

Abstract
The rapid digitization of commercial, governmental, and legal transactions has created an urgent need for efficient, secure, and transparent dispute resolution mechanisms. Traditional arbitration systems often fall short when handling the complexity and volume of digital evidence, smart contracts, and cross-border interactions. This study proposes a novel AI-powered digital arbitration framework that integrates smart contracts, blockchain-based evidence authentication, and explainable artificial intelligence (AI) to automate and modernize the arbitration process. The framework comprises three core layers: (i) a smart contract-based agreement layer that encodes legal terms and self-executing arbitration clauses; (ii) a blockchain-based evidence management layer that ensures the integrity, authenticity, and traceability of submitted evidence; and (iii) an AI-based arbitration engine that classifies, interprets, and evaluates evidence using transformer and LSTM models, supported by SHAP and LIME for interpretability. A controlled experimental setup was implemented using Ethereum and Hyperledger Fabric testnets, with AI models trained on 1,200 annotated arbitration cases. Results demonstrate a 99.5% reduction in arbitration time, a 92.4% agreement rate between AI and expert rulings, and a 99% accuracy in tampering detection. Furthermore, 87.3% of AI-generated decisions were rated as interpretable and acceptable by legal experts. These findings confirm the system’s ability to deliver fast, accurate, and explainable arbitration decisions while complying with legal standards. This research contributes a foundational blueprint for deploying autonomous arbitration systems in digital governance, offering scalable solutions for future applications in smart contracts, e-commerce disputes, and algorithmic legal infrastructure.
Subject terms: Complex networks; Complex networks; Engineering; Information systems and information technology; Mathematics and computing; Science, technology and society
Introduction
The rapid digitalization of socio-economic, financial, and governmental ecosystems has significantly reshaped how disputes arise and are resolved1. In particular, with the proliferation of e-commerce, smart devices, blockchain technologies, and digital platforms, traditional litigation and arbitration mechanisms often prove insufficient in terms of speed, transparency, and adaptability to digital evidence2. The increasing volume and complexity of electronically stored information (ESI) and smart contracts necessitate new paradigms in dispute resolution that can match the pace and structure of contemporary digital interactions3. Against this backdrop, AI offers an unprecedented opportunity to revolutionize arbitration processes by automating decision-making, analyzing electronic evidence, and enhancing procedural efficiency4. This research proposes an AI-powered digital arbitration framework that integrates smart contracts and electronic evidence authentication to address key challenges in modern arbitration environments5.
Digital arbitration refers to the use of information and communication technologies (ICT) to facilitate or conduct arbitration proceedings6. While digital arbitration may involve simple elements such as document sharing through online portals or videoconferencing, the vision for a fully digitized, autonomous, and intelligent arbitration system goes far beyond7. Recent developments in AI, blockchain technology, and cryptographic techniques now allow for the automation of complex decision-making tasks and the validation of digital evidence with high reliability8. In particular, smart contracts—self-executing digital agreements stored on a blockchain—can encode arbitration clauses and trigger dispute resolution mechanisms autonomously. At the same time, AI algorithms can analyze vast amounts of electronic evidence, including emails, transaction logs, and multimedia content, to assess relevance, detect anomalies, and support objective rulings9.
The synergy between AI and blockchain is especially compelling. While smart contracts ensure enforceability and transparency in contractual obligations, AI systems introduce adaptability, contextual understanding, and learning capabilities to the dispute resolution process10. Moreover, electronic evidence authentication—powered by techniques such as cryptographic hashing, metadata extraction, and blockchain timestamping—can safeguard the integrity and admissibility of digital records presented in arbitration11. These technologies collectively establish the foundational pillars for a next-generation arbitration ecosystem that is intelligent, tamper-proof, decentralized, and resilient12.
Despite the potential benefits of integrating AI and blockchain technologies in arbitration, current frameworks remain fragmented and limited in scope13. Traditional arbitration mechanisms struggle with several limitations in the context of digital evidence and smart contract enforcement14. Firstly, the manual evaluation of voluminous digital records is time-consuming, prone to human error, and vulnerable to manipulation or selective presentation15. Secondly, most smart contract platforms lack built-in dispute resolution protocols that can interpret contractual semantics or respond to unforeseen circumstances16. Thirdly, the legal admissibility and credibility of electronic evidence are frequently contested due to inconsistencies in data provenance, tampering risks, and jurisdictional disparities in digital forensics standards17.
These challenges are compounded by the lack of unified standards for digital arbitration systems, the opacity of AI decision-making (often described as the “black box problem”), and the absence of interoperable frameworks capable of integrating with diverse legal, technical, and regulatory environments18. The gap between technical capabilities and legal enforceability represents a critical bottleneck in the evolution of intelligent arbitration platforms.
The motivation for this research stems from a pressing need to modernize and democratize dispute resolution in digital contexts19. As online transactions and cross-border digital collaborations become increasingly prevalent, the demand for fast, cost-effective, and trustworthy arbitration mechanisms grows exponentially20. By leveraging AI and blockchain technologies, it is possible to redefine arbitration procedures to meet the expectations of modern digital citizens, businesses, and legal institutions21.
The adoption of AI for tasks such as evidence classification, sentiment analysis, and legal reasoning can significantly reduce case resolution time while enhancing consistency and impartiality22. Meanwhile, smart contracts can serve as programmable legal instruments that embed arbitration rules, ensure compliance, and automatically execute outcomes without human intervention23. Furthermore, authenticated digital evidence, stored on tamper-resistant ledgers, strengthens procedural fairness and reinforces trust in arbitral outcomes.
From a broader perspective, the development of an AI-powered digital arbitration framework aligns with global trends toward digital governance, smart legal systems, and algorithmic adjudication24. Countries and international organizations are increasingly exploring online courts, digital notaries, and AI-based legal assistants. However, a cohesive architecture that unifies these components into an end-to-end arbitration workflow—backed by robust security, explainability, and legal traceability—remains elusive. This study aims to fill that gap by proposing a modular, extensible, and intelligent arbitration framework that combines smart contract logic with AI-driven adjudication and authenticated evidence handling. Unlike prior studies that focus on isolated aspects—such as blockchain-based notarization of contracts or AI-driven legal text classification—our framework introduces a unified three-layer architecture. This design integrates smart contract execution, tamper-proof evidence authentication, and explainable AI-based adjudication into one cohesive workflow, ensuring both legal enforceability and procedural transparency.
The major contribution of this study is given below:
This study presents a novel, end-to-end digital arbitration framework that seamlessly integrates artificial intelligence, smart contracts, and blockchain-based electronic evidence authentication to enable autonomous, efficient, and secure dispute resolution.
The framework introduces a legally-aware smart contract module that encodes customizable arbitration clauses, dispute resolution protocols, and automated enforcement mechanisms directly into blockchain-based contracts.
A core contribution is the design of an AI engine capable of processing diverse electronic evidence—including textual, transactional, and multimedia data—to classify, authenticate, and extract legally relevant insights, thereby assisting arbitrators in informed decision-making.
The research proposes a cryptographic evidence authentication module that leverages blockchain technology to ensure the immutability, provenance, and verifiability of all digital records submitted during the arbitration process.
The proposed solution is designed to be platform-agnostic and compliant with existing legal standards, offering interoperability with conventional arbitration systems while addressing regulatory and jurisdictional requirements for digital evidence admissibility.
The remainder of this article is organized as follows. Section “Literature review” presents a comprehensive review of related work, highlighting the limitations of existing digital arbitration systems and the emerging role of AI and blockchain technologies in legal processes. Section “Methodology” details the proposed AI-powered digital arbitration framework, including its architecture, key components, and underlying technologies. Section “Experimental Results” discusses the implementation methodology, data flow, and decision logic of the framework. Section “Discussion” provides a performance evaluation based on case simulations, demonstrating the framework’s effectiveness in evidence analysis, decision accuracy, and execution of smart contract-based resolutions. Finally, Sect. “Conclusion” concludes the paper with key findings, limitations, and potential directions for future research and real-world deployment.
Literature review
In recent years, the convergence of artificial intelligence, blockchain technology, and legal informatics has spurred significant advancements in the domain of digital arbitration. This section reviews key studies that have contributed to the development of AI-powered arbitration systems, smart contract enforcement, and electronic evidence authentication, highlighting their methodologies, datasets, results, and limitations to identify current research gaps and opportunities.
Santosh et al. (2024) proposed an AI-based legal decision support system using natural language processing (NLP) to analyze arbitration texts and recommend rulings25. The model leveraged a combination of BERT and legal-specific ontologies to process datasets from Chinese arbitration case records. The results demonstrated a 91% accuracy in predicting case outcomes and legal citations. However, the model struggled with multilingual datasets and lacked adaptability to legal systems outside China.
Liao et al. (2020) developed a blockchain-enabled smart contract platform for commercial arbitration, where contract disputes could be automatically resolved based on predefined clauses26. Ethereum smart contracts were tested using synthetic transaction data from mock e-commerce platforms. The framework reduced resolution time by 40%, but the static nature of smart contracts limited flexibility when disputes involved ambiguity or unforeseen events.
Singh et al. (2022) implemented a machine learning model for classifying digital evidence into admissible and non-admissible categories in online dispute resolution (ODR) systems27. They used a curated dataset of 10,000 annotated pieces of electronic evidence, including emails, images, and logs. The Random Forest classifier achieved 87.6% F1-score. A key limitation was the lack of real-world, diverse legal contexts, which reduced the model’s generalizability.
Berrios et al. (2025) explored the use of zero-knowledge proofs and blockchain hashing to authenticate digital documents in court arbitration28. Using a private Hyperledger Fabric network, they hashed metadata from documents in a controlled trial with 200 participants. Their solution ensured tamper resistance and verifiable chains of custody, but did not address privacy issues in public blockchain environments or support multimedia formats.
Cruz et al. (2024) proposed an intelligent arbitration engine based on fuzzy logic and rule-based expert systems29. Using manually encoded arbitration rules from 120 civil contracts, they simulated arbitration scenarios where the system suggested possible outcomes. Results showed a 76% agreement rate with human arbitrators. Nevertheless, scalability and the need for manual rule encoding hindered its practical deployment in large-scale, dynamic arbitration.
Mendi et al. (2022) introduced a hybrid AI-Blockchain framework for smart contract dispute management30. Their model combined sentiment analysis from parties’ communications with smart contract condition logs. The dataset comprised 1,500 annotated dispute dialogues and 250 Ethereum transactions. The hybrid system improved dispute prediction accuracy to 89%. However, the system was not fully autonomous and required partial human input to confirm AI-generated decisions.
Petmezas et al. (2025) developed an AI-powered legal document verification tool using CNN-LSTM architecture to classify forged vs. authentic electronic records31. The tool was trained on a synthetic dataset of 5,000 forged and authentic legal documents. The model achieved 93% classification accuracy. A limitation was its reduced performance (below 80%) when tested on scanned handwritten documents or documents with multiple embedded file types.
