

Abstract
Despite many diverse theories that address closely related themes—e.g., probability theory, algorithmic complexity, cryptoanalysis, and pseudorandom number generation—a near-void remains in constructive methods certified to yield the desired “random” output. Herein, we provide explicit techniques to produce broad sets of both highly irregular finite and normal infinite sequences, based on constructions and properties derived from approximate entropy (ApEn), a computable formulation of sequential irregularity. Furthermore, for infinite sequences, we considerably refine normality, by providing methods for constructing diverse classes of normal numbers, classified by the extent to which initial segments deviate from maximal irregularity.
Keywords: normal numbers/maximally irregular/approximate entropy/deficit from equidistribution/combinatorial
There is a critical and ubiquitous need for general techniques to produce broad sets of both highly irregular finite and putatively “random” infinite sequences. Early this century, Borel (1) introduced the notion of normal number, whose base b expansions are equidistributed in the limit, for all individual digits, pairs of digits, triples, … As such, the sequences of digits of normal numbers have often been viewed (2, 3) as reasonable candidates for broad collections of “random sequences.” However, demonstrations of the existence of uncountably many normal numbers (1, 4) and of the fact that they constitute a set of Lebesgue measure 1 in the unit interval have been unaccompanied by general methods to explicitly construct them. Indeed, the difficulty of proving normality for any specific number is remarkably severe. Among the very few sets of known explicitly computable normal numbers, probably best known is Champernowne’s number 0.1234567891011… (5), which was thematically generalized by Copeland and Erdös (6).
A primary step toward filling this near-void was the introduction of the notion of a C-random (computationally random) sequence (7), an equivalent characterization of normality based on a measure of irregularity among successive digits, approximate entropy (ApEn). Applying this formulation, in ref. 7 we presented a perturbation strategy for generating large sets of normal numbers, starting from one such number.
Two advantages accrue from the ApEn formulation: an ability to identify finite maximally irregular sequences as fundamental building blocks for construction of normal numbers; and subsequently, an ability to quantify the magnitude of deviation of any sequence from maximal irregularity.
The purposes of this paper are specifications of constructive methods for generating: (i) large classes of finite maximally irregular sequences; (ii) large classes of normal numbers by appropriate concatenations of finite maximally irregular sequences; and (iii) diverse classes of normal numbers, classified by the (asymptotic behavior of the) extent to which initial segments deviate from maximal irregularity.
We emphasize that herein, we focus on equidistribution as the central notion of “randomness,” discussed further in endnote 1 below. The extreme limitations in attempting to utilize algorithmic complexity (an alternative notion of “randomness”) for actual constructions of highly irregular sequences have been previously described (7, 8).
The central result below is Theorem 10, our recipe for constructing normal sequences, with the next section, Varieties of Normal Numbers, indicating how to apply Theorem 10 to refine normal numbers into the aforementioned subclasses. The primary results that lead directly to Theorem 10 are (i) Theorem 1, relating maximal irregularity to most equidistributed; (ii) Theorem 3 and Algorithm 1, providing means to realize maximally irregular finite sequences; and (iii) Theorems 8 and 9, reconsidering and merging poignant, yet nonconstructive (abstract theoretical), developments by Besicovitch and Hanson with the present context of maximally irregular sequences to achieve the desired constructive methodology.
In the core text, we primarily analyze binary sequences; generalizations to the k-state alphabet are straightforward.
Approximate Entropy (ApEn) and Wrap-Around ApEn.
We quantify
irregularity utilizing approximate entropy, ApEn, formally defined in
refs. 7 and 8. The intuitive idea is that for a sequence of real
numbers u := (u(1),
u(2), … u(N)), ApEn(m, r,
N)(u) measures the logarithmic frequency
with which blocks (subsequences of contiguous sequence
points) of length m that are close together—i.e., within a
tolerance range r—remain close together for blocks
augmented by one position. Larger values of ApEn imply greater
irregularity in u, while smaller values
correspond to more instances of recognizable patterns in the sequence.
Further intuition about ApEn, as quantifying degrees of irregularity,
can be obtained by reviewing binary sequences of lengths 5 and 6, a
comparison of two binary sequences of length N = 20,
and the first N digits (for large values of N) in
the binary and decimal expansions of e, π, 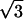 ,
and
,
and 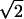 (7, 9).
(7, 9).
Formally, we have
Definition 1: Given a positive integer N and nonnegative integer m, with m ≤ N, a positive real number r and a sequence of real numbers u := (u(1), u(2), … u(N)), let the distance between two blocks x(i) and x(j), where x(i) = (u(i), u(i + 1), … u(i + m − 1)), be defined by d(x(i), x(j)) = maxk = 1,2,…,m (|u(i + k − 1) − u(j + k − 1)|). Then let Cim(r) = (number of j ≤ N − m + 1 such that d(x(i), x(j)) ≤ r)/(N − m + 1).
