

Summary
The primary benefit of identifying a valid surrogate marker is the ability to use it in a future trial to test for a treatment effect with shorter follow-up time or less cost. However, previous work has demonstrated potential heterogeneity in the utility of a surrogate marker. When such heterogeneity exists, existing methods that use the surrogate to test for a treatment effect while ignoring this heterogeneity may lead to inaccurate conclusions about the treatment effect, particularly when the patient population in the new study has a different mix of characteristics than the study used to evaluate the utility of the surrogate marker. In this paper, we develop a novel test for a treatment effect using surrogate marker information that accounts for heterogeneity in the utility of the surrogate. We compare our testing procedure to a test that uses primary outcome information (gold standard) and a test that uses surrogate marker information, but ignores heterogeneity. We demonstrate the validity of our approach and derive the asymptotic properties of our estimator and variance estimates. Simulation studies examine the finite sample properties of our testing procedure and demonstrate when our proposed approach can outperform the testing approach that ignores heterogeneity. We illustrate our methods using data from an AIDS clinical trial to test for a treatment effect using CD4 count as a surrogate marker for RNA.
Keywords: heterogeneity, hypothesis test, nonparametric methods, surrogate marker, treatment effect
1 |. INTRODUCTION
There has been a substantial growth in clinical and methodological research on identifying and using valid surrogate markers in the past few decades. A valid surrogate marker is a biological measurement that can be used as a replacement for a primary outcome of interest in a clinical study. Many statistical methods have been proposed to evaluate and validate surrogate markers using a wide variety of innovative methodological approaches.1,2,3,4,5 The primary benefit of identifying a valid surrogate marker is the ability to use it in a future trial to test for a treatment effect with less required follow-up time or less cost. For example, the U.S. Food and Drug Administration announced in 2020 that a surrogate marker that could be measured earlier than COVID-19 infection could be used to assess the vaccine efficacy in preventing infection,6 thus potentially allowing for earlier identification of effective vaccines.
Several statistical methods have been proposed in recent years to assess the treatment effect on the primary outcome based on surrogate marker information. For example, Parast et al. (2019)7 proposed a nonparametric approach to test for a treatment effect in a time-to-event outcome setting based on a surrogate marker measured at an earlier time point utilizing information about the relationship between the surrogate marker and primary outcome obtained from a prior study. Chen et al. (2020)8 suggested a model-based approach that uses surrogate information to make interim decisions about whether to drop a treatment arm or stop a trial for futility. Price et al. (2018)9 defined an optimal surrogate that optimally predicts a primary outcome and proposed super-learner and targeted super-learner based estimation procedures. Athey et al. (2019)10 proposed to combine multiple surrogate markers to predict a long term outcome and estimate a treatment effect, and explicitly characterized the difference between the treatment effect estimated based on the primary outcome versus the surrogate combination.
Previous clinical and methodological work has demonstrated potential heterogeneity in the utility of a surrogate marker i.e. that a surrogate marker may be more useful (with respect to capturing the treatment effect on the primary outcome) for some subgroups than for others.11 Parast et al. (2021)12 offers a nonparametric estimation procedure and formal test for heterogeneity of surrogate utility with respect to a baseline covariate. When such heterogeneity exists, existing methods that use the surrogate to test for a treatment effect while ignoring this heterogeneity may lead to inaccurate conclusions about the treatment effect, particularly when the patient population in the current study has a different mix of characteristics than the prior study (used to evaluate the utility of the surrogate marker).
For example, in the simulation study in this paper, we examine a setting where the estimated treatment effect based on the primary outcome is 33.7 (standard error [SE] = 1.6); applying the testing approach of Parast et al. (2019)7 which uses surrogate marker information but does not account for heterogeneity, the estimated treatment effect on the primary outcome is 39.2 (SE=3.5). The approach of Parast et al. (2019)7 guarantees that the treatment effect based on the surrogate will be a lower bound for the true treatment effect on the primary outcome under certain conditions. However, these conditions may be violated when there is heterogeneity in the utility of the surrogate and thus leads to this type of situation where the estimated treatment effect using the surrogate is much higher than that using the primary outcome. Our approach that we propose in this paper which incorporates heterogeneity produces a treatment effect estimate that retains the lower bound property, with similar power to the treatment effect using the primary outcome. While we focus on heterogeneity with respect to a continuous baseline covariate, we provide a motivational example in Appendix A where there is heterogeneity with respect to a discrete covariate, gender. In this example, the surrogate marker is strong among males (explaining 99% of the treatment effect on the primary outcome) but weaker among females (explaining 67%). In a new study where the distribution of gender is 95% female and 5% male and the treatment effect on the primary outcome is 38.95, using the surrogate marker and accounting for heterogeneity in surrogacy produces an estimated treatment effect on the primary outcome equal to 17.95 while ignoring heterogeneity produces an estimate of 44.5, again, failing to correctly provide a lower bound on the true treatment effect. In contrast, if we consider a future study where the distribution of gender is 5% female and 95% male, the treatment effect on the primary outcome is 74.05, while the treatment effect using the surrogate and accounting for heterogeneity is 71.05 versus not accounting for heterogeneity is 44.5, indicating a potential loss in power to detect a treatment effect when heterogeneity is ignored.
In this paper, we develop a novel test for a treatment effect using surrogate marker information that accounts for heterogeneity in the utility of the surrogate. We compare our testing procedure to a test that uses primary outcome information only (gold standard) and a test that uses surrogate marker information, but ignores heterogeneity. We demonstrate the validity of our testing procedure and derive the asymptotic properties of our estimator and variance estimates. A simulation study is used to examine the finite sample properties of our testing procedure and demonstrate when our proposed approach can outperform the testing approach that ignores heterogeneity. In particular, we demonstrate examples where the test of Parast et al. (2019)7 provides an incorrect estimate with respect to the treatment effect. We illustrate our approach using data from an AIDS clinical trial to test for a treatment effect using CD4 count as a surrogate marker for plasma HIV-1 RNA.
2 |. TESTING PROCEDURE
2.1 |. Notation and Setting
We focus on a setting where we are currently conducting a study to examine the effect of a treatment on a primary outcome of interest, denoted by , and we additionally have data available from a prior study. We assume that this prior study was used to examine the strength of the surrogate, denoted by , and heterogeneity in the utility of the surrogate, and has measurements of both and of the current study. Let denote the treatment indicators where treatment is randomized and (i.e., treatment vs. control), and denote a baseline covariate such that has been shown to have heterogeneous utility with respect to this covariate. Without loss of generality, we take to be continuous; all proposed procedures can easily accommodate a discrete as well. We focus on a setting with heterogeneity with respect to a single baseline covariate ; in Section 3.3, we discuss an extension to multiple . In addition, we assume we are in a setting where either is measured earlier than or is measured at the same time as but is less expensive, invasive or burdensome, and there is no censoring or missing data. Throughout this paper, we quantify surrogate strength/utility using the quantity: the proportion of treatment effect on the primary outcome explained by the treatment effect on the surrogate marker.13,3,5 We use potential outcomes notation where each person has a potential where is the outcome when and is the surrogate when . Observed data from the current study is denoted as and consists of , where denotes the number of individuals in treatment group g.
