

Summary:
We propose a broad class of so-called Cox-Aalen transformation models that incorporate both multiplicative and additive covariate effects on the baseline hazard function within a transformation. The proposed models provide a highly flexible and versatile class of semiparametric models that include the transformation models and the Cox-Aalen model as special cases. Specifically, it extends the transformation models by allowing potentially time-dependent covariates to work additively on the baseline hazard and extends the Cox-Aalen model through a predetermined transformation function. We propose an estimating equation approach and devise an Expectation-Solving (ES) algorithm that involves fast and robust calculations. The resulting estimator is shown to be consistent and asymptotically normal via modern empirical process techniques. The ES algorithm yields a computationally simple method for estimating the variance of both parametric and nonparametric estimators. Finally, we demonstrate the performance of our procedures through extensive simulation studies and applications in two randomized, placebo-controlled HIV prevention efficacy trials. The data example shows the utility of the proposed Cox-Aalen transformation models in enhancing statistical power for discovering covariate effects.
Keywords: Cox-Aalen model, ES algorithm, Estimating equations, Time-dependent covariates, Transformation models
1. Introduction
Censored failure time data are frequently encountered in epidemiological and biomedical studies. In the literature, the multiplicative and additive hazards models provide two principal frameworks for analyzing such data. The most popular multiplicative hazards model is the proportional hazards model (Cox, 1972), where the covariates are assumed to act multiplicatively on an unknown baseline hazard function. In contrast, the additive hazards models furnish an additive effect between the covariates and the baseline hazard function, enabling a direct reflection of the risk increase or decrease (Aalen, 1980; Huffer and McKeague, 1991; Lin and Ying, 1994). Without prior domain knowledge, it is hard to determine which approach is preferable among multiplicative and additive hazards models. In fact, both models may often be used to complement each other and provide more complete insights. Therefore, various multiplicative-additive hazard models have been proposed to capture both multiplicative and additive effects (Lin and Ying, 1995; Martinussen and Scheike, 2002). In particular, Scheike and Zhang (2002) suggested a Cox-Aalen model by replacing the baseline hazard function in the Cox model with Aalen’s additive model. The Cox-Aalen model has been studied for various types of censored data, e.g., right-censored (Scheike and Zhang, 2002), interval-censored (Boruvka and Cook, 2015), left-truncated and right-censored (Shen and Weng, 2018), left-truncated and mixed interval-censored (Shen and Weng, 2019), and recurrent-event (Qu and Sun, 2019).
Transformation models have also received wide attention in survival analysis. Dabrowska and Doksum (1988) introduced the class of linear transformation models, which includes the proportional hazards and proportional odds models (Pettitt, 1982; Bennett, 1983). Estimators for this class of models were proposed by Dabrowska and Doksum (1988), Cheng et al. (1995), Fine et al. (1998), Chen et al. (2002), among others. Zeng and Lin (2006) extended the linear transformation models to allow time-dependent covariates. Hereafter, we refer to this class of transformation models as Zeng and Lin’s model to avoid confusion. There is rich literature investigating Zeng and Lin’s model. Zeng and Lin (2006) proposed a nonparametric maximum likelihood estimator (NPMLE) in the presence of right-censored data. Zeng and Lin (2007) derived a system of self-consistent equations for the jump sizes of the baseline cumulative hazard function at exact failure times through an expectation-maximization (EM) algorithm. Chen (2009) showed that the self-consistent estimator derived in Zeng and Lin (2007) is asymptotically equivalent to a weighted Breslow-type estimator, which can be solved by a computationally-efficient iterative reweighting algorithm. Liu and Zeng (2013) investigated variable selection procedures by minimizing a weighted negative partial log-likelihood function plus an adaptive lasso penalty. More recently, Zeng et al. (2016) and Zhou et al. (2021) studied the nonparametric maximum likelihood estimation of Zeng and Lin’s model with interval-censored and partly interval-censored data, respectively.
However, one limitation of Zeng and Lin’s model is that all covariate effects are assumed to be multiplicative within the transformation function. This assumption is too restrictive in some applications. For example, in an analysis of risk factors on mortality among patients with myocardial infarction, Scheike and Zhang (2003) showed that some covariates (e.g., ventricular fibrillation and congestive heart failure) have additive effects while others (e.g., age and sex) have multiplicative effects. In addition, they pointed out that naively treating all covariates as multiplicative led to incorrect results when predicting survival probabilities. Another example is HIV prevention efficacy trials, for which HIV incidence varies across geographic regions and by sex/gender; thus, the different regions/sex/gender subgroups have different baseline hazard functions (Corey et al., 2021). Moreover, a Kaplan-Meier plot shows that survival curves for different regions cross, potentially suggesting an additive region effect. To the best of our knowledge, no existing work considers a class of semiparametric transformation models in which the baseline hazard function is allowed to depend on some potentially time-varying covariates additively. Therefore, it is desirable to provide a larger class of semiparametric transformation models that can accommodate both multiplicative and additive covariate effects under one unified framework.
The EM algorithm is a powerful tool for performing maximum likelihood estimation in the presence of latent variables or missing data (Dempster et al., 1977). In particular, various EM-type algorithms have been proposed to find NPMLE for semiparametric transformation models (Zeng and Lin, 2007; Liu and Zeng, 2013; Zeng et al., 2016; Zhou et al., 2021). In analogy to EM, Elashoff and Ryan (2004) proposed an expectation-solving (ES) algorithm that handles missing data for general estimating equations, greatly facilitating its application to a broader framework. When the complete-data estimating equations correspond to the score functions from the likelihood, the ES algorithm essentially reduces to the EM. The ES algorithm dramatically improves computational efficiency for solving estimating equations involving frailty or latent variables. For example, Johnson and Strawderman (2012) developed a smoothing expectation and substitution algorithm for the semiparametric accelerated failure time frailty model. Henderson and Rathouz (2018) considered an approximate EM procedure for a longitudinal latent class model for count data.
In this article, we propose a broad class of so-called Cox-Aalen transformation models that incorporate both multiplicative and additive covariate effects upon the baseline hazard function within a transformation. The proposed class of models is very flexible and contains Zeng and Lin’s model and the Cox-Aalen model as special cases. However, the multiplicative-additive structure within the transformation and the need to estimate several nonparametric functions simultaneously impose additional challenges for model estimation. To alleviate such difficulties, we devise an ES-type algorithm, which iterates between an E-step wherein functions of complete data are replaced by their expectations and an S-step where these expected values are substituted into the complete-data estimating equations, which are then solved. More specifically, within the S-step, the high-dimensional parameters are calculated explicitly, while the low-dimensional parameters are updated via the Newton-Raphson method. Consequently, the proposed ES algorithm is fast and stable even under a high percentage censoring rate, as evidenced by our simulation studies and real data applications. Another attraction of our approach is that we provide simple variance estimators for both parametric and nonparametric estimates. Furthermore, the theoretical properties of the proposed estimators are rigorously studied via modern empirical process techniques.
The rest of the article is organized as follows. In Section 2, we present the proposed Cox-Aalen transformation models. In Section 3, we formally describe the estimation procedure and establish the asymptotic properties of the proposed estimators. In Section 4, simulation studies are conducted to evaluate the finite-sample performance of the proposed method. In Section 5, we apply our method to two randomized HIV prevention efficacy trials. Section 6 concludes with a discussion.
