

Abstract
The ability of our current psychiatric nosology to accurately delineate clinical populations and inform effective treatment plans has reached a critical point with interventions only moderately successful and relapse rates high. These challenges continue to motivate the search for approaches to better stratify clinical populations into more homogenous delineations, to better inform diagnosis, disease evaluation, and prescribe and develop more precise treatment plans. The promise of ‘brain-based’ subtyping based on neuroimaging data is that finding subgroups of individuals with a common biological signature will facilitate the development of biologically-grounded, targeted treatments. The review provides a snapshot of the current state of the field in empirical brain-based subtyping studies in psychiatric child, adolescent and adult populations published between 2019 and March 2022. We found that there is vast methodological exploration and a surprising number of new methods being created for the specific purpose of brain-based subtyping. However, this methodological exploration and advancement is not being met with rigorous validation approaches that assess both reproducibility and clinical utility of the discovered brain-based subtypes. We also found evidence for a ‘collaboration crisis’, in which methodological exploration and advancements are not clearly grounded in clinical goals. We propose several steps that we believe are crucial in addressing these shortcomings in the field. We conclude, and agree with the authors of the reviewed studies, that the discovery of biologically-grounded subtypes would be a significant advancement for treatment development in psychiatry.
Keywords: Biotypes, Neuroimaging, Biomarkers, Precision Medicine, Reproducibility, Clinical Utility
Introduction
The constraints of our current symptom-based psychiatric nosology are well-established and critical. Clinicians currently rely on symptom presentations and clinical descriptions to broadly characterize individuals into clinically overlapping yet biologically heterogeneous psychiatric disorders. An integrative, multi-domain system that can produce clinically distinct and biologically homogenous diagnoses is lacking (1). Crucially, under this current nosology, standard behavior- and pharmacotherapy-based interventions have small effect sizes (2) and are often only 50% effective (1), with little progress made in the past decades (2). Largely, these challenges in improving treatment efficacy have been attributed to a lack of consideration of: 1) dimensional models for the underlying shared biological- and phenomenology-based features that exist along a continuum and overlap among disorders, and 2) the highly evidenced ‘heterogeneity problem’ that poses that different causal mechanisms may underlie psychiatric disorders for different subsets of individuals (3–7). This warrants the better characterization and stratification of individuals within a given diagnosis to inform clinical evaluation and treatment.
Data-driven methods, such as latent class or clustering approaches, stratify individuals by capturing the variation within and across clinical populations (7). These methods have been applied to psychiatric populations to generate homogenous clinical subgroups, called subtypes. In their simplest form, these approaches stratify populations by maximizing homogeneity within a dataset, ensuring subjects within the same subtype are similar and those in different subtypes distinct. This ‘subtyping’ of psychiatric populations can help disentangle heterogeneity by identifying behaviorally and biologically homogenous groups (7). These approaches may elucidate subtype-specific biomarkers that could predict specific membership and generate data-driven nosology to improve diagnostics (8). Furthermore, once reliable subtypes are identified, one can evaluate whether treatments are more or less effective between subtypes and tailor interventions accordingly (9). Previous work by Drysdale and colleagues (10) demonstrated that biologically derived subtypes within a single diagnostic group (Major Depressive Disorder) could enhance treatment success through the identification of subtype-specific neurobiological mechanisms that can be targeted differentially. The potential utility of these biologically-derived subtypes has inspired great interest in the field (11,12).
Traditionally, subtyping research has been conducted using behavior- or symptom-based data. Although behavior- and symptom-based data are the most directly observable and quantifiable characteristic of disease (13), they do not necessarily reflect information about the underlying biological mechanisms that cause them. Thus, with the increasing availability of neuroimaging data, subtyping research in health sciences has begun to explore the utility of subtypes derived from neuroimaging measures. Subtyping using neuroimaging data, here called brain-based subtyping, creates clusters of individuals with a common biological signature rather than a common set of behavior or symptom presentations. This provides a method for the identification of distinct subtypes of psychiatric disorders based on underlying neurobiological mechanisms. This is important because, while behavior- or symptom-based subtypes may reduce phenotypic heterogeneity, they may not additionally reduce biological heterogeneity (14,15). A failure to reduce biological heterogeneity within clinical populations becomes problematic if interventions only benefit those with similar underlying neurobiological deficits, rather than similar symptom profiles. Thus, identifying neurobiologically homogenous (brain-based) subtypes, within and across psychiatric disorders, may aid in further informing nosology and developing more effective targeted treatments.
While mounting clinical evidence supports neuroimaging-based subtyping as a promising approach for precision psychiatry (16), brain-based subtyping for psychiatric disorders remains a difficult endeavor. Clustering approaches have their own limitations [for comprehensive reviews: (17–21)], and using neuroimaging data for subtyping comes with an additional set of challenges. One such challenge, the ‘curse of dimensionality’, arises from the intrinsically high dimensionality of brain data (22–24). As the number of features increases (e.g., brain voxels), the number of data points required to train an algorithm increases exponentially (22–24). Another critical challenge is nuisance variation (22–24). This refers to unwanted variables (e.g., scanner drift, head motion, periodic physiological signals [heartbeat, respiration]) that may affect the measurement of interest (22–24). These unwanted ‘nuisance’ variables obstruct the signal of interest and must be removed before further analysis. Issues surrounding nuisance variation, especially those pertaining to data quality, have substantial effects on the reliability of neuroimaging data and its results (25–29). Thus, performing the most optimal brain-based subtyping research necessitates well-designed studies with careful data acquisition protocols aimed at combatting these obstacles.
In addition to data quality optimization, the implementation of validation strategies is fundamental to subtyping research. Validation strategies evaluate the aspects of a subtyping result that are not implicit: their generalizability, replicability, and translational properties. Without properly implementing these strategies, it is unclear whether a subtyping solution is replicable or yields any clinical use (i.e., whether it can be reliably implemented in practice and contribute to the advancement of psychiatric clinical care). Thus, subtyping studies must be equipped with two types of validation strategies: cluster reproducibility, and cluster utility. Since clustering algorithms present partitions in almost any case (8,16), clusters should be confirmed and extensively reproduced if the dataset is changed in any non-essential way (e.g., adding randomness to data, using similar populations from different sites/datasets). Cluster reproducibility strategies assess the stability, quality, and overall reproducibility of a cluster solution. They can be assessed in several ways, using either internal or external validation strategies (Box 1). Conversely, cluster utility strategies assess the clinical utility of the identified subtypes – whether clinically meaningful inferences can be derived from the cluster solution and used for translational purposes (Box 2). Importantly, even if a result is reproducible, its clinical utility is not a guarantee and often not clinically meaningful (30). Thus, designing subtyping studies that assess both cluster reproducibility and utility is essential to best achieve the goals set forth by this growing body of research.
Box 1: Validation Strategies: Cluster Reproducibility.
Internal Validation
Internal validation refers to validation strategies that either assess the stability of the cluster solution by splitting a single dataset and running the clustering over the different splits (via split-half, cross-validation, and/or subsampling methods, etc.) or use information internal to the clustering process (via cluster validity indices) to evaluate the stability and quality of the clustering solution. Both strategies are done without the addition of external information/data. Additionally, internal validation can help with model order selection (i.e., estimating the optimal number of clusters in the data). The most widely used approaches for cluster validation are based on cluster validity indices (76,77). Cluster validity indices measure the compactness, how closely related the objects in a cluster are to each other, and separation, how distinct the objects in a cluster are from the other clusters (76,78,79). Cluster validity indices have been found to detect cluster structure existing in the data reliably (77,80–82). These strategies can be used to assess the stability of the algorithm of choice, as well as the stability of the resultant model. Through using multiple random initializations, one can measure the robustness of the algorithm against the inherent randomness in the algorithms. Additionally, the stability of the model can be evaluated using data perturbations or subsampling methods, to measure the robustness against small perturbations (randomness) in the underlying data.
