

Abstract
In modern data science, dynamic tensor data prevail in numerous applications. An important task is to characterize the relationship between dynamic tensor datasets and external covariates. However, the tensor data are often only partially observed, rendering many existing methods inapplicable. In this article, we develop a regression model with a partially observed dynamic tensor as the response and external covariates as the predictor. We introduce the low-rankness, sparsity, and fusion structures on the regression coefficient tensor, and consider a loss function projected over the observed entries. We develop an efficient nonconvex alternating updating algorithm, and derive the finite-sample error bound of the actual estimator from each step of our optimization algorithm. Unobserved entries in the tensor response have imposed serious challenges. As a result, our proposal differs considerably in terms of estimation algorithm, regularity conditions, as well as theoretical properties, compared to the existing tensor completion or tensor response regression solutions. We illustrate the efficacy of our proposed method using simulations and two real applications, including a neuroimaging dementia study and a digital advertising study.
Keywords: Alzheimer’s disease, Digital advertising, Neuroimaging analysis, Nonconvex optimization, Tensor completion, Tensor regression
1. Introduction
In modern data science, dynamic tensor data are becoming ubiquitous in a wide variety of scientific and business applications. The data take the form of a multidimensional array and one mode of the array is time. It is often of keen interest to characterize the relationship between such time-varying tensor datasets and external covariates. One example is a neuroimaging study of Alzheimer’s disease (AD) (Thung et al. 2016). Anatomical magnetic resonance imaging (MRI) data are collected for 365 individuals with and without AD every six months over a two-year period. After preprocessing, each image is of dimension 32 × 32 × 32, and stacking these MRI images over time formulates a fourth-way tensor for each subject. An important scientific question is to understand how a patient’s structural brain atrophy is associated with clinical and demographic characteristics such as the patient’s diagnosis status, age and sex. Another example is a digital advertising study (Bruce, Murthi and Rao 2017). The click-through rate (CTR) of 20 active users reacting to digital advertisements from 2 publishers are recorded for 80 advertisement campaigns on a daily basis over a four-week period. The data for each campaign are formed as a tensor by user by publisher by time. An important business question is to understand how features of an advertisement campaign affect its effectiveness measured by CTR on the target audience. Both questions can be formulated as a supervised tensor learning problem. However, a crucial but often overlooked issue is that the tensor data are often only partially observed in real applications. For instance, in the neuroimaging study, not all individuals have completed all five biannual MRI scans in two years. In the digital advertising study, not all users are exposed to all campaigns nor react to all publishers. Actually, in our digital advertising data, more than 95% of the entire tensor entries are unobserved. In this article, we tackle the problem of supervised tensor learning with partially observed tensor data.
There are several lines of research that are closely related to but also clearly distinctive of the problem we address. The first line studies tensor completion (Jain and Oh 2014; Yuan and Zhang 2016, 2017; Xia and Yuan 2017; Zhang 2019). Tensor completion aims to fill in the unobserved entries of a partially observed tensor, usually by resorting to some tensor low-rankness and sparsity structures. It is unsupervised learning, as it involves no external covariates. While we also handle tensor data with unobserved entries and employ similar low-dimensional structures as tensor completion, our goal is not to complete the tensor. Instead, we target a supervised learning problem, and aim to estimate the relationship between the partially observed tensor datasets and external covariates. Consequently, our model formulation, estimation approach, and theoretical analysis are considerably different from tensor completion. The second line tackles tensor regression where the response is a scalar and the predictor is a tensor (Zhou, Li and Zhu 2013; Wang and Zhu 2017; Hao, Zhang and Cheng 2020; Han, Willett and Zhang 2020). By contrast, we treat tensor as the response and covariates as the predictor. When it comes to theoretical analysis, the two models involve utterly different techniques. The third line studies regressions with a tensor-valued response, while imposing different structural assumptions on the resulting tensor regression coefficient (Rabusseau and Kadri 2016; Li and Zhang 2017; Sun and Li 2017; Chen, Raskutti and Yuan 2019; Xu, Hu and Wang 2019). This line of work shares a similar goal as ours; however, none of these existing methods can handle a tensor response with partially observed entries. Moreover, none are able to pool information from the dynamic tensor data collected at adjacent time points. In our experiments, we show that focusing only on the subset of completely observed tensor data, or ignoring the structural smoothness over time would both lead to considerable loss in estimation accuracy. Finally, there have been a number of proposals motivated by similar applications and can handle missing values. Particularly, Li et al. (2013) considered an adaptive voxel-wise approach by modeling each entry of the dynamic tensor separately. We instead adopt a tensor regression approach by jointly modeling all entries of the entire tensor. We later numerically compare our method with Li et al. (2013) and other solutions. Xue and Qu (2020) studied regressions of multi-source data with missing values involving neuroimaging features. However, the images were summarized as a vector instead of a tensor, and were placed on the predictor side. Similarly, Feng et al. (2019) developed a scalar-on-image regression model with missing image scans. By contrast, we place the imaging tensor on the response side.
In this article, we develop a regression model with partially observed dynamic tensor as the response. We assume the coefficient tensor to be both sparse and low-rank, which reduces the dimension of the parameter space, lessens the computational complexity, and improves the interpretability of the model. Furthermore, we impose a fusion structure along the temporal mode of the tensor coefficient, which helps to pool the information from data observed at adjacent time points. All these assumptions are scientifically plausible, and have been widely used in numerous applications (Vounou et al. 2010; Zhou, Li and Zhu 2013; Yin et al. 2015; Rabusseau and Kadri 2016; Bi, Qu and Shen 2018; Tang, Bi and Qu 2019; Zhang et al. 2019). To handle the unobserved entries in the tensor response, we consider a loss function projected over the observed entries, which is then optimized under the low-rankness, sparsity and fusion constraints. We develop an efficient nonconvex alternating updating algorithm, and derive the finite-sample error bound of the estimator from each step of our optimization algorithm.
Unobserved entries in the tensor response have introduced serious challenges. The existing algorithms for estimating a sparse low-rank tensor and technical tools for asymptotic analysis are only applicable to either a single partially observed tensor or a fully observed tensor (e.g., Jain and Oh 2014; Sun and Li 2017). As a result, our proposal differs considerably in terms of estimation algorithm, regularity conditions, as well as theoretical properties. For estimation, since the unobserved entries can occur at different locations for different tensors, the loss function projected over the observed entries takes a complex form. The traditional vector-wise updating algorithms (Jain and Oh 2014; Sun and Li 2017) are no longer applicable. Alternatively, we propose a new procedure that updates the low-rank components of the coefficient tensor in an element-wise fashion (see Step 1 of Algorithm 1 and Equation (7) in Section 3). For regularity conditions, we add a μ-mass condition to ensure that sufficient information is contained in the observed entries for tensor coefficient estimation (see Assumption 1). We also place a lower bound on the probability of the observation p, and discuss its relation with the sample size, tensor dimension, sparsity level and mass parameter μ (see Assumptions 2 and 6). Our lower bound is different from that in the tensor completion literature (Jain and Oh 2014; Yuan and Zhang 2016, 2017; Xia and Yuan 2017), which considered only a single tensor; whereas we consider a collection of n tensors. Consequently, our lower bound on p depends on n, and tends to 0 as n tends to infinity. For theoretical properties, we show that the statistical error of our estimator has an interesting connection with the lower bound on p, which does not appear in the tensor response regression for complete data (Sun and Li 2017). This characterizes the loss at the statistical level when modeling with only partially observed tensors. In summary, our proposal is far from an incremental extension from the complete case scenario, and involves a new set of strategies for estimation and theoretical analysis.
We adopt the following notation throughout the article. Let [d] = {1, …, d}, and let ∘ and ⊗ denote the outer product and Kronecker product. For a vector , let ‖a‖ and ‖a‖0 denote its Euclidean norm and ℓ0 norm, respectively. For a matrix , let ‖A‖ denote its spectral norm. For a tensor , let be its (i1, …, im)th entry, and . Let unfoldm denote the mode-m unfolding of , which arranges the mode-m fibers to be the columns of the resulting matrix; for example, the mold-1 unfolding of a third-order tensor is unfold1 . Define the tensor spectral norm as , and the tensor Frobenius norm as . For , define the j-mode tensor product as , such that . For , j ∈ [m], define the multilinear combination of the tensor entries as , where is the ijth entry of aj. For two sequences an, bn, we say if an ≤ Cbn for some positive constant C.
The rest of the article is organized as follows. Section 2 introduces our regression model with a partially observed dynamic tensor response. Section 3 develops the estimation algorithm. Section 4 investigates the theoretical properties. Section 5 presents the simulation results, and Section 6 illustrates with two real-world datasets, a neuroimaging study and a digital advertising study. All technical proofs are relegated to the supplementary materials.
2. Model
Suppose at each time point t, we collect an mth-order tensor of dimension d1 × · · · × dm, t ∈ [T]. We stack the collected tensors , together, and represent it as an (m + 1)th-order tensor . Correspondingly, the (m + 1)th mode of is referred as the temporal mode. Suppose there are totally n subjects in the study. For each subject i, we collect a dynamic tensor represented as , along with a q-dimensional vector of covariates , i ∈ [n]. The response tensor can be partially observed, and the missing patterns can vary from subject to subject. We consider the following regression model:
| (1) |
where is an (m + 2)th-order coefficient tensor, and is an (m + 1)th-order error tensor independent of xi. Without loss of generality, we assume the data are centered, and thus drop the intercept term in model (1). The coefficient tensor captures the relationship between the dynamic tensor response and the predictor, and is the main object of interest in our analysis. For instance, describes the effect of the lth covariate on the time-varying pattern of the (i1, …, im)th entry of tensor . Next, we impose three structures on to facilitate its analysis.
