

Abstract
Objective
To investigate whether automatic analysis of the Semantic Verbal Fluency test (SVF) is reliable and can extract additional information that is of value for identifying neurocognitive disorders. In addition, the associations between the automatically derived speech and linguistic features and other cognitive domains were explored.
Method
We included 135 participants from the memory clinic of the Maastricht University Medical Center+ (with Subjective Cognitive Decline [SCD; N = 69] and Mild Cognitive Impairment [MCI]/dementia [N = 66]). The SVF task (one minute, category animals) was recorded and processed via a mobile application, and speech and linguistic features were automatically extracted. The diagnostic performance of the automatically derived features was investigated by training machine learning classifiers to differentiate SCD and MCI/dementia participants.
Results
The intraclass correlation for interrater reliability between the clinical total score (golden standard) and automatically derived total word count was 0.84. The full model including the total word count and the automatically derived speech and linguistic features had an Area Under the Curve (AUC) of 0.85 for differentiating between people with SCD and MCI/dementia. The model with total word count only and the model with total word count corrected for age showed an AUC of 0.75 and 0.81, respectively. Semantic switching correlated moderately with memory as well as executive functioning.
Conclusion
The one-minute SVF task with automatically derived speech and linguistic features was as reliable as the manual scoring and differentiated well between SCD and MCI/dementia. This can be considered as a valuable addition in the screening of neurocognitive disorders and in clinical practice.
Keywords: Alzheimer disease, Cognitive dysfunction, Neuropsychological tests, Speech
Introduction
The prevalence of dementia has increased over the last 40 years (Mattiuzzi & Lippi, 2020), and it will continue to increase rapidly in the upcoming years (Francke et al., 2018). Therefore, a timely (prodromal) dementia diagnosis is important since it can lead to earlier interventions and may help retain a patient’s functioning.
Patients with Alzheimer’s disease (ad) dementia, the most common type of dementia, can exhibit deficits on various cognitive domains, such as memory, executive functioning, and language. The latter shows as wordfinding problems, comprehension deficits, and/or repetition within speech even at an early stage of ad (Taler & Phillips, 2008). For example, in Subjective Cognitive Decline (SCD), pathological beta-amyloid levels were found to be associated with a decrease in the use of specific words, even before any other cognitive symptoms are present (Verfaillie et al., 2019). An increase in pauses and a decrease in the use of unique words were shown in Mild Cognitive Impairment (MCI; Taler & Phillips, 2008). In other words, subtle changes in speech and language could be an early predictor for the development of ad dementia and might therefore be an early hallmark to distinguish between normal and pathological aging. Accordingly, these speech and language indicators may contribute to a (more accurate) early diagnosis of ad, thereby leading to better selection for (clinical) trials and/or clinical care.
A commonly used verbal cognitive task is the Semantic Verbal Fluency (SVF) task, of which the total score is related to other cognitive domains, such as memory, executive functioning (switching), and attention (Pakhomov, Eberly, & Knopman, 2016; Zhao, Guo, & Hong, 2013). This total score was able to differentiate between healthy controls, MCI, and ad dementia (Chasles et al., 2020; Clark et al., 2009; Fagundo et al., 2008; Rinehardt et al., 2014; Teng et al., 2013; Wajman, Cecchini, Bertolucci, & Mansur, 2019). This was also found in people with vascular and Parkinson’s dementia (Cummings, Darkins, Mendez, Hill, & Benson, 1988; Desmond, 2004; Henry & Crawford, 2004; Nutter-Upham et al., 2008). The SVF also allows other potential diagnostic indicators to be retrieved, such as the number and length of pauses, semantic and temporal clustering, and switching (König et al., 2018; Laske et al., 2015; Tröger et al., 2019; Troyer, Moscovitch, & Winocur, 1997). These features are interesting as they are more fine-grained and could contribute to the differentiation between healthy controls, MCI, and dementia (König et al., 2018; Linz et al., 2019; Tröger et al., 2019). However, these variables are time-consuming to assess for the clinician manually.
Recently, automatic speech recognition software (ASR) made it possible to automatically recognize and derive words from speech fragments, which can also be used to score the SVF (Pakhomov, Marino, Banks, & Bernick, 2015). Next to the ASR, other algorithms were developed throughout the years to automatically score the SVF (Kim, Kim, Wolters, MacPherson, & Park, 2019). In addition, innovative technologies have become available to automatically extract more fine-grained speech and linguistic features from the SVF task, using machine learning. The automatic scoring of audio recordings from the SVF was already performed in the French language and turned out to be as valid and reliable in differentiating between healthy controls and MCI patients as manual scoring; they also have shown differentiating value of computational qualitative analysis between SCD, MCI, and dementia (König et al., 2018). However, this has not been investigated for the Dutch language. Automatic processing of verbal cognitive tasks, such as the one-minute SVF task, can also improve efficiency of the practical workflow and could lead to a blended way (pencil-and-paper and automatic) of working in clinical practice. The additional information of the automatically derived speech and linguistic features could also improve the early diagnostics of cognitive impairments for trial selection and in clinical practice.
In this study, we aimed to determine the accuracy of automated processing of the SVF task compared with manual processing. In addition, we investigated the diagnostic value of the automatically derived speech and linguistic features of the SVF in differentiating participants with SCD and MCI/dementia from a Dutch memory clinic, and the additional value of these automatically derived features compared with the simple total SVF score used in clinical practice. Lastly, the associations between the automatically derived speech and linguistic features and other cognitive domains were examined.
