

Summary:
Multivariate functional data present theoretical and practical complications which are not found in univariate functional data. One of these is a situation where the component functions of multivariate functional data are positive and are subject to mutual time warping. That is, the component processes exhibit a common shape but are subject to systematic phase variation across their domains in addition to subject-specific time warping, where each subject has its own internal clock. This motivates a novel model for multivariate functional data that connects such mutual time warping to a latent deformation-based framework by exploiting a novel time warping separability assumption. This separability assumption allows for meaningful interpretation and dimension reduction. The resulting Latent Deformation Model is shown to be well suited to represent commonly encountered functional vector data. The proposed approach combines a random amplitude factor for each component with population based registration across the components of a multivariate functional data vector and includes a latent population function, which corresponds to a common underlying trajectory. We propose estimators for all components of the model, enabling implementation of the proposed data-based representation for multivariate functional data and downstream analyses such as Fréchet regression. Rates of convergence are established when curves are fully observed or observed with measurement error. The usefulness of the model, interpretations, and practical aspects are illustrated in simulations and with application to multivariate human growth curves and multivariate environmental pollution data.
Keywords: Component processes, cross-component registration, functional data analysis, longitudinal studies, multivariate functional data, time warping
1. Introduction
Functional data analysis (FDA) has found important applications in many fields of research (e.g. biology, ecology, economics) and has spawned considerable methodological work as a subfield of statistics (Ramsay and Silverman, 2005; Wang et al., 2016; Ferraty and Vieu, 2006). In particular, the analysis of univariate functional data has driven the majority of developments in this area such as functional principal component analysis (Kleffe, 1973), regression (Cardot et al., 1999; Yao et al., 2005), and clustering (Chiou and Li, 2007; Jacques and Preda, 2014). In this paper we develop novel modeling approaches for multivariate functional data, which consist of samples of a finite dimensional vector whose elements are random functions (Chiou et al., 2014; Jacques and Preda, 2014) and have been much less studied. Dimension reduction is a common approach, with many studies focusing on extending univariate functional principal components analysis to the multivariate case (Happ and Greven, 2018; Han et al., 2018) and decomposition into marginal component processes and their interactions (Chiou et al., 2016).
Most methodological work has focused on traditional amplitude variation-based models for dimension reduction, while phase variation-based methods for multivariate functional data have found attention more recently: Brunel and Park (2014) proposed a method for estimating multivariate structural means and Park and Ahn (2017) introduced a model for clustering multivariate functional data in the presence of phase variation, while Carroll et al. (2021) combined the notions of dimension reduction and phase variability through a multivariate version of the shape-invariant model (Kneip and Engel, 1995), in which component processes share a common latent structure that is time-shifted across components. However, the assumption of a rigid shift-warping framework in this precursor work imposes a major parametric constraint on the warping structure and often the class of models that only feature simple shifts between the components is not rich enough for many real-world data. Our main contribution is a less-restrictive alternative approach, in which time characterization of individual-specific temporal effects and component-specific effects is achieved through a fully non-parametric deformation-based model.
A major motivation for this framework is that in many contexts, the component functions of a multivariate data vector may share a common structure that is subject to variation across modalities; the fundamental shape of growth curves is similar but not identical when studying timing patterns across body parts, for instance. A reviewer suggested to alternatively align the components for each subject in a constrained way; we demonstrate in this paper that an overall more compelling model is obtained by assuming a latent common curve is present at the population level, which brings with it the benefits of dimension reduction and a principled and novel representation of mutually time-warped functional data.
The proposed latent curve model introduces a shared shape-based model along with a characterization of individual- and component-level variation and allows for flexible and nuanced component effects. This ensures broad viability of the proposed approach and improved data fidelity when describing component-specific effects, which inform the time dynamics of a larger system at work. To this end, we introduce a representation of multivariate functional data which uses tools from time warping (Marron et al., 2015) and template deformation modeling (Bigot et al., 2009; Bigot and Charlier, 2011).
The organization of this paper is as follows. Section 2 discusses existing approaches for univariate curve registration and introduces the proposed Latent Deformation Model for component-warped multivariate functional data. We derive estimators of model components in Section 3 and illustrate the utility and performance of the proposed methodology through data analysis in Section 4. Asymptotic results are established in Section 5, and a discussion of goodness-of-fit issues and a simulation study are provided in the Appendix, which also contains auxiliary results and proofs.
2. Curve Registration and The Latent Deformation Model
The main idea of the Latent Deformation Model (LDM) that we introduce in this paper is to decompose multivariate phase variation into subject-specific and variable-specific warping components. When combined with a common, shape-defining template, these warping functions provide a lower-dimensional representation of the functional vector trajectories while characterizing the subject-level warping and population-wide patterns in the time dynamics across variables. In addition to the existence of a template function shared across subjects, the proposed LDM includes a modeling assumption that each subject has an “internal clock,” which is quantified through a subject-specific warping function. Similar assumptions have been previously explored in the cross-component registration paradigm of Carroll et al. (2021), which however restricted the component-wise phase variation to simple parametric shift functions. A major contribution of this paper is to widen the class of potential component warps beyond rigid shifts to allow for more flexible warping functions, so as to better capture variation that occurs non-uniformly across the time domain.
Before introducing the detailed mathematical machinery of the model, a brief overview of the general idea is as follows. We first introduce a flexible and separable component structure for warping functions, which are factorized into subject- and component-specific warpings and then proceed to develop estimates of these factor warping functions. The first step is to construct consistent estimates of the subject-specific warping functions which correspond to the internal clock of each subject. This is done by considering univariate warping problems for each functional variable separately and then averaging the resulting estimates of the component warping functions for each subject, resulting in a consistent estimate of the subject-specific time warping function. Eventually this then leads to consistent estimates of the underlying latent curve. Assuming that time-warped versions of this underlying latent curve generate the functional vector component-level distortions, in order to recover it, one component function is selected at random per subject, discarding the data from the other components, then aligning these curves across subjects. Once this consistent estimate of the underlying template curve has been obtained, consistent estimates of the component-level distortion functions are recovered by solving a penalized cost minimization problem. A schematic of the data generating mechanism of the LDM is provided in Figure 1. More detailed descriptions follow below.
Figure 1.
