

Abstract
Small molecule targeting of RNA has emerged as a new frontier in medicinal chemistry, but compared to the protein targeting literature our understanding of chemical matter that binds to RNA is limited. In this study, we reported Repository Of BInders to Nucleic acids (ROBIN), a new library of nucleic acid binders identified by small molecule microarray (SMM) screening. The complete results of 36 individual nucleic acid SMM screens against a library of 24,572 small molecules were reported (including a total of 1,627,072 interactions assayed). A set of 2,003 RNA-binding small molecules was identified, representing the largest fully public, experimentally derived library of its kind to date. Machine learning was used to develop highly predictive and interpretable models to characterize RNA-binding molecules. This work demonstrates that machine learning algorithms applied to experimentally derived sets of RNA binders are a powerful method to inform RNA-targeted chemical space.
Introduction
Recent years have seen an increased interest in targeting RNA with small molecules as an approach to develop novel chemical probes and therapeutics.[1] The potential for developing transformative therapeutics that target RNA is considerable. Of the ~3 billion base pairs in the human genome, estimates suggest that nearly 85% of this information is transcribed into RNA.[2] In contrast, just ~1.5% of transcribed sequences code for polypeptides.[3] Research into the non-coding functions of RNA has revealed numerous disease-relevant regulatory mechanisms that could conceivably be modulated by RNA-targeting molecules.[1a, 4] While estimates indicate that less than 15% of the proteome is “druggable”,[5] a far greater proportion of proteins have been implicated in disease states, and targeting the mRNA of “undruggable” proteins could represent a unique approach to impact the expression of pathogenic proteins.
To date, antisense molecules such as siRNAs, shRNAs, PNAs, and LNAs have been widely used to target RNA.[6] However, antisense technologies often bring challenges with distribution or cell permeability,[7] making small molecules that target RNA a highly attractive option. Early efforts to target RNAs with small molecules focused on molecules that recognize grooves in helices or non-specific chemical scaffolds such as aminoglycosides.[8] However, because RNA is single-stranded, it can form intramolecular base pairs and fold into a diverse array of highly complex structures that are capable of forming hydrophobic pockets that are likely to accept small molecule ligands.[9] Structures in RNA can be functionally relevant,[10] and may therefore represent opportunities to perturb RNA with small molecules.[11] To date, viral RNAs, riboswitches, ribosomal RNA, microRNAs (miRNAs), long non-coding RNAs (lncRNAs), and mRNAs have been targeted with small molecules.[1a, 1b, 8, 12] Compared to protein targets, RNA poses unique challenges due to its anionic phosphodiester backbone, the highly dynamic nature of many reported RNA structures, and a relative lack of atomic resolution structures of RNA. More work is needed to understand the chemical properties that drive RNA recognition by small molecules, and what makes a good RNA target.
While numerous studies have detailed the chemical properties of protein-binding molecules and what factors are likely to lead to the successful development of an inhibitor,[13] a comparably small number of studies have broadly described the properties of RNA-binding molecules. Efforts by the Hargrove laboratory,[14] Disney laboratory,[15] and a Merck research group[16] have described a number of chemotypes and chemical properties enriched in RNA binding small molecules. In addition, several databases exist to catalog RNA- and DNA- binding molecules. In this area, notable contributions include INFORNA (based on 2-dimensional combinatorial screening)[15c], R-BIND[14d, 14e] (focused on biologically active RNA-binding molecules) and NALDB[17] (which catalogs DNA- and RNA-binding molecules), all of which represent important resources for understanding chemical matter that interacts with nucleic acids. However, to date no laboratory has published full results from high-throughput screening against diverse RNA targets (including both hits and complete library composition). Such data would be uniquely valuable for developing advanced algorithms to characterize and understand RNA-binding chemical space.
Here, we disclose the complete results of 36 small molecule microarray (SMM) screens against nucleic acid targets. These targets represent diverse RNA structures and several DNA G-quadruplexes screened against a library of 24,572 commercially available drug-like small molecules. This dataset includes replicate assays and some oligos screened against a subset of the library, for a total of 1,627,072 interactions probed. Comparative analysis of these screens reveals information about the targetability of classes of nucleic acid structure and frequency of selective hit identification. While DNA structures are included in the dataset, much of the analysis herein is focused on RNA targets. We observe that many RNA-binding small molecules fall within “drug-like” chemical space, as defined by traditional medicinal chemistry parameters. However, such parameters were insufficient to distinguish protein and RNA binders in this dataset. We therefore enumerated ~1,600 chemical properties of our libraries and analyzed experimentally identified RNA-binding molecules using machine learning approaches. Logistic regression and neural network models point to a complex interplay of dozens of molecular descriptors able to distinguish between RNA- and protein-binding compounds. This work reveals that despite RNA and protein binders having similar drug-like properties, molecular determinants related to nitrogenous and aromatic rings, Van der Waals surface area, and topological charge can help distinguish between molecules of these two sets. This work defines a boundary between RNA- and protein-binding small molecules that will facilitate the design of chemical libraries as well as individual ligands that target RNA structures.
Results and Discussion:
To screen a collection of drug-like small molecules against nucleic acid targets, we assembled a library of commercially available compounds from diverse chemical sources that were compatible with SMM screening (each compound contained an amine or alcohol for attachment to the SMM slide). A custom set of 11,515 compounds was obtained from ChemDiv, 9,595 compounds from ChemBridge, and 1,593 compounds from the National Cancer Institute Diversity Set. In addition, 1,869 compounds were acquired from the National Center for Advancing Translational Sciences (NCATS) Mechanism Interrogation PlatE (MIPE) library,[18] representing mechanistically characterized, biologically active drugs and probes. In general, compounds from commercial vendors were chosen based on modern medicinal chemistry parameters such as molecular weight, hydrogen bond donors/acceptors, polar surface area, predicted solubility, and filtered to generally avoid most reactive chemical groups or assay interference chemotypes (e.g., “PAINS”[19]). A full description of the chemical library including SDF files and the analysis of chemical composition, are included in our Figshare repository.
