

Abstract
Nitrogen Dioxide (NO) is a common air pollutant associated with several adverse health problems such as pediatric asthma, cardiovascular mortality,and respiratory mortality. Due to the urgent society’s need to reduce pollutant concentration, several scientific efforts have been allocated to understand pollutant patterns and predict pollutants’ future concentrations using machine learning and deep learning techniques. The latter techniques have recently gained much attention due it’s capability to tackle complex and challenging problems in computer vision, natural language processing, etc. In the NO context, there is still a research gap in adopting those advanced methods to predict the concentration of pollutants. This study fills in the gap by comparing the performance of several state-of-the-art artificial intelligence models that haven’t been adopted in this context yet. The models were trained using time series cross-validation on a rolling base and tested across different periods using NO data from 20 monitoring ground-based stations collected by Environment Agency- Abu Dhabi, United Arab Emirates. Using the seasonal Mann-Kendall trend test and Sen’s slope estimator, we further explored and investigated the pollutants trends across the different stations. This study is the first comprehensive study that reported the temporal characteristic of NO across seven environmental assessment points and compared the performance of the state-of-the-art deep learning models for predicting the pollutants’ future concentration. Our results reveal a difference in the pollutants concentrations level due to the geographic location of the different stations, with a statistically significant decrease in the NO annual trend for the majority of the stations. Overall, NO concentrations exhibit a similar daily and weekly pattern across the different stations, with an increase in the pollutants level during the early morning and the first working day. Comparing the state-of-the-art model performance transformer model demonstrate the superiority of ( MAE:0.04 (± 0.04),MSE:0.06 (± 0.04), RMSE:0.001 (± 0.01), R: 0.98 (± 0.05)), compared with LSTM (MAE:0.26 (± 0.19), MSE:0.31 (± 0.21), RMSE:0.14 (± 0.17), R: 0.56 (± 0.33)), InceptionTime (MAE: 0.19 (± 0.18), MSE: 0.22 (± 0.18), RMSE:0.08 (± 0.13), R:0.38 (± 1.35) ), ResNet (MAE:0.24 (± 0.16), MSE:0.28 (± 0.16), RMSE:0.11 (± 0.12), R:0.35 (± 1.19) ), XceptionTime (MAE:0.7 (± 0.55), MSE:0.79 (± 0.54), RMSE:0.91 (± 1.06), R: 4.83 (± 9.38) ), and MiniRocket (MAE:0.21 (± 0.07), MSE:0.26 (± 0.08), RMSE:0.07 (± 0.04), R: 0.65 (± 0.28) ) to tackle this challenge. The transformer model is a powerful model for improving the accurate forecast of the NO levels and could strengthen the current monitoring system to control and manage the air quality in the region.
Supplementary Information
The online version contains supplementary material available at 10.1186/s40537-023-00754-z.
Keywords: Nitrogen Dioxide, Forecast, Artificial Intelligence, Deep Learning, Temporal Models, Transformer Model
Introduction
Humanity faces many global environmental challenges embedded in global warming, environmental degradation, biodiversity loss, and poor air quality [1–3]. Poor air quality, which contains a high level of gaseous air pollutants, negatively impacts human health by causing respiratory and pulmonary diseases and the environment by contributing to climate change and acid rain [1, 3–9]. The deterioration in the air quality was associated with rapid social development and urbanization, which increased human activities such as vehicle usage, traffic, cooking, and building cooling and heating [4]. In addition to the air pollutants produced by human activities, pollutants are also released from nature [1]. One of the major air pollutants is Nitrogen dioxide (NO).
NO is a toxic pollutant made up of nitrogen and oxygen atoms [10].The pollutant level increase in the air due to human and natural sources such as vehicles, aviation, manufacturing, power plants, indoor pollutant, soil processes, and lightning [3, 7–12].It is also known NO plays a vital role in increasing the density of other hazardous outdoor air pollutants such as ground-level ozone (O) and fine particles (PM) [11–13]. In 2019, NO was estimated to cause 637,000 new pediatric asthma incidents in China [7] and 1.85 million new cases globally [11].Besides asthma, it increases the risk of other diseases, such as cardiovascular mortality, respiratory mortality, and lung cancer incidence or mortality [3, 13]. To mitigate the pollutant’s adverse effects, the World Health Organization (WHO) issued new Air Quality Guidelines (AQG) on September 22, 2021, to set the annual average threshold of NO concentration to 10 micrograms per cubic (g/m) [7]. The scientific community also supported the efforts by conducting several epidemiological studies to reveal the association between pollutants and diseases and computational analyses to understand the pollutants’ pattern and predict pollutants’ future concentration. The previous computational analysis studies supported the atmospheric management decision-makers to track and monitor the pollutant level and issue applicable regulations and laws to reduce the adverse risk of NO pollutants (for sure by understanding its causes). These early warning system projects are directed toward understanding the pollutant’s hourly, daily, monthly, and annual concentration pattern [14], investigating the impact of different unexpected interventions such as the COVID-19 pandemic on it is level [11, 12, 15], and predict future pollutant concentration using statistical, machine learning (ML), and artificial intelligence (A.I.) methods [3, 8, 9]. The latter methods have recently gained much attention due it’s capability to tackle complex and challenging problems in computer vision, natural language processing, etc. Air quality prediction is also categorized as challenging and complex tasks that faces humanity due to the fact that the pollutants concentration is correlated and associated with several environmental and physical factors such as meteorological, traffic pollution, and industrial emissions that vary across time and space [8, 16]. Surveying the previous scientific efforts to build predictive models, earlies efforts focused in using classical statistical methods such as the auto-regressive model (AR), moving aver- age model (MA), auto-regressive integrated moving average model (ARIMA), and seasonal ARIMA (SARIMA) [17]. While the recent works moved toward utilized ML and A.I. algorithms such as the multilayer perceptron model (MLP) [1], long short-term memory (LSTM) [8],and Bidirectional convolutional LSTM [3]. The shift towards ML and A.I. algorithms, which remarkably outperform the performance of classical statistical methods, improves pollutant forecasting since those methods automatically learn and extract the features from the data and use the new data representation (extracted features) for generalization to the unseen data [8].
Even though the recent studies provide clear evidence of the power of ML and A.I. to improve the prediction of the future NO concentration with best reported R range from 0.87 to 0.9 and RMSE range from 0.21 to 19.14, the domain is still in its infancy to tackle this challenge. In the NO context, there is still a research gap in adopting those advanced deep learning for sequences data to predict the concentration of pollutants, as an example of unadopted techniques, Transformer for time series, MINImally RandOm Convolutional KErnel Transform (MiniRocket), InceptionTime etc.
The main objective of this study is to explore the NO temporal characteristics along with comparing and validating the performance of several state-of-the-art A.I. models, namely: MINImally RandOm Convolutional KErnel Transform (MiniRocket) [18], Residual Network (ResNet) for time series [19], XceptionTime [20], InceptionTime [21] and Transformer for time series [22] to improve the accuracy of NO forecasting. We trained our models using data collected and provided by Abu-Dhabi. Environment Agency- Abu Dhabi (EAD), United Arab Emirates (UAE), for different environmental monitoring stations. To recapitulate, the contributions of the paper are as follows:
This is the first study that investigates the temporal characteristics of NO concentration across 19 stations covering seven environmental assessment points in the UAE.
This work is among the first comprehensive work to adopt and compare the performance of several state-of-the-art deep learning models to improve the accuracy of forecasting future NO concentration.
Methods
Study area
UAE was established in 1971 and consists of seven emirates: Abu Dhabi, Dubai, Sharjah, Ajman, Umm Al Quwain, Ras Al Khaimah, and Fujairah. Abu-Dhabi, the UAE’s capital and the largest emirate accounts for 87% (67,000 km) of the total area with 23.5N 54.5E geographic coordinates [15].
In-Situ observation data of NO concentration
This study focuses on NO concentration prediction for several air quality stations in Abu Dhabi, which were collected and provided by the EAD. EAD is the environment regulator that aims to protect and enhance the region’s air quality, groundwater, and biodiversity. Since 2007, the agency started to collect and monitor air quality data; by operating 20 fixed ground stations with annual data capture of air quality is approximately 75% [23] in addition to 2 mobile stations across three regions in Abu Dhabi: Al Ain Region (Eastern Region), Al Dhafra Region (Western Region), and Central Region (Greater Abu Dhabi and it’s surrounding) (Fig. 1). The stations cover seven environmental assessment points: urban traffic, urban background, rural traffic, rural background, rural industrial, suburban background, and suburban industrial. The monitoring stations provided with air quality and meteorological sensors to record wind speed, wind direction, temperature, relative humidity, net radiation, barometric pressure, and pollutants such as Sulfur Dioxide (SO), Nitrogen Dioxide (NO), Ozone (O), Carbon Monoxide (CO), particulate matter (PM) and Hydrogen Sulfide (H2S) [24–26]. The monitors follow the technical testing standards of ISO/IEC 17,025:2017. The pollutants data measured across all the stations were transmitted to the Air Quality Management System database. The dataset gets further quality inspection, control, assessment, verification, and statistical processing to be presented on the EAD web portal (https://www.adairquality.ae). All the air pollution measurement systems follow ISO, CEN/EN, and U.S. standards [15]. Our focus in this study is NO micrograms per cubic (g/m) concentration data collected from 20 fixed ground stations from January 1, 2019, at 0:00 to December 31, 2020, at 23:00. For each station, we provided with 17,544 hly NO concentration values.
