

Abstract
Music commonly appears in behavioral contexts in which it can be seen as playing a functional role, as when a parent sings a lullaby with the goal of soothing a baby. Humans readily make inferences, on the basis of the sounds they hear, regarding the behavioral contexts associated with music. These inferences tend to be accurate, even if the songs are in foreign languages or unfamiliar musical idioms; upon hearing a Blackfoot lullaby, a Korean listener with no experience of Blackfoot music, language, or broader culture is far more likely to judge the music’s function as “used to soothe a baby” than “used for dancing”. Are such inferences shaped by musical exposure or does the human mind naturally detect links between these kinds of musical form and function? Children’s developing experience of music provides a clear test of this question. We studied musical inferences in a large sample of children recruited online (N = 5,033), who heard dance, lullaby, and healing songs from 70 world cultures and who were tasked with guessing the original behavioral context in which each was performed. Children reliably inferred the original behavioral contexts with only minimal improvement in performance from the youngest (age 4) to the oldest (age 16), providing little evidence for an effect of experience. Children’s inferences tightly correlated with those of adults for the same songs, as collected from a similar online experiment (N = 98,150). Moreover, similar acoustical features were predictive of the inferences of both samples. These findings suggest that accurate inferences about the behavioral contexts of music, driven by universal links between form and function in music across cultures, do not always require extensive musical experience.
Music is a ubiquitous part of human culture that plays a variety of functional roles in our day-to-day lives (Mehr et al., 2019; Trehub et al., 2015; Nettl, 2005; Lomax, 1968): We sing songs to entertain each other, to find spiritual connection, to tell stories, to regulate our emotions, or just to pass the time.
Whereas some musical contexts are idiosyncratic, as in the encoding of complex geographical knowledge in song by some groups of Indigenous Australians (Norris & Harney, 2014), other contexts are recurrent across societies and tend to co-occur with the same acoustic features. For example, lullabies tend to have slow tempos; smooth, minimally accented contours; and a narrow dynamic and pitch range, as has been long-established in western societies (Bergeson & Trehub, 1999; Trehub & Trainor, 1998; Trehub et al., 1993a), and recently in more globally representative samples of societies (Hilton et al., 2022; Mehr et al., 2019). The findings that music appears universally in conjunction with particular behavioral contexts (e.g., infant care), and that examples of music in a given context share particular acoustic features (e.g., minimal accents), imply a link between form and function in music production.
Adults are sensitive to this link, in that they reliably distinguish song functions even when examples are unfamiliar and foreign. This has been demonstrated in experiments where naïve listeners are asked to identify the context in which a song was originally used, purely on the basis of the sounds it contains. Adult listeners indeed identify lullabies when paired with love songs as foils (Trehub et al., 1993b) and distinguish lullabies, dance songs, healing songs, and love songs from one another (Mehr et al., 2019, 2018).
How do adults come to be sensitive to these musical form-function links? Across the lifespan, musical experience is ubiquitous and rich, including through infancy (Mendoza & Fausey, 2021; Yan et al., 2021) and childhood (Bonneville-Roussy et al., 2013; Mehr, 2014). It is therefore plausible that a sensitivity to form and function in music is the result of acquired associations through direct musical experience; especially so given humans’ detailed long-term memories for music (Krumhansl, 2010; Levitin & Cook, 1996), including in infancy (Mehr et al., 2016; Saffran et al., 2000), and the importance of implicit associative learning in musical knowledge (Rohrmeier & Rebuschat, 2012).
Two forms of evidence point to an alternative explanation, however. First, systematic form-function pairings are found in vocalizations throughout the animal kingdom (Fitch et al., 2002; Morton, 1977), and are thought to reflect innate aspects of vocal signaling (Mehr et al., 2021; Darwin, 1871). Indeed, emotional vocalizations are not only cross-culturally intelligible within humans (in speech: Cowen et al., 2019; Chronaki et al., 2018; Scherer et al., 2001; in music: Balkwill & Thompson, 1999), but also between species (Kamiloğlu et al., 2020; Filippi et al., 2017). Humans even extend these emotional inferences to non-animate environmental sounds (Ma & Thompson, 2015) and abstract shapes (Sievers et al., 2019). And a broader class of innate psychoacoustical relationships are thought to underlie the surprisingly robust cross-linguistic associations between certain speech sounds and meaning in the world’s languages (Yu et al., 2021; Blasi et al., 2016; Imai et al., 2008; Nuckolls, 1999). Form-function inferences in music may rely upon similar, largely-innate mechanisms.
Second, despite their lesser degree of exposure to music, relative to adults, infants are affected by music in ways that are predictable from behavioral function. For example, infants relax more in response to lullabies than non-lullabies, even when the songs are in unfamiliar languages and from unfamiliar cultures (Bainbridge et al., 2021); and infants move rhythmically more in response to metrical music than speech (Zentner & Eerola, 2010). While neither implies that infants are aware of the functions of the songs they hear, these early-developing responses to music may provide a grounding for later higher-level social inferences about music, which may develop through interaction with precocial social intelligence (Bohn & Frank, 2019; Mehr et al., 2016; Mehr & Spelke, 2017; Powell & Spelke, 2013; Herrmann et al., 2007; Tomasello et al., 2005), along with functional intuitions about other social signals, such as speech (Vouloumanos et al., 2014; Martin et al., 2012).
To test between these competing explanations — invoking learned vs. innate mechanisms — we studied musical inferences across early and middle childhood, focusing on whether and how these inferences change as children’s musical experience grows. Children participated in a citizen-science experiment (readers can try it with their children at https://themusiclab.org/quizzes/kfc) where they listened to examples of lullabies, dance songs, and healing songs from 70 mostly small-scale societies, drawn from the Natural History of Song Discography (Mehr et al., 2019), and were tasked with guessing the original behavioral context.
To examine the degree to which musical experience affected children’s inferences, we conducted a series of preregistered and exploratory analyses, asking (1) whether children are sensitive to form and function in music; (2) how their sensitivity changes over the course of childhood; (3) how children’s inferences compare to those of adults; and (4) whether and how children’s inferences are predictable from the acoustical features of the music.
Methods
Participants
Children visited the citizen science website https://themusiclab.org to participate. We posted links to the experiment on social media, which were spread via organic sharing, and we also advertised the experiment on https://childrenhelpingscience.com, a website disseminating information on web-based research for children (Sheskin et al., 2020). Recruitment was/is open-ended; at the time of analysis, we had complete data from 8,263 participants with reported ages from “3 or under” to “17 or older” in one-year increments. Ethics approval for the pilot experiment was provided by Victoria University of Wellington Human Ethics Committee (Application #0000023076); approval for the web-based naive listener experiment was provided by the Committee on the Use of Human Subjects, Harvard University (IRB17-1206).
We opted to only analyze the precisely year-long age bands, excluding the participants who responded with “3 or under” and “17 or older” (n = 2,752) since these are harder to interpret (but see SI Text 1 for a supplementary analysis of these participants). We also excluded children whose parents indicated that they had assisted their child during the experiment (n = 939); children who indicated they had played the game previously (n = 710); children with known hearing impairments (n = 516); children who were missing data from the test phase (n = 42); and children who had trials with responses faster than 100ms or slower than 10 seconds (n = 2,268). While the exclusion criteria for response times were not preregistered, we note that the main findings replicate under a variety of alternative exclusion decisions, or when not excluding any trials at all.
This left 5,033 participants for analysis (1,900 male, 2,923 female, 210 other; the cohort’s breakdown of age and gender, after exclusions, is in SI Figure 1). Participants reported speaking 128 native languages and being located in 127 countries (SI Tables 1 and 2).
Readers should note that the experiment itself was conducted in English (including both written and spoken/audible instructions), however. As such, despite the apparent diversity of countries of origin and native languages, these data should not be considered a representative sample of cultural or linguistic experiences, and is likely to be biased in certain ways (e.g., those with internet access who can speak English; see Discussion).
