

Abstract
In an attempt to reduce the infection rate of the COrona VIrus Disease-19 (Covid-19) countries around the world have echoed the exigency for an economical, accessible, point-of-need diagnostic test to identify Covid-19 carriers so that they (individuals who test positive) can be advised to self isolate rather than the entire community. Availability of a quick turn-around time diagnostic test would essentially mean that life, in general, can return to normality-at-large. In this regards, studies concurrent in time with ours have investigated different respiratory sounds, including cough, to recognise potential Covid-19 carriers. However, these studies lack clinical control and rely on Internet users confirming their test results in a web questionnaire (crowdsourcing) thus rendering their analysis inadequate. We seek to evaluate the detection performance of a primary screening tool of Covid-19 solely based on the cough sound from 8,380
clinically validated samples with laboratory molecular-test (2,339 Covid-19 positive and 6,041 Covid-19 negative) under quantitative RT-PCR (qRT-PCR) from certified laboratories. All collected samples were clinically labelled, i.e., Covid-19 positive or negative, according to the results in addition to the disease severity based on the qRT-PCR threshold cycle (Ct) and lymphocytes count from the patients. Our proposed generic method is an algorithm based on Empirical Mode Decomposition (EMD) for cough sound detection with subsequent classification based on a tensor of audio sonographs and deep artificial neural network classifier with convolutional layers called ‘DeepCough’. Two different versions of DeepCough based on the number of tensor dimensions, i.e., DeepCough2D and DeepCough3D, have been investigated. These methods have been deployed in a multi-platform prototype web-app ‘CoughDetect’. Covid-19 recognition results rates achieved a promising AUC (Area Under Curve) of 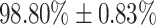 , sensitivity of
, sensitivity of 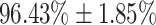 , and specificity of
, and specificity of 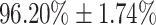 and average AUC of
and average AUC of 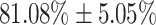 for the recognition of three severity levels. Our proposed web tool as a point-of-need primary diagnostic test for Covid-19 facilitates the rapid detection of the infection. We believe it has the potential to significantly hamper the Covid-19 pandemic across the world.
for the recognition of three severity levels. Our proposed web tool as a point-of-need primary diagnostic test for Covid-19 facilitates the rapid detection of the infection. We believe it has the potential to significantly hamper the Covid-19 pandemic across the world.
Keywords: Deep Learning, audio systems, smart healthcare
1. Introduction
The COrona VIrus Disease-19 (Covid-19) is an infectious disease caused by the newly discovered severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). Covid-19 bears stark similarities with the Severe Acute Respiratory Syndrome (SARS) as well as the common cold. According to the World Health Organization (WHO), the mild symptoms of Covid-19 can include fever, cough and shortness of breath akin to the common cold [1]. Like SARS in more severe cases, Covid-19 also causes pneumonia and/or significant breathing difficulties, and in some rare instances, the disease can be fatal with the overall mortality rate estimated to be 0.28 percent worldwide. The initial cases of Covid-19 were initially diagnosed as pneumonia on 31 December 2019, and later re-diagnosed as Covid-19.
Covid-19 has proven to be a very infectious disease with the virus (SARS-CoV-2) spreading quickly on coming in close contact with an infected person (mean infection rate of 2.5). More specifically, according to the WHO, the (Covid-19) virus is transmitted through direct contact with respiratory droplets of an infected person (generated through coughing and sneezing) [2]. The WHO declared it a global pandemic on 11 March 2020, within three months of first reported cases in China.
Covid-19 has put considerable strain on the health systems worldwide, with even developed countries struggling to test enough people to stop its spread effectively. Hence, taking the Covid-19 pandemic context in consideration, it is important to re-think the classical approaches for timely case finding [3], as well as to utilise the limited resources available most effectively [4].
In past pandemics, such as Malaria, a two pronged approach for a screening test was successfully employed to combat the spread of a prevalent virus [5]. In these two-stage strategies, the primary stage focuses on greater accessibility and ease of screening that is cost-effective. The primary stage is to ‘alert’ a potential carrier if they test positive on a primary screening test. In most cases, only those who test positive on the primary test go on to the secondary test, hence reducing the burden on the health system, and making the most of the resources available to conduct the secondary test. The secondary screening is where the null hypothesis that the participant is not carrying an infection is accepted or rejected. The current techniques employed for screening of Covid-19 use serology, and diagnosis is based on the presence of genetic material of the virus. Clinical molecular tests have robust diagnostic accuracy but require specialised equipment, as well as trained personnel to conduct the test. The turn-around time of these tests can vary from hours to several days.
Given the established success of two-pronged screening mechanisms to hamper the spread of infectious diseases, in this work, we aim to develop a web-based tool for the primary screening of Covid-19. The motivation is to identify Covid-19 carriers using a model trained with clinically validated cough signals since Covid-19 affects the respiratory system [6], [7], [8]. Established works have evidenced the possibility of using the latent sound characteristics of coughs to identify respiratory diseases [9], [10]. In addition, prior works have also reported that voluntary coughs (asymptomatic) contain sound characteristics that allow detecting abnormal pulmonary functioning and respiratory diseases [11], [12].
The remainder of this paper is structured as follows: Section 2 outlines a summary of contributions, Section 3 gives an overview of related work; Section 4 describes the procedural and methodological stages of the development of this technology; Section 5 evaluates the recognition and assessment results; Section 6 discusses the results and achievements; with conclusion in Section 7.
2. Summary of Contributions
The main contributions of this work are manifold and listed as follows:
-
1)
The proposed method ‘DeepCough’ achieves high accuracy, without the necessity of using specific pre-trained models or transfer learning of data from other studies. Hence, differently from related work, the proposed methodology is generic, paving the way for derivative works.
-
2)
In contrast to related work, we are able to evaluate the real capacities of detecting Covid-19 in a large clinically validated dataset (8,000+) where all data samples are matched with molecular-test of Covid-19 viral infection dispensed in certified laboratories to participants.
-
3)
Also unique to this work, the accompanying molecular-tests (qRT-PCR) along with the cough samples, allow us to predict as well the extent of the infection. This is studied in this work using either the cycle threshold (Ct) from the qRT-PCR test or lymphocyte counts.
-
4)
Furthermore, a full-stack automatic processing framework, from a raw sound stream to the test results, is also presented.
-
5)
Development of a tangible test service prototype, as a platform-independent web-app service, CoughDetect.com1
3. Related Work
In an attempt to better understand the Covid-19 infection, and its associated symptoms, scientists have been collecting a wide spectrum of information in the latest months. This includes, but is not limited to, the respiratory sounds related to Covid-19 [6], [8], [13], thermal imaging [14], digestive symptoms [15], as well as self reported surveys. The motivation of collating Covid-19 related information is to develop robust mechanisms for early detection of Covid-19. The most common symptoms of Covid-19 have been linked to pneumonia (cough, fever, shortness of breath, among others). Therefore, the analysis of cough audio signals is considered a viable course of action for a primary Covid-19 diagnosis [8].
In general, three different respiratory sounds have been investigated to detect Covid-19 in patients: voice, breath and cough. The voice is a bio-signal that has been studied for many years to decode emotional, mental and physical aspects of a speaker. Usman et al. [16] conclude that there is a strong correlation between speech and Covid-19 symptoms, and therefore endorse the usage of speech signals for detecting Covid-19.
Faezipour et al. [17] recommended the use of signal processing techniques in tandem with state-of-the-art machine learning and pattern recognition techniques for preliminary diagnosis of Covid-19 from breathing audio signals. However, neither of the studies [16] and [17] encompass the Covid-19 recognition at this stage, with the additional caveat of quality of breath sounds hinged on the sensitivity of the microphone.
Another notable work on breathing patterns is done by Wang et al. [18] who developed a respiratory simulation model (RSM) for detecting the abnormal respiratory patterns of people remotely, and unobtrusively using a depth camera. However, their proposed RSM did not incorporate data from Covid-19 carriers. Nevertheless, the use of video cameras may raise privacy concerns. Imran et al. [19] presented AI4COVID - an approach to classify coughs using deep learning, and achieved an accuracy of 92.85 percent. However, their dataset contains only 70 Covid-19 cough samples, which renders their analysis to be inconclusive.
Sharma et al. [20] presented Coswara,2 a database embodying respiratory sounds (cough, breath, and voice). This dataset is crowdsourced (volunteers from the web), i.e., not clinically controlled samples, with only eight positive Covid-19 samples at the time of writing of this study. Here, it is also important to note that sound modalities, especially voice, embodies privacy concerns since an individual can be identified from their voice [21]. Other notable database creation projects collecting data from the web include: Opensigma3 by MIT collects collecting cough samples, Corona Voice Detect4 by Voca.ai and Carnegie Mellon University (CMU) is collecting voice data, Covid Voice Detector5 also by CMU is collecting further voice samples, and finally, the Covid-19 Sounds App6 by the University of Cambridge is collecting crowdsourced samples of voice, cough, and breath.
A consensus derived from the related work referenced above is the challenge associated in the collection of clinically validated Covid-19 data which can be subsequently used for the training of Covid-19 recognition mechanisms. Towards this end, the data used in this study is collected following a strict protocol designed at laboratories and hospitals dedicated to Covid-19 diagnosis by expert immunologists. Another major strength of our proposed web-based app CoughDetect lies in the anonymity of the users. Coughs sounds are inherently anonymous. Collecting just cough sounds, along with the usage of in-house code only and strict privacy-preserving practices, we have ensured that participants share their cough samples without exposing their personal information. This robust quality control of our collected samples is an advantage of our work with respect to other studies, e.g., collecting clinical data via web questionnaires (crowdsourcing).
4. Methods for Developing a Point-of-Need COVID-19 Web-App Service From Only Cough Sound Samples
The cough samples are collected by means of an in-house developed web app named CoughDetect. The CoughDetect app (https://coughdetect.com) can be easily used with a laptop, mobile phone, or tablet, as shown in Fig. 1. The development of the whole stack for Covid-19 primary screening required the use of several technologies to capture, process, analyse and make the test available. An illustration of the proposed technology stack diagram for the CoughDetect operational architecture is shown in Fig. 2. The app records (.wav) sound files at 44,100Hz sample rate and transfers them to a secure data server using HTTP over SSL connection.
Fig. 1.