Fig. 1.

The study area map The geographic distribution of the 20 NO stations across UAE
Data Pre-processing
We used rolling k-fold cross-validation for training different models. We divide each station’s data into training and testing sets as in (Fig. 2). In the begin the training set -which we used to train different deep learning models- consists of the historical data from January 1, 2019, 0:00 until December 31, 2019, 23:00 (12 months) while the testing set -which we will use to evaluate and compare the performance of different models- consists of the data from January 1, 2020 0:00 until January 31, 2020 (one month ahead). We repeated the process in which every-time we add one more month to the training set and used them to predict one month ahead.
Fig. 2.

Time Series Cross-validation: The training set increases sequentially, maintaining the temporal order of the data for predicting one month ahead (testing set). The training set divided further into a training set and validation set using 80:20% for monitoring the models performance during training
Our data contains missing values which is expected from a real-life data (Additional file 1: Table S1 and Figures S1–S19); we notice a high percentage (62.64%) of NO concentrations values were missing from station 13; therefore, we excluded this station form the future analysis. To deal with missing values for the remaining stations, we applied univariate time series weighted moving average; this technique outperforms other techniques for dealing with time series missing values, as reported in [27]. Precisely for this study, the exponential weighted moving average (EWMA) technique with five moving average windows was applied:
| 1 |
Where, Z is the value of the series at time t; EWMA is the EWMA value at time t. w represents the weighting factors that decrease exponentially, e.g., at time (t-x,t+x); w= ; where x is observations directly next to a central value. After imputing the missing values, we average the daily NO concentration for each station and use the averaged values in this work for further analysis. Before training the different models, the input data was standardized by removing the mean and scaling to unit variance. We further divide our training data into two data sets: 80% training set and 20% validation set (Fig. 2); the validation set used to monitor and prevent overfitting during the training of different deep learning models by comparing validation errors to the training error over epochs.
Temporal characteristics of NO pollutant emissions
To reveal the annual trend of the univariate NO daily level, we used the seasonal Kendall test [14, 28]. It is a nonparametric test for testing the time series’ monotonic or consistent upward or download trends. The Seasonal Kendall S statistic is computed as following:
| 2 |
Where m is the total number of seasons, and S is ith season S from m. S is Mann-Kendall, which is computed using the following equation:
| 3 |
Where S computes the difference between the future measure values y and all the previous values y. The sign(y-y) is +1 (positive differences),0 (no differences), or -1 (negative differences).
After computing and summing the seasonal statistics (S), the normalized Z test statistic is computed as follows:
| 4 |
The positive value of the normalized Z imply an increased trend in the series, and the negative values indicate a decreased trend.
We also computed Theil-Sen’s Slope Estimator [28, 29], a nonparametric method used to quantify the change in the time series magnitude: direction and volume. This technique is robust since it is not affected by outliers present. The slope of two points in the time series is computed using the following equation:
| 5 |
Where i and j are two points in the time series. Sen’s method estimated slope (Q) as the median N values of Q; the Q estimated as following:
| 6 |
| 7 |
Where n is the total number of samples in the time series, all the statistical analyses were tested at the 95% significance level with a two-tailed test.
Predictive deep learning models
In this study, the daily NO concentration was predicted using several state-of-the-art deep learning models for time series and sequences, namely: MINImally RandOm Convolutional KErnel Transform (MiniRocket) [18, 30], Residual Network (ResNet) for time series [19], XceptionTime [20], InceptionTime [21] and Transformer for time series [22].
MiniRocket: is a high-speed, lesser computational state-of-the-art deep learning model. The methods select 10,000 non-random kernels with size 9 to generate model feature maps. Those kernels will vary in terms of the padding, dilation, non-trainable weights, and non-trainable bias. The model uses those fixed, non-trainable, and independent random convolutional kernels to extract a new feature (features maps) from the input sequence. The generated feature maps are fed to the proportion of positive values (PPV) pooling which used to detect a specific patterns from the input. Finally, it will pass into a linear model such as the ridge regression model or deep learning head for prediction.
ResNet:is a deep learning model consisting of three residual blocks with linear residual connection to reduce the vanishing gradient effect exhibited due to the increase of the network depth followed by a 1D global Average pooling layer. Each residual block consists of three convolutions layers with 7, 5, and 3 kernel filters followed by a 1D convolution layer; it ends with a batch normalization layer and Rectified Linear Unit (ReLU) activation function.
XceptionTime: architecture consists of stacking several XceptionTime modules with residual connection (a 1X1 Conv layer and batch normalization). In which the ReLU activation function is applied to the residual connection and the XceptionTime module feature map to introduce non-linearity in the network. The modules are followed by an adaptive average pooling layer to reduce overfitting and increase the robustness of the network to learn the temporal translation of the input sequence, and finally, several 1X1 convolution layers with batch normalization and ReLU. XceptionTime module includes two parallel paths: the first path has a 1X1 convolution layer followed by three Depthwise Separable Convolutions with different/multiple one-dimensional kernels to extract long and short-time dependency series features simultaneously. At the same time, the second path has a max pooling layer followed by a 1X1 Convolution layer. The module output consists of concatenating the feature maps learned by the two paths.
InceptionTime: The network consists of two residual blocks: each with three inception modules and two linear skip-connection (1X1 convolution layer), followed by global average pooling. The inception module contains two parallel paths: the first path has a bottleneck layer (one-dimensional Convolutional Neural Network (1DCNN)) that works as a dimensionality reduction to reduce the number of parameters and improve model generalization; the 1DCNN is followed by three parallel depthwise separable convolutions and pointwise convolutions layers with different filter sizes to learn long and short time dependency features. The second path has one MaxPooling followed by a bottleneck layer. The output of the inception module consists of the concatenation of the feature maps generated by two paths. Also, in this network, ReLU is used as an activation function. Similar to the XceptionTime, this model also adopts the one-dimensional: convolutional, max pooling, and batch normalization to apply for temporal data. The final network consists of ensembling five different inception networks with different weights and initialization to improve network stability.
Transformer or Transformer-decoder architecture: The model learns the long-term dependency in the sequence using a self-attention mechanism that gives more attention to the important subsets of the sequence over unimportant set. The model core component is the encoder part of the original transformer network to learn a new representation for the time series. The model needs to learn the association between previous tokens for encoding the current token. Each of the tokens will be assigned with query, key, and value. The query and the key will be used to decide the relationship between the current token and the previous one. While the value defines the new representation of the current token. The self-attention score of the previous and current tokens is calculated as the dot product of keys with queries, which will be fed to a softmax layer and scaled to create a ’soften’ probability distribution. The highest attentions score indicates a higher relevance between the current token and the previous token and vice versa. Finally, the current token’s encoder is calculated using the dot product of the scaled attention scores and token value vector. To account for the temporal characteristic of the time series, the positional encoding is added to the calculate the relative distance between the current token and the previous one. Since the input has a temporal resolution, the network used 1-DCNN to compute the keys and queries of the self-attention layer and positional encoding. Moreover, the model replaces layer normalization with batch normalization after the self-attention layer to alleviate the outliers’ issue in the time series dataset.
Table 1 presents the hyperparameters used to train the different deep learning models. All the models were trained using 100 epochs with 64 batch sizes,sequence of length 10,and Adam optimizer. In this study, we used a fixed architecture component for each mode; as reported in Table 1, we only tuned the learning rate for each station and model pair. The suggested learning rate was selected based on the valley algorithm.
Table 1.
