

Abstract
The human motor system rapidly adapts to systematic perturbations but the adapted behavior seems to be forgotten equally rapidly. The reason for this forgetting is unclear, as is how to overcome it to promote long-term learning. Here we show that adapted behavior can be stabilized by a period of binary feedback about success and failure in the absence of vector error feedback. We examined the time course of decay after adaptation to a visuomotor rotation through a “visual error clamp” condition—trials in which subjects received false visual feedback showing perfect directional performance, regardless of the movements they actually made. Exposure to this error-clamp following initial visuomotor adaptation led to a rapid reversion to baseline behavior. In contrast, exposure to binary feedback after initial adaptation turned the adapted state into a new baseline, to which subjects reverted after transient exposure to another visuomotor rotation. When both binary feedback and vector error were present, some subjects exhibited rapid decay to the original baseline, while others persisted in the new baseline. We propose that learning can be decomposed into two components – a fast-learning, fast-forgetting adaptation process that is sensitive to vector errors and insensitive to task success, and a second process driven by success that learns more slowly but is less susceptible to forgetting. These two learning systems may be recruited to different degrees across individuals. Understanding this competitive balance and exploiting the long-term retention properties of learning through reinforcement is likely to be essential for successful neuro-rehabilitation.
Keywords: reaching, motor control, error-based learning, reinforcement-based learning
Introduction
The human motor system possesses the remarkable capacity to rapidly adapt to external perturbations – either caused by manipulations of visual feedback (Krakauer et al., 2000) or limb dynamics (Krakauer et al., 1999; Shadmehr and Mussa-Ivaldi, 1994). This capacity allows compensation for a changing motor plant (Kording et al., 2007) and for drift in neural representation arising from intrinsic noise sources (Cheng and Sabes, 2007). Adaptation might be exploited to help entrain new patterns of movement during rehabilitation following brain injury or stroke (Reisman et al., 2007; Scheidt and Stoeckmann, 2007), except that newly learned mappings are unlearned even faster than they are learned in the first place (Patton et al., 2006; Reisman et al., 2007), i.e., the adapted behavior does not persist.
Adaptation is generally thought to occur through updating of an internal forward model in the cerebellum based on errors in the predicted outcome of a movement (Mazzoni and Krakauer, 2006; Taylor et al., 2010; Tseng et al., 2007). The transient nature of adapted states has generally been attributed to ‘forgetting’ of changes in this internal model. The decay of adaptation can be experimentally isolated by suppressing the errors that drive adaptation by artificially clamping errors to zero (Scheidt et al., 2000; Smith et al., 2006). Such paradigms reveal the natural dynamics of motor memories, and almost universally demonstrate a steady reversion towards baseline behavior (Huang and Shadmehr, 2009; Pekny et al., 2011; Smith et al., 2006). A curious exception is found in patients with cerebellar ataxia, who are grossly impaired in adaptation tasks (Tseng et al., 2007) but can still learn to compensate for a perturbation if it is introduced sufficiently gradually (Criscimagna-Hemminger et al., 2010). Having learnt to compensate for the perturbation, these patients do not exhibit decay during subsequent error clamp trials. Patients with cerebellar ataxia do not appear to compensate for perturbations by updating a forward model (Izawa et al., 2012; Synofzik et al., 2008) but instead appear to engage an alternative, reinforcement-based learning mechanism. The lack of subsequent decay suggests that, unlike movements learned through adaptation, movements learned through reinforcement remain stable over time.
We recently showed that a success-based learning mechanism (i.e., based on a movement’s success or failure) is present during visuomotor adaptation even when vector error feedback (i.e., detailed spatial information, such as movement amplitude and direction) is provided, and that this mechanism likely kicks in at asymptote when the successful action converged upon by adaptation is repeated (Huang et al., 2011). We hypothesized that providing only binary feedback about task success or failure at asymptote would promote this reinforcement mechanism and mitigate decay of adaptation in a manner similar to that seen in patients with cerebellar disease. We performed an experiment to test this idea in healthy subjects.