The goal in the current study is to test for a treatment effect on the primary outcome quantified as
Our aim is to leverage information from the prior study to test using surrogate marker information in order to reduce study follow-up time, costs, and/or participant burden, i.e., making inference on without using . We use a superscript p to denote “prior” when referring to data or quantities from the prior study. For example, we denote observed data from the prior study by , where is the sample size of treatment group .
2.2 |. Assumptions
Given that our setting rests on the existence of a valid surrogate marker, we first define to be a valid surrogate marker for if the following conditions hold:
(C1) is a monotone function of ;
(C2) for all and ;
(C3) for all and .
(C4) A large proportion of the treatment effect on the primary outcome can be explained by the treatment effect on the surrogate marker for all .
Assumptions (C1)-(C3) are parallel to those required in Wang and Taylor (2002)3 and Parast et al. (2017)14 and protect against the surrogate paradox situation.15 Assumption (C1) implies that the surrogate marker is either “positively” or “negatively” related to the time of the primary outcome, (C2) implies that there is a positive treatment effect on the surrogate marker, and (C3) implies that there is a non-negative residual treatment effect beyond that on the surrogate marker. Assumptions (C1-C3) together guarantee that , for all in the support of (see Appendix B). Lastly, (C4) states that the proportion of the treatment effect explained by the surrogate marker must be large and guarantees the strength of the surrogate marker of interest for all individuals in the study. While this is somewhat vague, there is no agreed upon value that signifies a “large” proportion, though previous work has tended to view values of 0.6-0.75 or higher as large.16,13,17 If the existing heterogeneity is such that the surrogate is strong for some and weak for other , it should not be used as a replacement of the primary outcome for all individuals in a future study. Instead, one may consider using the surrogate as a replacement only among those with a where the surrogate is strong; we discuss this further in the Discussion.
In order to ensure that the proposed test statistic to be described in Section 2.3, has a reasonable interpretation with respect to , we also require:
(C5) for all and ;
(C6) is estimable for any , where is the common compact support for both in .
Assumption (C5) implies that in the control groups, the current study and the prior study share the same conditional expectation for given and . This assumption is reasonable when, for example, the control condition in both studies are the same, such as “usual care.” Importantly, such an assumption is not required to hold for the treatment groups and it relaxes the requirement that the distribution of conditional on be transportable from the prior to current study. Even so, this assumption is admittedly very strong and needs to be carefully considered before using this approach; however, any testing procedure that attempts to borrow information from a prior study to test a hypothesis in a future study is going to require some type of strong transportability assumption. If there is reason to believe that such transportability between studies is not appropriate, then the prior study should not be considered for informing the future study. Assumption (C6) ensures that we can approximate for all observed pairs of and in the current study. We discuss robustness to these assumptions as well as additional assumptions needed for a causal interpretation in Appendix B.
2.3 |. Proposed Testing Procedure
Recall that our aim is to take advantage of information from the prior study to test using surrogate marker information such that this test accounts for known heterogeneity in the utility of the surrogate marker. To achieve this goal we note that can be expressed as:
| (1) |
where is the conditional cumulative distribution function of given , and is the cumulative distribution of . In expressing as (1), we have simply used a conditional expectation to incorporate and into our expression. By expressing in this way, this motivates the following earlier treatment effect definition:
| (2) |
| (3) |
where is the cumulative distribution function of in the current study. The only change in going from (1) to (2), is that we have replaced with in the first term which will ensure that this quantity provides a lower bound on the treatment effect. In the second equality, (3), we replace with which follows from Assumption (C5). The expression (3) is now a quantity that only involves which is the conditional risk in the prior study, and the distribution of and in the current study. Importantly, the expression does not involve from the current study at all. In practice, is unknown and must be replaced with an estimate, , which we describe in Section 3.1. Because of this, we define the following earlier average treatment effect quantity, where the ~ notation makes the dependence on information from the prior study explicit:
This quantity, , measures the treatment effect on a transformation of the surrogate marker and baseline covariate, i.e., the difference between and . First, due to randomization, has the same distribution between two treatment groups and has an appealing causal interpretation reflecting the treatment effect on the surrogate marker. Second, represents the part of the treatment effect on the primary outcome explained by the surrogate marker and an approximation to , which is the quantity of our primary interest. Under the null hypothesis of no average treatment effect on the primary outcome, there will also be no average treatment effect in any subgroup of patients with (see Appendix B). Under the null, Assumptions (C1)-(C3) imply that has the same distribution as for all in the support of , and thus, . Therefore, we may formally define our test statistic for based on the early average treatment effect as , where is a root-n consistent estimate of and is the estimated variance of . We reject when is large. In Section 3, we propose robust procedures to construct and . Obviously, this is a valid test for both the null and the null .
One important merit of constructing the test statistic based on an estimator of is that this earlier average treatment effect is smaller than if we used the true conditional expectations within each treatment group in probability. That is, and thus, is a conservative measure of the average treatment effect, . Importantly, this early treatment effect and associated test account for heterogeneity in the utility of the surrogate by explicitly utilizing a condition mean function that depends on . In the following section we describe other tests that may be considered; in our numerical studies, we compare our approach with these alternatives.
2.4 |. Alternative Testing Approaches
We consider two alternative tests that would be reasonable options for testing in this setting. The first quite obvious approach is simply to assume the primary outcome is measured in the current study and use primary outcome information to estimate and conduct a t-test of . This reflects the gold standard as it directly tests the hypothesis we are interested in. Importantly though, the whole point of this setting is to provide a way to not have to measure the primary outcome. We include this option so that we can compare to this gold standard.
The second alternative test we examine is one which uses information from the prior study about the relationship between the surrogate and the primary outcome, but does not account for heterogeneity. This test is an extension of a test proposed in Parast et al. (2019)7 which was developed for the time-to-event outcome setting. Our description of it here, for a non-survival setting, is new and will be useful in practice for those analyzing a non-survival study in a setting with no heterogeneity in the utility of the surrogate. Similar to our proposed test, but without regard for W, we note that where which motivates the following earlier treatment effect definition:
where . Since is unknown, we approximate with
where is a consistent estimator of . As with the proposed test, this early treatment effect quantity replaces with for both treatment groups and will ensure it is a lower bound on the under certain conditions. This test, however, requires the assumption that i.e., that this conditional expectation in the control group is the same in the current study as the prior study. It is important to note that this assumption may not hold when there is heterogeneity in the utility of the surrogate marker. To test , we instead test and define the test statistic for based on the early treatment effect as , where is a root-n consistent estimate of and is the estimated variance of . We reject and when is large.
In Appendix C, we discuss estimation and testing for using the primary outcome, propose estimation procedures to obtain and , and discuss why we do not consider directly testing the surrogate. Intuitively, we would expect that both our proposed test and this test based on should work well when there is no heterogeneity. When there is heterogeneity, we expect that the test based on (or even ) could lead to erroneous conclusions about the treatment effect and/or have less power than the proposed test.
