

Abstract
Background
Enhancing the safety of robot-assisted minimally invasive surgery (RAMIS) is critically dependent on improving the robot’s spatial understanding of the surgical scene. However, the quality of laparoscopic images is often negatively affected by factors such as uneven lighting, blurred textures, and occlusions, all of which can interfere with the accurate acquisition of depth information.
Methods
To address these challenges, we develop a depth estimation and pose tracking method that incorporates a dual-stream Transformer stereo matching network and a vision-based tracking technique.
Results
Experimental results indicate that the proposed method can effectively maintain the boundary information of anatomical structures and demonstrate better performance in the robustness of laparoscope pose tracking.
Conclusions
This paper presents a robotic-assisted minimally invasive surgery navigation framework that achieves accurate scene depth estimation and pose tracking, thereby enhancing the robot’s spatial understanding of the surgical environment.
Keywords: Minimally invasive surgery, Depth estimation, Laparoscope tracking, Tissue reconstruction
Background
Currently, Robot-Assisted Minimally Invasive Surgery (RAMIS) significantly enhances the flexibility and accuracy of surgical procedures, reduces the rate of bleeding, and shortens the postoperative recovery time, gradually showing greater advantages over traditional open surgery [1]. However, the narrow observation field and lack of depth information of the robot limit refined surgical operations and tend to increase surgical risks. To enhance the robot’s spatial understanding of the surgical scene, researchers propose the integration of navigation systems into RAMIS [2], with acquiring depth information for the surgical scene and tracking the laparoscope pose as its fundamental modules [3]. By estimating depth information through stereo matching techniques and subsequently reconstructing the 3D surgical scene, there is potential to address the issue of depth perception.
Stereo matching techniques can be divided into traditional computer vision and deep learning methods. Traditional computer vision methods, including algorithms based on regions and feature points such as block matching and window matching [4–6], are proven to possess good depth perception capabilities for high-quality outdoor images. However, traditional computer vision methods heavily rely on feature extraction and matching strategies, which makes the depth estimation susceptible to uneven lighting, image noise, and specular highlights. Moreover, these methods generally involve significant computational costs, failing to meet the precision and real-time requirements of the surgical scene [7, 8]. Recently, deep learning has been successfully applied to many tasks related to medical imaging, demonstrating state-of-the-art performance. However, in RAMIS, obtaining ground-truth datasets for stereo matching tasks is extremely challenging. Current deep learning methods generally use cross-domain datasets, such as traffic scenes, which are still not robust enough for the complex surgery scene. Therefore, how to integrate the advantages of traditional computer vision and deep learning technologies to improve the accuracy of stereo matching in laparoscopic images has become an urgent problem to be solved.
Further, the depth information obtained by inference and the external tracking device enable localization and navigation of the RAMIS [9]. Traditional methods using external trackers such as optical tracking system [10] and electromagnetic tracking system [11] may increase the system complexity when tracking the position and orientation of the laparoscope. Vision-based eliminate the need for external devices. Among these, certain visual methods such as marker-based tracking may require inserting invasive markers into organs during surgery [12]. Additionally, when organs are obscured by surgical instruments, tracking performance significantly worsens, which is not suitable for RAMIS. Therefore, accurately tracking the laparoscope pose using only the 2D images and inferred depth information, without external devices and invasive markers, is essential for successful RAMIS navigation.
To address the mentioned issues, an edge-preserving, learning-based method for depth estimation and localization in laparoscopic images is proposed. The method comprises two pipelines: a dual-stream Transformer [13] stereo matching network and laparoscope pose tracking. In the stereo matching network, considering the characteristics of uneven lighting and image noise in laparoscopic images, a dual-stream Transformer feature encoding module (TSTE) that extracts information from both the original and Contrast Limited Adaptive Histogram Equalization (CLAHE) processed images is introduced, thereby enhancing the contour features of key anatomical structures. To reduce the high computational cost of the Transformer and improve the network’s information extraction capability, a pyramid pooling module (PPM) is introduced into the multi-head self-attention (MHSA) mechanism, thereby constructing a pyramid pooling attention (PPA) mechanism. Furthermore, the possibility of multi-stage disparity feature extraction is explored, inspired by the ConvNeXt [14] network. A disparity ConvNeXt module (DConvNeXt) is constructed to encode the disparity features output by TSTE. In the aspect of laparoscope pose tracking, disparity optimization on the inferred disparity maps occurs by introducing a total variation L1 (TV-L1) optimization technique [15], enhancing the precision of the disparity maps. Subsequently, 3D reconstruction of the intraoperative scene is conducted based on the optimized disparity maps. Finally, the tracking challenge is framed within the context of an RGBD SLAM problem, thereby enabling robust laparoscope pose tracking by using depth information and an enhanced version of the ORB-SLAM3 [16] algorithm
Our main contributions are as follows:
Dual-stream feature extraction encoder is designed, which achieves a more thorough extraction of information from key anatomical structures.
A multi-stage feature extraction scheme for the dense prediction task of depth estimation is designed. The depth features output by TSTE are subjected to more refined feature extraction. Post-optimization processing of the depth map is performed based on the TV-L1 norm to reduce depth estimation errors caused by illumination differences between stereo images.
The pose tracking problem is transformed into an RGBD SLAM problem by leveraging inferred depth information, thereby achieving pose tracking without the external tracking devices and invasive markers.
In terms of depth estimation, edge preservation, and pose tracking, the proposed method demonstrate significant superiority on the benchmark endoscopic stereo dataset, in-vitro phantom dataset, and in-vivo dataset.
The remainder of this paper is organized as follows. Related work section reviews the related work on depth estimation, and the technical details of the proposed method is presented in Methods section. Experimental results are discussed in Results section. Finally, Discussion section provides discussion and conclusion.
Related work
Depth map estimation based on traditional computer vision
In the traditional computer vision field, in-depth research has been conducted on stereo matching methods based on both local and global approaches, focusing primarily on techniques such as graph cuts, bayesian methods, and variational methods. Yoon et al. [17] introduce a matching retrieval method utilizing an adaptive weight strategy, capable of effectively handling stereo matching tasks in texture-less and weakly textured regions. However, local stereo matching methods still face issues with matching errors and discontinuities, particularly in regions with weak or repetitive textures, which are prone to matching inaccuracies. To overcome the technical challenges associated with local stereo matching, Hernandez-Juarez et al. [18] employ a semi-global approach for efficient dense stereo matching, capable of dealing with large-scale scenes and moving objects. Hirschmuller et al. [19] combine semi-global matching with mutual information to address regions in images with rich textures. Cevahir et al. [20] introduce an edge-preserving mechanism based on semi-global matching, effectively retaining the edge information of images. Bleyer et al. [21] adopted the concept of oblique support windows to solve matching issues in regions lacking texture and those with significant disparities. However, both semi-global and global methods have high demands on image quality and are significantly affected by occlusions, highlights, and weak textures [22]. Moreover, the depth maps generated often exhibit stripe-like artifacts, necessitating post-processing for optimization.
Depth map estimation based on deep learning
Learning-based methods are end-to-end techniques that generally do not require post-processing steps, as described in the literature [23]. DPNet [24] proposes a deep pruning network for stereo matching that can effectively reduce the model’s parameters and computational cost. PatchMatchNet [25] introduces multi-scale feature fusion and global consistency constraints in its network design, enabling more accurate matching results in texture-less and occluded regions. EdgeStereo [26] improves matching accuracy in edge regions by incorporating edge information for context awareness. Pseudo-LiDAR++ [27] achieves depth estimation for autonomous driving scenes by combining stereo matching with object detection. HSMNet [28] and PSMNet [29] enhance the accuracy and robustness of stereo matching through multi-level pyramid structures and context-aware mechanisms. Unimatch [30] introduces the Transformer for global feature enhancement of images, thus improving matching accuracy. CFNet [31], CREStereo [32], and LEAStereo [33] are based on cascaded and fusion network design ideas, capable of improving stereo matching accuracy in complex scenes such as occlusions, texture-less surfaces, and lighting changes. For depth estimation of laparoscopic images, Stoyanov et al. [34] use salient points based on Lucas-Kanade to establish sparse feature matching. Zhou et al. [11] present post-processing refinement steps, to address low texture problems. Huang et al. [35] propose a self-supervised adversarial depth estimation method for laparoscopic binocular images. However, even the most advanced stereo matching networks still have significant limitations. For instance, these models are highly sensitive to complex lighting conditions and surface reflections. More importantly, existing stereo matching networks are mostly trained on large outdoor scene image datasets to improve the accuracy of disparity estimation. However, in practice, there is no sufficiently large and high-quality dataset available for training stereo matching tasks aimed at laparoscopic images.
