

Abstract
Incremental clustering algorithms play a vital role in various applications such as massive data analysis and real-time data processing. Typical application scenarios of incremental clustering raise high demand on computing power of the hardware platform. Parallel computing is a common solution to meet this demand. Moreover, General Purpose Graphic Processing Unit (GPGPU) is a promising parallel computing device. Nevertheless, the incremental clustering algorithm is facing a dilemma between clustering accuracy and parallelism when they are powered by GPGPU. We formally analyzed the cause of this dilemma. First, we formalized concepts relevant to incremental clustering like evolving granularity. Second, we formally proved two theorems. The first theorem proves the relation between clustering accuracy and evolving granularity. Additionally, this theorem analyzes the upper and lower bounds of different-to-same mis-affiliation. Fewer occurrences of such mis-affiliation mean higher accuracy. The second theorem reveals the relation between parallelism and evolving granularity. Smaller work-depth means superior parallelism. Through the proofs, we conclude that accuracy of an incremental clustering algorithm is negatively related to evolving granularity while parallelism is positively related to the granularity. Thus the contradictory relations cause the dilemma. Finally, we validated the relations through a demo algorithm. Experiment results verified theoretical conclusions.
1. Introduction
1.1. Background
Due to the exciting advancements in digital sensors, advanced computing, communication, and massive storage, tremendous amounts of data are being produced constantly in the modern world. The continuously growing data definitely imply great business value. However, data are useless by themselves; analytical solutions are demanded to pull meaningful insight from the data, such that effective decisions can be achieved. Clustering is an indispensable and fundamental data analysis method. The traditional clustering algorithm is executed in a batch-mode; namely, all data points are necessarily loaded into memory of the host machine. In addition, every data point can be accessed unlimited times during the algorithm execution. Nevertheless, the batch-mode clustering algorithm can not adjust the clustering result in an evolving manner. For instance, it is necessary to incrementally cluster the evolving temporal data such that the underlying structure can be detected [1]. In stream data mining, a preprocessing task like data reduction needs the support of incremental clustering [2, 3]. In addition, incremental clustering can significantly contribute to massive data searching [4]. To sum up, the evolving capability of incremental clustering is indispensable under certain scenarios, such as memory-limited applications, time-limited applications, and redundancy detection. A practical application may possess arbitrary combination of the three aforementioned characteristics. The incremental clustering algorithm proceeds in an evolving manner, namely, processing the input data step by step. In each step, the algorithm receives a newly arrived subset of the input and obtains the new knowledge of this subset. Afterwards, historic clusters of the previous step are updated with the new knowledge. Subsequently, the updated clusters serve as input of the next step. With regard to the first step, there is no updating operation. The new knowledge obtained in the first step serves as input of the second step. Application scenarios of incremental clustering generally raise high requirements on computing capacity of the hardware platform. General Purpose Graphic Processing Unit (GPGPU) is a promising parallel computing device. GPGPU has vast development prospects due to following superiorities: much rapider growing computing power than CPU, high efficiency-cost ratio, and usability.
1.2. Motivation and Related Works
Our previous work revealed that the existing incremental clustering algorithms are confronted with an accuracy-parallelism dilemma [5, 6]. In this predicament, the governing factor is the evolving granularity of the incremental clustering algorithm. For instance, the point-wise algorithms proceed in fine granularity. In each step, the algorithms only receive a single data point (serving as the new knowledge); this point will either be assigned to an existing historic cluster or induce an independent cluster in the historic clusters. Such algorithms generally achieve favorable clustering accuracy. However, they sacrifice parallelism due to strong data dependency. Namely, the next data point cannot be processed until the current one is completely processed. Modern GPGPUs can contain thousands of processing cores, while the number of existing historic clusters needs to increase progressively even if the number eventually reach the magnitude of thousand. GPGPU can fully leverage its computing power only if it runs abundant threads in a SIMD (Single Instruction Multiple Data) manner (commonly twice the number of processing cores or even more). In addition, the work-depth is inevitably no less than the amount of input data points under point-wise setting. Consequently, the computing power is ineluctably underutilized. Moreover, more kernel launches (GPGPU code execution) are required if work-depth is larger. Time overhead of kernel launch is generally high. Some representative point-wise incremental clustering algorithms were elaborated in [7–19]. Ganti et al. used block-evolving pattern to detect changes in stream data [20]. Song et al. adopted the block-wise pattern and proposed an incremental clustering algorithm of GMM (Gaussian Mixture Model) [21]. The algorithm of [21] proceeds in coarse granularity. Each step contains three substeps. First, obtain the new knowledge by running the standard EM (Expectation Maximum) algorithm on a newly received data block. Second, identify the statistically equivalent cluster pairs between the historic clusters and the new clusters. Finally, merge the equivalent cluster pairs separately. The standard EM algorithm of GMM is inherently GPGPU-friendly [22]. The algorithm of [21] maintains the inherent parallelism. However, its clustering accuracy exhibits degradation by order of magnitude, compared to its batch-mode counterpart (the standard EM algorithm of GMM) [5]. Moreover, we qualitatively analyzed the reason why block-wise pattern tends to induce accuracy degradation in our previous work [6]. Algorithms of [23, 24] are also block-wise. D-Stream is ostensibly point-wise [25]. Nevertheless, D-Stream is essentially block-wise due to the fact that mapping data points into grids can be parallelized in a SIMD manner. As far as we know, most existing works focus on clustering accuracy. However, existing algorithms, even the block-wise ones, do not explicitly consider algorithm parallelism on SIMD many-core processing devices like GPGPU. Some recent works formally analyzed issues of clustering or machine learning algorithms. Ackerman and Dasgupta pointed out a limitation that incremental clustering cannot detect certain types of cluster structure [26]. They formally analyzed the cause of this limitation and proposed conquering this limitation by allowing extra clusters. Our work is similar to that of [26] in the sense that we also formally analyzed the reason why incremental clustering is inefficient under certain conditions. In contrast, we elaborated our work under the context of GPGPU-acceleration. Ackerman and Moore also formally analyzed perturbation robustness of batch-mode clustering algorithm [27, 28]. Nevertheless, works of [27, 28] only concentrated on classical batch-mode clustering algorithms. Gepperth and Hammer qualitatively analyzed challenges that incremental learning is facing [29]. They pointed out a dilemma between stability and plasticity. However, we focus on the dilemma between accuracy and parallelism.
