

Abstract
Effective pandemic preparedness relies on anticipating viral mutations that are able to evade host immune responses to facilitate vaccine and therapeutic design. However, current strategies for viral evolution prediction are not available early in a pandemic—experimental approaches require host polyclonal antibodies to test against1–16, and existing computational methods draw heavily from current strain prevalence to make reliable predictions of variants of concern17–19. To address this, we developed EVEscape, a generalizable modular framework that combines fitness predictions from a deep learning model of historical sequences with biophysical and structural information. EVEscape quantifies the viral escape potential of mutations at scale and has the advantage of being applicable before surveillance sequencing, experimental scans or three-dimensional structures of antibody complexes are available. We demonstrate that EVEscape, trained on sequences available before 2020, is as accurate as high-throughput experimental scans at anticipating pandemic variation for SARS-CoV-2 and is generalizable to other viruses including influenza, HIV and understudied viruses with pandemic potential such as Lassa and Nipah. We provide continually revised escape scores for all current strains of SARS-CoV-2 and predict probable further mutations to forecast emerging strains as a tool for continuing vaccine development (evescape.org).
Subject terms: Immune evasion, Computational models
EVEscape, a flexible framework using deep learning and biophysical structural information, enables early identification of concerning mutations in viruses with pandemic potential, facilitating the development of vaccines and therapeutics.
Main
Viral diseases involve a complex interplay between immune detection in the host and viral evasion, often leading to the evolution of viral antigenic proteins. Antibody escape mutations affect viral reinfection rates and the duration of vaccine efficacy. Therefore, anticipating viral variants that avoid immune detection with sufficient lead time is key to developing optimal vaccines and therapeutics.
Ideally, we would be able to anticipate viral immune evasion using experimental methods such as pseudovirus assays1 and higher-throughput deep mutational scans2–16 (DMSs) that measure the ability of viral variants to bind to relevant antibodies. However, these experimental methods require antibodies or sera representative of the aggregate immune selection imposed on the virus, which become available only as large swaths of the population are infected or vaccinated, limiting the impact for early prediction of immune escape. In addition, as pandemic viruses can evolve rapidly (tens of thousands of new SARS-CoV-2 variants are sequenced each month), systematically testing all variants as they emerge is intractable, even without considering the effects of potential mutations on circulating strains.
It is therefore of interest to develop computational methods for predicting viral escape that can be used to identify mutations that may emerge. An ideal model would be able to assess escape likelihood for as-yet-unseen variation throughout the full antigenic protein, would inform the design of targeted experiments, would be revised with pandemic information and would make predictions with sufficient lead time for vaccine development (that is, before immune responses to the virus are observed). However, previous computational methods for forecasting viral fitness or immune escape depend critically on real-time sequencing or pandemic antibody structures, limiting their ability to predict unseen variants and making them impractical for vaccine development during the onset of a pandemic17–19.
In this work, we introduce EVEscape, a flexible framework that addresses the weaknesses of previous methods by combining a deep generative model trained on historical viral sequences with structural and biophysical constraints. Unlike previous methods, EVEscape does not rely on recent pandemic sequencing or antibodies, making it applicable both in the early stages of a viral outbreak and for continuing evaluation of emerging SARS-CoV-2 strains. By leveraging functional constraints learned from past evolution, as successfully demonstrated for predicting clinical variant effects20–22, EVEscape can capture relevant epistasis23–25 and thus predict mutant fitness in the context of any strain background. Moreover, EVEscape is adaptable to new viruses, as we demonstrate in both our validation on SARS-CoV-2, HIV and influenza and in predictions for the understudied Nipah and Lassa viruses. This approach enables advance warning of concerning mutations, facilitating the development of more effective vaccines and therapeutics. Such an early warning system could guide public health decision-making and preparedness efforts, ultimately minimizing the human and economic impact of a pandemic.
EVEscape combines deep learning models and biophysical constraints
Viral proteins that escape humoral immunity disrupt polyclonal antibody binding while retaining protein expression, protein folding, host receptor binding and other properties necessary for viral infection and transmission8. We built a modelling framework, EVEscape, that incorporates constraints from these different aspects of viral protein function learned from different data sources. We express the probability that a mutation will induce immune escape as the product of three probabilities: the likelihoods that a mutation will maintain viral fitness (‘fitness’ term), occur in an antibody-accessible region (‘accessibility’ term) and disrupt antibody binding (‘dissimilarity’ term) (Fig. 1a and Extended Data Fig. 1). These components are amenable to prepandemic data sources, allowing for early warning (Fig. 1b).
Fig. 1. Early prediction of antibody escape from deep generative sequence models, structural and biophysical constraints.

a, EVEscape assesses the likelihood of a mutation escaping the immune response on the basis of the probabilities of a given mutation maintaining viral fitness, occurring in an antibody epitope and disrupting antibody binding. b, EVEscape requires only information available early in a pandemic, before surveillance sequencing, antibody–antigen structures or experimental mutational scans are broadly available. This provides further early warning time critical for vaccine development. Ab, antibody. Panel a created with BioRender.com.
Extended Data Fig. 1. EVEscape model components.

We decompose the likelihood of a mutation to escape the immune response as the product of three components: probability of a given mutation to maintain viral fitness (fitness component), to occur in an antibody epitope (accessibility component), and to disrupt antibody binding (dissimilarity component). For fitness (bottom), we train a virus-specific Bayesian VAE on evolutionarily-related proteins to learn a distribution over sequences in that protein family. The ELBO term from the VAE is used as a tractable approximation to the sequence log likelihood, with Δ ELBOs thus quantifying the relative fitness of a given mutated sequence s with respect to the wild type w. Accessibility (top left) is quantified via the negative Weighted Contact Number (WCN) for a residue in a given conformation. If there are multiple conformations, the maximum negative WCN across conformations is used. Dissimilarity (top right) relies on change in key physicochemical properties induced by the mutation, such as hydrophobicity and charge. For all components, the operator f(.) represents a component-specific temperature-scaled logistic transform. Created with BioRender.com.
First, we estimated the fitness effect of substitution mutations (subsequently referred to as mutations) using EVE20, a deep variational autoencoder trained on evolutionarily related protein sequences (Supplementary Tables 1 and 2) that learns constraints underpinning structure and function for a given protein family. Consequently, EVE considers dependencies across positions (epistasis), capturing the changing effects of mutations as the dominant strain backgrounds diversify from the initial sequence23–25. We demonstrate the efficacy of EVE by comparing model predictions and data from mutational scanning experiments that measure several facets of fitness for thousands of mutations to viral proteins25–32. Model performance approaches the Spearman correlation (ρ) between experimental replicates, including viral replication for influenza26 (ρ = 0.53) and HIV25 (ρ = 0.48) (Extended Data Fig. 2 and Supplementary Tables 3 and 4). For SARS-CoV-2, we trained EVE across broad prepandemic coronavirus sequences, from sarbecoviruses including SARS-CoV-1 to ‘common cold’ seasonal coronaviruses including the alphacoronavirus NL63 (Supplementary Tables 1 and 2), and compared predictions with measures of expression (ρ = 0.45) and receptor binding30 (ρ = 0.26) (Extended Data Fig. 2 and Supplementary Table 4). We note that sites that expressed in the DMS experiments but were predicted to be deleterious by EVE were frequently in contact with non-assayed domains of the Spike protein or with the trimer interface, interactions not captured in the receptor-binding domain (RBD) yeast-display experiment (Extended Data Fig. 2f).
Extended Data Fig. 2. Fitness effects of viral proteins predicted from evolutionary sequence models.

