

Abstract
Integrating high-level semantically correlated contents and low-level anatomical features is of central importance in medical image segmentation. Towards this end, recent deep learning-based medical segmentation methods have shown great promise in better modeling such information. However, convolution operators for medical segmentation typically operate on regular grids, which inherently blur the high-frequency regions, i.e., boundary regions. In this work, we propose MORSE, a generic implicit neural rendering framework designed at an anatomical level to assist learning in medical image segmentation. Our method is motivated by the fact that implicit neural representation has been shown to be more effective in fitting complex signals and solving computer graphics problems than discrete grid-based representation. The core of our approach is to formulate medical image segmentation as a rendering problem in an end-to-end manner. Specifically, we continuously align the coarse segmentation prediction with the ambiguous coordinate-based point representations and aggregate these features to adaptively refine the boundary region. To parallelly optimize multi-scale pixel-level features, we leverage the idea from Mixture-of-Expert (MoE) to design and train our MORSE with a stochastic gating mechanism. Our experiments demonstrate that MORSE can work well with different medical segmentation backbones, consistently achieving competitive performance improvements in both 2D and 3D supervised medical segmentation methods. We also theoretically analyze the superiority of MORSE.
Keywords: Medical Image Segmentation, Implicit Neural Representation, Stochastic Mixture-of-Experts
1. Introduction
Medical image segmentation is one of the most fundamental and challenging tasks in medical image analysis. It aims at classifying each pixel in the image into an anatomical category. With the success of deep neural networks (DNNs), medical image segmentation has achieved great progress in assisting radiologists in contributing to a better disease diagnosis.
Until recently, the field of medical image segmentation has mainly been dominated by an encoder-decoder architecture, and the existing state-of-the-art (SOTA) medical segmentation models are roughly categorized into two groups: (1) convolutional neural networks (CNNs) [25,4,19,1,29,38,11,12,6,34,33], and (2) Transformers[2,5,35]. However, despite their recent success, several challenges persist to build a robust medical segmentation model: ❶ Classical deep learning methods require precise pixel/voxel-level labels to tackle this problem [37,36,30,31,32]. Acquiring a large-scale medical dataset with exact pixeland voxel-level annotations is usually expensive and time-consuming as it requires extensive clinical expertise [16,14,13,20,10,34]. Prior works [15,7] have used point-level supervision on medical image segmentation to refine the boundary prediction, where such supervision requires well-trained model weights and can only capture discrete representations on the pixel-level grids. ❷ Empirically, it has been observed that CNNs inherently store the discrete signal values in a grid of pixels or voxels, which naturally blur the high-frequency anatomical regions, i.e., boundary regions. In contrast, implicit neural representations (INRs), also known as coordinate-based neural representations, are capable of representing discrete data as instances of a continuous manifold, and have shown remarkable promise in computer vision and graphics [22,27,28]. Several questions then arise: how many pixel- or voxel-level labels are needed to achieve good performance? how should those coordinate locations be selected? and how can the selected coordinates and signal values be leveraged efficiently?
Orthogonally to the popular belief that the model architecture matters the most in medical segmentation (i.e., complex architectures generally perform better), this paper focuses on an under-explored and alternative direction: towards improving segmentation quality via rectifying uncertain coarse predictions. To this end, we propose a new INR-based framework, MORSE (iMplicit anatomical Rendering with Stochastic Experts). The core of our approach is to formulate medical image segmentation as a rendering problem in an end-to-end manner. We think of building a generic implicit neural rendering framework to have fine-grained control of segmentation quality, i.e., to adaptively compose coordinate-wise point features and rectify uncertain anatomical regions. Specifically, we encode the sampled coordinate-wise point features into a continuous space, and then align position and features with respect to the continuous coordinate.
We further hinge on the idea of mixture-of-experts (MoE) to improve segmentation quality. Considering our goal is to rectify uncertain coarse predictions, we regard multi-scale representations from the decoder as experts. During training, experts are randomly activated for features from multiple blocks of the decoder, and correspondingly the INRs of multi-scale representations are separately parameterized by a group of MLPs that compose a spanning set of the target function class. In this way, the INRs are acquired across the multi-block structure while the stochastic experts are specified by the anatomical features at each block.