3 |. ESTIMATION AND INFERENCE
3.1 |. Estimation of Proposed
For our proposed testing procedure, we first define
as nonparametric smoothed estimators of the conditional expectation of given in the prior study, and the conditional expectation of given and a bivariate function in the current study, respectively. Here, is a smooth symmetric density function with finite support, are specified bandwidths which may be data dependent, and denotes the sample size of group in the prior study. We utilize undersmoothing and select all bandwidths throughout to be of order , to eliminate the asymptotic bias, where in an effort to avoid a need for bias correction in subsequent statistical inference.
A very straightforward estimate of would be
| (4) |
which simply takes our estimated conditional mean function from the prior study and applies it to data in the current study. However, it is possible for us to improve upon this estimator in terms of efficiency. To do this, we note that
and thus we now consider an estimate of as
| (5) |
which is asymptotically equivalent to (4). Note that this estimate only uses and data from the current study (no data from the current study) and , which in turns depends on data in group from the previous study.
While either (4) or (5) would be consistent estimates of , we utilize the fact that the distributions of from the two treatment arms are identical due to randomization and construct the estimator:
| (6) |
We show in Appendix D that (6) improves upon the efficiency of (5). Essentially, is equivalent to an augmented version of the simple estimator (described below), taking advantage of the independence of W and treatment, since treatment was randomized.
In Appendix D we show that conditional on , is a consistent estimate of , and that weakly converges to a mean zero normal distribution as . A consistent estimate of the conditional variance of given the prior study, , can be obtained as
where and . Our testing procedure uses the test statistic and rejects the null hypothesis when . As and can be viewed as a consistent estimator of . More importantly, under Assumptions (C1), (C2), (C3) and (C5), as , indicating that the test for is a valid test for with probability approaching 1 as the sample size of the prior study increases to infinity.
Remark. The efficiency of the simple estimator
can be improved by considering the fact that for any transformation due to randomization. Specifically, one may consider a new class of consistent estimators indexed by ,
The optimal choice of minimizing the asymptotic variance is
In practice, can be consistently estimated by . Denote the resulting estimator of
In Appendix D we show that conditional on is a consistent estimate of and that weakly converges to a mean zero normal distribution as . The conditional variance of , can be consistently estimated by
In Appendix D, we show that is asymptotically equivalent to our proposed and .
3.2 |. Inference
To construct a confidence interval for we use our estimated variance and define a confidence interval as . We examine the empirical performance of our proposed estimation procedure, variance estimation, confidence interval construction, and testing procedure in Section 4.
It is important to note that we consider the prior study, the study from which we estimate the conditional mean function, , as fixed. This is a reasonable assumption given that in practice, there is truly some previously conducted prior study which one is using to inform testing in the current study. However, one could argue that this prior study should be considered random and that all inference should be derived as such. In such a case, the estimation of our point estimate would remain the same but the standard estimation and confidence interval construction would be more complex.
3.3 |. Multiple Baseline Covariates
While in this paper we focus only on heterogeneity with respect to a single baseline covariate, it may be the case that there is heterogeneity with respect to multiple baseline covariates. In such a case, one still can consider a straightforward estimator for the treatment effect using surrogate marker and baseline covariates:
where is an estimator of and is a baseline covariate vector of interest (including an intercept term, with a slight abuse of notation). The difficulty is that fully nonparametric estimation of will likely be infeasible for practical sample sizes with a vector of moderate dimension, e.g., ≥3. In such a case, one may be willing to consider a parametric or semi-parametric model. For example, an estimator can be obtained based on a simple regression model , where is a known, strictly increasing link function and and are unknown regression coefficients to be estimated based on the prior study. Alternatively, one could consider a more flexible varying coefficient model for such as , where , and is the unknown smooth function of to be estimated nonparametrically. This modeling approach would allow complex interactions between and . Here, we use the additional subscript in to emphasize the fact that this estimator of will now be fully or partially dependent on model assumptions, i.e., model-based. Certainly, given this model dependence, robustness (or lack thereof) to model misspecification would need to be carefully considered when using this approach in practice.
4 |. SIMULATION STUDY
4.1 |. Simulation Goals and Setup
The two main goals of our simulation study were: 1) to examine the finite sample properties of our estimation procedure for in terms of bias, accuracy of our variance calculation, and coverage of constructed confidence intervals, and 2) to compare testing results based on the three different testing quantities: (using the primary outcome, gold standard) vs. (using the surrogate marker, ignoring heterogeneity) vs. (using the surrogate marker, accounting for heterogeneity). For the testing results, we focus on the point estimates themselves, the resulting effect sizes (point estimate/standard error estimate), and power. Importantly, when there is heterogeneity, we do not necessarily aim to demonstrate improved power with our proposed approach but rather, to demonstrate settings where the testing procedure using (using the surrogate marker, ignoring heterogeneity) can be incorrect.
To achieve these goals, we examined eight simulation settings. For all settings, results were summarized over 500 replications; we examined all settings with (sample sizes in prior study) and (sample sizes in current study). All simulation settings were also repeated with (sample sizes in prior study) and ; results were similar and are not shown here. In setting 1, we generated data such that there was heterogeneity in the utility of the surrogate with respect to a baseline covariate and the distribution of this baseline covariate was different in the current study compared to the prior study. Specifically, in the prior study, which is fixed in all simulations, , , and . We then generate the outcomes from:
where throughout indicates a normal distribution with mean and variance . The motivation behind this setup was (a) to generate a surrogate marker where higher values are desirable and the surrogate level tends to be higher in the treated group, and (b) to generate an outcome where the surrogate marker is positively associated with the outcome but this association is stronger in magnitude in the treated group, reflecting residual treatment effect beyond the surrogate marker. In addition, to induce heterogeneity, we generate data such that the treatment effect on the primary outcome and the association between primary outcome and surrogate marker depend on whether the covariate is less than or greater than 5. With this setup, there was a statistically significant heterogeneity in surrogacy based on the test for heterogeneity proposed by Parast et al. (2021); the estimated proportion of treatment effect explained by the surrogate marker was 0.52 for and 0.95 for . In this setting, the in the current study was generated the same as in the prior study, but and were generated from a , which is different from the prior study. Note that for all patients in the current study, the surrogate strength is not very strong and thus, we would expect that using the surrogate but ignoring heterogeneity will lead to an overestimation of the treatment effect. While the variability of the primary outcome, , is large in both treatment groups, the size of the treatment effect is large as well. For example, in this setting, our results will show that the average estimated treatment effect on the outcome in the current study is 14.10, and the empirical power of testing the treatment effect is 100% using the primary outcome only.
In setting 2, and in the prior study were generated exactly the same as in setting 1, but and . The motivation behind this change in the distributions for the surrogate marker is that we aimed to make the treatment effect on both the primary outcome and surrogate marker smaller than in setting 1, in order to explore how the various tests performed when less power would be expected. As in setting 1, there was significant heterogeneity in surrogacy with the estimated proportion of treatment effect explained by the surrogate being 0.39 for and 0.90 for . The current study was generated the same as the prior study except that and were generated from a distribution. In contrast to setting 1, for all patients in the current study, the surrogate is strong and thus, we would expect that using the surrogate but ignoring heterogeneity will lead to an underestimation of the treatment effect. With respect to the size of the treatment effect and empirical power in this setting, our results will show that the average treatment effect on the outcome in the current study is 13.34 , and the empirical power of testing the treatment effect is 69% using the primary outcome only.