External Validation
While internal validation strategies provide a practical means for validating models, using the same data for model development and testing can inadvertently introduce ‘optimistic biases’ to the model (e.g., overfitting, inflated model accuracy), even when cross-validation methods are used (28). Thus, the best practice for maximizing model generalizability and replicability, and reducing bias during model evaluation, is through external validation (63). External validation strategies are those that test the learned model on an independent, externally collected but related dataset. This is done to evaluate whether the learned model generalizes and is replicable to a sufficient degree (64). By assessing the model on a more heterogeneous and representative sample, external validation helps to ensure that the derived model is not overfitting: fitting the discovery dataset too closely or fitting dataset idiosyncrasies (31,83).
Cluster Reproducibility Validation Strategies:
Internal Validation: Single Iteration: Assessing the stability of the cluster solution using a single iteration of split-sample methods or a single subsample split of the discovery dataset without replacement (80,84). Here, split-sample methods are used to evaluate whether the subtypes in each half exhibit similar profiles/patterns (31,38). Cluster validity indices can also be used on each split to assess if each half has similar model order selection and cluster stability.
Internal Validation: Repeated Iterations: Cluster validity indices over repeated iterations assess cluster stability by identifying whether the clusters can be reliably detected over repeated runs, resampling (e.g., bootstrapping, cross-validation, permutation testing), or when the data is perturbed (e.g., adding random noise to data and repeating clustering over many iterations). After each repeated iteration, a cluster validity index (e.g., Adjusted Rand Index, Variation of Information, Jaccard Coefficient) is computed, identifying the optimal number of clusters in the data, and thereby evaluating the stability of the cluster solution.
External Validation: Independent Classification: ‘Independent Classification’ is when a classification model (e.g., support vector machine) is trained on the identified subtypes from the discovery dataset and applied to an independent dataset. This assesses the generalizability of the identified subtypes by determining the proportion of individuals in the independent sample with the same distinctive brain patterns identified by the subtypes in the discovery set.
External Validation: Independent Replication: ‘Independent Replication’ requires repeating the same clustering analysis on an independent but related dataset. Importantly, the measures in the independent dataset can be brain, behavior, and/or clinical but must be the same or similar measures as used for initial cluster identification. If the identified subtypes from the initial subtyping analysis do in fact exist, repeating the analysis in a representative (independent) sample, using the same or similar measures, should recover reproducible subtypes.
Predictive Validation – Subtype Prediction: Predictive validation aims to tie subtyping methods with predictive methods to emphasize the ability of the identified subtypes to improve inferences concerning clinical distinctions or biological relevance (4). To do this, secondary measures can be used to make a model aiming to predict the subtypes. Secondary measures can be brain, behavior, and/or clinical measures as long as they are not the same or similar to the measures used for initial cluster identification. This predictive model would then be applied to an independent dataset to test the generalizability of the identified subtypes and validate that they are in fact linked to distinct and useful characteristics or outcomes of interest.
Box 2: Validation Strategies: Cluster Utility.
The clinical utility of subtypes and their practical implications, whether they aid in biomarker identification, informing nosology, estimating intervention efficacy, or developing personalized medicine approaches, relies on secondary measures and outcomes external to the subtypes themselves. To assess this clinical utility, secondary measures, data not used to define the subtypes, are required, and should be defined a priori (15). The type of secondary measures (behavioral, clinical, cognitive, biological) and the timeframe at which they are collected (cross-sectionally or longitudinally), constrain our ability to make inferences regarding the clinical usefulness of the derived subtypes. If, for example, the goal of the subtyping investigation was to identify distinctive clinical profiles useful for identifying differential treatment targets and informing diagnostic delineations, using cross-sectional data would suffice. Importantly, to enable the discovery of subtype-specific, differential, treatment targets, identifying subtypes rooted in underlying mechanisms is warranted. This would require the use of secondary measures that evaluate these differential mechanisms. If subtypes can be identified that are rooted in differences in underlying mechanisms (e.g., negative affect, cognitive control, approach behavior/reward processing), they have the potential for treatment targeting and might one day allow for development of more tailored, subtype-specific, treatments. While diagnostic or clinical assessments that evaluate symptoms along a severity gradient are common and useful, the sole use of these measures for subtype characterization may not clearly provide a means for the development of new targeted treatments.
Alternatively, if the goal of the subtyping investigation was to investigate whether the distinct clinical profiles had any practical treatment implication (i.e., estimate intervention efficacy), it would be necessary to prescribe interventions, follow these subtypes over-time, and record their treatment outcomes. Additionally, characterizing the subtypes using various data types is useful as biological measures can determine whether subtypes map onto physiology, and while strictly phenotypic characterizations may reduce phenotypic heterogeneity, they may not reduce biological heterogeneity (15).
Cluster Utility Validation Strategies:
Cross-Sectional Data: Treatment Target Identification: using cross-sectional, secondary measures of various types to evaluate whether the identified subtypes have distinct profiles or characterizations that could be potentially used to identify mechanisms or targets for future, differential treatments. Specifically, we aimed to differentiate ‘severity-based’ subtypes (i.e., subtypes that are characterized by a symptom-severity gradient: mild, moderate, severe types) or subtypes characterized purely by alterations in demographics (e.g., age, gender), from subtypes rooted in differences in underlying mechanisms (e.g., subtypes high/low on cognitive control, negative affect, reward-processing).
Cross-Sectional Data: Classification Methods: use cross-sectional data to build a classification model (via 3D convolutional neural network, support vector machine, etc.) that evaluates the ability of the identified subtypes to improve classification accuracy between each subtype and/or the control group, or improve diagnostic accuracy compared to the traditional diagnostic delineations (Diagnostic Statistical Manual [DSM] or International Classification of Diseases [ICD] categories).
Longitudinal Follow-Up: Clinical/Behavioral Assessment: evaluate the subtypes using the same behavioral or clinical measures used at initial subtype characterization from subsequent time points. This assesses the stability of the identified subtypes clinical profiles.
Longitudinal Follow-Up: Any Treatments: follow the identified subtypes through any pharmacotherapy or behavior-based treatment and evaluate the treatment response and efficacy over time. This can provide valuable information on intervention efficacy by identifying whether subtypes have differential responses to treatments.
Longitudinal Follow-Up: Differential Targeted Treatments: prescribe differential pharmacotherapy or behavior-based treatments to the identified subtypes, based on their distinct clinical or biological characterizations, to evaluate treatment outcome and efficacy.
Although there is much discussion regarding the necessity of validation strategies in psychiatric research (31–35), the importance and use of these strategies in subtyping have been overlooked (8,15). While other subtyping reviews have touched upon validation (15,36–38), to our knowledge, only one has explicitly reviewed the validation strategies being used in subtyping research (8). Specifically, Agelink van Rentergem and colleagues (8) investigated validation strategies in unsupervised subtyping research in autism spectrum disorder (ASD). They identified seven validation strategies that, in an ideal situation, would be implemented to maximally identify valid and reliable subtypes. They evaluated the use of these strategies in the ASD literature and found that very few were implemented. Although most of the reviewed studies identified subtypes, the authors concluded that there was a lack of evidence to support the validity or reliability of these subtypes.