Stimuli
Song excerpts were drawn from the Natural History of Song Discography (Mehr et al., 2019), a corpus of vocal music collected from 86 mostly small-scale societies, including hunter-gatherers, pastoralists, and subsistence farmers. Each song in this corpus was originally performed in one of four behavioral contexts: dance, healing, lullaby, and love. All recordings were selected on the basis of supporting ethnographic material, as opposed to the acoustic features of the songs (see: Mehr et al., 2018, 2019).
Because love songs were ambiguously detected in some prior work (Mehr et al., 2018), and given the difficulty of explaining this category to children, we omitted love songs from the experiment and studied only the remaining three contexts (dance, lullaby, and healing). This left 88 songs from 70 societies, sung in 30 languages (SI Table 3) and originating from locations corresponding to 46 countries (SI Figure 3).
Procedure
Participants could use a computer, mobile phone, or tablet; they were encouraged to use a computer, however, for easier user interface navigation. A schematic of the experiment is in Figure 1; it included a a progress bar, displayed throughout the experiment, which indicated the times when the child should be assisted by a parent and the times the child should not be assisted.
Figure 1.

Schematic of the test phase of the experiment. Children listened to the songs and indicated their responses in the context of an online game. a, Parents guided their children’s participation with the assistance of a progress bar, which indicated which portions of the experiment were intended to be for parents alone, parents and children together, or children alone. The progress bar was visible throughout the experiment. b, The game was narrated by Susie the Star, an animated character whose instructions were spoken aloud and printed in speech bubbles on the screen. c, During testing children listened to a series of songs. d, After each song, Susie asked them to guess its behavioral context and indicate their response by clicking or tapping an image (with accompanying text). The cartoon star was designed by Freepik.
Parents were instructed to begin the game without the child present, so that they could provide us with demographic information and become oriented to the interface. This information included whether the child had previously participated in the experiment; the child’s age, gender, country of residence, native language, any known hearing impairments; and whether or not the child would complete the experiment while wearing headphones. We also asked about the frequency with which the child was exposed to parental singing or recorded music in the home.
Parents then turned the experiment over to their children, who were guided by an animated character, “Susie the Star”. Susie provided verbal encouragement to keep the children motivated; explained the task instructions, which were also presented visually (although many of the youngest children were likely unable to read them); and reminded the children of these instructions throughout the experiment.
First, in a training phase, Susie played children a likely-to-be-familiar song (the “Happy Birthday” song) and asked them to identify what they thought it was used for, by selecting one of three choices: “singing for bath time”, “singing for school assembly” or “singing for celebrating a birthday”; 98% of children did so correctly on the first try.
Susie then explained the three song categories that children would be tested on in the experiment (lullaby, “for putting a baby to sleep”; healing, “to make a sick person feel better”; dance, “singing for dancing”). An illustration accompanied each song category’s description, to facilitate responses for children too young to read (see Figure 1). Before proceeding to the test trials, we asked parents whether they felt their child understood the task; 98% responded in the affirmative and those that did not were required to repeat the training trials.
Susie then played the children a counterbalanced set of six songs (two per song type) drawn randomly from the Natural History of Song Discography and presented in a random order. The excerpts were 14 seconds long and each played in its entirety before the child could advance. After each song, Susie asked “What do you think that song was for?” and children made a guess by clicking or tapping on a labeled illustration corresponding with one of the three song types (see Figure 1; i.e., a three-response classification task). After they indicated their inference, we also asked children to rate how much they liked the song, for use in a different study. Positive feedback was always given after each trial (e.g., “Good job!”), with an arbitrary number of “points” awarded (+20 points when correct and +15 points when incorrect).
Last, parents answered debriefing questions. The questions confirmed whether the child had worn headphones during the experiment (if, at the beginning of the study, the parent had stated the child would wear headphones; we opted not to exclude participants on the basis of headphone use, as the responses of children who wore headphones were comparable to those of children who did not), if the parent had assisted the child during the training portion of the experiment, and if the parent had assisted the child during the test questions (those who had were excluded from analyses; see Participants, above).
Pilot studies and preregistration
In designing the experiment, we first piloted the experiment in-person with four children (ages 6, 7, 9, and 10), to explore whether the procedure was well-explained and intuitive for children, and to observe potential parental interference. The children easily understood the task and did not elicit help from their parents; at times they rejected parental assistance (e.g., as if to say “I can do this on my own, mum”).
We continued by running a pilot version of the experiment with 500 children recruited online (50 children in each age group, range 3-12; 221 male, 267 female, 12 other) to provide a dataset for exploratory analyses. Based on these data, and our broader theoretical interests motivated in the introduction section of this paper, we preregistered three confirmatory hypotheses to be tested in a larger sample: (i) in the full cohort of children, accurate classification of behavioral contexts overall and in all three song types, including after adjusting for response bias via d′ analyses; (ii) a positive but modestly sized effect of age on accuracy (R2 < .05); and (iii) little to no effect of musical exposure in the home on accuracy.
We also pre-specified four other hypotheses that were not investigated in the exploratory sample. Two of these are studied in this paper: (iv) predicted correlations between children’s intuitions about the songs and adults’ intuitions, using an expanded sample from a previous study of adults (Mehr et al., 2019); and (v) a prediction that the musical features of the songs that are predictive of children’s intuitions about them, within a given song type, will correspond with musical features previously identified as universally associated with that song type (from Mehr et al., 2019). We leave the remaining two preregistered hypotheses for future research.
The preregistration is available at https://osf.io/56zne.
Notes on the unmoderated citizen-science approach
Most psychological studies of children are conducted in-person (e.g., in a laboratory or school) or in a moderated online setting (e.g., via videoconference). Our approach instead relies on an unmoderated, citizen-science approach. While this approach has the advantage of larger-scale, and often more diverse recruitment than in-person or moderated online studies (Hilton & Mehr, 2022; Li et al., 2022), it has two potential risks.
The risk of participant misrepresentation: Are the children really children?
As we did not directly observe the participants, we cannot verify that participants in the study are, in fact, children, as opposed to adults posing as children, or malicious automated participants (e.g., bots).
As no compensation was given, it is not clear what incentive there would be for either possibility, and there is growing evidence that relative to traditional compensated lab-based data collection, comparable results can be reliably obtained across a number of domains using online data collection with either compensated (Coppock, 2019; Ratcliff & Hendrickson, 2021) or uncompensated (Huber & Gajos, 2020; Hartshorne et al., 2019; Germine et al., 2012) recruitment. Nevertheless, we analyzed several forms of metadata to explore the risk of participant misrepresentation.
First, we examined the timecourse of participant recruitment across the child and adult cohorts (SI Figure 3). In particular, we inspected large spikes in recruitment, with the idea that spikes that are not explicable by known events could be attributable to bots or other malicious participants. All spikes in recruitment were attributable to known internet exposure such as viral news coverage, however, suggesting that increases in recruitment during these spikes corresponded with bona fide participants.
Second, we compared the times of study completion across the child and adult cohorts across several countries (SI Figure 4). Children generally keep different schedules than do adults (e.g., most adults do not attend elementary school) and thus, presumably, would have different opportunities to participate in the experiment. We found that participants in the child cohort were less likely to participate in the late night/early morning, relative to adults, a pattern consistent across 5 countries with large samples in both children and adults.
Third, we examined the patterns of response times within the child cohort in the experiment (SI Figure 5). Consistent with prior work showing that response time in perceptual and cognitive tasks decreases over the course of childhood (Hale, 1990; Kiselev et al., 2009), response times during the task decreased reliably as a function of self-reported age (F(1, 5,031) = 854.16, p < .001, R2 = 0.15; SI Figure 5).
These considerations suggest that the risk of participant misrepresentation is limited.
The risk of parental non-compliance: Did parents bias children’s responses?
As we did not directly observe the participants, we cannot verify whether or not parents complied with the instructions to let their children participate uninterrupted and without providing advice or other interference. We believe this risk is mitigated by several concerns, however.