In summary, our main contributions are as follows: (1) We propose a new implicit neural rendering framework that has fine-grained control of segmentation quality by adaptively composing INRs (i.e., coordinate-wise point features) and rectifying uncertain anatomical regions; (2) We illustrate the advantage of adopting mixture-of-experts that endows the model with better specialization of features maps for improving the performance; (3) Extensive experiments show that our method consistently improves performance compared to 2D and 3D SOTA CNN- and Transformer-based approaches; and (4) Theoretical analysis verifies the expressiveness of our INR-based model. Code is released at here.
2. Method
Let us assume a supervised medical segmentation dataset , where each input is a collection of scans, and refers to the ground-truth labels. Given an input scan , the goal of medical segmentation is to predict a segmentation map . Fig. 1 illustrates the overview of our MORSE. In the following, we first describe our baseline model for standard supervised learning, and subsequently present our MORSE. A baseline segmentation model consists of two main components: (1) encoder module, which generates the multi-scale feature maps such that the model is capable of modeling multi-scale local contexts, and (2) decoder module that makes a prediction using the generated multi-block features of different resolution. The entire model is trained end-to-end using the supervised segmentation loss [35] (i.e., equal combination of cross-entropy loss and dice loss).
Fig. 1.
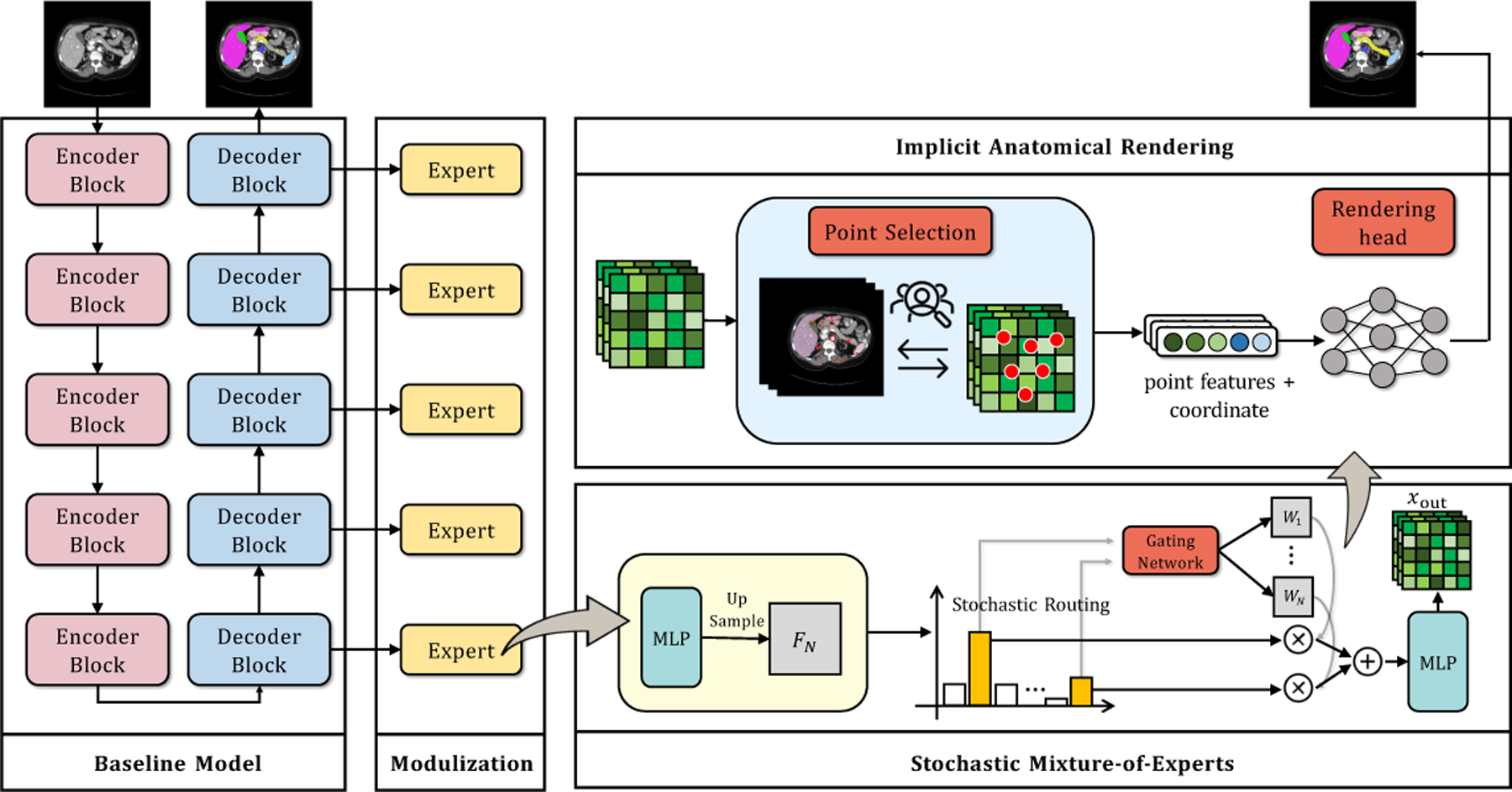
Illustration of the MORSE pipeline.