The CoughDetect app can be easily used with a) mobile phone, b) laptop or c) tablet connected with Internet.
Fig. 2.

A user can record his cough sample using the CoughDetect web or mobile app with complete anonymity. The user's cough sample is then analysed by DeepCough (the inference mechanism of CoughDetect) for primary screening of Covid-19. A user can receive one of the following two messages on successful analysis of his cough sample:  Your cough sound shares similarities to those of Covid-19 patients, if you are a high-risk individual, please contact health services immediately, otherwise quarantine yourself.
Your cough sound shares similarities to those of Covid-19 patients, if you are a high-risk individual, please contact health services immediately, otherwise quarantine yourself. 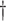 Our system does not recognise your pattern as similar to those with Covid-19 in our database, still if you feel the most likely symptoms, please contact health services.
Our system does not recognise your pattern as similar to those with Covid-19 in our database, still if you feel the most likely symptoms, please contact health services.
The three stages of the development stack include:
-
1)
Sound stream processing and Detection;
-
2)
A recognition method based on the generation of an Acoustic Cough tensor and Deep Learning (DeepCough);
-
3)
Development and Deployment of the framework in a Web Tool App (CoughDetect).
A flow chart delineating the steps in the inference mechanism of DeepCough is shown in Fig. 3. The pre-processing of the raw sound signals is done to increase the signal-to-noise ratio and reduce the signal size. Cough bursts are detected in the recording and the rest of the signal is discarded. A set of low-level acoustic descriptors (a.k.a. sonographs) are extracted from a pre-processed cough sound. Two- and three-dimensional (2D and 3D) tensors are generated from these descriptors. These tensors are fed to a convolutional deep neural network that allows classification of positive and negative Covid-19 cough samples. Additionally, positive patients are sub-classified according to severity: borderline positive, standard positive, high positive based on qRT-PCR values and lymphopenia, or normal lymphocytes based on their blood lymphocyte count, as shown in Fig. 3. Further details of research ethics and the different stages for building the CoughTensor and classification are presented next.
Fig. 3.

The overall flow diagram delineating the steps involved in the DeepCough, 2D and 3D, inference mechanism.
4.1. Research Ethics and Protocol
The collection of clinically validated cough data was carried out in collaboration with Hospital Costa del Sol Health Agency in Málaga, Spain and the National Laboratory for Research in Food Safety (LANIIA) laboratory in Nayarit, Mexico. The collection of the data started at the peak of the pandemic in Spain and Mexico on the 4th of April 2020 and lasted until the 21st of September 2020. The clinical protocols and research ethics are approved by the respective local institutional ethics committees (Code: BIOETIC_HUM_2020_02, Mexico; Code: APP_Covid19_03042020, Spain). The Nayarit Unit and Málaga hospital are both accredited centres for the molecular diagnosis of Covid-19 and are also ISO 9001 certified.
The cough samples are collected from patients coming to the named institutions for a qRT-PCR test for detection of SARS-Cov-2 (Covid-19) by registered nurses trained to use the CoughDetect app. At all stages of the cough sample collection, the guidelines to interact with potential Covid-19 patients recommended by the WHO are strictly followed. For instance, the nurse wears personal protective equipment at all times, and a protocol for the smartphone disinfection, each time a cough is recorded, is observed.
The user interface and control functions of the Web App have been developed with in-house code to uphold the anonymity of the users and minimise the possibility of information leakages to external entities. This is in conformity with both the EU General Data Protection Regulation (GDPR) and the UK Data Protection Act 2018. In addition, our research and application also meet the ethical standards of the Declaration of Helsinki. A written informed consent was collected from each participant prior to acquiring their data sample. Clinical data was collected for this study by healthcare professionals. Table 1, Fig. 4 summarises the demographic ratios and factors such as the number of days after first symptoms reported. In total, we collected 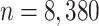 coughs, of which 2,339 coughs are from patients with a positive qRT-PCR test and 6,041 coughs are from patients with a negative qRT-PCR test. Of those patients who resulted negative in the qRT-PCR test, 47.46 percent had no symptoms, and 52.54 percent had symptoms, at the time of taking the samples. Of those patients who resulted positive in the qRT-PCR test, 20.00 percent had no symptoms, and 80.00 percent had symptoms, at the time of taking the samples.
coughs, of which 2,339 coughs are from patients with a positive qRT-PCR test and 6,041 coughs are from patients with a negative qRT-PCR test. Of those patients who resulted negative in the qRT-PCR test, 47.46 percent had no symptoms, and 52.54 percent had symptoms, at the time of taking the samples. Of those patients who resulted positive in the qRT-PCR test, 20.00 percent had no symptoms, and 80.00 percent had symptoms, at the time of taking the samples.
TABLE 1. Demographic Statistics of the Data (Covid-19 Positive and Negative Patients).
| Positive | Negative | |||||
|---|---|---|---|---|---|---|
| Measure | Age | Days
|
PCR CT | Age | Days
|
PCR CT |
| Mean | 39.44 | 7.74 | 29.21 | 38.74 | 7.90 | 40.23 |
| Median | 38 | 7 | 31 | 38 | 6 | 41 |
| Std. Dev. | 14.24 | 6.39 | 7.13 | 13.59 | 6.67 | 6.16 |
| Max | 79 | 60 | 37 | 79 | 50 | 43 |
| Min | 7 | 1 | 18 | 7 | 0 | 38 |
 number of days since the onset of symptoms.
number of days since the onset of symptoms.
Fig. 4.