Materials and Methods
Experimental procedures
Subjects
35 right-handed subjects (25 females, ages 19–34) participated in the study. All subjects were naive to the purpose of the experiments, signed an institutionally approved consent form, and were paid to participate. Subjects were randomly assigned to one of three groups: NA, BE+VE and BE, described below.
General experimental procedure
Subjects sat at a glass-surface table with their right arm supported on a lightweight sled that hovered on air cushions created by compressed-air jets, allowing frictionless planar motion of the arm. Subjects viewed the reflection of a computer display in a mirror suspended halfway between the subject’s hand and the LCD, so that the virtual image of the display in the mirror was in the plane of arm motion (veridical display). The mirror blocked the subjects’ view of their arm and hand. We used a “Flock of Birds” magnetic system (Ascension Technology, Burlington, VT) to record hand and arm position at 120 Hz, and custom routines (courtesy of Dr. Robert L. Sainburg, Penn State University, State College, PA) for real-time hand-position display.
Task
Subjects performed fast straight right arm movements through a large circular target (radius of 1 cm) displayed 8 cm away from a starting circle while receiving continuous visual feedback of the cursor’s position. When the cursor was 8 cm away from the start circle, a small white dot appeared at the location of the cursor. Throughout the experiment, in addition to visual feedback of cursor position, all groups heard a pleasant tone if the cursor hit the target, and received numerical feedback reporting their speed. All 3 subject groups had a short familiarization block (40 unperturbed trials to a target located at 100°, and 20 to the experimental target, located at 135°). The No Asymptote (NA) group spent minimal time at asymptote because subjects experienced a 45° CCW rotation for only 40 trials before transitioning to 100 “error clamp” trials, i.e., trials in which the cursor’s direction was artificially clamped to the center of the target and the pleasant sound was given regardless of hand direction (Fig. 1). Movement extent was not clamped and matched the distance of the hand from the start circle. The Binary Error + Vector Error group (BE + VE) was presented with a 30° counter clockwise (CCW) rotation of the cursor’s direction while reaching to the experimental target for 60 trials (Fig. 1). The 30° rotation then continued for an additional 80 trials (asymptotic phase). The asymptotic phase was followed by an additional 15° CCW rotation for 30 trials followed by 60 error clamp trials. Finally, subjects received accurate, unperturbed cursor feedback for 40 movements (washout). The Binary Error group (BE) differed from group BE + VE in only one critical respect: in the asymptotic phase, all cursor feedback was switched off and only the binary auditory feedback indicating target hit or miss remained (Fig. 1). To maintain their asymptotic behavior, subjects in the BE group received occasional refresher trials with continuous cursor feedback as well as binary feedback (14/80 of the trials). A further 6 subjects added to the BE and BE+VE groups (3 per group) were given 40 additional trials in the error clamp phase.
Figure 1.

Protocols for the 3 experimental groups: No asymptote (NA, top), Binary error feedback + Vector error feedback (BE+VE), and Binary feedback-only (BE) (bottom). Movement directions in hand space are represented by solid arrows. Corresponding cursor movement directions in visual space are represented by dashed arrows. Following a short baseline block, group NA adapted to 45° CCW rotation, and then were put into error clamp and washout blocks. The BE+VE and BE groups adapted to 30° CCW rotation, and then continued to an asymptote block. In the asymptote block, the BE group had visual feedback of cursor position removed, whereas the BE+VE group continued to receive both binary auditory and cursor feedback. Following asymptote, both groups adapted to an additional rotation of 15° CCW (to a total rotation of 45°) and were then put in error clamp and washout block. Apart from group BE during the Asymptote phase, all groups received vector error and binary error feedback throughout the experiment.
All subjects in the study were asked to report anything unusual occurring during the experiment. Approximately 20% of subjects commented on the rotation. Only one subject out of 35 (in the extended asymptote group) noticed the error clamp.
Data analysis
For offline analysis, we used custom routines written within the Igor software package (Wavemetrics, Lake Oswego, OR). Hand position at target extent (8 cm away from starting circle) was used as a measure of hand direction.
We compared inter-subject variability measures using an F-test for the ratio of variability measures computed for each group. Inter-subject variability was defined as the variance across subjects’ mean hand direction for the entire clamp block.
