

Abstract
The COVID-19 pandemic was accompanied by a marked increase in the use of music listening for self-regulation. During these challenging times, listeners reported they used music ‘to keep them company’; indicating that they may have turned to music for social solace. However, whether this is simply a figure of speech or an empirically observable effect on social thought that extends into mental imagery was previously unclear, despite its great potential for applications. Here, six hundred participants were presented with silence or task-irrelevant folk music in Italian, Spanish, or Swedish while performing a directed mental-imagery task in which they imagined a journey towards a topographical landmark. To control and differentiate possible effects of vocals and semantics on imagined content, the music was presented with or without vocals to the participants, of which half were native speakers and the other half non-speakers of the respective languages. As in previous studies, music, compared to silence, led to more vivid imagination and shaped emotional sentiment of the imagined content. In addition, we show that social interactions emerged as a clear thematic cluster in participants’ descriptions of their imagined content through Latent Dirichlet Allocation. Moreover, Bayesian Mixed effects models revealed that music increased imagined social content compared to silent baseline conditions. This effect remained robust irrespective of vocals or language comprehension. Using stable diffusion, we generated visualisations of participants’ imagined content. In a second experiment, a new group of participants’ ability to differentiate between visualisations of content imagined during silence and music listening increased when they listened to the associated music. Results converge to show that music, indeed, can be good company.
Keywords: Social interaction, Music, Imagination, Mental imagery
Subject terms: Human behaviour, Psychology
Introduction
Music can affect thought. It can evoke autobiographical memories1,2modulate emotions3 and induce mental imagery during unintentional mind-wandering4. In particular, mental imagery5 is commonly experienced during music listening. 57% of personal music listening episodes in everyday life is accompanied by mental imagery6, 73% of respondents in controlled lab environments report vivid imagery during music7, and 83% of attendees report that they regularly experience mental imagery during live-concerts8. In addition to affecting the prevalence of mental imagery, music can also affect imagined content.
Compared to silence, content imagined during music listening is more vivid and its emotional sentiment can change9,10. The content imagined often forms elaborate narratives and tends to occur at similar time points in the music across listeners11. Not only the ‘when’ but also the ‘what’ of music-induced mental imagery shows similarities among listeners12. Manual annotations of music-induced imagery reveal that it is often visual13 and contains scenes of nature or abstract shapes, colours, or objects14. Such convergence of imagined narratives during music appears even tighter when listeners share a cultural background15.
Furthermore, studies investigating music consumption during COVID-19-related lockdowns reported an increase in time devoted to music listening and reported that music was used for relaxation, mood modulation, escapism, and ‘to keep them company’16–20 (for a review see21). These are not isolated instances, as most of the 1868 Spanish citizens sampled in a recent study reported that they valued music ‘a lot’ (58.1%) or ‘often’ (25.7%) for its social company during the lockdowns18. In summary, these findings suggest that – in addition to affecting memory, modulating emotions, and supporting mental imagery – the thoughts induced during music listening might be related to sociality (also see22). This has important implications for evidence-based cognitive therapies that make use of intentional imagination, such as imagery rescripting23 and imagery exposure therapy24. Should music indeed be shown to systematically induce themes of social interaction into imagined content, then music-based paradigms that induce directed, intentional imagery would be a promising candidate in therapeutic and recreational settings to potentially aid cognitive therapy, alleviate loneliness, and build social confidence.
Support for music’s potential to influence social thought comes from the literature on music-evoked autobiographical where the word category most strongly represented is ‘social’ (10.8%)25. Compared to other autobiographical memory cues such as television26, social content in music-evoked memories is increased, though still less so than in others cues such as faces27 (also see28). However, though autobiographical memory can utilise mental imagery during recall29, mental imagery and memory are distinct processes and findings do not readily generalise30,31, in particular when considering intentional mental imagery of a novel scenario9 as commonly done in clinical settings32. In the context of mental imagery specifically, a recent study33 drew from previously published data to compare the content imagined during silence or music listening in a directed mental imagery task. One of their findings provided preliminary evidence that music, compared to silence, increases the frequency of words related to ‘social clout’. This is a promising lead, however, in their analysis the authors used a small set of pre-defined word categories (including ‘social clout’) rather than an agnostic bottom-up approach that does not pre-specify the word categories. In addition, as the study drew from existing data, they had no control over the musical stimuli or participants, could not test potential effects of lyrics, and note in their discussion the need for new, designated empirical studies specifically designed to explore music’s potential to induce thoughts of social interaction into mental imagery. Here, we provide a proof-of-thought investigation into whether music can shape mental imagery and, specifically, induce thoughts of social interaction into imagined content. We do not aim to show that all music does this, and we also do not aim to show that only music and no other stimuli have this capacity. Instead, in two experiment, we here aim to explicitly address empirically whether there is merit to the notion of ‘music as company’, because if there is, then this would have great applicational value for mental imagery techniques in recreational, professional, and clinical use23,34–42 which commonly occurs in silence.
Thus, in Experiment 1, we here sought to empirically test potential effects of music on imagined social content, whilst controlling for potential effects of the presence of vocals as well as the participants’ semantic understanding of the lyrics, using a directed mental imagery paradigm (Fig. 1). Participants described quantitative (vividness, imagined time passed, imagined distance travelled) and qualitative experiences (free format description) of their mental imagery after imagining a journey towards a landmark. During the mental imagery, participants listened to a silent baseline condition as well as six different music conditions. We examined songs in three different languages (Italian, Spanish, and Swedish), and tested them with and without lyrics, with both 100 native- and 100 non-speakers for each of respective language (600 participants in total). We used an intentional — rather than unintentional — imagery paradigm to facilitate the generalisation of our results to therapeutic settings. The free format responses were analysed through bottom-up natural language processing.
Fig. 1.
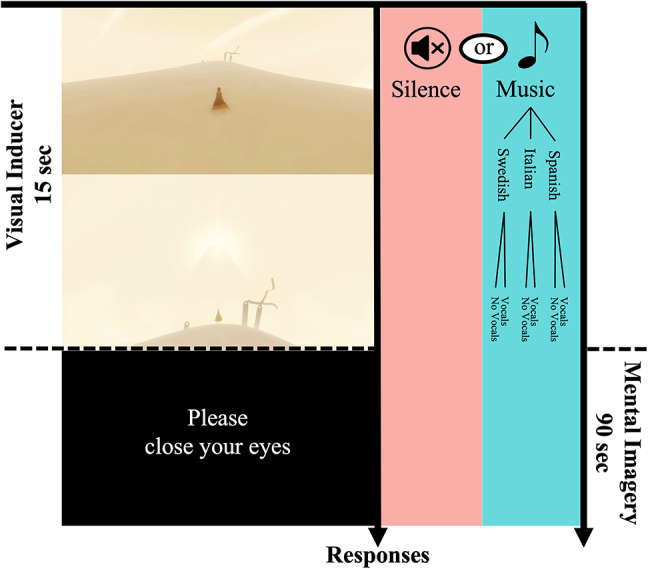
Schematic of the experimental paradigm. Participants viewed a 15-second-long visual inducer video. In the video, a figure ascends a small hill (top left). Once the figure reaches the top of the hill, a large mountain appears in the far distance, barely visible (middle left). Participants then heard a gong and were prompted to close their eyes and imagine a continuation of the figure’s journey towards the mountain. During the 90-second-long mental imagery phase, participants either listened to silence or music. Afterwards, they heard the gong again, prompting them to open their eyes and provide answers to a series of questions about vividness, imagined time passed, imagined distance travelled, and a free format description of their mental imagery before the next trial started. We collected data from 600 participants, split across the Spanish, Italian, and Swedish songs respectively. For each set of stimuli, we tested both the original songs, as well as versions that had the vocals removed through a source separation algorithm. For each language, we tested 100 native speakers, and 100 non-speakers of the respective language.