This library was screened against 27 RNA and 9 DNA targets belonging to diverse structural classes such as hairpins, G-quadruplexes (G4), pseudoknots (PK), three-way junctions (TWJ), and triple helices (TH). The results of several individual screens using this library have been published previously by our laboratory.[11, 20] We used the results of SMM screens for 36 nucleic acid targets against this library to compile the ROBIN library, a collection of 2,188 unique small molecules that were a hit for at least one nucleic acid target. A description of each nucleic acid target screened is described in Table S1. The protocol used in our SMM screens and our criteria for hit identification have been previously described.[21] Summarized data for these SMM screens including hit rates for individual structural classes of nucleic acids are reported in Table 1. The mean hit rates for all structural classes were less than one percent, comparable to what is seen for many protein targets in unbiased screening efforts. Selective hit rates, reporting only compounds that bound to the target of interest and no other target, were considerably lower. The hit rate, structure class, and sequence of each individual nucleic acid target can be found in Table S2. It is important to note that like all screening approaches, SMM screening introduces several biases to the dataset. For example, the amine/alcohol groups of compounds used for attachment on the slide could potentially prevent important interactions with nucleic acid targets. However, we and others have been successful in broadly deploying this technology to discover compounds with high affinity for diverse nucleic acid and protein targets[11, 20, 22].
Table 1.
Statistics for hit rates of 36 SMM screens classified by nucleic acid structure type. Included are hit rate (average hit rate for oligonucleotide targets in that class of structure) and selective hit rate (average hit rate for oligos, considering only compounds that bind to that target and no others).
| Structure Type | Count | Hit Rate (%) | Selective Hit Rate (%) |
|---|---|---|---|
|
| |||
| DNAG4 | 9 | 0.45 ± 0.18 | 0.12 ± 0.15 |
| RNAG4 | 6 | 0.78 ± 0.26 | 0.22 ± 0.15 |
| RNA Hairpin | 14 | 0.48 ± 0.26 | 0.16 ± 0.12 |
| RNA Pseudokrtot | 3 | 0.85 ± 0.15 | 0.33 ± 0.07 |
| RNA 3WJ | 2 | 0.79 ±0.18 | 0.23 ± 0.17 |
| RNA Triple Hélix | 2 | 0.61 ± 0.23 | 0.21 ± 0.02 |
While we have screened both DNA and RNA oligos on SMMs, the rest of our analysis focuses specifically on RNA-binding compounds. We therefore extracted 2,003 out of 2,188 compounds in the ROBIN library that were a hit for at least one RNA target as the ROBIN RNA-binding library. To quantitatively describe selectivity within this set, we calculated Gini coefficients for each of these RNA-binding compounds. The Gini coefficient is a metric derived from economic research on inequality that has been proposed as a way to quantitatively measure the selectivity of chemical probes including for RNA binders.[23] For example, a molecule that binds to only one target out of many would have a theoretical Gini coefficient of 1 and a molecule that binds to all targets equally would have a Gini coefficient of 0. A value above 0.75 has been proposed as a reasonable cutoff for selective chemical probes.[24] In our dataset, 1,287 compounds had Gini coefficients above 0.75, while 716 were below 0.75 (Figure S1). Thus, 36% of the identified hits displayed promiscuous binding to RNA, and selective hits were identified for each structure screened.
While compounds like aminoglycosides are capable of binding to nucleic acids with high affinity, the physical properties and lack of selectivity of these molecules make them poor candidates for further development as targeted therapeutics. To examine whether ROBIN RNA binders (2,003 compounds) have properties that more closely resemble those of classically defined “drug-like” molecules, we compared these compounds to FDA-approved drugs in a commercially available library from Selleck Chemicals. The library of FDA-approved drugs was filtered before analysis to remove nucleic acid derivatives, molecules with a high molecular weight (> 1000 Da), and molecules containing platinum or other metals for a final set of 2,350 compounds. We generated kernel density estimate (KDE) plots for six traditional medicinal chemistry parameters as described by Lipinski[25] and others[26] (molecular weight (MW), number of hydrogen bond acceptors (HBA) and donors (HBD), number of nitrogens, total polar surface area (TPSA), and Wildman-Crippen LogP (SLogP)). These distributions are shown for the FDA-approved set, ROBIN RNA-Binding library, and SMM Non-RNA Binders (the remaining compounds in SMM screening that did not bind to any screened RNA) (Figure 1A). As can be seen in the distribution plots, ROBIN RNA binders generally fall within drug-like chemical space as defined by a set of FDA-approved drugs.
Figure 1.

Comparison of ROBIN RNA binders and FDA-approved drugs. A) Kernel Density Estimate (KDE) plots of distributions of six common medicinal chemistry parameters for FDA-approved drugs (grey), ROBIN RNA binders (orange), and compounds from the SMM library that did not score as hits for any RNA (SMM Non-RNA Binders, blue). B) Receiver Operating Characteristic (ROC) curve for classification of ROBIN RNA binders and FDA-approved drugs using LASSO logistic regression. C) Five features with the highest odds ratios identified by LASSO. D) Five features with the lowest odds ratios identified by LASSO.