Depth map estimation based on supervised and unsupervised deep learning methods
Recent advancements in unsupervised and self-supervised learning methods for stereo depth estimation have shown significant promise, leveraging geometric and photometric consistency constraints between images to alleviate the need for dense ground truth annotations typically required in supervised learning. Notably, the Monodepth series, particularly Monodepth2, enhances performance by introducing custom photometric and depth losses and enforcing multi-view consistency to improve depth estimation accuracy [36]. Furthermore, several approaches, including those by Chen et al. [37], Liu et al. [38], and Guizilini et al. [39], have integrated various techniques such as spatial context information, optical flow estimation, and dual-network frameworks to enhance depth estimation performance. For example, Zhou et al. [40] proposed a self-supervised model utilizing monocular video streams, while Khamis et al. [41] focused on contextual information to improve depth accuracy. These advancements collectively underscore the potential of unsupervised and self-supervised learning in stereo depth estimation, particularly in challenging environments with limited labeled data, demonstrating robust and adaptable performance.
Minimally invasive surgical robots
Recent advancements in robot-assisted surgery have significantly improved procedural accuracy and training efficiency. Tan et al. [42] developed a robot-assisted training system leveraging deep reinforcement learning, allowing surgeons to refine their skills through immediate feedback in simulated environments. Additionally, they introduced a robust path planning method using Markov decision processes for flexible needle insertion [43], as well as a framework for this procedure utilizing universal distributional deep reinforcement learning to enhance precision in needle-tissue interactions [44]. Further advancements include the work by Yang et al. [45], who proposed a learning framework for robot-assisted surgery incorporating deep learning for real-time 3D reconstruction and path optimization. Similarly, Chen et al. [46] developed a real-time robotic surgical navigation system that integrates augmented reality (AR) to improve the visualization of anatomical structures during procedures. Moreover, Wang et al. [47] introduced an intelligent robotic system that employs machine learning for adaptive motion planning in minimally invasive surgeries, enhancing operational safety and efficacy.
Methods
Overview of framework
Figure 1 illustrates the framework for depth estimation and laparoscope pose tracking proposed in this study. The architecture of the stereo matching network is shown in Fig. 1a, where the rectified left and right RGB images are denoted as L and R, respectively. The network comprises three modules: the dual-stream Transformer encoding (TSTE) module, the pyramid pooling attention (PPA) module, and the disparity ConvNeXt (DConvNeXt) module. Initially, the CLAHE image enhancement technique is employed to augment the boundary information of critical anatomical structures in the images without unduly increasing the contrast of noise. Following this, the network receives both the original RGB images and those processed through CLAHE as its dual-stream inputs. In regions where the contour features are not distinct, the TSTE module use the Transformer backbone to efficiently extract valuable anatomical structure features and establish global relation modeling. The PPA module is designed to reduce the high computational cost of the TSTE module. By incorporating pyramid pooling into the multi-head self-attention (MHSA) mechanism within the visual Transformer, this module reduces the length of the image token sequences while enhancing semantic feature extraction. The DConvNeXt module explores the capabilities of ConvNeXt in dense prediction tasks, such as decoding 3D cost volumes, as depicted in Fig. 1b. Subsequently, with the inferred depth information, surface reconstruction from point clouds is performed, transforming the challenge of laparoscope pose tracking into an RGBD SLAM problem. Utilizing the acquired depth map, the reconstructed dense point cloud, and an enhanced ORB-SLAM3, robust tracking of the laparoscope pose is achieved, as shown in Fig. 1c. To clarify the operations shown in Fig. 1, the fusion between dual streams at each stage is performed via channel-wise concatenation using torch.cat along the channel dimension, rather than element-wise summation. This concatenation occurs after multi-scale feature extraction and channel adjustment, where the concatenated features serve as input to the cost-volume construction and subsequent 3D aggregation in the DConvNeXt module. Here,  denotes the feature map of one stream in the dual-stream feature extraction network at the corresponding network stage, and
denotes the feature map of one stream in the dual-stream feature extraction network at the corresponding network stage, and  represents the disparity feature map extracted by the DConvNeXt module after the fusion of the dual-stream feature maps.
represents the disparity feature map extracted by the DConvNeXt module after the fusion of the dual-stream feature maps.
Fig. 1.

The proposed framework for depth estimation and laparoscope pose tracking. (a) Two-stream transformer encoder; (b) Feature volume decoder; (c) Reconstruction and laparoscopic localization
The overall network architecture processes stereo laparoscopic images through the following sequential pipeline: Initially, both original RGB images and CLAHE-enhanced images are fed into the TSTE module (Dual-stream transformer encoder module section) for dual-stream feature extraction at multiple scales, aimed at capturing comprehensive spatial features. The extracted multi-scale features then pass through the PPA module (Pyramid pooling attention module section), which reduces computational overhead while preserving rich contextual information essential for depth estimation. Subsequently, the DConvNeXt module (Disparity ConvNeXt module section) constructs multi-scale 3D cost volumes and performs disparity feature extraction; this ultimately produces the final disparity map through soft-argmax regression. The network is optimized using the hybrid loss function (Loss function section), ensuring accurate gradient flow during training, and the inferred disparity maps undergo TV-L1 refinement (Refined TV-L1 disparity optimization section) before being utilized for surface reconstruction and laparoscope pose tracking (Surface reconstruction and laparoscope tracking section).
Dual-stream transformer encoder module
As shown in the first row of Fig. 2, laparoscopic images commonly exhibit issues such as blurred boundaries, weak textures, and specular reflections. To alleviate these issues, CLAHE is employed to enhance the laparoscopic images, with the enhanced images being displayed in the second row of Fig. 2. Subsequently, both the original and the processed images are used as the dual-stream input for the stereo matching network, enabling the network to better capture the anatomical structure features of the intraoperative scene from both the original and boundary-enhanced domains. The third row of Fig. 2 presents the ground truth depth maps.
Fig. 2.

Examples of image enhancement in the depth estimation dataset. (a) Original laparoscopic images; (b) Images after CLAHE processing; (c) Ground truth depth maps
As illustrated in Fig. 3, four dual-stream encoding models are designed, where feature maps extracted by the visual Transformer at various stages of the network are processed in parallel for disparity feature extraction in the DConvNeXt module. Specifically, pre- and post-CLAHE images are processed through dual-stream pathways, concatenating features along the batch dimension for efficient parallel processing. The primary distinction between these models lies in the selected processing stage: the TSTE-II model concatenates features from the second stage for parallel convolution before separation for stereo matching, while the TSTE-III model performs batch-wise processing at the third stage. In contrast, the TSTE-IV model keeps the feature maps from the two input streams completely independent throughout the pipeline. The effectiveness of the dual-stream encoding scheme is demonstrated in Results section through ablation experiments that compare original images with CLAHE-processed inputs on TSTE-I.
Fig. 3.

Classification of dual-stream encoding models
The architectural philosophy of the TSTE framework is built on a hierarchical multi-stream processing paradigm that balances feature distinctiveness with computational efficiency. A coarse-to-fine disparity estimation strategy is employed, enabling the processing of varying disparity ranges and spatial resolutions. Strategic dual-stream integration points (Stage 2 in TSTE-II, Stage 3 in TSTE-III) are utilized to optimize early feature sharing and modality-specific processing, ensuring low-level geometric features benefit from CLAHE-enhanced edge information while high-level semantic features maintain their discriminative power. This design follows a progressive refinement flow: raw stereo inputs are encoded into multi-scale feature representations, spatial relationships are captured through correlation-based cost volumes, and disparity regression is refined via multi-scale 3D processing. The resulting three-stage pipeline effectively addresses challenging visual conditions in laparoscopic surgery—such as specular reflections and texture-less regions—while ensuring the required real-time processing.
The integration of CLAHE for boundary enhancement within the dual-stream framework significantly improves the perception of key anatomical features during laparoscopic procedures. Blurred boundaries and weak textures can hinder effective depth estimation, and by incorporating enhanced images, a more robust feature extraction process is facilitated. This methodology prioritizes edge preservation, not only enhancing the accuracy of disparity estimation but also improving the model’s resilience to challenging visual conditions encountered in surgical environments. Consequently, the focus on edge information ensures successful delineation of critical structures, contributing to safer and more effective surgical interventions.
Pyramid pooling attention module
Visual Transformers are constrained by the quadratic computational complexity of self-attention mechanisms with respect to image token sequences, which becomes particularly problematic for high-resolution surgical images. To address this computational bottleneck while preserving rich spatial information essential for accurate stereo matching, the pyramid pooling module (PPM) is incorporated into the multi-head self-attention (MHSA) mechanism within the visual Transformer. This design philosophy aims to reduce computational costs while simultaneously extracting richer spatial hierarchical information across multiple scales.
Given the input feature map 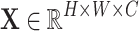 , it is first reshaped into a flattened representation
, it is first reshaped into a flattened representation 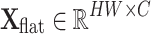 . To capture contextual information at different granularities, multiple average pooling layers with different pooling ratios are applied to the original feature map to generate feature pyramid maps:
. To capture contextual information at different granularities, multiple average pooling layers with different pooling ratios are applied to the original feature map to generate feature pyramid maps:
 |
1 |
where 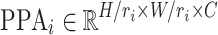 represents the i-th generated feature pyramid map with pooling ratio
represents the i-th generated feature pyramid map with pooling ratio 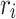 , and n denotes the number of pooling operations. The pooling ratios are empirically set as
, and n denotes the number of pooling operations. The pooling ratios are empirically set as 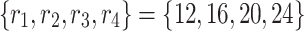 for the initial stage and are progressively halved for subsequent stages to maintain computational efficiency while preserving hierarchical feature representation.
for the initial stage and are progressively halved for subsequent stages to maintain computational efficiency while preserving hierarchical feature representation.
