

Abstract
Background:
Suicide among students is increasing in India and is a matter of grave concern. Early identification of students contemplating suicide would facilitate emergency intervention and may save precious lives.
Aim:
Our primary objective was to construct an artificial intelligence (AI) model employing an artificial neural network (ANN) architecture to predict students at risk of suicidal tendencies. This initiative was prompted by the necessity to implement a proactive and technologically driven strategy for identifying competitive exam-bound students facing heightened vulnerability. The aim was to facilitate timely interventions aimed at reducing the risk of self-harm.
Materials and Methods:
An AI model utilizing ANNs is devised for suicide risk prediction among exam-stressed students. A 33-feature input layer is curated based on literature and expert insights, with binary features assigned weighted values. A rigorous hyperparameter optimization approach using the Optuna library to select the most effective neural network model. Ridge regression was used to determine bias or variance in the dataset. Training and testing of the model are conducted using fictional and simulated profiles, respectively, and model performance is assessed through statistical metrics and the Cohen’s Kappa coefficient, benchmarked against expert evaluations.
Result:
The AI model demonstrates exceptional predictive capabilities for suicide risk assessment among competitive exam students. Quantitative Metrics: The model’s accuracy of 98% aligns predictions with outcomes, distinguishing risk categories. Precision at 100% identifies cases within predicted risks, minimizing false positives. A recall of 97% identifies true risk cases, highlighting sensitivity. F1 Score: The model’s F1 score of 98% balances precision and recall, indicating overall performance. Cohen’s Kappa: With a coefficient of 1.00, the model’s substantial agreement with experts underscores its consistent classifications.
Conclusion:
The study introduces an AI model utilizing ANNs for suicide risk prediction among stressed students. High precision, recall, and accuracy align with expert evaluations, highlighting its promise for timely risk identification. The model’s efficiency in evaluating large populations swiftly indicates its clinical potential. Refinement and real-world validation remain future considerations.
Keywords: Artificial intelligence, artificial neural network, deep learning, machine learning, suicide prediction
Suicide poses a multifaceted challenge that can be prevented, even though predicting it is complicated due to its cross-diagnostic nature and infrequent appearance in the general population. Disturbingly, most individuals who die by suicide have interacted with their medical professionals during the days and weeks leading up to their deaths. This indicates a failure to identify the risk and intervene, despite the chance for intervention.[1]
The alarming issue of increased suicide rates among students, especially those engaged in competitive exam preparation, has garnered significant attention. Apart from academic stressors, factors like parental expectations, family conflicts, interpersonal difficulties, susceptibility to addictive behaviors, disrupted sleep patterns, and waning interest in studies, contribute significantly to the elevated suicide risk. Additionally, a history of psychiatric disorders, a family history of suicide, medical illness, aspiration strain, and a history of past suicide attempts are important predictors of suicide.[2,3,4,5]
Over the past decade, substantial progress and endorsement of artificial intelligence (AI) across diverse sectors, particularly in the healthcare domain, have been witnessed. Within the context of mental health, AI presents significant opportunities for the development of innovative interventions. The evolution of AI has brought about a transformative paradigm in the creation of tools for suicide screening and detection of suicide risk.[1,6]
Detecting and predicting suicidal behavior early are crucial components in the management of suicide. Machine learning holds significant promise in enhancing predictions of future suicidal behavior and tracking shifts in risk levels over time. The adoption of artificial neural networks (ANNs) offers a promising avenue to effectively address this imperative concern. Earlier published papers have neglected the potential for in-depth suicide prediction and the influence of contextual factors on suicide rates, revealing a significant gap that emphasizes the necessity for comprehensive analysis in this field.[6,7,8,9,10]
To address this critical gap, the study aims to leverage AI models, particularly ANNs, which have emerged as compelling alternatives to conventional suicide risk assessment instruments like scales and checklists. In this background, we undertook the present study to formulate an AI model utilizing an artificial neural network architecture with the capacity to prognosticate students who may be susceptible to suicidal tendencies. This endeavor was driven by the imperative to establish a proactive and technologically driven approach to identifying students preparing for competitive exams who might be in a state of heightened vulnerability, thereby enabling timely interventions to mitigate the risk of self-harm.