2.1. Stochastic Mixture-of-Experts (SMoE) Module
Motivation
We want a module that encourages inter- and intra-associations across multi-block features. Intuitively, multi-block features should be specified by anatomical features across each block. We posit that due to the specialization-favored nature of MoE, the model will benefit from explicit use of its own anatomical features at each block by learning multi-scale anatomical contexts with adaptively selected experts. In implementation, our SMoE module follows an MoE design [21], where it treats features from multiple blocks of the decoder as experts. To mitigate potential overfitting and enable parameter-efficient property, we further randomly activate experts for each input during training. Our approach makes three major departures compared to [21] (i.e., SOTA segmention model): (1) implicitly optimized during training since it greatly trims down the training cost and the model scale; (2) using features from the decoder instead of the encoder tailored for our refinement goal; and (3) empirically showing that “self-slimmable” attribute delivers sufficiently exploited expressiveness of the model.
Modulization
We first use multiple small MLPs with the same size to process different block features and then up-sample the features to the size of the input scans, i.e., . With as the total number of layers (experts) in the decoder, we treat these upsampled features as expert features. We then train a gating network to re-weight the features from activated experts with the trainable weight matrices , where . Specifically, the gating network or router outputs these weight matrices satisfying using a structure depicted as follows:
| (1) |
The gating network first concatenates all the expert features along channels and uses several convolutional layers to get , where is the channel dimension. A softmax layer is applied over the last dimension (i.e., -expert) to output the final weight maps. After that, we feed the resultant output to another MLP to fuse multi-block expert features. Finally, the resultant output (i.e. the coarse feature) is given as follows:
| (2) |
where ⋅ denotes the pixel-wise multiplication, and .
Stochastic Routing
The prior MoE-based model [21] are densely activated. That is, a model needs to access all its parameters to process all inputs. One drawback of such design often comes at the prohibitive training cost. Moreover, the large model size suffers from the representation collapse issue [26], further limiting the model’s performance. Our proposed SMoE considers randomly activated expert sub-networks to address the issues. In implementation, we simply apply standard dropout to multiple experts with a dropping probability . For each training iteration, there are dropout masks placed on experts with the probability . That is, the omission of experts follows a Bernoulli distribution. As for inference, there is no dropout mask and all experts are activated.
2.2. Implicit Anatomical Rendering (IAR)
The existing methods generally assume that the semantically correlated information and fine anatomical details have been captured and can be used to obtain high-quality segmentation quality. However, CNNs inherently operate the discrete signals in a grid of pixels or voxels, which naturally blur the high-frequency anatomical regions, i.e., boundary regions. To address such issues, INRs in computer graphics are often used to replace standard discrete representations with continuous functions parameterized by MLPs [28,27]. Our key motivation is that the task of medical segmentation is often framed as a rendering problem that applies implicit neural functions to continuous shape/object/scene representations [22,27]. Inspired by this, we propose an implicit neural rendering framework to further improve segmentation quality, i.e., to adaptively compose coordinate-wise point features and rectify uncertain anatomical regions.
Point Selection
Given a coarse segmentation map, the rendering head aims at rectifying the uncertain boundary regions. A point selection mechanism is thus required to filter out those pixels where the rendering can achieve maximum segmentation quality improvement. Besides, point selection can significantly reduce computational cost compared to blindly rendering all boundary pixels. Therefore, our MORSE selects points for refinement given the coarse segmentation map using an uncertainty-based criterion. Specifically, MORSE first uniformly randomly samples candidates from all pixels where the hyper-parameter , following [9]. Then, based on the coarse segmentation map, MORSE chooses pixels with the highest uncertainty from these candidates, where . The uncertainty for a pixel is defined as SecondLargest , where is the logit vector of that pixel such that the coarse segmentation is given as . The rest pixels are sampled uniformly from all the remaining pixels. This mechanism ensures the selected points contain a large portion of points with uncertain segmentation which require refinement.
