

Abstract
Spiny projection neurons (SPNs) in dorsal striatum are often proposed as a locus of reinforcement learning in the basal ganglia. Here, we identify and resolve a fundamental inconsistency between striatal reinforcement learning models and known SPN synaptic plasticity rules. Direct-pathway (dSPN) and indirect-pathway (iSPN) neurons, which promote and suppress actions, respectively, exhibit synaptic plasticity that reinforces activity associated with elevated or suppressed dopamine release. We show that iSPN plasticity prevents successful learning, as it reinforces activity patterns associated with negative outcomes. However, this pathological behavior is reversed if functionally opponent dSPNs and iSPNs, which promote and suppress the current behavior, are simultaneously activated by efferent input following action selection. This prediction is supported by striatal recordings and contrasts with prior models of SPN representations. In our model, learning and action selection signals can be multiplexed without interference, enabling learning algorithms beyond those of standard temporal difference models.
Introduction
Numerous studies have proposed that the basal ganglia is a reinforcement learning system (Joel et al., 2002; Niv, 2009; Ito and Doya, 2011). Reinforcement learning algorithms use experienced and predicted rewards to learn to predict the expected future reward associated with an organism’s current state and the action to select in order to maximize this reward (Sutton and Barto, 2018). Spiny projection neurons (SPNs) in the striatum are well-positioned to take part in such an algorithm, as they receive diverse contextual information from the cerebral cortex and are involved in both action selection (in dorsal striatum; Packard and Knowlton, 2002; Seo et al., 2012; Balleine et al., 2007) and value prediction (in ventral striatum; Cardinal et al., 2002; Montague et al., 1996; O’Doherty et al., 2004). Moreover, plasticity of SPN input synapses is modulated by midbrain dopamine release (Wickens et al., 1996; Calabresi et al., 2000; Contreras-Vidal and Schultz, 1999). A variety of studies support the view that this dopamine release reflects reward prediction error (Schultz et al., 1997; Montague et al., 1996; Houk and Adams, 1995), which in many reinforcement learning algorithms is the key quantity used to modulate learning (Sutton and Barto, 2018; Niv, 2009).
Despite these links, several aspects of striatal physiology are difficult to reconcile with reinforcement learning models. SPNs are classified in two main types – direct-pathway (dSPNs) and indirect-pathway (iSPNs). These two classes of SPNs exert opponent effects on action based on perturbation data (Kravitz et al., 2010; Freeze et al., 2013; Lee and Sabatini, 2021), but also exhibit highly correlated activity (Cui et al., 2013). Moreover, dSPNs and iSPNs express different dopamine receptors (D1-type and D2-type) and thus undergo synaptic plasticity according to different rules. In particular, dSPN inputs are potentiated when coincident pre- and post-synaptic activity is followed by above-baseline dopamine activity, while iSPN inputs are potentiated when coincident pre- and post-synaptic activity is followed by dopamine suppression (Shen et al., 2008; Frank, 2005; Iino et al., 2020).
Prior studies have proposed that dSPNs learn from positive reinforcement to promote actions, and iSPNs learn from negative reinforcement to suppress actions (Cruz et al., 2022; Collins and Frank, 2014; Jaskir and Frank, 2023; Varin et al., 2023; Mikhael and Bogacz, 2016; Dunovan et al., 2019). However, we will show that a straightforward implementation of such a model fails to yield a functional reinforcement learning algorithm, as the iSPN learning rule assigns blame for negative outcomes to the wrong actions. Correct learning in this scenario requires a mechanism to selectively update corticostriatal weights corresponding to the chosen action, which is absent in prior models (see Discussion).
In this work, we begin by rectifying this inconsistency between standard reinforcement learning models of the striatum and known SPN plasticity rules. The iSPN learning rule reported in the literature reinforces patterns of iSPN activity that are associated with dopamine suppression, increasing the likelihood of repeating decisions that previously led to negative outcomes. We show that this pathological behavior is reversed if, after action selection, opponent dSPNs and iSPNs receive correlated efferent input encoding the animal’s selected action. A central contribution of our model is a decomposition of SPN activity into separate modes of activity for action selection and for learning, the latter driven by this efferent input. This decomposition provides an explanation for the apparent paradox that the activities of dSPNs and iSPNs are positively correlated despite their opponent causal functions (Cui et al., 2013), and provides a solution to the problem of multiplexing signals related to behavioral execution and learning. The model also makes predictions about the time course of SPN activity, including that dSPNs and iSPNs that are responsible for regulating the same behavior (promoting and suppressing it, respectively) should be coactive following action selection. This somewhat counterintuitive prediction contrasts with prior proposals that dSPNs that promote an action are coactive with iSPNs that suppress different actions (Mink, 1996; Redgrave et al., 1999). We find support for this prediction in experimental recordings of dSPNs and iSPNs during spontaneous behavior.
Next, we show that the nonuniformity of dSPN and iSPN plasticity rules enables more sophisticated learning algorithms than can be achieved in models with a single plasticity rule. In particular, it enables the striatum to implement so-called off-policy reinforcement learning algorithms, in which the corticostriatal pathway learns from the the outcomes of actions that are driven by other neural pathways. Off-policy algorithms are commonly used in state-of-the-art machine learning models, as they dramatically improve learning efficiency by facilitating learning from expert demonstrations, mixture-of-experts models, and replayed experiences (Arulkumaran et al., 2017). Following the implications of this model further, we show that off-policy algorithms require a dopaminergic signal in dorsal striatum that combines classic state-based reward prediction error with a form of action prediction error. We confirm a key signature of this prediction in recent dopamine data collected from dorsolateral striatum during spontaneous behavior.
Results
In line with previous experimental (Wickens et al., 1996; Calabresi et al., 2000; Contreras-Vidal and Schultz, 1999) and modeling (Sutton and Barto, 2018; Niv, 2009) studies, we model plasticity of corticostriatal synapses using a three-factor learning rule, dependent on coincident presynaptic activity, postsynaptic activity, and dopamine release (Fig 1A,B). Concretely, we model plasticity of the weight of a synapse from a cortical neuron with activity onto a dSPN or iSPN with activity as
| (1) |
| (2) |
where represents dopamine release relative to baseline, and the functions and model the dependence of the two plasticity rules on dopamine concentration.
Figure 1:

Corticostriatal action selection circuits and plasticity rules. A. Left, diagram of cortical inputs to striatal populations. Right, illustration of action selection architecture. Populations of dSPNs (blue) and iSPNs (red) in DLS are responsible for promoting and suppressing specific actions, respectively. Active neurons (shaded circles) illustrate a pattern of activity consistent with typical models of striatal action selection, in which dSPNs that promote a chosen action and iSPNs that suppress other actions are active. B. Illustration of three-factor plasticity rules at SPN input synapses, in which adjustments to corticostriatal synaptic weights depend on presynaptic cortical activity, SPN activity, and dopamine release. C. Illustration of different models of the dopamine-dependent factor in dSPN (blue) and iSPN (red) plasticity rules.
For dSPNs, the propensity of input synapses to potentiate increases with increasing dopamine concentration, while for iSPNs the opposite is true. This observation is corroborated by converging evidence from observations of dendritic spine volume, intracellular PKA measurements, and spike-timing dependent plasticity protocols (Shen et al., 2008; Gurney et al., 2015; Iino et al., 2020; Lee et al., 2021). For the three-factor plasticity rule above, these findings imply that is an increasing function of while is a decreasing function. Prior modeling studies have proposed specific plasticity rules that correspond to different choices of and , some examples of which are shown in Fig. 1C.
iSPN plasticity rule impedes successful reinforcement learning
Prior work has proposed that dSPNs activate when actions are performed and iSPNs activate when actions are suppressed (Fig. 1A). When an animal selects among multiple actions, subpopulations of dSPNs are thought to promote the selected action, while other subpopulations of iSPNs inhibit the unchosen actions (Mink, 1996; Redgrave et al., 1999). We refer to this general description as the “canonical action selection model” of SPN activity and show that this model, when combined with the plasticity rules above, fails to produce a functional reinforcement learning algorithm. This failure is specifically due to the iSPN plasticity rule. Later, we also show that the SPN representation predicted by the canonical action selection model is inconsistent with recordings of identified dSPNs and iSPNs. We begin by analyzing a toy model of an action selection task with two actions, one of which is rewarded. In the model, the probability of selecting an action is increased when the dSPN corresponding to that action is active and decreased when the corresponding iSPN is active. After an action is taken, dopamine activity reports the reward prediction error, increasing when reward is obtained and decreasing when it is not.
It is easy to see that the dSPN plasticity rule in Eq. (1) is consistent with successful reinforcement learning (Fig. 2A). Suppose action 1 is selected, leading to reward (Fig. 2A, center). The resulting dopamine increase potentiates inputs to the action 1 dSPN from cortical neurons that are active during the task, making action 1 more likely to be selected in the future (Fig. 2A, right).