Here, we provide a snapshot of the current state of the field regarding empirical brain-based subtyping studies in psychiatric child, adolescent and adult populations published between January 2019 and March 2022. We focused on methodological variation, comparing studies across different psychiatric diagnostic groups, rather than presenting an exhaustive synthesis in a single diagnosis or age group. As this field is still in its infancy, we believe that a systematic review of the results of brain-based subtyping separated by disorder would be premature and may bias conclusions. Thus, we included a wide range of ages and diagnoses to provide clinicians and researchers an accessible overview of the methodological practices and progress across this rapidly growing field. In contrast to Agelink van Rentergem et al. (8) we focus on validation strategies, encompassing both reproducibility and clinical utility, in studies investigating unsupervised and semi-supervised brain-based subtyping methods across psychiatric disorder populations. We assess whether this emergent body of brain-based subtyping research sufficiently evaluates and identifies reproducible and clinically useful subtypes within and across different clinical populations.
Methods
We performed a systematic review following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines for studies published in the past three years (39). The literature search (conducted on MEDLINE/PubMed and Embase between February and March 28th, 2022) combined variations of keywords relating to subtypes, psychiatric and neurodevelopmental disorders, neuroimaging, machine learning, and the brain (exact search syntax in Supplementary Methods). We included all empirical studies that aimed to identify data-driven, brain-based subtypes in child, adolescent, or adult psychiatric populations, using the inclusion and exclusion criteria described in Figure S1 and Supplementary Methods. All papers were independently assessed for quality and risk-of-bias by two authors (LRB, AZ) using the Cochrane Collaboration endorsed Newcastle-Ottawa Scale for observational studies (40). The protocol was not registered. Study screening and data extraction was performed by the first author (LRB), as described in the Supplementary Methods, and reviewed by senior author (AZ).
Validation Strategies
We evaluated the application of cluster reproducibility (Box 1) and cluster utility strategies (Box 2) in the included studies. See Supplementary Methods for more details on how these validation strategies were evaluated. To further explore methodological heterogeneity, we compared validation strategies between studies using newer and those using more traditional algorithms. Results were visualized using MATLAB (2021a), RStudio, and Excel.
Results
Thirty-eight studies of data-driven, brain-based subtyping in psychiatric disorders were reviewed and evaluated. We were able to extract all data from all included studies. A summary of the study characteristics and methodologies used is provided below (see Supplementary Tables S1, S2 for full details). Similar levels of bias as in previous systematic reviews were found (41). Most of the included studies (28 studies, 74%) demonstrated intermediate risk, with two (5%) demonstrating high and eight (21%) exhibiting low risk of bias (Supplementary Tables S3, S4).
Sample and Input Data Characteristics
Of the 38 studies retained, 55% used multi-site ‘consortium’ datasets to identify their initial subtype solution. There was large variation in the demographics, clinical populations, and in sample size used across studies (Supplementary Tables S1, S2; Supplementary Figure S2). The distribution of diagnoses was also varied, with eight studies investigating ‘mixed-samples’ (i.e., clinical groups including >1 psychiatric diagnosis), and even those subtyping within one diagnostic category showing variability in inclusion criteria (Supplementary Figure S3; Supplementary Table S2). Concerning neuroimaging data modalities, 20 studies used measures derived from structural Magnetic Resonance Imaging (MRI), and 18 studies used functional MRI (fMRI; Figure 1A; Supplementary Results; Supplementary Table S2). Further, five studies combined structural or functional modalities with psychometric or clinical symptom data as input to their subtyping analysis, here referred as data-integration techniques. Regarding feature selection and dimensionality reduction techniques: 23 studies used data-driven approaches, of which 13 different techniques were employed; 10 studies used a priori – theory-based – methods; and five studies used raw features as input to their subtyping analysis (Figure 1B; Supplementary Table S2).
Figure 1. Data modalities, dimensionality reduction & feature selection techniques, and clustering algorithms used.

A. Data modalities used. Data-integration refers to the integration or fusion of either functional or structural data with psychometric or clinical data that was then used as input to the clustering algorithms. B. Dimensionality reduction and feature selection techniques used. C. Clustering algorithms used. Algorithms in dark grey are unsupervised approaches, while those in light grey are semi-supervised methods. CHIMERA, Clustering of Heterogeneous Disease Effects via Distribution Matching of Imaging Patterns; CT, Cortical Thickness; dNTiC, Dynamic-N-way tri-clustering; DTI, Diffusion Tensor Imaging; FA, Fractional Anisotropy; HYDRA, Heterogeneity through Discriminative Analysis; S-GIMME, Subgrouping – Group Iterative Multiple Model Estimation. SA, Surface Area; Vol, Volume.
Analysis Characteristics
The 38 publications used 12 different clustering algorithms to identify their brain-based subtypes, 30 using unsupervised and 8 using semi-supervised approaches (Figure 1C; Supplementary Box S1, S2). The unsupervised, centroid/partition-based method, K-Means Clustering was most used (29%). Regarding semi-supervised approaches, the most prevalent method was HYDRA (42). In total, 15 subtyping analyses were performed in a combined clinical-control group, 13 studies used a strictly clinical group, 8 indirectly used the controls by clustering on differences between them and a matched clinical group, and 2 studies used both clinical and control groups for clustering (Supplementary Table S2). All studies used secondary measures to aid in the characterization of their subtypes. Most (63%) used demographic, behavioral, cognitive, and clinical assessments to describe and compare their identified subtypes. However, 37% of studies, in addition to the above-mentioned measures, utilized different neuroimaging and biological data for subtype characterization (Supplementary Table S2).
Validation Strategies
Cluster Reproducibility
Of the reproducibility strategies evaluated, the strategy most often adopted was the internal validation method using repeated iterations (Figure 2A). Overall, 15% of the studies did not report the use of any reproducibility strategies in their studies, and no studies used their identified subtypes for predictive validation.
Figure 2. Cluster reproducibility and cluster utility strategies used across the 38 papers.

A. Cluster reproducibility strategies. B. Cluster utility strategies.
Cluster Utility
While all studies utilized secondary measures to characterize their resultant subtypes (i.e., measures external to the clustering procedure), only 47% were able to identify marked functional/mechanism-based distinctions in profiles that could potentially lead to the development of differential targeted treatments for these subtypes. The remaining 53% either did not identify stable clusters to further investigate with secondary measures (11,43), identified subtypes mainly indexing severity, IQ, or demographic differences after surviving multiple comparison correction (44–57), or did not display any phenotypic heterogeneity (58–60). In total, 21% of studies applied classification methods to investigate the ability of their identified subtypes to improve diagnostic accuracy compared to the traditional diagnostic cut-offs based on DSM or ICD criteria. Further, the approaches using longitudinal follow-up data to assess clinical utility (i.e., assessing differential clinical/behavioral trajectories, any treatment efficacy, or differential treatment responses over time) were infrequently employed, 5%, 3% and 0% respectively (Figure 2B). To assess if a gap exists between the validation strategies used, we explored the relationship between a studies use of the more technical (“cluster reproducibility”) and more clinical (“cluster utility”) aspects of validation (Figure 3). Interestingly, an inverse relationship was found. Studies using a more stringent reproducibility strategy tended to use a less stringent clinical utility strategy, and vice-versa.
Figure 3. Relationship between a studies most stringent validation strategies used to assess cluster reproducibility and cluster utility (jittered).

Several studies used more than one validation strategy for both reproducibility and utility. Here, we performed a spearman rank-order correlation on the most stringent reproducibility versus most stringent clinical utility strategy used within each study. An inverse relationship (ρ = −0.10) was identified. Val, Validation.
Comparison of Validation Strategies by Traditional or New Algorithm Used
For studies using either traditional (Supplementary Box S1) or newly developed clustering approaches (Supplementary Box S2), reproducibility was assessed at around the same degree, 84% and 85% respectively (Figure 4A). However, the studies using newer algorithms less frequently employed external validation strategies (the more methodologically stringent approach) compared to the studies using the more traditional methods. Moreover, only 38% of studies that implemented newly developed algorithms assessed cluster utility (Figure 4B), in stark contrast to the 80% within studies that used more traditional methods (Figure 4B).
