

Abstract
When interacting with infants, humans often alter their speech and song in ways thought to support communication. Theories of human child-rearing, informed by data on vocal signaling across species, predict that such alterations should appear globally. Here, we show acoustic differences between infant-directed and adult-directed vocalizations across cultures. We collected 1,615 recordings of infant- and adult-directed speech and song produced by 410 people in 21 urban, rural, and small-scale societies. Infant-directedness was reliably classified from acoustic features only. Acoustic profiles of infant-directedness differed across language and music, but in consistent fashions. We then studied listener sensitivity to these acoustic features. We played the recordings to 51,065 people from 187 countries, recruited via an English-language website, who guessed whether each vocalization was infant-directed. Their intuitions were more accurate than chance, predictable in part by common sets of acoustic features, and robust to the effects of linguistic relatedness between vocalizer and listener. These findings inform hypotheses of the psychological functions and evolution of human communication.
The forms of many animal signals are shaped by their functions, a link arising from production- and reception-related rules that help to maintain reliable signal detection within and across species1–6. Form-function links are widespread in vocal signals across taxa, from meerkats to fish3,7–10, causing acoustic regularities that allow cross-species intelligibility11–14. This facilitates the ability of some species to eavesdrop on the vocalizations of other species, for example, as in superb fairywrens (Malurus cyaneus), who learn to flee predatory birds in response to alarm calls that they themselves do not produce15.
In humans, an important context for the effective transmission of vocal signals is between parents and infants, as human infants are particularly helpless16. To elicit care, infants use a distinctive alarm signal: they cry17. In response, adults produce infant-directed language and music (sometimes called “parentese”) in forms of speech and song with putatively stereotyped acoustics18–35.
These stereotyped acoustics are thought to be functional: supporting language acquisition36–39, modulating infant affect and temperament33,40,41, and/or coordinating communicative interactions with infants42–44. These theories all share a key prediction: like the vocal signals of other species, the forms of infant-directed vocalizations should be shaped by their functions, instantiated with clear regularities across cultures. Put another way, we should expect people to alter the acoustics of their vocalizations when those vocalizations are directed toward infants, and they should make those alterations in similar fashions worldwide.
The evidentiary basis for such a claim is controversial, however, given the limited generalizability of individual ethnographic reports and laboratory studies45; small stimulus sets46; and a variety of counterexamples47–53. Some evidence suggests that infant-directed speech is primarily characterized by higher and more variable pitch54 and more exaggerated and variable vowels23,55,56, based on studies in modern industrialized societies23,28,57–61 and a few small-scale societies62,63. Infants are themselves sensitive to these features, preferring them, even if spoken in unfamiliar languages64–66. But these acoustic features are less exaggerated or reportedly absent in some cultures51,59,67 and may vary in relation to the age and sex of the infant59,68,69, weighing against claims of cross-cultural regularities.
In music, infant-directed songs also seem to have some stereotyped acoustic features. Lullabies, for example, tend toward slower tempos, reduced accentuation, and simple repetitive melodic patterns31,32,35,70, supporting functional roles associated with infant care33,41,42 in industrialized34,71–73 and small-scale societies74,75. Infants are soothed by these acoustic features, whether produced in familiar76,77 or unfamiliar songs78, and both adults and children reliably associate the same features with a soothing function31,32,70. But cross-cultural studies of infant-directed song have primarily relied upon archival recordings from disparate sources29,31,32; an approach that poorly controls for differences in voices, behavioral contexts, recording equipment, and historical conventions, limiting the precision of findings and complicating their generalizability.
Measurements of the same voices producing multiple vocalizations, gathered from many people in many languages, worldwide, would enable the clearest analyses of whether and how humans alter the acoustics of their vocalizations when communicating with infants, helping to address the lack of consensus in the literature. Further, yoked analyses of both speech and song may explain how the forms of infant-directed vocalizations reliably differ from one another, testing theories of their shared or separate functions33,36–42.
We take this approach here. We built a corpus of infant-directed speech, adult-directed speech, infant-directed song, and adult-directed song from 21 human societies, totaling 1615 recordings of 410 voices (Fig. 1a, Table 1, and Methods; the corpus is open-access at https://doi.org/10.5281/zenodo.5525161). We aimed to maximize linguistic, cultural, geographic, and technological diversity: the recordings cover 18 languages from 11 language families and represent societies located on 6 continents, with varying degrees of isolation from global media, including 4 small-scale societies that lack access to television, radio, or the internet and therefore have strongly limited exposure to language and music from other societies. Participants were asked to provide all four vocalization types.
Fig. 1 |. Cross-cultural regularities in infant-directed vocalizations.
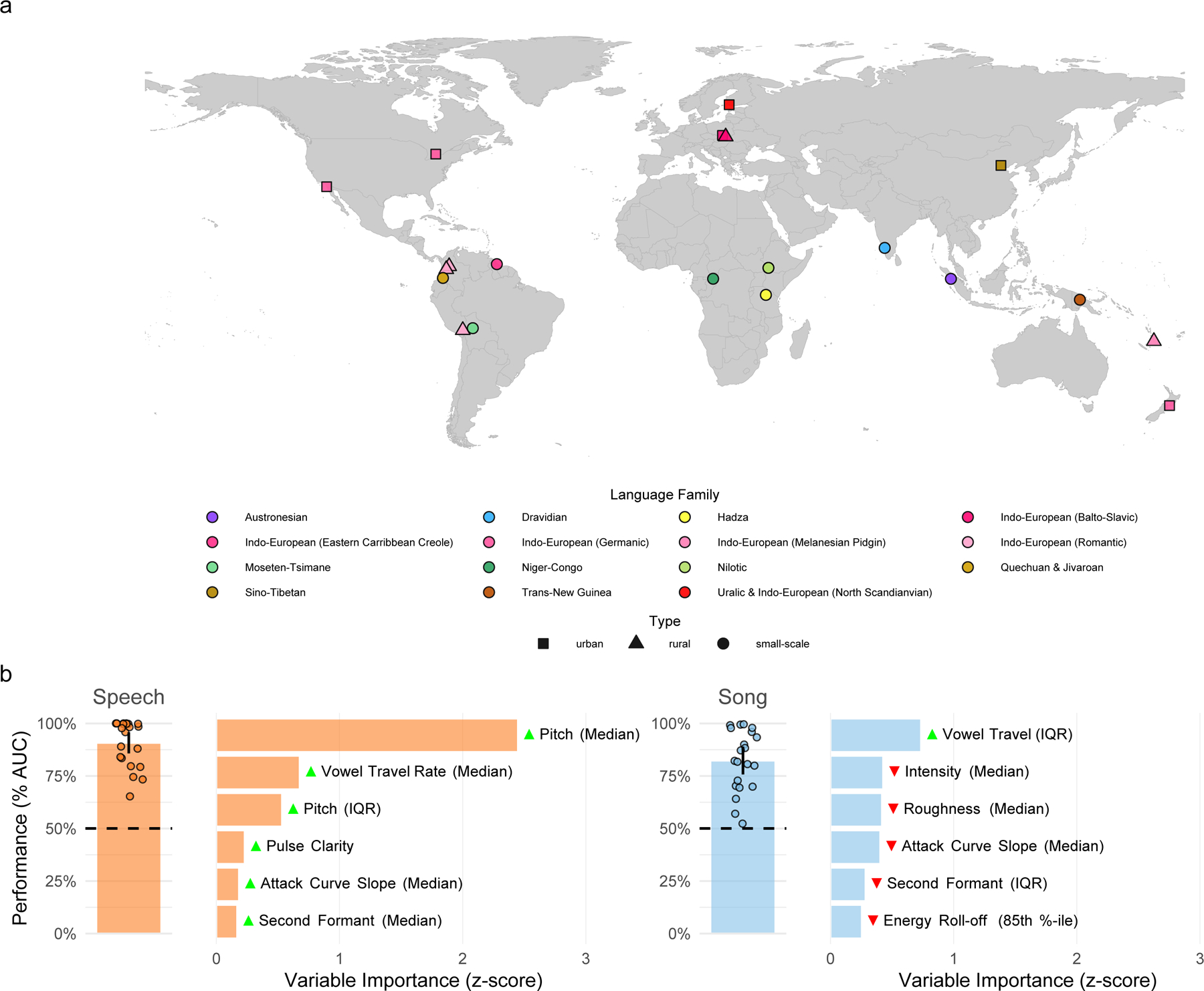
a, We recorded examples of speech and song from 21 urban, rural, or small-scale societies, in many languages. The map indicates the approximate locations of each society and is color-coded by the language family or sub-group represented by the society. b, Machine-learning classification demonstrates the stereotyped acoustics of infant-directed speech and song. We trained two least absolute shrinkage and selection operator (LASSO) models, one for speech and one for song, to classify whether recordings were infant-directed or adult-directed on the basis of their acoustic features. These predictors were regularized using fieldsite-wise cross-validation, such that the model optimally classified infant-directedness across all 21 societies studied. The vertical bars represent the mean classification performance across societies (n = 21 societies for both speech and song; quantified via receiver operating characteristic/area under the curve; AUC); the error bars represent 95% confidence intervals of the mean; the points represent the performance estimate for each fieldsite; and the horizontal dashed lines indicate chance level of 50% AUC. The horizontal bars show the six acoustic features with the largest influence in each classifier; the green and red triangles indicate the direction of the effect, e.g., with median pitch having a large, positive effect on classification of infant-directed speech. The full results of the variable selection procedure are in Supplementary Table 2, with further details in Methods.
Table 1.
Societies from which recordings were gathered.
| Region | Sub-Region | Society | Language | Language family | Subsistence type | Population | Distance to city (km) | Children per family | Recordings |
|---|---|---|---|---|---|---|---|---|---|
| Africa | Central Africa | Mbendjele BaYaka | Mbendjele | Niger-Congo | Hunter-Gatherer | 61–152 | 120 | 7 | 60 |
| Eastern Africa | Hadza | Hadza | Hadza | Hunter-Gatherer | 35 | 80 | 6 | 38 | |
| Nyangatom | Nyangatom | Nilotic | Pastoralist | 155 | 180 | 5.6 | 56 | ||
| Toposa | Toposa | Nilotic | Pastoralist | 250 | 180 | 5.2 | 60 | ||
| Asia | East Asia | Beijing | Mandarin | Sino-Tibetan | Urban | 21.5M | 0 | 1 | 124 |
| South Asia | Jenu Kurubas | Kannada | Dravidian | Other | 2000 | 15 | 1 | 80 | |
| Southeast Asia | Mentawai Islanders | Mentawai | Austronesian | Horticulturalist | 260 | 120 | Unknown | 60 | |
| Europe | Eastern Europe | Krakow | Polish | Indo-European | Urban | 771,069 | 0 | 1.54 | 44 |
| Rural Poland | Polish | Indo-European | Agriculturalists | 6,720 | 70 | 1.83 | 55 | ||
| Scandinavia | Turku | Finnish & Swedish | Uralic and Indo-European | Urban | 186,000 | 0 | 1.41 | 80 | |
| North America | North America | San Diego | English (USA) | Indo-European | Urban | 3.3M | 0 | 1.7 | 116 |
| Toronto | English (Canadian) | Indo-European | Urban | 5.9M | 0 | 1.5 | 198 | ||
| Oceania | Melanesia | Ni-Vanuatu | Bislama | Indo-European Creole | Horticulturalist | 6,000 | 224 | 3.78 | 90 |
| Enga | Enga | Trans-New Guinea | Horticulturalist | 500 | 120 | 6 | 22 | ||
| Polynesia | Wellington | English (New Zealand) | Indo-European | Urban | 210,400 | 0 | 1.45 | 228 | |
| South America | Amazonia | Arawak | English Creole | Indo-European | Other | 350 | 32 | 3 | 48 |
| Tsimane | Tsimane | Moseten-Tsimane | Horticulturalist | 150 | 234 | 9 | 51 | ||
| Sapara & Achuar | Quechua & Achuar | Quechuan & Jivaroan | Horticulturalist | 200 | 205 | 9 | 59 | ||
| Central Andes | Quechua/Aymara | Spanish | Indo-European | Agro-Pastoralist | 200 | 8 | 4 | 49 | |
| Northwestern South America | Afrocolombians | Spanish | Indo-European | Horticulturalist | 300–1,000 | 100 | 6.6 | 53 | |
| Colombian Mestizos | Spanish | Indo-European | Commercial Economy | 470,000 | 0 | 3.5 | 43 |
We used computational analyses of the acoustic forms of the vocalizations and a citizen-science experiment to test (i) the degree to which infant-directed vocalizations are cross-culturally stereotyped; and (ii) the degree to which naïve listeners detect infant-directedness in language and music.