MATERIAL AND METHODS
Participants, data preparation, and feature selection
To enable effective training of our suicide risk prediction model, we diligently generated a synthetic dataset containing 500 fictional student profiles. These profiles were thoughtfully categorized into two distinct risk levels: “No risk of suicide,” and “Risk of suicide present,” serving as the target (dependent) variable for our model’s predictive capabilities. These profiles were meticulously developed by the lead author for training the AI model [Figure 1].
Figure 1.
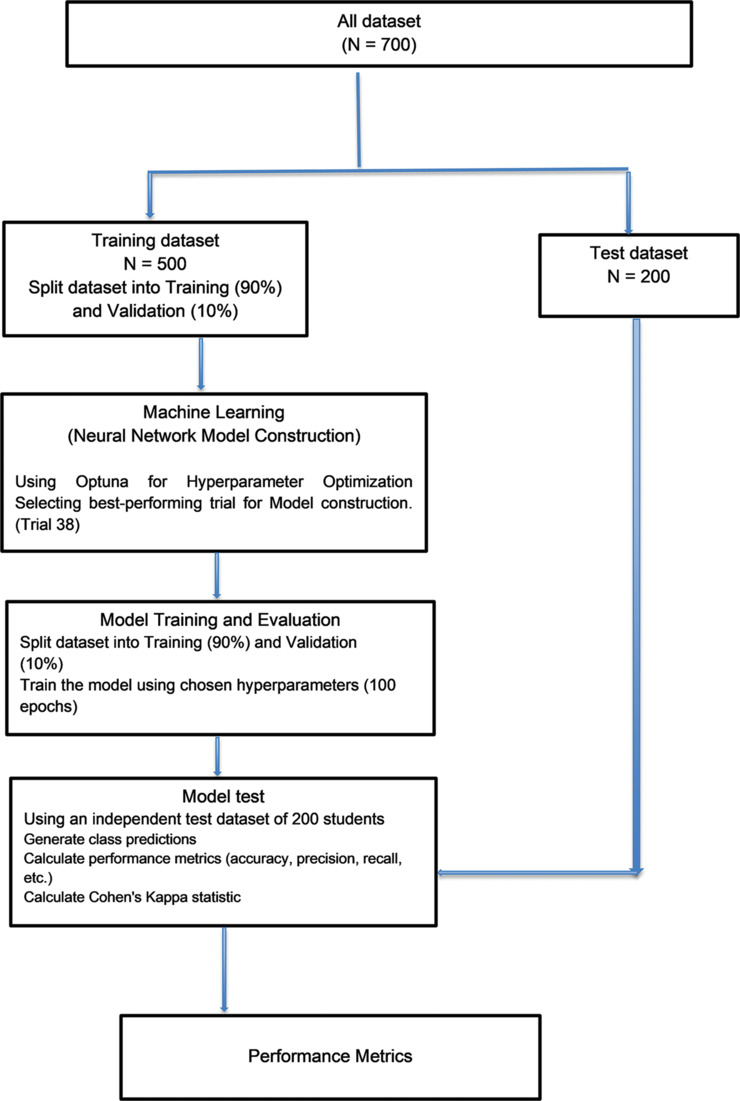
Schematic of prediction model development
To classify individuals into two risk categories, we relied on a set of 33 distinct features [Table 1], which served as independent variables. The selection of these 33 features was a meticulous process, drawing from various sources, including existing literature,[4,5,11] clinical data availability, expert opinions, and consensus among the authors. These features encompassed a wide range of domains, spanning from demographic attributes to personal experiences and self-reported emotions. Each feature followed a binary format, aligning with specific questions and typically categorized into ‘Yes’ or ‘No’ responses. Notably, each feature carried a weighted value reflective of its estimated impact on the likelihood of suicide risk. For instance, items such as ‘I am seriously thinking of suicide’ or ‘Have attempted suicide in the past but failed or was saved?’ held higher weights (value of 1), underscoring their critical role in immediate risk assessment. Conversely, certain demographic features, like age or sex, received uniform and relatively lower weights (value of 0.1), indicating their neutral contribution to risk differentiation within our model.
