

Abstract
The Nun study is a well-known longitudinal epidemiology study of aging and dementia that recruited elderly nuns who were not yet diagnosed with dementia (i.e., incident cohort) and who had dementia prior to entry (i.e., prevalent cohort). In such a natural history of disease study, multistate modeling of the combined data from both incident and prevalent cohorts is desirable to improve the efficiency of inference. While important, the multistate modeling approaches for the combined data have been scarcely used in practice because prevalent samples do not provide the exact date of disease onset and do not represent the target population due to left-truncation. In this paper, we demonstrate how to adequately combine both incident and prevalent cohorts to examine risk factors for every possible transition in studying the natural history of dementia. We adapt a four-state nonhomogeneous Markov model to characterize all transitions between different clinical stages, including plausible reversible transitions. The estimating procedure using the combined data leads to efficiency gains for every transition compared to those from the incident cohort data only.
Supplementary Information
The online version contains supplementary material available at 10.1007/s10985-023-09602-x.
Keywords: Combined cohort data, Incident cohort, Interval censoring, Left truncation, Multistate model, Prevalent cohort
Introduction
In the field of epidemiology, understanding the natural history of a chronic disease, which refers to the clinical course of a disease progress, is important for formulating prevention and control strategies for the disease. In dementia studies, the cognitive function of a senior is assessed periodically and summarized roughly as intact cognition, mild cognitive impairment (MCI), or dementia. The transitions among these states describe the natural history of the disease. An example is the Nun Study of aging and Alzheimer’s disease (Nun Study), which monitored nuns aged 75 years or older at entry for future disease progression with approximately annual examination up to 10 years. In this study cohort, some individuals were already found to be in the dementia state in their screening tests, yielding two sub-cohorts: the incident cohort of subjects without dementia at entry and followed for the potential diagnosis of dementia and death, and the prevalent cohort of subjects who were diagnosed with dementia at entry and followed up to death.
Of particular interest is the study of risk factors for cognitive decline and the duration from dementia onset to death. In the analyses using incident cohort data from the Nun Study, Tyas et al. (2007) concluded that the presence of apolipoprotein E4 allele (ApoE4) and low education increased the risk of transition to MCI but not the risk of the transition from MCI to dementia or death. Meanwhile, Wei et al. (2014) showed that both risk factors were positively associated with the transitions to MCI and dementia. Although the incident cohort is the collection of random samples from the target population, it is possibly limited in its ability to observe sufficient events of death. This factor can be mitigated by including the prevalent cohort with more failure events. Analyzing the combined data from the incident and prevalent cohorts leads to more efficiency in estimating baseline intensity functions and evaluating risk factors. In this paper, we revisit the association of risk factors with the transitions to MCI, dementia, and death by using both incident and prevalent cohorts from the Nun Study.
Analyzing the combined incident and prevalent cohort data is complex, owing to some unique and challenging data features. First, cognitive functioning is often assessed by intermittent visits, resulting in interval censored times for transitions. Second, since reverting from MCI back to intact cognition is fairly common in the natural history of dementia, the exact disease trajectory for a subject is difficult to ascertain. Third, the patients sampled in the midst of dementia usually cannot provide the exact starting date of the dementia. Only the remaining period of the progression from dementia to death, the time from study enrollment to death or loss to follow-up, is observed from the prevalent cohort. Lastly, the subjects from the prevalent cohort are likely to have longer durations from dementia to death compared to the dementia patients in the incidence cohort, which causes selection bias, i.e., the left-truncation problem. Failure to address these theoretical challenges when combining incident and prevalent cohorts may result in biased inference on the natural history of the disease and its association with risk factors.
With a single survival endpoint of interest, a few works from the literature have shown the benefits of combining both incident and prevalent cohorts. For example, Lee et al. (2019) proposed an efficient estimation procedure that uses both the incident and prevalent cohorts under a proportional mean residual life model with right-censored data. In other areas, Wolfson et al. (2019) suggested approaches for estimating the non-parametric estimators of the survival function with the combined data in myotonic dystrophy by assuming that the disease onset of a prevalent case was known to be within an interval. McVittie et al. (2020) constructed the parametric likelihood of the combined data to estimate hospital stay durations, subject to right-censoring and the assumption of stationarity. Although important, their methods are not applicable to describe the natural history of disease that is represented with transitions between multiple states and often observed with data subject to selection bias. Joint modeling of the combined data with multiple transitions has been proposed in the literature. For example, Kulathinal et al. (2020) showed a gain in efficiency by combining both the incident and prevalent cohorts under the multistate model framework. They postulated that the incidence of the event of interest could be retrospectively observed in the prevalent cohort. On the other hand, Saarela et al. (2009) and Gorfine et al. (2021) proposed estimation procedures to jointly model both prevalent and incident cases subject to right censoring when important information from the prevalent cases is uncertain. To the best of our knowledge, there is no prior work that addresses the topic of modeling interval-censored natural history data obtained from a combination of incident and prevalent cohorts, particularly when the onset of prevalent disease cannot be observed retrospectively.
