

Abstract
Commonly used semiparametric estimators of causal effects specify parametric models for the propensity score (PS) and the conditional outcome. An example is an augmented inverse probability weighting (IPW) estimator, frequently referred to as a doubly robust estimator, because it is consistent if at least one of the two models is correctly specified. However, in many observational studies, the role of the parametric models is often not to provide a representation of the data‐generating process but rather to facilitate the adjustment for confounding, making the assumption of at least one true model unlikely to hold. In this paper, we propose a crude analytical approach to study the large‐sample bias of estimators when the models are assumed to be approximations of the data‐generating process, namely, when all models are misspecified. We apply our approach to three prototypical estimators of the average causal effect, two IPW estimators, using a misspecified PS model, and an augmented IPW (AIPW) estimator, using misspecified models for the outcome regression (OR) and the PS. For the two IPW estimators, we show that normalization, in addition to having a smaller variance, also offers some protection against bias due to model misspecification. To analyze the question of when the use of two misspecified models is better than one we derive necessary and sufficient conditions for when the AIPW estimator has a smaller bias than a simple IPW estimator and when it has a smaller bias than an IPW estimator with normalized weights. If the misspecification of the outcome model is moderate, the comparisons of the biases of the IPW and AIPW estimators show that the AIPW estimator has a smaller bias than the IPW estimators. However, all biases include a scaling with the PS‐model error and we suggest caution in modeling the PS whenever such a model is involved. For numerical and finite sample illustrations, we include three simulation studies and corresponding approximations of the large‐sample biases. In a dataset from the National Health and Nutrition Examination Survey, we estimate the effect of smoking on blood lead levels.
Keywords: average causal effects, comparing biases, outcome model, propensity score
1. INTRODUCTION
Identifying an average causal effect of a treatment with observational data requires adjustment for background variables that affect both the treatment and the outcome under study. Often parametric models are assumed for parts of the joint distribution of the treatment, outcome, and background variables (covariates) and large‐sample properties of estimators are derived under the assumption that the parametric models are correctly specified.
Inverse probability weighting (IPW) estimators use the difference between the weighted means of the outcomes for the treatment groups as an estimator of the average causal effect. See, for example, the early paper by Hirano et al. (2003) for a nonparametric implementation of standard IPW estimators of the average causal effect. Under an assumption of no unmeasured confounding, IPW estimators reweight the observed outcomes to represent a full sample of potential outcomes, missing and observed, by letting each observed outcome account for itself and other individuals with similar characteristics. IPW estimators can be found in applied literature (see Chang et al., 2017; Kwon et al., 2015 for examples) and their properties have been generalized by Robins, Rotnitzky, and others (Robins & Rotnitzky, 1994; Robins et al., 1995, 2000) to address both confounding bias in observational studies and bias due to missing data. Vansteelandt et al. (2010) and Seaman and White (2013) provide reviews.
Properties of IPW estimators for estimating the average causal effect under the assumption that a parametric propensity score (PS) model is correctly specified have been described (il Kim et al., 2019; Lunceford & Davidian, 2004; Yao et al., 2010). Other studies of IPW estimators includes investigating properties when using different weights, for example, stabilized (Hernán et al., 2000; Hernán & Robins, 2006), normalized (Busso et al., 2014; Hirano & Imbens, 2001), or trimmed (Ma & Wang, 2020).
To decrease reliance on the choice of a parametric model and increase the efficiency of augmented IPW (AIPW) estimators, Robins and Rotnitzky (1994) proposed including a combination of regression adjustment with weighting based on the PS. See also the review by Seaman and Vansteelandt (2018). The AIPW estimators are referred to as doubly robust (DR) estimators (Bang & Robins, 2005; Tsiatis, 2007) because they are consistent estimators of the average causal effect if either a model for the PS or the outcome regression (OR) model is correct (Scharfstein et al., 1999). The efficiency of different DR estimators is a key property and the variances of the estimators have been described under correct specification of at least one of the models (Cao et al., 2009; Tan, 2010). When both models are correct, the estimator reaches the semiparametric efficiency bound described in Robins and Rotnitzky (1994). The large‐sample properties of IPW estimators with standard, normalized and variance minimized weights, together with an AIPW estimator were studied and compared in Lunceford and Davidian (2004) under correct specification of the PS and OR models. Multiply robust estimators allow several candidate models for the PS and OR, respectively. The property of multiple robustness means that the estimators are consistent for the true average treatment effect if any one of the multiple models is correctly specified (Han & Wang, 2013).
There are few studies of doubly or multiply robust estimators under misspecification of both (all) the PS and the OR models. Kang and Schafer (2007) studied and compared the performance of an AIPW estimator for missing data under misspecification of both the PS and OR model. They concluded that many DR methods perform better than simple IPW. However, a regression‐based estimator under a misspecified model was not improved upon. The paper was commented on and the relevance of the results was discussed by several authors. See, for example, Tsiatis and Davidian (2007), Tan (2007), and Robins et al. (2007). In Waernbaum (2012), a matching estimator was compared to IPW and AIPW estimators under misspecification of both the PS and OR models. Here, a robustness class for the matching estimator under misspecification of the PS model was described. Formulated in the missing data framework, Tan (2010) evaluated several semiparametric estimators, including IPW and AIPW estimators. In the evaluation, additional criteria were proposed describing robustness classes of the estimators. Vermeulen and Vansteelandt (2015) proposed a bias‐reduced AIPW estimator that locally minimizes the squared first‐order asymptotic bias under misspecification of both working models. One of the difficulties in the estimation of PSs occurs when the treatment groups have substantially different covariate distributions resulting in some PSs being close to zero or one. This lack of overlap raises issues with respect to model specification. Parametric binary response models, such as the commonly used probit and logit models, are similar in the middle areas of their arguments. However, for probabilities closer to zero or one, they tend to differ more resulting in the specified parametric model being more influential. In Zhou et al. (2020), misspecification of the PS linked to limited overlap is investigated for causal effect estimators using balancing weights (Li et al., 2018). Comparing IPW estimators with and without trimming with overlap weights, matching weights, and entropy weights, they find in extensive simulations that the latter three methods outperform the former (IPW and trimmed IPW) with respect to bias, root‐mean‐squared error and coverage (Zhou et al., 2020).
In this paper, we describe two commonly used IPW estimators and a prototypical AIPW estimator of the average causal effect under the assumption that none of the working models is correctly specified. For this purpose, we study the difference between the probability limit of the estimator under model misspecification and the true average causal effect. The purpose of this definition of the bias is that the estimators under study converge to a well‐defined limit, that is not, however, necessarily consistent for the true average causal effect. We study the biases of the (A)IPW estimators and compare them under the same misspecification of the PS model. The three estimators contain an error involving the ratio of the true PS and the limiting misspecified PS; however, the error affects the estimators in different ways. As the biases for the three estimators can be in different directions, we describe sufficient and necessary conditions using inequalities involving the absolute value of the biases. For a simple and a normalized IPW estimator, we show that the normalization in general moderates the bias due to the PS model misspecification. Comparing the IPW estimators to the AIPW estimator, the biases provide a means to describe when two wrong models are better than one, which would normally be the case for a moderate misspecification of the outcome model. Three simulation studies are performed to investigate the biases for finite samples. The data‐generating processes and the misspecified models from the simulation designs are also used for numerical approximations of the large‐sample properties derived in the paper.
The paper proceeds as follows. Section 2 presents the model and theory together with the estimators and their properties when the working models are correctly specified. Section 3 presents a general approach and associated assumptions to study model misspecification. In Section 4, the generic biases are derived and comparisons between the estimators are performed. We present three simulation studies in Section 5 containing both finite sample properties of the estimators and numerical large‐sample approximations. We apply the estimators under study on an observational dataset in Section 6 where we evaluate the effect of smoking on blood lead levels, and thereafter we conclude with a discussion.