1.3. Main Contribution
In this paper, we extend our previous works of [6, 30] in the following ways. First, some vital concepts (such as incremental clustering and evolving granularity) are formally defined. Second, we formally proved how evolving granularity exerts influence on accuracy and parallelism of incremental clustering algorithms. In this way, the starting point of our previous works can be formally validated. Finally, we demonstrated the theoretical conclusions through a demo algorithm. The conclusions will be the footstone of our future work.
2. Formal Definition of Terminologies
2.1. Terminologies on Incremental Clustering
Definition 1 (incremental clustering). —
x 1, x 2, x 3,…, x T is a series of data points (x i ∈ R d, 1 ≤ i ≤ T). The data points are partitioned into T1 sets: X 1, X 2, X 3,…, X T1. This partition satisfied the following conditions:
X j ≠ ∅ (j = 1,2, 3,…, T1).
If x i1 ∈ X j1, x i2 ∈ X j2 (i1 ≠ i2, j1 ≠ j2), then j2 > j1⇔i2 > i1.
A data analysis task adopts discrete time system and time stamps are labeled as 1,2, 3,…. This task is incremental clustering if and only if the following applies:
When t = 1, the task receives X 1. In time interval [1,2], the task partitions X 1 into clusters and C 1 is the set of these clusters. The entire input to the task is X 1.
When t = j (j = 2,3, 4,…), the task receives X t. In time interval [t, t + 1], the task resolves the set of clusters C t such that ∀x j ∈ ⋃1≤k≤t X k can find its affiliated cluster in C t. Entire inputs to the task are X t and C t.
Definition 2 (the tth step and historic clustering result of the tth step). —
An algorithm for incremental clustering is an incremental clustering algorithm. The time interval [t, t + 1] (t = 1,2, 3,…) is the tth step of an incremental clustering algorithm (or step t of an incremental clustering algorithm). C t is the historic clustering result of the tth step.
Definition 3 (micro-cluster). —
Let batchAlgorithm represent a batch-mode clustering algorithm. is the parameter of batchAlgorithm. batchAlgorithm can partition X t into subsets Subk (k = 1,2, 3,…, K t,new). is a constant vector. Subk is a -micro-cluster produced by batchAlgorithm if and only if the following applies:
X t = ⋃1≤k≤Kt,newSubk.
∀k1 ≠ k2, Subk1∩Subk2 = ∅.
Subk forms a data cloud in d-dimensional space. The hypervolume of this data cloud is positively related to ξ 0 (u) (u = 1,2, 3,…, p). Subk contains and only contains one data point if .
ξ 0 (u) (u = 1,2, 3,…, p) are all preset constant values.
Definition 4 (batch-mode part and incremental part of step t). —
Some incremental clustering algorithms divide step t (t = 1,2, 3,…) into two parts [21, 23–25]: In the first part, X t is partitioned into new clusters (or new micro-clusters) pursuant to certain similarity metrics. C t,new is the set of these clusters (or micro-clusters); in the second part, C t is resolved based on C t,new and C t−1 (if any). The number of clusters (or micro-clusters) in C t,new is denoted as K t,new. The first part can be accomplished by a batch-mode clustering algorithm; this part is the batch-mode part of step t. The second part is the incremental part of step t.
Definition 5 (benchmark algorithm, benchmark clustering result, and benchmark cluster). —
Denote X 1, X 2, X 3,…, X T1 (pursuant to Definition 1) as StrParti. Incremental clustering is applied to StrParti, and C T0 is the historic clustering result of the T0th step (T0 ≤ T1); let X B = ⋃1≤k≤T0 X k. If X B could be entirely loaded into memory of the host machine and were processed by a certain batch-mode clustering algorithm, then the resulting clusters were in a set of clusters denoted as C T0,benchmark. The batch-mode algorithm is called benchmark algorithm of the incremental clustering algorithm. C T0,benchmark is the benchmark clustering result up to step T0. An arbitrary cluster of C T0,benchmark is a benchmark cluster.
Definition 6 (local benchmark cluster). —
C T,Benchmark = {Cluk∣k = 1,2, 3,…, K T,Benchmark} is the benchmark clustering result up to the Tth step; Cluk (k = 1,2, 3,…, K T,Benchmark) represent the benchmark clusters in C T,benchmark. X t is the newly received data set of step t. All data points of X t are labeled such that points with the same label are affiliated to the same benchmark cluster. Partition X t into nonempty subsets, noted as SubCluk (k = 1,2, 3,…, K t′). These subsets satisfy the following conditions:
X t = ⋃1≤k≤Kt′SubCluk and ∀k1 ≠ k2, SubCluk1∩SubCluk2 = ∅.
If x i, x j ∈ X t then x i, x j ∈ SubCluu⇔x i and x i possess the same label.
SubCluu, SubCluv ⊂ X t; if x i ∈ SubCluu, x j ∈ SubCluv (u ≠ v), then x i and x j have different labels.
SubCluk (k = 1,2, 3,…, K t′) are called the local benchmark clusters of step t or local benchmark clusters for short. We abbreviate local benchmark cluster to LBC.
Definitions 1–4 actually provide terminologies to formally interpret the concept of incremental clustering as well as execution mechanism of incremental clustering. Definitions 5 and 6 furnish a benchmark to evaluate the accuracy of an incremental clustering algorithm.
2.2. Terminologies on Evolving Granularity, Clustering Accuracy, and Parallelism
Definition 7 (containing hypersurface of a data set). —
Let Cluw ⊂ R d represent a set of data points. HS is a hypersurface in the d-dimensional space. HS is the containing hypersurface of Cluw, if and only if HS is a close hypersurface and an arbitrary point of Cluw is within the interior of HS.
Definition 8 (envelope hypersurface, envelop body, and envelop hypervolume of a data set). —
Let Cluw ⊂ R d represent a set of data points. S HS = {HSu∣u = 1,2, 3,…, U} is the set of containing hypersurfaces of Cluw. Let V u represent the hypervolume encapsulated by HSu. Let HSv be a hypersurface. HSv is the envelope hypersurface of Cluw, if and only if HSv = arg minHSu∈SHS V u. Let ENw represent the envelope hypersurface of Cluw; the region encapsulated by ENw is the envelope body of Cluw; the hypervolume of this envelope body is the envelope hypervolume of Cluw.
