

Abstract
Empirical dynamic modelling (EDM) is becoming an increasingly popular method for understanding the dynamics of ecosystems. It has been applied to laboratory, terrestrial, freshwater and marine systems, used to forecast natural populations and has addressed fundamental ecological questions. Despite its increasing use, we have not found full explanations of EDM in the ecological literature, limiting understanding and reproducibility. Here we expand upon existing work by providing a detailed introduction to EDM. We use three progressively more complex approaches. A short verbal explanation of EDM is then explicitly demonstrated by graphically working through a simple example. We then introduce a full mathematical description of the steps involved. Conceptually, EDM translates a time series of data into a path through a multi‐dimensional space, whose axes are lagged values of the time series. A time step is chosen from which to make a prediction. The state of the system at that time step corresponds to a ‘focal point’ in the multi‐dimensional space. The set (called the library) of candidate nearest neighbours to the focal point is constructed, to determine the nearest neighbours that are then used to make the prediction. Our mathematical explanation explicitly documents which points in the multi‐dimensional space should not be considered as focal points. We suggest a new option for excluding points from the library that may be useful for short‐term time series that are often found in ecology. We focus on the core simplex and S‐map algorithms of EDM. Our new R package, pbsEDM, enhances understanding (by outputting intermediate calculations), reproduces our results and can be applied to new data. Our work improves the clarity of the inner workings of EDM, a prerequisite for EDM to reach its full potential in ecology and have wide uptake in the provision of advice to managers of natural resources.
Keywords: attractor reconstruction, delay embedding, model‐free forecasting, simplex projection, Takens' theorem
We provide a detailed introduction to empirical dynamic modelling (EDM), an increasingly popular method for understanding the dynamics of ecosystems. Our work provides greater clarity of the inner workings of EDM, a prerequisite for EDM to reach its full potential in ecology and have wide uptake in the provision of advice to managers of natural resources.
1. INTRODUCTION
Population forecasts are widely used to provide advice to natural resource managers and to understand how ecosystems might respond to a changing environment. They are usually made by prescribing a mathematical model to describe the system, fitting the model to data to estimate parameters and iterating the model forward in time, possibly under a range of future scenarios. For single populations, such models include Ricker models (e.g. Dorner et al., 2009), matrix population models (e.g. Caswell et al., 1999) and age‐structured models that require complex likelihood functions and computational Bayesian techniques to fit to data (e.g. Cleary et al., 2019). Multi‐trophic models of the marine ecosystem can consist of several coupled differential equations (e.g. Fasham et al., 1990).
Ecologists do have basic equations that might be considered as laws, such as a population will exponentially grow (or decline) under a constant environment (Turchin, 2001). However, even simple single‐species models consisting of a single difference equation can display qualitatively different behaviour with just slight changes in parameters (May, 1976). Multi‐trophic models of the marine ecosystem also exhibit such behaviour, yet it is hard to prescribe specific values to many parameters, such as growth and mortality (Edwards, 2001; Yool, 1998). Even slight structural changes in model formulation can also drastically change predictions (Wood & Thomas, 1999).
Empirical dynamic modelling (EDM) aims to avoid such issues by not requiring a mathematical model of the system being considered (Chang et al., 2017; Deyle et al., 2013; Munch et al., 2020; Sugihara & May, 1990; Ye et al., 2015). Therefore, there is no need to estimate parameters. Rather, EDM uses only the available data to calculate forecasts. It does this by translating time series of data into a path through multi‐dimensional space and making forecasts based on nearest spatial neighbours.
Recent examples demonstrate EDM's continuing application to fundamental problems in ecology. Ushio (2022) proposed a new hypothesis of how patterns of community diversity emerge, based on EDM analysis of environmental DNA data from experimental rice plots in Japan. Deyle et al. (2022) improved the quantitative understanding of food‐web and chemical changes in Lake Geneva by using a novel hybrid combination of a parametric physical model and an EDM analysis of the biogeochemical variables. Rogers et al. (2022) demonstrated that chaos is not rare in natural ecosystems by analysing a global database of single‐species population time series. Grziwotz et al. (2018) revealed complex environmental drivers of nine mosquito sub‐populations in French Polynesia. Karakoç et al. (2020) investigated community assembly and stability through an EDM analysis of populations of laboratory microbial communities. They found changes in species interactions that were driven by the presence of a predator, behaviour that is difficult to model with traditional Lotka‐Volterra‐type ecological models.
Such dependence of dynamics on another variable (predators in this case) is particularly amenable to analysis using EDM because EDM does not require explicitly prescribing equations, from the many choices available, to model such processes (Ye et al., 2015). As such, there may be a role for EDM in Ecosystem Based Fisheries Management, a current focus of several government agencies that takes into account the ecosystem when managing fisheries (Howell et al., 2021). Applications to fish populations have already been widespread, including cod (Sguotti et al., 2020), salmon (Ye et al., 2015) and tuna (Harford et al., 2017), plus forage fish such as menhaden, sardine and anchovy (Deyle et al., 2018; Sugihara et al., 2012). In simulation studies, EDM was found to provide low errors in forecasted fish recruitment (Van Beveren et al., 2021).
Here we expand upon the current literature that describes EDM, e.g. Chang et al. (2017), Deyle et al. (2013), Munch et al. (2020), Sugihara and May (1990), Ye et al. (2015), the third of which includes a useful glossary; see Munch et al. (2022) for an overview of recent advances in EDM, including methods for dealing with missing data. We build up a comprehensive description of the core simplex algorithm of EDM that explicitly gives the steps involved; such steps have probably not previously been described in such detail (G. Sugihara, Scripps Institution of Oceanography, pers. comm.). We use three progressively more detailed approaches, starting with a short verbal explanation. Next we give a graphical explanation (without all the precise details) for a simple example time series. Then we extend existing notation and derive the mathematics for the univariate situation, building on the explanation by Deyle et al. (2013). Technical mathematical concepts are kept to a minimum. We extend our derivation to the multivariate situation and the S‐map algorithm in Appendix S1.
Our motivation to obtain a deeper understanding of EDM originated in our desire to investigate the potential of using EDM to provide advice to fisheries managers, particularly in the context of considering ecosystem effects. We wanted to fully understand the methods so that we could write our own R package, pbsEDM (Rogers & Edwards, 2023), tailored to our specific applications. Despite the widespread use of EDM, we did not find a full description that explained all the steps unambiguously in sufficient detail for us to write our own independent code.
