

Abstract
Federated learning (FL)–a distributed machine learning that offers collaborative training of global models across multiple clients. FL has been considered for the design and development of many FL systems in various domains. Hence, we present a comprehensive survey and analysis of existing FL systems, drawing insights from more than 250 articles published in 2019-2024. Our review elucidates the functioning of FL systems, particularly in comparison with alternative distributed learning approaches. Considering the healthcare domain as an example, we define the building blocks of a typical FL healthcare system, including system architecture, federation scale, data partitioning, open-source frameworks, ML models, and aggregation algorithms. Furthermore, we identify and discuss key challenges associated with the design and implementation of FL systems within the healthcare sector while outlining the directions of future research. In general, through systematic categorization and analysis of existing FL systems, we offer insights to design efficient, accurate, and privacy-preserving healthcare applications using cutting-edge FL techniques.
Keywords: Federated learning, Aggregation algorithms, Data privacy, Data partitioning, Non-identically distributed data, Attacks
Graphical abstract

1. Introduction
In the present age of big data, artificial intelligence (AI) experts are keen on leveraging massive datasets for precise model training. Meanwhile, approaches capable of efficiently training models while preserving privacy are critical in domains such as healthcare, finance, defense, and Internet of Things (IoT) networks. In most industries, data are often scattered across various entities in isolated silos, primarily due to privacy concerns, security risks, business competition, and organizational complexities, limiting data sharing among organizations. However, machine learning (ML) models should be trained on aggregated data for optimal performance and impartiality. Traditionally, such aggregated data are centralized for training. However, privacy and security risks, single-center failures, and challenges in sharing massive amounts of data often limit the feasibility of such data centralization.
The healthcare sector has immense potential for AI applications, which shows considerable promise in revolutionizing patient care strategies and operational efficiency, as evidenced by the implementation of various tools, such as clinical decision support systems that leverage large amounts of pre-existing biomedical data to perform accurate diagnoses and create customized treatment plans [1], [2], [3]. However, current AI-based developments in the healthcare sector have yet to fully exploit their potential due to several barriers–including data availability–as highlighted in a recent report published by the US Government Accountability Office [4]. In particular, this report highlights the significant challenges associated with data access and curation, impeding research, data utilization, and progress in the healthcare sector. Stringent regulations restricting the sharing of biomedical data such as the EU's General Data Protection Regulation [5]. Even when good quality individual-level data is available, the process often involves lengthy applications mandating strict adherence to legal requirements for proper data usage and protection [6], [7], further limiting progress. In particular, Google has recently introduced FL [8], which allows users to leverage data without data centralization. This innovation ensures data privacy while enabling efficient, accurate and highly secure ML training, demonstrating immense potential for revolutionizing healthcare practices.
FL- also known as collaborative learning-is a technique of constructing high-quality, robust ML models via approaches involving data distribution across multiple clients instead of data storage on a single centralized server. Within this framework, independent clients develop local ML models using private data and store these models on a central server. These individual local models are further aggregated to create a new global model, which is subsequently shared with individual clients for further refinement (Fig. 1).
Fig. 1.

Different steps in the FL Framework for one iteration (Local models are represented in gray boxes near the clients and the global model is displayed next to the server).
Fig. 1 shows the primary components of an FL system, including a server, a communication computation framework, and a set of clients. Let us assume a scenario involving N clients (, , ..., ) each holding private data (, ,..., , respectively) with the aim of collectively training the model without sharing their respective data. FL facilitates such model training, where data from individual clients are collaboratively processed to train model without requiring direct sharing of data among them (i ϵ ). During this process, the server first selects an initial global model and shares this with all clients. The clients then train their local models using private data and relay it back to the server. Subsequently, the server aggregates the received models and updates the global model on the basis of the derived result. Finally, the server shares the global model with all clients. This iterative process continues until the model converges or a termination condition is satisfied.
The application of FL to biomedical and health data ensures the privacy of patients and healthcare providers, including hospitals. This technique enables data holders–such as hospitals or patients with medical data stored on their smartphones-to collectively analyze raw data without sharing it. In such a scenario, explicit sharing of collaborative models instead of local models specific to individual healthcare providers helps enforce privacy guarantees. However, this practice could have negative implications, including loss of information on in-hospital-acquired bacteria. In particular, the application of FL in medicine extends to the prediction of mortality rates, durations of hospital stay, durations of intensive care unit (ICU) stay, and identification of clinically similar patients with respect to their electronic health records (EHR). Furthermore, FL can facilitate brain tumor detection and whole brain segmentation in magnetic resonance imaging (MRI). Furthermore, FL applications can offer promising solutions to address pandemic situations [3], [9], [10], [11] and advance academic research in cancer and tumor treatments, mammograms, and genetic disorders [12]. ML FL models are reported to outperform those trained on a single datapoint, while also being more generalizable [4].
Healthcare presents unique and pressing challenges that make it an ideal but complex domain for FL. Patient data is often fragmented between multiple institutions, each with different electronic health record (EHR) systems, formats, and sampling protocols, leading to extreme data heterogeneity. Additionally, regulatory constraints such as the Health Insurance Portability and Accountability Act (HIPAA) in the US and the General Data Protection Regulation (GDPR) in the EU severely limit direct data sharing between hospitals, making traditional centralized machine learning approaches infeasible. The need for decentralized, privacy-preserving learning solutions is further amplified by the sensitivity of healthcare data and the critical consequences of model mispredictions. FL offers a promising solution by enabling collaborative model training without transferring raw patient data, but its deployment in healthcare is far from straightforward, requiring adaptation to clinical workflows, trust models, and compliance frameworks. Table 1 describes the significance statement, which summarizes the key motivations, contributions, and implications of this survey in the context of FL for healthcare.
Table 1.
Statement of Significance Table.
| Aspect | Description |
|---|---|
| Study Focus | A comprehensive review and analysis of FL systems with a focus on healthcare applications. |
| Innovation | Synthesizes insights from over 250 publications (2019-2024), providing a systematic categorization of FL systems. |
| Healthcare Relevance | Identifies the building blocks of FL systems tailored for healthcare, addressing privacy and data distribution challenges. |
| Key Contributions | - Comparative evaluation of FL with alternative distributed learning approaches. - In-depth discussion of federation scale, data partitioning, aggregation algorithms, and open-source frameworks. - Recommendations for future research in privacy-preserving and efficient FL systems. |
| Impact on Field | Serves as a resource for researchers and practitioners, guiding the design of robust FL systems for privacy-preserving healthcare applications. |
| Future Directions | Outlines challenges and opportunities, including addressing non-identical data distributions, system scalability, and robust privacy mechanisms. |
Recent developments in brain data analytics have been largely focused on integrating brain computer interfaces (BCI), neuromodulation, and FL to create secure, efficient, and personalized neurotechnological systems for treating neurological disorders or enhancing cognitive functions [13], [14]. BCIs, which facilitate direct communication between the brain and external devices, and neuromodulation, which can change neural activity occurring in the brain by directly stimulating it for therapeutic purposes, generate voluminous amounts of sensitive data. This requires robust data privacy, security, and computational scalability, and decentralized processing methods. Federated learning addresses these challenges by allowing machine learning models to be trained across many decentralized devices without sharing raw data, respecting user privacy and data protection regulations. This promising solution enables decentralized model training across multiple edge devices or institutions without requiring sensitive data to be shared. By keeping brain data local while sharing model updates, FL ensures privacy preservation and regulatory compliance, particularly important in clinical applications. In addition, FL allows for continuous personalized model refinement in real-time BCI applications and adaptive neuromodulation, fostering more accurate, responsive, and ethically aligned neurotechnological systems. Research studies show how FL can mitigate data heterogeneity and improve EEG-based classification tasks [15], [16]. In addition, the Augmented Robustness Ensemble algorithm incorporates privacy-protection techniques into BCI decoding, and security and performance are enhanced. Researchers confirm that FL can be on par with or even better than centralized models in the classification of emotions and motor imagery even under non-IID data conditions [17], [18]. Moreover, it has been illustrated that subject-adaptive FL methods achieve better classification results while maintaining serious data privacy [19]. Finally, some papers highlighted the imperativeness of federated techniques in the construction of strong and safe neurotechnologies based on ethics [20]. Overall, these efforts represent a promising way toward large-scale, privacy-conscientious brain data analytics and enabling real-time, personalized neuromodulation, and BCI applications.
The rest of the paper is organized as follows. Section 2 explains the research methodology used to select and analyze relevant studies. Section 3 reviews the related literature. Section 4 outlines the core components of FL-based healthcare systems. Section 5 discusses key challenges and open problems. Section 6 explores FL applications in healthcare and the underlying ML models. Finally, Section 7 summarizes the findings and outlines future directions.
2. Research methodology
2.1. Gathering data and strategic insights
For data collection, literature research was conducted in multiple databases-including Scopus, IEEE Xplore, JMIR, PubMed and Web of Science-targeting materials published from January 2017 to January 2024. This search used the keyword combinations of “federated learning” and “health *” to identify articles published from January 2020 to January 2024 in the selected databases. This strategy ensured a comprehensive collection of relevant scholarly articles. To efficiently extract essential information and minimize selection biases, we predominantly relied on abstract analysis to facilitate an objective evaluation of content related to our research topic.
2.2. Inclusion and exclusion criteria
Notably, we primarily focused on FL applications within healthcare settings, exploring specific ways through which FL can foster data privacy and collaboration without the need to centralize sensitive information. To ensure focus, articles introducing new FL techniques not explicitly designed for health-related applications were excluded, regardless of their potential relevance to general FL advances. Furthermore, the inclusion criteria were stringent, including only peer-reviewed articles, books, and conference proceedings while excluding conference abstracts and commentaries.
2.3. Study selection
The selection process began with the collection of 2,284 records through comprehensive searches performed in the selected databases, including Scopus, IEEE, JMIR, PubMed, and Web of Science. Of these, 774 duplicate records were promptly excluded. The further selection of the remaining 1,510 records eliminated 1,246 records for several reasons, such as non-adherence to the FL principles, publishing dates before 2020, or lack of relevance to healthcare. Subsequently, 264 reports were sought for retrieval. Following diligent eligibility evaluations, all 264 reports were deemed appropriate for inclusion. However, further detailed evaluations resulted in the exclusion of 105 reports that focused on generalized FL application scenarios in healthcare. The remaining 159 studies were included in the review and comprised various studies, including 22 considering centralized and decentralized ML models, 31 involving aggregation algorithms, 25 related to healthcare privacy, and 65 assorted studies.
This selection process was meticulously executed to ensure the compliance with the inclusion criteria and maintain the integrity of the scoping review. Fig. 2 outlines the selection process for this study, while Table 2 compares existing FL-based healthcare surveys with the current survey.
Fig. 2.

Preferred Reporting Items for Systematic Reviews and Meta-Analyses 2024; flow diagram of the selection process.
Table 2.
Comparisons of existing FL-based healthcare surveys with our survey.
| Contribution | Healthcare |
Research gap identification | Possible Solutions identification | Research review scope | ||
|---|---|---|---|---|---|---|
| Taxonomy comparison (All) | Underlying ML model | Privacy concern | ||||
| [21] | x | x | ✓ | ✓ | x | 2019-2023 |
| [22] | x | x | ✓ | ✓ | ✓ | 2017-2022 |
| [23] | x | x | x | ✓ | x | 2021-2022 |
| [24] | x | x | x | ✓ | ✓ | 2020-2023 |
| [25] | x | x | x | ✓ | ✓ | 2018-2023 |
| [26] | x | x | x | ✓ | x | 2019-2023 |
| [27] | x | x | ✓ | ✓ | x | 2017-2021 |
| [28] | x | x | ✓ | ✓ | ✓ | 2021-2023 |
| [29] | x | x | ✓ | ✓ | x | 2019-2022 |
| [30] | x | x | ✓ | ✓ | x | 2017-2020 |
| [31] | x | x | ✓ | ✓ | x | 2018-2021 |
| [32] | x | ✓ | x | ✓ | ✓ | 2019-2022 |
| [33] | x | ✓ | x | ✓ | x | 2015-2021 |
| Our work | ✓ | ✓ | ✓ | ✓ | ✓ | 2019-2024 |
2.4. Critical analysis of existing FL surveys in healthcare
While several surveys (e.g. [21], [22], [23]) have addressed federated learning (FL) in general, most lack a focused analysis of its application in healthcare. For example, the survey by Yang et al. [21] provides a broad overview of FL techniques, but lacks relevance to healthcare and domain-specific implications. Similarly, the work in [22] provides good coverage of the timeline and scope of FL, but provides minimal discussion of privacy issues or healthcare-specific challenges. Technical overviews such as those of [24], [25] and [26] offer useful architectural insights, but do not identify clear research gaps or practical implementation challenges in clinical settings. Some works (e.g., [27], [28], [29]) attempt to identify research challenges and propose solutions but lack depth in evaluating model robustness, scalability, and data heterogeneity issues typical in healthcare. Although [32] and [33] incorporate healthcare perspectives, they do not deeply compare data partitioning effects or modern privacy risks in multi-institutional setups. In contrast, our work provides a comprehensive and healthcare-specific review of FL, offering critical analysis, a unified taxonomy, and identified gaps, thus contributing a meaningful direction for future research.
3. Related literature
With the exponential growth of data in the modern world, traditional data mining and research analysis tools have become impractical due to the challenges in managing and sharing massive datasets [12]. Consequently, distributed algorithms for multiinstitutional learning have been developed as viable alternatives (Fig. 3).
Fig. 3.

Different approaches for distributed multi-institutional learning).
Secure multiparty computation (SMC)– a related but relatively primitive concept-enables joint computations of arbitrary functions among distributed institutions or parties without necessarily sharing personal raw data or intermediate computation steps. In this approach, only the final output is shared with the participants. Although SMC algorithms guarantee data privacy and demonstrate high precision by transforming centralized algorithms into distributed ones using cryptographic concepts, their efficiency is often hindered by the use of many cryptographic tools and the requirements for extensive communication [34], [35].
Split Learning (SL)– is a technique for distributed ML that preserves data privacy while allowing multiple parties to collaborate on model development. Within the SL framework, each party owns a portion of the data and performs local computations before sharing a small portion of the results with a central server [36]. Subsequently, the server aggregates all results to generate a global model, which is further shared with all parties for further refinement of individual local models. Considering that SL algorithms only allow sharing of local computation results while preventing data transfers among parties, they provide an efficient means of maintaining the privacy of sensitive data while allowing multi-party collaborations for model development. Consequently, SL has emerged as a vital technique for distributed multi-institutional learning, enabling multiple institutions to collaborate on model construction using personal data without compromising data privacy.
Specifically, the SL process involves the following steps:
-
•
Initialization: Each party initializes a local model using personal data.
-
•
Forward pass: Each party executes a forward pass on their local data using a local model.
-
•
Communication: Each party transmits a small portion of its forward-pass results to the central server using secure communication protocols to ensure data privacy.
-
•
Aggregation: The server aggregates the results of each party, generating a global model.
-
•
Backward pass: The server transmits the global model to individual parties, and using this global model, individual parties perform backward passes on their local data to update their local models.
-
•
Iteration: The above mentioned process is iterated over a fixed number of turns until the desired level of accuracy is achieved.
Previous studies have demonstrated the effectiveness of SL algorithms in various ML tasks, including image classification and natural language processing. Furthermore, several open-source frameworks, including TensorFlow Federated and PySyft, have been developed for SL implementation.
Statistical Distributed Learning (SDL)– creates distributed algorithms to compute the statistical parameters of the data. Specifically, in the SDL process of big data, a common approach involves randomly splitting available data (along with observations) into multiple subsets, which independently execute the required computations. Subsequent aggregations of all such local computations yield the final results, limiting communication (and information sharing) to the final step, thereby notably mitigating complexities and generating simpler algorithms. Standard SDL algorithms prioritize the estimation of statistical parameters while minimizing communication between participating entities [37], [38], [39], without considering privacy concerns.
The FL approach– introduced in 2016–aimed to facilitate efficient model training among distributed clients without sharing personal raw data. Thus, FL is a distributed ML approach that enables multiple clients to train a global model while ensuring their data privacy under the coordination of a central server. Within FL, localized data train individual models, which are further transmitted to a server for aggregation. The resulting aggregated and updated model is then relayed to all participants, who generate the final learning model through refinements. This process can be compared with the integration of SDL with a focus on privacy considerations. Furthermore, unlike SMC, FL focuses on preserving the privacy of client raw data rather than the privacy of intermediate aggregated data.
Consequently, FL has emerged as a crucial technique for distributed multiinstitutional learning, enabling multiple institutions to collaborate on model construction using personal data without compromising data privacy. Compared to traditional centralized ML approaches, FL offers numerous advantages-including enhanced privacy, reduced communication overhead, and increased scalability [40].
In particular, our extensive survey provides detailed comparisons among various FL applications in the healthcare sector (Table 3). Furthermore, by addressing typical topics such as taxonomy, ML models, and privacy concerns, identifying research gaps, and suggesting new approaches, our survey sets itself apart from previous surveys within this field. In addition, it presents in-depth reviews of relevant literature published in 2019-2024 and summarizes the latest developments in FL applications. In addition, it emphasizes privacy concerns and sets benchmarks against previous surveys to highlight trends and innovation opportunities. Our comprehensive approach follows the evolution of the field and serves as a critical reference for ongoing research and future developments, positioning itself as a key resource for FL-based healthcare practices. We aim to dissect the taxonomies of various FL approaches (including those yet to be discussed in this paper) and to detail the building blocks guiding the design of FL-based healthcare systems. The results of our comprehensive survey are anticipated to guide researchers in choosing the appropriate components when designing federated ML systems. This paper also summarizes current challenges and future research directions to pave the way for a new era of FL solutions.
Table 3.