2. MODEL AND THEORY
The potential outcome framework defines a causal effect as a comparison of potential outcomes that would be observed under different treatments (Rubin, 1974). Let X be a vector of pretreatment variables, referred to as covariates, T a binary treatment, with realized value if treated and if control. Under SUTVA (Rubin, 1980), the causal effect of the treatment is defined as a contrast between two potential outcomes, for example, the difference, , where Y(1) is the potential outcome under treatment and Y(0) is the potential outcome under the control treatment. The observed outcome Y is assumed to be the potential outcome for each level of the treatment , so that the data vector that we observe is , where are assumed independent and identically distributed copies. In the remainder of the paper, we will drop the subscript i for the random variables when not needed. Since each individual only can be subject to one treatment, either Y(1) or Y(0) will be missing. If the treatment is randomized, the difference between the sample averages of the treated and controls will be an unbiased estimator of the average causal effect , the parameter of interest. In the following, we will use the notation , for the marginal expectations and , for their conditional counterparts. We denote the probability of being treated conditional on the covariates, the PS by . When the treatment is not assigned randomly,common identification criteria include assumptions of no unmeasured confounding and overlap:
Assumption 1:
(No unmeasured confounding) ,
Assumption 2:
(Overlap) , and some ,
where the assumption that is bounded away from zero and one guarantees the existence of a consistent estimator (Khan & Tamer, 2010). Under Assumptions 1 and 2, we can estimate the average causal effect by weighting the observed outcomes with the inverse of the PSs, because
leading to an estimator defined by:
| (1) |
A common version of the simple IPW estimator in (1) is an IPW estimator with normalized weights
| (2) |
Using parametric IPW, we assume a finite‐dimensional model for .
Assumption 3:
(PS model) The PS follows a model parameterized by, , and is the estimated PS , with a consistent estimator of β.
Under Assumptions 1–3, the IPW estimators are consistent estimators of the average causal effect Δ with asymptotic distribution , . Asymptotic properties of (1) and (2) are described in Lunceford and Davidian (2004) under an assumption of a logistic regression model for the treatment assignment.
Similar to the modeling of the PS, it can be assumed that the OR follows a parametric model , .
Assumption 4:
(OR model) The conditional expectation, , , follows a model , parameterized by , and is the estimated OR , with a consistent estimator of .
In addition, we study a prototypical AIPW estimator (Lunceford & Davidian, 2004; Tsiatis, 2007)
| (3) |
Under Assumptions 1–4 and regularity conditions, the large‐sample distribution is .
For example, a model assumption for the treatment assignment could be a logistic regression model with the fitted values of the PS when is a maximum likelihood estimator of β. The OR model could be a linear model where , are the fitted values when is the ordinary least squares estimator.
3. MODEL MISSPECIFICATION
Our interest lies in the behaviors of the estimators when the PS and the OR models are misspecified. For this purpose, we replace Assumptions 3 and 4 with two other assumptions defining the probability limit of the estimators under a general misspecification. The misspecifications will further be used to define a general bias of the IPW and DR estimators. When the PS is misspecified an estimator, for example, a quasi‐maximum likelihood estimator (QMLE) is not consistent for β in Assumption 3. However, a probability limit for an estimator under model misspecification exists under general conditions, see, for example, White (1982, Theorem 2.2) for QMLE or Wooldridge (2010, Section 12.1) and Boos and Stefanski (2013, Theorem 7.1) for estimators that can be written as a solution of an estimating equation (M‐estimators).
In the following, and as an alternative to Assumptions 1 and 4, we will assume that such limits exist. Below we define an estimator of the PS under a misspecified model .
Assumption 5
(Misspecified PS‐model parameters) Let be an estimator under model misspecification, , then .
Under model misspecification, the probability limit of is generally well defined; however, is not equal to the true PS . In the following, we use the notation as the estimated PS under model misspecification and under Assumption 5. Below we give an example for true and misspecified parametric models, however, for Assumption 5, we do not need the existence of a true parametric model. We use the concept of quasi‐maximum likelihood used for maximum likelihood estimators when parts of the distribution are misspecified.
Example 1
For one confounder X and a true PS model, assume that we misspecify the PS with a probit model , that is, we misspecify the link function and omit a second‐order term. Let be the QML estimator of the parameters in obtained by maximizing the quasi‐likelihood
Then , under Assumption 5 and , where Ψ() is the CDF of a standard normal random variable.
When considering the existence of true and misspecified parametric models, as illustrated in Example 1, the parameters in β and the limiting parameters under the misspecified model need not to be of the same dimension. For instance, the true model could contain higher order terms and interactions that are not present in the estimation model.
The next assumption concerns overlap under model misspecification.
Assumption 6:
(Overlap under misspecification) , for some .
In addition to the PS model, we also consider misspecified OR models, , . Denote by , the estimator of the parameters in .
Assumption 7:
(Misspecified OR model parameters) Let be an estimator under model misspecification , , then , .
In the following, we use the notation as the estimated OR under model misspecification and under Assumption 7 and for the expected value , .
Assumptions 5 and 7 are defined for misspecified PS and OR models for the purpose of describing their influence on the estimation of Δ. The estimators (1)–(3) can be written by estimating equations where the equations solving for the PS and OR parameters are set up below the main equation for the (A)IPW estimators. See, for example, Lunceford and Davidian (2004) and Williamson et al. (2014). Assuming parametric PS and OR models, the IPW estimators correspond to solving estimating equations for the parameters , , and for the AIPW estimator estimating equations for the parameters . Using the notation for the misspecified models in Assumptions 5 and 7, the estimating equations change according to the dimensions of the parameters and , . A key condition for Assumptions 5 and 7 to hold is that the misspecification of the PS and/or OR provides estimating equations that uniquely define the parameters and , , although, as a consequence of the misspecification, the resulting (A)IPW estimators will be biased. In the next section, we present the asymptotic bias for the (A)IPW estimators under study with general expressions including the limits of the misspecified PS and OR models.
4. BIAS RESULTING FROM MODEL MISSPECIFICATION
4.1. General biases
We study the large‐sample bias of , , and under model misspecification and define the estimators , , and by replacing in Equations (1)–(3) with . For the AIPW estimator, we additionally replace with , .
To assess the properties of the estimators, we assume 1, 2, 5, 6, and 7 and regularity conditions (see Appendix A.1). We evaluate the difference between the probability limits of the estimators under model misspecification and the average causal effect Δ for the (A)IPW estimators.
Under Assumptions 1–2 and 5–6, the biases under model misspecification for and are
| (4) |
| (5) |
Under Assumptions 1–2 and 5–7, the bias under model misspecification for is
| (6) |
We refer to Equations (4)–(6) as the biases of the respective estimators, that is, Bias, Bias, and Bias although they are the difference between the probability limits of the estimators and the true Δ and not the difference in expectations. The double robustness property of is displayed by Equation (6) because if either or , , we have that .
4.2. Comparisons
The consequences of model misspecification for the estimators, respectively, can further be investigated from the general biases in Equations (4)–(6).
To study the role of the model misspecification, we compare the biases in Section 4.1 for two separate parts of the estimator. The first part concerns the bias with respect to μ1 and the second part with respect to μ0. The motivation behind this component‐wise comparison is that if each of the estimators of is unbiased, then the resulting estimator of is also unbiased. The inverse relationship between the model errors and has the result that the contribution to the overall bias from μ1 and μ0 may, in general, be of the same sign (see Appendix A.3). We define , , and as
| (7) |
| (8) |
| (9) |
For , the expression in (7) shows that the bias consists of a scaling between the model error and the conditional outcome . If the distribution of is positively skewed resulting in over estimation of the weighted mean , we see that for , the bias is mitigated because . A similar effect is obtained for a negatively skewed distribution of where . There is no correspondence to this bias reduction for .
The sign of the two biases in (7) and in (8) depends on the covariance of the PS‐model errors and the conditional outcome , because
and
implying that the biases can be in different directions for the same model misspecification. Here, depends only on the sign of the covariance, , whereas this is not the case for . It is not surprising that the covariance of and plays a role for the bias of the estimators. If was a constant, it could be taken out of the expectations of the first terms in (7) and (8) and the PS‐model ratio, , would be canceled by the denominator in (8). In this case, the bias for would be 0.
Next, we investigate inequalities involving the absolute values of the biases in Equations (7)–(9). (All derivations are given in Appendix A.3). The results can be directly applied for μ0 by replacing , with and with , see Appendix A.3.
First, to study the role of normalization for the IPW estimators, we compare and .
A sufficient and necessary condition for
| (10) |
is that
| (11) |
That is, the absolute value of the covariance between the PS‐model ratio and the conditional outcome is smaller than the absolute value of scaled with the PS‐model ratio.
To study the issue of misspecifying two models instead of one, we investigate the difference between the bias of the IPW estimators (7) and (8) and the bias of the AIPW estimator (9). We give a necessary condition for the bias of the AIPW estimator to be smaller than the bias of the simple IPW estimator:
If
then
| (12) |
By (12), we see that if the AIPW estimator improves upon the simple IPW estimator under misspecification of both the PS and the OR model, then the absolute value of the misspecified outcome model is less than double the absolute value of the true conditional mean under the same scaling of the PS‐model error, .
A sufficient condition for the AIPW estimator to have a smaller bias than the simple IPW estimator can be expressed as a comparison between the misspecified OR model and the true conditional outcomes under the same PS‐model error.
If
| (13) |
are either both positive or both negative, then .