a) EVE predictions are well correlated with a broad range of viral surface protein deep mutation scanning experiments surveying protein replication and function for SARS-CoV-2 RBD30,31 and Mpro32, H1N1 hemagglutinin26,27 and HIV env25,28,29. b) Site-averaged EVE predictions have similar correlations with site-averaged SARS-CoV-2 RBD DMS experiments as Potts model DCA37 or EVmutation21. c) EVE predictions have higher correlations with Flu H1, HIV Env, and SARS-CoV-2 RBD DMS experiments than grammaticality in CSCS42. d) EVE prediction captures a combination of SARS-CoV-2 RBD yeast expression and ACE2 binding - features both necessary for successful immune escape (EVE spearman with expression = 0.45, EVE spearman with ACE2 binding = 0.38 when low expression mutations are removed)30. e) The mammalian-cell RBD expression and ACE2 binding experiments are highly correlated, likely due to the alternate FACS-binning strategy and metric used for this ACE2 binding experiment31. EVE predictions are correlated with both measures. f) Site-averaged EVE scores predict several sites that tolerate mutants in the yeast-display RBD expression assay30 to be deleterious (red box)–many of these mutants are located at the interface between RBD and the rest of Spike protein. Sites in the red box in scatterplot are shown as spheres on the Spike structure (PDB: 7CAB).
The second model component, antibody accessibility, is motivated by the need to identify potential antibody binding sites without previous knowledge of B cell epitopes. The accessibility of each residue is computed from its negative weighted residue-contact number across available three-dimensional conformations (without antibodies), which captures both protrusion from the core structure and conformational flexibility33 (Supplementary Table 1). Finally, dissimilarity is computed using differences in hydrophobicity and charge, properties known to affect protein–protein interactions34. This simple metric correlates with experimentally measured within-site escape more than individual chemical properties, substitution-matrix derived distance or distance in the latent space of the EVE model (Extended Data Fig. 3f). To support modularity and interpretability of the impact of each component, each term is separately standardized and then fed into a temperature-scaled logistic function (Supplementary Methods and Supplementary Tables 5 and 6).
Extended Data Fig. 3. Understanding the roles of each EVEscape component.

a) EVEscape is more predictive of high-frequency pandemic mutations than ablations of any of its three components. Notably, the ablation of the dissimilarity term leads to similar performance at identifying low-frequency mutations, but inferior performance at identifying high-frequency mutations. b) Ablation analysis indicates that all features of EVEscape contribute to performance in predicting RBD escape mutants in deep mutational scanning experiments. c) EVEscape is more predictive than EVE alone at capturing frequent mutations (seen >50,000 times) in full Spike. VOC mutations with high EVE scores and lower EVEscape scores (i.e., A222V and T547K) are known to impact protein conformation and to not escape sera neutralization39. Mutations with the highest EVEscape but low EVE scores (i.e., R190S and R408S) are in hydrophobic pockets that may promote antibody binding38. d) Sites with either high WCN accessibility or high EVE fitness predictions have a greater percent of escape mutants (upper). WCN and EVE predictions provide similar information about the location of Spike epitopes as identified from antibody-Spike crystal structures in RCSB PDB (lower). e) Density of standard-scaled EVEscape components differ for SARS-CoV-2 RBD escape (and antibody epitope) mutations and non-escape mutations for WCN, RSA, EVE, and site-averaged EVEscape. All but 2 sites in the top 20% of EVEscape scores are in known antibody footprints or have escape mutations in experiments. f) Within-site point biserial correlations between residue dissimilarity metrics and SARS-CoV-2 DMS escape data at escape sites (sites with 3–17 escape mutations). More sites have a higher correlation for our charge-hydrophobicity metric than charge or hydrophobicity alone, BLOSUM62, residue size, or EVE latent space L1 distance. Bounds of boxplot are quartiles with the median as the measure of center.
Anticipating pandemic variation with prepandemic data
Extensive surveillance sequencing and experimentation prompted by the COVID-19 pandemic have presented a unique opportunity to assess the ability of EVEscape to predict immune evasion before escape mutations are observed. To test the model’s capacity to make early predictions, we carried out a retrospective study using only information available before the pandemic (training on Spike sequences across Coronaviridae available before January 2020; Supplementary Tables 1 and 2). We then evaluated the method by comparing predictions against what was subsequently learned about SARS-CoV-2 Spike immune interactions and immune escape.
The top predicted escape mutations for the whole of Spike were strongly biased towards the RBD and N-terminal domain (NTD), coincident with the bias for antigenic regions seen in the pandemic35 (Fig. 2a,b and Extended Data Fig. 4). Within these domains, EVEscape scores were biased towards neutralizing regions—the receptor-binding motif of the RBD and the neutralizing supersite36 in the NTD (Fig. 2c and Extended Data Fig. 4d). The ability of EVEscape to identify the most immunogenic domains of viral proteins without knowledge of specific antibodies or their epitopes could provide crucial information for early development of subunit vaccines in an emerging pandemic.
Fig. 2. EVEscape identifies antigenic regions without antibody information.

a, EVEscape scores (site-level maximum) mapped onto a representative Spike three-dimensional structure (Protein Data Bank (PDB) identifier: 7BNN) highlight high-scoring regions with many observed pandemic variants, both in the RBD and in the NTD. Spheres indicate sites with a total number of mutations observed more than 10,000 times in the GISAID sequence database. b, The top decile of EVEscape predictions span diverse epitope regions across Spike, but most of the predictions are in the NTD and RBD, which have a disproportionately high number of predicted EVEscape sites relative to their sequence length (enrichment). The regions considered are NTD (sequence positions 14–306), RBD (319–542), S1* (543–685) and S2 (686–1273), where S1* refers to the region in S1 between RBD and the S2. c, Neutralizing subregions—RBM (receptor-binding motif, 438–506) and NTD supersite36 (14–20,140–158, 245–263)—have significantly higher than average EVEscape scores, relative to a distribution of 150 random contiguous regions of the same length within the RBD and NTD, respectively.
Extended Data Fig. 4. EVEscape enrichment in regions of SARS-CoV-2 Spike.
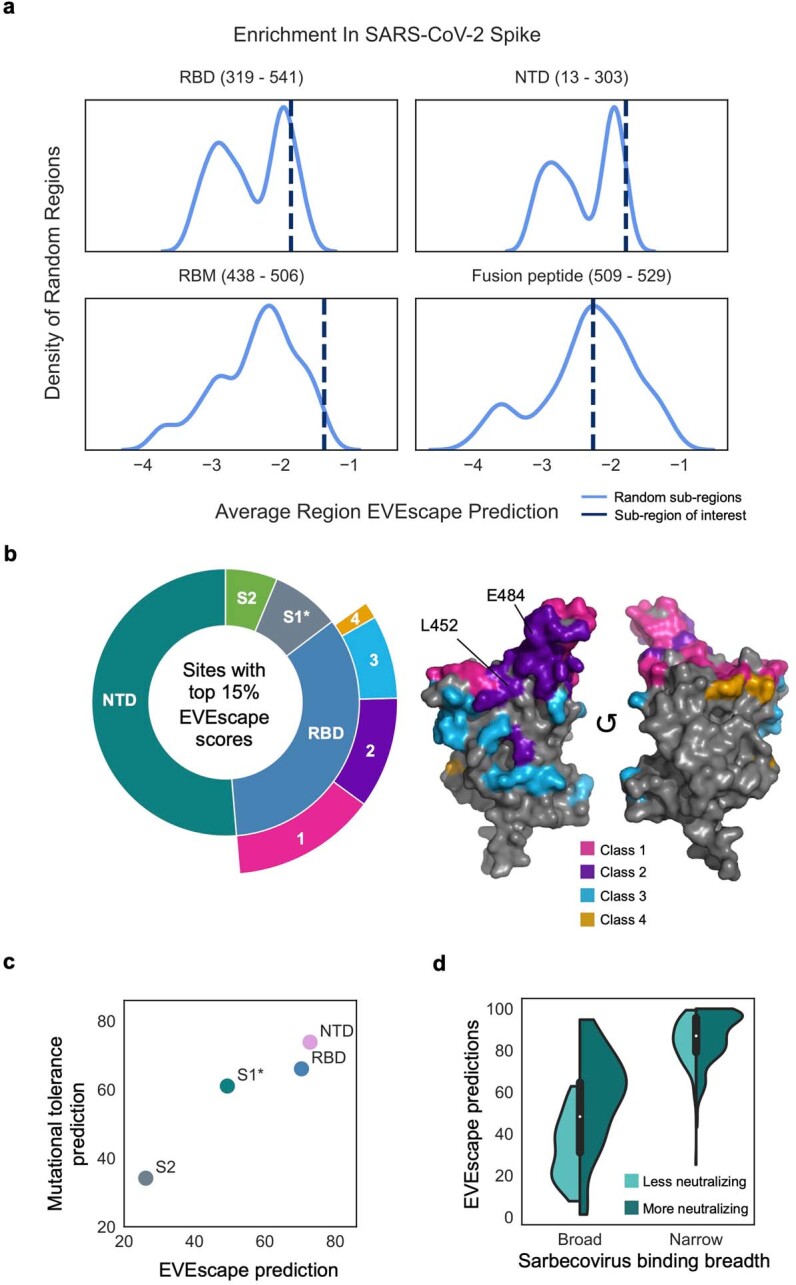
a) RBD (particularly receptor binding motif (RBM)) and N-terminal domain (NTD) have significantly enriched average EVEscape scores, relative to a distribution of 500 random contiguous regions of the same length from full Spike. Fusion peptide (not known for escape mutations) does not have enriched average EVEscape scores. b) EVEscape predictions cover diverse epitope regions across Spike and diverse RBD antibody classes (Supplementary Methods) (3D structure of RBD on the right), including known immunodominant sites (E484, K417, L452) (PDB ID: 7BNN). The regions considered are NTD (sequence positions 14 − 306), RBD (319 − 542), S1* (543 − 685), and S2 (686 − 1273), where S1* refers to the region in S1 between RBD and S2. c) Average region EVEscape predictions are highest in RBD and NTD, although NTD is more mutationally tolerant based on average fitness (EVE) score. d) EVEscape scores experimental escape mutants from narrow antibodies and broad neutralizing antibodies higher than those from broad, non-neutralizing antibodies. Sarbecovirus binding breath and neutralization from Starr et al. 8 Bounds of boxplot are quartiles with the median as the measure of center.
We next compared model predictions with mutations that were subsequently observed in the pandemic as deposited in GISAID (Global Initiative on Sharing All Influenza Data), which contains more than 750,000 unique sequences. For this analysis, we focused on the RBD of Spike, as this domain has been the most extensively studied owing to its immunodominance35.
Fifty percent of our top RBD predictions were seen in the pandemic by May 2023 (Fig. 3a; this proportion is robust to the threshold defining top escape mutations). The more often a mutation occurred in the pandemic, the more likely it was to be predicted by our method—66% of high-frequency observed substitutions were in the top EVEscape predictions (Fig. 3b). We expect that the highest-frequency mutations, seen in historical variants of concern (VOCs), will be enriched for escape variants that provide a fitness advantage in an immune population (while not expecting that all single substitutions in the VOCs will contribute to escape) (Fig. 3c and Extended Data Fig. 5).
Fig. 3. Prepandemic EVEscape is as accurate as intrapandemic experimental scans at anticipating pandemic variation.