We propose a multistate approach for analyzing interval-censored event history data that are observed from both incident and prevalent cohorts to examine the association of risk factors with the transitions that are involved in the natural history of the disease. The modelling of cognitive changes and death in dementia is illustrated with a nonhomogeneous multistate Markov model, allowing for the reversible transition between intact cognition and MCI and the transition from any cognitive state to death. Within a multistate modeling framework, we derive the distribution of dementia onset using event-history observations, and we use this to model the observable residual periods of prevalent samples in a general truncation structure. We present a likelihood-based estimation procedure for jointly modelling the combined data from incident and prevalent cohorts in Sect. 2. In Sect. 3, intensive simulation studies are conducted to investigate the finite sample performance of the estimation procedure and to show the efficiency gains of the estimators compared to those that are obtained using the incident cohort only. We use the proposed method to analyze the Nun Study in Sect. 4. Section 5 contains some concluding remarks.
Statistical methodologies
Notations and model
We denote the participant’s health status at a given time t by a multistate process X(t) that takes a finite number of the values for the states representing discrete clinical conditions or death. In dementia studies, the multistate processes are typically characterized with four states, namely , where 0 denotes cognitively intact for age, 1 denotes cognitive impairment, 2 denotes clinical dementia, and 3 denotes death. The biologically plausible transitions between the four states are depicted in Fig. 1, where the transition between state 0 and state 1 is potentially reversible, the transition from state 0 to 2 is assumed to proceed through MCI, and state 3 is the absorbing state that can be reached from all other states.
Fig. 1.
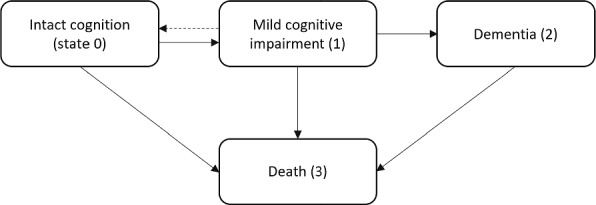
Transition diagram with four states for dementia: state 0 for intact cognition, state 1 for mild cognitive impairment (MCI), state 2 for dementia and state 3 for death
Assume that X(t) follows a conditional Markov multistate model with four states, characterized by the conditional transition probabilities,
where , and is a vector of risk factors. Then, the conditional transition intensity from k to l, , is
for and (Cox and Miller 1965). Let denote the transition probability matrix whose (k, l) entry is and denote the transition intensity matrix whose (k, l) entry is and . With the possible transitions shown in Fig. 1,
The transition probabilities for a continuous-time Markov process can be obtained by solving the following Kolmogorov forward equation,
| 1 |
where is the identity matrix. For a nonhomogeneous Markov model, however, the solution to equation (1) is intractable with non-trivial forms of , and it is computationally intensive to get the solution with covariates (Titman 2011). In some situations, an analytic solution to equation (1) is available; the first example is a progressive process with a small number of states (Pak et al. 2017, 2019), and the second example is a time transformation model that assumes the transition intensity matrix is a form of with the operation time h(t), where is the transition intensity matrix for a homogeneous Markov process and h(t) is a nonnegative function (Kalbfleisch and Lawless 1985; Omar et al. 1995; Hubbard et al. 2008). We adapt the time transformation model when constructing the likelihood function for event-history data.
We assume the multiplicative intensity model for each transition that is
| 2 |
where is the k-to-l baseline transition intensity and is the regression coefficient vector for the transition from state k to state l. We use the Weibull distribution to model the baseline transition intensities under the assumption of the same time dependency across transitions, namely, with unknown positive parameters, and . Then, the transition intensity matrix can be expressed as , where is the transition intensity matrix whose (k, l) entry is and . This implies that there exists a new time scale, h(t), which leads to the homogeneous process with the transition intensity matrix (Hubbard et al. 2008). Thus, we have , where .
We introduce additional notation to model the prevalent samples. The prevalent cohort includes participants who are alive but with dementia at the time of recruitment. Let U denote individual’s age at study enrollment. Further, we let be the age of onset for clinical dementia and be the age at death. Then, the prevalent cohort is formed by the individuals whose age at enrollment U is between and . Let denote the time from dementia onset to study enrollment and denote the time from dementia onset to death within a prevalent population of patients with dementia. Let (W, T) be a pair of for the observed samples in the prevalent cohort among those who are eligible to be sampled at the time of recruitment (i.e., ). Note that (W, T) is not exactly observed. This is because the exact age at dementia onset is generally unavailable from the prevalent cohort. We let , where V is the observed time from study recruitment to death and C denote a residual censoring time from study recruitment to loss of follow-up. The diagram in Fig. 2 depicts these notations for the prevalent sampling.
Fig. 2.

The diagram for left truncation in a prevalent cohort study: Case (1) is for a subject sampled in the cohort, and Case (2) is for a subject not sampled in the cohort
Likelihood and estimation
Consider a random sample of m independent subjects that are combined from both the incident and prevalent cohorts with respective sample sizes of and , where . Suppose that those in the incident cohort are labeled . Let be the state of the health condition at time t for the i-th subject (). For the i-th subject, we let denote the states, consecutively observed by observations with the corresponding time points , and denote a vector of baseline risk factors. In the Nun Study, the time to death was observed exactly when a subject died during the study. Let if the i-th subject died before the end of study and otherwise. Then, for and for .
