

Abstract
Background
The high rate of repeat attempts among individuals who have previously attempted suicide presents a critical challenge in public health and suicide prevention. While early and targeted intervention is crucial for this high-risk group, effectively identifying those most likely to re-attempt is a persistent difficulty, especially when public health resources are limited. This creates a pressing need for accurate and practical risk assessment tools. This study aims to address this gap by using machine learning to analyze a nationwide suicide surveillance database to identify key predictors of repeat suicide attempts and develop a robust predictive model to aid in resource allocation and early intervention.
Methods
This study analyzed data from 32,701 individuals, encompassing 31 features, recorded in Taiwan's National Suicide Surveillance System for 2020. We employed binary decision tree regression with multiple feature selection techniques to identify significant predictors of recurrent suicide attempts. A prediction model was then developed without requiring biological samples.
Results
History of mental illness, specific age groups, and supervision status of mentally ill patients emerged as primary influences on repeated suicide attempts. The prediction model achieved 66.3% accuracy in identifying potential repeat attempters, with a 57.9% success rate for predicting re-suicide events. These findings align with recent literature on suicide recurrence risk factors.
Conclusions
This study provides a practical risk assessment tool that enables early intervention for high-risk individuals without invasive biological sampling. The insights offer valuable guidance for government suicide prevention policies, especially when prioritizing cases with limited resources. Future enhancements through broader data integration and interdisciplinary cooperation could establish a more comprehensive prevention system to reduce the societal impact of suicidal behavior.
Trial registration
Not applicable as this was a retrospective database analysis rather than a randomized controlled trial.
Keywords: Suicide, Surveillance, Prevention, Suicide behavior, History of past mental illness
Background
Suicidal behavior imposes a profound societal burden, not only through the tragic loss of life but also through significant economic costs related to healthcare lost productivity and the deep psychological distress inflicted on families and communities [1, 2]. A critical challenge within suicide prevention is the high recurrence rate among individuals who have previously attempted suicide. This population represents a high-risk group that demands targeted and timely intervention. However, accurately identifying which individuals are most likely to make a repeat attempt from a large caseload remains a formidable task for public health systems, which often operate with limited resources. This creates an urgent need for practical, data-driven tools to stratify risk and guide the allocation of preventive care.
In response to this challenge, there has been a growing interest in applying machine learning (ML) and artificial intelligence (AI) to analyze large-scale health data for suicide risk prediction [3–5]. Numerous studies have demonstrated the potential of ML models to identify individuals at risk by analyzing electronic health records, insurance claims, and national registry data [6–8]. For instance, researchers have utilized models like random forests [9], and support vector machines [10] to predict suicidal behaviors, often achieving moderate to high accuracy. These studies have consistently identified predictors such as a history of mental illness, previous suicide attempts, specific demographic profiles, and substance use disorders as significant risk factors [11, 12].
Despite these advances, several critical gaps remain in the existing literature. First, many predictive models are"black boxes"(e.g., complex neural networks) whose decision-making processes are not easily interpretable by frontline clinicians. This lack of transparency can hinder trust and adoption in clinical practice, where understanding the"why"behind a risk score is crucial for intervention planning [13]. Second, some studies rely on data sources that are not universally available or practical for real-time screening, such as genetic markers or detailed clinical notes, limiting their scalability in public health settings [14]. Finally, many studies are conducted on region-specific or hospital-based cohorts, and their findings may not be generalizable to a nationwide population with diverse characteristics.
This study is grounded in the social safety net, a multi-layered system encompassing mental healthcare, community-based support, and case management services designed to protect vulnerable individuals. A primary challenge for this safety net is the efficient allocation of its finite resources to those at most significant risk. This study addresses this challenge directly. By developing a data-driven, interpretable predictive model, we aim to provide a pragmatic tool that enables frontline workers to systematically identify individuals with the highest probability of a repeat suicide attempt. This risk stratification allows prioritizing intensive interventions, such as enhanced follow-up and personalized care planning. Ultimately, by integrating this evidence-based tool into existing workflows, our goal is to strengthen the overall effectiveness and efficiency of Taiwan's national suicide prevention framework, ensuring that limited resources are directed where they are needed most.
Methods
Data source and study population
This research utilizes data from the National Suicide Surveillance System (NSSS) of Taiwan, benefiting from the comprehensive suicide attempt notifications mandated by the Taiwan Suicide Prevention Act of 2019. This regulatory backdrop minimizes selection bias, making the 2020 suicide attempt data robust for analysis. The dataset includes demographic information, suicide methods, reasons behind the attempts, and healthcare system interactions, tracking further attempts over a year to gauge repeat suicide risk. This study was approved by the National Taiwan University ethics committee and conducted using reasonable clinical practice procedures and the current revision of the Declaration of Helsinki. The study was conducted according to all applicable guidelines and regulations.
The final dataset comprised 32,701 individuals. The primary outcome variable was the occurrence of a repeat suicide attempt, which was operationally defined based on two criteria: the timeframe and the method of ascertainment. The timeframe was a one-year follow-up period after the initial reported attempt. A repeat attempt was identified if any new suicide attempt notification for the same individual was registered in Taiwan's National Suicide Surveillance System (NSSS) during this period. The NSSS receives mandatory, system-wide notifications from diverse official sources, including hospitals, police and fire departments, and social welfare agencies, as stipulated by the Taiwan Suicide Prevention Act. This multi-source, system-level definition comprehensively ascertains the outcome rather than relying on a single data stream like hospital records or self-reports. The distribution of the study population was as follows: 6,624 individuals (20.3%) were classified as repeat attempters and 26,077 individuals (79.7%) were classified as non-repeat attempters. This distribution reflects a significant class imbalance, a common characteristic of clinical and public health datasets, which required specific methodological handling during model development.