Comparisons of various methods for distributed multi-institutional learning.
| Approach | Computation | Communication | Data Heterogeneity | Privacy | Design Purpose |
|---|---|---|---|---|---|
| SDL | Distributed computation requirements | Low communication overhead, communication cost increases with the number of participating clients | Data is assumed to be independent and identically distributed across all parties | No privacy guarantees, but can be enhanced with additional methods | Efficient statistical model training |
| SL | Distributed computation and communication requirements, less than FL | Low communication overhead, communication cost increases with the number of participating clients | Able to handle data heterogeneity | High privacy guarantees | Privacy-preserving model training |
| SMC | Heavy use of cryptographic tools and significant communication requirements | High communication overhead, communication cost increases with the number of parties involved | Able to handle data heterogeneity | High privacy guarantees | Privacy-preserving computation without data sharing |
| FL | Distributed computation and communication requirements, less than SMC | Low communication overhead, communication cost increases with the number of participating clients | Aspires to deal with heterogeneous datasets | High privacy guarantees | Privacy-preserving model training |
4. Basic building blocks of FL-based healthcare systems
The key building blocks of an FL-based healthcare system include system architectures, data availability, data partitioning schemes, ML models, privacy techniques, aggregation algorithms, and available open source frameworks for FL system design [64], [65], [66], [67]. This section elaborates on each of these blocks, comparing and emphasizing their roles in supporting FL-based healthcare practices.
4.1. System architecture
Centralized and decentralized architectures represent primary FL system architectures.
-
•
In the centralized architecture, the central server shares an initial model with all clients, who subsequently compute local models using personal local data and relay these local models back to the central server for model aggregation, yielding a global model. The central server is entrusted with the execution of correct calculations, preserving the privacy of client data, and orchestrating the complete training process. Small reliable devices- such as mobile devices-often adopt a centralized architecture. However, the primary drawback of this architecture is the potential disruption of all client training processes in case of a central server failure.
-
•
In contrast, in the decentralized architecture, peer-to-peer communication among individual clients replaces communication with the central server, allowing each client to directly update the global parameters of the model, thereby minimizing the risk of a single-point failure. However, in this peer-to-peer communication approach, one client acts as a leader, initiating communication, establishing learning tasks, and aggregating and forwarding the summarized results to all other clients. Although organizations such as hospitals typically favor this architecture, the selection of reliable and available leaders can be challenging. Furthermore, in scenarios where the current leaders crash or are unavailable, the network needs a new leader out of the remaining clients.
Table 4 summarizes recent studies that adopt centralized and decentralized architectures. Typically, most healthcare applications adopt the centralized architecture.
Table 4.
Comparison of centralized and decentralized architecture and some of the recent applications.
| System Architecture | Advantages | Disadvantages | Applications | Ref. |
|---|---|---|---|---|
| Centralized |
Central server orchestrates the entire training process | Single point of failure | Healthcare-Hospital data | [41] |
| Healthcare-Hospital data | [42] | |||
| Healthcare-Clinical and hospital data | [43] | |||
| Simple compared to decentralized architecture | Healthcare-Clinical data | [44] | ||
| Healthcare-Covid 19 patients' data | [45] | |||
| Healthcare, Medical image data | [46] | |||
| IoT devices | [47] | |||
| Health data from wearable devices | [48] | |||
| Small reliable devices are generally use centralized architecture |
All clients are required to agree on one |
Cyber security-IoT and IIoT data | [49] | |
| Cyber security-IoT data | [50] | |||
| Networking-Intrusion detection dataset. | [51] | |||
| IoT devices-Electrical load data | [50] | |||
| Decentralized | Each client can directly update the global parameters of the model | Selecting a leader to initiate and aggregate the process is challenging. | Networking-sensor data | [52] |
| Public-social survey, census and sales data | [53] | |||
| Healthcare-hospital data | [54] | |||
| Reduces the risk of a single-point failure | Each client has its own behavior, it is hard to achieve collective tasks and global knowledge. | 5G enabled UAVs | [55] | |
| Vehicular network-Autonomous Driving Cars | [56] | |||
| Not suitable for small systems due to inefficient system management and performance | Medicine-drug discovery | [57] | ||
| Generally used by organizations | Vehicular network | [58] | ||
| Scaling and performance problems | Healthcare–X–ray images | [59] | ||
| Healthcare-clinical dataset | [60] | |||
| Healthcare-Cancer dataset | [61] | |||
| Cyber security | [62] | |||
| Anomaly detection-IoT data | [63] | |||
4.2. Data availability
Usually, within an FL-distributed data set framework, potential clients include organizations such as hospitals and banks or mobile and edge equipment, including wearable devices, routers, and integrated access devices. The “cross-silo” and “cross-device” architectures represent two primary design architectures for federation in FL systems. The cross-silo scheme typically involves some relatively reliable clients, while the cross-device scheme includes numerous clients. In the cross-silo approach, participating organizations, such as hospitals, collaborate to train a model using their private data, and each entity participates in all computation rounds [68], [69]. Meanwhile, the cross-device scheme involves multiple clients, each with their private data. All devices within this framework-including mobile and wearable devices-can be active or inactive at any timepoint, with device inactivity primarily resulting from several issues such as power loss or network concerns [70]. Within this scheme, clients are often active and participate in one round of computation. Consequently, a new set of active clients contributes their local data for model training in each round. In particular, both schemes execute model training without sharing individual private data. Table 5 compares the cross-silo and cross-device architectures. In general, cross-silo structures are widely adopted by organizations, while cross-device structures are used in mobile devices [65]. Furthermore, cross-silo structures demonstrate strong hardware capacities, better storage capabilities, and better performance than cross-device structures. Cross-silo structures typically deal with nonindependent and identically distributed (nonIID) data, with all clients being active participants. These architectures are powerful and have fewer failures, making them more stable than cross-device structures. However, cross-silo architectures are only scalable over a relatively small number of clients (approximately 2-100).
Table 5.
Comparison between FL schemes.
| Properties | Cross-Silo | Cross-Devices |
|---|---|---|
| Entities | Hospitals/ Organizations | Mobile/ IoT devices/ Wearable devices |
| Performance | High | Low |
| Scale | Relatively small [15] | Large |
| Stability | High stability [43] | Low stability |
| Communication reliability | Reliable – All clients participate in communication [14] | Unreliable – Communication of some clients may be lost during computation [15] |
| Number of clients | Typically, around 2-100 | Very large (millions) |
| Participation of clients for the computation | All clients in the communication should participate | Fraction of the clients only participates in the computation |
| Data distribution | Usually, non-IID | Usually, IID |
| Primary bottleneck | Computation/ communication | Communication. (Uses wi-fi or slower connections) [15] |
| Stateful/stateless | Clients are Stateful- They save the models of the previous round [16] | Clients are Stateless- do not save previous round information [16] |
| Reliability | Clients have comparatively few failures [43] | Clients are highly unreliable |
| Computation power | Entities often have high computation power | The only central server is assumed to have high computation power. |
4.3. Data partitioning in FL
Data partitioning in FL typically relies on the distribution of clients' data across the sample and attribute spaces. Notably, FL data partitioning schemes are categorized into horizontal, vertical, and federated transfer learning (FTL) data partitioning.
-
•
Horizontal data partitioning divides client datasets featuring the same attributes but different participants (the sample space). For instance, in a speech disorder-detection system, multiple users utter a given sentence (attribute space) into their smartphones with varying voices (sample space). Thereafter, local speech updates are averaged by a parameter server to generate a global speech recognition model [71]. Most FL-based medical applications adopt horizontal data partitioning [72], [73], [74], [75], [76], [77], [78], [79], [80], [81].
-
•
Vertical data partitioning divides client datasets featuring the same participants but varying attributes (with possible overlap). For instance, medical records maintained by hospitals-which can aid the decision-making efforts of insurance companies-and the records maintained by the insurance companies themselves may share patient details (same sample space) yet differ in their data fields (attribute space). The applications of vertical data partitioning in medicine are comparatively less widespread than those of horizontal data partitioning [82], [83], [84].
-
•
FTL data partitioning combines the horizontal and vertical partitioning approaches [82]. In other words, client datasets feature some overlap in the sample (participants) and attribute spaces, such as any collaborative disease diagnosis performed by hospitals worldwide (sample space) with varying features (attribute space), resulting in improved diagnosis accuracy [85], [86], [87]. However, research on FTL data partitioning is still in its nascent stages.
In horizontal and vertical FL data partitioning, the training data owned by various organizations must share identical attributes or sample spaces. In healthcare organizations where this is not feasible, the FTL partitioning scheme emerges as a viable alternative [85]. Table 6 summarizes the distinctions between these three data partitioning schemes.
Table 6.
Differences between the three data partitioning methods.
| Properties | Horizontal | Vertical | Federated Transfer |
|---|---|---|---|
| Advantage | Increases the total number of training samples, Improve accuracy | Increasing total feature dimension, Allows richer hypothesis building | Increases user samples and feature dimensions, Remedies the problem of inadequate data [88] |
| Methods | FedAvg [72], [8] | SecureBoost [89] | Transfer learning [67] |
| Application | IoT, Healthcare | Finance | Healthcare |
4.4. Machine-learning models
Theoretically, the FL framework can collaboratively train any ML model. However, in actual practice, FL applications have stringent requirements, presenting several challenges:
-
•
The complexity of the selected model must match the capacities of user devices. Although introducing surrogate parties can address this, they may compromise user privacy.
-
•
The availability, nature, and distribution of training data across clients must be considered during model selection.
Given the unavailability of a single model that is universally applicable across all datasets, selecting appropriate ML models is paramount. Supervised ML models commonly implemented in FL include linear models (LMs), tree models (TMs), and neural networks (NNs). However, unsupervised ML models include clustering approaches, the K-nearest neighbor (K-NN) algorithm, and principal component analysis (PCA).
There is no single model that works on every dataset. Therefore, selecting an appropriate ML model is very significant. The supervised ML models implemented in FL include linear models, tree models, and neural networks, while unsupervised ML models include clustering, K-NN, and PCA.
4.4.1. Linear models
LMs typically assume a linear relationship among two or more independent and dependent variables. These models include linear regression (LR) models [90], logistic regression models, ridge regression approaches, and support vector machines [65]. LMs are generally concise, straightforward, easy to implement, and robust [60]; hence, these approaches are extensively utilized for patient data (HER) prediction in FL. The stochastic gradient descent (SGD) algorithm-an efficient iterative optimization algorithm-is typically employed in FL for the implementation of ML models, including LMs. However, previous studies have implemented distributed linear regression without iterations [37].
4.4.2. Tree models
TMs facilitate easy training and feature smaller model dimensions than deep-learning models such as NNs. Decision trees (DTs) and the random forest algorithm represent the primary TMs commonly implemented in FL [91]. Among these, DTs often utilize gradient boosting decision trees (GBDTs) [89], which are adept at processing high-dimensional data and are commonly employed for decision-making applications, including those in clinical practices. However, in certain applications, GBDTs may suffer from inefficiency or low accuracy, hindering their practical applications [92], [53]. Recent FL studies have focused on improving the efficiency and accuracy of GBDTs [93], [94], [89], which are crucial for medical applications.
4.4.3. Advanced ML models: deep learning and unsupervised learning
FL in healthcare leverages both advanced deep learning models and unsupervised learning techniques to address diverse clinical data types and analytical needs. Deep learning models, such as convolutional and recurrent neural networks, are particularly effective for capturing complex, non-linear patterns in high-dimensional data like medical imaging and physiological time-series. At the same time, unsupervised models, including clustering and dimensionality reduction methods, are valuable in settings where labeled data is scarce or unavailable—facilitating tasks like patient stratification, anomaly detection, and exploratory analysis. This section presents an integrated overview of both model classes, highlighting their relevance, advantages, and limitations within FL-based healthcare systems.
Deep learning models
Neural Networks (NNs) are powerful models widely used in healthcare for capturing non-linear relationships in complex data. Applications span medical imaging, diagnostics, and time-series analysis [95], [96], [97]. However, their limited interpretability poses challenges in critical domains such as genomics and radiology [12].
In FL-based healthcare systems, CNNs are used for image analysis, RNNs and LSTMs for sequential data like ECGs, and MLPs for structured datasets. These models are typically trained using stochastic gradient descent (SGD), with global aggregation via algorithms such as FedAvg. Despite their effectiveness, training deep NNs in FL requires large datasets, high computational resources, and multiple communication rounds, making them costly and time-consuming.
However, training deep NNs in FL presents several computational and convergence challenges. Compared to linear models, NNs require substantially larger datasets to achieve generalizable performance. The training process becomes more resource-intensive as data volume, model depth, and the number of participating clients increase. Furthermore, in federated setups, NN training via SGD may demand numerous communication rounds for convergence, resulting in prolonged training times and higher energy costs. These limitations necessitate careful model selection and optimization in practical healthcare FL deployments. A comparative overview of ML models adopted in FL-based healthcare applications is provided in Table 7.
Table 7.
List of ML models used in FL medical applications.
| Work | Linear Models | DL models | Datasets |
Applications | |
|---|---|---|---|---|---|
| Name | Availability | ||||
| [37] | LR | - | Diabetic | Private | Prediction- length of stay in hospital |
| [50] | - | NN | eICU Collaborative research Database | Public | Mortality prediction |
| [42] | LoR | MLP | MIMIC-III | Public | In-hospital mortality prediction |
| [43] | SVM Perceptron LoR | - | LCED, MIMIC-III | Private, Public | Adversary drug reaction prediction, Mortality prediction |
| [45] | LoR | MLP | Covid-19 EHR | Private | Covid 19 patients' mortality prediction |
| [98] | SVM | ANN | MIMIC-III, i2b2 | Public | Patient representation, Phenotyping |
| [99] | LoR | NN | eICU Collaborative research Database | Public | Mortality prediction, Prolonged length of stay |
| [100] | - | RNN | Cerner Health Facts-HER database | Public | Preterm-birth prediction |
| [101] | - | CNN | Covid patient hospital data-Wuhan | Private | Pneumonia detection |
| [102] | LR, LoR | - | COPDGene, SHIP dataset | Public, Public | Genetic association |
| [48] | - | CNN, RNN | Health records from wearable devices | Public | Human activity prediction |
| [103] | - | CNN | Health data- X-ray, Ultrasound images | Private | Diagnosis of COVID-19 |
| [104] | LoR, SVM | - | INTERSPEECH 2020[82] | Public | Alzheimer's disease detection |
| [105] | - | MLP | MNIST, CIFAR10, CIFAR100 | Public | General |
| [60] | - | NN | BraTS, Clinical data | Public, Private | Cancer diagnosis |
| [46] | - | GNN | TCGA dataset[83] | Public | Histopathology |
Unsupervised models
Existing FL applications are predominantly based on supervised learning. However, unsupervised learning may prove beneficial in scenarios featuring either unlabeled data or data with limited labels. Examples of unsupervised learning methods frequently adopted in FL include clustering methods [69], PCA [106], and the K-NN classifier [107]. Notably, traditional centralized unsupervised learning methods face several limitations, especially regarding the protection of raw data and the computational burden associated with processing large-scale centralized datasets. Remarkably, FL clustering methods overcome these constraints, facilitating the handling of large datasets while preserving privacy [108]. ML models are promising for developing robust, accurate, and efficient FL-based healthcare systems. For instance, FL aids in predicting the rates of hospitalization because of cardiac events, tumors, cancer, and diabetes; rates of mortality; and durations of ICU stay. Furthermore, the benefits and application scope of FL extend to medical imaging, MRI-based whole brain segmentation, and brain tumor segmentation. The applicable ML model changes according to the dataset and prediction variables. Table 7 lists a few primary ML models employed in FL-based medical applications from 2019 to 2024.
4.4.4. Critical analysis of the performance of key FL algorithms in healthcare applications
Table 8 provides a comprehensive summary of performance metrics across a diverse range of FL algorithms applied in healthcare; however, certain limitations and conflicting observations merit deeper analysis. For instance, while the study by [48] reports an exceptionally high accuracy of 99.67% using FedAvg with BiLSTM+DRL, such results are uncommon in real-world cross-silo FL environments, raising questions about potential overfitting or limited dataset diversity. In contrast, other studies using FedAvg (e.g., [42], [43], and [45] consistently demonstrate modest accuracy and AUC values (e.g., 84% and 0.789 AUC), especially in the presence of DP, which typically introduces a trade-off between privacy and performance. The study by [43] using DP reports lower F1 scores (e.g., 0.820 for Perceptron) compared to non-private settings, reflecting a quantifiable privacy-utility trade-off. Moreover, several studies (e.g., [104], [111])) lack clear dataset size disclosure or data heterogeneity context, which limits the generalizability of reported metrics. Studies such as [109], [110]), which achieve 97% accuracy through added techniques like SMOTE and feature selection or EfficientNet architectures, may be difficult to reproduce in decentralized real-world hospital settings. These variations highlight not only algorithmic diversity but also a gap in standardized benchmarks and evaluation protocols across studies.
Table 8.
Performance Comparison of Key FL Algorithms in Healthcare Applications.
| Study | Aggregation Algorithm | ML/DL Model | Privacy Mechanism | Performance Metrics (Accuracy / AUC / Dice / F1) |
|---|---|---|---|---|
| [2] | Custom FedAvg | Neural Network | HE | Accuracy: 90% |
| [37] | SecureAvg | LoR | SMC | R2: 0.98 |
| [42] | FedAvg | LoR / MLP | FL | AUC: 0.7890 (LoR), 0.7769 (MLP) |
| [43] | FedAvg | LoR / SVM / Perceptron | FL + DP | F1 Score (MIMIC-III): 0.860 (LoR), 0.845 (SVM), 0.820 (Perceptron) |
| [45] | FedAvg | LoR / MLP | DP | Accuracy: 84% |
| [48] | FedAvg | BiLSTM + DRL (DL) | FL | Accuracy: 99.67% |
| AUC: 0.98, F1 Score: 98.92 | ||||
| [60] | FedAvg + CFA | U-Net (CNN-based) | FL | Dice Score: |
| 0.88 (Centralized), 0.85 (Decentralized) | ||||
| [79] | FSVRG | ANN / SVM (NLP) | Apache cTAKES (UIDs) | Accuracy: 81.5% |
| [100] | FUALA | RNN | FL | AU-ROC: 67.8 ± 2.7 |
| [103] | Clustered FL | VGG16 + FC layers | FL (edge-based) | F1 Score: |
| X-ray: 0.76 (COVID), 0.96 (Healthy) | ||||
| [104] | FedAvg + Secure Aggregation | LoR | FL + DP | Accuracy: 81.9% |
| [109] | FedAvg | DNN | FL with SMOTE + L1 Feature Selection | Accuracy: 97.54% |
| F1 Score: 97% | ||||
| [110] | FedAvg | EfficientNetB0 | FL + HE + DP | Accuracy: 98.60% |
| [111] | Weighted Avg | CNN | DP | Accuracy: 89% |
| [112] | FedAvg | CNN | Not Specified | Accuracy: 87% |
| [113] | FedAvg + LoRA | LLM (MobileBERT, MiniLM) | FL + LoRA (HIPAA, GDPR compliant) | F1 Score: 80.43 (BERT-base-uncasedFL) |
| MobileBERTFL: 67.11, MiniLMFL: 68.08 |
While deep learning and unsupervised models play vital roles in FL-based healthcare systems, their use introduces several practical limitations, particularly around training efficiency, communication cost, and system heterogeneity. Rather than elaborating on these challenges here, we provide a more detailed analysis of these issues-including convergence delays, client variability, and non-IID data-in Section 5.
