

Abstract
The integration of large language models (LLMs) in clinical medicine, particularly in critical care, has introduced transformative capabilities for analyzing and managing complex medical information. This technical note explores the application of LLMs, such as generative pretrained transformer 4 (GPT-4) and Qwen-Chat, in interpreting electronic healthcare records to assist with rapid patient condition assessments, predict sepsis, and automate the generation of discharge summaries. The note emphasizes the significance of LLMs in processing unstructured data from electronic health records (EHRs), extracting meaningful insights, and supporting personalized medicine through nuanced understanding of patient histories. Despite the technical complexity of deploying LLMs in clinical settings, this document provides a comprehensive guide to facilitate the effective integration of LLMs into clinical workflows, focusing on the use of DashScope's application programming interface (API) services for judgment on patient prognosis and organ support recommendations based on natural language in EHRs. By illustrating practical steps and best practices, this work aims to lower the technical barriers for clinicians and researchers, enabling broader adoption of LLMs in clinical research and practice to enhance patient care and outcomes.
Keywords: Large language model, Critical care
Introduction
The advent of large language models (LLMs) has revolutionized various fields, including clinical medicine. These models, powered by advanced machine learning algorithms and vast amounts of data, have shown remarkable potential in interpreting and generating human language. Their application in clinical research is particularly transformative,[1] offering new insights and capabilities in the analysis and management of complex medical information.[2,3]
In the domain of critical care, where timely and accurate interpretation of patient data is crucial, LLMs such as generative pretrained transformer 4 (GPT-4) and Qwen-Chat have demonstrated significant utility. For instance, in intensive care units (ICUs), LLMs can assist in the rapid assessment of patient conditions by analyzing clinical notes, lab results, and other patient records.[4] They are capable of predicting the likelihood of sepsis by detecting subtle trends in electronic health record (EHR) data,[5] which may otherwise be overlooked by human clinicians. Additionally, LLMs can automate the generation of comprehensive discharge summaries by synthesizing information from various parts of the patient's medical history, thus saving time for healthcare providers and ensuring consistent and thorough documentation.
Another critical application is the use of natural language processing (NLP) capabilities of LLMs for continuous patient monitoring. These models can process and interpret free-text notes in EHRs to monitor disease progression in critically ill patients,[6] track changes in patient status, identify potential complications, and suggest timely interventions based on the nuanced interpretation of clinical narratives.
A significant trend is the increasing integration of LLMs with EHR systems.[7] EHRs contain a wealth of unstructured data, including detailed clinical notes, patient histories, and physician observations. LLMs excel at parsing these large volumes of text, extracting meaningful insights, and identifying patterns that may not be immediately apparent to human readers. This ability to handle unstructured data is crucial in critical care, where quick and precise information retrieval can significantly impact patient outcomes. For instance, LLMs can assist in identifying patients at risk of deteriorating conditions by continuously analyzing EHR notes and flagging potential issues. They also support personalized medicine by tailoring treatment recommendations based on a nuanced understanding of patient histories documented in EHRs.
Despite their promising capabilities, the technical complexity of deploying and fine-tuning LLMs in clinical settings remains a significant barrier for many researchers. Implementing these technologies requires a deep understanding of both machine learning techniques and clinical domain knowledge, which can be daunting for those without specialized training in data science. Consequently, there is a pressing need for practical, accessible guides to help clinical researchers and practitioners leverage LLMs effectively. Our innovation lies in the development of an intuitive, step-by-step framework that demystifies the integration process, making it accessible even to those without a background in data science. This user-friendly guide provides actionable insights and best practices, empowering clinical researchers and practitioners to effectively harness the power of LLMs within their workflows.
By translating the technical intricacies of LLMs into clear, actionable steps, our work not only enhances the accessibility of these models but also paves the way for broader adoption across various healthcare settings. This innovation is a significant leap forward in making cutting-edge artificial intelligence (AI) technologies a reality in clinical practice, ultimately contributing to improved patient care and outcomes.
This document aims to serve as a comprehensive guide to help clinicians and researchers quickly master the skills needed to implement LLMs in their work, particularly in the context of critical care and the use of EHR text analysis. By lowering the technical barriers, we hope to enable more widespread adoption of LLMs in clinical research and practice, ultimately improving patient care and outcomes.
