

Abstract
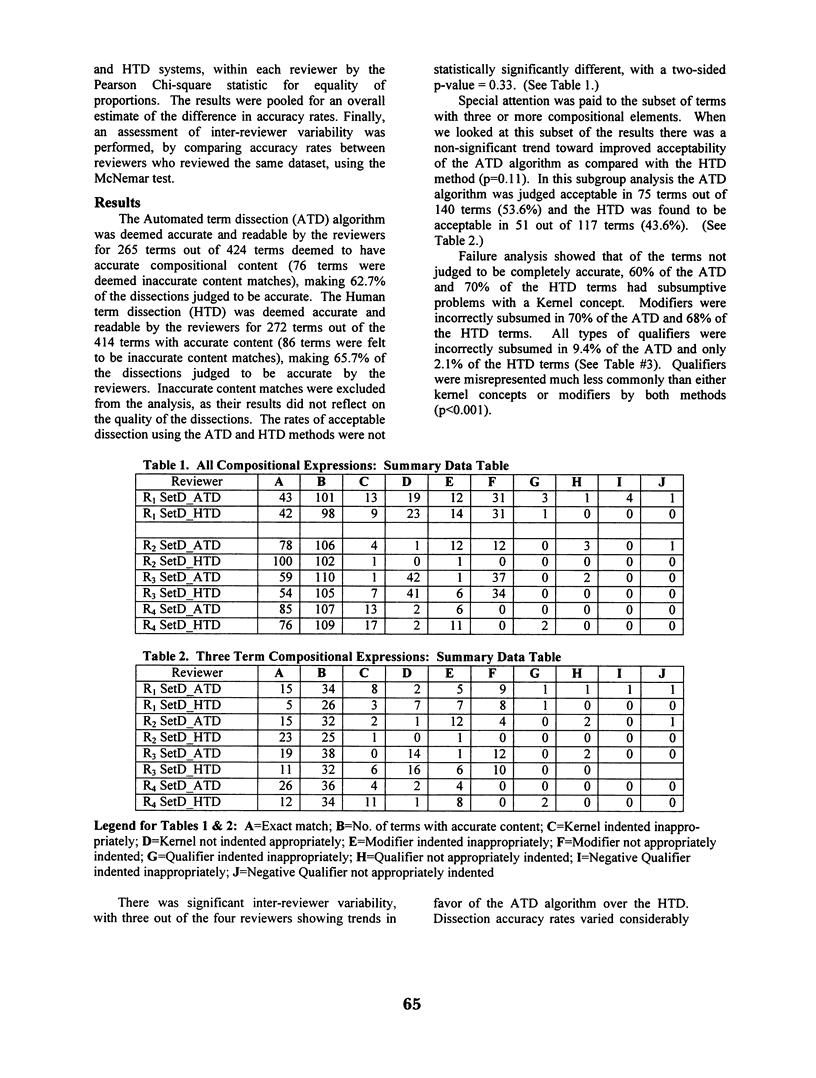
OBJECTIVE: To compare the accuracy of an automated mechanism for term dissection to represent the semantic dependencies within a compositional expression, with the accuracy of a practicing Internist to perform this same task. We also compare the results of four evaluators to determine the inter-observer variability and the variance between term sets, with respect to the accuracy of the mappings and the consistency of the failure analysis. METHODS: 500 terms, which required a compositional expression to effect an exact match, were randomly distributed into two sets of 250 terms (Set A and Set B). Set A was dissected using the Automated Term Dissection (ATD) Algorithm. A physician specializing in Internal Medicine dissected set B. He had no prior knowledge of the dissection algorithm or how it functioned. In this manuscript, the authors use Human Term Dissection (HTD) to refer to this method. Set A was randomized to two sets of 125 terms (Set A1 and Set A2). Set B was randomized to two sets of 125 terms (Set B1 and Set B2). A new set of 250 terms Set C was created from Set A1 and Set B2. A second new set of 250 terms Set D was created from Set A2 and Set B1. Two expert Indexers reviewed Set C and another two expert Indexers reviewed Set D. They were blinded to which terms were dissected by the clinician and which terms were dissected by the automated term dissection algorithm. The person providing the files for review to the Indexers was also unaware of which terms were dissected by ATD vs. the HTD method. The Indexers recorded whether or not the dissection was the best possible representation of the input concept. If not, a failure analysis was conducted. They recorded whether or not the dissection was in error and if so was a modifier not subsumed or was a Kernel concept subsumed when it should not have been. If a concept was missing, the Indexers recorded whether it was a Kernel concept, a modifier, a qualifier or a negative qualifier. RESULTS: The ATD method was judged to be accurate and readable in 265 out of the 424 terms with adequate content (62.7%). The HTD method was judged to be accurate in 272 out of 414 terms with adequate content (65.7%). There was no statistically significant difference between the rates of acceptability of the ATD and HTD methods (p = 0.33). There was a non-significant trend toward greater acceptability of the ATD method in the subgroup of terms with three or more compositional elements. ATD was acceptable in 53.6% of the terms where the HTD was only acceptable in 43.6% (p = 0.11). The failure analysis showed that both methods misrepresented kernel concepts and modifiers much more commonly than qualifiers (p < 0.001). CONCLUSIONS: There is no statistically significant difference in the accuracy and readability of terms dissected using the automated term dissection method when compared with human term dissection, as judged by four expert medical indexers. There is a non-significant trend toward improved performance of the ATD method in the subset of more complex terms. The authors submit that this may be due to a tendency for users to be less compulsive when the time to complete the task is long. Automated term dissection is a useful and perhaps preferable method for representing readable and accurate compound terminological expressions.