In Experiment 2, we used stable diffusion to visualise the content participants imagined in Experiment 1. In order to test whether there is a shared understanding of how music might influence mental imagery of others, we then presented 762 pairs of the generated images to 60 new participants. In each image pair, one image was based on a description obtained during a silent baseline trial, and one of the images was derived from description of the same prior participant of Experiment 1 during a music trial. For each pair, participants in Experiment 2 then chose which image was inspired by music as opposed to silence. Half of the participants performed the task in silence, whilst the other half listened to the original music used in Experiment 1 whilst performing the task (for more detail on the tasks, see the Method section).
Results
Experiment 1
Music influences vividness, sentiment, time, and distance imaged
Using Bayesian Mixed effects models and undirected hypothesis tests, we observed strong evidence (i.e., Evidence Ratios ≥ 39 for undirected hypothesis tests are denoted with ‘*’, see43) that music predicts higher vividness (β = 0.46, EE = 0.03, Odds(β > 0) > 9999*, Fig. 2A), more positive sentiment (β = 0.41, EE = 0.04, Odds(β > 0) > 9999*, Fig. 2B), more imagined time passed (β = 0.24, EE = 0.04, Odds(β > 0) > 9999*, Fig. 2C), and larger imagined distances travelled (β = 0.44, EE = 0.04, Odds(β > 0) > 9999*, Fig. 2D). We calculated Effective False Discovery Rate (EFDR), which is a Bayesian approach to report the probability of observing a False Positive, given the evidence and number of tests performed. Here, the EFDR for the two-sided tests performed was 0.0001, far below the convention of 0.05.
Fig. 2.

Posteriors distributions of expected predictions for standardised effects for Vividness (A), Sentiment (B), Time passed (C), and Distance travelled (D) in participants’ imagined journeys based on whether participants were listening to music (blue,  ) or not (red,
) or not (red,  ).
).
Imagined topics differ between silence and music
We analysed the content of the 4200 free format reports of imagined journeys using Latent Dirichlet Allocation44 — an unsupervised, bottom-up topic modelling approach to identify latent topic structures— with a nine-topic solution (based on45). For four of the topics (see Fig. 3 left, Topics I, II, V, and VI), we obtained strong evidence for differences between music and silent trials.
Fig. 3.

Topic weights by condition (left) and proportion of reports in which the topic was the predominant topic (right, separately for silence  , music
, music  , and both conditions combined
, and both conditions combined  +
+  ). Topics weights I, II, V, and VI differ significantly (*) between participants’ descriptions of their imagined journeys generated during silence (red,
). Topics weights I, II, V, and VI differ significantly (*) between participants’ descriptions of their imagined journeys generated during silence (red,  ) compared to those generated whilst listening to music (blue,
) compared to those generated whilst listening to music (blue,  ). Topic I is the predominant topic most commonly during music, and also shows the greatest difference between silent and music trials. Follow-up analysis (see Fig. 4) reveals that this topic is associated with themes pertaining to social interactions.
). Topic I is the predominant topic most commonly during music, and also shows the greatest difference between silent and music trials. Follow-up analysis (see Fig. 4) reveals that this topic is associated with themes pertaining to social interactions.
The largest difference was observed in Topic I, a distinct topic containing words related to social interactions (see Fig. 4A). We observed strong evidence that music was predictive of an increase in this topic (Topic I, e.g., “people”, “village”, “town”, “friend”, β = 0.43, EE = 0.04, Odds(β > 0) > 9999*). The only other topic which was also more dominant in the music compared to the silence conditions was a topic that contained predominantly words related to heroic adventures, (Topic II, Fig. 4B, e.g., “find”, “final”, “hope”, “fight”, “sword”, β = 0.13, EE = 0.04, Odds(β > 0) = 1999*). On the other hand, two clusters that were more prominent in the silence compared to the music conditions focused on words related to the task context, in terms of general features of the visual inducer video (Topic V, Fig. 4C, e.g., “walk”, “sand”, β = −0.31, EE = 0.04, Odds(β < 0) > 9999*) and other aspects explicitly mentioned in the task instructions (Topic VI, Fig. 5D, e.g., “hill”, “figure”, “gong”, β = −0.19, EE = 0.04, Odds(β < 0) > 9999*). The EFDR for the two-sided tests performed on this model was 0.000125.
Fig. 4.

Posterior distribution of the predicted effect of listening condition on the four topics (left) that showed a significant difference between music (red,  ) and silence (blue,
) and silence (blue,  ), as well as importance weighted word clouds (right), associated with the respective topic. Note, the spelling of some words is off, as all words were lemmatised and stemmed prior to analysis. Topics 3, 4, 7, 8, and 9 did not differentiate between music and silent trials and are therefore not shown here. However, word clouds for these topics can be found in the online supplement https://osf.io/jgce6/.
), as well as importance weighted word clouds (right), associated with the respective topic. Note, the spelling of some words is off, as all words were lemmatised and stemmed prior to analysis. Topics 3, 4, 7, 8, and 9 did not differentiate between music and silent trials and are therefore not shown here. However, word clouds for these topics can be found in the online supplement https://osf.io/jgce6/.
Fig. 5.

Social topic weight in the imagined content by auditory condition, the presence of vocals, and participants’ language proficiency for the language of the lyrics used in the study they are participating in (Spanish, Italian, or Swedish). Compared to silence, the majority (83%) of all music conditions show higher social topic weights in participants’ imagined journeys (indicated by ‘*’).
The increase in the social interaction topic weight was consistent across conditions. In particular, we did not find strong evidence for a general effect of vocals vs. no vocals, nor general effects or interaction based on whether participants were native speakers of the language used in the lyrics of the respective study they participated in (all Odds < 16.24). Furthermore, we performed directed hypothesis tests for each song to assess whether there was a higher social topic weight during the song compared to the silent baseline (i.e., Evidence Ratios ≥ 19 for directed hypothesis tests are denoted with ‘*’ in Fig. 5). We observed strong evidence for this in 30 out of the 36 music conditions tested (83%). The precise musical piece played seemed to further fine-tune the effect, with some songs showing much higher social topic weights than others (e.g., ITA-3 vs. ITA-1, β = 1.09, EE = 0.13, Odds(β > 0) = 3999*).
Whilst a detailed musical analysis of all stimuli is beyond the scope of this brief report, ITA-3, in particular, is an interesting case, as it is the only piece showing compelling evidence for an interaction between vocals and language proficiency, whereby the presence of vocals drastically increased the social topic weight, but only if the listener spoke the language (β = 0.44, EE = 0.18, Odds(β > 0) = 149.4*). The explanation might well lie in the specific lyrics of the piece (ITA-3: Nanni ‘Na gita a li castelli’), which describe social activities around vineyards. The EFDR for the one-sided tests performed on this model was 0.00639.
Musical expertise shows only minimal effects
We did not observe that musical expertise affects or interacts with whether music or silence was present in terms of vividness, sentiment, or the social topic weight of the imagined content (all Odds < 11.23). However, we observed that as musical expertise increased, so did the imagined time passed (β = 0.14, EE = 0.04, Odds(β > 0) > 9999*) and distance travelled (β = 0.7, EE = 0.04, Odds(β > 0) = 33.19*). Intriguingly, this was only observed in the silent but not in the music condition (Time β = −0.02, EE = 0.02, Odds(β > 0) = 0.13; Distance β = − 0.01, EE = 0.02, Odds(β > 0) = 0.2).
Experiment 2
Stable diffusion visualisation of imagined content captures the social topic
To provide readers with an intuitive understanding of the difference between the content imagined in the music and silent conditions, we used a stable diffusion model to visualise participants’ imagined content. Figure 6 (top) shows an example visualisation obtained from a participant’s free-format response in the silent and music conditions. Figure 6 (bottom) shows differences between the silent and music condition based on the latent structure the Latent Dirichlet Allocation identified across all three stimulus sets in Experiment 1. For this, the words contained within the nine topics identified by the Latent Dirichlet Allocation and weighted by their respective weights were further adjusted by the specific weight the music or silent condition attached to the respective topic. This means that the bottom row visualises what constitutes a representative, or stereotypical image for the silence and music conditions, based on the Latent Dirichlet Allocation weights. This bottom-up visualisation approach seems to capture the increased prevalence of social interaction across the three stimulus sets.