Materials and Methods
Participants
As part of the DeepSpA (Deep Speech Analysis) project, 135 participants were consecutively included from the BioBank Alzheimer Centre Limburg (BBACL) study (see characteristics in Table 1). From all included participants, 69 had SCD and 66 were diagnosed with MCI/dementia. The MCI/dementia group consisted of 53 participants with MCI and 13 participants with mild dementia (mean age = 77.4 years, SD = 6.5, and mean mini-mental state examination [MMSE] score = 23.3, SD = 2.7). BBACL is an ongoing prospective cohort study that includes consecutive patients from the memory clinic of the Maastricht University Medical Center+ (MUMC+). The inclusion criteria were MMSE ≥20 and a Clinical Dementia Rating scale (CDR) total score of ≤1. Exclusion criteria were non-neurodegenerative neurological diseases, a recent history of severe psychiatric disorders (such as major depression), the absence of a reliable informant, and the clinical judgment that a follow-up assessment after 1 year will not be feasible. The local Medical Ethical Committee (METC MUMC/UM) approved the study (MEC 15-4-100). Each participant gave written informed consent before the assessment.
Table 1.
Characteristics and comparisons between SCD and MCI/dementia participants (n = 135)
| SCD (N = 69) | MCI/dementia (N = 66) | Total (N = 135) | p-value | |
|---|---|---|---|---|
| Age, years | 62.2 (10.7) | 71.8 (9.6) | 66.9 (11.2) | <0.001 |
| Sex (% male) | 65.2 | 59.1 | 62.2 | 0.463 |
| Education (% low/mid/high) | 27.5/36.2/36.2 | 39.4/30.3/30.3 | 33.3/33.3/33.3 | 0.344 |
| CDR SOB | 0.8 (0.9) | 2.0 (1.7) | 1.4 (1.5) | <0.001 |
| DAD (%) | 94.6 (8.0) | 83.3 (16.0) | 88.7 (14.0) | <0.001 |
| MMSE [min-max] | 28.7 (1.2) [25–30] | 26.1 (2.6) [20–30] | 27.5 (2.4) [20–30] | <0.001 |
| Total word count SVF | 23.2 (6.4) | 15.3 (5.3) | 19.4 (7.1) | <0.001 |
| Z-score SVF | −0.1 (0.9) | −1.2 (0.9) | −0.6 (1.0) | <0.001 |
| Z-score VLT immediate recall | 0.4 (1.1) | −1.2 (1.2) | −0.4 (1.4) | <0.001 |
| Z-score VLT delayed recall | 0.2 (1.0) | −1.5 (1.3) | −0.6 (1.5) | <0.001 |
| Z-score Stroop-III | 0.0 (1.1) | −1.7 (3.7) | −0.7 (2.8) | 0.001 |
| Z-score TMT-B | 0.1 (1.1) | −1.1 (1.9) | −0.5 (1.6) | <0.001 |
| GDS-15 | 3.2 (2.4) | 3.3 (2.9) | 3.2 (2.6) | 0.722 |
Note. Abbreviations: CDR, Clinical Dementia Rating scale; SOB, Sum of Boxes; DAD, Disability Assessment for Dementia; MMSE, Mini-Mental State Examination; VLT, Verbal Learning Test; TMT, Trail Making Test; GDS-15, Geriatric Depression Scale-15 items.
Note. Data are presented as mean (SD), unless otherwise specified.
Clinical assessment and diagnosis
As part of the clinical memory clinic assessment, each participant underwent a standardized assessment including patient history, a full neurological and psychiatric assessment, and several scales and questionnaires. The CDR was used to measure disease severity (Morris, 1993; O’Bryant et al., 2010), the Disability Assessment for Dementia (DAD) for functioning in daily life (Gélinas, Gauthier, McIntyre, & Gauthier, 1999), and the Geriatric Depression Scale-15 items (GDS-15) for measuring depressive symptomatology (Sheikh, Hill, & Yesavage, 1986).
As part of the standardized clinical cognitive assessment, for measuring global cognition, the Mini-Mental State Examination (MMSE) was used (Folstein, Folstein, & McHugh, 1975; Kok & Verhey, 2002). The test administered to measure episodic memory was the immediate recall and delayed recall of the Verbal Learning Task-15 items (VLT) (Van Der Elst, Van Boxtel, Van Breukelen, & Jolles, 2005). For executive functioning, the Trail Making Test Part B was administered (TMT-B) or if absent the Concept Shifting Task Part C and the Stroop-Card III (Hammes, 1973; Schmand et al., 2012; Van der Elst et al., 2006b). In addition, the SVF task was used to measure SVF. In this task, the participant has to name as many animals as possible in 60 s (van der Elst et al., 2006a), which resulted in the SVF-clinical total score (golden standard).
The diagnoses were made by a multidisciplinary round, based on the Diagnostic and Statistical Manual of Mental Disorder (DSM-IV-TR, DSM 5) criteria for MCI (cognitive disorder not otherwise specified [NOS] in DSM-IV-TR; mild neurocognitive disorder in DSM 5) and dementia (major neurocognitive disorder; American Psychiatric Association, 2000, 2013). When the cognitive impairments were not severe enough to fulfil the criteria for MCI, participants were classified as having SCD (Jessen et al., 2014).