We used the Mordred software package[27] to generate 1,827 two-dimensional and three-dimensional molecular descriptors for each compound in ROBIN and the FDA-approved set, of which 1,664 features were successfully enumerated. The Mordred package was chosen because it is widely utilized, freely available, and high-performance (capable of parallel computation). We used the generated Mordred features to inform a logistic least absolute shrinkage and selection operator (LASSO)[28] regression model to perform binary classification on these compound sets. LASSO logistic regression is a penalized regression model that performs feature selection and removes redundant covariates automatically. The main advantage of LASSO lies in its ability to arrive at sparse solutions due to applying a L1-norm penalty on its coefficients. This analysis arrived at a panel of 41 molecular descriptors and was able to achieve an outstanding classification performance with mean area under the receiver operating characteristic (AUROC) of 0.87 using 10-fold cross-validation (Figure 1B). Figures 1C and 1D illustrate features with the five highest and lowest odds ratios, respectively. Features whose higher values favor RNA binding (features with the highest odds ratios) generally relate to nitrogen content and aromaticity of the molecule. On the other hand, features favoring FDA-approved drugs (features with the lowest odds ratios) relate to oxygen content and acidity. KDE plots showing the distribution of these 10 features are also shown for the FDA-approved set and the ROBIN RNA-binding library in Figure S2.
To visualize the distribution of ROBIN RNA binders within chemical space, we utilized a recently developed method known as TMAP (Tree MAP)[29]. TMAP enables visualization of large high-dimensional datasets in a human interpretable manner using a two-dimensional minimum spanning tree (MST). Tree-like configuration of this dimensionality reduction technique attempts to preserve the global and local patterns of the dataset and can outperform related algorithms like t-SNE and UMAP in performance. TMAP utilizes this tree-like layout to indicate clusters as branches. To illustrate the distribution of RNA binders in chemical space, we assembled 2,350 FDA-approved drugs as described earlier and 10,000 randomly selected compounds from BindingDB[30] (which catalogs small molecules that target proteins) with Kd or Ki < 10 nM, indicating tight binding to protein targets. We also added 2,003 compounds from the ROBIN RNA-binding library as representatives of RNA-binding chemical space. We encoded these chemical libraries with extended connectivity fingerprint up to 4 bonds (ECFP4) fingerprints that have been widely used in drug discovery studies[31]. Figure 2A illustrates the TMAP for these three datasets. As shown in the TMAP, ROBIN RNA binders are widely distributed in the branches, indicating the diverse chemical scaffolds of ROBIN RNA binders. In addition, Figure 2A illustrates a detail of the TMAP, where related structures are found in all three sets. Shown in blue are the common core structures of the molecules on the same branch.
Figure 2.

Classification of ROBIN RNA binders and protein binders. A) Left, TMAP of 10,000 BindingDB protein binders (blue), 2,350 FDA-approved drugs (black), and 2,003 ROBIN RNA binders (orange) encoded with ECFP4 fingerprints. Right, six structures shown from a detail of the TMAP illustrating related molecules on a branch. The blue part of the structures demonstrates the common core shared by the molecules on the branch. B) Precision recall (PR) curve for classification of augmented ROBIN RNA binders and BindingDB protein binders using the multi-layer perceptron (MLP) model. C) Confusion matrix showing the performance of the MLP on the test/holdout set. NPV refers to the negative predictive value. D) Performance metrics for the MLP model on the test/holdout set. E) Left, beeswarm plot illustrating how the top 20 most important features in the MLP impact the model’s output. Right, bar chart showing mean absolute SHAP values for each feature in the beeswarm plot. Each row of the bar chart is aligned with feature rows of the beeswarm plot.
To compare ROBIN RNA binders to protein-binding small molecules, we extracted the entire set of compounds from BindingDB with reported Kd or Ki < 10 nM to a protein target (77,678 compounds). We used the Mordred chemical descriptors to classify this set from the library of 2,003 ROBIN RNA binders using a class-weighted LASSO logistic regression model. The class-weighted approach corrects for the imbalance between the two sets in the cost function of the logistic regression model. Our classification performed with a mean area under the precision-recall curve (AUPRC) of 0.38 using 10-fold cross-validation (shown in the GitHub repository). Precision-recall (PR) curve is used in this case as receiver operating characteristic (ROC) curves can be misleading in cases of high class imbalance. This model, however, did not generalize to several experimentally validated compounds from the literature, potentially due to biases introduced by the minority class (ROBIN RNA binders) being outnumbered 39 to 1 in the training set. To generate a more class-balanced training set, we used an oversampling strategy to augment ROBIN RNA binders. Before augmenting the data, we removed 10% of the RNA and protein binders for an unbiased test/holdout set. Next, we split the remaining compounds in the experimental sets (1,803 RNA binders and 69,909 protein binders) into 10 stratified folds for cross-validation. Experimental RNA binders in each training set of the cross-validation (1,803 compounds) were augmented 30 fold by identifying related structures in the ZINC[32] database. Analogs were selected to have Tanimoto similarity > 0.85[33], molecular weight > 250, and cLogP between −1 and 5. If insufficient analogs were identified, the RNA binder was replicated until a total of 30 compounds were reached for each case. We trained the LASSO logistic regression model on this augmented training set, and each round of cross-validation was tested against the non-augmented set of RNA and protein binders (180 and 6,991 compounds, respectively). With the augmented ROBIN dataset, the LASSO logistic regression algorithm achieved mean AUPRC of 0.37 with 10-fold cross-validation. This model identified 294 molecular descriptors with non-zero coefficients (see GitHub repository). Notably, due to a large number of multicollinear molecular descriptors within the dataset, non-zero coefficients of these do not imply that these features are uniquely more important than other collinear molecular descriptors. Rather, LASSO randomly omits redundant covariates to arrive at a sparse solution. The selection of these 294 molecular descriptors by LASSO indicates that they are sufficient, but not necessarily unique, in successful binary classification of RNA- and protein-binding small molecules.