First, we designed the experiment to be easy to understand, so as to limit the need for children to ask for help. We used clear, child-friendly visual and audio elements and interactive training trials to help the child intuitively understand the task; for the parents, we included a progress bar throughout to communicate when parents should and should not intervene. These are depicted in Figure 1 and should in principle limit parent intervention. Indeed, in in-person pilot participants, children did not elicit any help from parents, and even discouraged their parents from intervening (see Pilot studies and preregistration, above).
Second, at the completion of the online experiment, we explicitly asked parents whether they complied with the request to not interfere with the child’s performance. Post-hoc prompts on task compliance have been shown to be effective in other uncompensated online experiments (Reinecke & Gajos, 2015); parents have little incentive to lie in response to such a question. The vast majority of parents stated that they did not assist their children in the experiment and we excluded those who did (see Participants, above). However, we cannot rule out the possibility that parents implicitly affected their child’s performance without intending to.
Third, even if parents did try to help their child, adult performance in the task reported here is far below ceiling (Mehr et al., 2019): parents would unlikely have been confident that they knew the answers themselves.
Fourth, the large sample size afforded by the unmoderated citizen-science approach can absorb considerable noise arising from violations to task compliance. It seems unlikely, for example, that the majority of parents (i.e., thousands of people) would have intentionally disregarded the clear instructions to not interfere. This is especially the case given one reward we did provide to parents: a few minutes of free time while their child was busy completing the experiment. As much of our cohort participated during the COVID-19 pandemic, when many parents had reduced childcare resources, we suspect that many parents welcomed the opportunity to not pay attention to their child’s responses.
These considerations suggest that the risk of parental non-compliance is limited.
Results
Children’s musical inferences are accurate
Children accurately inferred the behavioral context of the songs they listened to at a rate significantly above chance level of 33.3%, both overall (Figure 2a; M = 54.1%, SD = 21.6%, p < .001) and within each song type (dance = 71.7%; lullaby = 45.7%; healing = 44.9%; ps < .001), as they did in exploratory results, and confirming the first preregistered hypothesis.
Figure 2. Accurate classification of all three song types and cohort-wide, with no effect of age.
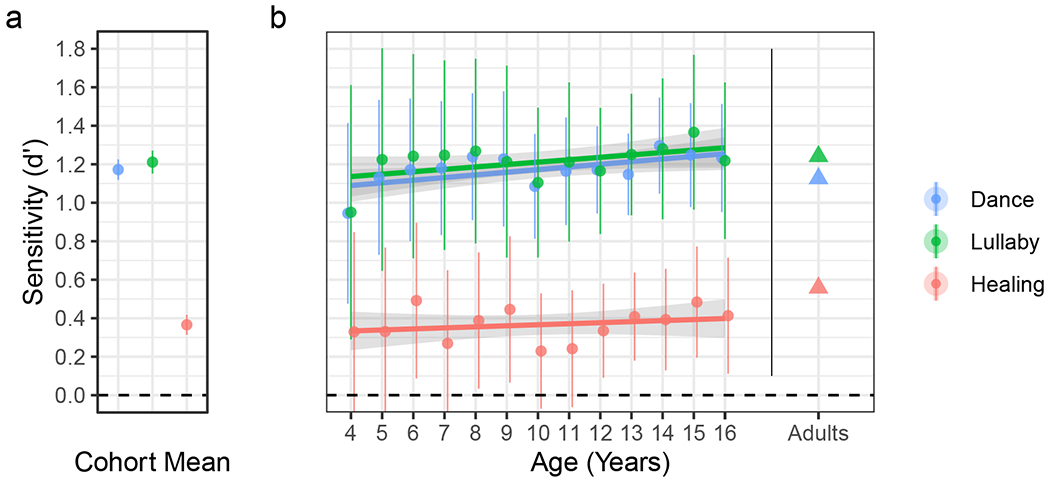
(a) Mean d-prime scores across all children show above-chance classification of each song type, independent of their response bias. (b) Above-chance sensitivity replicates for each age group, except for some of the healing song estimates whose 95% confidence-intervals crossed zero. Performance did not improve with age, either averaging across all song-types, or within dance, lullaby, or healing songs individually (ps > 0.05). As a reference, the rightmost triangular points depict performance in a similar experiment with 98,150 adults between 18 and 99 years of age (mean 31 years). Small differences in task demands make strict comparison to the children problematic, but qualitatively, they show comparable performance. In both panels, the circles indicate d-prime scores and the error bars indicate the 95% confidence intervals. In panel b, the three thick lines depict a linear regression for each song type and the shaded regions represent the 95% confidence intervals from each regression.
However, children did not use the three response options evenly (SI Figure 6a): they guessed “dance” most frequently (42.2%), followed by “healing” (36.2%), and least often guessed “lullaby” (21.6%). This is suggestive of a response bias, and as such, raw accuracy (i.e., percent correct) is difficult to interpret.
Thus, we also computed d′ scores to assess sensitivity to song function independently from response bias, doing so for the whole cohort, and for each age-group using a pooled estimator (Macmillan & Kaplan, 1985; see a simulation of the effect of this analytic choice in SI Figure 7). Lullabies were the most reliably classified (d′ = 1.21, 95% CI [1.15, 1.27], t(12) = 44.13, p < .001, d = 1.20; one-sample two-tailed t-test), closely followed by dance songs (d′ = 1.17, 95% CI [1.12, 1.23], t(12) = 47.76, p < .001, d = 1.69). Healing songs were the least reliably classified but still robustly above chance (d′ = 0.37, 95% CI [0.31, 0.42], t(12) = 15.38, p < .001, d = 0.49). Estimated criterion scores are reported in SI Figure 6b.
This principal result was robust to the inclusion or exclusion of two subgroups of participants whose reported ages were ambiguous (SI Text 1) and was consistent across subgroups of participants with different native languages and locations (SI Text 2).
Musical inferences did not appreciably improve with age
To measure the degree to which these inferences change through development, we fit a simple linear regression predicting children’s average accuracy from age. While the effect of age was statistically significant, the effect size was miniscule (F(1, 5,031) = 12.39, p < .001, R2 = 0.002), confirming our second pre-registered hypothesis. In an exploratory analysis, we tested the effect of age on d′ scores (instead of raw accuracy); the effects were comparable, with no age effect overall or in any of the song types individually (ps > 0.05).
Musical inferences are unrelated to children’s home musical environment
We tested the relationship between the frequency of parent-child musical interactions (i.e., singing or playing recorded music) and children’s musical inferences. Consistent with our third preregistered hypothesis, we found no evidence for a relationship between accuracy and the frequency of parental singing (SI Figure 8a; F(1, 5,029) = 0.84, p = 0.36), or with the frequency of recorded music (SI Figure 8b; F(1, 5,029) = 1.53, p = 0.22).
Musical inferences are highly similar between children and adults
With no substantive change in accuracy from early childhood to early adolescence, might children’s musical inferences be similar to those of adults? We used all available data from the “World Music Quiz” on https://themusiclab.org, a similar experiment for adults1 using the same general task design and stimuli (but with a fourth song type, “love songs”, and response option, “used to express love to another person”, neither of which were used in the children’s experiment). Data were available from 98,150 participants who were older than 18 years (57,436 male, 37,429 female, 2,168 other, 1,117 unknown/missing; mean age = 31.0 years, SD = 12.7, range: 18-99). We computed the song-wise proportion of guesses for each song type (i.e., a measure of how strongly each song cued a given behavioral context) within each cohort (i.e., children or adults) and regressed these scores on each other.
In all cases, children’s inferences were highly predictive of adults’, with R2 values approaching 1 (Figure 3a–c; dance: F(1, 86) = 3,008.72, R2 = 0.97; lullaby: F(1, 86) = 2,690.77, R2 = 0.97; healing: F(1, 86) = 365.45, R2 = 0.81; ps < .001), confirming our fourth pre-registered hypothesis. The strong relationship between the guesses of children and adults also held robustly across children of all ages and across the three song types, with uniformly high R2 values and slight increases in R2 through childhood (SI Figure 9).
Figure 3. Children and adults make highly similar musical inferences, which are driven by the same acoustic features.