In setting 3, in the prior study were generated as in setting 2, but and . The motivation behind this change in the distributions for was to explicitly make the surrogate useless among those with i.e., a more extreme version of setting 2. As expected, there was significant surrogacy heterogeneity with the treatment effect on the surrogate marker not explaining any of the treatment effect on the primary outcome among patients with , and explaining the majority of the treatment effect on the primary outcome among patients with (proportion explained ). Similar to setting 2, the current study was generated the same as the prior study except that and were generated from a distribution and thus, we expect a potentially larger gain in power using our proposed approach (though again, this is not our primary goal). With respect to the size of the treatment effect and empirical power in this setting, our results will show that the average treatment effect on the primary outcome in the current study is 13.34 , and the empirical power of testing the treatment effect is 69% using the primary outcome only, parallel to setting 2.
In setting 4, the prior study was generated exactly the same as in setting 1, and the current study was generated exactly the same as the prior study, i.e., and were generated from a distribution. Here, even though there is heterogeneity as described above for setting 1, since the covariate distribution is the same in prior and current studies, we expect the tests ignoring vs. accounting for heterogeneity to produce similar results. With respect to the size of the treatment effect and empirical power in this setting, our results will show that the average treatment effect on the primary outcome in the current study is 19.12 , and the empirical power of testing the treatment effect is 96% using the primary outcome only.
In setting 5, data were generated such that there is no heterogeneity. Specifically, in the prior study, , , , and , independent of the baseline covariate. The proportion of the treatment effect explained by the surrogate in the prior study was 0.47, which is homogeneous in the study population. Data from the current study was distributed the same as for the prior study. The purpose of this setting was to examine how the tests perform when there is no heterogeneity and no difference in distribution from the prior study to the current study. With respect to the size of the treatment effect and empirical power in this setting, our results will show that the average treatment effect on the outcome in the current study is 13.90 , and the empirical power of testing the treatment effect is 100% using the primary outcome only.
In setting 6, data are generated similar to setting 1 but with lower variability in the primary outcome resulting in a much larger effect size. In the prior study, , . For and , and , respectively. For and and , respectively. There was a substantial heterogeneity in the utility of the surrogate with the proportion of treatment effect explained by the surrogate being 0.67 for and 0.98 for . In the current study, the and were generated the same as in the prior study, but and were generated from a distribution. As in setting 1, since the surrogate strength is not very strong in the current study, we would expect that using the surrogate but ignoring heterogeneity will lead to an overestimation of the treatment effect. With respect to the size of the treatment effect and empirical power in this setting, our results will show that the average treatment effect on the outcome in the current study is 33.70 , and the empirical power of testing the treatment effect is 100% using the primary outcome only.
Settings 7 and 8 reflect a null treatment effect setting and we include them so that we may examine the empirical Type 1 error rate. In both settings, data from the prior study are generated as , and for . That is, there is neither treatment effect on the surrogate marker nor the treatment effect on the primary outcome, and and are positively associated. In setting 7, data in the current study are generated exactly as the prior study. In setting 8, data in the current study are generated such that are generated the same as the prior study, but , i.e., the distribution of the baseline covariate is different in the current study. The purpose of setting 8 is to specifically examine estimation and testing when there is no treatment effect and no heterogeneity, but the current study does have a different patient population compared to the prior study. In both settings, the true treatment effect on the primary outcome is 0 and the empirical Type 1 error of the test using the primary outcome is 0.06. In both settings, there is no empirical evidence that is an “informative” surrogate marker, and no empirical evidence of heterogeneity in surrogacy, as expected.
With respect to our bandwidth selection, we let and where and were the empirical standard deviation and inter-quartile range of , and and where and were the empirical standard deviation and inter-quartile range of , respectively, and and were the empirical standard deviation and inter-quartile range of , and .18,7
4.2 |. Simulation Results
Table 1 shows estimation results for for all settings, using our proposed estimating procedure. We examine bias in coverage with respect to both (fixed prior study) and . These results demonstrate good performance with minimal bias, average standard error estimates that are close to the empirical standard error, and coverage of the confidence intervals close to the nominal value of 95%.
TABLE 1.
Estimation results from the simulation study using the proposed procedure to estimate ; note that settings 7 and 8 are null settings with no treatment effect; bias and coverage are examined with respect to (prior study fixed) and ; bias with respect to , quantified as except for settings 7 and 8 where it is quantified without dividing by ; Bias = bias with respect to , quantified as except for settings 7 and 8 where it is quantified without dividing by the truth; ESE = empirical standard error, ASE = average standard error (average of the square root of the closed form variance estimate), coverage of 95% confidence intervals with respect to Cov = coverage of 95% confidence intervals with respect to
| Estimate | Bias | ESE | ASE | Cov | |||
|---|---|---|---|---|---|---|---|
|
| |||||||
| Setting 1 | 6.32 | 0.07 | 0.05 | 1.82 | 1.79 | 0.96 | 0.96 |
| Setting 2 | 12.53 | 0.05 | 0.07 | 5.39 | 5.22 | 0.94 | 0.94 |
| Setting 3 | 12.52 | 0.05 | 0.07 | 5.39 | 5.22 | 0.94 | 0.94 |
| Setting 4 | 14.72 | 0 | 0.05 | 4.12 | 4.13 | 0.96 | 0.95 |
| Setting 5 | 5.75 | 0.03 | 0.04 | 1.38 | 1.4 | 0.95 | 0.95 |
| Setting 6 | 12.97 | 0.01 | 0.02 | 1.05 | 1.27 | 0.98 | 0.98 |
| Setting 7 | −0.03 | 0.03 | 0.16 | 1.31 | 1.25 | 0.94 | 0.94 |
| Setting 8 | −0.03 | 0.03 | 0.16 | 1.31 | 1.26 | 0.94 | 0.94 |
Table 2 shows results from testing using , and . In setting 1 where there is heterogeneity and the distribution of in the current study is different from the prior study, results show that overestimates the treatment effect and thus, does not retain the lower boundedness property. In contrast, our approach using does not overestimate the treatment effect. The power using is smaller than that using , but this is expected since the data generation in this setting is such that the population in the current study is composed largely of individuals where the surrogate marker is not very strong. In setting 2 where there is again heterogeneity and the distribution of in the current study is different from the prior study, results show that both and are less than , but is much closer to and has power equivalent to that using . This, again, is what was expected since the data generation in this setting is such that the population in the current study is composed largely of individuals where the surrogate marker is strong. In setting 3, which is similar to setting 2 but we have made the data more extreme with the surrogate being useless for those with , results show a larger departure in from , and a larger decrease in power for compared to . In setting 4 where there is heterogeneity but the distribution of in both the prior study and the current study is the same, we see similar point estimates for and but a slightly higher standard error and lower power for . This indicates that in some settings, we may pay a price in terms of power and efficiency when we use the approach that accounts for heterogeneity when it is not necessary. In setting 5, where there is no heterogeneity, we see similar performance for and . In setting 6, where we have a very large treatment effect on the primary outcome, there is heterogeneity and the distribution of in the current study is different from the prior study, results show that, as expected, overestimates the treatment effect and does not retain the lower boundedness property, as in setting 1. In settings 7 and 8, where there is no treatment effect, results show that all three testing procedures perform well with an estimated treatment effect close to zero and Type 1 error rate close to 0.05. We additionally examined the efficiency gain comparing our proposed estimator to the simple estimator in (4); indeed, we did observe efficiency gains using our proposed estimator, quantified by the ratio of the estimated standard error using our proposed estimate to that using the simple estimate, that ranged from 0.79-0.98 across settings.