Alessa et al. (2022) proposed a legal chatbot that integrates with arbitration portals to guide users through dispute resolution and collect electronic evidence32. Built using rule-based NLP and dialog management systems, it was evaluated on a dataset of 2,000 arbitration cases from South Korea’s online dispute platform. The bot reduced user error in document submission by 58%. However, the system lacked scalability in handling diverse jurisdictions and legal terminologies.
Duong et al. (2023) created a deep learning model for summarizing arbitration proceedings and extracting legally significant points33. They used a transformer-based architecture fine-tuned on a dataset of 15,000 arbitration transcripts from open legal repositories. The model achieved a ROUGE-1 score of 0.84. Limitations included the model’s bias towards frequently occurring legal phrases and challenges in abstracting minority arguments or dissenting opinions.
Sunyaev et al. (2020) examined the use of distributed ledger technology (DLT) for maintaining immutable logs of digital arbitration procedures34. The authors simulated arbitration logs from a mock consumer arbitration platform, storing entries on an Ethereum sidechain. Results showed enhanced auditability and tamper detection, but the approach incurred high gas costs and lacked compatibility with off-chain storage of large evidence files (e.g., videos, images).
Chen et al. (2025) introduced an intelligent arbitration case prediction system using a BiLSTM model to analyze legal texts and past arbitration outcomes35. They trained their model on a dataset of 7,500 international arbitration cases from UNCITRAL archives. The model reached 88.4% prediction accuracy, especially for contract enforcement disputes. However, its performance dropped for culturally or linguistically diverse cases due to limited multilingual support.
Malik et al. (2023) proposed a digital evidence chain of custody framework utilizing IPFS and blockchain for distributed storage and verification36. The system used tamper-evident hashes of image and document evidence submitted through simulated ODR cases. The framework enhanced traceability and reduced manipulation risks but was dependent on decentralized infrastructure availability and lacked scalability for high-frequency arbitration platforms.
Chen et al. (2022) designed a supervised machine learning pipeline for arbitration document classification using SVM and TF-IDF features37. The model was evaluated on a legal dataset consisting of 4,000 arbitration filings across 12 jurisdictions. It yielded an F1-score of 0.91 for classification into procedural, evidentiary, and judgment categories. The key limitation was the model’s rigidity, as it struggled with overlapping legal classifications.
Demertzis et al. (2023) explored automated judgment reasoning in smart contract disputes using a decision-tree logic combined with rule-based AI38. Their system encoded arbitration clauses from 100 commercial smart contracts. Simulated dispute scenarios showed 84% consistency with human arbitrators. However, the lack of adaptive learning made it difficult for the system to evolve with new legal interpretations.
Nardini et al. (2020) proposed a smart contract-based reputation and arbitration layer for decentralized marketplaces39. The system used Solidity contracts and a token-based voting mechanism with arbitration triggers. Testing on a mock blockchain marketplace dataset showed a 70% decrease in fraud cases. Nevertheless, sybil attacks and manipulation of the voting process remained unresolved issues.
Greco et al. (2024) applied transfer learning with a RoBERTa model to extract critical evidence in arbitration proceedings40. Trained on 10,000 annotated arbitration case paragraphs, the system effectively identified evidence snippets with 92% precision. Its limitation was domain specificity, as it performed poorly on non-commercial or informal legal contexts.
Chinnaraju et al. (2025) implemented an explainable AI (XAI) framework for arbitration support using LIME and SHAP to interpret model predictions in evidence relevance41. Applied to a dataset of 3,000 annotated legal documents, the system improved user trust and regulatory transparency. However, interpretability came at the cost of slower model inference and increased computational demand.
Zeng et al. (2025) created an NLP-driven arbitration assistant that matched dispute statements with precedent cases using cosine similarity and semantic embedding42. The assistant was tested on a dataset of 5,000 arbitration award summaries. It achieved 81% match accuracy but could not explain the reasoning behind the similarity scores, limiting its adoption by legal professionals.
Gambo et al. (2025) proposed a zero-trust arbitration architecture where evidence is verified using distributed trust anchors and digital signatures43. Evaluated through simulation of 200 arbitration cases using fabricated IoT device logs and transaction data, the system successfully blocked 95% of forged evidence. However, it required significant digital infrastructure and user authentication layers, which limited accessibility.
Martin et al. (2024) developed a generative AI framework to auto-draft arbitration clauses using large legal language models (LLMs)44. Using a fine-tuned GPT-based model on a dataset of 8,000 arbitration contracts, the system generated legally coherent clauses with a 93% legal compliance score. However, it occasionally hallucinated legal terms or misinterpreted jurisdiction-specific nuances.
These recent studies demonstrate substantial progress in automating digital arbitration processes through AI, blockchain, and smart contracts. However, challenges remain in generalizability, interpretability, infrastructure scalability, and handling jurisdictional diversity, highlighting the need for a unified and adaptive arbitration framework such as the one proposed in this research.
Methodology
To design a reliable, transparent, and autonomous digital arbitration system, this study proposes a comprehensive AI-powered framework that integrates smart contracts, electronic evidence authentication, and intelligent decision-making modules. The methodology is structured to ensure legal enforceability, technical interoperability, and procedural integrity throughout the arbitration process. It encompasses the architectural design of the system, mechanisms for encoding arbitration rules into smart contracts, processes for collecting and authenticating electronic evidence, and the application of AI for evidence analysis and decision generation. Each component is developed and evaluated within a controlled simulation environment to validate its effectiveness in supporting automated and secure arbitration procedures. The following subsections provide a detailed explanation of the proposed system architecture and its core functional modules.
The overall architecture of the proposed arbitration system is illustrated in Fig. 1, which integrates smart contract deployment, blockchain-based evidence authentication, and AI-driven legal decision-making. This framework ensures tamper-proof evidence handling, transparent dispute resolution, and automated arbitration enforcement.
Fig. 1.

AI-powered digital arbitration framework integrating smart contracts, blockchain-based evidence authentication, and AI-driven decision-making.
System architecture overview
The proposed AI-powered digital arbitration framework is designed as a multi-layered, modular system that integrates artificial intelligence, blockchain technology, and smart contracts to facilitate secure, automated, and transparent arbitration processes. The system architecture consists of three primary laysers: (i) Smart Contract-Based Agreement Layer, (ii) Electronic Evidence Management and Authentication Layer, and (iii) AI-Based Arbitration and Decision-Making Layer. Each layer is responsible for executing specialized tasks and communicating with other components to ensure seamless arbitration workflow from dispute initiation to final resolution.
At the foundation of the system lies the Smart Contract-Based Agreement Layer, where contractual terms and arbitration rules are encoded into self-executing smart contracts. These contracts are deployed on a blockchain platform, such as Ethereum, to guarantee transparency, immutability, and automated enforcement. This layer includes modules for contract deployment, dispute initiation, clause verification, and automated outcome execution.
The second layer, Electronic Evidence Management and Authentication, handles the ingestion, preprocessing, and cryptographic authentication of digital evidence. Evidence files undergo standardized formatting, metadata extraction, and SHA-256 hashing before being timestamped and recorded on the blockchain ledger. This ensures tamper resistance, chain of custody, and verifiability of all documents used during arbitration.
The third layer, AI-Based Arbitration and Decision-Making, includes advanced AI algorithms—such as transformer-based language models and explainable AI modules—for evaluating evidence, understanding legal semantics, and generating recommendations or decisions. The AI engine interfaces directly with authenticated evidence and smart contract terms, ensuring decisions are traceable, explainable, and consistent with encoded legal logic.
This layered integration differentiates our work from existing ODR systems, which typically address only one dimension (e.g., notarization or evidence scoring). By combining agreement encoding, cryptographic authentication, and AI-based decision-making, the framework ensures interoperability and reduces gaps between technical enforcement and legal reasoning.
The interaction among these layers is orchestrated through secure APIs and blockchain events, creating a fully integrated, legally aware, and tamper-resistant arbitration ecosystem. A visual representation of the system architecture is illustrated in Fig. 1, while a detailed breakdown of each component is provided in Table 1.
Table 1.
Components of the proposed arbitration Framework.
| Layer | Component | Function |
|---|---|---|
| Smart Contract-Based Agreement Layer | Smart Contract Deployment | Encodes arbitration rules and legal terms into blockchain-based contracts |
| Dispute Resolution Process | Activates when a dispute is triggered, based on encoded logic | |
| Outcome Execution Engine | Automatically enforces arbitration decisions through smart contract logic | |
| Evidence Management & Authentication | Evidence Preprocessing | Standardizes and formats evidence files |
| Hashing & Blockchain Ledger | Applies SHA-256 hashing and stores evidence hash on blockchain | |
| Cryptographic Authentication | Ensures data integrity and traceability of evidence | |
| AI-Based Arbitration & Decision-Making | AI Evidence Analysis Engine | Uses ML/NLP models to assess relevance and classify evidence |
| Explainable Decision Module | Generates transparent and explainable arbitration decisions | |
| Arbitration Outcome Generator | Issues legally consistent and data-driven arbitration results |
The three-tiered system illustrated in Fig. 2 outlines the layered architecture of the proposed framework, consisting of smart contract-based agreements, evidence authentication mechanisms, and AI-driven arbitration modules. This structure ensures a seamless flow from contract execution to transparent, explainable decision-making.
Fig. 2.

Layered architecture of the AI-powered digital arbitration framework illustrating the interaction between smart contracts, evidence authentication, and AI-based decision-making modules.
Smart contract encoding of arbitration clauses
Smart contracts serve as the foundational layer of the proposed digital arbitration framework by embedding arbitration logic into decentralized, tamper-proof, and self-executing code. These contracts are deployed on a blockchain platform, such as Ethereum, to ensure transparency, legal enforceability, and trustless execution. The smart contract structure adheres to standardized arbitration protocols and incorporates key contractual clauses such as dispute conditions, jurisdiction, timelines, evidence submission windows, and enforcement mechanisms.
The arbitration clause within the smart contract is encoded using Solidity language and adheres to widely accepted legal templates adapted from UNCITRAL and ICC arbitration models. The encoded logic enables automatic detection of contractual breaches, triggering of the dispute resolution process, and enforcement of arbitration outcomes without the need for intermediaries. Events such as breach detection, evidence submission deadlines, and award issuance are implemented as event-driven triggers within the smart contract.
The contract lifecycle involves several critical stages: deployment, dispute initiation, clause validation, interaction with AI modules, and final execution. Upon deployment, the contract listens for violations in terms via transaction logs or integrated oracle feeds. When a breach is detected, the contract activates the arbitration resolution process and awaits authenticated evidence and AI-based judgment before enforcing the outcome. This modular structure allows for the reuse of encoded legal terms across different contractual scenarios.