2. Semiparametric Cox-Aalen Transformation Models
Let and denote and vectors of potentially time-varying covariates, and denote the failure time of interest. We propose a broad class of so-called Cox-Aalen transformation models such that the cumulative hazard function for conditional on and takes the form
| (1) |
where is a vector of unknown regression coefficients, is an unknown increasing function with , and is a pre-specified transformation function that is strictly increasing and thrice continuously differentiable with , and . In addition, let , where for . With fixed at 1, can be interpreted as a reference level of the risk. Generally, it is not meaningful to have equal or proportional to . For the choices of , it is useful to consider the class of frailty-induced transformations
| (2) |
where is a density function of a nonnegative random variable with support . The choice of the gamma density with unit mean and variance for yields the logarithmic transformations with specifying . The choice of the positive stable distribution with parameter yields the class of Box-Cox transformations . Note that is often considered to be a member of the above class with . By treating the latent variable as missing, the frailty-induced transformations are particularly useful in deriving EM type algorithms (Zeng and Lin, 2007; Liu and Zeng, 2013; Zeng et al., 2016; Zhou et al., 2021). Some remarks regarding the Cox-Aalen transformation models are as follows:
Remark 1: When for any , the right-hand side of (1) reduces to
| (3) |
Hence, Zeng and Lin’s model is a special case of the proposed model. Moreover, when is time-invariant, (3) further reduces to a class of linear transformation models with the form , where has a uniform distribution (Chen et al., 2002). The choices and yield the proportional hazards model and proportional odds model, respectively.
Remark 2: When , according to (1), the cumulative hazard function on the left-hand side can be written as
| (4) |
Thus, the conditional hazard function of is . Therefore, the Cox-Aalen model is a special case of the proposed models. In particular, when represent levels in a set of factors, model (4) further reduces to the stratified Cox model (Kalbfleisch and Prentice, 2002, Section 4.4).
Remark 3: for , the odds of surviving beyond time based on (1) are
In the special case where are time-independent covariates,
which is a stratified proportional odds model when is a random variable indicating strata.
As illustrated above, our proposed class of semiparametric models is very flexible and contains many popular models in survival analysis. To motivate our approach, we first set up the observed data likelihood and derive the NPMLE for a special case. Then, for more general situations, we propose estimating the parameters and using estimating equations along with an easily-implemented ES algorithm. Finally, the asymptotic properties of the resulting estimators are derived via modern empirical process theory (van der Vaart and Wellner, 1996).
3. Methods
3.1. Notations
For the th individual, let and be the failure time and censoring time, respectively. Let be the observed time and define . Thus, indicates that the exact failure time for the th individual was observed while implies censoring. For a random sample of participants, the observed data consist of for , where denotes the duration of the study. Moreover, we define and .
3.2. Nonparametric Maximum Likelihood Estimation
Assume that and are conditionally independent given and . Under the proposed Cox-Aalen transformation model (1), the likelihood for the observed data is
| (5) |
where and are the derivatives of and , respectively. The likelihood (5) involves and infinite dimensional parameters , and it may not be concave in these parameters. Thus, the nonparametric maximum likelihood techniques are usually employed to restrict the parameter space.
To establish a simple and efficient estimation procedure, we adopt the idea in Zeng and Lin (2007) by treating as a latent variable in the class of frailty-induced transformations (2). Note that model (1) is equivalent to the survival time with cumulative hazard function
| (6) |
because
Based on (2), it can be shown that the likelihood (5) is equivalent to
Now we consider nonparametric maximum likelihood estimation of and . Let denote the uniquely observed event times among the observations. Assume that the estimator for is a step function with jump size at . By the observation that , the estimator for is a step function with jump size at where for . Let be the complete data for the th participant. The complete-data log-likelihood function can be written as
| (7) |
where and .
To obtain the NPMLE of and , we propose an EM-type algorithm by treating as missing data. In the E-step, we evaluate the posterior mean of given the observed data, denoted by . The detailed calculations are given in the next subsection. In the M-step, we maximize the expectation of (7) conditional on the observed data. More specifically, we set the derivatives of the conditional expectation of (7) with respect to and to zeros, respectively. Then one can solve for the estimates through the following equations:
| (8) |
| (9) |
The dimension of the unknown parameters depends on , which could be a large number when is large or the censoring rate is low. Therefore, (8) and (9) are a system of high-dimensional nonlinear equations that is notoriously difficult to solve due to the curse of dimensionality. For a special case, i.e., is a vector of design variables for categories, there exist explicit formulae for calculating the high-dimensional parameters . See Web Appendix A for details. However, such explicit formulae do not exist for more general scenarios; hence we consider an alternative estimating equation approach to overcome the aforementioned computational difficulties.
3.3. Estimating Equations
Following Elashoff and Ryan (2004), we develop an expectation-solving (ES) algorithm for model (1) in this section. We begin by constructing a system of complete-data estimating equations based on model (6), which is equivalent to the proposed model (1) under the frailty-induced transformations (2). The connection between the proposed ES algorithm and the EM algorithm is discussed at the end of this section. Note that the intensity for is if is known. Let
where (, ) are the true values of (, ). It is clear that for any and . By treating as missing, we consider the following complete-data estimating equations
| (10) |
| (11) |
By the previous arguments that the nonparametric estimator for is a step function with jump size at , it follows that (10) and (11) can be written as
| (12) |
Write . We propose to estimate through an ES-type algorithm by treating as missing. The ES algorithm iterates between an E-step wherein the functions of the complete data are replaced by their expectations, and an S-step where these expected values are substituted into the complete-data estimating equations (12), which are then solved. After specifying initial values of the unknown parameters , say , the proposed ES algorithm iterates between the following two steps until convergence:
E-step. Evaluate the posterior means . When , the posterior density of given the observed data is proportional to , where . Hence we obtain
by taking the derivative twice of the equation , where and are the first and second derivatives of , respectively. When , the posterior density of given the observed data (, , , ) is proportional to , where . One can obtain . Therefore, the E-step can be summarized as
S-step. After replacing by , we solve (12) for . To this end, we propose the following nonlinear Gauss-Seidel method (Ortega and Rheinboldt, 1970; Ortega, 1972).
Step 1. Fix , update by solving
| (13) |
Note that for fixed , (13) is a system of linear equations with respect to and updating is independent of updating for . In particular, we have explicit formulae for updating , i.e.,
| (14) |
for .
Step 2. Fix , we update by solving the following equation using the Newton-Raphson method:
Note that within the S-step, we iterate between Step 1 and Step 2 until convergence. The S-step is declared convergent when the sum of the absolute differences of the estimates at two successive iterations is less than a small positive number, say 10−3.
We iterate between the E- and S-steps until convergence and denote the final estimates by . A natural estimator of is for . Moreover, recall that , hence we can estimate , via a kernel estimator
where is the kernel function and h is the bandwidth. Throughout this article, we choose the Epanechnikov kernel function, i.e., .
The proposed ES algorithm has several desirable features. First, a closed-form formula for computing is obtained in the E-step. Second, it avoids solving a large system of nonlinear equations in the S-step because the high-dimensional parameters are calculated explicitly while the low-dimensional parameter is updated via the Newton-Raphson method. Accordingly, the proposed ES algorithm performs stably and satisfactorily without calculating the inverse of any high-dimensional matrices. Third, when is a vector of design variables for categories, the corresponding ES algorithm coincides with the EM algorithm proposed in Section 3.2 by observing that for fixed , (8) and (13) share the same solution in terms of . This implies that the proposed ES estimator is also efficient under this special case. See Web Appendix B for detailed justifications. Similarly, it can be shown that the ES algorithm coincides with the EM algorithm When , i.e., . Finally, we remark that (13) can be considered as a weighted version of (8), where each participant is assigned weight .