To provide a numerical example, we assume a second‐order model in one variable and obtain the misspecified models' limits by omitting the second order term in both the PS (logistic regression) and the OR model (linear model). We use numerical approximations to provide values for the parameters in and , under the given true and misspecified models.
Example 2
For a covariate and a binary treatment , we assume a logistic PS model and a linear conditional outcome and misspecified nonlinearities in the models
In this example, we have that the inequality in (11) holds
We expect based on previous calculations that . Here, we have that Bias, Bias, confirming the result. To compare Bias with Bias, we check to see that
are both positive, which is consistent with the sufficient conditions for
of Equation (13). To confirm, Bias that is smaller than 0.16.
Comparing the biases between the AIPW estimator and the IPW estimator with normalized weights, we investigate the inequality . Here, we see that for to be true, the misspecified OR model is included in the necessary condition:
| (14) |
By (14), we see that in order for the AIPW estimator to improve upon the normalized IPW estimator, the (PS‐error scaled) outcome misspecification must lie within an interval defined by the true conditional outcome and the absolute value of the covariance of and . This means that the smaller the covariance, the greater the accuracy of the outcome model for to be less biased than .
For a sufficient condition for , we have that if
| (15) |
then
Illustrating the sufficient conditions with the data‐generating process in Example 2
are both positive, and
in agreement with (15).
Summarizing the results of the comparisons of the bias conditions, we note that the expected values of the product of the PS‐model error and the true and misspecified conditional outcomes play important roles. Here, the covariances of the PS‐model ratio and the true and misspecified conditional outcomes are two of their respective components. In Figure 1, we illustrate these parts with the data‐generating processes from Example 2. The PS‐model ratio deviates from 1 for both small and large values of X, but more so for larger values of X. Since both conditional outcomes and are strictly increasing, both covariances are positive ( and ) owing to the PS‐model ratio being larger for larger values of X. The interval characterization of the described conditions implies that if the two covariances are of the same magnitude, the bias of will often be smaller than the biases of and .
FIGURE 1.
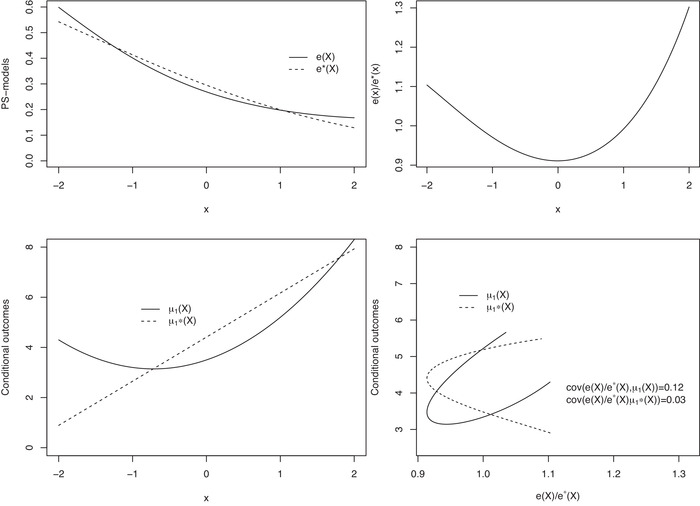
Illustration of the components of the biases using the data‐generating process from Example 2. Top left: and by X; top right: by X; bottom left: and by X; and bottom right: and by
5. SIMULATION STUDIES
5.1. Design
To investigate the asymptotic biases described in Section 4 and also the finite‐sample performance of , , and under model misspecification, we perform three simulation studies with three different designs A–C. The first part of the simulations evaluates the finite‐sample performance of the estimators and consist of 1000 replications of sample sizes 500, 1000, and 5000. In addition to the simulation results, we also give numerical approximations to the asymptotic biases by fitting the misspecified models with a large sample . The simulations and numerical approximations are carried out using R (R Core Team, 2020). The misspecified models are fitted with the glm() function and were selected in order to be well‐known simple models that could have been chosen in practice by a data analyst. The link functions together with the true parameter values are given in Tables 1 and 2, which also contain the details for the misspecified models.
TABLE 1.
Simulation Designs A–C
| True model | MISSPECIFIED MODEL | |||||
|---|---|---|---|---|---|---|
| Models | Class | Linear predictor and parameter values | Class | Linear predictor | ||
| Simulation 1 | ||||||
|
|
||||||
| Design A | ||||||
| PS | Binomial, logit |
|
Binomial, logit |
|
||
| OR | Gaussian, identity |
|
Gaussian, identity |
|
||
| Design B | ||||||
| PS | Binomial, logit |
|
Binomial, logit |
|
||
| OR | Gaussian, identity |
|
Gaussian, identity |
|
||
| Design C | ||||||
| PS | Binomial, cauchit |
|
Binomial, logit |
|
||
| OR | Gamma, identity |
|
Gaussian, identity |
|
||
| Simulation 2 | ||||||
|
|
||||||
| , | ||||||
|
|
||||||
| Design A | ||||||
| PS | Binomial, logit |
|
Binomial, logit |
|
||
| OR | Gaussian, identity |
|
Gaussian, identity |
|
||
| Design B | ||||||
| PS | Binomial, logit |
|
Binomial, logit | 1, Z 1 | ||
| OR | Gaussian, identity |
|
Gaussian, identity | 1, Z 2 | ||
| Design C | ||||||
| PS | Binomial, logit |
|
Binomial, logit | 1, Z 3 | ||
| OR | Gaussian, identity |
|
Gaussian, identity | 1, Z 4 | ||
TABLE 2.
Simulation Designs A–C
| True model | MISSPECIFIED MODEL | |||||
|---|---|---|---|---|---|---|
| Models | Class | Linear predictor and parameter values | Class | Linear predictor | ||
| Simulation 3 | ||||||
|
|
||||||
|
|
||||||
| Design A | ||||||
| PS | Binomial, logit |
|
Binomial, logit |
|
||
| OR | Poisson, log |
|
Gaussian, identity |
|
||
|
|
||||||
|
|
||||||
| Design B | ||||||
| PS | Binomial, logit |
|
Binomial, logit |
|
||
| OR | Poisson, log |
|
Gaussian, identity |
|
||
|
|
||||||
|
|
||||||
| Design C | ||||||
| PS | Binomial, logit |
|
Binomial, logit |
|
||
| OR | Poisson, log |
|
Gaussian, identity |
|
||
5.1.1. Simulation 1
The covariates are generated Uniform(1,4), Poisson(3) and Bernoulli(0.4). Generalized linear models are used to generate a binary treatment T and potential outcomes , with second‐order terms of X 1 and X 2 in both the PS and OR models, see Table 1. The PS distributions for the treated and controls are bounded away from 0 and 1 under the true models and under the model misspecifications (see Figure 2). The PS and OR models (for the AIPW estimator) are stepwise misspecified in the three designs (A, B, C).
-
A:
a quadratic term X 1 2 is omitted in the PS and OR models;
-
B:
two quadratic terms, X 1 2 and X 2 2, are omitted in the PS and OR models;
-
C:
two quadratic terms are omitted and both the OR and PS link functions are misspecified.
FIGURE 2.
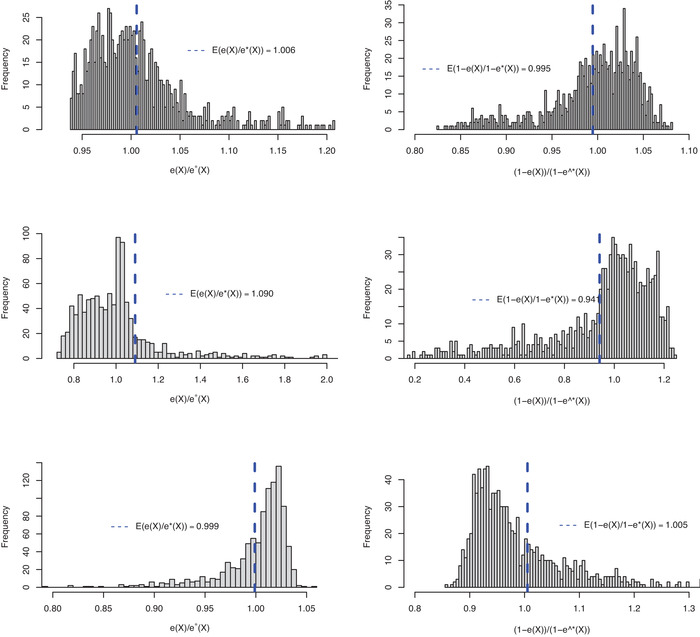
Illustration of the bias reduction in of the means and of the PS errors in Designs A, Simulation 1 (top), 2 (middle), and 3 (bottom)
5.1.2. Simulation 2
The design is inspired by the simulation study of Funk et al. (2011). We generate the same covariates where Normal(0,1), Normal(0,1), Uniform(0.1), and Normal(0,1). The treatment and outcomes are generated with second‐order terms of X 1 and X 2 in both the PS and OR models given in Table 1. In Figure 4, we see that the PS distributions, under both the true and misspecified models, have poorer overlap and values that are close to 0 and 1. The PS and OR models (for the AIPW estimator) are stepwise misspecified in three designs where:
-
A:
two quadratic terms, X 1 2 and X 2 2, are omitted in the PS model and X 1 2 and X 3 2 in the OR models;
FIGURE 4.