Figure 4. A comparison of the most stringent validation strategies implemented between the studies using traditional and newly developed algorithms.
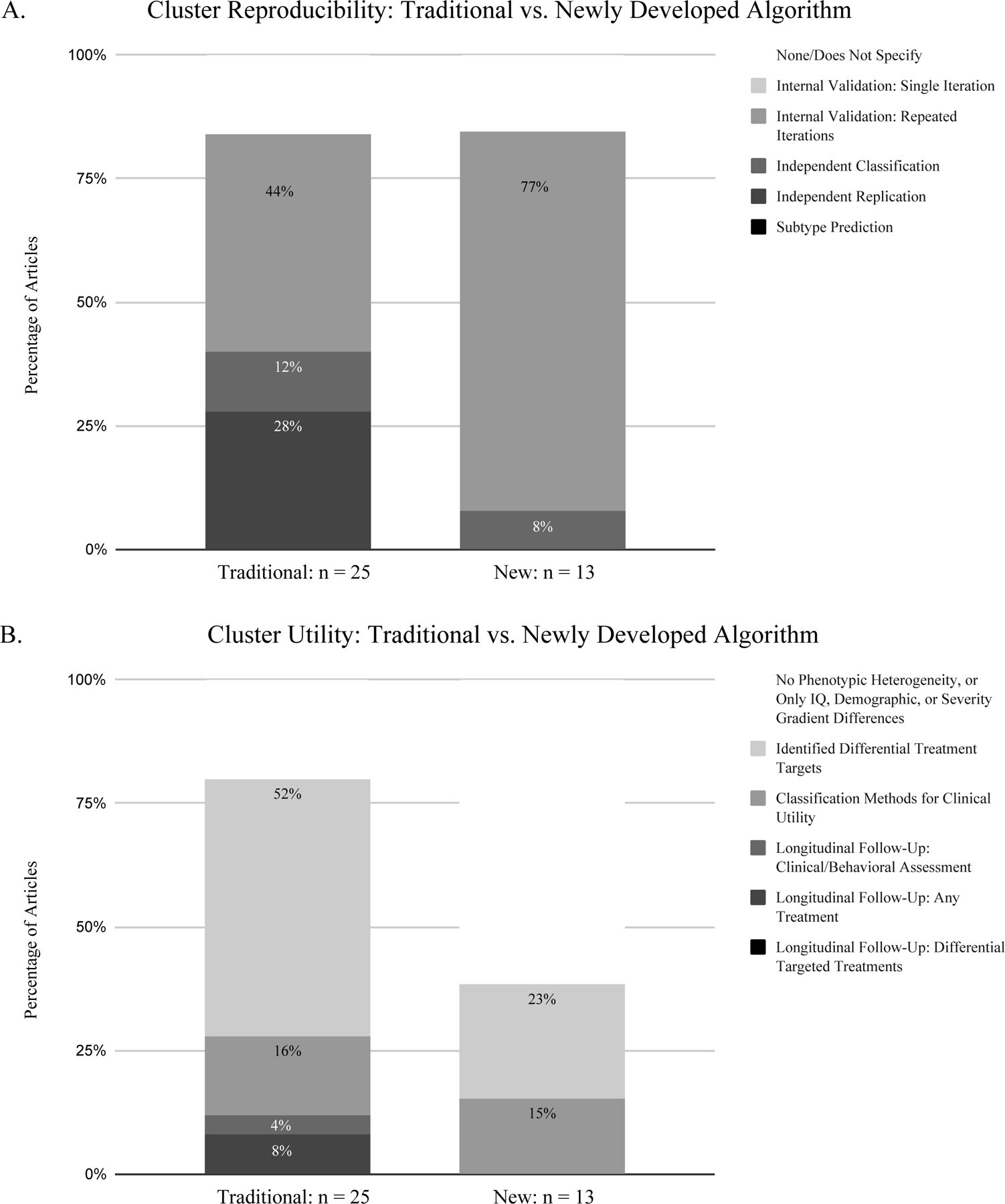
A. Cluster reproducibility validation strategies. B. Cluster utility validation strategies
Methodological Approaches and Subtype Characterization in a Single Disorder
For an example of the vast heterogeneity in methodological approaches observed within a single disorder, we summarized the approaches and characterization of subtyping ASD. Although the data modalities, feature selection, and clustering approaches were vastly different across the seven ASD studies, some of the secondary measures used for phenotypic subtype characterization were the same or similar across studies. This allowed us to synthesize and evaluate the convergence of the ASD findings based on their phenotypic characterization, even though these studies were methodologically heterogeneous. We were not able to do so in the other reviewed diagnoses because they showed significant heterogeneity not only in data modalities, feature selection and clustering approaches used, but in secondary measures used for subtype characterization.
All seven ASD papers utilized public consortium datasets [ABIDE (46,47,51,54,61), ENIGMA-ASD (49) and EU-AIMS-LEAP (62)]. The studies using ABIDE found between 2–3 clusters, while the studies using ENIGMA-ASD and EU-AIMS-LEAP data identified 4 and 5 clusters, respectively. Predominantly, secondary measures assessing symptom severity (via the Autism Diagnostic Observation Schedule [ADOS]) and/or IQ were used for subtype characterization. As such, the identified subtypes were primarily characterized by symptom severity and/or IQ gradients, defining clusters of individuals with either mild, moderate, or severe symptoms, and/or higher or lower IQ. Regarding validation strategies, only two of the seven papers used external validation (independent classification or independent replication) to assess the reproducibility of their subtypes (46,47), while five of these papers utilized classification methods to investigate the ability of the subtypes to improve diagnostic accuracy (46,47,51,54,62). The risk of bias was intermediate in six of the ASD studies (46,47,49,51,61,62), and low in one ASD study (54).
Discussion
This review aims to provide a snapshot of the current state of the field regarding empirical brain-based subtyping in psychiatric research. Our primary goal was to draw conclusions based on existing literature regarding methodologies, rather than synthesize results per diagnosis or age group. The aim was to provide an accessible overview of the methodological practices, progress and limitations across this growing field. We observed a great deal of ongoing methodological development. However, studies with more novel approaches rarely used the most stringent validation strategies. While it is encouraging that 82% of the reviewed studies assessed reproducibility with internal validation (repeated iteration) methods, few studies used stringent external validation approaches (13% independent classification, 18% independent replication, 0% subtype prediction), which are considered best practice for maximizing generalizability and replicability (63). Within the studies that were using novel algorithms, only 8% of studies employed stringent external validation strategies. Additionally, the clinical implications of subtyping results (or lack thereof) were rarely discussed in publications. Based on our evaluation, 47% of studies identified potentially useful treatment targets from their subtype characterizations, describing distinct functional/mechanism-based profiles through secondary measures (e.g., Executive Functioning-Driven Subtype, Atypical Affective-Processing Subtype). Another 32% of studies identified “severity gradients” (i.e., subtypes characterized by a severity class: mild, moderate, severe) or demographic differences, and hence did not identify differential functional mechanisms that could guide the development of personalized, “targeted” treatments. 18% of studies did not identify any differences on secondary measures between subtypes. Only 21% of studies investigated whether their identified subtypes could improve diagnostic accuracy through classification methods and authors very rarely discussed any clinical implications in their publications, or how to move forward if only biological, but no phenotypic heterogeneity was identified. Notably, only 8% of studies used longitudinal follow-up data to assess the stability of subtype characterization over time or differential treatment response by subtype.