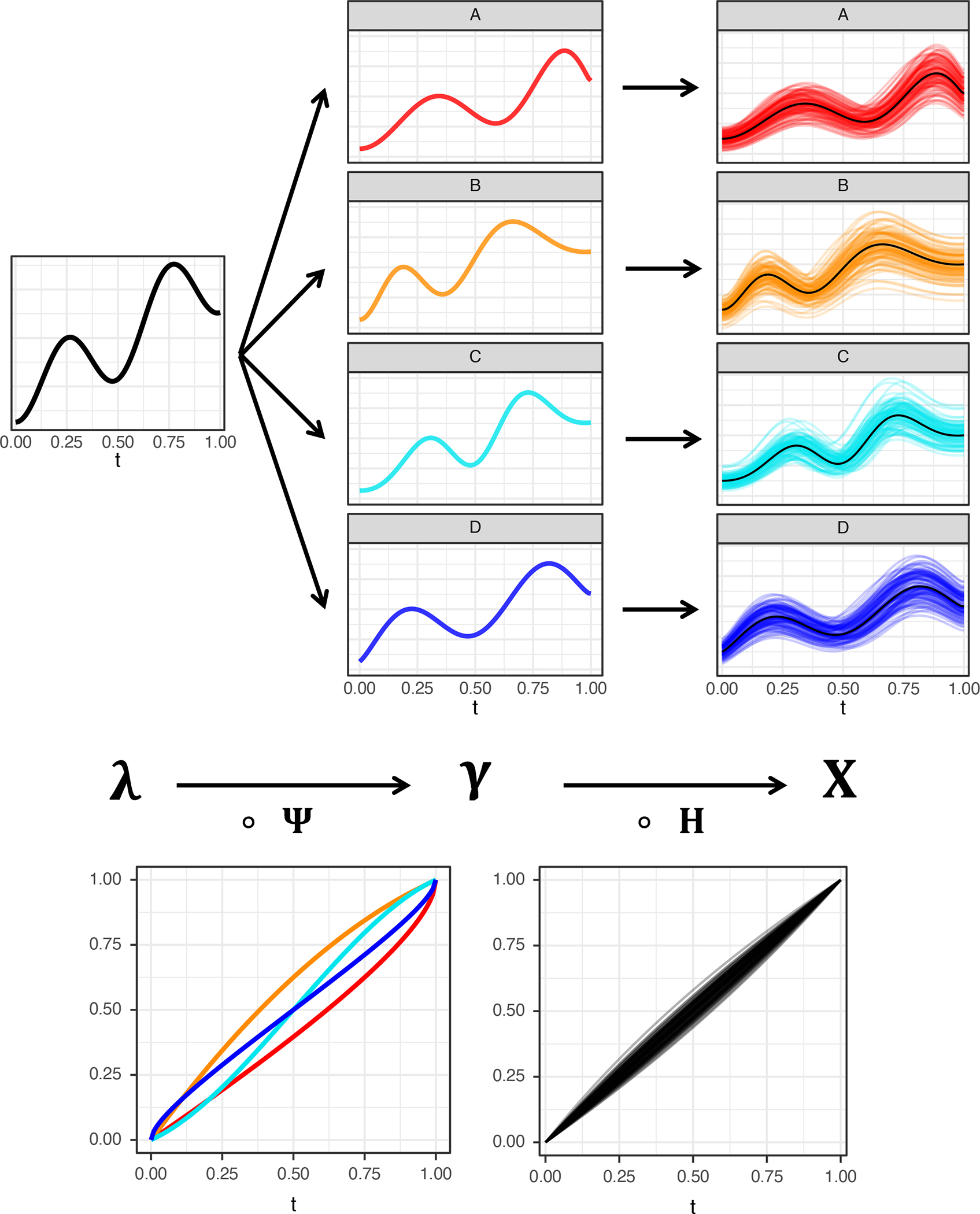
Schematic of the Latent Deformation Model, where denotes the latent base curve (top-left), denotes component deformations (bottom-left), denotes component tempos (top-center), denotes random subject-wise time distortion functions (bottomright), and denotes the observed multivariate curve data (top-right) resulting from the complete data generating mechanism.
2.1. The Univariate Curve Registration Problem
The classical univariate curve registration problem is characterized by the observation of a sample of curves , , observed on an interval , which are realizations of a fixed template subject to variation in their time domains. This domain variation is characterized by the monotonic time-warping functions which act as random homeomorphisms of . A classical model for this scenario is
| (1) |
The goal of curve registration is to estimate the distortions, , which are typically considered nuisance effects, in order to account for them before proceeding with further analysis, e.g., estimation of , functional principal component analysis, etc. A major branch of time-warping techniques is based on the idea of aligning processes to some reference curve which carries the main features in common across subjects. This reference curve is referred to as a template function and is employed by landmark-based registration methods (Kneip and Gasser, 1992; Kneip and Engel, 1995), pairwise curve alignment (Tang and Müller, 2008) or the Procrustes approach (Ramsay and Li, 1998), among many others. For a comprehensive review and additional references we refer to Marron et al. (2015).
While the curve registration literature is varied and rich in methodology, no single method has prevailed as a silver bullet in all warping contexts. Indeed, the debate over desirable properties of existing and future registration techniques continues and a gold-standard remains elusive. With this in mind, we emphasize that our aim here is not to advocate for one alignment method over another, but rather extend the ideas available for univariate registration to a multivariate problem with a composite warping function with fixed and random effects. In practice, any suitable registration method may be employed in the estimation step of the proposed Latent Deformation Model (see Estimation).
2.2. A Unified Model for Multivariate Time Dynamics and Time Warping Separability
Let denote a generic set of random functions with each component process in for an interval . Suppose further that each component is positive-valued, i.e. for all ; the assumption of positivity is made to make estimation of model components more straightforward and is certainly satisfied for applications to growth curves. Without loss of generality we consider the unit domain case . In the following, Greek letters denote fixed, unknown population quantities, while Latin letters represent random, individual-specific quantities.
The Latent Deformation Model (LDM) is motivated by situations where the functional forms of the component processes , (or any subset thereof) exhibit structural similarity, so that the information inherent in each component may be combined for overall improved model fitting and to estimate and analyze the mutual time warping structure. Denoting a random sample from a -dimensional stochastic process by , where , we model this shared structure through a latent curve , which characterizes the component curves through the relation
| (2) |
where is a fixed function, and the random amplitude factors and random time distortion functions reflect differences in realized curves across components and individuals. Without loss of generality we assume since it is always possible to rescale the latent curve without changing the model by employing amplitude factors and a standardized curve .
The distortion functions are elements of , the convex space of all smooth, strictly increasing functions with common endpoints, i.e., , , is a strictly increasing homeomorphism}. The elements of this space represent random homeomorphisms of the time domain and capture the presence of nonlinear phase variation. We further assume that the distortion functions may be decomposed as follows,
| (3) |
where the deterministic functions describe the component-based effects of time distortion and the random functions describe the subject-level phase variation.
This decomposition is key to our approach. A reviewer suggested to refer to it as a separability assumption and indeed it is analogous to the well-known notion of separability of covariance in function-valued stochastic process modeling (Chen et al., 2017; Liang et al., 2022) and we have adopted this suggestion, as it brings out a key aspect of the proposed LDM. As in the related covariance separability paradigm, time warping separability confers the advantages of better interpretability and dimension reduction over the more complex approaches that do not include this assumption.
Under the warping separability assumption, the time warping functions are decomposed into the warping maps that convey the relative time scale of the component and the warping maps that quantify the internal clock of the subject. These warping maps can be viewed as deformations from standard clock time, , to the system time of a given component or individual. As such we refer to the collection of functions as component-level deformation functions and the collection of functions as subject-level deformation functions.
The random subject level deformation functions obey some probability law on the convex space , where we assume that this probability law is such that exists and that there is no net distortion on average, i.e., for . This assumption has been referred to as “standardizing” the registration procedure (Kneip and Ramsay, 2008). It is a mild assumption, since were it the case that , with , then a standardized registration procedure is given by reparameterizing the warping functions as so that . Component deformation functions are also assumed to be standardized, but because they are deterministic and not random, the assumption becomes for . Together these conditions imply so that there is no net distortion from the latent curve .