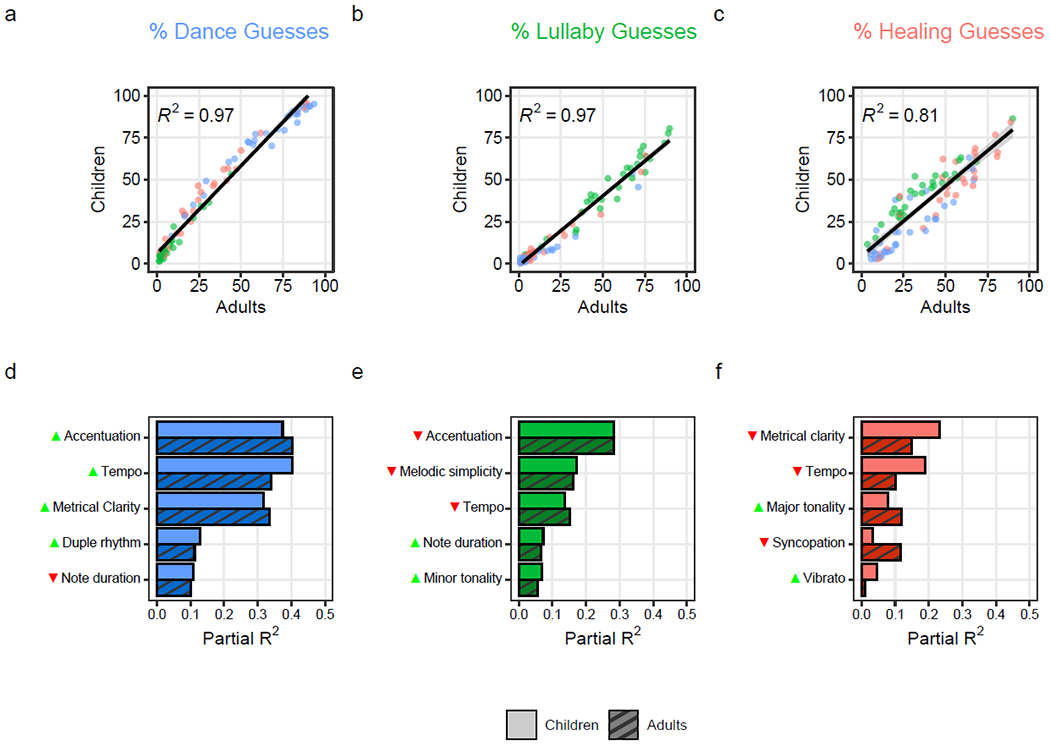
The scatterplots (a-c) show the tight correlations between children’s and adults’ musical inferences. Each point represents average percent guesses that it was (a) “for dancing”; (b) “for putting a baby to sleep”; and (c) “to make a sick person feel better”; the songs’ behavioral contexts are color-coded, with dance songs in blue, lullabies in green, and healing songs in red. The lines depict simple linear regressions and the gray shaded areas show the 95% confidence intervals from each regression. The bar plots (d-f) show the similar amounts of variance (partial-R2) in childrens’ (lighter bars) and adults’ (darker bars) guesses that is explained by musical features selected via LASSO regularization, for each of the three song types, computed from multiple regressions. The arrows beside each musical feature indicate the direction of effect, with green upwards arrows indicating increases (e.g., faster tempo) and red downward arrows indicating decreases (e.g., slower tempo).
In a more conservative, exploratory analysis, we transformed the measures of inferences from song-wise continuous scores (i.e., comparing the cohorts’ proportions of responses for each song type) to song-wise rank scores (e.g., integers from “most-guessed to be a lullaby” to “least-guessed to be a lullaby”). We quantified the strength of these relationships using the non-parametric Kendall’s rank correlation coefficient τ and found a strong positive correlation between children’s and adults’ inferences for all song types (dance: τ = 0.90; lullaby: τ = 0.85; healing: τ = 0.73; ps < .001).
Child and adult musical inferences are driven by the same acoustic correlates of musical function
As a further test of the fourth preregistered hypothesis, we explored what might drive children’s musical inferences. We analyzed which musical features were predictive of children’s guesses, within each song, and asked whether these musical features corresponded with those that were predictive of adults’ guesses.
We began with an initial set of 36 musical features (annotations from expert musicians and variables derived from transcriptions of the songs) that were previously studied in Mehr and colleagues (2019), which were z-scored to facilitate model fitting and comparison across features. To avoid overfitting, we then selected a smaller subset of the full 36 features via LASSO-regularized modeling (Friedman et al., 2016), performed separately for each song type (dance, lullaby, healing) and for each population (child, adult). Each model predicted the naive listener inferences for each of the 88 songs, and was trained with 10-fold cross-validation, repeated 10 times for robustness. We then conservatively discarded resulting model coefficients below an arbitrary threshold of 0.02 as a form of secondary regularization (erring on the side of a simpler model; further minimize overfitting).
The results lay out the musical features that most highly influence children’s and adults’ inferences for each song type (SI Table 4; which also describes the features themselves). To quantify their influence, we regressed the percentage of song-wise guesses in each category on the LASSO-selected musical features. For all three song types, the features explained substantial variability in listener inferences (dance: F(1, 82) = 45.45, R2 = 0.73; lullaby: F(1, 76) = 13.70, R2 = 0.66; healing: F(1, 81) = 20.50, R2 = 0.60; ps < .001).
Notably, the partial R2s from these models show that children’s and adults’ inferences, especially in the cases of lullabies and dance songs, were guided in a highly similar fashion: each musical feature explained a similar degree of variability in guessing behavior across the two cohorts (Figure 3d–f; full regression reporting is in SI Tables 5–7). Indeed, in a model predicting inferences from the LASSO-selected features for each song type, with a categorical variable for the cohort (children vs. adults), and interaction terms for each feature with cohort, children’s and adults’ inferences were not statistically distinguishable at the level of any musical feature (all interaction term ps > 0.05).
Children’s inferences are driven by objective acoustic correlates of musical function
Previous work demonstrated that a core set of musical features reliably distinguished dance songs, lullabies, and healing songs from one another across 30 world regions (Mehr et al., 2019). In an exploratory test of our fifth preregistered hypothesis, we tested the degree to which chilren’s inferences reflected these universal musical biases.
We first trained a LASSO multinomial logistic classifier to infer song type from the acoustic features, trained with leave-one-out cross-validation at the level of world region. We then derived predictions for each song in the corpus such that the predictions for songs in a given world-region were based on information from only songs in other regions. This yielded groupings of three probabilities per song (e.g., for an ambiguous song, the model might predict [0.3 dance; 0.3 lullaby; 0.4 healing], whereas for a less ambiguous song, the model might predict [0.8 dance; 0.0 lullaby; 0.2 healing]).
We asked how similar these groupings were to the songwise guessing proportions derived from the children’s responses. We found strong positive correlations for dance inferences (r = 0.80) and lullaby inferences (r = 0.67), and a moderate correlation for healing inferences (r = 0.43). Thus, children’s inferences, which, of course, are made without any explicit reference to acoustic features, were shaped by many of the same general acoustic features that objectively characterize song types across cultures.
This was not the case across all musical features, however. In contrast to the model comparing children and adults (above), where the two cohorts’ inferences could not be reliably distinguished on the basis of particular musical features (i.e., feature-by-cohort interaction terms were non-significant), we found some reliable differences in how the musical features operated worldwide and how they influenced children’s inferences.
In a model predicting song-wise probabilities from the LASSO-selected features for each song type, with a categorical variable for the data type (children’s inferences vs. objective classification), and interaction terms for each feature with data type, we found several statistically significant differences. For example, children were more likely to rate a song as “for dancing” when it had more rhythmic accentuation, faster tempo, greater metrical clarity, more duple rhythm, and shorter note durations, but in each case, children over-estimated their importance relative to the modeled objective differences (interaction ps < .05; see the full models in SI Tables 8–10). But the high degree of similarity between children’s and adults’ inferences suggests that the two groups make such errors in similar fashions, deviating from the features that reliably distinguish song types from one another worldwide.