Results
Rapid decay of adaptation in clamp trials
We first wanted to confirm the canonical result that adaptation decays rapidly during error clamp trials in the case of visuomotor rotation (decay has only previously been shown when visual feedback is removed in the case of visuomotor rotation (Galea et al., 2011)). Subjects in Group NA adapted to a 45° rotation and then were probed with visual error clamp trials that fixed the visual error at zero degrees (see Experimental Procedure). In the error clamp trials there was rapid decay of learning back to zero (Fig. 2A).
Figure 2.
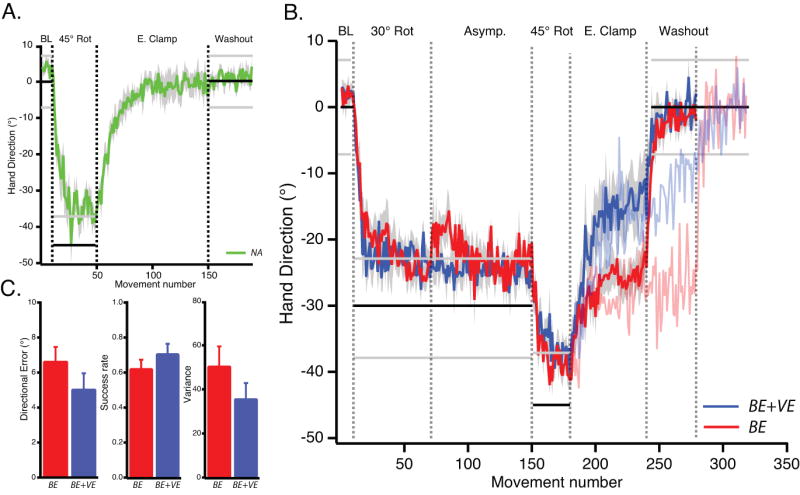
A. Averaged hand movement direction plotted against movement number for the NA group (green). Horizontal lines indicate the center (black lines) and edges (grey lines) of the target. Binary feedback was only given when movement direction was between the grey lines. Shading indicates SEM. During the error clamp block, subjects rapidly decay to their baseline mapping.
B. Averaged hand movement direction plotted against movement number for the BE group (red) and BE+VE group (blue). While both groups adapted to the 45° rotation, group BE decayed less in the subsequent error clamp block. Faint red and blue traces depict the behavior of 6 additional subjects (3 BE and 3 BE+VE subjects respectively) that experienced a longer error clamp block (continued until the rightmost dotted vertical line).
C. Group averages for performance measures at asymptote for the 30° rotation for BE (red) and BE+VE (blue) groups (last 20 trials of the asymptote block).
Adaptation decayed to a new baseline when only binary feedback was provided at asymptote
We recently argued that reinforcement of successful actions occurs when adaptation reaches asymptotic levels at which point the learned action is repeated (Huang et al., 2011). Although initial adaptation occurs through a model-based process dependent on vector prediction error, the resultant action that adaptation converges upon is remembered by a second learning system that is driven by success (i.e., an operant learning system) rather than vector error.
The core hypothesis of the current study was that we might be able to increase the contribution of the success–sensitive operant system, and thereby attenuate forgetting, by providing only binary feedback once adaptation reached asymptote. To test this prediction, we compared two groups, Binary Error and Vector Error (BE+VE) and Binary Error-only (BE). Both groups initially learned to compensate for a 30° rotation over a period of 60 trials. Once at asymptote, subjects in Group BE were provided only binary information about failure or success, whereas Group VE also received full vector error information about performance. After this asymptotic phase, the rotation was briefly increased to 45° after which subjects were probed in visual clamp trials.
The key prediction was that a period of binary reinforcement without vector error would create a more stable memory than when vector error was present. This was borne out: subjects in Group BE decayed to the asymptote on which they received only binary feedback during the 30° rotation phase and stayed there (Fig. 2B, red trace), whereas subjects in Group BE+VE showed a steady decay towards baseline (Fig. 2B, blue trace). We tested this difference through an analysis of variance, comparing reach direction between groups and between the phases of the experiment (F(1,19) = 8.25, p = 0.0098; comparison of last 10 trials, Group×Phase (asymptote/clamp) interaction). Thus differences in behavior during the clamp trials could not be attributed to differences in reach direction during asymptote. Instead, it appeared that Group BE+VE decayed significantly beyond their previous asymptote during the clamp trials (post-hoc comparison, t(10) = 3.22, p = 0.009), whereas Group BE did not(t(9) = 0.688, p = 0.51).