This lack of explanatory detail led to us developing the descriptions presented here to help users, particularly new ones, understand the inner workings of EDM. These descriptions include two aspects of EDM that we had not seen previously reported (though some practitioners may well be aware of them). We explicitly define the allowable focal points from which predictions can be made (aspect 1), and calculate the library (or set) of candidate nearest neighbours to use for predictions (aspect 2). This allows for a clearer understanding of how the size of the library depends on both the number of lags being considered in an analysis and on the time step from which a prediction is being made.
Note that EDM has been called ‘an equation‐free approach’ (Ye et al., 2015) due to it not specifying equations that represent a mathematical model to represent the system. The equations we introduce here do not represent a model, but explicitly and unambiguously explain the inner workings of EDM. The mathematical details themselves are not overly technical, mainly dealing with careful definitions of vectors and matrices, which first requires thoughtful consideration of notation, as is often the case (Edwards & Auger‐Méthé, 2019).
Practitioners of EDM should be aware that it has a long and strong theoretical background (Kantz & Schreiber, 2004; Packard et al., 1980; Schaffer & Kot, 1986; Stark et al., 2003; Takens, 1981), but do not need to understand the full details.
In our examples, the variables represent population numbers and associated environmental variables, but the methods are applicable to time series of any quantities in ecology or other fields. This does require that the system is not completely stochastic, and has some underlying deterministic rules (that may still be subject to some randomness). Our intention is for our pbsEDM R package to complement the popular R package rEDM (Park et al., 2023, with a tutorial at https://github.com/SugiharaLab/rEDM/blob/master/vignettes/rEDM‐tutorial.pdf) and Python package pyEDM (Park & Smith, 2023), to aid understanding and reproducibility. All intermediate calculations are available as output in pbsEDM and all code is in R, while rEDM contains C++ code (which is faster than R code but less readable than R to many ecologists); however, rEDM and pyEDM also include advanced algorithms that are not in pbsEDM. All code for reproducing our calculations and figures (each as a single function), and for applying methods to users' own data, is publicly available within pbsEDM (and File S1).
2. EXPLAINING EDM VERBALLY
The idea behind EDM is that we start with a simple time series of a variable, such as the annual values of the size of a population. We then construct additional time series of first‐differenced values (differences between consecutive values) and lags of those values (which compare the first‐differenced values with those in the past, such as 1 year previously or 2 years previously). These first‐differenced and lagged values then make up the components of vectors that can be plotted as points in a multi‐dimensional space known as a state space. Joining these points together in temporal order traces a path through the state space. To make a prediction from a point in the state space, the simplex algorithm finds the nearest neighbours (in terms of spatial distance in the state space) and sees where those neighbours went in their subsequent time step. A weighted average of these destinations yields the prediction. The key concept of EDM is the transforming of the time series of single values at each point in time, into points that lie in the multi‐dimensional state space. The points in the state space can reveal a geometric structure that is not apparent when viewing the data as a simple time series.
The reason that EDM can work is because the lagged values contain intrinsic information concerning the system. Ye et al. (2015) described the general concept as “local neighborhoods (and their trajectories) in the reconstruction [our state space] map to local neighborhoods (and their trajectories) of the original system”.
To expand on our brief verbal description, we now work through an analysis of an example time series using graphical explanations and then derive an explicit mathematical description of the simplex algorithm.
3. EXPLAINING EDM GRAPHICALLY
3.1. Plotting values from a simple time series in various ways
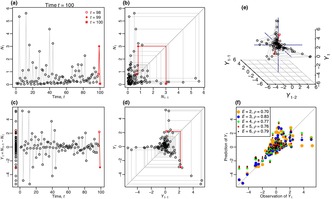
We start with a simple example time series of simulated data generated from a stochastic salmon population model that gives populations at times . The time series is used for illustrative purposes, not to make any claims about applying EDM to any particular scenario. Figure 1 shows how the data can be plotted in five different ways, to introduce the concepts underpinning EDM.
FIGURE 1.
Different ways of plotting a simple simulated time series. Panels are arranged so that the y axes are the same for (a) and (b), and then for (c), (d) and (f). (a) Population values (units of 100,000 individuals) are shown through time. The final time step () is shown in the title, and the final three values of are shown in red using the symbols indicated (these carry through to the other panels except (f)). (b) Same values in a phase plane, with against . The grey lines demonstrate the points progressing clockwise around the phase plane (see text). (c) Time series of resulting first‐differenced values , with all values also overlaid in a single column to the left of . (d) Phase plane of against reveals a geometric structure that is not apparent in the preceding panels. (e) Extends (d) to three dimensions, showing , and . (f) The predicted results and corresponding Pearson correlation coefficients, , of the observed values of for different values of embedding dimension . Figure A.1: Appendix S1 shows a controllable frame‐by‐frame animation of this figure for to , and Movie S1 gives a narrated version.
Figure 1a shows the simple time series of the size of the population at time , , with generally low and occasionally high values. In Figure 1b the same data are shown with plotted against the value at the previous time step, namely . This is a phase plane because there are two axes that represent variables and there is no time axis. Figure 1c introduces the first‐differenced values, defined as the difference between the population at the next time step and the current time step, that is, . By definition, can take negative and positive values (while since it represents the size of a population).
Figure 1d shows the phase plane of each against its lagged value , revealing some geometric structure in the data. This structure is inherently coming from the population being mostly at low levels, but with occasional high values followed by immediate drops back down to low levels. There is clearly a cluster of points around the origin, representing low values of (and ) for most of the time series, due to small changes between consecutive values of . There are three ‘arms’ along which the remaining points lie, plus empty areas of the phase plane that never appear to be visited. The central top arm contains points representing values of close to zero that are then followed by a large value of (a large increase in the population). When the system is at the location , as indicated by the red open circle in Figure 1d. At the next time step, , the system moves to , given by the red closed circle. A graphical way to view this is shown by the red lines in Figure 1d. First, trace horizontally from to the 1:1 line , so that the previous value on the y‐axis () becomes the new value on the x‐axis (when increases by 1, the old becomes the new ). Then trace up or down to reach the new value. This approach, inspired by the dynamical systems concept of ‘cobwebbing’ (Murray, 1989), leads to the tracing out of the path of the grey lines in Figure 1d. This path is always clockwise. For the full time series, this results in the bottom‐right arm, for which a large value of is always immediately followed by a large negative (a large decline). Continuing clockwise leads to the left arm, for which the large declines are followed by very minor changes close to zero, and so in the next time step the trajectory heads back into the central cluster.
The cobwebbing idea graphically shows that, for example, when the population experiences a large increase (large ), the next few time steps are expected to follow a certain path clockwise around the phase plane (namely, a large decrease in shown in the bottom‐right arm, followed by a small value of close to zero in the left arm). The idea of EDM is to harness such geometric structure in the spatial phase plane to make predictions in the time dimension.