Deep learning models selected hyperparameters used during training
| Model | Hyperparameters |
|---|---|
| MiniRocket | Number of features: 10000; Maximum dilations per kernel: 16; scoring: MSE |
| ResNet | Windows size = 24, filter size = 32, kernel sizes: 7, 5 and 4 |
| XceptionTime | Filter size = 16, adaptive average pooling: 32 |
| InceptionTime | Filter size = 32, kernel sizes: 24, depth : 6; dilation: 1 |
| Transformer | Windows size = 24, embedding size: 32, Size of the intermediate |
| feed forward layer:16, number of layers: 2 and number of heads: 4 |
Benchmarking
We benchmark our study using Long Short-Term Memory (LSTM) model to compare the performance of the state-of-the-art models against. LSTM is a recurrent neural network (RNN) for analyzing sequence data. It addresses long-term dependency problem which cause vanishing gradient problem in the RNN model. LSTM introduces three gates: forget gate, input gate, and output gate; those gates control the network memorizing process: read, store, and write historical information [31].
Models performance evaluation metrics
Four evaluation measures are used to evaluate and compare the performance of the different models, precisely, correlation coefficient (R), mean square error (MSE), root means square error (RMSE), and mean absolute error (MAE) [1].
The analyses were performed using R programming language (version 3.6.1): imputeTS [32] package (version 3.2) to impute time series missing values. In addition to several Python (version 3.8.13) packages: tsai [33](version 0.3.1) to train the deep learning models, scikit-learn (version 1.1.1) to compute the evaluation metrics, and pymannkendall ( version 1.4.2)to calculate the temporal characteristics of the time series.
Results
Temporal characteristics of NO pollutant emissions
The geographical study area of this work is the UAE; specifically, its capital Abu Dhabi. Figure 3 shows the average daily NO concentration for the 19 monitoring stations from January 1, 2019, to December 31, 2020; in parallel, table 2 presents the statistical description of the NO concentration for each station and trend statistical test. The monitoring stations cover seven environmental assessment points: urban traffic, urban background, rural traffic, rural background, rural industrial, suburban background, and suburban industrial.
Fig. 3.

NO concentration Daily mean NO concentration of 19 stations during the period from 1/1/2019–31/12/2022. The gray curves represent all the stations’ curves, while the colored curve represents the specific station trend
Table 2.
Statistical descriptions of the NO concentration for the 19 stations (Unit: micrograms per cubic (g/m))
| Station | Mean | Std. | Min | Max | Mann-Kendall | P-value | Theil-Sen’s | Trends |
|---|---|---|---|---|---|---|---|---|
| seasonal statistical test | Slope Estimator | |||||||
| Station 1 | 56.44 | 17.09 | 15.36 | 143.03 | −179 | 0.0 * | −10.51 | Decreasing |
| Station 2 | 31.42 | 13.97 | 7.40 | 89.71 | −165 | 0.0 * | −9.70 | Decreasing |
| Station 3 | 27.89 | 14.86 | 3.92 | 80.07 | −85 | 0.0 * | −5.17 | Decreasing |
| Station 4 | 47.8 | 21.98 | 5.74 | 159.70 | −11 | 0.6 * | −0.83 | No trend |
| Station 5 | 32.31 | 15.56 | 8.85 | 96.67 | 55 | 0.00 * | 2.51 | Increasing |
| Station 6 | 29.7 | 12.17 | 6.23 | 64.51 | −111 | 0.00 * | −5.19 | Decreasing |
| Station 7 | 42.13 | 23.69 | 7.156 | 156.62 | −127 | 0.00 * | −9.35 | Decreasing |
| Station 8 | 15.73 | 6.72 | 3.44 | 47.79 | −19 | 0.35 * | −0.74 | No trend |
| Station 9 | 14.85 | 6.23 | 3.95 | 45.00 | 61 | 0.00 * | 1.60 | Increasing |
| Station 10 | 9.63 | 1.44 | 6.60 | 16.86 | −60 | 0.00 * | −0.32 | Decreasing |
| Station 11 | 21.68 | 9.01 | 6.64 | 61.11 | 15 | 0.47 * | 0.41 | No trend |
| Station 12 | 16.68 | 5.75 | 5.08 | 39.5 | −113 | 0.00 * | −2.73 | Decreasing |
| Station 14 | 33.79 | 21.05 | 2.36 | 109.13 | −135 | 0.00 * | −7.50 | Decreasing |
| Station 15 | 32.70 | 20.69 | 4.58 | 128.26 | −181 | 0.0 * | −12.15 | Decreasing |
| Station 16 | 47.86 | 19.68 | 11.2 | 119.31 | −51 | 0.01 * | −3.40 | Decreasing |
| Station 17 | 14.81 | 5.44 | 4.02 | 33.90 | −103 | 0.00 * | −2.66 | Decreasing |
| Station 18 | 21.27 | 10.02 | 2.97 | 79.31 | −75 | 0.00 * | −2.88 | Decreasing |
| Station 19 | 23.38 | 12.77 | 3.51 | 76.33 | −71 | 0.00 * | −4.76 | Decreasing |
| Station 20 | 8.60 | 2.94 | 2.77 | 22.53 | −71 | 0.00 * | −1.18 | Decreasing |
p<.05
The highest mean NO concentration was reported in 2019 from station 1 (56.44 g/m; urban traffic), while the lowest average values were reported in station 20 (8.60 g/m, rural background) for the same year. From Fig. 3, we observed that NO concentration is lower in stations 10 and 20 (rural background) and higher in stations 1,4, 15, and 16 (all of them are in the Abu Dhabi Capital Region). There is an apparent annual periodicity in the NO emission; a high NO emission is found early in the year, reduced during the summertime, and increased again after the summertime. The nonparametric seasonal Mann-Kendall trend test and Sen’s slope estimator (Table 2) reported a significant decrease in the annual trend (p<0.05) of the NO concentration for most of the stations, however, a significant increase is reported for stations 5 and 9. Figure 4 presents the temporal hourly and daily NO concentration variations of the 19 stations during 2019 and 2020. Overall, NO concentrations exhibit a similar pattern across the different stations. During 2019 and 2022, Friday and Saturday were for the weekend, while Sunday until Thursday were the working days. The hourly emission of NO is highest in the early morning from 5:00 am to 10:00 am and lowest in the mid-afternoon from 2:00 pm to 4:00 pm. For the day of the week temporal variation, we can notice NO production is lower during weekends, especially Friday, the first day of the weekend, and increases during the working days. For stations 10 and 20, the temporal hourly and daily NO concentration is flattening since those regions represent a Rural Background consisting mainly of a desert; therefore, not so many human activities that contribute to increase the concentration of the pollutants.
Fig. 4.

NO temporal variation Temporal hourly and daily of the week NO concentration from variations for the 19 stations from 2019 to 2020. The hourly concentration of NO is highest in the early morning and lowest in the mid-afternoon. The station geo-location have an impact on the pollutant concentrates, the highest concentration found in the traffic area and lowers in the rural area
Predictive deep learning models
Using time series cross-validation, we trained the models using a series of training sets for each model to forecast NO concentration for one month ahead (the observation that forms the test set). The model performance metrics were computed by averaging the model performance over the test sets. We trained several state-of-the-art deep learning models for sequence data, namely, MiniRocket, ResNet for time series, XceptionTime, InceptionTime and Transformer for time series. In this study, we trained the models using data from different monitoring stations which exhibit various environmental assessment points. Table 3 presents the performance of the trained models in the testing set. Overall, the Transformer-based deep learning model reports the best performance in the unseen data compared with other deep learning models: MiniRocket, ResNet for time series, XceptionTime, and InceptionTime. For the Transformer model, the minimum RMSE is 0.00102 (±0.00071) reported by station 12 with MAE: 0.02488 (±0.0091) and MSE: 0.03018 (±0.01055). The same model reports the maximum RMSE (0.01468 (±0.03387)) for station 10 with MAE: 0.06707 (± 0.06861) and MSE: 0.08505 (±0.08629). The performance of the Transformer is outperform other models in all the stations. It is important to emphasize that R is a measure of goodness-of-fit, not a measure of model’s predictive capability [34]; the high R value for the model explained by the increase in the variance of the time series; in which having a larger variance in the time series can cause the R value to be closed to one, and can be deceiving when calculating the model quality. Finally for model interpenetration, we used permutation feature importance for interpreting the transformer model; Table 4 presents that the model assigned a high weights to the fourth day for predict the future NO value. In Fig. 5, we visualize the Transformer model’s average residual performance by calculating the difference between the predicted and actual values. Transformer-based models show good performance during fall and bad during summertime. During the Covid-19 period, the model performed severely due to the sudden change in the trends.
Table 3.