Further attesting to a gap between methodological development and clinical utility, the assessment of clinical utility was lower in studies using the newly developed algorithms (38%) compared to studies who implemented the more traditional algorithms (80%). Accordingly, we also found that studies often either focused on achieving a high degree of reproducibility, or a high degree of clinical utility, but rarely both. This was evidenced by the inverse relationship found between the different types of validation strategies implemented in each study (i.e., either a study stringently assessed cluster reproducibility and did not equally assess cluster utility, or vice-versa), and the lacking assessment of clinical utility within studies that used more advanced algorithms. In summary, we found evidence for a gap between technical development and a focus on clinical goals.
One Problem, Several (Ever-Increasing) Ways to Approach It
Even though this field of research is still in its infancy, there are a surprising number of new and dedicated brain-based subtyping methods being created. These new methods have, for example, proposed to a) recover clusters based on more individual-level patterns of dynamic effects, b) take normative-modelling approaches, or c) develop ways to combat the inherent limitations of clustering high dimensional neuroimaging data. Additionally, nearly all studies utilized a different combination of data modality and dimensionality reduction or feature selection prior to submitting the data to their (also vastly different) algorithm of choice. While a salient finding, significant methodological variation has been found across all subtyping literature, symptom- and brain-based (8,15,36). This vast methodological exploration, while warranted at such an early stage of the field, identifies continuously different, albeit potentially relevant, subtypes, with little convergence or consistency. While methodological exploration and development is critical for research growth and advancement, if not accompanied by adequate validation strategies, the generalizability and utility of the results cannot be reliably known.
The Importance of Validating Existing Subtyping Solutions
As validation strategies are currently not sufficiently assessed, it is unclear whether the subtypes that have already been identified yield any generalizability or practical implications. While the inclusion of more external validation and predictive subtyping approaches is highly recommended (4) and should be conducted when possible, we understand that the inadequacy of relevant and available datasets makes achieving this a difficult undertaking. However, between studies, it is possible to replicate one’s own or others’ subtyping results (8). So, it may be a practical idea to set up data use agreements to exchange datasets for replication, to be able to assess the reproducibility and clinical utility of existing subtyping solutions more easily. It may also be useful to compare novel approaches to ‘traditional’ approaches head-to-head. Doing this may enable the field to more systematically combat “research waste” and add more to the literature than merely another (unvalidated) subtyping solution derived from a unique combination of measures and algorithms (8,64).
Complexities of Brain-Based Subtyping
The complexities surrounding clustering methods are well-known and have been thoroughly discussed in both the machine-learning and applied literature (17–22,24,65). Namely, these difficulties reflect an algorithm’s ability to: handle high dimensional data, always derive a result regardless of the nature of the input data, and while the result is often cleanly partitioned, some data may not distinctly belong to any grouping. Additionally, different clustering algorithms may yield different solutions even when the same input data is used. Thus, constraining clustering algorithms to yield valid and meaningful solutions is a difficult endeavor. Moreover, clustering approaches applied to neuroimaging data come with added complexities, especially surrounding reliable and sufficiently powered neuroimaging measures.
Recent work by Marek and colleagues (66) has shown the extent of the ‘replicability crisis’, suggesting that effect sizes for inter-individual differences in brain structure or function are small, and to reliably model brain effects, sample sizes in the thousands would be required. While consortium studies are currently underway [e.g., the Adolescent Brain Cognitive Development Study (67)] collecting the number of subjects required for making reliable inferences in brain-wide association studies, a complementary and alternative endeavor may also be viable. This alternative, suggested by Gratton et al. (68), proposes that we can attempt to decrease the sample size requirement [as concluded by (66)] while still improving replicability by increasing both the amount of data collected per subject and data quality [the Signal-to-Noise Ratio (SNR)]. This may be a more practical solution for subtyping studies aimed at moving toward precision approaches, as the goal here is to understand individual differences that can drive someone’s disorder, rather than measure population-level variation in brain and behavior.
While anatomical data, as currently acquired, is reliable and of high quality (25), functional data that is collected using standard fMRI protocols is often less so. Ample evidence suggests that to achieve reliable functional neuroimaging data, the quantity and quality of data required, both at rest and in task-based paradigms, needs to increase (25–29). With regards to data quantity, currently standard fMRI acquisitions are between 5–10 minutes long. However, less than 10 minutes of fMRI data has been shown to yield exceptionally low reliability estimates (25–29). Thus, to improve the capacity for functional neuroimaging to identify reliable brain-based subtypes able to inform biomarker discovery, increased fMRI data per subject, roughly 30–60 minutes per acquired state, is suggested (25–29). In addition, the improvement of scanner hardware, software (sequences), and study design (paradigms) can aid in obtaining functional data of higher quality. Innovations such as improved denoising techniques (69,70) and multi-echo fMRI sequences (71–73), for example, will also enable us to achieve higher quality data.
For the fMRI-based studies reviewed, scan acquisition times ranged between 5 and 8:30 minutes (when reported). Given the substantial evidence (25–29), this is not enough functional data to yield reliable inferences regarding brain-behavior relationships or inform biomarker discovery. We hope to call attention to these limitations and urge caution when interpreting results born out of studies using short data acquisitions.
Insights From a Single Disorder: Autism Spectrum Disorder
The clinical manifestation of ASD is characterized by a wide range of symptoms that vary along a severity spectrum, with significant heterogeneity in both phenotypic presentation and etiology (46). Although phenotypic heterogeneity has been associated with atypical brain structure and function in ASD, the results are inconsistent across studies (61). This heterogeneity presents a critical challenge to better understanding the neurobiological mechanisms of ASD and advancing objective diagnostics and treatment optimization (51).
Here, we summarize the insights garnered from the literature on brain-based subtyping in ASD, while cautioning readers that the studies reviewed were not exhaustive but rather a snapshot of the emergent literature within the field. Our findings indicate that while clusters were identified in each of the seven ASD studies, the approaches used for subtype verification were heterogeneous, resulting in the identification of between 2 and 5 clusters. All seven studies profiled their subtypes using measures of symptom severity and/or IQ performance, while only one study considered functional/mechanism-based secondary measures. Importantly, even though these studies used different methodologies and identified different neurobiological subtypes, five of them were able to characterize their subtypes on a gradient of symptom severity and/or IQ performance (e.g., Mild-ASD Subtype, Severe-ASD Subtype). These findings of severity subtypes validate the conceptualization that autism is a spectrum disorder. Moreover, several studies also demonstrated that these brain-based severity subtypes led to improvements in diagnostic accuracy (46,47,51), highlighting the potential for neuroimaging-derived subtypes to inform clinical diagnostics.
A Way Forward: Solving the “Collaboration Crisis”
Although the field is in its infancy, the current assessment of validation strategies within brain-based subtyping is far from ideal. However, we agree with Miranda and colleagues (36) that this problem largely reflects the inadequacy of relevant and available data. Additionally, we suggest that the inadequate implementation of validation strategies may reflect a ‘collaboration crisis’ (74) in which researchers with expertise in methodological advancement fail to collaborate with clinicians (and vice versa). This leads to advancements that are not clearly grounded in clinical goals, and clinical research that lacks sound methodological implementation. While method exploration and development are critical to the advancement of research, doing so without accounting for translational utility hinders clinical application in the future. To identify subtypes that better inform nosology, can be used as biomarkers, and accelerate the development of precision medicine in psychiatry, we must think about the clinical goals.
A Recipe for Brain-Based Subtyping
Given our findings, we propose a “recipe” for well-designed brain-based subtyping studies to optimally inform nosology, biomarker discovery, and prescribe more effective, targeted treatments. This recipe contains 4 steps:
1). Have a Clear Question.