Comparison of various performance measures from the end of the asymptotic phase (last 20 trials) show no significant group effect on directional error (5° ± 0.93° for BE+VE and 6.6°±0.84° for BE, F(1,19) = 1.592, p = 0.222), success rate (0.7±0.06 for BE+VE and 0.62±0.05 for BE, F(1,19) = 1.097, p = 0.308), or variance (35.5±7.3 for BE+VE and 50.3±9.1 for BE, F(1,19) = 1.633, p = 0.217) (Fig. 2C). Examination of the entire asymptote (Fig. 2B) suggests that the performance of the BE+VE group was, if anything, superior to the performance of the BE group. In spite of this superiority, subjects in BE+VE were the ones whose adaptation decayed.
The robustness of the effect of binary feedback alone is apparent in 6 additional subjects that were added to Groups BE+VE and BE, who were allowed to continue in the zero-error clamp condition for 40 extra trials. The behavior of these extra subjects in BE showed no further decay from the newly reinforced behavior, whereas Group BE+VE continued to decay toward zero (Fig. 2C, fainter red and blue traces).
Inter-individual variability was higher for subjects who received both vector error feedback and binary error feedback
The 3 experimental groups also differed in the degree of inter-individual variability observed in the visual clamp trials (Fig. 3). Since group BE+VE experienced both vector error and binary feedback at asymptote, we speculate that each subject in this group weighted error-based and success-based learning differently, with some subjects showing behavior close to what is consistently seen in Group BE, others behaving similarly to Group NA, and gradations in-between. Indeed, inter-subject variability, computed across the entire clamp block, was significantly larger for Group BE+VE than for groups BE (F(10,9) = 3.785, p = 0.0268) and NA (F(10,7) = 6.079, p = 0.0128).
Figure 3.

Decay behavior for individual subjects (grey lines) during the error clamp block plotted along with the group mean (thick black line) for groups NA (A), BE+VE (B), and BE (C). Trials averaged across 10-trial bins. Vertical lines bound the clamp block. Inter-subject variability is higher for the BE+VE group.
Discussion
We have shown that after adaptation reaches asymptotic levels, a period of binary feedback without vector error feedback creates an attractor that shapes decay when visual errors are subsequently clamped to zero. This halting of decay is markedly different from previous findings in more conventional protocols – exemplified here by the behavior of Group NA, which was placed in clamp trials immediately after learning to counter a 45° perturbation and whose adaptation rapidly decayed back to baseline.
Persistent memories in error clamp trials have previously been noted in force field paradigms, though typically for only a small fraction of the initial adaptation (Smith et al., 2006). Such effects have previously been explained through models in which learning is comprised of multiple learning components that all learn from the same vector error signal, but adapt and forget on differing timescales (Kording et al., 2007; Smith et al., 2006). In this multiple timescale framework, initial learning is largely mediated by “fast” components, but longer exposure prompts a shift from “fast” to “slow” components of learning. Another potential explanation is that repetition leads to the formation of a bias towards the repeated direction (Diedrichsen et al., 2010; Verstynen and Sabes, 2011) and this bias acts to slow decay toward zero. Our results, however, are not consistent with either of these two explanations. A multi-state adaptation model cannot explain the lack of decay for group BE, because vector error, which is required to maintain adaptation in such models (e.g., Smith et al., 2006), was not provided and because the number of trials on asymptote was identical for the two groups. Nor can the difference in decay for groups BE and BE+VE be explained by a bias argument: the consistency of repetition at asymptote was not significantly different between the two groups and if anything consistency was greater for group BE+VE. Furthermore, a bias explanation would suggest that behavior in clamp trials should lie somewhere between the 0° baseline and the reinforced asymptote – not exactly on the asymptote, as we observed in group BE. Our findings imply instead that the “slow” system posited by previous models may be driven primarily by success-based reinforcement of actions, rather than by error. Adaptation over short timescales, by contrast, is sensitive to sensory prediction errors, but is insensitive to task success (Mazzoni and Krakauer, 2006). Recall of actions may also be more sensitive to success than error. In a recent study, removing an expected success cue prompted subjects to partially recall previously washed-out learning of a force field (Pekny et al., 2011).