Discussion
We found that children make accurate inferences concerning the behavioral contexts of unfamiliar foreign lullabies, dance songs, and healing songs. The songs were unfamiliar to the children and drawn from a representative sample of vocal music from 70 human societies, but their guessing patterns were well above chance and strikingly similar to those of adults. Older children (teenagers) performed no better than the youngest children in our sample (age 4), who already performed at adult-like levels. Musical exposure in the home, from either recorded music or parental singing, was also unrelated to children’s performance. These results suggest that the ability to infer musical function from acoustical forms, at least in the contexts studied here, develops early and requires minimal direct experience.
The similarities in children’s and adults’ inferences were detectable even at the level of individual musical features of each song. For example, faster tempo, more stable beat structure, and more rhythmic accentuation, led listeners to guess that a song was used for dancing; less rhythmic accentuation and slower tempo cued listeners that a song was used as a lullaby; and songs with a slower tempo and less beat stability suggested that a song was used for healing. Children’s inferences were also robustly correlated with those of a classifier trained on the objective acoustic differences in the corpus, demonstrating a link between early perceptual intuitions and universal acoustic biases that shape human music production. This link, and the few cases where children’s intuitions differed from universal biases, present an intriguing target for future research.
What explains these robust associations between musical features and functional inferences? We speculate that they tie into the prototypical emotional and physiological content of songs’ behavioral contexts. Across cultures, dance songs typically aim to increase arousal (e.g., energizing groups of people to dance) whereas lullabies aim to decrease it (e.g., soothing an infant: Hilton et al., 2022; Mehr et al., 2019). This is mirrored in the arousal-mediating effects of both rhythmic accentuation (Weninger et al., 2013; Ilie & Thompson, 2006; Schubert, 2004) and tempo (Yamamoto et al., 2007; Husain et al., 2002; Balch & Lewis, 1996; Holbrook & Anand, 1990). As in other universal acoustic form-function mappings (Perlman et al., 2021; Patten et al., 2018; Fitch et al., 2002; Fitch, 1997), this relationship may be grounded in the physics of sound production: the production of sounds with high tempo and accentuation, for example, requires more energy than does the production of slower, less accentuated sounds. These features are thus associated with higher arousal. Indeed, from a young age, infant arousal is reliably modulated by these features (Bainbridge et al., 2021; Cirelli et al., 2019).
Beat stability was also predictive of “used for dancing” inferences. Dancing characteristically involves temporal coordination, often between people and a perceived musical beat. As such, the more stable the beat, the more reliable it is as a cue to support temporal coordination. Children may naturally make this connection via the psychological effects of “groove”, an impulse for rhythmic body movement in response to music with high beat stability, fast tempos, more rhythmic accentuation, and a moderate amount of rhythmic complexity (Witek et al., 2014; Janata et al., 2012). In both children and adults, these features were the strongest predictors of “used for dancing” inferences, and there is some evidence that infants as young as 5 months share such impulses linking rhythmic musical features to movement (Zentner & Eerola, 2010).
The acoustic correlates of healing songs are more difficult to interpret. Their traditional behavioral context tends to be characterized by formal and religious activity across cultures (Mehr et al., 2019), such as those found in shamanistic healing rituals (Singh, 2018). But these rituals sometimes include dancing, and may thus constitute a fuzzier and less distinct category than dance or lullaby; for example, among both children and adults, the song most consistently categorized as a dance song (96% of the time) was, in fact, a healing song. The weaker discriminability of healing songs by naive listeners, and the weaker correlations between human inferences and objective distinguishing features underscores this fuzziness. This fuzziness is also germane to the behavioral context of healing songs more broadly, since a person’s health is rarely externally observable, unlike the relatively more concrete referents of babies sleeping and people dancing. Indeed, Singh (2018) argues that healing rituals often function in part to signal a healer’s otherworldliness and ability to transact with unobserved spiritual causes of health. So while music appears universally in the context of healing (Mehr et al., 2019; Singh, 2018), and has well-recognized potential in modern clinical settings (Cheever et al., 2018), the mechanisms and acoustical correlates of inferences about traditional healing songs are far less clear and require further study.
Together, our findings suggest that some form-function inferences about music may be more maturational rather than experiential in origin: requiring minimal direct experience to develop an initial capacity. Many other facets of music perception develop precocially in this way, including beat processing (Zentner & Eerola, 2010; Winkler et al., 2009; Phillips-Silver, 2005); sensitivity to basic tonal structure (Perani et al., 2010; Lynch & Eilers, 1992); prenatally present attentional orientations to music (Granier-Deferre et al., 2011); biases for socially-relevant musical information (Mehr et al., 2016; Mehr & Spelke, 2017); and indeed, distinct physiological responses to lullabies, relative to non-lullabies (Bainbridge et al., 2021). Some of these abilities continue to develop with experience; for example, in the first year of life, the perception of metrical (Hannon & Trehub, 2005) and tonal (Lynch et al., 1990) structures becomes tuned to regularities of the infants’ native musical culture, and later stages of this can even continue past 12 years of age in ways that depend upon rich experiential input (Brandt et al., 2012). By contrast, the present findings show an adult-like competence as late as 4 years of age (and potentially earlier; see SI Text 1), irrespective of variation in musical exposure.
This is not to say that experience does not shape listeners’ understanding of music. Experience shapes many facets of musicality, from musical preferences (Schellenberg et al., 2008; Peretz et al., 1998), to the enculturation of extramusical associations (Margulis et al., 2022). Experience can even exert subtle influences on our perception of basic structures of rhythm (Drake & Heni, 2003) and pitch (Jacoby et al., 2019); the influences need not be limited to musical experience, as shown by the effect of linguistic experiences on music processing (Liu et al., 2021). And while we studied a relatively diverse sample of children and a highly diverse set of recordings (see SI Tables 1–3), we did not systematically sample diverse experiences: the study instructions were in English and the children were recruited via an English-language website. These limitations suggest a need for further studies conducted in multiple languages and recruiting from a wide variety of geographic regions, so as to better characterize the potential effects of early musical experience on listeners’ understanding of music.
Our results raise the possibility that some forms of musical meaning may not be entirely experience-dependent, building instead on instinctive signalling mechanisms, not unlike those thought to govern many nonhuman-animal vocalizations (Mehr et al., 2021). From this perspective, foundations for musical understanding come from the combination of acoustic predispositions, shared with other species (Kamiloğlu et al., 2020; Filippi et al., 2017; Owren & Rendall, 2001); human-unique social-cognitive skills and biases (Herrmann et al., 2007), which play a key role in early learning (Liberman et al., 2017; Kinzler et al., 2007; Baldwin et al., 1996), including in music (Mehr & Krasnow, 2017; Xiao et al., 2017; Mehr et al., 2016); and their interaction with related modalities, such as movement and emotion (Sievers et al., 2019, 2013).
Thus, despite the variety of roles that music plays in our lives and the different meanings it can afford, shaped by culture and experience, the results reported here suggest that aspects of our musical intuitions are rooted in our biology. The psychology of music, like other acoustic predispositions, may develop as a natural component of the human mind.
Context of the research
This research builds on previous studies from our group (Mehr et al., 2019, 2018; Hilton et al., 2022), demonstrating (a) cross-cultural regularities in the associations between acoustical forms of music and particular behavioral contexts in which music appears; and (b) the sensitivity of adults to these associations. Here, we explored how musical experience in childhood shapes that sensitivity, using the same stimuli as previous work. We also compared children’s intuitions about music to adults’ directly, and analyzed how these intuitions correlate with specific musical features (providing clues about the mechanisms underlying the main effects). The results complement those of another recent study (Bainbridge et al., 2021), where infants showed differential physiological responses to unfamiliar foreign lullabies, relative to non-lullabies; those early-appearing, implicit responses to different forms of music, may help to explain children’s high performance in classifying behavioral contexts for music. Together, these studies inform theories of the basic design features of a human psychology of music, including debates surrounding the biological foundations of music (Mehr et al., 2020) and its relation to more general aspects of cognition (Hilton et al., 2020).