To maintain spatial coherence within the downsampled features—a critical requirement for stereo matching—relative position encoding is applied to each pyramid feature map through depthwise convolution:
 |
2 |
where  denotes a depthwise convolution with
denotes a depthwise convolution with  kernel size, and the residual connection preserves original feature information. This position encoding strategy is applied individually to each pyramid level, enabling the model to maintain spatial awareness across different scales without significantly increasing computational overhead.
kernel size, and the residual connection preserves original feature information. This position encoding strategy is applied individually to each pyramid level, enabling the model to maintain spatial awareness across different scales without significantly increasing computational overhead.
The encoded pyramid features are individually flattened and concatenated to form the unified token sequence:
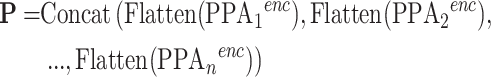 |
3 |
where  and the reduced sequence length is calculated as:
and the reduced sequence length is calculated as:
 |
4 |
The sequence length L is significantly smaller than the original length HW, achieving computational efficiency while retaining multi-scale contextual information.
In the modified MHSA computation, an asymmetric design is adopted where queries are generated from the original flattened input features while keys and values are derived from the pyramid-pooled features:
 |
5 |
where  ,
, 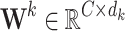 , and
, and 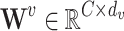 are learnable linear transformation matrices for query, key, and value projections, respectively. This results in
are learnable linear transformation matrices for query, key, and value projections, respectively. This results in  ,
, 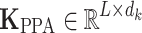 , and
, and  .
.
The attention computation is then performed as:
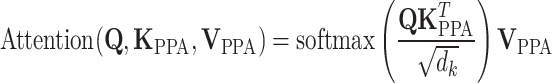 |
6 |
where the attention matrix has dimensions 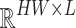 , significantly reducing the computational complexity from
, significantly reducing the computational complexity from  to
to 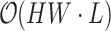 with
with 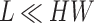 .
.
The asymmetric approach is employed to ensure that fine-grained spatial details are preserved in the query representation while leveraging multi-scale contextual information from the pyramid-pooled keys and values. The resulting attention mechanism is enhanced to model global contextual dependencies across different spatial scales, facilitating a better understanding of complex anatomical structures within surgical scenes. Accurate stereo correspondence establishment in challenging laparoscopic environments, characterized by specular reflections and texture-less regions, is thus achieved.
The efficiency of the PPA module lies in its ability to significantly reduce computational complexity from 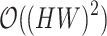 to
to 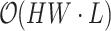 . This reduction allows for real-time processing of high-resolution images while preserving essential spatial and contextual information. As a result, the practical application of visual transformers in real-time surgical settings is enabled, enhancing both speed and accuracy in depth estimation and analysis.analysis.
. This reduction allows for real-time processing of high-resolution images while preserving essential spatial and contextual information. As a result, the practical application of visual transformers in real-time surgical settings is enabled, enhancing both speed and accuracy in depth estimation and analysis.analysis.
Disparity ConvNeXt module
As depicted in Fig. 4, the last layer output feature  from the TSTE module undergoes dimensional reshaping from its original form (C, D, H, W) to
from the TSTE module undergoes dimensional reshaping from its original form (C, D, H, W) to 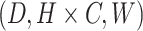 , yielding
, yielding  which serves as input to the feature volume decoder. The feature maps output at each stage of the ConvNeXt blocks are sequentially fused with the multi-scale feature maps from the TSTE module, progressing from the highest to the lowest resolution scale. Subsequently, a 3D convolutional network with pyramid pooling (Feature Volume Block) is constructed to further extract features from these fused multi-scale representations, thereby acquiring comprehensive contextual information across different disparity and spatial scales.
which serves as input to the feature volume decoder. The feature maps output at each stage of the ConvNeXt blocks are sequentially fused with the multi-scale feature maps from the TSTE module, progressing from the highest to the lowest resolution scale. Subsequently, a 3D convolutional network with pyramid pooling (Feature Volume Block) is constructed to further extract features from these fused multi-scale representations, thereby acquiring comprehensive contextual information across different disparity and spatial scales.
Fig. 4.

Disparity feature extraction module (DConvNext)
Specifically, the multi-scale 3D cost volume construction begins with computing correspondence costs along epipolar lines at different resolution scales. For each scale s, the cost volume 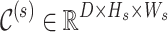 is constructed by evaluating feature similarities between left and right feature maps:
is constructed by evaluating feature similarities between left and right feature maps:
 |
7 |
where 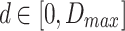 represents the disparity range, and
represents the disparity range, and  are the left and right feature maps at scale s.
are the left and right feature maps at scale s.
The DConvNeXt blocks process these cost volumes hierarchically through four stages ( to
to  ), where each stage corresponds to progressively refined disparity estimation:
), where each stage corresponds to progressively refined disparity estimation:
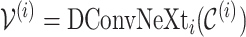 |
8 |
The feature fusion mechanism systematically combines multi-scale information from TSTE module outputs with the cost volume features:
 |
9 |
where  denotes concatenation operation, and
denotes concatenation operation, and  represents the feature maps from different stages of TSTE module.
represents the feature maps from different stages of TSTE module.
Following the disparity regression approach, the final disparity map is computed using a soft-argmax operation:
 |
10 |
where  is the final cost volume after multi-scale processing. The softmax operation is applied along the disparity dimension:
is the final cost volume after multi-scale processing. The softmax operation is applied along the disparity dimension:
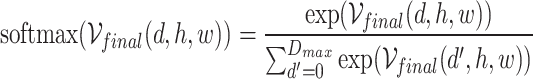 |
11 |
Soft-argmax regression is utilized to enable sub-pixel accuracy in disparity estimation while maintaining differentiability throughout the network. The disparity values are subsequently scaled by the divisor factor to recover the original disparity range:
 |
12 |
Through this network design, multi-scale disparity features of the abdominal cavity scene are effectively extracted, facilitating accurate inference of the scene’s depth information and precise localization of anatomical boundaries.
Loss function
Considering the scarcity of datasets with depth annotations in the abdominal cavity scene, and the fact that Transformer models require large-scale datasets to achieve optimal performance, the widely adopted KITTI [48] autonomous driving dataset is used for pre-train our model, which is commonly used in stereo matching tasks. This pre-training process yields the pre-trained model  . Furthermore, to mitigate the domain gap between the KITTI dataset and the abdominal cavity scene,
. Furthermore, to mitigate the domain gap between the KITTI dataset and the abdominal cavity scene, 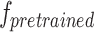 is fine-tuned using a small amount of data from the SCARED [49] dataset and the in-vitro phantom dataset. Subsequently, a refined binocular stereo matching network model
is fine-tuned using a small amount of data from the SCARED [49] dataset and the in-vitro phantom dataset. Subsequently, a refined binocular stereo matching network model 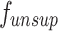 is built using unsupervised methods. For unsupervised training, the optimization process can be formulated as minimizing the following surgical scene perception loss function:
is built using unsupervised methods. For unsupervised training, the optimization process can be formulated as minimizing the following surgical scene perception loss function:
 |
13 |
where 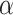 and
and 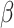 are weight parameters that will be specified in the experimental section.
are weight parameters that will be specified in the experimental section.
The unsupervised loss consists of the following three main components:
- Term 1:
 represents the structural dissimilarity loss between the left image (L) and the synthesized right image obtained by warping the right image (R) based on the predicted disparity map.
represents the structural dissimilarity loss between the left image (L) and the synthesized right image obtained by warping the right image (R) based on the predicted disparity map.
where N represents the total number of pixels in the image, the subscripts i and j respectively denote the values of the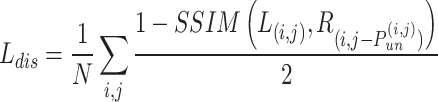
14  row and
row and 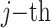 column in the image and disparity map.
column in the image and disparity map. 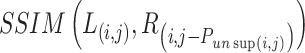 indicates the structural similarity between the warped right image
indicates the structural similarity between the warped right image  and the left image
and the left image  , quantifying their structural resemblance.
, quantifying their structural resemblance. - Term 2:
 is the photometric loss of the disparity map, which is used to make the disparity map predicted by
is the photometric loss of the disparity map, which is used to make the disparity map predicted by 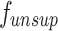 approach the prediction result of the supervised model
approach the prediction result of the supervised model 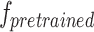 . This term is derived as:
. This term is derived as:
where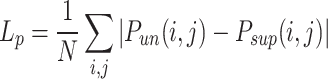
15  is the disparity map estimated by the unsupervised model
is the disparity map estimated by the unsupervised model 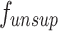 , and
, and  is the disparity map estimated by the supervised model
is the disparity map estimated by the supervised model 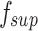 .