We first assume that admits a rank-r CP decomposition structure, in that,
| (2) |
where , , and . The CP structure is one of the most common low-rank structures (Kolda and Bader 2009), and is widely used in tensor data analysis (Zhou, Li and Zhu 2013; Anandkumar et al. 2014; Jain and Oh 2014; Yuan and Zhang 2016, 2017; Zhang 2019; Chen, Raskutti and Yuan 2019, among others). We next assume that is sparse, in that the decomposed components are sparse. That is, for j ∈ [m + 1], k ∈ [r], where
This assumption postulates that the covariates x’s effects are concentrated on a subset of entries of , which enables us to identify the most relevant regions in the dynamic tensor that are affected by the covariates. The sparsity assumption is again widely employed in numerous applications including neuroscience and online advertising (Bullmore and Sporns 2009; Vounou et al. 2010; Sun et al. 2017). We further assume a fusion structure on the decomposed components of . That is, for j ∈ [m + 1], k ∈ [r], where
and with Di,i = −1, Di,i+1 = 1 for i ∈ [d − 1], and other entries being zeros. This assumption encourages temporal smoothness and helps pool information from tensors observed at adjacent time points (Madrid-Padilla and Scott 2017; Sun and Li 2019). Putting the sparsity and fusion structures together, we have
| (3) |
We briefly comment that, since the dimension q of the covariates x is relatively small in our motivating examples, we have chosen not to impose any sparsity or fusion structure on the component , which is the last mode of the coefficient tensor . Nevertheless, we can easily incorporate such a structure for , or other structures. The extension is straightforward, and thus is not further pursued.
A major challenge we face is that many entries of the dynamic tensor response are unobserved. Let Ω ⊆ [d1] × [d2] × · · · × [dm+1] denote the set of indexes for the observed entries, and Ωi denote the set of indexes for the observed entries in , i ∈ [n]. We define a projection function ПΩ(·) that projects the tensor onto the observed set Ω, such that
We then consider the following constrained optimization problem:
| (4) |
In this optimization, both sparsity and fusion structures are imposed through ℓ0 penalties. Such nonconvex penalties have been found effective in high-dimensional sparse models (Shen, Pan and Zhu 2012; Zhu, Shen and Pan 2014) and fused sparse models (Rinaldo 2009; Wang et al. 2016).
3. Estimation
The optimization problem in Equation (4) is highly nontrivial, as it is a non-convex optimization with multiple constraints and a complex loss function due to the unobserved entries. We develop an alternating block updating algorithm to solve Equation (4), and divide our procedure into multiple alternating steps. First, we solve an unconstrained weighted tensor completion problem, by updating βk,1, …, βk,m +1, given wk and βk,m+2, for k ∈ [r]. Since each response tensor is only partially observed and different tensors may have different missing patterns, the commonly used vector-wise updating approach in tensor analysis is no longer applicable. To address this issue, we propose a new element-wise approach to update the decomposed components of the low-rank tensor. Next, we define a series of operators and apply them to the unconstrained estimators obtained from the first step, so to incorporate the sparsity and fusion constraints on βk,1, …, βk,m+1. Finally, we update wk and βk,m+2, both of which have closed-form solutions. We summarize the procedure in Algorithm 1, then discuss each step.

In Step 1, we solve an unconstrained weighted tensor completion problem,
| (5) |
where , and is a residual term defined as,
| (6) |
for i ∈ [n], k ∈ [r]. The optimization problem in Equation (5) has a closed-form solution. To simplify the presentation, we give this explicit expression when m = 2. For the case of m ≥ 3, the calculation is similar except involving more terms. Specifically, the lth entry of is
| (7) |
where if (l1, l2, l) ∈ Ωi, and otherwise. Here refers to the (l1, l2, l)th entry of . The expressions for and can be derived similarly. We remark that, Equation (7) is the key difference between our estimation method and those for a single partially observed tensor (Jain and Oh 2014), or a completely observed tensor (Sun and Li 2017). Particularly, the observed entry indicator appears in both the numerator and denominator, and is different across different entries of . Therefore, needs to be updated in an element-wise fashion, as could not be cancelled. After obtaining Equation (7), we normalize to ensure a unit norm.
In Step 2, we apply the sparsity and fusion constraints to obtained in the first step. Toward that goal, we define a truncation operator Truncate(a, τs), and a fusion operator Fuse(a, τf), for a vector and two integer-valued tuning parameters τs and τf, as,
where supp(a, τs) refers to the indexes of τs entries with the largest absolute values in a, and are the fusion groups. This truncation operator ensures that the total number of nonzero entries in a is bounded by τs, and is commonly employed in non-convex sparse optimizations (Yuan and Zhang 2013; Sun et al. 2017). The fusion groups are calculated as follows. First, the truncation operator is applied to . The resulting Truncate(Da, τf − 1) has at most (τf − 1) nonzero entries. Then the elements aj and aj+1 are put into the same group if [Truncate(Da, τf – 1)]j = 0. This procedure in effect groups the elements in a into τf distinct groups, which we denote as . Elements in each of the τf groups are then averaged to obtain the final result. Combining the two operators, we obtain the Truncatefuse(a, τs, τf) operator as,
where τs ≤ d is the sparsity parameter, and τf ≤ d is the fusion parameter. For example, consider a (0.1, 0.2, 0.4, 0.5, 0.6)⊤, τs = 3 and τf = 2. Correspondingly, Da = (0.1, 0.2, 0.1, 0.1)⊤. We then have Truncate(Da, τf – 1) = (0, 0.2, 0, 0)⊤. This in effect suggests that a1, a2 belong to one group, and a3, a4, a5 belong to the other group. We then average the values of a in each group, and obtain Fuse(a, τf) = (0.15, 0.15, 0.5, 0.5, 0.5)⊤. Lastly, Trun catefuse(a, τs, τf) = Truncate{Fuse(a, τf), τs} = Truncate{(0.15, 0.15, 0.5, 0.5, 0.5)⊤, 3}=(0, 0, 0.5, 0.5, 0.5)⊤. We apply the Truncatefuse operator to the unconstrained estimator obtained from the first step, with the sparsity parameter and the fusion parameter , and normalize the result to ensure a unit norm.
In Step 3, we update , given , , which has a closed-form solution,
| (8) |
where , and is as defined in Equation (6) by replacing with .
In Step 4, we update , given , , which again has a closed-form solution. Write , and . Then we have,
| (9) |
where 〈·,·〉 is the tensor inner product.
We make some remarks regarding the convergence of Algorithm 1. First, with a suitable initial value, the iterative estimator from Algorithm 1 converges to a neighborhood that is within the statistical precision of the true parameter at a geometric rate, as we show later in Theorems 1 and 2. These results also provide a theoretical termination condition for Algorithm 1. That is, when the computational error is dominated by the statistical error, we can stop the algorithm. In practice, we iterate the algorithm until the estimates from two consecutive iterations are close, that is, . Second, with any initial value, and if there are no sparsity and fusion constraints, that is, without the Truncatefuse step, then Algorithm 1 is guaranteed to converge to a stationary point, because the objective function monotonically decreases at each iteration (Wang and Li 2020). Finally, when imposing the sparsity and fusion constraints, the algorithmic convergence from any initial value becomes very challenging, since both constraints are non-convex. Actually, the general convergence of non-convex optimizations remains an open question. For instance, in the existing non-convex models that employ truncation in optimizations, including sparse PCA (Ma 2013), high-dimensional EM (Wang et al. 2015b), sparse phase retrieval (Cai, Li and Ma 2016), sparse tensor decomposition (Sun et al. 2017), and sparse generalized eigenvalue problem (Tan et al. 2018), the convergence to a stationary point has only been established for a suitable initial value, but not for any initial value. We leave this for future research.
The proposed Algorithm 1 involves a number of tuning parameters, including the rank r, the sparsity parameter , and the fusion parameter , j ∈ [m + 1]. We propose to tune the parameters by minimizing a BIC-type criterion,
| (10) |
where the total degrees of freedom df is the total number of unique nonzero entries of βk,j. The criterion in Equation (10) naturally balances the model fitting and model complexity. Similar BIC-type criterions have been used in tensor data analysis (Zhou, Li and Zhu 2013; Wang et al. 2015a; Sun and Li 2017). To further speed up the computation, we tune the three sets of parameters r, and sequentially. That is, among the set of values for r, , , we first tune r while fixing , at their maximum values. Then, given the selected r, we tune , while fixing at its maximum value. Finally, given the selected r and , we tune . In practice, we find such a sequential procedure yields good numerical performance.
4. Theory
We next derive the nonasymptotic error bound of the actual estimator obtained from Algorithm 1. We first develop the theory for the case of rank r = 1, because this case has clearly captured the roles of various parameters, including the sample size, tensor dimension, and proportion of the observed entries, on both the computational and statistical errors. We then generalize to the case of rank r > 1. Due to the involvement of the unobserved entries, our theoretical analysis is highly nontrivial, and is considerably different from Sun and Li (2017, 2019). We discuss in detail the effect of missing entries on both the regularity conditions and the theoretical properties.
We first introduce the definition of the sub-Gaussian distribution.
Definition 1 (sub-Gaussian).
The random variable ξ is said to follow a sub-Gaussian distribution with a variance proxy σ2, if , and for all , .
Next we introduce some basic model assumptions common for both r = 1 and r > 1. Let sj denote the number of nonzero entries in , j ∈ [m + 1], and s = maxj{sj}.
Assumption 1.
Assume the following conditions hold.
The predictor xi satisfies that ‖xi‖ ≤ c1, , i ∈ [n], and 1/c0 < λmin ≤ λmax < c0, where where λmin, λmax are the minimum and maximum eigenvalues of the sample covariance matrix , respectively, and c0, c1, c2 are some positive constants.
The true tensor coefficient in (1) satisfies the CP decomposition (2) with sparsity and fusion constraints (3), and the decomposition is unique up to a permutation. Moreover, where , , and c3 is some positive constant. Furthermore, .
The decomposed component is a μ-mass unit vector, in that .
The entries in the error tensor are iid sub-Gaussian with a variance proxy σ2.
The entries of the dynamic tensor response are observed independently with an equal probability p ∈ (0, 1].