The performance of different deep learning models for NO emission prediction in the testing set
| MAE | MSE | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Station | M0 | M1 | M2 | M3 | M4 | M5 | M0 | M1 | M2 | M3 | M4 | M5 |
| Station 1 | 0.19 (± 0.18) | 0.26 (± 0.19) | 0.21 (± 0.07) | 0.24 (± 0.16) | 0.04 (± 0.04) | 0.7 (± 0.55) | 0.22 (± 0.18) | 0.31 (± 0.21) | 0.26 (± 0.08) | 0.28 (± 0.16) | 0.06 (± 0.04) | 0.79 (± 0.54) |
| Station 2 | 0.17 (± 0.18) | 0.27 (± 0.24) | 0.24 (± 0.16) | 0.24 (± 0.17) | 0.05 (± 0.04) | 0.69 (± 0.21) | 0.21 (± 0.21) | 0.32 (± 0.3) | 0.28 (± 0.16) | 0.29 (± 0.22) | 0.07 (± 0.06) | 0.81 (± 0.2) |
| Station 3 | 0.13 (± 0.15) | 0.3 (± 0.28) | 0.18 (± 0.15) | 0.17 (± 0.15) | 0.04 (± 0.04) | 0.49 (± 0.28) | 0.16 (± 0.17) | 0.37 (± 0.35) | 0.21 (± 0.17) | 0.22 (± 0.18) | 0.05 (± 0.05) | 0.59 (± 0.27) |
| Station 4 | 0.1 (± 0.07) | 0.25 (± 0.16) | 0.17 (± 0.09) | 0.16 (± 0.1) | 0.05 (± 0.05) | 0.31 (± 0.26) | 0.12 (± 0.09) | 0.29 (± 0.17) | 0.21 (± 0.1) | 0.18 (± 0.12) | 0.06 (± 0.08) | 0.38 (± 0.27) |
| Station 5 | 0.09 (± 0.08) | 0.22 (± 0.14) | 0.21 (± 0.14) | 0.13 (± 0.09) | 0.05 (± 0.05) | 0.28 (± 0.14) | 0.11 (± 0.11) | 0.27 (± 0.18) | 0.26 (± 0.16) | 0.16 (± 0.13) | 0.06 (± 0.06) | 0.35 (± 0.15) |
| Station 6 | 0.11 (± 0.08) | 0.19 (± 0.22) | 0.16 (± 0.04) | 0.17 (± 0.12) | 0.04 (± 0.03) | 0.54 (± 0.24) | 0.14 (± 0.09) | 0.24 (± 0.25) | 0.2 (± 0.05) | 0.21 (± 0.13) | 0.05 (± 0.04) | 0.66 (± 0.26) |
| Station 7 | 0.08 (± 0.05) | 0.23 (± 0.08) | 0.12 (± 0.04) | 0.11 (± 0.07) | 0.03 (± 0.02) | 0.48 (± 0.18) | 0.1 (± 0.07) | 0.28 (± 0.09) | 0.14 (± 0.05) | 0.15 (± 0.09) | 0.04 (± 0.03) | 0.55 (± 0.17) |
| Station 8 | 0.08 (± 0.1) | 0.14 (± 0.13) | 0.16 (± 0.06) | 0.11 (± 0.07) | 0.04 (± 0.04) | 0.37 (± 0.17) | 0.1 (± 0.12) | 0.16 (± 0.15) | 0.2 (± 0.06) | 0.14 (± 0.1) | 0.04 (± 0.05) | 0.48 (± 0.18) |
| Station 9 | 0.13 (± 0.1) | 0.24 (± 0.17) | 0.19 (± 0.12) | 0.21 (± 0.19) | 0.04 (± 0.04) | 0.32 (± 0.18) | 0.16 (± 0.14) | 0.3 (± 0.21) | 0.25 (± 0.16) | 0.25 (± 0.22) | 0.05 (± 0.06) | 0.44 (± 0.22) |
| Station 10 | 0.18 (± 0.16) | 0.26 (± 0.17) | 0.19 (± 0.07) | 0.21 (± 0.12) | 0.07 (± 0.07) | 0.63 (± 0.43) | 0.23 (± 0.22) | 0.31 (± 0.21) | 0.23 (± 0.09) | 0.27 (± 0.16) | 0.09 (± 0.09) | 0.76 (± 0.42) |
| Station 11 | 0.12 (± 0.08) | 0.18 (± 0.16) | 0.21 (± 0.05) | 0.21 (± 0.11) | 0.04 (± 0.02) | 0.36 (± 0.15) | 0.15 (± 0.1) | 0.23 (± 0.2) | 0.25 (± 0.06) | 0.26 (± 0.13) | 0.04 (± 0.03) | 0.51 (± 0.16) |
| Station 12 | 0.07 (± 0.03) | 0.17 (± 0.1) | 0.13 (± 0.03) | 0.08 (± 0.04) | 0.02 (± 0.01) | 0.56 (± 0.25) | 0.09 (± 0.05) | 0.2 (± 0.11) | 0.15 (± 0.04) | 0.1 (± 0.05) | 0.03 (± 0.01) | 0.67 (± 0.27) |
| Station 14 | 0.09 (± 0.06) | 0.24 (± 0.21) | 0.18 (± 0.11) | 0.14 (± 0.11) | 0.03 (± 0.02) | 0.49 (± 0.27) | 0.1 (± 0.07) | 0.29 (± 0.25) | 0.21 (± 0.13) | 0.17 (± 0.13) | 0.03 (± 0.02) | 0.59 (± 0.26) |
| Station 15 | 0.07 (± 0.06) | 0.2 (± 0.15) | 0.14 (± 0.05) | 0.11 (± 0.08) | 0.02 (± 0.01) | 0.61 (± 0.22) | 0.09 (± 0.07) | 0.24 (± 0.18) | 0.17 (± 0.06) | 0.14 (± 0.11) | 0.03 (± 0.01) | 0.7 (± 0.21) |
| Station 16 | 0.11 (± 0.06) | 0.24 (± 0.15) | 0.18 (± 0.07) | 0.16 (± 0.09) | 0.04 (± 0.01) | 0.39 (± 0.27) | 0.14 (± 0.08) | 0.28 (± 0.17) | 0.22 (± 0.08) | 0.2 (± 0.11) | 0.05 (± 0.02) | 0.5 (± 0.28) |
| Station 17 | 0.08 (± 0.04) | 0.15 (± 0.15) | 0.17 (± 0.06) | 0.16 (± 0.09) | 0.03 (± 0.01) | 0.48 (± 0.29) | 0.1 (± 0.06) | 0.19 (± 0.19) | 0.21 (± 0.08) | 0.19 (± 0.11) | 0.04 (± 0.01) | 0.63 (± 0.29) |
| Station 18 | 0.11 (± 0.11) | 0.17 (± 0.24) | 0.18 (± 0.09) | 0.17 (± 0.17) | 0.04 (± 0.04) | 0.45 (± 0.24) | 0.14 (± 0.14) | 0.21 (± 0.28) | 0.21 (± 0.11) | 0.21 (± 0.2) | 0.05 (± 0.05) | 0.56 (± 0.23) |
| Station 19 | 0.09 (± 0.08) | 0.22 (± 0.13) | 0.14 (± 0.03) | 0.15 (± 0.09) | 0.03 (± 0.01) | 0.47 (± 0.26) | 0.11 (± 0.09) | 0.26 (± 0.16) | 0.18 (± 0.04) | 0.18 (± 0.1) | 0.04 (± 0.02) | 0.55 (± 0.26) |
| Station 20 | 0.11 (± 0.05) | 0.28 (± 0.12) | 0.16 (± 0.05) | 0.15 (± 0.08) | 0.03 (± 0.01) | 0.39 (± 0.26) | 0.13 (± 0.06) | 0.34 (± 0.15) | 0.19 (± 0.06) | 0.19 (± 0.1) | 0.04 (± 0.01) | 0.47 (± 0.28) |
| Average | 0.11 (±0.09) | 0.22 (±0.17) | 0.17 (±0.08) | 0.16 (±0.11) | 0.04 (±0.03) | 0.47 (±0.26) | 0.14 (±0.11) | 0.27 (±0.20) | 0.21 (±0.09) | 0.20 (±0.13 ) | 0.05 (±0.04) | 0.58 (±0.26) |