a, Percentages of top decile predicted escape mutations by EVEscape, mutational scan experiments (Bloom Set, Supplementary Table 5) and a previous computational model42 seen more than 100 times in GISAID by each date since the start of the pandemic. EVEscape using prepandemic sequences anticipates pandemic variation at least on par with mutational scan experiments using antibodies and sera available 10 or 17 months into the pandemic. Analysis focuses only on non-synonymous point mutations that are a single nucleotide distance away from the Wuhan viral sequence, as well as on the RBD of Spike as that is where experimental data are available. b, Percentages of observed pandemic mutations in top decile of escape predictions by observed frequency during the pandemic. High-frequency mutations in particular are well-captured by EVEscape. c, Most of the RBD mutations observed in VOC strains have high EVEscape scores and lower scores in the mutational scan experiments against pandemic sera. This is true even when considering a further set of mutations identified in mutational scanning experiments as significantly improving (in the top 2%) either RBD expression or ACE2 binding. d, EVEscape can predict escape mutations in the epitope of the former therapeutic antibody bamlanivimab. E484 is involved in a salt bridge with R96 and R50 of bamlanivimab, which lost Food and Drug Administration emergency use authorization owing to the emergence of Omicron, wherein E484A or E484K mutations (both predicted in the top 1% of EVEscape Spike predictions) escape binding because of the loss of these salt bridges41.e, Precision-recall curve for RBD escape predictions of EVEscape, EVEscape fitness component only (EVE model) and a previous computational model42 compared with DMS escape mutations (AUPRC reported with a comparison with a ‘null’ model in which escape mutations are randomly predicted). expr, expression.; no., number.
Extended Data Fig. 5. EVEscape as accurate as experimental scans at anticipating pandemic variation: retrospective analysis.

a) Top 10% of RBD escape predictions computed using either EVEscape, DMS experiments (Bloom Set, Table S4), or prior models42 seen by each date over 100 times in GISAID (left). DMS experiments are separated into which studies were available by each starting date. Top 10% of full Spike escape predictions computed using either EVEscape or prior SpikePro model18 seen by each date over 100 times in GISAID (right). b) Fraction of top mutations (at different percentage thresholds) predicted by EVEscape, DMS experiments, or prior models seen more than 1000 times in GISAID. c) The majority of Spike mutations in VOC strains have high EVEscape scores. d) Venn diagram comparing the top 10% (left) or 20% (right) of RBD sites predicted by EVEscape and by DMS experiments (Bloom Set Table S4). Each bin is stratified to indicate the number of sites observed >100 times over the full pandemic (stripe pattern). All sites in the top 20% of EVEscape predictions have been observed in the pandemic, and there is significantly more overlap between EVEscape and experiments when looking at the top 20% of their predictions as compared to the top 10%.
Not surprisingly, the fitness model component alone (here EVE20) was better that the full EVEscape model at predicting mutations seen at low frequency in the pandemic (that is, identifying 357 versus 298 of mutations seen 100–1,000 times in the pandemic in the top quartile), probably because these mutations retain viral function but do not necessarily affect antibody binding or have a strong fitness advantage over other strains. This indicates that the immune-specific components of EVEscape may reflect important pandemic constraints not represented in models of fitness alone20,37 and allow for mutation interpretability. For instance, VOC mutations R190S and R408S, with high EVEscape but low EVE scores, are in hydrophobic pockets that may facilitate significant immune escape38 (Extended Data Fig. 3c). Meanwhile, the few VOC mutations (A222V and T547K) with significant EVE—but not EVEscape—scores have known functional improvements such as monomer packing and RBD opening but do not affect escape39,40 (Extended Data Fig. 3c). Furthermore, the proportion of EVEscape predictions seen during the pandemic increased over time—from 3% in December 2020 to 50% in May 2023 (Fig. 3a)—and should continue to increase, an expected trend both as more variants are observed and as adaptive immune pressure increases with the growing vaccinated or previously infected population. Similarly, the fraction of mutations in VOC strains with high EVEscape scores has also increased over time (Fig. 3b).
Our model also predicted escape mutations that were subsequently observed in the pandemic in the epitopes of well-known therapeutic monoclonal antibodies under current or former emergency use authorization (Supplementary Table 7), for example, N440, E484A/K/Q and Q493R. These predictions demonstrate the interplay of our three model components; for instance, the high accessibility as well as mutability of E484 results in 50% of all possible mutations at this site in the top 2% of EVEscape predictions and includes E484A/K mutations in the top 1%—notable for escape from bamlanivimab41 (Fig. 3d)—because of their high dissimilarity scores. We also identify candidate escape mutations in these therapeutic epitopes that have not yet been observed at frequencies higher than 10,000—for instance variants to K444 and K417 (Supplementary Table 7), a subset of which are beginning to appear. This result indicates that escape sites could be well predicted before a pandemic and may have concrete applications for escape-resistant therapeutic design and early warning of waning effectiveness.
EVEscape represents a significant improvement over past computational methods. EVEscape is more than twice as predictive as previous unsupervised models42, both at predicting pandemic mutations (50% versus 24% of top predictions observed in the pandemic and 66% versus 17% of highest-frequency mutations predicted) and at anticipating experimental measures of antibody escape (0.53 versus 0.24 area under the precision-recall curve (AUPRC)) (Fig. 3a–c,e, Extended Data Fig. 5 and Supplementary Tables 4 and 8). All EVEscape components play a part in these predictions, with fitness predictions and accessibility metrics identifying sites of escape mutations, whereas dissimilarity identifies amino acids that facilitate escape within sites (Extended Data Fig. 3). Moreover, other computational methods18,19 focus on near-term prediction of strain dominance rather than longer-term anticipation of immune evasion, as they rely on pandemic sequences, antibody-bound Spike structures or both, limiting their early predictive capacity. It is therefore notable that EVEscape outperforms even supervised approaches at predicting mutations seen in the pandemic (Extended Data Fig. 5 and Supplementary Table 8).
Comparative accuracy of EVEscape and high-throughput experiments
We contextualized the performance of EVEscape in comparison with DMSs, which have been invaluable in identifying and predicting viral variants that may confer immune escape2–12. However, these experiments require polyclonal or monoclonal antibodies from infected or vaccinated people, limiting their early predictive capacity. For example, the DMS experiments conducted by 17 months into the pandemic (using 36 antibodies and 55 sera samples) were a third more predictive (46% versus 32% predicted mutations observed in the pandemic) than the experiments conducted 7 months previously (using just ten antibodies) (Fig. 3a, Extended Data Fig. 5 and 6 and Supplementary Table 6).
Extended Data Fig. 6. EVEscape comparison to escape deep mutational scans.