In addition to LASSO logistic regression, we utilized a more complex non-linear model to achieve a superior classification performance. We used a class of feedforward neural networks known as a multilayer perceptron (MLP). Using the same augmentation and cross-validation strategy, we reached a mean AUPRC score of 0.78 (Figure 2B) on our augmented set. This outstanding classification performance demonstrates the potential utility of this model to predict RNA- vs protein-binding behavior of different compounds. We have shown the confusion matrix and other relevant performance metrics of the model on the holdout/test set in Figures 2C and 2D, respectively.
The architecture and training of the MLP is shown in the Supporting GitHub repository. Despite the outstanding performance of the neural network, this algorithm is a “black box” algorithm meaning it is difficult to interpret how the algorithm handles the chemical features in its hidden layers.
Over the past several years, there have been significant advances in developing algorithms capable of calculating feature importance in predictions of complex models such as neural networks. One such method is SHapley Additive exPlanations (SHAP).[34] SHAP draws its inspiration from coalition game theory and provides local explanations for the importance of features in individual predictions. SHAP provides a higher payout to features that contribute more to the model performance. Higher absolute SHAP values for a chemical descriptor would therefore indicate higher importance of that feature to the model. In our SHAP analyses, protein binders are labeled as 0 and RNA binders as 1. Thus, higher SHAP value of a feature for a compound pulls the compound more toward RNA binding. In contrast, features with lower SHAP values push the compound more toward protein binding. Applying SHAP analysis to our MLP model, we identified the top 20 features with the highest mean absolute SHAP values. A beeswarm plot of these chemical features showing how they impact the model is illustrated in Figure 2E. Each row in the beeswarm plot corresponds to a feature and all compounds in the dataset are plotted for each feature as dots. The position of each dot along the X-axis denotes the SHAP value of the compound for that feature. In addition, the dot color indicates the feature value for each compound. For example, higher 6-membered aromatic hetero ring count (n6aHRing) values are associated with lower SHAP values meaning higher n6aHRing values pull the compound more to the protein binding side. It is clear that a complex set of chemical features relating to properties such as Van der Waals surface area (e.g., SlogP_VSA11, PEOE_VSA3, SlogP_VSA4, PEOE_VSA13), topological charge (e.g., JGI3, JGI5), aromaticity and nitrogen ring systems (e.g., n6aHRing, naHRing, SaasN, SaaaC), SP3 character (C1SP3), and hydrogen bond acceptors (nHBAcc) can be predictive for RNA binding within a set of drug-like chemical scaffolds.
While we have validated the performance of our MLP model on an unbiased holdout/test of 7,969 compounds,(Figures 2C and 2D), we also illustrated the performance of our model on eight well-characterized RNA and protein binders from the literature. It is important to note that these compounds did not exist in our training set and represent the model’s performance on new data never seen before by our MLP model. These compounds include ADQ (a small molecule binder of HOTAIR),[35] a compound that binds to the HIV transactivation response (TAR) hairpin (compound 4), [36] ribocil-A (a synthetic ligand for the FMN riboswitch),[37] and tetracycline (binds to the 30S and 50S subunit of bacterial ribosomes) (Figure 3A).[11] We also selected four widely used protein-targeting FDA-approved drugs with well-validated mechanisms of action including imatinib, ibrutinib, lovastatin, and nevirapine (Figure 3B). Notably, these four drugs are included in our SMM library but were not a hit for any RNA target. The neural network’s performance on these eight examples is illustrated in Figure 3. Here, it is clear that molecules previously validated to bind to RNA are predicted to have a high chance of RNA binding. In contrast, known protein binders not observed to bind to RNA in SMM screening are scored far lower in the model even though they were not included in the ML training.
Figure 3.

Performance of the MLP model on selected known RNA and protein binders. A) Model performance on four known RNA binders not included in the SMM screening library. B) Model performance on four known protein binders. Note that all the protein binders were printed on SMMs and showed low/no binding to RNA targets screened. In each case, the value reported represents probability of RNA binding relative to protein binding as predicted by the MLP model.
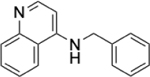
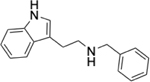
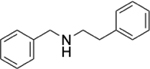
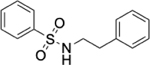
To identify substructures enriched in selective RNA binders, we curated a set of 423 functional groups and ring structures commonly found in FDA-approved drugs and screening libraries (see GitHub repository). We augmented this set with 39,436 Murcko scaffolds with MW < 300 extracted from Life Chemicals high-throughput screening library (502,902 compounds) for a final set of 39,859 unique ring structures, scaffolds, and chemotypes. Next, we scanned selective ROBIN RNA binders (Gini coefficient > 0.75) and SMM non-RNA binders for existence of these scaffolds and compared the two sets. Table 2 contains the 10 most enriched substructures in selective RNA binders with MW > 100. Diverse nitrogen heterocycles are enriched in RNA-binding compounds, which is consistent with their ability to engage in stacking and hydrogen bonding interactions that have been shown to be critical in small molecule RNA recognition previously. [14b]
Table 2.
