

Abstract
Due to language barrier, non-English users are unable to retrieve the most updated medical information from the U.S. authoritative medical websites, such as PubMed and MedlinePlus. A few cross-language medical information retrieval (CLMIR) systems have been utilizing MeSH (Medical Subject Heading) with multilingual thesaurus to bridge the gap. Unfortunately, MeSH has yet not been translated into traditional Chinese currently.
We proposed a semi-automatic approach to constructing Chinese-English MeSH based on Web-based term translation. The system provides knowledge engineers with candidate terms mined from anchor texts and search-result pages. The result is encouraging. Currently, more than 19,000 Chinese-English MeSH entries have been compiled. This thesaurus will be used in Chinese-English CLMIR in the future.
INTRODUCTION
A number of Web resources provide the public and healthcare professionals
with the most up-to-date findings in medicine, such as PubMed and MedlinePlus. Although
the access of such top-quality resources is free
and unlimited for users all around the world, most of this information
is available in English only. Non-English users therefore often encounter
great barrier of language when trying to access medical information
from these websites. In addition, most non-English consumers are not
familiar with medical terminology even in their first language. This
raises the language barrier even higher in medical information retrieval. For
example, most Chinese people know the Chinese layperson’s
term  (dementia for aged people) but not the medical term
(dementia for aged people) but not the medical term  (Alzheimer Disease). Currently, it is almost impossible for this population
to retrieve consumer health information they need from MedlinePlus. Thus, matching
Chinese medical terms, especially lay person’s
terms, to English medical terms becomes a critical challenge in order
to assist non-English users in finding useful medical information. Unfortunately, there
is no system providing Chinese-English cross-language
medical information retrieval (CLMIR) now.
(Alzheimer Disease). Currently, it is almost impossible for this population
to retrieve consumer health information they need from MedlinePlus. Thus, matching
Chinese medical terms, especially lay person’s
terms, to English medical terms becomes a critical challenge in order
to assist non-English users in finding useful medical information. Unfortunately, there
is no system providing Chinese-English cross-language
medical information retrieval (CLMIR) now.
Multilingual medical thesaurus plays a crucial role in CLMIR according to the experience of the CliniWeb1 and other CLMIR systems2,3. However, manual lexicography is time-consuming and not cost-effective. Till now, there is still no effective method to construct multilingual medical thesauri automatically. Most existing medical thesauri are manually built.
We proposed a new method to semi-automatically map Chinese medical terms to Medical Subject Headings (MeSH) and construct a bilingual medical thesaurus for Chinese-English CLMIR. MeSH is the most significant medical thesaurus in English and has been manually translated into many languages. However, traditional Chinese version of MeSH is still not available currently.
In this study, we constructed a part of traditional Chinese-English MeSH, via translating English medical terms in the MeSH into Chinese by using an integrated Web-based term translation method. In the past years, we have first proposed an integrated Web-based method that explores two kinds of Web resources, i.e., Web anchor text4,5 and search-result pages6 to effectively deal with the problems of multilingual translation for diverse unknown (new) Web query terms.
The present study has two major goals. First, we expect that the proposed semi-automatic method is able to help knowledge engineers to reduce manual efforts in the difficult task of compiling Chinese-English MeSH. Second, in the future, we will utilize the Chinese-English MeSH to develop a practical cross-language medical meta-search engine that could assist the laypersons to retrieve top-quality English medical information by submitting Chinese terms.
BACKGROUND
We first recall previous works on automatic monolingual term mapping and cross-language term translation.
Monolingual term mapping
For monolingual medical information retrieval, laypersons often encounter a problem that their search terms are not always compatible with the professional terms in medical documents. A number of research have focused on dealing with such problem7,8,9. Leroy and Chen have developed a Medical Concept Mapper to help users find medical information by providing them with appropriate medical search terms. However, currently, the problems of cross-language term mapping have not been emphasized in the medical domain.
Parallel-corpus-based term translation
In the research area of machine translation, a number of works have often used statistical techniques to automatically extract term translations from parallel text corpora, which contain aligned bilingual sentence pairs10. Although the method can achieve high translation accuracy, the unavailability of large-size parallel corpora in the medicine domain is still stuck in a thorny situation.
Comparable-corpus-based term translation
Less attention has been devoted to extracting term translation from comparable corpora, which contains texts with similar topic collected independently in respective language communities. Fung and Yee11 used a vector-space model and took a bilingual lexicon (called seed words) as feature sets to estimate the similarity between a word and its translation candidates. Chiao and Zweigenbaum12 adopted similar method to find French-English translation equivalents for new medical terms. Comparable corpora are easier to obtain, however, how to achieve better performance for higher translation coverage is still a challenging task.