. - Term 3:
 is the edge-aware smoothness loss, which is used to regularize the smoothness of the disparity map and enhance the proposed network’s ability to perceive edges, represented as:
is the edge-aware smoothness loss, which is used to regularize the smoothness of the disparity map and enhance the proposed network’s ability to perceive edges, represented as:
where
16 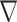 represents the gradient of the disparity.
represents the gradient of the disparity.
Refined TV-L1 disparity optimization
To enhance the stability of disparity estimation, the TV-L1 optimization model is introduced [50]. This model is capable of effectively handling non-Gaussian noise in images while preserving edge contours. The specific implementation method is outlined as follows:
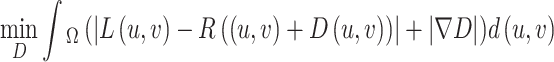 |
17 |
where 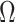 represents the image domain,
represents the image domain, 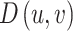 denotes the initial disparity map,
denotes the initial disparity map, 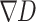 corresponds to the gradient of D, and
corresponds to the gradient of D, and 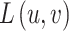 and represent the normalized intensities of the stereo images at position u, v.
and represent the normalized intensities of the stereo images at position u, v.
Since Eq. 17 is nonlinear and non-convex, a linear approximation of 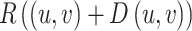 is necessary, which requires a well-initialized disparity. A refined disparity optimization method is proposed by feeding both the initial disparity map, obtained from the proposed stereo matching network, and the left image enhanced by CLAHE into the TV-L1 optimization process:
is necessary, which requires a well-initialized disparity. A refined disparity optimization method is proposed by feeding both the initial disparity map, obtained from the proposed stereo matching network, and the left image enhanced by CLAHE into the TV-L1 optimization process:
 |
18 |
where  is the left image enhanced by CLAHE. The optimization includes data matching and regularization terms, and ultimately minimizes the energy function iteratively, which has the potential to improve the accuracy and robustness of depth estimation.
is the left image enhanced by CLAHE. The optimization includes data matching and regularization terms, and ultimately minimizes the energy function iteratively, which has the potential to improve the accuracy and robustness of depth estimation.
The integration of the TV-L1 optimization method not only effectively mitigates noise but also plays a critical role in preserving edge features within images. This boundary enhancement is primarily facilitated by total variation regularization, which enables the safeguarding of essential structural information throughout the optimization process. Consequently, this approach significantly reduces distortion in depth estimation. In particular, when addressing complex scenes, TV-L1 optimization ensures that edge details in the depth map remain sharp and accurate, thereby enhancing the overall quality of the depth estimation. Remarkably, even in the presence of sparse or noisy input data, this method consistently delivers reliable depth estimations. This effectively reinforces its capability for edge preservation, establishing a robust foundation for accurate depth inference.
Surface reconstruction and laparoscope tracking
After optimizing the disparity map and incorporating the intrinsic parameters of the laparoscope, the depth map of the surgical scene can be obtained. Subsequently, a dense reconstruction of the scene’s point cloud can be achieved based on the depth map of the left image L. To improve the accuracy of the scene reconstruction and preserve the contour information of the tissues, it is necessary to smooth the point cloud containing surface features. The moving least squares (MLS) algorithm is employed for point cloud reconstruction. First, the point set  generated by ORB-SLAM3 is acquired. Further, a local reference plane
generated by ORB-SLAM3 is acquired. Further, a local reference plane  is established such that the weighted sum of the distances from
is established such that the weighted sum of the distances from  to the plane is minimized. Assuming
to the plane is minimized. Assuming  is the projection of the local center point of the point cloud onto plane H, the plane H can be obtained through local minimization:
is the projection of the local center point of the point cloud onto plane H, the plane H can be obtained through local minimization:
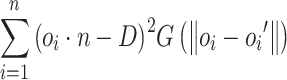 |
19 |
where the function 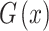 serves as the kernel of the MLS algorithm and is typically a Gaussian distribution.
serves as the kernel of the MLS algorithm and is typically a Gaussian distribution.
Furthermore, the parameters of ORB-SLAM3 are fine-tuned by increasing the number of features extracted from each image to four times the default value. This enhancement aims to improve the recognition and tracking capabilities for complex textures and dynamic changes in the surgical scene. Concurrently, in the triangulation process, the maximum allowable threshold between keypoints and reprojected map points is reduced by a factor of five. This adjustment constrains the range of points to be selected and the number of detectable map points. Finally, the depth information of the scene, the left image from the laparoscope, the reconstructed global scene, and the fine-tuned ORB-SLAM3 are integrated to develop an RGBD SLAM approach tailored for laparoscopic images. This integration enables robust tracking of the laparoscope pose.
Results
Implementation
In unsupervised fine-tuning, the SCARED dataset was organized into 20924, 4721 and 1186 frames for training, validation and test sets according to the original data organization. The in-vivo dataset was organized into 32000, 4000 and 4000 frames for training, validation and test sets. The Adam optimizer was employed, with 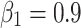 and
and 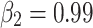 , and a batch size of 16. Hyperparameters
, and a batch size of 16. Hyperparameters  and
and 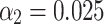 were selected for training, and the original images were randomly cropped to
were selected for training, and the original images were randomly cropped to  as the network input.
as the network input.
The training of the proposed method was conducted on a desktop equipped with an NVIDIA GeForce RTX 3090 GPU (24 GB), an Intel Xeon Gold 6254 CPU running at 3.10 GHz, and 128 GB of RAM. The system was configured with 954 GB of SSD NVMe storage and an additional 7.28 TB HDD for efficient data handling. Unsupervised fine-tuning was performed using the SCARED dataset, which was organized into 20,924 frames for training, 4,721 frames for validation, and 1,186 frames for testing. The in-vivo dataset was similarly organized into 32,000 frames for training, with 4,000 frames each allocated for validation and testing. The Adam optimizer was utilized, with hyperparameters set to  and
and  , and a batch size of 16. Additional hyperparameters
, and a batch size of 16. Additional hyperparameters 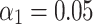 and
and 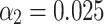 were employed during training. The original images were randomly cropped to a resolution of
were employed during training. The original images were randomly cropped to a resolution of  pixels for network input. The entire training process lasted approximately one week, with training sessions occurring daily throughout the day, allowing for extensive model refinement and performance optimization.
pixels for network input. The entire training process lasted approximately one week, with training sessions occurring daily throughout the day, allowing for extensive model refinement and performance optimization.
To evaluate the proposed method, a comparison was made with state-of-the-art stereo matching methods, including deep learning-based stereo matching approaches: HSMNET [28], PSMNet [29], Unimatch [30], CFNet [31], CREStereo [32], and LEAStereo [33], as well as non-learning methods: SGBM [19], SGBM_WLS [20], and PMS [21]. For the comparative methods, the deep learning models were fine-tuned for 100 epochs using the SCARED dataset in a supervised manner. This dataset is the same one that was employed for supervised training of the proposed network. Noticeable performance improvements were observed after fine-tuning these models compared to their original implementations.
Performance metrics
To ensure clarity, it should be specified that the evaluation metrics are based on benchmark stereo datasets—specifically, the Middlebury-v3 and KITTI-15 datasets. The Middlebury-v3 dataset is primarily used for indoor stereo vision problems, featuring a variety of scenes with known depth information, which facilitates the evaluation of stereo matching algorithms under controlled lighting conditions. In contrast, the KITTI-15 dataset is designed for outdoor stereo vision applications, comprising images captured in real driving scenarios that present more challenging conditions, including varying illumination and complex textures.
Considering the actual spatial dimensions of the abdominal cavity, metrics have been developed to cater to the depth perception needs of laparoscopic scenes. These metrics are divided into three groups:
The first group includes average error (avg error) and root mean square error (rmse), both measured in pixels. These metrics provide an overall measure of estimation accuracy: avg error calculates the mean absolute difference between estimated and true depth, while rmse focuses more on larger errors by taking the square root of the average squared differences.
The second group consists of bad-5, bad-10, and bad-15, representing the percentages of "bad" pixels with errors greater than 5, 10, and 15 pixels (or corresponding percentages of the true depth). These metrics allow for minor deviations while identifying significantly misestimated pixels, providing insight into the robustness of the depth estimation.
The third group includes A99, A95, and A90, which represent the 99th, 95th, and 90th percentiles of error pixels, respectively. These percentile-based metrics measure accuracy while ignoring larger deviations, which is particularly useful for understanding the distribution of errors and assessing the method’s performance on the majority of the depth map.
Performance of depth estimation for laparoscopic image
Datasets
Three datasets were utilized: a small portion of the SCARED dataset [49] and an in-vitro phantom dataset for supervised fine-tuning, and the larger portions of the SCARED dataset along with an in-vivo dataset for unsupervised training. In unsupervised fine-tuning, the SCARED dataset was organized into 20,924 frames for training, 4,721 frames for validation, and 1,186 frames for testing, while the in-vivo dataset consisted of 32,000 frames for training, and both the validation and test sets contained 4,000 frames each.