Fig. 6.

Visualisations obtained through stable diffusion. The top row shows visualisations from one participant’s free-format responses. The participant (ItaS1) described their mental imagery in the silence condition as ‘I imagined a dark walk, without emotions, alone, looking for some hope’, and in the music condition (ITA-2) as ‘I imagined a walk in the mountains with my family, all together, happy and carefree, we played, we laughed’. For the images in the bottom row, the stable diffusion model was provided with the average weight distributions across all three stimulus sets, for the respective words of the latent topics, separately for the music and silence conditions. This means that the words and prompt provided to the stable diffusion model in the bottom row are identical between the silence and music visualisation, only the weights for the words differ based on the quantitative results above.
The stable diffusion primarily serves as intuitive visualisation of our findings and not as inference itself (which we provided above). However, the resulting visualisations do seem to capture both the findings presented above, as well as findings of additional manual annotations of the data set that report generally darker (4% of Music and 12% of Silence trials describe dark settings or the absence of colour), less pleasant temperatures (5% of Music vs. 11% of Silence trials contain description of very hot or very cold temperatures), and less social (39% of Music vs. 12% of Silence trials contain social interactions) imagery in the silence compared to the music conditions. The online supplement (https://osf.io/jgce6/), contains rendered images based on each of the 4200 imaginary journeys, to provide readers with further intuitions of the differences between imagination during music listening and silence, and offer a rich dataset of written and visualised accounts of mental imagery for future studies.
Participants can differentiate stable diffusion visualisations of content imagined during music and silence, but only when listening to music
To explore whether there is a shared understanding of how music might influence mental imagery of other human listeners, and if so, whether the stable-diffusion images are able to capture this, we conducted another experiment. Sixty participants who did not participate in Experiment 1 and were sampled from a different population were presented with the stable diffusion images. In each trial, they saw one image generated of the description of the imagined content during the silent condition, and one of a music condition of the same participant. They were then asked to click on the image they thought represented the content the original participant imagined whilst listening to music. Half of the new participants completed the task in silence, whilst the other half completed the task whilst listening to the music associated with the image coming from the music condition. As shown in Fig. 7, the task was overall challenging for participants; and we did not observe compelling evidence that participants were able to perform above chance in silence condition (β = 0.07, EE = 0.04, Odds(β > 0) = 17.95). When participants listened to the original music, however, performance was increased (β = 0.22, EE = 0.06, Odds(β > 0) = 2665*), and we obtained strong evidence that they were able to perform the task (β = 0.29, EE = 0.05, Odds(β > 0) > 9999*). At the same time, in a free format voluntary response box inquiring about participants’ decision-making process, 20% of the participants in the music condition reported using the number of people shown in the images as a strategy, compared to only 13.33% in the silent condition (all responses available on https://osf.io/jgce6/).
Fig. 7.

Performance (left) and posterior distribution of expected predictions (right) for differentiating stable diffusion visualisation of content imagined during silence from that imagined during music. The new participants only performed above chance if they were listening to the music (blue,  ) that the original participants heard and not silence (red,
) that the original participants heard and not silence (red,  ) whilst performing the mental imagery task. Error bars indicate 95% CIs.
) whilst performing the mental imagery task. Error bars indicate 95% CIs.
Discussion
Many individuals reported turning to music for social solace during the COVID-19 pandemic16–19,21, however, whether this is a figure of speech or an empirically observable effect on social thought had not yet been tested in the context of deliberate mental imagery. For the first time, we now demonstrate that this is not simply a figure of speech, but that music can indeed induce themes of social interactions into listeners’ thoughts in a directed mental imagery task. Across a study on mental imagery that tested six hundred participants across three distinct stimulus sets, a clear topic related to social interactions emerged bottom-up from participants’ reported imagery, using an agnostic methodology in the form of Latent Dirichlet Allocation. Prevalence of this social topic was significantly raised in reports of mental imagery obtained when participants listened to music compared to silence. This result was robust and visible in most individual songs tested. Themes of social interactions were increased in music compared to silence, even when the listeners did not speak the language of the lyrics, excluding linguistic engagement and comprehension as an explanation. Furthermore, versions of the songs with the vocals removed entirely did not lead to a systematic decrease in the imagined social interactions, making the presence of the human voice also unlikely as an explanation for the observed effect. This provides empirical credibility and a concrete manifestation to the intuition that music provides social solace, as it does appear to facilitate social thought, which further supports a social function of music46.
It is reasonable to assume that music’s ability to induce social interactions into mental imagery is subject to the precise music selected and individual tested. Yet, the observed effects of music seem to generalise relatively well across the experimental conditions. Here, we tested a diverse set of stimuli and participants with varied cultural backgrounds, and we generally found qualitatively darker, colder, and less social imagery in silence compared to music. Furthermore, similar to previous studies, mental imagery during music listening was also more vivid and more positive in sentiment compared to silence9,10. This is of particular interest, as we tested intentional, directed imagery, akin to that utilised in recreational contexts such as roleplay47 or in clinical contexts48,49. This highlights music’s potential to support existing and emerging uses of mental imagery. For example, vividness of mental imagery in imagery exposure therapy is a predictor of treatment efficacy36 and fine emotional control of imagined content is key in imagery rescripting therapy23, and here we show that both –vividness and sentiment– can be affected by task-irrelevant music.
In addition, the present work also replicates previous findings that music can be used to shape spatio-temporal properties of the imagined content9,10. The phenomenon that music can affect judgements of time and distance has long been explored in the perception of physically present stimuli50(see51 for a review). With the growing evidence that this seems to generalise to mental imagery as well comes the possibility that music might be used in both therapeutic and recreational contexts to shape spatio-temporal aspects of imagined narratives. For example, by supporting imagined narrative that deliberately put large distances in both time and space between a client and a traumatic experience9.
It is important to note that music selection here was influenced by the authors’ familiarity and language proficiency as well as limited by the practical considerations of how many stimuli and participants could realistically be tested. We also deliberately used music from the folk genre in this proof-of-concept study, due to its tendency to be culturally idiomatic and having a strong history in use with themes of social interactions52. Whilst both songs and participants tested here span a diverse spectrum, generalisability to other musical styles and cultural contexts not tested here –in particular non-Western ones– requires further exploration. Nevertheless, the question of generalisability does not stand in the way of the main finding of this study, which is that music can influence mental imagery and induce themes of social interaction. Which music works best for this purpose, and which one does not, as well as how music selection or specific musical features interact with particular audiences are important questions for future empirical work. Such research would allow us to deepen our understanding of mental imagery and would open more, diverse, and better tailored ways of supporting recreational and clinical use of mental imagery techniques. For applicational purposes, however, it is relevant that music (and especially, by definition, respective folk music) is something that humans across cultures are familiar with and exposed to spontaneously as part of ecological cultural practices53, potentially easing stimulus generation to support mental imagery. We hope the present study can serve as a foundation for this expanding research, whilst inspiring the music community to creatively explore ways to shape mental imagery.
In an additional step, we used stable diffusion to visualise a representation of participants’ mental imagery. This step allowed for the visualisation of aspects of each participant’s individual mental imagery. This also allowed for the generation of a consensus visual representation of content imagined across participants in the two conditions based on the topic weights identified by the Latent Dirichlet Allocation. We propose this as a convenient method to allow researchers and readers to generate an intuitive understanding of the differences between conditions that could easily be applied to existing and upcoming mental imagery studies to complement the statistical analysis. We also showed that participants were able to differentiate above chance between visual representations of mental imagery generated during music listening from those generated during silence. However, we only obtained strong evidence for this when participants doing the differentiation task were also listening to the music that imagining participants had previously listened to. This supports previous findings that participants possess some insight of what other participants might imagine whilst listening to music54. However, overall, the performance in this task was comparably low. This is likely because this theory of mind of other participants’ music-induced imagined content had to survive two layers of abstraction. First, the abstraction from mental imagery to written responses, followed by the second abstraction in form of the stable diffusion visualisation of the written responses. We consider it remarkable that above chance performance was still possible after these two layers of abstractions paired with inter-individual as well as cultural differences between participants that did the mental imagery task and those that did the matching task. This observation highlights that stable diffusion could be a useful tool to represent participants’ imagined content.