We make some remarks about these conditions. Assumption 1(i) is placed on the design matrix, which is mild and can be easily verified when xi is of a fixed dimension. Assumption 1(ii) is about the key structures we impose on the coefficient tensor . It also ensures the identifiability of the decomposition of , which is always imposed in CP decomposition based tensor analysis (Zhou, Li and Zhu 2013; Sun and Li 2017; Chen, Raskutti and Yuan 2019). Assumption 1(iii) is to ensure that the mass of the tensor would not concentrate on only a few entries. In that extreme case, randomly observed entries of the tensor response may not contain enough information to recover . Note that, since is a vector of unit length, a relatively small μ implies that the nonzero entries in would be more uniformly distributed. This condition has been commonly imposed in the tensor completion literature for the same purpose (Jain and Oh 2014). Assumption 1(iv) assumes the error terms follow a sub-Gaussian distribution. This assumption is again fairly common in the theoretical analysis of tensor models (Cai et al. 2019; Xia, Yuan and Zhang 2020). Finally, Assumption 1(v) specifies the mechanism of how each entry of the tensor response is observed, which is assumed to be independent of each other and have an equal observation probability. We recognize that this is a relatively simple mechanism. It may not always hold in real applications, as the actual observation pattern of the tensor data can depend on multiple factors, and may not be independent for different entries. We impose this condition for our theoretical analysis, even though our estimation algorithm does not require it. In the tensor completion literature, this mechanism has been commonly assumed (Jain and Oh 2014; Yuan and Zhang 2016, 2017; Xia and Yuan 2017). We have chosen to impose this assumption because the theory of supervised tensor learning even for this simple mechanism remains unclear, and is far from trivial. We feel a rigorous theoretical analysis for this mechanism it deserves a full investigation. We leave the study under a more general observation mechanism for future research.
4.1. Theory With r = 1
To ease the notation and simplify the presentation, we focus primarily on the case with a third-order tensor response, that is, m = 2. This however does not lose generality, as all our results can be extended to the case of m > 2 in a straightforward fashion. Let d = max{d1, …, dm+1}. Next, we introduce some additional regularity conditions.
Assumption 2.
Assume the observation probability p satisfies that,
where c4 > 0 is some constant.
Due to Assumption 1(v), the observation probability p also reflects the proportion of the observed entries of the tensor response. Assumption 2 places a lower bound on this proportion to ensure a good recovery of the tensor coefficient. This bound depends on the sample size n, true sparsity parameter s, maximum dimension d, and mass parameter μ. We discuss these dependencies in detail. First, compared to the lower bound conditions on p in the tensor completion literature where a single tensor is considered (Jain and Oh 2014; Yuan and Zhang 2016, 2017; Xia and Yuan 2017; Cai et al. 2019), our lower bound is different, as it depends on the number of tensor samples n, and it tends to 0 as n tends to infinity. When n = 1, our lower bound is comparable to that in Jain and Oh (2014), Cai et al. (2019), with s replaced by d, as they did not consider any sparsity. Second, the lower bound on p increases as s decreases, that is, as the data become more sparse. This is because, when the sparsity is involved, both our tensor regression problem and the tensor completion problem become more difficult. Intuitively, when the sparsity increases, the nonzero elements may concentrate on only a few tensor entries. As a result, a larger proportion of the tensor entries needs to be observed to ensure that a sufficient number of nonzero elements can be observed for tensor estimation or completion. We also note that this condition on the lower bound on p is different from the sample complexity condition on n that we will introduce in Assumption 5. The latter suggests that the required sample size n decreases as s decreases. Third, when there is no sparsity, Jain and Oh (2014), Cai et al. (2019) showed that the lower bound on p is of the order (log d)4/(d3/2), which decreases as d increases. In our setting with the sparsity, however, the lower bound on p increases as d increases. Finally, the lower bound on p increases as the mass parameter μ increases. This is because when μ increases, the mass of the tensor may become more likely to concentrate on a few entries, and thus the entries need to be observed with a larger probability to ensure the estimation accuracy.
Assumption 3.
Assume the sparsity and fusion parameters satisfy that , , and . Moreover, define the minimal gap, . Assume that, for the positive constant C1 as defined in Theorem 1, we have
The condition for the sparsity parameter ensures that the truly nonzero elements would not be shrunk to zero. Similar conditions have been imposed in truncated sparse models (Yuan and Zhang 2013; Wang et al. 2015b; Sun et al. 2017; Tan et al. 2018). The conditions for the fusion parameter and the minimum gap ensure that the fused estimator would not incorrectly merge two distinct groups of entries in the true parameter. Such conditions are common in sparse and fused regression models (Tibshirani et al. 2005; Rinaldo 2009).
Assumption 4.
Define the initialization error . Assume that
where c2 is the same constant as in Assumption 1.
This assumption is placed on the initialization error of Algorithm 1, and requires that the initial values are reasonably close to the true parameters. Particularly, the condition on ϵ requires the initial error to be smaller than some constant, which is a relatively mild condition, since are unit vectors. Such constant initialization condition is commonly employed in the tensor literature (Sun and Li 2017; Han, Willett and Zhang 2020; Xia, Yuan and Zhang 2020). In Section 4.3, we further propose an initialization procedure, and show both theoretically and empirically that such a procedure can produce initial values that satisfy Assumption 4.
Assumption 5.
Assume the sample size n satisfies that
where c5 and c6 are some positive constants.
There are two terms in this lower bound, both of which are due to the error tensor in the model and the missing entries in the response tensor. In addition, the first term is needed to ensure the μ-mass condition is satisfied. When the observational probability p satisfies the lower bound requirement in Assumption 2, the required sample size decreases as s decreases, since in this case the number of free parameters decreases. When the strength of signal increases or the noise level σ decreases, the required sample size also decreases.
We now state the main theory for the estimator of Algorithm 1 when r = 1.
Theorem 1.
Suppose Assumptions 1–5 hold. When the tensor rank r = 1, the estimator from the tth iteration of Algorithm 1 satisfies that, with high probability,
where is the positive contraction coefficient, with ϵ as defined in Assumption 4, and the constant . Here, c2 is the same constant as defined in Assumptions 1, , are some positive constants, and q is fixed under Assumption 1(i).
The nonasymptotic error bound in Theorem 1 can be decomposed as the sum of a computational error and a statistical error. The former is related to the optimization procedure, while the latter is related to the statistical model. The statistical error decreases with a decreasing κ, an increasing signal-to-noise ratio as reflected by , an increasing sample size n and an increasing observation probability p. When p = 1 and σ = 1, the statistical error rate in our Theorem 1 actually improves the statistical error rate in the completely observed tensor response regression (Sun and Li 2017), which is of order . This improvement is achieved because we have employed a new proof technique using the covering number argument (Ryota and Taiji 2014) in bounding the sparse spectral of the error tensor, which allows us to obtain a sharper rate in terms of the sparsity parameter s. Moreover, when n = 1 and s = d, our statistical error rate matches with the rate in the nonsparse tensor completion (Cai et al. 2019).
One of the key challenges of our theoretical analysis is the complicated form of the element-wise estimator in Equation (7). Consequently, one cannot directly characterize the distance between and with a simple analytical form. Furthermore, the presence of noise error poses several fundamental challenges. The missing entries in noise tensors make existing proof techniques no longer applicable in our theoretical analysis. As we shall demonstrate later, we need to carefully control the upper bound of error tensor with missing entries.
We also briefly comment that, Theorem 1 provides a theoretical termination condition for Algorithm 1. When the number of iterations t exceeds O{log1/κ(ϵ/ε*)}, where ε* is the statistical error term in Theorem 1, then the computational error is to be dominated by the statistical error, and the estimator falls within the statistical precision of the true parameter.
4.2. Theory With r > 1
Next, we extend our theory to the general rank r > 1. The regularity conditions for the general rank case parallel those for the rank one case. Meanwhile, some modifications are needed, due to the interplay among different decomposed components βk,j.
Assumption 6.
Assume the observation probability p satisfies that
where c7 > 0 is some constants.
For the general rank case, the lower bound on the observation probability p depends additionally on the rank r and the ratio . In particular, the lower bound will increase with an increasing rank r, which suggests that more observations are needed if the rank of the coefficient tensor increases. When the sample size n = 1, our condition is comparable to that in tensor completion (Jain and Oh 2014), where the latter requires ignoring the logarithm term, with s replaced by d, as they do not consider any sparsity.
Assumption 7.
Assume the sparsity and fusion parameters satisfy that , , and . Moreover, define the minimal gap , . Assume that,
where positive constant C2 is the same constant as defined in Theorem 2.
This assumption is similar to Assumption 3, and it reduces to Assumption 3 when r = 1.
Assumption 8.
Define . Assume ϵ satisfies,
where c1, c2 are the same constants as defined in Assumption 1.
It is seen that the initial error depends on the rank r. The upper bound tightens as r increases, as in such a case, the tensor recovery problem becomes more challenging. It is also noted that, when r = 1, this condition is still stronger than that in Assumption 4. This is due to the interplay among different decomposed components in the general rank case.
Assumption 9.
Define the incoherence parameter . Assume,
where c1, c2 are the same constants as defined in Assumption 1.
For the general rank case, we need to control the correlations between the decomposed components across different ranks. The incoherence parameter ξ quantifies such correlations. As rank r increases, the upper bound on ξ becomes tighter. Similar conditions have been introduced in Anandkumar et al. (2014), Sun et al. (2017), and Hao, Zhang and Cheng (2020).
Assumption 10.
Assume the sample size n satisfies that,
where c5 and c6 are the same positive constants as defined in Assumption 5.
This assumption is similar to Assumption 5, and it reduces to Assumption 5 when r = 1.
We next state the main theory for the estimator of Algorithm 1 when r > 1.
Theorem 2.
Suppose Assumptions 1 and 6–10 hold. For a general rank r, the estimator from the tth iteration of Algorithm 1 satisfies that, with a high probability,
where
is the positive contraction coefficient, and the constants . Here c1, c2 is the same constant as defined in Assumptions 1, , are some positive constants, and q is fixed under Assumption 1(i).
The contraction coefficient is greater than κ in Theorem 1, which indicates that the algorithm has a slower convergence rate for the general rank case. Moreover, increases with an increasing rank r. This agrees with the expectation that, as the tensor recovery problem becomes more challenging, the algorithm will have a slower convergence rate.
4.3. Initialization
As the optimization problem in Equation (4) is nonconvex, the success of Algorithm 1 replies on good initializations. Motivated by Cai et al. (2019), we next propose a spectral initialization procedure for r = 1 and r > 1, respectively. Theoretically, we show that the produced initial estimator satisfies the initialization Assumption 4 when r = 1. Numerically, we demonstrate that the initialization error decays fast for both r = 1 and r > 1 cases as the sample size n increases, and thus the constant initialization error bound in the initialization Assumptions 4 and 8 is expected to hold with a sufficiently large n.
