H, Lukin MD. Quantum approximate optimization algorithm: Performance, mechanism, and implementation on near-term devices. Phys. Rev. X. 2020;10:021067. doi: 10.1103/PhysRevX.10.021067. [DOI] [Google Scholar]
- 19.Arrasmith A, Cincio L, Sornborger AT, Zurek WH, Coles PJ. Variational consistent histories as a hybrid algorithm for quantum foundations. Nat. Commun. 2019;10:3438. doi: 10.1038/s41467-019-11417-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Kaubruegger R, et al. Variational spin-squeezing algorithms on programmable quantum sensors. Phys. Rev. Lett. 2019;123:260505. doi: 10.1103/PhysRevLett.123.260505. [DOI] [PubMed] [Google Scholar]
- 21.Koczor B, Endo S, Jones T, Matsuzaki Y, Benjamin SC. Variational-state quantum metrology. New J. Phys. 2020;22:083038. doi: 10.1088/1367-2630/ab965e. [DOI] [Google Scholar]
- 22.Meyer JJ, Borregaard J, Eisert J. A variational toolbox for quantum multi-parameter estimation. NPJ Quantum Inf. 2021;7:89. doi: 10.1038/s41534-021-00425-y. [DOI] [Google Scholar]
- 23.Heya, K., Suzuki, Y., Nakamura, Y. & Fujii, K. Variational quantum gate optimization. arXiv:1810.12745 (arXiv preprint) (2018).
- 24.Khatri S, et al. Quantum-assisted quantum compiling. Quantum. 2019;3:140. doi: 10.22331/q-2019-05-13-140. [DOI] [Google Scholar]
- 25.Volkoff T, Holmes Z, Sornborger A. Universal compiling and (no-)free-lunch theorems for continuous-variable quantum learning. PRX Quantum. 2021;2:040327. doi: 10.1103/PRXQuantum.2.040327. [DOI] [Google Scholar]
- 26.Jones T, Benjamin SC. Robust quantum compilation and circuit optimisation via energy minimisation. Quantum. 2022;6:628. doi: 10.22331/q-2022-01-24-628. [DOI] [Google Scholar]
- 27.Paris M, Rehacek J. Quantum State Estimation. Springer; 2004. [Google Scholar]
- 28.Palmieri AM, et al. Experimental neural network enhanced quantum tomography. NPJ Quantum Inf. 2020;6:20. doi: 10.1038/s41534-020-0248-6. [DOI] [Google Scholar]
- 29.Cramer M, et al. Efficient quantum state tomography. Nat. Commun. 2010;1:149. doi: 10.1038/ncomms1147. [DOI] [PubMed] [Google Scholar]
- 30.Jackson C, van Enk SJ. Detecting correlated errors in state-preparation-and-measurement tomography. Phys. Rev. A. 2015;92:042312. doi: 10.1103/PhysRevA.92.042312. [DOI] [Google Scholar]
- 31.Moroder T, et al. Permutationally invariant state reconstruction. New J. Phys. 2012;14:105001. doi: 10.1088/1367-2630/14/10/105001. [DOI] [Google Scholar]
- 32.Ahmed S, Sánchez Muñoz C, Nori F, Kockum AF. Classification and reconstruction of optical quantum states with deep neural networks. Phys. Rev. Res. 2021;3:033278. doi: 10.1103/PhysRevResearch.3.033278. [DOI] [Google Scholar]
- 33.Tóth G, et al. Permutationally invariant quantum tomography. Phys. Rev. Lett. 2010;105:250403. doi: 10.1103/PhysRevLett.105.250403. [DOI] [PubMed] [Google Scholar]
- 34.Torlai G, et al. Neural-network quantum state tomography. Nat. Phys. 2018;14:447–450. doi: 10.1038/s41567-018-0048-5. [DOI] [Google Scholar]