Definition 9 (core hypersphere, margin hypersphere, core hypervolume, and margin hypervolume of a data set). —
Let Cluw ⊂ R d be a data set. ENw is the envelope hypersurface of Cluw; c e n t e r w represents the geometric center of the envelope body of Cluw. dist(x) represents the distance between c e n t e r w and an arbitrary point on ENw. distw,min = minx∈ENwdist(x); distw,max = maxx∈ENwdist(x).
A hypersphere is the core hypersphere of Cluw if and only if this hypershpere is centered at c e n t e r w and its radius is distw,min, noted as SPSurmin. The hypervolume encapsulated by SPSurmin is the core hypervolume of Cluw, noted as SPmin(Cluw).
A hypersphere is the margin hypersphere of Cluw if and only if it is centered at c e n t e r w and its radius is distw,max, noted as SPSurmax. The hypervolume encapsulated by SPSurmax is the margin hypervolume of Cluw, noted as SPmax(Cluw).
Definition 10 (core evolving granularity, margin evolving granularity, and average evolving granularity). —
In the tth step, the incremental clustering algorithm receives data set X t. X t is partitioned into nonempty subsets pursuant to certain metrics: Subk (k = 1,2, 3,…, K t,new) such that ∀k1 ≠ k2, Subk1∩Subk2 = ∅, and X t = ⋃1≤k≤Kt,newSubk. Let SPmin(Subk) be the core hypervolume of Subk. Then in the tth step, the core evolving granularity of the algorithm is SubGramin,t = min1≤k≤Kt,newSPmin(Subk).
Up to the Tth step, the core evolving granularity of the algorithm is Gramin,T = min1≤t≤TSubGramin,t.
Let SPmax(Subk) be the margin hypervolume of Subk. Then in the tth step, the margin evolving granularity of the algorithm is SubGramax,t = max1≤k≤Kt,newSPmax(Subk).
Up to the Tth step, the margin evolving granularity of the algorithm is Gramax,T = max1≤t≤TSubGramax,t. Let ENk be the envelope hypersurface of Subk, and SubSetk = ENk∩Subk; |SubSetk| is the number of data points within SubSetk; c e n t e r w represents the geometric center of the envelope body of Subk. distk,u represents the distance between c e n t e r w and x u. Let ave_distk = (∑xu∈SubSetkdistk,u)/|SubSetk|.
SPave(Subk) is the hypervolume of the hypersphere whose center is at c e n t e r w and radius is ave_distk. In the tth step, the average evolving granularity of the algorithm is SPave(Subk).
Up to the Tth step, the average evolving granularity of the algorithm is Graave,T = (∑t=1 TGraave,t K t,new)/∑t=1 T K t,new.
Definition 11 (different-to-same mis-affiliation). —
Different-to-same mis-affiliation is the phenomenon that, in step t, data points from different benchmark clusters are affiliated to the same cluster of C t,new or C t.
Definition 12 (same-to-different mis-affiliation). —
Same-to-different mis-affiliation is the phenomenon that, in step t, data points from the same benchmark cluster are affiliated to the different clusters of C t,new or C t.
We adopt Rand Index [31] to measure clustering accuracy. Larger Rand Index means higher clustering accuracy.
There are numerous criterions of cluster separation measurement in the existing literatures. We select Rand Index due to the fact that this criterion directly reflects our intent: measuring the clustering accuracy by counting occurrences of data point mis-affiliations.
Definition 13 (serial shrink rate (SSR)). —
Let incAlgorithm represent an incremental clustering algorithm. In step t (t = 1,2, 3,…), the batch-mode part generates microt micro-clusters. Suppose incAlgorithm totally clustered N data points up to step T 0. Up to step T 0, the serial shrink rate of incAlgorithm is
(1) Lower SSR means that less computation inevitably runs in a non-GPGPU-friendly manner. Consequently, smaller SSR means improved parallelism. Work-depth [32] of the algorithm can shrink if SSR is smaller. Hence, more computation can be parallelized.
3. Theorems of Evolving Granularity
3.1. Further Explanation on the Motivation
GPGPU-accelerated incremental clustering algorithms are facing a dilemma between clustering accuracy and parallelism. We endeavor to explain the cause of this dilemma through formal proofs. The purpose of our explanation is that the formal proofs reveal a possible solution to seek balance between accuracy and parallelism. This basic idea of this solution is discussed as follows.
In the batch-mode part of the tth step, data points from different local benchmark clusters may be mis-affiliated to the same micro-cluster of C t,new. Theorem 14 points out that the upper and lower bounds of the mis-affiliation probability are negatively related to margin evolving granularity and core evolving granularity, respectively. The proof of this theorem demonstrates that larger evolving granularity results in more occurrences of different-to-same mis-affiliation.
The batch-mode part should evolve in fine granularity to produce as many homogeneous micro-clusters as possible. Only in this context, the operations of incremental part are sensible. Namely, the incremental part cannot eliminate different-to-same mis-affiliation induced by the batch-mode part. The incremental part absorbs advantages of point-wise algorithms by processing micro-clusters sequentially. This part should endeavor to avoid both same-to-different and different-to-same mis-affiliations on the micro-cluster-level.
Nevertheless, Theorem 15 proves that parallelism is positively related to evolving granularity. Thus, the contrary relations cause the dilemma.
However, we can adopt GPGPU-friendly batch-mode clustering algorithm in the batch-mode part. Moreover, the total number of micro-clusters is much smaller than that of data points up to a certain step. Consequently, the work-depth can be dramatically smaller than that of a point-wise incremental clustering algorithm.
3.2. Theorem of Different-to-Same Mis-Affiliation
Theorem 14 . —
Let P t,mis represent the probability of different-to-same mis-affiliations induced by the batch-mode part of the tth step. Gramin,T and Gramax,T are the core evolving granularity and margin evolving granularity up to the Tth step, respectively. The upper bound of P t,mis is negatively related to Gramax,T and the lower bound of P t,mis is negatively related to Gramin,T.
Suppose X t contains K t′ local benchmark clusters (LBC). LBCSet t is a set containing these LBCs. Between any two adjacent LBCs there exists a boundary curve segment. The boundary curve segment between LBC SubClu k1 and LBC SubCluk2 (k1, k2 = 1,2, 3,…, K t′; k1 ≠ k2) is noted as Cur(k1,k2). Obviously, Cur(k1,k2) and Cur(k2,k1) represent the same curve segment. We define a probability function to represent P t,mis:
(2) where
(3) and V(SubCluk) is the hypervolume enclosed by envelope surface of SubClu k.