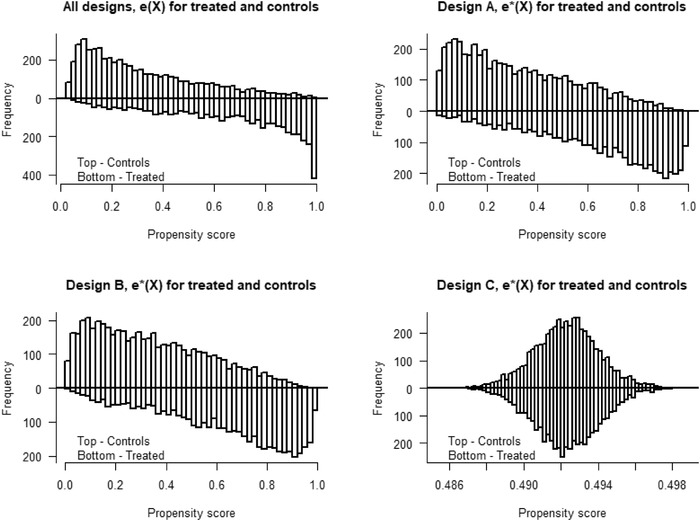 Overlap plots for the propensity score distributions, and for treated and controls for Design A (top), B (middle), and C (bottom) in Simulation 2
Overlap plots for the propensity score distributions, and for treated and controls for Design A (top), B (middle), and C (bottom) in Simulation 2 -
B:
two quadratic terms, X 1 2 and X 2 2, are omitted in the PS model and X 1 2 and X 3 2 in the OR models; and transformations of the first‐order terms, and , are applied in the PS and the OR models, respectively;
-
C:
two quadratic terms, X 1 2 and X 2 2, are omitted in the PS model and X 1 2 and X 3 2 in the OR models, X 3 and X 4 are omitted in the PS and the OR models, respectively; and transformations of the first‐order terms, and , are applied in the PS and the OR models, respectively.
5.1.3. Simulation 3
The design replicates the covariates and PS models of Zhou et al. (2020), in the setting referred to as medium treatment prevalence and PS distributions with good, moderate, and poor overlap (see Figure 5). In our design, the PS and OR models (for the AIPW estimator) are misspecified using the following variable transformations: , , and . Similarly, we generate such that ∼ .
FIGURE 5.
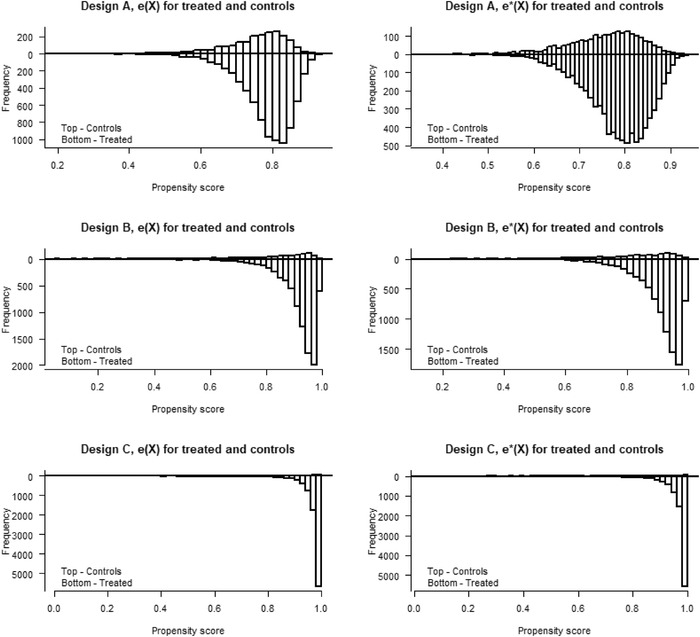
Overlap plots for the propensity score distributions, and for treated and controls for Design A (good overlap), B (moderate overlap), and C (poor overlap) in Simulation 3
The three simulation designs are:
-
A:
good PS distribution overlap, variable transformation, and misspecified link function for the OR model;
-
B:
moderate PS distribution overlap, variable transformation, and misspecified link function for the OR model;
-
C:
poor PS distribution overlap, variable transformation, and misspecified link function for the OR model.
5.2. Results
In Tables 3 and 4, we give the simulation bias, standard error, and mean squared error (MSE) of the three estimators. Tables 5, 6, 7 give numerical approximations for Bias, Bias, and Bias using a sample size of . When using the true models, that is, when studying the estimators , , and , the bias is small and decreases as the sample size increases. In Simulations 1 and 2, the standard errors follow the expected order with the smallest for followed by and (Lunceford & Davidian, 2004). In Simulation 3, the standard errors of and have similar magnitude. Figure 3 gives an illustration of the suppressing effect obtained by the normalization in . For Design A in Simulations 1–3, the figure gives histograms for the simulation model errors and together with vertical lines for the corresponding means.
TABLE 3.
Results for Simulations 1 and 2 for sample sizes 500, 1000, and 5000. In Simulation 1, Designs A and B share the same true models. In Simulation 2, the true models are the same in Designs A–C. All true models are given in Table 1.
| Estimators | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Simulation 1 | ||||||||||||||
|
|
|
|
||||||||||||
| n | Models | Design | Bias | SD | MSE | Bias | SD | MSE | Bias | SD | MSE | |||
| 500 | True | A B | 0.030 | 0.396 | 0.158 | 0.010 | 0.143 | 0.020 | 0.003 | 0.110 | 0.012 | |||
| False | A | 0.127 | 0.410 | 0.184 | 0.017 | 0.142 | 0.020 | 0.025 | 0.118 | 0.014 | ||||
| False | B | 0.316 | 0.372 | 0.238 | 0.044 | 0.124 | 0.017 | 0.026 | 0.117 | 0.014 | ||||
| True | C | 0.011 | 0.422 | 0.178 | 0.010 | 0.153 | 0.024 | 0.009 | 0.111 | 0.012 | ||||
| False | C | 0.235 | 0.336 | 0.168 | −0.051 | 0.140 | 0.022 | 0.047 | 0.118 | 0.016 | ||||
| 1000 | True | A B | 0.010 | 0.254 | 0.065 | 0.002 | 0.098 | 0.010 | −0.003 | 0.075 | 0.006 | |||
| False | A | 0.112 | 0.270 | 0.085 | 0.008 | 0.097 | 0.009 | 0.018 | 0.079 | 0.007 | ||||
| False | B | 0.283 | 0.253 | 0.144 | 0.033 | 0.085 | 0.008 | 0.019 | 0.078 | 0.006 | ||||
| True | C | −0.003 | 0.278 | 0.077 | 0.005 | 0.106 | 0.011 | 0.003 | 0.078 | 0.006 | ||||
| False | C | 0.219 | 0.223 | 0.098 | −0.055 | 0.095 | 0.012 | 0.040 | 0.083 | 0.008 | ||||
| 5000 | True | A B | 0.002 | 0.110 | 0.012 | 0.001 | 0.044 | 0.002 | −0.000 | 0.035 | 0.001 | |||
| False | A | 0.108 | 0.120 | 0.026 | 0.009 | 0.044 | 0.002 | 0.022 | 0.037 | 0.002 | ||||
| False | B | 0.291 | 0.107 | 0.096 | 0.036 | 0.039 | 0.003 | 0.023 | 0.036 | 0.002 | ||||
| True | C | −0.003 | 0.123 | 0.015 | 0.000 | 0.044 | 0.002 | −0.000 | 0.033 | 0.001 | ||||
| False | C | 0.219 | 0.098 | 0.057 | −0.060 | 0.041 | 0.005 | 0.038 | 0.036 | 0.003 | ||||
| Estimators | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Simulation 2 | ||||||||||||||
|
|
|
|
||||||||||||
| n | Models | Design | Bias | SD | MSE | Bias | SD | MSE | Bias | SD | MSE | |||
| 500 | True | A B C | 0.006 | 0.853 | 0.727 | 0.033 | 0.393 | 0.155 | 0.010 | 0.213 | 0.045 | |||
| False | A | 0.635 | 0.650 | 0.826 | 0.236 | 0.334 | 0.167 | 0.403 | 0.708 | 0.664 | ||||
| False | B | 0.440 | 0.732 | 0.728 | 0.084 | 0.381 | 0.152 | 0.217 | 0.582 | 0.385 | ||||
| False | C | 0.608 | 0.607 | 0.737 | 0.271 | 0.361 | 0.203 | 0.597 | 0.708 | 0.858 | ||||
| 1000 | True | A B C | 0.011 | 0.662 | 0.438 | 0.029 | 0.292 | 0.086 | 0.013 | 0.154 | 0.024 | |||
| False | A | 0.698 | 0.724 | 1.012 | 0.248 | 0.286 | 0.143 | 0.450 | 0.824 | 0.880 | ||||
| False | B | 0.455 | 0.681 | 0.669 | 0.084 | 0.340 | 0.123 | 0.230 | 0.531 | 0.335 | ||||
| False | C | 0.619 | 0.413 | 0.554 | 0.266 | 0.257 | 0.137 | 0.606 | 0.461 | 0.579 | ||||
| 5000 | True | A B C | 0.004 | 0.307 | 0.094 | 0.010 | 0.175 | 0.031 | 0.010 | 0.094 | 0.009 | |||
| False | A | 0.669 | 0.217 | 0.494 | 0.238 | 0.129 | 0.073 | 0.434 | 0.266 | 0.259 | ||||
| False | B | 0.430 | 0.231 | 0.238 | 0.078 | 0.142 | 0.026 | 0.217 | 0.176 | 0.078 | ||||
| False | C | 0.646 | 0.327 | 0.524 | 0.282 | 0.183 | 0.113 | 0.650 | 0.422 | 0.601 | ||||
TABLE 4.