In the age of ‘Big Data’, there is an immense amount of accessible information (e.g., environmental, behavioral, biological/physiological) and possibly many distinct and valid ways to subgroup the population based on this data (4). As it is challenging to find the “best” clustering solution, and even possible that no universal “best” structure exists, clusters should always be investigated in the context of their end-use (19). Thus, approaches for identifying subtypes must be tied to a defined question or outcome of interest to be relevant, have utility, and aid in achieving the goal set forth by subtyping research.
2). Collect/use dataset with relevant, high-quality data.
We recognize that a substantial proportion of current brain-based subtyping studies used datasets collected as part of previous consortium research. Just because there are large datasets available, does not mean these are well-suited to conduct subtyping research. Thus, it is critical that we collect (or use, if available) datasets that enable us to adequately investigate our defined question or outcome of interest, that critically have high enough data quality for making reliable inferences.
3). Be deliberate when choosing methodological approaches.
There are several types of subtyping approaches available, with more constantly being developed. Thus, before selecting an approach, it is imperative to understand the different techniques that can be used, their constraints, and how they affect the interpretation of the subtypes. Regarding input data: it is critical to understand how input features can bias subtyping results (75), and how using different combinations of input features, while they may yield valid results, may not all be equally useful for generalizability and clinical translation. Similarly, different algorithms have varied underlying assumptions that influence the clustering solution. Therefore, understanding these assumptions and their effects prior to implementation is critical.
4). Implement validation strategies that assess both reproducibility and clinical utility.
If the goal of psychiatric subtyping is to inform personalized medicine, it is crucial that both aspects of validation, reproducibility and utility, be adequately implemented, as the identification of one does not guarantee the other. Regarding reproducibility, while internal validation methods are a practical option, external and predictive validation strategies are essential to assess generalizability, reproducibility, and relevancy optimally. Regarding cluster utility, it is critical that studies use secondary measures aimed at characterizing distinct functional/mechanism-based subtypes and collect longitudinal follow-up data such that inferences on the relevance of subtypes for clinical trajectories can be assessed.
Conclusion
This review provides a snapshot of the current state of the field regarding empirical brain-based subtyping in psychiatric research in children, adolescents, and adults. We found a vast amount of new methodological exploration and approaches. However, this exploration and development does not often go hand-in-hand with rigorous validation approaches that examine both reproducibility and clinical utility. We believe that the root of this may be a ‘collaboration crisis’, a lack of grounding these methodological advancements in clinical goals. We propose considering the following steps for designing brain-based subtyping studies: 1) Having a clear research question, 2) Collecting/using datasets with relevant, high-quality data, 3) Being deliberate when choosing methodological approaches, and 4) Implementing validation strategies that assess both reproducibility and clinical utility. We agree with the authors of the reviewed studies that the discovery of biologically grounded subtypes would be a significant advancement for treatment development and precision medicine in psychiatry.
Supplementary Material
Acknowledgements
We would like to thank Andrea Maxwell for her helpful comments regarding the manuscript. EF is supported by grants from the National Institute on Drug Abuse (U24-DA041123; R01-DA056499; U24-DA055330; P50-DA048756) and from the National Institute of Mental Health (RF1-MH120025). DF is supported by grants from the National Institute on Drug Abuse (U01DA041148; 1U24DA055330-01) and from the National Institute of Mental Health (1R01MH123716-01A1; 1R37MH125829-01; R01MH096773-08A1). AZ is supported by the NARSAD Young Investigator Grant #29981 from the Brain & Behavior Research Foundation. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Disclosures
Dr. Damien Fair is co-founder, Director, and equity holder of Nous Imaging, which has licensed the FIRMM motion monitoring software. These interests have been reviewed and managed by the University of Minnesota in accordance with its Conflict-of-Interest policies. LRB, EF and AZ reported no biomedical financial interests or potential conflicts of interest.
References
- 1.Cuthbert BN, Insel TR (2013): Toward the future of psychiatric diagnosis: the seven pillars of RDoC. BMC Med 11: 126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Leichsenring F, Steinert C, Rabung S, Ioannidis JPA (2022): The efficacy of psychotherapies and pharmacotherapies for mental disorders in adults: an umbrella review and meta-analytic evaluation of recent meta-analyses. World Psychiatry 21: 133–145. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Insel T, Cuthbert B, Garvey M, Heinssen R, Pine DS, Quinn K, et al. (2010): Research domain criteria (RDoC): toward a new classification framework for research on mental disorders. Am J Psychiatry 167: 748–751. [DOI] [PubMed] [Google Scholar]
- 4.Feczko E, Miranda-Dominguez O, Marr M, Graham AM, Nigg JT, Fair DA (2019): The Heterogeneity Problem: Approaches to Identify Psychiatric Subtypes. Trends Cogn Sci 23: 584–601. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Pessoa L (2014): Understanding brain networks and brain organization. Phys Life Rev 11: 400–435. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Licinio J, Wong M-L (2013): A novel conceptual framework for psychiatry: vertically and horizontally integrated approaches to redundancy and pleiotropism that co-exist with a classification of symptom clusters based on DSM-5 [no. 8]. Mol Psychiatry 18: 846–848. [DOI] [PubMed] [Google Scholar]
- 7.Van Dam NT, O’Connor D, Marcelle ET, Ho EJ, Cameron Craddock R, Tobe RH, et al. (2017): Data-Driven Phenotypic Categorization for Neurobiological Analyses: Beyond DSM-5 Labels. Biol Psychiatry 81: 484–494. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Agelink van Rentergem JA, Deserno MK, Geurts HM (2021): Validation strategies for subtypes in psychiatry: A systematic review of research on autism spectrum disorder. Clin Psychol Rev 87: 102033. [DOI] [PubMed] [Google Scholar]
- 9.Mann K, Roos CR, Hoffmann S, Nakovics H, Leménager T, Heinz A, Witkiewitz K (2018): Precision Medicine in Alcohol Dependence: A Controlled Trial Testing Pharmacotherapy Response Among Reward and Relief Drinking Phenotypes. Neuropsychopharmacology 43: 891–899. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Drysdale AT, Grosenick L, Downar J, Dunlop K, Mansouri F, Meng Y, et al. (2017): Resting-state connectivity biomarkers define neurophysiological subtypes of depression [no. 1]. Nat Med 23: 28–38. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Dinga R, Schmaal L, Penninx BWJH, van Tol MJ, Veltman DJ, van Velzen L, et al. (2019): Evaluating the evidence for biotypes of depression: Methodological replication and extension of Drysdale et al. (2017). NeuroImage Clin 22: 101796. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Grosenick L, Shi TC, Gunning FM, Dubin MJ, Downar J, Liston C (2019): Functional and Optogenetic Approaches to Discovering Stable Subtype-Specific Circuit Mechanisms in Depression. Biol Psychiatry Cogn Neurosci Neuroimaging 4: 554–566. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Zhou X, Menche J, Barabási A-L, Sharma A (2014): Human symptoms–disease network [no. 1]. Nat Commun 5: 4212. [DOI] [PubMed] [Google Scholar]
- 14.Chaste P, Klei L, Sanders SJ, Hus V, Murtha MT, Lowe JK, et al. (2015): A Genome-wide Association Study of Autism Using the Simons Simplex Collection: Does Reducing Phenotypic Heterogeneity in Autism Increase Genetic Homogeneity? Biol Psychiatry 77: 775–784. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Marquand AF, Wolfers T, Mennes M, Buitelaar J, Beckmann CF (2016): Beyond Lumping and Splitting: A Review of Computational Approaches for Stratifying Psychiatric Disorders. Biol Psychiatry Cogn Neurosci Neuroimaging 1: 433–447. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Ivleva EI, Turkozer HB, Sweeney JA (2020): Imaging-Based Subtyping for Psychiatric Syndromes. Neuroimaging Clin N Am 30: 35–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Xu D, Tian Y (2015): A Comprehensive Survey of Clustering Algorithms. Ann Data Sci 2: 165–193. [Google Scholar]
- 18.Rokach L (2010): A survey of Clustering Algorithms. In: Maimon O, L Rokach, editors. Data Mining and Knowledge Discovery Handbook Boston, MA: Springer US, pp 269–298. [Google Scholar]
- 19.Luxburg U von Williamson RC, Guyon I (2012): Clustering: Science or Art? Proceedings of ICML Workshop on Unsupervised and Transfer Learning 65–79.