a) Maximum experimental escape values (over the set of antibodies with PDB structures) for each mutation vs. the minimum distance of the mutation site to a tested antibody—most escape mutations (to the right of dashed line) are to residues with atoms within 5Å of any residue on the antibody. For HIV, this is true for the mutations that do not involve loss of glycosylation. b) Impact of choice of RBD expression and ACE2 binding thresholds (dashed line uses thresholds chosen by Bloom escape papers and our paper) on AUPRC (normalized by “null” model – fraction of observed escapes) and # of mutations considered as escape. c) Impact of choice of escape threshold on RBD (Bloom and Xie data separated), Flu, and HIV AUPRC (normalized) and # of escape mutations (dashed line uses escape threshold chosen by our paper). d) Comparison of model performance (AUROC) between data from first escape DMS study (10 antibodies – Sept. 2020)3 and data available at present (338 antibodies, 55 sera samples). e) Precision-Recall curves (normalized by “null” model) (left) and receiver-operator curves (right) for models predicting DMS escape of SARS-CoV-2 RBD. f) AUPRC (normalized by “null” model) (left) and AUROC (right) values for models predicting DMS escape of SARS-CoV-2 RBD, Flu H1, and HIV Env. Note: The “null” model AUPRC is equivalent to the fraction of observed escapes, and therefore AUPRC values are not comparable between viral proteins with different fractions of escape mutations (i.e., SARS-CoV-2 RBD and HIV Env). The fraction of observed escapes in the DMS experiments are 0.19 for RBD, for 0.015 for Flu, and 0.006 for HIV – Flu and HIV data examined far fewer antibody and sera samples (Table S5).
Despite being computed on sequences available more than 17 months earlier, EVEscape was as good as or better than the latest DMS scans at anticipating pandemic variation (50% versus 46% predicted mutations observed, respectively, when considering the top decile of prediction) (Fig. 3a). As we considered higher-frequency mutations, EVEscape increasingly predicted a greater portion of pandemic variations than experiments (Fig. 3b) and predicted a larger fraction of mutations in VOC strains (Fig. 3c).
Discrepancies between EVEscape and experiments shed light on the complementary strengths of these approaches. EVEscape and experiments missed 43 and 48 pandemic mutations, respectively, that were predicted by the other method (Fig. 4a,d). These differences could indicate model inaccuracies, or they could reflect sparse sampling of host sera response in DMS experiments, as well as artefacts from experiments testing only the RBD domain and missing the full set of in vivo constraints. Indeed, as more antibodies were incorporated in experiments, the agreement between EVEscape and experimental predictions increased (Extended Data Fig. 6d). Most of the high EVEscape predictions that were not observed in experimental predictions were in known antibody epitopes (Fig. 4b and Extended Data Fig. 3e). By contrast, those mutations identified by the experiments that were below the threshold for EVEscape predictions were often predicted to have low fitness owing to high conservation in the alignment at those positions (Supplementary Table 6).
Fig. 4. EVEscape and experiments make distinct, complementary escape predictions.

a, Share of top decile of predicted escape mutations, predicted using EVEscape or mutational scan experiments (Bloom Set, Supplementary Table 5), seen so far more than 100 times in the pandemic. As the virus evolves further, more of the predicted escape mutations are expected to appear. b, RBD site-averaged EVEscape scores agree with site-averaged antibody escape experimental mutational scan measures (Bloom Set, Supplementary Table 5), with high EVEscape sites that are missing from experimental escape prediction found within known antibody footprints. Hue indicates known antibody footprints from the PDB (information that EVEscape as a prepandemic model does not use). c, Predicted escape mutations from experimental mutational scans (Bloom Set, Supplementary Table 5) measuring recognition by convalescent sera from patients infected with either Wuhan, Beta or Delta strains have high EVEscape scores. Sites that escape sera are coloured by whether they have occurred in the pandemic more than 1,000 times. d, Heatmaps illustrating the EVEscape scores of all single mutations to the Wuhan sequence of SARS-CoV-2 RBD. Top lines are sites with observed pandemic mutation frequency >100 and sites in the top 15% of DMS experimental predictions from mutational scan experiments.
The consensus between EVEscape and experiments is also of interest. Agreement was especially strong for polyclonal patient sera (Supplementary Table 8); in fact, half of the top 10% of EVEscape RBD sites were sera escape sites from experiments4–6,13,14 (Fig. 4c). Whereas antibody mutational scans are biased towards antibodies with potential therapeutic relevance, the escape mutations from polyclonal sera are of particular interest as they depict real pandemic selection pressures in convalescent patients and are thus crucial to considerations of reinfection and vaccine design. For instance, E484, mutated in several VOCs, had the highest experimental sera binding and was the top EVEscape predicted site.
Adapting EVEscape through its modular framework
The modular design of our framework facilitates its adaptability to the specific characteristics of a pandemic and to new data as they become available. To consider the effects of insertions and deletions (indels) on SARS-CoV-2 Spike immune escape, we replaced the EVE fitness component with TranceptEVE43, a recently developed protein large language model that has previously shown state-of-the-art performance for prediction of the effects of mutations, including indels, which both previous computational models and high-throughput experiments have been unable to capture for SARS-CoV-2. When applied to the pandemic, this model captured the most frequent single insertion and deletion, both at site 144, and each in the top decile of pandemic and random indel predictions (Extended Data Fig. 7). We also found that including glycosylation in the dissimilarity component for HIV Env, for which glycans play an important part in immune escape, improved model predictions of high-throughput experimental escape16 (the AUPRC increased by 10% when glycosylation was included for HIV; Extended Data Fig. 7). We also retrained EVE models with the addition of 11 million new sequences collected during the pandemic, which improved agreement with fitness DMS experiments by 20% (Extended Data Figs. 2 and 8 and Supplementary Tables 1 and 2). This model captured epistatic shifts between Wuhan and BA.2 strains, identifying changes in mutation fitness in the RBD and near BA.2 mutations, and predicting positive epistatic shifts for known convergent omicron mutations and probable epistatic wastewater mutations44 (Extended Data Fig. 8).
Extended Data Fig. 7. EVEscape adapts to new models: incorporating glycosylation and a transformer model of mutation fitness capable of scoring indels.