Positional Encoding
It is well-known that neural networks can be cast as universal function approximators, but they are inferior to high-frequency signals due to their limited learning power [23,18]. Unlike [9], we explore using the encoded positional information to capture high-frequency signals, which echoes our theoretical findings in Appendix A. Specifically, for a coordinate-based point , the positional encoding function is given as:
| (3) |
where and are the standardized coordinates with values in between [–1, 1]. The frequency are trainable parameters with Gaussian random initialization, where we set [3]. For each selected point, its position encoding will then be concatenated with the coarse features of that point (i.e., defined in Sec. 2.1), to output the fine-grained features.
Rendering Head
The fine-grained features are then fed to the rendering head whose goal is to rectify the uncertain predictions with respect to these selected points. Inspired by [9], the rendering head adopts 3-layer MLPs design. Since the rendering head is designed to rectify the class label of the selected points, it is trained using the standard cross-entropy loss .
Adaptive Weight Adjustment
Instead of directly leveraging pre-trained weights, it is more desirable to train the model from scratch in an end-to-end way. For instance, we empirically observe that directly using coarse masks by pretrained weights to modify unclear anatomical regions might lead to suboptimal results (See Sec. 3.1). Thus, we propose to modify the importance of as:
| (4) |
where is the index of the iteration, denotes the total number of iterations, and denotes the indicator function.
Training Objective
As such, the model is trained in an end-to-end manner using total loss .
3. Experiments
Dataset
We evaluate the models on two important medical segmentation tasks.
Synapse multi-organ segmentation1: Synapse multi-organ segmentation dataset contains 30 abdominal CT scans with 3779 axial contrast-enhanced abdominal clinical CT images in total. Each volume scan has variable volume sizes 512 × 512 × 85~512 × 512 × 198 with a voxel spatial resolution of ([0.54~0.54] × [0.98~0.98] × [2.5~5.0])mm3. For a fair comparison, the data split2 is fixed with 18 (2211 axial slices) and 12 patients’ scans for training and testing, respectively. The entire dataset has a high diversity of aorta, gallbladder, spleen, left kidney, right kidney, liver, pancreas, spleen, and stomach.
Liver segmentation: Multi-phasic MRI (MP-MRI) dataset is an in-house dataset including 20 patients, each including T1 weighted DCE-MRI images at three-time phases (i.e., pre-contrast, arterial, and venous). Here, our evaluation is conducted via 5-fold cross-validation on the 60 scans. For each fold, the training and testing data includes 48 and 12 cases, respectively.
Implementation Details
We use AdamW optimizer [17] with an initial learning rate , and adopt a polynomial-decay learning rate schedule for both datasets. We train each model for 30K iterations. For Synapse, we adopt the input resolution as 256×256 and the batch size is 4. For MP-MRI, we randomly crop 96×96×96 patches and the batch size is 2. For SMoE, following [21], all the MLPs have hidden dimensions [256, 256] with ReLU activations, the dimension of expert features are 256. We empirically set as 0.7. Following [9], is set as 2048, and 8192 for training and testing, respectively, and are 3, 0.75. We follow the same gating network design [21], which includes four 3 × 3 convolutional layers with channels [256, 256, 256, ] and ReLU activations. are set to 0.1. We adopt four representative models, including UNet [25], TransUnet [2], 3D-UNet [4], UNETR [5]. Specifically, we set for UNet [25], TransUnet [2], 3D-UNet [4], UNETR [5] with 5, 3, 3, 3, respectively. We also use Dice coefficient (DSC), Jaccard, 95% Hausdorff Distance (95HD), and Average Surface Distance (ASD) to evaluate 3D results. We conduct all experiments in the same environments with fixed random seeds (Hardware: Single NVIDIA RTX A6000 GPU; Software: PyTorch 1.12.1+cu116, and Python 3.9.7).
3.1. Comparison with State-of-the-Art Methods
We adopt classical CNN- and transformer-based models, i.e., 2D-based {UNet [25], TransUnet [2]} and 3D-based {3D-UNet [4], UNETR [5]}, and train them on {2D Synapse, 3D MP-MRI} in an end-to-end manner3.