Patients with cerebellar ataxia lack the ability to adapt to perturbations in the environment based on sensory prediction errors (Maschke et al., 2004; Taylor et al., 2010; Tseng et al., 2007). These patients can, however, learn to compensate for perturbations that are introduced gradually (Criscimagna-Hemminger et al., 2010; Izawa et al., 2012). Patients who learn this way do not decay back to baseline during subsequent clamp trials (Criscimagna-Hemminger et al., 2010). We propose that this spared ability to learn from small errors is due to the engagement of a distinct learning system, not dependent on the cerebellum, which is driven by reinforcement of successful actions. We believe that subjects in our Group BE, who were deprived of the ability to learn from sensory prediction errors, maintained their ability to counter the perturbation by engaging the same mechanism as the cerebellar patients in a gradual paradigm. The attenuated decay in Group BE+VE as compared with Group NA, is likely due to a partial engagement of reinforcement-based learning processes during the 80 trials spent at asymptote (Huang et al., 2011).
We found substantial variability across subjects within Group BE+VE, with some subjects performing like those in Group BE, and others like those in Group NA. Thus, each individual subject may have adopted a different balance between error-dependent and success-dependent learning. It should be noted that we cannot conclude definitively that the reduced decay in group BE+VE compared to group NA was due to more time on asymptote because adaptation in group NA was not performed serially (e.g., 30° and then 15°) but in one block of 45°. That said, the observation that some subjects in Group BE+VE also decayed rapidly in a manner comparable to NA makes an explanation of decay differences between NA and BE+VE based on the serial order of rotation presentation implausible.
We have previously shown that multiple learning mechanisms normally operate during adaptation to perturbations (Huang et al., 2011). Specifically, faster learning of a perturbation the second time around (savings) occurs as the result of model-free reinforcement of successful actions, and is not due to accelerated recall of a previously learned internal model. Thus, reinforcement-based learning appears to be recruited even when error feedback is provided and there is no explicit reward signal. Presumably, this learning is instead driven by an implicit reward signal related to successful execution of the task. We speculate that the same model-free mechanism that subserves savings is also responsible for the decay effects we observed here.
Although we predicted that success-based feedback would influence decay of the adapted state based on previous results in both healthy subjects (Huang et al., 2011; Izawa and Shadmehr, 2011) and patients with cerebellar disease (Criscimagna-Hemminger et al., 2010; Izawa et al., 2012), it is nevertheless surprising that we were able to strengthen the memory for a given action by removing vector error feedback rather than by adding anything new. Subjects in group BE did not receive any additional explicit reward – instead they were just provided with impoverished binary feedback about task success (whether they hit or missed the target). This is quite distinct from assessing the effect of explicit additional reward or punishment on motor memory retention (Abe et al., 2011). We believe that even implicit task success is able to drive learning - subjects always know if they have hit the target or not. Consequently, it is difficult to isolate vector-based learning.
Previous theories integrating model-free and model-based learning in sequential decision-making tasks have assumed independent, concurrent learning through both systems, which then compete at the time of recall (Daw et al., 2005). Our results could potentially be interpreted in a similar vein, with the states of the model-based and model-free components of learning being identical upon entering the clamp block, but with the balance of expression between them at the time of recall affected by the history of prior training. Alternatively, the decay we observe might be due to competition between multiple model-free memories – one reflecting the newly learned behavior, and one reflecting the original baseline behavior. According to this interpretation there may actually be no such thing as “forgetting” at all. Decay in clamp trials might simply reflect a gradual reversion to old habits.