Figure 1d also shows empty regions that the system does not visit, namely the top‐right area (a large increase of is never followed by another large increase: and are never both large), the bottom‐left area (a decline or slight increase is never followed by a large decline: and are never both very negative), and the top‐left area (a large decline is never followed by a large increase: a very negative is never followed by a large ). This last description translates to never going high, then low, then immediately high again.
The structure in Figure 1d represents the attractor on which the system evolves through time. This gives a useful way of thinking about EDM – the fundamental description of the dynamics of the system can be thought of as being given by the observed attractor (based solely on the data), rather than by a prescribed set of equations (Munch et al., 2020).
Figure 1e extends the two‐dimensional phase plane idea to three dimensions, showing against and . While Figure 1d included a lag of one time step, Figure 1e includes lags of one () and two () time steps. Again, this reveals an underlying geometric structure of the system (seen more clearly in the animated Figure A.1: Appendix S1 which shows the structure being built up through time). The three dimensions correspond, in EDM language, to an embedding dimension of , because the points are embedded in three‐dimensional space. This space is known as the state space (the multi‐dimensional equivalent of the two‐dimensional phase plane). The phase plane in Figure 1d corresponds to . Higher embedding dimensions (4, 5, 6, etc.) are also used, but obviously not easily plotted. The points at the left of Figure 1c show the distribution of values of in one dimension, which is essentially an embedding dimension of . This is not commonly used in EDM but is shown here to illustrate how we can have the points on a line for , on a phase plane (Figure 1d) for and a three‐dimensional plot (Figure 1e) for .
In hindsight, some of the aforementioned conclusions from Figure 1d can be teased out from Figures 1a,c, but the phase plane in (d) makes them much more apparent. However, EDM utilises structure in higher dimensions (i.e. using more lags) that cannot be easily visualised and cannot be inferred from the simple time series. Certainly, the structure in the three‐dimensional Figure 1e cannot be easily ascertained from the simple time series.
Figures 1a–e have simply plotted the data in different ways, there have been no statistical analyses or calculations beyond first‐differencing and lagging. Such plotting has revealed some structure behind the time series that is not immediately apparent in the simple time series plots. Figure 1f is discussed after we explain how EDM uses the geometric structure to make predictions.
3.2. Graphically demonstrating the simplex algorithm
For our example time series, we first choose a focal time , which means that we want to use EDM to predict where the system goes in the subsequent time step (Deyle et al., 2013). We choose, as an example, , such that we want to estimate (where the system goes in the next time step) given knowledge of the rest of the time series. We denote the estimated value as , and more generally, for a given we want to estimate .
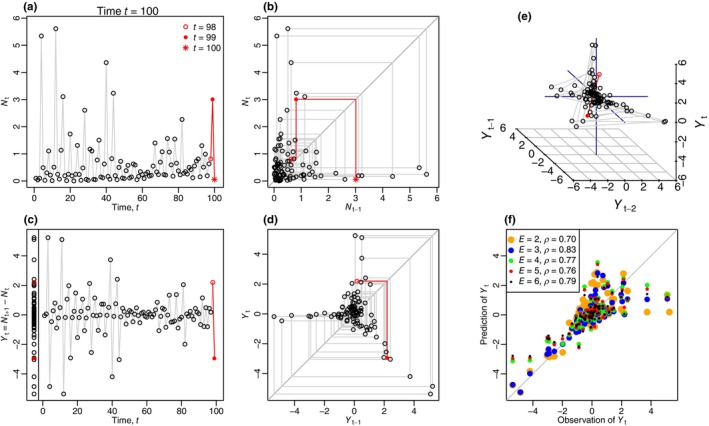
We can then compare the predicted value to its known value to see how well the simplex algorithm performs for . The state of the system at is highlighted in Figure 2, showing the values of and in the lagged phase plane. For the phase plane the nearest three neighbours are located (red circles). These are the nearest neighbours spatially, but this does not mean that they are close to each other in time; the actual times of these points are , and 98. The crux of EDM is to see where these points move to in the phase plane in their next time step, to make a prediction of where the focal point will go. The idea being that close points in the phase plane will move to close points for their subsequent time step, and this structure in the system allows us to estimate .
FIGURE 2.
For the example time series, embedding dimension yields the phase plane of against as in Figure 1d. Given focal time (blue circle indicating and ) we want to predict . The three nearest neighbours to the blue circle in the phase plane are shown by the red circles. These are at times 11, 43 and 98, though the times cannot be inferred from the phase plane. The purple arrows show where these points move to in the phase plane one time step later, namely to the points corresponding to times 12, 44 and 99. A weighted average of and (grey horizontal lines) then gives the estimate of (blue star). In this case it is close to the known true value of (green circle). An annotated animation of this figure is shown in Figure A.2: Appendix S1, and the figures for all valid values are shown in Figure A.3: Appendix S1.
The purple arrows in Figure 2 show where the three nearest neighbours move to in their subsequent time steps , and 99 (recall from the cobwebbing idea that the values become the new values, and so it is only the new values that give new information). A weighted average of these new values then gives our prediction of (the blue star), which here is close to the value of already known from our time series (green circle). The weighting is based on the relative closeness of the three nearest neighbours to the focal point (explained in detail later).
We can make similar predictions for all alternative values of the focal time (in addition to ), and evaluate how the predicted values compare to the known values . We then calculate the Pearson correlation coefficient () of these, which is the usual, but not the only, way to characterise the performance of EDM predictions (Ye et al., 2015), with representing a perfect positive correlation between observations and predictions. For the phase plane from Figure 2, which has embedding dimension , we have .
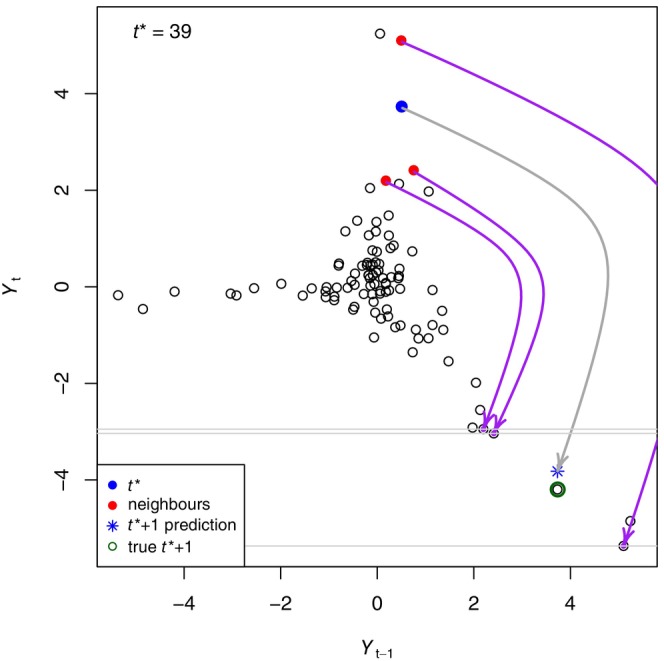
This idea is then repeated for prescribed embedding dimensions of , and the predicted and observed values up to are shown in Figure 1f, together with the corresponding . The best‐performing (highest ) embedding dimension is (Figure 3), and this is the dimension that would, therefore, be used in EDM to forecast the population into the future, beyond the timespan of the data.