Results for Simulation 3 for sample sizes 500, 1000, and 5000. The true and false models for Designs A–C are described in Table 2.
| Estimators | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Simulation 3 | ||||||||||||||
|
|
|
|
||||||||||||
| n | Models | Design | Bias | SD | MSE | Bias | SD | MSE | Bias | SD | MSE | |||
| 500 | True | A | −0.011 | 0.350 | 0.123 | −0.003 | 0.328 | 0.108 | −0.003 | 0.329 | 0.108 | |||
| False | A | −0.091 | 0.367 | 0.143 | 0.002 | 0.332 | 0.110 | −0.001 | 0.329 | 0.108 | ||||
| True | B | −0.050 | 1.133 | 1.284 | −0.000 | 0.655 | 0.429 | −0.019 | 0.697 | 0.486 | ||||
| False | B | −1.388 | 2.402 | 7.691 | 0.045 | 0.778 | 0.607 | 0.004 | 0.856 | 0.731 | ||||
| True | C | 0.059 | 3.546 | 12.566 | −0.018 | 1.260 | 1.587 | −0.033 | 1.430 | 2.043 | ||||
| False | C | −10.041 | 23.663 | 660.216 | 0.077 | 1.579 | 2.496 | 0.031 | 4.416 | 19.487 | ||||
| 1000 | True | A | 0.010 | 0.250 | 0.063 | 0.012 | 0.239 | 0.057 | 0.012 | 0.239 | 0.057 | |||
| False | A | −0.078 | 0.257 | 0.072 | 0.015 | 0.242 | 0.059 | 0.010 | 0.239 | 0.057 | ||||
| True | B | −0.016 | 0.703 | 0.493 | −0.006 | 0.440 | 0.194 | −0.008 | 0.445 | 0.198 | ||||
| False | B | −1.379 | 1.473 | 4.068 | 0.031 | 0.542 | 0.294 | −0.001 | 0.558 | 0.311 | ||||
| True | C | −0.139 | 2.347 | 5.522 | −0.000 | 0.952 | 0.906 | −0.002 | 1.028 | 1.055 | ||||
| False | C | −12.065 | 28.245 | 942.510 | 0.118 | 1.364 | 1.872 | −0.159 | 6.912 | 47.752 | ||||
| 5000 | True | A | 0.008 | 0.110 | 0.012 | 0.009 | 0.107 | 0.012 | 0.009 | 0.107 | 0.012 | |||
| False | A | −0.076 | 0.114 | 0.019 | 0.014 | 0.108 | 0.012 | 0.010 | 0.107 | 0.012 | ||||
| True | B | 0.001 | 0.291 | 0.085 | 0.005 | 0.206 | 0.042 | 0.005 | 0.206 | 0.043 | ||||
| False | B | −1.356 | 0.598 | 2.197 | 0.042 | 0.260 | 0.069 | 0.006 | 0.255 | 0.065 | ||||
| True | C | −0.033 | 0.988 | 0.976 | 0.008 | 0.449 | 0.202 | 0.007 | 0.462 | 0.213 | ||||
| False | C | −12.955 | 12.913 | 334.401 | 0.166 | 0.933 | 0.898 | 0.010 | 3.233 | 10.442 | ||||
TABLE 5.
Asymptotic approximations from Designs A–C in Simulation 1
| Design | ||||
|---|---|---|---|---|
| Parameter | A | B | C | |
| μ1 | 11.128 | 11.128 | 12.130 | |
|
|
11.094 | 11.094 | 12.098 | |
| μ0 | 8.630 | 8.627 | 9.633 | |
|
|
8.579 | 8.575 | 9.582 | |
| Bias | 0.106 | 0.298 | 0.212 | |
| Bias | 0.009 | 0.037 | −0.058 | |
| Bias | 0.021 | 0.025 | 0.037 | |
| Bias | 0.029 | 0.197 | 0.130 | |
| Bias | −0.028 | 0.023 | −0.089 | |
| Bias | 0.011 | 0.013 | 0.029 | |
|
|
1.005 | 1.016 | 1.019 | |
|
|
−0.028 | 0.022 | −0.094 | |
|
|
−0.038 | 0.009 | −0.121 | |
|
|
0.057 | 0.175 | 0.225 | |
|
|
0.029 | 0.197 | 0.132 | |
|
|
0.018 | 0.184 | 0.104 | |
| Bias | 0.078 | 0.101 | 0.082 | |
| Bias | 0.038 | 0.014 | 0.031 | |
| Bias | 0.011 | 0.012 | 0.008 | |
|
|
0.996 | 0.990 | 0.994 | |
|
|
−0.035 | −0.015 | −0.034 | |
|
|
−0.025 | −0.004 | −0.024 | |
|
|
−0.037 | −0.088 | −0.054 | |
|
|
−0.072 | −0.103 | −0.087 | |
|
|
−0.062 | −0.091 | −0.078 | |
TABLE 6.
Asymptotic approximations from Designs A–C in Simulation 2
| Design | ||||
|---|---|---|---|---|
| Parameter | A | B | C | |
| μ1 | 3.529 | 3.530 | 3.535 | |
|
|
3.460 | 3.953 | 3.472 | |
| μ0 | 1.337 | 1.331 | 1.335 | |
|
|
1.166 | 1.398 | 1.171 | |
| Bias | 0.642 | 0.422 | 0.622 | |
| Bias | 0.216 | 0.060 | 0.264 | |
| Bias | 0.397 | 0.203 | 0.631 | |
| Bias | 0.453 | 0.325 | 0.451 | |
| Bias | 0.091 | 0.024 | 0.150 | |
| Bias | 0.302 | 0.147 | 0.532 | |
|
|
1.102 | 1.081 | 1.080 | |
|
|
0.102 | 0.033 | 0.166 | |
|
|
−0.202 | −0.151 | −0.359 | |
|
|
0.359 | 0.285 | 0.283 | |
|
|
0.462 | 0.317 | 0.449 | |
|
|
0.151 | 0.168 | −0.082 | |
| Bias | 0.198 | 0.097 | 0.171 | |
| Bias | 0.133 | 0.036 | 0.113 | |
| Bias | 0.103 | 0.056 | 0.100 | |
|
|
0.947 | 0.953 | 0.952 | |
|
|
−0.124 | −0.036 | −0.116 | |
|
|
−0.031 | 0.024 | −0.017 | |
|
|
−0.071 | −0.062 | −0.064 | |
|
|
−0.195 | −0.099 | −0.180 | |
|
|
−0.093 | −0.042 | −0.073 | |
TABLE 7.