Supplementary Material
Acknowledgments
We thank all the families who participated in this research; C. Bainbridge, A. Bergson, M. Dresel, and J. Simson for assistance with designing and implementing the experiment; and L. Yurdum for helpful comments on the manuscript.
Funding Information
This research was supported by the Harvard Data Science Initiative (S.A.M.) and the National Institutes of Health Director’s Early Independence Award DP5OD024566 (S.A.M. and C.B.H.).
Footnotes
Note that a portion of these data were previously reported in Mehr and colleagues -Mehr et al. (2019) but were not analyzed in relation to children’s performance.
Author Note. All data and materials, including a reproducible version of this manuscript with all analysis and visualization code, are available at https://github.com/themusiclab/form-function-kids. Audio excerpts from the Natural History of Song Discography are available at https://osf.io/vcybz and can be explored interactively at https://themusiclab.org/nhsplots. The study was preregistered at https://osf.io/56zne. For assistance, please contact C.B.H., L.C-T., and S.A.M.
References
- Bainbridge CM, Bertolo M, Youngers J, Atwood S, Yurdum L, Simson J, Lopez K, Xing F, Martin A, & Mehr SA (2021). Infants relax in response to unfamiliar foreign lullabies. Nature Human Behaviour. 10.1038/s41562-020-00963-z [DOI] [PMC free article] [PubMed] [Google Scholar]
- Balch WR, & Lewis BS (1996). Music-Dependent Memory: The Roles of Tempo Change and Mood Mediation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10. [Google Scholar]
- Baldwin DA, Markman EM, Bill B, Desjardins RN, Irwin JM, & Tidball G (1996). Infants’ Reliance on a Social Criterion for Establishing Word-Object Relations. Child Development, 20. [PubMed] [Google Scholar]
- Balkwill L-L, & Thompson WF (1999). A cross-cultural investigation of the perception of emotion in music: Psychophysical and cultural cues. Music Perception, 17(1), 43–64. 10.2307/40285811 [DOI] [Google Scholar]
- Bergeson T, & Trehub S (1999). Mothers’ singing to infants and preschool children. Infant Behavior and Development, 22(1). [Google Scholar]
- Blasi DE, Wichmann S, Hammarström H, Stadler PF, & Christiansen MH (2016). Soundmeaning association biases evidenced across thousands of languages. Proceedings of the National Academy of Sciences, 113(39), 10818–10823. 10.1073/pnas.1605782113 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bohn M, & Frank MC (2019). The Pervasive Role of Pragmatics in Early Language. Annual Review of Developmental Psychology, 29. [Google Scholar]
- Bonneville-Roussy A, Rentfrow PJ, Xu MK, & Potter J (2013). Music through the ages: Trends in musical engagement and preferences from adolescence through middle adulthood. Journal of Personality and Social Psychology, 105(4), 703–717. 10.1037/a0033770 [DOI] [PubMed] [Google Scholar]
- Brandt A, Gebrian M, & Slevc LR (2012). Music and Early Language Acquisition. Frontiers in Psychology, 3. 10.3389/fpsyg.2012.00327 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheever T, Taylor A, Finkelstein R, Edwards E, Thomas L, Bradt J, Holochwost SJ, Johnson JK, Limb C, Patel AD, Tottenham N, Iyengar S, Rutter D, Fleming R, & Collins FS (2018). NIH/Kennedy Center workshop on music and the brain: Finding harmony. Neuron, 97(6), 1214–1218. 10.1016/j.neuron.2018.02.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chronaki G, Wigelsworth M, Pell MD, & Kotz SA (2018). The development of cross-cultural recognition of vocal emotion during childhood and adolescence. Scientific Reports, 8(1), 8659. 10.1038/s41598-018-26889-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cirelli LK, Jurewicz ZB, & Trehub SE (2019). Effects of maternal singing style on motherinfant arousal and behavior. Journal of Cognitive Neuroscience. 10.1162/jocn_a_01402 [DOI] [PubMed] [Google Scholar]
- Coppock A (2019). Generalizing from Survey Experiments Conducted on Mechanical Turk: A Replication Approach. Political Science Research and Methods, 7(3), 613–628. 10.1017/psrm.2018.10 [DOI] [Google Scholar]
- Cowen AS, Laukka P, Elfenbein HA, Liu R, & Keltner D (2019). The primacy of categories in the recognition of 12 emotions in speech prosody across two cultures. Nature Human Behaviour, 3(4), 369–382. 10.1038/s41562-019-0533-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Darwin C (1871). The descent of man. Watts & Co. [Google Scholar]
- Drake C, & Heni JBE (2003). Synchronizing with Music: Intercultural Differences. Annals of the New York Academy of Sciences, 999(1), 429–437. 10.1196/annals.1284.053 [DOI] [PubMed] [Google Scholar]
- Filippi P, Congdon JV, Hoang J, Bowling DL, Reber SA, Pašukonis A, Hoeschele M, Ocklenburg S, Boer B. de, Sturdy CB, Newen A, & Güntürkün O (2017). Humans recognize emotional arousal in vocalizations across all classes of terrestrial vertebrates: Evidence for acoustic universals. Proceedings of the Royal Society B: Biological Sciences, 284(1859). 10.1098/osf.io/rspb.2017.0990 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fitch WT (1997). Vocal tract length and formant frequency dispersion correlate with body size in rhesus macaques. The Journal of the Acoustical Society of America, 11. [DOI] [PubMed] [Google Scholar]
- Fitch WT, Neubauer J, & Herzel H (2002). Calls out of chaos: The adaptive significance of nonlinear phenomena in mammalian vocal production. Animal Behaviour, 63(3), 407–418. 10.1006/anbe.2001.1912 [DOI] [Google Scholar]
- Friedman J, Hastie T, & Tibshirani R (2016). Lasso and elastic-net regularized generalized linear models. Rpackage version 2.0-5. [Google Scholar]
- Germine L, Nakayama K, Duchaine BC, Chabris CF, Chatterjee G, & Wilmer JB (2012). Is the Web as good as the lab? Comparable performance from Web and lab in cognitive/perceptual experiments. Psychonomic Bulletin & Review, 19(5), 847–857. 10.3758/s13423-012-0296-9 [DOI] [PubMed] [Google Scholar]
- Granier-Deferre C, Bassereau S, Ribeiro A, Jacquet A-Y, & DeCasper AJ (2011). A melodic contour repeatedly experienced by human near-term fetuses elicits a profound cardiac reaction one month after birth. PLoS ONE, 6(2). 10.1371/journal.pone.0017304 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hale S (1990). A Global Developmental Trend in Cognitive Processing Speed. Child Development, 61(3), 653–663. [PubMed] [Google Scholar]
- Hannon EE, & Trehub SE (2005). Metrical categories in infancy and adulthood. Psychological Science, 16(1), 48–55. [DOI] [PubMed] [Google Scholar]
- Hartshorne JK, de Leeuw J, Goodman N, Jennings M, & O’Donnell TJ (2019). A thousand studies for the price of one: Accelerating psychological science with Pushkin. Behavior Research Methods, 51, 1782–1803. 10.3758/s13428-018-1155-z [DOI] [PubMed] [Google Scholar]
- Herrmann E, Call J, Hernàndez-Lloreda MV, Hare B, & Tomasello M (2007). Humans Have Evolved Specialized Skills of Social Cognition: The Cultural Intelligence Hypothesis. Science, 317(5843), 1360–1366. 10.1126/science.1146282 [DOI] [PubMed] [Google Scholar]
- Hilton CB, Asano R, & Boeckx CA (2020). Why musical hierarchies? Behavioral and Brain Sciences. [DOI] [PubMed] [Google Scholar]
- Hilton CB, Crowley L, Yan R, Martin A, & Mehr SA (2021, May 14). Children accurately infer behavioral contexts of unfamiliar foreign music. Retrieved from osf.io/b9tnu [DOI] [PMC free article] [PubMed]