The SCARED dataset was organized using a stratified sampling method to ensure that no similar samples overlapped between the training and testing sets, thus preventing data leakage. In the in-vitro phantom dataset, depth information was captured using a depth camera alongside the laparoscopic images to create data labels. This dataset provides a clear ground truth for supervised fine-tuning. The performance of the proposed method was validated using the test sets of the SCARED dataset and the SERV-CT dataset [51], as shown in Fig. 5. This careful organization of the datasets allows for a more reliable evaluation of our model’s accuracy, minimizing issues related to data contamination.
Fig. 5.

Examples of the SCARED dataset, the SERV-CT dataset, in-vitro phantom dataset, and in-vivo dataset
Subjective assessment
Subjective evaluation is based on visual observation by the surgeon, comparing the performance in depth estimation among different methods within the same image frame. Three representative surgical scenes (rich anatomical information, specular highlights, and weak textures, instrument occlusion) were selected from the SCARED dataset to evaluate the work. These scenes are available from the MICCAI EndoVis challenge and the Hamlyn Laparoscopic Dataset [52].
Figure 6 displays the depth maps estimated by ten stereo matching methods applied to the same raw image, along with the corresponding ground truth depths. While Fig. 6a illustrates that the proposed depth perception method provides overall smoothness and edge delineation, some limitations are also highlighted. Specifically, incorrect depth predictions are observed in regions with specular highlights, indicating a potential area for improvement. Challenges during tool-tissue contact are evidenced in Fig. 6c, where boundary delineation is not as effective as anticipated.
Fig. 6.

A subjective evaluation of the depth estimation performance in various classic surgical scenes by HSMNet [28], PSMNet [29], Unimatch [30], CFNet [31], CREStereo [32], LEAStereo [33], SGBM [19], SGBM_WLS [20], PMS [21], and the proposed method, also displaying the raw image and the ground truth depths. a Depth estimation in scenarios with abundant anatomical information on SCARED dataset. b Depth estimation in scenarios with strong specular highlights and weak textures on SCARED dataset. c Depth estimation in scenarios involving movement and occlusion of surgical instruments on SCARED dataset. d Depth estimation in scenarios involving organ occlusion on SERV-CT dataset
Moreover, inconsistency in the color mapping across the subfigures in Fig. 6 is acknowledged. To ensure accurate interpretation, standardization of the color mapping for all subfigures in the revised manuscript will be performed. This will clarify depth representations, allowing for a more direct comparison across methods. Overall, despite the identified limitations, robust performance is demonstrated by the proposed method in most scenarios, including occluded areas in abdominal scenes (Fig. 6d), where good depth estimation is achieved even in complex situations. However, it should be noted that there remain areas for improvement, particularly in maintaining depth estimation at the boundaries, which still exhibits a degree of enhancement.
Objective assessment
The performance of the depth estimation method was evaluated using disparity maps. Based on the metrics designed in the previous section, the performance of the proposed method was compared with nine other depth estimation methods, as shown in Table 1. Among all evaluation metrics, the best performance was achieved by the proposed method, which attained the lowest average error (avg error) of 18.203 pixels and a root mean square error (rmse) of 7.518 pixels. Furthermore, lower values of bad-15, bad-10, and bad-5 indicate that depth predictions of the scene can be made more robustly and accurately by the proposed depth estimation method. Simultaneously, lower values of a99, a95, and a90 suggest that superior performance in estimating depths at closer ranges is exhibited by the proposed method, thereby clearly capturing depth differences during the interaction between surgical instruments and soft tissues.
Table 1.
Performance comparison of the proposed stereo matching method with nine other methods on SCARED and SERV-CT datasets
| Methods | avg error (pixels) | rmse (pixels) | bad-15 (%) | bad-10 (%) | bad-5 (%) | a99 (pixels) | a95 (pixels) | a90 (pixels) |
|---|---|---|---|---|---|---|---|---|
| Ours | 18.203 | 7.518 | 7.65 | 8.72 | 20.56 | 24.631 | 23.894 | 23.541 |
| HSMNet [28] | 22.149 | 10.037 | 13.76 | 16.31 | 29.18 | 41.443 | 41.013 | 39.183 |
| PSMNet [29] | 22.149 | 10.037 | 13.76 | 16.31 | 29.18 | 41.443 | 41.013 | 39.183 |
| Unimatch [30] | 22.489 | 9.650 | 11.65 | 13.83 | 33.84 | 38.619 | 36.665 | 34.054 |
| CFNet [31] | 23.170 | 8.675 | 9.96 | 22.55 | 56.53 | 29.073 | 28.442 | 28.092 |
| CREStereo [32] | 21.141 | 9.843 | 14.02 | 24.86 | 37.38 | 37.785 | 34.107 | 33.099 |
| LEAStereo [33] | 23.481 | 9.860 | 10.91 | 11.98 | 39.25 | 35.653 | 34.221 | 33.323 |
| SGBM [19] | 21.280 | 10.393 | 19.87 | 21.18 | 21.71 | 37.512 | 36.418 | 34.035 |
| SGBM_WLS [20] | 41.046 | 9.939 | 80.06 | 85.46 | 93.26 | 47.185 | 46.677 | 46.514 |
| PMS [21] | 22.228 | 10.405 | 32.65 | 26.43 | 21.25 | 36.067 | 35.322 | 35.311 |
Ablation studies
In this section, ablation experiments were conducted to analyze the role of each module in the proposed stereo matching method. TSTE-I with raw image was used as the baseline for evaluating our network. Firstly, the TSTE module was evaluated, using a single-stream input of the raw image as the baseline, as shown in Table 2. The results indicate that fusing the original image with the image processed by CLAHE at the feature mapping level can effectively integrate the semantic information of the two domains. Image-level fusion performed poorly, falling below the baseline. Furthermore, the introduction of the PPA module has brought multi-scale and global information to the feature maps extracted by the Transformer block, resulting in significant improvements in rmse and avg error, as shown in Table 3.
Table 2.
Ablation study on dual-stream transformer multimodal fusion strategy (TSTE) on SCARED dataset
| Module | Input | avg error(pixels) | rmse(pixels) |
|---|---|---|---|
| Baseline | Raw Image | 23.467 | 10.214 |
| TSTE-I | Image with CLAHE | 24.233 | 11.211 |
| TSTE-I | Two-Stream | 23.679 | 10.998 |
| TSTE-II | Two-Stream | 19.458 | 8.589 |
| TSTE-III | Two-Stream | 18.838 | 8.846 |
| TSTE-IV | Two-Stream | 18.651 | 7.887 |
Table 3.
Ablation study on pyramid pooling attention module (PPA) on SCARED dataset
| Module | PPA | avg error(pixels) | rmse(pixels) |
|---|---|---|---|
| TSTE-IV | - | 19.432 | 8.501 |
| TSTE-IV | ✓ | 18.651 | 7.887 |
It should be noted that even in the absence of the DConvNeXt module, disparity features can still be effectively extracted through the existing stereo matching framework within the proposed architecture. Specifically, the computation of disparity relies on the left and right feature maps generated by the TSTE module. By constructing a multi-scale cost volume based on the feature similarities between these maps, disparity can be computed using traditional methods such as Block Matching or Sum of Absolute Differences. This approach facilitates robust disparity estimation despite the lack of specialized refinement provided by the DConvNeXt module. The final disparity map is derived utilizing soft regression techniques, which ensure high accuracy and maintain consistency across various model variants, thereby effectively capturing depth information from complex surgical scenes.
Furthermore, the impact of the disparity extraction module on model performance was compared, as shown in Table 4. The introduction of the DConvNeXt module was found to effectively enhance the network’s capability to extract and understand disparity features. Specifically, the average error metric was improved by 1.381 pixels, and the rmse error metric was improved by 1.498 pixels. This enhancement underscores the importance of the DConvNeXt module in capturing more accurate depth information from the input images.
Table 4.
Ablation study on disparity convnext module (DConvNeXt) on SCARED dataset
| Module | DConvNeXt | avg error(pixels) | rmse(pixels) |
|---|---|---|---|
| TSTE-IV | - | 20.032 | 9.385 |
| TSTE-IV | ✓ | 18.651 | 7.887 |
Subsequently, the impact of different loss functions on model performance was analyzed, as presented in Table 5. The results indicate that a hybrid training mode—which combines both supervised and unsupervised learning strategies—was employed, significantly enhancing model performance across all evaluated metrics. This approach allows the model to benefit from the strengths of labeled data while also leveraging the additional information provided by unlabelled data.
Table 5.
Ablation study highlighting the contribution of the proposed loss strategy
| Loss | avg error(pixels) | rmse(pixels) | bad-5(%) | a90(pixels) |
|---|---|---|---|---|
| Supervised | 19.721 | 9.217 | 22.43 | 24.249 |
| Unsupervised | 20.448 | 10.238 | 23.63 | 26.429 |
| Hybrid | 18.651 | 7.887 | 21.98 | 25.022 |
Overall, the integration of both the DConvNeXt module and the hybrid loss function has shown a clear progression in the model’s ability to achieve more accurate depth estimations, highlighting the effectiveness of the proposed strategies in improving depth perception.