Speech data processing
The SVF was audio recorded, scored, and processed using a mobile application provided by ki elements GmbH (iOS iPad version; ki elements, 2022). The application records the speech responses from participants, while the neuropsychological assessments were conducted. Therefore, the application uses the standard internal iPad microphone. The iPad was placed in front of the participant. After speech has been recorded, it was sent to ki elements backend for preprocessing (cutting speech into relevant parts and audio transformation), automatic speech recognition, and feature extraction. More specifically, the total word count, the speech and linguistic features (such as “semantic clustering,” “temporal clustering,” “mean word frequency,” and total word count per 10 s (e.g., total word count in 10–20 s), were automatically derived (ki elements, 2022; König et al., 2018; Linz et al., 2019; Troger et al., 2021; Tröger et al., 2019) (for the full list see the Appendix). In addition, the total word count was manually scored by listening to the recordings (manual total word count).
Statistical analyses
The data were analyzed with IBM SPSS Statistics Mac (version 27) and with R 4.1.2 (Team, 2013). Differences between groups were analyzed with independent t-tests for continuous variables and with Chi-square tests for categorical variables. When a variable was not normally distributed, a Mann–Whitney-U test was performed. Educational level was categorized into low (at most primary education), mid (junior vocational training), and high (senior vocational or academic training) according to a Dutch grading system (De Bie, 1987), which is comparable with the Standard Classification of Education (UNESCO, Paris, 1976). The intraclass correlation coefficient (ICC) of the total scores was calculated to examine the agreement between the application’s score and the independent clinical total score (golden standard), based on a mean-rating (k = 2), absolute-agreement, and 2-way-mixed-effects model. Effect sizes for the speech and linguistic features were calculated using the Z-statistic of the Mann–Whitney U test (|Z|/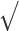 N), a nonparametric test due to the skewness of most of the speech and linguistic features. Pearson correlations were performed between the features and the other cognitive tasks (age, sex, and education adjusted z-scores were used). The heatmaps were made with the statistical program R 4.1.2 with the package corrplot. When a score was missing (N = 26), the full case was deleted (Wei, Simko, & Levy, 2021). Age, sex, and education adjusted Z-scores of the cognitive tests were based on published normative data for the Dutch population (van der Elst et al., 2006a; van der Elst et al., 2006b; Van Der Elst, Van Boxtel, Van Breukelen, & Jolles, 2005).
N), a nonparametric test due to the skewness of most of the speech and linguistic features. Pearson correlations were performed between the features and the other cognitive tasks (age, sex, and education adjusted z-scores were used). The heatmaps were made with the statistical program R 4.1.2 with the package corrplot. When a score was missing (N = 26), the full case was deleted (Wei, Simko, & Levy, 2021). Age, sex, and education adjusted Z-scores of the cognitive tests were based on published normative data for the Dutch population (van der Elst et al., 2006a; van der Elst et al., 2006b; Van Der Elst, Van Boxtel, Van Breukelen, & Jolles, 2005).
In Python 3.9.7, machine learning models (extra trees) were trained to differentiate between the two different groups (SCD vs. MCI/dementia) using the sklearn Python package (Pedregosa et al., 2011). Due to the limited sample size, no held out test set could be maintained. Instead, models were evaluated using Leave-One-Out Cross-Validation, a procedure in which one sample at a time is removed from the training set and used as a test case. This procedure was repeated for each sample and average of the model’s performance was calculated. Area under the receiver operating characteristics curve (AUC-ROC), which allow visualization of multiple different potential trade-offs between sensitivity and specificity, were created for three models with a different selection of features, namely (1) manual total word count only; (2) manual total word count and correction for age; and (3) manual total word count, correction for age and all automatically derived speech and linguistic features (without the word count in intervals of 10 s, Appendix). Sensitivity analyses were administered (correlations, AUC-ROC, and best features) in which the participants with mild dementia were excluded from the MCI/dementia group.
Results
Participants characteristics
The characteristics of the SCD and MCI/dementia participants are presented in Table 1. As expected, the MCI/dementia participants were significantly older than the SCD participants. The groups did not differ significantly for sex, education level, and GDS-score. On all other cognitive tasks and the CDR, SCD participants had significantly better scores than MCI/dementia participants.
Automatic total word count score
The ICC for describing the interrater reliability between the clinical total score (golden standard) and automatic scoring of the total word count of the SVF task was 0.84 (95% CI 0.33–0.94; Fig. 1). The mean difference between the clinical total score and the automatic score was 3.9 words with a range from −5 to 23 words. In 5 out of 135 people (3.7%), the automatic score missed more than 15 animals.
Fig. 1.

Scatterplot of the clinical and automatically derived SVF total word count.
Diagnosis classification
The ROC curves differentiating between SCD and MCI/dementia participants are shown in Fig. 2. The full model including the manual total word count, age, and the speech and linguistic features was able to differentiate between SCD and MCI/dementia participants (AUC = 0.85, Fig. 2). The full model including the speech and linguistic features had a slightly higher AUC in comparison to the age corrected total score (AUC = 0.81) and total word count alone (AUC = 0.75).
Fig. 2.