Results
Infant-directed vocalization is cross-culturally stereotyped
We studied 15 types of acoustic features in each recording (e.g., pitch, rhythm, timbre) via 94 summary variables (e.g., median, interquartile range) that were treated to reduce the influence of atypical observations (e.g., extreme values caused by loud wind, rain, and other background noises) (see Methods and Supplementary Methods; a codebook is in Supplementary Table 1). To minimize the potential for bias, we collected the acoustic data using automated signal extraction tools that measure physical characteristics of the auditory signal; such physical characteristics lack cultural information (in contrast to, e.g., human annotations) and thus can be applied reliably across diverse audio recordings.
First, we asked whether the acoustics of infant-directed speech and song are stereotyped in similar ways across the societies whose recordings we studied. Following previous work32, we used a least absolute shrinkage and selection operator (LASSO) logistic classifier79 with fieldsite-wise k-fold cross-validation, separately for speech and song recordings, using all 15 types of acoustic features (see Methods). This approach provides a strong test of cross-cultural regularity: the model is trained only on data from 20 of the 21 societies to predict whether each vocalization in the 21st society is infant- or adult-directed. The procedure is repeated 20 further times, with each society being held out, optimizing the model to maximize classification performance across the full set of societies. The summary of the model’s performance reflects, corpus-wide, the degree to which infant-directed speech and song are acoustically stereotyped, as high classification performance can only result from cross-cultural regularities.
The models accurately classified both speech and song, on average, across and within societies, with above-chance performance in 21 of 21 fieldsites for both speech and song (Fig. 1b; speech: area under the curve, AUC = 91%, 95% CI [86%, 96%]; song: AUC = 82%, 95% CI [76%, 89%]).
To test the reliability of these findings, we repeated them with two alternate cross-validation strategies, using the same cross-validation procedure but doing so across language families and geographic regions instead of fieldsites. The results robustly replicated in both cases (Supplementary Fig. 1). Moreover, to ensure that the main LASSO results were not attributable to particulars of the audio-editing process (see Methods), we also repeated them using unedited audio from the corpus; the results replicated again (Supplementary Fig. 2).
These findings show that the acoustic features of infant-directed speech and song are robustly stereotyped across the 21 societies studied here.
Infant-directedness differs acoustically in speech and song
We used two convergent approaches to determine the specific acoustic features that are predictive of infant-directedness in speech and song.
First, the LASSO procedure identified the most reliable predictors of contrasts between infant- and adult-directed vocalizations. The most influential of these predictors are reported in Fig. 1b, with their relative variable importance scores, and show substantial differences in the variables the model relied upon to reliably classify speech and song across cultures. For example, pitch (F0 median and interquartile range) and median vowel travel rate strongly differentiated infant-directedness in speech, but not in song; while vowel travel variability (interquartile range) and median intensity strongly differentiated infant-directedness in song, but not in speech. The full results of the LASSO variable selection are in Supplementary Table 2.
Second, in a separate exploratory-confirmatory analysis, we used mixed-effects regression to measure the expected difference in each acoustic feature associated with infant-directedness, separately for speech and song. Importantly, this approach estimates main effects adjusted for sampling variability and estimates fieldsite-level effects, allowing for tests of the degree to which the main effects differ in magnitude across cultures (e.g., for a given acoustic feature, if recordings from some fieldsites show larger differences between infant- and adult-directed speech than do recordings from other fieldsites). The analysis was preregistered.
The procedure identified 11 acoustic features that reliably distinguished infant-directedness in song, speech, or both (Fig. 2; statistics are in Supplementary Table 3); we also estimated these effects within each fieldsite (see the doughnut plots in Fig. 2 and full estimates in Extended Data Fig. 1).
Fig. 2 |. How people alter their voices when vocalizing to infants.
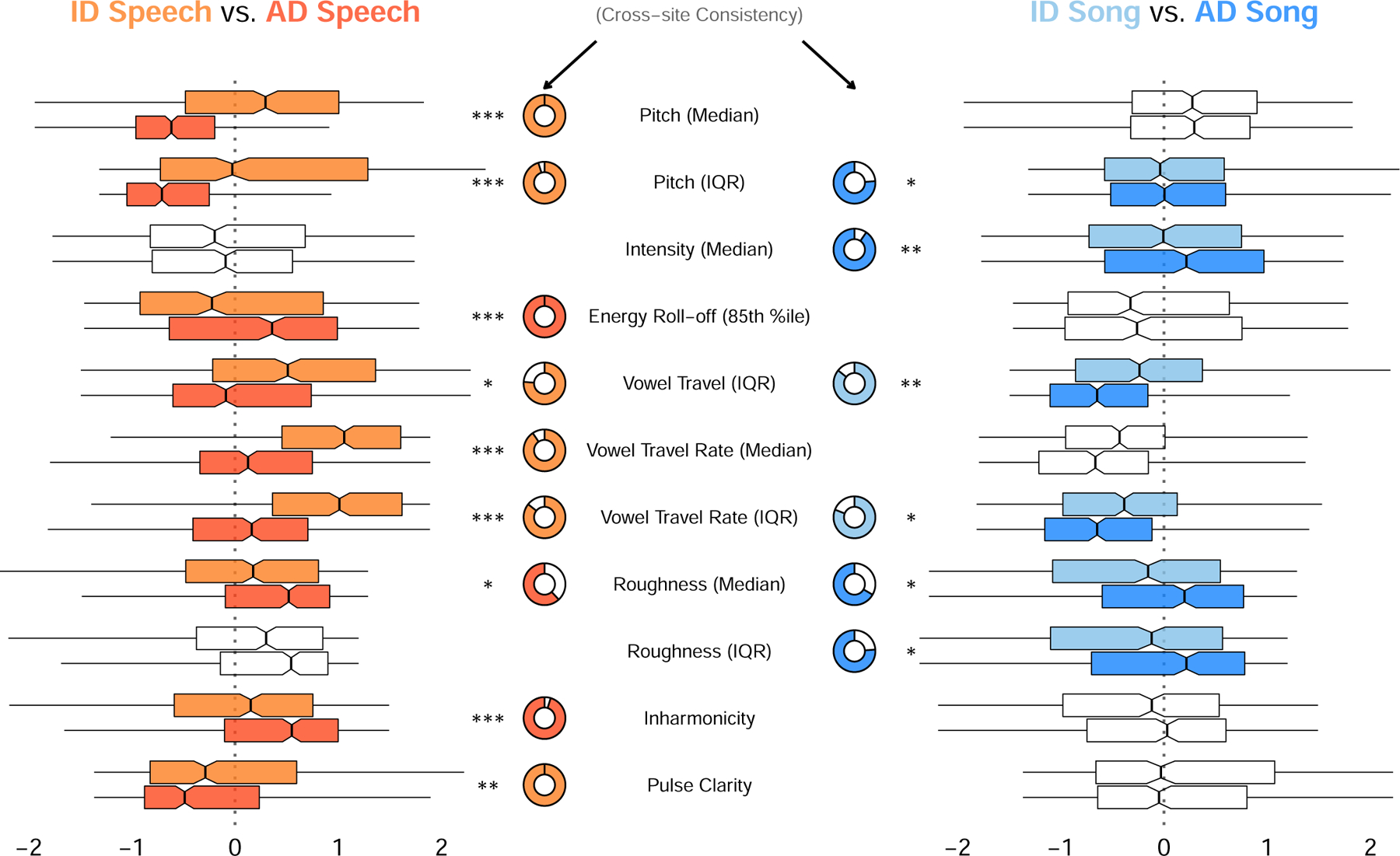
Eleven acoustic features had a statistically significant difference between infant-directed and adult-directed vocalizations, within-voices, in speech, song, or both. Consistent with the LASSO results (Fig. 1b and Supplementary Table 2), the acoustic features operated differently across speech and song. For example, median pitch was far higher in infant-directed speech than in adult-directed speech, whereas median pitch was comparable across both forms of song. Some features were highly consistent across fieldsites (e.g., lower inharmonicity in infant-directed speech than adult-directed speech), whereas others were more variable (e.g., lower roughness in infant-directed speech than adult-directed speech). The boxplots, which are ordered approximately from largest to smallest differences between effects across speech and song, represent each acoustic feature’s median (vertical black lines) and interquartile range (boxes); the whiskers indicate 1.5 × IQR; the notches represent the 95% confidence intervals of the medians; and the doughnut plots represent the proportion of fieldsites where the main effect repeated, based on estimates of fieldsite-wise random effects. Only comparisons that survived an exploratory-confirmatory analysis procedure are plotted; faded comparisons did not reach significance in confirmatory analyses. Significance values are computed via linear combinations with two-sided tests, following multi-level mixed-effects models (n = 1,570 recordings); *p < 0.05, **p < 0.01, ***p < 0.001; no adjustments made for multiple-comparisons due to the exploratory-confirmatory approach taken. Regression results are in Supplementary Table 3 and full reporting of fieldsite-level estimates is in Supplementary Table 5. Note: the model estimates are normalized jointly on speech and song data so as to enable comparisons across speech and song for each feature; as such, the absolute distance from 0 for a given feature is not directly interpretable, but estimates are directly comparable across speech and song.
In speech, across all or the majority of societies, infant-directedness was characterized by higher pitch, greater pitch range, and more contrasting vowels than adult-directed speech from the same voices (largely replicating the results of the LASSO approach; Fig. 1b and Supplementary Table 2). Several acoustic effects were consistent in all fieldsites (e.g., pitch, energy roll-off, pulse clarity), while other features, such as vowel contrasts and inharmonicity were consistent in the majority of them. These patterns align with prior claims of pitch and vowel-contrast being robust features of infant-directed speech23,60, and substantiate them across many cultures.
The distinguishing features of infant-directed song were more subtle than those of speech but nevertheless corroborate its purported soothing functions33,41,42: reduced intensity and acoustic roughness, although these were less consistent across fieldsites than the speech results. The less-consistent effects may result from the fact that while solo-voice speaking is fairly natural and representative of most adult-directed speech (i.e., people rarely speak at the same time), much of the world’s song occurs in social groups where there are multiple singers and accompanying instruments32,42,80. Asking participants to produce solo adult-directed song may have biased participants toward choosing more soothing and intimate songs (e.g., ballads, love songs; see Supplementary Table 4) or less naturalistic renditions of songs; and the production of songs in the presence of an infant, which could potentially alter participants’ singing style35. Thus, the distinctiveness of infant-directed song (relative to adult-directed song) may be underestimated here.