Asymptotic approximations from Designs A–C in Simulation 3
| Design | ||||
|---|---|---|---|---|
| Parameter | A | B | C | |
| μ1 | 9.903 | 9.899 | 9.899 | |
|
|
9.902 | 9.899 | 9.898 | |
| μ0 | 8.897 | 8.910 | 8.900 | |
|
|
8.895 | 8.909 | 8.904 | |
| Bias | −0.087 | −1.349 | −12.072 | |
| Bias | 0.005 | 0.046 | 0.151 | |
| Bias | −0.000 | 0.009 | 0.035 | |
| Bias | −0.009 | −0.022 | −0.006 | |
| Bias | −0.001 | −0.001 | 0.003 | |
| Bias | −0.000 | −0.000 | 0.003 | |
|
|
0.999 | 0.998 | 0.997 | |
|
|
−0.000 | −0.001 | −0.001 | |
|
|
−0.000 | −0.001 | −0.001 | |
|
|
−0.008 | −0.021 | −0.030 | |
|
|
−0.009 | −0.022 | −0.031 | |
|
|
−0.009 | −0.022 | −0.031 | |
| Bias | −0.077 | −1.328 | −12.040 | |
| Bias | 0.006 | 0.047 | 0.153 | |
| Bias | 0.000 | 0.009 | 0.036 | |
|
|
1.009 | 1.160 | 2.427 | |
|
|
−0.005 | −0.050 | −0.376 | |
|
|
−0.005 | −0.046 | −0.344 | |
|
|
0.083 | 1.426 | 12.714 | |
|
|
0.077 | 1.376 | 12.338 | |
|
|
0.077 | 1.379 | 12.366 | |
FIGURE 3.
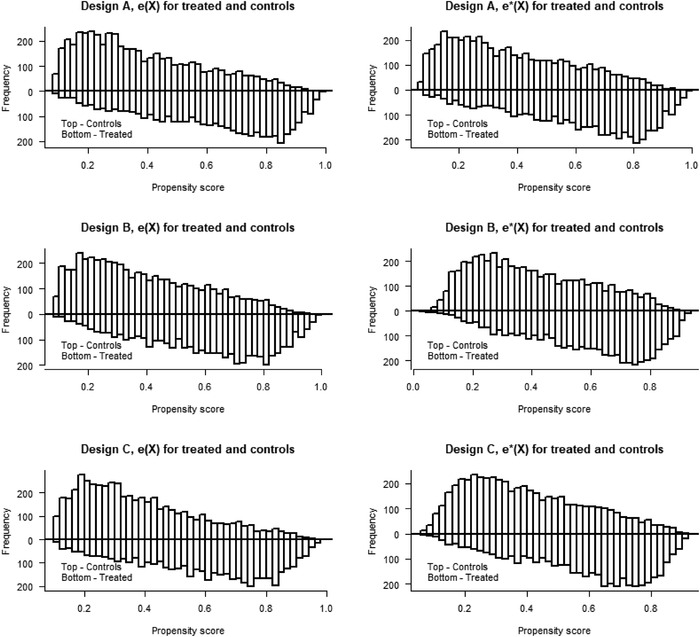
Overlap plots for the propensity score distributions, and for treated and controls for Design A (top), B (middle), and C (bottom) in Simulation 1
Under misspecification, the bias in all three simulations and all designs are close to the asymptotic approximations, at least for the largest sample size. For example, in Design C in Simulation 3 with poor overlap, the bias of is smaller than when although for , the bias of is smaller than that is what we see in the asymptotic approximation. For the simulations with poor overlap (both in Simulation 2 and Simulation 3, Design C), the bias is very large because the model misspecification for , and both and have substantially smaller biases.
In Simulation 1, is the largest. and are similar, although is slightly smaller in most cases. In Simulation 2, with poorer overlap, is the smallest for all three study designs, demonstrating the stabilizing effect of the normalization. Here, in Designs A and B, is smaller than but for Design C, they are similar. In Simulation 3, for the largest sample size, is the smallest for all three Designs A–C.
For the MSE in Simulation 1, is the smallest; however, the difference with regard to is not large. In Simulation 2, Designs A and B, the MSE of is the smallest, followed by the MSE of and . For Design C, the MSE of is greater than the MSE of . In Simulation 3, the MSE of and is similar for Designs A and B. For Design C, with poor overlap, the MSE is much smaller for .
Studying the two different parts of the biases illustrate how‐not only the variances, but also the biases, get inflated from the lack of overlap in the PS distribution. In Simulation 3 in the design with poor overlap (see Table 7), we have that is small but is very large. This result is owing to the ratio being instable because of sparse data for values close to 0. Correspondingly, we see that the mean is far away from 1. In the previous section, we described the stabilizing properties of the normalized IPW, counteracting the model misspecification error. The standard errors under misspecification follow the same pattern as under the true models, which can be expected under regularity conditions from semiparametric theory, see, for example, Boos and Stefanski (2013, Chapter 7.2). In Simulation 2, the standard errors of are the smallest followed by for Designs A and B and for Design C. In Simulation 3, the standard errors of are the smallest followed by and for Designs B and C corresponding to moderate and poor PS distribution overlap.
To relate the simulations to the sufficient and necessary conditions derived in Section 4.2, the related expressions from the asymptotic approximations are shown in Tables 5–7. The expectations and covariances that are used for the necessary and sufficient conditions in Equations (11)–(15) can be applied to draw the corresponding conclusions of the estimators. As an example, we see that the necessary condition for the absolute values of Bias to be smaller than the absolute value of Bias holds for both , and in Simulation 1, but the same condition is not satisfied in Simulation 2.
6. DATA EXAMPLE
As a motivating example, we analyze data from the National Health and Nutrition Examination Survey (NHANES, 2007–2008) for the purpose of estimating the effect of smoking on blood lead levels. Earlier studies have suggested that increased blood lead levels are associated with chronic kidney disease and peripheral arterial diseases (Muntner et al., 2005). Higher blood lead levels are also associated with mortality in the general U.S. population (Menke et al. 2006). The NHANES dataset studied here is a subset of the data previously analyzed by Hsu and Small (2013) evaluating the relationship between smoking and blood lead levels for the treated population (ATT) with a matching approach. To improve overlap for the estimation of the average causal effect, Δ, we select the study population of males, . The covariate set is also expanded with four more covariates from the original NHANES demographic data. The treated individuals are defined as daily smokers () and the controls are individuals who had smoked fewer than 100 cigarettes during their life and no cigarettes in the last 30 days (). The outcome of interest is blood lead levels (micrograms per deciliter, μg/dL). We control for the covariates, age, army service, marriage, birth country, education, family size, and income‐to‐poverty level, see Table 8. For this dataset, we apply the three estimators using a logistic propensity score model and for the AIPW estimator, we additionally use a linear OR model with the same covariates. The overlap is displayed in the mirror histogram of Figure 6a together with balance diagnostics in Figure 6b. Here, we see that the balance reduction achieved from the weighing seems satisfactory for most of the covariates, having standardized mean differences within a balance threshold of 0.10. However, for the age squared, army service, college education group, and the group born in Spanish‐speaking countries other than Mexico, they have standardized mean differences just exceeding this threshold. Applying the simple IPW estimator, , smoking increases the blood lead levels with 1.10 μg/dL (95% CI: 0.63–1.56), whereas the normalized version, results in a smaller estimated effect of 0.88 μg/dL and a smaller standard error (95% CI: 0.59–1.18). The AIPW estimator, , further reduces the effect estimate to 0.86 μg/dL and the standard error (95% CI:0.57–1.14, see Table 9). Although applying the estimators to the data does not give information on possible bias due to model misspecification, our results from Section 4 provide guidance to rely on the estimates from or , that is, 0.88 or 0.86 μg/dL with corresponding confidence intervals, rather than the higher value from , of 1.10 μg/dL.
TABLE 8.