Receiver operator curve of the extra tree classification model 1, for total word count only; model 2, for total word count only and the correction for age; model 3 for total word count, the correction for age and the speech and linguistic features, in differentiating between SCD and MCI/dementia participants.
A sensitivity analysis showed that after excluding the participants with dementia (N = 13), the increase in AUC remained essentially the same (AUC including speech and linguistic features increased from 0.73 [word count only] to 0.80).
Effect sizes of specific speech and linguistic features
Table 2 shows the significantly differentiating features of all 32 included features between SCD and MCI/dementia participants. The highest effect sizes were found for (1) total word count, (2) number of semantic switches, (3) temporal mean switch transition, (4) semantic mean cluster size, and (5) mean word frequency. A sensitivity analysis, in which participants with dementia were excluded from the MCI/dementia group, resulted in essentially the same top differentiating features, in which “total word count” and “number of semantic switches” remained the best in differentiating SCD from MCI participants (see Supplementary material online, Table S1).
Table 2.
Speech and linguistic features with significant group differences between the SCD and MCI/dementia group
| Feature | Z-value | p-value | Effect size |
|---|---|---|---|
| Total word count | -6.687 | <0.001 | 0.573 |
| Number of semantic switches | -5.861 | 0.002 | 0.504 |
| Temporal mean switch transition | -4.063 | <0.001 | 0.350 |
| Semantic mean cluster size | -3.434 | <0.001 | 0.296 |
| Mean word frequency | -3.319 | <0.001 | 0.286 |
| Number of temporal switches | -3.030 | <0.001 | 0.261 |
| Temporal mean time intracluster transition | -2.848 | 0.004 | 0.245 |
| Temporal mean cluster size | -2.528 | 0.011 | 0.218 |
Correlations between speech and linguistic features and other cognitive tasks
The correlations between the automatically derived speech and linguistic features themselves and other cognitive tests are displayed in Fig. 3.
Fig. 3.

Heatmap reporting the observed correlation coefficients between the automatically retrieved SVF speech and linguistic features (see the Appendix), cognitive tasks, and daily functioning. Positive correlations are presented in blue and negative correlations are presented in red. A stronger correlation has a darker color and a bigger circle, whereas weak correlations have a lighter color and smaller circle (N = 109, due to casewise deletion in case of missing values).
All temporally related features were highly significant correlated with each other, as were all semantically related features. Moreover, “number of semantic switches” and “number of temporal switches” were positively correlated, whereas “semantic number of switches” had a negative correlation with “mean word frequency.” Both the “temporal number of switches” and the “semantic number of switches” were positively correlated with the word counts in intervals of ten seconds. Secondly, both the “number of semantic switches” and “number of temporal switches” were positively correlated with “total word count” of the SVF. Moreover, a negative correlation between “mean word frequency” and “temporal mean switch transition” correlated negatively with total word count of the fluency (Fig. 3).
Correlations between the automatically derived linguistic features and other cognitive tests are also displayed in Fig. 3. The “number of semantic switches” was positively correlated with the MMSE (cognitive functioning in general), VLT immediate and delayed recall scores (episodic memory), and with the executive functioning tasks (Stroop-III and TMT-B). For disease severity, the “number of semantic switches” and “number of temporal switches” had a negative correlation with the CDR-SOB. In a sensitivity analysis excluding the participants with dementia, the correlations remained essentially the same (see Supplementary material online, Fig. S1).
Discussion
In this study, we examined an automated analysis method of the SVF task in the early diagnostics of cognitive disorders in a Dutch memory clinic setting. Results showed that the automatically retrieved total word count was comparable to the manually retrieved total word count with a high ICC. Moreover, the automatically derived speech and linguistic features had a high diagnostic differentiating ability between SCD and MCI/dementia participants in a memory clinic setting. This discriminative value was slightly higher than the discriminative value of the total word count only. Furthermore, as expected some of the speech and linguistic features correlated with performance in other cognitive domains (such as executive functioning, and memory) and disease severity.
In previous research, the comparability of manual and automatic scoring of the SVF was already found in other languages, such as French (König et al., 2018). In the present study, we were able to replicate these findings for the Dutch language, although in 5 of the 135 (3.7%) cases in our sample, the automatic scoring missed more than 15 animals. A more detailed analysis showed that this was mainly caused by fast speech, very low speech volume, or a strong local dialect of the participant. Further improvement of the application in dealing with these factors might improve the automatic scoring.
The full model including the SVF total count and automatically derived speech and linguistic features based on the Dutch language could accurately differentiate between SCD and MCI/dementia participants. A recent study including French-speaking participants also found that these speech and linguistic features could differentiate people with SCD from people with MCI (König et al., 2018). The discriminative value of this full model was slightly higher than the models based on total word count only. This reflects a slight increase in differentiating value of these automatically derived speech and linguistic features compared with the traditionally used total word count. This suggests that the automatic processing of the SVF and its speech and linguistic features can differentiate more accurately between the two diagnostic groups. Although this result needs to be interpreted carefully, as the increase was limited and the clinical value therefore questionable. The sensitivity analysis excluding participants with dementia from the MCI/dementia group showed that SCD and MCI participants could be differentiated, indicating that the SVF task is able and sensitive to detect differences in cognitive mildly impaired people. This is also in line with previous research (Taler & Phillips, 2008).