Future research will have to further investigate the precise underlying musical and acoustic features responsible for music’s ability to affect mental imagery and induce themes of social interactions therein. A thorough understanding of the relevant underlying parameters would enable targeted or even adaptive music composition to affect mental imagery in recreational and clinical settings and would further improve listeners’ access to social solace through music. To this end, we hope that our publicly available data set containing imagery, vividness, sentiment, imagined time travelled, imagined time passed, free format responses, Latent Dirichlet Allocation, topic weights, manual annotations, and corresponding stable diffusion visualisations of all 4200 imagined journeys will prove useful for future research (https://osf.io/jgce6/). Overall, it seems music can indeed be good company.
Method
Participants
Data collection of the mental imagery task in Experiment 1 was split into three parts, each differing in the stimuli tested (music in Spanish, Italian, or Swedish). For each part, we tested 100 native-speakers of the respective language, and 100 non-speakers of the language, for a total of 600 participants across the three parts. Only submissions without missing responses were accepted. All participants were required to be fluent in English and to have normal or corrected-to-normal hearing. We recruited participants through Prolific Academia as it provides access to international samples and offers language proficiency filters. Table 1 provides further descriptive information on each participant sample. Participation was reimbursed with 10 GBP and all participants provided informed consent. The study received ethics approval from the institutional review board of the École Polytechnique Fédérale de Lausanne (067-2020/02.10.2020), as well as Western Sydney University (H14358).
Table 1.
Overview of participant samples.
| Exp. | Language | Speaker | N | Mean Age(SD, MinMax). Gender | Nationality (%) |
|---|---|---|---|---|---|
| 1 | Spanish | Native Speaker | 100 | 27.7(7.8, 19−56), F = 34, M = 66 | Mexican(45), Spanish(36), Chilean(10), Venezuelan(4), Argentinean(1), Colombian(1), Italian(1), Puerto Rican(1), American(1) |
| Non-Speaker | 100 | 30.7(8.4, 19−58) F = 24, M = 76 | British(34), Polish(24), South African(10), Italian(6), Greek(4), Hungarian(3), Indian(3), Portuguese(3), American(3), Australian(1), Estonian(1), Finnish(1), French(1), Lithuanian(1), Dutch(1), Nigerian(1), Turkish(1), Vietnamese(1), Zimbabwean(1) | ||
| 2 | Italian | Native Speaker | 100 | 26.7(6.5, 19−60), F = 45, M = 52, ND = 3 | Italian(96), Czech(1), Moldovan(1) |
| Non-Speaker | 100 | 28.4(8.5, 19−59), F = 37, M = 59, ND = 4 | Polish(21), Portuguese(14), British(14), South African(10), Mexican(7), American(4), Hungarian(3), Spanish(3), Czech(2), French(2), German(2), Belgian(1), Bulgarian(1), Chinese(1), Greek(1), Indonesian(1), Irish(1), Israeli(1), Lebanese(1), New Zealander(1), Nigerian(1), Filipino(1), Slovenian(1), Tunisian(1), Zimbabwean(1) | ||
| 3 | Swedish | Native Speaker | 100 | 30.8(9.9, 19−66), F = 33, M = 63, ND = 4 | Swedish(84), Finnish(9), Afghan(1), Danish(1), British(1), American(1) |
| Non-Speaker | 100 | 27.1(7.4, 19−62), F = 47, M = 49, ND = 4 | South African(23), Polish(21), Italian(8), Hungarian(6), Portuguese(6), British(6), Greek(4), Mexican(4), Spanish(3), Canadian(2), Estonian(2), Dutch(2), Slovenian(2), Afghan(1), French(1), Indian(1), Iranian(1), Israeli(1), Kenyan(1), Zimbabwean(1) |
Note. Of the total of 600 participants, six participants preferred not to disclose their age and thirteen preferred not to disclose their nationality. ND = Not disclosed.
For the perceptual matching task, we recruited 60 additional participants from the student population at Western Sydney University who were randomly allocated to a music (N = 30, MAge = 20.7, SDAge = 4; self-identified gender: Female = 23, Male = 6, Other = 1) or silence condition (N = 30, MAge = 22.1, SDAge = 6.6; self-identified gender: Female = 27, Male = 2, Other = 1). None of this sample participated in the original mental imagery task, and Australian participants comprised only a negligible proportion of the participants in the original mental imagery study (0.167%). Participation was reimbursed with course credit. The perceptual matching study also received ethics approval from the institutional review board of Western Sydney University (H14358). All participants provided informed consent, and all experiments were conducted in accordance with the declaration of Helsinki.
Stimuli
All stimuli generally adhered to folk genres with lyrics in Spanish, Italian, or Swedish. In this proof-of-concept study, we chose the folk genre due to its tendency of being culturally idiomatic, and strong tradition in being used during social interactions, or covering themes of social interactions52. We chose these three languages as they are familiar to the researchers conducting this research and participant samples with the respective language proficiency could be recruited in sufficient numbers through the same platform (Prolific Academia). The stimuli for the three studies were selected by the co-author native to the corresponding language (see Table 2). Folk styles across these three stimulus sets vary dramatically, resulting in reasonably diverse set of stimuli (see https://osf.io/jgce6/ for detailed musical feature analyses). The lyrical content of the stimuli also showed great differences, ranging from memento moris to descriptions of grape festivals (see https://osf.io/jgce6/ for original lyrics as well as English translations). The number of stimuli in each part of Experiment 1 was chosen to be compatible with prior research9,10. The first 105 s of each song was used to match with the trial duration, starting with the onset of the visual inducer. At the beginning and end of each stimulus, a brief fade-in and fade-out was applied to avoid clipping. Whilst participants could self-adjust loudness to their personal preference, each stimulus was loudness normalized to be comparable with each other and prior studies9,10 to the common value of −23 LUFS ± 5*10–7, as per EBU R-12855, using the pyloudnorm Python library56.
Table 2.
Overview of the music stimuli presented to participants in the three parts of experiment 1 alongside a silent baseline condition.
| Exp | Language | Song ID | Title | Performer | Composer | Year | Lyrics Compr. (NonNative/Native) |
|---|---|---|---|---|---|---|---|
| 1 | Spanish | SPA-1 | Preludio para el año 3001 | Amelita Baltar | Astor Piazzola | 1994 | 12.59/92.87 |
| SPA-2 | Luna Tucumana | Mercedes Sosa | Atahualpa Yupanqui | 1993 | 13.64/88.05 | ||
| SPA-3 | Pedacito de mi vida | Celina Y Reutilio | Celina y Reutilio | 1989 | 12.23/93.97 | ||
| 2 | Italian | ITA-1 | Passacaglia della vita | Marco Beasley | Traditional | 2005 | 10.97/90.18 |
| ITA-2 | Addio mia bella, addio! | Coro e Banda del Tricolore | Carlo Alberto Bosi | 2020 | 15.73/86.5 | ||
| ITA-3 | Nanni (‘Na gita a li castelli’) | Lando Fiorini | Franco Silvestri | 1993 | 16.84/91.12 | ||
| 3 | Swedish | SWE-1 | Jämtlandssången | Triakel | Wilhelm Peterson-Berger | 2021 | 7.19/58.47 |
| SWE-2 | Inte har jag pengar inte är jag pank | Ranarim | Traditional | 2006 | 8.15/80.26 | ||
| SWE-3 | Fager som en ros | Ranarim | Traditional | 2006 | 8.28/75.19 |
Note. As most Italian folksongs57, the ones adopted as stimuli in this experiment exhibit linguistic features of local dialects (e.g., the Roman dialect in “Gita a li castelli”) and archaisms (e.g., in “Passacaglia della vita”). For the purpose of our study, we were interested in comparing the induced imagery as a function of lyrics comprehension, thus contrasting native speakers and non-native speakers. In this respect. despite some morphological and lexical differences with modern Italian, the lyrics in our stimuli remain largely comprehensible by native Italian speakers, and comparably obscure to non-native speakers: in particular, self-reported comprehension scores (0 = poor, 100 = perfect) for our stimuli were significantly higher among native compared to non-native speakers for all stimuli.