Substructures enriched in selective ROBIN RNA binders. Ten scaffolds and ring structures enriched in selective ROBIN RNA binders relative to SMM Non-RNA binders. Values indicate frequency of occurrence and fold change in binders relative to non-binders.
| Substructure | Selective ROBIN RNA Binders |
SMM NorvRNA Binders |
Fold Change |
|---|---|---|---|
|
| |||
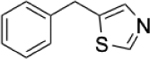
|
0.31% | 0.01% | 31.0 |
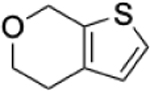
|
0.31% | 0.05% | 6.20 |
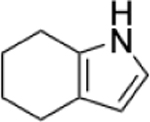
|
0.62% | 0.15% | 4.13 |
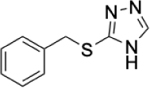
|
0.31% | 0.08% | 3.88 |
|
0.31% | 0.08% | 3.88 |
|
0.47% | 0.14% | 3.36 |
|
1.09% | 0.36% | 3.03 |
|
0.39% | 0.14% | 2.79 |
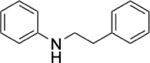
|
0.31% | 0.12% | 2.58 |
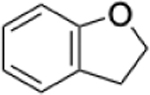
|
0.39% | 0.16% | 2.44 |
Targeting RNA with small molecules has become a promising area in medicinal chemistry. However, there remain comparatively few examples of small molecules with drug-like physical properties that bind to RNA. The work disclosed here represents a complete account and in-depth analysis of 36 high-throughput screens against diverse nucleic acid structures from therapeutically relevant genes/transcripts. The full composition of a 24,572-compound screening library used to perform these screens is included in the supporting GitHub repository. We use machine learning algorithms including logistic regression (LASSO) and neural networks to develop predictive algorithms for RNA binding based on the results of these screens. These algorithms achieve outstanding performance in classifying a library of potential RNA binders, reaching an AUPRC value of 0.78. Evaluation of selected examples of known RNA and protein binders provides further evidence for the model’s utility. Furthermore, analysis of chemical structures found in sets of both RNA binders and protein binders offers insights into the types of chemical matter that bind preferentially to RNA.
It has been shown that RNAs can adopt folds that possess hydrophobic pockets suitable for small molecule binding that are by many metrics similar to hydrophobic pockets on proteins.[9] While examples of small molecules that bind to RNA have been published, it has proven highly challenging to identify compounds that both bind to RNA and have desirable physical properties. Toward this end, the chemical library reported here was not assembled to represent RNA-binding chemical space but rather to represent compounds likely to be suitable as starting points for medicinal chemistry campaigns. Factors considered when designing the library include commercial availability, synthetic tractability, drug-like properties including solubility, cell permeability, and molecular weight, and lack of reactive/promiscuous functional groups (e.g., “PAINS”[19]). Also included are a large set of FDA-approved drugs and mechanistically characterized inhibitors. The compounds in this library were screened against diverse RNA and DNA structures, including hairpins, triple helices, three-way junctions, pseudoknots, and G-quadruplexes, providing a broad measure of the ability of small molecules to recognize common nucleic acid structures. Analysis of these screens demonstrates that hit rates for many nucleic acids are comparable to rates frequently seen for proteins, ranging from 0.22% to 1.19% for an individual screen (mean hit rates for all classes was below 1%). When selectivity is factored in hit rates decrease considerably, facilitating the removal of promiscuous/non-specific nucleic acid binders. Here, it is clear that structures such as RNA G4s, pseudoknots, and three-way junctions have the highest selective hit rates. Previous work has indicated that these classes of structure often have suitable hydrophobic pockets and are associated with diverse biological functions, further highlighting their potential as RNA targets.[38] Quantitative assessment of binding selectivity using the Gini coefficient metric revealed that while many molecules were nonselective, the majority exhibited more selective behavior, with roughly two-thirds of hits having a Gini coefficient greater than 0.75.
We analyzed distributions of common drug-like properties such as molecular weight, hydrogen bond donors/acceptors, nitrogen content, total polar surface area, and predicted aqueous solubility (SLogP) for RNA binders identified in ROBIN. These parameters, however, are insufficient to distinguish RNA binders from FDA-approved drugs. We used a set of 1,664 chemical descriptors of each compound to perform a binary classification between FDA-approved drugs and RNA binders from ROBIN with LASSO logistic regression. This algorithm identified a panel of 41 chemical descriptors that was able to differentiate RNA binders from FDA-approved drugs (AUROC = 0.87). Although complex, these parameters contain some commonalities. For example, several features relating to nitrogen content were identified (e.g., SsNH3, SssNH2, SssNH, and AMID_N), indicating the importance of amines and nitrogenous heterocycles in RNA binders. RNA binders were found to have higher values for descriptors describing aromatic ring systems (e.g., n5aHRing, and SaasC), likely due to the propensity of such systems to stack with nucleobases. In contrast, higher values for several oxygen-related descriptors (e.g., NdO, AMID_O, and nAcid) were found in FDA-approved drugs over RNA binders.