a) The EVEscape fitness component can be substituted with a new generative model, Trancept-EVE43 that is capable of scoring substitutions as well as insertions and deletions. EVEscape using TranceptEVE as the fitness model performs equivalently to EVEscape using EVE at predicting substitutions from deep mutational scans that escape antibody binding. b) Percent of the top 10% EVEscape predicted substitutions using either EVE or TranceptEVE that were observed at different frequency thresholds during the pandemic shows that EVEscape with TranceptEVE is just as good as, or better than, EVEscape using EVE at predicting pandemic substitutions. c) Histogram of EVEscape scores (with TranceptEVE as a fitness model) for all single deletions to Spike. Single deletions seen in the pandemic more than 1000 times (vertical lines) are predicted higher than most other single deletions, especially the very frequent pandemic deletion Y144- (seen more than a million times). d) Incorporating glycosylation in EVEscape improves performance on HIV Env. Precision-Recall (with AUPRC normalized by “null” model – fraction of observed escapes) (left) and AUROC (right) of EVEscape and EVEscape+Gly models predicting DMS escape mutations for SARS-CoV-2 RBD, Flu H1, and HIV Env. e) Scatterplot of HIV Env maximum DMS escape vs. EVEscape predictions with and without glycosylation. Hue indicates mutations that cause loss of glycosylation. The majority of HIV Env escape mutations involve glycosylation loss, and EVEscape+Gly performs better on these mutations.
Extended Data Fig. 8. EVEscape later in a pandemic: using pandemic data and capturing epistatic shifts.

a) Incorporating pandemic sequences in EVE training data results in a greater distinction between the distributions of escape and non-escape mutation EVE scores. b) Histogram of epistatic shift values between Wuhan and BA.2 strain EVE models for all single mutations, calculated as linear regression residuals. Convergent mutations that arise multiple times in Omicron lineages (mutations at sites 346, 444, 452, 460, and 486) are highlighted on the left. Wastewater mutations seen mid-202144 that were rarely seen clinically in patients, and so likely epistatic, are highlighted on the right. c) Max epistatic shift magnitudes of mutations at sites mutated in BA.2 shows high epistatic shifts concentrated in the RBD. d) Large epistatic shifts for mutations on Wuhan and BA.2 strains are concentrated at sites proximal to BA.2 mutations.
Strain forecasting with EVEscape
A key application of an escape prediction framework is to identify circulating strains with high immune escape potential soon after their emergence, enabling the deployment of targeted vaccines and therapeutics before their spread. Although the World Health Organization seeks to identify new high-risk variants as they arise, new strains are occurring at an increasing rate, with tens of thousands of new SARS-CoV-2 strains each month now, a scale unfeasible for experimental risk assessment. To create strain-level escape predictions, we aggregated EVEscape predictions across all individual Spike mutations in a strain. We evaluated EVEscape strain predictions for their alignment with experimental measures of strain immune evasion, as well as their identification of known escape strains from pools of random sequences and from other strains observed at the same pandemic timepoint.
First, we found that prepandemic EVEscape strain scores correlated well with the results of experiments quantifying vaccinated sera neutralization of 21 strains19 (ρ = 0.81; Fig. 5a and Supplementary Table 9) and were better than those obtained with an existing computational strain-scoring method (ρ = 0.77)19, even though that method used 332 pandemic antibody-Spike structures for the prediction. Second, we found that EVEscape strain scores for VOCs were consistently higher than random sequences at the same mutational depth; in particular, the Beta, Gamma, Delta, Omicron BA.4, BA.2.12.1, BA.2.75, XBB.1.5 and CH.1.1 strain scores were in the top 1% of these generated sequence scores (Extended Data Fig. 9). EVEscape strain scores for Delta and the later Omicron VOCs were also in the top 1% against sequences composed only of mutations already known to be favourable—mutations sampled from other VOCs (Extended Data Fig. 9).
Fig. 5. Identifying strains with high escape potential and forecasting escape for future pandemics.

a, Prepandemic EVEscape scores computed for pandemic strains correlate with fold reduction in pseudovirus 50% neutralization titre19 for each strain relative to the Wuhan strain (ρ = 0.81, n = 21). Linear regression line shown with a 95% confidence interval. b, Distributions of newly emerging EVEscape strain (unique combination of mutations) scores for non-VOCs throughout 15 periods of the pandemic, with counts of unique new strains per period. EVEscape strain scores increased throughout the pandemic. High-frequency VOC (occurring more than 5,000 times) scores are shown as vertical lines in the first period in which each emerged; new VOCs were predicted to have higher escape scores than most strains in all previous time periods. c, Pandemic circulating strains are grouped according to their EVEscape decile relative to other strains emerging in the same non-overlapping two-week surveillance window. The relative prevalence of each EVEscape decile over the course of the pandemic is plotted in a stacked line-plot. More than 40% of circulating strains on average fall into the top 10% bin. Proportions do not sum to 100% as strains that emerged before the surveillance period of September 2020 to June 2023 are not included. d, VOCs (dotted lines) were among the highest scoring of hundreds or thousands of new strains (histograms) within their two-week window of emergence, enabling EVEscape to forecast which strains will dominate as soon as they appear after only a single observation. e, Site-wise maximum EVEscape scores on Lassa virus glycoprotein structure (PDB: 7PUY). We show agreement between sites of high EVEscape scores (in red) and escape mutations with experimental evidence (shown with spheres). freq., frequency.
Extended Data Fig. 9. EVEscape strain forecasting.

a) VOCs have high EVEscape scores compared to combinations of random mutations (sampled either from all possible single substitution mutations or from mutations previously observed in VOCs) at the same mutation depth, particularly Delta and later Omicron strains. b) VOCs are among the highest scoring new, unique strains for their two-week period of emergence using a prepandemic EVEscape model.
Last, we examined the ability of EVEscape to identify immune-evading strains as they emerged in the pandemic. EVEscape scores increased throughout the pandemic and were higher for more recent VOCs, reflecting their increased propensity for immune escape (Fig. 5b). Moreover, EVEscape scores for newly emerging VOCs were higher than those for almost all strains in previous time periods (Fig. 5b). Taken together, these results indicate the promise of EVEscape as an early-detection tool for picking out the most concerning variants from the large pool of available pandemic sequencing data. We therefore examine the utility of EVEscape as a tool to identify strains with high escape potential as they emerge. We classify ‘high-escape strains’ as the top decile of sequences with the highest EVEscape scores of all new and distinct strains present during a two-week surveillance window. These high-escape strains were consistently the predominant variants throughout the pandemic, constituting on average more than 40% of circulating sequences (Fig. 5c). Moreover, in the two-week windows in which the VOC strains Alpha, Beta, Gamma and Omicron BA.1 emerged, each VOC ranked first of hundreds or thousands of new strains (Fig. 5d and Extended Data Fig. 9). This demonstrates the ability of EVEscape to forecast which strains will dominate as soon as they appear after only a single observation, even as experimental testing of all emerging strains has become intractable.
To enable real-time variant escape tracking, we make monthly predictions (Supplementary Table 9) available on our website (evescape.org), with EVEscape rankings of newly occurring variants from GISAID and interactive visualizations of probable future mutations to our top predicted strains. In sum, the EVEscape model captures relative immune evasion of successful strains and can identify concerning strains from pools of random combinations of mutations as well as from their temporal peers.
EVEscape generalizes to other viral families with pandemic potential
Most viruses with pandemic potential are subjected to far less surveillance and research than SARS-CoV-2. One of the main features of EVEscape is the ability to predict viral antibody escape before a pandemic—without the consequent increase in data during a pandemic—to select vaccine sequences and therapeutics most likely to provide lasting protection, to assess strains as they arise and to provide a watch list for mutations that might compromise any existing therapies. As one of the first comprehensive analyses of escape in these viruses, we applied the EVEscape methodology to predict escape mutations to the Lassa virus and Nipah virus surface proteins; these viruses cause sporadic outbreaks of Lassa haemorrhagic fever in West Africa and highly lethal Nipah virus infection outbreaks in Bangladesh, Malaysia and India. Crucially, the three mutants present in Lassa that are known to escape neutralizing antibodies45 were all in the top 10% of EVEscape predictions, indicating that EVEscape captures features relevant to Lassa glycoprotein antibody escape (Fig. 5e and Supplementary Table 6). EVEscape predictions also identified ten of 11 known escape mutants to Nipah antibodies46–50 (Extended Data Fig. 10).
Extended Data Fig. 10. EVEscape predictions for potential pandemics.