| R2 | RMSE | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Station 1 | M0 | M1 | M2 | M3 | M4 | M5 | M0 | M1 | M2 | M3 | M4 | M5 |
| Station 2 | 0.38 (± 1.35) | 0.56 (± 0.33) | 0.65 (± 0.28) | 0.35 (± 1.19) | 0.98 (± 0.05) | −4.83 (± 9.38) | 0.08 (± 0.13) | 0.14 (± 0.17) | 0.07 (± 0.04) | 0.11 (± 0.12) | 0.0 (± 0.01) | 0.91 (± 1.06) |
| Station 3 | 0.9 (± 0.09) | 0.71 (± 0.31) | 0.79 (± 0.15) | 0.82 (± 0.12) | 0.99 (± 0.01) | −1.43 (± 1.82) | 0.09 (± 0.18) | 0.19 (± 0.25) | 0.1 (± 0.12) | 0.13 (± 0.19) | 0.01 (± 0.01) | 0.69 (± 0.32) |
| Station 4 | 0.92 (± 0.09) | 0.54 (± 0.4) | 0.84 (± 0.12) | 0.85 (± 0.12) | 0.99 (± 0.01) | −1.71 (± 3.32) | 0.06 (± 0.1) | 0.25 (± 0.4) | 0.07 (± 0.11) | 0.08 (± 0.12) | 0.0 (± 0.01) | 0.43 (± 0.32) |
| Station 5 | 0.93 (± 0.07) | 0.55 (± 0.34) | 0.79 (± 0.15) | 0.85 (± 0.11) | 0.98 (± 0.04) | −0.92 (± 4.43) | 0.02 (± 0.03) | 0.12 (± 0.13) | 0.05 (± 0.06) | 0.05 (± 0.06) | 0.01 (± 0.03) | 0.22 (± 0.34) |
| Station 6 | 0.92 (± 0.09) | 0.52 (± 0.36) | 0.51 (± 0.54) | 0.87 (± 0.11) | 0.97 (± 0.05) | −0.2 (± 1.39) | 0.02 (± 0.05) | 0.11 (± 0.17) | 0.09 (± 0.11) | 0.04 (± 0.07) | 0.01 (± 0.01) | 0.15 (± 0.1) |
| Station 7 | 0.95 (± 0.04) | 0.85 (± 0.2) | 0.9 (± 0.05) | 0.9 (± 0.08) | 1.0 (± 0.01) | −0.32 (± 1.04) | 0.03 (± 0.04) | 0.12 (± 0.26) | 0.04 (± 0.02) | 0.06 (± 0.08) | 0.0 (± 0.01) | 0.51 (± 0.32) |
| Station 8 | 0.9 (± 0.1) | 0.22 (± 0.36) | 0.79 (± 0.13) | 0.79 (± 0.17) | 0.98 (± 0.02) | −2.83 (± 3.58) | 0.01 (± 0.02) | 0.09 (± 0.05) | 0.02 (± 0.02) | 0.03 (± 0.03) | 0.0 (± 0.0) | 0.33 (± 0.19) |
| Station 9 | 0.96 (± 0.06) | 0.85 (± 0.21) | 0.82 (± 0.13) | 0.92 (± 0.06) | 0.99 (± 0.01) | −0.31 (± 1.43) | 0.03 (± 0.06) | 0.05 (± 0.08) | 0.04 (± 0.03) | 0.03 (± 0.05) | 0.0 (± 0.01) | 0.26 (± 0.17) |
| Station 10 | 0.95 (± 0.05) | 0.72 (± 0.28) | 0.84 (± 0.16) | 0.86 (± 0.13) | 0.99 (± 0.01) | 0.34 (± 0.62) | 0.05 (± 0.08) | 0.14 (± 0.15) | 0.09 (± 0.13) | 0.11 (± 0.18) | 0.01 (± 0.02) | 0.24 (± 0.28) |
| Station 11 | 0.86 (± 0.17) | 0.78 (± 0.15) | 0.82 (± 0.19) | 0.75 (± 0.37) | 0.98 (± 0.03) | −2.59 (± 5.73) | 0.1 (± 0.23) | 0.14 (± 0.18) | 0.06 (± 0.05) | 0.1 (± 0.11) | 0.01 (± 0.03) | 0.74 (± 0.8) |
| Station 12 | 0.96 (± 0.05) | 0.9 (± 0.13) | 0.9 (± 0.06) | 0.9 (± 0.07) | 1.0 (± 0.0) | 0.61 (± 0.23) | 0.03 (± 0.04) | 0.09 (± 0.12) | 0.07 (± 0.03) | 0.09 (± 0.07) | 0.0 (± 0.0) | 0.28 (± 0.18) |
| Station 13 | 0.96 (± 0.04) | 0.79 (± 0.17) | 0.88 (± 0.06) | 0.95 (± 0.02) | 0.99 (± 0.01) | −1.83 (± 2.23) | 0.01 (± 0.01) | 0.05 (± 0.05) | 0.02 (± 0.01) | 0.01 (± 0.01) | 0.0 (± 0.0) | 0.52 (± 0.3) |
| Station 14 | 0.94 (± 0.05) | 0.62 (± 0.33) | 0.78 (± 0.16) | 0.86 (± 0.13) | 0.99 (± 0.01) | −5.16 (± 13.18) | 0.02 (± 0.02) | 0.14 (± 0.22) | 0.06 (± 0.08) | 0.05 (± 0.07) | 0.0 (± 0.0) | 0.41 (± 0.3) |
| Station 15 | 0.95 (± 0.03) | 0.64 (± 0.28) | 0.79 (± 0.13) | 0.86 (± 0.11) | 0.99 (± 0.0) | −3.96 (± 4.17) | 0.01 (± 0.02) | 0.09 (± 0.11) | 0.03 (± 0.02) | 0.03 (± 0.04) | 0.0 (± 0.0) | 0.54 (± 0.29) |
| Station 16 | 0.93 (± 0.04) | 0.66 (± 0.25) | 0.81 (± 0.08) | 0.86 (± 0.08) | 0.99 (± 0.0) | −0.25 (± 1.33) | 0.02 (± 0.03) | 0.11 (± 0.11) | 0.06 (± 0.05) | 0.05 (± 0.05) | 0.0 (± 0.0) | 0.33 (± 0.3) |
| Station 17 | 0.97 (± 0.02) | 0.87 (± 0.16) | 0.86 (± 0.07) | 0.9 (± 0.06) | 0.99 (± 0.01) | −1.06 (± 2.93) | 0.01 (± 0.02) | 0.07 (± 0.1) | 0.05 (± 0.04) | 0.05 (± 0.05) | 0.0 (± 0.0) | 0.47 (± 0.38) |
| Station 18 | 0.95 (± 0.05) | 0.86 (± 0.21) | 0.88 (± 0.05) | 0.89 (± 0.11) | 0.99 (± 0.01) | −0.46 (± 1.8) | 0.04 (± 0.09) | 0.12 (± 0.29) | 0.06 (± 0.08) | 0.08 (± 0.17) | 0.01 (± 0.01) | 0.36 (± 0.28) |
| Station 19 | 0.96 (± 0.04) | 0.68 (± 0.31) | 0.87 (± 0.08) | 0.88 (± 0.07) | 0.99 (± 0.0) | −0.7 (± 1.91) | 0.02 (± 0.04) | 0.1 (± 0.1) | 0.03 (± 0.01) | 0.04 (± 0.05) | 0.0 (± 0.0) | 0.37 (± 0.29) |
| Station 20 | 0.92 (± 0.07) | 0.46 (± 0.24) | 0.83 (± 0.06) | 0.84 (± 0.1) | 0.99 (± 0.01) | −0.47 (± 1.29) | 0.02 (± 0.02) | 0.14 (± 0.11) | 0.04 (± 0.02) | 0.05 (± 0.04) | 0.0 (± 0.0) | 0.3 (± 0.33) |
| Average | 0.91 (±0.13) | 0.67 (±0.26) | 0.81 (±0.14) | 0.84 (±0.17) | 0.99 (±0.02) | −1.48 (±3.25 ) | 0.04 (±0.06) | 0.12 (±0.16) | 0.06 (±0.05) | 0.06 (±0.08) | 0.00 (±0.01) | 0.42 (±0.34) |
M0: InceptionTime; M1: LSTM; M2: MiniRocket, M3: ResNet, M4: TSTransformer and M5: XceptionTime
Table 4.