Combining (2) and (3) yields the Latent Deformation Model (LDM) for multivariate functional data, given by
| (4) |
In practice, it may be useful to pose the model in an equivalent form, defining the component-warped versions of the latent curve as so that
| (5) |
In this form, the curves convey the “typical” time progression of the latent curve according to the component’s system time, so we refer to this composition as the component tempo function. The component tempo functions can be viewed as the synchronized processes for each component after accounting for random subject-level time distortions.
2.3. Cross-Component Deformation Maps
Marginal Cross-Component Deformations
To understand and quantify the relative timings between any pair of components, , it is useful to define their cross-component deformation , which is the deformation that, when applied to the component, maps its tempo to that of the component,
| (6) |
so that . Because the component deformations can be represented as distribution functions and are closed under composition, the cross-component deformation (XCD) may also be represented as a distribution function and is interpreted similarly to an ordinary component tempo. While the component tempo expresses the component’s timing patterns in terms of clock time, the cross-component deformation expresses the same patterns relative to the tempo of the component.
For example, consider a pair of component processes, Component A and Component B, for which Component A tends to lag behind the latent curve, while the Component B precedes it. An example of this can be seen in the red and orange curves, respectively, in Figure 1. The corresponding red deformation, , falls below the diagonal and conveys the lagged tempo, while the orange deformation, lies above the diagonal and expresses an accelerated system time. The deformation function then sits above the diagonal and represents the time-acceleration needed to bring the red tempo in line with the orange component.
Subject-Level Cross-Component Deformations
While the marginal XCDs describe the general time relations between components on a population level, we may also be interested to see how an individual’s component processes relate to one another. This perspective may be especially useful when trying to understand intercomponent dynamics which are mediated by covariate effects. Conceptually it is straightforward to extend the notion of cross-component deformations to individuals by searching for the warping function which brings the individual’s component in line with the . A natural definition under the LDM is then
| (7) |
since this choice gives . In practice, this proportionality will become equality once random amplitude factors are dealt with during estimation. Statistics based on the XCDs can be used in downstream analyses like hypothesis testing and regression. Several data illustrations are given in the applications of Section 4.
3. Model Estimation and Curve Reconstruction
3.1. Internal Clock Estimation and Component-wise Alignment
The proposed model estimation procedure relies on solving several univariate warping problems of type (1). It is important to note that any of the warping methods described in Section 2 may be used for practical implementation. In our implementation we choose the pairwise alignment method of Tang and Müller (2008), which provides an explicit representation of the warping functions and satisfies some properties required by our theory in order to derive convergence rates. This pairwise alignment is easily implemented with the R package fdapace (Carroll et al., 2020). For a detailed discussion of the pairwise warping method we refer to the supplement.
For the estimation of the model components, under the LDM, each component , , gives rise to a univariate warping problem. To see this, consider for a fixed component the sample of univariate curves . Using the normalized curves , estimation of and for the component is a consequence of
| (8) |
which coincides with a warping framework of type (1) with , and . Replacing by in (8) is necessary in order to eliminate the random amplitude factors . Since the random functions are homeomorphisms, we have . Thus the normalized curves do not depend on the factors .
Applying an estimation method like pairwise warping for each of the subcollections , results in estimates of the subject-level warping function, . Taking the mean of the resulting warping functions gives an estimate for the subject-specific warp,
| (9) |
For the overall penalty parameter associated with the pairwise warping implementation we set
| (10) |
where , , is the default choice of the penalty parameter for each of the registrations, as per Tang and Müller (2008). With subject time warping estimators in hand, a plug-in estimate of is obtained by averaging the component-aligned curves,
| (11) |
3.2. Global Alignment and Latent Curve Estimation
A central idea in the estimation of the LDM is the fact that any univariate curve contains information about the latent curve, regardless of which component is considered. This motivates a perspective in which we temporarily ignore the multivariate structure of the data and expand our scope to the full collection of curves, . For each subject , select one of its component curves at random as a representative. Call this representative curve and denote its normalized counterpart by . Selecting one of the components at random ensures that we have for all , . The collection of curves can be thought of as realizations of subject to some random distortion , where if the component curve is selected. Define as the event that the curve comes from the collection of component curves, . Conditional on the event (which happens with probability for all ), it follows that . Then, on average there is no net warping from the latent curve, as
| (12) |
This observation motivates the warping problem
| (13) |
The critical implication of this relation is that if we expand our scope to the full collection and apply a traditional method like pairwise warping to obtain for all , the latent curve can be estimated by averaging the globally-aligned curves,
| (14) |
The estimators of the component deformations are motivated by recalling that
Using a spline representation (see Section A of Appendix), we write
| (15) |
and estimate the component warps by solving the penalized minimization problem,
| (16) |
with as the default choice of penalty parameter in line with Tang and Müller (2008). Finally, we obtain the component warps as
| (17) |
3.3. Measurement Error and Curve Reconstruction
Note that under the assumption of fully observed curves without measurement error, the amplitude factors are known. Often in practice, this is not realistic, and the factors must be estimated by, e.g., where denotes a smoothing estimate of a function that is observed with noise, as described in the following section. We note that these smoothing methods introduce a finite bias on the amplitude factors, but as the number of time points in the observation grid goes to infinity, our proposed estimate is asymptotically unbiased as shown in Theorem 1f. of Section 5. We refer to the Appendix for a detailed discussion of applying smoothing methods with the LDM.
After the smoothing step, estimates are obtained by substituting the smoothed curves in for and implementing the procedure described in Sections 3.2 and 3.3. Once all model components are estimated, plug-in estimates of the composite distortion functions and marginal and subject-level component deformation functions are an immediate consequence,
| (18) |
| (19) |
| (20) |
Additionally, fitted curves based on the LDM can be obtained as
| (21) |
These fits can be viewed through the lens of dimension reduction as their calculation require only estimated functions as opposed to curves in the original data. This constitutes a novel representation for multivariate functional data that is distinct from the common functional principal component representations.
4. Data Applications
4.1. Zürich Growth Study
From 1954 to 1978, a longitudinal study on human growth and development was conducted at the University Children’s Hospital in Zürich. The sitting heights, arm lengths, and leg lengths of a cohort of children were measured on a dense time grid and these data can be viewed as densely sampled multivariate functional data. We focus on the timing of pubertal growth spurts, which usually occur between ages 9 and 18. It is standard in the growth curve literature to examine the derivatives of the growth curves, i.e. the growth velocities, instead of the curves themselves (Gasser et al., 1984). The velocities have a peak during puberty, with the crest location representing the age when an individual is growing fastest.
The timings and curvatures of these peaks are critical in informing growth patterns. In a first step, we estimated these growth velocities by local linear smoothing (Fig. 2). It is well known that there is a difference in the pubertal growth patterns of boys and girls. This distinction is clear from just a simple inspection of the growth velocities in Figure 1. It is then of scientific interest, with practical implications for auxologists, pediatricians and medical practitioners, to further study and quantify the differential between the onset of puberty for boys and girls, differentiated by different body parts.
Figure 2.