Using Dashscope to Implement Judgment on Patient Prognosis and Disposal Based on Natural Language in Electronic Medical Records (EMRs)
The integration of LLMs in the medical field has significantly advanced the way we process and analyze EMRs. With tools like DashScope,[8] healthcare providers can leverage these models to extract crucial insights and make informed decisions about patient care, including prognosis assessment and recommendations for organ support. Below, we will walk through how to use DashScope's application programming interface (API) to achieve this. DashScope is a set of API services provided by Alibaba Cloud, allowing developers to invoke models such as Qwen-turbo. Through DashScope, it is very convenient to integrate LLMs to perform various complex NLP tasks. We can utilize the DashScope API to complete prognostic judgment and organ support recommendations based on the patient's current medical history.
Step-by-step guide
Set up your environment
Before using DashScope, ensure that you have the DashScope Python SDK installed and properly configured. If you have not installed it yet, you can do so using pip in your terminal:
pip install dashscope
Define the function to analyze EMR data
We will create a Python function that takes a patient's history/note as input, processes it using a LLM, and returns a prognosis assessment along with support recommendations.
![]()
Code explanation
Importing necessary tools
The first few lines bring in some tools that the code will use.
dashscope is a special Python library that helps us connect to the DashScope service, which provides powerful AI models for analyzing text.
Setting up the API key
DashScope requires a special key (like a password) to allow access to their services. This is called an API key.
dashscope.api_key is set to ‘YOUR-API-KEY,’ which is a placeholder for an actual key you get from the DashScope service.

Let us break down this code in a way that is easy to understand, even if you are not familiar with programming. This code is designed to take a patient's medical history and use a sophisticated AI model to provide an assessment of their prognosis (how likely they are to recover or deteriorate) and recommend any necessary organ support, such as using a ventilator or other medical interventions.
Code explanation
Function definition
The function prognosis_and_support_recommendation_dashscope is defined to perform the main task. It takes in two things:
patient_history: This is a string that describes the patient's current medical condition.
max_tokens: This is a number that limits how long the AI's response can be (default is 512 characters).
Constructing the prompt
Inside the function, we create a “prompt,” which is a piece of text that tells the AI model exactly what we want it to do.
The prompt includes instructions to the AI to look at the patient history and provide a prognosis (how likely the patient is to die, using terms like “very likely” or “unlikely”) and recommend necessary organ support types.
Calling the AI model
The dashscope.Generation.call function is used to send the prompt to DashScope's AI model named “qwen-turbo.”
Parameters provided include:
model: Specifies the model to use.
prompt: The instructions and patient history.
max_tokens: Limits the length of the AI's response.
Temperature: Controls how creative or varied the response can be. Lower values make the response more predictable; higher values make it more diverse.
Examining the response
The code prints out the structure of the response from the AI to help understand what it contains.
The response is checked to see if it has a section called “output” that includes the generated text.
Extracting the AI's answer
If the response includes the expected “output” with text, that text is saved in the variable answer.
If not, it raises an error, indicating something went wrong with the response format.
Parsing the generated text
The code then searches through the AI's response to find specific keywords that indicate the prognosis and the recommended types of organ support.
It uses lists of keywords: one for possible prognoses and another for types of support.
Finding prognosis and recommendations
It looks through the AI's answer for any of the prognosis keywords (e.g., “very likely”).
It also searches for any of the support keywords (e.g., “ventilator”).
The first prognosis keyword found is saved as prognosis, and all the support keywords found are saved in a list called support_recommendations.
Returning the results
Finally, the function returns two pieces of information:
prognosis: The AI's judgment on the patient's prognosis.
support_recommendations: A list of recommended organ support strategies.
Summary
In simpler terms, this code takes a description of a patient's current health situation, asks an AI model to analyze it, and then tells us:
How likely the patient is to die soon (“prognosis”).
What types of medical support might be needed (like using a ventilator or medications to support the organs).
The AI model does the heavy lifting of analyzing the text and providing insights based on its understanding of medical data. This can help doctors and healthcare providers make informed decisions quickly.
Usage example

Let us break down the provided Python code, which uses the DashScope API to analyze a patient's medical history written in Chinese. The goal is to determine the patient's prognosis and recommend any necessary organ support.
Code explanation
-
1.Medical History in Chinese:
-
-We start with a string called patient_history that contains a detailed description of a patient's medical condition in Chinese.
-
-This history includes symptoms like fever, chest tightness, shortness of breath, and other diagnostic results like blood oxygen levels and computed tomography (CT) scans.
-
-
-
2.Function Call:
-
-The prognosis_and_support_recommendation_dashscope function is called with patient_history as its argument.