4.5. Privacy techniques
FL facilitates collaborative model learning without necessitating raw data sharing. However, with continuous model updates throughout the training process, intermediate model parameters are shared among all clients, potentially leaking sensitive client data [114]. FL models adopt one of the four techniques- SMC, homomorphic encryption (HE) [115], differential privacy (DP) [116], and trusted execution environments (TEEs) [117]-to avoid privacy breaches.
4.5.1. Homomorphic encryption
HE is a cryptographic technique that enables the computation of encrypted data without data decryption. This approach facilitates data computations without requiring data exposure to unauthorized parties [118]. Considering distributed multi-institutional learning, HE allows multiple institutions to collaborate on ML model construction without sharing their raw data. Here, each institution can encrypt its data before transmitting it to the server for computation. Next, the server can perform computations on the encrypted data without retaining any related information. Subsequently, the generated model can be relayed to participating institutions for personalized applications [90], [119], [120].
-
•
Fully homomorphic encryption (FHE) enables operations on encrypted data without the need for decryption. Although FHE provides strong privacy, it is too slow for most practical uses.
-
•
Partially homomorphic encryption (PHE) supports the execution of one operation type on encrypted data-such as addition or multiplication-making it less powerful but more efficient than FHE.
-
•
Somewhat homomorphic encryption (SHE) allows the implementation of a limited set of operations on encrypted data -such as addition and multiplication -with some complexity restrictions. Therefore, SHE is less powerful than FHE but more efficient than PHE.
HE enables direct computation on encrypted data. For a ciphertext , the encryption scheme ensures:
where ∘ is an operation on ciphertexts and ⁎ is the corresponding plaintext operation. In FHE, both additions and multiplications are supported an arbitrary number of times. However, due to bootstrapping and ciphertext expansion, FHE is computationally infeasible for large models or real-time scenarios.
PHE schemes like Paillier (additive) and RSA (multiplicative) support a single operation (e.g., encrypted addition):
HE approaches have become critical in distributed multiinstitutional learning applications, where multiple institutions must collaborate on ML model construction without sharing individual raw data. As highlighted, the HE technique can encrypt data before data transmission to the server, which can perform computations on the data without accessing the plaintext. The generated encrypted model can then be transmitted to participating institutions that can decrypt and implement the model in personalized applications [121]. Popular HE libraries-including Microsoft SEAL [122], HElib [123], and Palisade [124]-can facilitate efficient and secure implementations of HE schemes in various applications, including multi-institutional learning.
4.5.2. Secure multiparty computation
SMC is a cryptographic tool that enables multiple parties to perform joint computations of the aggregated data set without sharing their raw data. SMC allows n parties to collaboratively compute a function on their private inputs without revealing them. One common approach is incremental secret sharing, where a value v is split into shares such that:
SMC employs various protocols, including secret sharing, oblivious transfer, and garbled circuits. Among these, in secret sharing, private data are divided into multiple encoded parts known as secret shares, which reveal no information regarding the original data. The minimum number of shares required to reveal the secret is identified as the threshold. During an oblivious transfer, another widely used cryptographic protocol-a sender-transmits one value out of several to a receiver, but retains no information regarding this value. Meanwhile, in Yao's garbled circuit protocol, multiple clients can jointly compute functions using garbled Boolean circuits on their sensitive data while preserving input privacy. Although SMC techniques are usually lossless and preserve accuracy while maintaining privacy, they incur significant communication overhead. Although SMC techniques have been used to preserve the privacy of intermediate model results in FL, their communication costs can be unrealistic, particularly in cross-device configurations, because FL requires multiple model updates until convergence [35], [125], [126], [127].
4.5.3. Differential privacy
DP is a privacy-enhancing technique that introduces random noise into query results, or, in our case, into model parameters. DP provides a mathematically rigorous privacy guarantee by ensuring that the output of a computation is statistically indistinguishable whether or not a specific individual's data are included. A random mechanism satisfies -DP if for all measurable subsets S of the output space and all datasets D and differ in at most one record:
In FL, the most commonly used method is DP-SGD, where each client clips the per-sample gradient to a fixed norm C, and Gaussian noise is added before averaging:
DP provides a tunable privacy-utility trade-off but introduces stochastic noise that can impair model convergence, especially in imbalanced or small medical datasets.
DP facilitates the sharing of statistical information regarding a dataset while protecting individual privacy. Furthermore, the introduction of noise ensures minimal changes in model parameters in the event of record removal [116]. Consequently, this approach ensures that no participant exerts a “detectable” influence on the generated model. Previous studies have implemented DP mechanisms in FL to prevent information leakage from intermediate and final model parameters. Furthermore, in these techniques, noise is typically introduced into the client-side local parameters before uploading them to the server for aggregation, potentially preventing privacy breaches. However, such noise additions can adversely affect the accuracies of local and global models, along with their convergence speeds. Furthermore, configuring DP parameters is often challenging [128], [129], but the DP approach is generally favored for its lower computation overhead compared to other privacy mechanisms [130], [131], [132].
4.5.4. Trusted execution environment -TEE
TEEs are hardware-based privacy-preserving approaches featuring separation kernels as their fundamental components. TEEs are isolated processing environments that facilitate secure data processing, without interference from other system components. TEEs create secure environments within central processors, offering robust privacy and integrity guarantees for stored or processed data and codes. In FL systems, TEEs are often employed on the client side for local training and on the server side for secure aggregation. However, TEEs typically incur high communication overhead and require remarkable storage capacities [117]. Furthermore, TEEs may experience substantial performance deterioration due to additional internal operations to ensure security. Moreover, TEEs are susceptible to hardware attacks that compromise the integrity of the underlying codes [133], [134].
Table 9 summarizes the privacy mechanisms commonly adopted in FL to enhance user privacy protection.
Table 9.
Various privacy protection mechanisms and their comparisons.
| Mechanism | Approach | Technique | Advantages | Disadvantages |
|---|---|---|---|---|
| Differential Privacy | Addition of random noise to shared parameters | Noise addition | Preserves privacy Low computation overhead Not vulnerable to inference from the final output (as the final output is protected by noise addition) | Accuracy loss from added random noise Privacy parameters are hard to set |
| Secure Multiparty Computation | Application of SMC protocols on shared parameters | Secret sharing, Oblivious Transfer, Garbled Circuit | Preserves privacy and accuracy | Computation overhead Communication complexity Vulnerable to inference from the final output |
| Homomorphic Encryption | Application of HE on shared parameters | Partial homomorphic encryption (Additive or multiplicative) | Preserves privacy Relatively small accuracy loss | Computation overhead Communication complexity Vulnerable to inference from the final output. |
| Trusted execution environments | Perform aggregation on secured Hardware | Separation kernel isolation method | Strong privacy and security. | Expensive Computational overhead Vulnerable to hardware attacks |
Tradeoff Between Privacy and Utility: While privacy-preserving techniques such as HE, SMC, and DP enhance data confidentiality, they often come with a trade-off in terms of utility-particularly model accuracy or training efficiency. For example, a stronger noise in DP improves privacy, but degrades accuracy. Similarly, while fully homomorphic encryption offers strong confidentiality, it significantly increases computational overhead.
Fig. 4 provides a clear visualization of the conceptual trade-off between privacy strength and model utility (e.g., accuracy or F1 score) for DP, HE, SMC, and TEE. The privacy strength is plotted on the x-axis (abstract scale from 1 to 10), while the corresponding model utility is shown on the y-axis as a percentage. Utility values are generated using hypothetical but representative mathematical functions that mimic trends reported in the literature. As the privacy level increases, DP shows a steep decline in utility due to excessive noise, whereas HE and SMC maintain moderate accuracy but suffer from computational overhead. TEE, on the other hand, preserves utility more effectively with only a slight linear drop, which represents a minimal impact on performance.
Fig. 4.
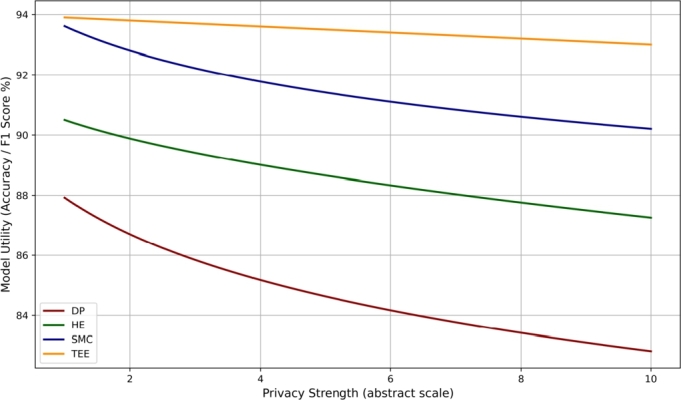
Trade-off Between Privacy Strength and Model Utility Graph.
4.6. Aggregation algorithms
LM and deep-learning model computations typically rely on optimization algorithms that are inherently sequential and require numerous iterations to converge to a local minimum of a function. Hence, despite being computationally efficient, these approaches require numerous training rounds to produce satisfactory models. GD and its variants-such as SGD variants, minibatch GD, and distributed GD-are most commonly employed as optimization algorithms in FL [135], [136], with the application of SGD prominent in local model computations.
Usually, in FL frameworks, aggregation algorithms are essential to integrate local model parameters derived from all clients at each iteration stage to generate a global model. Subsequently, the clients iterate through the learning process beginning with this new global model until an adequate model is obtained or a stopping criterion is reached. In particular, ideal aggregation algorithms are expected to (1) limit the number of iterations, thereby ensuring rapid convergence; (2) reduce the local computation duration per iteration on the client side; and (3) reduce communication overheads between clients and the server.
The FedAvg algorithm [8] is the first and most widely adopted aggregation algorithm in FL. Within its framework, a randomly selected subset of clients implements SGD on their local data to generate local model parameters, which are transmitted to the server for parameter averaging and subsequent global model generation. Subsequently, this process is repeated with the selection of a new random subset of clients. FedAvg [8] is the foundational aggregation algorithm for FL. In each communication round, a subset of clients performs local stochastic gradient descent (SGD) for multiple epochs and sends the resulting model weights to a central server. The server computes the global model w as a weighted average:
where is the number of data samples in client i and is the total number of samples in all selected clients. Although FedAvg is communication efficient, its convergence is hindered under non-IID data due to client drift and weight divergence.
Although FedAvg is the most popular aggregation algorithm, it may not always yield a suitable model in practical scenarios. In particular, when dealing with heterogeneous, unbalanced, and variable-distribution client data, FedAvg can adversely affect model aggregation, convergence, and accuracy, introducing communication burdens. Recent studies have attempted to improve the accuracy of FedAvg while reducing its computational overhead through modifications such as FedProx and FSVRG [137], [138], [139], [140], [141], [142], [143], [144], [145].
The FedAvg algorithm and its variants are predominantly adopted in FL horizontal data partitioning frameworks. FedProx [140] addresses the instability of FedAvg by modifying the local target with a proximal term that penalizes deviation from the global model . The local loss function on client i becomes:
where μ is a tunable regularization parameter. This term reduces local model divergence and improves robustness to data heterogeneity, making it better suited for healthcare applications where client data distributions can vary significantly. The frame [139] introduces control variates to mitigate the impact of client drift in non-IID settings. Each client maintains a local control variate and the server maintains a global control variate c. These are used to correct the update direction during local training:
where η is the learning rate. The stack is particularly effective in scenarios where clients perform many local updates between communication rounds, such as resource-constrained healthcare IoT environments. Given that vertical data partitioning systems require collaborations between parties in every iteration, implementations of the FedAvg algorithm and its variants can be challenging [72], [146], [147]. However, some vertically partitioned FL techniques employ concatenation for local model aggregation [148]. In particular, TMs cannot be optimized using SGD. Instead, they require specialized frameworks, such as the GBDT [89], [94], [149] Other aggregation algorithms leverage the architectures of models for training [150], [37], [115], [151], [148], [152]. Although specialized methods can yield higher accuracy, their applications are limited compared to those of other models. Recent studies have integrated privacy mechanisms-such as SecureBoost [149] for DT and SecAgg [153] for NN—-into the framework of aggregation algorithms. Table 10 summarizes recent (2020-2022) popular state-of-the-art studies on aggregation algorithms, classified according to (1) algorithm employed for local model computation, (2) adopted aggregation method, (3) utilized ML models and (4) adopted data partitioning scheme. In particular, some of these algorithms are tailored for medical applications.
Table 10.
Aggregation Algorithms.
| FL Aggregation Algorithm | Algorithm for local models | Aggregation Method | ML Model | Data Partitioning |
|---|---|---|---|---|
| FedAvg [8] | Stochastic GD | Average | NN, LM | Horizontal |
| FedProx [140] | LogR, NN | Horizontal | ||
| FEDPER [137] | NN | Horizontal | ||
| SCAFFOLD [139] | LogR, NN | Horizontal | ||
| FedPage [145] | LM | Horizontal | ||
| FedNova [143] | LogR, NN | Horizontal | ||
| Per-FedAvg [138] | NN | Horizontal | ||
| FedAdam [142] | LogR, NN | Horizontal | ||
| FedCM [144] | NN | Horizontal | ||
| FedDF [141] | NN | Horizontal | ||
| FedRobust [154] | NN | Horizontal | ||
| PFedMe [155] | LogR, NN | Horizontal | ||
| VANE [156] | LM | Horizontal | ||
| FedSGD [157] | LM, NN | Horizontal | ||
| FedDPGAN [81] | NN, KNN, SVM | Horizontal | ||
| Weighted FedAvg [81] | NN | Horizontal | ||
| FedV [147] | LM | Vertical | ||
| FedBCD [146] | LogR, NN | Vertical | ||
| FedCluster [150] | Cluster | Horizontal and Vertical | ||
| CORK [158] | NN | Horizontal | ||
| FedMDFG [159] | NN | Horizontal | ||
| FedDELTA [160] | LogR, CNN | Horizontal | ||
| CROWDFL [161] | NN | Horizontal | ||
| FedHealth [85] | NN | FTL | ||
| FedMA [152] | NN Specialized | NN | Horizontal | |
| FedGraphNN [151] | Sum | NN | Vertical | |
| GBDT [89] | DT Specialized | DT | Horizontal | |
| SecureBoost [149] | DT | Vertical | ||
| Fed-EINI [94] | DT | Vertical | ||
| FeARH [75] | Distributed GD | Average | LM, NN | FTL |
| FastSecAgg [162] | Mini-batch GD | NN | Horizontal |
Most aggregation methods assume that all clients work reliably and use similar models, which is often unrealistic. In practice, healthcare FL deployments face issues such as straggler clients, hardware heterogeneity, and nonstationary data, which necessitate adaptive and fault-tolerant aggregation protocols. In addition, there is a lack of comprehensive benchmarking of these algorithms under realistic clinical workloads, which limits their practical generalizability and adoption in real-world healthcare environments.
4.7. Open-source FL systems
Using software libraries for FL implementation can improve the effectiveness of FL. The seven primary open-source FL frameworks currently under active development include Google TensorFlow Federated [163], Federated AI Technology Enabler (FATE) [164], OpenMined PySyft (PySyft) [165], Baidu PaddleF [166], FL and Differential Privacy Framework [167], FedML [168], and DataSHIELD [169], [170] (Table 11).
Table 11.
Features of Open-Source FL Systems.
| Properties | TFF | FATE | PySyft | PFL | FL&DP | FedML | DataSHIELD |
|---|---|---|---|---|---|---|---|
| System Architecture | Centralized, Decentralized | Centralized | Decentralized | Centralized, Decentralized | Centralized | Centralized, Decentralized | Centralized |
| Data Partitioning | Horizontal | Horizontal, Vertical | Horizontal | Horizontal, Vertical | Horizontal | Horizontal, Vertical | Horizontal, Vertical |
| Scale | Cross-Silo | Cross-Silo | Cross-Silo, Cross-Devices | Cross-Silo, Cross-Devices | Cross-Silo | Cross-Silo, Cross-Devices | Cross-Silo |
| Machine Learning Models | NN, LM | NN, DT, LM | NN, LM | NN, LM | NN, LM, Clustering | NN, LM | PCA, LM, NN, KNN, Clustering |
| Privacy Mechanisms | DP | DP, SMC, HE | DP, SMC, HE | DP, SMC | DP | SMC | Anonymization |
| Aggregation Method | FedAvg, FedSGD | SecureBoost, SecAgg, FedAvg | FedAvg, SplitNN | SecAgg, FedAvg, SplitNN | FedAvg, Weighted FedAvg, FedCluster | FedAvg, SplitNN | Customizable |
As depicted in Table 11, FATE is the most comprehensive system that supports numerous ML models under horizontal and vertical partitioning conditions with varying federation scales. Furthermore, compared with other open-source systems, FATE offers more privacy mechanisms and implements numerous aggregation algorithms. However, FATE exclusively supports centralized and cross-device architectures. In contrast, FedML integrates several state-of-the-art FL algorithms, supporting centralized and decentralized setups. Furthermore, it supports cross-device and cross-silo architectures. However, its application scope is restricted to fewer ML models and privacy mechanisms.