TABLE 2.
Testing results from the simulation study comparing testing results based on the three different testing quantities: (using the primary outcome, gold standard) vs. (using the surrogate marker, ignoring heterogeneity) vs. (using the surrogate marker, accounting for heterogeneity); ESE = empirical standard error, ASE = average standard error (average of the square root of the closed form variance estimate), Effect size = estimate divided by the estimated standard error (i.e., square root of the closed form variance estimate), Power/Type 1 error = proportion of replications for which the test rejects the null i.e., p-value of the test is
| Setting 1 | |||||
|---|---|---|---|---|---|
|
| |||||
| Estimate | ESE | ASE | Effect size | Power | |
|
| |||||
| Δ | 14.10 | 1.64 | 1.65 | 8.55 | 1.00 |
| 14.53 | 3.61 | 3.65 | 3.99 | 0.98 | |
| 6.32 | 1.82 | 1.79 | 3.62 | 0.95 | |
|
| |||||
| Setting 2 | |||||
|
| |||||
| Estimate | ESE | ASE | Effect size | Power | |
|
| |||||
| Δ | 13.34 | 5.54 | 5.42 | 2.47 | 0.69 |
| 7.64 | 3.38 | 3.31 | 2.31 | 0.64 | |
| 12.53 | 5.39 | 5.22 | 2.39 | 0.67 | |
|
| |||||
| Setting 3 | |||||
|
| |||||
| Estimate | ESE | ASE | Effect size | Power | |
|
| |||||
| Δ | 13.34 | 5.54 | 5.42 | 2.47 | 0.69 |
| 6.00 | 2.81 | 2.76 | 2.18 | 0.58 | |
| 12.52 | 5.39 | 5.22 | 2.39 | 0.67 | |
|
| |||||
| Setting 4 | |||||
|
| |||||
| Estimate | ESE | ASE | Effect size | Power | |
|
| |||||
| Δ | 19.12 | 5.17 | 5.20 | 3.68 | 0.96 |
| 14.64 | 3.66 | 3.66 | 4.01 | 0.98 | |
| 14.72 | 4.12 | 4.13 | 3.56 | 0.95 | |
|
| |||||
| Setting 5 | |||||
|
| |||||
| Estimate | ESE | ASE | Effect size | Power | |
|
| |||||
| Δ | 13.90 | 1.64 | 1.65 | 8.43 | 1.00 |
| 5.77 | 1.38 | 1.38 | 4.18 | 0.99 | |
| 5.75 | 1.38 | 1.40 | 4.09 | 0.99 | |
|
| |||||
| Setting 6 | |||||
|
| |||||
| Estimate | ESE | ASE | Effect size | Power | |
|
| |||||
| Δ | 33.70 | 1.61 | 1.60 | 21.08 | 1.00 |
| 39.12 | 3.51 | 3.50 | 11.18 | 1.00 | |
| 12.97 | 1.05 | 1.27 | 10.23 | 1.00 | |
|
| |||||
| Setting 7 | |||||
|
| |||||
| Estimate | ESE | ASE | Effect size | Type 1 error | |
|
| |||||
| Δ | −0.05 | 1.39 | 1.35 | −0.04 | 0.06 |
| −0.03 | 1.31 | 1.27 | −0.02 | 0.06 | |
| −0.03 | 1.31 | 1.25 | −0.02 | 0.06 | |
|
| |||||
| Setting 8 | |||||
|
| |||||
| Estimate | ESE | ASE | Effect size | Type 1 error | |
|
| |||||
| Δ | −0.05 | 1.37 | 1.33 | −0.04 | 0.06 |
| −0.03 | 1.31 | 1.27 | −0.02 | 0.06 | |
| −0.03 | 1.31 | 1.26 | −0.02 | 0.06 | |
In summary, results from this simulation study show 1) good finite sample performance of our estimation and inference procedures for ) a potential slight loss in power when using the proposed compared to when accounting for heterogeneity is not needed, and 3) a potential for inaccurate conclusions and/or loss in power when is used instead of the proposed when accounting for heterogeneity is needed.
5 |. APPLICATION
We apply our proposed approach to test for a treatment effect based on a heterogeneous surrogate using data from two distinct AIDS clinical trials, the AIDS Clinical Trials Group (ACTG) 320 Study and the ACTG 193A Study.19,20 These data are publicly available upon request from the AIDS Clinical Trial Group21. We consider the ACTG 320 Study as our prior study and the ACTG 193A Study as our current study. The ACTG 320 study was conducted among HIV-infected patients with a CD4 cell count of 200 or less per cubic millimeter and was a randomized, double-blind trial that compared a two-drug regimen (two nucleoside reverse transcriptase inhibitors [NRTI]) with a three-drug regimen (two NRTIs plus indinavir). There were a total of 830 participants, with 412 in the two-drug regimen group and 418 in the three-drug regimen group. The ACTG 193A study was a randomized, double-blind trial conducted among HIV-infected patients with a CD4 cell count of 50 or less per cubic millimeter. We focus on the comparison of a two-drug regimen (NRTIs) with a three-drug regimen (two NRTIs plus nevirapine). There were a total of 657 participants, with 327 in the two-drug regimen group and 330 in the three-drug regimen group. Our primary outcome is the change in plasma HIV-1 RNA from baseline to 24 weeks; our surrogate marker is change in CD4 cell count from baseline to 24 weeks, as CD4 is relatively less expensive to measure compared to RNA.22 Both and are available in ACTG 320 while only is available in the publicly available data of ACTG 193A. Previous work has demonstrated significant heterogeneity in the utility of with respect to , baseline CD4 count, with the surrogate strength being stronger among those with a lower baseline CD4 count and weaker among those with a higher baseline CD4 count12 as shown in Figure 1. We aim to use our proposed method to test for a treatment effect on RNA using CD4 count as a surrogate marker, accounting for the known heterogeneity in the utility of the surrogate which was demonstrated in the prior study.
FIGURE 1.