-
-This function, which we defined earlier, interacts with the DashScope AI to analyze the patient's medical history.
-
-
-
3.Printing the Results:
-
-After the function processes the input, it returns two pieces of information:
-
•prognosis: This tells us how likely it is that the patient will recover or deteriorate.
-
•support_recommendations: This provides a list of recommended medical interventions or support, such as using a ventilator or medications.
-
•
-
-These results are printed out for us to see.
-
-
Implementing Chain of Thought Prompts
To enhance the diagnostic and recommendation process, we can use the Chain of Thought prompting method.[9] This method involves guiding the AI model through a series of logical steps or questions to break down the problem and reason through it. This approach helps the model to provide more accurate and detailed responses.
We will create a prompt that first asks the AI to analyze the patient's symptoms and diagnostic results, then consider potential causes and conditions, and finally provide a prognosis and recommend necessary organ support.
Here is how we can modify the code to include this Chain of Thought approach:


Explanation of the enhanced function
-
1.Constructing the Prompt:
-
-We construct a detailed prompt that guides the AI through each step of the Chain of Thought process. The AI is instructed to provide detailed reasoning and thoughts at each step.
-
-
-
2.Calling the DashScope API:
-
-The API call remains similar, but we now expect the AI to provide a more detailed and structured response.
-
-
-
3.Extracting and Parsing the Response:
-
-The AI's response is examined, and we split it into distinct steps based on the provided prompt structure.
-
-The answer is split into segments labeled “Step” to capture each step of the reasoning process.
-
-
-
4.Identifying Prognosis and Support Recommendations:
-
-We look for keywords related to prognosis and support recommendations in the AI's response.
-
-These are extracted and stored in the prognosis and support_recommendations variables.
-
-
-
5.Returning Detailed Thoughts:
-
-The function returns a list of detailed thoughts (thoughts), each representing a step in the AI's reasoning process.
-
-
Example usage


Example output
When running the function with the provided patient_history, the output will include:
-
1.
Prognosis: A summary of the likelihood of death, such as “likely” or “unlikely.”
-
2.
Recommended Organ Support: A list of suggested medical interventions, such as using a ventilator.
-
3.
Detailed Thoughts: Step-by-step explanations of how the AI arrived at its conclusions, reflecting the Chain of Thought process.
Why chain of thought?
The Chain of Thought method helps the AI model to:
-
-
Break Down Complex Tasks: By dividing the analysis into smaller steps, the model can focus on each aspect systematically.
-
-
Improve Accuracy: This approach reduces ambiguity and helps the model provide more accurate and detailed responses.
-
-
Follow Logical Reasoning: It ensures the AI follows a logical sequence, making its conclusions more understandable and reliable.
Using this method enhances the AI's ability to analyze medical data and provide actionable insights, making it a valuable tool in healthcare settings.
Downstream analysis
After using the LLM like DashScope to predict the prognosis and recommend organ support strategies based on patient history, several downstream analyses can be performed to evaluate the effectiveness and accuracy of these predictions. These analyses typically involve comparing the LLM's predictions with actual outcomes, human expert judgments, and patient outcomes based on adherence to the recommended strategies.
Downstream analysis steps
- Step 1: Comparison with True Outcomes:
- Objective: Assess how accurately the LLM predictions match the real-world outcomes of patients.
- Method: Calculate metrics such as accuracy, sensitivity, specificity, and F1-score by comparing the LLM's predictions to the actual patient outcomes recorded in the medical records.
- Step 2: Comparison with Human Doctors:
- Objective: Evaluate how the LLM's predictions align with those made by experienced human doctors.
- Method: Perform agreement analysis (such as Cohen's Kappa) to measure the consistency between the LLM's recommendations and the decisions made by clinicians.
- Step 3: Outcome Analysis for Patients Receiving Recommended Support:
- Objective: Determine the impact of following the LLM's recommended organ support strategies on patient outcomes.
- Method: Conduct comparative studies or cohort analysis to compare outcomes (e.g., survival rates, recovery times) between patients who received the recommended support and those who did not.
Example analysis in R
Here is a step-by-step example of how to perform these analyses in R using hypothetical data.
Step 1: Comparing LLM predictions with true outcomes.
Let us assume we have a dataset with the following columns: - patient_id: Unique identifier for each patient. - true_outcome: The actual outcome (e.g., “very likely,” “likely,” “unlikely,” “very unlikely”). - llm_prediction: The outcome predicted by the LLM.