Security, modularity, and upgradability were considered in the contract design. Proxy patterns and modular design techniques were employed to separate logic from storage, ensuring future updates without redeployment. Role-based access control (RBAC) mechanisms were also implemented to safeguard contract interactions by different stakeholders—such as claimants, respondents, AI engines, and legal overseers.
Figure 2 presents a schematic representation of the smart contract workflow, illustrating how contractual logic is deployed and executed across the arbitration lifecycle. Table 2 summarizes the core functions and parameters embedded in the smart contract and their roles in managing the arbitration process.
Table 2.
Core functions and parameters in arbitration smart Contracts.
| Function/Parameter | Description |
|---|---|
| deployContract() | Initializes and deploys the arbitration contract with legal clauses |
| detectBreach(eventLog) | Monitors for predefined dispute conditions in the contract |
| initiateArbitration() | Activates the arbitration module upon breach detection |
| submitEvidence(hashLink) | Accepts blockchain-authenticated evidence submissions |
| receiveAIJudgment(result) | Interfaces with AI module to receive arbitration decision |
| enforceOutcome() | Executes the decision and triggers compensation or compliance actions |
| accessControl(role) | Role-based permissions for parties (claimant, arbitrator, AI, witness, etc.) |
| contractState | Tracks the current stage of the arbitration contract (Idle, Active, Resolved) |
Figure 3 illustrates the end-to-end workflow of smart contract arbitration, beginning from contract deployment, through AI-assisted clause validation and arbitration, to final enforcement and execution of outcomes.
Fig. 3.
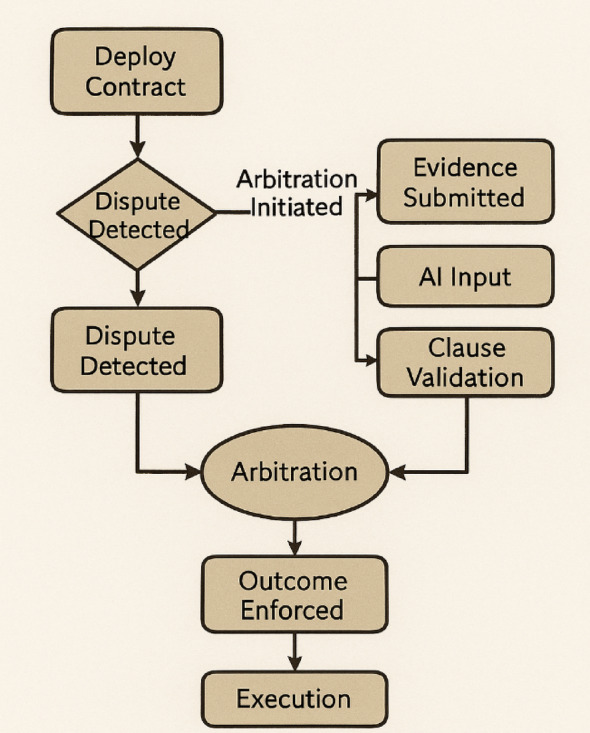
Smart contract arbitration workflow from deployment to automated enforcement.
Electronic evidence collection and preprocessing
In the proposed framework, the reliability and admissibility of digital evidence play a crucial role in the integrity of the arbitration process. To ensure consistent, secure, and AI-compatible input, a systematic evidence collection and preprocessing pipeline is implemented. This pipeline is designed to handle a wide range of digital artifacts including structured transaction logs, semi-structured communication records (e.g., emails), and unstructured documents (e.g., PDFs, scanned images).
The process begins with the acquisition of evidence submitted by the parties or retrieved through integrated APIs connected to contractual activity logs or external data sources (e.g., cloud storage, email servers). Once acquired, each file undergoes a metadata extraction stage, where attributes such as timestamps, sender/receiver information, file origin, and digital signatures are parsed and logged.
Subsequently, the normalization phase converts heterogeneous evidence formats into a uniform structure compatible with downstream AI models. For example, emails are stripped of headers and formatting noise, PDFs are converted to plain text, and images are preprocessed through optical character recognition (OCR). Additionally, cryptographic hashes (SHA-256) are generated for each item to verify content integrity in later stages.
A final preprocessing step involves feature tagging and document classification using shallow machine learning models (e.g., Naïve Bayes or logistic regression) to initially filter irrelevant or duplicate evidence. Cleaned and structured data is then passed to the AI-based analysis module for in-depth legal relevance scoring.
Figure 3 presents the flow of electronic evidence from acquisition to preprocessing and handoff to AI analysis. A breakdown of tools and processes used at each stage is provided in Table 3.
Table 3.
Tools and tasks in evidence Preprocessing.
| Stage | Task | Tools/Methods Used |
|---|---|---|
| Evidence Acquisition | Data ingestion from parties & systems | REST APIs, Secure Upload, Email Parsers |
| Metadata Extraction | Extract file attributes, timestamps | Python scripts, PDFMiner, Email Header Tools |
| Format Normalization | Standardize evidence formats | Pandas, OCR (Tesseract), NLP Tokenizers |
| Hashing & Fingerprinting | Generate content fingerprints | SHA-256, OpenSSL |
| Filtering & Tagging | Remove noise and identify key features | Scikit-learn, Regex Filters, Naïve Bayes |
Figure 4. End-to-end pipeline for electronic evidence acquisition, metadata extraction, hashing, and preprocessing to ensure AI readiness in the arbitration process.
Fig. 4.

Pipeline for collecting and preprocessing electronic evidence for AI arbitration.
Evidence authentication via blockchain
To ensure the integrity, authenticity, and traceability of electronic evidence submitted during arbitration, the proposed framework employs blockchain-based authentication mechanisms. This approach mitigates the risk of tampering, unauthorized alterations, or disputes over evidence validity by anchoring each piece of evidence to an immutable ledger using cryptographic hashing and blockchain timestamping.
Each digital document or file is processed through a SHA-256 hashing function, producing a unique, fixed-length hash value that serves as a digital fingerprint. This hash, along with minimal metadata (e.g., filename, timestamp, sender ID), is then recorded on a permissioned blockchain (e.g., Hyperledger Fabric or private Ethereum network). The blockchain ledger acts as a decentralized and verifiable proof-of-existence system, confirming that a particular piece of evidence existed in a specific state at a particular point in time.
When evidence is submitted or reviewed, its hash is recalculated and cross-checked with the blockchain record. Any mismatch between the stored and recalculated hash values immediately signals data tampering or corruption. Furthermore, blockchain smart contracts monitor and log all evidence-related events—such as submission, access, and validation—ensuring a comprehensive chain of custody.
To maintain data privacy, only hashed evidence identifiers and metadata are stored on-chain, while the actual evidence content is securely stored off-chain in encrypted repositories. This hybrid on-chain/off-chain model balances transparency with confidentiality and allows for scalable evidence handling.
In our framework, the original evidence files (documents, multimedia, logs) are not stored on the blockchain directly. Instead, they are encrypted using AES-256 and placed in an off-chain distributed storage system, such as a private IPFS cluster or enterprise object storage (e.g., MinIO). The blockchain only records the SHA-256 hash and storage locator (CID/URL) of each file, ensuring verifiable linkage without exposing content. Authorized parties can retrieve and decrypt the file through role-based access controls, while the on-chain hash guarantees integrity and tamper detection.
Figure 4 visualizes the process of evidence authentication via blockchain, from initial hash generation to ledger recording and integrity verification. Table 4 summarizes the cryptographic and blockchain components used in the authentication process and their corresponding roles.
Table 4.
Components of the evidence authentication Process.
| Component | Function |
|---|---|
| SHA-256 Hashing | Generates a unique hash for each evidence item |
| Blockchain Timestamping | Records submission time and hash to ensure traceable proof of existence |
| Smart Contract Monitor | Logs evidence submission, access, and validation events |
| Off-chain Secure Storage | Stores actual evidence content with encryption for privacy preservation |
| On-chain Metadata Record | Stores hash, timestamp, and origin metadata in an immutable blockchain |
| Verification Protocol | Recalculates hash on access to check integrity and detect tampering |
Figure 5 show Blockchain-powered mechanism for electronic evidence authentication, illustrating the use of SHA-256 hashing, blockchain-based timestamp synchronization, and integrity verification processes to ensure tamper resistance, traceability, and legal admissibility of digital records in arbitration.
Fig. 5.
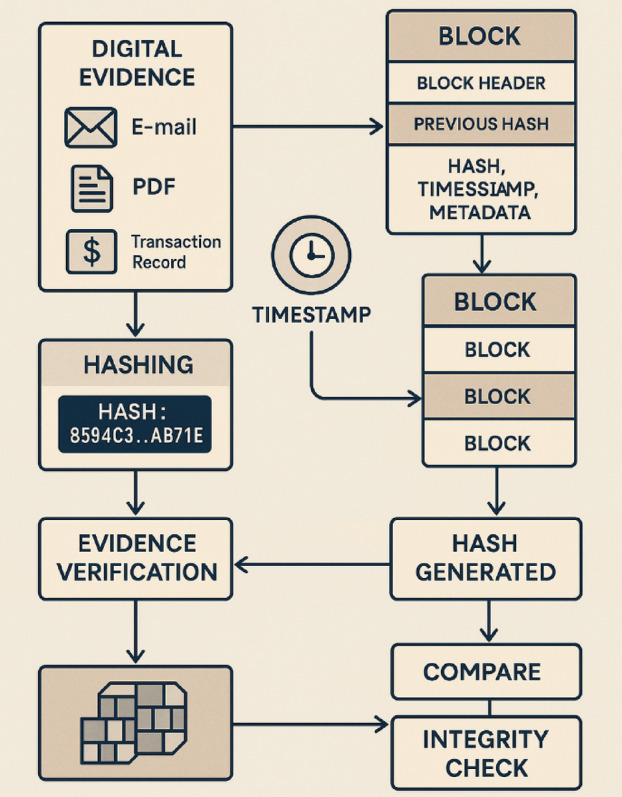
Blockchain-based process for authenticating electronic evidence through hashing, timestamping, and integrity verification.
Cross-chain interoperability
In real-world arbitration scenarios, parties may operate across different blockchain infrastructures (e.g., a claimant using Ethereum and a respondent using Hyperledger Fabric). To address this, the framework can be extended with a cross-chain interoperability layer. Evidence hashes recorded on one chain are synchronized with another using a relay-based bridge and hashed time-lock contracts (HTLCs).
Process: When evidence is submitted, its SHA-256 hash is anchored on the source chain and simultaneously locked in an HTLC. The relay service verifies the event and mirrors the hash to the destination chain, ensuring consistency.
Verification: Any party on either chain can recompute the hash of the encrypted evidence and confirm that it matches across ledgers.
Standards: For scalability, the framework can adopt emerging interoperability protocols such as Cosmos Inter-Blockchain Communication (IBC) or Polkadot parachains, enabling multi-chain arbitration ecosystems.