The observed event history data from the incident cohort consist of , where and . We assume that the disease progression is a Markov process and is independent across subjects. Denote the vector of all model parameters by . The likelihood for the incident cohort of the i-th subject who was alive at the end of the study, denoted by , can be expressed as the product of the transition probabilities, which is
| 3 |
where can be approximated by with a possible time point of being in intact cognition, such as the age at which the disease initiated.
In the Nun Study, a subject’s cognitive state at the moment of death was unknown unless they were diagnosed with dementia before death. Multiple possible risks of death may exist after the last cognitive assessment of the subject. For example, if the last assessment of a subject was the MCI state, there were three possible risks of death: (1) cognitive function was improved and she died in the cognitive intact state, (2) dementia was not developed before death and she died in the MCI state, and (3) dementia was developed and she died in the dementia state. The likelihood for the i-th subject of the incident cohort who died during the study (i.e., the subject with for ) is then
| 4 |
Therefore, the likelihood of the incident cohort data, , is
| 5 |
Next, we construct the likelihood for the prevalent cohort after adjusting for left-truncation. Based on our multistate model, the probability density function of the age of dementia onset given the covariates , denoted by , is
| 6 |
Then, the conditional density function of given follows:
| 7 |
where and are, respectively, the density function and the survival function for given .
We assume that is independent of given and . Note that the subjects from the prevalent cohort of the Nun Study are among those who have due to the prevalent sampling, and T is dependent of (W, V) due to their relationship in . If a subject from the prevalent cohort dies during the study, the age of study enrollment U and the residual survival time V are observable. With (6) and (7), the joint density of (U, V) given and the sampling constraint, denoted by , follows:
where is the probability density function for given , and
A parametric family of distribution can be used for . Length-biased sampling can also be assumed by letting be a uniform distribution over , where is a constant that makes the probability mass for (Shen et al. 2009).
Since the transition that is possible for a subject with dementia is the transition toward death, the information on study enrollment and last assessment suffices to describe the prevalent cohort data. Let be the age at study enrollment and be the observed time from study entry to the last assessment for the i-th subject. Then, the observed data for the i-th subject consist of , , , and . We denote the prevalent cohort data as , where and .
Assume that C is independent of given . Then, the likelihood for the prevalent cohort is proportional to
| 8 |
where , is a vector of the same model parameters for the target population of the incident cohort, and is a vector of the parameters in .
The likelihood function for combined data from incident and prevalent cohorts can be expressed as the product of the likelihoods given in (5) and (8),
| 9 |
We can estimate and by maximizing the logarithm of the likelihood in (9).
The likelihood function can readily be extended to handle the event history data with interval-censored events in the prevalent cohort. Assume that the residual period of a prevalent subject is only known to be within a specific interval, i.e., , where and for right-censoring. The likelihood for the prevalent cohort can be generalized to
| 10 |
where is the interval of (L, R) for the i-th subject, and . Thus, the likelihood function for the combined data with interval-censored prevalent samples is proportional to the product of the likelihoods given in (5) and (10).
The maximum likelihood implementation requires calculating integrals over finite or infinite intervals, which may not have analytic solutions. In such a case, we obtain a numerical integral value by using the Gauss-Jacobi quadrature after transforming an integral over the unit interval (0, 1). The statistical inference about can be performed with the asymptotic distribution of , which we approximate by , where is the observed information matrix.
Simulation studies
We conducted a series of simulation studies to assess finite sample properties of the proposed likelihood-based approach. Two different sets of sample sizes for the incident cohort and the prevalent cohort were considered: (a) ( and ) and (b) ( and ). We generated two independent covariates from and , i.e., . In data generation of the life-history process for a subject, the Weibull baseline transition intensities were used with the set of parameters: , , , , , , and . The coefficients of for transitions, denoted by , were chosen to be , , , , , and . Ten cognitive assessment times for each subject were simulated to generate interval censored data, which were set to and for . With these assessment rules, about of subjects were still alive at the last assessment. For the prevalent cohort, the distribution of was assumed to follow the Weibull distribution that is , and the residual censoring time C was generated from , where c was set to achieve two censoring percentages, and . Lastly, 1000 replicates were generated in each set of sample sizes for Monte Carlo simulations.
Tables 1 and 2 show the simulation results for estimating from the combined cohort data with the different censoring rates of a prevalent cohort, along with the results of fitting a multistate model to the incident cohort data only. The mean estimates from all simulated cohort data are close to the true parameter values. The empirical standard errors of the estimates are almost the same as the mean of the estimated asymptotic standard errors, and they decrease by almost when the sample size doubles. The coverage probability for every estimator is also close to the nominal level. We further calculated the relative efficiency (RE) of the two approaches, defined as the ratio of the mean square error of the estimator from the combined cohort to that from the incident cohort. As expected, the approach using the combined cohort data has the highest efficiency gain in estimating with the range of REs being about from 7.4 to 11.7 across all scenarios. The censoring rate of the prevalent samples is negatively related to the RE of . The efficiency gains in estimating the baseline intensity for the 2-to-3 transition are also depicted in Fig. 3; the 95% pointwise confidence intervals of the baseline intensities from the combined cohort data are narrower than those of the incident cohort data. Although the prevalent samples provide the information on the 2-to-3 transition only, REs of the parameters for other transitions also tend to be over one. This implies that combining the incident and prevalent cohorts affects the estimation of overall transition probabilities.