Voice separation
Each stimulus was presented twice, once with vocals and once without vocals. To create the no-vocals versions, we used a commercial source separation algorithm58 on each song. DemixPro is a separation algorithm based on deep neural networks trained to separate vocals from backing instruments in music mixes and is generally used for music production applications. The separation process was completely automatic without any pre- or post-processing applied to the tracks or any manual editing. All tracks were in stereo format, sampled at 44.1 kHz.
Experimental task
Directed mental imagery task
The imagination task deployed here has been previously used to investigate music induced imagination9,10,59. In this task, participants watched a visual inducer video that serves as common reference for participants’ mental imagery. The video shows a figure travelling up a small hill, before a vague landmark in form of a large mountain appears in the far distance (see Fig. 1). The video is a clip from the video game “Journey” with written permission from Jenova Chen, CEO of ThatGameCompany (see https://thatgamecompany.com). The video was used in prior studies, and even participants familiar with its origin were able to perform the task9,10,60. It was used because it has a clear start point (small hill in the beginning) and clear end point of the journey (mountain in the distance), whereas the path connecting them is entirely shrouded, providing clear direction to participants, without being too descriptive about what happens in between. For the present experiment, the video was particularly useful, due to the solitary nature of the figure.
Fifteen seconds into the video, participants heard a gong sound that prompted them to close their eyes and imagine a continuation of the figure’s journey towards the large mountain. During the 90 s of the mental imagery period, the screen was black with white lettering stating, “Please close your eyes”. After the mental imagery period, participants heard the gong sound again, prompting them to open their eyes and provide their responses (see Table 3).
Table 3.
Questions and response format.
| ID | Question | Response format |
|---|---|---|
| 1 | How much time really passed between the two gong sounds? | Minutes; Seconds |
| 2 | How far away do you estimate the mountain to be at the beginning of the journey? | Kilometres; Metres |
| 3 | How much time passed in your imagination? | Years; Months; Days; Hours; Minutes; Seconds |
| 4 | How far did you travel in your imagination? | Kilometres; Metres |
| 5 | How vivid (clear) was the imagery you experienced compared to experiences in real life? | Numeric response with 0 (not very clear) – 100 (very clear) |
| 6 | Please describe your imagination in as much detail as possible. | Free format text box |
Written instruction on the screen (see https://osf.io/jgce6/ for all instructions) informed participants that if their mental imagery included time and distance skips, then they should include these into their estimates as well. For example, if they imagined a detailed journey of an hour, then imagined travelling for an additional day without filling this journey with distinct content (skipping), and then imagined a continuation for another hour, they were instructed to report 1 day and 2 h. Questions 1 and 2 only served the purpose of highlighting the difference between real and imagined time as well as distance. As responses differed considerably between these two questions (Median Time|Imagined−Real| = 14350 s, SD = 21699418, r =.012; Median Distance|Imagined−Real| = 5000 m, SD = 228209, r =.4) participants seemed to be aware of the difference. Individuals generally differ in the timescales of their imagination. Some imagined journeys on very small timescales (seconds), whereas other participants report differences between journeys on very large timescales (years)9. To account for this, question 3 allows participants the opportunity to specify time on a wide variety of metrics.
Each participant was presented with seven trials in random order. Each trial was identical, differing only in whether music was played, and if so, which music it was (see Stimuli section). Participants were instructed to “please treat every repetition independently from one another. You can imagine a similar or a totally different journey every time. This is entirely up to you” and informed that “there are no restrictions on your imagination, but please always keep the mountain in sight. This is because after your imagination you will be asked a few questions about the time and distance travelled in your imagination, and the mountain can help you orientate”.
Upon completion of all mental-imagery trials, participants filled out an online version of the Goldsmiths Musical Sophistication Index61. For the present study, we used musical training to account for potential musical expertise effects. In total, the study took 30 to 60 min to complete, depending on the depth of detail provided by the participants in question 6.
Perceptual matching task
Written instructions on the screen explained to participants that they would see many pairs of images and that these images were computer-generated based on peoples’ description of what happened during an imaginary journey towards a mountain. They were also informed that during these imaginary journeys, participants were either listening to music or silence. Of the two images shown simultaneously on the screen, one showed content imagined during silence and the other showed content imagined during music listening, based on the descriptions of the same person. After these explanations, participants were instructed that, in each trial, it was their task to click on the picture they thought represented content the person imagined during music listening. After making their choice, a new trial appeared with two images from a different participant. The study was structured in 9 blocks, one for each of the 9 songs of the original mental imagery task. After each block, participants were prompted to take a break and click continue, whenever they felt ready to the start the next block. In total, each participant performed 762 trials, each containing a pair of images to be judged. The order of blocks was randomised between participants, as was the order of trials within each block, as well as the location of the silent and music images within each trial (left or right).
A priori, we established a set of rules to keep this proof-of-concept study conservative. First, we only tested picture dyads where in both trials the original participant was able to generate mental imagery and where the stable diffusion images did not contain any readable text (~ 16% removed). This was important as many participants struggled imagining anything during the silent condition and presenting a trial in the matching task, where only one the music-based image showed content, or one of the two images comprises nothing but the written word ‘nothing’ would constitute a confound. Second, we would not correct spelling mistakes before passing the mental imagery description to the stable diffusion model, as this might introduce a non-transparent experimenter bias. Retrospectively, we would advise against this in future studies, as this rule, whilst being more conservative, likely added noise to the data reducing the probability of observing meaningful effects (e.g., some participants reported walking through the dessert rather than the desert…). Third, as the total number of images (4200) was unreasonably large to be presented to each participant and there is a limit to the available student population for the proof-of-concept perceptual matching study, we only tested images generated from the mental imagery of non-speakers in all three parts of Experiment 1, whilst listening to the no-vocals conditions. A priori we reasoned this to be the least homogeneous set of responses and thus likely the most conservative subset available for testing. Fourth, we would include images containing visual artefact, as long as they did not explicitly give away the experimental condition. We reasoned this to be the most principled approach as any noise images with artefacts would introduce would only make it harder to observe compelling evidence, whilst at the same time avoid any potential for experimenter effects. In each set, participants were randomly allocated to the Music or No-Music group. Participants in the Music condition performed the differentiation task whilst listening to original contextual music that the participants imagining the content also listened to, whereas participants in the No-Music conditions were not provided with the contextual music.
The task took between 30 and 45 min, depending on the length of the voluntary breaks between blocks. At the end of the task, participants filled out a demographic questionnaire, provided a subjective difficulty rating of the task (7-point Likert scale, 1 easy to 7 hard), and had the opportunity to share the strategy they deployed to do the task through a free-format text response. All data can be found in the online supplement (https://osf.io/jgce6/).
Analytical approach
Statistical inference
Our approach closely followed previous ones43,62–69, including those using the same paradigm9,10. For all statistical inference, we used Bayesian Mixed Effects models70 implemented in R71 using the brms package72. In each model, we standardised all continuous variables (M = 0, SD = 1), referenced all factorial variables to the silence condition, and provided the model with a weakly informative prior (t-distribution; M = 0, SD = 1, df = 3)73. In the models for the mental imagery task, the dependent variable (Vividness, Sentiment, Time, Distance, Topic Weight, or manual annotations) was predicted based on the audio conditions of interest and the participants’ proficiency in the respective language (coded as a Boolean variable), whilst accounting for participant and trial random intercepts. Initially, we also controlled for musical training from the Gold-MSI, however, as it did not carry predictive value in most instances, we dropped this predictor everywhere but where we observed strong evidence in its favour.