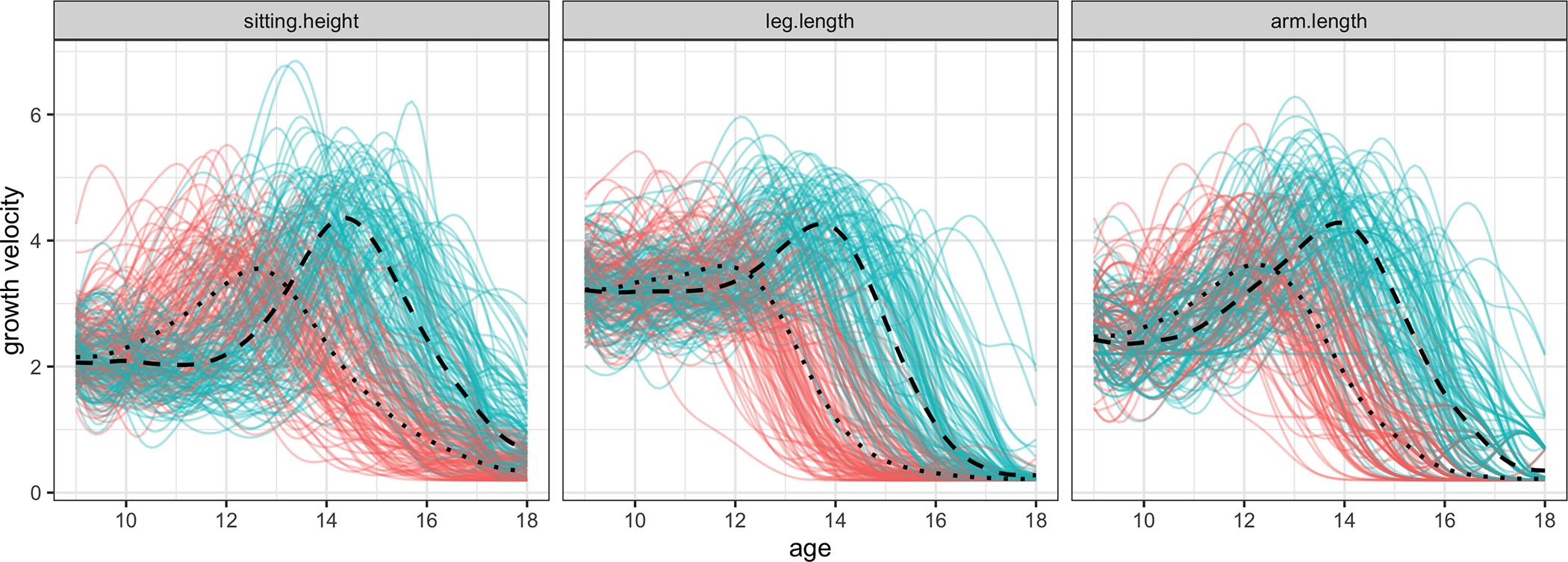
Growth velocities (in cm/year) during puberty for boys (blue) and girls (red). Scaled component tempo functions are marked for boys and girls with dashed and dotted lines, respectively.
For the Zürich Longitudinal Growth Study, the biological clocks accelerate and deviate from clock time rapidly between the ages of 9 and 12 for girls and between the ages of 12 and 15 for boys (represented by the black dashed line on the diagonal). Component tempos for boys and girls are a simple way to summarize these differences (Fig. 2, dashed and dotted lines, respectively), as they serve as the structural means of the timing functions.
Considering the joint time dynamics of the modalities, we restrict our analysis to the boys for the sake of brevity. A natural place to start when comparing growth patterns is the component tempos, which are displayed for each modality in the left panel of Fig. 3. The dynamics of joint development emerges when examining the order of peaks across modalities. Leg length is first, followed by arm length, while sitting height lags behind. The tempos have similar slopes during puberty, though leg length has the most gradual spurt and sitting height the sharpest, perhaps because its lagged onset results in a smaller window between the onset of its growth spurt and the maturation date of 18 years. While it is possible for an individual to experience some minor growth past the age of 18, in the Zürich study such cases were rare and so this complication was ignored. The component deformations displayed in Fig. 3 (right) further illustrate the nature of each body part’s tempo relative to baseline. Remarkably, the tempo of arm length is nearly identical to the latent curve. This suggests that the arm can be used a representative modality which mirrors a child’s overall development.
Figure 3.
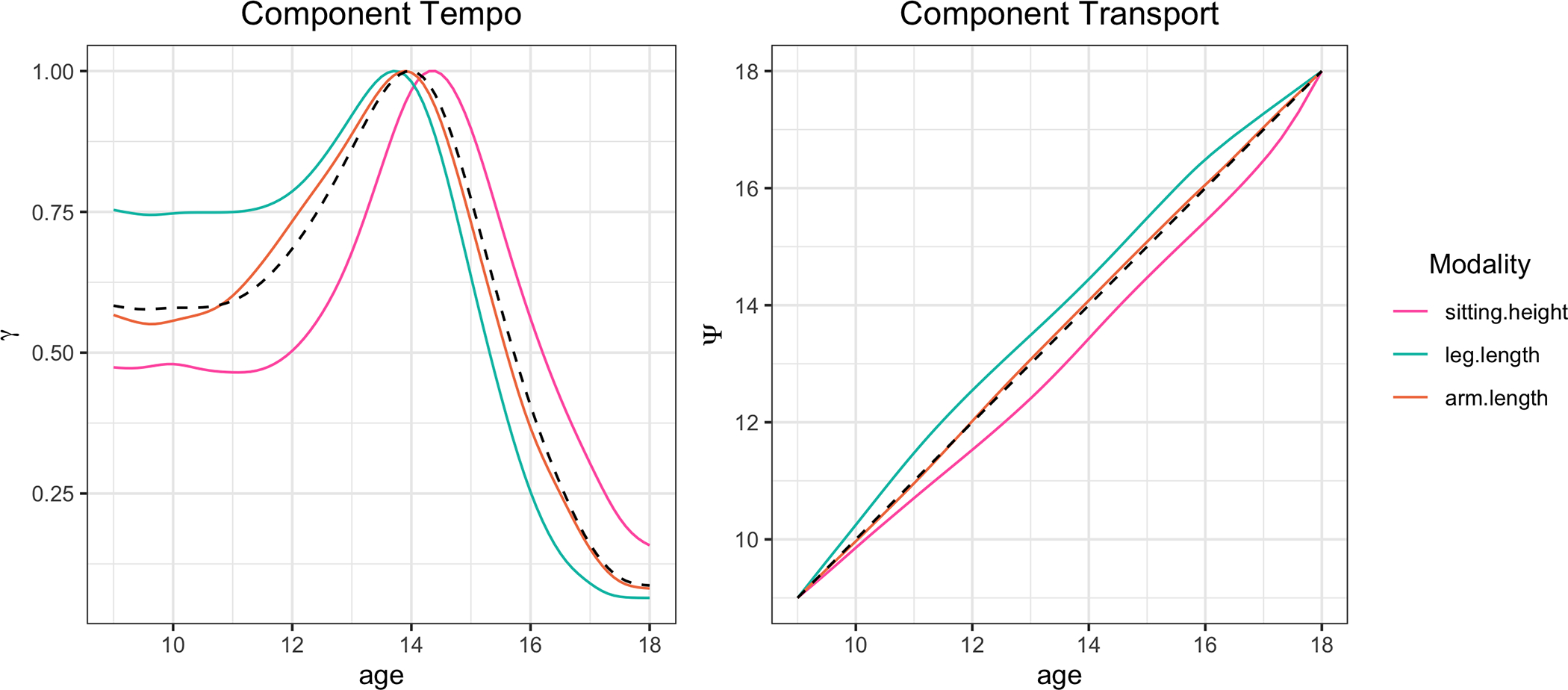
Component tempos (left) and deformations (right) for growth modalities. The dashed line represents the tempo and deformation for the latent tempo, .