Because FDA-approved drugs often contain unusually complex structures such as those derived from natural products, we also assembled a different set of protein binders extracted from the BindingDB database identified from medicinal chemistry programs. We extracted a set of 77,678 compounds with Kd or Ki < 10 nM with a protein target from BindingDB. We visualized the distribution of ROBIN RNA binders, FDA-approved drugs and BindingDB protein binders using their ECFP4 fingerprints on a TMAP to identify clustering patterns of these libraries. This analysis revealed that RNA binders from ROBIN represent diverse scaffolds that are well distributed within the represented chemical space. One potential utility of this TMAP could be identifying FDA-approved drugs or validated inhibitor scaffolds enclosed within RNA-binding branches. For example, in Figure 2, we identified several potential RNA binders similar to ozanimod, a sphingosine-1-phosphate receptor modulator. This information could be useful to identify RNA off-targets of known drugs or to design RNA-targeted molecules from known bioactive scaffolds. The approach of using core RNA-binding scaffolds to identify targets of FDA-approved drugs was recently used to characterize palbociclib as a potent binder of the HIV TAR hairpin.[39] A separate approach also recently indicated that protein-targeting FDA approved drugs similar to known RNA binders can also have RNA-binding character.[40]
We also used LASSO logistic regression and neural networks to classify RNA binders from 77,678 protein binders from traditional medicinal chemistry programs (as identified in BindingDB). In this case, we generated an augmented set of RNA binders based on Tanimoto similarity to compounds identified from SMM screens to generate a large dataset that avoids imbalanced classification issues. On this augmented dataset, the LASSO model returned a mean AUPRC of 0.37, while the neural network algorithm performed with an AUPRC of 0.78. Generally, features found to be important for RNA binding in both algorithms included Lipinski parameters, features describing Van der Waals surface area, heteroaromatic ring content, and measures of topological charge. Together, these algorithms identify a complex set of molecular features that can be used to describe and predict RNA-binding behavior within a set of drug-like molecules. Intriguingly, a recent study by Hargrove and co-workers also reported the importance of Van der Waals surface area in RNA-binding behavior in a completely different set of molecules, highlighting the importance of this property.[14c] In addition to performing classification, we also identified chemical scaffolds that are enriched in selective RNA binders (Table 2). In this analysis, the most enriched substructures contain nitrogen heterocycles, including both saturated and unsaturated rings. This finding is consistent with previous reports highlighting the importance of hydrogen bonding and pi stacking for RNA-small molecule interactions.[14b] Benzimidazole, aminoquinoline, and indole structures, frequently seen in reports of RNA binders, were also identified.
This work introduces ROBIN, a new experimentally derived library of 2,188 nucleic acid-binding small molecules, including 2,003 molecules that bind to RNA. To our knowledge, the ROBIN library, and the associated screening dataset, is the largest fully public, experimentally derived investigation of RNA-binding small molecules. The work described here includes information on the targetability of RNA hairpins, DNA and RNA G-quadruplexes, RNA triple helices, RNA pseudoknots, and RNA three-way junctions. This work complements highly valuable existing databases such as R-BIND, INFORNA, and NALDB.[14e, 15c, 17] Distinct from other studies, we report the full results of screens, including hits/binders and non-binders, for a total of 1,627,072 probed binding interactions on SMMs. We used the RNA-binding set of hits to classify RNA binders from FDA-approved drugs and protein-binding ligands using machine learning. While the common drug-like properties of ROBIN RNA binders compare favorably to those of drug-like protein binders, our machine learning analysis reveals molecular descriptors relating to Van der Waals surface area, nitrogen-containing ring systems, and charge differ between the two sets. This dataset will likely find broad use in other informatic applications. As one example, this dataset or the approach described herein could be used to develop screening libraries tailored to identify novel RNA-binders, or ligands specific for classes of structure. This study demonstrates that machine learning-based approaches can be used to characterize RNA-binding chemical space and reveal complex sets of molecular properties that are highly predictive of RNA binding within drug-like chemical libraries. Key to this work was access to a large collection of high throughput screening data on diverse nucleic acid targets, a dataset that is now public. This work is an important step toward developing RNA-targeted small molecules as novel therapeutics.
Supplementary Material
Acknowledgments
The authors would like to thank Marc Nicklaus, Ph.D., Megan Peach, Ph.D., and Curran Rhodes, Ph.D. for helpful discussions during the preparation of this manuscript. We thank NCATS and the National Cancer Institute for providing samples of some of the compounds used in this study. This research was supported by the Intramural Research Program of the National Institutes of Health, National Cancer Institute, Center for Cancer Research, project number Z01 BC011585 07 (PI, J. S. Schneekloth, Jr). This work utilized the computational resources of the NIH HPC Biowulf cluster (http://hpc.nih.gov).
Footnotes
Supporting Information
Code used for machine learning algorithms and tables summarizing the results of SMM screening are available on GitHub (https://github.com/ky66/ROBIN). Supporting datasets, including composition of the SMM screening library, the ROBIN database, the augmented ROBIN dataset, FDA-approved drugs set, BindingDB compounds, and tables of chemical descriptors for these data are available on Figshare (https://doi.org/10.6084/m9.figshare.20401974).
Conflicts of interest:
The authors declare the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: T.E.H.A. and R.K. are current employees of Ladder Therapeutics Inc. and may hold stock or other financial interests in Ladder Therapeutics Inc.