FIGURE 3.
Dependence of the Pearson correlation coefficient, , on embedding dimension, , for the example time series from Figure 1. The best fitting model is given by the highest , and corresponds to which is what would be used to forecast . We have shown high enough values of to show a clear decline in , but in general the maximum considered should be about (Munch et al., 2020), which is 10 here.
4. EXPLAINING EDM MATHEMATICALLY
We now develop the above ideas using a more formal mathematical approach. We mostly follow and adapt the description given by Deyle et al. (2013), extending their work to give a full mathematical description that leads to a deeper understanding of EDM and its limitations. The simplex algorithm is described for a univariate time series, such as an annual survey estimate of a population, and extended to the multivariate case and the S‐map technique (Sugihara, 1994) in Appendix S1. Notation is extended from that defined clearly by Deyle et al. (2013), and summarised in Table 1 for reference.
TABLE 1.
The main notation used here.
| Notation | Definition | |
|---|---|---|
| Indices | ||
|
|
Index for time; | |
|
|
Number of time steps | |
|
|
Focal time at which we know the state of the system and want to predict the state at | |
| Variables | ||
|
|
Value, such as population size, at | |
|
|
First‐difference value | |
|
|
Estimate of | |
| EDM calculations | ||
|
|
Vector of length defining the axes of the lagged state space, for example, | |
|
|
Realised values of the components of , for example, ; each element of is the value along each axis of the ‐dimensional space, where the axes are defined by components of | |
|
|
Realised values of the components of at the focal time | |
|
|
Embedding dimension, the number of dimensions of the state space in which the system is being embedded to look for the nearest neighbours to the focal point ; is the length of | |
|
|
Matrix with rows representing time and columns representing each of the components of ; row represents the system state at time with the jth element representing the jth component of | |
|
|
Library for a given and , consisting of the set of that are candidates to be considered as nearest neighbours of | |
|
|
The number of vectors in the library | |
|
|
The usual value of for a given , defined as ; | |
|
|
After calculating the distance between and each in the library, gives the time index of the that is the nearest neighbour to , corresponds to the second nearest neighbour, etc. | |
4.1. Algorithm for simplex projection
We consider a univariate time series of population size at each time . As earlier, we first‐difference the data to give scalars
| (1) |
for , such that the first value, , is defined, with undefined. First‐differencing is often done to help remove any simple linear mean trend (Chang et al., 2017). The aim of the analysis is to estimate , that is, the population the year after the final year of data, by estimating and then rearranging (1) to give .
The simplex algorithm was detailed as steps (i) to (vii) by Deyle et al. (2013). These are summarised and extended in Table 2 to give an overall idea of the approach and then expanded upon here.
TABLE 2.
The steps of the simplex algorithm (extended from Deyle et al., 2013).
| Step | Brief description |
|---|---|
| (i) | Translate the time series values into vectors in the multi‐dimensional state space defined by a given embedding dimension |
| (ii) | Pick a focal time from which to predict |
| (iii) | Define the set of library vectors of candidate nearest neighbours to the focal point |
| (iv) | Calculate the distances between appropriate points in the state space |
| (v) | Identify the nearest neighbours to the focal point |
| (vi) | Make a prediction using a weighted average of the known next positions of the nearest neighbours |
| (vii) | Repeat steps (ii)–(vi) for all appropriate focal times |
| (viii) | Calculate the correlation coefficient between predictions and the known observations |
| (ix) | Repeat steps (i)–(viii) for different values of , using the optimal one ( with maximum correlation coefficient) to forecast the future value of the population |
(i) For a given embedding dimension , we define the vector in lagged space as containing and consecutive lags down to :
| (2) |
So has length with each element defining an axis that we will be using to construct the ‐dimensional state space. Actual realised values (numbers) for a particular are recorded in vectors , with each element referring to its corresponding axis definition in . For example, with our simulated time series from Figure 1, yields
| (3) |
with defining the axes of the state space.
The components of from (3) give the column headings of matrix :
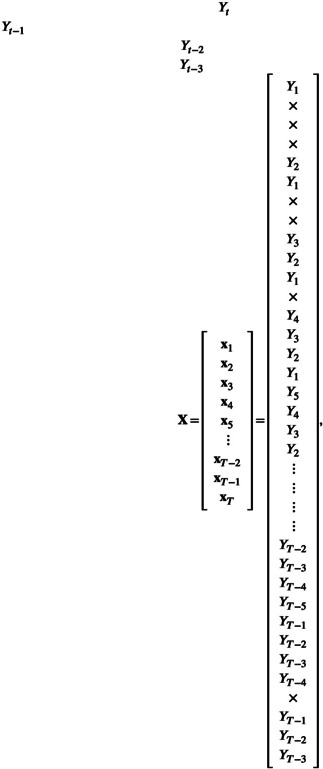 |
(4) |
for which row consists of the explicit values of (implicitly understood to be written here as a row vector) with undefined values indicated by . Vectors and are undefined because the for are undefined. Some brief descriptions of the simplex algorithm do not mention that some points should be excluded from the library (e.g. Hsieh et al., 2005; Ye et al., 2015), while Deyle et al. (2013) did note that the first few time values will not have a vector in the state space; here we make that more explicit. Also, does not exist because is undefined in (1); however, we include it in because we will want to forecast and it is helpful for to have rows.
Matrix (4) is for . Extending this for a general value of we have
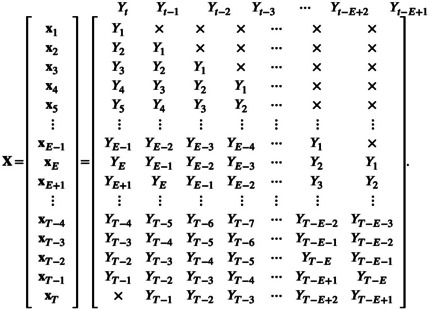 |
(5) |
For a given time series of length , the larger the value of , the larger the size of the upper‐right triangle of undefined values, because a larger embedding dimension requires more lagged values. The first row that is fully known (requiring that exists) is when .