We first present the initialization procedure for r = 1 in Algorithm 2. Denote . Let , and , where Пoff-diag(·) keeps only the off-diagonal entries of the matrix. Let be the rank-r decomposition of B1. Next, let , , and be the rank-r decomposition of B2. We then feed U1 and U2 into Algorithm 2. When r = 1, we have , whose column space is the span of . A natural way to estimate the column space of E(A1) is from the principal space of . Similar to Cai et al. (2019), we exclude the diagonal entries of to remove their influence on the principal directions. To retrieve tensor factors from the subspace estimate, we first generate random vectors from normal distribution, that is, in line 3 and in line 7 of Algorithm 2. Then we project the random vectors and onto U1 and U2. This projection step helps mitigate the perturbation incurred by both unobserved values and data noise (Cai et al. 2019). Note that . Correspondingly, the left leading singular vector corresponding to the largest absolute singular value of is expected to be close to . Similarly, the right leading singular vector of is expected to be close to . Following the same argument, we can obtain a good estimate of and from . Then, in line 11 of Algorithm 2, we match the identified singular vector pairs with . That is, let . Set , the remaining one in the pair (v3, v4) as , and . Next, given , , , we obtain , by solving the following optimization,
Finally, leting , we obtain the initial estimates and as
| (11) |

We next present the initialization procedure for r > 1 in Algorithm 3. We first apply Algorithm 2 to generate two sets , . Since and are from , and , are from , we merge the two and find the triplet . Next, we search for such that is maximized. This is because the selected vectors are expected to be close to true factors when is large (Sun et al. 2017). We also remove all those triplets that are close to , since they eventually generate the same decomposition vectors up to the tolerance parameter. We then iteratively refine the selected vectors. In our numerical experiments, we have found that one iteration is often enough, and the algorithm is not sensitive to the tolerance parameter ϵth because of the used refinement step.
Next, we present a proposition showing that the initial estimator obtained from Algorithm 2 satisfies the initialization Assumption 4 when r = 1. The theoretical guarantee for the r > 1 case is very challenging, and we leave it for future research.

Proposition 1.
Suppose Assumptions 1, 2, 3, and 5 hold. Furthermore, suppose for some large enough , for some constant . Then, the initial estimator produced by Algorithm 2 satisfies that
We make some remarks about Proposition 1. First, this result shows that the error of the initial estimator obtained from Algorithm 2 decays with n, and thus the constant initialization error bound on ϵ in Assumption 4 is guaranteed to hold as n increases. Second, the estimation error in Proposition 1 is slower than the statistical error rate in Theorem 1 when . This suggests that, after obtaining the initial estimator from Algorithm 2, applying the alternating block updating Algorithm 1 could further improve the error rate of the estimator.
Finally, we conduct a simulation to evaluate the empirical performance of the proposed spectral initialization Algorithms 2 and 3. We simulate the coefficient tensor . We generate the entries of , k ∈ [2], j ∈ [3] from iid standard normal, and set as (1, 1, 1, 1, 1)⊤. We then normalize each vector to have a unit norm, and set . We consider two ranks, r = 1 and r = 2, while we vary the sample size n = {20, 40, 60, 80, 100}. We then generate the error tensor with iid standard normal entries, and the response tensor , with each entry missing with probability 0.5. For Algorithms 2 and 3, we set L = 30, ϵth= 0.8, and as dj. Figure 1 reports the error, , of the initial estimator based on 100 data replications. It is seen that, as the sample size increases, the estimation error decreases rapidly. This agrees with our finding in Proposition 1, and suggests that the constant initialization error bound in Assumptions 4 and 8 is to hold when n is sufficiently large.
Figure 1.
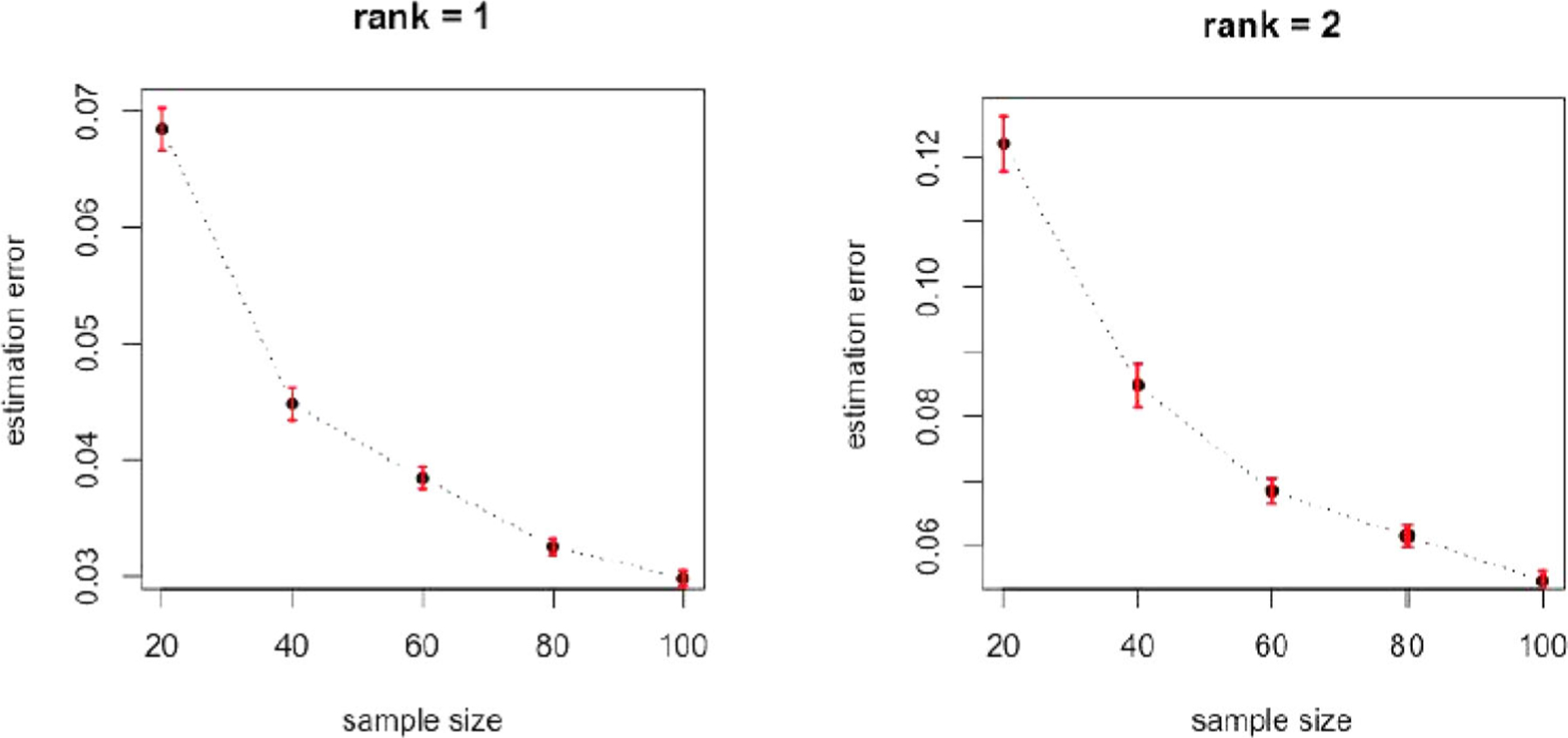
Estimation error of the initial estimator by the spectral initialization algorithms as the sample size increases. The left panel is for r = 1, and the right panel is for r = 2.
5. Simulations
We carry out simulations to investigate the finite-sample performance of our proposed method. For easy reference, we call our method Partially ObServed dynamic Tensor rEsponse Regression (POSTER). We also compare with some alternative solutions. One competing method is the multiscale adaptive generalized estimating equations method (MAGEE) proposed by Li et al. (2013), which integrated a voxel-wise approach with generalized estimating equations for adaptive analysis of dynamic tensor imaging data. Another competing method is the sparse tensor response regression method (STORE) proposed by Sun and Li (2017), which considered a sparse tensor response regression model but did not incorporate fusion type smoothness constraint and can only handle completely observed data. In our analysis, STORE is applied to the complete samples only. Moreover, to examine the effect of using the partially observed samples and incorporating structural smoothness over time, we also consider our method applied to the completely observed samples, or without fusion constraint, which serve as two benchmarks.
We consider two patterns for the unobserved entries, block missing in Section 5.1 and random missing in Section 5.2. Both patterns are common in real data applications. For instance, in our neuroimaging example, individual subjects would miss some scheduled biannual scans, and as a result, the entire tensor images are unobserved, and the missing pattern is more likely a block missing. In our digital advertising example, on the other hand, some users may randomly react to only a subset of advertisements on certain days, and the missing pattern would be closer to a random missing. Finally, in Section 5.3, we consider a model used in Li et al. (2013). The data generation does not comply with our proposed model, and we examine the performance of our method under model misspecification.
To evaluate the estimation accuracy, we report the estimation error of the coefficient tensor measured by , and the estimation error of the decomposed components measured by . To evaluate the variable selection accuracy, we compute the true positive rate as the mean of TPRj, and the false positive rate as the mean of FPRj, where is the true positive rate of the estimator in mode j, and is the false positive rate of the estimator in mode j.
5.1. Block Missing
In the first example, we simulate a fourth-order tensor response , where the fourth mode corresponds to the time dimension, and there are blocks of tensor entries missing along the time mode. More specifically, we generate the coefficient tensor as , where d1 = d2 = d3 = 32, T = 5, q = 5, and the true rank r = 2.We generate the entries of , j ∈ [4] as iid standard normal.We then apply the Truncatefuse operator on , j ∈ [3] with the true sparsity and fusion parameters (sj, fj), j ∈ [3], and apply the Fuse operator to with the true fusion parameter f4. We set the true sparsity parameters sj = s0 × dj, j ∈ [3] with s0 = 0.7, and set the true fusion parameters fj = f0 × dj, j ∈ [4], with f0 ∈ {0.3, 0.7}. A smaller f implies a smaller number of fusion groups in . We set , a vector of all ones. We then normalize each vector to have a unit norm. We set the weight , with a larger weight indicating a stronger signal. Next, we generate the q-dimensional predictor vector xi whose entries are iid Bernoulli with probability 0.5, and the error tensor , whose entries are iid standard normal. Finally, we generate the response tensor following model (1). We set the blocks of entries of along the fourth mode randomly missing. Among all n subjects, we set the proportion of subjects with missing values mn ∈ {0.8, 0.9}, and for each subject with missing values, we set the proportion of missing blocks along the time mode as mt ∈ {0.4, 0.6}. For example, n = 100, mn = 0.8 and mt = 0.4 means there are 80 subjects out of 100 having partially observed tensors, and for each of those 80 subjects, the tensor observations at 2 out of 5 time points are missing.