a) Density distributions of cycle threshold (Ct), lymphocyte count, age, and days from first symptoms from the samples of Covid-19 positive patients. b) Percentage ratios of sex (Male, Female, and Not Specified) and level of positivity (Borderline Positive, Standard Positive, and High Positive) of samples from positive Covid-19 patients displayed in pie charts. c) Percentage ratios of sex (Male, Female, and Not Specified) of samples from negative Covid-19 displayed in a pie chart along with density distribution of age for Covid-19 negative patients.
4.2. Cough Sound Pre-Processing and Detection
Cough samples (.wav) are were acquired at 44.10 kHz, Pulse-code modulation (PCM) format, monochannel. The raw sound data is low pass filtered with a cutoff frequency of 1 kHz. A Chebyshev type-2 second order filter with a transition frequency of 10Hz is applied to retain the high pitch sound of cough while attenuating background sounds simultaneously. Before cough detection, the filtered sound signal is decimated. For an initial bout of sounds in the recording, such as initial involuntary voice before coughing, envelope analysis detects the first peak amplitude and the following signal is subsequently trimmed.
The cough detection algorithm with the filtered audio signals is based on empirical mode decomposition (EMD) [22], [23]. EMD is a fully data-driven signal processing technique that does not employ base functions. EMD splits a sequence into a set of smaller sequences, referred to as intrinsic mode functions (IMFs), or simply modes, whereby each mode contains the energy associated at a certain scale. EMD has become popular in many applications, e.g., wearable sensors [24], perhaps because the decomposition occurs in the same space as the original sequence.
EMD is applied to find the modes that better reflect the coughing periods. These periods are empirically selected to essentially detect cough burst in the filtered sound recordings. Individual or a set of IMFs can be objectively used for signal filtering, peak detection and signal reconstruction. For cough detection, depending on the noise level of the signal, certain IMFs contain rich information related to the peaks associated with coughs. Based on testing a number of signals with various noise levels, the 5th and the 9th modes are found as the prime IMFs essential for detection.
The instantaneous amplitudes (IAs) of the selected modes (5th and 9th) are calculated by the Hilbert Transform [22]. The IAs of the selected modes are averaged, low pass filtered using a median filter with a window size of 500 signal samples, and normalised. Thresholding is performed using local signal peak detection: A signal sample is a local mode or peak if it has the local maximal value being preceded (to the left) by a value difference of 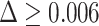 . Thresholding the processed IAs partitions the original signal into cough and non-cough burst event. A summary of the EMD based algorithm for cough detection is depicted in Fig. 5.
. Thresholding the processed IAs partitions the original signal into cough and non-cough burst event. A summary of the EMD based algorithm for cough detection is depicted in Fig. 5.
Fig. 5.

A pictorial illustration of the steps involved in the detection algorithm.
The detection algorithm produces a sequence of binary values: ones for cough and zeros for non-cough segments. A post-processing step joins consecutive cough bursts (segments) which are part of a single or main cough. To do this, an additional threshold is specified to decide whether to join neighbouring cough bursts with a distance shorter than 1,500 decimated signal samples (0.34 seconds). Once an entire cough sound is detected, the rest of the signal is discarded. In addition, segments of short duration (length less than 400 signal samples) were discarded as they were often found to be more representative of short spikes in the signals due to ambient noise rather than part of a cough sound. The final output is a vector of indices that indicates where a cough in a raw sound stream is found.
4.3. A CoughTensor of Sonographs
Following detection, the information contained in the audio signals is transformed into a tensor form. We focused on representations that capture the main acoustic properties of the coughs. We used three types of sonographs: 1) Mel-frequency Cepstral Coefficients (MFCCs), 2) Mel-scaled spectrogram (MelSpec), and 3) Linear Predictive Coding Spectrum (LPCS) coefficients. These sound representations have specific properties for classification in intelligent audio analysis. We describe them here and discuss what they can inform us about coughs sounds.
4.3.1. Mel-Frequency Cepstral Coefficients
MFCCs take into account human auditory perception, where low frequencies are better understood than high frequencies. The frequency bands are logarithmically located according to the Mel scale, which simulates the human auditory response more appropriately than the linearly spaced bands while at the same time disregards all other information. This descriptor is robust to variations in speech across subjects as well as the variations in recording conditions. MFCCs have been widely used in frequency domain speech recognition [25], [26], [27]. The computation of MFCCs involves the following main steps: (i) blocking of pre-processed cough sounds into overlapping windows to avoid loss of information at the ends of windows, (ii) applying hamming window on each frame to taper ends of a frame to zero so that spectral leakage can be avoided during the implementation of Fourier Transformation (FT), and (iii) computation of the power spectrum by applying FT. Next, (iv) the computed spectrum is passed through Mel-spaced band pass filters, where each filter provides the sum of energy for each frame. Finally, (v) the application of discrete cosine transformation yields MFCCs.
4.3.2. Mel-Scaled Spectrogram
The MelSpec is a sonograph where frequencies are converted to the Mel scale in order to visually assess the energy distribution in the signal. The distribution of the energy in the Mel-based spectrum is relevant for the detection of Covid-19 positive samples. Fig. 6 provide examples of the energy spectrum for positive and negative samples. It can be observed that when a Covid-19 patient starts coughing, the energy is in the low-frequency region. However, over time the energy shifts to the high-frequency region. The lower frequencies at the start may be due to pain, and later perhaps the extra efforts required for coughing make the signal more irregular and complex over time. A similar trend is also observed in the voice of people who are suffering from pain due to vocal folds disorders. Extra efforts in speaking render the signal complex which result in an irregular spectrum (continuous voice breaks and disperses energy) compared to a healthy person [28], [29]. In contrast, for a Covid-19 negative person, the energy is uniformly distributed among all frequencies. Therefore, the stark differences in MelSpecs from Covid-19 positive and negative individuals can be leveraged for successful identification of Covid-19 infection.
Fig. 6.