P t,mis(r) reaches the upper bound if r equals the radius corresponding to the margin evolving granularity (Definition 10) in step t; P t,mis(r) reaches the lower bound if r equals the radius corresponding to the core evolving granularity (Definition 10) in step t.

Proof —
In order to more intuitively interpret this theorem, we discuss the upper and lower bounds in two-dimensional space. The following proof can be generalized to higher-dimensional space.
In two-dimensional space, the envelop hypersurface (Definition 8) degenerates to an envelope curve. The core hypersphere and margin hypersphere (Definition 9) degenerate to a core circle and a margin circle, respectively. The envelop body degenerates to the region enclosed by the envelope curve. The envelope hypervolume degenerates to the area enclosed by the envelope curve. Let incAlgorithm represent an incremental clustering algorithm. Each step of incAlgorithm includes batch-mode part and incremental part.
(1) Partition Data Points Pursuant to Local Benchmark Clusters. incAlgorithm receives X t in the tth step. Partition X t into local benchmark clusters (Definition 6, LBC for short): SubCluu (u = 1,2, 3,…, K t′). Let AR = ⋃u=1 Kt′SubCluu. ENu is the envelope curve of SubCluu. V(SubCluu) represents the area enclosed by SubCluu. Assume that SubCluu (u = 1,2, 3,…, K t′) are convex sets. (We can partition SubCluu into a set of convex sets if it is not a convex set.)
(2) Partition the Boundary Curve between Two Local Benchmark Clusters into Convex Curve Segments. Let C u r be the set of boundary curves between any two adjacent LBCs. C u r = {Curk∣k = 1,2, 3,…, K} where Curk is the boundary curve segment between two adjacent LBCs. Consider an arbitrary LBC SubCluu. Suppose that there are totally U LBCs adjacent to SubCluu. The boundary curves segments are Curu (1), Curu (2),…, Curu (U). These boundary curve segments can be consecutively connected to form a closed curve such that only data points of SubCluu are within the enclosed region. Further partition Curk into a set of curve segments such that Curk,g (g = 1,2, 3,…, G k) are all convex curve segments. Curk,g can be viewed as a set of data points.
(3) Construct Auxiliary Curves. Figure 1(a) illustrates an example of adjacent LBCs and a boundary curve. The black, gray, and white small circles represent three distinct LBCs (For clarity of the figure, we use small circles to represent data points). The black bold curve is the boundary curve between the black and white LBCs. We cut out a convex curve segment from this boundary curve, noted as Curk,g. Figure 1(b) magnifies Curk,g. Assume that the analysis formula of Curk,g is y = t(x) (x ∈ D k,g = [x 1, x 2]).
Let CirE be a circle centered at point E. The radius of CirE is threshold (threshold ∈ R +). Place CirE to the right of Curk,g. Roll CirE along Curk,g such that CirE is always tangent to CirE. Let CirI be a circle centered at point I. The radius of CirI is also threshold. Place CirI to the left of Curk,g. Roll CirI along Curk,g such that all points of CirI are always to the left of Curk,g, except the points of tangency between CirI and Curk,g. The trajectories of points E, I form two curves, y = t 1(x) and y = t 2(x), respectively. Adjust the starting and ending points of t1(x) and t2(x) such that the definition domains of both curves are D k,g = [x 1, x 2].
(4) Characteristics of New Clusters. In step t, X t is partitioned into new clusters (or new micro-clusters) (Definition 3) pursuant to certain methods. Let GR be a set containing data points of an arbitrary new cluster. Without loss of generality, let envelope curve of GR be a circle centered at c e n t e r GR, noted as ENGR. The radius of this circle is noted as radius. We can view c e n t e r GR as a random variable. This random variable represents the possible coordinates of GR's center. Let D(SubCluu) represent a set of all vectors enclosed by envelope curve of SubCluu in d-dimensional (d = 2) space (including vectors on the envelope curve). Let D(AR) = ⋃u=1 Kt′ D(SubCluu). The statistical characteristic of X t is unknown before X t is processed. Consequently, it is reasonable to assume that centerGR obeys the uniform distribution on D(AR). Namely, we assume that every point within D(AR) is possible to be GR's center and the probabilities of every point are equal.
(5) Criterion of Different-to-Same Mis-Affiliation. Assume that we can neglect distance between the boundary curve and the right side of the black LBC's envelope curve in Figure 1. Similarly, assume that we can neglect distance between the boundary curve and the left side of the white LBC's envelope curve. The criterion of different-to-same mis-affiliation is as follows.
If ENGR∩Curk,g ≠ ∅, then GR contains data points of at least two distinct local benchmark clusters.
Smaller distance between c e n t e r GR and Curk,g means higher probability of different-to-same mis-affiliation induced by the batch-mode part; the larger the radius is, the higher the probability is.
In Figure 1(b), two lines (x = x 1, x = x 2) and two curves (y = t 1(x), y = t 2(x)) form an open domain, noted as D threshold ∈ R 2. Let Set represent the set of threshold values that make the following causal relationship hold:
c e n t e r GR ∈ D threshold and threshold ≤ radius⇒ENGR∩Curk,g ≠ ∅.
Part (3) of this proof explained the meaning of threshold (threshold ∈ R +). GR's threshold with regard to Curk,g is threshlod max = maxthreshold∈Set threshold. D critical = D threshold|threshold=threshlodmax. Different-to-same mis-affiliation can still occur as long as radius is sufficiently large even if centerGR ∉ D critical.
(6) Three Typical Situations of Different-to-Same Mis-Affiliation Induced by Batch-Mode Part. The value of threshold max is dramatically influenced by the following factors: first: shape of LBC's envelop curve and second: the relative positions of Curk,g and GR. Shape of LBC's envelope curve is generally irregular. We simplify the proof without loss of generality. As illustrated by Figure 2, assume that three sectors are consecutively connected to form the envelope curve. In addition, three sectors' centers overlapped on point O. Radiuses of sectors 1, 2, and 3 are r1, r2, and r3, respectively. r1 equals to the radius of the margin envelope circle. r3 equals to the radius of the core envelope circle. r2 is between r1 and r3. Generally, distances between point O and points on the envelope curve are between r1 and r3. Sector 2 can represent these ordinary points.