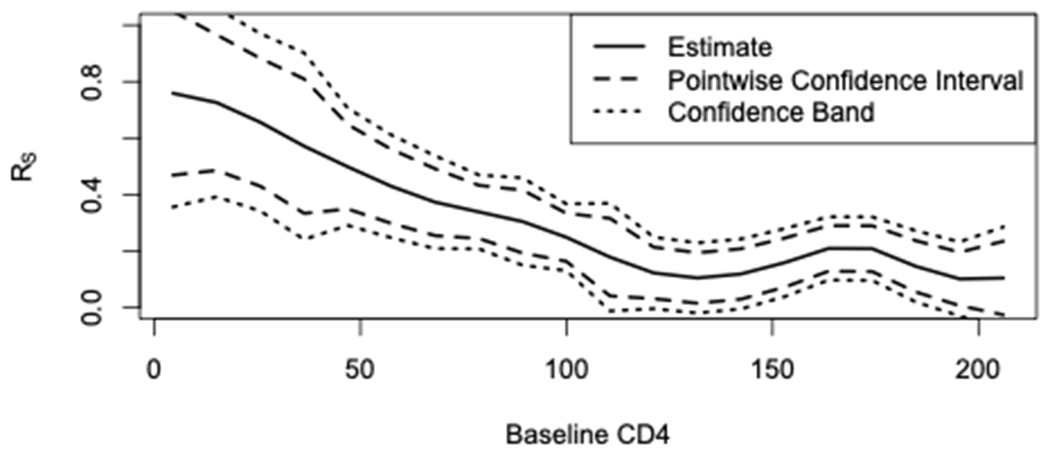
Estimated proportion of the treatment effect on the primary outcome (change in RNA) explained by the treatment effect on the surrogate marker (change in CD4), denoted as RS, as a function of baseline CD4
In Figure 2 we show the distribution of the baseline covariate, baseline CD4, in the prior study compared to the current study. Clearly, the current study is composed of a different participant population with lower CD4 counts due to the study eligibility criteria. In Figure 1, we also see that the surrogate is strongest in this subgroup. Using our proposed approach, we obtain a treatment effect estimate of (standard error ) with a p-value . Note that since lower plasma HIV-1 RNA is better, a negative change in RNA indicates a beneficial treatment effect for the three-drug regimen. Using the approach that does not account for heterogeneity, we obtain a treatment effect estimate closer to the null, but still significant: . That is, while the overall conclusion regarding the treatment effect based on the surrogate would be significant using either test, our proposed test provides a treatment effect point estimate that is larger in magnitude. This is expected since the surrogate strength is greater in this subgroup that makes up the current study, and our proposed approach takes advantage of that information.
FIGURE 2.
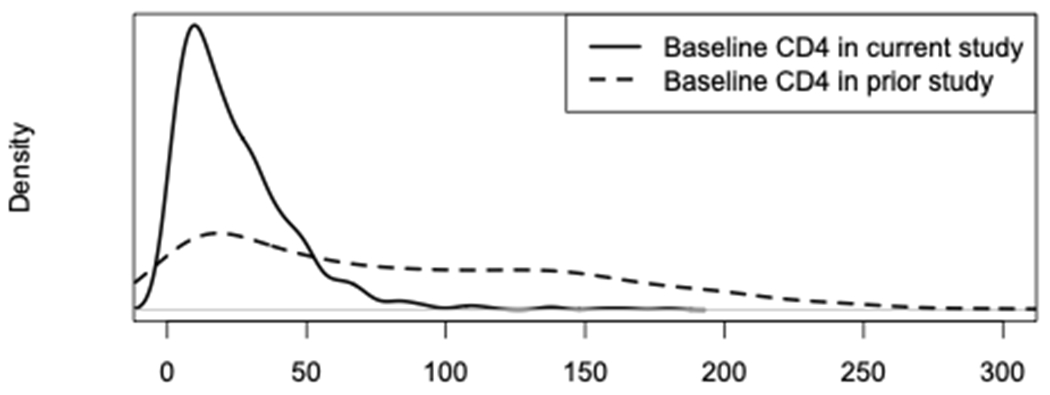
Distribution of baseline CD4 in current study vs. prior study
6 |. DISCUSSION
For settings where it is known that the strength of a surrogate marker varies by a certain baseline characteristic, we have proposed an approach and estimation procedures to appropriately test for a treatment effect using only the surrogate marker, accounting for this known heterogeneity. We demonstrated good finite sample performance of our estimation procedure and showed that our proposed testing procedure can outperform an approach that does not account for heterogeneity. An R package implementing the methods proposed here, named hettest, is available at https://github.com/laylaparast/hettest.
While we largely focus, specifically in the numerical studies, on settings where the distribution of is different in the current study as compared to the prior study, it is still possible for a test based on , i.e., ignoring heterogeneity, to provide inaccurate results about the treatment effect when there is heterogeneity in the utility of the surrogate and the is distributed the same in the two studies; we provide an example in Appendix E.
In the presence of heterogeneity, both the treatment effect and the utility of the surrogate marker may depend on . While we focus exclusively on the average treatment effect in this paper, it may be of interest to test for a treatment effect based on alternative summaries that account for such heterogeneity. For example, one may define and the subgroup specific earlier treatment effect . Then we may test for a treatment effect based on by examining a functional of such as or , the area under the curve produced by . Such alternative summaries of the treatment effect across a baseline covariate, , are not unique to the surrogate marker setting as they have been extensively discussed in the general heterogeneous treatment effect literature.23,24 However, these alternative summaries may also prove useful in the heterogeneous surrogate setting and may offer new insights over simply looking at the average treatment effect.
Importantly, we require Assumptions (C1) – (C4) and in practice, they may be violated. Specifically, if the existing heterogeneity is such that the surrogate is not strong or, worse, the treatment effect on the surrogate marker and primary endpoint may be in different directions for some , the surrogate should not be used as a replacement of the primary outcome for all individuals in a future study. Instead, one may consider using the surrogate as a replacement only among those with a where assumptions (C1) – (C4) hold. To achieve this, one could consider first identifying a region of interest where the surrogacy is sufficiently strong e.g., such that the conditional average treatment effect on the primary endpoint and the proportion explained by the surrogate for , is between 0.50 and 1.0, and then apply the proposed testing procedure that replaces with for testing the average treatment effect in the subpopulation . If one is interested in studying the average treatment effect in the entire study population, one may combine the proposed test statistic with a new but simple test statistic measuring the strength of the treatment effect based on actual primary endpoints for patients in the complement of . Such a hybrid approach has the potential to reduce costs if is less costly to measure than and/or reduce the follow-up time needed for those in if is measured earlier than . Though not exactly within this context, previous work has explored the potential for auxiliary information (including but not limited to surrogate markers) to improve efficiency when testing for a treatment or intervention effect.25,26 While this is beyond the scope of this paper, further work on this topic within the framework of a heterogeneous surrogate is warranted.
Our proposed approach has some limitations. First, if the current study includes participants with values outside the observed distribution in the prior study, our approach will not be able to obtain for that without extrapolation. In such a case, when there is observed heterogeneity in the prior study, use of the surrogate marker to test for a treatment effect in the current study should likely be limited to those with contained in the prior study. Second, given our use of kernel smoothing, we require a relatively large sample size. Robust nonparametric methods for surrogate markers are lacking in general for small sample size settings; future work in this area would be needed. Lastly, we require several assumptions, outlined in Section 2.2, which are generally untestable though they may be empirically explored using the observed data. These assumptions are needed for identifiability, to ensure our lower-boundedness property of (i.e., ), and to guard against the surrogate paradox which occurs when the surrogate and outcome are positively associated, the treatment has a positive effect on the surrogate, but the treatment in fact has a negative effect on the outcome.15 The surrogate paradox is especially of concern here as our primary goal is to make a conclusion about the treatment effect on the primary outcome based on information about the surrogate marker. While these assumptions are strong, they are more likely to hold than the parallel assumptions required for 7 to be valid due to the additional conditioning on . Further work on methods that allow for more relaxed assumptions and/or that allow one to assess sensitivity to violations of these assumptions would be useful.27
Supplementary Material
ACKNOWLEDGEMENTS
Support for this research was provided by National Institutes of Health grant R01DK11835. We are grateful to the AIDS Clinical Trial Group for providing the AIDS clinical trial data.