Energy contours of the Auditory Processed Spectrum (APS) representation which is related to MFCCs [29] (a-c) Covid-19 positive patients (d-f) Covid-19 negative persons. Darker colors represent lower energy in the spectrum, while lighter color means higher energy.
4.3.3. Linear Predictive Coding Spectrum (LPCS) Coefficients
LPCS models the emission source of an acoustic signal. LPCS is based on the source-filter model of phonatory signals. It is frequently used for the processing of speech and infant cry. Linear predictive coding analysis estimates the values of a signal as a linear function of previous samples. LPCS is a simplified vocal tract model that reflects the speech production system using a source-filter model. LPCS derives a compact representation of the spectral magnitude of brief duration signals (e.g., coughs). Its parametric analysis allows more accurate spectral resolution than the non-parametric FT when the signal is stationary for only a short time [30]. This sound representation has been used for assessing the vocality of cough sounds [31] and detecting coughs from other human sounds [32].
To generate the acoustic sonographs, we used two open-source tools Librosa [33] and OpenSmile [34].
For each audio frame, we extracted MFCCs with 33 coefficients, MelSpec with 33 bands, and LPCS with 33 line spectral pair frequencies from 33 coefficients. We obtained three matrices of 33 columns by the number of frames of the audio sample. The three sonographs are stacked to form a three-dimensional tensor. Since cough samples have different durations, they have different number of frames. For all samples, the tensor is padded with zeros to complete 100 × 33 × 3 matrices (see Fig. 3) to obtain matrices of the same shape before passing them to the training stage. We set Librosa and OpenSmile to use a sampling rate of 22050 and a hop length of 512. The 100 frames are equivalent to around 2.3 seconds. We chose this tensor length as the minimum duration of a cough event after pre-processing and detection (Section 4.2) falls in this range. Additionally, using this length we ensure that no spurious noise is included in the audio input.
4.4. Classification of the CoughTensor via Convolutional Neural Networks ‘DeepCough’
The CoughTensor generated in Section 4.3 are input to a stack of convolution blocks. Fig. 7 illustrates the architecture of DeepCough along with the dimensions of each layer. The sonograph tensor is fed to the convolution blocks in a manner analogous to how RGB images are processed. The first dimension corresponds to the horizontal axis of the sonograph (time frames), the second dimension is the vertical axis (frequencies, bands, coefficients), and the third dimension is the type of sonograph. For comparison purposes we defined two types of DeepCough:
-
1)
DeepCough2D: The CoughTensor where 2D MelSpec is included in the tensor only, making a tensor spanning two dimensions (frequency and time) i.e.,
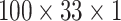 .
.
-
2)
DeepCough3D: The CoughTensor stacks all sonographs described in Section 4.3, with additional third dimension added for each sonograph hence rendering a tensor size of
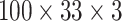 .
.
Fig. 7.

(a) An illustration of the architecture of the Convolutional Neural Network (CNN) with (b) dimensions of convolutional blocks (B1-B4), max-pooling layers, a global averaging (GA), and a dense (D) layer.
Each convolutional block is composed of the following layers:
-
•
Convolutional layers with rectifier linear units (ReLU): Convolution window is set to
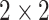 (height/width) and initial padding is set to the length of the input tensor. The input dimensions are row, column and channels.
(height/width) and initial padding is set to the length of the input tensor. The input dimensions are row, column and channels. -
•
Max pooling layer: The pooling window is also set to
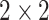 for height and width.
for height and width. -
•
Dropout layer: A drop out level of 20 percent probability in each block to deter the model from over-fitting.
This basic block is stacked four times, permitting a balance between architectural depth and complexity. The stack is followed by subsequent layers to transform the intermediate layer outputs for the final layer:
-
•
A global average pooling layer (GA): It averages all spatial dimensions of the input tensor until the spatial dimension is one.
-
•
Dense layer (D): A dense layer yielding an output equivalent to the number of classes (one per class).
-
•
Softmax layer: A softmax type action function that performs classification over the inputs.
Adaptive Moment Activation (ADAM) is the optimiser used to train the network with a categorical cross-entropy loss function. The evaluation metric during training for ADAM is the sum between resultant area under the curve (AUC) and balanced accuracy. The entire model is implemented in Keras [35] with Tensorflow backend.
The remarkable classification prowess of DeepCough arises from representation learning via convolutional neural networks of the sonograph representations. It is not only an intuitive approach for the analysis of pattern singularities in cough sounds but also has the capacity to integrate information from different sonographs, therefore jointly performing pattern analysis in the information that comes to represent emission (MFCCs, MelSpec) and perception characteristics (LPCS) of sounds (Section 4.3).
4.5. Development and Deployment of DeepCough as an Anonymous Web-Based Primary Screening for COVID-19
The methods described in this paper are deployed in a Web App proof of concept (POC) available at https://coughdetect.com. The main objectives of the interface are as follows:
-
•
Enable a sleek and multi-platform Web App that can be accessed from any device with connectivity to the Internet without installation i.e., like accessing any other Web page.
-
•
Capable of running without the use of session cookies (page reload) or third party services to ensure patient's anonymity is upheld.
-
•
Interaction with user-server should be one-off and response. Multiple interactions with the server are prevented by reducing the number of requests to the server.
The use of MERN (MongoDB, ExpressJS, ReactJS, NodeJS) stack enables a true separation of layers allowing flexible control over each front-end and back-end component as depicted in Fig. 2. React fundamentally uses SPA (Single Page Application) approach to quickly load a single resource (index.js) that contains the entire application rather than sending HTTP requests to the server every time a user wants to navigate elsewhere within the app. Not having to reload the page disables the need for storing cookies in the user machine that can be used to re-identify the user. The front-end logic is mainly javascript code that will be run in the client machine.
Functional interaction, such as recording the cough, passing it over to the server for evaluation and receiving feedback, is done using a custom-built self-hosted API instance solution on a different port. Connections to the server are always encrypted using Hypertext Transfer Protocol Secure (HTTPS). Locally, in the server machine, the node.js endpoint interacts with a python-based API that implements the algorithms and methods from Sections 4.2, 4.3, and 4.4. Once the server receives an audio stream, the processing pipeline is activated, a prediction of the test is issued, and an asynchronous message is returned to the user (client), through the same established secured connection, to update the Web App with the result of the test as illustrated in Fig. 2.
5. Results and Evaluation
In this section we present A) the recognition results of DeepCough for the detection of Covid-19 versus non-Covid-19, and B) further categorisation of the Covid-19 positive samples into groups indicating the grade of Covid-19 disease, with respect to qRT-PCT and lymphocyte counts separately. A comparison of our proposed method DeepCough3D with approaches in related work (AI4COVID [19], Coswara [20]) and Cough against Covid [36]), as well as Auto-ML [37] is also presented.
5.1. Evaluation of COVID-19 Detection With DeepCough
The classification results are reported for a stratified  cross-folding replication strategy for internal validity. A sample can only be exclusive member of one fold. In each iteration a disjoint fold is left out for testing, a different one for validation and the remaining are used for training. The confusion matrix for DeepCough3D, shown in Table 3, demonstrates the classification prowess of DeepCough3D with true positives at 97.18 percent and true negatives at 96.64 percent.
cross-folding replication strategy for internal validity. A sample can only be exclusive member of one fold. In each iteration a disjoint fold is left out for testing, a different one for validation and the remaining are used for training. The confusion matrix for DeepCough3D, shown in Table 3, demonstrates the classification prowess of DeepCough3D with true positives at 97.18 percent and true negatives at 96.64 percent.
TABLE 3. Normalized Confusion Matrix for DeepCough3D.
| Positive | Negative | ||
|---|---|---|---|
| Covid-19 | True Positive | False Negative | Actual Positive |
| 97.18% | 2.82% | ||
| 2273 | 66 | ||
| False Positive | True Negative | Actual Negative | |
| 3.36% | 96.64% | ||
| 203 | 5838 |
We also compare our proposed method with approaches in related work as well as AutoML [37]. AutoML is a full model meta-learning algorithm that combines Bayesian optimisation in a set of shallow machine learning algorithms, such as k-nearest neighbours, naïve Bayes, support vector machines, decision trees, random forest, and boosted classifiers. Auto-ML uses Bayesian optimisation of the AUC score to find for a method or their combinations (viz. pipelines), as well as the model hyper-parameters that yield the highest classification performance as delineated in Fig. 8. It further considers feature selection through information gain, relief, 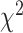 statistics. The Auto-ML method is trained with flattened vectors of audio signal descriptors (Mel-Frequency Cepstral Coefficients, Zero-Crossing Rate, Roll-Off Frequency, and Spectral Centroid).
statistics. The Auto-ML method is trained with flattened vectors of audio signal descriptors (Mel-Frequency Cepstral Coefficients, Zero-Crossing Rate, Roll-Off Frequency, and Spectral Centroid).
Fig. 8.