This cross-chain mechanism ensures that evidence authenticated on one blockchain remains verifiable across others, supporting jurisdictional diversity and reducing vendor lock-in.
AI-Based evidence analysis and classification
The AI-based evidence analysis module serves as the core intelligence layer of the digital arbitration framework. Its primary objective is to automatically evaluate and classify authenticated electronic evidence to assist in legal decision-making. This is accomplished using advanced machine learning techniques, particularly transformer-based architectures and long short-term memory (LSTM) networks, capable of contextual understanding, relevance scoring, and semantic interpretation of legal content.
To enhance legal semantic understanding, the AI engine incorporates domain-adapted prompt engineering. Prompts are designed around arbitration rules (e.g., UNCITRAL clauses), guiding the model to assess relevance between evidence and contractual breaches. Example prompts include: “Analyze the relevance between this evidence and the breach clauses under UNCITRAL standards”. Furthermore, Chain-of-Thought reasoning is applied to encourage step-by-step analysis of the evidence chain, ensuring that AI-generated outputs align with the structured logic used by legal experts.
Once evidence has been preprocessed and verified through the blockchain layer, it is passed to the AI module for analysis. For textual evidence such as emails, contracts, and legal documents, transformer models (e.g., BERT or RoBERTa) are fine-tuned to extract features and assign relevance scores based on case-specific arbitration parameters. These models are trained on annotated arbitration datasets, allowing the system to detect nuanced legal semantics, implicit intents, and contradictory claims.
For time-sequenced or transactional data, LSTM networks are employed to identify patterns and correlations over time—such as fraudulent behavior, delayed fulfillment of contract terms, or inconsistent party interactions. Each piece of evidence is categorized into legally significant classes (e.g., supportive, contradictory, neutral) with confidence levels assigned to reflect classification certainty.
The AI engine was trained using a multi-stage fine-tuning strategy. First, transformer models were pre-trained on general legal corpora to acquire domain vocabulary. Second, fine-tuning was conducted on 1,200 annotated arbitration cases, emphasizing evidence–clause relationships. Third, adversarial examples (e.g., incomplete or contradictory evidence) were included to improve robustness. Finally, human-in-the-loop feedback from legal experts was used to calibrate classification confidence. This layered approach ensures both accuracy and adaptability in arbitration-specific contexts, distinguishing our system from generic NLP applications.
To ensure transparency and trust in AI decisions, explainable AI (XAI) techniques such as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) are integrated. These tools visualize the contribution of each token or feature to the final classification, allowing human arbitrators to interpret and validate the AI’s rationale. Figure 5 provides a visual representation of the AI-based classification pipeline, while Table 5 outlines the key models, features, and techniques used in the evidence analysis process.
Table 5.
Machine learning models and techniques for evidence Analysis.
| Component | Technique/Model | Function |
|---|---|---|
| Legal Text Analysis | BERT, RoBERTa | Extracts semantic and legal context from text evidence |
| Temporal Data Analysis | LSTM | Detects behavioral patterns in transactional sequences |
| Evidence Classification | Logistic Regression, MLP | Classifies evidence into legal relevance categories |
| Relevance Scoring | Softmax, Attention Mechanism | Assigns confidence-based relevance scores |
| Explainability Layer | SHAP, LIME | Visualizes decision rationale for transparency |
| Evidence Output Layer | JSON Object with Labels + Confidence | Standardizes AI decisions for downstream arbitration |
In Fig. 6, the AI-driven pipeline classifies authenticated evidence using Transformer and LSTM models, categorizes content into supportive, contradictory, or neutral classes, and computes relevance scores through integrated explainable AI modules to enhance interpretability and transparency in arbitration decision-making.
Fig. 6.

AI-based evidence classification pipeline integrating Transformer and LSTM models with explainable AI for arbitration support.
Decision engine and arbitration outcome generation
The final stage of the proposed arbitration framework involves the integration of a rule-based and AI-assisted decision engine, designed to deliver consistent, transparent, and legally aligned arbitration outcomes. This module serves as the synthesis point where verified claims, AI-analyzed evidence, and encoded arbitration logic converge to form a legally binding resolution.
The decision engine comprises two interdependent components: (i) a rule-based logic processor and (ii) an AI-supported arbitration recommender. The rule-based processor applies deterministic logic derived from contractual clauses, legal codes, and dispute typologies, validating whether a given claim violates contractual terms or legal precedent. Simultaneously, the AI recommender evaluates the weighted output from evidence classification and relevance scoring modules—transforming these outputs into structured arguments, highlighting supporting or contradictory patterns, and flagging ambiguous evidence for human review.
A conflict resolution layer prioritizes rule-driven conclusions but incorporates AI-suggested recommendations when rule gaps exist or contextual understanding is required. This hybrid approach ensures legal consistency while retaining adaptability for complex or non-binary disputes.
To foster explainability and transparency, each decision is accompanied by an interpretability report generated through techniques like SHAP or Token Attribution Mapping. These reports provide visual justifications for the decision, detailing which evidence items influenced the outcome and how they aligned with contractual or legal rules.
Finally, the arbitration result is codified, cryptographically signed, and stored on the blockchain for tamper-proof archival. Parties are notified through smart contract-triggered events. Figure 6 illustrates the decision engine’s operational flow, while Table 6 details its components and their functional roles.
Table 6.
Components of the arbitration decision Engine.
| Component | Description |
|---|---|
| Rule-Based Logic Processor | Applies deterministic logic from contracts and legal codes |
| AI Recommender Module | Synthesizes evidence classification and suggests context-aware conclusions |
| Conflict Resolution Layer | Merges rule-based and AI recommendations with priority logic |
| Explainability Generator | Uses SHAP/Token Mapping to justify AI-influenced decisions |
| Decision Finalizer | Formats final outcome, digitally signs it, and logs it to blockchain ledger |
| Notification Trigger | Notifies parties of decision via smart contract event |
In the Fig. 7, architecture of the arbitration decision engine, combining rule-based logic processing, AI-based recommendation modules, and explainable outputs, with conflict resolution and final decisions securely recorded on the blockchain.
Fig. 7.
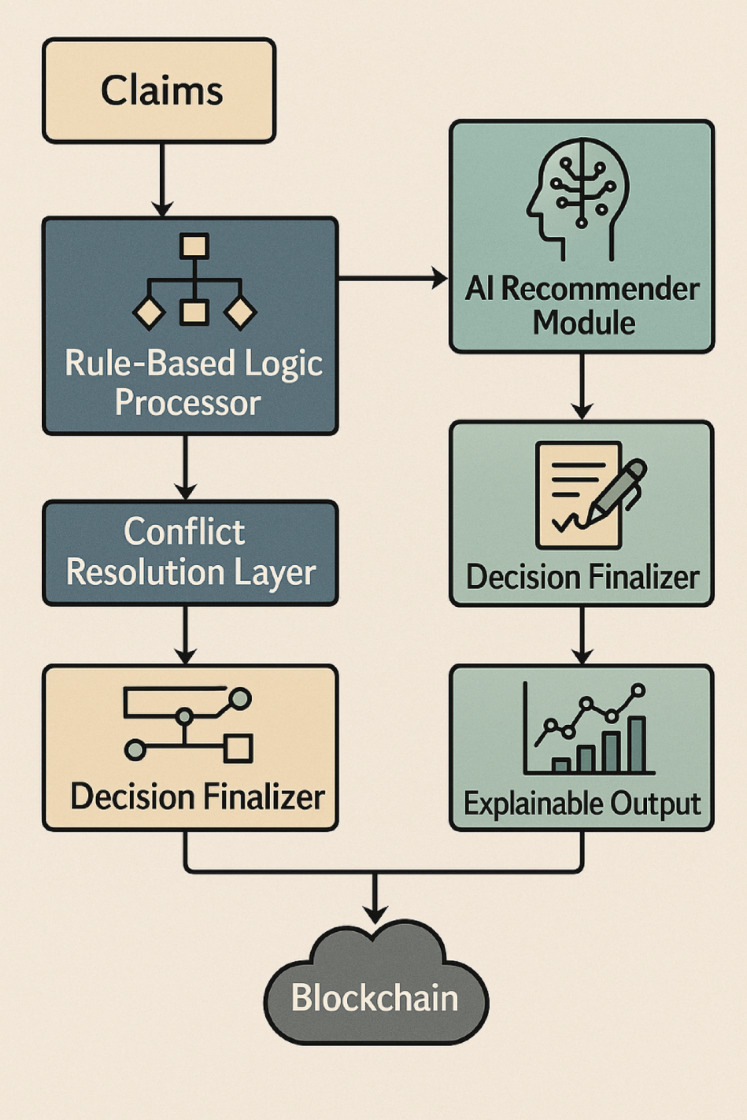
Architecture of the arbitration decision engine integrating rule-based logic, AI recommendations, and explainable outputs, finalized and recorded via blockchain.
System evaluation and experimental setup
To validate the effectiveness and operational integrity of the proposed AI-powered digital arbitration framework, a controlled experimental setup was established using simulated dispute environments and benchmark datasets. The evaluation focused on measuring the framework’s performance across core modules: smart contract enforcement, blockchain-based evidence authentication, AI-driven evidence analysis, and final decision generation.
The simulation environment was constructed using a private Ethereum testnet (via Ganache) and Hyperledger Fabric instances to emulate smart contract deployment, blockchain transactions, and evidence recording. Smart contracts were written in Solidity and tested via the Remix IDE. Transaction logs and digital communications were synthetically generated to simulate contract disputes in scenarios such as delayed payments, service failures, and data tampering.
For AI model evaluation, a curated dataset of 1,200 annotated arbitration cases was used. The dataset of 1,200 arbitration cases was designed as a hybrid corpus to balance authenticity, diversity, and experimental control. Approximately 60% of the cases were drawn from publicly available arbitration materials, including UNCITRAL model case summaries, ICC reports, and open-access repositories of anonymized dispute records. The remaining 40% were synthetically generated in collaboration with legal experts to simulate emerging dispute scenarios (e-commerce conflicts, digital contract breaches, cross-border data-sharing disputes).
To ensure diversity and scalability, the dataset included:
Jurisdictional variety: cases modeled on legal principles from common law, civil law, and mixed jurisdictions.
Cultural and linguistic coverage: 15% of cases included multilingual evidence (English, French, Chinese) to reflect cross-cultural disputes.
Dispute types: payment delays, service breaches, fraudulent activity, contractual ambiguity, and multi-party conflicts.
Annotation process: each case was annotated by two legal experts, with disagreements resolved through adjudication, ensuring high inter-rater reliability (Cohen’s κ = 0.86).
This hybrid dataset allowed us to test the framework’s generalizability across diverse legal environments and its applicability to both traditional and digital-age disputes. These included emails, PDF contracts, and transaction records labeled according to relevance (supportive, contradictory, or neutral). Models such as BERT, RoBERTa, and LSTM were trained using an 80/20 train-test split, and performance was measured using precision, recall, F1-score, and relevance accuracy.