Finally, after demonstrating the effectiveness of the designed modules, the performance after module integration was further compared. A single-stream input of raw images without adding any of the modules designed in this paper was used as the baseline. As shown in Table 6, the TSTE and PPA modules can effectively improve avg error and rmse. Compared to Model 3, the DConvNeXt module can further enhance various performance evaluation metrics. When our proposed method is introduced to the baseline, avg error, rmse, bad-5, and a99 reached 18.651 pixels, 7.887 pixels, 21.36%, and 25.022 pixels, respectively.
Table 6.
Ablation study on the integration of proposed modules on SCARED dataset
| Number | Modules | avg error (pixels) | rmse (pixels) | bad-5 (%) | a99 (pixels) | |||
|---|---|---|---|---|---|---|---|---|
| TSTE | PPA | DConvNeXt | Hybrid Loss | |||||
| 1 | - | - | - | - | 26.528 | 13.534 | 28.39 | 32.738 |
| 2 | ✓ | - | - | - | 23.527 | 11.730 | 25.73 | 29.745 |
| 3 | ✓ | ✓ | - | - | 22.264 | 10.839 | 24.85 | 28.749 |
| 4 | ✓ | ✓ | ✓ | - | 20.947 | 9.586 | 21.98 | 25.269 |
| 5 | ✓ | ✓ | ✓ | ✓ | 18.651 | 7.887 | 21.36 | 25.022 |
Generalization performance experiments
The evaluation of the proposed method on additional datasets, specifically Middlebury-v3 [53], KITTI-15 [54], and the NYU Depth Dataset V2 [55], is detailed in Table 7. On the Middlebury-v3 dataset, which comprises high-quality stereo images, the model achieved an impressive average error of 12.345 pixels and an rmse error of 5.678 pixels. This performance underscores the effectiveness of the model in scenarios where high-resolution images are available, further validating its applicability to fine-depth estimation tasks. In testing the proposed method on the KITTI-15 dataset, which features challenging real-world driving scenarios, the average error was measured at 16.789 pixels and an rmse error of 7.234 pixels. This indicates that, despite the complexities of real-world scenes, the model maintained competitive performance, showcasing its adaptability across various contexts. The NYU Depth Dataset V2 presents a different challenge with indoor scenes illuminated by varied Lighting conditions. The model reported an average error of 19.980 pixels, along with an rmse error of 8.456 pixels. While these results indicate slightly higher error rates, they still reflect the robustness of the proposed method when applied to complex indoor environments. Overall, these results highlight the model’s robust generalization capability across diverse datasets, affirming its potential utility in practical depth estimation applications in both indoor and outdoor settings.
Table 7.
Generalization performance of the proposed method on additional datasets
Performance of laparoscope localization for navigation
3D dense reconstruction
Based on the depth estimation for each frame, a three-dimensional dense reconstruction of the entire surgical scene was able to be performed. In this study, we conducted a qualitative analysis of the performance of our proposed reconstruction method on the SCARED test set and compared it with the open-source SLAM method, ORBSLAM3 (see Fig. 7). The results show that, despite the fast movement of the laparoscope, the complexity of the surgical scene, and the presence of slight deformations, our reconstruction method was still able to accurately estimate the underlying 3D point cloud and preserve reasonable anatomical structural boundary contours.
Fig. 7.

Surgical scene dense reconstruction: a Input binocular laparoscopic images, b Dense surgical scene reconstructed from different viewpoints, c Sparse surgical scene reconstructed based on SLAM
Tracking accuracy evaluation
The performance of the laparoscope pose tracking module was subsequently verified. Four types of motion—Zoom-in, Zoom-out, Follow, and Random—were defined for the evaluation of the proposed method. These motion types were not inherent to the SCARED dataset but were derived from a combination of visual analysis and manual annotation based on the characteristics observed during the tracking evaluation.
The motion accuracy was evaluated on the SCARED dataset, which inherently contains pose information for each keyframe captured During the depth collection process. Motions were performed at speeds ranging from 1 cm/s to 3 cm/s and at depths from 2 cm to 15 cm. The Zoom-in motion involved moving inward along the body surface, while the Zoom-out motion described the opposite action. Additionally, a Follow motion mode was defined, where the laparoscope tracks a specific target or point of interest, maintaining a consistent distance as the target moves. This mode simulates the behavior of a surgeon or assistant following anatomical structures within the surgical field, ensuring that the laparoscope remains centered on the area of interest without significant deviation. In contrast, Random motion involved unpredictable and erratic movements, simulating scenarios in which the laparoscope may operate without a fixed reference or target. This mode evaluates the robustness of the tracking algorithm against non-linear and non-sequential movements, which could occur in dynamic surgical environments.
As shown in Fig. 8, the proposed reconstruction method was demonstrated to robustly track the motion state of the laparoscope without significant random fluctuations. This stability in tracking ensures consistent performance during surgical procedures, where precision is critical. A quantitative analysis of tracking accuracy was further conducted, with the translation and rotation errors related to pose estimation presented in Table 8. Notably, it was found that the average errors for translation and rotation were only 2.315 mm and 2.386 degrees, respectively. These low error values indicate a high level of precision in tracking the laparoscope’s position and orientation, which is essential for effective surgical navigation. Furthermore, the results suggest that the tracking method not only adheres to the specified accuracy requirements for laparoscope tracking in real surgical scenes but also demonstrates robustness against variations in motion dynamics. This capability is particularly beneficial for complex surgical environments, where maintaining accurate position tracking is crucial for patient safety and surgical efficacy.
Fig. 8.

Schematic of laparoscope pose tracking. (a) Zoom-in motion; (b) Zoom-out motion; (c) Follow motion; (d) Random motion
Table 8.
Performance evaluation of the laparoscope pose tracking module
| Motion | ORB_SLAM3 [16] (avg error) | LSD_SLAM [56] (avg error) | RTAB_Map [57] (avg error) | Ours (avg error) |
|---|---|---|---|---|
| Zoom-in | 16.712mm, 28.365° | 15.234mm, 27.456° | 14.785mm, 26.345° | 2.456mm, 2.709° |
| Zoom-out | 15.594mm, 26.434° | 14.153mm, 25.987° | 13.998mm, 25.678° | 2.377mm, 2.376° |
| Follow | 12.543mm, 19.233° | 12.876mm, 18.789° | 12.543mm, 18.456° | 2.435mm, 2.325° |
| Random | 18.379mm, 29.235° | 17.789mm, 28.123° | 17.345mm, 27.987° | 1.993mm, 2.132° |
| Average | 15.807mm, 28.365° | 15.013mm, 25.589° | 14.670mm, 25.117° | 2.315mm, 2.386° |
Runtime
After completing the performance verification of each module, the real-time performance of the proposed surgical robot navigation system was evaluated. Figure 9 shows the experimental platform that was assembled, which consists of a Jaka robot, Olympus laparoscope system, main operator, and an abdominal phantom. The combination of these high-performance processors and the advanced graphics card ensures that the runtime performance metrics listed in our study are achieved under these specifications. Additionally, the workstation’s high-performance hardware and optimized software configurations support the computational demands of our method. The workstation configuration during the inference phase is the same as that during the network training phase to ensure consistent efficiency and stability in real-time performance.
Fig. 9.

Laparoscope pose tracking performance verification platform
To achieve precise control in minimally invasive surgery, adherence to the principles of the Remote Center of Motion (RCM) is essential. The RCM strategy allows the surgical tool to rotate around a fixed point, significantly improving stability and minimizing trauma to surrounding tissues.
In this configuration, let the current operation position be denoted as 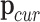 , the target position as
, the target position as 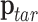 , and the RCM point as
, and the RCM point as  . The corresponding velocities can be defined as follows:
. The corresponding velocities can be defined as follows:
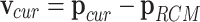 |
20 |
where  represents the velocity vector at the current position, indicating how the current position deviates from the RCM point.
represents the velocity vector at the current position, indicating how the current position deviates from the RCM point.
To govern the motion effectively, the angular displacement about the RCM point can be calculated as:
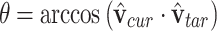 |
21 |
where  is the angle between the current and target direction vectors.
is the angle between the current and target direction vectors.
The overall transformation encompassing both current and target positions can thus be described as:
 |
22 |
where 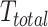 represents the net transformation from the current to the target position.
represents the net transformation from the current to the target position.
To find the required joint angles  that achieve
that achieve 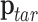 , the inverse kinematics solution
, the inverse kinematics solution  must be computed. The Jacobian matrix
must be computed. The Jacobian matrix  relates the joint velocities to end-effector velocities and is expressed as:
relates the joint velocities to end-effector velocities and is expressed as:
 |
23 |
where 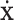 denotes the end-effector velocity vector.
denotes the end-effector velocity vector.
To ensure that the robotic arm adheres to these velocities while transitioning smoothly between the current and target positions, a control law is proposed:
 |
24 |
where 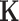 is a gain matrix that scales the difference between the desired joint angles
is a gain matrix that scales the difference between the desired joint angles 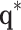 and the current joint angles
and the current joint angles 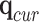 .
.
Through the integration of these kinematic equations and control principles, the robotic arm can effectively perform the necessary maneuvers while maintaining safety and precision during minimally invasive surgical procedures.