Data preprocessing and missing data handling
Before analysis, the dataset underwent a preprocessing step to handle missing values. We employed a casewise deletion (also known as listwise deletion) approach. This method excluded any record containing missing data in one or more of the 31 predictor variables used in this study. This approach was chosen due to the requirements of the decision tree algorithm, which cannot process incomplete records. After excluding incomplete cases, the final dataset used for model development and validation consisted of 32,701 complete individual records.
Feature engineering and selection
The analysis included 31 features extracted from the NSSS database, encompassing demographics, suicide methods, documented reasons for the attempt, and interactions with the healthcare system. To robustly identify the most influential predictors of repeat suicide attempts and avoid the bias of a single method, we implemented a multi-faceted feature selection strategy.
This strategy involved employing five distinct algorithms to evaluate feature importance:
Minimum Redundancy Maximum Relevance (MRMR), Chi-Squared Test, ReliefF, ANOVA, and the Kruskal–Wallis Test. Each method assessed the features from a different statistical perspective, providing a comprehensive evaluation.
We established a score-based system to synthesize the results from these five methods into a single, robust ranking. We identified the top five ranking features for each of the five methods and assigned scores from 5 (for rank 1) down to 1 (for rank 5). The final importance score for each feature was calculated by summing the scores it received across all five methods. This aggregated score was then used to establish the final feature ranking, with the complete results in Table 3. This approach ensures that the highest-ranked features are those consistently identified as important across multiple analytical techniques.
Table 3.
Feature selection methods and feature rankings
| Rank 1 (Score = 5) | Rank 2 (Score = 4) | Rank 3 (Score = 3) | Rank 4 (Score = 2) | Rank 5 (Score = 1) | |
|---|---|---|---|---|---|
| MRMR | Age Group (5) | History of Past Mental Illness (4) | DVV (3) | Gender (2) | MIPS (1) |
| Chi-Squared Test | History of Past Mental Illness (5) | MIPS (4) | Occupation (3) | Age Group (2) | DCSM (1) |
| ReliefF | Whether Living with Others (5) | DVP (4) | MIPS (3) | Child Perpetrators (2) | Poisonous Substances (1) |
| ANOVA | History of Past Mental Illness (5) | MIPS (4) | Age Group (3) | Gender (2) | Marital Status (1) |
| Kruskal–Wallis Test | History of Past Mental Illness (5) | MIPS (4) | Age Group (3) | Gender (2) | Marital Status (1) |
Score total result: History of Past Mental Illness(19) > MIPS(16) > Age Group(13) > Gender(6) > Whether Living with Others(5) > DVP(4) > DVV (3) = Occupation(3) > Child Perpetrators(2) = Marital Status (2) > DCSM(1) = Poisonous Substances(1)
Model selection and rationale
While various machine learning models, such as Random Forest and Support Vector Machines, are known for high predictive accuracy, we deliberately selected the binary decision tree model for this study. The primary justification is the critical importance of model interpretability in a clinical and public health context. This research aims to create a black-box predictor and develop a practical"white-box"tool that offers transparent, rule-based logic [15]. This transparency allows frontline workers to understand the exact factors leading to a risk classification, which is crucial for building user trust and informing targeted interventions. We, therefore, prioritized interpretability, accepting a potential trade-off in predictive accuracy to ensure the model's practical utility.
The decision tree models were implemented in MATLAB R2023a using the Classification Learner App and its associated functions based on the CART (Classification and Regression Trees) algorithm. The standard Gini's diversity index was used as the criterion for splitting nodes.
Model validation strategy
To ensure our model's robustness and generalizability and avoid overfitting, we employed a tenfold cross-validation strategy instead of a single training/testing split. The entire dataset (N = 32,701) was randomly partitioned into 10 equally sized subsets, or"folds."The model was then trained on nine folds and validated on the remaining one. This process was repeated 10 times, with each fold serving as the validation set exactly once. The final performance metrics reported are the average results from these 10 validation folds. This method provides a more stable and less biased estimate of the model's performance on unseen data.
Handling of imbalanced data
Given the imbalanced nature of our dataset (20.3% repeat attempters vs. 79.7% non-repeaters), a standard classification algorithm would be biased towards the majority class. To mitigate this, we implemented a cost-sensitive learning strategy. During the model training process, we assigned a higher misclassification cost to the minority class (repeat attempters) by adjusting the cost matrix to [0, 5; 1, 0]. This higher penalty for false negatives forces the model to focus more on correctly identifying the high-risk minority class.
Performance evaluation metrics
To comprehensively assess the model's performance, especially in imbalanced data, we used overall accuracy metrics derived from the confusion matrix of the tenfold cross-validation results.
Results
Suicide prevention association of Taiwan: statistical database for 2020
Table 1 presents the study participants'demographic and psychosocial characteristics, highlighting distinct patterns between the suicide reattempt (SR) and non-SR groups. The SR Group and the non-SR group have a higher proportion of females, constituting 60.9% and 72.8%, respectively. Young adults, particularly in the 15–24 age bracket, are more prevalent in the SR group (32.8%) compared to the non-SR group (21.1%). Unmarried individuals dominate both groups, making up 57% of the SR group and 43.9% of the non-SR group. The most common educational attainment is a high school diploma, observed in 34.8% of the SR group and 32.8% of the non-SR group. A significant finding is the higher incidence of psychiatric disorders in the SR group (55.2%) compared to the non-SR group (34.1%), correlating with greater utilization of psychiatric healthcare services (27.6% in the SR group vs. 14.6% in the non-SR group). This data suggests that individuals prone to suicide reattempts are more likely to be younger, unmarried, have a high school level education, suffer from psychiatric disorders, and engage more with psychiatric healthcare services.