The exploratory-confirmatory analyses provided convergent evidence for opposing acoustic trends across infant-directed speech and song, as did an alternate approach using principal-components analysis; three principal components most strongly distinguished speech from song, infant-directed song from adult-directed song, and infant-directed speech from adult-directed speech (Supplementary Results and Extended Data Fig. 2). Replicating the LASSO findings, for example, median pitch strongly differentiated infant-directed speech from adult-directed speech, but it had no such effect in music; pitch variability had the opposite effect across language and music; and further differences were evident in pulse clarity, inharmonicity, and energy roll-off. These patterns are consistent with the possibility of differentiated functional roles across infant-directed speech and song18,33,34,42,77,78,81.
Some acoustic features were nevertheless common to both language and music; in particular, overall, infant-directedness was characterized by reduced roughness, which may facilitate parent-infant signalling5,41 through better contrast with the sounds of screaming and crying17,82; and increased vowel contrasts, potentially to aid language acquisition36,37,39 or as a byproduct of socio-emotional signalling1,56.
Listeners are sensitive to infant-directedness
If people worldwide reliably alter their speech and song when interacting with infants, as the above findings demonstrate, this may enable listeners to make reliable inferences concerning the intended targets of speech and song, consistent with functional accounts of infant-directed vocalization33,36–42,83,84. We tested this secondary hypothesis in a simple listening experiment, conducted in English using web-based citizen-science methods85.
We played excerpts from the vocalization corpus to 51,065 people (after exclusions; see Methods) in the “Who’s Listening?” game on The Music Lab, a citizen-science platform for auditory research. The participants resided in 187 countries (Fig. 3b) and reported speaking 199 languages fluently (including second languages, for bilinguals). We asked them to judge, quickly, whether each vocalization was directed to a baby or to an adult (see Methods and Extended Data Fig. 3). Readers may participate in the naïve listener experiment by visiting https://themusiclab.org/quizzes/ids.
Fig. 3 |. Naïve listeners distinguish infant-directed vocalizations from adult-directed vocalizations across cultures.
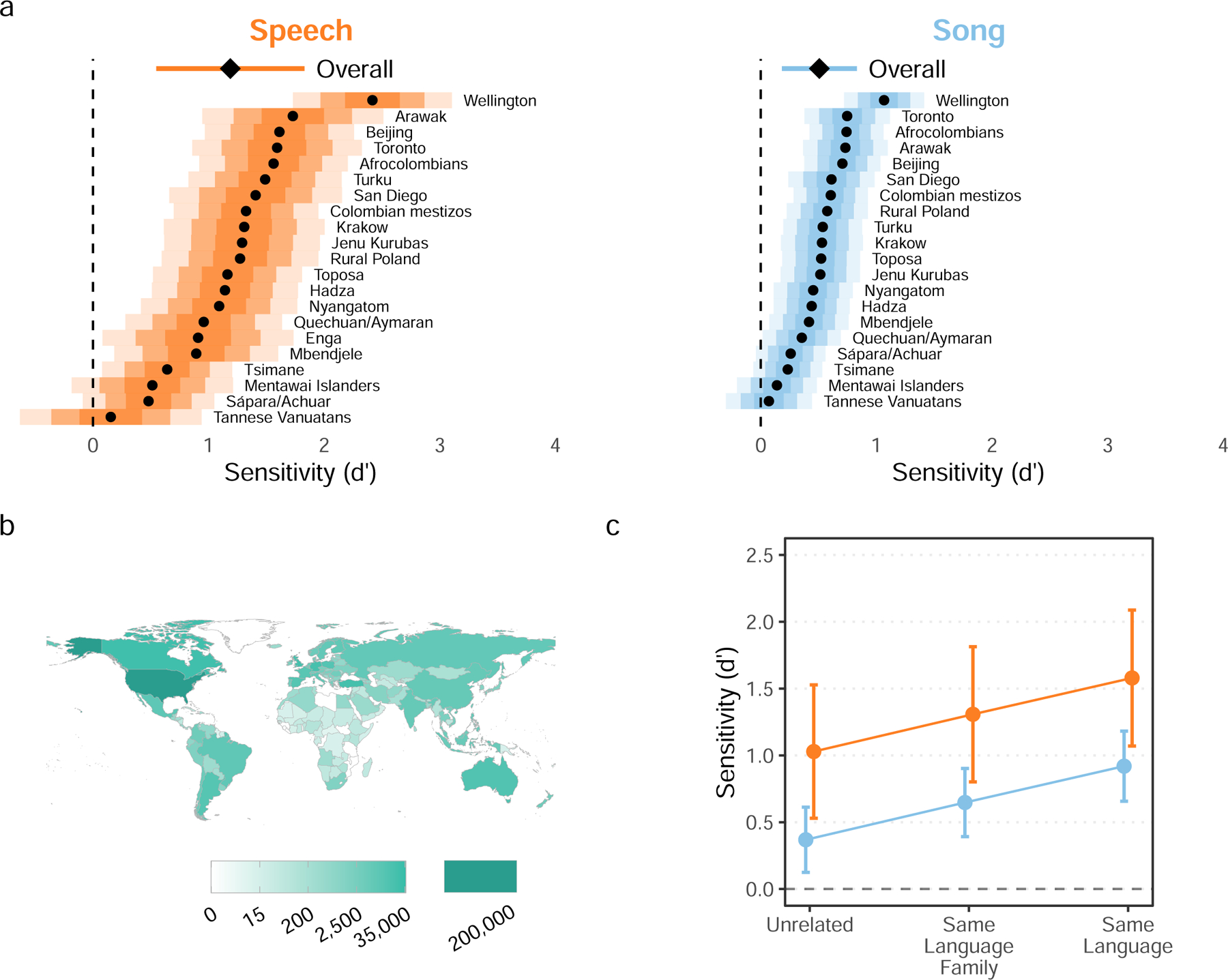
Participants listened to vocalizations drawn at random from the corpus, viewing the prompt “Someone is speaking or singing. Who do you think they are singing or speaking to?” They could respond with either “adult” or “baby” (Extended Data Fig. 3). From these ratings (after exclusion n = 473 song recordings; n = 394 speech recordings), we computed listener sensitivity (d′). a, Listeners reliably detected infant-directedness in both speech and song, overall (indicated by the diamonds, with 95% confidence intervals indicated by the horizontal lines), and across many fieldsites (indicated by the black dots), although the strength of the fieldsite-wise effects varied substantially (see the distance between the vertical dashed line and the black dots; the shaded regions represent 50%, 80%, and 95% confidence intervals, in increasing order of lightness). Note that one fieldsite-wise d′ could not be estimated for song; complete statistical reporting is in Supplementary Table 5. b, The participants in the citizen-science experiment hailed from many countries; the gradients indicate the total number of vocalization ratings gathered from each country. c, The main effects held across different combinations of the linguistic backgrounds of vocalizer and listener. We split all trials from the main experiment into three groups: those where a language the listener spoke fluently was the same as the language of the vocalization (n = 82,094; those where a language the listener spoke fluently was in the same major language family as the language of the vocalization (n = 110,664), and those with neither type of relation (n = 285,378). The plot shows the estimated marginal effects of a mixed-effects model predicting d′ values across language and music examples, after adjusting for fieldsite-level effects. The error bars represent 95% confidence-intervals of the mean. In all three cases, the main effects replicated; increases in linguistic relatedness corresponded with increases in sensitivity.
The responses were strongly biased toward “baby” responses when hearing songs and away from “baby” responses when hearing speech, regardless of the actual target of the vocalizations (Extended Data Fig. 4). To correct for these response biases, we used d-prime analyses at the level of each vocalist, i.e., analyzing listeners’ sensitivity to infant-directedness in speech and song (Supplementary Methods). Unless noted otherwise, all estimates reported here are generated by mixed-effects linear regression, adjusting for fieldsite nested within world region, via random effects.
The listeners’ intuitions were accurate, on average and across fieldsites (Fig. 3a; response times shown in Extended Data Fig. 5). Sensitivity (d′) was significantly higher than the chance level of 0 (speech: d′ = 1.19, t4.65 = 3.63, 95% CI [0.55, 1.83], p = 0.017; song: d′ = 0.51, t4.52 = 3.06, 95% CI [0.18, 0.83], p = 0.032; n.b., all p-values reported in this paper are two-sided). These results were robust to learning effects (Supplementary Fig. 3) and to multiple data trimming decisions. For example, they repeated whether or not recordings with confounding contextual/background cues (e.g., an audible infant) were excluded and also when data from English-language recordings, which were likely understandable to participants, were excluded (Supplementary Results).
To test the consistency of listener inferences across cultures, we estimated fieldsite-level sensitivity from the random effects in the model. Cross-site variability was evident in the magnitude of sensitivity effects: listeners were far better at detecting infant-directedness in some sites than others (with very high d′ in the Wellington, New Zealand site for both speech and song, but marginal d′ in Tannese Vanuatans, for example). Nevertheless, the estimated mean fieldsite-wise d′ was greater than 0 in both speech and song in all fieldsites (Fig. 3a); with 95% confidence intervals not overlapping with 0 in 18 of 21 fieldsites for speech and 16 of 20 for song (Supplementary Table 5; one d′ estimate could not be computed for song due to missing data). Most fieldsite-wise sample sizes after exclusions were small (see Methods), so we caution that fieldsite-wise estimates are far less interpretable than the overall d′ estimate reported above.
Analyses of cross-cultural variability among listeners revealed similarities in their perception of infant-directedness. In particular, coefficient of variation scores revealed little variation in listener accuracy across countries of origin (2.3%) and native languages (1.1%), with the estimated effects of age and gender both less than 1%. And more detailed demographic characteristics available for a subset of participants in the United States, including socioeconomic status and ethnicity, also explained little variation in accuracy (Supplementary Results). These findings suggest general cross-demographic consistency in listener intuitions.
One important aspect of listeners was predictive of their performance, however: their degree of relatedness to the vocalizer, on a given trial. To analyze this, we estimated fixed effects for three forms of linguistic relatedness between listener and vocalizer: (i) weak relatedness, when a language the listener spoke fluently was from a different language family than that of the vocalization (e.g., when the vocalization was in Mentawai, an Austronesian language, and the listener’s native language was Mandarin, a Sino-Tibetan language); (ii) moderate relatedness, when the languages were from the same language family (e.g., when the vocalization was in Spanish and the listener spoke fluent English, which are both Indo-European languages); or (iii) strong relatedness, when a language the listener spoke fluently exactly matched the language of the vocalization.
Sensitivity was significantly above chance in all cases (Fig. 3c), with increases in performance associated with increasing relatedness (unrelated: estimated speech d′ = 1.03, song d′ = 0.37; same language family: speech d′ = 1.31, song d′ = 0.65; same language: speech d′ = 1.58, song d′ = 0.92). Some of this variability is likely attributable to trivial language comprehensiblity (i.e., in cases of strong relatedness, listeners very likely understood the words of the vocalization, strongly shaping their infant-directedness rating).
These findings provide an important control, as they demonstrate that the overall effects (Fig. 3a) are not attributable to linguistic similarities between listeners and vocalizers (Fig. 3c), which could, for example, allow listeners to detect infant-directedness on the basis of the words or other linguistic features of the vocalizations, as opposed to their acoustic features. And while the experiment’s instructions were presented in English (suggesting that all listeners likely had at least a cursory understanding of English), the findings were robust to the exclusion of all English-language recordings (Supplementary Results).
We also found suggestive evidence of other, non-linguistic links between listeners and vocalizers being predictive of sensitivity. For example, fieldsite population size and distance to the nearest urban center were correlated estimated sensitivity to infant-directedness in that fieldsite. These and similar effects (Supplementary Results) suggest that performance was somewhat higher in the larger, more industrialized fieldsites that are more similar to the environments of internet users, on average. But these analyses are necessarily coarser than the linguistic relatedness tests reported above.