- Hilton CB, & Mehr SA (2022). Citizen science can help to alleviate the generalizability crisis. Behavioral and Brain Sciences. [DOI] [PubMed] [Google Scholar]
- Hilton CB, Moser CJ, Bertolo M, Lee-Rubin H, Amir D, Bainbridge CM, Simson J, Knox D, Glowacki L, Alemu E, Galbarczyk A, Jasienska G, Ross CT, Neff MB, Martin A, Cirelli LK, Trehub SE, Song J, Kim M, … Mehr SA (2022). Acoustic regularities in infant-directed speech and song across cultures. Nature Human Behaviour. 10.1101/2020.04.09.032995 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holbrook MB, & Anand P (1990). Effects of Tempo and Situational Arousal on the Listener’s Perceptual and Affective Responses to Music. Psychology of Music, 18(2), 150–162. 10.1177/0305735690182004 [DOI] [Google Scholar]
- Huber B, & Gajos KZ (2020). Conducting online virtual environment experiments with uncompensated, unsupervised samples. PLOS ONE, 15(1), e0227629. 10.1371/journal.pone.0227629 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Husain G, Thompson WF, & Schellenberg EG (2002). Effects of Musical Tempo and Mode on Arousal, Mood, and Spatial Abilities. Music Perception, 20(2), 151–171. 10.1525/mp.2002.20.2.151 [DOI] [Google Scholar]
- Ilie G, & Thompson WF (2006). A Comparison of Acoustic Cues in Music and Speech for Three Dimensions of Affect. Music Perception, 23(4), 319–330. 10.1525/mp.2006.23.4.319 [DOI] [Google Scholar]
- Imai M, Kita S, Nagumo M, & Okada H (2008). Sound symbolism facilitates early verb learning. Cognition, 109(1), 54–65. 10.1016/j.cognition.2008.07.015 [DOI] [PubMed] [Google Scholar]
- Jacoby N, Undurraga EA, McPherson MJ, Valdés J, Ossandón T, & McDermott JH (2019). Universal and non-universal features of musical pitch perception revealed by singing. Current Biology, 29(19), 3229–3243. 10.1016/j.cub.2019.08.020 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Janata P, Tomic ST, & Haberman JM (2012). Sensorimotor coupling in music and the psychology of the groove. Journal of Experimental Psychology: General, 141(1), 54–75. 10.1037/a0024208 [DOI] [PubMed] [Google Scholar]
- Kamiloğlu RG, Slocombe KE, Haun DB, & Sauter DA (2020). Human listeners’ perception of behavioural context and core affect dimensions in chimpanzee vocalizations. Proceedings of the Royal Society B, 287(1929), 20201148. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kinzler KD, Dupoux E, & Spelke ES (2007). The native language of social cognition. Proceedings of the National Academy of Sciences, 104(30), 12577–12580. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kiselev S, Espy KA, & Sheffield T (2009). Age-related differences in reaction time task performance in young children. Journal of Experimental Child Psychology, 102(2), 150–166. 10.1016/j.jecp.2008.02.002 [DOI] [PubMed] [Google Scholar]
- Krumhansl CL (2010). Plink: “Thin Slices” of Music. Music Perception, 27(5), 337–354. 10.1525/mp.2010.27.5.337 [DOI] [Google Scholar]
- Levitin DJ, & Cook PR (1996). Memory for musical tempo: Additional evidence that auditory memory is absolute. Perception & Psychophysics, 58(6), 927–935. 10.3758/BF03205494 [DOI] [PubMed] [Google Scholar]
- Li W, Germine LT, Mehr SA, Srinivasan M, & Hartshorne J (2022). Developmental psychologists should adopt citizen science to improve generalization and reproducibility. Infant and Child Development, 23. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liberman Z, Woodward AL, & Kinzler KD (2017). The Origins of Social Categorization. Trends in Cognitive Sciences, 21(7), 556–568. 10.1016/j.tics.2017.04.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu J, Hilton CB, Bergelson E, & Mehr SA (2021). Language experience shapes music processing across 40 tonal, pitch-accented, and non-tonal languages. bioRxiv. 10.1101/2021.10.18.464888 [DOI] [Google Scholar]
- Lomax A (1968). Folk song style and culture. American Association for the Advancement of Science. [Google Scholar]
- Lynch MP, & Eilers RE (1992). A study of perceptual development for musical tuning. Perception & Psychophysics, 52(6), 599–608. 10.3758/BF03211696 [DOI] [PubMed] [Google Scholar]
- Lynch MP, Eilers RE, Oller DK, & Urbano RC (1990). Innateness, Experience, and Music Perception. Psychological Science, 1(4), 272–276. 10.1111/j.1467-9280.1990.tb00213.x [DOI] [Google Scholar]
- Ma W, & Thompson WF (2015). Human emotions track changes in the acoustic environment. Proceedings of the National Academy of Sciences, 112(47), 14563–14568. 10.1073/pnas.1515087112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Macmillan NA, & Kaplan HL (1985). Detection Theory Analysis of Group Data: Estimating Sensitivity From Average Hit and False-Alarm Rates. Psychological Bulletin, 15. [PubMed] [Google Scholar]
- Margulis EH, Wong PCM, Turnbull C, Kubit BM, & McAuley JD (2022). Narratives imagined in response to instrumental music reveal culture-bounded intersubjectivity. Proceedings of the National Academy of Sciences, 119(4), e2110406119. 10.1073/pnas.2110406119 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martin A, Onishi KH, & Vouloumanos A (2012). Understanding the abstract role of speech in communication at 12months. Cognition, 123(1), 50–60. 10.1016/j.cognition.2011.12.003 [DOI] [PubMed] [Google Scholar]
- Mehr SA (2014). Music in the home: New evidence for an intergenerational link. Journal of Research in Music Education, 62(1), 78–88. 10.1177/0022429413520008 [DOI] [Google Scholar]
- Mehr SA, & Krasnow MM (2017). Parent-offspring conflict and the evolution of infant-directed song. Evolution and Human Behavior, 38(5), 674–684. 10.1016/j.evolhumbehav.2016.12.005 [DOI] [Google Scholar]
- Mehr SA, Krasnow MM, Bryant GA, & Hagen EH (2020). Origins of music in credible signaling. Behavioral and Brain Sciences, 1–41. 10.1017/S0140525X20000345 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mehr SA, Krasnow M, Bryant GA, & Hagen EH (2021). Origins of music in credible signaling. Behavioral and Brain Sciences. 10.31234/osf.io/nrqb3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mehr SA, Singh M, Knox D, Ketter DM, Pickens-Jones D, Atwood S, Lucas C, Jacoby N, Egner AA, Hopkins EJ, Howard RM, Hartshorne JK, Jennings MV, Simson J, Bainbridge CM, Pinker S, O’Donnell TJ, Krasnow MM, & Glowacki L (2019). Universality and diversity in human song. Science, 366(6468), 957–970. 10.1126/science.aax0868 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mehr SA, Singh M, York H, Glowacki L, & Krasnow MM (2018). Form and function in human song. Current Biology, 28(3), 356–368. 10.1016/j.cub.2017.12.042 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mehr SA, Song LA, & Spelke ES (2016). For 5-month-old infants, melodies are social. Psychological Science, 27(4), 486–501. 10.1177/0956797615626691 [DOI] [PubMed] [Google Scholar]
- Mehr SA, & Spelke ES (2017). Shared musical knowledge in 11-month-old infants. Developmental Science, 21(2). [DOI] [PubMed] [Google Scholar]
- Mendoza JK, & Fausey CM (2021). Everyday music in infancy. Developmental Science. 10.31234/osf.io/sqatb [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morton ES (1977). On the occurrence and significance of motivation-structural rules in some bird and mammal sounds. The American Naturalist, 111(981), 855–869. [Google Scholar]
- Nettl B (2005). The Study of Ethnomusicology (2nd Edition). University of Illinois Press. [Google Scholar]