Table 1.
The demographic and basic information of suicide attempters in 2020
| Non-reattempt (N = 26077) N (%) |
Reattempt (N = 6624) N (%) |
χ2 | |
|---|---|---|---|
| Gender | < 0.001 | ||
| Male | 10194 (39.1) | 1799 (27.2) | |
| Female | 15883 (60.9) | 4825 (72.8) | |
| Age | < 0.001 | ||
| 0–14 | 1276 (4.9) | 499 (7.5) | |
| 15–24 | 5499 (21.1) | 2170 (32.8) | |
| 25–34 | 4584 (17.6) | 1256 (19) | |
| 35–44 | 5142 (19.7) | 1271 (19.2) | |
| 45–54 | 3637 (13.9) | 775 (11.7) | |
| 55–64 | 2556 (9.8) | 382 (5.8) | |
| 65–74 | 1584 (6.1) | 146 (2.2) | |
| 75 + | 1712 (6.6) | 124 (1.9) | |
| Marriage | < 0.001 | ||
| Married | 8149 (31.2) | 1396 (21.1) | |
| Single | 11457 (43.9) | 3775 (57) | |
| Widowed | 1367 (5.2) | 136 (2.1) | |
| Divorce | 4288 (16.4) | 1132 (17.1) | |
| Unknown | 816 (3.1) | 185 (2.8) | |
| Education level | < 0.001 | ||
| Uneducated | 187 (0.7) | 16 (0.2) | |
| Elementary school | 1454 (5.6) | 312 (4.7) | |
| Junior high school | 6917 (26.5) | 1911 (28.8) | |
| Senior high school | 8547 (32.8) | 2305 (34.8) | |
| College | 3234 (12.4) | 916 (13.8) | |
| Master & PhD | 345 (1.3) | 91 (1.4) | |
| Unknown | 5393 (20.7) | 1073 (16.2) | |
| Past psychiatric history | 8885 (34.1) | 3655 (55.2) | < 0.001 |
| Psychiatric patients registered for community aftercare | 3779 (14.5) | 1827 (27.6) | < 0.001 |
| Severe psychiatric patients | 292 (1.1) | 154 (2.3) | < 0.001 |
| Domestic violence assailants | |||
| High risk | 393 (1.5) | 133 (2) | < 0.001 |
| Low risk | 2044 (7.8) | 793 (12) | < 0.001 |
| Victims of domestic violence | < 0.001 | ||
| High risk | 476 (1.8) | 198 (3) | |
| Low risk | 2471 (9.5) | 968 (14.6) | |
| Offenders of children and adolescent abuse | 386 (1.5) | 157 (2.4) | < 0.001 |
| Victims of children and adolescent abuse | 193 (0.7) | 99 (1.5) | < 0.001 |
| Offenders of sexual abuse | 103 (0.4) | 16 (0.2) | 0.064 |
| Received opioids replacement therapy | 300 (1.2) | 87 (1.3) | 0.273 |
This study analyzes 31 quantifiable features from a database to identify key factors in suicide prevention, detailed in Table 2 with abbreviations for brevity. We categorize these features into"Detailed Classification"and"Rough Classification"based on their attributes, and some features are further divided into two distinct problem types, labeled (1) and (2). The aim is to explore how these features correlate with the likelihood of patients attempting suicide again within one year following their initial attempt. We denote non-repeat suicide attempts as"0"and repeat attempts as"1". While the study encompasses 32 features, including the occurrence of repeat suicide attempts, it primarily examines the relationship between the 31 features and repeat attempts to understand their influence and inform prevention strategies.
Table 2.
List of 31 variables in database
| Feature | Description | Data type | |
|---|---|---|---|
| 1 | Indigenous Population | Indicates if the individual identifies as an indigenous person | Binary |
| 2 | Detailed Classification of Suicide Methods – DCSM | The specific method used in the suicide attempt, categorized | Nominal |
| 3 | Age Group | Individuals'ages are categorized into specific brackets, as shown in Table 1 | Ordinal |
| 4 | Alternative Therapies | Indicates if the individual received alternative therapies | Binary |
| 5 | Corresponding City | The city of residence of the individual | Nominal |
| 6 | Poisonous Substances | Asks whether the individual has ever used any type of illicit drugs | Binary |
| 7 | High-Risk Domestic Violence Victims – HRDVV | Indicates if the individual is identified as a high-risk victim of domestic violence | Binary |
| 8 | Domestic Violence Perpetrators – DVP | Indicates if the individual has a history of perpetrating domestic violence | Binary |
| 9 | Domestic Violence Victims – DVV | Indicates if the individual has a history of being a victim of domestic violence | Binary |
| 10 | Occupation | The individual's profession, categorized into predefined classes | Nominal |
| 11 | Rough Classification of Suicide Reasons (1)—RCSR (1) | Primary categorized reason for the suicide attempt | Nominal |
| 12 | Mentally Ill Patients Under Supervision – MIPS | Indicates if the individual is a registered psychiatric patient requiring community aftercare | Binary |
| 13 | History of Past Mental Illness | Indicates if the individual has a documented history of any mental illness | Binary |
| 14 | Detailed Classification of Suicide Reasons (2)—DCSR (2) | Secondary categorized reason for the suicide attempt | Nominal |
| 15 | Reporting Registration Unit | The specific unit that registered the suicide attempt report | Nominal |
| 16 | Type of Reporting Registration Unit – TRRU | The category of the reporting registration unit (e.g., hospital, clinic) | Nominal |
| 17 | City of Reporting Registration Unit – CRRU | The city where the reporting registration unit is located | Nominal |
| 18 | Reporting Unit | The initial unit that reported the suicide attempt | Nominal |
| 19 | Type of Reporting Unit | The category of the initial reporting unit | Nominal |
| 20 | City of Reporting Unit | The city where the initial reporting unit is located | Nominal |
| 21 | Education Level | The highest level of education attained by the individual | Ordinal |
| 22 | Employment Status | The individual's current employment status (e.g., employed, unemployed) | Nominal |
| 23 | Living Situation—Whether Living with Others | Indicates whether the individual lives alone or with others | Binary |
| 24 | Marital Status | The individual's marital status (e.g., single, married, divorced) | Nominal |
| 25 | Severely Ill Mental Health Patients – SIMHP | Indicates if the individual is classified as having a severe psychiatric illness | Binary |
| 26 | Gender | The gender of the individual | Binary |
| 27 | Sexual Assault Perpetrators | Indicates if the individual has a history of sexual assault perpetration | Binary |
| 28 | Rough Classification of Suicide Reasons (2)—RCSR (2) | An alternative classification for the reason for the attempt | Nominal |
| 29 | Child Perpetrators | Indicates if the individual is an offender in a child abuse case | Binary |
| 30 | Child Victims | Indicates if the individual is a victim of child abuse | Binary |
| 31 | Willingness to Receive Care | Indicates the individual's willingness to accept follow-up care services | Binary |
In Table 2, we differentiate the Data Type column into three categories:
Binary variables, which assume exactly two possible values;
Nominal variables, which comprise multiple categories without any inherent order; and
Ordinal variables, which comprise multiple categories with a defined order or ranking.