3.4. Variance Estimator
In this section, we provide easy-to-compute variance estimators for both the parametric estimates and the nonparametric estimates , . Note that is a function of the observed data and the unknown parameter . With the collection of , the proposed ES estimator is intrinsically equivalent to solving the following observed-data estimating equation: , where ,
| (15) |
Note that also depend on the observed data and the unknown parameter . Here, we compress the notation when there is no confusion. From (15), one can easily note that can be expressed as the sum of independent terms:
Let be the derivative of with respect to . The covariance matrix of is consistently estimated by
| (16) |
Therefore, the variance covariance matrix of can be consistently estimated by the lower right-hand corner of (16). The variance covariance matrix of can be consistently estimated by the upper left-hand corner of (16).
In addition, recall that and for , such that the variance for and are
Variance estimators are obtained by replacing by in the above expressions.
3.5. Asymptotic Properties
In this subsection, we present the asymptotic properties of the proposed ES estimator. let , and . Hence, the posterior mean of can be written as .
Let denote the true probability measure and denote the empirical measure. In addition, let be the parameters of interest and be the true values of the parameters. Then the proposed ES estimator is a Z-estimator solving the following observed-data estimating equation
for , where
Let be a function in , where denotes the set of functions with total variation bounded by 1 on . Define
Similar to Gao et al. (2017) and van der Vaart and Wellner (1996, Section 3.3.1), the proposed ES estimator (, ) is equivalent to the root of the estimating equation
for all .
Write and . Note that and are actually -dependent. Rigorously speaking, we should write and , but in the rest of the article, we suppress the letter when there is no confusion. The proposed ES estimator is a Z-estimator that satisfies . To establish the asymptotic properties, we assume the following regularity conditions:
Condition 1. With probability one, and have bounded total variation in .
Condition 2. Let be a compact set of and be the class of functions with bound variation over . The true parameter (, ) belongs to with an interior point of and is continuous over with . Here denotes the product space .
Condition 3. With probability one, there exists a positive constant such that and . If there exists a vector and a deterministic function such that with probability one, then and for any .
Condition 4. The transformation function is thrice continuously differentiable on with , and .
Condition 5. Let be the Fréchet derivative of with respect to at . See Web Appendix C for detailed expressions of . We assume that is an invertible map.
Remark 4: Conditions 1 and 2 state the boundedness of the covariates and the compactness of the Euclidean parameter space, which are conventional conditions used in most regression analyses. Condition 3 ensures the existence and uniqueness of the jump sizes in (14). Condition 4 ensures that the transformation function is strictly increasing on . Condition 5 is a classical condition for Z-estimators.
Theorem 1: Under Conditions 1 – 5, the proposed ES estimator (, ) is strongly consistent to (, ).
Theorem 2: Under Conditions 1 – 5, converges weakly to a zero-mean Gaussian process in the metric space .
Here, we let be the closed linear span for linear functionals of . For each , is contained in the Banach space , where for . Thus, is contained in the Banach space . Here, stands for the product space . Detailed proofs of the above theorems are presented in Web Appendix C.
4. Simulation Studies
We carried out extensive simulation studies to evaluate the finite-sample performance of the proposed estimation and inference procedures. Suppose that the failure time follows the Cox-Aalen transformation model with the cumulative hazard function
Here, is a time-dependent covariate where and are independent , , and is a time-independent covariate. We set , , and consider four different configurations for , :
Scenario 1. with , and .
Scenario 2. with , and .
Scenario 3. with , where and , and .
Scenario 4. Let be a categorical variable that takes values in with equal probability. , where , , , and .
For the transformation functions, we consider the class of logarithmic transformations with and 1, where specifies the Cox-Aalen model. For all setups, we let be the duration of the study. For each study participant, we generate one censoring time . We set if , and 0 otherwise. This process yields about 75 – 85% right-censored observations for and 1. For each dataset, we applied the proposed ES algorithm by setting the initial value of to 0 and the initial value of to be for each . We also tried other initial values, yielding almost identical results. We set , 500 or 800, and all simulation results are based on 1000 replicates.
Table 1 summarizes the results for estimation of and for all scenarios. Despite the high censoring percentage, from Table 1, one can see that the proposed procedures perform well in several ways: (i) the estimators are virtually unbiased; (ii) the estimated standard error is fairly close to the empirical standard error; (iii) the empirical coverage probability of 95% confidence intervals are all close to the nominal 95% level; (iv) when the sample size increases, the bias, and the variability of the parameter estimator, decreases. Thus, our proposed estimation procedures are reliable for various Cox-Aalen transformation models.