DataSHIELD–subjected to continuous developments is a framework tailored to the domains of healthcare and social sciences and enables advanced statistical analyses of individual-level data from multiple sources without data pooling. The approach adopted by DataSHIELD differs from that of other systems. Specifically, for a research question of interest, participating clients select a set of variables to be analyzed and subsequently create local problem-specific datasets. The individual clients then independently analyze their generated datasets and anonymize their results before sharing them with the central server for aggregation. The process repeats until a final result is obtained, and the aggregation method of the central server is custom-defined to efficiently address the question. Furthermore, the specific anonymization process is not predefined within the system, but is specified during the computation based on the best practices and data protection rules frequently employed within the given domain. This flexibility makes DataSHIELD more versatile than other available systems. However, it may still encounter challenges such as result inconsistencies and/or disagreements on anonymization methods.
4.8. Representative healthcare datasets in FL
To enhance the depth of our comparative analysis, we identify and summarize the five main data sets that are most frequently used in FL healthcare research. These datasets are selected based on their recurrence in literature, data richness, public availability, and relevance to core healthcare prediction tasks such as mortality estimation, disease diagnosis, and physiological signal analysis. Table 12 categorizes these datasets into three major types: tabular medical data, one-dimensional time-series data, and image-based data. The MIMIC-III, eICU and Cerner Health Facts datasets represent structured clinical data commonly used in FL for tasks such as mortality and prediction of adverse events. The MIT-BIH dataset provides standardized ECG signals and is widely applied in signal-based FL experiments. Lastly, publicly available chest X-ray and CT datasets related to COVID-19 have been instrumental in validating FL models for image-based disease diagnosis. These datasets are favored due to their large sample sizes, diverse patient demographics, and compatibility with privacy-preserving FL frameworks across real-world healthcare settings.
Table 12.
Top Five Datasets Used in FL for Healthcare: Categorized by Data Type.
| Dataset | Data Modality | Data Type | Why It Ranks Top |
|---|---|---|---|
| MIMIC-III | ICU EHR Records | Tabular Medical Data | Public, large-scale dataset used for mortality and ADR prediction across multiple FL studies. |
| eICU Collaborative DB | ICU Patient Data | Tabular Medical Data | Realistic multi-institution EHR; widely used for mortality prediction in horizontal FL settings. |
| Cerner Health Facts | EHR from 50 Hospitals | Tabular Medical Data | Massive real-world dataset; supports non-IID federated prediction of preterm birth. |
| MIT-BIH ECG | ECG Signal (Time-Series) | One-Dimensional Data | Gold-standard ECG signal dataset for arrhythmia detection; benchmarks FL performance on time-series data. |
| Chest X-ray / CT (COVID) | X-ray / CT Images | Image-Based Data | Widely used for FL-based pneumonia/COVID-19 diagnosis using CNNs; high clinical relevance. |
Fig. 5 presents a summarized design of a FL-based healthcare system, highlighting its key components such as design architecture, data availability and partitioning methods, machine learning models, privacy techniques, aggregation algorithms, and open-source platforms commonly used for implementation. While open-source FL frameworks provide flexible platforms for implementation, real-world deployments in healthcare introduce several technical and domain-specific challenges. The following section highlights these challenges and examines ongoing efforts to address them.
Fig. 5.

Summarized FL design healthcare system.
5. Challenges and open problems in federated learning
The volumes of medical datasets grow rapidly over time as patients undergo treatment and monitoring, resulting in rapidly growing, massive, and dynamic datasets. The design of efficient FL algorithms capable of demonstrating high accuracy, minimum processing durations, and reduced memory usage is crucial. FL provides a means of accessing extensive patient data obtained from various locations, paving the way for future innovations. This section discusses the main challenges associated with FL systems [171], [140], [172], [173], [155], [140], [174] and their impacts on FL implementation in healthcare services compared to conventionally distributed data computations and traditional privacy-preserving learning techniques.
5.1. Communication overhead
Medical data is often distributed across numerous locations. Given that distributed learning trains a model on the entire distributed dataset, intense communication among clients is required to obtain the final result. These extensive communication requirements are among the main bottlenecks of traditionally distributed learning approaches. Remarkably, SDL and FL attempt to minimize communication overhead by restricting raw data to the client side and transmitting local model parameters for global model training. However, FL systems often involve numerous clients (hundreds of hospitals or millions of smart mobile phones and wearable devices), requiring several-parameter communications for global model updates. For example, the authors of [175], [156] used 350 and 1,000 iterations to train their global regression models, while those of [72] adopted 200 iterations to train their NN model. Meanwhile, the authors of [176] utilized 25 iterations to train a DT model, implying that healthcare applications require high-performance algorithms to improve the quality of healthcare service.
To improve efficiency and reduce communication costs of FL systems [177], [178], [179], three parameters must be considered: (i) total iterations performed, along with the communication load per iteration; (ii) sizes of messages shared between clients and the server at each iteration; and (iii) complexity of the aggregation algorithm adopted by the server at each iteration.
-
•
Number of iterations and communication load per iteration: researchers have devoted considerable efforts toward the minimization of the number of iterations required to obtain a desired model, as well as the overall communication load encountered during each iteration. Several optimization algorithms for local model computations have been introduced to enhance model convergence durations in FL systems [146]. However, some of these algorithms reduce communication costs at the expense of partial deterioration in accuracy [180], [181]. Other methods recommend the transmission of model updates from a selected client set instead of all, substantially reducing communication costs per iteration [182], [183].
-
•
Message size at each iteration: further efficiency improvements can be realized by reducing the message size. Dankar et al. [37], [90] designed a secure feature selection method for a distributed LR model, which reduced the communication cost per client by decreasing the number of features. Furthermore, while compression techniques and quantization methods are adopted to reduce message sizes [184], [185], [186], [187], the former approaches can compromise the accuracy of the model. Given that high analysis accuracies are required in the medical domain, adopting compression techniques is not advisable.
-
•
Complexity of the aggregate algorithm: The complexity of the adopted aggregation algorithm is another critical parameter that influences efficiency. Remarkable research efforts have been devoted to the development of faster aggregation methods (Table 10). For instance, Bonawitz et al. [188] implemented a quantization method for efficient communication, highlighting certain challenges encountered during parameter configurations. Furthermore, the study reported that manipulations of the learning rate, model update frequency, and number of quantization bits could reduce overall communication costs.
5.2. Systems diversity -systems heterogeneity
Devices like wearables and smartphones often have limited storage, power, and network access, making FL more difficult [189]. For instance, poor network connectivity can result in interrupted communication between clients and the server. Meanwhile, limited memory storage and computational capacities of mobile phones and wearable devices can cause delays in model transmission and hinder active client participation, leading to difficulties in gradient updates. Several key strategies for addressing system heterogeneity have been proposed by previous studies; These include improving system fault tolerances (improved system ability to continue operations despite failures of one or more components), implementing asynchronous communication (facilitating model update transfers without time constraints) and performing active device sampling (selecting active client devices) [140]. Among these, fault tolerance is critical for cross-device FL to ensure uninterrupted operations despite possible dropouts of participating devices before completing training iterations, which can compromise computations and bias device sampling schemes (if only failure-prone devices are ignored). Standard techniques for improving fault tolerance in FL involve reducing the number of participating clients per round and excluding faulty devices [188], [169]. However, these techniques may yield less efficient models, which is undesirable in the medical field with high critical efficiencies.
5.3. Non-IID data -statistical heterogeneity
Most healthcare institutions adopting FL-including hospitals, clinical organizations, and pharmaceutical and insurance companies-may not possess independent and IID datasets. Several factors-including variations in geographic locations and data collection times-can contribute to these differences. Local datasets often differ in features and labels, making training inconsistent across clients [190], [191], [192], [193]. Recent experiments have demonstrated that the FedAvg algorithm using non-IID data demonstrates poor accuracies and convergence speeds [8]. Zhao et al. [194] explain that non-IID data leads to convergence latency, loss of accuracy, and decrease in model utility. Hence, in medical applications requiring high accuracies and efficiencies, addressing non-IID data is crucial. Thus, Jeong et al. [195] proposed a data augmentation scheme using generative adversarial networks (GANs). Within this scheme, local datasets are augmented with synthetic data to transform them into balanced and independent datasets, thereby reducing communication overhead and improving accuracy. However, this method necessitates additional complex training of the GAN (on the server side), compromising raw data privacy as each client needs to upload a few data samples to the server. Alternative approaches for improving accuracy and model applicability [196], [197], [198]-as well as for accelerating model convergence rates [199]-have been introduced; however, finding a low-complexity-burden solution that preserves privacy remains a challenge.
While GAN-based data augmentation has shown promise in alleviating non-IID challenges by generating synthetic samples to balance data distributions across clients, recent studies have raised concerns about potential privacy leakage through GAN outputs [115], [200]. Adversarial clients could exploit GANs to reconstruct sensitive attributes or even identifiable features of training data, especially in healthcare settings where patterns can be patient-specific.
As a safer alternative, [201], [138] has been proposed to improve the generalization of the model across heterogeneous client distributions without relying on synthetic data generation. Meta-learning frameworks, such as Model-Agnostic Meta-Learning (MAML), aim to train a global initialization that can be quickly adapted to each client's local distribution using a few steps of fine-tuning. This approach naturally fits non-IID scenarios, as it allows personalization while preserving the shared structure of the task.
Other viable techniques include clustered FL [150], which dynamically groups clients with similar data distributions and trains separate models per cluster, and data-free distillation [195], which transfers knowledge between models without exchanging raw data or synthetic examples. Incorporating these alternative methods can significantly reduce privacy risks while still mitigating data heterogeneity.
5.4. Attacks
FL is recognized as a privacy-preserving technique that protects sensitive healthcare information by keeping data localized with owners and sharing only model updates during training. Within FL, model updates are often shared with a central server for aggregation and redistribution. Consequently, since no raw data are shared with the central server, no sensitive information is exposed. However, existing FL algorithms exhibit several vulnerabilities that can be exploited by adversaries to compromise patient data privacy [202], [203]. These vulnerabilities can be exploited by either insiders-such as the server or participating clients-or outsiders. Insider attacks can be categorized as active/malicious-which deviate from the FL protocol and yield erroneous model outputs in scenarios where the server tampers with the global model or clients alter their inputs-and passive-wherein participants strictly adhere to the protocol but attempt to learn the private data of honest clients-attacks. Fig. 6 illustrates the classification of certain primary privacy attacks on FL systems, along with their proposed solutions (last row). The following description summarizes these attacks.
Fig. 6.

Some common privacy attacks on FL systems and their corresponding solutions).
5.4.1. Privacy attacks
Inference attacks can occur during the learning process or after the release of the output. In particular, the former attack types are linked to client-server communications [204], [205]. These attacks are passive and result in privacy breaches. Hitaj et al. [200] reported an example of an inference attack in which a GAN was employed to exploit the real-time nature of the FL-learning process. Here, the GAN was trained using shared local models to generate new data samples with the same distribution as the original training dataset. Another common inference attack is membership inference, which determines whether a specific sample was used for model training [206]. In addition, property inference attacks seek to infer the properties of a training sample subset using the properties of the target model (i.e., the proportion of samples used to train the model for a specific attribute) [207]. Inferences on the final output use the final model to infer details regarding the input data. Relevant examples can be found in previous reports [46], [43], [114].
5.4.2. Security attacks
Poisoning attacks pose security risks in FL systems; these attacks usually occur during training and impact the training dataset or local model, ultimately affecting the performance of the global ML model [208]. Poisoning attacks can be classified into those involving data poisoning, model poisoning, and data modifications. Furthermore, poisoning attacks could lead to indirect privacy breaches. For instance, a well-crafted poisoning attack could prompt the inadvertent release of training data from a model.
In data poisoning attacks, malicious clients manipulate their local training data, generating noisy samples to train global model parameters and transmit them to the server [209]. During data injection attacks-subcategories of data poisoning attacks-malicious clients inject false data into the local training data of normal clients. Such at tacks ultimately modify the subset of model updates transmitted to the server, potentially poisoning the final FL model.
In model poisoning attacks, a malicious party alters local model updates before transmitting them to the server or introduces concealed backdoors into the current global model [210]. Previous studies have discussed the execution of such attacks [210], [211] and recommended corresponding solutions [201], [212].
In data modification attacks, malicious agents modify the complete distributed training dataset [213]. For instance, adversaries may spoof IP addresses-altering the content within the source IP header-to compromise servers and internal networks.
Byzantine attacks are classified as poisoning attacks, specifically within the context of FL or distributed systems. In these attacks, certain nodes (clients) in the FL process-referred to as “Byzantine nodes”-act maliciously or fail unexpectedly, transmitting erroneous, random, or even hostile updates to the central server, disrupting the learning process, slowing down the global model as a whole, or adding biases [214]. To counter such attacks, several Byzantine robust aggregation rules have been introduced, including the Krum and multi-Krum rules, the trimmed mean and median, and fast Byzantine aggregation [215], [216], [217].
Recent advances in Byzantine-robust aggregation have introduced more adaptive strategies beyond classical methods like Krum and Trimmed Mean. FABA (Fast Byzantine Aggregation) [223] improves robustness by iteratively removing the most deviant gradients from the mean before aggregation, offering faster convergence than Krum [224]. Zeno++ [225] assigns a descent-based score to each client update using a clean validation dataset, filtering out updates that do not sufficiently reduce the loss. While effective, both approaches require additional resources-FABA assumes gradient similarity, and Zeno++ relies on trusted data at the server-posing practical constraints in certain healthcare deployments. Nonetheless, they mark important steps toward resilient FL under adversarial conditions.
Previously mentioned privacy mechanisms-including the SMC, HE, DP, and TEEs-are employed to prevent these attacks. These schemes are typically integrated into FL applications to mitigate privacy attacks [153], [149], [94], [37], [115], [89], [146], [162], [175], [147], [226]. However, they often exhibit the following inherent limitations:
SMC preserving confidentiality of local parameters, protecting data from inferences during learning [100], [227]. However, this technique cannot defend data against inference in output attacks [114] and is typically computationally expensive, imposing a great deal of computational burdens.
HE protects client data by enabling encrypted computations and defends against inference attacks during the learning process [149], [228], [229], [120]. This technique retains the accuracy of the final output and minimizes information leakage. Basically, it operates by encrypting all communication between clients and the server. However, the communication overhead increases considerably with increasing features, iterations, and clients. The HE approach assumes the presence of a trusted third party to generate and distribute HE keys-a condition often unsatisfied in the FL setup. Dankar et al. [90] compared the efficiencies of diverse cryptographic techniques (secret sharing and garbled circuits) and HE, demonstrating its superiority despite its increased complexity.
DP reduces communication costs compared to other privacy mechanisms [230], protecting data against poisoning and inference attacks, such as membership attacks [231]. In addition, it protects the data from inference over output attacks (by perturbing intermediate and final model parameters). However, repeated noise addition negatively affects performance and accuracy. Specifically, the noise introduced by the DP approach can obscure the influence of individual updates, including those from Byzantine nodes, complicating the introduction of precisely crafted updates that would exert predictable effects on the aggregated model. DP adds random noise, which can reduce predictability and may affect the accuracy of the model. In the presence of differentially private outputs (model updates), attackers struggle to verify whether poisoned data points or malicious updates exerted their intended effects on the model, thereby protecting the model against targeted poisoning attacks.
TEEs facilitate local training on the client side and model aggregation on the server side, but impose computational overhead on the client side. Furthermore, limited clients memories may complicate the training of intricate ML models.
Considering these inherent limitations, previous studies have proposed adopting approaches that combine these techniques to aggregate their benefits and overcome their shortcomings. For instance, Truex et al. [114] proposed a method that combines the DP and HE approaches, minimizing the injection of noise without compromising privacy; this highly scalable approach protects data against inference threats, yielding reasonably accurate models. Gu et al. [232] devised a method that leverages DP and SMC secret sharing; this approach bolstered model robustness against poisoning attacks by injecting noise into model updates. However, such noise settings often limit model utility and robustness. Furthermore, the secret sharing approach introduces additional computation and communication costs. Conversely, Mondal et al. [227] introduced a framework that integrated the TEE and DP approaches, substantially reducing training and communication durations. Furthermore, the method preserved privacy and was resistant to data poisoning and model poisoning attacks, albeit at the cost of global model accuracy.
5.5. Practical challenges and real-world case studies
While theoretical advances in FL have been promising, real-world deployments in healthcare present several non-trivial hurdles. These include system heterogeneity, legal constraints, inconsistent labeling protocols, and the need for robust orchestration and monitoring infrastructure. Additionally, attacks such as model inversion and poisoning still pose active threats even with modern privacy-preserving techniques.
Case studies like NVIDIA Clara and the Federated Tumor Segmentation Challenge demonstrate the potential and the pitfalls of FL at scale. These experiences underscore the importance of standardizing data pipelines, accommodating site dropouts, and adopting hybrid strategies for learning and privacy. Conversely, some FL deployments, such as cross-border COVID-19 prediction efforts, highlight the barriers created by regional policies, non-uniform infrastructure, and coordination challenges. These insights provide valuable lessons that can guide more scalable and secure FL systems in the future.
5.6. Addressing statistical and system heterogeneity in practice
Heterogeneity in federated healthcare environments arises in two major forms: statistical heterogeneity the (non-IID data distributions across clients) and system heterogeneity (variations in computation, storage, and network capabilities).
Statistical Heterogeneity: Several techniques have been proposed to handle data skew across clients. Algorithms such as FedProx [140] introduce a proximal term to local loss functions to reduce update divergence, showing improved stability in imbalanced data settings. SCAFFOLD [139] uses control variates to counter client drift, particularly effective under extreme non-IID distributions. FedDyn and FedCurv integrate dynamic regularization or curvature-aware updates to enhance convergence.
In real-world healthcare, however, effectiveness is mixed. While FedProx has demonstrated stable training under patient-level data heterogeneity, it often requires careful tuning of the regularization parameter μ. Similarly, control variates in SCAFFOLD require additional communication and memory, which can be a barrier in low-resource clinical settings. Moreover, very few clinical FL deployments have openly benchmarked these methods under real-world non-IID scenarios, limiting generalizability.
System Heterogeneity: To handle variations in client capabilities, adaptive aggregation methods such as FedNova [143] and asynchronous protocols like FedAsync [233] have been proposed. These methods compensate for stragglers and allow clients to contribute partial updates. Lightweight models or model pruning are also commonly used to reduce local resource demands.