Although ordinal variables inherently convey a hierarchical structure, our current model offers limited interpretability for such features. Consequently, we treat ordinal variables as nominal variables in our analysis while emphasizing the opportunity to exploit their ordered nature in the Discussion section for more nuanced insights.
Model interpretability analysis for recurring suicide cases
To thoroughly investigate the association between individual repeat suicide events and various features, this study employs binary decision tree regression analysis. This method divides the dataset into several subsets through a tree structure, simplifying the prediction for each subset. Each node reflects the decision rules learned based on the data features. The advantage of this approach lies in the interpretability of the model, providing an intuitive way to understand the impact of data features on the prediction results [16, 17].
This study constructed a binary decision tree regression model using the feature values in Table 2 and individual repeat suicide events. The"fitrtree"function in Matlab R2023a was used, setting the maximum tree depth to 10. The visualized interpretability results of the model are presented in Fig. 1. The results indicate that the most critical feature in the model is"History of Past Mental Illness,"suggesting that cases with a history of mental illness have a strong association with the occurrence of repeat suicide events.
Fig. 1.

Decision Tree Model Interpretability Results. Utilizing a tree structure to examine the top 10 significant levels affecting repeated suicide attempts
The"Age Group"classification includes 0–4 years (age groups), 5–9, 10–14, 15–19, 20–24, 25–29, 30–34, 35–39, 40–44, 45–49, 50–54, 55–59, 60–64, 65–69, 70–74, 75 and above, and unknown. Although this method cannot determine the strength of the association between specific age groups and the occurrence of events, it can be determined that the classification of"Age Group"is divided by 8.5. The system's coding ages above 8 include 55–59, 60–64, 65–69, 70–74, 75 and above, 5–9, 0–4, and unknown (note: the coding in the questionnaire system is not arranged according to age). Despite not being arranged by age, based on the interpretability shown by the model, it can be understood that the division is made at the age of 55. Therefore, according to the model's interpretability, this implies that the group aged 55 and above may have a higher association with the occurrence of repeat suicide events.
This study has compiled a detailed analysis of the model's judgment path for future reference by other researchers to promote the public interest.
History of Past Mental Illness → Age Group → Mentally Ill Patients Under Supervision
History of Past Mental Illness → Age Group → Domestic Violence Perpetrators
History of Past Mental Illness → Age Group → Gender
History of Past Mental Illness → Age Group → Mentally Ill Patients Under Supervision
Ranking the importance of various features in recurring suicide cases
To objectively explore the correlation between individual repeat suicide events and other features, this study employs various feature selection and importance evaluation methods, including MRMR (Minimum Redundancy Maximum Relevance) [18], Chi-Squared Test [19], ReliefF [20], ANOVA [21], and Kruskal–Wallis Test [22].
MRMR aims to select features that simultaneously exhibit high correlation and low redundancy. The Chi-Squared Test evaluates the independence between features and target variables. ReliefF is a method for assessing feature importance and is suitable for multi-class problems. ANOVA is used to test for significant differences in means between different groups. The Kruskal–Wallis Test is a non-parametric method suitable for situations where the data does not follow a normal distribution.
Figures 2, 3, 4, 5 and 6 show the importance ranking of individual repeat suicide events and other features using MRMR, Chi-Squared Test, ReliefF, ANOVA, and Kruskal–Wallis Test methods, respectively.
Fig. 2.

MRMR algorithm
Fig. 3.