Table 1.
Simulation results for estimation of the regression parameters under Scenarios 1 to 4
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | SE | SEE | CP | Bias | SE | SEE | CP | ||
| Scenario 1 | |||||||||
| 0 | 200 | 0.003 | 0.350 | 0.340 | 0.950 | −0.014 | 0.587 | 0.574 | 0.947 |
| 500 | 0.007 | 0.212 | 0.212 | 0.952 | −0.005 | 0.354 | 0.359 | 0.956 | |
| 800 | −0.003 | 0.172 | 0.167 | 0.948 | −0.001 | 0.279 | 0.285 | 0.951 | |
| 0.5 | 200 | −0.001 | 0.380 | 0.369 | 0.949 | −0.014 | 0.639 | 0.630 | 0.950 |
| 500 | 0.007 | 0.227 | 0.230 | 0.961 | −0.002 | 0.388 | 0.395 | 0.957 | |
| 800 | −0.004 | 0.185 | 0.181 | 0.951 | −0.001 | 0.302 | 0.313 | 0.951 | |
| 1 | 200 | −0.002 | 0.402 | 0.402 | 0.956 | −0.020 | 0.690 | 0.699 | 0.957 |
| 500 | 0.008 | 0.246 | 0.252 | 0.957 | 0.002 | 0.415 | 0.437 | 0.968 | |
| 800 | −0.005 | 0.198 | 0.198 | 0.946 | −0.003 | 0.323 | 0.347 | 0.957 | |
| Scenario 2 | |||||||||
| 0 | 200 | 0.004 | 0.337 | 0.334 | 0.954 | −0.002 | 0.574 | 0.563 | 0.942 |
| 500 | 0.006 | 0.208 | 0.209 | 0.962 | −0.004 | 0.348 | 0.353 | 0.960 | |
| 800 | −0.002 | 0.169 | 0.164 | 0.945 | −0.006 | 0.275 | 0.280 | 0.949 | |
| 0.5 | 200 | −0.002 | 0.363 | 0.362 | 0.951 | −0.014 | 0.624 | 0.620 | 0.948 |
| 500 | 0.008 | 0.223 | 0.227 | 0.954 | −0.000 | 0.384 | 0.389 | 0.963 | |
| 800 | −0.003 | 0.184 | 0.179 | 0.946 | −0.003 | 0.300 | 0.308 | 0.948 | |
| 1 | 200 | −0.005 | 0.389 | 0.396 | 0.957 | −0.019 | 0.672 | 0.690 | 0.958 |
| 500 | 0.007 | 0.240 | 0.248 | 0.957 | 0.002 | 0.412 | 0.432 | 0.965 | |
| 800 | −0.004 | 0.197 | 0.195 | 0.944 | −0.005 | 0.325 | 0.342 | 0.961 | |
| Scenario 3 | |||||||||
| 0 | 200 | 0.005 | 0.288 | 0.287 | 0.958 | −0.009 | 0.494 | 0.486 | 0.947 |
| 500 | 0.002 | 0.180 | 0.180 | 0.949 | −0.004 | 0.305 | 0.305 | 0.953 | |
| 800 | −0.001 | 0.146 | 0.141 | 0.949 | −0.009 | 0.245 | 0.241 | 0.950 | |
| 0.5 | 200 | 0.001 | 0.319 | 0.321 | 0.954 | −0.009 | 0.552 | 0.555 | 0.953 |
| 500 | 0.001 | 0.198 | 0.202 | 0.956 | −0.004 | 0.348 | 0.348 | 0.953 | |
| 800 | −0.001 | 0.160 | 0.159 | 0.947 | −0.009 | 0.276 | 0.276 | 0.942 | |
| 1 | 200 | 0.010 | 0.343 | 0.365 | 0.964 | −0.002 | 0.624 | 0.647 | 0.962 |
| 500 | −0.002 | 0.216 | 0.229 | 0.959 | −0.002 | 0.380 | 0.403 | 0.963 | |
| 800 | −0.006 | 0.175 | 0.180 | 0.963 | −0.003 | 0.305 | 0.318 | 0.960 | |
| Scenario 4 | |||||||||
| 0 | 200 | 0.010 | 0.339 | 0.334 | 0.951 | −0.011 | 0.572 | 0.562 | 0.938 |
| 500 | 0.005 | 0.211 | 0.209 | 0.948 | −0.003 | 0.348 | 0.353 | 0.958 | |
| 800 | −0.000 | 0.169 | 0.164 | 0.948 | −0.000 | 0.280 | 0.279 | 0.948 | |
| 0.5 | 200 | 0.007 | 0.366 | 0.362 | 0.946 | −0.014 | 0.615 | 0.619 | 0.947 |
| 500 | 0.003 | 0.228 | 0.227 | 0.950 | −0.005 | 0.378 | 0.389 | 0.968 | |
| 800 | 0.001 | 0.183 | 0.179 | 0.950 | −0.001 | 0.308 | 0.307 | 0.949 | |
| 1 | 200 | 0.002 | 0.389 | 0.396 | 0.951 | −0.008 | 0.657 | 0.690 | 0.960 |
| 500 | 0.002 | 0.244 | 0.248 | 0.957 | 0.002 | 0.412 | 0.433 | 0.967 | |
| 800 | 0.001 | 0.195 | 0.196 | 0.956 | 0.000 | 0.330 | 0.341 | 0.954 | |
Note: Bias, bias of the parameter estimator; SE, empirical standard error of the parameter estimator; SEE, mean of the standard error estimator; CP, empirical coverage percentage of the 95% confidence interval.
Figure 1 shows the estimation results for the cumulative regression functions in Scenario 1. The proposed estimators are again virtually unbiased and the estimated curves are able to capture the shapes of the true cumulative regression functions very well; the estimated standard errors are close to the empirical standard errors; and the confidence intervals have reasonably accurate coverage probabilities. To save space, estimation results for via the kernel smoothing approach with bandwidth are provided in Web Appendix D for Scenario 1. In addition, estimation results for and under Scenarios 2 and 4 are also presented in Web Appendix D. These results further confirm the satisfactory performance of our proposed method in various numerical settings. We also conducted simulation studies to investigate the robustness of the proposed estimator under the misspecification of the function. The setups were the same as Scenario 3, and simulation results are displayed in Web Appendix D. The results suggested that the misspecification of the transformation function led to biased estimates and lower coverage probabilities than the nominal levels.
Figure 1.
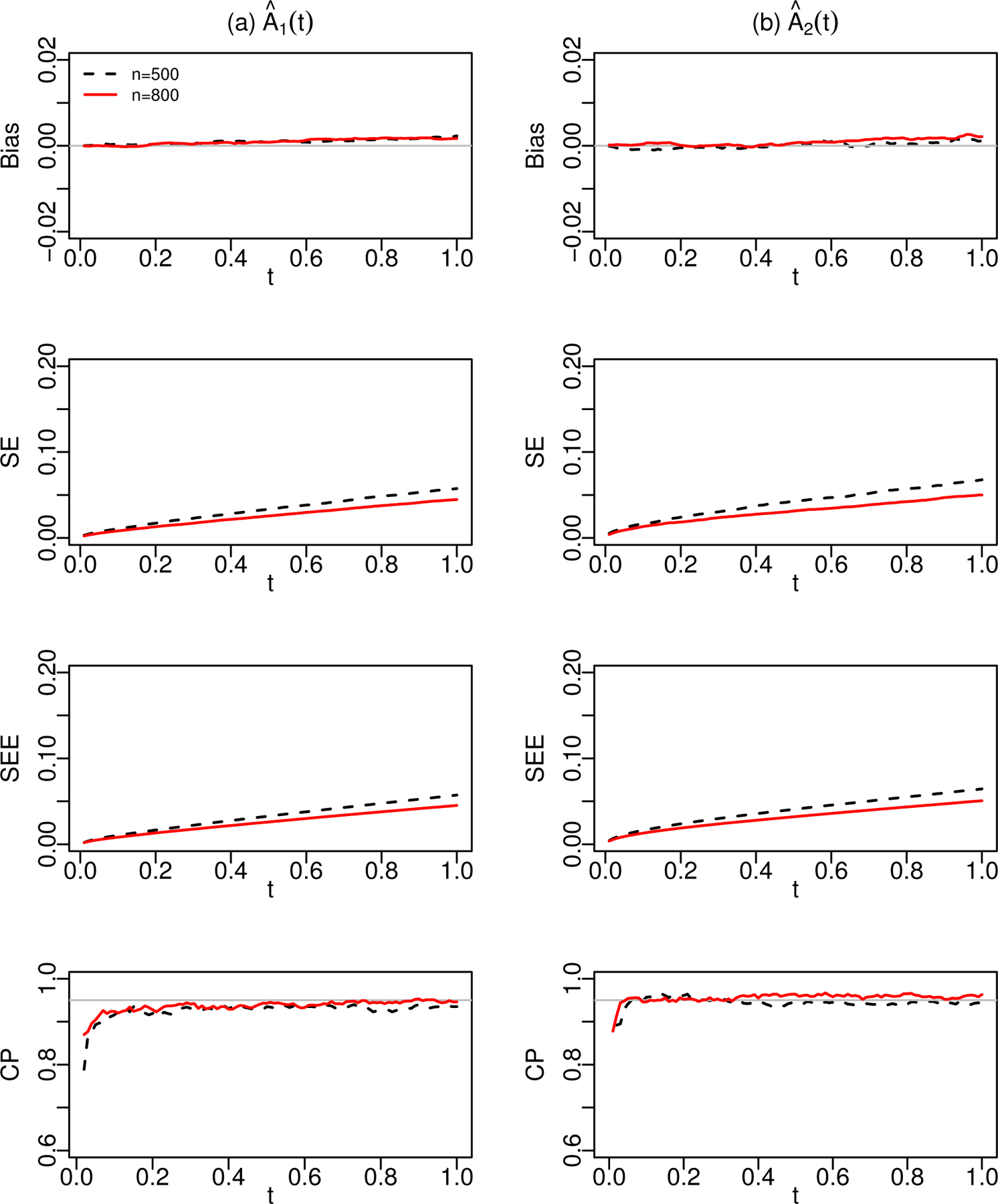
Estimation results for (a) and (b) in Scenario 1, under the logarithmic transformation with . The dashed and solid lines are for data sets with and , respectively. Bias, SE, SEE, and CP stand, respectively, for the bias, empirical standard error, mean of the standard error estimator, and empirical coverage probability of the 95% confidence interval.
Moreover, we demonstrate the superiority of our proposed model over Zeng and Lin’s model in one simulation example. Specifically, we generated the data from our proposed Cox-Aalen transformation model where one covariate has a multiplicative effect, and the other has an additive effect. If we falsely assume that both covariates have multiplicative effects and fit Zeng and Lin’s model, we will obtain biased estimates of the survival function and cumulative hazard. Thus, our proposed model can better capture complex hazard functions. See Web Appendix D for details.