Feature Importance of the Transformer model using Cross-validation: The permutation feature importance reported the decrease in the MAE score when the single value is randomly shuffled. The most important features are the one with a higher values
| Station | Lag 10 | Lag 9 | Lag 8 | Lag 7 | Lag 6 | Lag 5 | Lag 4 | Lag 3 | Lag 2 | Lag 1 |
|---|---|---|---|---|---|---|---|---|---|---|
| Station 1 | 0.02 (± 0.01) | 0.02 (± 0.01) | 0.02 (± 0.01) | 0.02 (± 0.01) | 0.02 (± 0.01) | 0.02 (± 0.01) | 1.06 (± 0.03) | 0.02 (± 0.01) | 0.02 (± 0.01) | 0.02 (± 0.01) |
| Station 2 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.92 (± 0.04) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 3 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 1.03 (± 0.03) | 0.01 (± 0.0) | 0.01 (± 0.01) | 0.01 (± 0.0) |
| Station 4 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.01) | 1.0 (± 0.04) | 0.01 (± 0.01) | 0.01 (± 0.01) | 0.01 (± 0.0) |
| Station 5 | 0.02 (± 0.01) | 0.02 (± 0.0) | 0.02 (± 0.01) | 0.02 (± 0.01) | 0.03 (± 0.01) | 0.02 (± 0.01) | 0.89 (± 0.05) | 0.02 (± 0.01) | 0.02 (± 0.01) | 0.02 (± 0.01) |
| Station 6 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 1.06 (± 0.03) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 7 | 0.03 (± 0.01) | 0.03 (± 0.01) | 0.03 (± 0.01) | 0.03 (± 0.01) | 0.03 (± 0.01) | 0.04 (± 0.01) | 0.94 (± 0.03) | 0.04 (± 0.02) | 0.04 (± 0.01) | 0.03 (± 0.01) |
| Station 8 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 1.02 (± 0.03) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 9 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 1.05 (± 0.05) | 0.01 (± 0.01) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 10 | 0.01 (± 0.01) | 0.01 (± 0.01) | 0.01 (± 0.0) | 0.01 (± 0.01) | 0.01 (± 0.01) | 0.02 (± 0.01) | 1.02 (± 0.05) | 0.01 (± 0.01) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 11 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 1.05 (± 0.03) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 12 | 0.02 (± 0.01) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.02 (± 0.0) | 0.02 (± 0.01) | 0.02 (± 0.01) | 1.0 (± 0.01) | 0.02 (± 0.01) | 0.02 (± 0.01) | 0.02 (± 0.01) |
| Station 14 | 0.01 (± 0.0) | 0.02 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.02 (± 0.0) | 0.02 (± 0.0) | 0.93 (± 0.04) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 15 | 0.02 (± 0.01) | 0.02 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.02 (± 0.01) | 0.01 (± 0.0) | 1.03 (± 0.03) | 0.02 (± 0.01) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 16 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.02 (± 0.01) | 0.02 (± 0.01) | 0.01 (± 0.01) | 0.02 (± 0.01) | 1.07 (± 0.02) | 0.02 (± 0.01) | 0.02 (± 0.0) | 0.01 (± 0.0) |
| Station 17 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 1.04 (± 0.04) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 18 | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.01) | 1.03 (± 0.04) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) |
| Station 19 | 0.01 (± 0.01) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.0) | 1.0 (± 0.04) | 0.01 (± 0.0) | 0.01 (± 0.0) | 0.01 (± 0.01) |
| Station 20 | 0.02 (± 0.01) | 0.03 (± 0.0) | 0.03 (± 0.01) | 0.02 (± 0.01) | 0.03 (± 0.01) | 0.03 (± 0.01) | 1.07 (± 0.04) | 0.03 (± 0.01) | 0.03 (± 0.01) | 0.03 (± 0.01) |
Fig. 5.
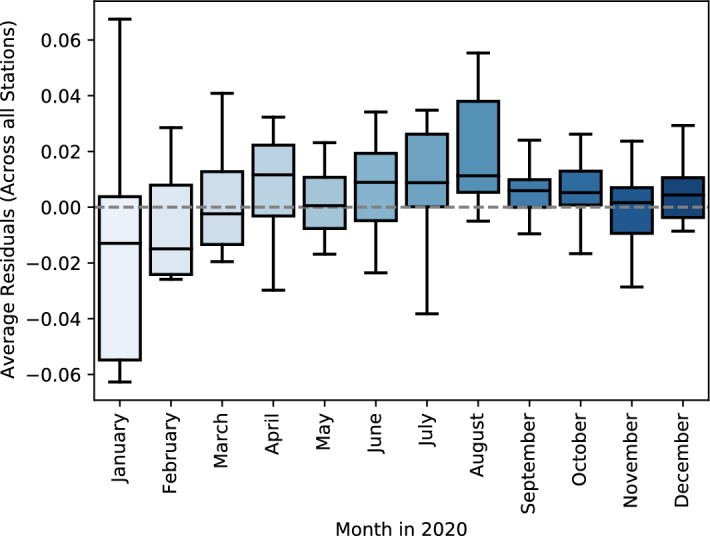
TSTransformer Residuals: TSTransformer Model average residuals of NO concentrations for each month in 2020 (Across all the stations) on the testing set
Discussion
The atmospheric model and its composition research are receiving increased interest among the scientific community to tackle major global challenges such as climate change, air quality, urbanization, etc. [2]. One of the important atmospheric research tracks is a short-term and annual average air quality forecast that supports the decision makers to adopt the appropriate regulations and laws for improving air quality and public health [2, 8]. Air quality prediction is considered a challenging task since air pollutants concentration is governed by environmental and physical factors such as meteorological factors, traffic pollution, and industrial emissions that vary across time and space [8, 16].
This study aims to investigate the NO patterns in the UAE and implement several state-of-the-art deep learning models, MiniRocket, ResNet for time series, XceptionTime, InceptionTime, and Transformer, for future NO forecasting using historical data. The data was collected from different monitoring stations that distributed and exhibited various environmental assessment regions across Abu-Dhabi: urban traffic, urban background, rural traffic, rural background, rural industrial, suburban background, and suburban industrial. The UAE’s primary sources of NO emissions come from the production and refining of oil and gas, power generation, and water desalination, while the second source is from vehicles and ships [35]. From Fig. 3, Station 1, which has the highest pollutant emissions located in an urban area with traffic; so, the vehicle emission explains this increase in the pollutant, while station 20, which has the lowest NO emission, is a rural area. We can conclude that traffic is one of the primary sources of NO concentrations. In general, we notice a reduction in the NO pollutants during summertime; the latter is explained by the involvement of NO in producing the ground-level ozone (O) pollutant during summer. From a chemical point of view, NO and carbon monoxide are photochemical reactions combined with solar radiation to produce O; most of these reactions happen during summer [8, 36]. Most stations exhibit a decrease in the annual NO level except for stations 5 and 9. The reduction in the pollutant trend of most stations reflects the UAE’s efforts to improve the air quality. Some of the notable efforts are: launching the National Air Quality Platform [37] for the researchers to study the different factors that affect pollutant levels in the region; collaborating with several federal and local government agencies to create joint initiatives and best practices to improve air quality; encouraging the society to reduce the pollutants emission and adopt environment-friendly practices [38]. In 2020 and with the spread of coronavirus disease (COVID-19), UAE took several measures to control the spread of the disease, such as lockdown and social distancing; those measures significantly reduced the NO emission, as reported in [15]. This study confirmed the same findings (Fig. 3); NO concentration was decreased from the End of March 2020 until early July 2020; due to mobility restrictions (traffic and vehicles usage reduction); these findings are valid for all the stations except for the Al Dhafra Region stations (a vast expanse of the desert). For the day of the week temporal pattern, the pollutant emission increases in the early morning, especially during the working days, due to motor vehicle movement and traffic. The daily pattern is expected to change; as in 2022, all the federal government entities in the UAE operates from Monday until half day on Friday, with the weekend starting from the second half of Friday until Sunday [39].
For the predictive model, the Transformer-based deep learning model outperforms other models to forecast daily NO concentration for one month ahead; the best performance was reported in station 12 (MAE:0.02488 (±0.0091), MSE:0.03018 (±0.01055), RMSE: 0.00102 (±0.00071), R: 0.99376 (±0.00692)). While XceptionTime reported the worst results across all the stations. The transformer model’s superiority is explained by the attention head, which is a powerful technique to effectively learn the new representation of the sequence data by relating different positions in the sequence. The overall performance of the Transformer model indicates it is capable of capturing the pollutants’ daily and weekly cycle patterns exhibited in the pollutants trend (Figs. 3, 4). One of the limitations is the existence of the none meteorological interventions such as Covid-19, which lower the model performance. Overall, the model’s performance is good when trained using different time series, which exhibited different variability of NO concentration. In cooperated with other pollutants data could be improved the overall model performance.