Table 1:
Socio-demographic and clinical profile of the students in the test dataset (n=200)
| Feature | Yes | No |
|---|---|---|
| Age | (<18 years) n=120 | (>18 years) n=80 |
| Sex | (Male) n=120 | (Female) n=80 |
| Poor financial condition of a family | 68 | 132 |
| Living alone | 120 | 80 |
| Living in Hostel | 124 | 76 |
| Studying here because my parents want me to do this | 79 | 121 |
| Your performance is not according to your expectations | 84 | 116 |
| Parents not satisfied with your results | 89 | 111 |
| Several family problems or stressful environments in the family | 75 | 125 |
| Family does not support you | 92 | 108 |
| Recent breakup from boyfriend/girlfriend | 53 | 147 |
| Suffered from psychiatric illness/mental illness in the past | 37 | 163 |
| A close family member has a psychiatric illness | 44 | 156 |
| Suicide by any close family member recently or in the past | 26 | 174 |
| Suicide by any close friend recently | 35 | 165 |
| Suffering from any medical illness like diabetes, asthma, hypertension, etc. | 34 | 166 |
| Taking excess alcohol/drugs/playing online games | 57 | 143 |
| Suffered sexual or physical abuse, or emotional abuse (in the past or recently) | 50 | 150 |
| Unable to feel any emotion for the last few days | 79 | 121 |
| Are you feeling sad or very anxious for the last few days | 94 | 106 |
| Feeling humiliated by others (friends, family, teachers) | 64 | 136 |
| Feeling you are trapped/stuck here currently and there is no escape | 81 | 119 |
| Feeling lonely for the last few days | 84 | 116 |
| Feeling hopeless about your future | 78 | 122 |
| Lost interest in everything for the last few days | 76 | 124 |
| Experiencing difficulty in sleeping at night | 86 | 114 |
| Tried to hurt yourself in the past | 43 | 157 |
| Having thoughts about harming yourself | 39 | 161 |
| Having thoughts like life is not worth living? | 49 | 151 |
| Searching for ways on the internet about how to die | 32 | 168 |
| Tried to commit suicide in the past but failed or was saved | 29 | 171 |
| Recently injured yourself intentionally | 31 | 169 |
The weighted values assigned to features in our study were determined through expert consensus, involving professionals such as psychologists and psychiatrists. This approach ensured that each feature’s impact on suicide risk was assessed collectively by experts in the field. Through discussions and evaluations, a consensus was reached, resulting in the assignment of weights. This method drew from diverse perspectives and clinical insights, enhancing the precision of our predictive model.
Neural network architecture and model compilation
A neural network model was constructed to address the task of binary classification, aimed at determining risk levels within a given dataset. In our study, we employed a rigorous hyperparameter optimization approach using the Optuna library to select the most effective neural network model for the critical task of classifying suicide risk. Optuna is an open-source Python library for hyperparameter optimization. It provides a framework for efficiently searching for the best combination of hyperparameters to optimize the performance of machine learning models, deep learning models, and other computational tasks.
Hyperparameter optimization
We conducted a total of 50 trials to find the optimal combination of hyperparameters. The best-performing trial, Trial 38, achieved an outstanding classification accuracy of 98% on the test data.
Best Model Hyperparameters (Trial 38).
Number of Hidden Layers: 5.
Number of Neurons in Each Hidden Layer:
Layer 0: 140 neurons.
Layer 1: 118 neurons.