As shown in Table 9, the average running times of the reconstruction and localization modules were tested by conducting 10 sets of experiments and capturing 5000 frames of images with a resolution of 1920  1080. The average latency for processing each frame image During depth estimation was 35.42ms. Subsequently, the average running time for reconstruction and localization across all 10 sets of data was calculated, resulting in 45.69ms. The data presented above indicate that the proposed method has the potential for application in real-time scenes.
1080. The average latency for processing each frame image During depth estimation was 35.42ms. Subsequently, the average running time for reconstruction and localization across all 10 sets of data was calculated, resulting in 45.69ms. The data presented above indicate that the proposed method has the potential for application in real-time scenes.
Table 9.
Average runtime of the proposed method
| Pipeline | Task | Time (ms) |
|---|---|---|
| Depth Estimation | Stereo Matching | 20.25 |
| Disparity Optimization | 15.17 | |
| Average | 35.42 | |
| Tracking | Dense Scene Reconstruction | 40.34 |
| Laparoscope localization | 5.35 | |
| Average | 45.69 |
Discussion
In laparoscopic images, abrupt changes in depth often occur at anatomical structure boundaries, leading to operational errors if the depth estimation is inaccurate at these positions. The proposed depth estimation network addresses this issue by focusing on depth estimation problems at boundaries. Additionally, the introduction of the TV-L1 norm effectively mitigates errors caused by specular highlights and occlusions during depth estimation.
Laparoscopic surgical robots are designed with a wire-driven mechanism to meet the requirements for a remote center of motion constraint and a lightweight design. However, due to the hysteresis effect of wires, the accuracy of the laparoscope pose obtained directly from robotic arm kinematics is relatively low. The tracking method proposed in this paper aims to achieve precise and robust tracking of the laparoscope pose based solely on image information captured by the laparoscope, without increasing the master-slave communication delay of the surgical robot.
In practical clinical applications, the proposed depth estimation method employs a hybrid training approach that combines supervised and unsupervised learning, significantly enhancing the system’s generalization capabilities. This hybrid approach leverages the accuracy of labeled data while exploiting the latent information in a large amount of unlabeled data, improving the model’s adaptability to various surgical scenarios. Furthermore, the TV-L1 norm in the post-processing scheme shows potential for further improving depth estimation accuracy. By balancing gradient preservation and denoising effects, the TV-L1 norm better handles the complex lighting and reflections common in surgical environments, providing more reliable depth information. These improvements collectively ensure the practical feasibility and high performance of the depth estimation method in diverse clinical settings.
In this study, errors are reported in pixels instead of real-world units like millimeters. This choice is made due to the image-based nature of tasks such as depth estimation and tracking. Using pixels is standard in computer vision, facilitating easier comparison of results across different studies. Converting to millimeters would require additional camera and scene information, potentially introducing more uncertainty. Pixel-based errors directly demonstrate algorithmic performance on images. While pixel errors are reported, real-world distances can be estimated if needed, using additional calibration data.
The designed depth perception module effectively captures the depth information of laparoscopic images while maintaining clear anatomical structure edges and smooth soft tissue surfaces. Experimental results show that the proposed method is more robust than state-of-the-art methods in scenes with severe lighting differences, weak textures, highlights, and occlusions. Additionally, a visual tracking module integrates the reconstructed stereo anatomical structure to achieve robust laparoscope tracking without external devices. The framework is evaluated qualitatively and quantitatively on three datasets, demonstrating its accuracy and efficiency. In future work, we aim to further improve the speed and accuracy of the proposed method, as well as explore solutions to enhance depth estimation accuracy in the edge regions of images.
Conclusion
In this paper, a learning-driven RAMIS navigation framework with boundary preservation capabilities is proposed. This framework can achieve 3D dense reconstruction and laparoscope pose tracking of the surgical scene solely using laparoscopic images, thereby enhancing the robot’s spatial understanding of the surgical scene and improving the safety of the surgery.
Acknowledgements
The authors acknowledge the financial support from the National Natural Science Foundation of China (Grant No. 52525504) and the Tianjin Excellent Young Scientists Fund Program (Grant No. 24JCJQJC00090).
Authors’ contributions
B.G., J.Z., B.Y., and J.L. conceived and designed the study. B.G. and J.Z. performed the experiments and analyzed the data. B.Y. contributed to the software development and data interpretation. J.L. supervised the project. All authors contributed to writing and revising the manuscript, and approved the final version for submission.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 52525504, by Tianjin Excellent Young Scientists Fund Program under Grant 24JCJQJC00090.
Data availability
The source code and datasets supporting the conclusions of this article are publicly available in GitHub repositories: laparoscopic pose tracking materials at https://github.com/guanbo-tju/Laparoscopic-pose-tracking-and-AR and endoscopic depth estimation materials at https://github.com/guanbo-tju/Endoscopic-Depth-Estimation.
Declarations
Ethics approval and consent to participate
Not applicable. This study does not involve human participants.
Consent for publication
Not applicable. This study does not involve human participants.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Chen K, M Beeraka N, Zhang J, Reshetov IV, Nikolenko VN, Sinelnikov MY, et al. Efficacy of da Vinci robot-assisted lymph node surgery than conventional axillary lymph node dissection in breast cancer–A comparative study. Int J Med Robot Comput Assist Surg. 2021;17(6):e2307. [DOI] [PubMed] [Google Scholar]
- 2.Wang Z, Lu B, Long Y, Zhong F, Cheung TH, Dou Q, et al. Autolaparo: A new dataset of integrated multi-tasks for image-guided surgical automation in laparoscopic hysterectomy. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer; 2022. pp. 486–96.
- 3.Luo H, Yin D, Zhang S, Xiao D, He B, Meng F, et al. Augmented reality navigation for liver resection with a stereoscopic laparoscope. Comput Methods Programs Biomed. 2020;187:105099. [DOI] [PubMed] [Google Scholar]
- 4.Hamid MS, Abd Manap N, Hamzah RA, Kadmin AF. Stereo matching algorithm based on deep learning: a survey. J King Saud Univ. 2022;34(5):1663–73. [Google Scholar]
- 5.Jiang X, Ma J, Xiao G, Shao Z, Guo X. A review of multimodal image matching: methods and applications. Inf Fusion. 2021;73:22–71. [Google Scholar]
- 6.Xu C, Lu S, Liu W, Bai Y, Han C. Improved fast stereo matching algorithm based on convolutional neural networks. In: 2019 IEEE International Conferences on Ubiquitous Computing & Communications (IUCC) and Data Science and Computational Intelligence (DSCI) and Smart Computing, Networking and Services (SmartCNS). Piscataway: IEEE; 2019. pp. 768–73.
- 7.Huang B, Nguyen A, Wang S, Wang Z, Mayer E, Tuch D, et al. Simultaneous depth estimation and surgical tool segmentation in laparoscopic images. IEEE Trans Med Robot Bionics. 2022;4(2):335–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Huang B, Zheng JQ, Nguyen A, Xu C, Gkouzionis I, Vyas K, et al. Self-supervised depth estimation in laparoscopic image using 3D geometric consistency. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer; 2022. pp. 13–22.
- 9.Doughty M, Ghugre NR, Wright GA. Augmenting performance: a systematic review of optical see-through head-mounted displays in surgery. J Imaging. 2022;8(7):203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Wang J, Suenaga H, Hoshi K, Yang L, Kobayashi E, Sakuma I, et al. Augmented reality navigation with automatic marker-free image registration using 3-D image overlay for dental surgery. IEEE Trans Biomed Eng. 2014;61(4):1295–304. [DOI] [PubMed] [Google Scholar]
- 11.Zhou H, Jagadeesan J. Real-time dense reconstruction of tissue surface from stereo optical video. IEEE Trans Med Imaging. 2019;39(2):400–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Prendergast JM, Formosa GA, Heckman CR, Rentschler ME. Autonomous localization, navigation and haustral fold detection for robotic endoscopy. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE; 2018. pp. 783–90.
- 13.Chitty-Venkata KT, Mittal S, Emani M, Vishwanath V, Somani AK. A survey of techniques for optimizing transformer inference. J Syst Archit. 2023;144:102990. 10.1016/j.sysarc.2023.102990. [Google Scholar]
- 14.Woo S, Debnath S, Hu R, Chen X, Liu Z, Kweon IS, et al. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE; 2023. pp. 16133–42.
- 15.Liu Y, Li Y, Yi X, Hu Z, Zhang H, Liu Y. Micro-expression recognition model based on TV-L1 optical flow method and improved ShuffleNet. Sci Rep. 2022;12(1):17522. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Campos C, Elvira R, Rodríguez JJG, Montiel JM, Tardós JD. Orb-SLAM3: an accurate open-source library for visual, visual-inertial, and multimap slam. IEEE Trans Robot. 2021;37(6):1874–90. [Google Scholar]
- 17.Yoon KJ, Kweon IS. Adaptive support-weight approach for correspondence search. IEEE Trans Pattern Anal Mach Intell. 2006;28(4):650–6. [DOI] [PubMed] [Google Scholar]
- 18.Hernandez-Juarez D, Chacón A, Espinosa A, Vázquez D, Moure JC, López AM. Embedded real-time stereo estimation via semi-global matching on the GPU. Procedia Comput Sci. 2016;80:143–53. [Google Scholar]
- 19.Hirschmuller H. Stereo processing by semiglobal matching and mutual information. IEEE Trans Pattern Anal Mach Intell. 2007;30(2):328–41. [DOI] [PubMed] [Google Scholar]
- 20.Çiğla C, Alatan AA. Efficient edge-preserving stereo matching. In: 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops). Piscataway: IEEE; 2011. pp. 696–9.