Listener intuitions are modulated by vocalization acoustics
Last, we studied the degree to which the acoustic features of the recordings were predictive of listeners’ intuitions concerning them (measured as the experiment-wide proportions of infant-directedness ratings for each vocalization, in a similar approach to other research70). These proportions can be considered a continuous measure of perceived infant-directedness, per the ears of the naïve listeners. We trained two LASSO models to predict the proportions, with the same fieldsite-wise cross-validation procedure used in the acoustic analyses reported above. Both models explained variation in human listeners’ intuitions, albeit more so in speech than in song (Fig. 4; speech R2 = 0.59; song R2 = 0.18, ps < 0.0001; p-values calculated using robust standard errors), likely because the acoustic features studied here more weakly guided listeners’ intuitions in song than they did in speech.
Fig. 4 |. Human inferences about infant-directedness are predictable from acoustic features of vocalizations.
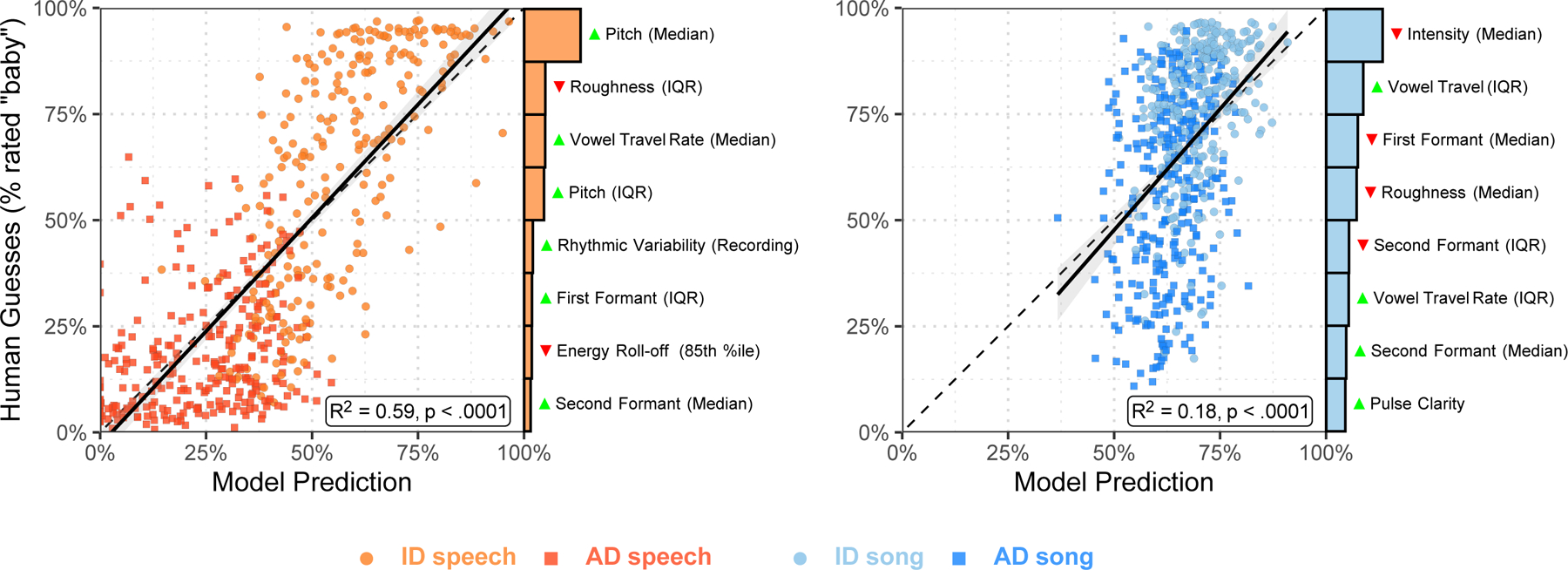
To examine the degree to which human inferences were linked to the acoustic forms of the vocalizations, we trained two LASSO models to predict the proportion of “baby” responses for each non-confounded recording from the human listeners. While both models explained substantial variability in human responses, the model for speech was more accurate than the model for song, in part because the human listeners erroneously relied on acoustic features for their predictions in song that less reliably characterized infant-directed song across cultures (see Figs. 1b and 2). Each point represents a recorded vocalization (after exclusions n = 528 speech recordings; n = 587 song recordings), plotted in terms of the model’s estimated infant-directedness of the model and the average “infant-directed” rating from the naïve listeners; the barplots depict the relative explanatory power of the top 8 acoustical features in each LASSO model, showing which features were most strongly associated with human inferences (the green or red triangles indicate the directions of effects, with green higher in infant-directed vocalizations and red lower); the dotted diagonal lines represent a hypothetical perfect match between model predictions and human guesses; the solid black lines depict linear regressions (speech: F(1,526) = 773, R2 = 0.59; song: F(1, 585) = 126, R2 = 0.18; ps < .0001; p-values computed using robust standard errors); and the grey ribbons represent the standard errors of the mean, from the regressions.
If human inferences are attuned to cross-culturally reliable acoustic correlates of infant-directedness, one might expect a close relationship between the strength of actual acoustic differences between vocalizations on a given feature and the relative influence of that feature on human intuitions. To test this question, we correlated how strongly a given acoustic feature distinguished infant-directed from adult-directed speech and song (Fig. 2; estimated with mixed-effects modeling) with the variable importance of that feature in the LASSO model trained to predict human intuitions (the bar plots in Fig. 4). We found a strong positive relationship for speech (r = 0.72) and a weaker relationship for song (r = 0.36).
This difference may help to explain the weaker intuitions of the naïve listeners in song, relative to speech: naïve listeners’ inferences about speech were more directly driven by acoustic features that actually characterize infant-directed speech worldwide, whereas their inferences about song were erroneously driven by acoustic features that less reliably characterize infant-directed song worldwide. For example, songs with higher pulse clarity and median second formats, and lower median first formants were more likely to be rated as infant-directed, but these features did not reliably correlate with infant-directed song across cultures in the corpus (and, accordingly, neither approach to the acoustic analyses identified them as reliable correlates of infant-directedness in music). Intuitions concerning infant-directed song may also have been driven by more subjective features of the recordings, higher-level acoustic features that we did not measure, or both.
We note, however, that the interpretation of this difference may be limited by the representativeness of the sample of recordings: the differences in the models’ ability to predict listeners’ intuitions could alternatively be driven by differences in the true representativeness of one or more of the vocalization types.
Discussion
We provide convergent evidence for cross-cultural regularities in the acoustic design of infant-directed speech and song. Infant-directedness was robustly characterized by core sets of acoustic features, across the 21 societies studied, and these sets of features differed reliably across speech and song. Naïve listeners were sensitive to the acoustical regularities, as they reliably identified infant-directed vocalizations as more infant-directed than adult-directed vocalizations, despite the fact that the vocalizations were of largely unfamiliar cultural, geographic, and linguistic origin.
Thus, despite evident variability in language, music, and infant care practices worldwide, when people speak or sing to fussy infants, they modify the acoustic features of their vocalizations in similar and mutually intelligible ways across cultures. This evidence supports the hypothesis that the forms of infant-directed vocalizations are shaped by their functions, in a fashion similar to the vocal signals of many non-human species.
These findings do not mean that infant-directed speech and song always sound the same across cultures. Indeed, the classification accuracy of a machine-learning model varied, with some fieldsites demonstrating larger acoustic differences between infant- and adult-directed vocalizations than other fieldsites. Similarly, the citizen-science participants’ ratings of infant-directedness differed substantially in magnitude across fieldsites. But such variability also does not imply the absence of cross-cultural regularities. Instead, they support an account of acoustic variation stemming from epigenetic rules: species-typical traits which bias cultural variation in one direction rather than another86. Put another way, the pattern of evidence strongly implies a core set of cross-cultural acoustic and perceptual regularities which are also shaped by culture.
By analyzing both speech and song recorded from the same voices, we discerned precise differences in the ways infant-directedness is instantiated in language and music. In response to the same prompt of addressing a “fussy infant”, infant-directedness in speech and song was instantiated with opposite trends in acoustic modification (relative to adult-directed speech and song, respectively): infant-directed speech was more intense and contrasting (e.g., more pitch variability, higher intensity) while infant-directed song was more subdued and soothing (e.g., less pitch variability, lower intensity). These acoustic dissociations comport with functional dissociations, with speech being more attention-grabbing, the better to distract from baby’s fussiness37,38; and song being more soothing, the better to lower baby’s arousal32,33,41,77,78,83,84. Speech and song are both capable of playful or soothing roles53 but each here tended toward one acoustic profile over the other, despite both types of vocalization being elicited here in the same context: vocalizations used “when the baby is fussy”.
Many of the reported acoustic differences are consistent with properties of vocal signalling in non-human animals, raising the intriguing possibility that the designs of human communication systems are rooted in the basic principles of bioacoustics1–15. For example, in both speech and song, infant-directedness was robustly associated with purer and less harsh vocal timbres, and greater formant-frequency dispersion (expanded vowel space). And in speech, one of the largest and most cross-culturally robust effects of infant-directedness was higher pitch (F0). In non-human animals, these features have convergently evolved across taxa in the functional context of signalling friendliness or approachability in close contact calls1,3,56,87, in contrast to alarm calls or signals of aggression, which are associated with low-pitched, rough sounds with less formant dispersal4,88–90. The use of these features in infant care may originate from signalling approachability to baby, but may have later acquired further functions more specific to the human developmental context. For example, greater formant-frequency dispersion accentuates vowel contrasts, which could facilitate language acquisition36,56,91–93; and purer vocal timbre may facilitate communication by contrasting conspicuously with the acoustic context of infant cries5 (for readers unfamiliar with infants, their cries are acoustically harsh17,82).
Such conspicuous contrasts may have the effect of altering speech to make it more song-like when interacting with infants, as Fernald18 notes: “… the communicative force of [parental] vocalizations derive not from their arbitrary meanings in a linguistic code, but more from their immediate musical power to arouse and alert, to calm, and to delight”.
Comparisons of the acoustic effects across speech and song reported here support this idea. Infant-directedness altered the pitch level (F0) of speech, bringing it roughly to a level typical of song, while also increasing pulse clarity. These characteristics of music have been argued to originate from elaborations to infant-directed vocalizations, where both use less harsh but more variable pitch patterns, more temporally variable and expansive vowel spaces, and attention-orienting rhythmic cues to provide infants with ostensible “flashy” signals of attention and pro-social friendliness41,42,54,94,95. Pitch alterations are not absent from infant-directed song, of course; in one study, mothers sang a song at higher pitch when producing a more playful rendition, and a lower pitch when producing a more soothing rendition76. But on average, both infant- and adult-directed song, along with infant-directed speech, tend to be higher in pitch than adult-directed speech. In sum: the constellation of acoustic features that characterize infant-directedness in speech, across cultures, are rather musical.
The current study has several limitations, leaving open at least four sets of further questions. First, the results are suggestive of universality in the production of infant-directed vocalizations, because the corpus covers a swath of geographic locations (21 societies on 6 continents), languages (12 language families), and different subsistence regimes (8 types) (see Table 1). But the participants studied do not constitute a representative sample of humans, nor do the societies or languages studied constitute a representative sample of human societies or languages. Future work is needed to assess the validity of such a universality claim by studying infant-directed vocalizations in a wider range of human societies, and by using phylogenetic methods to examine whether people in societies that are distantly related nonetheless produce similar infant-directed vocalizations.