(ii) Pick a focal time for which we know and want to predict the value of , with the prediction denoted . In the ‐dimensional state space, we do this by requiring knowledge of the full and then estimating to give us our estimate of from (2). Not all values of are available to use for (aspect 1; briefly explained in Table 3), which will be made explicit shortly. Note that we call for general a ‘prediction’, reserving the term ‘forecast’ for estimating future and beyond the existing data.
TABLE 3.
Two aspects of EDM that we document here to aid new users of EDM.
| Aspect | Brief description |
|---|---|
| 1 | The allowable focal point times (from which to make predictions) depend explicitly upon the embedding dimension . They require lagged values that do not extend before the start of the time series or beyond the end of it |
| 2 | We explicitly calculate the library of candidate nearest neighbours of the focal point, and derive a new relationship showing how the size of the library depends on both and |
(iii) Given , define the library of candidate nearest neighbours of . To determine the library we start with an expanded version of from (5) for general , and systematically cross out and various that must be excluded from the library due to four conditions, resulting in

The four conditions for excluding components from the library of candidate nearest neighbours are:
cannot be a nearest neighbour to itself—excludes ;
Several are not fully defined (contain )—excludes and ;
Exclude any for which we do not know (since we need to know where the nearest neighbours go in the subsequent time step in (vi))—excludes ;
It may not be appropriate to use any that includes , since we are trying to predict —excludes . This is further investigated later.
The resulting library is given by the remaining set of vectors that are not crossed out in (6), namely:
| (7) |
for those that are defined, where the notation emphasises that the library depends upon both and ; this is aspect 2. For a time series of length , Figure 4 shows how the size of the library, , varies with and .
FIGURE 4.
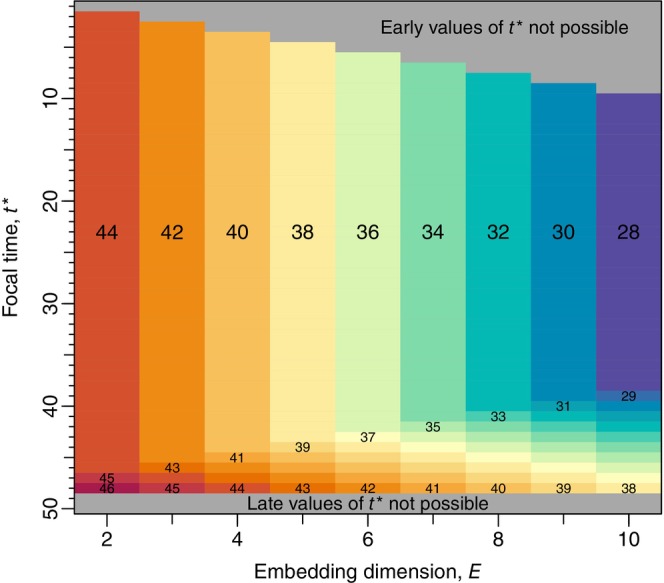
The number of components of the library, , depends on the interplay between embedding dimension and focal time , as derived in (11) and shown here for any univariate time series of length . The axis is inverted to compare with (6). The top grey area indicates values that are not possible because the required lagged values (based on ) extend before the start of the time series. The bottom grey area indicates values that are not possible because for the first‐difference value is not known, and for the predicted state at is not known (and we first want to compare predictions to known values.) For each value of , the majority of values are , as shown by the large‐font numbers (indicating , etc.; see later text) that define the colours. Colours increment by one going down the figure, as illustrated by the small‐font numbers. For , for example, can only take values between 8 and 48, and the library size is usually 32, but incrementally increases from 33 to 40 as increases from 41 to 48.
Returning to the idea from (ii) of determining the valid values of , we now flesh out aspect 1, determining the allowable values of and how these depend on . Matrix in (6) shows that is not defined for , such that cannot take these values; this is the top‐right grey region of Figure 4. Also, is not defined and so cannot equal . The value is also excluded because in step (viii) we want to compare the prediction with the known state, which cannot be done for since is not defined. Though note that can later be used to forecast and hence and , which is the aim of the analysis. Excluding and corresponds to the bottom grey region in Figure 4, leaving allowable values for the focal time of , which are the non‐grey combinations in Figure 4.
Usually, the library has components, as indicated by the bulk of values for each value of in Figure 4 (e.g. , since ). Intuitively, the library has fewer components as gets larger because the larger uses more temporal lags which creates a higher dimensional state space, resulting in having more columns and subsequently more crossed out in (6) and more grey area at the top (small values) of Figure 4.
However, the library size also depends on , and we denote it by . We now derive , as used to create Figure 4. For a given , for certain values of , because for larger the crossed out components in the middle rows of (6) overlap with the crossed out and components, or do not exist since they have times . This overlapping first happens when , such that and the library is
| (8) |
which has size . In Figure 4, this corresponds to (for ) and (for ).
For the next value, , we have
| (9) |
which has size , corresponding to and in Figure 4.
This pattern incrementally increases until we get to , near the end of the time series, for which and are the same. So in (6), gets excluded both because we do not know (exclusion condition c) and because it contains (condition d). This overlap means that the library is
| (10) |
which has size . In Figure 4, for this is the aforementioned , and for , this is, .
In summary, the library is given by (7) and is bigger for relatively large , with size explicitly given by
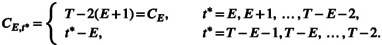 |
(11) |
It was previously noted that (for a given ) the library will consist of all possible vectors formed from the time series, except for the target vector (Deyle et al., 2013). However, here we have shown that other vectors also need to be excluded and that the library size also depends explicitly on (that we have not seen stated previously). In our example, this means that for the library size can vary from 32 to 40 depending on the focal time (Figure 4).
(iv) The next step is to calculate the Euclidean distance in the state space between the focal point and each point in the library. The Euclidean distance between two vectors and is defined as
| (12) |
(v) Rank every vector in the library with respect to its Euclidean distance from , and define to be the time index of the vector with rank . So the nearest neighbour has rank 1 and will have time index , the second nearest will have rank 2 and time index , etc. The closest state‐space vectors and indicate points in the library for which the system was in the most similar state to the focal time , for this particular state‐space reconstruction (value of ). Of interest are the nearest neighbours, which form a simplex in the ‐dimensional state space (hence the ‘simplex algorithm’). A simplex in an ‐dimensional space consists of points (a triangle for , a tetrahedron or triangular pyramid for , etc.). In Figure 2, for which , the nearest neighbours (red points) are at times and . Thus, based on and its lagged value , the system appears closest to its state at time 39 at times 43, 11 and 98 (times that are not necessarily close to 39, but the system is similar in the state space); this is the core concept of EDM, and is certainly not discernible from viewing the data as a simple time series.