Table 1.
Simulation results for estimating with incident cohort data only or with the combined cohort ( and ) under different censoring rates for the prevalent cohort. The coefficient vector for k-l transition is denoted by , where for and for
| Truth | 0.20 | 0.20 | 0.10 | 0.20 | 0.20 | 0.20 | 0.20 | 0.30 | 0.20 | 0.20 | 0.30 | 0.20 |
| Incident cohort only | ||||||||||||
| 0.01 | 0.01 | 0.02 | 0.02 | 0.01 | 0.06 | 0.01 | 0.04 | 0.01 | 0.08 | 0.01 | 0.01 | |
| 0.15 | 0.67 | 0.27 | 1.04 | 0.33 | 1.32 | 0.28 | 1.22 | 0.27 | 1.09 | 0.36 | 1.62 | |
| 0.15 | 0.65 | 0.25 | 1.05 | 0.32 | 1.31 | 0.27 | 1.17 | 0.26 | 1.10 | 0.36 | 1.57 | |
| 0.95 | 0.95 | 0.96 | 0.96 | 0.95 | 0.95 | 0.96 | 0.94 | 0.95 | 0.96 | 0.95 | 0.95 | |
| Combined cohorts with no censored prevalent samples | ||||||||||||
| Bias | 0.01 | 0.02 | 0.01 | 0.02 | 0.02 | 0.05 | 0.01 | 0.04 | 0.01 | 0.05 | 0.00 | 0.01 |
| ESE | 0.15 | 0.63 | 0.26 | 1.02 | 0.32 | 1.30 | 0.26 | 1.16 | 0.25 | 1.03 | 0.11 | 0.48 |
| SE | 0.15 | 0.62 | 0.25 | 1.02 | 0.32 | 1.29 | 0.26 | 1.11 | 0.24 | 1.03 | 0.11 | 0.46 |
| CP | 0.95 | 0.95 | 0.95 | 0.96 | 0.96 | 0.95 | 0.95 | 0.94 | 0.94 | 0.96 | 0.95 | 0.94 |
| 1.10 | 1.13 | 1.05 | 1.04 | 1.07 | 1.03 | 1.08 | 1.10 | 1.16 | 1.11 | 11.28 | 11.63 | |
| Combined cohorts with 15% censored prevalent samples | ||||||||||||
| Bias | 0.01 | 0.01 | 0.00 | 0.03 | 0.03 | 0.07 | 0.01 | 0.03 | 0.00 | 0.05 | 0.01 | 0.01 |
| ESE | 0.15 | 0.60 | 0.25 | 1.05 | 0.32 | 1.32 | 0.27 | 1.16 | 0.25 | 1.08 | 0.12 | 0.50 |
| SE | 0.15 | 0.62 | 0.25 | 1.03 | 0.32 | 1.30 | 0.26 | 1.11 | 0.24 | 1.03 | 0.12 | 0.49 |
| CP | 0.95 | 0.95 | 0.96 | 0.94 | 0.95 | 0.95 | 0.94 | 0.94 | 0.94 | 0.94 | 0.95 | 0.96 |
| RE | 1.07 | 1.24 | 1.14 | 0.99 | 1.05 | 1.00 | 1.04 | 1.10 | 1.16 | 1.02 | 9.25 | 10.50 |
| Combined cohorts with 30% censored prevalent samples | ||||||||||||
| Bias | 0.01 | 0.02 | 0.01 | 0.03 | 0.01 | 0.08 | 0.01 | 0.01 | 0.00 | 0.00 | 0.00 | 0.01 |
| ESE | 0.15 | 0.63 | 0.25 | 1.02 | 0.32 | 1.31 | 0.27 | 1.16 | 0.24 | 1.05 | 0.13 | 0.52 |
| SE | 0.15 | 0.62 | 0.25 | 1.03 | 0.32 | 1.29 | 0.26 | 1.11 | 0.24 | 1.03 | 0.12 | 0.53 |
| CP | 0.95 | 0.94 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.94 | 0.95 | 0.96 |
| RE | 1.11 | 1.12 | 1.13 | 1.03 | 1.06 | 1.01 | 1.08 | 1.11 | 1.29 | 1.08 | 8.12 | 9.86 |
the empirical bias
the empirical standard error of the parameter estimator
the average of the standard error estimator
the coverage of the 95% confidence interval with the Normal approximation
the relative efficiency obtained by the ratio of the mean-squared error from the combined cohort to that from the incident cohort
Table 2.