Second, the naïve listener experiment tested a large number of participants and covered a diverse set of countries and native languages, raising the possibility that results may generalize. But the results may not generalize because the instructions of the experiment were presented in English, on an English-language website. Future work may determine their generality by testing perceived infant-directedness in multilingual experiments, to more accurately characterize cross-cultural variability in the perception of infant-directedness; and by testing listener intuitions among groups with reduced exposure to a given set of infant-directed vocalizations, such as very young infants or people from isolated, distantly related societies, as in related efforts27,64,96. Such research would benefit in particular from a focus on societies previously reported to have unusual vocalization practices, infant care practices, or both47,49–51; and would also clarify the extent to which convergent practices across cultures are due to cultural borrowing (in the many cases where societies are not fully isolated from the influence of global media).
Third, most prior studies of infant-directed vocalizations use elicited recordings20,23,26,30,39,76, as did we. While this method may underestimate the differences between infant-directed and adult-directed vocalizations, whether and how simulated infant-directed speech and song differ from their naturalistic counterparts is poorly understood. Future work may explore this issue by analyzing recordings of infant-directed vocalizations that are covertly and/or unobtrusively collected in a non-elicited manner, as in research using wearable recording devices for infants73,97. This may also resolve potential confounds from the wording of instructions to vocalizers.
Last, we note that speech and song are used in multiple contexts with infants, of which “addressing a fussy infant” is just one18,34. One curious finding may bear on general questions of the psychological functions of music: naïve listeners displayed a bias toward “adult” guesses for speech and “baby” guesses for song, regardless of their actual targets. We speculate that listeners treated “adult” and “baby” as the default reference levels for speech and song, respectively, against which acoustic evidence was compared, a pattern consistent with theories that posit song as having a special connection to infant care in human psychology33,42.
Methods
Vocalization corpus
We built a corpus of 1,615 recordings of infant-directed song, infant-directed speech, adult-directed song, and adult-directed speech (all audio is available at https://doi.org/10.5281/zenodo.5525161). Participants (N = 411) living in 21 societies (Fig. 1a and Table 1) produced each of these vocalizations, respectively, with a median of 15 participants per society (range 6–57). From those participants for whom information was available, most were female (86%) and nearly all were parents or grandparents of the focal infant (95%). Audio for one or more examples was unavailable from a small minority of participants, in cases of equipment failure or when the participant declined to complete the full recording session (25 recordings, or 1.5% of the corpus, were missing).
Recordings were collected by principal investigators and/or staff at their field sites, all using the same data collection protocol. They translated instructions to the native language of the participants, following the standard research practices at each site. There was no procedure for screening out participants, but we encouraged our collaborators to collect data from parents rather than non-parents. Fieldsites were selected partly by convenience (i.e., via recruiting principal investigators at fieldsites with access to infants and caregivers) and partly to maximize cultural, linguistic, and geographic diversity (see Table 1).
For infant-directed song and infant-directed speech, participants were asked to sing and speak to their infant as if they were fussy, where “fussy” could refer to anything from frowning or mild whimpering to a full tantrum. At no fieldsites were difficulties reported in the translation of the English word “fussy”, suggesting that participants understood it. For adult-directed speech, participants spoke to the researcher about a topic of their choice (e.g., they described their daily routine). For adult-directed song, participants sang a song that was not intended for infants; they also stated what that song was intended for (e.g., “a celebration song”). Participants vocalized in the primary language of their fieldsite, with a few exceptions (e.g., when singing songs without words; or in locations that used multiple languages, such as Turku, which included both Finnish and Swedish speakers).
For most participants (90%) an infant was physically present during the recording (the infants were 48% female; age in months: M = 11.40; SD = 7.61; range 0.5–48). When an infant was not present, participants were asked to imagine that they were vocalizing to their own infant or grandchild, and simulated their infant-directed vocalizations (a brief discussion is in Supplementary Results).
In all cases, participants were free to determine the content of their vocalizations. This was intentional: imposing a specific content category on their vocalizations (e.g., “sing a lullaby”) would likely alter the acoustic features of their vocalizations, which are known to be influenced by experimental contexts98. Some participants produced adult-directed songs that shared features with the intended soothing nature of the infant-directed songs; data on the intended behavioral context of each adult-directed song are in Supplementary Table 4.
All recordings were made with Zoom H2n digital audio recorders, using foam windscreens (where available). To ensure that participants were audible along with researchers, who stated information about the participant and environment before and after the vocalizations, recordings were made with a 360° dual x-y microphone pattern. This produced two uncompressed stereo audio files (WAV) per participant at 44.1 kHz; we only analyzed audio from the two-channel file on which the participant was loudest.
The principal investigator at each fieldsite provided standardized background data on the behavior and cultural practices of the society (e.g., whether there was access to mobile-phones/TV/radio, and how commonly people used ID speech or song in their daily lives). Most items were based on variables included in the D-PLACE cross-cultural corpus99.
The 21 societies varied widely in their characteristics, from cities with millions of residents (Beijing) to small-scale hunter-gatherer groups of as few as 35 people (Hadza). All of the small-scale societies studied had limited access to TV, radio, and the internet, mitigating against the influence of exposure to the music and/or infant care practices of other societies. Four of the small-scale societies (Nyangatom, Toposa, Sápara/Achuar, and Mbendjele) were completely without access to these communication technologies.
The societies also varied in the prevalence of infant-directed speech and song in day-to-day life. The only site reported to lack infant-directed song in contemporary practice was the Quechuan/Aymaran site, although it was also noted that people from this site know infant-directed songs in Spanish and use other vocalizations to calm infants. Conversely, the Mbendjele BaYaka were noted to use infant-directed song, but rarely used infant-directed speech. In most sites, the frequency of infant-directed song and speech varied. For example, among the Tsimane, song was reportedly infrequent in the context of infant care; when it appears, however, it is apparently used to soothe and encourage infants to sleep.
Our default strategy was to analyze all available audio from the corpus. In some cases, however, this was inadvisable (e.g., in the naïve listener experiment, when a listener might understand the language of the recording, and make a judgment based on the recording’s linguistic content rather than its acoustic content); all exclusion decisions are explicitly stated throughout.
Acoustic analyses
Acoustic feature extraction
We manually extracted the longest continuous and uninterrupted section of audio from each recording (i.e., isolating vocalizations by the participant from interruptions from other speakers, the infant, and so on), using Adobe Audition. We then used the silence detection tool in Praat100, with minimum sounding intervals at 0.1 seconds and minimum silent intervals at 0.3 seconds, to remove all portions of the audio where the participant was not speaking (i.e., the silence between vocalization phrases). These were manually concatenated in Python, producing denoised recordings, which were subsequently checked manually to ensure minimal loss of content.
We extracted and subsequently analyzed acoustic features using Praat100, and MIRtoolbox101, and computed additional rhythm features using discrete Fourier transforms of the signal102, and normalized pairwise variability of syllabic events103. These features consisted of measurements of pitch (e.g., F0, the fundamental frequency), timbre (e.g., roughness), and rhythm (e.g., tempo; n.b., because temporal measures would be affected by the concatenation process, we computed these variables on unconcatenated audio only); all summarized over time: producing 94 variables in total. We standardized feature values within-voices, eliminating between-voice variability. Further technical details are in Supplementary Methods.
For both the LASSO analyses (Fig. 1b) and the regression-based acoustic analyses (Fig. 2), we restricted the variable set to 27 summary statistics of median and interquartile range, as these correlated highly with other summary statistics (e.g., maximum, range) but were less sensitive to extreme observations.
The LASSO modeling, mixed-effect modeling, and PCA analysis were all run on the full corpus with only a few exceptions: we excluded 10 recordings due to missing values on one or more acoustic features and a further 35 recordings where one or more recording was missing from the same vocalist, leaving 1,570 recordings for the analysis.
LASSO modeling
We trained least absolute shrinkage and selection operator (LASSO) logistic classifiers with cross-validation using tidymodels104. For both speech and song, these models were provided with the set of 27 acoustic variables described in the previous section. These raw features were then demeaned for speech and song separately within-voices and then normalized at the level of the whole corpus. During model training, multinomial log-loss was used as an evaluation metric to fit the lambda parameter of the model.
For the main analyses (Fig. 1b, Supplementary Table 2, and Supplementary Fig. 2) we used a k-fold cross-validation procedure at the level of fieldsites. Alternate approaches used k-fold cross-validation at the levels of language family and world region (Supplementary Fig. 1). We evaluated model performance using a receiver operating characteristic metric, binary area-under-the-curve (AUC). This metric is commonly used to evaluate the diagnostic ability of a binary classifier; it yields a score between 0% and 100%, with a chance level of 50%.
Mixed-effects modeling
Following a preregistered exploratory-confirmatory design, we fitted a multi-level mixed-effects regression predicting each acoustic variable from the vocalization types, after adjusting for voice and fieldsite as random effects, and allowing them to vary for each vocalization type separately. To reduce the risk of Type I error, we performed this analysis on a randomly selected half of the corpus (exploratory, weighting by fieldsite) and only report results that successfully replicated in the other half (confirmatory). We did not correct for multiple tests because the exploratory-confirmatory design restricts the tests to those with a directional prediction.
These analyses deviated from the preregistration in two minor ways. First, we retained planned comparisons within vocalization types, but we eliminated those that compared across speech and song when we found much larger acoustic differences between speech and song overall than the differences between infant- and adult-directed vocalizations (a fact we failed to predict). As such, we adopted the simpler approach of post-hoc comparisons that were only within speech and within song. For transparency, we still report the preregistered post-hoc tests in Supplementary Fig. 4, but suggest that these comparisons be interpreted with caution. Second, to enable fieldsite-wise estimates (reported in Extended Data Fig. 1), we normalized the acoustic data corpus-wide and included a random effect of participant, rather than normalizing within-voices (as within-voice normalization would set all fieldsite-level effects to 0, making cross-fieldsite comparisons impossible).
Naïve listener experiment
We analyzed all data available at the time of writing this paper from the “Who’s Listening?” game at https://themusiclab.org/quizzes/ids, a continuously running jsPsych105 experiment distributed via Pushkin106, a platform that facilitates large-scale citizen-science research. This approach involves the recruitment of volunteer participants, who typically complete experiments because the experiments are intrinsically rewarding, with larger and more diverse samples than are typically feasible with in-laboratory research85,107. A total of 68,206 participants began the experiment, the first in January 2019 and the last in October 2021. Demographics in the sub-sample of United States participants are in Supplementary Table 6.
We played participants vocalizations from a subset of the corpus, excluding those that were less than 10 seconds in duration (n = 111) and those with confounding sounds produced by a source other than the target voice in the first 5 seconds of the recording (e.g., a crying baby or laughing adult in the background; n = 366), as determined by two independent annotators who remained unaware of vocalization type and fieldsite with disagreements resolved by discussion. A test of the robustness of the main effects to this exclusion decision is in Supplementary Results. We also excluded participants who reported having previously participated in the same experiment (n = 3,889); participants who reported being younger than 12 years old (n = 1,519); and those who reported having a hearing impairment (n = 1,437).
This yielded a sample of 51,065 participants (gender: 22,862 female, 27,045 male, 1,117 other, 41 did not disclose; age: median 22 years, interquartile range 18–29). Participants self-reported living in 187 different countries (Fig. 3b) and self-reported speaking 172 first languages and 147 second languages (27 of which were not in the list of first languages), for a total of 199 different languages. Roughly half the participants were native English speakers from the United States. We supplemented these data with a paid online experiment, to increase the sampling of a subset of recordings in the corpus (Supplementary Methods).
Participants listened to at least 1 and at most 16 vocalizations drawn from the subset of the corpus (as they were free to leave the experiment before completing it) for a total of 495,512 ratings (infant-directed song: n = 139,708; infant-directed speech: n = 99,482; adult-directed song: n = 132,124; adult-directed speech: n = 124,198). The vocalizations were selected with blocked randomization, such that a set of 16 trials included 4 vocalizations in English and 12 in other languages; this method ensured that participants heard a substantial number of non-English vocalizations. This yielded a median of 516.5 ratings per vocalization (interquartile range 315–566; range 46–704) and thousands of ratings for each society (median = 22,974; interquartile range 17,458–25,177). The experiment was conducted only in English, so participants likely had at least a cursory knowledge of English; a test of the robustness of the main effects when excluding English-language recordings is in Supplementary Results.