- 20.Jain AK (2010): Data clustering: 50 years beyond K-means. Pattern Recognit Lett 31: 651–666. [Google Scholar]
- 21.Jain AK, Dubes RC (1988): Algorithms for Clustering Data Prentice-Hall, Inc. [Google Scholar]
- 22.Marquand AF, Rezek I, Buitelaar J, Beckmann CF (2016): Understanding Heterogeneity in Clinical Cohorts Using Normative Models: Beyond Case-Control Studies. Biol Psychiatry 80: 552–561. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Marquand AF, Kia SM, Zabihi M, Wolfers T, Buitelaar JK, Beckmann CF (2019): Conceptualizing mental disorders as deviations from normative functioning [no. 10]. Mol Psychiatry 24: 1415–1424. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Kriegel H-P, Kröger P, Zimek A (2009): Clustering high-dimensional data: A survey on subspace clustering, pattern-based clustering, and correlation clustering. ACM Trans Knowl Discov Data 3: 1:1–1:58. [Google Scholar]
- 25.Elliott ML, Knodt AR, Ireland D, Morris ML, Poulton R, Ramrakha S, et al. (2020): What Is the Test-Retest Reliability of Common Task-Functional MRI Measures? New Empirical Evidence and a Meta-Analysis. Psychol Sci 31: 792–806. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Gordon EM, Laumann TO, Gilmore AW, Newbold DJ, Greene DJ, Berg JJ, et al. (2017): Precision Functional Mapping of Individual Human Brains. Neuron 95: 791–807.e7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Laumann TO, Gordon EM, Adeyemo B, Snyder AZ, Joo SJ, Chen M-Y, et al. (2015): Functional System and Areal Organization of a Highly Sampled Individual Human Brain. Neuron 87: 657–670. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Zuo X-N, Xu T, Milham MP (2019): Harnessing reliability for neuroscience research [no. 8]. Nat Hum Behav 3: 768–771. [DOI] [PubMed] [Google Scholar]
- 29.O’Connor D, Potler NV, Kovacs M, Xu T, Ai L, Pellman J, et al. (2017): The Healthy Brain Network Serial Scanning Initiative: a resource for evaluating inter-individual differences and their reliabilities across scan conditions and sessions. GigaScience 6: 1–14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Ioannidis JPA (2016): Why Most Clinical Research Is Not Useful. PLOS Med 13: e1002049. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Woo C-W, Chang LJ, Lindquist MA, Wager TD (2017): Building better biomarkers: brain models in translational neuroimaging. Nat Neurosci 20: 365–377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Dwyer DB, Falkai P, Koutsouleris N (2018): Machine Learning Approaches for Clinical Psychology and Psychiatry. Annu Rev Clin Psychol 14: 91–118. [DOI] [PubMed] [Google Scholar]
- 33.Walter M, Alizadeh S, Jamalabadi H, Lueken U, Dannlowski U, Walter H, et al. (2019): Translational machine learning for psychiatric neuroimaging. Prog Neuropsychopharmacol Biol Psychiatry 91: 113–121. [DOI] [PubMed] [Google Scholar]
- 34.Paulus MP, Thompson WK (2021): Computational Approaches and Machine Learning for Individual-Level Treatment Predictions. Psychopharmacology (Berl) 238: 1231–1239. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Bzdok D, Meyer-Lindenberg A (2018): Machine Learning for Precision Psychiatry: Opportunities and Challenges. Biol Psychiatry Cogn Neurosci Neuroimaging 3: 223–230. [DOI] [PubMed] [Google Scholar]
- 36.Miranda L, Paul R, Pütz B, Koutsouleris N, Müller-Myhsok B (2021): Systematic Review of Functional MRI Applications for Psychiatric Disease Subtyping. Front Psychiatry 12: 665536. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Wolfers T, Floris DL, Dinga R, van Rooij D, Isakoglou C, Kia SM, et al. (2019): From pattern classification to stratification: towards conceptualizing the heterogeneity of Autism Spectrum Disorder. Neurosci Biobehav Rev 104: 240–254. [DOI] [PubMed] [Google Scholar]
- 38.Marquand AF, Wolfers T, Dinga R (2019): Phenomapping: Methods and Measures for Deconstructing Diagnosis in Psychiatry. In: IC Passos, B Mwangi, F Kapczinski, editors. Personalized Psychiatry: Big Data Analytics in Mental Health Cham: Springer International Publishing, pp 119–134. [Google Scholar]
- 39.Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. (2021): The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. Syst Rev 10: 89. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Wells G, Shea B, O’Connell D, Robertson J, Peterson J, Losos M, Tugwell P (2000): The Newcastle-Ottawa Scale (NOS) for Assessing the Quality of Nonrandomized Studies in Meta-Analysis 12. [Google Scholar]
- 41.Lo CK- L, Mertz D, Loeb M (2014): Newcastle-Ottawa Scale: comparing reviewers’ to authors’ assessments. BMC Med Res Methodol 14: 45. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Varol E, Sotiras A, Davatzikos C (2017): HYDRA: revealing Heterogeneity of imaging and genetic patterns through a multiple max-margin Discriminative Analysis framework. NeuroImage 145: 346–364. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Dajani DR, Burrows CA, Nebel MB, Mostofsky SH, Gates KM, Uddin LQ (2019): Parsing Heterogeneity in Autism Spectrum Disorder and Attention-Deficit/Hyperactivity Disorder with Individual Connectome Mapping. Brain Connect 9: 673–691. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Ahrenholtz R, Hiser J, Ross MC, Privratsky A, Sartin-Tarm A, James GA, Cisler JM (2021): Unique neurocircuitry activation profiles during fear conditioning and extinction among women with posttraumatic stress disorder. J Psychiatr Res 141: 257–266. [DOI] [PubMed] [Google Scholar]
- 45.Chand GB, Dwyer DB, Erus G, Sotiras A, Varol E, Srinivasan D, et al. (2020): Two distinct neuroanatomical subtypes of schizophrenia revealed using machine learning. Brain 143: 1027–1038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Chen D, Jia T, Zhang Y, Cao M, Loth E, Lo C- YZ, et al. (2021): Neural Biomarkers Distinguish Severe From Mild Autism Spectrum Disorder Among High-Functioning Individuals. Front Hum Neurosci 15. Retrieved July 24, 2022, from 10.3389/fnhum.2021.657857 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Chen H, Uddin LQ, Guo X, Wang J, Wang R, Wang X, et al. (2019): Parsing brain structural heterogeneity in males with autism spectrum disorder reveals distinct clinical subtypes. Hum Brain Mapp 40: 628–637. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Honnorat N, Dong A, Meisenzahl-Lechner E, Koutsouleris N, Davatzikos C (2019): Neuroanatomical heterogeneity of schizophrenia revealed by semi-supervised machine learning methods. Schizophr Res 214: 43–50. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Li T, Hoogman M, Roth Mota N, Buitelaar JK, ENIGMA-ASD working group, Vasquez AA, et al. (2022): Dissecting the heterogeneous subcortical brain volume of autism spectrum disorder using community detection. Autism Res Off J Int Soc Autism Res 15: 42–55. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Liang S, Deng W, Li X, Greenshaw AJ, Wang Q, Li M, et al. (2020): Biotypes of major depressive disorder: Neuroimaging evidence from resting-state default mode network patterns. NeuroImage Clin 28: 102514. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Liu G, Shi L, Qiu J, Lu W (2022): Two neuroanatomical subtypes of males with autism spectrum disorder revealed using semi-supervised machine learning. Mol Autism 13: 9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Pan Y, Pu W, Chen X, Huang X, Cai Y, Tao H, et al. (2020): Morphological Profiling of Schizophrenia: Cluster Analysis of MRI-Based Cortical Thickness Data. Schizophr Bull 46: 623–632. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Rahaman MA, Damaraju E, Turner JA, van Erp TGM, Mathalon D, Vaidya J, et al. (2022): Tri-Clustering Dynamic Functional Network Connectivity Identifies Significant Schizophrenia Effects Across Multiple States in Distinct Subgroups of Individuals. Brain Connect 12: 61–73. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Reardon AM, Li K, Langley J, Hu XP (2022): Subtyping Autism Spectrum Disorder Via Joint Modeling of Clinical and Connectomic Profiles. Brain Connect 12: 193–205. [DOI] [PubMed] [Google Scholar]