Layer 2: 117 neurons.
Layer 3: 125 neurons.
Layer 4: 81 neurons.
Activation Function: Sigmoid.
Optimizer: Adam.
Learning Rate: 4.44e-05.
Batch Size: 64.
Dropout Rate: 0.157.
The model was trained using the training dataset with chosen hyperparameters. The training spanned 100 epochs to ensure convergence.
Model training and performance evaluation
The synthetic training dataset for this study was developed by the lead author and comprised 500 students’ fictional profiles. To ensure robust model training and evaluation, the dataset was partitioned into two subsets: a training set and a validation set, adhering to a split ratio of 90% for training and 10% for validation. This division strategy was employed to facilitate rigorous model development and assessment, aligning with best practices in machine learning and data analysis, and divided into batches of size 64 for optimized convergence.
Additionally, to assess potential sources of bias and variance (underfitting and overfitting), we applied Ridge regression. The Ridge regression model achieved a low training Mental Status Examination (MSE) of 0.01, indicating an excellent fit to the training data, albeit with potential overfitting concerns. However, the model showed a drop in performance when applied to the test dataset, with a test MSE of 0.09, highlighting the challenge of balancing model complexity and generalization in suicide risk prediction.
The trained neural network model, complemented by Ridge regression validation, was subjected to evaluation using an independent test dataset of 200 students’ simulated profiles. To generate these profiles a specially tailored Google Form was developed, containing 33 questions to collect the data. Two consultant psychiatrists (GM and KB) and three senior resident doctors working in the department of psychiatry and well-versed in mental health assessment of suicidal patients, collaboratively filled out 200 Google Forms to construct the simulated profiles.
Class predictions for the test data were generated, and performance metrics were computed to ascertain the model’s predictive capabilities.
Data analysis
For statistical and machine learning analysis, Python was employed, leveraging libraries such as TensorFlow for neural network design, compilation, and training. The panda’s library facilitated data preprocessing and manipulation, while matplotlib aided in visualizing results like plots and confusion matrices. Evaluation employed functions from the sci-kit-learn library to gauge model performance across various metrics.
Prediction and comparative analysis
In our analysis of prediction performance, we harnessed a comprehensive suite of statistical metrics, encompassing accuracy, precision, recall, sensitivity, specificity, and the F1 score. To accommodate potential class imbalances in the data, we opted for a weighted average approach when calculating precision, recall, F1 score, and ROC AUC score. Furthermore, we visually illustrated the model’s classification proficiency through the construction of a confusion matrix. To quantify the agreement between the model’s predictions and the expert diagnoses provided by consultant psychiatrists on the test dataset, we employed Cohen’s Kappa statistic.
Ethical clearance
Ethical clearance to conduct the study was given by the Institute Ethics Committee (IECT) of the institute where this study was conducted.
RESULTS
Table 1 depicts the socio-demographic and clinical profile of the students (test dataset). In this study, a total of 200 students’ test profiles were created based on 33 features (potential predictor variable) as mentioned earlier, and their demographics were characterized based on age and gender. Among the participants, 80 individuals were under the age of 18, while the remaining 120 participants were 18 years or older. Additionally, the study population was further divided by gender, with 80 females and 120 males.
Our predictive model for suicide risk assessment demonstrated highly promising performance. The accuracy of the model was notably high at 97.5%, indicating its proficiency in correctly classifying individuals into the ‘No Risk’ and ‘Risk Present’ categories. Precision, which reflects the model’s ability to minimize false positives, was 94.57%, further affirming its precision in identifying those truly at risk. Impressively, the model exhibited a perfect recall of 100%, suggesting its capacity to correctly detect all individuals at risk, minimizing false negatives [Table 2].