We also can interpret the cross-component deformations, , , estimated as per (19). The magnitude of the XCD map’s deviation from the identity shows how dissimilar two components are. For example, sitting height and leg length are the most distinct modalities of growth among those considered here, and their XCD map exhibits the most pronounced departure from the identity. An intuitive interpretation of the map is that expresses the component’s timing patterns relative to the component’s as a baseline. For example, when the leg tempo is at time , the comparable time point for the sitting height tempo is approximately at , as illustrated in Fig. 4.
Figure 4.
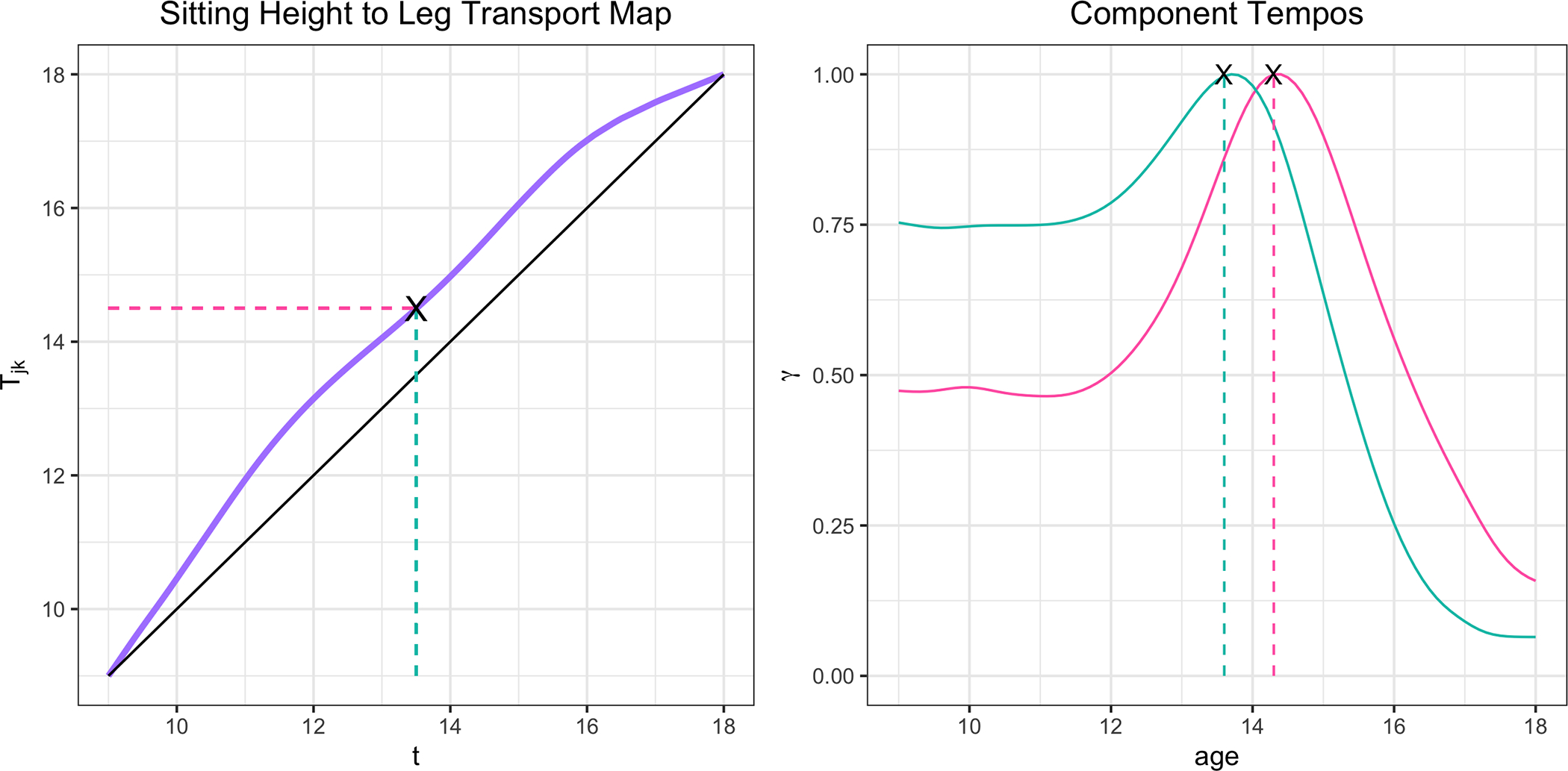
The cross-component deformation map which expresses the sitting height’s timing patterns relative to the leg length’s as a baseline. The peak of pubertal growth rate for the leg occurs at approximately age 13.5, while the maximum growth velocity for sitting height growth occurs at approximately years old.
4.2. Air Pollutants in Sacramento, CA
The study of air pollutants has been a topic of interest for atmospheric scientists and environmentalists alike for several decades. In particular, increased ground-level ozone () concentrations have been shown to have harmful effects on human health. Unlike many air pollutants, surface ozone is not directly emitted by sources of air pollution (e.g. road traffic); it is formed as a result of interactions between nitrogen oxides and volatile organic compounds in the presence of sunlight (Abdul-Wahab, 2001). Because of this interaction, compounds such as nitrogen dioxide are known and important precursors of increased ozone concentrations (Tu et al., 2007).
The California Environmental Protection Agency has monitored hourly air pollutant concentrations at several station locations since the 1980s. Here we consider the sample of weekday trajectories of ozone (), and nitrogen oxides () concentrations during the summer of 2005 in Sacramento (Fig. 5). Smooth trajectories were obtained from raw data using local linear weighted least squares. Gervini (2015) has previously investigated a similar dataset in the context of warped functional regression, where the primary aim was to model phase variation explicitly in order to relate the timing of peak concentrations of to those of .
Figure 5.