Figure 2:

Consequences of the canonical action selection model of SPN activity. A. Example in which dSPN plasticity produces correct learning. Left: cortical inputs to the dSPN and iSPN are equal prior to learning. Shading of corticostriatal connections indicates synaptic weight, and shading of blue and red circles denotes dSPN/iSPN activity. Middle: action 1 is selected, corresponding to elevated activity in the dSPN that promotes action 1 and the iSPN that suppresses action 2. In this example, action 1 leads to reward and increased DA activity. This potentiates the input synapse to the action 1-promoting dSPN and (depending on the learning rule, see Fig. 1) depresses the input to the action 2-suppressing iSPN. Right: in a subsequent trial, cortical input to the action 1-promoting dSPN is stronger, increasing the likelihood of selecting action 1. Here, the dSPN-mediated effect of increasing action 1’s probability overcomes the iSPN-mediated effect of decreasing action 2’s probability. B. Example in which iSPN plasticity produces incorrect learning. Same as A, but in a scenario in which action 2 is selected leading to punishment and a corresponding decrease in DA activity. As a result, the input synapse to the action 2-promoting dSPN is (depending on the learning rule) depressed, and the input to the action 1-suppressing iSPN is potentiated. On a subsequent trial, the probability of selecting action 2 rather than action 1 is greater, despite action 2 being punished. Note that the dSPN input corresponding to action 2 is (potentially) weakened, which correctly decreases the probability of selecting action 2, but this effect is not sufficient to overcome the strengthened action 1 iSPN activity. C. Performance of a simulated striatal reinforcement learning system in go/no-go tasks with different reward contingencies. D. Same as C, but for action selection tasks with two cortical input states, two available actions, and one correct action per state, under different reward protocols.
At first glance, it may seem that a similar logic would apply to iSPNs, since their suppressive effect on behavior and reversed dependence on dopamine concentration are both opposite to dSPNs. However, a more careful examination reveals that the iSPN plasticity rule in Eq. (2) does not promote successful learning. In the canonical action selection model, dSPNs promoting a selected action and iSPNs inhibiting unselected actions are active. If a negative outcome is encountered leading to a dopamine decrease, Eq. (2) predicts that inputs to iSPNs corresponding to unselected actions are strengthened (LTP in Fig. 2B, center). This makes the action that led to the negative outcome more rather than less likely to be taken when the same cortical inputs are active in the future (Fig. 2B, right). More generally, the model demonstrates that, while the plasticity rule of Eq. (1) correctly reinforces dSPN activity patterns that lead to positive outcomes, Eq. (2) incorrectly reinforces iSPN activity patterns that lead to negative outcomes. The function of iSPNs in inhibiting action does not change the fact that such reinforcement is undesirable.
We note that, depending on the learning rule (Fig. 1C), inputs to dSPNs that promote the selected action may be weakened (LTD in Fig. 2B, left), which correctly disincentivizes the action that led to a negative outcome. However, this dSPN effect competes with the pathological behavior of the iSPNs and is often unable to overcome it. We also note that, if dopamine increases lead to depression of iSPN inputs (Fig. 1A, center, right), positive outcomes will lead to actions that were correctly being inhibited by iSPNs to be less inhibited in the future. Thus, both positive and negative outcomes may cause incorrect iSPN learning. Some sources suggest that while dopamine suppression increases D2 receptor activation, dopamine increase has little effect on D2 receptors (Dreyer et al., 2010), corresponding to the rectified model of (Fig. 1C, left). In this case, pathological iSPN plasticity behavior still manifests when dopamine activity is suppressed (as in the examples of Fig. 2B).
We simulated learning of multiple tasks with the three-factor plasticity rules above, with dopamine activity modeled as reward prediction error obtained using a temporal difference learning rule. In a go/no-go task with one cue in which the “go” action is rewarded (Supp. Fig. 1), the system learns the wrong behavior when negative performance feedback is provided on no-go trials, and thus iSPN plasticity is the main driver of learning (Fig. 2C). We also simulated a two-alternative forced choice task in which there are two cues (corresponding to different cortical input patterns), each with a corresponding target action. When performance feedback consists of rewards for correct actions, the system learns the task, as dSPNs primarily drive the learning. However, when instead performance feedback consists of giving punishments for incorrect actions, the system does not learn the task, as iSPNs primarily drive the learning (Fig. 2D). We note that, in principle, this problem could be avoided if the learning rate of iSPNs were very small compared to that of dSPNs, ensuring that reinforcement learning is always primarily driven by the dSPN pathway (leaving iSPNs to potentially perform a different function). However, this alternative would be inconsistent with prior studies indicating a significant role for the indirect pathway in reinforcement learning (Peak et al., 2020; Lee and Sabatini, 2021). The model we introduce below makes use of contributions to learning from both pathways.
Efferent activity in SPNs enables successful reinforcement learning
We have shown that the canonical action selection model, when paired with Eqs. (1) and (2), produces incorrect learning. What pattern of SPN activity would produce correct learning? In the model, the probability of selecting an action is determined by the “difference mode” , where and are the activities of dSPN and iSPN neurons associated with that action. We analyzed how the plasticity rule of Eqs. (1) and (2) determines changes to this difference mode. In the simplest case in which the SPN firing rate is a linear function of cortical input (that is, ) and plasticity’s dependence on dopamine concentration is also linear (that is, ; Fig. 1C, center), the change in the probability of selecting an action due to learning is
| (3) |
Changes to the “difference mode” are therefore driven by the “sum mode” . This implies that the activity pattern that leads to correct learning about an action’s outcome is different from the activity pattern that selects the action. To promote or inhibit, respectively, an action that leads to a dopamine increase or decrease, this analysis predicts that both dSPNs that promote and iSPNs that inhibit the action should be co-active. A more general argument applies for other learning rules and firing rate nonlinearities: as long as is an increasing function of total input current, has positive slope, and has negative slope, changes in difference mode activity will be positively correlated with sum mode activity (see Supplemental Information).
The key insight of the above argument is that the pattern of SPN activity needed for learning involves simultaneous excitation of dSPNs that promote the current behavior and iSPNs that inhibit it. This differs from the pattern of activity needed to drive selection of that behavior in the first place. We therefore propose a model in which SPN activity contains a substantial efferent component that follows action selection and promotes learning, but has no causal impact on behavior. In the model, feedforward corticostriatal inputs initially produce SPN activity whose difference mode causally influences action selection, consistent with the canonical model (Fig. 3A, left). When an action is performed, both dSPNs and iSPNs responsible for promoting or inhibiting that action receive efferent excitatory input, producing sum-mode activity. Following this step, SPN activity reflects both contributions (Fig. 3A, center). The presence of sum-mode activity leads to correct synaptic plasticity and learning (Fig. 3A, right). Unlike the canonical action selection model (Fig. 1A), this model thus predicts an SPN representation in which, after an action is selected, the most highly active neurons are those responsible for regulating that behavior and not other behaviors.
Figure 3:

The efference model of SPN activity. A. Illustration of the efference model in an action selection task. Left: feedforward SPN activity driven by cortical inputs. Center: once action 2 is selected, efferent inputs excite the dSPN and iSPN responsible for promoting and suppressing action 2. Efferent activity is combined with feedforward activity, such that the action 2-associated dSPNs and iSPNs are both more active than the action 1 dSPNs and iSPNs, but the relative dSPN and iSPN activity for each action remains unchanged. This produces strong LTD and LTP in the action 2-associated dSPNs and iSPNs upon a reduction in dopamine activity. Right: In a subsequent trial, this plasticity correctly reduces the likelihood of selecting action 2. B. The activity levels of the dSPN and iSPN populations that promote and suppress a given action can be plotted in a two-dimensional space. The difference mode influences the probabiility of taking that action, while activity in the sum mode drives future changes to activity in the difference mode via plasticity. Efferent activity excites the sum mode. C. Performance of a striatal RL system using the efference model on the tasks of Fig. 2C. D. Performance of a striatal RL system using the efference model on the tasks of Fig. 2D.
In SPN activity space, the sum and difference modes are orthogonal to one another. This orthogonality has two consequences. First, it implies that encoding the action in the difference mode (as in the canonical action selection model) produces synaptic weight changes that do not promote learning, consistent with the competing effects of dSPN and iSPN plasticity that we previously described. Second, it implies that adding efferent activity along the sum mode, which produces correct learning, has no effect on action selection. The model thus provides a solution to the problem of interference between “forward pass” (action selection) and “backward pass” (learning) activity, a common issue in models of biologically plausible learning algorithms (see Discussion).