We can calculate the confusion matrix and derive performance metrics.


Step 2: Comparing LLM recommendations with human doctors.
Assuming we have another column doctor_prediction representing the prognosis given by human doctors:

Step 3: Analyzing outcomes based on recommended support.
Assume our dataset includes the following columns:
patient_id: Unique identifier for each patient.
llm_support_recommended: Whether the LLM recommended organ support (“yes” or “no”).
support_received: Whether the patient actually received organ support (“yes” or “no”).
outcome: The patient's outcome after the support decision (“improved” or “worsened”).
Here is how we can perform the analysis in R:
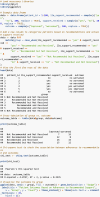
Explanation of the analysis
- Data Preparation:
-
-We first categorize patients into four groups based on whether they received the support recommended by the LLM.
-
-
- Cross-tabulation:
-
-We create a contingency table (outcome_table) to show the distribution of patient outcomes across these four groups.
-
-
- Chi-squared Test:
-
-The chi-squared test (chi_test) assesses if there is a significant association between the adherence to recommendations and the patient outcomes. This test helps determine if following the LLM's recommendations is statistically associated with better outcomes.
-
-
- Visualization:
-
-We use a bar plot to visualize the count of patients in each outcome category for the four groups. This plot helps in understanding how outcomes vary depending on whether patients adhered to the LLM's recommended support or not.
-
-
Insights from the analysis
- Effectiveness of Recommendations:
-
-By comparing outcomes across the four groups, we can infer how effective the LLM's recommendations are. For instance, if the “Recommended and Received” group shows significantly better outcomes than the “Recommended but Not Received” group, it suggests that following the LLM's recommendations leads to better patient outcomes.
-
-
- Decision-making Patterns:
-
-The “Not Recommended but Received” group can highlight cases where the clinical decision deviated from the LLM's suggestion, potentially offering insights into human judgment in clinical settings.
-
-
- Clinical Impact:
-
-Understanding the impact of adherence to LLM recommendations can guide future decision-making processes and help integrate AI recommendations more effectively into clinical practice.
-
-
This approach provides a comprehensive view of the LLM's impact on patient care and the importance of adhering to its recommendations. (Figure 1)
Figure 1.

Patient outcomes based on adherence to recommended support. This bar plot illustrates the distribution of patient outcomes according to their adherence to organ support recommendations made by a LLM. The data categorize patients into four groups: (1) Recommended and Received: Patients for whom the LLM recommended organ support, and who actually received the support. (2) Recommended but Not Received: Patients for whom the LLM recommended organ support, but who did not receive the support. (3) Not Recommended but Received: Patients for whom the LLM did not recommend organ support, but who received the support regardless. (4) Not Recommended and Not Received: Patients for whom the LLM did not recommend organ support, and who did not receive the support. The plot shows the count of patients with outcomes classified as “improved” or “worsened” within each group. The “x” axis represents the four patient groups, while the “y” axis indicates the number of patients. The outcomes are color-coded: blue for “improved” and red for “worsened.” This visualization helps in understanding the effectiveness of adhering to the LLM's support recommendations. For instance, a higher count of “improved” outcomes in the “Recommended and Received” group compared to the “Recommended but Not Received” group would suggest that following the LLM's recommendations positively impacts patient outcomes. The data used for this analysis includes 100 patients, and the statistical significance of the differences in outcomes was assessed using a chi-squared test, with results indicating a potential association between adherence to recommendations and improved outcomes. LLM: Large language model.
Conclusions
This tutorial demonstrates how to leverage LLMs like DashScope's Qwen-turbo to analyze EMRs for patient prognosis and organ support recommendations. Through detailed steps, we illustrated how LLMs can be employed to generate prognostic assessments and suggest critical interventions based on patient history. We also provided methods for evaluating these AI-generated recommendations by comparing them with actual patient outcomes and traditional clinical judgments.
By categorizing patients into groups based on their adherence to the LLM's recommendations, we explored how these recommendations could impact clinical outcomes. This approach not only enhances our understanding of the LLM's capabilities but also provides a framework for clinicians and researchers to systematically assess and validate the effectiveness of AI in clinical settings.
Moreover, the provided R code examples offer a practical guide for performing key analyses, such as confusion matrices, Cohen's Kappa for agreement measurement, and chi-squared tests for association assessment. These tools are crucial for assessing the performance and reliability of LLMs in predicting clinical outcomes.