Flowchart outlining the model selection process with Auto-ML [37].
Models were implemented in Python and trained on an Ubuntu Linux machine with AMD(R) Threadripper(R), 3.40 GHz processor and 32 GB of RAM. Training time in this machine for 10-folds of the DeepCough approach was 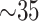 minutes. We further deployed the trained models in an Oracle cloud virtual machine with eight cores (CPU only) as the back-end of the Web app (Section 4.5. In this setting, the detection of a cough in a sound stream lasts in the range of 6-12 seconds and the results of the test are issued in 1-2 seconds.
minutes. We further deployed the trained models in an Oracle cloud virtual machine with eight cores (CPU only) as the back-end of the Web app (Section 4.5. In this setting, the detection of a cough in a sound stream lasts in the range of 6-12 seconds and the results of the test are issued in 1-2 seconds.
Performance comparison of DeepCough 2D and 3D versus other related approaches and Auto-ML in terms of statistical measures of AUC, precision, sensitivity, and specificity are listed in Table 2. A bar graph of the same results is shown in Fig. 9a for a visual comparison. In Fig. 9b the recognition performance of DeepCough3D is primarily assessed in terms of the AUC since AUC allows considering both sensitivity and specificity for different cut-points and gives a better view of the benefit of the binary classifier with skewed samples, e.g., more negatives than positives, than standard accuracy. All of the above results conclude that DeepCough 3D approach afforded the highest significant performance rates in most statistics for the classification of Covid-19 positive versus negative cough samples.
TABLE 2. A Comparison of Statistical Performance Measures of DeepCough3D With DeepCough2D, AutoML [37], AI4COVID[19], Coswara [20], and Cough Against (Versus) Covid [36] for Recognition of COVID-19 Coughs.
| DeepCough3D | DeepCough2D | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC (M1) | Precision (M2) | Sensitivity (M3) | Specificity (M4) | M1 | M2 | M3 | M4 | M1 | M2 | M3 | M4 | |
| DeepCough3D | 98.80  0.83 0.83 |
96.54 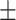 1.75 1.75 |
96.43 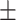 1.85 1.85 |
96.20 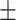 1.74 1.74 |
- | - | - | - | ** | ** | ** | ** |
| DeepCough2D | 96.20  1.18 1.18 |
89.87  1.46 1.46 |
89.63 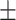 1.57 1.57 |
86.55 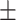 4.64 4.64 |
** | ** | ** | ** | - | - | - | - |
| AutoML | 69.04 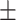 17.50 17.50 |
78.28 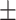 7.78 7.78 |
48.70 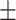 23.71 23.71 |
63.26 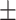 11.74 11.74 |
** | ** | ** | ** | ** | * | ** | 0.22 |
| AI4COVID | 92.36 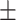 1.96 1.96 |
85.93 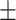 2.87 2.87 |
85.87 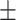 2.87 2.87 |
81.36 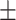 4.31 4.31 |
** | ** | ** | ** | ** | ** | ** | ** |
| Coswara | 87.69 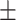 3.86 3.86 |
84.08 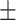 3.57 3.57 |
81.99  5.47 5.47 |
83.45  3.48 3.48 |
** | ** | ** | ** | 0.33 | 0.14 | 0.16 | 0.32 |
| Cough-vs-Covid | 66.41 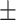 4.23 4.23 |
76.04 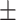 2.53 2.53 |
76.64  2.28 2.28 |
67.00 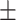 4.29 4.29 |
** | ** | ** | ** | ** | ** | ** | ** |
The p-values for t-test are statistically significant (*: 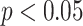 , **:
, **: 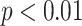 ) for the average of all statistical metrics (M1-M4) for DeepCough3D in comparison to other methods. Likewise, the p-values for t-test for DeepCough2D are also reported.
) for the average of all statistical metrics (M1-M4) for DeepCough3D in comparison to other methods. Likewise, the p-values for t-test for DeepCough2D are also reported.
Fig. 9.

a) Statistical metrics comparison of DeepCough with the other best and worst methods tested. b) Receiver Operating Characteristic (ROC) for DeepCough and other methods to detect pulmonary infection (Covid-19) coughs versus other type of coughs using this study database.
5.2. Assessing the Grade of Infection From COVID-19 Positives Samples
In this study, alongside the cough samples, we also collected the outcomes from quantitative real time polymerase chain test (qRT-PCR) and lymphocyte count (blood ratio) tests. qRT-PCR test is currently considered the gold standard for detecting a positive Covid-19 infection. qRT-PCR test detects the (Covid-19) virus’ RNA within a patient's genetic material. In qRT-PCR test, the RNA is reverse transcribed to DNA using specific enzymes. Additional short fragments of DNA, that are complementary to transcribed viral DNA, are then added. Some DNA strands are programmed to release a fluorescent dye. The amount of fluorescence is monitored in each cycle, until a threshold is surpassed. The fewer the cycles (Ct) it takes to surpass this threshold, the higher the severity of the infection. During the Covid-19 pandemic, a challenge is to identify patients with low and mild levels of infection or asymptomatic, so called ‘carriers’ [38]. Regardless of their asymptomatic conditions, positive qRT-PCR detection can be done with an adequate sample pooling to deal with potential borderline Ct values from these patients [39]. For this experiment, we labelled a cough sample in terms of whether it came from a patient whose Ct values were borderline positive (30  Ct < 35), standard positive (20
Ct < 35), standard positive (20 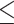 Ct < 30) or strong positive (Ct
Ct < 30) or strong positive (Ct 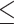 20).
20).
The performance results for the recognition of the cough sample using DeepCough2D and DeepCough3D are displayed in Fig. 10a and enlisted in Table 4. Overall, performance results show a recognition rate well above chance level and average AUC of 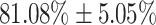 for DeepCough3D. This can potentially be helpful to support two-stage screening protocols previously discussed in the introduction. The recognition of the disease severity was better at discriminating samples coming from the highly discerning groups, i.e., borderline and high positive, but struggled with the intermediate group. This is, however expected as intermediate samples can have a mixed pattern of cough acoustics to those loosely or highly affected. Nevertheless, its specificity was highly better than for the two other groups.
for DeepCough3D. This can potentially be helpful to support two-stage screening protocols previously discussed in the introduction. The recognition of the disease severity was better at discriminating samples coming from the highly discerning groups, i.e., borderline and high positive, but struggled with the intermediate group. This is, however expected as intermediate samples can have a mixed pattern of cough acoustics to those loosely or highly affected. Nevertheless, its specificity was highly better than for the two other groups.
Fig. 10.