We asked participants to classify each vocalization as either directed toward a baby or an adult. The prompt “Someone is speaking or singing. Who do you think they are singing or speaking to?” was displayed while the audio played; participants could respond with either “adult” or “baby”, either by pressing a key corresponding to a drawing of an infant or adult face (when the participant used a desktop computer) or by tapping one of the faces (when the participant used a tablet or smartphone). The locations of the faces (left vs. right on a desktop; top vs. bottom on a tablet or smartphone) were randomized participant-wise. Screenshots are in Extended Data Fig. 3.
We asked participants to respond as quickly as possible, a common instruction in perception experiments, to reduce variability that could be introduced by participants hearing differing lengths of each stimulus; to reduce the likelihood that participants used linguistic content to inform their decisions; and to facilitate a response-time analysis (Extended Data Fig. 5), as jsPsych provides reliable response time data108. We also used the response time data as a coarse measure of compliance, by dropping trials where participants were likely inattentive, responding very quickly (less than 500 ms) or slowly (more than 5 s). Most response times fell within this time window (82.1% of trials).
The experiment included two training trials, using English-language recordings of a typically infant-directed song (“The wheels on the bus”) and a typically adult-directed song (“Hallelujah”); 92.7% of participants responded correctly by the first try and 99.5% responded correctly by the second try, implying that the vast majority of the participants understood the task.
As soon as they made a choice, playback stopped. After each trial, we told participants whether or not they had answered correctly and how long, in seconds, they took to respond. At the end of the experiment, we showed participants their total score and percentile rank (relative to other participants).
Ethics
Ethics approval for the collection of recordings was provided by local institutions and/or the home institution of the collaborating author who collected data at each fieldsite. These included the Bioethics Committee, Jagiellonian University (1072.6120.48.2017); Board for Research Ethics, Åbo Akademi University; Committee on the Use of Human Subjects, Harvard University (IRB16–1080 and IRB18–1739); Ethics Committee, School of Psychology, Victoria University of Wellington (0000023076); Human Investigation Committee, Yale University (MODCR00000571); Human Participants Ethics Committee, University of Auckland (018981); Human Research Protections Program, University of California San Diego (161173); Institutional Review Board, Arizona State University (STUDY00008158); Institutional Review Board, Florida International University (IRB-17–0067); Institutional Review Board, Future Generations University; Max Planck Institute for Evolutionary Anthropology; Research Ethics Board, University of Toronto (33547); Research Ethics Committee, University College London (13121/001); Review Board for Ethical Standards in Research, Toulouse School of Economics/IAST (2017–06-001 and 2018–09-001); and Tanzania Commission for Science and Technology (COSTECH). Ethics approval for the naïve listener experiment was provided by the Committee on the Use of Human Subjects, Harvard University (IRB17–1206). Informed consent was obtained from all participants.
Statistics & Reproducibility
All data and code are provided (see the Data availability and Code availability statements). The sample sizes were not chosen a priori for either the participants who provided recordings or the participants in the naïve listener experiment. All data exclusions are fully reported (see the corresponding Methods sections, above) and these decisions were either made prior to the analyses being conducted (e.g., excluding naïve listeners reporting hearing impairment), or, for post-hoc exclusion decisions, were justified by subsequent analyses (e.g., when a confound was discovered after the fact). For an example of the latter, in order to compute d′ scores at the level of each vocalist, both infant-directed and adult-directed versions of a vocalization (speech or song) were required, so we excluded the small number of vocalists that did not have complete pairs. The experiment did not involve any randomization of conditions or experimenter blinding, although the selection of recordings the participants heard was randomized. For all statistical tests, assumptions were assessed visually; when potential violations to normality of residuals were detected, we used robust standard errors to compute p-values.
Extended Data
Extended Data Fig. 1 |. Variation across societies of infant-directed alterations.
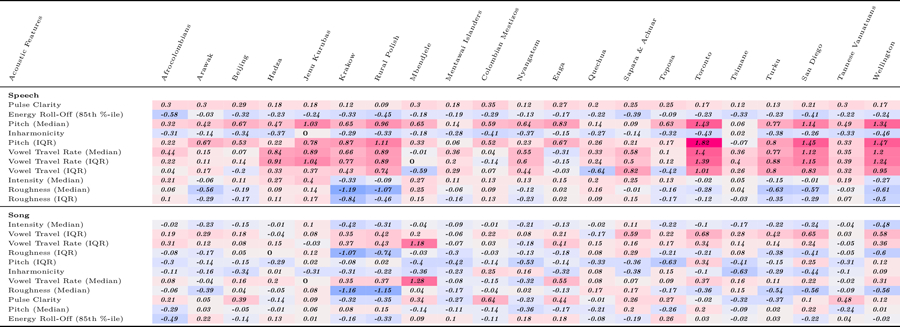
Estimated differences between infant-directed and adult-directed vocalizations, for acoustic feature, in each fieldsite (corresponding with the doughnut plots in Fig. 2). The estimates are derived from the random-effect components of the mixed-effects model reported in the main text. Cells of the table are shaded to facilitate the visibility of corpus-wide consistency (or inconsistency): redder cells represent features where infant-directed vocalizations have higher estimates than adult-directed vocalizations and bluer cells represent features with the reverse pattern. Within speech and song, acoustic features are ordered by their degree of cross-cultural regularity; some features showed the same direction of effect in all 21 societies (for example, for speech, median pitch and pitch variability), whereas others were more variable.
Extended Data Fig. 2 |. Principal-components analysis of acoustic features.
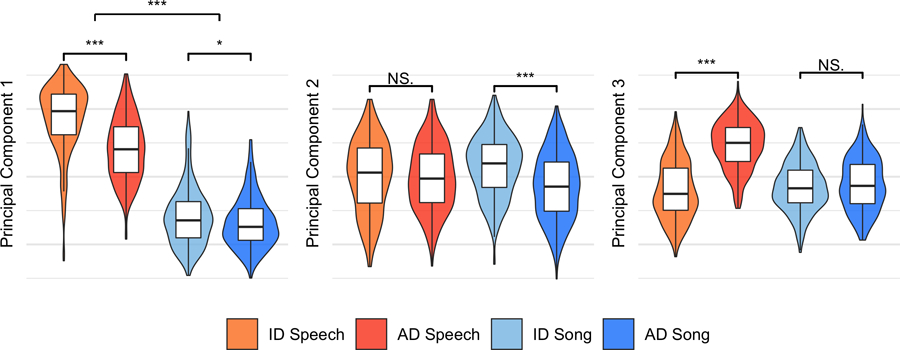
As an alternative approach to the acoustics data, we ran a principal-components analysis on the full 94 acoustic variables, to test whether an unsupervised method also yielded opposing trends in acoustic features across the different vocalization types. It did. The first three components explained 39% of total variability in the acoustic features. Moreover, the clearest differences between vocalization types accorded with the LASSO and mixed-effects modelling (Figs. 1b and 2). The first principal component most strongly differentiated speech and song, overall; the second most strongly differentiated infant-directed song from adult-directed song; and the third most strongly differentiated infant-directed speech from adult-directed speech. The violins indicate kernel density estimations and the boxplots represent the medians (centres), interquartile ranges (bounds of boxes) and 1.5xIQR (whiskers). Significance values are computed via two-sided Wilcoxon signed-rank tests (n = 1,570 recordings); *p < 0.05, **p < 0.01, ***p < 0.001. Feature loadings are in Supplementary Table 7.
Extended Data Fig. 3 |. Screenshots from the naive listener experiment.
On each trial, participants heard a randomly selected vocalization from the corpus and were asked to quickly guess to whom the vocalization was directed: an adult or a baby. The experiment used large emoji and was designed to display comparably on desktop computers (a) or tablets/smartphones (b).
Extended Data Fig. 4 |. Response biases in the naive listener experiment.
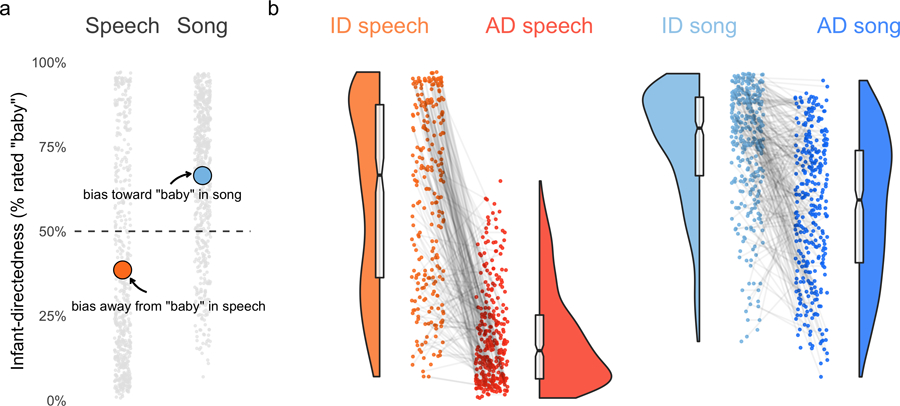
a, Listeners showed reliable biases: regardless of whether a vocalization was infant- or adult-directed, the listeners gave speech recordings substantially fewer “baby” responses than expected by chance, and gave song recordings substantially more “baby” responses. The grey points represent average ratings for each of the recordings in the corpus that were used in the experiment (after exclusions, n = 1,138 recordings from the corpus of 1,615), split by speech and song; the orange and blue points indicate the means of each vocalization type; and the horizontal dashed line represents hypothetical chance level of 50%. b, Despite the response biases, within speech and song, the raw data nevertheless showed clear differences between infant-directed and adult-directed vocalizations, that is, by comparing infant-directedness scores within the same voice, across infant-directed and adult-directed vocalizations (visible here in the steep negative slopes of the grey lines). The main text results report only d’ statistics for these data, for simplicity, but the main effects are nonetheless visible here in the raw data. The points indicate average ratings for each recording; the grey lines connecting the points indicate the pairs of vocalizations produced by the same voice; the half-violins are kernel density estimations; the boxplots represent the medians, interquartile ranges and 95% confidence intervals (indicated by the notches); and the horizontal dashed lines indicate the response bias levels (from a).
Extended Data Fig. 5 |. Response-time analysis of naive listener experiment.
We recorded the response times of participants in their mobile or desktop browsers, using jsPsych (see Methods), and asked whether, when responding correctly, participants more rapidly detected infant-directedness in speech or song. They did not: a mixed-effects regression predicting the difference in response time between infant-directed and adult-directed vocalizations (within speech or song), adjusting hierarchically for fieldsite and world region, yielded no significant differences (ps > .05 from two-sided linear combination tests; no adjustments made for multiple comparisons). The grey points represent average ratings for each of the recordings in the corpus that were used in the experiment (after exclusions, n = 1,138 recordings from the corpus of 1,615), split by speech and song; the grey lines connecting the points indicate the pairs of vocalizations produced by the same participant; the half-violins are kernel density estimations; and the boxplots represent the medians, interquartile ranges and 95% confidence intervals (indicated by the notches).