Web-based term translation
As mentioned above, the conventional methods suffer from the problems of the lack of large-size parallel corpora and the shortage of translation coverage of comparable corpora in medical domain. Thus, we try to apply an integrated Web-based method to effectively deal with medical term mapping by exploring Web anchor text4,5 and search-result pages6. In the following sections, we will introduce these two kinds of Web resources and describe how to explore these resources.
METHOD AND MATERIAL
Due to the limit of paper length, we can only briefly describe here our Web-based term translation method for medical term mapping. For more details, please refer to our previous works4,5,6.
Web-based multilingual term translation
Figure 1 shows the architecture of the integrated Web-based method through mining anchor texts and search-result pages for compilation of the Chinese-English MeSH.
Figure 1.

The architecture of Web-based term translation for the compilation of Chinese-English MeSH.
1. Procedure
To extract term translation through mining Web resources, three major processing steps are required:
Corpus collection: Collect comparable/mixed texts from the Web as a bilingual/multilingual corpus.
Translation candidate extraction: Extract translation candidates from the collected corpus.
Translation selection: Estimate the similarity for each translation candidate and determine the most possible translations.
Both anchor-text mining and search-result mining follow the three-step procedure.
2. Anchor-text mining
2.1 Anchor text
An anchor text is the descriptive part of an out-link of a Web page used to provide a brief description of the linked Web page. There are a variety of anchor texts in multiple languages that might link to the same pages from all over the world. For a source (unknown) term appearing in an anchor text of a Web page, it is likely that its corresponding target translations may appear together in other anchor texts linking to the same page. Such a bundle of anchor texts pointing together to the same page is called as an anchor-text set.
2.2 Procedure
Corpus collection: To make good use of Web anchor texts, we had collected 1,980,816 traditional Chinese Web pages in Taiwan, and then extracted 109,416 pages (URLs), whose anchor-text sets contained both traditional Chinese and English terms, as the anchor-text-set corpus for extracting Chinese-English translation of medical terms.
Translation candidate extraction: Three keyword extraction methods have been used to extract Chinese key terms from anchor-text corpus: PAT-tree-based, Query-log-based, and Tagger-based methods4. After key term extraction we select top k (k = 50) high frequent terms as translation candidates.
Translation selection: Use anchor-text mining to estimate the similarity based on the following model.
2.3 Probabilistic inference model
Based on a multilingual anchor-text corpus, we may determine the probable target translations for a source term by using a probabilistic model. This model assumes that a translation candidate had a higher chance of being a translation only if it frequently co-occurred with the source term in the same anchor text sets. Furthermore, it assumes that the translation candidates in the anchor texts of the pages with higher authority may be more reliable. Hence, the similarity between a source English term E and a Chinese translation candidate C was estimated as:
| (1) |
where Ui represents a web page, P(Ui) is the probability used to estimate the authority of Ui, and its definition is P(Ui)= L(Ui)/∑j=1,n L(Uj), where L(Uj) indicates the number of in-links of page Uj. The values of P(E|Ui) and P(C|Ui) were estimated by calculating the probability of E and C appearing in the anchor-text set of the Ui’s, respectively. The probabilistic inference model was proposed to model the authority of pages, which cannot be represented by conventional methods and yet was shown to be important to increase accuracy of term translation4.
3. Search-result mining
Even if we can collect large amounts of pages from the Web and build up a corpus of anchor-text sets, the translation coverage of diverse query terms is still limited to our collected corpus. To enhance the coverage rate of term translation in medicine domains, we have exploited search-result pages.
To explore Web search results, we utilize co-occurrence relations and context information between a source English term and Chinese translation candidates to enhance the coverage rate of translation extraction of unknown terms. We adopted the chi-square test and context-vector analysis that could achieve better performance.
3.1 Search-result pages
According to our observations, many Chinese search-result pages from search
engines contain rich snippets of summaries with a mixture of Chinese
and English texts. Therefore, when we search explicitly for English
terms (e.g., “Alzheimer disease”) in Chinese-language
pages from Google, it is likely that the search result will include
relevant snippets containing its Chinese translation  (Alzheimer Disease), or even layperson’s term
(Alzheimer Disease), or even layperson’s term 
 (dementia for aged people).
(dementia for aged people).
3.2 Procedure
Corpus collection: To obtain the search-result pages of source English medical terms, we submit them to search engines (e.g., Google). Basically, we collected page frequency of term occurrence and only the first 100 retrieved snippets to extract contextual terms as feature vectors for computing similarity between target translation candidates and source terms.