Main Results
The results for 2D synapse multi-organ segmentation and 3D liver segmentation are shown in Tables 1 and 2, respectively. The following observations can be drawn: (1) Our MORSE demonstrates superior performance compared to all other training algorithms. Specifically, Compared to UNet, TransUnet, 3D-UNet, and UNETR baselines, our MORSE with all experts selected obtains 3.36%~6.48% improvements in Dice across two segmentation tasks. It validates the superiority of our proposed MORSE. (2) The stochastic routing policy shows consistent performance benefits across all four network backbones on 2D and 3D settings. Specifically, we can observe that our SMoE framework improves all the baselines, which is within expectation since our model is implicitly “optimized” given evolved features. (3) As is shown, we can observe that IAR consistently outperforms PointRend across all the baselines (i.e., UNet, TransUnet, 3D-UNet, and UNETR) and obtain {1.59%, 1.07%, 2.03%, 1.14%} performance boosts on two segmentation tasks, highlighting the effectiveness of our proposal in INRs. (4) With Implicit PointRend [3] equipped, all the models’ performances drop. We find: adding Implicit PointRend leads to significant performance drops of −2.78%, −5.57%, −1.18%, and −1.23% improvements, compared with the SOTA baselines (i.e., UNet, TransUnet, 3D-UNet, and UNETR) on two segmentation tasks, respectively. Importantly, we find that: [3] utilizes INRs for producing different parameters of the point head for each object with point-level supervision. As this implicit function does not directly optimize the anatomical regions, we attribute this drop to the introduction of additional noise during training, which leads to the representation collapse. This further verifies the effectiveness of our proposed IAR. In Appendix Figs. 2 and 3, we provide visual comparisons from various models. We can observe that MORSE yields sharper and more accurate boundary predictions compared to all the other training algorithms.
Table 1.
Quantitative comparisons for multi-organ segmentation on the Synapse multiorgan CT dataset. The best results are indicated in bold.
| Method | Average | Aorta Gallbladder | Kidney (L) | Kidney (R) | Liver | Pancreas | Spleen | Stomach | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DSC ↑ | Jaccard ↑ | 95HD ↓ | ASD ↓ | |||||||||
| UNet (Baseline) [25] | 70.11 | 59.39 | 44.69 | 14.41 | 84.00 | 56.70 | 72.41 | 62.64 | 86.98 | 48.73 | 81.48 | 67.96 |
| + PointRend [9] | 71.52 | 61.34 | 43.19 | 13.70 | 85.74 | 57.14 | 75.42 | 63.27 | 87.32 | 50.16 | 81.82 | 71.29 |
| + Implicit PointRend [3] | 67.33 | 59.73 | 52.44 | 22.15 | 76.32 | 51.99 | 70.28 | 70.36 | 81.69 | 43.77 | 77.18 | 67.05 |
| + Ours (MoE) | 72.83 | 62.64 | 40.44 | 13.15 | 86.11 | 59.51 | 75.81 | 67.10 | 87.82 | 52.11 | 83.48 | 70.86 |
| + Ours (SMoE) | 74.86 | 64.94 | 37.69 | 12.66 | 86.39 | 63.99 | 77.96 | 68.93 | 88.88 | 53.62 | 86.12 | 72.98 |
| + Ours (IAR) | 73.11 | 62.98 | 34.01 | 12.67 | 86.28 | 60.25 | 76.58 | 65.34 | 88.32 | 52.12 | 83.47 | 72.51 |
| + Ours (IAR+MoE) | 75.37 | 65.65 | 33.34 | 11.43 | 87.00 | 64.45 | 78.14 | 70.13 | 89.32 | 52.33 | 85.20 | 76.40 |
| + Ours (MORSE) | 76.59 | 66.97 | 32.00 | 10.67 | 87.28 | 64.73 | 80.58 | 71.87 | 90.04 | 54.60 | 86.67 | 76.93 |
| TransUnet (Baseline) [2] | 77.49 | 64.78 | 31.69 | 8.46 | 87.23 | 63.13 | 81.87 | 77.02 | 94.08 | 55.86 | 85.08 | 75.62 |
| + PointRend [9] | 78.30 | 65.88 | 34.17 | 8.62 | 87.93 | 63.96 | 83.47 | 77.23 | 94.86 | 56.45 | 85.76 | 76.75 |
| + Implicit PointRend [3] | 71.92 | 60.62 | 41.42 | 18.55 | 78.39 | 61.64 | 79.59 | 73.20 | 89.61 | 50.01 | 80.17 | 62.75 |
| + Ours (MoE) | 77.85 | 65.30 | 32.75 | 7.90 | 87.40 | 63.46 | 82.34 | 77.88 | 94.14 | 56.12 | 85.24 | 76.25 |
| + Ours (SMoE) | 78.68 | 65.98 | 31.86 | 7.00 | 87.60 | 66.21 | 82.62 | 78.12 | 94.88 | 57.59 | 85.97 | 76.48 |
| + Ours (IAR) | 79.37 | 66.50 | 30.13 | 7.25 | 88.63 | 66.76 | 83.70 | 79.50 | 95.26 | 57.10 | 86.90 | 77.10 |
| + Ours (IAR+MoE) | 79.60 | 66.99 | 27.59 | 6.54 | 88.73 | 66.83 | 83.85 | 80.19 | 95.98 | 57.12 | 86.92 | 77.21 |
| + Ours (MORSE) | 80.85 | 68.53 | 26.61 | 6.46 | 88.92 | 67.53 | 84.83 | 81.68 | 96.83 | 59.70 | 87.73 | 79.58 |
Table 2.