Statistical performance results for the recognition of possible markers of disease severity.
TABLE 4. Statistical Metrics for the Classification Results of Positive Cough Samples Labelled as Borderline Positive, Standard Positive and Strong Positives Based on qRT-PCR Results by DeepCough2D and DeepCough3D.
| DeepCough | Statistical | Borderline | Standard | High | Average |
|---|---|---|---|---|---|
| Model | Metric | Positive | Positive | Positive | of 3 classes |
| DeepCough2D | AUC |
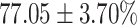
|

|
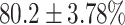
|
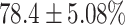
|
| F1-score |
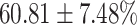
|

|
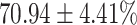
|

|
|
| Precision |
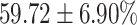
|

|
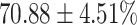
|
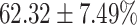
|
|
| Sensitivity |
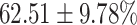
|

|
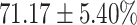
|
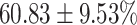
|
|
| Specificity |
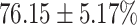
|
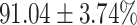
|
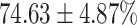
|

|
|
| DeepCough3D | AUC |
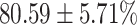
|
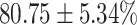
|

|
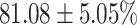
|
| F1-score |

|

|
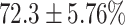
|
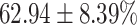
|
|
| Precision |
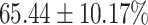
|

|
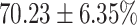
|
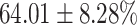
|
|
| Sensitivity |

|
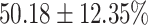
|
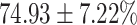
|
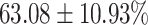
|
|
| Specificity |
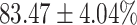
|
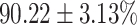
|

|
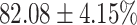
|
Another marker of disease severity that we have explored is lymphocyte count (viz. lymphopenia versus normal levels of lymphocyte counts). Lymphopenia is a condition defined as when patients have a blood lymphocyte percentage (LYM%) lower than 20 percent. Lymphopenia is the frequency associated with a severe infection or illness. The performance results from the recognition of lymphopenia versus normal levels of lymphocytes are graphically displayed in Fig. 10b. Although some works have suggested lymphocyte count as a way to grade Covid-19 severity [40], our results to predict an infection grade using this marker are not as good as when labelled by the qRT-PCR test. However, the performance of DeepCough3D could also be hampered, at this occasion, by subset levels of lymphocyte counts that can be affected by biological and inter-subject variabilities [41], [42].
6. Discussion
The Covid-19 pandemic has proven difficult to contain not only because of its high infection rate, but also because the symptoms of Covid-19 borne stark similarities with other viruses such as the common-flu and pneumonia. Hence, it has been particularly challenging for carriers of Covid-19 to know that they have been infected by Covid-19, therefore furthering the spread of Covid-19. To facilitate the early detection of Covid-19, we have developed a test from clinically validated Covid-19 positive and negative individuals that provided a cough sample and performed a molecular-based test in certified laboratories.
This is a multi-center study, with populations from Spain and Mexico, to ensure the trained inference mechanism of DeepCough3D is unbiased towards particular demographic characteristics. In addition, the proposed DeepCough3D model, subsequently embedded in CoughDetect for recognition of Covid-19 coughs, was compared against related work and Auto-ML [37]. AutoML is a method for algorithm selection and hyper-parameter tuning, optimised through a full model selection strategy. In all the performance metrics for Covid-19 positives recognition, DeepCough3D performed better, as noted in Table 2. The reported results reaffirm that DeepCough3D learning method used is successful in distinguishing between Covid-19 positive and negative cough samples.
The performance of DeepCough3D for establishing whether a given cough sample is from a Covid-19 positive or negative patient is clinically sound as a primary test or pre-screening with an AUC of 98.80 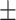 0.83, a sensitivity of
0.83, a sensitivity of 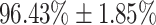 , and a specificity of
, and a specificity of  . The strength of DeepCough3D lies in high recognition performance over a large set of clinically validated cough samples earmarked with molecular test. This resolutely corroborates the informational potential of the latent audio sonographs of coughs to detect an acute pulmonary disease such as Covid-19. The diagnostic sensitivity of the gold-standard molecular test for Covid-19, i.e., qRT-PCR, is 98 percent for nasopharyngeal swab tests, whereas for saliva is 91 percent [43]. However, the reported averaged sensitivity of commercial serological kits (e.g., based on lateral flow immunoassays) for Covid-19 was only 65 percent average (49.0 percent min. to 78.2 percent max.) [44].
. The strength of DeepCough3D lies in high recognition performance over a large set of clinically validated cough samples earmarked with molecular test. This resolutely corroborates the informational potential of the latent audio sonographs of coughs to detect an acute pulmonary disease such as Covid-19. The diagnostic sensitivity of the gold-standard molecular test for Covid-19, i.e., qRT-PCR, is 98 percent for nasopharyngeal swab tests, whereas for saliva is 91 percent [43]. However, the reported averaged sensitivity of commercial serological kits (e.g., based on lateral flow immunoassays) for Covid-19 was only 65 percent average (49.0 percent min. to 78.2 percent max.) [44].
7. Conclusion
In this work, a primary screening test for Covid-19 is proposed and assessed using clinically validated cough samples of participants, who jointly performed a molecular-test (qRT-PCR) in our partner hospitals. The proposed test framework is powered by a generic cough identification algorithm based in EMD and a recognition method named DeepCough3D. This latter method generates a 3D audio tensor to leverage the strength of a convolutional neural network approach to identify the latent characteristics in Covid-19 cough signals. The performance of DeepCough3D attains an AUC of 98.80 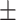 0.83, a sensitivity of
0.83, a sensitivity of  , that is comparable to the reported sensitivity (
, that is comparable to the reported sensitivity ( ) of accelerated serology tests based on saliva [45]. The proposed generic method does not require using specific transfer learning models or data from other studies, paving the way for derivative works. The proposed approach outperforms related works and other state-of-the-art methods. Further, the quality of our clinically controlled and validated large dataset increases our confidence in the validity of these results.
) of accelerated serology tests based on saliva [45]. The proposed generic method does not require using specific transfer learning models or data from other studies, paving the way for derivative works. The proposed approach outperforms related works and other state-of-the-art methods. Further, the quality of our clinically controlled and validated large dataset increases our confidence in the validity of these results.
In addition to the development of a recognition test for Covid-19 using coughs, this work further investigates the possibility to recognise the extent of the Covid-19 infection in Covid-19 positive participants. This is undertaken with the qRT-PCR test and the lymphocyte count, and the results greatly surpassed chance levels of performance, indicating the feasibility of assessing severity to some extend. Classification of the coughs in three severity levels, defined by the resulting Ct of the molecular test for Covid-19, yields an average AUC of 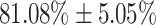 . This could potentially serve as an additional functional feature to diagnose the extent of the Covid-19 infection in a given Covid-19 carrier. This can help facilitate effective management of healthcare facilities during a pandemic, such as ventilators, which were in short supply during the first wave of the Covid-19 pandemic around the world.
. This could potentially serve as an additional functional feature to diagnose the extent of the Covid-19 infection in a given Covid-19 carrier. This can help facilitate effective management of healthcare facilities during a pandemic, such as ventilators, which were in short supply during the first wave of the Covid-19 pandemic around the world.
Furthermore, the entire framework has been embodied as a web-app service available at CoughDetect.com. The motivation for developing this alternative test based on coughs is to have a fast turn-around for Covid-19 point-of-need primary test to a) reduce the burden on specialised personnel for clinical or secondary diagnosis of Covid-19, b) to make the primary screening available to masses at large from the comfort of their homes at negligible costs, and c) the anonymity of the participants is kept at the core by using in-house custom code to power the analysis and recording only their cough sounds. It can also be used as an electronic health certificate at public places such as airports, and schools.
In the midst of a global pandemic, the significance of our proposed point-of-need primary test, developed and tested on clinically validated data, is paramount. Our proposed primary test can mitigate the logistics, long turn-around time, and cost of clinical diagnostic test of Covid-19. For future works, parameter tuning of the sonograph representations and complementary analysis of coughing behaviours could be explored to investigate further improvements in performance. It would also be of interest to investigate whether tracking of Covid-19 progression can be done using DeepCough3D.
8. Author Contributions
JAP contributed to the conceptualisation and coordination of the work, methodology, implementation, analysis, figures and writing of the manuscript. HPE contributed to the organisation of the study, methodology, implementation, analysis, figures and writing of the manuscript. ET, MGP & ABT worked in the data collection and laboratory analysis. MK was involved in the writing of the manuscript, elaboration of figures and analyses. ARP, ORG, & ATG contributed to the implementation of the proposed approach, and comparison methods. DJ contributed to the signal processing and cough sound detection. ZA worked in the sonograph analysis. NG worked in the implementation of the web-app prototype. CGR contributed to the coordination, methodology and appraisal of the work.
Acknowledgments
The authors would like to thank the reviewers for the helpful and constructive comments. They are also grateful to Oracle for Research for providing computational and related resources for this research.
Biographies