Our results are also consistent with the idea of competition between systems at the time of learning. The fact that retention was better in Group BE, despite overall performance being, if anything, worse during the asymptote, suggests that adaptation based on vector-error (which is rapidly forgotten) may have suppressed learning via reinforcement. When vector-error feedback is removed, the more stable reinforcement system is forced into participation prematurely, leading to more stable behavior. A recent study that showed that when subjects were only given binary reward to learn an incremental rotation they increased their exploratory variability – variability not seen when they were also provided with error feedback (Izawa and Shadmehr, 2011). There is a precedent for one kind of learning being suppressed at the expense of another. In Drosophila, the mushroom body (a brain structure crucial for learning and memory in this species) inhibits operant conditioning in favor of classical conditioning even when both kinds of learning could potentially proceed in parallel (Brembs, 2009).
We conclude that adaptation occurs through an error-based learning mechanism but that an additional success-based reinforcement process is responsible for longer-term retention of the solution found by adaptation. This finding could have profound implications for neuro-rehabilitation. Recent studies have shown that adaptation paradigms can quite quickly normalize both reaching movements and gait in patients with neurologic disorders (Reisman et al., 2007; Scheidt and Stoeckmann, 2007). The problem, however, is that patients quickly revert to their abnormal baseline behaviors once the perturbation is removed. These observations are entirely consistent with our current findings – subjects will decay back to their reinforced baseline from a newly adapted mapping. We predict that if patients were provided with only binary feedback once they had been adapted to the desirable movement then this might ensure that they retain the desired movement across sessions. In effect, our paradigm accelerates the natural progression by which transient adaptation becomes consolidated into long-term habit.
Acknowledgments
We thank Tomoko Kitago and Juan Camilo Cortes for assistance in developing the paradigm and Robert S. Sainburg for sharing experiment-control software. This research was supported by NIH grant R01NS052804 (JWK, PM), the Machiah Foundation/Jewish Community Federation (LS), and the Parkinson’s Disease Foundation (PM).
References
- Abe M, Schambra H, Wassermann EM, Luckenbaugh D, Schweighofer N, Cohen LG. Reward improves long-term retention of a motor memory through induction of offline memory gains. Curr Biol. 2011;21:557–62. doi: 10.1016/j.cub.2011.02.030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brembs B. Mushroom bodies regulate habit formation in Drosophila. Curr Biol. 2009;19:1351–5. doi: 10.1016/j.cub.2009.06.014. [DOI] [PubMed] [Google Scholar]
- Cheng S, Sabes PN. Calibration of visually guided reaching is driven by error-corrective learning and internal dynamics. J Neurophysiol. 2007;97:3057–69. doi: 10.1152/jn.00897.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Criscimagna-Hemminger SE, Bastian AJ, Shadmehr R. Size of error affects cerebellar contributions to motor learning. J Neurophysiol. 2010;103:2275–84. doi: 10.1152/jn.00822.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Daw ND, Niv Y, Dayan P. Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nat Neurosci. 2005;8:1704–11. doi: 10.1038/nn1560. [DOI] [PubMed] [Google Scholar]
- Diedrichsen J, White O, Newman D, Lally N. Use-dependent and error-based learning of motor behaviors. J Neurosci. 2010;30:5159–66. doi: 10.1523/JNEUROSCI.5406-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Galea JM, Vazquez A, Pasricha N, Orban de Xivry JJ, Celnik P. Dissociating the Roles of the Cerebellum and Motor Cortex during Adaptive Learning: The Motor Cortex Retains What the Cerebellum Learns. Cereb Cortex. 2011;21:1761–70. doi: 10.1093/cercor/bhq246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang VS, Haith A, Mazzoni P, Krakauer JW. Rethinking motor learning and savings in adaptation paradigms: model-free memory for successful actions combines with internal models. Neuron. 2011;70:787–801. doi: 10.1016/j.neuron.2011.04.