Simulation results for estimating with incident cohort data only or with the combined cohort ( and ) under different censoring rates for the prevalent cohort. The coefficient vector for k-l transition is denoted by , where for and for
| Truth | 0.20 | 0.20 | 0.10 | 0.20 | 0.20 | 0.20 | 0.20 | 0.30 | 0.20 | 0.20 | 0.30 | 0.20 |
| Incident cohort only | ||||||||||||
| Bias | 0.00 | 0.02 | 0.00 | 0.01 | 0.00 | 0.05 | 0.01 | 0.00 | 0.012 | 0.01 | 0.01 | 0.04 |
| ESE | 0.11 | 0.45 | 0.18 | 0.73 | 0.22 | 0.91 | 0.196 | 0.80 | 0.18 | 0.753 | 0.25 | 1.12 |
| SE | 0.11 | 0.45 | 0.18 | 0.73 | 0.22 | 0.91 | 0.189 | 0.81 | 0.18 | 0.768 | 0.25 | 1.06 |
| CP | 0.95 | 0.95 | 0.94 | 0.96 | 0.96 | 0.95 | 0.945 | 0.95 | 0.95 | 0.957 | 0.95 | 0.94 |
| Combined cohorts with no censored prevalent samples | ||||||||||||
| Bias | 0.00 | 0.01 | 0.01 | 0.01 | 0.00 | 0.05 | 0.00 | 0.006 | 0.01 | 0.01 | 0.00 | 0.00 |
| ESE | 0.10 | 0.43 | 0.18 | 0.71 | 0.22 | 0.90 | 0.189 | 0.76 | 0.171 | 0.71 | 0.08 | 0.32 |
| SE | 0.10 | 0.43 | 0.17 | 0.72 | 0.22 | 0.90 | 0.181 | 0.77 | 0.167 | 0.72 | 0.08 | 0.32 |
| CP | 0.95 | 0.96 | 0.94 | 0.96 | 0.95 | 0.95 | 0.934 | 0.95 | 0.944 | 0.96 | 0.96 | 0.97 |
| RE | 1.09 | 1.10 | 1.04 | 1.05 | 1.01 | 1.022 | 1.08 | 1.103 | 1.12 | 1.13 | 10.57 | 11.71 |
| Combined cohorts with 15% censored prevalent samples | ||||||||||||
| Bias | 0.01 | 0.02 | 0.01 | 0.01 | 0.00 | 0.01 | 0.01 | 0.010 | 0.01 | 0.00 | 0.00 | 0.02 |
| ESE | 0.10 | 0.42 | 0.18 | 0.74 | 0.23 | 0.91 | 0.186 | 0.78 | 0.173 | 0.71 | 0.08 | 0.34 |
| SE | 0.10 | 0.43 | 0.17 | 0.71 | 0.22 | 0.90 | 0.181 | 0.78 | 0.167 | 0.72 | 0.08 | 0.35 |
| CP | 0.94 | 0.96 | 0.95 | 0.95 | 0.95 | 0.95 | 0.954 | 0.95 | 0.943 | 0.95 | 0.96 | 0.95 |
| RE | 1.10 | 1.12 | 1.07 | 1.01 | 0.97 | 1.01 | 1.10 | 1.069 | 1.11 | 1.13 | 9.30 | 10.19 |
| Combined cohorts with 30% censored prevalent samples | ||||||||||||
| Bias | 0.00 | 0.01 | 0.01 | 0.03 | 0.02 | 0.03 | 0.00 | 0.009 | 0.00 | 0.02 | 0.00 | 0.01 |
| ESE | 0.10 | 0.46 | 0.18 | 0.71 | 0.217 | 0.95 | 0.19 | 0.78 | 0.170 | 0.73 | 0.09 | 0.39 |
| SE | 0.10 | 0.44 | 0.18 | 0.72 | 0.220 | 0.90 | 0.18 | 0.78 | 0.168 | 0.72 | 0.09 | 0.37 |
| CP | 0.95 | 0.94 | 0.95 | 0.94 | 0.955 | 0.94 | 0.94 | 0.95 | 0.946 | 0.95 | 0.94 | 0.93 |
| RE | 1.12 | 1.03 | 1.04 | 1.05 | 1.009 | 0.98 | 1.10 | 1.08 | 1.12 | 1.11 | 7.44 | 8.23 |
the empirical bias
the empirical standard error of the parameter estimator
the average of the standard error estimator
the coverage of the 95% confidence interval with the Normal approximation
the relative efficiency obtained by the ratio of the mean-squared error from the combined cohort to that from the incident cohort
Fig. 3.
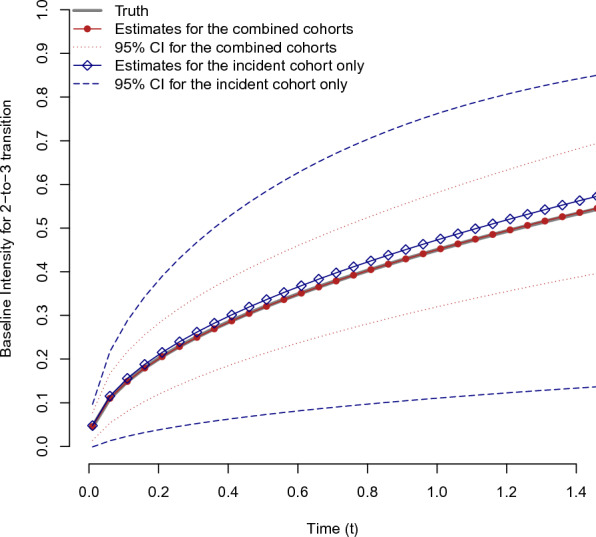
The average of the estimated baseline intensities with the pointwise 95% confidence intervals, obtained from the combined cohort data (red) and the incident cohort only (blue) under the scenario with , , and 30% censoring rate for the prevalent cohort (Color figure online)
The results for the baseline intensity parameters and the parameters in g(w) are relegated to the Supplementary Information. They show similar trends to the regression parameters. The RE of ranges from 5.2 to 6.7 across all scenarios. A slight improvement in efficiency also was shown in the estimation of other baseline intensity parameters, especially for , as their REs were greater than one. The parameters in g(w) also were reasonably close to the true values with the coverage probabilities close to the nominal level.