- 35.Blume-Kohout R. Optimal, reliable estimation of quantum states. New J. Phys. 2010;12:043034. doi: 10.1088/1367-2630/12/4/043034. [DOI] [Google Scholar]
- 36.Fiderer LJ, Schuff J, Braun D. Neural-network heuristics for adaptive Bayesian quantum estimation. PRX Quantum. 2021;2:020303. doi: 10.1103/PRXQuantum.2.020303. [DOI] [Google Scholar]
- 37.Gross D, Liu Y-K, Flammia ST, Becker S, Eisert J. Quantum state tomography via compressed sensing. Phys. Rev. Lett. 2010;105:150401. doi: 10.1103/PhysRevLett.105.150401. [DOI] [PubMed] [Google Scholar]
- 38.Flammia ST, Gross D, Liu Y-K, Eisert J. Quantum tomography via compressed sensing: Error bounds, sample complexity and efficient estimators. New J. Phys. 2012;14:095022. doi: 10.1088/1367-2630/14/9/095022. [DOI] [Google Scholar]
- 39.Czerwinski A. Dynamic state reconstruction of quantum systems subject to pure decoherence. Int. J. Theor. Phys. 2020;59:3646–3661. doi: 10.1007/s10773-020-04625-8. [DOI] [Google Scholar]
- 40.Flurin E, Martin LS, Hacohen-Gourgy S, Siddiqi I. Using a recurrent neural network to reconstruct quantum dynamics of a superconducting qubit from physical observations. Phys. Rev. X. 2020;10:011006. doi: 10.1103/PhysRevX.10.011006. [DOI] [Google Scholar]
- 41.Mäkinen A, Ikonen J, Partanen M, Möttönen M. Reconstruction approach to quantum dynamics of bosonic systems. Phys. Rev. A. 2019;100:042109. doi: 10.1103/PhysRevA.100.042109. [DOI] [Google Scholar]
- 42.Lvovsky AI, Raymer MG. Continuous-variable optical quantum-state tomography. Rev. Mod. Phys. 2009;81:299. doi: 10.1103/RevModPhys.81.299. [DOI] [Google Scholar]
- 43.D’Ariano GM, De Laurentis M, Paris MG, Porzio A, Solimeno S. Quantum tomography as a tool for the characterization of optical devices. J. Opt. B Quantum Semiclassical Opt. 2002;4:S127. doi: 10.1088/1464-4266/4/3/366. [DOI] [Google Scholar]
- 44.Takeda K, et al. Quantum tomography of an entangled three-qubit state in silicon. Nat. Nanotechnol. 2021;20:1–5. doi: 10.1038/s41565-021-00925-0. [DOI] [PubMed] [Google Scholar]
- 45.Liu Y, et al. Variational quantum circuits for quantum state tomography. Phys. Rev. A. 2020;101:052316. doi: 10.1103/PhysRevA.101.052316. [DOI] [Google Scholar]
- 46.Lee SM, Lee J, Bang J. Learning unknown pure quantum states. Phys. Rev. A. 2018;98:052302. doi: 10.1103/PhysRevA.98.052302. [DOI] [Google Scholar]
- 47.Lee SM, Park HS, Lee J, Kim J, Bang J. Quantum state learning via single-shot measurements. Phys. Rev. Lett. 2021;126:170504. doi: 10.1103/PhysRevLett.126.170504. [DOI] [PubMed] [Google Scholar]
- 48.Aaronson, S. Shadow tomography of quantum states. 10.48550/ARXIV.1711.01053 (2017).
- 49.Huang H-Y, Kueng R, Preskill J. Predicting many properties of a quantum system from very few measurements. Nat. Phys. 2020;16:1050–1057. doi: 10.1038/s41567-020-0932-7. [DOI] [Google Scholar]
- 50.White, C. D. & Wilson, J. H. Mana in haar-random states. arXiv:2011.13937 (arXiv preprint) (2020).