Quantitative comparisons for liver segmentation on the Multi-phasic MRI dataset. The best results are indicated in bold.
| Method | Average | Method | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|
| DSC ↑ | Jaccard ↑ | 95HD ↓ | ASD ↓ | DSC ↑ | Jaccard ↑ | 95HD ↓ | ASD ↓ | ||
| 3D-UNet (Baseline) [4] | 89.19 | 81.21 | 34.97 | 10.63 | UNETR (Baseline) [5] | 89.95 | 82.17 | 24.64 | 6.04 |
| + PointRend [9] | 89.55 | 81.80 | 30.88 | 10.12 | + PointRend [9] | 90.49 | 82.36 | 21.06 | 5.59 |
| + Implicit PointRend [3] | 88.01 | 79.83 | 37.55 | 12.86 | + Implicit PointRend [3] | 88.72 | 80.18 | 26.63 | 10.58 |
| + Ours (MoE) | 89.81 | 82.06 | 29.96 | 10.15 | + Ours (MoE) | 90.70 | 82.80 | 15.31 | 5.93 |
| + Ours (SMoE) | 90.16 | 82.28 | 28.36 | 9.79 | + Ours (SMoE) | 91.02 | 83.29 | 15.12 | 5.64 |
| + Ours (IAR) | 91.22 | 83.30 | 27.84 | 8.89 | + Ours (IAR) | 91.63 | 83.83 | 14.25 | 4.99 |
| + Ours (IAR+MoE) | 92.77 | 83.94 | 26.57 | 7.51 | + Ours (IAR+MoE) | 93.01 | 84.70 | 13.29 | 4.84 |
| + Ours (MORSE) | 93.59 | 84.62 | 19.61 | 6.57 | + Ours (MORSE) | 93.85 | 85.53 | 12.33 | 4.38 |
Visualization of IAR Modules
To better understand the IAR module, we visualize the point features on the coarse prediction and refined prediction after the IAR module in Appendix Fig. 4. As is shown, we can see that IAR help rectify the uncertain anatomical regions for improving segmentation quality.
3.2. Ablation Study
We first investigate our MORSE equipped with UNet by varying (i.e., stochastic rate) and (i.e., experts) on Synapse. The comparison results of and are reported in Table 3. We find that using performs the best when the expert capacity is . Similarly, when reducing the expert number, the performance also drops considerably. This shows our hyperparameter settings are optimal.
Table 3.
Effect of stochastic rate and expert number .
| DSC[%] ↑ | ASD[voxel] ↓ | N | DSC[%] ↑ | ASD[voxel] ↓ | |
|---|---|---|---|---|---|
| 0.1 | 75.41 | 11.96 | 1 (No MoE) | 75.11 | 11.67 |
| 0.2 | 75.68 | 11.99 | 2 | 75.63 | 11.49 |
| 0.5 | 76.06 | 10.43 | 3 | 75.82 | 11.34 |
| 0.7 | 76.59 | 10.67 | 4 | 76.16 | 11.06 |
| 0.9 | 74.16 | 11.32 | 5 | 76.59 | 10.67 |
Moreover, we conduct experiments to study the importance of Adaptive Weight Adjustment (AWA). We see that: (1) Disabling AWA and training from scratch causes unsatisfied performance, as echoed in [9]. (2) Introducing AWA shows a consistent advantage compared to the other. This demonstrates the importance of the Adaptive Weight Adjustment.
4. Conclusion
In this paper, we proposed MORSE, a new implicit neural rendering framework that has fine-grained control of segmentation quality by adaptively composing coordinate-wise point features and rectifying uncertain anatomical regions. We also demonstrate the advantage of leveraging mixture-of-experts that enables the model with better specialization of features maps for improving the performance. Extensive empirical studies across various network backbones and datasets, consistently show the effectiveness of the proposed MORSE. Theoretical analysis further uncovers the expressiveness of our INR-based model.