More specifically, the speech and linguistic features that could best distinguish between the SCD and MCI/dementia group were (1) total word count, (2) number of semantic switches, (3) temporal mean switch transition, (4) semantic mean cluster size, and (5) mean word frequency. Previous research already demonstrated the diagnostic accuracy of the SVF total word count (Chasles et al., 2020; Clark et al., 2009; Fagundo et al., 2008; Rinehardt et al., 2014; Teng et al., 2013; Wajman et al., 2019). In addition, a higher number of semantic switches, a lower temporal switch transition, a larger semantic cluster size, and naming less common Dutch animals resulted in better performance on the SVF task, which is associated with a lower chance to be cognitively impaired. An in-depth explanation for these findings could be the correlations with other cognitive tasks, as explained below.
Some speech and linguistic features correlated strongly with each other and with the total word count. Troyer et al. (1997) has previously established that semantic clustering and switching were correlated, which was in line with our finding. “Mean word frequency” negatively correlated with “number of semantic switches.” In other words, naming the most common animals in the Dutch language might result in fewer semantic switches. In addition, the “number of temporal switches” and “number of semantic switches” correlated positively with all the word counts in the 10-s intervals and with total word count. This could be explained by participants who switched more also named more animals within the first, second, third, fourth, fifth, and last 10 s of the 1-min task. The correlation between the features could indicate that the easier a person switches between temporal or semantic clusters, the more animals one can name and less common animal names are used. From a clinical perspective, one could argue that if a participant has a certain strategy in switching between semantic clusters, the participant would have fewer switches and that would give a higher total word count. However, the present findings showed that frequent switching results in a higher score on the SVF. This shows that a good performance on the SVF can be explained by different cognitive strategies. Lastly, “mean word frequency” and “temporal mean switch transition” correlated negatively with total word count. This could imply that naming the most common words in the Dutch language and a slow transition between temporal cluster leads to a lower total word count or vice versa.
Moreover, the “number of semantic switches” correlated positively with general cognitive functioning (MMSE), episodic memory, and executive functioning (switching between concepts and inhibiting an automatic response). This is in line with previous research stating that the SVF task is related to memory and executive functioning, such as cognitive flexibility (Pakhomov et al., 2016; Tröger et al., 2019; Zhao et al., 2013). Our results might indicate that the total word count of the SVF is related to more cognitive domains than verbal fluency only. Furthermore, “number of semantic switches” and “number of temporal switches” had a negative correlation with disease severity, which could imply that the more a participant is able to switch, the less severe the cognitive impairment is. All in all, switching between temporal and semantic clusters was related to better performance on the SVF task, as well as memory and executive functioning tasks.
The results from this study suggest that automatic processing of the SVF task could potentially improve the efficiency of the workflow and could save time for the clinicians and researcher. It could be an easy and quick tool to screen participants for clinical trials. The automated SVF takes only 1 min to complete and provides additional information beyond a clinician rated total word count alone. In addition, the automatic processing of other verbal cognitive tasks could also be of added value in differentiating between SCD and MCI/dementia persons.
A limitation in this study is the heterogeneity of the MCI/dementia group. We did not distinguish between MCI and dementia, due to the limited number of people with dementia. However, additional sensitivity analyses showed that excluding these participants from the analyses did not change the results substantially. In future research, more people with dementia should be included to investigate whether the SVF is able to distinguish between groups along the cognitive spectrum ranging from SCD to mild dementia. Moreover, it would be interesting to examine whether the SVF task could be administered remotely, for example, phone assessment, to simplify screening even further for clinical trials and monitor disease course, for example, for people living in medical deserts with less access to care facilities. For patients, phone assessment could even lower the burden and could be more comfortable. Moreover, utilizing a longitudinal design would be of interest as one would be able to examine whether cognitive decline could be predicted with the SVF task and which speech and linguistic feature is mostly related to disease progression.
In conclusion, the one-minute SVF task including automatically derived speech and linguistic features can differentiate between SCD and MCI/dementia participants. Therefore, the SVF might have potential as an easy, quick, and noninvasive tool to screen participants for clinical trials.
Supplementary Material
Acknowledgements
The data collection was performed and coordinated by DtH, NP, AG, LB, IR, FV, and MdV. NL and JT calculated the speech and linguistic features. DtH, IR, MdV, AK, and FV all contributed to the conception of the research question of this study. DtH drafted the manuscript and performed the statistical analyses. The machine learning models were performed by DtH and SvA, where the scripts were developed in collaboration with NL and JT. All authors participated in the interpretation of the data and revised drafts of the manuscript for important intellectual content. All authors read and approved the final manuscript.