In simulations, we confirm that unlike the canonical action selection model, this efference model solves go/no-go (Fig. 3C) and action selection (Fig. 3D) tasks regardless of the reward protocol. Although the derivation above assumes linear SPN responses and linear dependences of plasticity on dopamine concentration, our model enables successful learning even using a nonlinear model of SPN responses and a variety of plasticity rules (Fig. 3C,D; see Supplemental Information for a derivation that explains this general success). Finally, we also confirmed that our results apply to cases in which actions are associated with distributed modes of dSPN and iSPN activity, and with a larger action space (Supp. Fig. 2). This success arises from the ability to form orthogonal subspaces for action selection and learning in this distributed setting. Although we describe the qualitative behavior of our model using discrete action spaces for illustrative purposes, we expect such representations to be more faithful to neural recordings.
Temporal dynamics of the efference model
We simulated a two-alternative forced choice task using a firing rate model of SPN activity. This allowed us to directly visualize dynamics in the sum and difference modes and verify that the efference model prevents interference between them. In each trial of the forced choice task, one of two stimuli is presented and one of two actions is subsequently selected (Fig. 4A, top row). The selected action is determined by the difference mode activity of action-encoding SPNs during the first half of the stimulus presentation period. The sum mode is activated by efferent input during the second half of this period. Reward is obtained if the correct action is selected in a trial, and each stimulus has a different corresponding correct action. Plasticity of cortical weights encoding stimulus identity onto SPNs is governed by Eqs. (1), (2).
Figure 4:
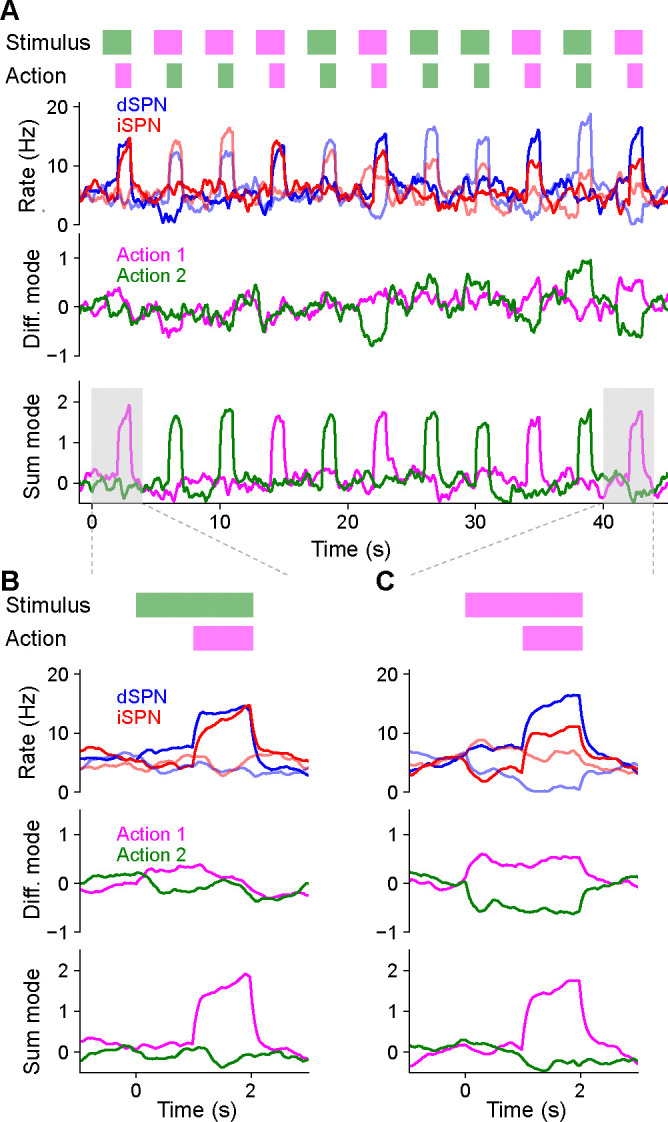
Temporal dynamics of the efference model in a two-alternative forced choice task. A. Top row: In each trial, either stimulus 1 (magenta) or stimulus 2 (green) is presented for 2 s. After 1 s, either action 1 (magenta) or action 2 (green) is selected based on SPN activity. A correct trial is one in which action 1 (resp. 2) is selected after stimulus 1 (resp. 2) is presented. Second row: Firing rates of four SPNs. Dark and light colors denote SPNs that represent action 1 and action 2, respectively. Third and fourth rows: Projection of SPN activity onto difference and sum modes for actions 1 and 2. B. Same as A, but illustrating the first trial, in which stimulus 2 is presented and action 1 is incorrectly selected. C. Same as B, but illustrating the last trial, in which stimulus 1 is presented and action 1 is correctly selected.
The model learned the correct policy in about 10 trials. Early in learning, difference mode activity is small and primarily driven by noise, leading to random action selection (Fig. 4B). However, sum mode activity is strongly driven after an action is selected (Fig. 4B, bottom). As learning progresses, the magnitude of the difference mode activity evoked by the stimulus increases (Fig. 4B, third row). Late in learning, dSPN and iSPN firing rates are more separable during stimulus presentation, leading to correct action selection (Fig. 4C, second row). Both difference and sum mode activity is evident late in learning, with the former leading the latter (Fig. 4C, bottom two rows).
Throughout the learning process, difference and sum mode activity for the two actions are separable and non-interfering, even when both are present simultaneously. As a result, action selection is not disrupted by efferent feedback. We conclude that the efference model multiplexes action selection and learning signals without separate learning phases or gated plasticity rules. While we illustrated this in a task with sequential trials for visualization purposes, this non-interference enables learning based on delayed reward and efferent feedback from past actions even as the selection of subsequent actions unfolds.
Efference model predicts properties of SPN activity
Thus far, we have provided theoretical arguments and model simulations that suggest that simultaneous efferent input to opponent dSPNs and iSPNs is necessary for reinforcement learning, given known plasticity rules. We next sought to test this prediction in neural data. We predict these dynamics to be particularly important in scenarios where the action space is large and actions are selected continuously, without a clear trial structure. We therefore used data from a recent study which recorded bulk and cellular dSPN and iSPN activity in spontaneously behaving mice (Fig. 5A; Markowitz et al., 2018). As no explicit rewards or task structure were provided during recording sessions, we adopted a modeling approach that makes minimal assumptions about the inputs to SPNs besides the core prediction of efferent activity. Specifically, we used a network model in which (1) populations of dSPNs and iSPNs promote or suppress different actions, (2) the feedforward inputs to all SPNs are random, (3) actions are sampled with log-likelihoods scaling according to the associated dSPN and iSPN difference mode, and (4) efferent activity excites the sum mode corresponding to the chosen action.
Figure 5:

Comparisons of model predictions about bulk dSPN and iSPN activity to experimental data. A. Schematic of experimental setup, taken from Markowitz et al. (2018). Neural activity and kinematics of spontaneously behaving mice are recorded, and behavior is segmented into stereotyped “behavioral syllables” using the MoSeq pipeline. B. In simulation of efference model with random feedforward cortical inputs, cross-correlation of total dSPN and iSPN activity. C. Cross-correlation between fiber photometry recordings of bulk dSPN and iSPN activity in freely behaving mice, using the data from Markowitz et al. (2018). Line thickness indicates standard error of the mean.
In this model, difference mode dSPN and iSPN activity drives behaviors, and those behaviors cause efferent activation of the corresponding sum mode. As a result, on average, dSPN activity tends to lead to increased future iSPN activity, while iSPN activity leads to decreased future dSPN activity. Consequently, the temporal cross-correlation between total dSPN activity and iSPN activity is asymmetric, with present dSPN activity correlating more strongly with future iSPN activity than with past iSPN activity (Fig. 5B). Such asymmetry is not predicted by the canonical action selection model, or models that assume dSPNs and iSPNs are co-active. Computing the temporal cross-correlation in the bulk two-color photometry recordings of dSPN and iSPN activity, we find a very similar skewed relationship in the data (Fig. 5C). We confirmed this result is not an artifact of the use of different indicators for dSPN and iSPN activity by repeating the analysis on data from mice where the indicators were reversed and finding the same result (Supp. Fig. 3).
Our model makes even stronger predictions about SPN population activity and its relationship to action selection. First, it predicts that both dSPNs and iSPNS exhibit similar selectivity in their tuning to actions. This contrasts with implementations of the canonical action selection model in which iSPNs are active whenever their associated action is not being performed and thus are more broadly tuned than dSPNs (Fig. 1A). Second, it also predicts that efferent activity excites dSPNs that promote the currently performed action and iSPNs that suppress the currently performed action. As a result, dSPNs whose activity increases during the performance of a given action should tend to be above baseline shortly prior to the performance of that action. By contrast, iSPNs whose activity increases during an action should tend to be below baseline during the same time interval (Fig. 6A, left; Fig. 4C). Moreover, this effect should be action-specific: the dSPNs and iSPNs whose activity increases during a given action should display negligible average fluctuations around the onset of other actions (Fig. 6A, right). These predictions can also be reinterpreted in terms of the sum and difference modes. The difference mode activity associated with an action is elevated prior to selection of that action, while the sum mode activity is excited following action selection (Fig. 6B; Fig. 4C). These two phases of difference and sum mode activity are not predicted by the canonical action selection model.