For the perceptual matching task, we modelled the dependent variable (Correct Response, Subjective Task Difficulty) based on the condition (Music vs. No-Music), whilst accounting for random effects of participant, trial as well as block number. Instead of a Gaussian identity link as in the previous analysis, we used a Bernoulli logit link to model the binary Correct/Incorrect responses in the perceptual matching task. We report coefficients (β), the estimate error of the coefficient (EE), as well as the evidence ratios for a hypothesis test that a given predictor has an effect greater or smaller than 0 (Odds(β > or < 0)). Like previous studies, for convenience we use ‘*’ to denote effects that can be considered ‘significant’ under an alpha level 5% (i.e., evidence ratio ≥ 19 for one-sided, and ≥ 39 for two-sided hypothesis tests, see43).
Vividness ratings were provided by the participants responses. Sentiment was calculated by first using the python library NLTK74 to filter stop-words, lemmatize, and stem participants’ free format response. Then, we estimated sentiment on the pre-processed data with the VADER library75, which uses its reference dictionary to map lexical features to a continuum from emotionally negative to positive. The obtained sentiment scores code whether a word has an overall positive (Sentiment Score > 0) or negative (Sentiment Score < 0) connotation and expresses the intensity of that connotation through its magnitude. We then averaged the word-wise sentiment scores for each report of each participant, to obtain one score per trial. Whilst directly provided by the participant, imagined time and distance varied dramatically between individuals, ranging from 0.1 m to over 1 million kilometres and 1 s to more than 27 years. As this study focuses on the variations of imagined time and distance across conditions, we log-scaled reported times and distances, and then standardised them (M = 0, SD = 1) for each participant.
Hypothesis tests on Bayesian Mixed effects models are robust to issues of multiple testing. Nevertheless, false discovery rates can still accumulate when performing multiple tests when using weakly informative prior, as we are using here76. For transparency, we thus report Effective False Discovery Rate (EFDR) in the result section, which is a Bayesian mean to account for the increasing rate of Type 1 errors due to multiple testing, by calculating the effective probability of reporting a false positive, given the posterior probabilities observed across the tests made77,78. This means, EFDR increases as the number of tests increases and when evidence becomes smaller. EFDRs were calculated using the ‘bayefdr’ package79. Throughout our analysis, EFDR never exceeded 0.00125, far below the conventional threshold of 0.05.
Topic analysis
We first pre-processed the free-format responses by removing stop-words, punctuation, numbers, words that occur fewer than 5 times across the 4200 reports, and extra white space, and then converted all letters to lower case and stemmed all words. We then deployed Latent Dirichlet Allocation44 using the LDA package80 in R, an unsupervised method to identify the content of a fixed number of topics within the corpus. To identify the number of topics prior to analysis, as seen in Fig. 8, we used a common density-based metric45 implemented in the ldatuning package81.
Fig. 8.

Number of topic search. The topic model performs best when the density (based on average cosine distance between topics, see45) reaches a minimum. Based on this analysis, we set fixed the number of topics to 9 (blue shade) prior to investigating the individual topics.
Stable diffusion visualisation
We used the Automatic1111 stable diffusion web UI (https://github.com/AUTOMATIC1111/stable-diffusion-webui), based on the Gradio library82 accessed through custom Python code (based on https://github.com/TheLastBen/fast-stable-diffusion, also see Dreambooth83. The main reason why we opted for the Automatic1111 stable diffusion web UI is because it allows to weigh each input word separately. Whilst for the visualisation of individual reports (see https://osf.io/jgce6/), as exemplified in Fig. 6 top row, equal word weighting is sufficient, making most stable diffusion models a viable choice, this becomes more complex for the aggregated images as seen in Fig. 6 bottom row. For these, we made use of the Latent Dirichlet Allocations’ 9-topic solution. Each topic consists of numerous words associated with this topic, as well as the relative weight of each word to this specific topic (for example, see Fig. 4). For the images seen in the bottom row of Fig. 6, we first identified in each topic the five words with the strongest weights, and we standardised the corresponding weights by dividing the weights by the maximum weight observed within the respective topic to avoid punishing topics with flatter word weights (e.g., topic II) or prioritising topics with more narrow distributions (e.g., topic I or V) during visualisation. Then, we min-max scaled the relative average importance of the different topics (0.09 to 0.12 on the LDA’s scale, see Fig. 3), separately for the music and silence condition, to achieve a more effective weighting scale for the stable diffusion model (0.2 to 2). Finally, we multiplied the standardised weights of the words contained in each topic with the respective scaled topic weight in the music and silence condition separately. This results in two word lists with word weightings that we can use as visualisation prompts for the stable diffusion mode, whereby the silence and music visualisation contain exactly the same words (as determined by the 9-topic solution) but differ in the weights attached to them, based on the data observed in Experiment 1.
As stable diffusion can differ based on the random seed, all the examples shown in Fig. 6 were generated with a fixed random seed (14358067202002102272, i.e., our concatenated ethics approval number). Note that we are not claiming that these images show what participants visualised to any particular degree of approximation; instead, we provide these images as an intuitive visualisation of the difference between the music and silence condition both on an individual level (e.g., Fig. 6 top row) as well as while abstracting summary features at the population level (Fig. 6 bottom row) level. These visualisations may also serve as objects for further research. For the purpose of future research, we also created a second set of images not used in the present study, for which we pre-conditioned the stable diffusion model on a seed image from the video that participants saw (first frame, shown in Fig.2, top left). Whilst also showing the clear distinction between conditions visible in Fig, 6, the resulting images much closer resemble the visual inducer, and thus are a more homogenous set than the images tested here, which could be useful for some future research. As with the images used here, this set of images can be found in the online supplement as well.
Manual annotations
To further corroborate our bottom-up, data driven analysis, a research assistant —unfamiliar with the study’s design, conditions, and aims — annotated all mental imagery reports in terms of imagined social interactions, temperature, brightness, and narrative perspective (69% First: ‘I’; 27% Third: ‘He’, ‘She’, ‘It’, ‘They’; 4% Unclear, similar between Music and Silence trials). The annotator was only provided with the free format accounts of the imagined journeys and did not have access to any other aspect of the data, such as experimental conditions, other responses, or demographics. The exact instructions and definitions given to the annotator can also be found in the online supplement (https://osf.io/jgce6/).
Acknowledgements
This work was supported by the Swiss National Science Foundation (SNF) under the SPARK grant scheme awarded to Dr. Steffen A. Herff (CRSK-1_196567/1) and by the Australian Government through the Australian Research Council (ARC) under the Discovery Early Career Researcher Award (DECRA, DE220100961) awarded to Dr. Steffen A. Herff, and by the University of Sydney through a Sydney Horizon Fellowship awarded to Dr. Steffen A. Herff. We thank the members of the MARCS Music & Science group, in particular Prof. Roger Dean, Dr. Andrew Milne, and Uğur Kaya . We also thank all members of the Sydney Music, Mind, and Body Lab, as well as Prof. Christian Herff, Dr. Felix Dobrowohl, and Dr. Lauren Fairley for constructive feedback on an earlier draft of the manuscript. We thank Farrah Sa’adullah for her support doing the data collection of the perceptual matching task. Finally, we thank all our participants who shared their imagination with us.
Author contributions
S.A.H. conceived the project, designed the experiment, and collected and analyzed the data. G.C. selected the stimuli with Italian lyrics and performed all Italian to English translations. P.E. selected the stimuli with Swedish lyrics and performed all Swedish to English translations. E.C. performed the source separation, selected the stimuli with Spanish lyrics, and performed all Spanish to English translations. S.A.H. wrote the manuscript. G.C, P.E., E.C., contributed to writing and editing.
Data availability
The datasets collected and analysed during the current study are available through the Open Science Framework (https://osf.io/jgce6/).
Declarations
Competing interests
The authors declare no competing interests.
Ethics declaration
The study received ethics approval from the institutional review board of the École Polytechnique Fédérale de Lausanne (067-2020/02.10.2020), as well as Western Sydney University (H14358). All participants provided informed consent, and all experiments were conducted in accordance with the declaration of Helsinki.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Belfi, A. M., Karlan, B. & Tranel, D. Music evokes vivid autobiographical memories. Memory24, 979–989 (2016). [DOI] [PubMed] [Google Scholar]
- 2.Jakubowski, K. & Ghosh, A. Music-evoked autobiographical memories in everyday life. Psychol. Music. 49, 649–666 (2021). [Google Scholar]
- 3.Juslin, P. N. & Sloboda, J. A. Music and emotion. In: The Psychology of Music (ed Deutsch, D.) Elsvier Academic (2013).