(vi) In one time step, each vector moves to its corresponding location . We use the nearest neighbours (so ) and take a weighted average of the first components of the resulting . By definition from (6), ; it is only the first component of this vector that we are estimating (the other components are already known). Hence the weighted average only concerns the first component of the nearest‐neighbour vectors, namely the . We make a prediction for using equation S1 from Deyle et al. (2013):
| (13) |
where the weights are
| (14) |
The weights downweight the contribution of each based on the closeness of to relative to the closeness of (the closest vector) to ; note that Deyle et al. (2013) had the above summations to , but they should be to for the nearest neighbours, as in Sguotti et al. (2020). By definition, the weight of the closest vector is always .
(vii) For short time series (like our example) cross‐validation is used to test how well the method performs on the known data. This involves repeating steps (ii)‐(vi) with all valid values of for which we can compare the observed with the predicted . Longer time series can be split to use the first half to predict the second half (Deyle et al., 2013).
(viii) Determine the correlation coefficient, , between the observed and predicted , defined as
| (15) |
where and , and these means, and the summations in (15) are over the valid values of (as in Figure 4).
(ix) Repeat steps (i) to (viii) for a sequence of embedding dimensions . The that gives the highest is considered to perform best, namely (giving ) for our example time series (Figure 3). That is used to forecast the future value of the population, , by setting to estimate and rearranging (1) to give . Note that, regarding aspect 1, is allowed here for forecasting ; its exclusion in (6) is only for determining . If increases with such that there is no optimal , this suggests a high‐dimensional essentially random process for all practical purposes, such that the system is difficult to model (Hsieh et al., 2005).
For our simulated data and , our pbsEDM implementation of steps (i)–(ix) gives yielding . Thus, the forecast is of a negative population, which is obviously unrealistic. Predictions of the first‐differenced are weighted averages of observed values of , so they must lie within the range of the observed values (e.g. Figure 2). More extreme values are not possible. But there is nothing to stop the resulting predictions being more extreme than for the observed values of , which includes allowing negative values. Negative values are predicted for six in our example time series (see File S1). We suggest the simple remedy of replacing the negative predictions with the smallest observed value from the original time series. A second option is to replace with (which can be negative), although results will differ because relative distances of nearest neighbours will change, altering the weights in (14); Rogers et al. (2022) implemented both and . A third option is to not first‐difference the original data (discussed below).
Relatedly, we find , but calculating the correlation based on and instead, by replacing with in (15), gives 0.54; for we get 0.70 and 0.28. Thus, we caution that high correlation based on does not necessarily imply high correlation based on , which is what we are interested in (see below and File S1).
Condition (d) above is that it may be appropriate to exclude from the library of candidate nearest neighbours of the focal point . This is based on the principle that when testing the predictive accuracy of a method it is problematic to use information about the value being predicted. The method should not have any knowledge of the known value of the quantity.
For our simulated data and , we find that predictions are the same when using pbsEDM or rEDM, except for (0.838 for pbsEDM versus 1.368 for rEDM) and (0.412 versus 0.177). For , we find that rEDM uses as one of the three nearest neighbours to , and hence uses it in the prediction , despite it including (which is what we are trying to predict). We find this by changing the value of to a large value such that is no longer a close neighbour of , and the rEDM code then gives the exact same answer as for pbsEDM (also agreeing with some earlier code that we wrote independently of pbsEDM); see File S1.
Similarly, for we find that rEDM uses as a nearest neighbour of , but this neighbour includes the value of that we are trying to predict (and we suggest it should be excluded). The default in rEDM is to not exclude any temporally adjacent neighbours, although the exclusionRadius argument allows the user to exclude nearest temporal neighbours within exclusionRadius time steps of (i.e. this would exclude the exclusionRadius number of both above and below in (6), which can help deal with autocorrelation). For short time series as we have in our fisheries applications, we would like to retain as many potential neighbours as possible, and so in pbsEDM our default is as described above in (6) and (7), and we also provide options to match the settings from rEDM. Differences between such options will become more important for higher embedding dimensions than 2, since the excluded points , become more numerous as increases.
Note that forecasting involves setting , for which the excluded points just referred to would be the undefined . So although the different options will not directly affect the nearest neighbours of and the calculation, they do affect the calculation of and hence the choice of used for forecasting, which can indeed influence .
For our simulated data the largest is for (Figure 1c). Predicting requires which is valid for but no higher (Figure 4). Yet is the poorest estimated value of all (being the right‐most point of Figure 1f). So the most poorly estimated point is included in the calculations only for , which seems an unfair constraint when comparing for different (Figure 3) to find the optimal to use for forecasting. Future investigations could examine whether restricting calculations to the same set of , based on Figure 4, should be done when determining the optimal .
Whether to apply the first‐differencing or not will be time‐series dependent. Chang et al. (2017) state that linear trends in the original data should be removed, either by simple regression or taking the first‐difference, to make the time series stationary. First‐differencing was not strictly necessary for our example time series (there was no clear linear trend in the ), yet the first‐differenced lagged values in Figure 1d do demonstrate geometric structure that is not seen in the non‐first‐differenced values in Figure 1b. Our explanations are the same without first‐differencing, with simply taking the value instead of . Real applications can test sensitivity to first‐differencing.
In Appendix S1 we extend the above mathematical description to the multivariate situation of analysing multiple variables, such as populations of several species or a population and an index of local temperature. The library of candidate nearest neighbours to the focal point can again be calculated. The size of the library does not depend on the chosen embedding dimension, just on the maximum lag, , used for any of the variables. The size is once more represented by Figure 4, but with the ‐axis replaced by . So the library size does not change if further variables are added unless they are lagged more than the existing variables such that increases. We describe the S‐map algorithm in Appendix S1 and apply it to our simulated data set.
5. DISCUSSION
We have derived a thorough description of the core methods of EDM, yielding previously undocumented aspects that improve understanding. Having gained a deeper understanding of EDM, our work suggests potential enhancements. For example, the closest neighbours are typically selected for the simplex algorithm (to form a simplex in the ‐dimensional space), but simulations could investigate how altering the numbers of neighbours (an easily changed parameter in rEDM) might improve accuracy. This could lead to developing a bootstrapping approach to produce confidence intervals for simplex predictions. Simulation testing could determine the observed coverage of such intervals (and also for bootstrap intervals from the S‐map algorithm, as used by Karakoç et al., 2020).