Now define
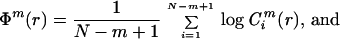 |
ApEn(m, r, N)(u) = Φm(r) − Φm+1(r), m ≥ 1; ApEn(0, r, N)(u) = −Φ1(r).
While restricting attention to binary sequences of 0s and 1s, we set r < 1 as our measure of resolution. Thus we are monitoring precise matches in the blocks x(i) and x(j). In this setting we suppress the dependence of ApEn on r below.
A length N sequence u is defined as {m, N}-irregular if it achieves the maximal ApEn(m, N) value among all sequences of length N; and it is defined as N-irregular (N-random) if it is {m, N}-irregular for m = 0, 1, 2, … , mcrit(N). In ref. 7, we employed the choice mcrit(N) = max(m: 22m ≤ N), motivated by the methods of Ornstein and Weiss (10), which can be used to show that for uN = (u(1), u(2), … u(N)), N ≥ 1, a so-called “typical realization” of a Bernoulli process, then limN→∞ ApEn(mcrit(N), N) (uN) = h = entropy of the process. Superexponential growth of N as a function of mcrit(N) thus is a useful criterion for aligning maximally irregular finite sequences with ergodic theory technology. However, our normal number constructions require tighter control over irregularity in blocks of length m for more values of m than is imposed by mcrit(N) = max(m: 22m ≤ N). For all developments below, we specify mcrit(N) = max(m: 2m < N).¶ Both choices of mcrit(N) are consistent with the idea of finite “random sequence,” as exemplified by the following theorem, proved in ref. 9:
Theorem 1. A sequence u is N-random if and only if for 1 ≤ m ≤ mcrit(N) + 1, the expression
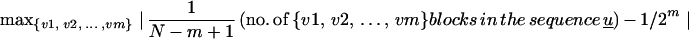 |
1 |
is a minimum (among length-N sequences), where the max is evaluated over all blocks {v1, v2, … , vm} where vi = 0 or 1 for all 1 ≤ i ≤ m.
Thus maximal ApEn agrees with intuition for maximally equidistributed sequences, while allowing us to grade the remaining sequences in terms of proximity to maximality.
For infinite sequences u = (u(1), u(2), …) and r < 1, define u(N) = (u(1), u(2), … , u(N)), ApEn(m, N)(u) := ApEn(m, N)(u(N)), and ApEn(m)(u) := limN→∞ ApEn(m, N)(u(N)). Asymptotic ApEn(m) values converge to log 2 along maximally irregular binary sequences (7). This fact motivates the following formulation of an infinite “random sequence.”
Definition 2: An infinite binary sequence u is called computationally random, denoted as C-random, if and only if ApEn(m)(u) = log 2 for all m ≥ 0.
As pointed out in ref. 7, joint independence in probability theory for binary random variables reduces to C-randomness of realizations with probability one.
Our constructions of C-random sequences are facilitated by introducing a wrap-around version of approximate entropy, denoted by ApEnw. The intuitive idea is to consider sequences of length N in a circular arrangement. Then for all m, blocks of length m are defined beyond the end of the original sequence by periodic extension. Thus averages in the calculation of ApEnw are always over N consecutive blocks. Formally, we introduce
Definition 3: Given a positive integer N, a nonnegative integer m, a positive real number r, and a sequence of real numbers u := (u(1), u(2), … u(N)), define the block xw(i) = (u(i), u(i + 1), … u(i + m − 1)), with u(N + k) := u(k) for 1 ≤ k ≤ N. For all 1 ≤ i, j ≤ N, define the distance between two blocks by d(xw(i), xw(j)) = maxk=1,2,…,m (|u(i + k − 1) − u(j + k − 1)|). Then let Ci,wm(r) = (number of j ≤ N such that d(xw(i), xw(j)) ≤ r)/N. Now define Φwm(r) = 1/N ∑i=1N log Ci,wm(r), and ApEnw(m, r, N)(u) = Φwm(r) − Φwm+1(r), m ≥ 1; ApEnw(0, r, N)(u) = − Φw1(r).
Here we again set r < 1 and suppress the dependence of ApEnw(m, r, N) on r, and simply write it as ApEnw(m, N).
Analogous to the original ApEn setting, for binary sequences of length N, we define {m, N} wr-random (wr-irregular) sequences as those that achieve max ApEnw(m, N)(u) where the maximum is evaluated over the set of all binary sequences of length N. Corresponding definitions ensue for N wr-random and Cw-random.
Some properties are now noted regarding ApEnw.