Table 2:
Classification Metrics
| Metric | Value |
|---|---|
| Accuracy | 0.975 |
| Precision | 0.9457 |
| Recall (true positive rate) | 1.0000 |
| F1 Score | 0.9721 |
| Cohen’s Kappa | 1.0001 |
| Micro-average F1 Score | 0.9750 |
| Macro-average F1 Score | 0.9747 |
| Specificity (true negative rate) | 0.9558 |
| Sensitivity (true positive rate) | 1.0 |
The F1 score, a harmonic mean of precision and recall, was calculated at 97.21%, highlighting the model’s overall robustness in handling both false positives and false negatives. The confusion matrix provided a detailed breakdown of the model’s classifications, with 108 instances correctly identified as ‘No Risk’ and 87 instances correctly identified as ‘Risk Present,’ along with minimal misclassifications [Tables 2 and 3, Figure 2].
Table 3:
Confusion Matrix
| Actual/Predicted | No risk (0) | Risk present (1) |
|---|---|---|
| No risk (0) | 108 | 5 |
| Suicide risk present (1) | 0 | 87 |
Figure 2.
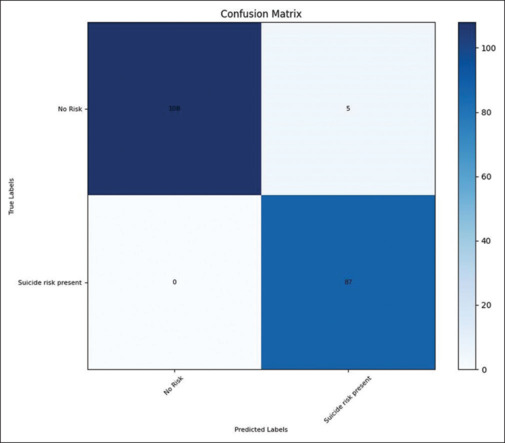
Confusion Matrix
Cohen’s Kappa statistic, measuring agreement beyond chance, yielded a high value of 1.00, indicating strong concordance between the model’s predictions and expert psychiatrists’ diagnoses. Additionally, both micro-average and macro-average F1 scores reinforced the model’s balanced performance across different evaluation strategies [Table 2].
The sensitivity (true positive rate) of 100% signified the model’s ability to identify all individuals genuinely at risk, while the specificity (true negative rate) of 95.58% indicated its proficiency in correctly identifying those without risk. Moreover, the ROC AUC score of 99.87% illustrated the model’s excellent discriminatory power [Table 2 and Figure 3].
Figure 3.
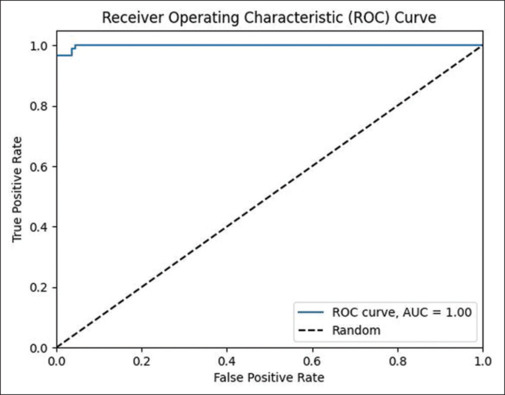
Receiver Operating Characteristic Area Under Curve (ROC AUC Score)
DISCUSSION
Most of the studies while trying to predict suicide risk have utilized supervised learning approaches, encompassing ensemble learning techniques (notably random forests), naïve Bayes classification, decision trees, logistic/least squares regression, and support vector machines (SVM) and very few studies have tried to use unsupervised learning approaches such as artificial neural networks.[1,8]
Research efforts focused on evaluating the accuracy of diagnostic classification employ machine learning techniques in conjunction with extensive datasets or a substantial number of variables. The objective is to identify individuals susceptible to suicide risk by classifying outcomes as binary, indicating the presence or absence of such risk. These investigations are commonly termed classification studies. This binary approach facilitates a clear and efficient categorization of individuals, enhancing the precision of discerning those at risk of suicide.[1] Our study similarly adopts a classification study design, wherein we strive to formulate a model capable of predicting three distinct categories for vulnerable students: “no risk,” “risk present,” and “high risk.”