- 21.Bleyer M, Rhemann C, Rother C. Patchmatch stereo-stereo matching with slanted support windows. In: Bmvc. vol. 11. Durham: BMVA Press; 2011. pp. 1–11.
- 22.Lu Z, Wang J, Li Z, Chen S, Wu F. A resource-efficient pipelined architecture for real-time semi-global stereo matching. IEEE Trans Circuits Syst Video Technol. 2021;32(2):660–73. [Google Scholar]
- 23.Du S, Liu Y, Zhao M, Shi Z, You Z, Li J. A comprehensive survey: Image deraining and stereo-matching task-driven performance analysis. IET Image Process. 2022;16(1):11–28. [Google Scholar]
- 24.Duggal S, Wang S, Ma WC, Hu R, Urtasun R. Deeppruner: Learning efficient stereo matching via differentiable patchmatch. In: Proceedings of the IEEE/CVF international conference on computer vision. Piscataway:IEEE; 2019. pp. 4384–93.
- 25.Li L, Zhang S, Yu X, Zhang L. PMSC: PatchMatch-based superpixel cut for accurate stereo matching. IEEE Trans Circuits Syst Video Technol. 2016;28(3):679–92. [Google Scholar]
- 26.Song X, Zhao X, Fang L, Hu H, Yu Y. Edgestereo: an effective multi-task learning network for stereo matching and edge detection. Int J Comput Vis. 2020;128(4):910–30. [Google Scholar]
- 27.Padmavathi K, Asha C, Maya VK. A novel medical image fusion by combining TV-L1 decomposed textures based on adaptive weighting scheme. Eng Sci Technol Int J. 2020;23(1):225–39. [Google Scholar]
- 28.Yang G, Manela J, Happold M, Ramanan D. Hierarchical deep stereo matching on high-resolution images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE; 2019. pp. 5515–24.
- 29.Chang JR, Chen YS. Pyramid stereo matching network. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway:IEEE; 2018. pp. 5410–8.
- 30.Xu H, Zhang J, Cai J, Rezatofighi H, Yu F, Tao D, et al. Unifying flow, stereo and depth estimation. IEEE Trans Pattern Anal Mach Intell. 2023:13941–58. 10.1109/TPAMI.2023.3298645. [DOI] [PubMed] [Google Scholar]
- 31.Shen Z, Dai Y, Rao Z. Cfnet: Cascade and fused cost volume for robust stereo matching. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE; 2021. pp. 13906–15.
- 32.Li J, Wang P, Xiong P, Cai T, Yan Z, Yang L, et al. Practical stereo matching via cascaded recurrent network with adaptive correlation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022. pp. 16263–72.
- 33.Cheng X, Zhong Y, Harandi M, Dai Y, Chang X, Li H, et al. Hierarchical neural architecture search for deep stereo matching. Adv Neural Inf Process Syst. 2020;33:22158–69. [Google Scholar]
- 34.Stoyanov D, Scarzanella MV, Pratt P, Yang GZ. Real-time stereo reconstruction in robotically assisted minimally invasive surgery. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2010: 13th International Conference, Beijing, China, September 20-24, 2010, Proceedings, Part I 13. Cham:Springer; 2010. pp. 275–82. [DOI] [PubMed]
- 35.Huang B, Zheng JQ, Nguyen A, Tuch D, Vyas K, Giannarou S, et al. Self-supervised generative adversarial network for depth estimation in laparoscopic images. In: Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part IV 24. Cham: Springer; 2021. pp. 227–37.
- 36.Godard C, Mac Aodha O, Brostow GJ. A Survey on Deep Learning for Stereo Vision. In: CVPR. Piscataway: IEEE; 2019. pp. 3828–38.
- 37.Chen Z, Ye X, Yang W, Xu Z, Tan X, Zou Z, et al. Revealing the Reciprocal Relations Between Self-Supervised Stereo and Monocular Depth Estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE; 2021. https://dl.acm.org/doi/10.1145/3502827.3502828
- 38.Liu C, Liu M, Wang Z. DeepPruner: A Feature Discrimination Approach for Stereo Matching. In: ICCV. Piscataway:IEEE; 2021. pp.4384–93.
- 39.Guizilini V, Lee KH, Ambrus R, Gaidon A. Learning optical flow, depth, and scene flow without real-world labels. IEEE Robot Autom Lett. 2022;7(1):1232–40. [Google Scholar]
- 40.Zhou T, Brown M, Snavely N, Lowe DG. Unsupervised Learning of Depth and Ego-Motion from Video. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE; 2017. pp. 1851–58.
- 41.Khamis S, Al-Baali M, Liang D. Self-Supervised Monocular Depth Estimation with Contextual Information. In: CVPR. Piscataway:IEEE; 2020. pp.668–78.
- 42.Tan X, Chng CB, Su Y, Lim KB, Chui CK. Robot-assisted training in laparoscopy using deep reinforcement learning. IEEE Robot Autom Lett. 2019;4(2):485–92. [Google Scholar]
- 43.Tan X, Yu P, Lim KB, Chui CK. Robust path planning for flexible needle insertion using Markov decision processes. Int J Comput Assist Radiol Surg. Cham:Springer;2018. 10.1007/s11548-018-1783-x. [DOI] [PubMed] [Google Scholar]
- 44.Tan X, Lee Y, Chng CB, Lim KB, Chui CK. Robot-assisted flexible needle insertion using universal distributional deep reinforcement learning. Int J Comput Assist Radiol Surg. 2020;15(2):341–9. [DOI] [PubMed] [Google Scholar]
- 45.Yang X, Liu Y, Zhang J. Learning framework for robot-assisted surgery incorporating deep learning for real-time 3D reconstruction and path optimization. IEEE Trans Med Robot Bionics. 2023;5(2):123–34. [Google Scholar]
- 46.Chen H, Zhao L, Wang T. Real-time robotic surgical navigation system with augmented reality integration. Surg Endosc. 2022;36(7):1234–45.33660123 [Google Scholar]
- 47.Wang X, Tan Y, Li J. An intelligent robotic system for adaptive motion planning in minimally invasive surgeries. J Robot Surg. 2023;17(6):789–800. [Google Scholar]
- 48.Menze M, Geiger A. Object scene flow for autonomous vehicles. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway:IEEE; 2015. pp. 3061–70.
- 49.Shao S, Pei Z, Chen W, Zhu W, Wu X, Sun D, et al. Self-supervised monocular depth and ego-motion estimation in endoscopy: Appearance flow to the rescue. Med Image Anal. 2022;77:102338. [DOI] [PubMed] [Google Scholar]
- 50.Padmavathi K, Asha C, Maya VK. A novel medical image fusion by combining TV-L1 decomposed textures based on adaptive weighting scheme. Eng Sci Technol Int J. 2020;23(1):225–39. [Google Scholar]
- 51.Edwards PE, Psychogyios D, Speidel S, Maier-Hein L, Stoyanov D. SERV-CT: A disparity dataset from cone-beam CT for validation of endoscopic 3D reconstruction. Med Image Anal. 2022;76:102302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Ye M, Johns E, Handa A, Zhang L, Pratt P, Yang GZ. Self-supervised siamese learning on stereo image pairs for depth estimation in robotic surgery. 2017. arXiv preprint arXiv:1705.08260. https://arxiv.org/abs/1705.08260
- 53.Scharstein D, Szeliski R. A comparative evaluation of depth estimation algorithms: A case study. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piacataway:IEEE; 2009. pp. 1–8.
- 54.Geiger A, Lenz P, Urtasun R. Vision meets robotics: the kitti dataset. Int J Robotics Res. London:SAGE Publications; 2013;32:1231–7. [Google Scholar]
- 55.Silberman N, Huang TD, Farhadi A. NYU Depth V2: Improving the Accuracy of Depth Maps with a Single RGB Image. In: Int Conf Comput Vis. Piscataway:IEEE;2012. pp.3372-80.
- 56.Engel J, Schöps T, Cremers D. LSD-SLAM: Large-scale direct monocular SLAM. In: European conference on computer vision. Cham: Springer; 2014. pp. 834–49.
- 57.Labbé M, Michaud F. Rtab-map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation. J Field Robot. 2019;36(2):416–46. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The source code and datasets supporting the conclusions of this article are publicly available in GitHub repositories: laparoscopic pose tracking materials at https://github.com/guanbo-tju/Laparoscopic-pose-tracking-and-AR and endoscopic depth estimation materials at https://github.com/guanbo-tju/Endoscopic-Depth-Estimation.