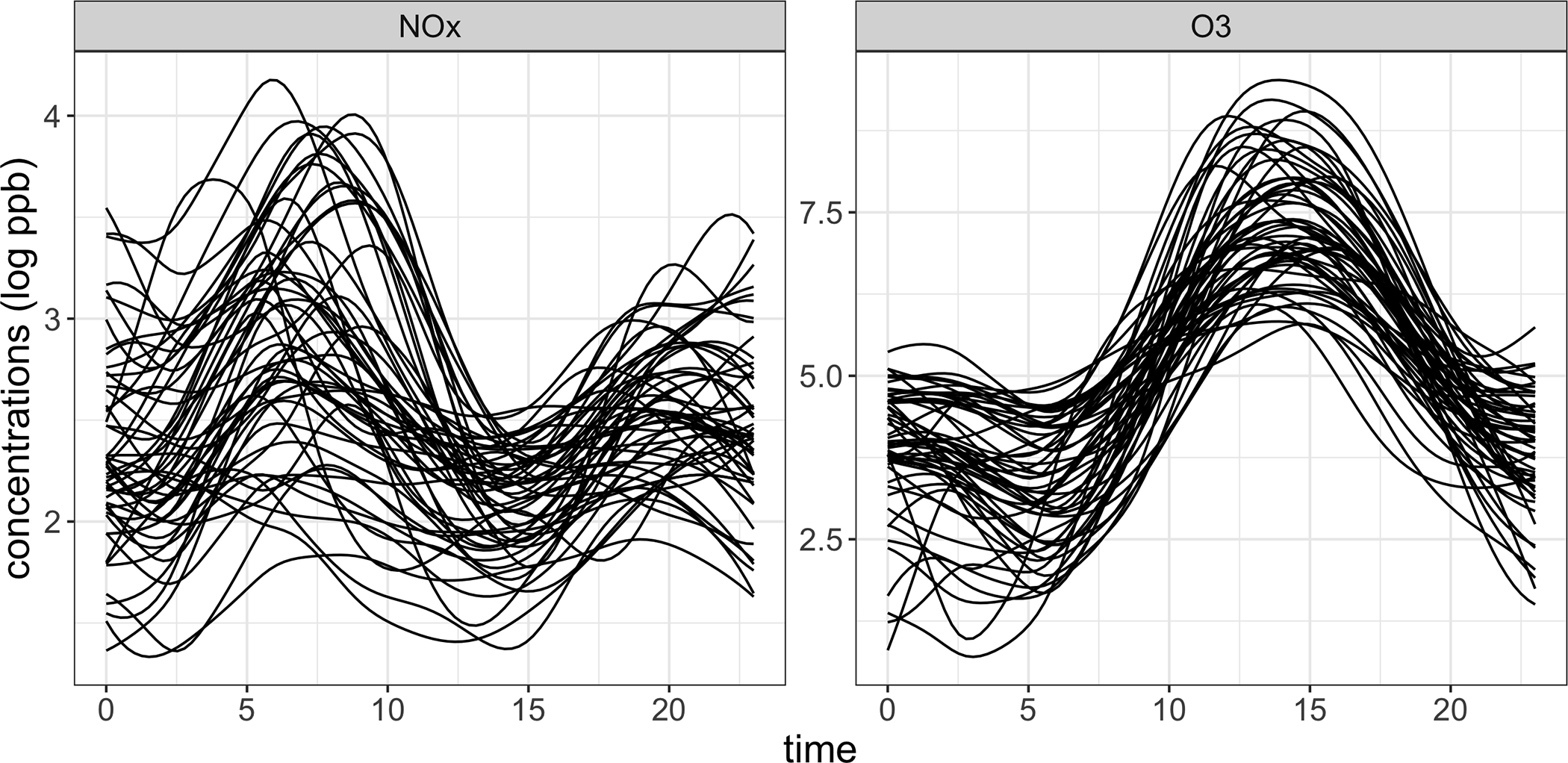
24–hour trajectories of (left) and ozone (right), concentrations in parts per billion (ppb) on a log scale.
The chemistry of the compounds as well as a visual inspection of the curves suggests that the are two distinct classes of pollutants. concentrations tend to peak around 8 a.m., reflecting standard morning commute hours and the impact of traffic emissions on air quality. On the other hand, ozone levels peak around 2 to 3 p.m., indicating that the synthesis mechanism induces a lag of up to approximately 6 hours.
It is then of interest to study whether meteorological factors might affect the rate of ozone synthesis. Individual component deformations combined with Fréchet regression for distributions provide a natural framework for this (Petersen and Müller, 2019). Subject-specific deformations from concentrations to ozone concentrations, , were calculated as per (20) for each day. Global Fréchet regression was then applied through fitting the model
| (22) |
where denotes the conditional Fréchet mean of the deformation given the covariate , the wind speed recorded a given day. Here, is the 2–Wasserstein distance (Villani, 2003) and the weights are derived from global linear regression and defined as (Petersen and Müller, 2019), where and represent the sample mean and variance of the observed wind speeds, respectively. The model was fit using the R package frechet, observing that the deformation functions can be represented as distribution functions (Chen et al., 2020).
Figure 6 displays the observed deformations and the fits obtained from Fréchet regression using windspeed as a predictor. The rainbow gradient corresponds to windspeeds ranging from 3 to 10 knots and their associated fitted deformations are overlaid the original data. The regression fits suggest that days with lower windspeeds correspond with deformations which are further from the diagonal, indicating an exaggerated lag between peak concentrations of and ozone. On the other hand, days with high wind speeds have fitted deformations very near the diagonal which suggests that windier settings accelerate the synthesis process. Intuitively this is a reasonable result in terms of the physical interpretation, as more wind will result in a higher rate of collisions of the particles, and thus quicker production of ozone after peak emission. The Fréchet value was 0.44, which suggests that wind speed explains a considerable amount of variation in the observed deformations.
Figure 6.
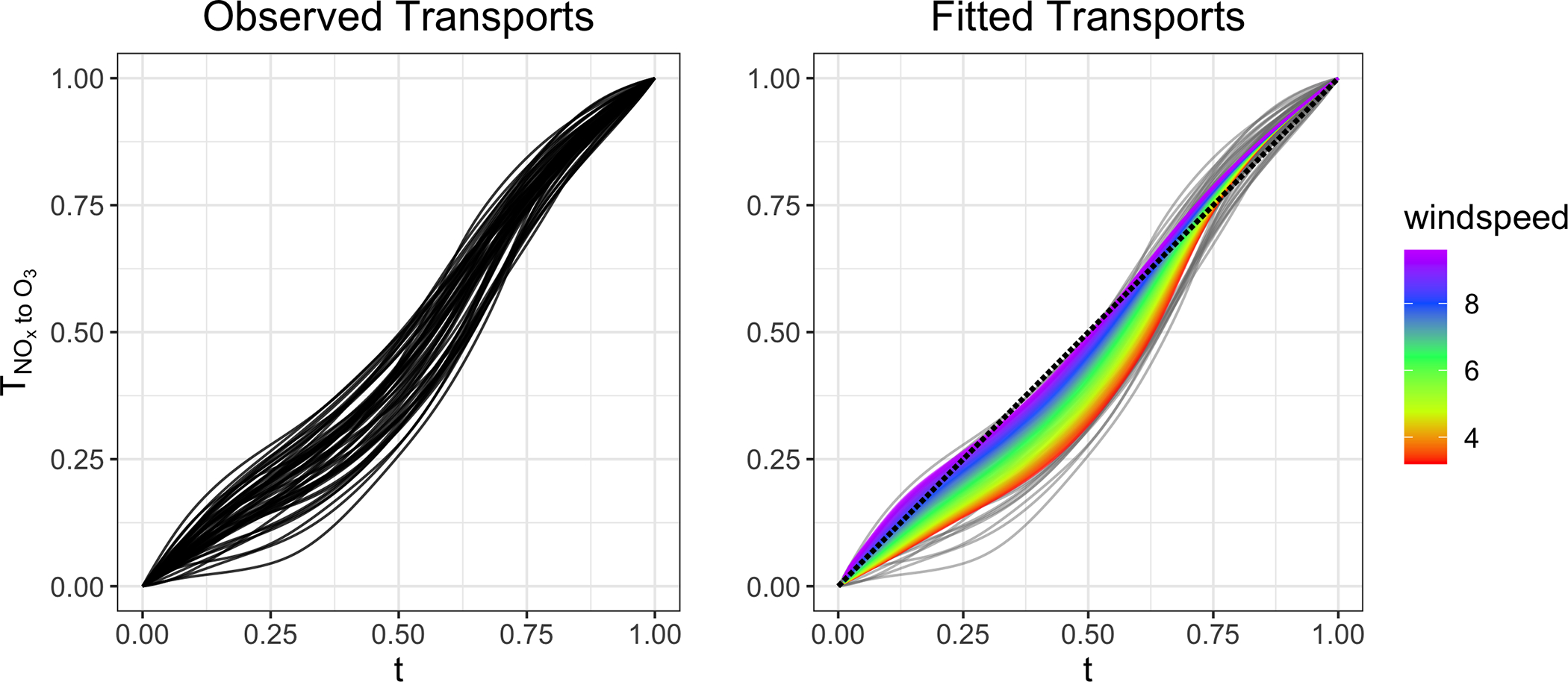
Fréchet regression of -to- cross-component deformations onto daily max windspeeds in knots. Windier days correspond to more linear deformation functions, which suggests synthesis more closely follow emission. Less windy days are associated with more pronounced lags between the pollutants.