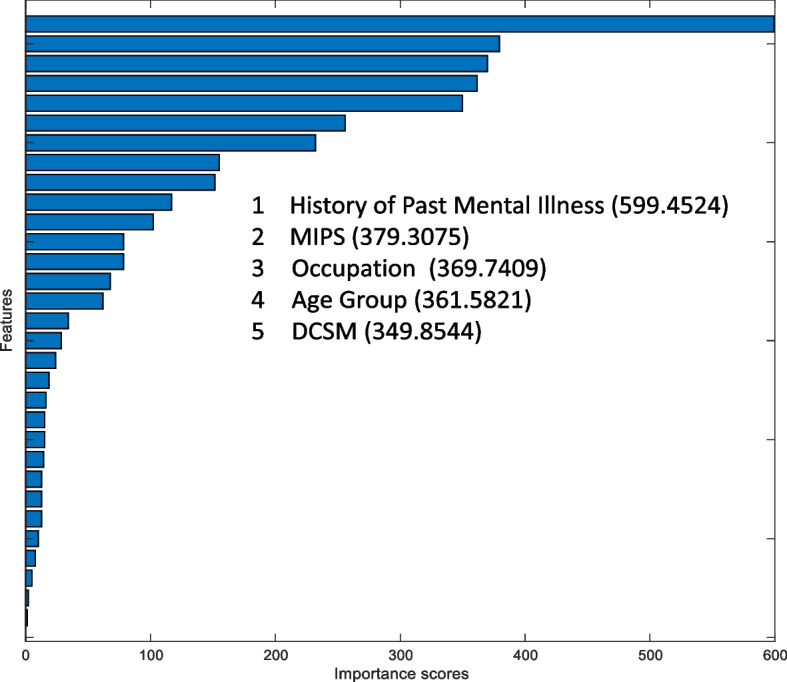
Chi-Squared test
Fig. 4.

ReliefF algorithm
Fig. 5.
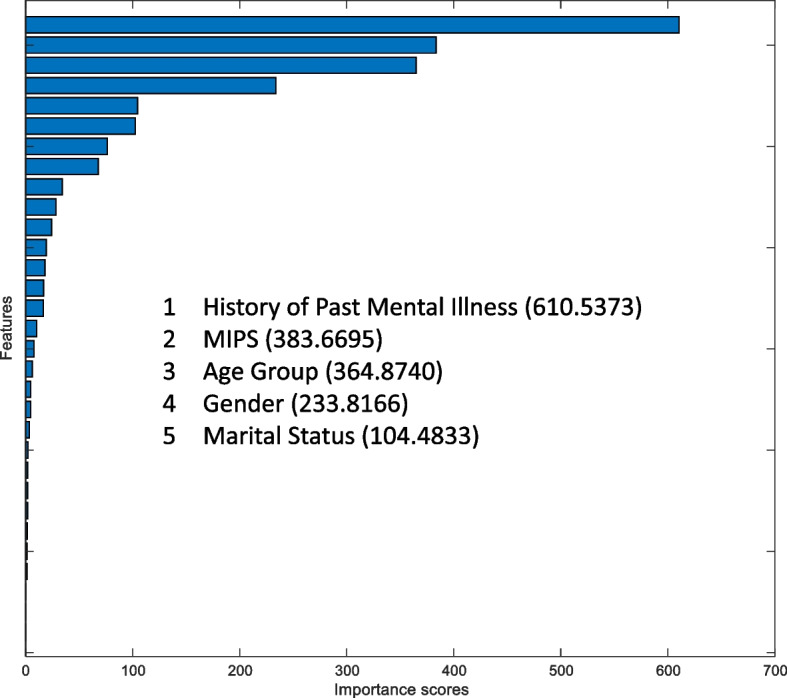
ANOVA algorithm
Fig. 6.
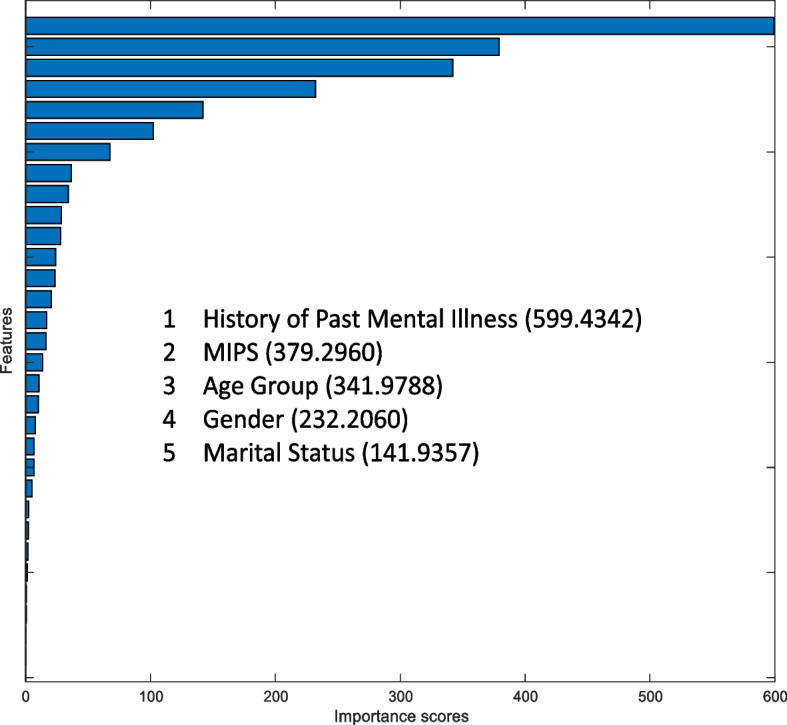
Kruskal–Wallis test
Based on the theoretical foundations of the above feature selection methods, although each method has advantages and disadvantages, this study compiles the results of these feature selection methods, as shown in Table 3, to more objectively identify handy features. Table 3 summarizes the top five rankings in Figs. 2, 3, 4, 5 and 6 and assigns different scores to the top five rankings. The final results are as follows: History of Past Mental Illness (19) > MIPS (16) > Age Group (13) > Gender (6) > Whether Living with Others (5) > DVP (4) > DVV (3) = Occupation (3) > Child Perpetrators (2) = Marital Status (2) > DCSM (1) > Poisonous Substances (1). In summary, the results indicate that a History of Past Mental Illness is the most critical feature, which is consistent with the interpretability results of the model. Moreover, MIPS, Age Group, and Gender are also roughly consistent with the interpretability results of the model.