- 4.Koelsch, S., Bashevkin, T., Kristensen, J., Tvedt, J. & Jentschke, S. Heroic music stimulates empowering thoughts during mind-wandering. Sci. Rep-Uk. 9, 1–10 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Konishi, M. What Is Mind-Wandering? In: Music and Mental Imagery (eds Küssner MB, Taruffi L, Floridou GA). Routledge (2022).
- 6.Taruffi, L. Mind-wandering during personal music listening in everyday life: Music-evoked emotions predict thought Valence. Int. J. Environ. Res. Public Health. 18, 12321 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Dahl, S., Stella, A. & Bjørner, T. Tell me what you see: an exploratory investigation of visual mental imagery evoked by music. Music Sci, (2022).
- 8.Deil, J. et al. Mind-wandering during contemporary live music: an exploratory study. Music Sci, 10298649221103210 (2022).
- 9.Herff, S. A., Cecchetti, G., Taruffi, L. & Déguernel, K. Music influences vividness and content of imagined journeys in a directed visual imagery task. Sci. Rep-Uk. 11, 1–12 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Herff, S. A., McConnell, S., Ji, J. L. & Prince, J. B. Eye Closure Interacts with Music to Influence Vividness and Content of Directed Imagery. Music & Science5, 20592043221142710 (2022). [Google Scholar]
- 11.Margulis, E. H., Williams, J., Simchy-Gross, R. & McAuley, J. D. When did that happen? The dynamic unfolding of perceived musical narrative. Cognition226, 105180 (2022). [DOI] [PubMed] [Google Scholar]
- 12.Margulis, E. H. & McAuley, J. D. Using music to probe how perception shapes imagination. Trends Cogn. Sci.26 (10), 829–831 (2022). [DOI] [PubMed] [Google Scholar]
- 13.Taruffi, L. & Küssner, M. B. A review of music-evoked visual mental imagery: conceptual issues, relation to emotion, and functional outcome. Psychomusicology: Music Mind Brain. 29, 62–74 (2019). [Google Scholar]
- 14.Küssner, M. B. & Eerola, T. The content and functions of vivid and soothing visual imagery during music listening: findings from a survey study. Psychomusicology: Music Mind Brain. 29, 90–99 (2019). [Google Scholar]
- 15.Margulis, E. H., Wong, P. C. M., Turnbull, C., Kubit, B. M. & McAuley, J. D. Narratives imagined in response to instrumental music reveal culture-bounded intersubjectivity. Proceedings of the National Academy of Sciences 119, e2110406119 (2022). [DOI] [PMC free article] [PubMed]
- 16.Ziv, N., Hollander-Shabtai, R. & Music COVID-19: changes in uses and emotional reaction to music under stay-at-home restrictions. Psychol. Music. 50, 475–491 (2022). [Google Scholar]
- 17.Fink, L. K. et al. Viral tunes: changes in musical behaviours and interest in Coronamusic predict socio-emotional coping during COVID-19 lockdown. Humanities Social Sci. Communications8, (2021).
- 18.Cabedo-Mas, A., Arriaga-Sanz, C. & Moliner-Miravet, L. Uses and perceptions of music in times of COVID-19: a Spanish population survey. Front. Psychol.11, 606180 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Ribeiro, F. S., Braun Janzen, T., Passarini, L. & Vanzella, P. Exploring changes in musical behaviors of caregivers and children in social distancing during the COVID-19 outbreak. Front. Psychol.12, 633499 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Groarke, J. M., MacCormac, N., McKenna-Plumley, P. E. & Graham-Wisener, L. Music listening was an emotional resource and social surrogate for older adults during the COVID-19 pandemic: A qualitative study. Behav. Change. 39, 168–179 (2022). [Google Scholar]
- 21.Hansen, N. C. Music for hedonia and eudaimonia: During pandemic social isolation. In: Arts and Mindfulness Education for Human Flourishing (eds Chemi T, Brattico E, Fjorback LO, Harmat L) (2021).
- 22.Ayyildiz, C. et al. Music as social surrogate? A qualitative analysis of older adults’ choices of music to alleviate loneliness. Music Sci, (2025).
- 23.Holmes, E. A., Arntz, A. & Smucker, M. R. Imagery rescripting in cognitive behaviour therapy: images, treatment techniques and outcomes. J. Behav. Ther. Exp. Psychiatry. 38, 297–305 (2007). [DOI] [PubMed] [Google Scholar]
- 24.Mendes, D. D., Mello, M. F., Ventura, P., De Medeiros Passarela, C. & De Jesus Mari, J. A systematic review on the effectiveness of cognitive behavioral therapy for posttraumatic stress disorder. Int. J. Psychiatry Med.38, 241–259 (2008). [DOI] [PubMed] [Google Scholar]
- 25.Janata, P., Tomic, S. T. & Rakowski, S. K. Characterisation of music-evoked autobiographical memories. Memory15, 845–860 (2007). [DOI] [PubMed] [Google Scholar]
- 26.Jakubowski, K., Belfi, A. M. & Eerola, T. Phenomenological differences in music-and television-evoked autobiographical memories. Music Perception: Interdisciplinary J.38, 435–455 (2021). [Google Scholar]
- 27.Belfi, A. M., Bai, E., Stroud, A., Twohy, R. & Beadle, J. N. Investigating the role of involuntary retrieval in music-evoked autobiographical memories. Conscious. Cogn.100, 103305 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Jakubowski, K. & Eerola, T. Music evokes fewer but more positive autobiographical memories than emotionally matched sound and word cues. J. Appl. Res. Memory Cognition. 11, 272 (2022). [Google Scholar]
- 29.Greenberg, D. L. & Knowlton, B. J. The role of visual imagery in autobiographical memory. Mem. Cognit.42, 922–934 (2014). [DOI] [PubMed] [Google Scholar]
- 30.Laeng, B., Bloem, I. M., D’Ascenzo, S. & Tommasi, L. Scrutinizing visual images: the role of gaze in mental imagery and memory. Cognition131, 263–283 (2014). [DOI] [PubMed] [Google Scholar]
- 31.Robin, F., Moustafa, A. & El Haj, M. The image of memory: relationship between autobiographical memory and mental imagery in Korsakoff syndrome. Appl. Neuropsychology: Adult. 29, 120–126 (2022). [DOI] [PubMed] [Google Scholar]
- 32.Hackmann, A., Bennett-Levy, J. & Holmes, E. A. Oxford Guide To Imagery in Cognitive Therapy (Oxford University Press, 2011).
- 33.Taruffi, L., Ayyildiz, C. & Herff, S. A. Thematic Contents of Mental Imagery are Shaped by Concurrent Task-Irrelevant Music. Imagination Cognition Personality43(2), 169–192 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Castellar, F., Cavaleri, R. & Herff, S. A. Mental imagery, music, and their combined use improve psychological States and motor skill performance in a ball-throwing task. OSF, (2025).
- 35.Castellar, F., Cavaleri, R., Taruffi, L. & Herff, S. A. Exploring the synergistic effectiveness of music and mental imagery to improve motor skill performance in sports: a systematic review. OSF, (2025).