APPENDIX
APPENDIX A
Discrete Example
Let denote the primary outcome and denote the surrogate marker. We use potential outcomes notation where each person has a potential where and are the outcome and surrogate when the patient receives treatment . Our main quantity of interest is the treatment effect on the primary outcome quantified as . The earlier treatment effect incorporating information is defined in the main text as
| (1) |
where . In this example, we will have heterogeneity in the utility of the surrogate with respect to gender. Consider our prior study, which we refer to as Study A in this example, and is shown in Figure 1. The Study A sample is 50% female and 50% male. For all individuals, are independent of gender, and . For females, and . It can be shown that for females, and . The proportion of the treatment effect on the primary outcome that is explained by the surrogate among females is thus 15/37=41%, which would not be considered as a strong surrogacy. For males, and . It can be shown that for males, and the proportion explained by the surrogate marker is 97% among males, representing strong surrogacy.
To calculate for a future study, let’s consider the conditional mean that is central to this calculation, ) where the superscript indicates that this is referring to the prior study, i.e., study A. In this example, this would be . Now assume our current study is Study B shown in Figure 1 which is 95% female and 5% male. Importantly, the joint distributions of in males and females remain as described above; the only difference is the distribution of gender. The treatment effect, in this new study is 0.95×37+0.05×76=38.95. If one were to calculate not accounting for this known heterogeneity in the utility of the surrogate, the quantity obtained would be , recalling that and for all individuals in both studies. However, using our proposed approach which does account for heterogeneity, we use as the earlier treatment effect, defined in the main text as:
Thus, . Therefore and no longer retains the property of providing a lower bound on the treatment effect on .
Now we consider a study, labeled Study in Figure 1, which is 95% males and 5% females. Using similar calculations, we can show that and . Thus, in this case, will provide better lower bound for and the test based on is expected to be more powerful than that based on . The discrete case, as illustrated in this example, is relatively straightforward in terms of how to go about calculating the needed quantities separately by group and appropriately accounting for the different distribution in the new study. The continuous baseline covariate case, however, is more complex, and our Appendix C presents an example such that even if the prior and current studies have the same distribution for covariates, may still fail to be a valid lower bound for .
APPENDIX B
As noted in this text, Assumptions (C1) – (C3) together guarantee that , for all in the support of . This result is due to the derivation:
where . That is, while treatment effect heterogeneity is allowed, the directions of the conditional average treatment effect among subgroups of patients with need to be consistent. One important implication is that under the null , i.e., no average treatment effect, the conditional average treatment effect for all as well. Furthermore, from the derivation, it is clear that if and only if both
, i.e., and
.
Specifically, implies that there is no treatment effect on the distribution of the surrogate marker in the subgroup of patients with . In summary, under Assumptions (C1)-(C3)
This relationship allows us to test the common null via testing a seemingly more restrictive null that , for all in the support of .
For (C2) and (C3), if the primary outcome or surrogate are such that lower values are “better”, one can simply define the outcome/surrogate as where is the initial value.
Assumptions (C5) – (C6) are not required for the validity of the testing procedure proposed in the next section in that the p-value under the null follows a uniform distribution even without them, but it allows us to estimate a lower bound of the average treatment effect, , and construct the corresponding test statistic.
Under the following additional assumptions:
(C7) and ;
(C8) and ,
the treatment effect on the surrogate marker defined in Section 2.3 and on the primary outcome can be interpreted within a causal framework: the proposed test statistic is an estimate of the portion of the treatment effect on the primary outcome attributable to the treatment effect on the surrogate marker. Otherwise, the proposed treatment effect on the surrogate marker can always serve as a lower bound for the average treatment effect on and can be used in practice without assuming them.
To summarize, Assumptions (C1) – (C4) are needed for the validity of the proposed testing procedure, Assumptions (C5) – (C6) allow us to interpret the test statistic based on he surrogate marker and baseline covariate only as a “conservative” estimator (or a lower bound) of the average treatment effect on the primary outcome, and causal interpretation of the lower is possible under additional assumptions (C7) – (C8).
APPENDIX C
To estimate using the primary outcome (gold standard) we use and conduct a t-test to test .
To estimate , we use the nonparametric estimation approach of7 by estimating as
and then estimate as
Note that this estimate only uses data from the current study (no data from the current study) and data from the previous study in group only. To obtain an estimate for the standard error of , we simply take the empirical standard deviation of the transformed surrogate i.e., let , and then where indicates the empirical variance. This alternative testing procedure would then use the test statistic and reject the null hypothesis when .
Importantly, one may also consider simply using the surrogate markers measured in the current study and define and conduct a t-test of . The disadvantage of this approach is that there is no way to relate and i.e., the estimate of does not give any helpful information about the magnitude of . In addition, this approach does not take advantage of information from the previous study nor does it account for heterogeneity in the utility of the surrogate marker. For these reasons, we do not compare our approach to this test.
APPENDIX D
Our proposed estimator for is
Let . It is obvious that . Also, let .
In this section, we only consider the randomness in the current study, i.e., the probability measure is conditional on . Now consider the centered term
which is
where and is the nonparametric estimator for the density function of based on observations in treatment group 1. Now, consider the expansion
uniform in . Therefore,
Similarly,
and
| (2) |
| (3) |
Therefore, when , the right hand side of (3) becomes , and thus
Finally, we have
which converges weakly to a mean zero Gaussian distribution with a variance of
Therefore, the variance of can be estimated as
Next, we will derive the asymptotical distribution of . It is clear that
Therefore, and are asymptotically equivalent. Furthermore, noting that
and
we have
Similarly,
Therefore, the variance of can also be consistently estimated by
and .
APPENDIX E
Here, we provide an example where there is heterogeneity in the utility of the surrogate and the is distributed the same in the prior study and current study, but still fails to provide a lower bound for . In both the prior study and the current study, we assume that , and , where is a positive constant, and and are two independent standard normals. It is obvious that and
Next, we have
and
Consequently, in this setting, even though the has the same distribution in both studies.
FIGURE 1.