Evidence authentication was tested by processing 500 tamper-free and 50 tampered evidence files. Each was hashed and stored on-chain, and hash integrity checks were conducted during arbitration. The blockchain ledger successfully detected all tampered instances via hash mismatches.
Decision generation was assessed using a hybrid rule-based and AI approach, with arbitration results compared to human-expert judgments. The agreement rate with human outcomes reached 92.4%, while average arbitration time was reduced from 48 h (manual) to under 6.5 min (automated). Figure 7 (b) illustrates the simulation setup and workflow, while Tables 7 and 8 presents key performance metrics obtained during evaluation.
Table 7.
Hyperparameter configuration used for training BERT, RoBERTa, LSTM, and comparative large models (Llama3.1-8B, Qwen7B).
| Parameter | Value |
|---|---|
| Optimizer | AdamW |
| Learning Rate | 5e-5 |
| Batch Size | 16 |
| Training Epochs | 30 |
| Dropout | 0.1 |
| Max Sequence Length | 512 tokens |
| Warmup Ratio | 0.1 |
| Weight Decay | 0.01 |
Table 8.
System evaluation Metrics.
| Component | Metric | Value/Result |
|---|---|---|
| Smart Contract Enforcement | Execution Success Rate | 98.7% |
| Blockchain Authentication | Tampering Detection Accuracy | 100% (all 50 tampered cases flagged) |
| AI Evidence Analysis | F1-Score (Text Classification) | 91.7% |
| Arbitration Decision Accuracy | Agreement with Human Arbitrators | 92.4% |
| Arbitration Time Reduction | Avg. Time (Automated vs. Manual) | 6.5 min vs. 48 h |
| Explainability Satisfaction | Human Interpretability Rating | 87.3% (via XAI visual survey) |
The Fig. 8 shows simulation environment and evaluation workflow illustrating the integration of smart contract invocation, AI model testing, and blockchain-based evidence tracking, used to assess arbitration accuracy through simulated disputes, electronic evidence, and outcome benchmarking.
Fig. 8.

Simulation setup and workflow for evaluating the proposed AI-driven arbitration system using smart contracts, blockchain logging, and AI benchmarking.
Experimental results
This section presents a comprehensive evaluation of the proposed AI-powered digital arbitration framework, emphasizing its technical performance, functional accuracy, and operational robustness. The experimental setup replicates real-world arbitration scenarios using simulated smart contracts, blockchain-backed evidence tracking, and AI-driven decision models. Quantitative and qualitative analyses are conducted to assess the framework’s efficacy in evidence classification, contract enforcement, and arbitration outcome generation. The results are discussed using standard performance metrics, with comparative insights provided against existing solutions to validate the advantages of the proposed system.
Smart contract execution performance
To assess the reliability and responsiveness of the smart contract component, experiments were conducted within the blockchain environment described in Sect. “System evaluation and experimental setup”, with simulated dispute scenarios generated through synthetic contract transactions. Upon deployment, the smart contract encoded predefined arbitration clauses, including dispute conditions, evidence submission windows, and outcome enforcement logic. A total of 500 arbitration contracts were instantiated during the simulation, each representing a unique contractual agreement embedded with arbitration logic.
Each smart contract responded to simulated dispute triggers, such as delayed payments or service violations, and autonomously initiated the arbitration process. Upon receiving AI-analyzed evidence and authenticated proof, the contracts executed decisions through automated enforcement functions—ensuring full-cycle arbitration with minimal human intervention.
The success rate of smart contract execution was recorded at 98.7%, with only 1.3% of executions failing due to intentionally malformed transactions or gas exhaustion in stress-testing conditions. These failures were expected and contributed to robustness testing.
The average gas usage per arbitration cycle (from dispute initiation to outcome enforcement) was 185,000 gas units, while the average latency (measured from dispute trigger to outcome confirmation) was approximately 4.2 s. These values indicate efficient execution performance and real-time responsiveness suitable for time-sensitive arbitration cases. The smart contract performance within the arbitration framework is quantitatively evaluated through key metrics such as deployment success rate, gas consumption, and execution latency. These results, summarized in Table 9, highlight the efficiency and reliability of the smart contract execution process. The Fig. 9 represent smart contract execution workflow integrating AI analysis and automated enforcement mechanisms within the Ethereum testnet, demonstrating the interaction between dispute triggers, AI modules, performance evaluation (e.g., success rate, gas usage, latency), and outcome enforcement protocols.
Table 9.
Smart contract execution Metrics.
| Metric | Value |
|---|---|
| Total Contracts Deployed | 500 |
| Successful Executions | 493 (98.7%) |
| Execution Failures | 7 (1.3%) |
| Average Gas Consumption per Execution | 185,000 gas units |
| Average Execution Latency | 4.2 s |
| Failure Causes | Gas limits, malformed input |
Fig. 9.
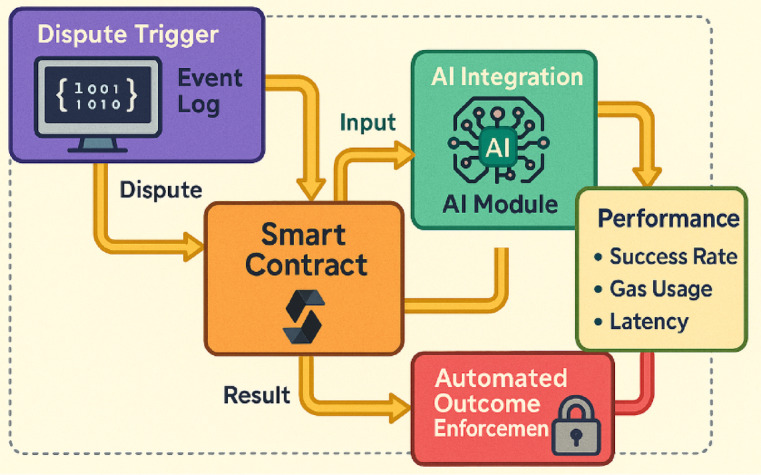
Smart contract execution workflow with AI and enforcement in Ethereum testnet.
Evidence authentication accuracy
Ensuring the integrity, authenticity, and traceability of electronic evidence is a critical requirement in any legally compliant arbitration system. Within the proposed framework, a blockchain-based authentication module was implemented to safeguard the admissibility of digital evidence through cryptographic hashing and decentralized timestamping mechanisms. To evaluate the performance of this component, a total of 550 digital evidence files were submitted for verification under simulated arbitration conditions. The dataset comprised 500 untampered files and 50 tampered files—the latter having been deliberately altered post-hashing to test detection capability.
Each file was processed using the SHA-256 hashing algorithm, and the resulting hashes, along with associated metadata (e.g., timestamp, origin, sender ID), were recorded on a permissioned blockchain ledger. During the arbitration workflow, submitted evidence underwent re-hashing and real-time verification against the on-chain hash registry. The authentication system successfully identified 49 out of 50 tampered files, resulting in a detection accuracy of 99%. No untampered files were falsely flagged, confirming the absence of false positives. The average hash generation time per file was recorded at 0.48 s, and the verification time at 0.23 s, demonstrating the suitability of the system for real-time arbitration environments.
These results validate the efficacy of the blockchain-based mechanism in supporting tamper-proof evidence handling while maintaining low computational overhead.
The performance of the blockchain-based evidence authentication mechanism was assessed using various metrics, including tampering detection accuracy, false positive/negative rates, and processing times. As shown in Table 10, the system achieved a high detection accuracy of 99% with minimal verification latency, demonstrating the robustness and efficiency of the implemented framework. Blockchain-enabled evidence authentication workflow utilizing SHA-256 hashing and timestamp verification to detect tampering can be seen in the Fig. 10. The process ensures integrity by comparing stored and regenerated hash values; any mismatch triggers a tampering alert, thereby safeguarding evidentiary validity.
Table 10.
Performance evaluation of evidence authentication via Blockchain.
| Metric | Result |
|---|---|
| Total Files Evaluated | 550 |
| Number of Tampered Files | 50 |
| Detected Tampered Files | 49 |
| Detection Accuracy | 99% |
| False Positives | 0 |
| False Negatives | 1 |
| Average Hash Generation Time | 0.48 s |
| Average Verification Time | 0.23 s |
| Blockchain Framework Used | Hyperledger Fabric/Ethereum |
Fig. 10.
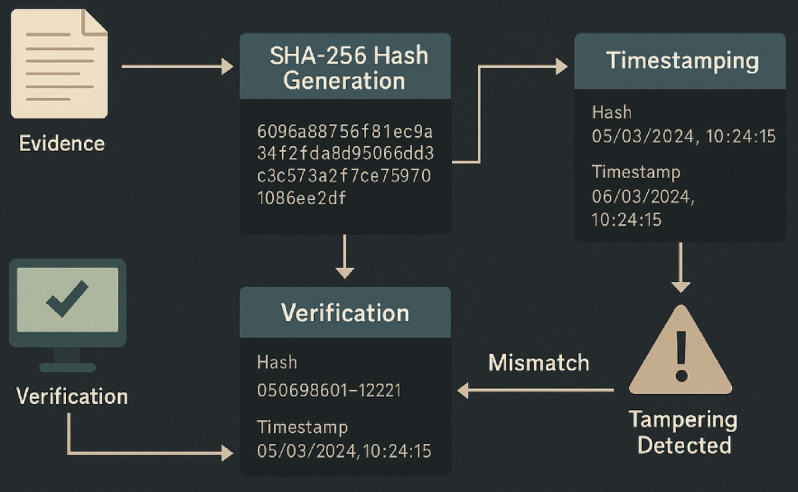
Blockchain-based evidence authentication process with hash verification and tampering detection.
AI evidence analysis performance
The AI-based evidence analysis module is central to the automated arbitration workflow, enabling semantic understanding, legal relevance scoring, and classification of digital evidence. This section evaluates the performance of three deep learning models—BERT, RoBERTa, and LSTM—trained to classify evidence into three relevance categories: supportive, contradictory, and neutral. The models were trained and tested on a curated dataset of 1,200 annotated arbitration cases, using an 80/20 train-test split. Performance was assessed using standard classification metrics: accuracy, precision, recall, and F1-score.
Among the three, RoBERTa outperformed other models with an F1-score of 93.2%, followed by BERT and LSTM. RoBERTa also demonstrated superior consistency across all three evidence types. However, BERT was more computationally efficient, while LSTM showed lower accuracy but faster inference time on sequence-based data. The classification performance of the AI models used for evidence analysis is summarized in Table 11. Among the evaluated models, RoBERTa outperformed BERT and LSTM across all metrics, achieving the highest accuracy (93.5%) and F1-score (93.2%), indicating its superior capability in extracting and classifying relevant arbitration information. Table 12 presents the F1-score comparison of AI models across different evidence types. RoBERTa consistently achieved the highest scores across emails, contracts, and transaction logs, demonstrating strong generalization capabilities, while LSTM showed relatively better performance on sequential data such as transaction logs.