A prominent aspect of our study is the origin of the training dataset, which stems from carefully crafted fictional student profiles designed to closely parallel the real-life challenges experienced by students preparing for competitive exams in a highly stressful environment. Purposefully integrating these fictional profiles into our artificial neural network model was a strategic decision. This decision was underpinned by the recognition that employing fictional student profiles, akin to using a convenience sample or reanalyzing archived datasets through machine learning methodologies, aligns with established and commonly adopted research practices.[1]
In this context, our approach offered several advantages. First, by crafting fictional profiles, we were able to tailor the characteristics and attributes of the students to match the specific requirements of our study. This control over the dataset allowed us to systematically manipulate key features related to suicide risk, enabling a more focused investigation into the predictive capabilities of our model.
Second, employing fictional profiles granted us the ability to generate a diverse range of scenarios that might encompass a broad spectrum of suicide risk factors. This diversity ensured that the model was exposed to a comprehensive array of potential risk indicators, enhancing its capacity to identify nuanced patterns and associations that might not have been as evident in real-world data. The use of fictional profiles allowed us to explore a wide array of risk factors and interactions in a controlled environment, enabling a more focused and precise evaluation of our model’s performance.
Furthermore, the controlled nature of the fictional profiles enabled us to create a balanced dataset with specific risk characteristics, which might be challenging to achieve when working with real-world data. This balanced dataset contributed to a more robust training and validation process, reducing the potential bias that could arise from imbalanced real-world datasets.
The selection of the 33 aforementioned features in our study for predicting suicide risk was a meticulously undertaken process, drawing from a blend of sources including existing literature,[4,5,11] the availability of clinical data, expert insights, and preliminary qualitative findings. These chosen attributes encompass a diverse array of domains, ranging from demographic characteristics to personal experiences and self-reported emotions. Notably, all these features adhere to a binary format, aligning with specific inquiries and typically categorized as ‘Yes’ or ‘No’ responses. Our methodology was designed to ensure that the model undergoes testing using data that faithfully reflects the actual circumstances.
Machine learning holds immense promise in enhancing the accuracy of forecasts concerning future suicidal behavior.[12,13,14] Deep learning, a subset of machine learning within AI, involves automatic data representation learning using computational methods. Unlike traditional machine learning, deep learning algorithms autonomously extract features through error-based learning. This distinguishes deep learning from its counterparts. Central to deep learning are neural networks, which learn intricate input-output mappings using computational cells known as “neurons”. The depth of neural network layers differentiates shallow networks from deep neural networks (DNNs). DNNs, with more than three layers, learn hierarchical data representations akin to human brain mechanisms for information extraction from data.[10,11,12]
Artificial neural networks offer a significant advantage in that they eliminate the necessity for assuming a linear relationship among values. They are adept at modeling prediction challenges that encompass numerous features characterized by undefined functions.[14]
AI’s significance in predicting adolescent suicide risk is underscored by studies. Jung et al.[15] utilized ML to assess suicide risk in 60,000 Korean adolescents, achieving 77.5% to 79% accuracy with models like support vector machines and neural networks. Corke et al.[16] highlighted ML’s potential to improve suicide risk prediction by considering more factors. While its superiority over other methods is uncertain, ML models outperformed traditional logistic regression, notably achieving an accuracy of 0.867 (86.7%) when assessing risk factors like depressed mood, stress awareness, alcohol abuse, and socioeconomic background.
The performance of our ANN model is compelling, boasting an accuracy of 98%. This is particularly significant given the model’s predictions are nearly analogous to the determinations made by seasoned consultant psychiatrists.
The confusion matrix provides more granular insight into the model’s performance. It confirms that the model is especially adept at predicting the “No risk of suicide” category, with a minimal number of false positives. However, minor discrepancies emerge in the other risk categories, suggesting room for fine-tuning.