Table 1 reports the average criteria based on 30 data replications with mn = 0.8. The results with mn =0.9 are similar qualitatively and are reported in the Appendix. Since the method MAGEE of Li et al. (2013) does not decompose the coefficient tensor and does not carry out variable selection, the corresponding criteria of and selection are reported as NA. From Table 1, it is clearly seen that our proposed method outperforms all other competing methods in terms of both estimation accuracy and variable selection accuracy.
Table 1.
Simulation example with block missing, for varying missing proportions mn, mt, signal strength , and fusion setting f0.
| (mn, mt) | f 0 | method | Error of | Error of | TPR | FPR | |
|---|---|---|---|---|---|---|---|
| (0.8, 0.4) | 30 | 0.3 | STORE | 0.586 (0.055) | 0.992 (0.109) | 0.879 (0.016) | 0.369 (0.035) |
| MAGEE | 1.397 (0.005) | NA | NA | NA | |||
| Complete | 0.232 (0.051) | 0.366 (0.104) | 0.952 (0.017) | 0.104 (0.026) | |||
| No-fusion | 0.125 (0.003) | 0.112 (0.005) | 1.000 (0.000) | 0.120 (0.000) | |||
| POSTER | 0.069 (0.003) | 0.068 (0.005) | 1.000 (0.000) | 0.020 (0.004) | |||
| 0.7 | STORE | 0.574 (0.063) | 0.905 (0.113) | 0.878 (0.019) | 0.343 (0.043) | ||
| MAGEE | 1.411 (0.003) | NA | NA | NA | |||
| Complete | 0.207 (0.038) | 0.259 (0.082) | 0.979 (0.008) | 0.103 (0.021) | |||
| No-fusion | 0.120 (0.003) | 0.111 (0.006) | 1.000 (0.000) | 0.072 (0.000) | |||
| POSTER | 0.102 (0.003) | 0.098 (0.006) | 1.000 (0.000) | 0.055 (0.003) | |||
| 40 | 0.3 | STORE | 0.287 (0.055) | 0.402 (0.104) | 0.957 (0.013) | 0.212 (0.028) | |
| MAGEE | 1.233 (0.002) | NA | NA | NA | |||
| Complete | 0.085 (0.022) | 0.087 (0.044) | 0.995 (0.005) | 0.036 (0.011) | |||
| No-fusion | 0.115 (0.004) | 0.111 (0.005) | 1.000 (0.000) | 0.120 (0.000) | |||
| POSTER | 0.063 (0.004) | 0.067 (0.005) | 1.000 (0.000) | 0.020 (0.004) | |||
| 0.7 | STORE | 0.167 (0.036) | 0.160 (0.06) | 0.984 (0.009) | 0.131 (0.029) | ||
| MAGEE | 1.250 (0.002) | NA | NA | NA | |||
| Complete | 0.142 (0.030) | 0.190 (0.073) | 0.984 (0.008) | 0.107 (0.026) | |||
| No-fusion | 0.107 (0.003) | 0.115 (0.005) | 1.000 (0.000) | 0.093 (0.021) | |||
| POSTER | 0.093 (0.004) | 0.094 (0.006) | 1.000 (0.000) | 0.074 (0.019) | |||
| (0.8, 0.6) | 30 | 0.3 | STORE | 0.579 (0.057) | 0.975 (0.109) | 0.883 (0.016) | 0.360 (0.034) |
| MAGEE | 1.515 (0.004) | NA | NA | NA | |||
| Complete | 0.233 (0.051) | 0.366 (0.104) | 0.952 (0.017) | 0.108 (0.026) | |||
| No-fusion | 0.155 (0.006) | 0.146 (0.008) | 1.000 (0.000) | 0.120 (0.000) | |||
| POSTER | 0.089 (0.006) | 0.091 (0.009) | 1.000 (0.000) | 0.023 (0.005) | |||
| 0.7 | STORE | 0.434 (0.058) | 0.729 (0.120) | 0.924 (0.015) | 0.248 (0.034) | ||
| MAGEE | 1.528 (0.004) | NA | NA | NA | |||
| Complete | 0.207 (0.038) | 0.259 (0.082) | 0.979 (0.008) | 0.103 (0.021) | |||
| No-fusion | 0.151 (0.007) | 0.150 (0.009) | 1.000 (0.000) | 0.072 (0.000) | |||
| POSTER | 0.128 (0.008) | 0.121 (0.010) | 1.000 (0.000) | 0.058 (0.002) | |||
| 40 | 0.3 | STORE | 0.228 (0.045) | 0.323 (0.096) | 0.971 (0.011) | 0.178 (0.021) | |
| MAGEE | 1.310 (0.003) | NA | NA | NA | |||
| Complete | 0.090 (0.022) | 0.176 (0.073) | 0.983 (0.010) | 0.054 (0.016) | |||
| No-fusion | 0.142 (0.006) | 0.142 (0.008) | 0.999 (0.001) | 0.124 (0.003) | |||
| POSTER | 0.082 (0.006) | 0.089 (0.009) | 1.000 (0.000) | 0.023 (0.004) | |||
| 0.7 | STORE | 0.228 (0.047) | 0.290 (0.090) | 0.969 (0.012) | 0.146 (0.029) | ||
| MAGEE | 1.325 (0.003) | NA | NA | NA | |||
| Complete | 0.137 (0.022) | 0.205 (0.076) | 0.955 (0.016) | 0.159 (0.038) | |||
| No-fusion | 0.131 (0.005) | 0.141 (0.010) | 0.999 (0.001) | 0.073 (0.002) | |||
| POSTER | 0.110 (0.006) | 0.122 (0.016) | 0.999 (0.001) | 0.061 (0.003) |
NOTES: Reported are the average estimation errors of and , and the true and false positive rates of selection based on 30 data replications (the standard errors in the parentheses). Five methods are compared: STORE of Sun and Li (2017), MAGEE of Li et al. (2013), method applied to the complete data only (Complete), our method without the fusion constraint (No-fusion), and our proposed method (POSTER).
The computational time of our method scales linearly with the sample size and tensor dimension. Consider the simulation setup with mn = 0.8, mt = 0.4, wk = 30, and f0 = 0.3 as an example. When we fix d1 = 32 and other parameters, the average computational time of our method was 112.5, 200.3, and 384.2 seconds for the sample size n = 100, 200, and 300, respectively. When we fix n = 100 and other parameters, the average computational time of our method was 42.5, 82.3, and 101.8 sec for the tensor dimension d1 = 10, 20, and 30, respectively. The reported computational time does not include tuning. All simulations were run on a personal computer with a 3.2 GHz Intel Core i5 processor.
5.2. Random Missing
In the second example, we simulate data similarly as in Section 5.1, but the entries of the response tensor are randomly missing. We set the observation probability p ∈ {0.3, 0.5}. For this setting, MAGEE cannot handle a tensor response with randomly missing entries, whereas STORE or our method applied to the complete data cannot handle either, since there is almost no complete , with the probability of observing a complete being . Therefore, we can only compare our proposed method with the variation that imposes no fusion constraint. Table 2 reports the results based on 30 data replications. It is seen that incorporating the fusion structure clearly improves the estimation accuracy. Moreover, Table 2 shows that the estimation error of our method decreases when the signal strength increases or when the observation probability p increases. These patterns agree with our theoretical findings.
Table 2.
Simulation example with random missing, for varying observation probability p, signal strength , and fusion setting f0.
| p | f 0 | method | Error of | Error of | TPR | FPR | |
|---|---|---|---|---|---|---|---|
| 0.5 | 30 | 0.3 | No-fusion | 0.091 (0.001) | 0.059 (0.001) | 1.000 (0.000) | 0.121 (0.001) |
| POSTER | 0.055 (0.001) | 0.037 (0.001) | 1.000 (0.000) | 0.021 (0.004) | |||
| 0.7 | No-fusion | 0.088 (0.001) | 0.056 (0.001) | 1.000 (0.000) | 0.099 (0.026) | ||
| POSTER | 0.079 (0.002) | 0.051 (0.001) | 1.000 (0.000) | 0.079 (0.024) | |||
| 40 | 0.3 | No-fusion | 0.068 (0.001) | 0.044 (0.001) | 1.000 (0.000) | 0.120 (0.000) | |
| POSTER | 0.042 (0.001) | 0.029 (0.001) | 1.000 (0.000) | 0.019 (0.003) | |||
| 0.7 | No-fusion | 0.066 (0.001) | 0.043 (0.001) | 1.000 (0.000) | 0.072 (0.000) | ||
| POSTER | 0.059 (0.001) | 0.039 (0.001) | 1.000 (0.000) | 0.056 (0.003) | |||
| 0.3 | 30 | 0.3 | No-fusion | 0.119 (0.002) | 0.078 (0.002) | 0.998 (0.001) | 0.148 (0.023) |
| POSTER | 0.077 (0.002) | 0.054 (0.002) | 1.000 (0.000) | 0.052 (0.016) | |||
| 0.7 | No-fusion | 0.113 (0.002) | 0.074 (0.002) | 0.998 (0.001) | 0.104 (0.026) | ||
| POSTER | 0.103 (0.002) | 0.066 (0.002) | 0.998 (0.001) | 0.086 (0.024) | |||
| 40 | 0.3 | No-fusion | 0.092 (0.020) | 0.060 (0.001) | 1.000 (0.000) | 0.120 (0.000) | |
| POSTER | 0.058 (0.001) | 0.042 (0.001) | 1.000 (0.000) | 0.025 (0.005) | |||
| 0.7 | No-fusion | 0.084 (0.001) | 0.054 (0.001) | 0.999 (0.000) | 0.074 (0.001) | ||
| POSTER | 0.075 (0.001) | 0.049 (0.001) | 1.000 (0.000) | 0.054 (0.030) |
NOTES: Reported are the average estimation errors of and of , and the true and false positive rates of selection based on 30 data replications (the standard errors in the parentheses). Two methods are compared: our method without the fusion constraint (No-fusion), and our proposed method (POSTER).