Supplementary Material
Acknowledgments
This research was supported by the Harvard University Department of Psychology (M.M.K. and S.A.M.); the Harvard College Research Program (H.L-R.); the Harvard Data Science Initiative (S.A.M.); the National Institutes of Health Director’s Early Independence Award DP5OD024566 (S.A.M. and C.B.H.); the Academy of Finland Grant 298513 (J. Antfolk); the Royal Society of New Zealand Te Apārangi Rutherford Discovery Fellowship RDF-UOA1101 (Q.D.A., T.A.V.); the Social Sciences and Humanities Research Council of Canada (L.K.C.); the Polish Ministry of Science and Higher Education grant N43/DBS/000068 (G.J.); the Fogarty International Center (P.M., A. Siddaiah, C.D.P.); the National Heart, Lung, and Blood Institute, and the National Institute of Neurological Disorders and Stroke Award D43 TW010540 (P.M., A. Siddaiah); the National Institute of Allergy and Infectious Diseases Award R15-AI128714-01 (P.M.); the Max Planck Institute for Evolutionary Anthropology (C.T.R., C.M.); a British Academy Research Fellowship and Grant SRG-171409 (G.D.S.); the Institute for Advanced Study in Toulouse, under an Agence nationale de la recherche grant, Investissements d’Avenir ANR-17-EURE-0010 (L.G., J. Stieglitz); the Fondation Pierre Mercier pour la Science (C.S.); and the Natural Sciences and Engineering Research Council of Canada (S.E.T.). We thank the participants and their families for providing recordings; Lawrence Sugiyama for supporting pilot data collection; Juan Du, Elizabeth Pillsworth, Polly Wiessner, and John Ziker for collecting or attempting to collect additional recordings; Ngambe Nicolas for research assistance in the Republic of the Congo; Zuzanna Jurewicz for research assistance in Toronto; Maskota Delfi and Rustam Sakaliou for research assistance in Indonesia; Willy Naiou and Amzing Altrin for research assistance in Vanuatu; S. Atwood, Anna Bergson, Dara Li, Luz Lopez, and Emilė Radytė for project-wide research assistance; and Jonathan Kominsky, Lindsey Powell, and Lidya Yurdum for feedback on the manuscript.
Footnotes
Code availability
Analysis and visualization code; a reproducible R Markdown manuscript; and code for the naïve listener experiment are available at https://github.com/themusiclab/infant-speech-song and are permanently archived at https://doi.org/10.5281/zenodo.6562398.
Competing interests statement
The authors declare no competing interests.
Data availability
The audio corpus is available at https://doi.org/10.5281/zenodo.5525161. All data, including supplementary fieldsite-level data and the recording collection protocol, are available at https://github.com/themusiclab/infant-speech-song and are permanently archived at https://doi.org/10.5281/zenodo.6562398. The preregistration for the auditory analyses is at https://osf.io/5r72u.
References
- 1.Morton ES On the occurrence and significance of motivation-structural rules in some bird and mammal sounds. The American Naturalist 111, 855–869 (1977). [Google Scholar]
- 2.Endler JA Some general comments on the evolution and design of animal communication systems. Philosophical Transactions of the Royal Society B: Biological Sciences 340, 215–225 (1993). [DOI] [PubMed] [Google Scholar]
- 3.Owren MJ & Rendall D Sound on the rebound: Bringing form and function back to the forefront in understanding nonhuman primate vocal signaling. Evolutionary Anthropology 10, 58–71 (2001). [Google Scholar]
- 4.Fitch WT, Neubauer J & Herzel H Calls out of chaos: The adaptive significance of nonlinear phenomena in mammalian vocal production. Animal Behaviour 63, 407–418 (2002). [Google Scholar]
- 5.Wiley RH The evolution of communication: Information and manipulation. Animal Behaviour 2, 156–189 (1983). [Google Scholar]
- 6.Krebs J & Dawkins R Animal signals: Mind-reading and manipulation. in Behavioural Ecology: An Evolutionary Approach (eds. Krebs J & Davies N) 380–402 (Blackwell, 1984). [Google Scholar]
- 7.Karp D, Manser MB, Wiley EM & Townsend SW Nonlinearities in meerkat alarm calls prevent receivers from habituating. Ethology 120, 189–196 (2014). [Google Scholar]
- 8.Slaughter EI, Berlin ER, Bower JT & Blumstein DT A test of the nonlinearity hypothesis in great-tailed grackles (Quiscalus mexicanus). Ethology 119, 309–315 (2013). [Google Scholar]
- 9.Wagner WE Fighting, assessment, and frequency alteration in Blanchard’s cricket frog. Behavioral Ecology and Sociobiology 25, 429–436 (1989). [Google Scholar]
- 10.Ladich F Sound production by the river bullhead, Cottus gobio L. (Cottidae, Teleostei). Journal of Fish Biology 35, 531–538 (1989). [Google Scholar]
- 11.Filippi P et al. Humans recognize emotional arousal in vocalizations across all classes of terrestrial vertebrates: Evidence for acoustic universals. Proceedings of the Royal Society B: Biological Sciences 284, (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Lingle S & Riede T Deer mothers are sensitive to infant distress vocalizations of diverse mammalian species. The American Naturalist 184, 510–522 (2014). [DOI] [PubMed] [Google Scholar]
- 13.Custance D & Mayer J Empathic-like responding by domestic dogs (Canis familiaris) to distress in humans: An exploratory study. Animal Cognition 15, 851–859 (2012). [DOI] [PubMed] [Google Scholar]
- 14.Lea AJ, Barrera JP, Tom LM & Blumstein DT Heterospecific eavesdropping in a nonsocial species. Behavioral Ecology 19, 1041–1046 (2008). [Google Scholar]
- 15.Magrath RD, Haff TM, McLachlan JR & Igic B Wild birds learn to eavesdrop on heterospecific alarm calls. Current Biology 25, 2047–2050 (2015). [DOI] [PubMed] [Google Scholar]
- 16.Piantadosi ST & Kidd C Extraordinary intelligence and the care of infants. Proceedings of the National Academy of Sciences 113, 6874–6879 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Soltis J The signal functions of early infant crying. Behavioral and Brain Sciences 27, 443–458 (2004). [PubMed] [Google Scholar]
- 18.Fernald A Human maternal vocalizations to infants as biologically relevant signals: An evolutionary perspective. in The adapted mind: Evolutionary psychology and the generation of culture (eds. Barkow JH, Cosmides L & Tooby J) 391–428 (Oxford University Press, 1992). [Google Scholar]
- 19.Burnham E, Gamache JL, Bergeson T & Dilley L Voice-onset time in infant-directed speech over the first year and a half. in Proceedings of Meetings on Acoustics ICA2013 19, 060094 (ASA, 2013). [Google Scholar]
- 20.Fernald A & Mazzie C Prosody and focus in speech to infants and adults. Developmental Psychology 27, 209–221 (1991). [Google Scholar]
- 21.Ferguson CA Baby talk in six languages. American Anthropologist 66, 103–114 (1964). [Google Scholar]
- 22.Audibert N & Falk S Vowel space and F0 characteristics of infant-directed singing and speech. in Proceedings of the 19th international conference on speech prosody 153–157 (2018). [Google Scholar]
- 23.Kuhl PK et al. Cross-language analysis of phonetic units in language addressed to infants. Science 277, 684–686 (1997). [DOI] [PubMed] [Google Scholar]
- 24.Englund KT & Behne DM Infant directed speech in natural interaction: Norwegian vowel quantity and quality. Journal of Psycholinguistic Research 34, 259–280 (2005). [DOI] [PubMed] [Google Scholar]
- 25.Fernald A The perceptual and affective salience of mothers’ speech to infants. in The origins and growth of communication (1984). [Google Scholar]
- 26.Falk S & Kello CT Hierarchical organization in the temporal structure of infant-direct speech and song. Cognition 163, 80–86 (2017). [DOI] [PubMed] [Google Scholar]
- 27.Bryant GA & Barrett HC Recognizing intentions in infant-directed speech: Evidence for universals. Psychological Science 18, 746–751 (2007). [DOI] [PubMed] [Google Scholar]
- 28.Piazza EA, Iordan MC & Lew-Williams C Mothers consistently alter their unique vocal fingerprints when communicating with infants. Current Biology 27, 3162–3167 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Trehub SE, Unyk AM & Trainor LJ Adults identify infant-directed music across cultures. Infant Behavior and Development 16, 193–211 (1993). [Google Scholar]
- 30.Trehub SE, Unyk AM & Trainor LJ Maternal singing in cross-cultural perspective. Infant Behavior and Development 16, 285–295 (1993). [Google Scholar]
- 31.Mehr SA, Singh M, York H, Glowacki L & Krasnow MM Form and function in human song. Current Biology 28, 356–368 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Mehr SA et al. Universality and diversity in human song. Science 366, 957–970 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Trehub SE Musical predispositions in infancy. Annals of the New York Academy of Sciences 930, 1–16 (2001). [DOI] [PubMed] [Google Scholar]
- 34.Trehub SE & Trainor L Singing to infants: Lullabies and play songs. Advances in Infancy Research 12, 43–78 (1998). [Google Scholar]
- 35.Trehub SE et al. Mothers’ and fathers’ singing to infants. Developmental Psychology 33, 500–507 (1997). [DOI] [PubMed] [Google Scholar]
- 36.Thiessen ED, Hill EA & Saffran JR Infant-directed speech facilitates word segmentation. Infancy 7, 53–71 (2005). [DOI] [PubMed] [Google Scholar]
- 37.Trainor LJ & Desjardins RN Pitch characteristics of infant-directed speech affect infants’ ability to discriminate vowels. Psychonomic Bulletin & Review 9, 335–340 (2002). [DOI] [PubMed] [Google Scholar]
- 38.Werker JF & McLeod PJ Infant preference for both male and female infant-directed talk: A developmental study of attentional and affective responsiveness. Canadian Journal of Psychology/Revue Canadienne de Psychologie 43, 230–246 (1989). [DOI] [PubMed] [Google Scholar]
- 39.Ma W, Fiveash A, Margulis EH, Behrend D & Thompson WF Song and infant-directed speech facilitate word learning. Quarterly Journal of Experimental Psychology 73, 1036–1054 (2020). [DOI] [PubMed] [Google Scholar]
- 40.Falk D Prelinguistic evolution in early hominins: Whence motherese? Behavioral and Brain Sciences 27, 491–502 (2004). [DOI] [PubMed] [Google Scholar]
- 41.Mehr SA & Krasnow MM Parent-offspring conflict and the evolution of infant-directed song. Evolution and Human Behavior 38, 674–684 (2017). [Google Scholar]
- 42.Mehr SA, Krasnow MM, Bryant GA & Hagen EH Origins of music in credible signaling. Behavioral and Brain Sciences 1–41 (2020). doi: 10.1017/S0140525X20000345 [DOI] [PMC free article] [PubMed]
- 43.Senju A & Csibra G Gaze Following in Human Infants Depends on Communicative Signals. Current Biology 18, 668–671 (2008). [DOI] [PubMed] [Google Scholar]
- 44.Hernik M & Broesch T Infant gaze following depends on communicative signals: An eye-tracking study of 5- to 7-month-olds in Vanuatu. Developmental Science 22, e12779 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Henrich J, Heine SJ & Norenzayan A The weirdest people in the world? Behavioral and Brain Sciences 33, 61–83 (2010). [DOI] [PubMed] [Google Scholar]
- 46.Yarkoni T The generalizability crisis. Behavioral and Brain Sciences 45, e1 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Broesch T & Bryant GA Fathers’ Infant-Directed Speech in a Small-Scale Society. Child Development 89, e29–e41 (2018). [DOI] [PubMed] [Google Scholar]
- 48.Ochs E & Schieffelin B Language acquisition and socialization. Culture theory: Essays on mind, self, and emotion 276–320 (1984).