Appendix. Speech and linguistic features
| Speech and linguistic feature | Description |
|---|---|
| Traditionally administered: | |
| Total word count | The total number of animals named |
| New speech and linguistic features: | |
| Mean word frequency | The word frequency is based on frequently occurring versus unusual Dutch animal words. |
| Word frequency range | The difference between the most and the least frequent word mentioned by a participant. |
| Temporal mean cluster size | Words that are named together in time are a temporal cluster. The average size of the clusters is based on the time in which the participant names the animals |
| Number of temporal switches | The total number of switches between temporal clusters, the count of how many times a patient starts a new temporal cluster. |
| Temporal mean time in cluster | Average time naming words in the cluster. Words tend to be produced in temporal clusters, with a short time interval between words in a temporal cluster |
| Temporal mean time intracluster transition | Mean time it takes to switch between different temporal clusters. Words tend to be produced in temporal clusters and not evenly distributed over time, you see a longer pause between temporal clusters |
| Temporal mean time switch transition | The average time it takes to switch between temporal clusters. |
| Semantic mean cluster size | Words that are named together are a semantic cluster. The average size of the semantic clusters based on the time in which the participant names the animals. Clusters were for example organized by living environment, human use, and zoological categories according to Troyer et al. (1997). |
| Number of semantic switches | The total number of switches between semantic clusters (Troyer et al., 1997) |
| Semantic intercluster similarity | The similarity between words in the semantic cluster (Troyer et al., 1997) |
| Semantic intracluster similarity | The similarity between words of different semantic clusters (Troyer et al., 1997) |
| Word count in intervals of 10 s | Number of animals named per 10-s interval, for example, total word count in 10–20 s |
Contributor Information
Daphne ter Huurne, Department of Psychiatry and Neuropsychology, Alzheimer Centrum Limburg, School for Mental Health and Neuroscience, Maastricht University, Maastricht, the Netherlands.
Inez Ramakers, Department of Psychiatry and Neuropsychology, Alzheimer Centrum Limburg, School for Mental Health and Neuroscience, Maastricht University, Maastricht, the Netherlands.
Nina Possemis, Department of Psychiatry and Neuropsychology, Alzheimer Centrum Limburg, School for Mental Health and Neuroscience, Maastricht University, Maastricht, the Netherlands.
Leonie Banning, Department of Psychiatry and Neuropsychology, Alzheimer Centrum Limburg, School for Mental Health and Neuroscience, Maastricht University, Maastricht, the Netherlands.
Angelique Gruters, Department of Psychiatry and Neuropsychology, Alzheimer Centrum Limburg, School for Mental Health and Neuroscience, Maastricht University, Maastricht, the Netherlands.
Stephanie Van Asbroeck, Department of Psychiatry and Neuropsychology, Alzheimer Centrum Limburg, School for Mental Health and Neuroscience, Maastricht University, Maastricht, the Netherlands.
Alexandra König, National Institute for Research in Computer Science and Automation (INRIA), Stars Team, Sophia Antipolis, France.
Nicklas Linz, ki elements, Saarbrücken, Germany.
Johannes Tröger, ki elements, Saarbrücken, Germany.
Kai Langel, Janssen Clinical Innovation, Beerse, Belgium.
Frans Verhey, Maastricht University Medical Center+ (MUMC+), Department of Psychiatry and Psychology, Maastricht, the Netherlands.
Marjolein de Vugt, Maastricht University Medical Center+ (MUMC+), Department of Psychiatry and Psychology, Maastricht, the Netherlands.
Data availability
A dataset with deidentified participant data and a data dictionary may be made available upon reasonable request from a qualified investigator, subject to a signed data access agreement.
Funding
This work was supported by European Institute for Innovation and Technology (EIT)— Health (Grant number: 19249).
Conflict of Interest
For ki:elements, JT and NL are employed by company ki:elements, which developed the mobile application and calculated the speech and linguistic features. NL and JT own shares of the company.
References
- American Psychiatric Association (2000). Diagnostic and statistical manual of mental disorders (4th ed.). Washington DC: American Psychiatric Association.
- American Psychiatric Association (2013). Diagnostic and statistical manual of mental disorders (5th ed.). Washington, DC: American Psychiatric Association.
- Chasles, M.-J., Tremblay, A., Escudier, F., Lajeunesse, A., Benoit, S., Langlois, R. et al. (2020). An examination of semantic impairment in amnestic MCI and AD: What can we learn from verbal fluency? Archives of Clinical Neuropsychology, 35(1), 22–30. 10.1093/arclin/acz018. [DOI] [PubMed] [Google Scholar]
- Clark, L. J., Gatz, M., Zheng, L., Chen, Y.-L., McCleary, C., & Mack, W. J. (2009). Longitudinal verbal fluency in normal aging, preclinical, and prevalent Alzheimer’s disease. American Journal of Alzheimer's Disease and Other Dementias, 24(6), 461–468. 10.1177/1533317509345154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cummings, J. L., Darkins, A., Mendez, M., Hill, M. A., & Benson, D. F. (1988). Alzheimer's disease and Parkinson's disease: Comparison of speech and language alterations. Neurology, 38(5), 680–680, 684. 10.1212/WNL.38.5.680. [DOI] [PubMed] [Google Scholar]
- De Bie, S. E. (1987). Standaardvragen 1987: Voorstellen voor uniformering van vraagstellingen naar achtergrondkenmerken en interviews [standard questions 1987: Proposal for uniformization of questions regarding background variables and interviews]. Leiden, The Netherlands: Leiden University Press. [Google Scholar]
- Desmond, D. W. (2004). The neuropsychology of vascular cognitive impairment: Is there a specific cognitive deficit? Journal of the Neurological Sciences, 226(1–2), 3–7. 10.1016/j.jns.2004.09.002. [DOI] [PubMed] [Google Scholar]
- Fagundo, A. B., López, S., Romero, M., Guarch, J., Marcos, T., & Salamero, M. (2008). Clustering and switching in semantic fluency: Predictors of the development of Alzheimer's disease. International Journal of Geriatric Psychiatry: A journal of the psychiatry of late life and allied sciences, 23(10), 1007–1013. 10.1002/gps.2025. [DOI] [PubMed] [Google Scholar]
- Folstein, M. F., Folstein, S. E., & McHugh, P. R. (1975). “Mini-mental state”: A practical method for grading the cognitive state of patients for the clinician. Journal of Psychiatric Research, 12(3), 189–198. 10.1016/0022-3956(75)90026-6. [DOI] [PubMed] [Google Scholar]
- Francke, A., Heide, I., Bruin, S. D., Gijsen, R., Poos, R., & Verbeek, M. (2018). Een samenhangend beeld van dementie en dementiezorg: kerncijfers, behoeften, aanbod en impact. In Themarapportage van de Staat van Volksgezondheid en Zorg. Utrecht: Nivel The Netherlands Institute for Health Services Research.