Summary statistics for covariates in the NHANES data. Means and sd for lead, age, income‐to‐poverty level and family size, proportions for education, missing income, race, army service, marriage indicator, and birth country
| Nonsmokers | Smokers | Overall | ||||
|---|---|---|---|---|---|---|
| Variables |
|
|
|
|||
| Blood lead level (μg/dL) | 1.91 (1.70) | 2.77 (2.37) | 2.15 (1.95) | |||
| Age | 48.7 (17.5) | 46.0 (14.7) | 48.0 (16.0) | |||
| Education | ||||||
| Less than 9th grade | 131 (13.0%) | 51 (13.2%) | 182 (13.1%) | |||
| 9–11th grade | 126 (12.5%) | 99 (25.6%) | 225 (16.2%) | |||
| High school graduate | 243 (24.2%) | 132 (34.2%) | 375 (26.9%) | |||
| Some college | 238 (23.7%) | 86 (22.3%) | 324 (23.3%) | |||
| College | 268 (26.6%) | 18 (14.7%) | 286 (20.5%) | |||
| Income | ||||||
| Income‐to‐poverty level | 2.79 (1.55) | 2.14 (1.48) | 2.61 (1.56) | |||
| Missing | 86 (8.5%) | 23 (6.0%) | 109 (7.8%) | |||
| Not missing | 920 (91.5%) | 363 (94.0%) | 1283 (92.2%) | |||
| Race | ||||||
| White | 428 (42.5%) | 241 (62.4%) | 669 (48.1%) | |||
| Black | 190(18.9%) | 78 (20.2%) | 268 (19.3%) | |||
| Mexican American | 206 (20.5%) | 24 (6.2%) | 230 (16.5%) | |||
| Other Hispanic | 120 (11.9%) | 22 (5.7%) | 142 (10.2%) | |||
| Other races | 62 (6.2%) | 21 (5.4%) | 83 (6.0%) | |||
| Served in Army | ||||||
| Yes | 192 (19.1%) | 90 (23.3%) | 282 (20.2%) | |||
| No | 814 (80.9%) | 296 (76.7%) | 1100 (79.7%) | |||
| Married | ||||||
| Yes | 640 (46.0%) | 164 (11.8%) | 804 (57.8%) | |||
| No | 366 (26.3%) | 222 (15.9%) | 588 (42.2%) | |||
| Birth country | ||||||
| Born in 50 U.S. states or Washington, DC | 685(68.0%) | 341 (88.3%) | 1026 (73.7%) | |||
| Born in Mexico | 126 (12.5%) | 10(2.6%) | 136(9.8%) | |||
| Born in other Spanish speaking country | 97 (9.6%) | 17 (4.4%) | 116 (8.3%) | |||
| Born in other Non‐Spanish speaking country | 98 (9.7%) | 18 (4.7%) | 114 (8.2%) | |||
| Family size | 3.04 (1.67) | 2.87 (1.76) | 2.99 (1.70) |
FIGURE 6.
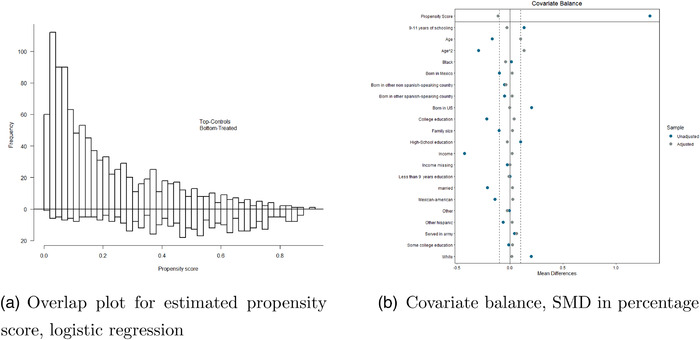
NHANES; data example
TABLE 9.
Results from (A)IPW estimators, effect of smoking on blood lead levels
| Estimator |
|
s.e. | 95% CI | |
|---|---|---|---|---|
|
|
1.10 | 0.24 | (0.63 − 1.56) | |
|
|
0.88 | 0.15 | (0.59 − 1.18) | |
|
|
0.86 | 0.14 | (0.57 − 1.14) |
7. DISCUSSION
In this paper, we investigate biases of two IPW estimators and an AIPW estimator under model misspecification. For this purpose, we use a generic probability limit, under misspecification of the PS and OR models, which exists under general conditions. Since the PS enters the estimator in different ways for the IPW estimators under study, the consequences of the model misspecification are not the same. The bias of the IPW estimators depends on the covariance between the PS‐model error and the conditional outcome in different ways and the resulting bias can be in opposite directions. For the IPW estimators, normalization has the potential of reducing the bias because it scales the estimator in a mitigating manner. Comparing the bias of the AIPW estimator with a simple IPW estimator, the necessary condition for the AIPW estimator to have a smaller bias is that the expectation of the outcome model under misspecification is less than twice the true conditional outcome, where the expectations include a scaling with the PS‐model error. For comparison with the normalized IPW estimator, the (PS‐error scaled) misspecified outcome involves an interval defined by the true conditional outcome adding and subtracting the absolute value of the covariance between the PS‐model error and the conditional outcome.
The biases and conditions are exemplified in three simulation studies where the fitted misspecified models fails in specifying nonlinearities, functional form (through misspecified link functions), and covariates. The simulation studies are also accompanied by numerical approximations of the large‐sample biases. The third simulation study specifically compares the impact of good, moderate, and poor overlap on the bias due to model misspecification. Here, we see that it is not only the variance that gets inflated from PS values close to 0 or 1, but the bias due to model misspecification also increases rapidly. The normalized IPW and AIPW estimators show a more stable performance. The bias expressions of the IPW and AIPW estimators suggest that the AIPW estimator has a smaller bias than the IPW estimators even under moderate misspecification of the outcome model. For the AIPW estimator, poor overlap and large differences between and are compensated for by outcome model assumptions in the area where data are sparse. However, in the simulations, the normalized IPW estimator also performs well due to the implicit stabilization from the PS‐model errors. Since all biases include the PS‐model error, we suggest that a researcher should be careful when modeling the PS even though an OR model is additionally involved.
OPEN RESEARCH BADGES
This article has earned an Open Data badge for making publicly available the digitally‐shareable data necessary to reproduce the reported results. The data is available in the Supporting Information section.
This article has earned an open data badge “Reproducible Research” for making publicly available the code necessary to reproduce the reported results. The results reported in this article could fully be reproduced.
Supporting information
Supporting Information.
ACKNOWLEDGMENT
The authors acknowledge Professor Elena Stanghellini for valuable input. Financial support was received from the Royal Swedish Academy of Sciences and the Swedish Research Council (grant number 2016‐00703).
APPENDIX A.
A.1. Regularity conditions
The convergence in probability of , , and to their corresponding expectations would follow directly from a weak law of large numbers (WLLN) for an iid sample of except for the estimated parameters in and in , . To justify the biases in Section 4, consider a general representation of a function where and
| (A1) |
The in (A1) corresponds to for , , and for and under Assumptions 5 and 7, the consistency of is ensured. Regularity conditions for the function g can be given, see, for example, Boos and Stefanski (2013, Theorem 7.3) who show that (A1) holds for differentiable functions with bounded derivatives (w.r.t. θ). The regularity conditions for , for the three estimators, imply conditions on the models and such that the regularity condition for g is satisfied. Under (A1), we can insert the limiting values and and their corresponding and , when taking a WLLN.
A.2. Biases
Under the regularity conditions and Assumptions 5–6 (IPW) and 5–7 (AIPW), we derive the bias in Equation (4). For :
and
subtracting with Δ gives
A.3. Comparisons
To study the consequences of model misspecification for the estimators, we compare each difference involving and separately. For example, we study the bias of
Since the errors and are inversely related, we would normally not expect that the biases from the two parts and cancel each other out. For example, if , then we might expect that and similarly for negative values. However, if there is large effect modification on the difference scale, the two components might be in different directions.
Inequalities concerning the biases are made with respect to the absolute values for two parts separately, for example, for Bias, we investigate
| (A2) |
Since , the second part is
| (A3) |
and similarly for (8). The conditions derived for the first part of the biases, (7) and (8), can be directly applied to the second part of the biases replacing , with and with . In a similar manner, we have for Bias
and the conditions derived for the first part of the bias, (9), can be directly applied to (A3) additionally replacing with .
Necessary and sufficient condition for in (10)
-
1.
Assuming that :
We have(A4) -
2.
.
Necessary condition for in (12)
-
1.Assuming that :
Here, we have
and(A6) - 2.
Sufficient condition for in (13)
The sufficient condition follows from the above by adding to the necessary condition that
are either both positive or both negative, since then either (A6) or (A7) holds.
Necessary condition of Equation 14
-
1.Assuming that:
Here, we have
and(A8) - 2.
Sufficient condition of (15)
If and are both positive
then,
and
If and are both negative, then we have
and
and the necessary condition from Equation (14) follows.