Translation candidate extraction: Methods to extract Chinese translation candidates from the search-result pages are the same as the methods adopted in the anchor-text mining except that the candidate number is set to k = 20 in order to reduce computation load.
Translation selection: Use search-result mining to estimate the similarity based on the following model.
3.3 Chi-square test
Based on co-occurrence analysis, chi-square test6 (χ2) is adopted to estimate semantic similarity between the source term E and the target candidate C. The similarity measure is defined as
| (2) |
where a, b, c and d are the numbers of pages retrieving from search engines by submitting Boolean queries: “E and C”, “E and not C”, “not E and C”, and “not E and not C”, respectively; N is the total number of pages, i.e., N = a + b + c + d.
3.4 Context-vector analysis
Due to the nature that Chinese pages often contain English texts, the source English term E and the Chinese translation candidate C may share common contextual terms in the search-result pages. The similarity between E and C will be computed based on their context feature vectors in the vector-space model. The conventional TFIDF weighting scheme is used and defined as
| (3) |
where f(ti, p) is the frequency of term ti in search-result page p, N is the total number of Web pages, and n is the number of the pages containing ti. Finally, we use the cosine measure to estimate the similarity as:
| (4) |
4. Combined method
The anchor-text-based method is effective to extract translations of high frequent Web query terms, while the search-result-based method has higher coverage of translations for unknown query terms. In order to combine the advantages of these two methods, we use a linear combination of inverse ranks to compute the similarity measure as follows:
| (5) |
where αm is an assigned weight for each similarity measure Sm, and Rm(E, C) represents the similarity rank of each target candidate C with respect to its source term E and is assigned to be from 1 to k (candidate number) according to similarity measure Sm(E, C) in decreasing order. The values of the weights αm is empirically assigned as αAT = 0.39, αx2 = 0.28, and αCV = 0.33 based on our previous experiments6.
RESULTS
To determine the feasibility of the proposed Web-based term translation method to help knowledge engineers reduce efforts in building the Chinese-English MeSH by providing correct translation candidates, we first conducted a preliminary experiment to evaluate the performance of automatically translating the English MeSH terms into Chinese.
We randomly selected two sets of 300 disease terms as the test sets from 9,646 terms in Diseases concept of the MeSH tree structure. The average top-n inclusion rate was adopted as an evaluation metric4. For a set of query terms, its top-n inclusion rate was defined as the percentage of source terms whose correct translations could be found in the first n extracted translations.
Table 1 shows that for the test set 1, the overall candidate matching (including exact and partial matching) achieved 23.6%, 51.66%, and 63.9% for the top-1, top-5, and top-10 inclusion rates, respectively. Although the top-1 inclusion rate (i.e., accuracy for automatic extraction) is low, top-10 inclusion rate is relatively high. The inclusion rates in top-5 and top-10 are fairly stable across the two data sets. Therefore, the proposed method is still effective to provide knowledge engineers with possibly correct translations in compiling translations. Table 2 shows some examples of Chinese translations of English MeSH terms that were successfully extracted by the proposed method.
Table 1.
Inclusion rates of Chinese translation for two test sets of 300 MeSH disease terms
| Test Set | Candidate Matching | Top-1 | Top-5 | Top-10 |
|---|---|---|---|---|
| Set-1 | Exact | 3.3% | 10.0% | 15.3% |
| Partial | 20.3% | 41.6% | 48.6% | |
| Overall | 23.6% | 51.6% | 63.9% | |
| Set-2 | Exact | 6.6% | 11.3% | 15.0% |
| Partial | 26.0% | 41.0% | 48.3% | |
| Overall | 32.6% | 52.3% | 63.3% |
Table 2.
Some examples of correct Chinese translations extracted for English MeSH terms
| English MeSH Term | Extracted Chinese Translation (Correct) |
|---|---|
| Pierre Robin Syndrome |  |
| Chorioretinitis |  |
| Cerebral Ventricle Neoplasms |  |
| Empty Sella Syndrome |  |
DISCUSSION
Although the performance of exact translation was not satisfying, more
than 60% of the partially correct translations appear in the top
ten candidates. This is still very usseful in saving labor time in
constructing the Chinese-English MeSH. We developed an efficient interface, called
Chinese-English MeSH Compilation System. Figure 2 shows the system consisting three major parts. Part 1 displays the English
MeSH term and its Chinese translation after compilation. Part 2 provides
knowledge engineers efficient compilation with checkboxes as well
as text input button. Additionally, some auxiliary resources are added
to augment the lack of translations in Part 3. The interface suggests
about 30 translation candidates, which increases the chance of covering
more layperson’s terms. For instance, “Down Syndrome” has
Chinese Chinese translations  or
or 
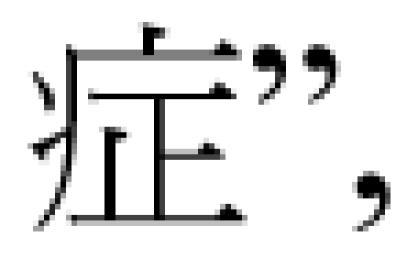 and is popularly called
and is popularly called  (see Figure 2).