The reporting of cross-validation techniques, which involve dividing data into training and test sets for evaluating model performance, was inconsistent across studies to determine suicide risk. Only a few investigations have utilized separate datasets, for training and testing their models.[1] In this study, we have utilized separate datasets for training and testing the model prediction. In our study, a value of 1.0 of Cohen’s Kappa coefficient implies a perfect agreement between the ANN model and consultant psychiatrists’ diagnosis, which further substantiates the reliability and efficacy of our model.
In the context of the Indian healthcare landscape, a conspicuous scarcity of psychiatrists prevails, and the prevailing clinical methodologies used for assessing the risk of suicide are encumbered by several limitations. These limitations encompass substantial time requirements, and cost barriers, and often mandate the presence of skilled practitioners for accurate administration.[17,18]
The implications emerging from this study hold significant importance, particularly regarding the prospective integration of AI models as adjunctive tools within clinical settings. The AI model subjected to investigation in this study demonstrates a remarkable capability to efficiently assess hundreds to thousands of students within mere seconds to minutes, thereby identifying individuals necessitating immediate intervention or further in-depth examination. This capacity not only addresses the resource constraints prevalent in clinical contexts but also underscores the potential of AI in augmenting suicide risk evaluation processes in an expedited and accurate manner.
Future studies could delve into improving the model’s prediction accuracy for categories where discrepancies arose. Additionally, testing the model on real-life data, as opposed to fictional profiles, would be the next step to understanding its practical applications.
Limitations
This study, while displaying promising methodology and results, is constrained by several limitations. Primarily, reliance on fictional student profiles, despite meticulous curation, may not encompass the full complexity of real-life scenarios. The influence of biases from select consultant interpretations could impact authentic category representation. The modest dataset size of approximately 500 profiles for training the artificial neural network raises concerns within the AI and deep learning context. Larger datasets could enhance model training and generalizability. A binary response format for questions related to depressive symptoms and suicidal ideation might oversimplify, missing nuanced student experiences. The study’s focus on competitive exam preparation limits generalizability, excluding diverse backgrounds and stressors. Additionally, reliance on pre-published risk factors might overlook evolving nuances or novel elements. Though the model’s accuracy and Cohen’s Kappa coefficient are notable, confusion matrix discrepancies in specific risk categories indicate potential for enhancement. Without iterative feedback, refinement opportunities could be missed. Ethically, AI usage for sensitive outcomes like suicide risk prompts caution, even with fictional profiles and ethical clearances. Concerns persist about AI misuse in critical areas without human oversight.
CONCLUSION
The developed ANN model holds promise for suicide risk assessment among students, showcasing high precision, recall, and accuracy comparable to expert psychiatric evaluations. AI could emerge as a potent tool in modern psychiatry’s arsenal, provided limitations are addressed to bolster research credibility and model applicability.
Data availability
Data can be made available on reasonable request.
Author's contribution
Concept, design, definition of intellectual content: VG. Literature search, data acquisition: GM, KB, SC. Manuscript preparation: VG. Manuscript editing and manuscript review. GM, SC, SD, TA. Guarantor: VG.
Conflicts of interest
There are no conflicts of interest.
Funding Statement
Nil.