- Norris RP, & Harney BY (2014). Songlines and Navigation in Wardaman and other Australian Aboriginal Cultures. Journal of Astronomical History and Heritage, 17(2), 15. [Google Scholar]
- Nuckolls JB (1999). The Case for Sound Symbolism. Annual Review of Anthropology, 28(1), 225–252. 10.1146/annurev.anthro.28.1.225 [DOI] [Google Scholar]
- Owren MJ, & Rendall D (2001). Sound on the rebound: Bringing form and function back to the forefront in understanding nonhuman primate vocal signaling. Evolutionary Anthropology, 10(2), 58–71. 10.1002/evan.1014 [DOI] [Google Scholar]
- Patten KJ, McBeath MK, & Baxter LC (2018). Harmonicity: Behavioral and Neural Evidence for Functionality in Auditory Scene Analysis. Auditory Perception & Cognition, 1(3-4), 150–172. 10.1080/25742442.2019.1609307 [DOI] [Google Scholar]
- Perani D, Saccuman MC, Scifo P, Spada D, Andreolli G, Rovelli R, Baldoli C, & Koelsch S (2010). Functional specializations for music processing in the human newborn brain. Proceedings of the National Academy of Sciences, 107(10), 4758–4763. 10.1073/pnas.0909074107 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peretz I, Gaudreau D, & Bonnel A-M (1998). Exposure effects on music preference and recognition. Memory & Cognition, 26(5), 884–902. 10.3758/BF03201171 [DOI] [PubMed] [Google Scholar]
- Perlman M, Paul J, & Lupyan G (2021). Vocal communication of magnitude across language, age, and auditory experience. Journal of Experimental Psychology: General. 10.1037/xge0001103 [DOI] [PubMed] [Google Scholar]
- Phillips-Silver J (2005). Feeling the Beat: Movement Influences Infant Rhythm Perception. Science, 308(5727), 1430–1430. 10.1126/science.1110922 [DOI] [PubMed] [Google Scholar]
- Powell LJ, & Spelke ES (2013). Preverbal infants expect members of social groups to act alike. Proceedings of the National Academy of Sciences, 110(41), E3965–E3972. 10.1073/pnas.1304326110 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ratcliff R, & Hendrickson AT (2021). Do data from mechanical Turk subjects replicate accuracy, response time, and diffusion modeling results? Behavior Research Methods, 53(6), 2302–2325. 10.3758/s13428-021-01573-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reinecke K, & Gajos KZ (2015). Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing. [Google Scholar]
- Rohrmeier M, & Rebuschat P (2012). Implicit Learning and Acquisition of Music. Topics in Cognitive Science, 4(4), 525–553. 10.1111/j.1756-8765.2012.01223.x [DOI] [PubMed] [Google Scholar]
- Saffran JR, Loman MM, & Robertson RRW (2000). Infant memory for musical experiences. Cognition, 77(1), B15–B23. 10.1016/S0010-0277(00)00095-0 [DOI] [PubMed] [Google Scholar]
- Schellenberg EG, Peretz I, & Vieillard S (2008). Liking for happy- and sad-sounding music: Effects of exposure. Cognition & Emotion, 22(2), 218–237. 10.1080/02699930701350753 [DOI] [Google Scholar]
- Scherer KR, Banse R, & Wallbott HG (2001). Emotion Inferences from Vocal Expression Correlate Across Languages and Cultures. Journal of Cross-Cultural Psychology, 32(1), 76–92. 10.1177/0022022101032001009 [DOI] [Google Scholar]
- Schubert E (2004). Modeling Perceived Emotion With Continuous Musical Features. Music Perception, 21(4), 561–585. 10.1525/mp.2004.21.4.561 [DOI] [Google Scholar]
- Sheskin M, Scott K, Mills CM, Bergelson E, Bonawitz E, Spelke ES, Fei-Fei L, Keil FC, Gweon H, Tenenbaum JB, Jara-Ettinger J, Adolph KE, Rhodes M, Frank MC, Mehr SA, & Schulz L (2020). Online developmental science to foster innovation, access, and impact. Trends in Cognitive Sciences. 10.1016/j.tics.2020.06.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sievers B, Lee C, Haslett W, & Wheatley T (2019). A multi-sensory code for emotional arousal. Proceedings of the Royal Society B, 286(1906). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sievers B, Polansky L, Casey M, & Wheatley T (2013). Music and movement share a dynamic structure that supports universal expressions of emotion. Proceedings of the National Academy of Sciences, 110(1), 70–75. 10.1073/pnas.1209023110 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Singh M (2018). The cultural evolution of shamanism. Behavioral and Brain Sciences, 41, 1–62. [DOI] [PubMed] [Google Scholar]
- Tomasello M, Carpenter M, Call J, Behne T, & Moll H (2005). Understanding and sharing intentions: The origins of cultural cognition. Behavioral and Brain Sciences, 28(05), 675–691. 10.1017/S0140525X05000129 [DOI] [PubMed] [Google Scholar]
- Trehub SE, Ghazban N, & Corbeil M (2015). Musical affect regulation in infancy. Annals of the New York Academy of Sciences, 1337(1), 186–192. 10.1111/nyas.12622 [DOI] [PubMed] [Google Scholar]
- Trehub SE, & Trainor L (1998). Singing to infants: Lullabies and play songs. Advances in Infancy Research, 12, 43–78. [Google Scholar]
- Trehub SE, Unyk AM, & Trainor LJ (1993a). Adults identify infant-directed music across cultures. Infant Behavior and Development, 16(2), 193–211. 10.1016/0163-6383(93)80017-3 [DOI] [Google Scholar]
- Trehub SE, Unyk AM, & Trainor LJ (1993b). Maternal singing in cross-cultural perspective. Infant Behavior and Development, 16(3), 285–295. [Google Scholar]
- Vouloumanos A, Martin A, & Onishi KH (2014). Do 6-month-olds understand that speech can communicate? Developmental Science, 17(6), 872–879. 10.1111/desc.12170 [DOI] [PubMed] [Google Scholar]
- Weninger F, Eyben F, Schuller BW, Mortillaro M, & Scherer KR (2013). On the Acoustics of Emotion in Audio: What Speech, Music, and Sound have in Common. Frontiers in Psychology, 4. 10.3389/fpsyg.2013.00292 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Winkler I, Háden GP, Ladinig O, Sziller I, & Honing H (2009). Newborn infants detect the beat in music. Proceedings of the National Academy of Sciences, 106(7), 2468–2471. 10.1073/pnas.0809035106 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Witek MAG, Clarke EF, Wallentin M, Kringelbach ML, & Vuust P (2014). Syncopation, Body-Movement and Pleasure in Groove Music. PLoS ONE, 9(4). 10.1371/journal.pone.0094446 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xiao NG, Quinn PC, Liu S, Ge L, Pascalis O, & Lee K (2017). Older but not younger infants associate own-race faces with happy music and other-race faces with sad music. Developmental Science. 10.1111/desc.12537 [DOI] [PubMed] [Google Scholar]
- Yamamoto M, Naga S, & Shimizu J (2007). Positive musical effects on two types of negative stressful conditions. Psychology of Music, 35(2), 249–275. 10.1177/0305735607070375 [DOI] [Google Scholar]
- Yan R, Jessani G, Spelke E, Villiers P. de, Villiers J. de, & Mehr S (2021). Across demographics and recent history, most parents sing to their infants and toddlers daily. Philosophical Transactions of the Royal Society B: Biological Sciences. 10.31234/osf.io/fy5bh [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yu CS-P, McBeath MK, & Glenberg AM (2021). The gleam-glum effect: /i:/ versus /λ/ phonemes generically carry emotional valence. Journal of Experimental Psychology: Learning, Memory, and Cognition. 10.1037/xlm0001017 [DOI] [PubMed] [Google Scholar]
- Zentner M, & Eerola T (2010). Rhythmic engagement with music in infancy. Proceedings of the National Academy of Sciences, 107(13), 5768–5773. 10.1073/pnas.1000121107 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.