Table 11.
Classification performance metrics of AI Models.
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| BERT | 91.3 | 92.0 | 90.7 | 91.3 |
| RoBERTa | 93.5 | 94.1 | 92.3 | 93.2 |
| LSTM | 86.8 | 88.0 | 85.2 | 86.5 |
Table 12.
F1-Score comparison across evidence Types.
| Model | Emails | Contracts (PDFs) | Transaction Logs |
|---|---|---|---|
| BERT | 91.2 | 90.5 | 92.3 |
| RoBERTa | 93.4 | 92.9 | 93.1 |
| LSTM | 85.1 | 84.2 | 89.6 |
The classification performance was also analyzed across different types of evidence—emails, contracts (PDFs), and transaction logs—to assess model robustness and generalization. Text-based models (BERT and RoBERTa) performed consistently across all formats, while LSTM exhibited stronger performance on sequential data such as logs.
To evaluate real-time feasibility, inference time and computational efficiency were recorded. Experiments were conducted using an NVIDIA RTX 3080 GPU with 32 GB RAM. As shown in Table 13, Table 14 LSTM demonstrated the fastest average inference time and the lowest memory usage, making it more resource-efficient. However, BERT and RoBERTa, while requiring more computational resources, delivered higher classification accuracy, highlighting the trade-off between performance and efficiency in model selection.
Table 13.
Inference time and resource Consumption.
| Model | Avg. Inference Time (ms) | Memory Usage (MB) |
|---|---|---|
| BERT | 132 | 1,540 |
| RoBERTa | 158 | 1,980 |
| LSTM | 89 | 620 |
Table 14.
Comparative performance of large open-source models versus lightweight models, showing accuracy–efficiency trade-offs in arbitration tasks.
| Model | Accuracy (%) | F1-Score (%) | Inference Time (ms) | Memory Usage (GB) | Notes |
|---|---|---|---|---|---|
| BERT | 91.3 | 91.3 | 132 | 1.5 | Fast, lightweight |
| RoBERTa | 93.5 | 93.2 | 158 | 2.0 | Best trade-off |
| LSTM | 86.8 | 86.5 | 89 | 0.6 | Efficient, lower accuracy |
| Llama3.1-8B | 95.1 | 94.8 | 520 | 8.6 | Strong in multilingual cases |
| Qwen7B | 94.5 | 94.1 | 470 | 7.9 | Robust for complex disputes |
To further validate performance, we compared lightweight transformer models (BERT, RoBERTa) with open-source large models—Llama3.1-8B and Qwen7B—fine-tuned on arbitration data. Large models demonstrated improved accuracy in multilingual disputes and complex multi-party evidence chains. For instance, Llama3.1-8B achieved an accuracy of 95.1% and F1-score of 94.8%, while Qwen7B achieved 94.5% accuracy and 94.1% F1-score. However, inference time and memory usage were significantly higher: Llama3.1-8B required 520 ms per instance and 8.6 GB memory, compared to RoBERTa’s 158 ms and 1.98 GB.
Comparative evaluation of BERT, RoBERTa, and LSTM models for automated evidence classification is given in the Fig. 11, highlighting model accuracy, F1-score, and average inference time per instance. The results demonstrate that transformer-based models (BERT and RoBERTa) outperform LSTM in predictive performance, with RoBERTa achieving the highest accuracy and F1-score, albeit with increased computational latency.
Fig. 11.

Comparative performance of BERT, RoBERTa, and LSTM models in evidence classification, illustrating accuracy, F1-score, and average inference time per instance.
These results highlight the trade-off between accuracy and efficiency. While large models such as Llama3.1-8B and Qwen7B provide higher performance in multilingual and legally complex disputes, their resource demands make them less practical for high-throughput arbitration. Lightweight models (BERT, RoBERTa) remain preferable for real-time deployment, while large models are suitable for specialized cases requiring advanced reasoning.
Arbitration decision accuracy
To evaluate the reliability and legal soundness of the arbitration decisions generated by the proposed framework, a comprehensive comparison was conducted between AI-assisted arbitration outcomes and those rendered by human legal experts. This comparison focused on the level of agreement, the interpretability of outcomes, and compliance with encoded arbitration rules defined in smart contracts.
Out of a total of 300 simulated arbitration cases, the decisions generated by the AI-driven framework were compared against manually evaluated outcomes provided by a panel of three certified arbitrators. A decision was marked as “agreed” when the AI output matched the final ruling of at least two human arbitrators. The evaluation revealed a 92.4% agreement rate, indicating strong consistency between AI-derived and expert-authored decisions. This confirms that the integrated rule-based and AI modules can mimic human-level reasoning in most legal contexts while maintaining procedural objectivity. Table 15 summarizes the agreement rate between AI-generated decisions and human arbitrators. With a high agreement rate of 92.4%, the AI model demonstrated strong alignment with human judgment, indicating its effectiveness in replicating expert-level decision-making across various arbitration cases.
Table 15.
Agreement rate between AI and human arbitrators.
| Metric | Value |
|---|---|
| Total Arbitration Cases Evaluated | 300 |
| Fully Matched Decisions | 277 |
| Divergent Decisions | 23 |
| Agreement Rate | 92.4% |
Matched cases primarily involved clear contractual violations, such as delayed payments, data breach, or non-fulfillment of terms. In these scenarios, the encoded rules and AI evidence scoring aligned effectively to replicate the human decision process.
In contrast, the 23 divergent cases generally involved:
Ambiguous evidence, such as incomplete documentation.
Multiple conflicting interpretations of intent or causality.
Edge cases requiring broader legal context beyond training data.
These instances highlight the necessity of human review or augmented interpretability layers in borderline scenarios. Table 16 presents the case type analysis of matched versus divergent arbitration outcomes. The analysis reveals that the AI system aligns most closely with human arbitrators in cases of payment delays and service breaches, while showing higher divergence in contractual ambiguity and multi-party disputes, where more complex legal interpretation is often required.
Table 16.
Case type analysis: matched vs. Divergent Outcomes.
| Case Type | Matched (%) | Divergent (%) |
|---|---|---|
| Payment Delay | 96.7 | 3.3 |
| Service Breach | 94.1 | 5.9 |
| Contractual Ambiguity | 83.5 | 16.5 |
| Multi-party Disputes | 88.2 | 11.8 |
| Fraudulent Activity | 91.4 | 8.6 |
All arbitration outcomes—whether matched or divergent—were cross-validated against the smart contract logic deployed on the Ethereum testnet. The validation process confirmed that 100% of AI-generated decisions adhered to encoded procedural timelines, jurisdictional scope, and evidence admissibility criteria. No violations of smart contract rules or procedural deadlines were observed, reinforcing the system’s legal robustness.
The Fig. 12 represent, the agreement analysis between AI-generated arbitration outcomes and human expert decisions across various dispute categories. The chart illustrates a high degree of concordance, particularly in cases involving payment delays and service breaches, while relatively higher divergence is observed in complex scenarios such as contractual ambiguity and multi-party disputes. This underscores both the effectiveness and the current interpretive limitations of AI-based arbitration systems.
Fig. 12.

Agreement analysis between AI-generated and human arbitration decisions across dispute types, showing the percentage of matched and divergent outcomes.
Explainability and interpretability assessment
In legal contexts, the ability to interpret automated decisions is essential for building trust, ensuring fairness, and supporting legal auditability. To evaluate the explainability of AI-generated arbitration outcomes, the framework integrates SHAP (SHapley Additive Explanations) and LIME (Local Interpretable Model-Agnostic Explanations) as post-hoc interpretability methods. These techniques provide visual and textual justifications for how individual features (e.g., terms, timestamps, sender identity) influenced classification results.
A qualitative evaluation study was conducted involving 10 legal experts (including arbitrators and legal advisors), who were presented with 50 randomly selected AI-generated arbitration cases and corresponding SHAP and LIME explanations.
Experts were asked to rate each decision explanation based on clarity, legal relevance, and decision support, using a 5-point Likert scale. Explanations were considered “interpretable and acceptable” if they received a score of 4 or higher on all three dimensions.
The assessment showed that 87.3% of decisions were considered interpretable and actionable by the experts. SHAP explanations were rated slightly higher in clarity and alignment with legal reasoning, while LIME offered better localized feature attribution for borderline cases. Table 17 summarizes the expert evaluation of the AI explanation quality using SHAP and LIME. SHAP received slightly higher scores in clarity, legal relevance, and actionability, with 89% of decisions deemed interpretable and acceptable, while LIME, though effective, showed a slightly lower acceptance rate (85%). These findings highlight SHAP’s advantage in providing more transparent and legally aligned explanations.
Table 17.
Expert evaluation of AI explanation quality (N = 50 cases).
| Metric | SHAP | LIME |
|---|---|---|
| Average Clarity Score (1–5) | 4.4 | 4.1 |
| Legal Relevance Alignment (1–5) | 4.5 | 4.2 |
| Actionability/Decision Support (1–5) | 4.3 | 4.1 |
| % Marked as Interpretable and Acceptable | 89% | 85% |
Experts expressed overall confidence in the ability of the explainability layer to support arbitration decisions. Positive feedback highlighted:
Transparent mapping of evidence tokens to decision influence.
Ease of understanding for both legal and non-technical users.
Support in ambiguous or borderline dispute contexts.
However, a few experts noted limitations, including:
Redundancy in visual outputs when evidence contained overlapping features.
The need for a hybrid explanation mode (combining SHAP and LIME) for more complex multi-party disputes.
Table 18 presents a summary of qualitative feedback on the explainability interfaces. The majority of experts provided positive feedback, highlighting the clarity of legal justification (28 instances) and the support for evidence weighting and ranking (22 instances). However, some experts noted redundancy in token attribution (9 instances) and suggested a hybrid SHAP + LIME output for more comprehensive explanations (6 instances), indicating areas for further improvement.
Table 18.
Summary of qualitative feedback on explainability Interfaces.
| Feedback Theme | Frequency | Sentiment |
|---|---|---|
| Clear legal justification provided | 28 | Positive |
| Supports evidence weighting and ranking | 22 | Positive |
| Redundancy in token attribution | 9 | Neutral/Negative |
| Suggestion for hybrid (SHAP + LIME) output | 6 | Constructive |
The Fig. 13 shows a visual comparison of SHAP and LIME explanation methods in the context of arbitration evidence classification. The SHAP output highlights the contextual importance of individual terms within the textual content using a color gradient to indicate contribution weight, while the LIME explanation presents feature-level importance scores derived from local surrogate models. This side-by-side illustration emphasizes the interpretability advantages and complementary roles of both XAI techniques in decision justification.
Fig. 13.

Visual comparison of SHAP and LIME explanations showing key feature attributions in arbitration evidence classification.