Figure 6:

Comparisons of model predictions about action-tuned SPN subpopulations to experimental data. A. Activity of dSPNs (blue) and iSPNs (red) around the onset of their associated action (left) or other actions (right) in the simulation from Fig. 5. B. Same information as A, but plotting activity of the sum (dSPN + iSPN) and difference (dSPN − iSPN) modes. C. For an example experimental session, dSPN activity modes associated with each of the behavioral syllables, in z-scored firing rate units. D. Correlation between identified dSPN and iSPN activity modes in two random subsamples of the data, for shuffled (left, circles) and real (right, x’s) data. E. Projection of dSPN (blue) and iSPN (red) activity onto the syllable-associated modes identified in panel C, around the onset of the associated syllable (left panel) or other syllables (right panel) averaged across all syllables. Error bars indicate standard error of the mean across syllables. F. Same as panel E, restricting the analysis to mice in which dSPNs and iSPNs were simultaneously recorded. G. Same data as panel F, but plotting activity of the sum (dSPN + iSPN) and difference (dSPN − iSPN) modes.
To test these hypotheses, we used calcium imaging data collected during spontaneous mouse behavior (Markowitz et al., 2018). The behavior of the mice was segmented into consistent, stereotyped kinematic motifs referred to as “behavioral syllables,” as in previous studies (Fig. 5A). We regard these behavioral syllables as the analogs of actions in our model. First, we examined the tuning of dSPNs and iSPNs to different actions and found that, broadly consistent with what our model predicts, both subpopulations exhibit similar selectivities (Supp. Fig. 4). Next, to test our predictions about dynamics before and after action selection (Fig. 6A,B), we identified, for each syllable, dSPN and iSPN population activity vectors (“modes”) that increased the most during performance of that syllable (Fig. 6C). We confirmed that these modes are meaningful by checking that modes identified using two disjoint subsets of the data are correlated (Fig. 6D). We then plotted the activity of these modes around the time of onset of the corresponding syllable, and averaged the result across the choice of syllables (Fig. 6E). The result displays remarkable agreement with the model prediction in Fig. 6A.
The majority of the above data consisted of recordings of either dSPNs or iSPNs from a given mouse. However, in a small subset (n=4) of mice, dSPNs and iSPNs were simultaneously recorded and identified. We repeated the analysis above on these sessions, and found the same qualitative results (Fig. 6F). The simultaneous recordings further allowed us to visualize the sum and difference mode activity (Fig. 6G), which also agrees with the predictions of our model (Fig. 6B).
Efference model enables off-policy reinforcement learning
Prior studies have argued for the importance of motor efference copies during basal ganglia learning, in particular when action selection is influenced by other brain regions (Fee, 2014; Lindsey and Litwin-Kumar, 2022). Indeed, areas such as the motor cortex and cerebellum drive behavior independent of the basal ganglia (Exner et al., 2002; Wildgruber et al., 2001; Ashby et al., 2010; Silveri, 2021; Bostan and Strick, 2018). Actions taken by an animal may therefore at times differ from those most likely to be selected by striatal outputs (Fig. 7A), and it may be desirable for corticostriatal synapses to learn about the consequences of these actions.
Figure 7:

The efference model enables off-policy reinforcement learning. A. Illustration of the efference model when the striatum shares control of behavior with other pathways. In this example, striatal activity biases the action selection toward choosing action 2, but other neural pathways override the striatum and cause action 1 to be selected instead (left). Following action selection, efferent activity excites the dSPN and iSPN associated with action 1. However, the outputs of the striatal population remain unchanged. B. Performance of RL models in a simulated action selection task (10 cortical states, 10 available actions, in each state one of the actions results in a reward of 1 and the others result in zero reward). Control is shared between the striatal RL circuit and anothere pathway that biases action selection toward the correct action. Different lines indicate different strength of striatal control relative to the strength of the other pathway. Line style (dashed or solid) indicates the efference model: off-policy efference excites SPNs associated with the selected action, while on-policy efference excites SPNs associated with the action most favored by the striatum. C. Schematic of different reinforcement learning models of dopamine activity. The standard TD error models predicts that dopamine activity is sensitive to reward, the predicted value of the current state, and the predicted value of the previous state. The Q-learning error model predicts sensitivity to reward, the predicted value of the current state, and the predicted value of the previous state-action pair. D. In the task of panel B using the off-policy efference model, comparison between different models of dopamine activity as striatal control is varied (the Q-learning error model was used in panel B). E. Correlation between predicted and actual syllable-to-syllable transition matrix. Predictions were made according to different models of the relationship between dopamine activity and behavior, using observed average dopamine activity associated with syllable transitions in the data of Markowitz et al. (2023). Each dot indicates a different experimental session.
In the reinforcement learning literature, this kind of learning is known as an “off-policy” algorithm, as the reinforcement learning system (in our model, the striatum) learns from actions that follow a different policy than its own. Off-policy learning has been observed experimentally, for instance in the consolidation of cortically driven behaviors into subcortical circuits including dorsolateral striatum (Kawai et al., 2015; Hwang et al., 2019; Mizes et al., 2023). Such learning requires efferent activity in SPNs that reflects the actions being performed, rather than the action that would be performed based on the striatum’s influence alone.
We modeled this scenario by assuming that action selection is driven by weighted contributions from both the striatum and other motor pathways and that the ultimately selected action drives efferent activity (Fig. 7A; see Methods). We found that when action selection is not fully determined by the striatum, such efferent activity is critical for successful learning (Fig. 7B). Notably, in our model, efferent activity has no effect on striatal action selection, due to the orthogonality of the sum and difference modes (Fig. 3B). In a hypothetical alternative model in which the iSPN plasticity rule is the same as that of dSPNs, the efferent activity needed for learning is not orthogonal to the output of the striatum, impairing off-policy learning (Supp. Fig. 5). Thus, efferent excitation of opponent dSPNs/iSPNs is necessary both to implement correct learning updates given dSPN and iSPN plasticity rules, and to enable off-policy reinforcement learning.
Off-policy reinforcement learning predicts relationship between dopamine activity and behavior
We next asked whether other properties of striatal dynamics are consistent with off-policy reinforcement learning. We focused on the dynamics of dopamine release, as off-policy learning makes specific predictions about this signal. Standard temporal difference (TD) learning models of dopamine activity (Fig. 7C, top) determine the expected future reward (or “value”) associated with each state using the following algorithm:
| (4) |
| (5) |
where and indicate current and previous states, indicates the currently received reward, is a learning rate factor, and is the TD error thought to be reflected in phasic dopamine responses. These dopaminergic responses can be used as the learning signal for a updating action selection in dorsal striatum (Eq. 1, 2), an arrangement commonly referred to as an“actor-critic” architecture (Niv, 2009).
TD learning of a value function is an on-policy algorithm, in that the value associated with each state is calculated under the assumption that the system’s future actions will be similar to those taken during learning. Hence, such algorithms are is poorly suited to training an action selection policy in the striatum in situations where the striatum does not fully control behavior, as the values will not reflect the expected future reward associated with a state if the striatum were to dictate behavior on its own. Off-policy algorithms such as Q-learning solve this issue by learning an action-dependent value function , which indicates the expected reward associated with taking action in action (Fig. 7C, bottom), via the following algorithm:
| (6) |
| (7) |
This algorithm predicts that the dopamine response is action-dependent. The significance of on-policy vs. off-policy learning algorithms can be demonstrated in simulations of operant conditioning tasks in which control of action selection is shared between the striatum and another “tutor” pathway that biases responses toward the correct action. When the striatal contribution to decision-making is weak, it is unable to learn the appropriate response when dopamine activity is modeled as a TD error (Fig. 7D). On the other hand, a Q-learning model of dopamine activity enables efficient striatal learning even when control is shared with another pathway.
For the spontaneous behavior paradigm we analyzed previously (Fig. 5A), Q-learning but not TD learning of predicts sensitivity of dopamine responses to the likelihood of the previous syllable-to-syllable transition. Using recordings of dopamine activity in the dorsolateral striatum in this paradigm (Markowitz et al., 2023), we tested whether a Q-learning model could predict the relationship between dopamine activity and behavioral statistics, comparing it to TD learning of and other alternatives (see Supplemental Information). The Q-learning model matches the data significantly better than alternatives (Fig. 7E), providing support for a model of dorsal striatum as an off-policy reinforcement learning system.