Site-maximum EVEscape scores for Nipah Virus fusion protein (left) and Glycoprotein (right) depict regions of high EVEscape scores. Known escape mutations with experimental evidence46–50 (little is known for this understudied virus with pandemic potential) are highlighted with spheres.
Moreover, we demonstrate generalizability to influenza hemagglutinin15 and HIV Env16 using DMS evaluation (Extended Data Fig. 6). On the basis of these findings, we provide all single mutant escape predictions for these proteins (Supplementary Table 6) to inform active and continuing vaccine development efforts with the goal of mitigating future epidemic spread and morbidity.
Discussion
One of the greatest obstacles to the development of vaccines and therapeutics to contain a viral epidemic is the high genetic diversity derived from viral mutation and recombination, especially under pressure from the host immune system. An early sense of potential escape mutations could inform vaccine and therapeutic design to better curb viral spread. Computational models can learn from the viral evolutionary record available at pandemic onset and are widely extensible to mutations and their combinations. However, new pandemic constraints (such as immunity) are unlikely to be captured. To achieve early escape prediction, EVEscape combines a model trained on historical viral evolution with a biologically informed strategy using only protein structure and biophysical constraints to anticipate the effects of immune selection. Through a retrospective analysis of the SARS-CoV-2 pandemic, we demonstrate that EVEscape forecasts pandemic escape mutations and can predict which emerging strains have high escape potential. This computational approach can preempt predictions from experiments that rely on pandemic antibodies and sera by many months while providing similar accuracy.
EVEscape provides surprisingly accurate early predictions of prevalent escape mutations but cannot anticipate all constraints unique to a new pandemic to determine the precise trajectory of viral evolution. This method will be best leveraged in synergy with experiments developed to measure immune evasion and enhanced with pandemic data as they become available. Early in a pandemic, EVEscape can predict probable escape mutations for prioritized experimental screening with the first available sera samples—validated escape mutations could be strong candidates for multivalent vaccines. EVEscape can also identify structural regions with high escape potential, so therapeutic antibody candidates with few potential escape mutants in their binding footprint may be accelerated. Later in a pandemic, EVEscape can rank emerging strains, as well as mutants on top of prevalent strains, for their escape potential, flagging concerning variants early for rapid experimental characterization and incorporation into vaccine boosters. The model could also be augmented to leverage current knowledge on virus-specific immune targeting and mutation tolerance from experimental and pandemic surveillance data. In return, our computational framework can inform this collective understanding by proposing escape variant libraries for focused experimental investigations.
EVEscape is a modular, scalable and interpretable probabilistic framework designed to predict escape mutations early in a pandemic and to identify observed strains and their mutants that are most likely to thrive in a populace with widespread preexisting immunity as the pandemic progresses. To this end, we provide EVEscape scores for all single mutation variants of SARS-CoV-2 Spike to the Wuhan strain, as well as scores for all observed strains and predictions of single mutation effects on the most concerning emerging strain backgrounds, with plans to continuously update with new strains. As the framework is generalizable across viruses, EVEscape can be used from the start for future pandemics, as well as to better understand and prepare for emerging pathogens. To further accelerate broad and effective vaccine development, we provide EVEscape mutation predictions for all single mutations to influenza, HIV, Lassa virus and Nipah virus surface proteins. Methods are provided in the Supplementary Information.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Online content
Any methods, additional references, Nature Portfolio reporting summaries, source data, extended data, supplementary information, acknowledgements, peer review information; details of author contributions and competing interests; and statements of data and code availability are available at 10.1038/s41586-023-06617-0.
Supplementary information
Supplementary Methods.
Description of model inputs, including taxa of sequences in SARS-CoV-2 Spike and RBD training alignments (RBD and Spike without pandemic data are the primary alignments used throughout this paper), EVE training alignment summary statistics and PDB structures capturing diverse protein conformations used for accessibility calculations.
Alignments used for EVE models for Lassa virus, Nipah virus, SARS-CoV-2, HIV and influenza.
EVE, EVmutation and independent model mutation scores for DMS fitness experiments for SARS-CoV-2, HIV and influenza.
Experimental details of DMS fitness and escape experiments and EVE, EVmutation and independent model performance (Spearman correlations) for DMS fitness prediction experiments. Escape DMS data used for EVEscape validation.
EVEscape performance for selection of factor-specific temperature scaling.
EVEscape scores for all SARS-CoV-2, HIV, influenza, Lassa virus and Nipah virus mutations. Includes pandemic counts, RBD antibody class and DMS escape experiment scores used for Spike.
Forecasting of clinical antibody epitope escape mutations.
EVEscape performance on escape DMS data is generalizable across viruses and robust to antibody and sera samples. Precision-recall (with AUPRC normalized by ‘null’ model) and area under the receiver operating curve for predicting DMS escape mutations, for SARS-CoV-2 RBD, influenza H1 and HIV Env, as well as SARS-CoV-2 RBD antibody and sera stratification.
EVEscape scores for all SARS-CoV-2 pandemic lineages and scores for strain neutralization variants.
Acknowledgements for all GISAID sequences.
Source data
Acknowledgements
We thank members of the Marks laboratory and the OATML group for many valuable discussions. N.N.T. is supported by an NIH NIGMS F32 fellowship (GM141007-01A1). N.N.T. and N.J.R. were supported by the Chan Zuckerberg Initiative CZI2018-191853. S.G. is supported by a Takeda Fellowship. S.G., N.Y. and D.R. are supported by the Coalition for Epidemic Preparedness Innovations (CEPI). P.N. is supported by GSK and the UK Engineering and Physical Sciences Research Council (EPSRC ICASE award no. 18000077). Y.G. holds a Turing AI Fellowship (Phase 1) at the Alan Turing Institute, which is supported by EPSRC grant reference V030302/1. N.Y. is supported by CEPI. D.S.M. holds a Ben Barres Early Career Award by the Chan Zuckerberg Initiative as part of the Neurodegeneration Challenge Network, CZI2018-191853, and is supported by CEPI. Fig. 1a and Extended Data Fig. 1 were created in part with BioRender.com.
Extended data figures and tables
Author contributions
N.N.T., S.G., P.N. and D.S.M. led the research and conceived the modelling. N.N.T., S.G. and P.N. implemented the modelling framework and analysis. N.J.R. supported the data preparation. N.Y. assisted with technical advice and data processing. D.R. helped with web tool development. N.N.T., S.G., P.N., Y.G., C.S. and D.S.M. wrote the manuscript with feedback from all authors.
Peer review
Peer review information
Nature thanks Eugene Koonin and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Data availability