REFERENCES
- 1.Bernert RA, Hilberg AM, Melia R, Kim JP, Shah NH, Abnousi F. Artificial intelligence and suicide prevention: A systematic review of machine learning investigations. Int J Environ Res Public Health. 2020;17:5929. doi: 10.3390/ijerph17165929. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Yadav S, Srivastava SK. Correlational study of academic stress and suicidal ideation among students. Indian J Public Health Res Dev. 2020;11:56–61. [Google Scholar]
- 3.Kar SK, Rai S, Sharma N, Singh A. Student suicide linked to NEET examination in India: A media report analysis study. Indian J Psychol Med. 2021;43:183–5. doi: 10.1177/0253717620978585. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Lyu J, Zhang J. BP neural network prediction model for suicide attempt among Chinese rural residents. J Affect Disord. 2019;246:465–73. doi: 10.1016/j.jad.2018.12.111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Nebhinani N, Kuppili PP, Kapoor V, Singhai K, Mamta Reflections of medical students on causes of rising suicide among medical aspirants. J Indian Assoc Child Adolesc Ment Health. 2020;16:102–8. [Google Scholar]
- 6.Kumar V, Sznajder KK, Kumara S. Machine learning based suicide prediction and development of suicide vulnerability index for US counties. Npj Mental Health Res. 2022;1:1–8. doi: 10.1038/s44184-022-00002-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Johnson KB, Wei WQ, Weeraratne D, Frisse ME, Misulis K, Rhee K, et al. Precision medicine, AI, and the future of personalized health care. Clin Transl Sci. 2021;14:86–93. doi: 10.1111/cts.12884. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Nordin N, Zainol Z, Mohd Noor MH, Chan LF. Suicidal behaviour prediction models using machine learning techniques: A systematic review. Artif Intell Med. 2022;132:102395. doi: 10.1016/j.artmed.2022.102395. doi: 10.1016/j.artmed.2022.102395. [DOI] [PubMed] [Google Scholar]
- 9.Parsa M, Koudys JW, Ruocco AC. Suicide risk detection using artificial intelligence: The promise of creating a benchmark dataset for research on the detection of suicide risk. Front Psychiatry. 2023;14:1186569. doi: 10.3389/fpsyt.2023.1186569. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Nordin N, Zainol Z, Mohd Noor MH, Chan LF. Suicidal behaviour prediction models using machine learning techniques: A systematic review. Artif Intell Med. 2022 Oct;132:102395. doi: 10.1016/j.artmed.2022.102395. doi: 10.1016/j.artmed.2022.102395. [DOI] [PubMed] [Google Scholar]
- 11.Franklin JC, Ribeiro JD, Fox KR, Bentley KH, Kleiman EM, Huang X, et al. Risk factors for suicidal thoughts and behaviors: A meta-analysis of 50 years of research. Psychol Bull. 2017;143:187. doi: 10.1037/bul0000084. [DOI] [PubMed] [Google Scholar]
- 12.Zhu Y, Wang M, Yin X, Zhang J, Meijering E, Hu J. Deep learning in diverse intelligent sensor based systems. Sensors (Basel) 2022;23:62. doi: 10.3390/s23010062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.TensorFlow. Available from: https://www.tensorflow.org/ . [Last accessed on 2023 Aug 31]
- 14.Ayat S, Farahani HA, Aghamohamadi M, Alian M, Aghamohamadi S, Kazemi Z. A comparison of artificial neural networks learning algorithms in predicting tendency for suicide. Neural Comput Applic. 2013;23:1381–6. [Google Scholar]
- 15.Jung JS, Park SJ, Kim EY, Na KS, Kim YJ, Kim KG. Prediction models for high risk of suicide in Korean adolescents using machine learning techniques. PloS One. 2019;14:e0217639. doi: 10.1371/journal.pone.0217639. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Corke M, Mullin K, Angel-Scott H, Xia S, Large M. Meta-analysis of the strength of exploratory suicide prediction models; from clinicians to computers. BJPsych Open. 2021;7:e26. doi: 10.1192/bjo.2020.162. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Shah P, Parikh A, Gediya A, Patel D. Attitude Of Healthcare Workers Towards Psychiatry: A Cross-Sectional Study. Indian Journal of Applied-Basic Medical Sciences. 2022;24:219–26. [Google Scholar]
- 18.Khan NZ, Javed MA. Use of artificial intelligence-based strategies for assessing suicidal behavior and mental illness: A literature review. Cureus. 2022;14:e27225. doi: 10.7759/cureus.27225. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data can be made available on reasonable request.