- Gélinas, I., Gauthier, L., McIntyre, M., & Gauthier, S. (1999). Development of a functional measure for persons with Alzheimer’s disease: The disability assessment for dementia. The American Journal of Occupational Therapy, 53(5), 471–481. 10.5014/ajot.53.5.471. [DOI] [PubMed] [Google Scholar]
- Hammes, J. G. W. (1973). The STROOP color-word test: Manual. Amsterdam: Swets & Zeitlinger.
- Henry, J. D., & Crawford, J. R. (2004). Verbal fluency deficits in Parkinson's disease: A meta-analysis. Journal of the International Neuropsychological Society, 10(4), 608–622. 10.1017/S1355617704104141. [DOI] [PubMed] [Google Scholar]
- Jessen, F., Amariglio, R. E., Van Boxtel, M., Breteler, M., Ceccaldi, M., Chételat, G. et al. (2014). A conceptual framework for research on subjective cognitive decline in preclinical Alzheimer's disease. Alzheimer's & Dementia, 10(6), 844–852. 10.1016/j.jalz.2014.01.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ki:elements . (2022). Ki:Elements. https://ki-elements.de
- Kim, N., Kim, J. H., Wolters, M. K., MacPherson, S. E., & Park, J. C. (2019). Automatic scoring of semantic fluency. Frontiers in Psychology, 10, 1020. 10.3389/fpsyg.2019.01020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kok, R., & Verhey, F. (2002). Gestandaardiseerde MMSE (, pp. 1–2). Zeist: Altrecht GGZ. [Google Scholar]
- König, A., Linz, N., Tröger, J., Wolters, M., Alexandersson, J., & Robert, P. (2018). Fully automatic speech-based analysis of the semantic verbal fluency task. Dementia and Geriatric Cognitive Disorders, 45(3–4), 198–209. 10.1159/000487852. [DOI] [PubMed] [Google Scholar]
- Laske, C., Sohrabi, H. R., Frost, S. M., López-de-Ipiña, K., Garrard, P., Buscema, M. et al. (2015). Innovative diagnostic tools for early detection of Alzheimer's disease. Alzheimer's & Dementia, 11(5), 561–578. 10.1016/j.jalz.2014.06.004. [DOI] [PubMed] [Google Scholar]
- Linz, N., Fors, K. L., Lindsay, H., Eckerström, M., Alexandersson, J., & Kokkinakis, D. (2019). Temporal analysis of the semantic verbal fluency task in persons with subjective and mild cognitive impairment. Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology. Minneapolis, Minnesota: Association for Computational Liinguistics.
- Mattiuzzi, C., & Lippi, G. (2020). Worldwide disease epidemiology in the older persons. European Geriatric Medicine, 11(1), 147–153. 10.1007/s41999-019-00265-2. [DOI] [PubMed] [Google Scholar]
- Morris, J. C. (1993). The clinical dementia rating (CDR): Current version and scoring rules. Neurology, 43(11), 2412–2414. 10.1212/wnl.43.11.2412-a. [DOI] [PubMed] [Google Scholar]
- Nutter-Upham, K. E., Saykin, A. J., Rabin, L. A., Roth, R. M., Wishart, H. A., Pare, N. et al. (2008). Verbal fluency performance in amnestic MCI and older adults with cognitive complaints. Archives of Clinical Neuropsychology, 23(3), 229–241. 10.1016/j.acn.2008.01.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O’Bryant, S. E., Lacritz, L. H., Hall, J., Waring, S. C., Chan, W., Khodr, Z. G. et al. (2010). Validation of the new interpretive guidelines for the clinical dementia rating scale sum of boxes score in the national Alzheimer's coordinating center database. Archives of Neurology, 67(6), 746–749. 10.1001/archneurol.2010.115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pakhomov, S. V., Eberly, L., & Knopman, D. (2016). Characterizing cognitive performance in a large longitudinal study of aging with computerized semantic indices of verbal fluency. Neuropsychologia, 89, 42–56. 10.1016/j.neuropsychologia.2016.05.031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pakhomov, S. V., Marino, S. E., Banks, S., & Bernick, C. (2015). Using automatic speech recognition to assess spoken responses to cognitive tests of semantic verbal fluency. Speech Communication, 75, 14–26. 10.1016/j.specom.2015.09.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O. et al. (2011). Scikit-learn: machine learning in Python. Journal of Machine Learning Research. [Google Scholar]
- Rinehardt, E., Eichstaedt, K., Schinka, J. A., Loewenstein, D. A., Mattingly, M., Fils, J. et al. (2014). Verbal fluency patterns in mild cognitive impairment and Alzheimer's disease. Dementia and Geriatric Cognitive Disorders, 38(1–2), 1–9. 10.1159/000355558. [DOI] [PubMed] [Google Scholar]