5. An HIV Prevention Study Example
In this section, we apply the proposed model and methods to two harmonized randomized trials, HIV Vaccine Trials Network (HVTN) 704/HIV Prevention Trials Network (HPTN) 085 and HVTN 703/HPTN 081 (Corey et al., 2021), designed to determine whether a broadly neutralizing monoclonal antibody (bnAb) can prevent the acquisition of human immunodeficiency virus type 1 (HIV). The HVTN 704/HPTN 085 trial enrolled 2687 men who have sex with men and transgender persons in the Americas and Europe, and HVTN 703/HPTN 081 enrolled 1924 females in sub-Saharan Africa. For each trial, HIV uninfected participants were randomly assigned in 1:1:1 ratio to receive infusions of a bnAb (VRC01) at a dose of 10 mg per kilogram of body weight (low-dose group), VRC01 at 30 mg per kilogram (high-dose group) or saline placebo, administered at 8-week intervals for 10 total infusions. The primary efficacy endpoint was diagnosis of HIV infection by the week 80 trial visit, and HIV testing was conducted at each 4-week trial visit starting at week 0. For participants acquiring HIV infection, the diagnosis date was determined by the adjudicated diagnosis date based on validated assays (Corey et al., 2021). Participant follow-up is right-censored by the minimum of their last negative HIV sample collection date and weeks (Corey et al., 2021). Therefore, the observed data consist of exact and right-censored observations.
Among the 4559 HIV negative participants from both trials, 1401 are in the U.S. and Switzerland, 1249 in Brazil and Peru, 1009 in South Africa, and 900 in other sub-Saharan African countries (Switzerland was pooled with the U.S. given few participants in Switzerland). We analyze the two trials pooled together, which is valid given the harmonized protocols such that essentially the study is one trial in two distinct study populations. There were a total of 174 HIV infection diagnosis endpoints in the two trials pooled, including 60 out of 1520 participants in the low-dose group, 47 out of 1520 in the high-dose group, and 67 out of 1519 in the placebo group. The numbers of HIV infection diagnosis endpoints by region are reported in Web Appendix E. Participants were categorized by age (in years old) into four groups, [17, 20], [21, 30], [31, 40] and [41, 52], with 540, 2651, 1102 and 266 participants, respectively.
Figure 2 reveals that the risk of HIV infection diagnosis in different regions crosses over. Therefore, without imposing proportional hazards for different regions, we consider the following Cox-Aalen transformation model to assess the association between treatment assignment, age, and region with the time since the first infusion to HIV infection diagnosis:
Figure 2.
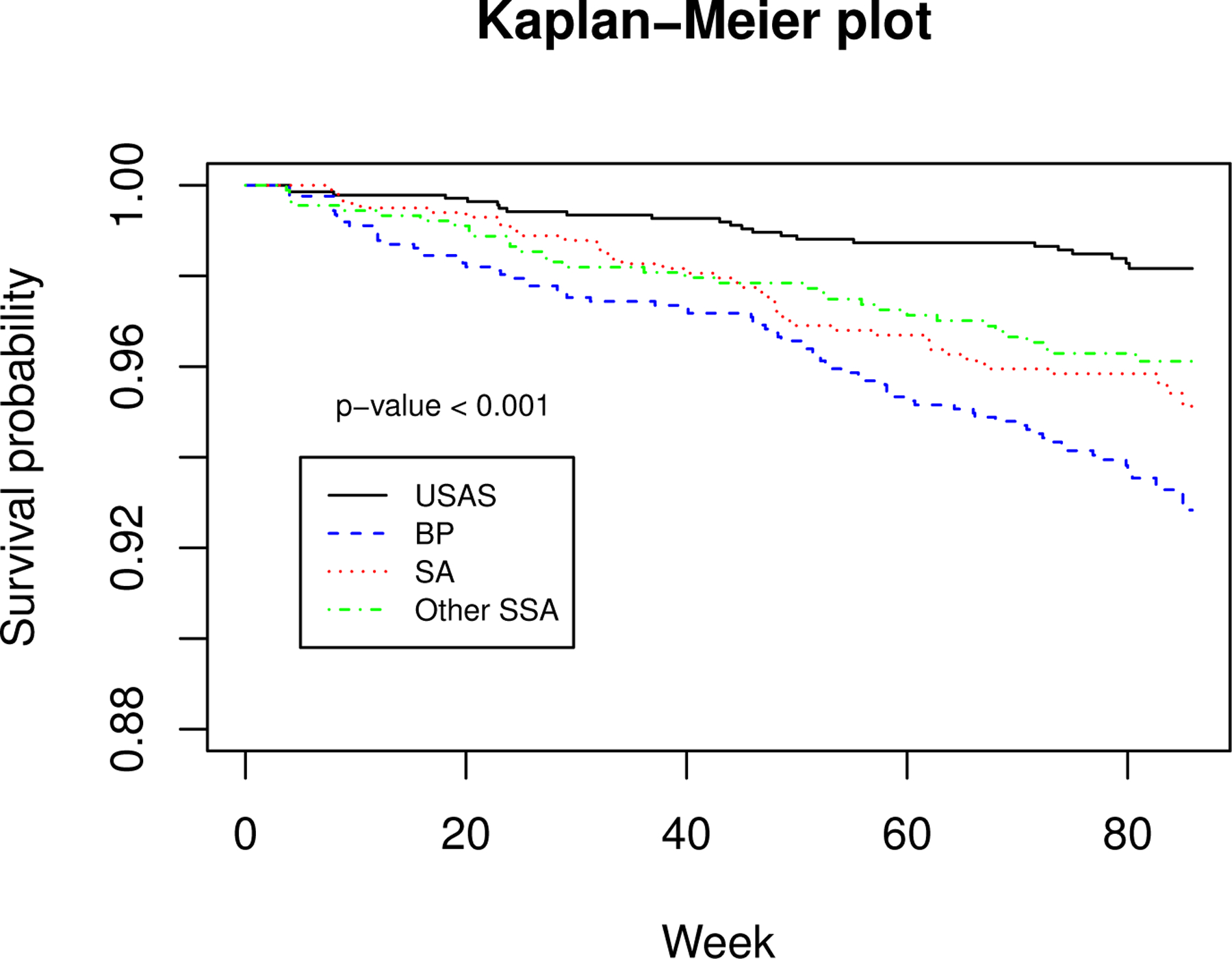
Kaplan-Meier plot for four regions in the full cohort. Here, “USAS”, “BP”, “SA” and “Other SSA” represent USA and Switzerland, Brazil and Peru, South Africa and other sub-Saharan African countries, respectively.
where is the unknown regression coefficients and with . Here, , where and are indicators of being assigned to the low-dose and high-dose group, respectively, with the placebo group as the reference group; , , are indicators of the age groups [21, 30], [31, 40] and [41, 52], respectively, with [17, 20] as the reference age group. In addition, let , where , , are indicators of participants from Brazil and Peru, South Africa, and other sub-Saharan African countries, respectively. The participants from USA and Switzerland are considered as the reference group.
We conducted the analysis using the class of logarithmic transformations , with values ranging from 0 to 3 with an increment of 0.1. The value that maximizes the log-likelihood function evaluated at the final parameter estimates was selected. The log-likelihood is maximized at , though the values do not change greatly for different values of due to a high censoring rate (about 96.2%); this phenomenon is verified in our simulation studies (see Web Appendix E for details).