Previous studies applied different ML and AI models to improve the NO concentration prediction. One of the earliest studies [13] used cluster-based bagging machine learning models to predict NO concentration for the state of California. The model was trained using historical NO data, traffic-related NO modeled by CALINE4 dispersion model, traffic density, distance to shoreline and roadways, air temperature, population density, humidity, precipitation, and wind speed. The model reported (R=0.870.9, RMSE=0.210.27). Another study utilized Tehran metropolis air quality data, Iran [1], to build a multi-linear regression (MLR) and multilayer perceptron model (MLP) models and used the trained model to forecast future NO concentration. The study improved NO prediction by incorporating additional features to the model, such as traffic and green space information, the day of the week, and meteorological parameters. The MLP model reported (R = 0.89, RMSE= 0.32) which outperform MLR (R = 0.81, RMSE= 13.151). A third study used data from 35 monitoring stations in Beijing, China [8], to propose a novel multi-output and multi-index supervised learning model based on LSTM. The model predicts several air pollutants: PM, CO, NO, O, and SO, using meteorological and gaseous pollutant data from the closest five neighbors' stations-as input to the model. The model best performance reported for NO prediction was (R = 0.875, RMSE= 9.688, MAE = 6.47). Another study [9]also used China monitoring stations data; it proposed a novel method that integrates discrete wavelet transformation for time series decomposition followed by training LSTM Network to improve NO level prediction. The model inputs multiple covariates: PM, PM, NO, SO, O, CO, wind speed, temperature, and weather conditions. The reported performance of the proposed model in the unseen data is MAE =4.3377 and RMSE = 5.9291. Finally, a recent study [3], using Madrid, Spain, data proposed several deep learning models, namely LSTM and ConvLSTM and Bidirectional convolutional LSTM (BiConvLSTM), to predict NO level. The model inputs NO historical information, ultraviolet radiation, wind speed, wind direction, temperature, relative humidity, barometric pressure, solar irradiance, precipitation and traffic intensity, occupancy time, and average traffic speed of 24 monitoring stations. It found that BiConvLSTM (RMSE = 19.14, MAE =13.06) outperform LSTM (RMSE =38.89, MAE =32.17) and ConvLSTM (RMSE =32.95, MAE =32.04) for NO prediction.
Even though there are several efforts to improve the accuracy of future NO level prediction using machine learning and deep learning models, the best reported R and RMSE from the previous published works range from 0.87 to 0.9 and from 0.21 to 19.14, respectively. NO prediction is a complex task, that is why all the previous works integrate environmental and physical factors such as traffic data, wind speed, wind direction, humidity, air temperature, and air pressure to reach the best-reported results.
By validating that NO exhibits a periodic pattern, as reported in Fig. 3 and Fig. 4, we implemented several state-of-the-art deep learning models for sequence data using NO historical information only to predict future NO levels. This study proves that Transformer deep learning models are superior to learning the temporal data representation to make precision forecasting compared to statistical models, machine learning, and early neural network models. Even though there is a change in the NO pattern due to the COVID-19 pandemic, the models reported a reasonable performance in comparison with what had been reported in the literature so far.
Conclusion
In this study, we implement various state-of-the-art deep learning models to predict the NO emissions using pollutant univariate historical data; the models were tested across different monitoring stations in Abu-Dhabi that exhibit various environmental assessment points. We reveal a general decrease in the NO annual patterns for most stations, and we confirm the impact of the COVID-19 lockdown on reducing the NO. Using the Transformer deep learning model for time series data, we improved the accuracy of NO forecasting. Our findings outperformed all the results reported in the literature for the same task using only NO historical data. This study trained and validated the models on a particular type of air pollutant (NO); however, several hazardous pollutants are of significant importance for atmospheric management decisions, such as PM, O, etc. Future work will be directed toward implementing and testing the different deep learning models to predict different air pollutants concentrations; predicting NO concentrations at hourly intervals and using the deep learning techniques to reveal the association between different pollutants such as NO and ozone production. Moreover, this study implemented different models for each station (in total we trained 1,368: 6 models, 19 stations, 12 months prediction for cross-validation), which are computationally time-consuming and expensive. Investigating the capabilities of training a single model and adopt it(transfer learning) to all other stations will be considered to reduce the computation resource.
Supplementary Information
Additional file 1: Table S1: Missing Value Percentages in the 20 UAE monitoring stations. Figure S1. Station 1 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S2: Station 2 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S3: Station 3 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements.Figure S4: Station 4 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S5: Station 5 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S6: Station 6 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S7: Station 7 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S8: Station 8 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S9: Station 9 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S10: Station 10 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S11: Station 11 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements.Figure S12: Station 12 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S13: Station 14 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S14: Station 15 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S15: Station 16 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S16: Station 17 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S17: Station 18 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S18: Station 19 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S19: Station 20 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements
Acknowledgements
We would like to thank Environment Agency- Abu Dhabi (EAD) for their assistance in providing this study’s data.
Abbreviations
- AL
Artificial intelligence
- AQG
Air Quality Guidelines
- AR
Auto-Regressive model
- ARIMA
Auto-Regressive Integrated Moving Average model
- BiConvLSTM
Bidirectional Convolutional LSTM
- CO
Carbon Monoxide
- EAD
Environment Agency-Abu Dhabi
- EWMA
Exponential Weighted Moving Average
- HS
Hydrogen Sulfide
- LSTM
Long Short-Term Memory
- MA
Moving Average model
- MAE
Mean Absolute Error
- MiniRocket
MINImally RandOm Convolutional KErnel Transform
- ML
Machine Learning
- MLP
MultiLayer Perceptron model
- MLR
Multilinear Regression
- MSE
Mean Square Error
- NO
Nitrogen Dioxide
- O
Ozone
- PM
Particulate Matter
- R
Coefficient of determination
- ReLU
Rectified Linear Unit
- ResNet
Residual Network
- RMSE
Root Means Square Error
- RNN
Recurrent Neural Network
- SARIMA
Seasonal ARIMA
- SO
Sulfur Dioxide
- UAE
United Arab Emirates
- WHO
World Health Organization
Author Contributions
A.A. conceived and conducted the experiment(s), AA and RW Conceptualization. AA and RW Writing, Review and Editing, All authors read and approved the final manuscript.
Funding
There was no funding source for this study.
Availability of data and materials
The data that support the findings of this study are available from Environment Agency - Abu Dhabi Air Quality Data but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available by submit a request to Environment Agency - Abu Dhabi Air Quality Data.
Declarations
Ethics approval and consent to participate
Not applicable
Consent for publication
Not applicable
Conflict of interests
The authors declare that they have no competing interests.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Aamna AlShehhi, Email: aamna.alshehhi@ku.ac.ae.
Roy Welsch, Email: rwelsch@mit.edu.
References
- 1.Shams SR, Jahani A, Kalantary S, Moeinaddini M, Khorasani N. Artificial intelligence accuracy assessment in NO2 concentration forecasting of metropolises air. Sci Rep. 2021;11(1):1805. doi: 10.1038/s41598-021-81455-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Baklanov A, Zhang Y. Advances in air quality modeling and forecasting. Global Transit. 2020;2:261–270. doi: 10.1016/j.glt.2020.11.001. [DOI] [Google Scholar]
- 3.Iskandaryan D, Ramos F, Trilles S. Bidirectional convolutional LSTM for the prediction of nitrogen dioxide in the city of Madrid. PLOS ONE. 2022;17(6):0269295. doi: 10.1371/journal.pone.0269295. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Ngarambe J, Joen SJ, Han C-H, Yun GY. Exploring the relationship between particulate matter, CO, SO2, NO2, O3 and urban heat island in Seoul Korea. J Hazard Mat. 2021;403:123615. doi: 10.1016/j.jhazmat.2020.123615. [DOI] [PubMed] [Google Scholar]
- 5.Lee M, Lin L, Chen C-Y, Tsao Y, Yao T-H, Fei M-H, Fang S-H. Forecasting air quality in Taiwan by using machine learning. Sci Rep. 2020;10(1):4153. doi: 10.1038/s41598-020-61151-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Xiao F, Yang M, Fan H, Fan G, Al-qaness MAA. An improved deep learning model for predicting daily PM2.5 concentration. Sci Rep. 2020;10(1):20988. doi: 10.1038/s41598-020-77757-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Hu Y, Ji JS, Zhao B. Restrictions on indoor and outdoor NO2 emissions to reduce disease burden for pediatric asthma in China: A modeling study. The Lancet Regional Health Western Pacific 24 (2022). Elsevier. Accessed from 02 Aug 2022. [DOI] [PMC free article] [PubMed]