Despite these advancements, in practice, deployments often revert to FedAvg or rely on custom orchestration frameworks due to the complexity of implementing robust asynchronous schemes. As a result, system heterogeneity remains one of the primary blockers to widespread adoption of FL in various healthcare settings.
Overall, while many promising solutions exist at the algorithmic level, their real-world effectiveness in heterogeneous clinical settings is still under-evaluated, indicating a pressing need for more deployment-focused studies and empirical benchmarking.
6. FL for healthcare and underlying ML model- healthcare application
FL demonstrates promising application potential across various industries, including medicine, sales, and finance. However, data within these domains are typically scattered and cannot be directly aggregated for model training because of several factors, including privacy concerns, data security risks, and intellectual property rights. FL applications in healthcare data analytics benefit healthcare providers (hospitals) and consumers (patients) [234], [235]. EHR data, health data recorded by patients using portable devices, and other forms of health-related information enhance healthcare outcomes and address data access challenges, particularly in precision medicine. Healthcare records are usually stored in various locations and data silos-such as hospitals, pharmacies, insurance companies, and personal devices. Traditionally, these data are stored within a central database for easy access. However, given the sensitive nature of medical data, data centralization is particularly challenging, impeding research progress in the health domain and restricting improvements in patient outcomes. To avoid this, the federal or distributed ML approaches train models using various data sources. Individual locally trained models aggregate to form a global model. In such a scenario, each healthcare center or mobile user (possessing medical data on their smartphones) needs to share local models or parameters instead of their data to obtain an accurate diagnosis model. Notably, these federal or distributed ML approaches have been extensively researched [236], [237], [85], [238].
Table 13 summarizes the studies mentioned above conducted in the healthcare domain (ADR: adverse drug reaction).
Table 13.
Summary of healthcare FL systems categorized by data type and highlighting privacy usage.
| References | Aggregation | Model | Privacy Mechanism | Data Division | Goal | Privacy |
|---|---|---|---|---|---|---|
| Tabular Medical Data | ||||||
| [218] | FADL | NN | Curated Data | Horizontal | Mortality prediction | No |
| [42] | Weighted mean | LR, MLP | Curated Data | Virtual distributed | Mortality prediction | No |
| [43] | Weighted mean | SVM, LR, Perceptron | e-DP | Horizontal, 10 sites | ADR, Mortality rate | Yes |
| [44] | Class ratio/loss | SVM, SLP, LR | Sentinel system | Horizontal, 2 sites | ADR prediction | Yes |
| [54] | cPDS | Sparse SVM | De-identified data | 5-10 hospitals | Cardiac event prediction | No |
| [45] | FedAvg | LR, MLP | Noise addition | Horizontal (5 hospitals) | COVID-19 mortality | Yes |
| [76] | CBFL | DL | Data encoding | Non-IID, 50 hospitals | Mortality, survival | Yes |
| [107] | Patient Hashing | Hash, k-NN | Homomorphic encryption | Horizontal (3 sites) | Patient similarity | Yes |
| [219] | ADMM | Tensor Factorization | TRIP | Horizontal | Phenotyping | Yes |
| [98] | FSVRG | ANN, SVM (NLP) | Apache cTAKES (UIDs) | Random split | Patient representation | Yes |
| [99] | FedAvg | LR, NN | DPSGD | Horizontal (31 hospitals) | Mortality, stay length | Yes |
| [100] | FUALA | RNN | Permutation vector | Horizontal (50 hospitals) | Preterm-birth prediction | Yes |
| [102] | PLINK | LM, Logistic, Chi-square | sPLINK | Horizontal | Genetic association | Yes |
| One-Dimensional Data (ECG, EEG) | ||||||
| [146] | Custom | NN | Privacy-preserving storage | ECG, IoT devices | Arrhythmia detection | Yes |
| [112] | FedAvg | CNN | Decentralized FL | Horizontal ECG | EEG classification | No |
| [148] | SplitNN | DL | Decentralized | Vertical split | Deep learning | No |
| [106] | ADMM, Feature extraction | PCA | ENIGMA | Vertical biomedical data | Brain structure learning | Yes |
| [41] | COMED, MKRUM, AFA | NN | e-DP, k-anonymity | Horizontal split | Diabetes, heart failure | Yes |
| Image-Based Data (X-ray, CT, MRI) | ||||||
| [101] | UCADI | CNN | Homomorphic encryption | Horizontal CT scans | Chest diagnosis | Yes |
| [111] | Weighted average | DNN | Differential Privacy | Horizontal (4-32 institutions) | Image segmentation | Yes |
| [220] | Average parameters | LR, SVM, NN | Encryption | Mobile distributed data | Intrusion detection | Yes |
| [85] | FedHealth | CNN, KNN, SVM, RF | Homomorphic encryption | Wearable data federated | Activity recognition | Yes |
| [221] | Harmonic average | Classifier | Not specified | Horizontal partitioned | Disease classification | No |
| [222] | FedAvg | NN | Homomorphic encryption | Horizontal retina images | Blindness detection | Yes |
First, healthcare researchers have extensively focused on several deep learning techniques and LMs for prediction because deep learning methods can efficiently yield high-quality results, reducing diagnostic errors in healthcare systems. In addition, deep learning models can accurately and efficiently analyze structured and unstructured EHRs, including clinical notes, laboratory test results, diagnoses, and medication prescriptions. In addition, LMs are widely employed in several health systems. Compared to deep learning techniques, these models are simple and easy to implement. Furthermore, regression analysis-a crucial statistical method for LMs-facilitates the analysis of health data to identify and characterize relationships among several factors; regression analyzes enable healthcare institutions to accurately target at-risk individuals requiring tailored behavioral health plans to improve their daily health habits and potentially leading to better patient health and lower treatment costs.
Second, healthcare data are primarily partitioned, employing the horizontal data partitioning approach, because healthcare data originate from local EHR systems featuring identical attributes but diverse patient data. In addition, studies have utilized the vertical partitioning scheme for EHR systems containing similar patient data but featuring different attributes.
Third, studies have shown that DP and HE are the leading techniques for ensuring privacy protection. In decentralized FL, the DP approach injects local noise into the outputs of each customer. Meanwhile, HE-a powerful cryptographic tool-enables secure multiparty computation by allowing participants to compute function values while concealing them. Moreover, encryption helps protect patients' health information during transmission from users to the server. Given the criticality of privacy mechanisms, designing models with minimum communication costs and high accuracy is challenging.
Finally, most of the above mentioned studies involve scenarios where hospitals actively engage in constructing accurate and robust statistical models using EHR data for health predictions, primarily using cross-silo architectures. Designing a decentralized federated system with a trusted party is another key challenge because a trusted party must be robust against dishonest or malicious parties. Notably, FL effectiveness depends on the adopted data-partitioning and ML models. Specifically, partitioning schemes frequently adopted in FL include horizontal, vertical, and combined horizontal and vertical partitioning approaches. Previous studies have predominantly focused on designing efficient FL approaches for healthcare applications, primarily employing horizontal partitioning. Within these frameworks, hospital EHR systems feature identical attributes but hold diverse patient data. Furthermore, cross-silo architectures are most commonly employed with central servers, executing all aggregations on the server side.
Recent healthcare prediction shows that the main predictions for medical applications include mortality prediction, preterm birth prediction, adverse drug reaction, disease prediction, and hospitalization. Table 14 points out that there is no specific ML model for healthcare applications. This includes both linear and non-linear ML models. Depending on the prediction variable, the model may change. So, we have to design an algorithm that applies to both linear and nonlinear.
Table 14.
Summary of healthcare predictions and underlying ML models.
| Predictions | ML models |
|---|---|
| Mortality prediction | LR, NN, MLP, LogR |
| Preterm birth | RNN |
| Adverse drug reaction | SVM, MLP, LR |
| Disease prediction | NN |
| Hospitalization | SVM |
6.1. Critical analysis of healthcare FL systems by data type and privacy use
Table 13 presents a comprehensive overview of FL healthcare systems categorized by data type (tabular, one-dimensional and image-based), aggregation model, privacy mechanisms, and system objectives. Although the table effectively illustrates the diversity in data modalities and FL configurations, it reveals several notable gaps and inconsistencies. First, tabular medical data studies show inconsistent integration of privacy mechanisms-several systems (e.g. [218], [42], [54] omit privacy protection entirely, despite working with sensitive EHRs, potentially compromising data confidentiality. In contrast, studies such as Choudhury [43], [44] adopt differential privacy (e-DP) with clear privacy objectives, but with limited performance benchmarking, making it difficult to assess the real utility-privacy trade-off.
In the one-dimensional data domain, while techniques such as e-DP and k-anonymity [41] demonstrate privacy intent, other works like [148] entirely lack privacy measures, raising concerns about vertical split vulnerabilities. The inclusion of privacy-preserving storage [146] hints at architectural protection, but lacks details on the encryption standards used.
Within image-based FL studies, privacy is more commonly adopted (e.g., [101], [111], [85], probably due to increased regulatory scrutiny and public attention to the use of image data. However, some studies such as [221] do not report any privacy mechanism despite working with disease classification on patient imaging-this lack of transparency undermines trust and replicability.
In general, the table underscores that while privacy-preserving techniques, such as HE and DP are gaining traction, their usage is uneven and often unquantified. Many studies prioritize model performance without reporting the overhead or degradation caused by privacy mechanisms, which limits comparability. Future work should strive to consistently report on the impact of privacy on utility and clarify why specific mechanisms are used or omitted, particularly in high-risk healthcare domains.
The preceding sections reviewed FL applications in healthcare care using various ML models, highlighting its role in collaborative privacy-preserving analysis. We now conclude by reflecting on the impact of the review and outlining future research directions.
7. Summary and outlook
This review synthesizes a broad range of literature on FL in healthcare care, addressing privacy mechanisms, model types, data modalities, and real-world frameworks. Its importance lies in the comprehensive scope and categorization of FL systems by data type and privacy integration, helping researchers identify strengths, gaps, and method comparisons in real healthcare conditions. Given the sensitivity of data such as genetic profiles or mental health records, deploying ethical and privacy-preserving FL systems is crucial. This review supports future research by highlighting key trends, challenges, and opportunities in federated healthcare.
7.1. Significance of the review
Given the sensitive nature of medical data, FL applications in the healthcare sector face several challenges, particularly when dealing with medical issues such as mental health problems, HIV / AIDS, and genetic conditions associated with potential discrimination or social stigma. Accidental disclosure or inference of patient data from FL models can profoundly impact the lives of affected individuals and society, leading to increased stigma and reluctance to seek medical attention. For example, when FL is used to improve HIV / AIDS diagnostic models in healthcare facilities, strict privacy and security protocols protect patient information and prevent privacy breaches that could exacerbate social stigma and discourage individuals from seeking necessary medical care.
To protect patient privacy in such fragile situations, FL-based healthcare systems must adopt specific privacy-preserving measures. One such measure is DP, which obscures specific data points and protects the data of patients diagnosed with sensitive medical issues by adding noise to model updates. Meanwhile, HE ensures data encryption throughout the computation to prevent unauthorized access. Furthermore, SMC enables patient confidentiality across multiple institutions, facilitating the creation of collaborative models without revealing personal patient information. In addition, strict access controls and comprehensive audit trails are vital for monitoring data access, ensuring that only authorized personnel can access model information and that all forms of access are transparent and accountable. These protective measures are essential for adhering to the unique security and privacy requirements of FL-based healthcare applications, as well as for supporting FL applications in delicate medical areas and satisfying the evolving needs of the field.
Recent healthcare prediction data reveal that mortality, premature birth, adverse drug reaction, disease, and hospitalization predictions constitute the primary FL-based predictions in the medical field. No ML model is universally applicable to all healthcare applications (Table 14) because scenarios involving different prediction variables may require different models. Consequently, we must design algorithms that are applicable to linear and nonlinear ML approaches.
7.2. Major obstacles in FL heathcare systems
The primary components required to build an FL-based healthcare system are described below. The previous section discussed the main challenges faced by FL applications in healthcare settings. This section summarizes the difficulties encountered in developing an efficient and effective FL algorithm suited for healthcare applications. In particular, the efficiency of such an algorithm depends on its design parameters. Furthermore, Fig. 7 illustrates the primary considerations involved in designing an FL algorithm suited for healthcare applications, along with certain potential solutions, including the following:
-
•
Communication efficiency in FL-based healthcare systems: Enhancing communication efficiency is paramount in FL-based healthcare systems, where minimization of the number of communication rounds and reduction in message sizes are essential for managing massive datasets across medical institutions. Notably, innovative algorithms that minimize communication overheads can significantly expedite collaborative model training in healthcare settings. For instance, leveraging synthetic data to create more precise initial models, as demonstrated by Dankar et al. [37], can considerably reduce the number of required iterations, thus increasing the efficiency of FL in medical applications.
-
•
Handling data variability in FL within the medical domain: Statistical heterogeneity issues are magnified in healthcare settings because of the diverse and non-IID nature of medical data. In particular, environmental factors and societal variables, such as air quality or community health practices, can bias the data collected by different healthcare providers. To address this, aggregation algorithms suited to such unique data distributions are essential for maintaining the accuracy of FL models in healthcare applications.
-
•
Adapting FL to healthcare system diversity: FL-based healthcare systems must adapt to the asynchronous and unpredictable nature of client contacts, particularly with the emergence of patient empowerment and personal data ownership trends. With growing support for individual ownership of biomedical data, new FL algorithms must be designed to tolerate system heterogeneity and ensure resilience against client dropouts in patient-centered healthcare models.
-
•
Protecting patient data against privacy attacks: Notably, the intermediate results of FL-based healthcare systems are susceptible to privacy breaches that could expose sensitive patient information. Despite the implementation of privacy-enhancing measures, striking a balance among various factors including computational efficiency, communication overhead, and model accuracy remains challenging. Furthermore, protecting FL-based healthcare systems from insider threats, such as malicious clients or compromised servers, necessitates sophisticated yet efficient cryptographic solutions to protect patient data.
-
•
Healthcare FL system architecture considerations: Tailoring FL algorithms to satisfy the specific requirements of healthcare networks-involving centralized cross-device and decentralized cross-silo systems-necessitates careful considerations of network topology. This is particularly critical in peer-to-peer healthcare settings, where direct communication between clients requires a nuanced approach to system design to ensure seamless and secure data exchanges.
-
•
Optimizing ML models for healthcare applications: In healthcare settings, selecting appropriate ML parameters is crucial for enhancing model performance and efficiency. Appropriate parameter tuning and the development of effective stopping criteria are essential for achieving optimal convergence in medical FL models, ensuring high accuracies and mitigating the need for extensive communication rounds [239]. Moreover, designing efficient FL-based healthcare systems remains challenging, primarily because of inadequate considerations of certain factors. For instance, the configurations of algorithmic design parameters–including total communication rounds, learning rate parameters, and number of local model updates-are inadequately investigated. Furthermore, despite the negative influence of unbalanced and non-IID data on algorithm performance and accuracy, such data are frequently employed in FL-based healthcare systems. In addition, differences in the availability of client devices introduce various forms of bias, similar to handling device connection losses during communication. Furthermore, collaboratively constructing a fully decentralized algorithm to learn personalized models presents another challenge. Thus, designing efficient and accurate privacy-preserving biomedical FL frameworks remains an ongoing concern.
Fig. 7.

Primary design challenges of FL-based healthcare systems, along with some solutions.
Contemporary research efforts focus on isolating these challenges and treating them separately, often disregarding the effects of their solutions on other parameters. In fact, achieving simultaneous improvements in the efficiency, accuracy, and privacy of ML models remains an unresolved issue. Fig. 8 illustrates some of the key challenges and open problems in applying federated learning to healthcare systems, including issues related to data heterogeneity, privacy preservation, scalability, and real-world deployment constraints. In conclusion, several of the issues and challenges mentioned above inherently span multiple disciplines. To effectively address these challenges, a comprehensive system is required that guarantees the privacy, security, fairness, communication efficiency, and accuracy of FL systems.
Fig. 8.

Some of the challenges and open problems in FL healthcare system.
CRediT authorship contribution statement
Nisha Thorakkattu Madathil: Writing – original draft. Fida K. Dankar: Writing – review & editing. Marton Gergely: Writing – review & editing. Abdelkader Nasreddine Belkacem: Writing – review & editing. Saed Alrabaee: Supervision.
Declaration of Competing Interest
The authors certify that they have NO affiliations with or involvement in any organization or entity with any financial interest (such as honoraria; educational grants; participation in speakers' bureaus; membership, employment, consultancies, stock ownership, or other equity interest; and expert testimony or patent-licensing arrangements), or non-financial interest (such as personal or professional relationships, affiliations, knowledge or beliefs) in the subject matter or materials discussed in this manuscript.
Contributor Information
Nisha Thorakkattu Madathil, Email: 201990156@uaeu.ac.ae.
Fida K. Dankar, Email: fida_dankar@hotmail.com.
Marton Gergely, Email: mgergely@uaeu.ac.ae.
Abdelkader Nasreddine Belkacem, Email: belkacem@uaeu.ac.ae.
Saed Alrabaee, Email: salrabaee@uaeu.ac.ae.
References
- 1.Davenport T., Kalakota R. The potential for artificial intelligence in healthcare. Future Healthc J. 2019;6(2):94. doi: 10.7861/futurehosp.6-2-94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Lysaght T., Lim H.Y., Xafis V., Ngiam K.Y. AI-assisted decision-making in healthcare: the application of an ethics framework for big data in health and research. Asian Bioeth Rev. 2019;11:299–314. doi: 10.1007/s41649-019-00096-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.McGlynn E.A., Lieu T.A., Durham M.L., Bauck A., Laws R., Go A.S., et al. Developing a data infrastructure for a learning health system: the portal network. J Am Med Inform Assoc. 2014;21(4):596–601. doi: 10.1136/amiajnl-2014-002746. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.https://eptanetwork.org/database/policy-briefs-reports/1898-artificial-intelligence-in-health-care-benefits-%20and-challenges-of-machine-learning-in-drug-development-staa Artificial Intelligence in Health Care: Benefits and Challenges of Machine Learning in Drug Development (STAA) - Policy Briefs & Reports.