Let GR rotate around O. Figures 2(a), 2(b), and 2(c) illustrate three characteristic positions of GR during the rotation. In Figure 2(a), threshold is r 1. D critical covers the largest area. In Figure 2(c), threshold is r 3. D critical covers the smallest area.
(7) Probability of Different-to-Same Mis-Affiliation Induced by Batch-Mode Part: Lower Bound. As aforemetioned, a boundary curve between two LBCs can be partitioned into curve segments. Data points on both sides of a curve segment are affiliated to the same cluster if different-to-same mis-affiliation occurs (this mis-affiliation occurs in the batch-mode part of a certain step). Let Curk,g represent a curve segment from a boundary curve. Let P k,g be the probability that data points on both sides of Curk,g are affiliated to the same cluster. Considering all boundary curves in X t, P t,mis represents the total probability of different-to-same mis-affiliation in the batch-mode part of step t.
Let r min,T be the radius of the hypersphere corresponding to core evolving granularity up to step T. Assume that auxiliary curves y = t 1(x) and y = t 2(x) are constructed under threshold = r min,T. On the basis of the previous parts of proof, we can draw the following inequalities:
(4) (8) Probability of Different-to-Same Mis-Affiliation Induced by Batch-Mode Part: Upper Bound. Let r max,T be the radius of the hypersphere corresponding to margin evolving granularity. Assume that auxiliary curves y = t 1(x) and y = t 2(x) are constructed under threshold = r max,T. On the basis of the previous parts of proof, we can draw the following inequalities:
(5)
Figure 1.
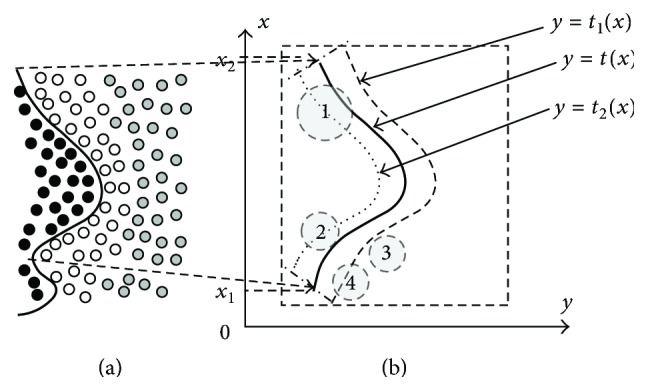
Relation between evolving granularity and different-to-same mis-affiliation induced by the batch-mode part.
Figure 2.

Typical examples of different-to-same mis-affiliations induced by batch-mode part.
3.3. Discussions on Theorem 14
(1) Theorem 14 focuses on different-to-same mis-affiliations other than same-to-different mis-affiliations. Hence we assume that we can neglect the distance between Curk,g and envelope curve of the corresponding LBC (part (5) of the proof).
The probability of different-to-same mis-affiliation will be lower if this distance is not negligible. Consequently, inequalities (5) still hold. In this case, inequalities (4) give the lower bound under the worst situation.
(2) For simplification, we assume the envelope curve of GR is a circle (part (4) of the proof). Theorem 14 still holds even if the envelope curve is of arbitrary shape. The core evolving granularity is determined by distw,min (Definition 9). Larger distw,min always means higher P t,mis regardless of the envelope curves shape, or vice versa.
(3) Based on Theorem 14, we can declare that P t,mis is positively related to the hypervolume of GR's envelope body. In the batch-mode part of step t, we can partition X t into more clusters (or micro-clusters) such that data points of each cluster (or micro-cluster) scatter within a smaller range in the d-dimensional space.
(4) The batch-mode part of ordinary block-wise algorithm clusters X t without a global view of ⋃t′=1 t X t′. Consequently, C t,new is facing a high probability of different-to-same mis-affiliations. This means that numerous new clusters (or micro-clusters) in C t,new are containing heterogeneous data points. No matter what methods the algorithm uses to identify and merge homogeneous clusters (or micro-clusters) between C t−1 and C t,new (incorporates C t,new into C t−1 to obtain C t), clusters in C t will dramatically differentiate from the benchmark clusters up to step t.
3.4. Theorem of Parallelism
Let incAlgorithm represent an incremental clustering algorithm. Step t of incAlgorithm includes two parts: batch-mode part and incremental part. The batch-mode part uses a GPGPU-friendly batch-mode clustering algorithm to partition X t into micro-clusters. The incremental part merges these micro-clusters into C t−1 sequentially and obtains C t if t ≥ 2. The incremental part clusters the micro-clusters sequentially to obtain C 1 if t = 1.
Theorem 15 . —
Let Gra ave,T represent average evolving granularity of incAlgorithm up to step T. Serial Shrink Rate of incAlgorithm is negatively related to Gra ave,T.
Proof —
Suppose incAlgorithm totally clustered N data points up to step T. Let mClui ∈ ⋃t=1 T C t,new (i = 1,2, 3,…, microN T) be a micro-cluster, where microN T = ⋃t=1 Tmicrot and micort is the number of micro-clusters obtained by batch-mode part of step t. Larger Graave,T means that each cluster in ⋃t=1 T C t,new tends to contain more data points. Thus ⋃t=1 Tmicrot decreases. Pursuant to the above analysis and Definition 13, SSR declines when Graave,T increases.
Pursuant to Theorem 15 and Definition 13, parallelism of incAlgorithm is positively related to Graave,T under measurement of work-depth.
3.5. Cause of the Accuracy-Parallelism Dilemma
incAlgorithm degrades to a point-wise incremental clustering algorithm if every micro-cluster produced by the batch-mode part of step t (t = 1,2, 3,…) contains and only contains one data point. In this case, Gramin,T, Gramax,T, and Graave,T all reach the lowest bound. No different-to-same mis-affiliation occurs in batch-mode part and the clustering accuracy tends to rise. However, SSR = 1 and parallelism of incAlgorithm reach the lowest bound under measurement of work-depth.