References
- [1].a) Meyer SM, Williams CC, Akahori Y, Tanaka T, Aikawa H, Tong Y, Childs-Disney JL, Disney MD, Chem Soc Rev 2020, 49, 7167–7199; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Connelly CM, Moon MH, Schneekloth JS Jr., Cell Chem Biol 2016, 23, 1077–1090; [DOI] [PMC free article] [PubMed] [Google Scholar]; c) Umuhire Juru A, Hargrove AE, J Biol Chem 2021, 296, 100191. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].Hangauer MJ, Vaughn IW, McManus MT, PLoS Genet 2013, 9, e1003569. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].a) Clamp M, Fry B, Kamal M, Xie X, Cuff J, Lin MF, Kellis M, Lindblad-Toh K, Lander ES, Proc Natl Acad Sci U S A 2007, 104, 19428–19433; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Ezkurdia I, Juan D, Rodriguez JM, Frankish A, Diekhans M, Harrow J, Vazquez J, Valencia A, Tress ML, Hum Mol Genet 2014, 23, 5866–5878. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].a) Esteller M, Nat Rev Genet 2011, 12, 861–874; [DOI] [PubMed] [Google Scholar]; b) Lekka E, Hall J, FEBS Lett 2018, 592, 2884–2900. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].a) Hopkins AL, Groom CR, Nat Rev Drug Discov 2002, 1, 727–730; [DOI] [PubMed] [Google Scholar]; b) Russ AP, Lampel S, Drug Discov Today 2005, 10, 1607–1610; [DOI] [PubMed] [Google Scholar]; c) Dang CV, Reddy EP, Shokat KM, Soucek L, Nat Rev Cancer 2017, 17, 502–508. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].a) Crooke ST, Liang XH, Baker BF, Crooke RM, J Biol Chem 2021, 296, 100416; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Roberts TC, Langer R, Wood MJA, Nat Rev Drug Discov 2020, 19, 673–694. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Kuijper EC, Bergsma AJ, Pijnappel W, Aartsma-Rus A, J Inherit Metab Dis 2021, 44, 72–87. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Thomas JR, Hergenrother PJ, Chem Rev 2008, 108, 1171–1224. [DOI] [PubMed] [Google Scholar]
- [9].a) Hewitt WM, Calabrese DR, Schneekloth JS Jr., Bioorg Med Chem 2019, 27, 2253–2260; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Warner KD, Hajdin CE, Weeks KM, Nat Rev Drug Discov 2018, 17, 547–558. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Mustoe AM, Busan S, Rice GM, Hajdin CE, Peterson BK, Ruda VM, Kubica N, Nutiu R, Baryza JL, Weeks KM, Cell 2018, 173, 181–195 e118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Abulwerdi FA, Xu W, Ageeli AA, Yonkunas MJ, Arun G, Nam H, Schneekloth JS Jr., Dayie TK, Spector D, Baird N, Le Grice SFJ, ACS Chem Biol 2019, 14, 223–235. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Falese JP, Donlic A, Hargrove AE, Chem Soc Rev 2021, 50, 2224–2243. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].a) Attwood MM, Fabbro D, Sokolov AV, Knapp S, Schioth HB, Nat Rev Drug Discov 2021, 20, 798; [DOI] [PubMed] [Google Scholar]; b) Yang D, Zhou Q, Labroska V, Qin S, Darbalaei S, Wu Y, Yuliantie E, Xie L, Tao H, Cheng J, Liu Q, Zhao S, Shui W, Jiang Y, Wang MW, Signal Transduct Target Ther 2021, 6, 7; [DOI] [PMC free article] [PubMed] [Google Scholar]; c) Bagal SK, Brown AD, Cox PJ, Omoto K, Owen RM, Pryde DC, Sidders B, Skerratt SE, Stevens EB, Storer RI, Swain NA, J Med Chem 2013, 56, 593–624. [DOI] [PubMed] [Google Scholar]
- [14].a) Morgan BS, Forte JE, Culver RN, Zhang Y, Hargrove AE, Angew Chem Int Ed Engl 2017, 56, 13498–13502; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Padroni G, Patwardhan NN, Schapira M, Hargrove AE, RSC Med Chem 2020, 11, 802–813; [DOI] [PMC free article] [PubMed] [Google Scholar]; c) Cai Z, Zafferani M, Akande OM, Hargrove AE, J Med Chem 2022, 65, 7262–7277; [DOI] [PMC free article] [PubMed] [Google Scholar]; d) Donlic A, Swanson EG, Chiu LY, Wicks SL, Juru AU, Cai Z, Kassam K, Laudeman C, Sanaba BG, Sugarman A, Han E, Tolbert BS, Hargrove AE, ACS Chem Biol 2022, 17, 1556–1566; [DOI] [PMC free article] [PubMed] [Google Scholar]; e) Morgan BS, Sanaba BG, Donlic A, Karloff DB, Forte JE, Zhang Y, Hargrove AE, ACS Chem Biol 2019, 14, 2691–2700. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].a) Tran T, Disney MD, Nat Commun 2012, 3, 1125; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Haniff HS, Knerr L, Liu X, Crynen G, Bostrom J, Abegg D, Adibekian A, Lekah E, Wang KW, Cameron MD, Yildirim I, Lemurell M, Disney MD, Nat Chem 2020, 12, 952–961; [DOI] [PMC free article] [PubMed] [Google Scholar]; c) Disney MD, Winkelsas AM, Velagapudi SP, Southern M, Fallahi M, Childs-Disney JL, ACS Chem Biol 2016, 11, 1720–1728. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Rizvi NF, Santa Maria JP Jr., Nahvi A, Klappenbach J, Klein DJ, Curran PJ, Richards MP, Chamberlin C, Saradjian P, Burchard J, Aguilar R, Lee JT, Dandliker PJ, Smith GF, Kutchukian P, Nickbarg EB, SLAS Discov 2020, 25, 384–396. [DOI] [PubMed] [Google Scholar]