5. Theoretical Results
Our results focus on convergence of the components of the LDM described in (4) as the number of curves and the number of observations per curve tend to infinity. We require the following assumptions on (L) the components of the Latent Deformation Model and (S) the smoothing methodology in the presence of discretely observed curves:
(L1) The latent curve is a bounded function. For any non-degenerate interval .
(L2) For and .
Assumption (L1) bounds the latent curves and its derivatives and ensures there are no flat stretches and the uniqueness of the component estimates. (L2) ensures that the ranges of the random processes are bounded away from zero and infinity with high probability; this condition is needed for the uniform convergence of the smoothing estimate.
(S0) The time points , depend on the sample size and constitute a dense regular design with smooth design density with that generates the time points according to , , where denotes the quantile function associated with . The second derivative is bounded, .
(S1) The kernel function is a probability density function with support [−1, 1], symmetric around zero, and uniformly continuous on its support, with .
(S2) For each , the sequences and satisfy (1) , and (2) , , and as
These assumptions guarantee the consistent estimation of curves simultaneously, as shown in the following Proposition. We observe that (S2) is for example satisfied if the bandwidth sequence is chosen such that .
Proposition 1:
Under assumptions (S0–S2), if , , we have the uniform convergence
| (23) |
The rate also extends to the standardized versions ,
| (24) |
This result agrees with the existing results in the literature, in that it is a special case of a general result for metric-space valued functional data (see Chen and Müller (2022)), now here in the case of real-valued functions. The estimators of the latent curve and component deformations involve averages of the smoothing estimates over the sample of curves as . The corresponding rates of convergence will thus rely on the uniform summability of the difference between the smoothed and true curves over and we then have a uniform rate of for an arbitrarily small in lieu of the above rate ; see Lemma 1 in the Appendix. The proposed estimators also rely on the mechanics of the pairwise warping methods, whose convergence properties have been established in a general form in Tang and Müller (2008) and Chen and Müller (2022). Lemma 2 in the Appendix states these rates in the specific framework of the Latent Deformation Model. We are now in a position to state our main result, which establishes rates of convergence for the estimators of the components of the Latent Deformation Model as follows.
Theorem 1:
Under assumptions (L1), (L2), and (S0–S2), with for an arbitrarily small and penalty parameters as described in (10) and (16), we have for all , ,
, and
The three terms in the rates correspond, in order, to (1) the parametric rate achieved through the standard central limit theorem, (2) the smoothing rate which is dependent on the number of observations per curve , and (3) a rate due to the well-known bias introduced by the penalty parameters used in the regularization steps. Additionally, if we suppose that is bounded below by a multiple of , then the rates corresponding to the smoothing steps are bounded above by . If we take the penalty parameters to be , a rate of convergence can be achieved for each of the estimators in Theorem 1 a.-e. Otherwise if , for any , the convergence is limited by the smoothing step and achieves the rate of .
Corollary 1:
Suppose the penalty parameters . If the random trajectories are fully observed without error or the trajectories are recorded with at least a multiple of observations per curve, with , then under the assumptions of Theorem 1, we have for all , ,
,
,
,
, and
.
The asymptotic results for the cross-component deformations then follow immediately from the rates established in Theorem 1.
Theorem 2:
Under assumptions of Theorem 1 for , ,
and
.
A similar corollary for cross-component deformations follows in the case of fully observed curves or dense enough designs.
Corollary 2:
Suppose the penalty parameters . If the random trajectories are fully observed without error or are recorded with at least a multiple of observations per curve, with , then under the assumptions of Theorem 1, we have for , ,
and
.
Corollaries 1 and 2 suggest that, on dense enough measurement schedules, parametric rates of convergence are achievable for the components of the LDM.
Remark 1:
For any cycle of components indexed by the sequence,
with arbitrary length and , their respective cross-component deformations satisfy
This result ensures that the system of cross-componentdeformations maps prevents inconsistencies within itself. For example, if for three components , , and , the pairwise deformations and suggest that Component tends to precede Component which itself tends to precede Component , this implies that the deformations must indicate that Component tends to precede Component . Furthermore, mapping a component tempo through other components and then back to itself will result in the original component tempo, unchanged. Next we consider the convergence rates of reconstructed curves as per (21), putting all model components together.
Theorem 3:
Under assumptions of Theorem 1 for ,
Again a parametric rate is achievable on dense enough designs.
Corollary 3:
Suppose the penalty parameters . If the random trajectories are fully observed without error or the trajectories are recorded with at least a multiple of observations per curve, with , then under the assumptions of Theorem 1, we have for , ,
6. Concluding Remarks
The Latent Deformation Model (LDM) provides a novel decomposition for a large class of practically relevant multivariate functional data by quantifying their inter-component time dynamics. A separability assumption that makes it possible to factor overall time warping into component-specific and subject-specific time warping components is crucial. The ensuing simple representation for multivariate functional data includes two fixed effect terms (the latent curve and a collection of component-level warping functions) and two random effect terms (a random amplitude vector and a collection of subject-level warping functions). This representation requires the estimation of only one random warping function and amplitude vector per subject, in addition to deterministic functions overall.
In some cases these components may be reduced even further. For example, when subject-level warping is negligible or part of a pre-processing step, a special case of the model arises in which time dynamics are fully characterized by the fixed effect curves and one random scalar per component. Alternatively, if subject-level time warping is present but further dimension reduction is desired, transformation of warps by the LQD transform (Petersen et al., 2016) or other means (see, e.g. Happ et al. (2019)) will permit a Karhunen-Loève expansion in –space. Applying the LDM and truncating this expansion at an appropriate number of eigenfunctions, say , creates a representation of multivariate functional data using only random scalars, as opposed to a standard FPCA representation which requires variables.
A limitation of this framework is the fact that slight deviations from a common latent curve will always occur in practice. An implicit assumption in applying the LDM is that the magnitude of nuisance peaks is negligible in comparison to the dominant features of the latent curve. Simulations which examine the robustness of component estimates in the presence of model misspecification or more pronounced nuisance peaks are in the supplement.
The LDM serves both as an extension of existing univariate functional warping methods, as well as a stepping stone for many new potential models for multivariate functional data analysis and registration. Future directions of note include harnessing cross-component deformation maps for imputating components in partially observed multivariate functional data, or relaxing structural assumptions to allow for more flexible functional relationships between different latent curves for distinct subsets of components; e.g. allowing for multiple latent curves, , with for some function . Spatiotemporal applications are also promising for the LDM, in which the vector components are indexed by location. Then component warping functions may reveal time trends across geographic regions.