Parallelism of incAlgorithm rises with the growth of Graave,T. Nevertheless, different-to-same mis-affiliation inevitably occurs. Whatever method the incremental part of step t (t = 1,2, 3,…) adopts to execute micro-cluster-level clustering, incAlgorithm cannot eliminate such mis-affiliations. Moreover, such mis-affiliations will exert negative influence on the operation of identifying homogeneous micro-clusters. Consequently, clustering accuracy drops. However, SSR decreases and parallelism rises.
4. Experiments
In this section, we validate Theorems 14 and 15 through a demo algorithm. Details of this demo algorithm can be found in our previous work [6]. Let demoAlgorithm represent the demo algorithm. The batch-mode part of demoAlgorithm uses mean-shift algorithm to generate micro-clusters. The incremental part of demoAlgorithm extends Self-organized Incremental Neural Network (SOINN) algorithm [7] to execute micro-cluster-level clustering. We validate the variation trends of accuracy and parallelism with respect to evolving granularity. Issues such as improving cluster accuracy of the demo algorithm and adaptively seeking balance between accuracy and parallelism are left as future work.
The benchmark algorithm of demoAlgorithm is batch-mode mean-shift algorithm. Accuracy metrics include the final cluster number, Peak Signal to Noise Ratio (PSNR), and Rand Index. In addition to Serial Shrink Ratio (SSR), we define parallel-friendly rate (PFR) to measure parallelism of demoAlgorithm.
In order to intuitively show the clustering results, images are used as input datasets. The clustering output is the segmented image. Evolving granularity is measured by bandwidth parameters of mean-shift algorithm. Bandwidth parameters are noted in the format of (feature bandwidth, spatial bandwidth).
4.1. Additional Performance Metrics
(1) Accuracy Metrics. Up to step T0, the final cluster number of demoAlgorithm is the quantity of clusters in C T0. Homogenous data points tend to fall into different clusters in the final result if the incremental clustering algorithm produces excessively more clusters than the benchmark algorithm, or vice versa. Consequently, demoAlgorithm tends to achieve higher accuracy if demoAlgorithm can resolve a closer final cluster number to that of the benchmark algorithm.
PSNR values of both incremental clustering result and benchmark result are calculated with respect to the original image.
(2) Parallelism Metrics. Assume that demoAlgorithm runs on a single-core processor. In step t (t = 1,2, 3,…), the batch-mode part consumes time T 1,t and generates microt micro-clusters; the incremental part consumes time T 2,t. Suppose demoAlgorithm totally clustered N data points up to step T 0. Up to step T 0, the parallel-friendly rate (PFR) of demoAlgorithm is PFR = ∑t=1 T0 T 1,t/(∑t=1 T0(T 1,t + T 2,t)). Larger PFR means superior parallelism.
4.2. Hardware and Software Environment
All experiments are executed on a platform equipped with an Intel Core2TM E7500 CPU, and a NVIDIA GTX 660 GPU. The main memory size of CPU is 4 GB. Linux of 2.6.18-194.el5 kernel is used with gcc 4.1.2 and CUDA5.0.
CUDA grid size is always set to 45. CUDA block size is set to 64. Double precision data type is used in floating point operations on both CPU and GPGPU. Batch-mode mean-shift is used as benchmark algorithm. Uniform kernel is used with mean-shift algorithm [33] for both batch-mode part of demoAlgorithm and benchmark algorithm.
4.3. Input Data Sets
We use grayscale images as input. One pixel corresponds to a input data point. The dimension of a data point (vector) is d = 3. Components of the 3-dimensional vector are X-coordinate of the pixel, Y-coordinate of the pixel, and grayscale value of the pixel, respectively. We selected ten natural scenery images (data set 1) and twenty aerial geographical images (data set 2) from USC SIPI data set [34]. Each image is evenly divided into 128 × 128 data blocks. These blocks are successively input to demoAlgorithm. Every image of data set 1 is incrementally clustered in CPU-only mode and GPGPU-powered mode, separately. Incrementally clustering an image of data set 2 in CPU-only mode is excessively time-consuming due to the large data volume. Consequently, the task of incrementally clustering these images is only executed in GPGPU-powered mode.
4.4. Experiment Results and Discussion
Bandwidth parameters (8,6) and (10,8) are excessively large for mean-shift algorithm (both incremental part of demoAlgorithm and benchmark algorithm). Under this parameter setting, accuracy of benchmark clustering results is excessively inferior. Consequently, it is not meaningful to compare accuracy between the incremental clustering algorithm and the benchmark. Thus, we omitted the experiment results under granularities (8,6) and (10,8) in Tables 1 and 2 and Figures 4, 5, and 6.
Table 1.
Comparison of final cluster number.
| Demo algorithm | Benchmark algorithm | |||||
|---|---|---|---|---|---|---|
| (2,1) | (4,2) | (6,4) | (2,1) | (4,2) | (6,4) | |
| Boat | 2372 | 1444 | 589 | 2517 | 1536 | 632 |
| Cars | 2348 | 1151 | 261 | 2481 | 1133 | 270 |
| f16 | 1388 | 749 | 406 | 1469 | 827 | 356 |
| Hill | 2466 | 1552 | 525 | 2540 | 1623 | 540 |
| Peppers | 1715 | 845 | 385 | 1838 | 943 | 413 |
| Sailboat | 2208 | 1762 | 1051 | 2326 | 1817 | 1106 |
| Stream | 2558 | 2312 | 1524 | 2656 | 2437 | 1574 |
| Tank | 2374 | 1137 | 172 | 2425 | 1146 | 178 |
| Truck | 1631 | 986 | 339 | 1700 | 996 | 338 |
| Trucks | 2607 | 2256 | 681 | 2766 | 2360 | 693 |
Table 2.
Dataset 2: max and min Rand Index under ascending granularities.
| Granularity (measured by bandwidth) | |||
|---|---|---|---|
| (2,1) | (4,2) | (6,4) | |
| Max | 0.9997 | 0.9983 | 0.9850 |
| (usc2.2.05) | (usc2.2.17) | (usc2.2.17) | |
| Min | 0.8369 | 0.5025 | 0.1501 |
| (usc2.2.02) | (usc2.2.02) | (usc2.2.07) | |
Figure 4.

Data set 1: variation trends of Rand Index with respect to evolving granularity.
Figure 5.

truck: original image and incremental clustering results under three ascending granularity values.
Figure 6.

usc22.02: original image and incremental clustering results under three ascending granularity values.