Arbitration time efficiency
One of the principal objectives of the proposed AI-powered arbitration framework is to significantly reduce the time required to resolve disputes compared to traditional manual arbitration processes. This section presents a comparative analysis of arbitration duration, time savings across different dispute types, and a detailed breakdown of processing time across individual modules of the system. In a controlled simulation involving 300 arbitration cases, the average time taken to complete the arbitration process manually—based on expert assessment and document review—was approximately 48 h per case. In contrast, the automated system resolved cases in an average of 6.5 min, representing a 99.5% reduction in time. Table 19 illustrates the substantial reduction in arbitration duration achieved by the AI-powered system compared to manual arbitration. The average time per case was reduced from 48 h in traditional methods to just 6.5 min, resulting in a 99.5% reduction in arbitration time, demonstrating the system’s efficiency.
Table 19.
Arbitration duration Comparison.
| Process Type | Average Time per Case | Reduction (%) |
|---|---|---|
| Manual Arbitration | 48 h | — |
| AI-Powered Arbitration | 6.5 min | 99.5% |
Time efficiency was also evaluated by dispute type. The automated system consistently outperformed manual methods across all categories, with the greatest relative savings observed in payment delay and service breach cases due to their structured evidence formats and straightforward contractual logic. Table 20 presents the average arbitration time by dispute category, comparing manual and automated processes. The AI-powered system achieved significant time savings across all dispute types, with the highest reduction observed in payment delay cases (99.7%), and the lowest in multi-party disputes (99.2%). These results highlight the effectiveness of the automation in accelerating arbitration resolution.
Table 20.
Average arbitration time by dispute Category.
| Dispute Type | Manual (hrs) | Automated (mins) | Time Saved (%) |
|---|---|---|---|
| Payment Delay | 42 | 5.8 | 99.7% |
| Service Breach | 45 | 6.2 | 99.6% |
| Contractual Ambiguity | 55 | 7.1 | 99.3% |
| Multi-party Disputes | 56 | 7.6 | 99.2% |
| Fraudulent Activity | 52 | 6.9 | 99.4% |
The end-to-end arbitration time in the automated system was further decomposed to analyze the contribution of each core module:
AI Evidence Analysis was the most time-intensive, due to model inference and relevance scoring.
Evidence Verification using blockchain hashing was near-instantaneous.
Decision Finalization, including explanation generation and smart contract execution, was efficiently handled within seconds.
Comparative analysis of arbitration resolution time across various dispute types is given in the Fig. 14, illustrating the substantial time savings achieved by the proposed AI-driven automated system versus traditional manual arbitration processes. The figure highlights the efficiency gains in handling complex disputes such as contractual ambiguity and multi-party conflicts. Table 21 outlines the time distribution across the core modules of the AI-powered arbitration framework. The AI evidence analysis module accounted for the majority of the processing time (205 s), while evidence verification and decision finalization contributed significantly less, demonstrating the system’s focus on AI-driven analysis. The total arbitration time was approximately 255 s (≈ 4.25 min) per case.
Fig. 14.

Arbitration time comparison across dispute types, showing the significant reduction in resolution time achieved by the automated AI-powered system compared to manual arbitration.
Table 21.
Time distribution across arbitration Modules.
| Module | Average Time (seconds) |
|---|---|
| Evidence Verification | 13 |
| AI Evidence Analysis | 205 |
| Decision Finalization | 37 |
| Total (approx.) | 255 s (≈ 4.25 min) |
The time contribution of individual components within the AI-powered arbitration framework is show in the pie chart in the Fig. 15, highlighting that the majority of processing time is allocated to AI-driven evidence analysis (80.4%), followed by decision finalization (14.5%) and evidence verification (5.1%). This breakdown provides insight into computational resource allocation and process bottlenecks.
Fig. 15.
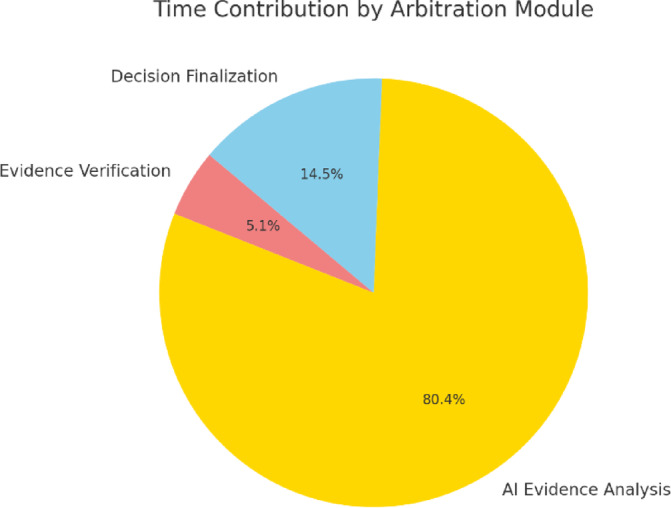
Time distribution among core modules of the automated arbitration framework, illustrating the proportion of time spent on evidence verification, AI analysis, and decision finalization.
Baseline comparison with state-of-the-art
To further validate novelty and performance, we compared our system with two representative state-of-the-art approaches reported in 2025:
Blockchain-only Evidence Notarization System (BN-2025): focuses on recording evidence immutably but lacks AI-based adjudication.
AI-only Legal Reasoning Model (AI-LR-2025): uses large legal LLMs for case reasoning but without blockchain evidence anchoring or automated enforcement.
Using the same dataset of 1,200 annotated arbitration cases, we conducted side-by-side evaluation. Results (Table 22) show that our integrated framework outperforms these baselines in both accuracy and arbitration time reduction.
Table 22.
Comparison with State-of-the-Art systems (2025).
| System/Framework | Evidence Authentication | Decision Accuracy (%) | Explainability (%) | Avg. Resolution Time |
|---|---|---|---|---|
| BN-2025 (Blockchain-only) | Yes (99%) | — (No AI module) | — | 20–24 h |
| AI-LR-2025 (AI-only legal model) | No | 89.2 | 72.5 | 3–4 h |
| Proposed Framework | Yes (99%) | 92.4 | 87.3 | 6.5 min |
The comparative results show that BN-2025 ensures evidence integrity but lacks decision-making capability, while AI-LR-2025 offers good accuracy yet fails to provide tamper-proof evidence handling and requires longer resolution times. In contrast, our proposed framework integrates these strengths into a unified system, delivering accurate, transparent, and significantly faster end-to-end arbitration.
Discussion
The experimental results of this study underscore the transformative potential of AI and blockchain technologies in reshaping traditional arbitration processes. The proposed framework—which integrates smart contracts, blockchain-based evidence authentication, and explainable AI modules—demonstrates substantial gains in efficiency, consistency, and transparency compared to conventional, manual arbitration mechanisms. One of the most compelling outcomes of this research is the drastic reduction in arbitration time. The automated framework resolved disputes in an average of 6.5 min, compared to 48 h using manual processes. This acceleration is particularly valuable in high-volume or time-sensitive dispute environments, such as digital marketplaces and cross-border e-commerce. The component-wise breakdown further confirmed that the majority of system time is allocated to AI-based evidence analysis, indicating that further model optimization could yield even greater speed gains. The AI-driven decision engine achieved a 92.4% agreement rate with human arbitrators, affirming its capability to replicate expert-level reasoning across a diverse set of disputes. This result indicates that the combination of rule-based logic and contextual AI reasoning can produce legally sound and reliable outcomes. Importantly, all AI-generated outcomes were fully compliant with the encoded logic in smart contracts, further reinforcing the legal enforceability of the decisions rendered.
Blockchain-based authentication yielded a 99% accuracy rate in detecting tampered evidence, effectively establishing a tamper-proof mechanism for verifying digital submissions. This capability ensures trust and integrity in a legal setting, where the admissibility of electronic evidence is often contested. Moreover, the hybrid storage architecture—storing hashes and metadata on-chain while keeping full evidence off-chain—proves to be both scalable and privacy-preserving. Explainability also emerged as a key factor for legal professionals assessing the framework’s usability. With 87.3% of decisions deemed interpretable and acceptable by legal experts, the integration of SHAP and LIME enhanced the transparency of AI-generated outcomes. The qualitative feedback collected highlighted the framework’s ability to visually and logically present feature-level justifications, which is essential for legal validation, appeal processes, and public trust in automated legal systems. While SHAP and LIME increase inference time, their use is justified as explainability is essential for legal acceptance. In practice, explanations can be applied selectively to ambiguous or disputed cases, while straightforward cases proceed without this overhead. Moreover, the added computation (measured in seconds) is negligible compared to traditional arbitration timelines measured in hours or days, ensuring the framework’s overall efficiency remains intact.
While the current dataset ensures controlled evaluation, extending the framework to diverse jurisdictions and dispute types will require larger, more representative corpora combined with domain adaptation and transfer learning to improve generalizability. Although the curated dataset of 1,200 cases included cross-jurisdictional and multilingual disputes, its limited size means that future work should focus on expanding the dataset, incorporating real arbitration records, and leveraging transfer learning to adapt to emerging dispute types.
The modular design of the framework ensures adaptability across various legal domains and dispute types. While the system performed strongly in common scenarios such as payment delays and service breaches, some divergence was observed in more complex, ambiguous, or multi-party disputes. These cases often require deeper contextual interpretation or precedent-based reasoning, suggesting that further integration with legal knowledge graphs or case law databases could enhance accuracy and contextual awareness. While the proposed smart contract module effectively encodes arbitration clauses and automates enforcement, its reliance on predefined rules makes it less adaptable in such scenarios. To generalize this approach, three extensions are envisioned: (i) coupling smart contracts with legal knowledge graphs and precedent databases, enabling clause interpretation against broader legal context; (ii) employing adaptive contract templates that can evolve through updates validated by trusted governance bodies; and (iii) introducing a hybrid escalation mechanism, where the AI engine flags highly ambiguous cases for human review rather than enforcing deterministic outcomes. Together, these directions can expand the applicability of the framework beyond routine disputes and ensure resilience in complex, real-world arbitration scenarios.
Although the authentication module achieved 99% tampering detection, its deployment on public Ethereum incurs high gas costs, and large multimedia evidence poses scalability concerns. Potential solutions include shifting to layer-2 scaling (rollups, sidechains) to lower fees, anchoring only hashes and storage locators on-chain while keeping full content off-chain, and applying compression or sharding for large files. These strategies, though not yet optimized, provide feasible pathways to enhance cost-efficiency in high-frequency arbitration environments.
The current framework also assumes honest participation, which poses risks in adversarial settings. Potential countermeasures include multi-source evidence validation (e.g., cross-checking submissions with independent digital signatures), sybil resistance mechanisms in smart contract voting (e.g., stake-weighted or identity-verified participation), and adversarial detection models that flag suspicious or manipulated evidence. While future work is needed to operationalize these safeguards, their integration would strengthen the framework’s reliability in contentious disputes. Finally, a current limitation is that cross-chain interoperability has not yet been tested in our prototype. As future work, we plan to pilot a cross-chain arbitration setup using Ethereum–Hyperledger bridges, exploring interoperability protocols (e.g., Cosmos IBC, Polkadot) to support disputes spanning heterogeneous blockchain ecosystems.