The lower panel of Table 2 shows the regression parameter estimates for the selected transformation function (). High-dose VRC01 significantly lowers the risk of HIV infection diagnosis, while low-dose VRC01 does not. The model fit also shows a significant association between older age and a lower risk of HIV infection diagnosis. Figure 3 displays the estimated baseline cumulative hazard function for the four different regions. The risk of HIV infection diagnosis is the highest in Brazil and Peru and lowest in the U.S. and Switzerland. The estimates for South Africa and other sub-Saharan African countries cross; in particular, South Africa has a lower risk at early times after the first infusion but a higher risk at later times. In addition, Figure 3 shows that the HIV infection diagnosis hazards are not proportional across geographic regions. Figure 4 plots the estimates of conditional survival functions at sixteen different combinations of covariates: four age groups crossed with four regions. This figure further confirms our findings above. In Web Appendix E, we also report the analysis results under other values of r and observe the same patterns.
Table 2.
Regression analysis results for the HIV trials from Zeng and Lin’s model fit to each of the four geographic regions separately and the proposed Cox-Aalen transformation model based on the full cohort data with the logarithmic transformation with
| USA/Switzerland |
Brazil/Peru |
|||||
| Covariates | Est | SE | p-value | Est | SE | p-value |
| Low-dose | −0.107 | 0.484 | 0.825 | −0.167 | 0.276 | 0.545 |
| High-dose | −0.437 | 0.524 | 0.404 | −0.279 | 0.283 | 0.325 |
| 21 − 30 | −0.454 | 0.630 | 0.472 | −0.525 | 0.262 | 0.045 |
| 31 − 40 | −2.709 | 1.141 | 0.018 | −1.283 | 0.396 | 0.001 |
| 41 − 52 | −1.152 | 0.903 | 0.202 | −16.859 | 1.668 | < 0.001 |
| South Africa |
Other SSA |
|||||
| Covariates | Est | SE | p-value | Est | SE | p-value |
|
| ||||||
| Low-dose | −0.025 | 0.354 | 0.943 | −0.080 | 0.400 | 0.842 |
| High-dose | −0.392 | 0.392 | 0.317 | −0.509 | 0.449 | 0.258 |
| 21 – 30 | −0.187 | 0.380 | 0.623 | −0.480 | 0.498 | 0.335 |
| 31 – 40 | −0.954 | 0.601 | 0.112 | −0.719 | 0.586 | 0.220 |
| 41 – 52 | −13.867 | 2.366 | < 0.001 | −13.871 | 2.626 | < 0.001 |
| The Proposed Model |
||||||
| Covariates | Est | SE | p-value | |||
|
|
||||||
| Low-dose | −0.108 | 0.178 | 0.542 | |||
| High-dose | −0.363 | 0.190 | 0.056 | |||
| 21 – 30 | −0.429 | 0.187 | 0.022 | |||
| 31 – 40 | −1.219 | 0.274 | < 0.001 | |||
| 41 – 52 | −1.989 | 0.721 | 0.006 | |||
Note: Est and SE stand for the estimates of the regression parameters and the estimated standard errors, respectively. “Other SSA” is for other sub-Saharan African countries. “USA/Switzerland”, “Brazil/Peru”, “South Africa”, and “Other SSA” correspond to the estimation results by fitting Zeng and Lin’s model to each geographic region. “The Proposed Model” corresponds to the estimation results when fitting the proposed Cox-Aalen transformation models to the full cohort data.
Figure 3.
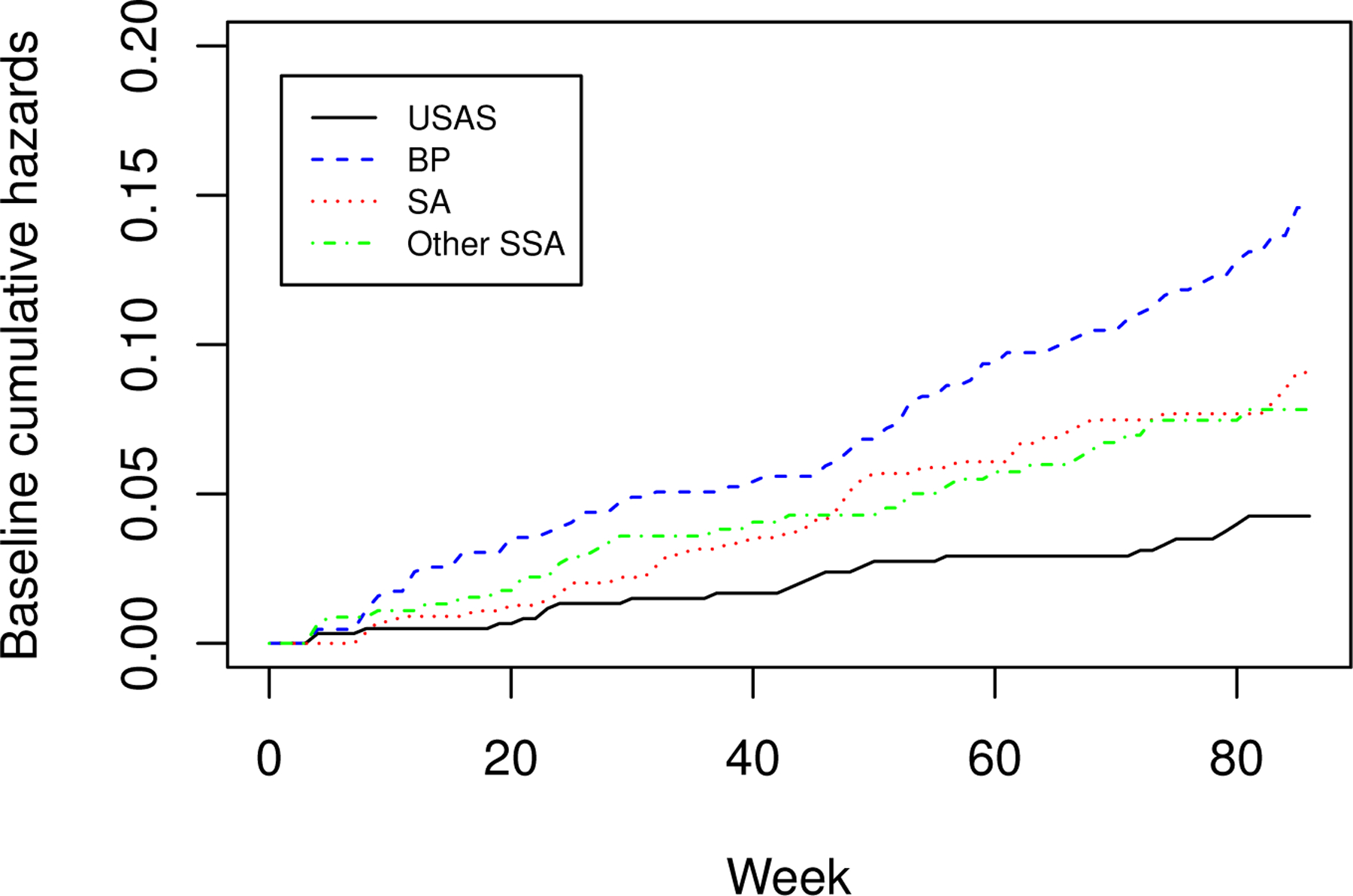
Estimated baseline cumulative hazard function for four regions under the logarithmic transformation with . Here, “USAS”, “BP”, “SA” and “Other SSA” represent USA and Switzerland, Brazil and Peru, South Africa and other sub-Saharan African countries, respectively.
Figure 4.