5.3. Model Misspecification
In the third example, we simulate data from the model in Li et al. (2013). Data generated this way does not comply with our proposed model (1), and we examine the performance of our method under model misspecification. Following Li et al. (2013), we simulate a third-order tensor response , where the first two modes correspond to imaging space and the third mode corresponds to the time dimension, with d1 = d2 = 88, T = 3, and the sample size n = 80. At voxel (j, k) the response of subject i at time point l is simulated according to
The predictor vector xi,l = (1, xi,l,2, xi,l,3)⊤, and we consider two settings of generating xi,l. The first setting is that xi,l,2 is time-dependent and is generated from a uniform distribution on [l − 1, l] for l = 1, 2, 3, and xi,l,3 is time independent and is generated from a Bernoulli distribution with probability 0.5. The second setting is that both xi,l,2 and xi,l,3 are time independent and are generated from a Bernoulli distribution with probability 0.5. The error term ϵi,j,k = (ϵi,j,k,1, ϵi,j,k,2, ϵi,j,k,3)⊤ is generated from a multivariate normal N(0, Σ), where the diagonal entries of Σ are 1 and , l1, l2 = 1, 2, 3. The coefficient , and the coefficient image is divided into six different regions with two different shapes. Following Li et al. (2013), we set to (0, 0), (0.05, 0.9), (0.1, 0.8), (0.2, 0.6), (0.3, 0.4) and (0.4, 0.2) in those six regions. Among the 80 subjects, the first half have their 88 × 88 images observed only at the first two time points.
Figure 2 presents the true and estimated image of , along with the estimation error of the coefficient tensor . The standard error shown in parenthesis is calculated based on 20 replications. The results for are similar and hence are omitted. It is seen that our method is able to capture all six important regions in both settings of covariates, even if the model is misspecified. When the covariates are time dependent, our method is comparable to Li et al. (2013). When the covariates are time independent, our estimator is more accurate compared to the method of Li et al. (2013).
Figure 2.
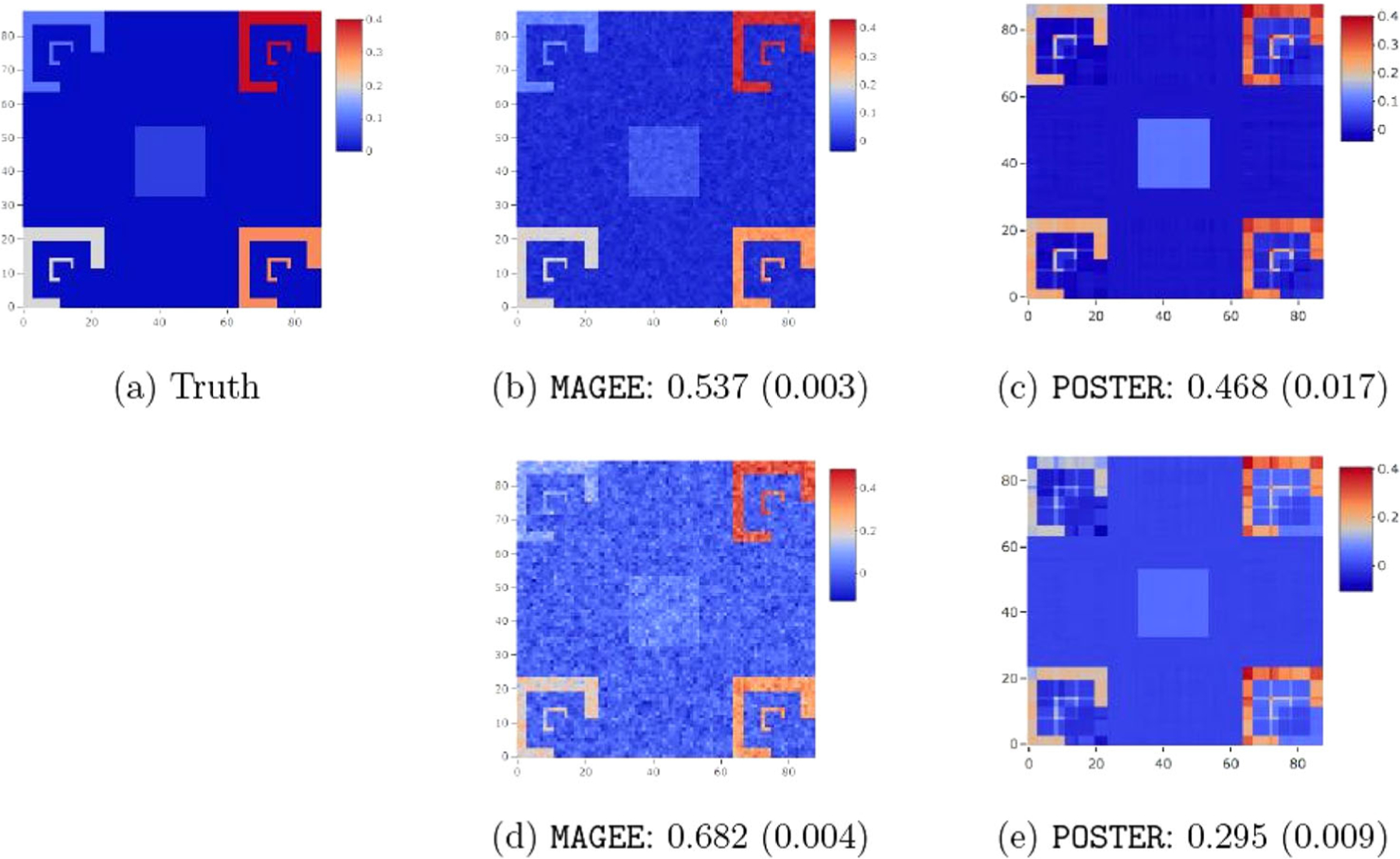
True and estimated image of . The top left panel is the true image of with six regions. The middle panels are the estimated images by MAGEE, and the right panels by our method POSTER. The top panels correspond to the time dependent covariates, and the bottom panels the time independent covariates. The estimation error (with the standard error in the parenthesis) based on 20 data replications is reported for each image.
6. Applications
We illustrate the proposed method with two real data applications. The first is a neuroimaging study, where about 50% of subjects have at least one imaging scan missing. The second is a digital advertising study, where about 95% of tensor entries are missing.
6.1. Neuroimaging Application
The first example is a neuroimaging study of dementia. Dementia is a broad category of brain disorders with symptoms associated with decline in memory and daily functioning (Sosa-Ortiz, Acosta-Castillo and Prince 2012). It is of keen scientific interest to understand how brain structures change and differ between dementia patients and healthy controls, which in turn would facilitate early disease diagnosis and development of effective treatment.
The data we analyze are from Alzheimer’s disease neuroimaging initiative (ADNI, http://adni.loni.usc.edu), where anatomical MRI images were collected from n = 365 participates every six months over a two-year period. Each MRI image, after preprocessing and mapping to a common registration space, is summarized in the form of a 32 × 32 × 32 tensor. For each participant, there are at the most five scans, but many subjects missed some scheduled scans, and 178 subjects out of 365 have at least one scan missing. For each subject, we stack the MRI brain images collected over time as a fourth-order tensor, which is to serve as the response . Its dimension is 32 × 32 × 32 × 5, and there are block missing entries. Among these subjects, 127 have dementia and 238 are healthy controls. In addition, the baseline age and sex of the subjects were collected. As such, the predictor vector xi consists of the binary diagnosis status, age and sex. Our goal is to identify brain regions that differ between dementia patients and healthy controls, while controlling for other covariates.
We apply MAGEE, STORE and our POSTER method to this data set. Figure 3 shows the heatmap of the estimated coefficient tensor at the baseline time point obtained by the three methods. It is seen that the estimate from MAGEE identifies a large number of regions with relatively small signals. Both STORE and POSTER identify several important brain regions, and the parameters in those identified regions are negative, indicating that those regions become less active for patients with dementia. The regions identified by the two methods largely agree with each other, with one exception, that is, Brodmann area 38, which POSTER identifies but STORE does not. The regions identified by both include the hippocampus and the surrounding medial temporal lobe. These findings are consistent with existing neuroscience literature. Hippocampus is found crucial in memory formation, and medial temporal lobe is important for memory storage (Smith and Kosslyn 2007). Hippocampus is commonly recognized as one of the first regions in the brain to suffer damages for patients with dementia (Hampel et al. 2008). There is also clear evidence showing that medial temporal lobe is damaged for dementia patients (Visser et al. 2002). In addition to those two important regions, our method also identifies a small part of the anterior temporal cortex, that is, Brodmann area 38, which is highlighted in Figure 3. This area is involved in language processing, emotion and memory, and is also among the first areas affected by AD, which is the mostcommon type of dementia (Delacourte et al. 1998).
Figure 3.