Javier Andreu-Perez (Senior Member, IEEE) received the PhD degree from Lancaster University, U.K. He is currently senior lecturer of human-centred artificial intelligence at the University of Essex, U.K., and chair of the Smart Health Technologies Group. He is also a senior research fellow at the University of Jaen (Spain) and an associate editor-in-chief of the journal Neurocomputing.

Humberto Pérez-Espinosa received the PhD degree from the National Institute of Astrophysics, Optics and Electronics. He is currently a researcher at CICESE-UT3, Nayarit, Mexico, in intelligent audio analysis. He is a member of the Mexican National System of Researchers and visiting fellow at the University of Essex, U.K.

Eva Timonet received the PhD degree at the University of Malaga, Spain. She is currently the head of the Nursing Unit at the Junta de Andalucia, Health Agency Costa del Sol and senior research scientist at the Institute of Biomedical Research in Malaga (IBIMA), Spain.

Mehrin Kiani received the MSc degree at Imperial College London, U.K. She is currently working toward the PhD degree in computational intelligence for health sciences at the The Smart Health Technologies Group, University of Essex, U.K.

Manuel I. Girón-Pérez received the PhD degree from University of Guadalajara, Mexico. He is currently a clinical professor at the Autonomous University of Nayarit, Mexico. He is a member of the Mexican National Academy of Medicine, the Mexican Academy of Science, and National System of Researchers.

Alma B. Benitez-Trinidad received the PhD degree from the Autonomous University of Nayarit, Mexico. She is currently a research associate of toxicology. She is a member of the National System of Researchers of Mexico, and a professor at the Autonomous University of Nayarit, Mexico.

Delaram Jarchi (Senior Member, IEEE) received the PhD degree at University of Cardiff U.K. She is currently an assistant professor of advanced signal processing at the University of Essex, U.K., and a member of the Embedded Technologies and Smart Health Technologies Group.

Alejandro Rosales-Pérez received the PhD degree from the National Institute of Astrophysics, Optics and Electronics. He is currently a senior research scientist at CIMAT, Monterrey, Mexico, in machine learning and pattern recognition. He is member of the Mexican National System of Researchers.

Nick Gatzoulis received the BSc degree at the University of Essex, U.K. He is currently working toward the MSc degree. He is also a research officer at the University of Essex, U.K., and full stack software developer in web applications applications.

Orion F. Reyes-Galaviz received the PhD degree from the University of Alberta, Canada, where he was research assistant. He is currently a senior machine learning engineer at Laivly, Canada. He is also an associate investigator at INAOE.

Alejandro Torres-García received the PhD degree in computational intelligence from the National Institute of Astrophysics, Optics and Electronics. He is currently research assistant of biosignal processing at INAOE. He is also an associate researcher at NTNU, Norway.

Carlos A. Reyes-García received the PhD degree from Florida State University, Tallahassee, Florida, in computational intelligence. He is currently a professor and senior investigator of biosignal processing at INAOE. His research interest includes intelligent spectrographic audio analysis.

Zulfiqar Ali received the PhD degree from Universiti Teknologi PETRONAS, Malasia. He is currently an assistant professor of digital speech processing, privacy protection, and audio forensics at the University of Essex, U.K.