Discussion
We have presented a model of reinforcement learning in the dorsal striatum in which efferent activity excites dSPNs and iSPNs that promote and suppress, respectively, the currently selected action. Thus, following action selection, iSPN activity counteruintively represents the action that is inhibited by the currently active iSPN population. This behavior contrasts with previous proposals in which iSPN activity reflects actions being inhibited. This model produces updates to corticostriatal synaptic weights given the known opposite-sign plasticity rules in dSPNs and iSPNs that correctly implement a form of reinforcement learning (Fig. 3), which in the absence of such efferent activity produce incorrect weight updates (Fig. 2). The model makes several novel predictions about SPN activity which we confirmed in experimental data (Figs. 5, 6). It also enables multiplexing of action selection signals and learning signals without interference. This facilitates more sophisticated learning algorithms such as off-policy reinforcement learning, which allows the striatum to learn from actions that were driven by other neural circuits. Off-policy reinforcement learning requires dopamine to signal action-sensitive reward predictions errors, which agrees better with experimental recordings of striatal dopamine activity than alternative models (Fig. 7).
Other models of striatal action selection
Prior models have modeled the opponent effects of dopamine on dSPN and iSPN plasticity (Frank, 2005; Collins and Frank, 2014; Jaskir and Frank, 2023). In these models, dSPNs come to represent the positive outcomes and iSPNs the negative outcomes associated with a stimulus-action pair. Such models can also represent uncertainty in reward estimates (Mikhael and Bogacz, 2016). Appropriate credit assignment in these models requires that only corticostriatal weights associated with SPNs encoding the chosen action are updated. Our model clarifies how the neural activity required for such selective weight updates can be multiplexed with the neural activity required for action selection, without requiring separate phases for action selection and learning.
Bariselli et al. (2019) also argue against the canonical action selection model and propose a competitive role for dSPNs and iSPNs that is consistent with our model. However, the role of efferent activity and distinctions between action- and learning-related signals are not discussed.
Our model is related to these prior proposals but identifies motor efference as key for appropriate credit assignment across corticostriatal synapses. It also provides predictions concerning the temporal dynamics of such signals (Fig. 4) and a verification of these using physiological data (Fig. 7).
Other models of efferent inputs to the striatum
Prior work has pointed out the need for efference copies of decisions to be represented in the striatum, particularly for actions driven by other circuits (Fee, 2014). Frank (2005) propose a model in which premotor cortex outputs collateral signals to the striatum that represent the actions under consideration, with the striatum potentially biasing the decision based on prior learning. Through bidirectional feedback (premotor cortex projecting to striatum, and striatum projecting to premotor cortex indirectly through the thalamus) a decision is collectively made by the combined circuit, and the selected action is represented in striatal activity, facilitating learning about the outcome of the action. While similar to our proposal in some ways, this model implicitly assumes that the striatal activity necessary for decision-making is also what is needed to facilitate learning. As we point out in this work, due to the opponent plasticity rules in dSPNs and iSPNs, a post-hoc efferent signal that is not causally relevant to the decision-making process is necessary for appropriate learning.
Other authors have proposed models in which efferent activity is used for learning. In the context of vocal learning in songbirds, Fee and Goldberg (2011) proposed that the variability-generating area LMAN, which projects to the song motor pathway, sends collateral projections to Area X, which undergoes dopamine-modulated plasticity. In this model, the efferent inputs to Area X allow it to learn which motor commands are associated with better song performance (signaled by dopamine). Similar to our model, this architecture implements off-policy reinforcement learning in Area X, with HVC inputs to Area X being analogous to corticostriatal projections in our model. However, in our work, the difference in plasticity rules between dSPNs and iSPNs is key to avoiding interference between efferent learning-related activity and feedforward action selection-related activity. A similar architecture was proposed in Fee (2012) in the context of oculomotor learning, in which oculomotor striatum receives efferent collaterals from the superior colliculus and/or cortical areas which generate exploratory variability. Lisman (2014) also propose a high-level model of striatal efferent inputs similar to ours, and also point out the issue with the iSPN plasticity rule assigning credit to inappropriate actions without efferent inputs. Rubin et al. (2021) argue that sustained efferent input is necessary for temporal credit assignment when reward is delayed relative to action selection.
Our model is consistent with these prior proposals, but describes how efferent input must be targeted to opponent SPNs. In our work, the distinction between dSPN and iSPN plasticity rules is key to enable multiplexing of action-selection and efferent learning signals without interference. Previous authors have proposed other mechanisms to avoid interference. For instance, Fee (2014) propose that efferent inputs might influence plasticity without driving SPN spiking by synapsing preferentially onto dendritic shafts rather than spines. To avoid action selection-related spikes interfering with learning, the system may employ spike timing-dependent plasticity rules that are tuned to match the latency at which efferent inputs excite SPNs. While these hypotheses are not mutually exclusive to ours, our model requires no additional circuitry or assumptions beyond the presence of appropriately tuned efferent input (see below) and opposite-sign plasticity rules in dSPNs and iSPNs, due to the orthogonality of the sum and difference modes. An important capability enabled by our model is that action selection and efferent inputs can be multiplexed simultaneously, unlike the works cited above, which posit the existence of temporally segregated action-selection and learning phases of SPN activity.
Biological substrates of striatal efferent inputs
Efferent inputs to the striatum must satisfy two important conditions for our model to learn correctly. Neither of these has been conclusively demonstrated, and the two conditions thus represent predictions or assumptions necessary for our model to function. First, they must be appropriately targeted: when an action is performed, dSPNs and iSPNs associated with that action must be excited, but other dSPNs and iSPNs must not be. The striatum receives topographically organized inputs from cortex (Peters et al., 2021) and thalamus (Smith et al., 2004), with neurons in some thalamic nuclei exhibiting long-latency responses (Minamimoto et al., 2005). SPNs tuned to the same behavior tend to be located nearby in space (Barbera et al., 2016; Shin et al., 2020; Klaus et al., 2017). This anatomical organization could enable action-specific efferent inputs. We note that this does not require a spatially specific dopaminergic signal (Wärnberg and Kumar, 2023). In our models, we assume that dopamine conveys a global, scalar prediction error. Another possibility is that targeting of efferent inputs could be tuned via plasticity during development. For instance, if a dSPN promotes a particular action, reward-independent Hebbian plasticity of its efferent inputs would potentiate those inputs that encode the promoted action. Reward-independent anti-Hebbian plasticity would serve an analogous function for iSPNs. Alternatively, if efferent inputs are fixed, plasticity downstream of striatum could adapt the causal effect of SPNs to match their corresponding efferent input.
A second key requirement of our model is that efferent input synapses should not be adjusted according to the same reward-modulated plasticity rules as the feedforward corticostriatal inputs, as these rules would disrupt the targeting of efferent inputs to the corresponding SPNs. This may be achieved in multiple ways. One possibility is that efferent inputs project from different subregions or cell types than feedforward inputs and are subject to different forms of plasticity. Alternatively, efferent input synapses may have been sufficiently reinforced that they exist in a less labile, “consolidated” synaptic state. A third possibility is that the system may take advantage of latency in efferent activity. Spike timing dependence in SPN input plasticity has been observed in several studies (Shen et al., 2008; Fino et al., 2005; Pawlak and Kerr, 2008; Fisher et al., 2017). This timing dependence could make plasticity sensitive to paired activity in state inputs and SPNs while being insensitive to paired activity in efferent inputs and SPNs. Investigating the source of efferent inputs to SPNs and how it is differentiated from other inputs is an important direction for future work.
Extensions and future work
We have assumed that the striatum selects among a finite set of actions, each of which corresponds to mutually uncorrelated patterns of SPN activity. In reality, there is evidence that the striatal code for action is organized such that kinematically similar behaviors are encoded by similar SPN activity patterns (Klaus et al., 2017; Markowitz et al., 2018). Other work has shown that the dorsolateral striatum can exert influence over detailed kinematics of learned motor behaviors, rather than simply select among categorically distinct actions (Dhawale et al., 2021). A more continuous, structured code for action in dorsolateral striatum is useful in allowing reinforcement learning to generalize between related actions. The ability afforded by our model to multiplex arbitrary action selection and learning signals may facilitate these more sophisticated coding schemes. For instance, reinforcement learning in continuous-valued action spaces requires a three-factor learning rule in which the postsynaptic activity factor represents the discrepancy between the selected action and the action typically selected in the current behavioral state (Lindsey and Litwin-Kumar, 2022), which in our model would be represented by efferent activity in SPNs. Investigating such extensions to our model and their consequences for SPN tuning is an interesting future direction.
In this work we find strong empirical evidence for our model of efferent activity in SPNs and show that in principle it enables off-policy reinforcement learning capabilities. A convincing experimental demonstration of off-policy learning capabilities would require a way of identifying the causal contribution of SPN activity to action selection, in order to distinguish between actions that are consistent (on-policy) or inconsistent (off-policy) with SPN outputs. This could be achieved through targeted stimulation of SPN populations, or by recording SPN activity during behaviors that are known to be independent of striatal influence (Mizes et al., 2023). Simultaneous recordings in SPNs and other brain regions would also facilitate distinguishing between actions driven by striatum from those driven by other pathways. Our model predicts that the relative strength of fluctuations in difference mode versus sum mode activity should be greatest during striatum-driven actions. Such experimental design would also enable a stronger test of the Q-learning model of dopamine activity: actions driven by other regions should lead to increased dopamine activity, as they will be predicted according to the striatum’s learned action-values to have low value.