Establishing a prediction model for repeat suicide events in individuals
This study addresses imbalanced data in suicide prevention research by utilizing Decision Tree methods for classification. To prioritize the prediction of rare repeat suicide events, we modified the Cost matrix in Matlab's Classification Learner App to [0 0.4; 1 0] and implemented tenfold cross-validation to strengthen the model's reliability and accuracy.
Our analysis crucially relies on the Confusion Matrix to differentiate between true positives, true negatives, false positives, and false negatives, explicitly aiming to enhance true negative rates. This method intends to more effectively pinpoint individuals at heightened risk of repeat suicide attempts, aiding in the deployment of precise interventions.
The Medium Tree model, when trained with all features presented in Table 2 and summarized performance in Table 4, demonstrated notable success in identifying repeat suicide incidents. This model, by focusing on four key predictors—History of Past Mental Illness, MIPS, Age Group, and Gender—achieved a 59.7% recognition rate for predicting repeat suicide attempts, as detailed in Table 5.
Table 4.
Predictive model construction for recurring suicide cases using decision trees on all features
| Accuracy (Validation) | Confusion matrix | |
|---|---|---|
| Fine tree | 66.7% | 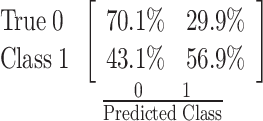 |
| Medium tree | 65.1% |  |
| Coarse tree | 66.5% |  |
Table 5.
Predictive model construction for recurring suicide cases using a medium tree with key features
| Accuracy (Validation) | Confusion matrix | Features |
|---|---|---|
| 66.8% | 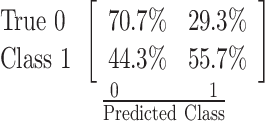 |
History of Past Mental Illness (19) |
| MIPS (16) | ||
| Age Group (13) | ||
|
Gender (6) Whether Living with Others (5) | ||
| DVP (4) | ||
| DVV (3) = Occupation (3) | ||
| Child Perpetrators (2) = Marital Status (2) | ||
| DCSM (1) = Poisonous Substances (1) | ||
| 66.8% |  |
History of Past Mental Illness (19) |
| MIPS (16) | ||
| Age Group (13) | ||
| Gender (6) | ||
| Whether Living with Others (5) | ||
| DVP (4) | ||
| DVV (3) = Occupation (3) | ||
| Child Perpetrators (2) = Marital Status (2) | ||
| 66.7% | 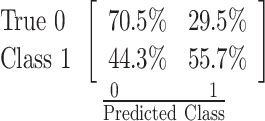 |
History of Past Mental Illness (19) |
| MIPS (16) | ||
| Age Group (13) | ||
| Gender (6) | ||
| Whether Living with Others (5) | ||
| DVP (4) | ||
| DVV (3) = Occupation (3) | ||
| 66.3% |  |
History of Past Mental Illness (19) |
| MIPS (16) | ||
| Age Group (13) | ||
| Gender (6) | ||
| Whether Living with Others (5) | ||
| DVP (4) | ||
| 66.3% |  |
History of Past Mental Illness (19) |
| MIPS (16) | ||
| Age Group (13) | ||
| Gender (6) | ||
| Whether Living with Others (5) | ||
| 66.3% |  |
History of Past Mental Illness (19) |
| MIPS (16) | ||
| Age Group (13) | ||
| Gender (6) | ||
| 66.3% | 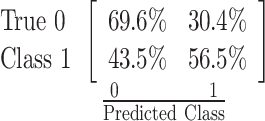 |
History of Past Mental Illness (19) |
| MIPS (16) | ||
| Age Group (13) |
This selection of predictors underpins our Optimizable Tree Model, which proved highly effective after rigorous parameter optimization in forecasting repeat suicide attempts. The model's efficacy is visually depicted in Fig. 7, highlighting the importance of strategic feature selection and advanced modeling in enhancing suicide prevention strategies.
Fig. 7.

Confusion matrix for optimizable tree model
Discussion
This study addresses the significant socio-economic impacts of suicidal behavior, highlighting the strain on public health systems, loss of productivity, and the profound psychological toll on the affected families, often leading to"Complicated Grief (CG) [23]. The complexity of suicidal behavior, rooted in multifaceted brain mechanisms and mental health issues [24], necessitates a broad-based prevention strategy encompassing public health policies, mental health support, and community education, supplemented by AI technology to enhance risk prediction and intervention planning.
Our decision tree model identifies key predictors of repeat suicide attempts, including age (particularly over 55), a history of past mental illness, and Mental Illness Severity (MIPS), corroborating findings from recent studies [25–27]. These factors suggest that targeted interventions could significantly mitigate the risk of repeat attempts.
An important finding of this study is the identification of “Gender” as a significant predictor for repeat suicide attempts. This conclusion is not merely an indirect implication of the model but is substantiated by multiple lines of data evidence. First, descriptive statistical analysis shows that the proportion of females in the repeat-attempt group (72.8%) is significantly higher than in the non-repeat-attempt group (60.9%). Second, to ensure objectivity, this study employed an integrated assessment of five feature selection methods, and the results showed that “Gender” ranked fourth in importance among all predictors. Most critically, our binary decision tree model provides a clear decision pathway: “History of Past Mental Illness → Age Group → Gender.” This indicates that within a specific risk profile, after accounting for psychiatric history and age, Gender is a key node for the model to stratify individual risk levels further. Although the data-driven approach of this study cannot explain the underlying psychosocial factors contributing to this gender disparity, the finding is consistent with the broad body of research that acknowledges the significant role of Gender in suicidal ideation and behavior. This also suggests that future research could explore the specific reasons for this gender difference within the sociocultural context of Taiwan.
Further analysis through feature selection reinforced the importance of mental illness history, MIPS, and age as crucial predictors, with a focus on the nuanced role of individual case management in preventing repeat suicide attempts. This approach, avoiding reliance solely on machine learning, ensures a robust and evidence-based framework for understanding and addressing suicide risk.