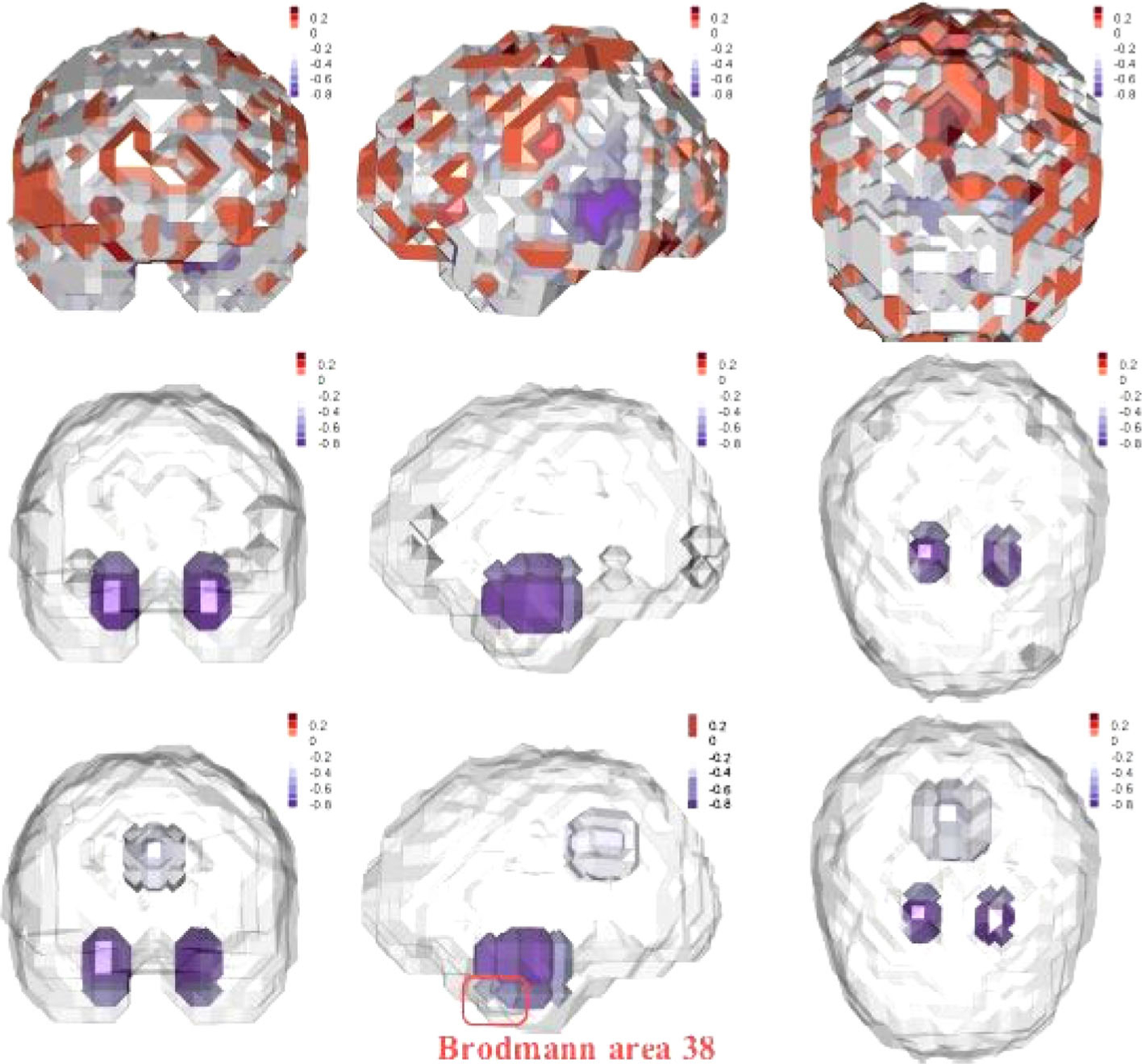
Neuroimaging application example. Shown are the estimated coefficient tensor overlaid on a randomly selected brain image. Top to bottom: MAGEE, STORE, and our method POSTER. Left to right: frontal view, side view, and top view.
6.2. Digital Advertising Application
The second example is a digital advertising study of CTR for some online advertising campaign. CTR is the number of times a user clicks on a specific advertisement divided by the number of times the advertisement is displayed. It is a crucial measure to evaluate the effectiveness of an advertisement campaign, and plays an important role in digital advertising pricing (Richardson, Dominowska and Ragno 2007).
The data we analyzed are obtained from a major internet company over four weeks in May to June 2016. The CTR of 80 advertisement campaigns were recorded for 20 users by 2 different publishers. Since it is of more interest to understand the user behavior over different days of a week, the data were averaged by days of a week across the four-week period. For each campaign, we stack the CTR data of different users and publishers over seven days of the week as a third-order tensor, which serves as the response . Its dimension is 20 × 2 × 7, and there are 95% entries missing. Such a missing percentage, however, is not uncommon in online advertising, since a user usually does not see every campaign in every publisher every day. For each campaign, we also observe two covariates. One covariate is the topic of the advertisement campaign, which takes three categorical values, “online dating,” “investment,” or “others.” The other covariate is the total number of impressions of the advertisement. The predictor vector xi consists of these two covariates. Our goal is to study how the topic and total impression of an advertisement influence its effectiveness measured by CTR.
Due to the large proportion of missing values and nearly random missing patterns, neither MAGEE nor STORE are applicable to this dataset. We applied our method. For the categorical covariate, topic, we created two dummy variables, one indicating whether the topic was “online dating” or not, and the other indicating whether the topic was “investment” or not. Figure 4 shows the heatmap of the estimated coefficient tensor for one publisher, whereas the result for the other publisher is similar and is thus omitted. The rows of the heatmap represent the users and the columns represent the days of a week. We first consider the topic of “online dating.” The top left panel shows that, for this topic, the CTR is higher than other topics during the weekend. The top right panel shows that, if the total impression on “online dating” increases, then the CTR increases more on weekends than weekdays. It is also interesting to see that the topic of “online dating” has a negative impact on the CTR on Mondays. We next consider the topic of “investment.” The bottom left panel shows that, for this topic, the CTR is lower than other topics for most users during the weekend. The bottom right panel shows that, if the total impression increases, the CTR increases more on weekends than weekdays. These findings are useful for managerial decisions. Based on the findings about “online dating,” one should increase the allocation of “online dating”-related advertisements on weekends, and decrease the allocation on Mondays. On the other hand, the allocation recommendation for “investment”-related advertisements are different. For most users, one should allocate more such advertisements during the early days of a week, and fewer during weekends. For a small group of users who seem to behave differently from the majority, some personalized recommendations regarding “investment” advertisements can also be beneficial.
Figure 4.
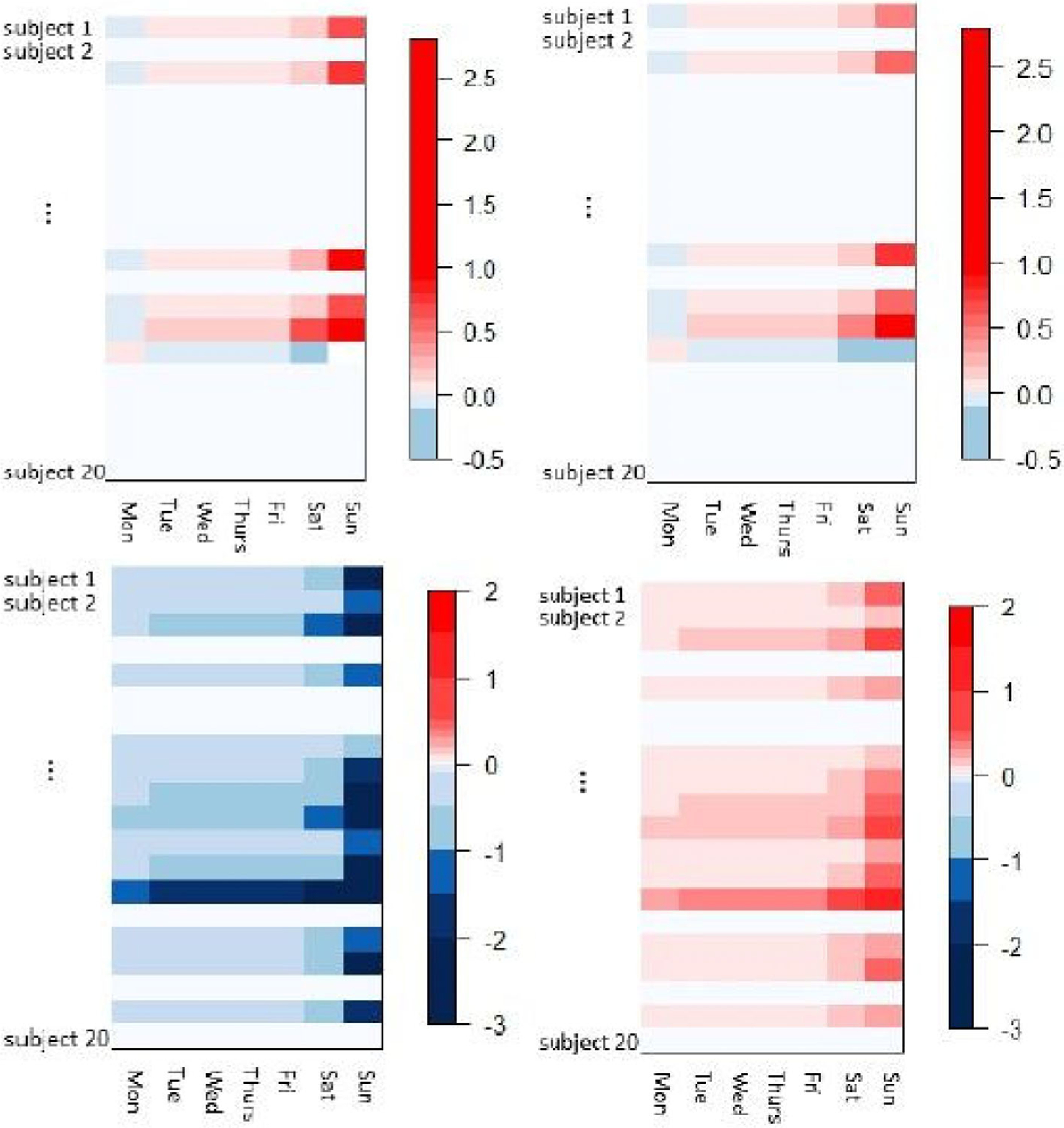
Digital advertising application example. Shown are the estimated coefficient tensor. In each panel, the rows represent users and columns represent days of a week. The top panels are for the topic “online dating,” and the bottom panels for “investment.” The left panels are slices from the topic mode, and the right panels are slices from the impression mode.
Supplementary Material
Acknowledgments
The authors thank to the editor Professor Ian McKeague, the associate editor and two anonymous reviewers for their valuable comments and suggestions which led to a much improved article. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the Office of Naval Research, the National Science Foundation, or the National Institutes of Health.
Funding
Will Wei Sun’s research was partially supported by ONR grant N00014-18-1-2759. Jingfei Zhang’s research was partially supported by NSF grant DMS-2015190. Lexin Li’s research was partially supported by NIH grants R01AG061303, R01AG062542, and R01AG034570.
Footnotes
Supplementary materials for this article are available online. Please go to www.tandfonline.com/r/JASA.
Supplementary Material
The supplementary materials collect all technical proofs and additional numerical results.