The data analysed and generated in this study, including multiple sequence alignments used in training, single-mutant pandemic frequency data and fitness and escape DMS data used for validation, and predictions from our model are available in the Supplementary Information and at https://evescape.org/ and https://github.com/OATML-Markslab/EVEscape. All SARS-CoV-2 pandemic strain sequencing data are available through https://gisaid.org/. We acknowledge all data contributors, that is, the authors and their originating laboratories responsible for obtaining the specimens, and their submitting laboratories for generating the genetic sequence and metadata and sharing through the GISAID initiative. The evaluation of this study was based on metadata associated with 15,667,960 sequences available on GISAID up to 6 June 2023 and accessible at 10.55876/gis8.230814cp (Supplementary File 1). RBD DMS data used for model evaluation are available from https://github.com/jbloomlab/SARS2_RBD_Ab_escape_maps; a complete list of DMS data used for evaluation is available in Supplementary Table 4. We also evaluated against clinical antibody escape susceptibility data from https://covdb.stanford.edu/. We used the following Protein Data Bank (PDB) identifiers: 6VXX, 6VYB, 7CAB, 7BNN, 1RVX, 5FYL, 7TFO, 7PUY, 5EVM, 7TY0 and 7TXZ (Supplementary Table 1). Previous models of antibody escape are available from https://github.com/3BioCompBio/SpikeProSARS-CoV-2 and https://github.com/brianhie/viral-mutation. Multiple sequence alignments were constructed with sequences from https://www.uniprot.org/uniref/?facets=identity%3A1.0&query=%2A. Source data are provided with this paper.
Code availability
The model code is available at https://github.com/OATML-Markslab/EVEscape.
Competing interests
D.S.M. is an advisor for Dyno Therapeutics, Octant, Jura Bio, Tectonic Therapeutic and Genentech and is a cofounder of Seismic Therapeutic. C.S. is an advisor for CytoReason Ltd. The remaining authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
These authors contributed equally: Nicole N. Thadani, Sarah Gurev, Pascal Notin
Extended data
is available for this paper at 10.1038/s41586-023-06617-0.
Supplementary information
The online version contains supplementary material available at 10.1038/s41586-023-06617-0.
References
- 1.Schmidt F, et al. Measuring SARS-CoV-2 neutralizing antibody activity using pseudotyped and chimeric viruses. J. Exp. Med. 2020;217:e20201181. doi: 10.1084/jem.20201181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Dong J, et al. Genetic and structural basis for SARS-CoV-2 variant neutralization by a two-antibody cocktail. Nat. Microbiol. 2021;6:1233–1244. doi: 10.1038/s41564-021-00972-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Greaney AJ, et al. Complete mapping of mutations to the SARS-CoV-2 Spike receptor-binding domain that escape antibody recognition. Cell Host Microbe. 2021;29:44–57.e9. doi: 10.1016/j.chom.2020.11.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Greaney, A. J. et al. Mapping mutations to the SARS-CoV-2 RBD that escape binding by different classes of antibodies. Nat. Commun.12, 4196 (2021). [DOI] [PMC free article] [PubMed]
- 5.Greaney AJ, et al. Comprehensive mapping of mutations in the SARS-CoV-2 receptor-binding domain that affect recognition by polyclonal human plasma antibodies. Cell Host Microbe. 2021;29:463–476.e6. doi: 10.1016/j.chom.2021.02.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Greaney AJ, et al. Antibodies elicited by mRNA-1273 vaccination bind more broadly to the receptor binding domain than do those from SARS-CoV-2 infection. Sci. Transl Med. 2021;13:eabi9915. doi: 10.1126/scitranslmed.abi9915. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Starr TN, et al. Prospective mapping of viral mutations that escape antibodies used to treat COVID-19. Science. 2021;371:850–854. doi: 10.1126/science.abf9302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Starr TN, et al. SARS-CoV-2 RBD antibodies that maximize breadth and resistance to escape. Nature. 2021;597:97–102. doi: 10.1038/s41586-021-03807-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Starr TN, Greaney AJ, Dingens AS, Bloom JD. Complete map of SARS-CoV-2 RBD mutations that escape the monoclonal antibody LY-CoV555 and its cocktail with LY-CoV016. Cell Rep. Med. 2021;2:100255. doi: 10.1016/j.xcrm.2021.100255. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Tortorici MA, et al. Broad sarbecovirus neutralization by a human monoclonal antibody. Nature. 2021;597:103–108. doi: 10.1038/s41586-021-03817-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Cao Y, et al. Omicron escapes the majority of existing SARS-CoV-2 neutralizing antibodies. Nature. 2022;602:657–663. doi: 10.1038/s41586-021-04385-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Cao Y, et al. BA.2.12.1, BA.4 and BA.5 escape antibodies elicited by Omicron infection. Nature. 2022;608:593–602. doi: 10.1038/s41586-022-04980-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Greaney AJ, et al. A SARS-CoV-2 variant elicits an antibody response with a shifted immunodominance hierarchy. PLoS Pathog. 2022;18:e1010248. doi: 10.1371/journal.ppat.1010248. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Greaney AJ, et al. The SARS-CoV-2 Delta variant induces an antibody response largely focused on class 1 and 2 antibody epitopes. PLoS Pathog. 2022;18:e1010592. doi: 10.1371/journal.ppat.1010592. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Doud MB, Lee JM, Bloom JD. How single mutations affect viral escape from broad and narrow antibodies to H1 influenza hemagglutinin. Nat. Commun. 2018;9:1386. doi: 10.1038/s41467-018-03665-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Dingens AS, Arenz D, Weight H, Overbaugh J, Bloom JD. An antigenic atlas of HIV-1 escape from broadly neutralizing antibodies distinguishes functional and structural epitopes. Immunity. 2019;50:520–532.e3. doi: 10.1016/j.immuni.2018.12.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Obermeyer F, et al. Analysis of 6.4 million SARS-CoV-2 genomes identifies mutations associated with fitness. Science. 2022;376:1327–1332. doi: 10.1126/science.abm1208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Pucci F, Rooman M. Prediction and evolution of the molecular fitness of SARS-CoV-2 variants: introducing SpikePro. Viruses. 2021;13:935. doi: 10.3390/v13050935. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Beguir K, et al. Early computational detection of potential high-risk SARS-CoV-2 variants. Comput. Biol. Med. 2023;155:106618. doi: 10.1016/j.compbiomed.2023.106618. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Frazer J, et al. Disease variant prediction with deep generative models of evolutionary data. Nature. 2021;599:91–95. doi: 10.1038/s41586-021-04043-8. [DOI] [PubMed] [Google Scholar]
- 21.Hopf TA, et al. Mutation effects predicted from sequence co-variation. Nat. Biotechnol. 2017;35:128–135. doi: 10.1038/nbt.3769. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Riesselman AJ, Ingraham JB, Marks DS. Deep generative models of genetic variation capture the effects of mutations. Nat. Methods. 2018;15:816–822. doi: 10.1038/s41592-018-0138-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Gong LI, Suchard MA, Bloom JD. Stability-mediated epistasis constrains the evolution of an influenza protein. eLife. 2013;2:e00631. doi: 10.7554/eLife.00631. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Starr TN, et al. Shifting mutational constraints in the SARS-CoV-2 receptor-binding domain during viral evolution. Science. 2022;377:420–424. doi: 10.1126/science.abo7896. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Haddox HK, Dingens AS, Hilton SK, Overbaugh J, Bloom JD. Mapping mutational effects along the evolutionary landscape of HIV envelope. eLife. 2018;7:e34420. doi: 10.7554/eLife.34420. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Doud MB, Bloom JD. Accurate measurement of the effects of all amino-acid mutations on influenza hemagglutinin. Viruses. 2016;8:155. doi: 10.3390/v8060155. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Wu NC, et al. Different genetic barriers for resistance to HA stem antibodies in influenza H3 and H1 viruses. Science. 2020;368:1335–1340. doi: 10.1126/science.aaz5143. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Roop JI, Cassidy NA, Dingens AS, Bloom JD, Overbaugh J. Identification of HIV-1 envelope mutations that enhance entry using macaque CD4 and CCR5. Viruses. 2020;12:241. doi: 10.3390/v12020241. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Duenas-Decamp M, Jiang L, Bolon D, Clapham PR. Saturation mutagenesis of the HIV-1 envelope CD4 binding loop reveals residues controlling distinct trimer conformations. PLoS Pathog. 2016;12:e1005988. doi: 10.1371/journal.ppat.1005988. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Starr TN, et al. Deep mutational scanning of SARS-CoV-2 receptor binding domain reveals constraints on folding and ACE2 binding. Cell. 2020;182:1295–1310.e20. doi: 10.1016/j.cell.2020.08.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Chan KK, Tan TJC, Narayanan KK, Procko E. An engineered decoy receptor for SARS-CoV-2 broadly binds protein S sequence variants. Sci. Adv. 2021;7:eabf1738. doi: 10.1126/sciadv.abf1738. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Flynn JM, et al. Comprehensive fitness landscape of SARS-CoV-2 Mpro reveals insights into viral resistance mechanisms. eLife. 2022;11:e77433. doi: 10.7554/eLife.77433. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Lin C-P, et al. Deriving protein dynamical properties from weighted protein contact number. Proteins. 2008;72:929–935. doi: 10.1002/prot.21983. [DOI] [PubMed] [Google Scholar]