The challenges of predicting suicidal intent, as evidenced by varied success rates in existing studies, underline the need for advanced methodologies, including genetic markers and biological samples, despite their ethical and practical limitations. This study's findings, with a 66.3% overall recognition rate and a 57.9% success rate in predicting repeat suicide attempts, contribute to the ongoing discourse on effective suicide prevention strategies, emphasizing the value of interdisciplinary research, policy formulation, and the judicious application of AI technologies in crafting targeted interventions. While this accuracy may be considered moderate within the machine learning domain, it is essential to contextualize this result within our study's primary objective: to deliver a highly interpretable and practical tool. As detailed in the Methods section, we deliberately selected the'white-box'decision tree model to ensure that frontline workers could comprehend the basis of risk assessment, prioritizing this over potentially more accurate yet opaque'black-box'algorithms. This emphasis on interpretability is vital for fostering user trust and informing effective interventions, a value we contend is more critical than pursuing higher predictive metrics.
Conclusions
This study mainly adopts database analysis technology and extracts data on suicide characteristics from the database. The related case management methods, historical patterns, and potentially dangerous behavior will be analyzed to predict future suicide risk. Suicidal behavior has many negative impacts on society and the economy, including increasing the burden on the public health system, leading to productivity loss, and causing heavy psychological stress for the patients'families. Preventing suicide requires interdisciplinary collaboration, including public health policies, mental health support, community education, and destigmatization. Artificial intelligence technology plays a crucial role in analyzing large amounts of relevant data, predicting suicide risk, providing personalized intervention plans, and optimizing the allocation of public health resources.
This study used machine learning methods to analyze the database of Taiwan's suicide prevention system and identified key factors influencing re-suicide, including history of mental illness, age, and mentally ill patients under supervision. The research findings are generally consistent with recent literature, confirming the correlation between these characteristics and re-suicide events. The re-suicide event prediction model established in this study achieved an overall recognition rate of 66.3% without extracting biological samples, and the success rate of predicting re-suicide reached 57.9%. Although including biological samples could further improve the model's accuracy, considering the cost and human rights implications, the method used in this study still has practical value.
The research results can provide important references for the government in formulating suicide prevention policies and help identify high-risk cases for timely intervention and care when resources are limited. In the future, we can further integrate diverse data sources, optimize prediction models, and strengthen interdisciplinary cooperation to establish a more comprehensive suicide prevention system from multiple aspects, thereby reducing the negative impact of suicidal behavior on society.
Acknowledgements
This study used data from linked databases “National Suicide Surveillance System (NSSS) maintained by the Taiwan Suicide Prevention Center, Taiwan. The authors would like to thank all the colleagues at the Taiwan Suicide Prevention Center for their administrative help. The Ministry of Health and Welfare, Executive Yuen, Taiwan, supported the study.
Trial registration
Not applicable as this was a retrospective database analysis rather than a randomized controlled trial.
Abbreviations
- NSSS
National Suicide Surveillance System
- CG
Complicated Grief
- ML
Machine Learning
- AI
Artificial Intelligence
- SR
Suicide Reattempt
- MRMR
Minimum Redundancy Maximum Relevance
- MIPS
Mental Illness Severity
Authors’ contributions
JH (Conceptualization: Led research direction and design; Methodology: Developed research methods; Project Administration: Managed overall research coordination; Writing—Original Draft: Wrote the initial manuscript); SL (Investigation: Conducted primary experiments and data collection; Data Curation: Managed and maintained research data; Formal Analysis: Performed statistical analysis; Writing—Review & Editing: Participated in manuscript review and revision); MH (Validation: Assisted in experimental result verification; Software: Developed data analysis programs; Resources: Assisted with experimental materials preparation; Writing—Review & Editing: Contributed to manuscript review and revision; Writing—Original Draft: Wrote the initial manuscript). All authors approved the final manuscript.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Data availability
The datasets analyzed during the current study are available from the corresponding author upon reasonable request, subject to approval from the Taiwan Suicide Prevention Center and in compliance with relevant data protection regulations.
Declarations
Ethics approval and consent to participate
This study protocol, titled"Development and Evaluation of National Suicide Prevention Strategies: Study on Integrative Data Bank of Public Health,"was reviewed and approved by the Research Ethics Committee of National Taiwan University (NTU-REC) on June 11, 2024 (Approval No.: 202404HM037).