Supplementary Material
Table 4.
Ablation studies of the Adaptive Weight Adjustment (AWA).
| Method | DSC[%] ↑ | ASD[voxel] ↓ |
|---|---|---|
| w/o AWA & train w/ from scratch | 70.56 | 14.89 |
| w/o AWA & train w/ in | 75.42 | 12.00 |
| w/ AWA | 76.59 | 10.67 |
Footnotes
All comparison experiments are using their released code.
References
- 1.Chen C, Qin C, Qiu H, Ouyang C, Wang S, Chen L, Tarroni G, Bai W, Rueckert D: Realistic adversarial data augmentation for mr image segmentation. In: MICCAI; (2020) [DOI] [PubMed] [Google Scholar]
- 2.Chen J, Lu Y, Yu Q, Luo X, Adeli E, Wang Y, Lu L, Yuille AL, Zhou Y: Transunet: Transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:2102.04306 (2021) [Google Scholar]
- 3.Cheng B, Parkhi O, Kirillov A: Pointly-supervised instance segmentation. In: CVPR; (2022) [Google Scholar]
- 4.Çiçek Ö, Abdulkadir A, Lienkamp SS, Brox T, Ronneberger O: 3d u-net: learning dense volumetric segmentation from sparse annotation. In: MICCAI; (2016) [Google Scholar]
- 5.Hatamizadeh A, Tang Y, Nath V, Yang D, Myronenko A, Landman B, Roth H, Xu D: Unetr: Transformers for 3d medical image segmentation. In: WACV; (2022) [Google Scholar]
- 6.He Y, Lin F, Tzeng NF, et al. : Interpretable minority synthesis for imbalanced classification. In: IJCAI; (2021) [Google Scholar]
- 7.Huang R, Lin M, Dou H, Lin Z, Ying Q, Jia X, Xu W, Mei Z, Yang X, Dong Y, et al. : Boundary-rendering network for breast lesion segmentation in ultrasound images. Medical Image Analysis (2022) [DOI] [PubMed] [Google Scholar]
- 8.Jacot A, Gabriel F, Hongler C: Neural tangent kernel: Convergence and generalization in neural networks. Advances in neural information processing systems 31 (2018) [Google Scholar]
- 9.Kirillov A, Wu Y, He K, Girshick R: Pointrend: Image segmentation as rendering. In: CVPR; (2020) [Google Scholar]
- 10.Lai Z, Oliveira LC, Guo R, Xu W, Hu Z, Mifflin K, Decarli C, Cheung SC, Chuah CN, Dugger BN: Brainsec: Automated brain tissue segmentation pipeline for scalable neuropathological analysis. IEEE; Access (2022) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lai Z, Wang C, Cheung S.c., Chuah CN: Sar: Self-adaptive refinement on pseudo labels for multiclass-imbalanced semi-supervised learning. In: CVPR. pp. 4091–4100 (2022) [Google Scholar]
- 12.Lai Z, Wang C, Gunawan H, Cheung SCS, Chuah CN: Smoothed adaptive weighting for imbalanced semi-supervised learning: Improve reliability against unknown distribution data. In: ICML. pp. 11828–11843 (2022) [Google Scholar]
- 13.Lai Z, Wang C, Hu Z, Dugger BN, Cheung SC, Chuah CN: A semi-supervised learning for segmentation of gigapixel histopathology images from brain tissues. In: EMBC. IEEE; (2021) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Lai Z, Wang C, Oliveira LC, Dugger BN, Cheung SC, Chuah CN: Joint semi-supervised and active learning for segmentation of gigapixel pathology images with cost-effective labeling. In: ICCV; (2021) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Li H, Yang X, Liang J, Shi W, Chen C, Dou H, Li R, Gao R, Zhou G, Fang J, et al. : Contrastive rendering for ultrasound image segmentation. In: MICCAI. Springer; (2020) [Google Scholar]
- 16.Lin F, Yuan X, Peng L, Tzeng NF: Cascade variational auto-encoder for hierarchical disentanglement. In: ACM CIKM; (2022) [Google Scholar]
- 17.Loshchilov I, Hutter F: Decoupled weight decay regularization. In: ICLR; (2019) [Google Scholar]
- 18.Mildenhall B, Srinivasan PP, Tancik M, Barron JT, Ramamoorthi R, Ng R: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM (2021) [Google Scholar]
- 19.Oktay O, Schlemper J, Folgoc LL, Lee M, Heinrich M, Misawa K, Mori K, McDonagh S, Hammerla NY, Kainz B, et al. : Attention u-net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999 (2018) [Google Scholar]