(see Figure 2).
Figure 2.

The Chinese-English MeSH Compilation System.
We have observed the effectiveness of this system based on a preliminary experiment. Two part-time knowledge engineers with the skills in the area of medical information systems have compiled over 19,000 entries of the Chinese-English MeSH (about 42,000 entries in total) during three months. They reported that using this system not only saved them a lot of time but also mental efforts in term mapping.
The major advantage of our Web-based method is that we have no need to use any bilingual medical dictionary while Chiao’s 12 work utilizing 4,963 seed pairs by using comparable-corpus-based method. Thus, our method is language-independent and easy to extend to other language pairs if the source and the target languages often appear in the same text (e.g., Korean-English and Japanese-English6). However, the utilization of this method might be limited if the two languages are seldom mixed in the text (e.g., French-English). Also, using the method to translate from English Consumer Health vocabulary may be valuable for Chinese speaking consumers.
There are several directions for improvement in the future. For example, the difference between top-10 (63.9%) and top-1 (23.6%) inclusion rates is around 40%, showing the magnitude of potential improvement in top-1 inclusion rate. We observed that most errors resulted from Chinese word segmentation, medical term recognition, and similarity computation of low-frequency terms. Our future work should focus on these issues in order to improve the inclusion rates.
Currently, we are trying to utilize the Chinese-English MeSH to develop a prototype of cross-language medical meta-search engine, MMODE, which could assist the laypersons to retrieve top-quality English medical information by using Chinese terms (http://mmode.twbbs.org/mmode/).
REFERENCES
- 1.Hersh WR, Donohoe LC. SAPHIRE International: A Tool for Cross-Language Information Retrieval. Proc AMIA Symp. 1998:673–7. [PMC free article] [PubMed] [Google Scholar]
- 2.Rosemblat G, Gemoets D, Browne AC, Tse T. Machine translation-supported cross-language information retrieval for a consumer health resource. Proc AMIA Symp. 2003:564–8. [PMC free article] [PubMed] [Google Scholar]
- 3.Tran TD, Garcelon N, Burgun A, Le Beux P. Experiments in Cross-language Medical Information Retrieval Using a Mixing Translation Module. Medinfo. 2004:946–9. [PubMed] [Google Scholar]
- 4.Lu WH, Chien LF, Lee HJ. Translation of Web Queries using Anchor Text Mining. ACM Transactions on Asian Language Information Processing. 2002;1(2):159–72. [Google Scholar]
- 5.Lu WH. Term Translation Extraction Using Web Mining Techniques, PhD thesis, Department of Computer Science and Information Engineering, National Chiao Tung University 2003.
- 6.Cheng PJ, Teng JW, Chen RC, Wang JH, Lu WH, Chien LF. Translating Unknown Queries with Web Corpora for Cross-Language Information Retrieval. Proc 27th ACM SIGIR. 2004:146–53. [Google Scholar]
- 7.Joubert M, Fieschi M, Robert JJ, Volot F, Fieschi D. UMLS-based Conceptual Queries to Biomedical Information Databases: An Overview of the Project ARIANE. J Am Med Inform Assoc. 1998 Jan;5(1):52–61. doi: 10.1136/jamia.1998.0050052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Leroy G, Chen HC. Meeting Medical Terminology Needs-the Ontology-Enhanced Medical Concept Mapper. IEEE Transactions on Information Technology in Biomedicine. 2001;5(4):261–70. doi: 10.1109/4233.966101. [DOI] [PubMed] [Google Scholar]
- 9.Cimino JJ. Vocabulary and health care information technology: state of the art. Journal of the American Society for Information Science. 1995;46:777–82. [Google Scholar]
- 10.Gale WA. and Church KW. Identifying Word Correspondances in Parallel Texts, Proc DARPA Speech and Natural Language Workshop 1991.
- 11.Fung P, Yee LY. An IR Approach for Translating New Words from Nonparallel, Comparable Texts. Proc 36th ACL. 1998:414–20. [Google Scholar]
- 12.Chiao YC, Zweigenbaum P. Looking for French-English translations in comparable medical corpora. J Am Med Inform Assoc. 2002;8(suppl):150–4. [PMC free article] [PubMed] [Google Scholar]