Full text
PDF



Selected References
These references are in PubMed. This may not be the complete list of references from this article.
- Bernauer J., Franz M., Schoop D., Schoop M., Pretschner D. P. The compositional approach for representing medical concept systems. Medinfo. 1995;8(Pt 1):70–74. [PubMed] [Google Scholar]
- Campbell K. E., Musen M. A. Representation of clinical data using SNOMED III and conceptual graphs. Proc Annu Symp Comput Appl Med Care. 1992:354–358. [PMC free article] [PubMed] [Google Scholar]
- Chute C. G., Elkin P. L. A clinically derived terminology: qualification to reduction. Proc AMIA Annu Fall Symp. 1997:570–574. [PMC free article] [PubMed] [Google Scholar]
- Elkin P. L., Bailey K. R., Chute C. G. A randomized controlled trial of automated term composition. Proc AMIA Symp. 1998:765–769. [PMC free article] [PubMed] [Google Scholar]
- Evans D. A., Cimino J. J., Hersh W. R., Huff S. M., Bell D. S. Toward a medical-concept representation language. The Canon Group. J Am Med Inform Assoc. 1994 May-Jun;1(3):207–217. doi: 10.1136/jamia.1994.95236153. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Musen M. A., Wieckert K. E., Miller E. T., Campbell K. E., Fagan L. M. Development of a controlled medical terminology: knowledge acquisition and knowledge representation. Methods Inf Med. 1995 Mar;34(1-2):85–95. [PubMed] [Google Scholar]
- Musen M. A., Wieckert K. E., Miller E. T., Campbell K. E., Fagan L. M. Development of a controlled medical terminology: knowledge acquisition and knowledge representation. Methods Inf Med. 1995 Mar;34(1-2):85–95. [PubMed] [Google Scholar]
- Price C., Bentley T. E., Brown P. J., Schulz E. B., O'Neil M. Anatomical characterisation of surgical procedures in the Read Thesaurus. Proc AMIA Annu Fall Symp. 1996:110–114. [PMC free article] [PubMed] [Google Scholar]
- Rassinoux A. M., Miller R. A., Baud R. H., Scherrer J. R. Compositional and enumerative designs for medical language representation. Proc AMIA Annu Fall Symp. 1997:620–624. [PMC free article] [PubMed] [Google Scholar]
- Rector A. L., Glowinski A. J., Nowlan W. A., Rossi-Mori A. Medical-concept models and medical records: an approach based on GALEN and PEN&PAD. J Am Med Inform Assoc. 1995 Jan-Feb;2(1):19–35. doi: 10.1136/jamia.1995.95202545. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rector A. L., Nowlan W. A., Glowinski A. Goals for concept representation in the GALEN project. Proc Annu Symp Comput Appl Med Care. 1993:414–418. [PMC free article] [PubMed] [Google Scholar]
- Rector A. L., Nowlan W. A. The GALEN project. Comput Methods Programs Biomed. 1994 Oct;45(1-2):75–78. doi: 10.1016/0169-2607(94)90020-5. [DOI] [PubMed] [Google Scholar]
- Rector A. L. Thesauri and formal classifications: terminologies for people and machines. Methods Inf Med. 1998 Nov;37(4-5):501–509. [PubMed] [Google Scholar]
- Rogers J. E., Rector A. L. Terminological systems: bridging the generation gap. Proc AMIA Annu Fall Symp. 1997:610–614. [PMC free article] [PubMed] [Google Scholar]
- Schulz E. B., Barrett J. W., Price C. Read Code quality assurance: from simple syntax to semantic stability. J Am Med Inform Assoc. 1998 Jul-Aug;5(4):337–346. doi: 10.1136/jamia.1998.0050337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schulz E. B., Price C., Brown P. J. Symbolic anatomic knowledge representation in the Read Codes version 3: structure and application. J Am Med Inform Assoc. 1997 Jan-Feb;4(1):38–48. doi: 10.1136/jamia.1997.0040038. [DOI] [PMC free article] [PubMed] [Google Scholar]