- 20.Oliveira LC, Lai Z, Siefkes HM, Chuah CN: Generalizable semi-supervised learning strategies for multiple learning tasks using 1-d biomedical signals. In: NeurIPS 2022 Workshop on Learning from Time Series for Health (2022) [Google Scholar]
- 21.Ou Y, Yuan Y, Huang X, Wong ST, Volpi J, Wang JZ, Wong K: Patcher: Patch transformers with mixture of experts for precise medical image segmentation. In: MICCAI. Springer; (2022) [Google Scholar]
- 22.Park JJ, Florence P, Straub J, Newcombe R, Lovegrove S: Deepsdf: Learning continuous signed distance functions for shape representation. In: CVPR; (2019) [Google Scholar]
- 23.Rahaman N, Baratin A, Arpit D, Draxler F, Lin M, Hamprecht F, Bengio Y, Courville A: On the spectral bias of neural networks. In: ICML. PMLR; (2019) [Google Scholar]
- 24.Rahimi A, Recht B: Random features for large-scale kernel machines. Advances in neural information processing systems 20 (2007) [Google Scholar]
- 25.Ronneberger O, Fischer P, Brox T: U-net: Convolutional networks for biomedical image segmentation. In: MICCAI; (2015) [Google Scholar]
- 26.Shazeer N, Mirhoseini A, Maziarz K, Davis A, Le Q, Hinton G, Dean J: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017) [Google Scholar]
- 27.Sitzmann V, Martel J, Bergman A, Lindell D, Wetzstein G: Implicit neural representations with periodic activation functions. In: NeurIPS; (2020) [Google Scholar]
- 28.Tancik M, Srinivasan P, Mildenhall B, Fridovich-Keil S, Raghavan N, Singhal U, Ramamoorthi R, Barron J, Ng R: Fourier features let networks learn high frequency functions in low dimensional domains. In: NeurIPS; (2020) [Google Scholar]
- 29.Xue Y, Xu T, Zhang H, Long LR, Huang X: Segan: Adversarial network with multi-scale 11 loss for medical image segmentation. Neuroinformatics (2018) [DOI] [PubMed] [Google Scholar]
- 30.You C, Dai W, Liu F, Su H, Zhang X, Staib L, Duncan JS: Mine your own anatomy: Revisiting medical image segmentation with extremely limited labels. arXiv preprint arXiv:2209.13476 (2022) [Google Scholar]
- 31.You C, Dai W, Min Y, Liu F, Zhang X, Clifton DA, Zhou SK, Staib LH, Duncan JS: Rethinking semi-supervised medical image segmentation: A variance-reduction perspective. arXiv preprint arXiv:2302.01735 (2023) [PMC free article] [PubMed] [Google Scholar]
- 32.You C, Dai W, Min Y, Staib L, Sekhon J, Duncan JS: Action++: Improving semi-supervised medical image segmentation with adaptive anatomical contrast. arXiv preprint arXiv:2304.02689 (2023) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.You C, Dai W, Staib L, Duncan JS: Bootstrapping semi-supervised medical image segmentation with anatomical-aware contrastive distillation. In: IPMI; (2023) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.You C, Yang J, Chapiro J, Duncan JS: Unsupervised wasserstein distance guided domain adaptation for 3d multi-domain liver segmentation. In: Interpretable and Annotation-Efficient Learning for Medical Image Computing (2020) [Google Scholar]
- 35.You C, Zhao R, Liu F, Chinchali S, Topcu U, Staib L, Duncan JS: Class-aware generative adversarial transformers for medical image segmentation. In: NeurIPS; (2022) [PMC free article] [PubMed] [Google Scholar]
- 36.You C, Zhao R, Staib LH, Duncan JS: Momentum contrastive voxel-wise representation learning for semi-supervised volumetric medical image segmentation. In: MICCAI; (2022) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.You C, Zhou Y, Zhao R, Staib L, Duncan JS: Simcvd: Simple contrastive voxel-wise representation distillation for semi-supervised medical image segmentation. IEEE Transactions on Medical Imaging (2022) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Zhou Z, Rahman Siddiquee MM, Tajbakhsh N, Liang J: Unet++: A nested u-net architecture for medical image segmentation. In: Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support (2018) [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.