- 5.Regulation (EU) 2016/679 of the European Parliament and of the council. Regulation (EU) 2016;679:2016. P. Regulation. [Google Scholar]
- 6.Dankar F.K., Badji R. A risk-based framework for biomedical data sharing. J Biomed Inform. 2017;66:231–240. doi: 10.1016/j.jbi.2017.01.012. [DOI] [PubMed] [Google Scholar]
- 7.Howe B., Stoyanovich J., Ping H., Herman B., Gee M. Synthetic data for social good. 2017. arXiv:1710.08874 arXiv preprint.
- 8.McMahan B., Moore E., Ramage D., Hampson S., y Arcas B.A. Artificial intelligence and statistics. PMLR; 2017. Communication-efficient learning of deep networks from decentralized data; pp. 1273–1282. [Google Scholar]
- 9.Islam A., Shin S.Y. 2022 13th international conference on information and communication technology convergence (ICTC) IEEE; 2022. A blockchain-based privacy sensitive data acquisition scheme during pandemic through the facilitation of federated learning; pp. 83–87. [Google Scholar]
- 10.Pandianchery M.S., Sowmya V., Gopalakrishnan E., Ravi V., Soman K. Centralized cnn–gru model by federated learning for covid-19 prediction in India. IEEE Trans Comput Soc Syst. 2023 [Google Scholar]
- 11.Kujur A., Bharathi S.V., Pramod D. 2023 international conference on advancement in computation & computer technologies (InCACCT) IEEE; 2023. Application of horizontal federated learning for critical resource allocation-lessons from the covid-19 pandemic; pp. 101–106. [Google Scholar]
- 12.Wang S., Jiang X., Singh S., Marmor R., Bonomi L., Fox D., et al. Genome privacy: challenges, technical approaches to mitigate risk, and ethical considerations in the United States. Ann NY Acad Sci. 2017;1387(1):73–83. doi: 10.1111/nyas.13259. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Belkacem A.N., Jamil N., Palmer J.A., Ouhbi S., Chen C. Brain computer interfaces for improving the quality of life of older adults and elderly patients. Front Neurosci. 2020;14:692. doi: 10.3389/fnins.2020.00692. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Belkacem A.N., Jamil N., Khalid S., Alnajjar F. On closed-loop brain stimulation systems for improving the quality of life of patients with neurological disorders. Front Human Neurosci. 2023;17 doi: 10.3389/fnhum.2023.1085173. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Liu R., Chen Y., Li A., Ding Y., Yu H., Guan C. Aggregating intrinsic information to enhance bci performance through federated learning. Neural Netw. 2024;172 doi: 10.1016/j.neunet.2024.106100. [DOI] [PubMed] [Google Scholar]
- 16.Jia T., Meng L., Li S., Liu J., Wu D. Federated motor imagery classification for privacy-preserving brain-computer interfaces. IEEE Trans Neural Syst Rehabil Eng. 2024 doi: 10.1109/TNSRE.2024.3457504. [DOI] [PubMed] [Google Scholar]
- 17.Mongardi S., Pinoli P. Adjunct proceedings of the 32nd ACM conference on user modeling, adaptation and personalization. 2024. Exploring federated learning for emotion recognition on brain-computer interfaces; pp. 622–626. [Google Scholar]
- 18.Hu K., Liu R., Yu H. Proceedings of the 5th distributed artificial intelligence conference (DAI'23) 2023. Horizontal federated learning for brain-computer interface. [Google Scholar]
- 19.Ju C., Gao D., Mane R., Tan B., Liu Y., Guan C. 2020 42nd annual international conference of the IEEE engineering in medicine & biology society (EMBC) IEEE; 2020. Federated transfer learning for eeg signal classification; pp. 3040–3045. [DOI] [PubMed] [Google Scholar]
- 20.Xia K., Duch W., Sun Y., Xu K., Fang W., Luo H., et al. Privacy-preserving brain–computer interfaces: a systematic review. IEEE Trans Comput Soc Syst. 2022;10(5):2312–2324. [Google Scholar]
- 21.Mosaiyebzadeh F., Pouriyeh S., Parizi R.M., Sheng Q.Z., Han M., Zhao L., et al. Privacy-enhancing technologies in federated learning for the Internet of healthcare things: a survey. Electronics. 2023;12(12):2703. [Google Scholar]
- 22.Prasad V.K., Bhattacharya P., Maru D., Tanwar S., Verma A., Singh A., et al. Federated learning for the Internet-of-medical-things: a survey. Mathematics. 2022;11(1):151. [Google Scholar]
- 23.Patel V.A., Bhattacharya P., Tanwar S., Gupta R., Sharma G., Bokoro P.N., et al. Adoption of federated learning for healthcare informatics: emerging applications and future directions. IEEE Access. 2022;10:90792–90826. [Google Scholar]
- 24.Bashir A.K., Victor N., Bhattacharya S., Huynh-The T., Chengoden R., Yenduri G., et al. Federated learning for the healthcare metaverse: concepts, applications, challenges, and future directions. IEEE Internet Things J. 2023 [Google Scholar]
- 25.Taha Z.K., Yaw C.T., Koh S.P., Tiong S.K., Kadirgama K., Benedict F., et al. A survey of federated learning from data perspective in the healthcare domain: challenges, methods, and future directions. IEEE Access. 2023 [Google Scholar]
- 26.Hamood Alsamhi S., Hawbani A., Shvetsov A.V., Kumar S., et al. Advancing pandemic preparedness in healthcare 5.0: a survey of federated learning applications. Adv Hum-Comput Interact. 2023;2023 [Google Scholar]
- 27.Ali M., Naeem F., Tariq M., Kaddoum G. Federated learning for privacy preservation in smart healthcare systems: a comprehensive survey. IEEE J Biomed Health Inform. 2022;27(2):778–789. doi: 10.1109/JBHI.2022.3181823. [DOI] [PubMed] [Google Scholar]
- 28.Rahman M.A. 2023 IEEE globecom workshops (GC Wkshps) IEEE; 2023. A survey on security and privacy of multimodal llms-connected healthcare perspective; pp. 1807–1812. [Google Scholar]
- 29.Rani S., Kataria A., Kumar S., Tiwari P. Federated learning for secure iomt-applications in smart healthcare systems: a comprehensive review. Knowl-Based Syst. 2023 [Google Scholar]
- 30.Xu J., Glicksberg B.S., Su C., Walker P., Bian J., Wang F. Federated learning for healthcare informatics. J Healthcare Inform Res. 2021;5:1–19. doi: 10.1007/s41666-020-00082-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Dinh C.N., Quoc-Viet P., Pathirana P.N., Ming D., Seneviratne A., Zihuai L., et al. Federated learning for smart healthcare: a survey. ACM Comput Surv. 2023 1937–01. [Google Scholar]
- 32.Choi G., Cha W.C., Lee S.U., Shin S.-Y. Survey of medical applications of federated learning. Healthc Inform Res. 2024;30(1):3. doi: 10.4258/hir.2024.30.1.3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Joshi M., Pal A., Sankarasubbu M. Federated learning for healthcare domain-pipeline, applications and challenges. ACM Trans Comput Healthcare. 2022;3(4):1–36. [Google Scholar]
- 34.Choi J.I., Butler K.R. Secure multiparty computation and trusted hardware: examining adoption challenges and opportunities. Secur Commun Netw. 2019;2019 [Google Scholar]
- 35.Liu F., Zheng Z., Shi Y., Tong Y., Zhang Y. A survey on federated learning: a perspective from multi-party computation. Front Comput Sci. 2024;18(1) [Google Scholar]
- 36.Huang B., Zhao H., Wang L., Qian W., Yin Y., Deng S. Decentralized proactive model offloading and resource allocation for split and federated learning. 2024. arXiv:2402.06123 arXiv preprint.
- 37.Dankar F.K., Madathil N., Dankar S.K., Boughorbel S. Privacy-preserving analysis of distributed biomedical data: designing efficient and secure multiparty computations using distributed statistical learning theory. JMIR Med Inform. 2019;7(2) doi: 10.2196/12702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Liu J., Huang J., Zhou Y., Li X., Ji S., Xiong H., et al. From distributed machine learning to federated learning: a survey. Knowl Inf Syst. 2022;64(4):885–917. [Google Scholar]
- 39.Madathil N.T., Harous S. 2020 11th IEEE annual ubiquitous computing, electronics & mobile communication conference (UEMCON) IEEE; 2020. Central versus distributed statistical computing algorithms-a comparison; pp. 0087–0092. [Google Scholar]
- 40.Kairouz P., McMahan H.B., Avent B., Bellet A., Bennis M., Bhagoji A.N., et al. Advances and open problems in federated learning. Found Trends Mach Learn. 2021;14(1–2):1–210. [Google Scholar]
- 41.Grama M., Musat M., Muñoz-González L., Passerat-Palmbach J., Rueckert D., Alansary A. Robust aggregation for adaptive privacy preserving federated learning in healthcare. 2020. arXiv:2009.08294 arXiv preprint.
- 42.Sharma P., Shamout F.E., Clifton D.A. Preserving patient privacy while training a predictive model of in-hospital mortality. 2019. arXiv:1912.00354 arXiv preprint.
- 43.Choudhury O., Gkoulalas-Divanis A., Salonidis T., Sylla I., Park Y., Hsu G., et al. Differential privacy-enabled federated learning for sensitive health data. 2019. arXiv:1910.02578 arXiv preprint. [PMC free article] [PubMed]
- 44.Choudhury O., Park Y., Salonidis T., Gkoulalas-Divanis A., Sylla I., et al. AMIA annual symposium proceedings, vol. 2019. American medical informatics association. 2019. Predicting adverse drug reactions on distributed health data using federated learning; p. 313. [PMC free article] [PubMed] [Google Scholar]
- 45.Vaid A., Jaladanki S.K., Xu J., Teng S., Kumar A., Lee S., et al. Federated learning of electronic health records improves mortality prediction in patients hospitalized with covid-19. MedRxiv. 2020 doi: 10.2196/24207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Adnan M., Kalra S., Cresswell J.C., Taylor G.W., Tizhoosh H.R. Federated learning and differential privacy for medical image analysis. Sci Rep. 2022;12(1):1953. doi: 10.1038/s41598-022-05539-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Hasan B.T., Idrees A.K. Federated learning for iot/edge/fog computing systems. 2024. arXiv:2402.13029 arXiv preprint.
- 48.Arikumar K., Prathiba S.B., Alazab M., Gadekallu T.R., Pandya S., Khan J.M., et al. Fl-pmi: federated learning-based person movement identification through wearable devices in smart healthcare systems. Sensors. 2022;22(4):1377. doi: 10.3390/s22041377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Ferrag M.A., Friha O., Hamouda D., Maglaras L., Janicke H. Edge-iiotset: a new comprehensive realistic cyber security dataset of iot and iiot applications for centralized and federated learning. IEEE Access. 2022;10:40 281–40 306. [Google Scholar]
- 50.Gholizadeh N., Musilek P. Federated learning with hyperparameter-based clustering for electrical load forecasting. Internet of Things. 2022;17 [Google Scholar]
- 51.Tang Z., Hu H., Xu C. A federated learning method for network intrusion detection. Concurr Comput Pract Exp. 2022;34(10) [Google Scholar]
- 52.Chen Z., Li D., Zhu J., Zhang S. Dacfl: dynamic average consensus-based federated learning in decentralized sensors network. Sensors. 2022;22(9):3317. doi: 10.3390/s22093317. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Zhao L., Ni L., Hu S., Chen Y., Zhou P., Xiao F., et al. IEEE INFOCOM 2018-IEEE conference on computer communications. IEEE; 2018. Inprivate digging: enabling tree-based distributed data mining with differential privacy; pp. 2087–2095. [Google Scholar]
- 54.Brisimi T.S., Chen R., Mela T., Olshevsky A., Paschalidis I.C., Shi W. Federated learning of predictive models from federated electronic health records. Int J Med Inform. 2018;112:59–67. doi: 10.1016/j.ijmedinf.2018.01.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Feng C., Liu B., Yu K., Goudos S.K., Wan S. Blockchain-empowered decentralized horizontal federated learning for 5g-enabled uavs. IEEE Trans Ind Inform. 2021;18(5):3582–3592. [Google Scholar]
- 56.Khan L.U., Tun Y.K., Alsenwi M., Imran M., Han Z., Hong C.S. A dispersed federated learning framework for 6g-enabled autonomous driving cars. IEEE Trans Netw Sci Eng. 2022 [Google Scholar]
- 57.Liang X., Bandara E., Zhao J., Shetty S. Blockchain in life sciences. Springer; 2022. A blockchain-empowered federated learning system and the promising use in drug discovery; pp. 113–139. [Google Scholar]
- 58.Barbieri L., Savazzi S., Brambilla M., Nicoli M. Decentralized federated learning for extended sensing in 6g connected vehicles. Veh Commun. 2022;33 [Google Scholar]
- 59.Qiu W., Ai W., Chen H., Feng Q., Tang G. Decentralized federated learning for industrial iot with deep echo state networks. IEEE Trans Ind Inform. 2022 [Google Scholar]
- 60.Tedeschini B.C., Savazzi S., Stoklasa R., Barbieri L., Stathopoulos I., Nicoli M., et al. Decentralized federated learning for healthcare networks: a case study on tumor segmentation. IEEE Access. 2022;10:8693–8708. [Google Scholar]
- 61.Kalra S., Wen J., Cresswell J.C., Volkovs M., Tizhoosh H.R. Decentralized federated learning through proxy model sharing. Nat Commun. 2023;14(1):2899. doi: 10.1038/s41467-023-38569-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Beltrán E.T.M., Gómez Á.L.P., Feng C., Sánchez P.M.S., Bernal S.L., Bovet G., et al. Fedstellar: a platform for decentralized federated learning. Expert Syst Appl. 2024;242 [Google Scholar]
- 63.Lian Z., Su C. Proceedings of the 2022 ACM on Asia conference on computer and communications security. 2022. Decentralized federated learning for Internet of things anomaly detection; pp. 1249–1251. [Google Scholar]
- 64.Kholod I., Yanaki E., Fomichev D., Shalugin E., Novikova E., Filippov E., et al. Open-source federated learning frameworks for iot: a comparative review and analysis. Sensors. 2020;21(1):167. doi: 10.3390/s21010167. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Li Q., Wen Z., Wu Z., Hu S., Wang N., Li Y., et al. A survey on federated learning systems: vision, hype and reality for data privacy and protection. IEEE Trans Knowl Data Eng. 2021 [Google Scholar]
- 66.Mothukuri V., Parizi R.M., Pouriyeh S., Huang Y., Dehghantanha A., Srivastava G. A survey on security and privacy of federated learning. Future Gener Comput Syst. 2021;115:619–640. [Google Scholar]
- 67.Saha S., Ahmad T. Federated transfer learning: concept and applications. Intell Artif. 2021;15(1):35–44. [Google Scholar]
- 68.Huang C., Tang M., Ma Q., Huang J., Liu X. Promoting collaborations in cross-silo federated learning: challenges and opportunities. IEEE Commun Mag. 2023 [Google Scholar]
- 69.Sun Y., Kountouris M., Zhang J. How to collaborate: towards maximizing the generalization performance in cross-silo federated learning. 2024. arXiv:2401.13236 arXiv preprint.
- 70.Wang B., Zhang Y.J., Cao Y., Li B., McMahan H.B., Oh S., et al. Can public large language models help private cross-device federated learning? 2023. arXiv:2305.12132 arXiv preprint.
- 71.Nguyen D.C., Pham Q.-V., Pathirana P.N., Ding M., Seneviratne A., Lin Z., et al. Federated learning for smart healthcare: a survey. ACM Comput Surv. 2022;55(3):1–37. [Google Scholar]
- 72.Chen Y., Sun X., Jin Y. Communication-efficient federated deep learning with layerwise asynchronous model update and temporally weighted aggregation. IEEE Trans Neural Netw Learn Syst. 2019;31(10):4229–4238. doi: 10.1109/TNNLS.2019.2953131. [DOI] [PubMed] [Google Scholar]
- 73.Chhikara P., Singh P., Tekchandani R., Kumar N., Guizani M. Federated learning meets human emotions: a decentralized framework for human–computer interaction for iot applications. IEEE Internet Things J. 2020;8(8):6949–6962. [Google Scholar]
- 74.Chowdhury A., Kassem H., Padoy N., Umeton R., Karargyris A. Brainlesion: glioma, multiple sclerosis, stroke and traumatic brain injuries: 7th international workshop, BrainLes 2021, held in conjunction with MICCAI 2021, virtual event, September 27, 2021, revised selected papers, part I. Springer; 2022. A review of medical federated learning: applications in oncology and cancer research; pp. 3–24. [Google Scholar]
- 75.Cui J., Zhu H., Deng H., Chen Z., Liu D. Fearh: federated machine learning with anonymous random hybridization on electronic medical records. J Biomed Inform. 2021;117 doi: 10.1016/j.jbi.2021.103735. [DOI] [PubMed] [Google Scholar]
- 76.Huang L., Shea A.L., Qian H., Masurkar A., Deng H., Liu D. Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records. J Biomed Inform. 2019;99 doi: 10.1016/j.jbi.2019.103291. [DOI] [PubMed] [Google Scholar]
- 77.Feki I., Ammar S., Kessentini Y., Muhammad K. Federated learning for covid-19 screening from chest X-ray images. Appl Soft Comput. 2021;106 doi: 10.1016/j.asoc.2021.107330. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Li X., Gu Y., Dvornek N., Staib L.H., Ventola P., Duncan J.S. Multi-site fmri analysis using privacy-preserving federated learning and domain adaptation: abide results. Med Image Anal. 2020;65 doi: 10.1016/j.media.2020.101765. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Liu J.C., Goetz J., Sen S., Tewari A. Learning from others without sacrificing privacy: simulation comparing centralized and federated machine learning on mobile health data. JMIR mHealth uHealth. 2021;9(3) doi: 10.2196/23728. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Rehman A., Razzak I., Xu G. Federated learning for privacy preservation of healthcare data from smartphone-based side-channel attacks. IEEE J Biomed Health Inform. 2022 doi: 10.1109/JBHI.2022.3171852. [DOI] [PubMed] [Google Scholar]
- 81.Zhang L., Shen B., Barnawi A., Xi S., Kumar N., Wu Y. Feddpgan: federated differentially private generative adversarial networks framework for the detection of covid-19 pneumonia. Inf Syst Front. 2021;23(6):1403–1415. doi: 10.1007/s10796-021-10144-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Cha D., Sung M., Park Y.-R., et al. Implementing vertical federated learning using autoencoders: practical application, generalizability, and utility study. JMIR Med Inform. 2021;9(6) doi: 10.2196/26598. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Liu J., Zhou X., Mo L., Ji S., Liao Y., Li Z., et al. Distributed and deep vertical federated learning with big data. Concurr Comput Pract Exp. 2023;35(21) [Google Scholar]
- 84.Liu Y., Kang Y., Zou T., Pu Y., He Y., Ye X., et al. Vertical federated learning: concepts, advances, and challenges. IEEE Trans Knowl Data Eng. 2024 [Google Scholar]
- 85.Chen Y., Qin X., Wang J., Yu C., Gao W. Fedhealth: a federated transfer learning framework for wearable healthcare. IEEE Intell Syst. 2020;35(4):83–93. [Google Scholar]
- 86.Li X., Zhang C., Li X., Zhang W. Federated transfer learning in fault diagnosis under data privacy with target self-adaptation. J Manuf Syst. 2023;68:523–535. [Google Scholar]
- 87.Tan Y.N., Tinh V.P., Lam P.D., Nam N.H., Khoa T.A. A transfer learning approach to breast cancer classification in a federated learning framework. IEEE Access. 2023;11:27462–27476. [Google Scholar]
- 88.Yang Q., Liu Y., Chen T., Tong Y. Federated machine learning: concept and applications. ACM Trans Intell Syst Technol. 2019;10(2):1–19. [Google Scholar]
- 89.Li Q., Wen Z., He B. Practical federated gradient boosting decision trees. Proc AAAI Conf Artif Intell. 2020;34(04):4642–4649. [Google Scholar]
- 90.Dankar F., Madathil N. Secure linear regression algorithms: a comparison. Advances in smart technologies applications and case studies: selected papers from the first international conference on smart information and communication technologies; SmartICT 2019, September 26-28, 2019, Saidia, Morocco; Springer; 2020. pp. 166–174. [Google Scholar]
- 91.Liu Y., Ma Z., Liu X., Wang Z., Ma S., Ren K. Revocable federated learning: a benchmark of federated forest. 2019. arXiv:1911.03242 arXiv preprint.