We also performed a sensitivity analysis when the density of was incorrectly specified under the current simulation settings (see Table S3 of the Supplementary Information). We considered two misspecified cases: is assumed to follow (1) the exponential distribution and (2) the uniform distribution (i.e., the length-biased sampling). In summary, the parameter estimates from the proposed method were found to be reasonably robust against the misspecification of the form for g(w).
Application
The Nun Study is a longitudinal study of aging and dementia with a cohort of 678 participants who were born before 1917 and recruited among members of the School Sisters of Notre Dame congregation in the United States. The cognitive status of each participant was assessed annually for close to a decade and their awareness of deficits were classified into four stages according to severity: cognitively intact for age, cognitive deficit not affecting activities of daily living, cognitive deficit affecting one or more activities of daily living, and clinical dementia. Ages at their assessments and deaths were also recorded during the follow-up, along with two important covariates, the presence of at least one apolipoprotein E4 allele (APOE4) and their level of education (EDUCAT). To reduce dimensionality, we grouped the participants’ status into four states and recorded them as follows: 0 for intact cognition, 1 for MCI, 2 for dementia, and 3 for death.
We applied the proposed approach to data from 501 subjects with complete baseline information. Among them, 424 were in the intact cognition or MCI state (i.e., incidence cases), while 77 were diagnosed with clinical dementia (i.e., prevalent cases) at their study recruitment. In the incident cohort, about 36% progressed to dementia and only 29% died with dementia during the follow-up. In the prevalent cohort, about 97% died during the follow-up. The flow chart for the samples of the incident cohort and the prevalent cohort from the Nun Study is available in the Supplementary Information. The average age at the first assessment was 82.53 years for the incident cohort and 85.89 years for the prevalent cohort. Table 3 shows the distribution of risk factors by cohort. The combined cohorts consist of more dementia cases in each group compared to the incident cohort. In the analysis, 75 years old, which is the earliest age at the intact cognition state in the incident cohort, is set as the initial time point of disease progression. The exponential distribution is used for the density of , which implies that the period between dementia onset and study entry does not depend on the dementia onset itself.
Table 3.
Distribution of risk factors by cohort with the number of patients who experienced dementia before death during the study and the number of death at last follow-up
| Incident cohort only | Combined cohorts | |||||
|---|---|---|---|---|---|---|
| () | () | |||||
| Size | Dementia (%) | Death (%) | Size | Dementia (%) | Death (%) | |
| APOE4 | ||||||
| Presence | 82 | 39 (48%) | 65 (79%) | 111 | 68 (61%) | 93 (84%) |
| Absence | 342 | 114 (33%) | 243 (71%) | 390 | 162 (42%) | 290 (74%) |
| EDUCAT | ||||||
| College and higher | 383 | 134 (35%) | 274 (72%) | 432 | 183 (42%) | 323 (75%) |
| Others | 41 | 19 (46%) | 34 (83%) | 69 | 47 (68%) | 60 (87%) |
The resulting parameter estimates and their standard errors, respectively obtained by analyzing the combined cohorts data and the incident cohort data only, are shown in Table 4. In model estimation, the proposed method was refitted to the data sets without the regression coefficients for the 0-to-3 transition because their estimates were close to zero. The results with both incident and prevalent cohorts of the Nun Study show that ApoE4 promotes the cognitive decline of a subject, in that an ApoE4 carrier is expected to have a relatively longer time of the transition from MCI back to intact cognition (p value = 0.011); a higher risk of being in MCI, which is marginally significant (p value = 0.054); and a shorter time of the transition from MCI to dementia (p value = 0.032), compared to a non-carrier. The education level of a subject is found to be significantly associated with the 0-to-1 and 2-to-3 transitions; the higher level of education (12 years or more) is found to decrease the risk of progression from intact cognition to MCI (p value = 0.003) and increase the risk of death with dementia (p value = 0.049). The results of incident cohort data show similar results with those of the combined cohort data except that education level was not significantly related to the 2-to-3 transition. The positive association between higher education and mortality with dementia also has been reported in other studies (Stern et al. 1995; Contador et al. 2017).
Table 4.