- [17].Kumar Mishra S, Kumar A, Database (Oxford) 2016, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Mathews Griner LA, Guha R, Shinn P, Young RM, Keller JM, Liu D, Goldlust IS, Yasgar A, McKnight C, Boxer MB, Duveau DY, Jiang JK, Michael S, Mierzwa T, Huang W, Walsh MJ, Mott BT, Patel P, Leister W, Maloney DJ, Leclair CA, Rai G, Jadhav A, Peyser BD, Austin CP, Martin SE, Simeonov A, Ferrer M, Staudt LM, Thomas CJ, Proc Natl Acad Sci U S A 2014, 111, 2349–2354. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Baell JB, Holloway GA, J Med Chem 2010, 53, 2719–2740. [DOI] [PubMed] [Google Scholar]
- [20].a) Journey SN, Alden SL, Hewitt WM, Peach ML, Nicklaus MC, Schneekloth JS Jr., Medchemcomm 2018, 9, 2000–2007; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Calabrese DR, Zlotkowski K, Alden S, Hewitt WM, Connelly CM, Wilson RM, Gaikwad S, Chen L, Guha R, Thomas CJ, Mock BA, Schneekloth JS Jr., Nucleic Acids Res 2018, 46, 2722–2732; [DOI] [PMC free article] [PubMed] [Google Scholar]; c) Connelly CM, Numata T, Boer RE, Moon MH, Sinniah RS, Barchi JJ, Ferre-D’Amare AR, Schneekloth JS Jr., Nat Commun 2019, 10, 1501; [DOI] [PMC free article] [PubMed] [Google Scholar]; d) Patel N, Abulwerdi F, Fatehi F, Manfield IW, Le Grice S, Schneekloth JS Jr., Twarock R, Stockley PG, J Mol Biol 2022, 434, 167557; [DOI] [PMC free article] [PubMed] [Google Scholar]; e) Yang M, Carter S, Parmar S, Bume DD, Calabrese DR, Liang X, Yazdani K, Xu M, Liu Z, Thiele CJ, Schneekloth JS, Nucleic Acids Res 2021, 49, 7856–7869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Connelly CM, Abulwerdi FA, Schneekloth JS Jr., Methods Mol Biol 2017, 1518, 157–175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].a) Henley MJ, Koehler AN, Nat Rev Drug Discov 2021, 20, 669–688; [DOI] [PubMed] [Google Scholar]; b) Duffner JL, Clemons PA, Koehler AN, Curr Opin Chem Biol 2007, 11, 74–82; [DOI] [PubMed] [Google Scholar]; c) Hong JA, Neel DV, Wassaf D, Caballero F, Koehler AN, Curr Opin Chem Biol 2014, 18, 21–28. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Ursu A, Childs-Disney JL, Angelbello AJ, Costales MG, Meyer SM, Disney MD, ACS Chem Biol 2020, 15, 2031–2040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Drewry DH, Wells CI, Andrews DM, Angell R, Al-Ali H, Axtman AD, Capuzzi SJ, Elkins JM, Ettmayer P, Frederiksen M, Gileadi O, Gray N, Hooper A, Knapp S, Laufer S, Luecking U, Michaelides M, Muller S, Muratov E, Denny RA, Saikatendu KS, Treiber DK, Zuercher WJ, Willson TM, PLoS One 2017, 12, e0181585. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Lipinski CA, Lombardo F, Dominy BW, Feeney PJ, Adv Drug Deliv Rev 2001, 46, 3–26. [DOI] [PubMed] [Google Scholar]
- [26].Veber DF, Johnson SR, Cheng HY, Smith BR, Ward KW, Kopple KD, J Med Chem 2002, 45, 2615–2623. [DOI] [PubMed] [Google Scholar]
- [27].Moriwaki H, Tian YS, Kawashita N, Takagi T, J Cheminform 2018, 10, 4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Tibshirani R, Journal of the Royal Statistical Society: Series B (Methodological) 1996, 58, 267–288. [Google Scholar]
- [29].Probst D, Reymond JL, J Cheminform 2020, 12, 12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Liu T, Lin Y, Wen X, Jorissen RN, Gilson MK, Nucleic Acids Res 2007, 35, D198–201. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].a Rogers D, Hahn M, J Chem Inf Model 2010, 50, 742–754; [DOI] [PubMed] [Google Scholar]; b Riniker S, Landrum GA, J Cheminform 2013, 5, 26; [DOI] [PMC free article] [PubMed] [Google Scholar]; c Awale M, Reymond JL, J Chem Inf Model 2019, 59, 10–17. [DOI] [PubMed] [Google Scholar]
- [32].Sterling T, Irwin JJ, J Chem Inf Model 2015, 55, 2324–2337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].Martin YC, Kofron JL, Traphagen LM, J Med Chem 2002, 45, 4350–4358. [DOI] [PubMed] [Google Scholar]
- [34].Lundberg SM, Lee S-I, ArXiv 2017, abs/1705.07874. [Google Scholar]
- [35].Ren Y, Wang YF, Zhang J, Wang QX, Han L, Mei M, Kang CS, Clin Epigenetics 2019, 11, 29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Sztuba-Solinska J, Shenoy SR, Gareiss P, Krumpe LR, Le Grice SF, O’Keefe BR, Schneekloth JS Jr., J Am Chem Soc 2014, 136, 8402–8410. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Howe JA, Wang H, Fischmann TO, Balibar CJ, Xiao L, Galgoci AM, Malinverni JC, Mayhood T, Villafania A, Nahvi A, Murgolo N, Barbieri CM, Mann PA, Carr D, Xia E, Zuck P, Riley D, Painter RE, Walker SS, Sherborne B, de Jesus R, Pan W, Plotkin MA, Wu J, Rindgen D, Cummings J, Garlisi CG, Zhang R, Sheth PR, Gill CJ, Tang H, Roemer T, Nature 2015, 526, 672–677. [DOI] [PubMed] [Google Scholar]
- [38].a) Staple DW, Butcher SE, PLoS Biol 2005, 3, e213; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Giedroc DP, Cornish PV, Virus Res 2009, 139, 193–208; [DOI] [PMC free article] [PubMed] [Google Scholar]; c) Kharel P, Becker G, Tsvetkov V, Ivanov P, Nucleic Acids Res 2020, 48, 12534–12555. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Shortridge MD, Vidalala V, Varani G, bioRxiv 2022, 2022.2001.2020.477126. [Google Scholar]
- [40].Fang L, Velema WA, Lee Y, Lu X, Mohsen MG, Kietrys AM, Kool ET, bioRxiv 2022, 2022.2007.2018.500496. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.