(1) Data Set 1: Natural Scenery Images. Table 1 shows the final cluster numbers resolved by the demo algorithm and the benchmark algorithm. Suppose we single out the cluster number values from column 2 (or 3, 4). Afterwards, we compute the average of this column of values. Let aveN inc represent this average. Suppose we single out cluster number values out of column 5 (or 6, 7). Afterwards, we compute the average of this column of values. Let aveN bench represent this average. For example, aveN inc is (2372 + 2348 + 1388 + 2466 + 1715 + 2208 + 2558 + 2374 + 1631 + 2607)/10 = 2166.7 in terms of column 2. aveN bench is (2517 + 2481 + 1469 + 2540 + 1838 + 2326 + 2656 + 2425 + 1700 + 2766)/10 = 2271.8 with regard to column 5.
Under the three ascending granularities, values of aveN inc/aveN bench are 0.9537, 0.9578, and 0.9726, respectively. The final cluster number of demo algorithm is in acceptable agreement with that of the benchmark algorithm.
Figure 3 shows PFR and SSR of the first five inputs from data set 1. The figure reflects positive relation between evolving granularity and parallelism. We omitted the other images due to the fact that they show analogue trends. Figure 4 illustrates the negative relation between accuracy and evolving granularity.
Figure 3.

Data set 1: variation trends of PFR and SSR.
We select granularity (4,2) as a balance point between accuracy and parallelism based on experience. truck has the lowest Rand Index value on this balance point.
Figure 5 shows the original image and experiment results on truck. We can draw a similar conclusion from Figure 5 as that of Figures 3 and 4: speedup rises and accuracy degrades when evolving granularity increases. Moreover, Figure 5 shows the final cluster number values and PSNR values of both incremental clustering result and benchmark result, as well as the speedup. In addition to validating Theorems 14 and 15, our demo algorithm can produce acceptable-accuracy result on certain inputs such as truck.
(2) Data Set 2: Aerial Geographical Images. We continue to use symbols explained in part one of this subsection. Values of (aveN inc/aveN bench) under three ascending granularities are 0.9954, 1.1063, and 1.1345, respectively. Overall, the final cluster number of our demo algorithm is close to that of the benchmark algorithm.
In order to avoid unnecessary details, we only list the maximum and minimum Rand Index values (and corresponding image names) under each evolving granularity in Table 2. Similarly, we only list the maximum and minimum SSR values in Table 3. These experiment results can still validate Theorems 14 and 15. We still choose granularity (4,2) as a balance point between accuracy and parallelism based on experience. usc.2.02 has the lowest Rand Index value on granularity (4,2).
Table 3.
Dataset 2: max and min SSR values under ascending granularities.
| Granularity (measured by bandwidth) | |||||
|---|---|---|---|---|---|
| (2,1) | (4,2) | (6,4) | (8,6) | (10,8) | |
| Min | 3.7E − 03 (usc2.2.02) | 2.1E − 03 (usc2.2.02) | 6.3E − 04 (usc2.2.03) | 6.1E − 04 (usc2.2.03) | 1.2E − 04 (usc2.2.03) |
| Max | 1.0E − 02 (usc2.2.17) | 9.5E − 03 (usc2.2.17) | 6.2E − 03 (usc2.2.17) | 3.3E − 03 (usc2.2.01) | 2.1E − 03 (usc2.2.08) |
Figure 6 shows the final cluster number values and PSNR values of both incremental clustering result and benchmark result. In addition to validating Theorems 14 and 15, our demo algorithm can produce acceptable-accuracy result on certain inputs such as usc.2.02.
5. Conclusion
In this paper we theoretically analyzed the cause of accuracy-parallelism dilemma with respect to the GPGPU-powered incremental clustering algorithm. Theoretical conclusions were validated by a demo algorithm.
Our future work will focus on identifying the suitable granularity for a given incremental clustering task and decreasing mis-affiliations through variable data-block-size.
Acknowledgments
The authors' sincere thanks go to Dr. Bo Hong (AT & T Corporation; School of Electrical and Computer Engineering, Georgia Institute of Technology, USA). This work is supported by the following foundations: Science and Technology Development Program of Weifang (2015GX008, 2014GX028), Doctoral Program of Weifang University (2016BS03), Fundamental Research Funds for the Central Universities (Project no. 3102016JKBJJGZ07), Colleges and Universities of Shandong Province Science and Technology Plan Projects (J13LN82), Natural Science Foundation of China (no. 61672433), and the Ph.D. Programs Foundation of Ministry of Education of China (no. 20126102110036).