Results of the parameter estimation in each transition using the combined cohorts and the incident cohort from the Nun Study
| Combined cohorts | Incident cohort only | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| (Transition) | 0-to-1 | 1-to-0 | 1-to-2 | 1-to-3 | 2-to-3 | 0-to-1 | 1-to-0 | 1-to-2 | 1-to-3 | 2-to-3 |
| APOE4 (presence=1, absence=0) | ||||||||||
| Estimate | 0.28 | 0.68 | 0.40 | 0.09 | 0.10 | 0.26 | 0.71 | 0.39 | 0.07 | 0.19 |
| SE | 0.15 | 0.27 | 0.19 | 0.26 | 0.16 | 0.15 | 0.27 | 0.19 | 0.27 | 0.21 |
| EDCAT (college and higher=1, others=0) | ||||||||||
| Estimate | 0.89 | 0.62 | 0.17 | 0.59 | 0.34 | 0.91 | 0.60 | 0.12 | 0.64 | 0.16 |
| SE | 0.30 | 0.43 | 0.24 | 0.34 | 0.17 | 0.31 | 0.44 | 0.25 | 0.39 | 0.26 |
Figure 4 shows the estimated baseline intensity for the 2-to-3 transition with pointwise 95% confidence intervals. The analysis results of the combined data from the incident and prevalent cohorts show narrower 95% pointwise confidence intervals than those of the incident cohort data only. The estimated density of the dementia onset in the prevalent population is presented in Fig. 5 as a byproduct of the analysis of the combined data. The median onset age of dementia was 86.43 (95% CI: ) for an ApoE4 carrier with low education and 87.66 (95% CI: ) for a non-carrier with low education. The estimated median survival after the onset of dementia was 3.13 years (95% CI: ) for a patient with ApoE4 and a higher level of educational attained from the combined cohort data, while it was 3.04 years (95% CI: ) from the incident cohort data.
Fig. 4.
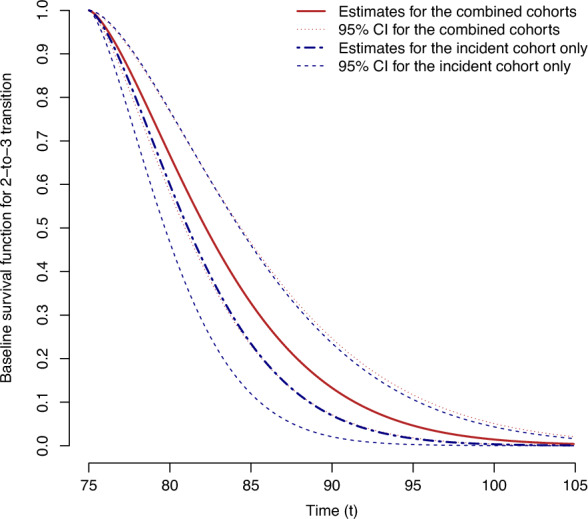
The estimated baseline survival functions with the pointwise 95% confidence intervals, obtained from the combined cohort (red) and the incident cohort (blue) of the Nun Study
Fig. 5.

The density of the dementia onset in the prevalent population by the presence of the apolipoprotein E4 allele and the level of education
Discussion
In this paper, we propose a multistate approach based on the likelihood-based inference to assess the effects of risk factors on the transitions that are related to the natural history of disease by using event history data that consists of both incident and prevalent samples. In the observational studies that are designed to follow the life course of a disease, prevalent samples are commonly available because patients receiving routine care in healthcare facilities are often within a study population. In the analysis with the prevalent samples, identifying the age of disease onset is essential because it plays a key role in addressing sampling bias induced by the prevalent sampling scheme. However, it is often difficult to retrospectively identify age of onset for many chronic diseases. The proposed method overcomes this challenge by using the complementary information that both incident cohort and prevalent cohort provide to each other, while accounting for interval censored observations of transition times between disease states.
The approach was illustrated by incorporating parametric transition intensities into a multistate model; however, it can be easily modified with other flexible forms such as a locally weighted smoother (Hubbard et al. 2008) and linear splines (Pak et al. 2019), although a substantial increase in the number of parameters to estimate is inevitable with many cases of possible transitions. By utilizing the commonly used temporal homogeneity model for transition intensity, we have a parsimonious model to capture the potential reversible transition between intact cognition and MCI in dementia progression. Alternatively, one could employ piecewise constant models to accommodate the more flexible temporal trend of the disease process, though it will require more transition events being observed to obtain stable estimates (Pérez-Ocón et al. 2001; Titman 2011).
As with other prevalent-data settings, it would be a challenge to incorporate time-dependent covariates into the analysis of combined data. If the time-dependent covariates are specified differently relative to each transition, one must know which transitions a prevalent individual went through before the development of dementia. Nevertheless, with extra information for the prevalent samples or modeling assumptions, one may incorporate time-dependent covariates when combining the incident and prevalent cohorts, which merits future research.
The key benefit of the analysis of the event history data is that one can simultaneously assess the effects of risk factors on every transition that represents the natural history of the disease. The proposed method can be applied to event history data from other disease studies. An example is with studies on the natural history of the coronavirus disease (COVID-19), where the information from travelers who are found to be infected upon arrival (i.e., prevalent samples) can be a complement to the study on the endpoints of death or recovery in periods of quarantine.
Supplementary Information
Below is the link to the electronic supplementary material.