- 51.Haug T, Bharti K, Kim M. Capacity and quantum geometry of parametrized quantum circuits. PRX Quantum. 2021;2:040309. doi: 10.1103/PRXQuantum.2.040309. [DOI] [Google Scholar]
- 52.Schuld M, Bocharov A, Svore KM, Wiebe N. Circuit-centric quantum classifiers. Phys. Rev. A. 2020 doi: 10.1103/physreva.101.032308. [DOI] [Google Scholar]
- 53.Sim S, Johnson PD, Aspuru-Guzik A. Expressibility and entangling capability of parameterized quantum circuits for hybrid quantum-classical algorithms. Adv. Quantum Technol. 2019;2:1900070. doi: 10.1002/qute.201900070. [DOI] [Google Scholar]
- 54.Kuzmak AR. Measuring distance between quantum states on a quantum computer. Quantum Inf. Process. 2021;20:269. doi: 10.1007/s11128-021-03196-9. [DOI] [Google Scholar]
- 55.Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv:1412.6980 (arXiv preprint) (2014).
- 56.Stokes J, Izaac J, Killoran N, Carleo G. Quantum natural gradient. Quantum. 2020;4:269. doi: 10.22331/q-2020-05-25-269. [DOI] [Google Scholar]
- 57.McClean JR, Boixo S, Smelyanskiy VN, Babbush R, Neven H. Barren plateaus in quantum neural network training landscapes. Nat. Commun. 2018;9:4812. doi: 10.1038/s41467-018-07090-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Cerezo M, Sone A, Volkoff T, Cincio L, Coles PJ. Cost function dependent barren plateaus in shallow parametrized quantum circuits. Nat. Commun. 2021;12:1791. doi: 10.1038/s41467-021-21728-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Holmes Z, Sharma K, Cerezo M, Coles PJ. Connecting ansatz expressibility to gradient magnitudes and barren plateaus. PRX Quantum. 2022;3:010313. doi: 10.1103/PRXQuantum.3.010313. [DOI] [Google Scholar]
- 60.Ortiz Marrero C, Kieferová M, Wiebe N. Entanglement-induced barren plateaus. PRX Quantum. 2021;2:040316. doi: 10.1103/PRXQuantum.2.040316. [DOI] [Google Scholar]
- 61.Wang S, et al. Noise-induced barren plateaus in variational quantum algorithms. Nat. Commun. 2021;12:6961. doi: 10.1038/s41467-021-27045-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Ferrie C. Self-guided quantum tomography. Phys. Rev. Lett. 2014;113:190404. doi: 10.1103/PhysRevLett.113.190404. [DOI] [PubMed] [Google Scholar]
- 63.Spall J. Multivariate stochastic approximation using a simultaneous perturbation gradient approximation. IEEE Trans. Autom. Control. 1992;37:332–341. doi: 10.1109/9.119632. [DOI] [Google Scholar]
- 64.Mitarai K, Negoro M, Kitagawa M, Fujii K. Quantum circuit learning. Phys. Rev. A. 2018;98:032309. doi: 10.1103/PhysRevA.98.032309. [DOI] [Google Scholar]
- 65.Schuld M, Bergholm V, Gogolin C, Izaac J, Killoran N. Evaluating analytic gradients on quantum hardware. Phys. Rev. A. 2019;99:032331. doi: 10.1103/PhysRevA.99.032331. [DOI] [Google Scholar]
- 66.Anselmetti G-LR, Wierichs D, Gogolin C, Parrish RM. Local, expressive, quantum-number-preserving VQE ansätze for fermionic systems. New J. Phys. 2021;23:113010. doi: 10.1088/1367-2630/ac2cb3. [DOI] [Google Scholar]
- 67.Harrow AW, Napp JC. Low-depth gradient measurements can improve convergence in variational hybrid quantum-classical algorithms. Phys. Rev. Lett. 2021;126:140502. doi: 10.1103/PhysRevLett.126.140502. [DOI] [PubMed] [Google Scholar]
- 68.Stokes J, Izaac J, Killoran N, Carleo G. Quantum natural gradient. Quantum. 2020;4:269. doi: 10.22331/q-2020-05-25-269. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data are available from the corresponding authors upon reasonable request.
All codes used to produce the findings of this study are available at: https://github.com/vutuanhai237/UC-VQA.