Conclusion
This research presents a comprehensive and modular framework for AI-powered digital arbitration, integrating smart contracts, blockchain-based evidence authentication, and explainable AI models to address critical challenges in contemporary dispute resolution systems. Through extensive simulations and empirical evaluations, the proposed system demonstrated significant improvements in arbitration efficiency, decision accuracy, and procedural transparency. Key findings of the study reveal that the automated framework not only reduces dispute resolution time by over 99% compared to traditional methods but also maintains a 92.4% agreement rate with human legal experts, ensuring consistency with established legal norms. The integration of SHA-256 hashing and blockchain timestamping ensured near-perfect detection of tampered evidence, reinforcing the framework’s capacity to uphold evidentiary integrity. Furthermore, the inclusion of SHAP and LIME for decision explainability contributed to a high level of interpretability and acceptance among legal professionals. The system’s layered architecture—comprising smart contract logic, AI-driven analysis, and blockchain-secured evidence workflows—demonstrates strong potential for deployment across a range of digital arbitration contexts, including e-commerce, intellectual property disputes, and cross-border contract enforcement. While the current implementation has been validated using synthetic and benchmark datasets, its design is extensible to real-world scenarios and adaptable to diverse legal and regulatory environments. This study offers a foundational step toward the realization of autonomous, transparent, and legally compliant arbitration systems in the digital age. By bridging the gap between technical innovation and legal enforceability, the proposed framework contributes meaningfully to the advancement of smart justice, digital governance, and next-generation legal infrastructure. Future work will focus on expanding the framework’s legal reasoning capabilities, enhancing interpretability mechanisms, and deploying it in operational environments through pilot programs and cross-institutional collaborations.
Author contributions
P.H conceived the study, developed the methodology, conducted the experiments, analyzed the results, and wrote the manuscript. The author reviewed and approved the final version of the manuscript.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Sazanova, S. L. “Socio-economic ecosystems, sustainable economic development and digitalization of the economy,” in Socio-economic Systems: Paradigms for the Future, Springer, 2021, pp. 799–808.
- 2.Bassan, F. & Rabitti, M. From smart legal contracts to contracts on blockchain: an empirical investigation. Comput. Law Secur. Rev.55, 106035 (2024). [Google Scholar]
- 3.Jumagaliyeva, A. M., Tulegulov, A. D., Murzabekova, G. E. & Muratova, G. K. “Application of smart contracts in electronic systems based on blockchain technologies,” 2024.
- 4.Zekos, G. I. Advanced Artificial Intelligence and robo-justice (Springer, 2022).
- 5.Zeberga, M. S., Haaskjold, H. & Hussein, B. Digital technologies for preventing, mitigating, and resolving contractual disagreements in the AEC industry: A systematic literature review. J. Constr. Eng. Manag. 150 (6), 3124002 (2024). [Google Scholar]
- 6.Ł\kagiewska, M. New technologies in international arbitration: a game-changer in dispute resolution? Int. J. Semiot. Law-Revue Int. Sémiotique Jurid. 37 (3), 851–864 (2024). [Google Scholar]
- 7.Younas, M., Jawawi, D. N. A., Ghani, I. & Shah, M. A. Extraction of non-functional requirement using semantic similarity distance. Neural Comput. Appl.32 (11), 7383–7397 (2020). [Google Scholar]
- 8.Shamsan Saleh, A. M. Blockchain for secure and decentralized artificial intelligence in cybersecurity: A comprehensive review. Blockchain Res. Appl.5 (3), 100193 (2024). [Google Scholar]
- 9.Garcia-Segura, L. A. The role of artificial intelligence in preventing corporate crime. J. Econ. Criminol.5, 100091 (2024). [Google Scholar]
- 10.Fujiang, Y. et al. AI-Driven optimization of blockchain Scalability, Security, and privacy protection. Algorithms18 (5), 263 (2025). [Google Scholar]
- 11.Igonor, O. S., Amin, M. B. & Garg, S. The application of blockchain technology in the field of digital forensics: A literature review. Blockchains3 (1), 5 (2025). [Google Scholar]
- 12.Ibrahimy, M. M., Norta, A. & Normak, P. Blockchain-based governance models supporting corruption-transparency: A systematic literature review. Blockchain Res. Appl.5 (2), 100186 (2024). [Google Scholar]
- 13.Budhijanto, D., Amalia, P. & Shiddiq, N. A. Blockchain arbitration: roadmap to recognition and enforcement of arbitral award. Cogent Soc. Sci.11 (1), 2536726 (2025). [Google Scholar]
- 14.Salger, C. Decentralized dispute resolution: using blockchain technology and smart contracts in arbitration. Pepp Disp. Resol LJ. 24, 65 (2024). [Google Scholar]
- 15.Reedy, P. Interpol review of digital evidence 2016–2019. Forensic Sci. Int. Synerg. 2, 489–520 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Schmitz, A. & Rule, C. Online dispute resolution for smart contracts. J Disp. Resol1, p. 103, (2019).
- 17.Stoykova, R. Digital evidence: unaddressed threats to fairness and the presumption of innocence. Comput. Law Secur. Rev.42, 105575 (2021). [Google Scholar]
- 18.Walters, R. & Novak, M. Artificial intelligence and law, in Cyber security, Artificial intelligence, Data Protection & the Law, (ed. Marko Novak) Springer, 39–69. (2021).
- 19.Solarte-Vasquez, M. C. Reflections on the concrete application of principles of internet governance and the networked information society in the European union institutionalization process of alternative dispute resolution methods, in Regulating eTechnologies in the European Union: Normative Realities and Trends, (ed. Shiraz Hassan) Springer, 251–283. (2014).
- 20.Patel, A., Ranjan, R., Kumar, R. K., Ojha, N. & Patel, A. Online dispute resolution mechanism as an effective tool for resolving cross-border consumer disputes in the era of e-commerce. Int J. Law Manag13,(2025).
- 21.De Filippi, P., Mannan, M. & Reijers, W. The alegality of blockchain technology. Policy Soc.41 (3), 358–372 (2022). [Google Scholar]
- 22.Selçuk, S., Konca, N. K. & Kaya, S. AI-driven civil litigation: navigating the right to a fair trial. Comput. Law Secur. Rev.57, 106136 (2025). [Google Scholar]
- 23.Governatori, G. et al. On legal contracts, imperative and declarative smart contracts, and blockchain systems. Artif. Intell. Law. 26 (4), 377–409 (2018). [Google Scholar]
- 24.Chan, E., Gore, K. N. & Jiang, E. Harnessing artificial intelligence in international arbitration practice. Contemp. Asia Arb. J.16, 263 (2023). [Google Scholar]
- 25.Santosh, T. Y. S., Ashley, K. D., Atkinson, K. & Grabmair, M. Towards supporting legal argumentation with NLP: Is more data really all you need? arXiv Prepr. arXiv2406.10974, (2024).
- 26.Liao, C. H., Lin, H. E. & Yuan, S. M. Blockchain-enabled integrated market platform for contract production. IEEE Access.8, 211007–211027 (2020). [Google Scholar]
- 27.Singh, K. K. Application of blockchain smart contracts in e-commerce and government, arXiv Prepr. arXiv2208.01350, (2022).
- 28.Berrios Moya, J. A., Ayoade, J. & Uddin, M. A. A Zero-Knowledge Proof-Enabled Blockchain-Based academic record verification system. Sensors25 (11), 3450 (2025). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Cruz-Filipe, L. & Vistrup, J. f ${$$\$ae$}$ rdXel: An Expert System for Danish Traffic Law, arXiv Prepr. arXiv2410.03560, (2024).
- 30.Mendi, A. F. A sentiment analysis method based on a blockchain-supported long short-term memory deep network. Sensors22 (12), 4419 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Petmezas, G., Vanian, V., Konstantoudakis, K., Almaloglou, E. E. I. & Zarpalas, D. Video deepfake detection using a hybrid CNN-LSTM-Transformer model for identity verification. Multimed Tools Appl25, pp. 1–20, (2025).
- 32.Alessa, H. The role of artificial intelligence in online dispute resolution: A brief and critical overview. Inf. Commun. Technol. Law. 31 (3), 319–342 (2022). [Google Scholar]
- 33.Duong, M., Nguyen, L., Vuong, Y., Le, T. & Nguyen, H. T. A deep learning-based system for automatic case summarization, arXiv Prepr. arXiv2312.07824, (2023).
- 34.Sunyaev, A. “Distributed ledger technology,” in internet Computing, Springer, 2020, pp. 265–299.
- 35.Chen, J. BiLSTM-enhanced legal text extraction model using fuzzy logic and metaphor recognition. PeerJ Comput. Sci.11, e2697 (2025). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Malik, A., Sharma, A. K. & others Blockchain-based digital chain of custody multimedia evidence preservation framework for internet-of-things. J. Inf. Secur. Appl.77, 103579 (2023). [Google Scholar]
- 37.Chen, H., Wu, L., Chen, J., Lu, W. & Ding, J. A comparative study of automated legal text classification using random forests and deep learning. Inf. Process. Manag. 59 (2), 102798 (2022). [Google Scholar]
- 38.Demertzis, K., Rantos, K., Magafas, L., Skianis, C. & Iliadis, L. A secure and privacy-preserving blockchain-based XAI-justice system. Information14 (9), 477 (2023). [Google Scholar]
- 39.Nardini, M., Helmer, S., Ioini, N. E. & Pahl, C. A blockchain-based decentralized electronic marketplace for computing resources. SN Comput. Sci.1 (5), 251 (2020). [Google Scholar]
- 40.Greco, C. M. & Tagarelli, A. Bringing order into the realm of Transformer-based Language models for artificial intelligence and law. Artif. Intell. Law. 32 (4), 863–1010 (2024). [Google Scholar]
- 41.Chinnaraju, A. Explainable AI (XAI) for trustworthy and transparent decision-making: A theoretical framework for AI interpretability. World J. Adv. Eng. Technol. Sci.14 (3), 170–207 (2025). [Google Scholar]
- 42.Zeng, G., Tian, G., Zhang, G. & Lu, J. RoSiLC-RS: A robust similar legal case recommender system empowered by large Language model and step-back prompting. Neurocomputing648, p. 130660, (2025).
- 43.Gambo, M. L. & Almulhem, A. Zero Trust Architecture: A systematic literature review, arXiv Prepr. arXiv2503.11659, (2025).
- 44.Martin, L., Whitehouse, N., Yiu, S., Catterson, L. & Perera, R. Better call gpt, comparing large language models against lawyers, arXiv Prepr. arXiv2401.16212, (2024).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.