(i) Virtually the same criterion as that given by Theorem 1 characterizes the maximally wr-irregular ApEnw sequences, via the same proof—-the only changes in the wrap-around setting are that all sums go from 1 to N (not N − m + 1), since evaluation of the number of {v1, v2, … , vm} blocks in the sequence u includes consideration of the wrap-around subblocks. Accordingly, in the expression corresponding to Eq. 1, we average by dividing by N, rather than N − m + 1.
(ii) For any sequence, ApEn and ApEnw values will be reasonably close—i.e., O(log N/N), as their definitions differ only in the treatment of endpoint effects. Precisely, we have:
Theorem 2. For any length N sequence u,
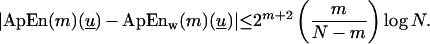 |
Proof: First, we recast Φm(0) in the ApEn definition in an alternative form, based on state space frequencies. Let X(m) := {all blocks {v1, v2, … , vm} where vi = 0 or 1 for all 1 ≤ i ≤ m}; and define fv1,v2, … ,vm as the frequency of occurrences of {v1, v2, … , vm} in u—i.e., (no. of such occurrences)/(N − m + 1). Then it is straightforward to see that Φm(0) = ∑X(m) fv1,v2, … ,vm log fv1,v2, … ,vm. Similarly, we have Φwm(0) = ∑X(m) fwv1,v2, … ,vm log fwv1,v2, … ,vm, where fwv1,v2, … ,vm = (no. of occurrences, including wrap-around instances, of {v1, v2, … , vm})/N.
Then |ApEn(m)(u) − ApEnw(m)(u)| ≤ |Φm(0) − Φwm(0)| + |Φm+1(0) − Φwm+1(0)| ≤ ∑X(m)| fv1,v2,… ,vm log fv1,v2,… ,vm wv1,v2, … ,vm log fwv1,v2, … ,vm| + ∑X(m+1)|fv1,v2, … ,vm+1log fv1,v2, … ,vm+1 − fwv1,v2, … ,vm+1 log fwv1,v2, … ,vm+1|. We bound all terms on the right side of this inequality by the mean value theorem, applied to f(x) = x log x, observing that |f(x) − f(x*)| ≤ maxt∈[x,x*]|(x − x*)(1 + log t)|. Applied to the above, for x = fv1,v2, … ,vk and x* = fwv1,v2, … ,vk, we deduce that |ApEn(m)(u) − ApEnw(m)(u)| ≤ 2m [(m − 1)/(N − m + 1)]log N + 2m+1[m/(N − m)]log N ≤ 2m+2[m/(N − m)]log N, which completes the proof.
In particular, for large N, N-wr-irregular ApEnw sequences will be nearly N-irregular ApEn sequences, and conversely.
(iii) ApEnw is u-shift invariant (mod N)—i.e., for any u := (u(1), u(2), … u(N)) and any k ≤ N, ApEnw(u) = ApEnw(v), where v := (v(1), v(2), … v(N)) = (u(1 + k(mod N)), (u(2 + k(mod N)), … , u(N + k (mod N))). The proof of this observation is straightforward.
(iv) Given this shift invariance, as well as ApEnw invariance to sequence negation and reversal, the number of distinct equivalence classes comprising all N-wr-irregular sequences appears to be relatively small, an important property. For example, a single generator suffices to produce all N-wr-irregular sequences for N = 4 (4 maximal sequences) and N = 5 (10 maximal sequences), and all 18 6-wr-irregular sequences come from the above actions applied to 2 generators (e.g., {1, 1, 1, 0, 0, 0} and {1, 1, 0, 1, 0, 0}).
Construction of Highly Irregular Sequences.
We first consider the 2k-wr-irregular sequences, since they have an elegant characterization and are central to our other constructions. For this case, some directly transferable theory has been developed, in the study of shift registers, which have been extensively applied to communications and coding problems (11–13). One class of shift register sequences that has received special focus is full-length nonlinear shift register sequences (“full cycles”)—i.e., periodic sequences of length 2k such that all different binary k-tuples appear exactly once in a periodic portion of a sequence (14). The existence of full cycles for all k was shown by Good (15) and deBruijn (16). For one period u of a full cycle, it is immediate upon aggregation that any length-m block with m ≤ k occurs precisely 2k−m times in u. Thus, by the wrap-around version of Theorem 1, we infer that the periods of full cycles constitute the 2k-wr-irregular sequences, restated as
Theorem 3. For any 2k-wr-irregular sequence u, each binary k-tuple occurs as a length-k block precisely once in u.
We next resolve whether any given length k sequence can be the initial segment of some wr-irregular sequence.
Theorem 4. Given any length k sequence v := {v(1), v(2), … , v(k)}, there exists a 2k-wr-irregular sequence u for which the initial segment of u is v—i.e., u(i) = v(i) for 1 ≤ i ≤ k.