As LLM technology continues to advance, its integration into clinical research and decision-making will likely become more seamless and widespread. This tutorial serves as a foundational guide for clinical researchers and practitioners looking to harness the power of LLMs to improve patient care and outcomes. Future work should focus on further refining these models and expanding their applicability across diverse clinical scenarios. By doing so, we can ensure that LLMs contribute effectively and safely to the advancement of personalized and precise medicine.
CRediT Authorship Contribution Statement
Zhongheng Zhang: Writing – review & editing, Writing – original draft, Formal analysis, Conceptualization. Hongying Ni: Writing – review & editing, Methodology, Data curation.
Acknowledgments
Acknowledgments
None.
Funding
Z.Z received funding from the China National Key Research and Development Program [grant numbers 2023YFC3603104, 2022YFC2504503], a collaborative scientific project co-established by the Science and Technology Department of the National Administration of Traditional Chinese Medicine and the Zhejiang Provincial Administration of Traditional Chinese Medicine [grant number GZY-ZJ-KJ-24082], General Health Science and Technology Program of Zhejiang Province [grant number 2024KY1099], the Huadong Medicine Joint Funds of the Zhejiang Provincial Natural Science Foundation of China [grant number LHDMD24H150001], National Natural Science Foundation of China [grant numbers 82272180, 82472243], the Project of Drug Clinical Evaluate Research of Chinese Pharmaceutical Association [grant number CPA-Z06-ZC-2021–004], and Project of Zhejiang University Longquan Innovation Center (grant number ZJDXLQCXZCJBGS2024016).
Ethics Statement
Not applicable.
Conflict of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data Availability
The data sets generated during and/or analyzed during the current study are available from the corresponding author upon reasonable request.
Editor: Jingling Bao/ Zhiyu Wang
References
- 1.Sblendorio E., Dentamaro V., Lo Cascio A., Germini F., Piredda M., Cicolini G. Integrating human expertise & automated methods for a dynamic and multi-parametric evaluation of large language models’ feasibility in clinical decision-making. Int J Med Inform. 2024;188 doi: 10.1016/j.ijmedinf.2024.105501. [DOI] [PubMed] [Google Scholar]
- 2.Chung P., Fong C.T., Walters A.M., Aghaeepour N., Yetisgen M., O'Reilly-Shah V.N. Large language model capabilities in perioperative risk prediction and prognostication. JAMA Surg. 2024;159(8):928–937. doi: 10.1001/jamasurg.2024.1621. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Iqbal U., Lee L.T., Rahmanti A.R., Celi L.A., Li Y.J. Can large language models provide secondary reliable opinion on treatment options for dermatological diseases? J Am Med Inform Assoc. 2024;31(6):1341–1347. doi: 10.1093/jamia/ocae067. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Saner F.H., Saner Y.M., Abufarhaneh E., Broering D.C., Raptis D.A. Comparative analysis of artificial intelligence (AI) languages in predicting sequential organ failure assessment (SOFA) scores. Cureus. 2024;16(5):e59662. doi: 10.7759/cureus.59662. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Amrollahi F., Shashikumar S.P., Razmi F., Nemati S. Contextual embeddings from clinical notes improves prediction of sepsis. AMIA Annu Symp Proc. 2021;2020:197–202. [PMC free article] [PubMed] [Google Scholar]
- 6.Lorenzoni G., Gregori D., Bressan S., Ocagli H., Azzolina D., Da Dalt L., et al. Use of a large language model to identify and classify injuries with free-text emergency department data. JAMA Netw Open. 2024;7(5) doi: 10.1001/jamanetworkopen.2024.13208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Cabral S., Restrepo D., Kanjee Z., Wilson P., Crowe B., Abdulnour R.E., et al. Clinical reasoning of a generative artificial intelligence model compared with physicians. JAMA Intern Med. 2024;184(5):581–583. doi: 10.1001/jamainternmed.2024.0295. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Cloud A. Dashscope: dashscope client SDK library. Available from: https://dashscope.aliyun.com.[Accessed on June 16, 2024].
- 9.Wei J., Wang X., Schuurmans D., Bosma M., Ichter B., Xia F., et al. Chain-of-thought prompting elicits reasoning in large language models. Available from: https://arxiv.org/abs/2201.11903 [Accessed on January 10, 2023].
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data sets generated during and/or analyzed during the current study are available from the corresponding author upon reasonable request.