- Schmand, B., Houx, P., de Koning, I., Hoogman, M., Muslimovic, D., & Rienstra, A. (2012). Normen van psychologische tests voor gebruik in de klinische neuropsychologie [norms for psychological tests for use in clinical neuropsychology]. Published on the website of the section Neuropsychology of the Dutch Institute of Psychology (Nederlandse Instituut van Psychologen. [Google Scholar]
- Sheikh, J. I., Hill, R. D., & Yesavage, J. A. (1986). Long-term efficacy of cognitive training for age-associated memory impairment: A six-month follow-up study. Developmental Neuropsychology, 2(4), 413–421. 10.1080/87565648609540358. [DOI] [Google Scholar]
- Taler, V., & Phillips, N. A. (2008). Language performance in Alzheimer's disease and mild cognitive impairment: A comparative review. Journal of Clinical and Experimental Neuropsychology, 30(5), 501–556. 10.1080/13803390701550128. [DOI] [PubMed] [Google Scholar]
- Team, R. C . (2013). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org/. [Google Scholar]
- Teng, E., Leone-Friedman, J., Lee, G. J., Woo, S., Apostolova, L. G., Harrell, S. et al. (2013). Similar verbal fluency patterns in amnestic mild cognitive impairment and Alzheimer's disease. Archives of Clinical Neuropsychology, 28(5), 400–410. 10.1093/arclin/act039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Troger, J., Lindsay, H., Mina, M., Linz, N., Kloppel, S., Kray, J. et al. (2021). Patients with amnestic MCI fail to adapt executive control when repeatedly tested with semantic verbal fluency tasks. Journal of the International Neuropsychological Society, 28(6), 620–627. 10.1017/S1355617721000849. [DOI] [PubMed] [Google Scholar]
- Tröger, J., Linz, N., König, A., Robert, P., Alexandersson, J., Peter, J. et al. (2019). Exploitation vs. exploration-computational temporal and semantic analysis explains semantic verbal fluency impairment in Alzheimer's disease. Neuropsychologia, 131, 53–61. 10.1016/j.neuropsychologia.2019.05.007. [DOI] [PubMed] [Google Scholar]
- Troyer, A. K., Moscovitch, M., & Winocur, G. (1997). Clustering and switching as two components of verbal fluency: Evidence from younger and older healthy adults. Neuropsychology, 11(1), 138–146. 10.1037/0894-4105.11.1.138. [DOI] [PubMed] [Google Scholar]
- United Nations Educational, & Scientific and Cultural Organisation (UNESCO) (1976). International standard classification of education (ISCED). Paris: Author. [Google Scholar]
- Van Der Elst, W., Van Boxtel, M. P., Van Breukelen, G. J., & Jolles, J. (2005). Rey's verbal learning test: Normative data for 1855 healthy participants aged 24–81 years and the influence of age, sex, education, and mode of presentation. Journal of the International Neuropsychological Society, 11(3), 290–302. 10.1017/S1355617705050344. [DOI] [PubMed] [Google Scholar]
- Van Der Elst, W. I. M., Van Boxtel, M. P., Van Breukelen, G. J., & Jolles, J. (2006a). Normative data for the animal, profession and letter M naming verbal fluency tests for Dutch speaking participants and the effects of age, education, and sex. Journal of the International Neuropsychological Society, 12(1), 80–89. 10.1017/S1355617706060115. [DOI] [PubMed] [Google Scholar]
- Van der Elst, W., Van Boxtel, M. P., Van Breukelen, G. J., & Jolles, J. (2006b). The concept shifting test: Adult normative data. Psychological Assessment, 18(4), 424–432. 10.1037/1040-3590.18.4.424. [DOI] [PubMed] [Google Scholar]
- Verfaillie, S. C., Witteman, J., Slot, R. E., Pruis, I. J., Vermaat, L. E., Prins, N. D. et al. (2019). High amyloid burden is associated with fewer specific words during spontaneous speech in individuals with subjective cognitive decline. Neuropsychologia, 131, 184–192. 10.1016/j.neuropsychologia.2019.05.006. [DOI] [PubMed] [Google Scholar]
- Wajman, J. R., Cecchini, M. A., Bertolucci, P. H. F., & Mansur, L. L. (2019). Quanti-qualitative components of the semantic verbal fluency test in cognitively healthy controls, mild cognitive impairment, and dementia subtypes. Applied Neuropsychology. Adult, 26(6), 533–542. 10.1080/23279095.2018.1465426. [DOI] [PubMed] [Google Scholar]
- Wei, T., Simko, V., & Levy, M. (2021). Package “corrplot”: Visualization of a correlation matrix. 2017. Version 0.84.
- Zhao, Q., Guo, Q., & Hong, Z. (2013). Clustering and switching during a semantic verbal fluency test contribute to differential diagnosis of cognitive impairment. Neuroscience Bulletin, 29(1), 75–82. 10.1007/s12264-013-1301-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
A dataset with deidentified participant data and a data dictionary may be made available upon reasonable request from a qualified investigator, subject to a signed data access agreement.