- 8.Seng D, Zhang Q, Zhang X, Chen G, Chen X. Spatiotemporal prediction of air quality based on LSTM neural network. Alex Eng J. 2021;60(2):2021–2032. doi: 10.1016/j.aej.2020.12.009. [DOI] [Google Scholar]
- 9.Liu B, Zhang L, Wang Q, Chen J. A novel method for regional NO2 concentration prediction using discrete wavelet transform and an LSTM network. Comput Intell Neurosci. 2021;2021:14. doi: 10.1155/2021/6631614. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Ogen Y. Assessing nitrogen dioxide (NO2) levels as a contributing factor to coronavirus (COVID-19) fatality. Sci Total Environ. 2020;726:138605. doi: 10.1016/j.scitotenv.2020.138605. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Anenberg SC, Mohegh A, Goldberg DL, Kerr GH, Brauer M, Burkart K, Hystad P, Larkin A, Wozniak S, Lamsal L. Long-term trends in urban NO2 concentrations and associated paediatric asthma incidence: estimates from global datasets. Lancet Planet Health. 2022;6(1):49–58. doi: 10.1016/S2542-5196(21)00255-2. [DOI] [PubMed] [Google Scholar]
- 12.Cooper MJ, Martin RV, Hammer MS, Levelt PF, Veefkind P, Lamsal LN, Krotkov NA, Brook JR, McLinden CA. Global fine-scale changes in ambient NO2 during COVID-19 lockdowns. Nature. 2022;601(7893):380–387. doi: 10.1038/s41586-021-04229-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Li L, Girguis M, Lurmann F, Wu J, Urman R, Rappaport E, Ritz B, Franklin M, Breton C, Gilliland F, Habre R. Cluster-based bagging of constrained mixed-effects models for high spatiotemporal resolution nitrogen oxides prediction over large regions. Environ Int. 2019;128:310–323. doi: 10.1016/j.envint.2019.04.057. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Yousefian F, Faridi S, Azimi F, Aghaei M, Shamsipour M, Yaghmaeian K, Hassanvand MS. Temporal variations of ambient air pollutants and meteorological influences on their concentrations in Tehran during 2012–2017. Sci Rep. 2020;10(1):292. doi: 10.1038/s41598-019-56578-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Teixidó O, Tobías A, Massagué J, Mohamed R, Ekaabi R, Hamed HI, Perry R, Querol X, Al Hosani S. The influence of COVID-19 preventive measures on the air quality in Abu Dhabi (United Arab Emirates) Air Qual Atm Health. 2021;14(7):1071–1079. doi: 10.1007/s11869-021-01000-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Zhang X, Just AC, Hsu H-HL, Kloog I, Woody M, Mi Z, Rush J, Georgopoulos P, Wright RO, Stroustrup A. A hybrid approach to predict daily NO2 concentrations at city block scale. Sci Total Environ. 2021;761:143279. doi: 10.1016/j.scitotenv.2020.143279. [DOI] [PubMed] [Google Scholar]
- 17.Dey T, Tyagi P, Sabath MB, Kamareddine L, Henneman L, Braun D, Dominici F. Counterfactual time series analysis of short-term change in air pollution following the COVID-19 state of emergency in the United States. Sci Rep. 2021;11(1):23517. doi: 10.1038/s41598-021-02776-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Dempster A, Schmidt DF, Webb GI. MiniRocket: A Very Fast (Almost) Deterministic Transform for Time Series Classification. In: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pp. 248–257. Association for Computing Machinery, Virtual Event, Singapore (2021). 10.1145/3447548.3467231. 10.1145/3447548.3467231. [DOI]
- 19.Ismail Fawaz H, Forestier G, Weber J, Idoumghar L, Muller P-A. Deep learning for time series classification: a review. Data Mining Knowl Discov. 2019;33(4):917–963. doi: 10.1007/s10618-019-00619-1. [DOI] [Google Scholar]
- 20.Rahimian E, Zabihi S, Atashzar SF, Asif A, Mohammadi A. XceptionTime: a novel deep architecture based on depthwise separable convolutions for hand gesture classification. arXiv. 2019 doi: 10.48550/arXiv.1911.03803. [DOI] [Google Scholar]
- 21.Ismail Fawaz H, Lucas B, Forestier G, Pelletier C, Schmidt DF, Weber J, Webb GI, Idoumghar L, Muller P-A, Petitjean F. InceptionTime: finding AlexNet for time series classification. Data Mining Knowl Discov. 2020;34(6):1936–1962. doi: 10.1007/s10618-020-00710-y. [DOI] [Google Scholar]
- 22.Zerveas G, Jayaraman S, Patel D, Bhamidipaty A, Eickhoff C. A Transformer-based Framework for Multivariate Time Series Representation Learning. In: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pp. 2114–2124. Association for Computing Machinery, Virtual Event, Singapore (2021). Type: 10.1145/3447548.3467401. 10.1145/3447548.3467401. [DOI]
- 23.Abu Dhabi Government Media Office: The Environment Agency Abu Dhabi Expanded its Air Quality Monitoring Programme in 2021 (2022). https://www.mediaoffice.abudhabi/en/environment/the-agency-expanded-its-air-quality-monitoring-programme-in-2021/ Accessed from 05 Oct 2022.
- 24.Environment Agency- Abu Dhabi: Welcome to the Environment Agency - Abu Dhabi (EAD) 2022. https://www.ead.gov.ae/en Accessed 19 Nov 2022.
- 25.Environment Agency- Abu Dhabi: Air Quality 2022. https://www.ead.gov.ae/en/experience-green-abu-dhabi/things-to-know/air-quality Accessed 19 Nov 2022.
- 26.Environment Agency- Abu Dhabi: Air Quality Annual Report 2019 (2022). https://www.ead.gov.ae/storage/uploads/posts/EIM-AIR-QUALITY-ANNUAL-ENG-2019-v2.pdf Accessed 15 Oct 2022.
- 27.Wijesekara L, Liyanage L. Comparison of imputation methods for missing values in air pollution data: case study on Sydney air quality index, 2020: 257–269.
- 28.Gholami H, Moradi Y, Lotfirad M, Gandomi MA, Bazgir N, Shokrian Hajibehzad M. Detection of abrupt shift and non-parametric analyses of trends in runoff time series in the Dez river basin. Water Supp. 2021;22(2):1216–1230. doi: 10.2166/ws.2021.357. [DOI] [Google Scholar]
- 29.Aamir E, Hassan I. Trend analysis in precipitation at individual and regional levels in Baluchistan, Pakistan. IOP Conference Series: Materials Science and Engineering 414, 012042 (2018).
- 30.Bondugula RK, Udgata SK, Sivangi KB. A novel deep learning architecture and MINIROCKET feature extraction method for human activity recognition using ECG, PPG and inertial sensor dataset. Appl Intell. 2022 doi: 10.1007/s10489-022-04250-4. [DOI] [Google Scholar]
- 31.Xu S, Li W, Zhu Y, Xu A. A novel hybrid model for six main pollutant concentrations forecasting based on improved LSTM neural networks. Sci Rep. 2022;12(1):14434. doi: 10.1038/s41598-022-17754-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Moritz S, Bartz-Beielstein T. imputeTS: time series missing value imputation in R. R J. 2017 doi: 10.3261/RJ-2017-009. [DOI] [Google Scholar]
- 33.Oguiza, I. tsai - A state-of-the-art deep learning library for time series and sequential data (2020). https://github.com/timeseriesAI/tsai Accessed 10 Oct 2022.
- 34.Duveiller G, Fasbender D, Meroni M. Revisiting the concept of a symmetric index of agreement for continuous datasets. Sci Rep. 2016;6(1):19401. doi: 10.1038/srep19401. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.gulfnews, Zenifer Khaleel: Huge efforts on to improve air quality in Abu Dhabi (2017). https://gulfnews.com/uae/huge-efforts-on-to-improve-air-quality-in-abu-dhabi-1.2144445 Accessed 10 Aug 2022.
- 36.Cichowicz R, Wielgosiński G, Fetter W. Dispersion of atmospheric air pollution in summer and winter season. Environ Monit Assess. 2017;189(12):605. doi: 10.1007/s10661-017-6319-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.National Center of Meteorology: National Air Quality Platform - NAQP - NCM (2022). https://airquality.ncm.ae/?lang=en Accessed 10 Aug 2022.
- 38.Emirates News Agency-WAM, Tariq alfaham: Ministry of Climate Change and Environment inaugurates National Air Quality Platform (2020). https://wam.ae/en/details/1395302868050 Accessed 10 Aug 2022.
- 39.Emirates News Agency-WAM, Rola Alghoul and MOHD AAMIR: UAE Government announces four and half day working week (2021). https://www.wam.ae/en/details/1395303000412 Accessed 10 Aug 2022.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Additional file 1: Table S1: Missing Value Percentages in the 20 UAE monitoring stations. Figure S1. Station 1 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S2: Station 2 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S3: Station 3 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements.Figure S4: Station 4 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S5: Station 5 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S6: Station 6 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S7: Station 7 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S8: Station 8 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S9: Station 9 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S10: Station 10 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S11: Station 11 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements.Figure S12: Station 12 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S13: Station 14 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S14: Station 15 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S15: Station 16 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S16: Station 17 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S17: Station 18 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S18: Station 19 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements. Figure S19: Station 20 NO2 concentration: A)Missing values distribution: The missing regions are highlighted. B) Missing values imputation: visualization of missing value replacements
Data Availability Statement
The data that support the findings of this study are available from Environment Agency - Abu Dhabi Air Quality Data but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available by submit a request to Environment Agency - Abu Dhabi Air Quality Data.