In our model, the difference between dSPN and iSPN plasticity rules is key to enabling multiplexing of action-selection and learning-related activity without interference. Observed plasticity rules elsewhere in the brain are also heterogeneous; for instance, both Hebbian and anti-Hebbian behavior are observed in cortico-cortical connections (Koch et al., 2013; Chindemi et al., 2022). It is an interesting question whether a similar strategy may be employed outside the striatum, and in other contexts besides reinforcement learning, to allow simultaneous encoding of behavior and learning-related signals without interference.
Methods
Numerical simulations
Code implementing the model is available on GitHub.
Basic model architecture
In our simulated learning tasks, we used networks with the following architecture.
SPNs receive inputs from cortical neurons. In our simulated go/no-go tasks, there is a single cortical input neuron (representing a task cue) with activity equal to 1 on each trial. In simulated tasks with multiple different task cues (such as the two-alternative forced choice task), there is a population of cortical input neurons, each of which is active with activity 1 when the corresponding task cue is presented and 0 otherwise. The task cue is randomly chosen with uniform probability each trial.
For each of the actions available to the model, there is an assigned dSPN and iSPN. We choose to use a single neuron per action for simplicity of the model, but our model could easily be generalized to use population activity to encode actions. The activities of the dSPN and iSPN associated with action are denoted as and , respectively. Each dSPN and iSPN receives inputs from cortical neurons, and the synaptic input weights from cortical neuron to dSPN or iSPN associated with action are denoted as or . Feedforward SPN activity is given by
| (8) |
| (9) |
where is a nonlinear activation function. We choose to be the rectified linear function: .
Action selecton depends on SPN activity in the following manner. The log-likelihood of an action being performed is proportional to . That is, dSPN activity increases the likelihood of taking the action and iSPN activity decreases the likelihood of taking the action. Concretely, the probability of action being taken is:
| (10) |
where is a parameter controlling the degree of stochasticity in action selection (higher corresponds to more deterministic choices), and controls the probability that no action is taken. In the simulated go/no-go tasks we choose and in the tasks involving selection among multiple actions we choose . Except where otherwise noted we used in all task simulations.
Models of SPN activity following action selection
In the “canonical action selection model” (Fig. 1), following action selection, the activity of the dSPN associated with the selected action and the activity of all iSPNs associated with unselected actions are set to 1. Biologically, this activity pattern can be implemented via effective mutual inhibition between SPNs with opponent functions (dSPNs tuned to different actions, iSPNs tuned to different actions, and dSPN/iSPN pairs tuned to the same action) and mutual excitation between SPNs with complementary functions (dSPNs tuned to one action and iSPNs to another) (Burke et al., 2017).
In the proposed efference model, following selection of an action , activity of the SPNs associated with action is updated as follows:
| (11) |
| (12) |
where equals 1 for and 0 otherwise. The parameter controls the strength of efferent excitation.
Learning rules
In all models, SPN input weights are initialized at 1 and weight updates proceed according to the plasticity rules given below:
| (14) |
| (15) |
where is a learning rate, set to 0. throughout all learning simulations (except the tutoring simulations of Fig. 7 where it is set to 0.01). In the paper we experiment with various choices of and .
| (16) |
| (17) |
| (18) |
with the offset sigmoid parameters chosen as (taken from Cruz et al. (2022)). The quantity indicates an estimate of reward prediction error. In our experiments in Fig 2 and Fig. 3 we use temporal difference learing to compute :
| (19) |
| (20) |
where is a learning rate, set to 0. throughout all learning simulations (except the tutoring simulations of Fig. 7 where it is set to 0.25) and indicates the cortical input state (indicating which cue is being presented). is initialized at 0.
In our experiments in Fig. 7 we use Q-learning to enable off-policy learning, corresponding to the following value for :
| (21) |
where indicates the action that was just taken in response to state , and is taken to be equal to the striatal output in response to the state .
Firing rate simulations
In each trial of the two-alternative forced choice task (Fig. 4), one of two stimuli is presented for 2 s. Cortical activity representing the stimulus is encoded in a one-hot vector. Four SPNs are modeled, one dSPN and one iSPN for each of two actions. The dynamics of SPN follows:
| (22) |
Here, denotes positive rectification, represent corticostriatal weights initialized following a Gaussian distribution with mean 0 and standard deviation 1 Hz, is an Ornstein-Uhlenbeck noise process with time constant 600 ms and variance 1/60 Hz2, denotes efferent input, and is a bias term. Simulations were performed with .
On each trial, an action is selected based on the average difference-mode activity for the two actions during the first 1 s of stimulus presentation. In the second half of the stimulus presentation period, efferent input is provided to the dSPN and iSPN corresponding to the chosen action by setting for these neurons. Learning proceeds according to
| (23) |
where in the second half of the stimulus presentation period for dSPNs after a correct action is taken and iSPNs after an incorrect action is taken, and −1 otherwise, and .
Experimental prediction simulations
For the model predictions of Fig. 5 and Fig. 6, we used the following parameters: and set such that the no-action option was chosen 50% of the time. Feedforward SPN activity was generated from a Gaussian process with kernel (exponentially decaying autocorrelation with a time constant of 10 timesteps). Efference activity also decayed exponentially with a time constant of 10 timesteps. Action selection occured every 10 timesteps based on the SPN activity at the preceding timestep.
Neural data analysis
For our analysis of SPN data we used recordings previously described by Markowitz et al. (2018). For our analysis of dopamine data we used the recordings described in Markowitz et al. (2023).
Fiber photometry data
Adeno-associated viruses (AAVs) expressing Cre-On jRCaMP1b and Cre-Off GCaMP6s were injected into the dorsolateral striatum (DLS) of Drd1a-Cre mice to measure bulk dSPN (red) and iSPN (green) activity via multicolor photometry. Activity of each indicator was recorded at a rate of 30Hz using an optical fiber implanted in the right DLS. Data was collected during spontaneous behavior in a circular open field, for 5–6 sessions of 20 minutes each for each mouse. In the reversed indicator experiments of Supp. Fig. 3, A2a-Cre mice were injected with a mixture of the same AAVs, labeling iSPNs with jRCaMP1b (red) and dSPNs with GCaMP6s (green). More details are reported in Markowitz et al. (2018).
In our data analyses in Fig. 5C and Supp. Fig 3, for each session ( and , respectively) we computed the autocorrelation and cross-correlation of the dSPN and iSPN indicator activity across the entire session.
Miniscope data
Drd1a-Cre AAVs expressing GCaMP6f were injected into the right DLS of Drd1a-Cre mice (to label dSPNs) and A2a-Cre mice (to label iSPNs). A head-mounted single-photon microscope was coupled to a gradient index lens implanted into the dorsal striatum above the injection site. Recordings were made, as for the photometry data, during spontaneous behavior in a circular open field. Calcium activity was recorded from a total of 653 dSPNs and 794 iSPNs for these mice, with the number of neurons per mouse ranging from 27–336. To enable simultaneous recording of dSPNs and iSPNs in the same mice, a different protocol was used: Drd1a-Cre mice were injected with an AAV mixture which labeled both dSPNs and iSPNS with GCaMP6s, but additionally selectively labeled dSPNS with nuclear-localized dTomato. This procedure enabled (in mice) cell-type identification of dSPNs vs. iSPNs with a two-photon microscope which was cross-referenced with the single-photon microscope recordings. More details are given in Markowitz et al. (2018). In our analyses, these data were used for the simultaneous-recording analyses in Fig. 6L,M,N,O and were also combined with the appropriate single-pathway data in the analyses of Fig. 6J,K.
Behavioral data
Mouse behavior in the circular open field was recorded as follows: 3D pose information was recorded using a depth camera at a rate of 30Hz. The videos were preprocessed to center the mouse and align the nose-to-tail axis across frames and remove occluding objects. The videos were then fed through PCA to reduce the dimensinoality of the data and fed into the MoSeq algorithm (Wiltschko et al., 2015) which fits a generative model to the video data that automatically infers a set of behavioral “syllables” (repeated, stereotyped behavioral kinematics) and assigns each frame of the video to one of these syllables. More details on MoSeq are given in Wiltschko et al. (2015) and more details on its application to this dataset are given in Markowitz et al. (2018). There were 89 syllables identified by MoSeq that appear across all the sessions. We restricted our analysis to the set of 62 syllables that appear at least 5 times in each behavioral session.