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang VS, Shadmehr R. Persistence of motor memories reflects statistics of the learning event. J Neurophysiol. 2009;102:931–40. doi: 10.1152/jn.00237.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Izawa J, Criscimagna-Hemminger SE, Shadmehr R. Cerebellar contributions to reach adaptation and learning sensory consequences of action. J Neurosci. 2012;32:4230–9. doi: 10.1523/JNEUROSCI.6353-11.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Izawa J, Shadmehr R. Learning from sensory and reward prediction errors during motor adaptation. PLoS Comput Biol. 2011;7:e1002012. doi: 10.1371/journal.pcbi.1002012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kording KP, Tenenbaum JB, Shadmehr R. The dynamics of memory as a consequence of optimal adaptation to a changing body. Nat Neurosci. 2007;10:779–86. doi: 10.1038/nn1901. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krakauer JW, Ghilardi MF, Ghez C. Independent learning of internal models for kinematic and dynamic control of reaching. Nat Neurosci. 1999;2:1026–31. doi: 10.1038/14826. [DOI] [PubMed] [Google Scholar]
- Krakauer JW, Pine ZM, Ghilardi MF, Ghez C. Learning of visuomotor transformations for vectorial planning of reaching trajectories. J Neurosci. 2000;20:8916–24. doi: 10.1523/JNEUROSCI.20-23-08916.2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maschke M, Gomez CM, Ebner TJ, Konczak J. Hereditary cerebellar ataxia progressively impairs force adaptation during goal-directed arm movements. J Neurophysiol. 2004;91:230–8. doi: 10.1152/jn.00557.2003. [DOI] [PubMed] [Google Scholar]
- Mazzoni P, Krakauer JW. An implicit plan overrides an explicit strategy during visuomotor adaptation. J Neurosci. 2006;26:3642–5. doi: 10.1523/JNEUROSCI.5317-05.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Patton JL, Stoykov ME, Kovic M, Mussa-Ivaldi FA. Evaluation of robotic training forces that either enhance or reduce error in chronic hemiparetic stroke survivors. Exp Brain Res. 2006;168:368–83. doi: 10.1007/s00221-005-0097-8. [DOI] [PubMed] [Google Scholar]
- Pekny SE, Criscimagna-Hemminger SE, Shadmehr R. Protection and expression of human motor memories. J Neurosci. 2011;31:13829–39. doi: 10.1523/JNEUROSCI.1704-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reisman DS, Wityk R, Silver K, Bastian AJ. Locomotor adaptation on a split-belt treadmill can improve walking symmetry post-stroke. Brain. 2007;130:1861–72. doi: 10.1093/brain/awm035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Scheidt RA, Reinkensmeyer DJ, Conditt MA, Rymer WZ, Mussa-Ivaldi FA. Persistence of motor adaptation during constrained, multi-joint, arm movements. J Neurophysiol. 2000;84:853–62. doi: 10.1152/jn.2000.84.2.853. [DOI] [PubMed] [Google Scholar]
- Scheidt RA, Stoeckmann T. Reach adaptation and final position control amid environmental uncertainty after stroke. J Neurophysiol. 2007;97:2824–36. doi: 10.1152/jn.00870.2006. [DOI] [PubMed] [Google Scholar]
- Shadmehr R, Mussa-Ivaldi FA. Adaptive representation of dynamics during learning of a motor task. J Neurosci. 1994;14:3208–24. doi: 10.1523/JNEUROSCI.14-05-03208.1994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith MA, Ghazizadeh A, Shadmehr R. Interacting adaptive processes with different timescales underlie short-term motor learning. PLoS Biol. 2006;4:e179. doi: 10.1371/journal.pbio.0040179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Synofzik M, Lindner A, Thier P. The cerebellum updates predictions about the visual consequences of one’s behavior. Curr Biol. 2008;18:814–8. doi: 10.1016/j.cub.2008.04.071. [DOI] [PubMed] [Google Scholar]
- Taylor JA, Klemfuss NM, Ivry RB. An explicit strategy prevails when the cerebellum fails to compute movement errors. Cerebellum. 2010;9:580–6. doi: 10.1007/s12311-010-0201-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tseng YW, Diedrichsen J, Krakauer JW, Shadmehr R, Bastian AJ. Sensory prediction errors drive cerebellum-dependent adaptation of reaching. J Neurophysiol. 2007;98:54–62. doi: 10.1152/jn.00266.2007. [DOI] [PubMed] [Google Scholar]
- Verstynen T, Sabes PN. How each movement changes the next: an experimental and theoretical study of fast adaptive priors in reaching. J Neurosci. 2011;31:10050–9. doi: 10.1523/JNEUROSCI.6525-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]