- 36.Mota, N. P. et al. Imagery vividness ratings during exposure treatment for posttraumatic stress disorder as a predictor of treatment outcome. Behav. Res. Ther.69, 22–28 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Davidson-Kelly, K., Schaefer, R. S., Moran, N. & Overy, K. Total inner memory: deliberate uses of multimodal musical imagery during performance Preparation. Psychomusicology: Music Mind Brain. 25, 83 (2015). [Google Scholar]
- 38.Keller, P. E. Mental imagery in music performance: underlying mechanisms and potential benefits. Ann. N. Y. Acad. Sci.1252, 206–213 (2012). [DOI] [PubMed] [Google Scholar]
- 39.Carroll, C. Enhancing reflective learning through role-plays: the use of an effective sales presentation evaluation form in student role-plays. Mark. Educ. Rev.16, 9–13 (2006). [Google Scholar]
- 40.Van Hasselt, V. B., Romano, S. J. & Vecchi, G. M. Role playing: applications in hostage and crisis negotiation skills training. Behav. Modif.32, 248–263 (2008). [DOI] [PubMed] [Google Scholar]
- 41.Oliva, J. R., Morgan, R. & Compton, M. T. A practical overview of de-escalation skills in law enforcement: helping individuals in crisis while reducing Police liability and injury. J. Police Crisis Negotiations. 10, 15–29 (2010). [Google Scholar]
- 42.Agboola Sogunro, O. Efficacy of role-playing pedagogy in training leaders: some reflections. J. Manage. Dev.23, 355–371 (2004). [Google Scholar]
- 43.Milne, A. J. & Herff, S. A. The perceptual relevance of balance, evenness, and entropy in musical rhythms. Cognition203, 104233 (2020). [DOI] [PubMed] [Google Scholar]
- 44.Blei, D. M., Ng, A. Y. & Jordan, M. I. Latent dirichlet allocation. J. Mach. Learn. Res.3, 993–1022 (2003). [Google Scholar]
- 45.Cao, J., Xia, T., Li, J. T., Zhang, Y. D. & Tang, S. A density-based method for adaptive LDA model selection. Neurocomputing72, 1775–1781 (2009). [Google Scholar]
- 46.Clayton, M. The social and personal functions of music in cross-cultural perspective. In: The Oxford handbook of music psychology (eds Hallam S, Cross I, Thaut MH) (2009).
- 47.Wright, J. C., Weissglass, D. E. & Casey, V. Imaginative role-playing as a medium for moral development: dungeons & Dragons provides moral training. J. Humanistic Psychol.60, 99–129 (2020). [Google Scholar]
- 48.Hirsch, C. R. & Holmes, E. A. Mental imagery in anxiety disorders. Psychiatry6, 161–165 (2007). [Google Scholar]
- 49.Pearson, J., Naselaris, T., Holmes, E. A. & Kosslyn, S. M. Mental imagery: functional mechanisms and clinical applications. Trends Cogn. Sci.19, 590–602 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Droit-Volet, S., Bigand, E., Ramos, D. & Bueno, J. L. Time flies with music whatever its emotional Valence. Acta. Psychol.135, 226–232 (2010). [DOI] [PubMed] [Google Scholar]
- 51.Schäfer, T., Fachner, J. & Smukalla, M. Changes in the representation of space and time while listening to music. Front. Psychol.4, 508 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Lomax, A. Folk Song Style and Culture (Routledge, 2017).
- 53.Cross, I. Music, cognition, culture, and evolution. Ann. Ny Acad. Sci.930, 28–42 (2001). [DOI] [PubMed] [Google Scholar]
- 54.McAuley, J. D., Wong, P. C. M., Mamidipaka, A., Phillips, N. & Margulis, E. H. Do you hear what I hear? Perceived narrative constitutes a semantic dimension for music. Cognition212, 104712 (2021). [DOI] [PubMed] [Google Scholar]
- 55.EBU-Tech. R 128, loudness normalisation and permitted maximum level of audio signals. EBU Recommendation Geneva, (2014).
- 56.Steinmetz, C. csteinmetz1/pyloudnorm. v0.1.0 edn (2019).
- 57.Magrini, T. et al. Italy: II. Traditional music. In: Grove Music Online). Oxford University Press (2001).
- 58.AudiosourceRE DemixPro. V4.0 edn (2022).
- 59.Ayyildiz, C., Prince, J., Delalande, J. & Herff, S. A. Traffic Jams: Music and Traffic Noise Interact to Influence the Vividness and Sentiment of Directed Mental Imagery. OSF, (2025).
- 60.Ayyildiz, C., Irish, M., Milne, A. & Herff, S. A. Micro-variations in timing and loudness affect music-evoked mental imagery. OSF, (2025).
- 61.Müllensiefen, D., Gingras, B., Musil, J. & Stewart, L. The musicality of non-musicians: an index for assessing musical sophistication in the general population. PloS One. 9, e89642 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Quiroga-Martinez, D. R. et al. Musical prediction error responses similarly reduced by predictive uncertainty in musicians and non‐musicians. Eur. J. Neurosci.51, 2250–2269 (2020). [DOI] [PubMed] [Google Scholar]
- 63.Beveridge, S., Cano, E. & Herff, S. A. The effect of low-frequency equalisation on preference and sensorimotor synchronisation in music. Q. J. Experimental Psychol.75, 475–490 (2022). [DOI] [PubMed] [Google Scholar]
- 64.Smit, E. A., Dobrowohl, F. A., Schaal, N. K., Milne, A. J. & Herff, S. A. Perceived Emotions of Harmonic Cadences. Music & Science3, 2059204320938635 (2020). [Google Scholar]
- 65.Smit, E. A., Milne, A. J., Sarvasy, H. S. & Dean, R. T. Emotional responses in Papua new Guinea show negligible evidence for a universal effect of major versus minor music. Plos One. 17, e0269597 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Cecchetti, G., Herff, S. A. & Rohrmeier, M. A. Musical garden paths: evidence for syntactic revision beyond the linguistic domain. Cogn. Sci.46, e13165 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Cecchetti, G., Herff, S. A. & Rohrmeier, M. A. Musical syntactic structure improves memory for melody: evidence from the processing of ambiguous melodies. In: Proceedings of the Annual Meeting of the Cognitive Science Society) (2021).
- 68.Herff, S. A. et al. Prefrontal high gamma in ECoG tags periodicity of musical rhythms in perception and imagination. eNeuro7, 784991 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Herff, S. A., Harasim, D., Cecchetti, G., Finkensiep, C. & Rohrmeier, M. A. Hierarchical syntactic structure predicts listeners’ sequence completion in music. In: Proceedings of the 43rd Annual Conference of the CognitiveScience Society). Cognitive Science Society (2021).
- 70.Baayen, R. H., Davidson, D. J. & Bates, D. M. Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang.59, 390–412 (2008). [Google Scholar]
- 71.R-Core-Team R: A Language and Enviornment for Statistical Computing (R Foundation for Statistical Computing, 2013).
- 72.Bürkner, P. Advanced bayesian multilevel modeling with the R package Brms. The R Journal10, (2018).
- 73.Gelman, A., Jakulin, A., Pittau, M. G. & Su, Y. A weakly informative default prior distribution for logistic and other regression models. Annals Appl. Stat.2, 1360–1383 (2008). [Google Scholar]
- 74.Loper, E., Bird, S. & Nltk The natural language toolkit. arXiv preprint cs/0205028, (2002).
- 75.Hutto, C. & Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In: Proceedings of the International AAAI Conference on Web and Social Media) (2014).
- 76.Gelman, A., Hill, J. & Yajima, M. Why we (usually) don’t have to worry about multiple comparisons. J. Res. Educational Eff.5, 189–211 (2012). [Google Scholar]
- 77.Newton, M. A., Noueiry, A., Sarkar, D. & Ahlquist, P. Detecting differential gene expression with a semiparametric hierarchical mixture method. Biostatistics5, 155–176 (2004). [DOI] [PubMed] [Google Scholar]
- 78.Vallejos, C. A., Richardson, S. & Marioni, J. C. Beyond comparisons of means: Understanding changes in gene expression at the single-cell level. Genome Biol.17, 1–14 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.VallejosGroup Bayesian Estimation and Optimisation of Expected False Discovery Rate. (2022).
- 80.Chang, J. Package ‘lda’. Citeseer (2010).
- 81.Nikita, M. Package ‘ldatuning’.) (2016).
- 82.Abid, A. et al. Hassle-free sharing and testing of ml models in the wild. arXiv preprint arXiv:190602569, (2019).
- 83.Ruiz, N. et al. Fine tuning text-to-image diffusion models for subject-driven generation. arXiv preprint arXiv:220812242, (2022).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets collected and analysed during the current study are available through the Open Science Framework (https://osf.io/jgce6/).