Syllable-tuned SPN activity mode analysis
In our analysis, we first z-scored the activity of each neuron across the data collected for each mouse. We divided the data by the boundaries of behavioral syllables and split it into two equally sized halves (based on whether the timestamp, rounded to the nearest second, of the behavioral syllable was even or odd). To compute the activity modes associated with each behavioral syllable, we first computed the average change in activity for each neuron during each syllable and fit a linear regression model to predict this increase from a one-hot vector indicating the syllable identity. The resulting coefficients of this regression indicate the directions (“modes”) in activity space that increase the most during performance of each of the behavioral syllables. We linearly time-warped the data in each session based on the boundaries of each MoSeq-identified behavioral syllable, such that in the new time coordinates each behavioral syllable lasted 10 timesteps. The time course of the projection of SPN activity along the modes associated with each behavioral syllable was then computed around the onset of that syllable, or around all other sllables. As a way of crossvalidating the analysis, we performed the regression on one half of the data and plotted the average mode activity on the other half of the data (in both directions, and averaged the results). We averaged the resulting time courses of mode activity across all choices of behavioral syllables. This analysis was performed for each mouse and the results in Fig. 6 show means and standard errors across mice.
Dopamine activity data and analysis
For 7E we used data from Markowitz et al. (2023). Mice virally expressing the dopamine reporter dLight1.1 in the DLS were recorded with a fiber cannula implanted above the injection site. Mice were placed in a circular open field for 30 minute sessions and allowed to behave freely while spontaneous dLight activity was recorded. MoSeq (described above) was used to infer a set of behavioral syllables observed across all sessions. As in Markowitz et al. (2023), the data were preprocessed by computing the maximum dLight value during each behavioral syllable. These per-syllable dopamine values were z-scored across each session and used as our measure of dopamine activity during each syllable. We then computed an table of the average dopamine activity during each syllable conditioned on the previous syllable having been syllable , denoted as . We also computed the table of probabilities of transitioning from syllable to syllable across the dataset, denoted as . These tables were computed separately for each mouse. In Fig. 7E we report the Pearson correlation coefficient between the predicted and actual values of . We then experimented with several alternative models (see Supplemental Information) that predict based on . In Fig. 7E we report the Pearson correlation coefficient between the predicted and actual values of .
Supplementary Material
Acknowledgments
We thank Jaeeon Lee for providing the initial inspiration for this project, Sean Escola for fruitful discussions, and Steven A. Siegelbaum for comments on the manuscript. J.L. is supported by the Mathers Foundation and the Gatsby Charitable Foundation. J.M. is supported by a Career Award at the Scientific Interface from the Burroughs Wellcome Fund, a fellowship from the Sloan Foundation, and a fellowship from the David and Lucille Packard Foundation. S.R.D. is supported by NIH grants RF1AG073625, R01NS114020, U24NS109520, the Simons Foundation Autism Research Initiative, and the Simons Collaboration on Plasticity and the Aging Brain. A.L.-K. is supported by the Mathers Foundation, the Burroughs Wellcome Foundation, the McKnight Endowment Fund, and the Gatsby Charitable Foundation.
Footnotes
Declaration of interests
S.R.D. sits on the scientific advisory boards of Neumora and Gilgamesh Therapeutics, which have licensed or sub-licensed the MoSeq technology.
References
- Arulkumaran K., Deisenroth M. P., Brundage M., and Bharath A. A. (2017). Deep reinforcement learning: A brief survey. IEEE Signal Processing Magazine, 34(6):26–38. [Google Scholar]
- Ashby F. G., Turner B. O., and Horvitz J. C. (2010). Cortical and basal ganglia contributions to habit learning and automaticity. Trends in Cognitive Sciences, 14(5):208–215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Balleine B. W., Delgado M. R., and Hikosaka O. (2007). The role of the dorsal striatum in reward and decision-making. Journal of Neuroscience, 27(31):8161–8165. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barbera G., Liang B., Zhang L., Gerfen C. R., Culurciello E., Chen R., Li Y., and Lin D.-T. (2016). Spatially compact neural clusters in the dorsal striatum encode locomotion relevant information. Neuron, 92(1):202–213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bariselli S., Fobbs W., Creed M., and Kravitz A. (2019). A competitive model for striatal action selection. Brain Research, 1713:70–79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bostan A. C. and Strick P. L. (2018). The basal ganglia and the cerebellum: nodes in an integrated network. Nature Reviews Neuroscience, 19(6):338–350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burke D. A., Rotstein H. G., and Alvarez V. A. (2017). Striatal local circuitry: a new framework for lateral inhibition. Neuron, 96(2):267–284. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calabresi P., Gubellini P., Centonze D., Picconi B., Bernardi G., Chergui K., Svenningsson P., Fienberg A. A., and Greengard P. (2000). Dopamine and camp-regulated phosphoprotein 32 kda controls both striatal long-term depression and long-term potentiation, opposing forms of synaptic plasticity. Journal of Neuroscience, 20(22):8443–8451. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cardinal R. N., Parkinson J. A., Hall J., and Everitt B. J. (2002). Emotion and motivation: the role of the amygdala, ventral striatum, and prefrontal cortex. Neuroscience & Biobehavioral Reviews, 26(3):321–352. [DOI] [PubMed] [Google Scholar]
- Chindemi G., Abdellah M., Amsalem O., Benavides-Piccione R., Delattre V., Doron M., Ecker A., Jaquier A. T., King J., Kumbhar P., et al. (2022). A calcium-based plasticity model for predicting long-term potentiation and depression in the neocortex. Nature Communications, 13(1):3038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Collins A. G. and Frank M. J. (2014). Opponent actor learning (opal): modeling interactive effects of striatal dopamine on reinforcement learning and choice incentive. Psychological Review, 121(3):337. [DOI] [PubMed] [Google Scholar]
- Contreras-Vidal J. L. and Schultz W. (1999). A predictive reinforcement model of dopamine neurons for learning approach behavior. Journal of Computational Neuroscience, 6(3):191–214. [DOI] [PubMed] [Google Scholar]
- Cruz B. F., Guiomar G., Soares S., Motiwala A., Machens C. K., and Paton J. J. (2022). Action suppression reveals opponent parallel control via striatal circuits. Nature, 607(7919):521–526. [DOI] [PubMed] [Google Scholar]
- Cui G., Jun S. B., Jin X., Pham M. D., Vogel S. S., Lovinger D. M., and Costa R. M. (2013). Concurrent activation of striatal direct and indirect pathways during action initiation. Nature, 494(7436):238–242. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dhawale A. K., Wolff S. B., Ko R., and Ölveczky B. P. (2021). The basal ganglia control the detailed kinematics of learned motor skills. Nature Neuroscience, 24(9):1256–1269. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dreyer J. K., Herrik K. F., Berg R. W., and Hounsgaard J. D. (2010). Influence of phasic and tonic dopamine release on receptor activation. Journal of Neuroscience, 30(42):14273–14283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dunovan K., Vich C., Clapp M., Verstynen T., and Rubin J. (2019). Reward-driven changes in striatal pathway competition shape evidence evaluation in decision-making. PLoS Computational Biology, 15(5):e1006998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Exner C., Koschack J., and Irle E. (2002). The differential role of premotor frontal cortex and basal ganglia in motor sequence learning: evidence from focal basal ganglia lesions. Learning & Memory, 9(6):376–386. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fee M. S. (2012). Oculomotor learning revisited: a model of reinforcement learning in the basal ganglia incorporating an efference copy of motor actions. Frontiers in Neural Circuits, 6:38. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fee M. S. (2014). The role of efference copy in striatal learning. Current Opinion in Neurobiology, 25:194–200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fee M. S. and Goldberg J. H. (2011). A hypothesis for basal ganglia-dependent reinforcement learning in the songbird. Neuroscience, 198:152–170. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fino E., Glowinski J., and Venance L. (2005). Bidirectional activity-dependent plasticity at corticostriatal synapses. Journal of Neuroscience, 25(49):11279–11287. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fisher S. D., Robertson P. B., Black M. J., Redgrave P., Sagar M. A., Abraham W. C., and Reynolds J. N. (2017). Reinforcement determines the timing dependence of corticostriatal synaptic plasticity in vivo. Nature Communications, 8(1):334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Frank M. J. (2005). Dynamic dopamine modulation in the basal ganglia: a neurocomputational account of cognitive deficits in medicated and nonmedicated parkinsonism. Journal of Cognitive Neuroscience, 17(1):51–72. [DOI] [PubMed] [Google Scholar]