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
References
- 1.Wang P., Zhang P., Zhou C., Li Z., Yang H. Hierarchical evolving Dirichlet processes for modeling nonlinear evolutionary traces in temporal data. Data Mining and Knowledge Discovery. 2017;31(1):32–64. doi: 10.1007/s10618-016-0454-1. [DOI] [Google Scholar]
- 2.Ramírez-Gallego S., Krawczyk B., García S., Woźniak M., Herrera F. A survey on data preprocessing for data stream mining: current status and future directions. Neurocomputing. 2017;239:39–57. doi: 10.1016/j.neucom.2017.01.078. [DOI] [Google Scholar]
- 3.García S., Luengo J., Herrera F. Data Preprocessing in Data Mining. Springer; 2015. [DOI] [Google Scholar]
- 4.Ordoñez A., Ordoñez H., Corrales J. C., Cobos C., Wives L. K., Thom L. H. Grouping of business processes models based on an incremental clustering algorithm using fuzzy similarity and multimodal search. Expert Systems with Applications. 2017;67:163–177. doi: 10.1016/j.eswa.2016.08.061. [DOI] [Google Scholar]
- 5.Chen C., Mu D., Zhang H., Hong B. A GPU-accelerated approximate algorithm for incremental learning of Gaussian mixture model. Proceedings of the 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops (IPDPSW '12); May 2012; Shanghai, China. pp. 1937–1943. [DOI] [Google Scholar]
- 6.Chen C., Mu D., Zhang H., Hu W. Towards a moderate-granularity incremental clustering algorithm for GPU. Proceedings of the 2013 5th International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC '13); October 2013; Beijing, China. pp. 194–201. [DOI] [Google Scholar]
- 7.Furao S., Hasegawa O. An incremental network for on-line unsupervised classification and topology learning. Neural Networks. 2006;19(1):90–106. doi: 10.1016/j.neunet.2005.04.006. [DOI] [PubMed] [Google Scholar]
- 8.Furao S., Ogura T., Hasegawa O. An enhanced self-organizing incremental neural network for online unsupervised learning. Neural Networks. 2007;20(8):893–903. doi: 10.1016/j.neunet.2007.07.008. [DOI] [PubMed] [Google Scholar]
- 9.Zheng J., Shen F., Fan H., Zhao J. An online incremental learning support vector machine for large-scale data. Neural Computing and Applications. 2013;22(5):1023–1035. doi: 10.1007/s00521-011-0793-1. [DOI] [Google Scholar]
- 10.Zhou A., Cao F., Qian W., Jin C. Tracking clusters in evolving data streams over sliding windows. Knowledge and Information Systems. 2008;15(2):181–214. doi: 10.1007/s10115-007-0070-x. [DOI] [Google Scholar]
- 11.Zhang X., Furtlehner C., Sebag M. Data streaming with affinity propagation. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 2008;5212(2):628–643. doi: 10.1007/978-3-540-87481-2_41. [DOI] [Google Scholar]
- 12.Zhang X., Furtlehner C., Perez J., Germain-Renaud C., Sebag M. Toward autonomic grids: analyzing the job flow with affinity streaming. Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD ’09); July 2009; pp. 987–995. [DOI] [Google Scholar]
- 13.Zhang X., Furtlehner C., Germain-Renaud C., Sebag M. Data stream clustering with affinity propagation. IEEE Transactions on Knowledge and Data Engineering. 2014;26(7):1644–1656. doi: 10.1109/TKDE.2013.146. [DOI] [Google Scholar]
- 14.Lühr S., Lazarescu M. Incremental clustering of dynamic data streams using connectivity based representative points. Data and Knowledge Engineering. 2009;68(1):1–27. doi: 10.1016/j.datak.2008.08.006. [DOI] [Google Scholar]
- 15.Yang D., Rundensteiner E. A., Ward M. O. Neighbor-based pattern detection for windows over streaming data. Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology (EDBT '09); March 2009; pp. 529–540. [DOI] [Google Scholar]
- 16.Lughofer E. A dynamic split-and-merge approach for evolving cluster models. Evolving Systems. 2012;3(3):135–151. doi: 10.1007/s12530-012-9046-5. [DOI] [Google Scholar]
- 17.Yang H., Fong S. Incrementally optimized decision tree for noisy big data. Proceedings of the 1st International Workshop on Big Data, Streams and Heterogeneous Source Mining: Algorithms, Systems, Programming Models and Applications (BigMine '12); August 2012; Beijing, China. pp. 36–44. [DOI] [Google Scholar]
- 18.Yuan X.-T., Hu B.-G., He R. Agglomerative mean-shift clustering. IEEE Transactions on Knowledge and Data Engineering. 2012;24(2):209–219. doi: 10.1109/TKDE.2010.232. [DOI] [Google Scholar]
- 19.Wei L.-Y., Peng W.-C. An incremental algorithm for clustering spatial data streams: exploring temporal locality. Knowledge and Information Systems. 2013;37:453–483. doi: 10.1007/s10115-013-0636-8. [DOI] [Google Scholar]
- 20.Ganti V., Gehrke J., Ramakrishnan R. Mining data streams under block evolution. ACM SIGKDD Explorations Newsletter. 2002;3(2):1–10. doi: 10.1145/507515.507517. [DOI] [Google Scholar]
- 21.Song M., Wang H. Highly efficient incremental estimation of Gaussian mixture models for online data stream clustering. Proceedings of the Defense and Security (SPIE '05); 2005; Orlando, Florida, USA. p. p. 174. [DOI] [Google Scholar]
- 22.Kumar N. S. L. P., Satoor S., Buck I. Fast parallel expectation maximization for gaussian mixture models on GPUs using CUDA. Proceedings of the 11th IEEE International Conference on High Performance Computing and Communications (HPCC '09); June 2009; pp. 103–109. [DOI] [Google Scholar]
- 23.Aggarwal C. C., Han J., Wang J., Yu P. S. A framework for clustering evolving data streams. Proceedings of the 29th international conference on Very large data bases (VLDB ’03); 2003. [Google Scholar]
- 24.Guha S., Meyerson A., Mishra N., Motwani R., O'Callaghan L. Clustering data streams: Theory and practice. IEEE Transactions on Knowledge and Data Engineering. 2003;15(3):515–528. doi: 10.1109/TKDE.2003.1198387. [DOI] [Google Scholar]
- 25.Tu L., Chen Y. Stream data clustering based on grid density and attraction. ACM Transactions on Knowledge Discovery from Data. 2009;3(3, article 12) doi: 10.1145/1552303.1552305. [DOI] [Google Scholar]
- 26.Ackerman M., Dasgupta S. Incremental clustering: the case for extra clusters. Advances in Neural Information Processing Systems. 2014;1:307–315. [Google Scholar]
- 27.Ackerman M., Moore J. When is Clustering Perturbation Robust? Computing Research Repository. 2016 [Google Scholar]
- 28.Ackerman M., Moore J. Clustering faulty data: a formal analysis of perturbation robustness. 2016, https://arxiv.org/abs/1601.05900.
- 29.Gepperth A., Hammer B. Incremental learning algorithms and applications. Proceedings of the 24th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN '16); April 2016; pp. 357–368. [Google Scholar]
- 30.Chen C., Mu D., Zhang H., Hu W. Nonparametric incremental clustering: a moderate-grained algorithm. Journal of Computational Information Systems. 2014;10(3):1183–1193. doi: 10.12733/jcis9598. [DOI] [Google Scholar]
- 31.Hubert L., Arabie P. Comparing partitions. Journal of Classification. 1985;2(1):193–218. doi: 10.1007/BF01908075. [DOI] [Google Scholar]
- 32.Shiloach Y., Vishkin U. An O (n2 logn) parallel max-flow algorithm. Journal of Algorithms. 1982;2:1128–1146. [Google Scholar]
- 33.Huang M., Men L., Lai C. Accelerating mean shift segmentation algorithm on hybrid CPU/GPU platforms. In Proceedings of the International Workshop on Modern Accelerator Technologies for GIScience (MAT4GIScience '12); 2012. [Google Scholar]
- 34.USC-SIPI[DB/OL] 2013, http://sipi.usc.edu/database/