- 92.Liu Y., Ma Z., Liu X., Ma S., Nepal S., Deng R. Boosting privately: privacy-preserving federated extreme boosting for mobile crowdsensing. 2019. arXiv:1907.10218 arXiv preprint.
- 93.Madathil N.T., Dankar F.K. 2021 IEEE 12th annual ubiquitous computing, electronics & mobile communication conference (UEMCON) IEEE; 2021. Privacy-preserving id3 algorithms: a comparison; pp. 0016–0022. [Google Scholar]
- 94.Chen X., Zhou S., Yang K., Fan H., Wang H., Wang Y., et al. Fed-eini: an efficient and interpretable inference framework for decision tree ensembles in federated learning. 2021. arXiv:2105.09540 arXiv preprint.
- 95.Krizhevsky A., Sutskever I., Hinton G.E. Imagenet classification with deep convolutional neural networks. Commun ACM. 2017;60(6):84–90. [Google Scholar]
- 96.Sundermeyer M., Schlüter R., Ney H. Thirteenth annual conference of the international speech communication association. 2012. Lstm neural networks for language modeling. [Google Scholar]
- 97.Tian Z., Zhang R., Hou X., Liu J., Ren K. Federboost: private federated learning for gbdt. 2020. arXiv:2011.02796 arXiv preprint.
- 98.Liu D., Dligach D., Miller T. Proceedings of the conference. Association for computational linguistics. Meeting, vol. 2019. NIH Public Access; 2019. Two-stage federated phenotyping and patient representation learning; p. 283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.Pfohl S.R., Dai A.M., Heller K. Federated and differentially private learning for electronic health records. 2019. arXiv:1911.05861 arXiv preprint.
- 100.Boughorbel S., Jarray F., Venugopal N., Moosa S., Elhadi H., Makhlouf M. Federated uncertainty-aware learning for distributed hospital ehr data. 2019. arXiv:1910.12191 arXiv preprint.
- 101.Xu Y., Ma L., Yang F., Chen Y., Ma K., Yang J., et al. A collaborative online ai engine for ct-based covid-19 diagnosis. medRxiv. 2020 [Google Scholar]
- 102.Nasirigerdeh R., Torkzadehmahani R., Matschinske J., Frisch T., List M., Späth J., et al. sPLINK: a federated, privacy-preserving tool as a robust alternative to meta-analysis in genome-wide association studies. bioRxiv. 2020 doi: 10.1186/s13059-021-02562-1. 2020–06. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103.Qayyum A., Ahmad K., Ahsan M.A., Al-Fuqaha A., Qadir J. Collaborative federated learning for healthcare: multi-modal covid-19 diagnosis at the edge. IEEE Open J Comput Soc. 2022;3:172–184. [Google Scholar]
- 104.Li J., Meng Y., Ma L., Du S., Zhu H., Pei Q., et al. A federated learning based privacy-preserving smart healthcare system. IEEE Trans Ind Inform. 2021;18(3) [Google Scholar]
- 105.Zhou H., Lan T., Venkataramani G.P., Ding W. Every parameter matters: ensuring the convergence of federated learning with dynamic heterogeneous models reduction. Adv Neural Inf Process Syst. 2024;36 [Google Scholar]
- 106.Silva S., Gutman B.A., Romero E., Thompson P.M., Altmann A., Lorenzi M. 2019 IEEE 16th international symposium on biomedical imaging (ISBI 2019) IEEE; 2019. Federated learning in distributed medical databases: meta-analysis of large-scale subcortical brain data; pp. 270–274. [Google Scholar]
- 107.Lee J., Sun J., Wang F., Wang S., Jun C.-H., Jiang X., et al. Privacy-preserving patient similarity learning in a federated environment: development and analysis. JMIR Med Inform. 2018;6(2) doi: 10.2196/medinform.7744. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 108.Kim Y., Al Hakim E., Haraldson J., Eriksson H., da Silva J.M.B., Fischione C. ICC 2021-IEEE international conference on communications. IEEE; 2021. Dynamic clustering in federated learning; pp. 1–6. [Google Scholar]
- 109.Almufareh M.F., Tariq N., Humayun M., Almas B. A federated learning approach to breast cancer prediction in a collaborative learning framework. Healthcare. 2023;11(24) doi: 10.3390/healthcare11243185. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 110.Muthalakshmi M., Jeyapal K., Vinoth M., P S D., Murugan N.S., Sheela K.S. 2024 5th international conference on electronics and sustainable communication systems (ICESC) IEEE; 2024. Federated learning for secure and privacy-preserving medical image analysis in decentralized healthcare systems; pp. 1442–1447. [Google Scholar]
- 111.Sheller M.J., Reina G.A., Edwards B., Martin J., Bakas S. Multi-institutional deep learning modeling without sharing patient data: a feasibility study on brain tumor segmentation. Brainlesion: glioma, multiple sclerosis, stroke and traumatic brain injuries: 4th international workshop, BrainLes 2018, held in conjunction with MICCAI 2018, revised selected papers, Part I 4; Granada, Spain, September 16, 2018; Springer; 2018. pp. 92–104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 112.Gao D., Ju C., Wei X., Liu Y., Chen T., Yang Q. Hhhfl: hierarchical heterogeneous horizontal federated learning for electroencephalography. 2019. arXiv:1909.05784 arXiv preprint.
- 113.Sarwar S. Fedmentalcare: towards privacy-preserving fine-tuned llms to analyze mental health status using federated learning framework. 2025. arXiv:2503.05786 arXiv preprint.
- 114.Truex S., Baracaldo N., Anwar A., Steinke T., Ludwig H., Zhang R., et al. Proceedings of the 12th ACM workshop on artificial intelligence and security. 2019. A hybrid approach to privacy-preserving federated learning; pp. 1–11. [Google Scholar]
- 115.Hardy S., Henecka W., Ivey-Law H., Nock R., Patrini G., Smith G., et al. Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption. 2017. arXiv:1711.10677 arXiv preprint.
- 116.Dwork C. Differential privacy: a survey of results. Theory and applications of models of computation: 5th international conference. Proceedings 5; TAMC 2008, Xi'an, China, April 25-29, 2008; Springer; 2008. pp. 1–19. [Google Scholar]
- 117.Mo F., Haddadi H., Katevas K., Marin E., Perino D., Kourtellis N. Proceedings of the 19th annual international conference on mobile systems, applications, and services. 2021. Ppfl: privacy-preserving federated learning with trusted execution environments; pp. 94–108. [Google Scholar]
- 118.Gentry C. Stanford University; 2009. A fully homomorphic encryption scheme. [Google Scholar]
- 119.Pedrouzo-Ulloa A., Boudguiga A., Chakraborty O., Sirdey R., Stan O., Zuber M. 2023 IEEE international conference on cyber security and resilience (CSR) IEEE; 2023. Practical multi-key homomorphic encryption for more flexible and efficient secure federated average aggregation; pp. 612–617. [Google Scholar]
- 120.Zhou C., Ansari N. Securing federated learning enabled nwdaf architecture with partial homomorphic encryption. IEEE Netw Lett. 2023 [Google Scholar]
- 121.Gentry C. Computing arbitrary functions of encrypted data. Commun ACM. 2010;53(3):97–105. [Google Scholar]
- 122.https://www.microsoft.com/en-us/research/project/microsoft-seal/ Microsoft SEAL.
- 123.https://github.com/shaih/HElib HElib.
- 124.https://palisade-crypto.org/ Palisade.
- 125.Tran A.T., Luong T.D., Pham X.S. International symposium on integrated uncertainty in knowledge modelling and decision making. Springer; 2023. A novel privacy-preserving federated learning model based on secure multi-party computation; pp. 321–333. [Google Scholar]
- 126.Muazu T., Mao Y., Muhammad A.U., Ibrahim M., Kumshe U.M.M., Samuel O. A federated learning system with data fusion for healthcare using multi-party computation and additive secret sharing. Comput Commun. 2024;216:168–182. [Google Scholar]
- 127.Sahinbas K., Catak F.O. Interpretable cognitive Internet of things for healthcare. Springer; 2023. Secure multi-party computation-based privacy-preserving data analysis in healthcare iot systems; pp. 57–72. [Google Scholar]
- 128.Dankar F.K., El Emam K. Practicing differential privacy in health care: a review. Trans Data Priv. 2013;6(1):35–67. [Google Scholar]
- 129.Mohassel P., Zhang Y. 2017 IEEE symposium on security and privacy (SP) IEEE; 2017. Secureml: a system for scalable privacy-preserving machine learning; pp. 19–38. [Google Scholar]
- 130.Bagdasaryan E., Poursaeed O., Shmatikov V. Differential privacy has disparate impact on model accuracy. Adv Neural Inf Process Syst. 2019;32 [Google Scholar]
- 131.Cao X., Başar T., Diggavi S., Eldar Y.C., Letaief K.B., Poor H.V., et al. Communication-efficient distributed learning: an overview. IEEE J Sel Areas Commun. 2023 [Google Scholar]
- 132.Li B., Qi P., Liu B., Di S., Liu J., Pei J., et al. Trustworthy ai: from principles to practices. ACM Comput Surv. 2023;55(9):1–46. [Google Scholar]
- 133.Liu H., Zhou H., Chen H., Yan Y., Huang J., Xiong A., et al. A federated learning multi-task scheduling mechanism based on trusted computing sandbox. Sensors. 2023;23(4):2093. doi: 10.3390/s23042093. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 134.Cao Y., Zhang J., Zhao Y., Su P., Huang H. Srfl: a secure & robust federated learning framework for iot with trusted execution environments. Expert Syst Appl. 2024;239 [Google Scholar]
- 135.Qian Q., Jin R., Yi J., Zhang L., Zhu S. Efficient distance metric learning by adaptive sampling and mini-batch stochastic gradient descent (sgd) Mach Learn. 2015;99:353–372. [Google Scholar]
- 136.Patrikar S. Batch, mini batch and stochastic gradient descent. 2019. 2021. https://towardsdatascience.com/batch-mini-batch-stochastic-gradientdescent-7a62ecba642a
- 137.Arivazhagan M.G., Aggarwal V., Singh A.K., Choudhary S. Federated learning with personalization layers. 2019. arXiv:1912.00818 arXiv preprint.
- 138.Fallah A., Mokhtari A., Ozdaglar A. Personalized federated learning with theoretical guarantees: a model-agnostic meta-learning approach. Adv Neural Inf Process Syst. 2020;33:3557–3568. [Google Scholar]
- 139.Karimireddy S.P., Kale S., Mohri M., Reddi S., Stich S., Suresh A.T. International conference on machine learning. PMLR; 2020. Scaffold: stochastic controlled averaging for federated learning; pp. 5132–5143. [Google Scholar]
- 140.Li T., Sahu A.K., Talwalkar A., Smith V. Federated learning: challenges, methods, and future directions. IEEE Signal Process Mag. 2020;37(3):50–60. [Google Scholar]
- 141.Lin T., Kong L., Stich S.U., Jaggi M. Ensemble distillation for robust model fusion in federated learning. Adv Neural Inf Process Syst. 2020;33:2351–2363. [Google Scholar]
- 142.Reddi S., Charles Z., Zaheer M., Garrett Z., Rush K., Konečnỳ J., et al. Adaptive federated optimization. 2020. arXiv:2003.00295 arXiv preprint.
- 143.Wang J., Liu Q., Liang H., Joshi G., Poor H.V. Tackling the objective inconsistency problem in heterogeneous federated optimization. Adv Neural Inf Process Syst. 2020;33:7611–7623. [Google Scholar]
- 144.Xu J., Wang S., Wang L., Yao A.C.-C. Fedcm: federated learning with client-level momentum. 2021. arXiv:2106.10874 arXiv preprint.
- 145.Zhao H., Li Z., Richtárik P. Fedpage: a fast local stochastic gradient method for communication-efficient federated learning. 2021. arXiv:2108.04755 arXiv preprint.
- 146.Liu Y., Kang Y., Zhang X., Li L., Cheng Y., Chen T., et al. A communication efficient collaborative learning framework for distributed features. 2019. arXiv:1912.11187 arXiv preprint.
- 147.Xu R., Baracaldo N., Zhou Y., Anwar A., Joshi J., Ludwig H. Proceedings of the 14th ACM workshop on artificial intelligence and security. 2021. Fedv: privacy-preserving federated learning over vertically partitioned data; pp. 181–192. [Google Scholar]
- 148.Vepakomma P., Gupta O., Swedish T., Raskar R. Split learning for health: distributed deep learning without sharing raw patient data. 2018. arXiv:1812.00564 arXiv preprint.
- 149.Cheng K., Fan T., Jin Y., Liu Y., Chen T., Papadopoulos D., et al. Secureboost: a lossless federated learning framework. IEEE Intell Syst. 2021;36(6):87–98. [Google Scholar]
- 150.Chen C., Chen Z., Zhou Y., Kailkhura B. 2020 IEEE international conference on big data (big data) IEEE; 2020. Fedcluster: boosting the convergence of federated learning via cluster-cycling; pp. 5017–5026. [Google Scholar]
- 151.He C., Balasubramanian K., Ceyani E., Yang C., Xie H., Sun L., et al. Fedgraphnn: a federated learning system and benchmark for graph neural networks. 2021. arXiv:2104.07145 arXiv preprint.
- 152.Wang H., Yurochkin M., Sun Y., Papailiopoulos D., Khazaeni Y. Federated learning with matched averaging. 2020. arXiv:2002.06440 arXiv preprint.
- 153.Bonawitz K., Ivanov V., Kreuter B., Marcedone A., McMahan H.B., Patel S., et al. Practical secure aggregation for federated learning on user-held data. 2016. arXiv:1611.04482 arXiv preprint.
- 154.Reisizadeh A., Farnia F., Pedarsani R., Jadbabaie A. Robust federated learning: the case of affine distribution shifts. Adv Neural Inf Process Syst. 2020;33:21 554–21 565. [Google Scholar]
- 155.Dinh C.T., Tran N., Nguyen J. Personalized federated learning with Moreau envelopes. Adv Neural Inf Process Syst. 2020;33:21 394–21 405. [Google Scholar]
- 156.Wang F., Zhu H., Lu R., Zheng Y., Li H. A privacy-preserving and non-interactive federated learning scheme for regression training with gradient descent. Inf Sci. 2021;552:183–200. [Google Scholar]
- 157.Mills J., Hu J., Min G. 2021. Faster federated learning with decaying number of local sgd steps. [Google Scholar]
- 158.Zhao J., Zhu H., Wang F., Lu R., Li H., Tu J., et al. Cork: a privacy-preserving and lossless federated learning scheme for deep neural network. Inf Sci. 2022;603:190–209. [Google Scholar]
- 159.Pan Z., Wang S., Li C., Wang H., Tang X., Zhao J. Fedmdfg: federated learning with multi-gradient descent and fair guidance. Proc AAAI Conf Artif Intell. 2023;37(8):9364–9371. [Google Scholar]
- 160.Wang L., Guo Y., Lin T., Tang X. Delta: diverse client sampling for fasting federated learning. Adv Neural Inf Process Syst. 2024;36 [Google Scholar]
- 161.Zhao B., Liu X., Chen W.-N., Deng R. Crowdfl: privacy-preserving mobile crowdsensing system via federated learning. IEEE Trans Mob Comput. 2022 [Google Scholar]
- 162.Kadhe S., Rajaraman N., Koyluoglu O.O., Ramchandran K. Fastsecagg: scalable secure aggregation for privacy-preserving federated learning. 2020. arXiv:2009.11248 arXiv preprint.
- 163.Bonawitz K., Eichner H., Grieskamp W., Huba D., Ingerman A., Ivanov V., et al. Towards federated learning at scale: system design. Proc Mach Learn Syst. 2019;1:374–388. [Google Scholar]
- 164.https://github.com/FederatedAI/FATE FederatedAI/FATE. Federated AI Ecosystem. Available:
- 165.https://blog.openmined.org/tag/pysyft/ PySyft, OpenMined Blog. Available:
- 166.http://research.baidu.com/Blog/index-view?id=126 Baidu Research. Available:
- 167.https://sherpa.ai/technology/ Sherpa.ai Privacy-Preserving Artificial Intelligence Platform. Available:
- 168.He C., Li S., So J., Zeng X., Zhang M., Wang H., et al. Fedml: a research library and benchmark for federated machine learning. 2020. arXiv:2007.13518 arXiv preprint.