- Freeze B. S., Kravitz A. V., Hammack N., Berke J. D., and Kreitzer A. C. (2013). Control of basal ganglia output by direct and indirect pathway projection neurons. Journal of Neuroscience, 33(47):18531–18539. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gurney K. N., Humphries M. D., and Redgrave P. (2015). A new framework for cortico-striatal plasticity: behavioural theory meets in vitro data at the reinforcement-action interface. PLoS Biology, 13(1):e1002034. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Houk J. C. and Adams J. L. (1995). 13 a model of how the basal ganglia generate and use neural signals that. Models of information processing in the basal ganglia, page 249. [Google Scholar]
- Hwang E. J., Dahlen J. E., Hu Y. Y., Aguilar K., Yu B., Mukundan M., Mitani A., and Komiyama T. (2019). Disengagement of motor cortex from movement control during long-term learning. Science Advances, 5(10):eaay0001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iino Y., Sawada T., Yamaguchi K., Tajiri M., Ishii S., Kasai H., and Yagishita S. (2020). Dopamine d2 receptors in discrimination learning and spine enlargement. Nature, 579(7800):555–560. [DOI] [PubMed] [Google Scholar]
- Ito M. and Doya K. (2011). Multiple representations and algorithms for reinforcement learning in the cortico-basal ganglia circuit. Current Opinion in Neurobiology, 21(3):368–373. [DOI] [PubMed] [Google Scholar]
- Jaskir A. and Frank M. J. (2023). On the normative advantages of dopamine and striatal opponency for learning and choice. eLife, 12:e85107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joel D., Niv Y., and Ruppin E. (2002). Actor–critic models of the basal ganglia: New anatomical and computational perspectives. Neural Networks, 15(4–6):535–547. [DOI] [PubMed] [Google Scholar]
- Kawai R., Markman T., Poddar R., Ko R., Fantana A. L., Dhawale A. K., Kampff A. R., and Ölveczky B. P. (2015). Motor cortex is required for learning but not for executing a motor skill. Neuron, 86(3):800–812. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klaus A., Martins G. J., Paixao V. B., Zhou P., Paninski L., and Costa R. M. (2017). The spatiotemporal organization of the striatum encodes action space. Neuron, 95(5):1171–1180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Koch G., Ponzo V., Di Lorenzo F., Caltagirone C., and Veniero D. (2013). Hebbian and anti-hebbian spike-timing-dependent plasticity of human cortico-cortical connections. Journal of Neuroscience, 33(23):9725–9733. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kravitz A. V., Freeze B. S., Parker P. R., Kay K., Thwin M. T., Deisseroth K., and Kreitzer A. C. (2010). Regulation of parkinsonian motor behaviours by optogenetic control of basal ganglia circuitry. Nature, 466(7306):622–626. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee J. and Sabatini B. L. (2021). Striatal indirect pathway mediates exploration via collicular competition. Nature, 599(7886):645–649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee S. J., Lodder B., Chen Y., Patriarchi T., Tian L., and Sabatini B. L. (2021). Cell-type-specific asynchronous modulation of pka by dopamine in learning. Nature, 590(7846):451–456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lindsey J. and Litwin-Kumar A. (2022). Action-modulated midbrain dopamine activity arises from distributed control policies. Advances in Neural Information Processing Systems, 35:5535–5548. [Google Scholar]
- Lisman J. (2014). Two-phase model of the basal ganglia: implications for discontinuous control of the motor system. Philosophical Transactions of the Royal Society B: Biological Sciences, 369(1655):20130489. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Markowitz J. E., Gillis W. F., Beron C. C., Neufeld S. Q., Robertson K., Bhagat N. D., Peterson R. E., Peterson E., Hyun M., Linderman S. W., et al. (2018). The striatum organizes 3d behavior via moment-to-moment action selection. Cell, 174(1):44–58. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Markowitz J. E., Gillis W. F., Jay M., Wood J., Harris R. W., Cieszkowski R., Scott R., Brann D., Koveal D., Kula T., et al. (2023). Spontaneous behaviour is structured by reinforcement without explicit reward. Nature, 614(7946):108–117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mikhael J. G. and Bogacz R. (2016). Learning reward uncertainty in the basal ganglia. PLoS Computational Biology, 12(9):e1005062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Minamimoto T., Hori Y., and Kimura M. (2005). Complementary process to response bias in the centromedian nucleus of the thalamus. Science, 308(5729):1798–1801. [DOI] [PubMed] [Google Scholar]
- Mink J. W. (1996). The basal ganglia: focused selection and inhibition of competing motor programs. Progress in Neurobiology, 50(4):381–425. [DOI] [PubMed] [Google Scholar]
- Mizes K. G., Lindsey J., Escola G. S., and Ölveczky B. P. (2023). Dissociating the contributions of sensorimotor striatum to automatic and visually guided motor sequences. Nature Neuroscience, pages 1–14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Montague P. R., Dayan P., and Sejnowski T. J. (1996). A framework for mesencephalic dopamine systems based on predictive hebbian learning. Journal of Neuroscience, 16(5):1936–1947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Niv Y. (2009). Reinforcement learning in the brain. Journal of Mathematical Psychology, 53(3):139–154. [Google Scholar]
- O’Doherty J., Dayan P., Schultz J., Deichmann R., Friston K., and Dolan R. J. (2004). Dissociable roles of ventral and dorsal striatum in instrumental conditioning. Science, 304(5669):452–454. [DOI] [PubMed] [Google Scholar]
- Packard M. G. and Knowlton B. J. (2002). Learning and memory functions of the basal ganglia. Annual Review of Neuroscience, 25(1):563–593. [DOI] [PubMed] [Google Scholar]
- Pawlak V. and Kerr J. N. (2008). Dopamine receptor activation is required for corticostriatal spike-timing-dependent plasticity. Journal of Neuroscience, 28(10):2435–2446. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peak J., Chieng B., Hart G., and Balleine B. W. (2020). Striatal direct and indirect pathway neurons differentially control the encoding and updating of goal-directed learning. eLife, 9:e58544. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peters A. J., Fabre J. M., Steinmetz N. A., Harris K. D., and Carandini M. (2021). Striatal activity topographically reflects cortical activity. Nature, 591(7850):420–425. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Redgrave P., Prescott T. J., and Gurney K. (1999). The basal ganglia: a vertebrate solution to the selection problem? Neuroscience, 89(4):1009–1023. [DOI] [PubMed] [Google Scholar]
- Rubin J. E., Vich C., Clapp M., Noneman K., and Verstynen T. (2021). The credit assignment problem in cortico-basal ganglia-thalamic networks: A review, a problem and a possible solution. European Journal of Neuroscience, 53(7):2234–2253. [DOI] [PubMed] [Google Scholar]
- Schultz W., Dayan P., and Montague P. R. (1997). A neural substrate of prediction and reward. Science, 275(5306):1593–1599. [DOI] [PubMed] [Google Scholar]
- Seo M., Lee E., and Averbeck B. B. (2012). Action selection and action value in frontal-striatal circuits. Neuron, 74(5):947–960. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shen W., Flajolet M., Greengard P., and Surmeier D. J. (2008). Dichotomous dopaminergic control of striatal synaptic plasticity. Science, 321(5890):848–851. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shin J. H., Song M., Paik S.-B., and Jung M. W. (2020). Spatial organization of functional clusters representing reward and movement information in the striatal direct and indirect pathways. Proceedings of the National Academy of Sciences, 117(43):27004–27015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Silveri M. C. (2021). Contribution of the cerebellum and the basal ganglia to language production: Speech, word fluency, and sentence construction—evidence from pathology. The Cerebellum, 20(2):282–294. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith Y., Raju D. V., Pare J.-F., and Sidibe M. (2004). The thalamostriatal system: a highly specific network of the basal ganglia circuitry. Trends in Neurosciences, 27(9):520–527. [DOI] [PubMed] [Google Scholar]
- Sutton R. S. and Barto A. G. (2018). Reinforcement learning: An introduction. MIT press. [Google Scholar]
- Treves A. and Rolls E. T. (1991). What determines the capacity of autoassociative memories in the brain? Network: Computation in Neural Systems, 2(4):371. [Google Scholar]
- Varin C., Cornil A., Houtteman D., Bonnavion P., and de Kerchove d’Exaerde A. (2023). The respective activation and silencing of striatal direct and indirect pathway neurons support behavior encoding. Nature Communications, 14(1):4982. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wärnberg E. and Kumar A. (2023). Feasibility of dopamine as a vector-valued feedback signal in the basal ganglia. Proceedings of the National Academy of Sciences, 120(32):e2221994120. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wickens J., Begg A., and Arbuthnott G. (1996). Dopamine reverses the depression of rat corticostriatal synapses which normally follows high-frequency stimulation of cortex in vitro. Neuroscience, 70(1):1–5. [DOI] [PubMed] [Google Scholar]
- Wildgruber D., Ackermann H., and Grodd W. (2001). Differential contributions of motor cortex, basal ganglia, and cerebellum to speech motor control: effects of syllable repetition rate evaluated by fmri. NeuroImage, 13(1):101–109. [DOI] [PubMed] [Google Scholar]
- Willmore B. and Tolhurst D. J. (2001). Characterizing the sparseness of neural codes. Network: Computation in Neural Systems, 12(3):255. [PubMed] [Google Scholar]
- Wiltschko A. B., Johnson M. J., Iurilli G., Peterson R. E., Katon J. M., Pashkovski S. L., Abraira V. E., Adams R. P., and Datta S. R. (2015). Mapping sub-second structure in mouse behavior. Neuron, 88(6):1121–1135. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.