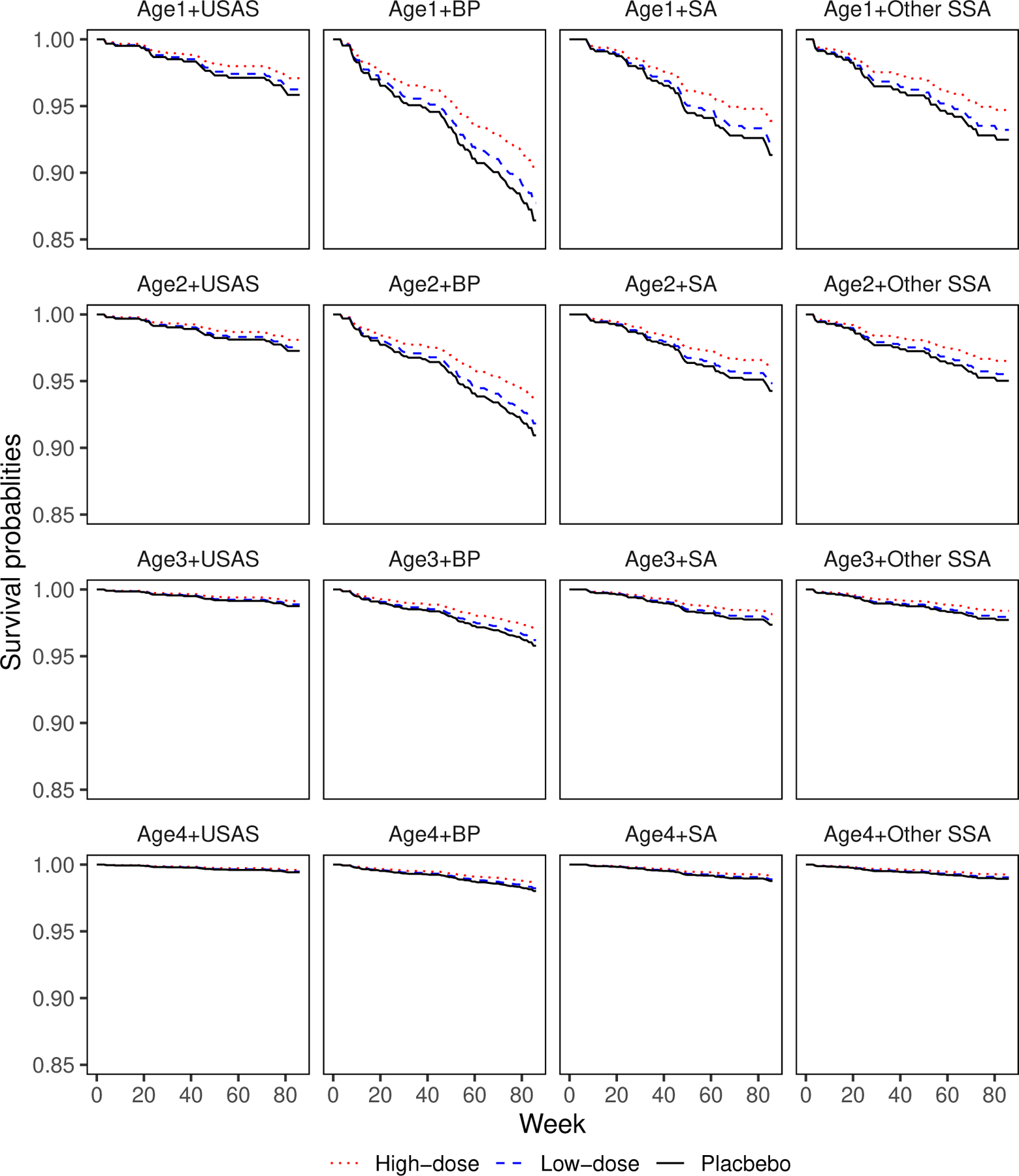
Estimated survival functions by considering different combinations of covariates under the proposed model with the transformation with . Here, “Age1”, “Age2”, “Age3” and “Age4” stand for the age goups, [17, 20], [21, 30], [31, 40] and [41, 52], respectively. “USAS”, “BP”, “SA” and “Other SSA” represent USA and Switzerland, Brazil and Peru, South Africa and other sub-Saharan African countries, respectively.
The four other panels of Table 2 (upper panels) show results from Zeng and Lin’s model fit to each of the four geographic regions separately; this method was not applied to the full cohort (pooled) data because it cannot flexibly model the differences in baseline cumulative hazards and the diagnostics support lack of fit. In these results, the p-values for the effect of high-dose VRC01 markedly increase, and the coefficient estimates for the age group [41, 52] are unstable because there are very few HIV infection diagnosis endpoints in this age group in the three regions Brazil and Peru, South Africa, and other sub-Saharan African countries. Therefore, the results from the Cox-Aalen transformation modeling –which could be based on the full cohort data through flexible specifications of the baseline cumulative hazard functions – provide new insights with improved precision and power beyond insights achieved from the application of Zeng and Lin’s model.
6. Discussion
In this article, we proposed a class of semiparametric Cox-Aalen transformation models that includes Zeng and Lin’s model (Zeng and Lin, 2006; Zeng et al., 2016) and the Cox-Aalen model (Scheike and Zhang, 2002) as special cases. By considering the class of frailty-induced transformations, we successfully developed a fast and stable ES algorithm to estimate the parametric and nonparametric components of the proposed model along with easy-to-compute variance estimators. In addition, the asymptotic properties of our proposed estimators are rigorously studied. Elashoff and Ryan (2004) pointed out that an ES algorithm can be regarded as a block Newton-Gauss-Seidel algorithm (see Ortega 1972, p.146). Following Ortega (1972, p.147), an ES algorithm converges locally to the solution, , of if the Jacobian matrix is nonsingular at and the largest eigenvalue of is less than 1. For general estimating equations, the two conditions above are difficult to verify in advance, especially for the second condition. Nevertheless, the matrix is needed to calculate the variance of in (16), and hence one can check the required conditions numerically.
In real data applications, we ascertain whether a covariate has a multiplicative or additive effect based on the following criteria. First, we may employ the underlying biological, physical meaning, or other domain knowledge for decision-making. Second, initial data exploration can be performed for each covariate, such as drawing the Kaplan-Meier (KM) plot. If the KM curves cross, this covariate should be modeled additively. Third, similar to Qu and Sun (2019), Yu et al. (2019), we may employ some AIC or BIC-based procedures. In particular, all possible combinations of covariate effects will be examined. However, it is easy to see that this is inefficient when there are many covariates. In addition, Scheike and Zhang (2003) proposed supremum tests to determine the multiplicative and additive parts of the Cox-Aalen model. It is worthwhile to investigate if similar testing procedures can be constructed for our proposed model. More theoretical and numerical studies are needed, which we leave for future work.
Indeed, the outlined procedures for determining the covariates for the multiplicative or additive components are valid for a given class of the Cox-Aalen transformation model. In practice, when the KM curves corresponding to different values or groups of values of a certain covariate, say , cross, the effects of this covariate are not necessarily additive. In addition to the possibility that the effect of is additive, there are a number of ways that the proportionality can fail, e.g., not as a part of under the Cox-Aalen transformation model. For example, the effect of could be time-varying as in the Cox model with time-varying regression coefficients studied by Cai and Sun (2003). In another scenario, the contributions from the additive components and the multiplicative components of the model may not be in the multiplicative form. In addition to choosing the right covariates for the multiplicative and additive components of the model, mis-specifying the transformation function can result in erroneous inferences.