Francisco Rivas Ruiz received the MSc degee in clinical trials and methodology of Behavioral and Health Sciences. He is currently coordinator of the Area of Methodological, Documentary and Ethical Advice of the Research and Innovation Unit of the Costa del Sol Health Agency. His main research interest includes the evaluation of health results in chronic diseases.
Footnotes
Contributor Information
Javier Andreu-Perez, Email: javier@andreuperez.net.
Alejandro Rosales-Pérez, Email: alejandro.rosales@cimat.mx.
Carlos A. Reyes-García, Email: kargaxxi@inaoep.mx.
References
- [1].Coronavirus symptoms WHO, 2020. Accessed: Aug. 19, 2020. [Online]. Available: https://www.who.int/health-topics/coronavirus
- [2].Modes of transmission of virus causing COVID-19: Implications for IPC precaution recommendations, 2020. Accessed: Aug. 19, 2020. [Online]. Available: https://www.who.int/news-room
- [3].Bedford J. et al. , “COVID-19: Towards controlling of a pandemic,” Lancet, vol. 395, no. 10229, pp. 1015–1018, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Cohen J. and Kupferschmidt K., “Countries test tactics in ‘war’ against COVID-19,” Sci., vol. 367, no. 6484, pp. 1287–1288, Mar. 2020. [DOI] [PubMed] [Google Scholar]
- [5].Vial H., Taramelli D., Boulton I. C., Ward S. A., Doerig C., and Chibale K., “CRIMALDDI: Platform technologies and novel anti-malarial drug targets,” Malaria J., vol. 12, no. 1, 2013, Art. no. 396. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Eliezer M. et al. , “Sudden and complete olfactory loss of function as a possible symptom of COVID-19,” JAMA Otolaryngol Head Neck Surgery, vol. 146, pp. 674–675, 2020. [DOI] [PubMed] [Google Scholar]
- [7].Li L.-Q. et al. , “Covid-19 patients’ clinical characteristics, discharge rate, and fatality rate of meta-analysis,” J. Med. Virol., vol. 92, no. 6, pp. 577–583, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Latif S. et al. , “Leveraging data science to combat COVID-19: A comprehensive review,” IEEE Trans. Artif. Intell., vol. 1, no. 1, pp. 85–103, Aug. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Swarnkar V., Abeyratne U. R., Amrulloh Y. A., and Chang A., “Automated algorithm for wet/dry cough sounds classification,” in Proc. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc., 2012, pp. 3147–3150. [DOI] [PubMed] [Google Scholar]
- [10].Chatrzarrin H., Arcelus A., Goubran R., and Knoefel F., “Feature extraction for the differentiation of dry and wet cough sounds,” in Proc. IEEE Int. Symp. Med. Meas. Appl., 2011, pp. 162–166. [Google Scholar]
- [11].Abaza A. A. et al. , “Classification of voluntary cough sound and airflow patterns for detecting abnormal pulmonary function,” Cough, vol. 5, no. 1, 2009, Art. no. 8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Infante C., Chamberlain D. B., Kodgule R., and Fletcher R. R., “Classification of voluntary coughs applied to the screening of respiratory disease,” in Proc. 39th Annu. Int. Conf. IEEE Eng. Med. Biol. Soc., 2017, pp. 1413–1416. [DOI] [PubMed] [Google Scholar]
- [13].Xu Z. et al. , “Enhanced forensic speaker verification using a combination of DWT and MFCC feature warping in the presence of noise and reverberation conditions,” Respiratory Med., vol. 8, pp. 420–422, 2020. [Google Scholar]
- [14].Ting D. S. W., Carin L., Dzau V., and Wong T. Y., “Digital technology and COVID-19,” Nat. Med., vol. 26, pp. 459–461, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Pan L. et al. , “Clinical characteristics of COVID-19 patients with digestive symptoms in Hubei, China: A descriptive, cross-sectional, multicenter study,” Amer. J. Gastroenterol, vol. 115, pp. 766–773, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Usman M., Wajid M., Zubair M., and Ahmed A., “On the possibility of using speech to detect COVID- 19 symptoms: An overview and proof of concept,” Dept. Elect. Eng., King Khalid Univ., Sci Rep., 2020.
- [17].Faezipour M. and Abuzneid A., “Smartphone-based self-testing of COVID-19 using breathing sounds,” Telemed. E-Health, vol. 26, no. 10, pp. 1202–1205, 2020. [DOI] [PubMed] [Google Scholar]
- [18].Wang Y., Hu M., Li Q., Zhang X.-P., Zhai G., and Yao N., “Abnormal respiratory patterns classifier may contribute to large-scale screening of people infected with COVID-19 in an accurate and unobtrusive manner,” IEEE Internet Things J., vol. 7, no. 9, 2020. [Google Scholar]
- [19].Imran A. et al. , “AI4COVID-19: AI enabled preliminary diagnosis for COVID-19 from cough samples via an app,” Informat. Med. Unlocked, vol. 20, 2020, Art. no. 100378. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Sharma N. et al. , “Coswara–A database of breathing, cough, and voice sounds for COVID-19 diagnosis,” in Proc. 36th Ann. Conf. Int. Speech Commun. Assoc., 2020, pp. 1–5.
- [21].Hollien H. F., Forensic Voice Identification. New York, NY, USA: Academic Press, 2002. [Google Scholar]
- [22].Huang N. E. et al. , “The empirical mode decomposition and the hilbert spectrum for nonlinear and non-stationary time series analysis,” Proc. Roy. Soc. A, vol. 454, no. 1971, pp. 903–995, Mar. 1998. [Google Scholar]
- [23].Rilling G., Flandrin P., and Goncalves P., “On empirical mode decomposition and its algorithms,” in Proc. IEEE-EURASIP Workshop Nonlinear Signal Image Process., 2003, pp. 8–11. [Google Scholar]
- [24].Sanei S., Jarchi D., and Constantinides A. G., Body Sensor Networking, Design and Algorithms. Hoboken, NJ, USA: Wiley, 2020. [Google Scholar]
- [25].Shi L., Ahmad I., He Y., and Chang K., “Hidden Markov model based drone sound recognition using MFCC technique in practical noisy environments,” J. Commun. Netw., vol. 20, no. 5, pp. 509–518, 2018. [Google Scholar]
- [26].Do C.-T., Pastor D., and Goalic A., “On the recognition of cochlear implant-like spectrally reduced speech with MFCC and HMM-based ASR,” IEEE Trans. Audio Speech Lang. Process., vol. 18, no. 5, pp. 1065–1068, Jul. 2009. [Google Scholar]
- [27].Al-Ali A. K. H., Dean D., Senadji B., Chandran V., and Naik G. R., “Pathological findings of COVID-19 associated with acute respiratory distress syndrome,” Lancet Respiratory Med., vol. 8, no. 4, pp. 420–422, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Ali Z., Hossain M. S., Muhammad G., and Sangaiah A. K., “An intelligent healthcare system for detection and classification to discriminate vocal fold disorders,” Future Gener. Comput. Syst., vol. 85, pp. 19–28, 2018. [Google Scholar]
- [29].Ali Z., Elamvazuthi I., Alsulaiman M., and Muhammad G., “Automatic voice pathology detection with running speech by using estimation of auditory spectrum and cepstral coefficients based on the all-pole model,” J. Voice, vol. 30, no. 6, pp. 757–e7, 2016. [DOI] [PubMed] [Google Scholar]
- [30].O’Shaughnessy D., “Linear predictive coding,” IEEE Potentials, vol. 7, no. 1, pp. 29–32, Feb. 1988. [Google Scholar]
- [31].Van Hirtum and A., Berckmans D., “Assessing the sound of cough towards vocality,” Med. Eng. Phys., vol. 24, no. 7/8, pp. 535–540, 2002. [DOI] [PubMed] [Google Scholar]
- [32].Swarnkar V., Abeyratne U. R., Amrulloh Y., Hukins C., Triasih R., and Setyati A., “Neural network based algorithm for automatic identification of cough sounds,” in Proc. 35th Annu. Int. Conf. IEEE Eng. Med. Biol. Soc., 2013, pp. 1764–1767. [DOI] [PubMed] [Google Scholar]
- [33].McFee B. et al. , “librosa: Audio and music signal analysis in python,” in Proc. 14th Python Sci. Conf., 2015, pp. 18–25. [Google Scholar]
- [34].Eyben F., Wöllmer M., and Schuller B., “Opensmile: The munich versatile and fast open-source audio feature extractor,” in Proc. 18th ACM Int. Conf. Multimedia, 2010, pp. 1459–1462. [Google Scholar]
- [35].Chollet F. et al. , “Keras: The python deep learning library,” 2018. [Online] Avaliable: https://keras.io
- [36].Bagad P. et al. , “Cough against COVID: Evidence of COVID-19 signature in cough sounds,” Wadhwani Inst. Artif. Intell., Mumbai, India, Sci. Rep., 2020.
- [37].Feurer M., Eggensperger K., Falkner S., Lindauer M., and Hutter F., “Auto-sklearn 2.0,” Univ. Freiburg, Freiburg, Germany, Sci. Rep., 2020.
- [38].Day M., “COVID-19: Identifying and isolating asymptomatic people helped eliminate virus in italian village,” Brit. Med. J., vol. 368, pp. m1165–m1165, 2020. [DOI] [PubMed] [Google Scholar]
- [39].Lohse S. et al. , “Pooling of samples for testing for SARS-CoV-2 in asymptomatic people,” Lancet Infectious Diseases, vol. 20, pp. 1231–1232, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Huang I. and Pranata R., “Lymphopenia in severe coronavirus disease-2019 (COVID-19): Systematic review and meta-analysis,” J. Intensive Care, vol. 8, no. 1, pp. 1–10, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Tosato F., Bernardi D., Sanzari M. C., Pantano G., and Plebani M., “Biological variability of lymphocyte subsets of human adults’ blood,” Clinica Chimica Acta, vol. 424, pp. 159–163, 2013. [DOI] [PubMed] [Google Scholar]
- [42].Lymphocytopenia | NHLBI, NIH,” 2020. Accessed: Aug. 18, 2020. [Online]. Available: https://www.nhlbi.nih.gov/health-topics/lymphocytopenia
- [43].Diagnostic testing and screening for SARS-CoV-2, 2020. Accessed: Aug. 20, 2020. [Online]. Available: https://www.ecdc.europa.eu/en/covid-19/
- [44].Bastos M. L. et al. , “Diagnostic accuracy of serological tests for COVID-19: Systematic review and meta-analysis,” Brit. Med. J., vol. 370, pp. 1–13, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [45].Márk C. L. et al. , “Saliva as a candidate for COVID-19 diagnostic testing: A meta-analysis,” Front. Med., vol. 7, 2020, Art. no. 465. [DOI] [PMC free article] [PubMed] [Google Scholar]