Consent for publication
All authors have reviewed the manuscript and agreed to its publication.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Giabbanelli PJ, Rice KL, Nataraj N, Brown MM, Harper CR. A systems science approach to identifying data gaps in national data sources on adolescent suicidal ideation and suicide attempt in the United States. BMC Public Health. 2023;23(1):627. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Thorne B, O’Reilly M. Operationalizing strategic objectives of suicide prevention policy: police-led LOSST LIFFE model. Death Stud. 2022;46(9):2077–84. [DOI] [PubMed] [Google Scholar]
- 3.Haroz EE, Grubin F, Goklish N, Pioche S, Cwik M, Barlow A, Waugh E, Usher J, Lenert MC, Walsh CG. Designing a clinical decision support tool that leverages machine learning for suicide risk prediction: development study in partnership with native American care providers. JMIR Public Health Surveillance. 2021;7(9):e24377 . [DOI] [PMC free article] [PubMed]
- 4.Myhre MO, Kildahl AT, Astrup H, Bergsager D, Walby FA: Suicide in services for mental health and substance use: a national hybrid registry surveillance system. Health Inform J. 2023;29(1):14604582231167439. [DOI] [PubMed]
- 5.Ranapurwala SI, Miller VE, Carey TS, Gaynes BN, Keil AP, Fitch CV, Swilley-Martinez ME, Kavee AL, Cooper T, Dorris S, et al. Innovations in suicide prevention research (INSPIRE): a protocol for a population-based case-control study. Inj Prev. 2022;28(5):483–90. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Moglia V, Johnson O, Cook G, de Kamps M, Smith L. Artificial intelligence methods applied to longitudinal data from electronic health records for prediction of cancer: a scoping review. BMC Med Res Methodol. 2025;25(1):24. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Golas SB, Shibahara T, Agboola S, Otaki H, Sato J, Nakae T, Hisamitsu T, Kojima G, Felsted J, Kakarmath S, et al. A machine learning model to predict the risk of 30-day readmissions in patients with heart failure: a retrospective analysis of electronic medical records data. BMC Med Inform Decis Mak. 2018;18(1):44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Caruana A, Bandara M, Musial K, Catchpoole D, Kennedy PJ. Machine learning for administrative health records: a systematic review of techniques and applications. Artif Intell Med. 2023;144:102642. [DOI] [PubMed] [Google Scholar]
- 9.Bazrafshan M, Sayehmiri K. Predicting suicidal behavior outcomes: an analysis of key factors and machine learning models. BMC Psychiatry. 2024;24(1):841. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Gan Y, Kuang L, Xu X-M, Ai M, He J-L, Wang W, Hong S, Chen JM, Cao J, Zhang Q. Research on prediction model of adolescent suicide and self-injury behavior based on machine learning algorithm. Front Psychiatry. 2025;15:2024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Riera-Serra P, Navarra-Ventura G, Castro A, Gili M, Salazar-Cedillo A, Ricci-Cabello I, Roldán-Espínola L, Coronado-Simsic V, García-Toro M, Gómez-Juanes R, et al. Clinical predictors of suicidal ideation, suicide attempts and suicide death in depressive disorder: a systematic review and meta-analysis. Eur Arch Psychiatry Clin Neurosci. 2024;274(7):1543–63. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Leza L, Haro B, López-Goñi JJ, Fernández-Montalvo J. Substance use disorder and lifetime suicidal behaviour: a scoping review. Psychiatry Res. 2024;334:115830. [DOI] [PubMed] [Google Scholar]
- 13.Akhtar K, Yaseen MU, Imran M, Khattak SBA, M MN. Predicting inmate suicidal behavior with an interpretable ensemble machine learning approach in smart prisons. PeerJ Comput Sci. 2024;10:e2051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Drago A. Genetic signatures of suicide attempt behavior: insights and applications. Expert Rev Proteomics. 2024;21(1–3):41–53. [DOI] [PubMed] [Google Scholar]
- 15.Min-Wei H, Bo-Lin J, Kai-Sen F, Chia-Yi W, Ming-Been L, Chia-Ta C, Chun-Ying C. Application of machine learning analysis for prediction of repeated suicide attempts among the attempters: a nationwide population study in Taiwan. J Suicidol. 2023;18(1):487–92. [Google Scholar]
- 16.Loh WY. Classification and regression trees. Wires Data Min Knowl. 2011;1(1):14–23. [Google Scholar]
- 17.Old O, Friedrichson B, Zacharowski K, Kloka JA. Entering the new digital era of intensive care medicine: an overview of interdisciplinary approaches to use artificial intelligence for patients’ benefit. Eur J Anaesthesiol Intensive Care. 2023;2(1):e0014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Peng H, Long F, Ding C. Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell. 2005;27(8):1226–38. [DOI] [PubMed] [Google Scholar]
- 19.Kishore K, Jaswal V. Statistics corner: chi-squared test. J Postgraduate Med Educ Res. 2023;57(1):40–4. [Google Scholar]
- 20.Aslan N, Ozmen Koca G, Kobat MA, Dogan S. Multi-classification deep CNN model for diagnosing COVID-19 using iterative neighborhood component analysis and iterative ReliefF feature selection techniques with X-ray images. Chemometr Intell Lab Syst. 2022;224:104539. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Nasiri H, Alavi SA. A novel framework based on deep learning and ANOVA feature selection method for diagnosis of COVID-19 cases from chest x-ray images. Comput Intell Neurosci. 2022;2022:4694567. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Mondal H, Mondal S, Majumder R, De R. Conduct common statistical tests online. Indian Dermatol Online J. 2022;13(4):539–42. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Latham AE, Prigerson HG. Suicidality and bereavement: complicated grief as psychiatric disorder presenting greatest risk for suicidality. Suicide Life Threat Behav. 2004;34(4):350–62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Abou Chahla MN, Khalil MI, Comai S, Brundin L, Erhardt S, Guillemin GJ. Biological factors underpinning suicidal behaviour: an update. Brain Sci. 2023;13(3):505. [DOI] [PMC free article] [PubMed]
- 25.Flood J, Butler A. 27 An evaluation of suicidality of those over 65 years referred to liaison psychiatry in the acute hospital setting. Age Ageing. 2023;52(Supplement_3).
- 26.Raschke N, Mohsenpour A, Aschentrup L, Fischer F, Wrona KJ. Socioeconomic factors associated with suicidal behaviors in South Korea: systematic review on the current state of evidence. BMC Public Health. 2022;22(1):129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Demesmaeker A, Amad A, Chazard E, Demarty AL, Schlienger H, Lehmann E, Debien C, Jardon V, Bounebache K, Rey G et al. Suicide and all-cause mortality within 1 year after a suicide attempt in the vigilans cohort. J Clin Psychiat. 2023;84(6):22m14520. [DOI] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets analyzed during the current study are available from the corresponding author upon reasonable request, subject to approval from the Taiwan Suicide Prevention Center and in compliance with relevant data protection regulations.