Assessing the adequacy of the proposed model is crucial because model misspecification affects the validity of inference and prediction accuracy. For Zeng and Lin’s model, Chen et al. (2012) considered appropriate time-dependent residuals and constructed various graphical and numerical procedures for model assessment. In our analysis of the HIV prevention trial data, we use the log-likelihood to select the transformation function, even though the log-likelihood surface is relatively flat. Similar to Chen et al. (2012), we suggest constructing the cumulative sums of residuals over the argument of the transformation function, i.e., to check the transformation form, where . A thorough theoretical and numerical investigation of model misspecification is still needed for the proposed model. We are currently pursuing this direction.
Supplementary Material
Acknowledgements
This research is part of Xi Ning’s Ph.D. dissertation. This research was partially supported by the National Institutes of Health, National Institute of Allergy and Infectious Diseases [grant numbers UM1 AI68635 and R37 AI054165]. The research of Xi Ning was also supported, in part, by the 2022 Graduate School Summer Fellowship Program from the University of North Carolina at Charlotte (UNC Charlotte). Yinghao Pan’s work was partially supported by funds provided by UNC Charlotte. The research of Yanqing Sun was also partially supported by the National Science Foundation [grant number DMS-1915829] and the Reassignment of Duties fund provided by UNC Charlotte. We thank the HIV Vaccine Trials Network (HVTN) for providing the data analyzed in this article, especially Dr. Yunda Huang. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Footnotes
Supporting Information
Web Appendices, Tables, and Figures referenced in Sections 3, 4 and 5, along with the simulated datasets and R code, are all available with this paper at the Biometrics website on Wiley Online Library. In addition, the dataset and R code are also available at https://github.com/xining1/CoxAalen-transformation.
Data Availability Statement
The data that support the findings of this paper are available in the Supporting Information of this article.
References
- Aalen O (1980). A model for nonparametric regression analysis of counting processes. In Mathematical statistics and probability theory, pages 1–25. Springer. [Google Scholar]
- Bennett S (1983). Analysis of survival data by the proportional odds model. Statistics in medicine 2, 273–277. [DOI] [PubMed] [Google Scholar]
- Boruvka A and Cook RJ (2015). A Cox-Aalen model for interval-censored data. Scandinavian Journal of Statistics 42, 414–426. [Google Scholar]
- Cai Z and Sun Y (2003). Local linear estimation for time-dependent coefficients in Cox’s regression models. Scandinavian Journal of Statistics 30, 93–111. [Google Scholar]
- Chen K, Jin Z, and Ying Z (2002). Semiparametric analysis of transformation models with censored data. Biometrika 89, 659–668. [Google Scholar]
- Chen L, Lin D, and Zeng D (2012). Checking semiparametric transformation models with censored data. Biostatistics 13, 18–31. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen Y-H (2009). Weighted Breslow-type and maximum likelihood estimation in semi-parametric transformation models. Biometrika 96, 591–600. [Google Scholar]
- Cheng S, Wei L, and Ying Z (1995). Analysis of transformation models with censored data. Biometrika 82, 835–845. [Google Scholar]
- Corey L, Gilbert PB, Juraska M, Montefiori DC, Morris L, Karuna ST, Edupuganti S, Mgodi NM, deCamp AC, Rudnicki E, et al. (2021). Two randomized trials of neutralizing antibodies to prevent HIV-1 acquisition. New England Journal of Medicine 384, 1003–1014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cox DR (1972). Regression models and life-tables. Journal of the Royal Statistical Society: Series B (Methodological) 34, 187–202. [Google Scholar]
- Dabrowska DM and Doksum KA (1988). Partial likelihood in transformation models with censored data. Scandinavian journal of statistics pages 1–23.
- Dempster AP, Laird NM, and Rubin DB (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological) 39, 1–22. [Google Scholar]
- Elashoff M and Ryan L (2004). An EM algorithm for estimating equations. Journal of Computational and Graphical Statistics 13, 48–65. [Google Scholar]
- Fine J, Ying Z, and Wei L (1998). On the linear transformation model for censored data. Biometrika 85, 980–986. [Google Scholar]
- Gao F, Zeng D, and Lin D-Y (2017). Semiparametric estimation of the accelerated failure time model with partly interval-censored data. Biometrics 73, 1161–1168. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Henderson NC and Rathouz PJ (2018). AR (1) latent class models for longitudinal count data. Statistics in medicine 37, 4441–4456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huffer FW and McKeague IW (1991). Weighted least squares estimation for aalen’s additive risk model. Journal of the American Statistical Association 86, 114–129. [Google Scholar]
- Johnson LM and Strawderman RL (2012). A smoothing expectation and substitution algorithm for the semiparametric accelerated failure time frailty model. Statistics in Medicine 31, 2335–2358. [DOI] [PubMed] [Google Scholar]
- Kalbfleisch JD and Prentice RL (2002). The statistical analysis of failure data Wiley. [Google Scholar]
- Lin D and Ying Z (1995). Semiparametric analysis of general additive-multiplicative hazard models for counting processes. The annals of Statistics pages 1712–1734.
- Lin DY and Ying Z (1994). Semiparametric analysis of the additive risk model. Biometrika 81, 61–71. [Google Scholar]
- Liu X and Zeng D (2013). Variable selection in semiparametric transformation models for right-censored data. Biometrika 100, 859–876. [Google Scholar]
- Martinussen T and Scheike TH (2002). A flexible additive multiplicative hazard model. Biometrika 89, 283–298. [Google Scholar]
- Ortega JM (1972). Numerical analysis: a second course SIAM.
- Ortega JM and Rheinboldt WC (1970). Iterative solution of nonlinear equations in several variables SIAM. [Google Scholar]
- Pettitt AN (1982). Inference for the linear model using a likelihood based on ranks. Journal of the Royal Statistical Society: Series B (Methodological) 44, 234–243. [Google Scholar]
- Qu L and Sun L (2019). The cox–aalen model for recurrent-event data with a dependent terminal event. Statistica Neerlandica 73, 234–255. [Google Scholar]
- Scheike TH and Zhang M. j. (2002). An additive–multiplicative Cox–Aalen regression model. Scandinavian Journal of Statistics 29, 75–88. [Google Scholar]
- Scheike TH and Zhang M-J (2003). Extensions and applications of the Cox-Aalen survival model. Biometrics 59, 1036–1045. [DOI] [PubMed] [Google Scholar]
- Shen P-S and Weng LN (2018). The Cox–Aalen model for left-truncated and right-censored data. Communications in Statistics-Theory and Methods 47, 5357–5368. [Google Scholar]
- Shen P. s. and Weng LN (2019). The cox-aalen model for left-truncated and mixed interval-censored data. Statistics 53, 1152–1167. [Google Scholar]
- van der Vaart A and Wellner JA (1996). Weak convergence and empirical processes: with applications to statistics Springer, New York. [Google Scholar]
- Yu G, Li Y, Zhu L, Zhao H, Sun J, and Robison LL (2019). An additive– multiplicative mean model for panel count data with dependent observation and dropout processes. Scandinavian Journal of Statistics 46, 414–431. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zeng D and Lin D (2006). Efficient estimation of semiparametric transformation models for counting processes. Biometrika 93, 627–640. [Google Scholar]
- Zeng D and Lin D (2007). Maximum likelihood estimation in semiparametric regression models with censored data. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 69, 507–564. [Google Scholar]
- Zeng D, Mao L, and Lin D (2016). Maximum likelihood estimation for semiparametric transformation models with interval-censored data. Biometrika 103, 253–271. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou Q, Sun Y, and Gilbert PB (2021). Semiparametric regression analysis of partly interval-censored failure time data with application to an AIDS clinical trial. Statistics in Medicine 40, 4376–4394. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The data that support the findings of this paper are available in the Supporting Information of this article.