Waernbaum, I. , & Pazzagli, L. (2023). Model misspecification and bias for inverse probability weighting estimators of average causal effects. Biometrical Journal, 65, 2100118. 10.1002/bimj.202100118
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are openly available at https://github.com/IngWae/Bias_AIPW
REFERENCES
- Bang, H. , & Robins, J. M. (2005). Doubly robust estimation in missing data and causal inference models. Biometrics, 61(4), 962–973. [DOI] [PubMed] [Google Scholar]
- Boos, D. D. , & Stefanski, L. (2013). M‐estimation (estimating equations). In Boos D. D. & Stefanski L. A. (Eds.), Essential statistical inference (Vol. 120, pp. 297–337). Springer. [Google Scholar]
- Busso, M. , DiNardo, J. , & McCrary, J. (2014). New evidence on the finite sample properties of propensity score reweighting and matching estimators. Review of Economics and Statistics, 96(5), 885–897. [Google Scholar]
- Cao, W. , Tsiatis, A. A. , & Davidian, M. (2009). Improving efficiency and robustness of the doubly robust estimator for a population mean with incomplete data. Biometrika, 96(3), 723–734. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang, S.‐H. , Chou, I.‐J. , Yeh, Y.‐H. , Chiou, M.‐J. , Wen, M.‐S. , Kuo, C.‐T. , See, L.‐C. , & Kuo, C.‐F. (2017). Association between use of non‐vitamin k oral anticoagulants with and without concurrent medications and risk of major bleeding in nonvalvular atrial fibrillation. JAMA, 318(13), 1250–1259. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Funk, M. J. , Westreich, D. , Wiesen, C. , Stürmer, T. , Brookhart, M. A. , & Davidian, M. (2011). Doubly robust estimation of causal effects. American Journal of Epidemiology, 173(7), 761–767. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Han, P. , & Wang, L. (2013). Estimation with missing data: Beyond double robustness. Biometrika, 100(2), 417–430. [Google Scholar]
- Hernán, M. A. , Brumback, B. , & Robins, J. M. (2000). Marginal structural models to estimate the causal effect of zidovudine on the survival of hiv‐positive men. Epidemiology, 11(5), 561–570. [DOI] [PubMed] [Google Scholar]
- Hernán, M. A. , & Robins, J. M. (2006). Estimating causal effects from epidemiological data. Journal of Epidemiology and Community Health, 60(7), 578–586. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hirano, K. , & Imbens, G. W. (2001). Estimation of causal effects using propensity score weighting: An application to data on right heart catheterization. Health Services and Outcomes Research Methodology, 2(3), 259–278. [Google Scholar]
- Hirano, K. , Imbens, G. W. , & Ridder, G. (2003). Efficient estimation of average treatment effects using the estimated propensity score. Econometrica, 71(4), 1161–1189. [Google Scholar]
- Hsu, J. Y. , & Small, D. S. (2013). Calibrating sensitivity analyses to observed covariates in observational studies. Biometrics, 69(4), 803–811. [DOI] [PubMed] [Google Scholar]
- il Kim, K. (2019). Efficiency of average treatment effect estimation when the true propensity is parametric. Econometrics, 7(2), 25. [Google Scholar]
- Kang, J. D. , & Schafer, J. L. (2007). Demystifying double robustness: A comparison of alternative strategies for estimating a population mean from incomplete data. Statistical Science, 22(4), 523–539. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Khan, S. , & Tamer, E. (2010). Irregular identification, support conditions, and inverse weight estimation. Econometrica, 78(6), 2021–2042. [Google Scholar]
- Kwon, T. , Jeong, I. G. , Lee, J. , Lee, C. , You, D. , Hong, B. , Hong, J. H. , Ahn, H. , & Kim, C.‐S. (2015). Adjuvant chemotherapy after radical cystectomy for bladder cancer: A comparative study using inverse‐probability‐of‐treatment weighting. Journal of Cancer Research and Clinical Oncology, 141(1), 169–176. [DOI] [PubMed] [Google Scholar]
- Li, F. , Morgan, K. L. , & Zaslavsky, A. M. (2018). Balancing covariates via propensity score weighting. Journal of the American Statistical Association, 113(521), 390–400. [Google Scholar]
- Lunceford, J. K. , & Davidian, M. (2004). Stratification and weighting via the propensity score in estimation of causal treatment effects: A comparative study. Statistics in Medicine, 23(19), 2937–2960. [DOI] [PubMed] [Google Scholar]
- Ma, X. , & Wang, J. (2020). Robust inference using inverse probability weighting. Journal of the American Statistical Association, 115(532), 1851–1860. [Google Scholar]
- Menke, A. , Muntner, P. , Batuman, V. , Silbergeld, E. K. , & Guallar, E. (2006). Blood lead below 0.48 μmol/l (10 μg/dl) and mortality among us adults. Circulation, 114(13), 1388–1394. [DOI] [PubMed] [Google Scholar]
- Muntner, P. , Menke, A. , DeSalvo, K. B. , Rabito, F. A. , & Batuman, V. (2005). Continued decline in blood lead levels among adults in the united states: The National Health and Nutrition Examination Surveys. Archives of Internal Medicine, 165(18), 2155–2161. [DOI] [PubMed] [Google Scholar]
- R Core Team . (2020). R: A language and environment for statistical computing. R Foundation for Statistical Computing. [Google Scholar]
- Robins, J. , Hernán, M. , & Brumback, B. (2000). Marginal structural models and causal inference in epidemiology. Epidemiology (Cambridge, Mass.), 11(5), 550–560. [DOI] [PubMed] [Google Scholar]
- Robins, J. M. , & Rotnitzky, A. (1994). Estimation of regression coefficients when some regressors are not always observed. Journal of the American Statistical Association, 89(427), 846–866. [Google Scholar]
- Robins, J. M. , Rotnitzky, A. , & Zhao, L. P. (1995). Analysis of semiparametric regression models for repeated outcomes in the presence of missing data. Journal of the American Statistical Association, 90(429), 106–121. [Google Scholar]
- Robins, J. , Sued, M. , Lei‐Gomez, Q. , & Rotnitzky, A. (2007). Comment: Performance of double‐robust estimators when “inverse probability” weights are highly variable. Statistical Science, 22(4), 544–559. [Google Scholar]
- Rubin, D. (1980). Discussion of “randomization analysis of experimental data in the fisher randomization test” by D. Basu. Journal of the American Statistical Association, 75, 591–593. [Google Scholar]
- Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 66(5), 688–701. [Google Scholar]
- Scharfstein, D. O. , Rotnitzky, A. , & Robins, J. M. (1999). Adjusting for nonignorable drop‐out using semiparametric nonresponse models. Journal of the American Statistical Association, 94(448), 1096–1120. [Google Scholar]
- Seaman, S. R. , & Vansteelandt, S. (2018). Introduction to double robust methods for incomplete data. Statistical Science, 33(2), 184–197. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Seaman, S. R. , & White, I. R. (2013). Review of inverse probability weighting for dealing with missing data. Statistical Methods in Medical Research, 22(3), 278–295. [DOI] [PubMed] [Google Scholar]
- Tan, Z. (2007). Comment: Understanding OR, PS and DR. Statistical Science, 22(4), 560–568. [Google Scholar]
- Tan, Z. (2010). Bounded, efficient and doubly robust estimation with inverse weighting. Biometrika, 97(3), 661–682. [Google Scholar]
- Tsiatis, A. A. (2007). Semiparametric theory and missing data. Springer Science & Business Media. [Google Scholar]
- Tsiatis, A. A. , & Davidian, M. (2007). Comment: Demystifying double robustness: A comparison of alternative strategies for estimating a population mean from incomplete data. Statistical Science, 22(4), 569–573. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vansteelandt, S. , Carpenter, J. , & Kenward, M. G. (2010). Analysis of incomplete data using inverse probability weighting and doubly robust estimators. Methodology, 6(1), 37–48. [Google Scholar]
- Vermeulen, K. , & Vansteelandt, S. (2015). Bias‐reduced doubly robust estimation. Journal of the American Statistical Association, 110(511), 1024–1036. [Google Scholar]
- Waernbaum, I. (2012). Model misspecification and robustness in causal inference: Comparing matching with doubly robust estimation. Statistics in Medicine, 31(15), 1572–1581. [DOI] [PubMed] [Google Scholar]
- White, H. (1982). Maximum likelihood estimation of misspecified models. Econometrica: Journal of the Econometric Society, 50(1), 1–25. [Google Scholar]
- Williamson, E. , Forbes, A. , & White, I. (2014). Variance reduction in randomised trials by inverse probability weighting using the propensity score. Statistics in Medicine, 33(1), 721–737. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wooldridge, J. (2010). Econometric analysis of cross section and panel data. Econometric Analysis of Cross Section and Panel Data. MIT Press. [Google Scholar]
- Yao, L. , Sun, Z. , & Wang, Q. (2010). Estimation of average treatment effects based on parametric propensity score model. Journal of Statistical Planning and Inference, 140(3), 806–816. [Google Scholar]
- Zhou, Y. , Matsouaka, R. A. , & Thomas, L. (2020). Propensity score weighting under limited overlap and model misspecification. Statistical Methods in Medical Research, 29(12), 3721–3756. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supporting Information.
Data Availability Statement
The data that support the findings of this study are openly available at https://github.com/IngWae/Bias_AIPW