- 169.Wallace S.E., Gaye A., Shoush O., Burton P.R. Protecting personal data in epidemiological research: datashield and uk law. Publ Health Genom. 2014;17(3):149–157. doi: 10.1159/000360255. [DOI] [PubMed] [Google Scholar]
- 170.Wilson R., Butters O., Avraam D., Baker J., Tedds J., Turner A., et al. Datashield–new directions and dimensions. Data Sci J. 2017;16 [Google Scholar]
- 171.Aledhari M., Razzak R., Parizi R.M., Saeed F. Federated learning: a survey on enabling technologies, protocols, and applications. IEEE Access. 2020;8:140699–140725. doi: 10.1109/access.2020.3013541. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 172.Liu Y., Yuan X., Xiong Z., Kang J., Wang X., Niyato D. Federated learning for 6g communications: challenges, methods, and future directions. China Commun. 2020;17(9):105–118. [Google Scholar]
- 173.Mammen P.M. Federated learning: opportunities and challenges. 2021. arXiv:2101.05428 arXiv preprint.
- 174.Xiao B., Yu X., Ni W., Wang X., Poor H.V. Over-the-air federated learning: status quo, open challenges, and future directions. Fundam Res. 2024 [Google Scholar]
- 175.Mandal K., Gong G. Proceedings of the 2019 ACM SIGSAC conference on cloud computing security workshop. 2019. Privfl: practical privacy-preserving federated regressions on high-dimensional data over mobile networks; pp. 57–68. [Google Scholar]
- 176.Chen W., Ma G., Fan T., Kang Y., Xu Q., Yang Q. Secureboost+: a high performance gradient boosting tree framework for large scale vertical federated learning. 2021. arXiv:2110.10927 arXiv preprint.
- 177.Almanifi O.R.A., Chow C.-O., Tham M.-L., Chuah J.H., Kanesan J. Communication and computation efficiency in federated learning: a survey. Internet of Things. 2023;22 [Google Scholar]
- 178.Li Y., Li F., Yang S., Zhang C., Zhu L., Wang Y. A cooperative analysis to incentivize communication-efficient federated learning. IEEE Trans Mob Comput. 2024 [Google Scholar]
- 179.Rahimi M.M., Bhatti H.I., Park Y., Kousar H., Kim D.-Y., Moon J. Evofed: leveraging evolutionary strategies for communication-efficient federated learning. Adv Neural Inf Process Syst. 2024;36 [Google Scholar]
- 180.Konečnỳ J., McMahan H.B., Yu F.X., Richtárik P., Suresh A.T., Bacon D. Federated learning: strategies for improving communication efficiency. 2016. arXiv:1610.05492 arXiv preprint.
- 181.Suresh A.T., Felix X.Y., Kumar S., McMahan H.B. International conference on machine learning. PMLR; 2017. Distributed mean estimation with limited communication; pp. 3329–3337. [Google Scholar]
- 182.Jahani-Nezhad T., Maddah-Ali M.A., Li S., Caire G. 2022 IEEE international symposium on information theory (ISIT) IEEE; 2022. Swiftagg: communication-efficient and dropout-resistant secure aggregation for federated learning with worst-case security guarantees; pp. 103–108. [Google Scholar]
- 183.Luping W., Wei W., Bo L. 2019 IEEE 39th international conference on distributed computing systems (ICDCS) IEEE; 2019. Cmfl: mitigating communication overhead for federated learning; pp. 954–964. [Google Scholar]
- 184.https://www.sciencedirect.com/topics/engineering/golomb-code Golomb Code - an overview. Available:
- 185.Caldas S., Konečny J., McMahan H.B., Talwalkar A. Expanding the reach of federated learning by reducing client resource requirements. 2018. arXiv:1812.07210 arXiv preprint.
- 186.Chen M., Shlezinger N., Poor H.V., Eldar Y.C., Cui S. Communication-efficient federated learning. Proc Natl Acad Sci. 2021;118(17) doi: 10.1073/pnas.2024789118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 187.Sattler F., Wiedemann S., Müller K.-R., Samek W. 2019 international joint conference on neural networks (IJCNN) IEEE; 2019. Sparse binary compression: towards distributed deep learning with minimal communication; pp. 1–8. [Google Scholar]
- 188.Bonawitz K., Salehi F., Konečnỳ J., McMahan B., Gruteser M. 2019 53rd asilomar conference on signals, systems, and computers. IEEE; 2019. Federated learning with autotuned communication-efficient secure aggregation; pp. 1222–1226. [Google Scholar]
- 189.Abdelmoniem A.M., Ho C.-Y., Papageorgiou P., Canini M. A comprehensive empirical study of heterogeneity in federated learning. IEEE Internet Things J. 2023 [Google Scholar]
- 190.Wen D., Jeon K.-J., Huang K. Federated dropout—a simple approach for enabling federated learning on resource constrained devices. IEEE Wirel Commun Lett. 2022;11(5):923–927. [Google Scholar]
- 191.Naas S.-A., Sigg S. 2023 IEEE 97th vehicular technology conference (VTC2023-Spring) IEEE; 2023. Fast converging federated learning with non-iid data; pp. 1–6. [Google Scholar]
- 192.Lee H., Seo D. Fedlc: optimizing federated learning in non-iid data via label-wise clustering. IEEE Access. 2023 [Google Scholar]
- 193.Li Z., Sun Y., Shao J., Mao Y., Wang J.H., Zhang J. Feature matching data synthesis for non-iid federated learning. IEEE Trans Mob Comput. 2024 [Google Scholar]
- 194.Zhao Y., Li M., Lai L., Suda N., Civin D., Chandra V. Federated learning with non-iid data. 2018. arXiv:1806.00582 arXiv preprint.
- 195.Jeong E., Oh S., Kim H., Park J., Bennis M., Kim S.-L. Communication-efficient on-device machine learning: federated distillation and augmentation under non-iid private data. 2018. arXiv:1811.11479 arXiv preprint.
- 196.Li X., Huang K., Yang W., Wang S., Zhang Z. On the convergence of fedavg on non-iid data. 2019. arXiv:1907.02189 arXiv preprint.
- 197.Liu L., Zhang J., Song S., Letaief K.B. ICC 2020-2020 IEEE international conference on communications (ICC) IEEE; 2020. Client-edge-cloud hierarchical federated learning; pp. 1–6. [Google Scholar]
- 198.Zhou Z., Li Y., Ren X., Yang S. Towards efficient and stable k-asynchronous federated learning with unbounded stale gradients on non-iid data. IEEE Trans Parallel Distrib Syst. 2022;33(12):3291–3305. [Google Scholar]
- 199.Wu H., Wang P. Node selection toward faster convergence for federated learning on non-iid data. IEEE Trans Netw Sci Eng. 2022;9(5):3099–3111. [Google Scholar]
- 200.Hitaj B., Ateniese G., Perez-Cruz F. Proceedings of the 2017 ACM SIGSAC conference on computer and communications security. 2017. Deep models under the gan: information leakage from collaborative deep learning; pp. 603–618. [Google Scholar]
- 201.Jiang Y., Wang S., Valls V., Ko B.J., Lee W.-H., Leung K.K., et al. Model pruning enables efficient federated learning on edge devices. IEEE Trans Neural Netw Learn Syst. 2022 doi: 10.1109/TNNLS.2022.3166101. [DOI] [PubMed] [Google Scholar]
- 202.Lindell Y. Encyclopedia of data warehousing and mining. IGI Global; 2005. Secure multiparty computation for privacy preserving data mining; pp. 1005–1009. [Google Scholar]
- 203.Zhang K., Song X., Zhang C., Yu S. Challenges and future directions of secure federated learning: a survey. Front Comput Sci. 2022;16:1–8. doi: 10.1007/s11704-021-0598-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 204.Almadhoun N., Ayday E., Ulusoy Ö. Inference attacks against differentially private query results from genomic datasets including dependent tuples. Bioinformatics. 2020;36(Supplement_1) doi: 10.1093/bioinformatics/btaa475. i136–i145. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 205.Aono Y., Hayashi T., Wang L., Moriai S., et al. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans Inf Forensics Secur. 2017;13(5):1333–1345. [Google Scholar]
- 206.Zhang J., Zhang J., Chen J., Yu S. ICC 2020-2020 IEEE international conference on communications (ICC) IEEE; 2020. Gan enhanced membership inference: a passive local attack in federated learning; pp. 1–6. [Google Scholar]
- 207.Luo X., Wu Y., Xiao X., Ooi B.C. 2021 IEEE 37th international conference on data engineering (ICDE) IEEE; 2021. Feature inference attack on model predictions in vertical federated learning; pp. 181–192. [Google Scholar]
- 208.Muñoz-González L., Biggio B., Demontis A., Paudice A., Wongrassamee V., Lupu E.C., et al. Proceedings of the 10th ACM workshop on artificial intelligence and security. 2017. Towards poisoning of deep learning algorithms with back-gradient optimization; pp. 27–38. [Google Scholar]
- 209.Fang M., Cao X., Jia J., Gong N.Z. Proceedings of the 29th USENIX conference on security symposium. 2020. Local model poisoning attacks to Byzantine-robust federated learning; pp. 1623–1640. [Google Scholar]
- 210.Bagdasaryan E., Veit A., Hua Y., Estrin D., Shmatikov V. International conference on artificial intelligence and statistics. PMLR; 2020. How to backdoor federated learning; pp. 2938–2948. [Google Scholar]
- 211.Sun Z., Kairouz P., Suresh A.T., McMahan H.B. Can you really backdoor federated learning? 2019. arXiv:1911.07963 arXiv preprint.
- 212.Liu K., Dolan-Gavitt B., Garg S. Fine-pruning: defending against backdooring attacks on deep neural networks. Research in attacks, intrusions, and defenses: 21st international symposium. Proceedings 21; RAID 2018, Heraklion, Crete, Greece, September 10-12, 2018; Springer; 2018. pp. 273–294. [Google Scholar]
- 213.Shafahi A., Huang W.R., Najibi M., Suciu O., Studer C., Dumitras T., et al. Poison frogs! Targeted clean-label poisoning attacks on neural networks. Adv Neural Inf Process Syst. 2018;31 [Google Scholar]
- 214.Blanchard P., El Mhamdi E.M., Guerraoui R., Stainer J. Machine learning with adversaries: Byzantine tolerant gradient descent. Adv Neural Inf Process Syst. 2017;30 [Google Scholar]
- 215.Chen Y., Su L., Xu J. Distributed statistical machine learning in adversarial settings: Byzantine gradient descent. Proc ACM Meas Anal Comput Syst. 2017;1(2):1–25. [Google Scholar]
- 216.Wu Z., Ling Q., Chen T., Giannakis G.B. Federated variance-reduced stochastic gradient descent with robustness to Byzantine attacks. IEEE Trans Signal Process. 2020;68:4583–4596. [Google Scholar]
- 217.Mhamdi E.M.E., Guerraoui R., Rouault S. The hidden vulnerability of distributed learning in byzantium. 2018. arXiv:1802.07927 arXiv preprint.
- 218.Liu D., Miller T., Sayeed R., Mandl K.D. Fadl: federated-autonomous deep learning for distributed electronic health record. 2018. arXiv:1811.11400 arXiv preprint.
- 219.Kim Y., Sun J., Yu H., Jiang X. Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 2017. Federated tensor factorization for computational phenotyping; pp. 887–895. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 220.Schneble W. 2018. Federated learning for intrusion detection systems in medical cyber-physical systems. Ph.D. dissertation. [Google Scholar]
- 221.Zhang F., Shuai Z., Kuang K., Wu F., Zhuang Y., Xiao J. Unified fair federated learning for digital healthcare. Patterns. 2024;5(1) doi: 10.1016/j.patter.2023.100907. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 222.Wang B., Li H., Guo Y., Wang J. Ppflhe: a privacy-preserving federated learning scheme with homomorphic encryption for healthcare data. Appl Soft Comput. 2023;146 [Google Scholar]
- 223.Xia Q., Tao Z., Hao Z., Li Q. IJCAI. 2019. Faba: an algorithm for fast aggregation against Byzantine attacks in distributed neural networks. [Google Scholar]
- 224.El-Mhamdi E.-M., Guerraoui R., Rouault S. 2020 international symposium on reliable distributed systems (SRDS) IEEE; 2020. Fast and robust distributed learning in high dimension; pp. 71–80. [Google Scholar]
- 225.Xie C., Koyejo S., Gupta I. International conference on machine learning. PMLR; 2020. Zeno++: robust fully asynchronous sgd; pp. 10 495–10 503. [Google Scholar]
- 226.Alalawi M., Madathil N.T., Darota S.K., Abula W., Alrabaee S., Melhem S.B. 2024 IEEE frontiers in education conference (FIE) IEEE; 2024. Evaluating and boosting cybersecurity awareness with an ai-integrated mobile app; pp. 1–9. [Google Scholar]
- 227.Mondal A., More Y., Rooparaghunath R.H., Gupta D. 2021 IEEE European symposium on security and privacy (EuroS&P) IEEE; 2021. Poster: flatee: federated learning across trusted execution environments; pp. 707–709. [Google Scholar]
- 228.Ku H., Susilo W., Zhang Y., Liu W., Zhang M. Privacy-preserving federated learning in medical diagnosis with homomorphic re-encryption. Comput Stand Interfaces. 2022;80 [Google Scholar]
- 229.Park J., Lim H. Privacy-preserving federated learning using homomorphic encryption. Appl Sci. 2022;12(2):734. [Google Scholar]
- 230.Jung K., Baek I., Kim S., Chung Y.D. Lafd: local-differentially private and asynchronous federated learning with direct feedback alignment. IEEE Access. 2023 [Google Scholar]
- 231.Liu P., Xu X., Wang W. Threats, attacks and defenses to federated learning: issues, taxonomy and perspectives. Cybersecurity. 2022;5(1):1–19. [Google Scholar]
- 232.Gu X., Li M., Xiong L. Precad: privacy-preserving and robust federated learning via crypto-aided differential privacy. 2021. arXiv:2110.11578 arXiv preprint.
- 233.Xie C., Koyejo S., Gupta I. Asynchronous federated optimization. 2019. arXiv:1903.03934 arXiv preprint.
- 234.Thummisetti B.S.P., Atluri H. Advancing healthcare informatics for empowering privacy and security through federated learning paradigms. Int J Sustain Dev Comput Sci. 2024;1(1):1–16. [Google Scholar]
- 235.Dasaradharami Reddy K., Gadekallu T.R., et al. A comprehensive survey on federated learning techniques for healthcare informatics. Comput Intell Neurosci. 2023;2023 doi: 10.1155/2023/8393990. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 236.Gupta A., Misra S., Pathak N., Das D. Fedcare: federated learning for resource-constrained healthcare devices in iomt system. IEEE Trans Comput Soc Syst. 2023 [Google Scholar]
- 237.Ghosh S., Ghosh S.K. Feel: federated learning framework for elderly healthcare using edge-iomt. IEEE Trans Comput Soc Syst. 2023 [Google Scholar]
- 238.Sezer B.B., Turkmen H., Nuriyev U. Ppfchain: a novel framework privacy-preserving blockchain-based federated learning method for sensor networks. Internet Things. 2023;22 [Google Scholar]
- 239.Wang J., Charles Z., Xu Z., Joshi G., McMahan H.B., Al-Shedivat M., et al. A field guide to federated optimization. 2021. arXiv:2107.06917 arXiv preprint.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Usually, within an FL-distributed data set framework, potential clients include organizations such as hospitals and banks or mobile and edge equipment, including wearable devices, routers, and integrated access devices. The “cross-silo” and “cross-device” architectures represent two primary design architectures for federation in FL systems. The cross-silo scheme typically involves some relatively reliable clients, while the cross-device scheme includes numerous clients. In the cross-silo approach, participating organizations, such as hospitals, collaborate to train a model using their private data, and each entity participates in all computation rounds [68], [69]. Meanwhile, the cross-device scheme involves multiple clients, each with their private data. All devices within this framework-including mobile and wearable devices-can be active or inactive at any timepoint, with device inactivity primarily resulting from several issues such as power loss or network concerns [70]. Within this scheme, clients are often active and participate in one round of computation. Consequently, a new set of active clients contributes their local data for model training in each round. In particular, both schemes execute model training without sharing individual private data. Table 5 compares the cross-silo and cross-device architectures. In general, cross-silo structures are widely adopted by organizations, while cross-device structures are used in mobile devices [65]. Furthermore, cross-silo structures demonstrate strong hardware capacities, better storage capabilities, and better performance than cross-device structures. Cross-silo structures typically deal with nonindependent and identically distributed (nonIID) data, with all clients being active participants. These architectures are powerful and have fewer failures, making them more stable than cross-device structures. However, cross-silo architectures are only scalable over a relatively small number of clients (approximately 2-100).
Table 5.
Comparison between FL schemes.
| Properties | Cross-Silo | Cross-Devices |
|---|---|---|
| Entities | Hospitals/ Organizations | Mobile/ IoT devices/ Wearable devices |
| Performance | High | Low |
| Scale | Relatively small [15] | Large |
| Stability | High stability [43] | Low stability |
| Communication reliability | Reliable – All clients participate in communication [14] | Unreliable – Communication of some clients may be lost during computation [15] |
| Number of clients | Typically, around 2-100 | Very large (millions) |
| Participation of clients for the computation | All clients in the communication should participate | Fraction of the clients only participates in the computation |
| Data distribution | Usually, non-IID | Usually, IID |
| Primary bottleneck | Computation/ communication | Communication. (Uses wi-fi or slower connections) [15] |
| Stateful/stateless | Clients are Stateful- They save the models of the previous round [16] | Clients are Stateless- do not save previous round information [16] |
| Reliability | Clients have comparatively few failures [43] | Clients are highly unreliable |
| Computation power | Entities often have high computation power | The only central server is assumed to have high computation power. |