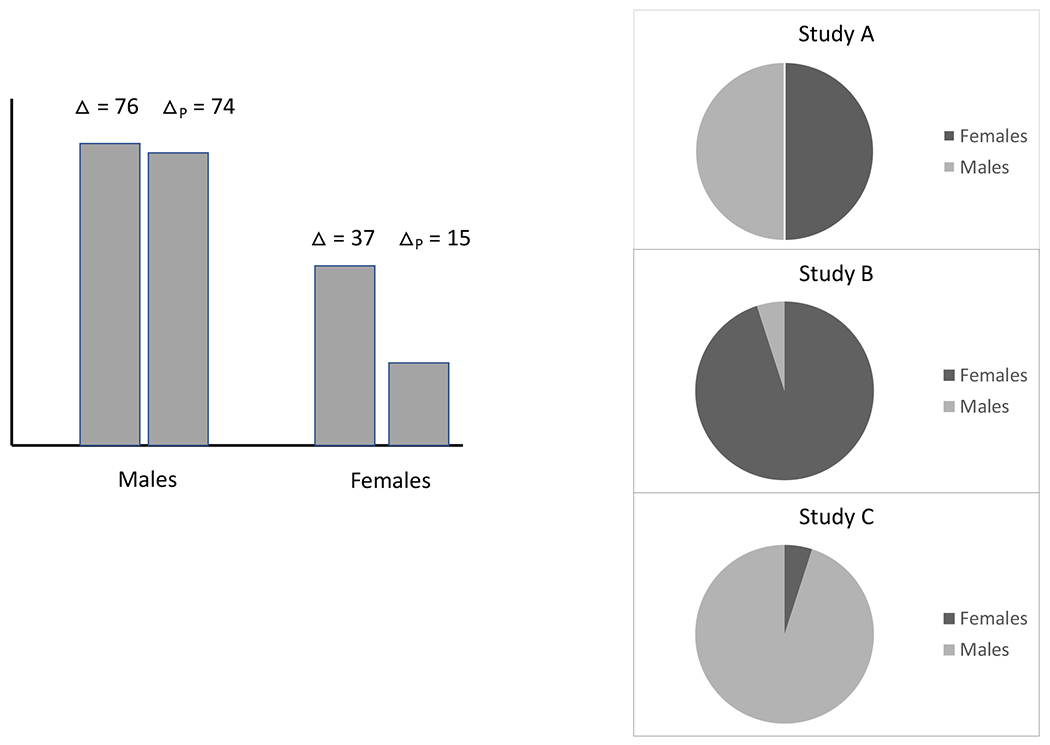
Discrete data example
References
- 1.Prentice RL. Surrogate endpoints in clinical trials: definition and operational criteria. Statistics in medicine 1989; 8(4): 431–440. [DOI] [PubMed] [Google Scholar]
- 2.Burzykowski T, Molenberghs G, Buyse M. The evaluation of surrogate endpoints. Springer; . 2005. [Google Scholar]
- 3.Wang Y, Taylor JM. A measure of the proportion of treatment effect explained by a surrogate marker. Biometrics 2002; 58(4): 803–812. [DOI] [PubMed] [Google Scholar]
- 4.Gilbert PB, Hudgens MG. Evaluating candidate principal surrogate endpoints. Biometrics 2008; 64(4): 1146–1154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Parast L, McDermott MM, Tian L. Robust estimation of the proportion of treatment effect explained by surrogate marker information. Statistics in Medicine 2016; 35(10): 1637–1653. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Avorn J, Kesselheim AS. Up is down—pharmaceutical industry caution vs. federal acceleration of Covid-19 vaccine approval. New England Journal of Medicine 2020; 383(18): 1706–1708. [DOI] [PubMed] [Google Scholar]
- 7.Parast L, Cai T, Tian L. Using a surrogate marker for early testing of a treatment effect. Biometrics 2019; 75(4): 1253–1263. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Chen X, Hartford A, Zhao J. A model-based approach for simulating adaptive clinical studies with surrogate endpoints used for interim decision-making. Contemporary clinical trials communications 2020; 18: 100562. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Price BL, Gilbert PB, Laan v dMJ. Estimation of the optimal surrogate based on a randomized trial. Biometrics 2018; 74(4): 1271–1281. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Athey S, Chetty R, Imbens GW, Kang H. The surrogate index: Combining short-term proxies to estimate long-term treatment effects more rapidly and precisely. tech. rep, National Bureau of Economic Research; 2019. [Google Scholar]
- 11.Lin D, Fischl MA, Schoenfeld D. Evaluating the role of CD4-lymphocyte counts as surrogate endpoints in human immunodeficiency virus clinical trials. Statistics in medicine 1993; 12(9): 835–842. [DOI] [PubMed] [Google Scholar]
- 12.Parast L, Cai T, Tian L. Testing for Heterogeneity in the Utility of a Surrogate Marker. Biometrics, In press 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Freedman LS, Graubard BI, Schatzkin A. Statistical validation of intermediate endpoints for chronic diseases. Statistics in medicine 1992; 11(2): 167–178. [DOI] [PubMed] [Google Scholar]
- 14.Parast L, Cai T, Tian L. Evaluating Surrogate Marker Information using Censored Data. Statistics in Medicine 2017; 36(11): 1767–1782. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.VanderWeele TJ. Surrogate measures and consistent surrogates. Biometrics 2013; 69(3): 561–565. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Lin D, Fleming T, De Gruttola V, others. Estimating the proportion of treatment effect explained by a surrogate marker. Statistics in medicine 1997; 16(13): 1515–1527. [DOI] [PubMed] [Google Scholar]
- 17.Eastell R, Barton I, Hannon R, Chines A, Garnero P, Delmas P. Relationship of early changes in bone resorption to the reduction in fracture risk with risedronate. Journal of Bone and Mineral Research 2003; 18(6): 1051–1056. [DOI] [PubMed] [Google Scholar]
- 18.Scott D. Multivariate density estimation. Wiley, New York. 1992. [Google Scholar]
- 19.Henry K, Erice A, Tierney C, et al. A randomized, controlled, double-blind study comparing the survival benefit of four different reverse transcriptase inhibitor therapies (three-drug, two-drug, and alternating drug) for the treatment of advanced AIDS. Journal of acquired immune deficiency syndromes and human retrovirology 1998; 19(4): 339–349. [DOI] [PubMed] [Google Scholar]
- 20.Hammer SM, Squires KE, Hughes MD, et al. A controlled trial of two nucleoside analogues plus indinavir in persons with human immunodeficiency virus infection and CD4 cell counts of 200 per cubic millimeter or less. New England Journal of Medicine 1997; 337(11): 725–733. [DOI] [PubMed] [Google Scholar]
- 21.ACTG. AIDS Clinical Trial Group: Proposals and Collaboration. https://actgnetwork.org/submit-a-proposal/; 2021.
- 22.Calmy A, Ford N, Hirschel B, et al. HIV viral load monitoring in resource-limited regions: optional or necessary?. Clinical infectious diseases 2007; 44(1): 128–134. [DOI] [PubMed] [Google Scholar]
- 23.Cai T, Tian L, Wong PH, Wei L. Analysis of randomized comparative clinical trial data for personalized treatment selections. Biostatistics 2011; 12(2): 270–282. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Zhao L, Tian L, Cai T, Claggett B, Wei LJ. Effectively selecting a target population for a future comparative study. Journal of the American Statistical Association 2013; 108(502): 527–539. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Fleming TR, Prentice RL, Pepe MS, Glidden D. Surrogate and auxiliary endpoints in clinical trials, with potential applications in cancer and AIDS research. Statistics in medicine 1994; 13(9): 955–968. [DOI] [PubMed] [Google Scholar]
- 26.Pepe MS. Inference using surrogate outcome data and a validation sample. Biometrika 1992; 79(2): 355–365. [Google Scholar]
- 27.Elliott MR, Conlon AS, Li Y, Kaciroti N, Taylor JM. Surrogacy marker paradox measures in meta-analytic settings. Biostatistics 2015; 16(2): 400–412. doi: 10.1093/biostatistics/kxu043 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.