Readers searching the literature should be aware of other terms that describe EDM‐type approaches, including nonlinear forecasting, state‐space reconstruction, Takens' theorem, time‐delay embedding and Jacobian Lyapunov exponents. To delve into the more technical background behind EDM, we recommend the books by Ott et al. (1994), particularly Chapter 5 on ‘The Theory of Embedding’ and the included reprints of Sauer (1993) and Sugihara and May (1990), and Huffaker et al. (2017), particularly Chapter 3 on ‘Phase Space Reconstruction’.
The use of EDM can allow for time‐varying productivity (or other ecosystem changes) to be implicitly accounted for in applications such as fisheries management. For example, Ye et al. (2015) found that including time series of sea surface temperature when forecasting salmon populations using EDM performed better than not including temperature, and that EDM outperformed parametric models. Fruitful research could further compare EDM with parametric time‐varying models (for which it is necessary but hard to prescribe an explicit mathematical relationship between productivity and time). How this would directly inform decision‐making requires further investigation, since, in general, accounting for nonstationarity in the ecosystem requires careful consideration of how to determine the benchmarks or reference points that are used to determine the status of stocks (Holt & Michielsens, 2020). So although we have described EDM as an alternative to parametric mechanistic modelling, both approaches can be used together in various complementary ways (Munch et al., 2020), and this may indeed be how EDM fulfils its potential in practical management applications.
AUTHOR CONTRIBUTIONS
Andrew M. Edwards: Conceptualization (equal); data curation (equal); formal analysis (lead); funding acquisition (equal); investigation (equal); methodology (equal); project administration (equal); software (equal); supervision (equal); validation (lead); visualization (lead); writing – original draft (lead); writing – review and editing (lead). Luke Rogers: Data curation (equal); formal analysis (supporting); investigation (equal); methodology (equal); software (equal); writing – review and editing (supporting). Carrie Holt: Conceptualization (equal); data curation (equal); formal analysis (supporting); funding acquisition (equal); investigation (equal); methodology (equal); project administration (equal); supervision (equal); writing – original draft (supporting); writing – review and editing (supporting).
Supporting information
Appendix S1
Movie S1
File S1
Data S1
ACKNOWLEDGEMENTS
We thank Joe Watson, John Holmes and Travis Tai for useful comments on earlier drafts, plus three anonymous reviewers and the Editors for their comments that have improved this work. We are also grateful to George Sugihara, Hao Ye, Erik Saberski and Joseph Park for informative discussions. LAR thanks Fisheries and Oceans Canada for postdoctoral funding through FSERP (Fisheries Science and Ecosystem Research Program).
Edwards, A. M. , Rogers, L. A. , & Holt, C. A. (2024). Explaining empirical dynamic modelling using verbal, graphical and mathematical approaches. Ecology and Evolution, 14, e10903. 10.1002/ece3.10903
DATA AVAILABILITY STATEMENT
No new data were collected. All results are reproducible from the File S1.
REFERENCES
- Caswell, H. , Fujiwara, M. , & Braul, S. (1999). Declining survival probability threatens the North Atlantic right whale. Proceedings of the National Academy of Sciences of the United States of America, 96, 3308–3313. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang, C.‐W. , Ushio, M. , & Hsieh, C.‐H. (2017). Empirical dynamic modeling for beginners. Ecological Research, 32, 785–796. [Google Scholar]
- Cleary, J. S. , Hawkshaw, S. , Grinnell, M. H. , & Grandin, C. (2019). Status of B.C. Pacific Herring (Clupea pallasii) in 2017 and forecasts for 2018. Fisheries and Oceans Canada. Canadian Science Advisory Secretariat Research Document, 2018/028, v + 285 p.
- Deyle, E. , Schueller, A. M. , Ye, H. , Pao, G. M. , & Sugihara, G. (2018). Ecosystem‐based forecasts of recruitment in two menhaden species. Fish and Fisheries, 19, 769–781. [Google Scholar]
- Deyle, E. R. , Bouffard, D. , Frossard, V. , Schwefel, R. , Melack, J. , & Sugihara, G. (2022). A hybrid empirical and parametric approach for managing ecosystem complexity: Water quality in Lake Geneva under nonstationary futures. Proceedings of the National Academy of Sciences of the United States of America, 119, e2102466119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deyle, E. R. , Fogarty, M. , Hsieh, C.‐H. , Kaufman, L. , MacCall, A. D. , Munch, S. B. , Perretti, C. T. , Ye, H. , & Sugihara, G. (2013). Predicting climate effects on Pacific sardine. Proceedings of the National Academy of Sciences of the United States of America, 110, 6430–6435. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dorner, B. , Peterman, R. M. , & Su, Z. (2009). Evaluation of performance of alternative management models of Pacific salmon (Oncorhynchus spp.) in the presence of climatic change and outcome uncertainty using Monte Carlo simulations. Canadian Journal of Fisheries and Aquatic Sciences, 66, 2199–2221. [Google Scholar]
- Edwards, A. M. (2001). Adding detritus to a nutrient‐phytoplankton‐zooplankton model: a dynamical‐systems approach. Journal of Plankton Research, 23, 389–413. [Google Scholar]
- Edwards, A. M. , & Auger‐Méthé, M. (2019). Some guidance on using mathematical notation in ecology. Methods in Ecology and Evolution, 10, 92–99. [Google Scholar]
- Fasham, M. J. R. , Ducklow, H. W. , & McKelvie, S. M. (1990). A nitrogen‐based model of plankton dynamics in the oceanic mixed layer. Journal of Marine Research, 48, 591–639. [Google Scholar]
- Grziwotz, F. , Strauß, J. F. , Hsieh, C.‐H. , & Telschow, A. (2018). Empirical dynamic modelling identifies different responses of Aedes Polynesiensis subpopulations to natural environmental variables. Scientific Reports, 8, 16768. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Harford, W. J. , Karnauskas, M. , Walter, J. F. , & Liu, H. (2017). Non‐parametric modeling reveals environmental effects on bluefin tuna recruitment in Atlantic, Pacific, and Southern Oceans. Fisheries Oceanography, 26, 396–412. [Google Scholar]