- 55.Wen J, Varol E, Sotiras A, Yang Z, Chand GB, Erus G, et al. (2022): Multi-scale semi-supervised clustering of brain images: Deriving disease subtypes. Med Image Anal 75: 102304. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Wen J, Fu CHY, Tosun D, Veturi Y, Yang Z, Abdulkadir A, et al. (2022): Characterizing Heterogeneity in Neuroimaging, Cognition, Clinical Symptoms, and Genetics Among Patients With Late-Life Depression. JAMA Psychiatry 79: 464–474. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Yang T, Frangou S, Lam RW, Huang J, Su Y, Zhao G, et al. (2021): Probing the clinical and brain structural boundaries of bipolar and major depressive disorder [no. 1]. Transl Psychiatry 11: 1–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Itahashi T, Fujino J, Hashimoto R, Tachibana Y, Sato T, Ohta H, et al. (2020): Transdiagnostic subtyping of males with developmental disorders using cortical characteristics. NeuroImage Clin 27: 102288. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Kwak S, Kim M, Kim T, Kwak Y, Oh S, Lho SK, et al. (2020): Defining data-driven subgroups of obsessive–compulsive disorder with different treatment responses based on resting-state functional connectivity [no. 1]. Transl Psychiatry 10: 1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Li T, van Rooij D, Roth Mota N, Buitelaar JK, ENIGMA ADHD Working Group, Hoogman M, et al. (2021): Characterizing neuroanatomic heterogeneity in people with and without ADHD based on subcortical brain volumes. J Child Psychol Psychiatry 62: 1140–1149. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Easson AK, Fatima Z, McIntosh AR (2019): Functional connectivity-based subtypes of individuals with and without autism spectrum disorder. Netw Neurosci 3: 344–362. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Zabihi M, Floris DL, Kia SM, Wolfers T, Tillmann J, Arenas AL, et al. (2020): Fractionating autism based on neuroanatomical normative modeling [no. 1]. Transl Psychiatry 10: 1–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Scheinost D, Noble S, Horien C, Greene AS, Lake EMR, Salehi M, et al. (2019): Ten simple rules for predictive modeling of individual differences in neuroimaging. NeuroImage 193: 35–45. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Ramspek CL, Jager KJ, Dekker FW, Zoccali C, van Diepen M (2021): External validation of prognostic models: what, why, how, when and where? Clin Kidney J 14: 49–58. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Skinner HA, Blashfield RK (19830101): Increasing the impact of cluster analysis research: The case of psychiatric classification. J Consult Clin Psychol 50: 727. [DOI] [PubMed] [Google Scholar]
- 66.Marek S, Tervo-Clemmens B, Calabro FJ, Montez DF, Kay BP, Hatoum AS, et al. (2022): Reproducible brain-wide association studies require thousands of individuals [no. 7902]. Nature 603: 654–660. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Volkow ND, Koob GF, Croyle RT, Bianchi DW, Gordon JA, Koroshetz WJ, et al. (2018): The conception of the ABCD study: From substance use to a broad NIH collaboration. Dev Cogn Neurosci 32: 4–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Gratton C, Nelson SM, Gordon EM (2022): Brain-behavior correlations: Two paths toward reliability. Neuron 110: 1446–1449. [DOI] [PubMed] [Google Scholar]
- 69.Fair DA, Miranda-Dominguez O, Snyder AZ, Perrone A, Earl EA, Van AN, et al. (2020): Correction of respiratory artifacts in MRI head motion estimates. NeuroImage 208: 116400. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Moeller S, Pisharady PK, Ramanna S, Lenglet C, Wu X, Dowdle L, et al. (2021): NOise reduction with DIstribution Corrected (NORDIC) PCA in dMRI with complex-valued parameter-free locally low-rank processing. NeuroImage 226: 117539. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Kundu P, Inati SJ, Evans JW, Luh W-M, Bandettini PA (2012): Differentiating BOLD and non-BOLD signals in fMRI time series using multi-echo EPI. NeuroImage 60: 1759–1770. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Kundu P, Voon V, Balchandani P, Lombardo MV, Poser BA, Bandettini PA (2017): Multi-echo fMRI: A review of applications in fMRI denoising and analysis of BOLD signals. NeuroImage 154: 59–80. [DOI] [PubMed] [Google Scholar]
- 73.Lombardo MV, Auyeung B, Holt RJ, Waldman J, Ruigrok ANV, Mooney N, et al. (2016): Improving effect size estimation and statistical power with multi-echo fMRI and its impact on understanding the neural systems supporting mentalizing. NeuroImage 142: 55–66. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Lakens D (2017, August 4): The 20% Statistician: Towards a more collaborative science with StudySwap. The 20% Statistician Retrieved July 26, 2022, from http://daniellakens.blogspot.com/2017/08/towards-more-collaborative-science-with.html
- 75.von Luxburg U (2007): A tutorial on spectral clustering. Stat Comput 17: 395–416. [Google Scholar]
- 76.Arbelaitz O, Gurrutxaga I, Muguerza J, Pérez JM, Perona I (2013): An extensive comparative study of cluster validity indices. Pattern Recognit 46: 243–256. [Google Scholar]
- 77.Dangl R, Leisch F (2020): Effects of Resampling in Determining the Number of Clusters in a Data Set. J Classif 37: 558–583. [Google Scholar]
- 78.Von Luxburg U (2010): Clustering stability: an overview. Found Trends® Mach Learn 2: 235–274. [Google Scholar]
- 79.Liu Y, Li Z, Xiong H, Gao X, Wu J (2010): Understanding of Internal Clustering Validation Measures. 2010 IEEE International Conference on Data Mining 911–916.
- 80.Lange T, Roth V, Braun ML, Buhmann JM (2004): Stability-based validation of clustering solutions. Neural Comput 16: 1299–1323. [DOI] [PubMed] [Google Scholar]
- 81.Mufti G, Bertrand P, Moubarki L (2005): Determining the number of groups from measures of cluster validity. Proc ASMDA 2005.
- 82.Roth V, Lange T, Braun M, Buhmann J (2002): A resampling approach to cluster validation. In Intl. Conf. on Computational Statistics 123–128.
- 83.Ho SY, Phua K, Wong L, Bin Goh WW (2020): Extensions of the External Validation for Checking Learned Model Interpretability and Generalizability. Patterns 1: 100129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Ben-Hur A, Elisseeff A, Guyon I (2002): A stability based method for discovering structure in clustered data. Pac Symp Biocomput Pac Symp Biocomput 6–17. [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.