Acknowledgements
This work was partially supported by the National Research Foundation of Korea (NRF) grant 2021R1G1A1009269 (DP), the National Cancer Institute grants R01CA269696 and P30CA016672 (JN and YS) and the National Institute on Aging AG0386561 (RK). We also thank Jessica Swann for her editorial assistance.
Declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- Contador I, Stern Y, Bermejo-Pareja F, Sanchez-Ferro A, Benito-Leon J. Is educational attainment associated with increased risk of mortality in people with dementia? A population-based study. Curr Alzheimer Res. 2017;14(5):571–576. doi: 10.2174/1567205013666161201200209. [DOI] [PubMed] [Google Scholar]
- Cox D, Miller H. The theory of stochastic processes. New York: Chapman and Itall; 1965. [Google Scholar]
- Gorfine M, Keret N, Ben Arie A, Zucker D, Hsu L. Marginalized frailty-based illness-death model: application to the UK-biobank survival data. J Am Stat Assoc. 2021;116(535):1155–1167. doi: 10.1080/01621459.2020.1831922. [DOI] [Google Scholar]
- Hubbard R, Inoue L, Fann J. Modeling nonhomogeneous Markov processes via time transformation. Biometrics. 2008;64(3):843–850. doi: 10.1111/j.1541-0420.2007.00932.x. [DOI] [PubMed] [Google Scholar]
- Kalbfleisch J, Lawless J. The analysis of panel data under a Markov assumption. J Am Stat Assoc. 1985;80(392):863–871. doi: 10.1080/01621459.1985.10478195. [DOI] [Google Scholar]
- Kulathinal S, Säävälä M, Auranen K, Saarela O (2020) Estimation of marriage incidence rates by combining two cross-sectional retrospective designs: Event history analysis of two dependent processes. arXiv preprint arXiv:2009.01897
- Lee C, Ning J, Kryscio R, Shen Y. Analysis of combined incident and prevalent cohort data under a proportional mean residual life model. Stat Med. 2019;38(12):2103–2114. doi: 10.1002/sim.8098. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McVittie J, Wolfson D, Stephens D, Addona V, Buckeridge D. Parametric models for combined failure time data from an incident cohort study and a prevalent cohort study with follow-up. Int J Biostatist. 2020 doi: 10.1515/ijb-2020-0042. [DOI] [PubMed] [Google Scholar]
- Omar R, Stallard N, Whitehead J. A parametric multistate model for the analysis of carcinogenicity experiments. Lifetime Data Anal. 1995;1(4):327–346. doi: 10.1007/BF00985448. [DOI] [PubMed] [Google Scholar]
- Pak D, Li C, Todem D, Sohn W. A multistate model for correlated interval-censored life history data in caries research. J R Stat Soc Ser C. 2017;66(2):413–423. doi: 10.1111/rssc.12186. [DOI] [Google Scholar]
- Pak D, Li C, Todem D. Semiparametric analysis of correlated and interval-censored event-history data. Stat Methods Med Res. 2019;28(9):2754–2767. doi: 10.1177/0962280218788383. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pérez-Ocón R, Ruiz-Castro J, Gámiz-Pérez M. Non-homogeneous Markov models in the analysis of survival after breast cancer. J R Stat Soc Ser C. 2001;50(1):111–124. doi: 10.1111/1467-9876.00223. [DOI] [Google Scholar]
- Saarela O, Kulathinal S, Karvanen J. Joint analysis of prevalence and incidence data using conditional likelihood. Biostatistics. 2009;10(3):575–587. doi: 10.1093/biostatistics/kxp013. [DOI] [PubMed] [Google Scholar]
- Shen Y, Ning J, Qin J. Analyzing length-biased data with semiparametric transformation and accelerated failure time models. J Am Stat Assoc. 2009;104(487):1192–1202. doi: 10.1198/jasa.2009.tm08614. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stern Y, Tang M, Denaro J, Mayeux R. Increased risk of mortality in Alzheimer’s disease patients with more advanced educational and occupational attainment. Ann Neurol Official J Am Neurol Assoc Child Neurol Soc. 1995;37(5):590–595. doi: 10.1002/ana.410370508. [DOI] [PubMed] [Google Scholar]
- Titman A. Flexible nonhomogeneous Markov models for panel observed data. Biometrics. 2011;67(3):780–787. doi: 10.1111/j.1541-0420.2010.01550.x. [DOI] [PubMed] [Google Scholar]
- Tyas S, Salazar J, Snowdon D, Desrosiers M, Riley K, Mendiondo M, Kryscio R. Transitions to mild cognitive impairments, dementia, and death: findings from the nun study. Am J Epidemiol. 2007;165(11):1231–1238. doi: 10.1093/aje/kwm085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wei S, Xu L, Kryscio R. Markov transition model to dementia with death as a competing event. Comput Stat Data Anal. 2014;80:78–88. doi: 10.1016/j.csda.2014.06.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wolfson D, Best A, Addona V, Wolfson J, Gadalla S. Benefits of combining prevalent and incident cohorts: an application to myotonic dystrophy. Stat Methods Med Res. 2019;28(10–11):3333–3345. doi: 10.1177/0962280218804275. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.