- Holt, C. A. , & Michielsens, C. G. J. (2020). Impact of time‐varying productivity on estimated stock‐recruitment parameters and biological reference points. Canadian Journal of Fisheries and Aquatic Sciences, 77, 836–847. [Google Scholar]
- Howell, D. , Schueller, A. M. , Bentley, J. W. , Buchheister, A. , Chagaris, D. , Cieri, M. , Drew, K. , Lundy, M. G. , Pedreschi, D. , Reid, D. G. , & Townsend, H. (2021). Combining ecosystem and single‐species modeling to provide ecosystem‐based fisheries management advice within current management systems. Frontiers in Marine Science, 7, 607831. [Google Scholar]
- Hsieh, C.‐H. , Glaser, S. M. , Lucas, A. J. , & Sugihara, G. (2005). Distinguishing random environmental fluctuations from ecological catastrophes for the North Pacific Ocean. Nature, 435, 336–340. [DOI] [PubMed] [Google Scholar]
- Huffaker, R. , Bittelli, M. , & Rosa, R. (2017). Nonlinear time series analysis with R. Oxford University Press. [Google Scholar]
- Kantz, H. , & Schreiber, T. (2004). Nonlinear time series analysis. Cambridge University Press. [Google Scholar]
- Karakoç, C. , Clark, A. T. , & Chatzinotas, A. (2020). Diversity and coexistence are influenced by time‐dependent species interactions in a predator‐prey system. Ecology Letters, 23, 983–993. [DOI] [PubMed] [Google Scholar]
- May, R. M. (1976). Simple mathematical models with very complicated dynamics. Nature, 261, 459–467. [DOI] [PubMed] [Google Scholar]
- Munch, S. B. , Brias, A. , Sugihara, G. , & Rogers, T. L. (2020). Frequently asked questions about nonlinear dynamics and empirical dynamic modelling. ICES Journal of Marine Science, 77, 1463–1479. [Google Scholar]
- Munch, S. B. , Rogers, T. L. , & Sugihara, G. (2022). Recent developments in empirical dynamic modelling. Methods in Ecology and Evolution, 14, 732–745. [Google Scholar]
- Murray, J. D. (1989). Mathematical Biology, volume 19 of Biomathematics. Springer‐Verlag. [Google Scholar]
- Ott, E. , Suaer, T. , & Yorke, J. A. (1994). Coping with chaos: Analysis of chaotic data and the exploitation of chaotic systems. Wiley series in nonlinear science. John Wiley and Sons, Inc. [Google Scholar]
- Packard, N. H. , Crutchfield, J. P. , Farmer, J. D. , & Shaw, R. S. (1980). Geometry from a time series. Physical Review Letters, 45, 712–716. [Google Scholar]
- Park, J. , & Smith, C. (2023). pyEDM: Python wrapper for cppEDM using pybind11. Python package version 1.14.0.2. https://pepy.tech/project/pyEDM
- Park, J. , Smith, C. , Sugihara, G. , & Deyle, E. (2023). rEDM: Empirical Dynamic Modeling (EDM). R package version 1.15.1. https://CRAN.R‐project.org/package=rEDM
- Rogers, L. A. , & Edwards, A. M. (2023). pbsEDM: An R package to implement some of the methods of empirical dynamic modelling. R package version 1.0.0. https://github.com/pbs‐assess/pbsEDM
- Rogers, T. L. , Johnson, B. J. , & Munch, S. B. (2022). Chaos is not rare in natural ecosystems. Nature Ecology & Evolution, 6, 1105–1111. [DOI] [PubMed] [Google Scholar]
- Sauer, T. (1993). Time series prediction using delay coordinate embedding. In Weigend A. S. & Gershenfeld N. A. (Eds.), Time series prediction: Forecasting the future and understanding the past, Santa Fe Institute studies in the science of complexity XV (pp. 175–194). Addison‐Wesley. [Google Scholar]
- Schaffer, W. M. , & Kot, M. (1986). Chaos in ecological systems: the coals that Newcastle forgot. Trends in Ecology & Evolution, 1, 58–63. [DOI] [PubMed] [Google Scholar]
- Sguotti, C. , Otto, S. A. , Cormon, X. , Werner, K. M. , Deyle, E. , Sugihara, G. , & Möllmann, C. (2020). Non‐linearity in stock‐recruitment relationships of Atlantic cod: insights from a multi‐model approach. ICES Journal of Marine Science, 77, 1492–1502. [Google Scholar]
- Stark, J. , Broomhead, D. S. , Davies, M. E. , & Huke, J. (2003). Delay embeddings for forced systems. II. Stochastic forcing. Journal of Nonlinear Science, 13, 519–577. [Google Scholar]
- Sugihara, G. (1994). Nonlinear forecasting for the classification of natural time series. Philosophical Transactions of the Royal Society of London, Series A, 348, 477–495. [Google Scholar]
- Sugihara, G. , May, R. , Ye, H. , Hsieh, C.‐H. , Deyle, E. , Fogarty, M. , & Munch, S. (2012). Detecting causality in complex ecosystems. Science, 338, 496–500. [DOI] [PubMed] [Google Scholar]
- Sugihara, G. , & May, R. M. (1990). Nonlinear forecasting as a way of distinguishing chaos from measurement error in time series. Nature, 344, 734–741. [DOI] [PubMed] [Google Scholar]
- Takens, F. (1981). Detecting strange attractors in turbulence. In Rand D. & Young L. S. (Eds.), Dynamical systems and turbulence, Warwick 1980, volume 898 of Lecture Notes in Mathematics (pp. 366–381). Springer. [Google Scholar]
- Turchin, P. (2001). Does population ecology have general laws? Oikos, 94, 17–26. [PubMed] [Google Scholar]
- Ushio, M. (2022). Interaction capacity as a potential driver of community diversity. Proceedings of the Royal Society B, 289, 20212690. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Beveren, E. , Benoît, H. P. , & Duplisea, D. E. (2021). Forecasting fish recruitment in age‐structured population models. Fish and Fisheries, 22, 941–954. [Google Scholar]
- Wood, S. N. , & Thomas, M. B. (1999). Super‐sensitivity to structure in biological models. Proceedings of the Royal Society of London. Series B, 266, 565–570. [Google Scholar]
- Ye, H. , Beamish, R. J. , Glaser, S. M. , Grant, S. C. H. , Hsieh, C.‐H. , Richards, L. J. , Schnute, J. T. , & Sugihara, G. (2015). Equation‐free mechanistic ecosystem forecasting using empirical dynamic modeling. Proceedings of the National Academy of Sciences of the United States of America, 112, E1569–E1576. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yool, A. (1998). The dynamics of open‐ocean plankton ecosystem models. Ph.D. thesis, University of Warwick, U.K.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Appendix S1
Movie S1
File S1
Data S1
Data Availability Statement
No new data were collected. All results are reproducible from the File S1.