References
- Anandkumar A, Ge R, Hsu D, and Kakade SM (2014), “A Tensor Approach to Learning Mixed Membership Community Models,” Journal of Machine Learning Research, 15, 2239–2312. [Google Scholar]
- Bi X, Qu A, and Shen X (2018), “Multilayer Tensor Factorization With Applications to Recommender Systems,” Annals of Statistics, 46, 3308–3333. [Google Scholar]
- Bruce NI, Murthi B, and Rao RC (2017), “A Dynamic Model for Digital Advertising: The Effects of Creative Format, Message Content, and Targeting on Engagement,” Journal of Marketing Research, 54, 202–218. [Google Scholar]
- Bullmore E, and Sporns O (2009), “Complex Brain Networks: Graph Theoretical Analysis of Structural and Functional Systems,” Nature Reviews Neuroscience, 10, 186–198. [DOI] [PubMed] [Google Scholar]
- Cai C, Li G, Poor H, and Chen Y (2019), “Nonconvex Low-Rank Tensor Completion From Noisy Data,” NeurIPS, 32, 1863–1874. [Google Scholar]
- Cai TT, Li X, and Ma Z (2016), “Optimal Rates of Convergence for Noisy Sparse Phase Retrieval Via Thresholded Wirtinger Flow,” The Annals of Statistics, 44, 2221–2251. [Google Scholar]
- Chen H, Raskutti G, and Yuan M (2019), “Non-Convex Projected Gradient Descent for Generalized Low-Rank Tensor Regression,” Journal of Machine Learning Research, 20, 1–37. [Google Scholar]
- Delacourte A, David JP, Sergeant N, Buée L, Wattez A, Vermersch P, Ghozali F, Fallet-Bianco C, Pasquier F, Lebert F, Petit H, Di Menza C (1998), “The Biochemical Pathway of Neurofibrillary Degeneration in Aging and Alzheimer’s Disease,” American Academy of Neurology, 52, 1158–1165. [DOI] [PubMed] [Google Scholar]
- Feng X, Li T, Song X, and Zhu H (2019), “Bayesian Scalar on Image Regression With Non-Ignorable Non-Response,” Journal of the American Statistical Association, 115, 1574–1597. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hampel H, Burger K, Teipel SJ, Bokde AL, Zetterberg H, Blennow K (2008), “Core Candidate Neurochemical and Imaging Biomarkers of Alzheimer’s Disease,” Alzheimer’s and Dementia, 4, 38–48. [DOI] [PubMed] [Google Scholar]
- Han R, Willett R, and Zhang A (2020), “An Optimal Statistical and Computational Framework for Generalized Tensor Estimation,” arXiv:2002.11255.
- Hao B, Zhang A, and Cheng G (2020), “Sparse and Low-Rank Tensor Estimation Via Cubic Sketchings,” IEEE Transactions on Information Theory, 66, 5927–5964. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jain P, and Oh S (2014), “Provable Tensor Factorization With Missing data,” Advances in Neural Information Processing Systems, 2, 1431–1439. [Google Scholar]
- Kolda TG, and Bader BW (2009), “Tensor Decompositions and Applications,” SIAM Review, 51, 455–500. [Google Scholar]
- Li L, and Zhang X (2017), “Parsimonious Tensor Response Regression,” Journal of the American Statistical Association, 112, 1131–1146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li Y, Gilmore JH, Shen D, Styner M, Lin W, and Zhu H (2013), “Multiscale Adaptive Generalized Estimating Equations for Longitudinal Neuroimaging Data,” NeuroImage, 72, 91–105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ma Z (2013), “Sparse Principal Component Analysis and Iterative Thresholding,” Annals of Statistics, 41, 772–801. [Google Scholar]
- Madrid-Padilla O, and Scott J (2017), “Tensor Decomposition With Generalized Lasso Penalties,” Journal of Computational and Graphical Statistics, 26, 537–546. [Google Scholar]
- Rabusseau G, and Kadri H (2016), “Low-Rank Regression With Tensor Responses,” in Advances in Neural Information Processing Systems, (Vol. 29), eds. Lee D, Sugiyama M, Luxburg U, Guyon I and Garnett R, Barcelona, Spain: Curran Associates, Inc. [Google Scholar]
- Richardson M, Dominowska E, and Ragno R (2007), “Predicting Clicks: Estimating the Click-Through Rate for New Ads,” in Proceedings of the 16th International Conference on World Wide Web. Banff, Alberta, Canada: ACM Press. [Google Scholar]
- Rinaldo A (2009), “Properties and Refinements of the Fused Lasso,” The Annals of Statistics, 37, 2922–2952. [Google Scholar]
- Ryota T, and Taiji S (2014), “Spectral Norm of Random Tensors,” arXiv:1407.1870.
- Shen X, Pan W, and Zhu Y (2012), “Likelihood-Based Selection and Sharp Parameter Estimation,” Journal of American Statistical Association, 107, 223–232. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith EE, and Kosslyn SM (2007), Cognitive Psychology: Mind and Brian, Upper Saddle River, NJ: Prentice-Hall, 279–306. [Google Scholar]
- Sosa-Ortiz AL, Acosta-Castillo I, and Prince MJ (2012), “Epidemiology of Dementias and Alzheimer’s Disease,” Archives of Medical Research, 43, 600–608. [DOI] [PubMed] [Google Scholar]
- Sun W, Lu J, Liu H, and Cheng G (2017), “Provable Sparse Tensor Decomposition,” Journal of the Royal Statistical Society, Series B, 79, 899–916. [Google Scholar]
- Sun WW, and Li L (2017), “Store: Sparse Tensor Response Regression and Neuroimaging Analysis,” Journal of Machine Learning Research, 18, 1–37. [Google Scholar]
- ——— (2019), “Dynamic Tensor Clustering,” Journal of American Statistical Association, 114, 1894–1907. [Google Scholar]
- Tan KM, Wang Z, Liu H, and Zhang T (2018), “Sparse Generalized Eigenvalue Problem: Optimalstatistical Rates Via Truncated Rayleigh Flow,” Journal of the Royal Statistical Society, Series B, 80, 1057–1086. [Google Scholar]
- Tang X, Bi X, and Qu A (2019), “Individualized Multilayer Tensor Learning With an Application in Imaging Analysis,” Journal of the American Statistical Association, 115, 836–851. [Google Scholar]
- Thung K-H, Wee C-Y, Yap P-T, and Shen D (2016), “Identification of Progressive Mild Cognitive Impairment Patients Using Incomplete Longitudinal MRI Scans,” Brain Structure and Function, 221, 3979–3995. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tibshirani R, Saunders M, Rosset S, Zhu J, and Knight K (2005), “Sparsity and Smoothness Via the Fused Lasso,” Journal of the Royal Statistical Society, Series B, 67, 91–108. [Google Scholar]
- Visser P, Verhey FRJ, Hofman PAM, Scheltens P, Jolles J (2002), “Medial Temporal Lobe Atrophy Predicts Alzheimer’s Disease in Patients With Minor Cognitive Impairment,” Journal of Neurology, Neurosurgery and Psychiatry, 72, 491–497. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vounou M, Nichols TE, Montana G, Initiative ADN (2010), “Discovering Genetic Associations With High-Dimensional Neuroimaging Phenotypes: A Sparse Reduced-Rank Regression Approach,” Neuroimage, 53, 1147–1159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang M, and Li L (2020), “Learning From Binary Multiway Data: Probabilistic Tensor Decomposition and its Statistical Optimality,” Journal of Machine Learning Research, 21, 1–38. [PMC free article] [PubMed] [Google Scholar]
- Wang X, and Zhu H (2017), “Generalized Scalar-on-Image Regression Models Via Total Variation,” Journal of the American Statistical Association, 112, 1156–1168. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Y, Sharpnack J, Smola A, and Tibshirani R (2016), “Trend Filtering on Graphs,” Journal of Machine Learning Research, 17, 1–41. [Google Scholar]
- Wang Y, Tung H-Y, Smola A, and Anandkumar A (2015a), “Fast and Guaranteed Tensor Decomposition Via Sketching,” in Advances in Neural Information Processing Systems (Vol. 1), eds. Cortes C, Lee DD, Sugiyama M and Garnett R, Cambridge, MA: MIT Press. pp. 991–999. [Google Scholar]
- Wang Z, Gu Q, Ning Y, and Liu H (2015b), “High Dimensional EM Algorithm: Statistical Optimization and Asymptotic Normality,” NeurIPS, 28, 2512–2520. [PMC free article] [PubMed] [Google Scholar]
- Xia D, and Yuan M (2017), “On Polynomial Time Methods for Exact Low Rank Tensor Completion,” Foundations of Computational Mathematics, 19, 1–49. [Google Scholar]
- Xia D, Yuan M, and Zhang C (2020), “Statistically Optimal and Computationally Efficient Low Rank Tensor Completion From Noisy Entries,” Annals of Statistics, 49(1), 76–99. [Google Scholar]
- Xu Z, Hu J, and Wang M (2019), “Generalized Tensor Regression With Covariates on Multiple Modes,” arXiv:1910.09499.
- Xue F, and Qu A (2020), “Integrating Multisource Block-Wise Missing Data in Model Selection,” Journal of the American Statistical Association, 1–14. [Google Scholar]
- Yin H, Cui B, Chen L, Hu Z, and Zhou X (2015), “Dynamic User Modeling in Social Media Systems,” ACM Transactions on Information Systems, 33, 1–44. [Google Scholar]
- Yuan M, and Zhang C (2016), “On Tensor Completion Via Nuclear Norm Minimization,” Foundations of Computational Mathematics, 16, 1031–1068. [Google Scholar]
- ——— (2017), “Incoherent Tensor Norms and their Applications in Higher Order Tensor Completion,” IEEE Transactions on Information Theory, 63, 6753–6766. [Google Scholar]
- Yuan X-T, and Zhang T (2013). “Truncated Power Method for Sparse Eigenvalue Problems,” Journal of Machine Learning Research, 14, 899–925. [Google Scholar]
- Zhang A (2019), “Cross: Efficient Low-Rank Tensor Completion,” Annals of Statistics, 47, 936–964. [Google Scholar]
- Zhang Z, Allen GI, Zhu H, and Dunson D (2019), “Tensor Network Factorizations: Relationships Between Brain Structural Connectomes and Traits,” NeuroImage, 197, 330–343. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou H, Li L, and Zhu H (2013), “Tensor Regression With Applications in Neuroimaging Data Analysis,” Journal of the American Statistical Association, 108, 540–552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu Y, Shen X, and Pan W (2014), “Structural Pursuit Over Multiple Undirected Graphs,” Journal of the American Statistical Association, 109, 1683–1696. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.