- 49.Schieffelin BB The give and take of everyday life: Language, socialization of Kaluli children (CUP Archive, 1990). [Google Scholar]
- 50.Ratner NB & Pye C Higher pitch in BT is not universal: Acoustic evidence from Quiche Mayan. Journal of child language 11, 515–522 (1984). [DOI] [PubMed] [Google Scholar]
- 51.Pye C Quiché mayan speech to children. Journal of child language 13, 85–100 (1986). [DOI] [PubMed] [Google Scholar]
- 52.Heath SB Ways with words: Language, life and work in communities and classrooms (cambridge university Press, 1983). [Google Scholar]
- 53.Trehub SE Challenging infant-directed singing as a credible signal of maternal attention. Behavioral and Brain Sciences (2021). [DOI] [PubMed]
- 54.Räsänen O, Kakouros S & Soderstrom M Is infant-directed speech interesting because it is surprising? – Linking properties of IDS to statistical learning and attention at the prosodic level. Cognition 178, 193–206 (2018). [DOI] [PubMed] [Google Scholar]
- 55.Cristia A & Seidl A The hyperarticulation hypothesis of infant-directed speech. Journal of child language 41, 913–934 (2014). [DOI] [PubMed] [Google Scholar]
- 56.Kalashnikova M, Carignan C & Burnham D The origins of babytalk: Smiling, teaching or social convergence? Royal Society Open Science 4, 170306 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Grieser DL & Kuhl PK Maternal speech to infants in a tonal language: Support for universal prosodic features in motherese. Developmental Psychology 24, 14 (1988). [Google Scholar]
- 58.Fisher C & Tokura H Acoustic cues to grammatical structure in infant-directed speech: Cross-linguistic evidence. Child Development 67, 3192–3218 (1996). [PubMed] [Google Scholar]
- 59.Kitamura C, Thanavishuth C, Burnham D & Luksaneeyanawin S Universality and specificity in infant-directed speech: Pitch modifications as a function of infant age and sex in a tonal and non-tonal language. Infant Behavior and Development 24, 372–392 (2001). [Google Scholar]
- 60.Fernald A Intonation and communicative intent in mothers’ speech to infants: Is the melody the message? Child Development 60, 1497–1510 (1989). [PubMed] [Google Scholar]
- 61.Farran LK, Lee C-C, Yoo H & Oller DK Cross-Cultural Register Differences in Infant-Directed Speech: An Initial Study. PLOS ONE 11, e0151518 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Broesch TL & Bryant GA Prosody in Infant-Directed Speech Is Similar Across Western and Traditional Cultures. Journal of Cognition and Development 16, 31–43 (2015). [Google Scholar]
- 63.Broesch T, Rochat P, Olah K, Broesch J & Henrich J Similarities and Differences in Maternal Responsiveness in Three Societies: Evidence From Fiji, Kenya, and the United States. Child Development 87, 700–711 (2016). [DOI] [PubMed] [Google Scholar]
- 64.ManyBabies Consortium. Quantifying sources of variability in infancy research using the infant-directed-speech preference. Advances in Methods and Practices in Psychological Science 3, 24–52 (2020). [Google Scholar]
- 65.Soley G & Sebastian-Galles N Infants’ expectations about the recipients of infant-directed and adult-directed speech. Cognition 198, 104214 (2020). [DOI] [PubMed] [Google Scholar]
- 66.Byers-Heinlein K et al. A Multilab Study of Bilingual Infants: Exploring the Preference for Infant-Directed Speech. Advances in Methods and Practices in Psychological Science 30 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Fernald A et al. A cross-language study of prosodic modifications in mothers’ and fathers’ speech to preverbal infants. Journal of Child Language 16, 477–501 (1989). [DOI] [PubMed] [Google Scholar]
- 68.Kitamura C & Burnham D Pitch and Communicative Intent in Mother’s Speech: Adjustments for Age and Sex in the First Year. Infancy 4, 85–110 (2003). [Google Scholar]
- 69.Kitamura C & Lam C Age-Specific Preferences for Infant-Directed Affective Intent. Infancy 14, 77–100 (2009). [DOI] [PubMed] [Google Scholar]
- 70.Hilton C, Crowley L, Yan R, Martin A & Mehr S Children infer the behavioral contexts of unfamiliar foreign songs (2021). doi: 10.31234/osf.io/rz6qn [DOI] [PMC free article] [PubMed]
- 71.Yan R et al. Across demographics and recent history, most parents sing to their infants and toddlers daily (2021). doi: 10.31234/osf.io/fy5bh [DOI] [PMC free article] [PubMed]
- 72.Custodero LA, Rebello Britto P & Brooks-Gunn J Musical lives: A collective portrait of American parents and their young children. Journal of Applied Developmental Psychology 24, 553–572 (2003). [Google Scholar]
- 73.Mendoza JK & Fausey CM Everyday music in infancy. Developmental Science (2021). doi: 10.31234/osf.io/sqatb [DOI] [PMC free article] [PubMed]
- 74.Konner M Aspects of the developmental ethology of a foraging people. in Ethological Studies of Child Behaviour (ed. Blurton Jones NG) 285–304 (Cambridge University Press, 1972). [Google Scholar]
- 75.Marlowe F The Hadza hunter-gatherers of Tanzania (University of California Press, 2010). [Google Scholar]
- 76.Cirelli LK, Jurewicz ZB & Trehub SE Effects of maternal singing style on mother–infant arousal and behavior. Journal of Cognitive Neuroscience (2019). doi: 10.1162/jocn_a_01402 [DOI] [PubMed]
- 77.Cirelli LK & Trehub SE Familiar songs reduce infant distress. Developmental Psychology (2020). doi: 10.1037/dev0000917 [DOI] [PubMed]
- 78.Bainbridge CM et al. Infants relax in response to unfamiliar foreign lullabies. Nature Human Behaviour (2021). doi: 10.1038/s41562-020-00963-z [DOI] [PMC free article] [PubMed]
- 79.Friedman J, Hastie T & Tibshirani R Lasso and elastic-net regularized generalized linear models Rpackage version 2.0–5. (2016).
- 80.Hagen EH & Bryant GA Music and dance as a coalition signaling system. Human Nature 14, 21–51 (2003). [DOI] [PubMed] [Google Scholar]
- 81.Corbeil M, Trehub SE & Peretz I Singing delays the onset of infant distress. Infancy 21, 373–391 (2016). [Google Scholar]
- 82.Arnal LH, Flinker A, Kleinschmidt A, Giraud A-L & Poeppel D Human screams occupy a privileged niche in the communication soundscape. Current Biology 25, 2051–2056 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Mehr SA, Kotler J, Howard RM, Haig D & Krasnow MM Genomic imprinting is implicated in the psychology of music. Psychological Science 28, 1455–1467 (2017). [DOI] [PubMed] [Google Scholar]
- 84.Kotler J, Mehr SA, Egner A, Haig D & Krasnow MM Response to vocal music in Angelman syndrome contrasts with Prader-Willi syndrome. Evolution and Human Behavior 40, 420–426 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Hilton CB & Mehr SA Citizen science can help to alleviate the generalizability crisis. Behavioral and Brain Sciences (2022). [DOI] [PubMed]
- 86.Lumsden CJ & Wilson EO Translation of epigenetic rules of individual behavior into ethnographic patterns. Proceedings of the National Academy of Sciences 77, 4382–4386 (1980). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Fitch WT Vocal tract length and formant frequency dispersion correlate with body size in rhesus macaques. The Journal of the Acoustical Society of America 11 (1997). [DOI] [PubMed] [Google Scholar]
- 88.Blumstein DT, Bryant GA & Kaye P The sound of arousal in music is context-dependent. Biology Letters 8, 744–747 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Reber SA et al. Formants provide honest acoustic cues to body size in American alligators. Scientific Reports 7, 1816 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90.Reby D et al. Red deer stags use formants as assessment cues during intrasexual agonistic interactions. Proceedings of the Royal Society B: Biological Sciences 272, 941–947 (2005). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Bertoncini J, Bijeljac-Babic R, Jusczyk PW, Kennedy LJ & Mehler J An investigation of young infants’ perceptual representations of speech sounds. Journal of Experimental Psychology: General 117, 21–33 (1988). [DOI] [PubMed] [Google Scholar]
- 92.Werker JF & Lalonde CE Cross-language speech perception: Initial capabilities and developmental change. Developmental Psychology 24, 672 (1988). [Google Scholar]
- 93.Polka L & Werker JF Developmental changes in perception of nonnative vowel contrasts. Journal of Experimental Psychology: Human Perception and Performance 20, 421–435 (1994). [DOI] [PubMed] [Google Scholar]
- 94.Trainor LJ, Clark ED, Huntley A & Adams BA The acoustic basis of preferences for infant-directed singing. Infant Behavior and Development 20, 383–396 (1997). [Google Scholar]
- 95.Tsang CD, Falk S & Hessel A Infants prefer infant-directed song over speech. Child Development 88, 1207–1215 (2017). [DOI] [PubMed] [Google Scholar]
- 96.McDermott JH, Schultz AF, Undurraga EA & Godoy RA Indifference to dissonance in native Amazonians reveals cultural variation in music perception. Nature 535, 547–550 (2016). [DOI] [PubMed] [Google Scholar]
- 97.Bergelson E et al. Everyday language input and production in 1001 children from 6 continents (under review). [DOI] [PMC free article] [PubMed]
- 98.Trehub SE, Hill DS & Kamenetsky SB Parents’ sung performances for infants. Canadian Journal of Experimental Psychology 51, 385–396 (1997). [DOI] [PubMed] [Google Scholar]
- 99.Kirby KR et al. D-PLACE: A Global Database of Cultural, Linguistic and Environmental Diversity. PLOS ONE 11, e0158391 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 100.Boersma P Praat, a system for doing phonetics by computer. Glot. Int 5, 341–345 (2001). [Google Scholar]
- 101.Lartillot O, Toiviainen P & Eerola T A Matlab toolbox for music information retrieval. in Data analysis, machine learning and applications (eds. Preisach C, Burkhardt H, Schmidt-Thieme L & Decker R) 261–268 (Springer Berlin Heidelberg, 2008). [Google Scholar]
- 102.Patel AD Musical rhythm, linguistic rhythm, and human evolution. Music Perception 24, 99–104 (2006). [Google Scholar]
- 103.Mertens P The prosogram: Semi-automatic transcription of prosody based on a tonal perception model. in Speech Prosody 2004, International Conference (2004). [Google Scholar]
- 104.Kuhn M & Wickham H Tidymodels: A collection of packages for modeling and machine learning using tidyverse principles (2020).
- 105.de Leeuw JR jsPsych: A JavaScript library for creating behavioral experiments in a Web browser. Behavior Research Methods 47, 1–12 (2015). [DOI] [PubMed] [Google Scholar]
- 106.Hartshorne JK, de Leeuw J, Goodman N, Jennings M & O’Donnell TJ A thousand studies for the price of one: Accelerating psychological science with Pushkin. Behavior Research Methods 51, 1782–1803 (2019). [DOI] [PubMed] [Google Scholar]
- 107.Sheskin M et al. Online developmental science to foster innovation, access, and impact. Trends in Cognitive Sciences (2020). doi: 10.1016/j.tics.2020.06.004 [DOI] [PMC free article] [PubMed]
- 108.Anwyl-Irvine A, Dalmaijer ES, Hodges N & Evershed JK Realistic precision and accuracy of online experiment platforms, web browsers, and devices. Behavior Research Methods 53, 1407–1425 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The audio corpus is available at https://doi.org/10.5281/zenodo.5525161. All data, including supplementary fieldsite-level data and the recording collection protocol, are available at https://github.com/themusiclab/infant-speech-song and are permanently archived at https://doi.org/10.5281/zenodo.6562398. The preregistration for the auditory analyses is at https://osf.io/5r72u.