Supplementary Material
Acknowledgments
We wish to thank two referees for very useful suggestions. This research was supported in part by NSF grant DMS-2014626.
Footnotes
Supporting Information
Web Appendices referenced in Sections 3 and 6 and R code that implements the Latent Deformation Model are available with this paper at the Biometrics website on Wiley Online Library.
Data Availability Statement
The air pollutant data used in the application section are publicly available on the California Air Resource Board’s website: https://www.arb.ca.gov/adam. The growth curve data are proprietary to the Zürich University Children’s Hospital and therefore not shared.
References
- Abdul-Wahab SA (2001). Ier photochemical smog evaluation and forecasting of short-term ozone pollution levels with artificial neural networks. Process Safety and Environmental Protection 79, 117–128. [Google Scholar]
- Bigot J and Charlier B (2011). On the consistency of fréchet means in deformable models for curve and image analysis. Electronic Journal of Statistics 5, 1054–1089. [Google Scholar]
- Bigot J, Gadat S, and Loubes J-M (2009). Statistical m-estimation and consistency in large deformable models for image warping. Journal of Mathematical Imaging and Vision 34, 270–290. [Google Scholar]
- Brunel NJ-B and Park J (2014). Removing phase variability to extract a mean shape for juggling trajectories. Electron. J. Statist. 8, 1848–1855. [Google Scholar]
- Cardot H, Ferraty F, and Sarda P (1999). Functional linear model. Statistics & Probability Letters 45, 11–22. [Google Scholar]
- Carroll C, Gajardo A, Chen Y, Dai X, Fan J, Hadjipantelis P, Han K, Ji H, Lin S, Dubey P, et al. (2020). fdapace: functional data analysis and empirical dynamics. R package version 0.5.6. [Google Scholar]
- Carroll C, Müller H-G, and Kneip A (2021). Cross-component registration for multivariate functional data, with application to growth curves. Biometrics 77, 839–851. [Google Scholar]
- Chen K, Delicado P, and Müller H-G (2017). Modeling function-valued stochastic processes, with applications to fertility dynamics. Journal of the Royal Statistical Society, Series B (Theory and Methodology) 79, 177–196. [Google Scholar]
- Chen Y, Gajardo A, Fan J, Zhong Q, Dubey P, Han K, Bhattacharjee S, and Müller H-G (2020). frechet: Statistical Analysis for Random Objects and Non-Euclidean Data. R package version 0.2.0. [Google Scholar]
- Chen Y and Müller H-G (2022). Uniform convergence of local fréchet regression and time warping for metric-space-valued trajectories. Annals of Statistics 50, 1573–1592. [Google Scholar]
- Chiou J-M, Chen Y-T, and Yang Y-F (2014). Multivariate functional principal component analysis: A normalization approach. Statistica Sinica 24, 1571–1596. [Google Scholar]
- Chiou J-M and Li P-L (2007). Functional clustering and identifying substructures of longitudinal data. Journal of the Royal Statistical Society. Series B. Statistical Methodology 69, 679–699. [Google Scholar]
- Chiou J-M, Yang Y-F, and Chen Y-T (2016). Multivariate functional linear regression and prediction. Journal of Multivariate Analysis 146, 301–312. [Google Scholar]
- Ferraty F and Vieu P (2006). Nonparametric Functional Data Analysis. Springer, New York, New York. [Google Scholar]
- Gasser T, Köhler W, Müller H-G, Kneip A, Largo R, Molinari L, and Prader A (1984). Velocity and acceleration of height growth using kernel estimation. Annals of Human Biology 11, 397–411. [DOI] [PubMed] [Google Scholar]
- Gervini D (2015). Warped functional regression. Biometrika 102, 1–14. [Google Scholar]
- Han K, Hadjipantelis PZ, Wang J-L, Kramer MS, Yang S, Martin RM, and Müller H-G (2018). Functional principal component analysis for identifying multivariate patterns and archetypes of growth, and their association with long-term cognitive development. PloS one 13, e0207073. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Happ C and Greven S (2018). Multivariate functional principal component analysis for data observed on different (dimensional) domains. Journal of the American Statistical Association 113, 649–659. [Google Scholar]
- Happ C, Scheipl F, Gabriel A-A, and Greven S (2019). A general framework for multivariate functional principal component analysis of amplitude and phase variation. Stat 8, e220. [Google Scholar]
- Jacques J and Preda C (2014). Model-based clustering for multivariate functional data. Computational Statistics and Data Analysis 71, 92–106. [Google Scholar]
- Kleffe J (1973). Principal components of random variables with values in a separable Hilbert space. Statistics: A Journal of Theoretical and Applied Statistics 4, 391–406. [Google Scholar]
- Kneip A and Engel J (1995). Model estimation in nonlinear regression under shape invariance. The Annals of Statistics pages 551–570. [Google Scholar]
- Kneip A and Gasser T (1992). Statistical tools to analyze data representing a sample of curves. The Annals of Statistics 20, 1266–1305. [Google Scholar]
- Kneip A and Ramsay JO (2008). Combining Registration and Fitting for Functional Models. Journal of the American Statistical Association 103, 1155–1165. [Google Scholar]
- Liang D, Huang H, Guan Y, and Yao F (2022). Test of weak separability for spatially stationary functional field. Journal of the American Statistical Association pages 1–14.35757777 [Google Scholar]
- Marron JS, Ramsay JO, Sangalli LM, and Srivastava A (2015). Functional data analysis of amplitude and phase variation. Statistical Science 30, 468–484. [Google Scholar]
- Park J and Ahn J (2017). Clustering multivariate functional data with phase variation. Biometrics 73, 324–333. [DOI] [PubMed] [Google Scholar]
- Petersen A and Müller H-G (2019). Fréchet regression for random objects with euclidean predictors. Annals of Statistics 47, 691–719. [Google Scholar]
- Petersen A, Müller H-G, et al. (2016). Functional data analysis for density functions by transformation to a hilbert space. Annals of Statistics 44, 183–218. [Google Scholar]
- Ramsay JO and Li X (1998). Curve registration. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 60, 351–363. [Google Scholar]
- Ramsay JO and Silverman BW (2005). Functional Data Analysis. Springer Series in Statistics. Springer, New York, second edition. [Google Scholar]
- Tang R and Müller H-G (2008). Pairwise curve synchronization for functional data. Biometrika 95, 875–889. [Google Scholar]
- Tu J, Xia Z-G, Wang H, and Li W (2007). Temporal variations in surface ozone and its precursors and meteorological effects at an urban site in china. Atmospheric Research 85,310–337. [Google Scholar]
- Villani C (2003). Topics in Optimal Transportation. American Mathematical Society. [Google Scholar]
- Wang J-L, Chiou J-M, and Müller H-G (2016). Functional data analysis. Annual Review of Statistics and its Application 3, 257–295. [Google Scholar]
- Yao F, Müller H-G, and Wang J-L (2005). Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association 100, 577–590. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The air pollutant data used in the application section are publicly available on the California Air Resource Board’s website: https://www.arb.ca.gov/adam. The growth curve data are proprietary to the Zürich University Children’s Hospital and therefore not shared.