- 34.Chothia C, Janin J. Principles of protein–protein recognition. Nature. 1975;256:705–708. doi: 10.1038/256705a0. [DOI] [PubMed] [Google Scholar]
- 35.Piccoli L, et al. Mapping neutralizing and immunodominant sites on the SARS-CoV-2 spike receptor-binding domain by structure-guided high-resolution serology. Cell. 2020;183:1024–1042.e21. doi: 10.1016/j.cell.2020.09.037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Cerutti G, et al. Potent SARS-CoV-2 neutralizing antibodies directed against spike N-terminal domain target a single supersite. Cell Host Microbe. 2021;29:819–833.e7. doi: 10.1016/j.chom.2021.03.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Rodriguez-Rivas J, Croce G, Muscat M, Weigt M. Epistatic models predict mutable sites in SARS-CoV-2 proteins and epitopes. Proc. Natl Acad. Sci. USA. 2022;119:e2113118119. doi: 10.1073/pnas.2113118119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Bangaru S, et al. Structural analysis of full-length SARS-CoV-2 spike protein from an advanced vaccine candidate. Science. 2020;370:1089–1094. doi: 10.1126/science.abe1502. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Ginex T, et al. The structural role of SARS-CoV-2 genetic background in the emergence and success of spike mutations: the case of the spike A222V mutation. PLoS Pathog. 2022;18:e1010631. doi: 10.1371/journal.ppat.1010631. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Zhao LP, et al. Rapidly identifying new Coronavirus mutations of potential concern in the Omicron variant using an unsupervised learning strategy. Res. Sq. 2022 doi: 10.21203/rs.3.rs-1280819/v1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Tada T, et al. Increased resistance of SARS-CoV-2 Omicron variant to neutralization by vaccine-elicited and therapeutic antibodies. eBioMedicine. 2022;78:103944. doi: 10.1016/j.ebiom.2022.103944. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Hie B, Zhong ED, Berger B, Bryson B. Learning the language of viral evolution and escape. Science. 2021;371:284–288. doi: 10.1126/science.abd7331. [DOI] [PubMed] [Google Scholar]
- 43.Notin, P. et al. TranceptEVE: combining family-specific and family-agnostic models of protein sequences for improved fitness prediction. Preprint at bioRxiv10.1101/2022.12.07.519495 (2022).
- 44.Smyth DS, et al. Tracking cryptic SARS-CoV-2 lineages detected in NYC wastewater. Nat. Commun. 2022;13:635. doi: 10.1038/s41467-022-28246-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Buck TK, et al. Neutralizing antibodies against Lassa virus lineage I. mBio. 2022;13:e0127822. doi: 10.1128/mbio.01278-22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Borisevich V, et al. Escape from monoclonal antibody neutralization affects henipavirus fitness in vitro and in vivo. J. Infect. Dis. 2016;213:448–455. doi: 10.1093/infdis/jiv449. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Wang Z, et al. Architecture and antigenicity of the Nipah virus attachment glycoprotein. Science. 2022;375:1373–1378. doi: 10.1126/science.abm5561. [DOI] [PubMed] [Google Scholar]
- 48.Xu K, et al. Crystal structure of the Hendra virus attachment G glycoprotein bound to a potent cross-reactive neutralizing human monoclonal antibody. PLoS Pathog. 2013;9:e1003684. doi: 10.1371/journal.ppat.1003684. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Dang HV, et al. An antibody against the F glycoprotein inhibits Nipah and Hendra virus infections. Nat. Struct. Mol. Biol. 2019;26:980–987. doi: 10.1038/s41594-019-0308-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Dang HV, et al. Broadly neutralizing antibody cocktails targeting Nipah virus and Hendra virus fusion glycoproteins. Nat. Struct. Mol. Biol. 2021;28:426–434. doi: 10.1038/s41594-021-00584-8. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary Methods.
Description of model inputs, including taxa of sequences in SARS-CoV-2 Spike and RBD training alignments (RBD and Spike without pandemic data are the primary alignments used throughout this paper), EVE training alignment summary statistics and PDB structures capturing diverse protein conformations used for accessibility calculations.
Alignments used for EVE models for Lassa virus, Nipah virus, SARS-CoV-2, HIV and influenza.
EVE, EVmutation and independent model mutation scores for DMS fitness experiments for SARS-CoV-2, HIV and influenza.
Experimental details of DMS fitness and escape experiments and EVE, EVmutation and independent model performance (Spearman correlations) for DMS fitness prediction experiments. Escape DMS data used for EVEscape validation.
EVEscape performance for selection of factor-specific temperature scaling.
EVEscape scores for all SARS-CoV-2, HIV, influenza, Lassa virus and Nipah virus mutations. Includes pandemic counts, RBD antibody class and DMS escape experiment scores used for Spike.
Forecasting of clinical antibody epitope escape mutations.
EVEscape performance on escape DMS data is generalizable across viruses and robust to antibody and sera samples. Precision-recall (with AUPRC normalized by ‘null’ model) and area under the receiver operating curve for predicting DMS escape mutations, for SARS-CoV-2 RBD, influenza H1 and HIV Env, as well as SARS-CoV-2 RBD antibody and sera stratification.
EVEscape scores for all SARS-CoV-2 pandemic lineages and scores for strain neutralization variants.
Acknowledgements for all GISAID sequences.
Data Availability Statement
The data analysed and generated in this study, including multiple sequence alignments used in training, single-mutant pandemic frequency data and fitness and escape DMS data used for validation, and predictions from our model are available in the Supplementary Information and at https://evescape.org/ and https://github.com/OATML-Markslab/EVEscape. All SARS-CoV-2 pandemic strain sequencing data are available through https://gisaid.org/. We acknowledge all data contributors, that is, the authors and their originating laboratories responsible for obtaining the specimens, and their submitting laboratories for generating the genetic sequence and metadata and sharing through the GISAID initiative. The evaluation of this study was based on metadata associated with 15,667,960 sequences available on GISAID up to 6 June 2023 and accessible at 10.55876/gis8.230814cp (Supplementary File 1). RBD DMS data used for model evaluation are available from https://github.com/jbloomlab/SARS2_RBD_Ab_escape_maps; a complete list of DMS data used for evaluation is available in Supplementary Table 4. We also evaluated against clinical antibody escape susceptibility data from https://covdb.stanford.edu/. We used the following Protein Data Bank (PDB) identifiers: 6VXX, 6VYB, 7CAB, 7BNN, 1RVX, 5FYL, 7TFO, 7PUY, 5EVM, 7TY0 and 7TXZ (Supplementary Table 1). Previous models of antibody escape are available from https://github.com/3BioCompBio/SpikeProSARS-CoV-2 and https://github.com/brianhie/viral-mutation. Multiple sequence alignments were constructed with sequences from https://www.uniprot.org/uniref/?facets=identity%3A1.0&query=%2A. Source data are provided with this paper.
The model code is available at https://github.com/OATML-Markslab/EVEscape.