Proof: Choose an arbitrary 2k-wr-irregular sequence {s(i)}. By Theorem 3, the block {v(i)}1≤i≤k occurs precisely once in {s(i)}. Define {u(i)} as the result of successive 1-shifts of {s(i)} that leaves {v(i)} as the initial block in {u(i)}. Since ApEnw is shift-invariant, we infer the 2k-wr-irregularity of {u(i)}.
Notably, deBruijn (16) showed that the number of full 2k-length cycles N(k) := 22k-1−k. Upon recognizing that all 2k translations of one period of a full cycle are distinct from one another and from any period from another full cycle, we infer
Theorem 5. There are precisely 2kN(k) = 22k-12k-wr-irregular sequences.
Thus for N = 2k, precisely
1/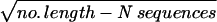 =
1/
=
1/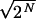 are
N-wr-irregular. Also, note that this fraction of
N-wr-irregular sequences is much smaller than the coarse
upper bound given in ref. 7, p. 2085, of
1/
are
N-wr-irregular. Also, note that this fraction of
N-wr-irregular sequences is much smaller than the coarse
upper bound given in ref. 7, p. 2085, of
1/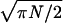 .
.
Moreover, the proofs of both Good and deBruijn provide a direct bridge to the combinatorial study of rooted trees, directed graphs, and necklaces. However, these proofs were nonconstructive, so the need remained for algorithmic “recipes” to construct full cycles. An outstanding source for many such algorithms is Fredricksen (ref. 14, section 3). We now briefly describe the two best-known such algorithms. Also readily usable from ref. 14 are the algorithms given by “prefer same,” by “cross-join pairs,” and by the method of appropriately splicing mirrored full cycles of span k − 1 to generate full cycles of span k (ref. 14, section 3e).
(i) Linear shift registers are sequences defined by a recurrence relation of order n, s(i + n) = ∑j=0n−1 c(j)s(i + j). Associated is a characteristic polynomial f(x) = 1 + c(1)x + … + c(n − 1)xn−1 + xn. If f(0) ≠ 0, f has exponent k if f(x) | xk + 1 but f(x)ł xj + 1 for any 0 < j < k (where | denotes divides). It is known from Galois theory (13) that [over the 2 element field GF(2)] if f(x) has degree k, then f(x) has an exponent ≤ 2k − 1. An irreducible polynomial of degree k is called primitive if its exponent = 2k − 1. Primitive polynomials exist for all degrees k (ref. 13). The key result is that for a linear shift register corresponding to a primitive polynomial of degree k, the output sequence is an “m(k)-sequence”—i.e., the shift register goes through each of its 2k − 1 nonnull states before it repeats (11). Upon insertion of a 0 prior to the unique k block {0 0 0 … 0 1} in one period of an m(k)-sequence, the resultant length 2k sequence is directly seen to be a full cycle.
Tables of primitive polynomials exist—e.g., appendix C of ref. 13 for degree ≤ 34. However, the set of primitive polynomials supplies us with only some, but not nearly all, 2k-wr-irregular sequences. Indeed, there are φ(2k − 1)/k primitive polynomials of degree k over GF(2), for φ(m) the Euler φ-function (12). Thus, e.g., there are 2 primitive polynomials of degree 4 over GF(2), f1 = 1 + x + x4 and f2 = 1 + x3 + x4, in contrast to 16 full cycles of length 16.
(ii) “Prefer 1” Algorithm: (A) Write k 0s. (B) For the nth sequence bit, n > k, write 1 if the newly formed k-tuple has not previously appeared in the sequence. Increase n and repeat B; otherwise (C) for the nth sequence bit, write 0. If the newly formed k-tuple has not previously appeared, increase n and go to B; otherwise stop.
This algorithm produces a full cycle. Notably, all full cycles can be generated by using “Prefer 1” repeatedly via “backtracking” (14); i.e., after we have generated the Prefer 1 sequence, succeeding sequences are determined by changing the final 1 to 0, and by using the algorithm, electing to place a 1 if the k-tuple formed is new but placing a 0 if 1 is prohibited. In this mode, the algorithm may terminate before the sequence is full length. If it terminates early, continue by again changing the final 1 to 0, proceeding as above.
For N ≠ 2k, both a theoretical description of and constructive algorithms for N-wr-irregular sequences appear to be much less elegant and relatively less straightforward, compared with the N = 2k setting. Insight into some of the complications are apparent from considering the 12-wr-irregular sequence u := {1 1 0 1 1 1 0 0 1 0 0 0}. It can be readily seen that (i) no length-4 block can be inserted into u to form a 16-wr-irregular sequence; (ii) u cannot be produced by insertion of a length-4 block to some 8-wr-irregular sequence; and notably, (iii) u provides a counterexample to the conjecture that each N-wr-irregular sequence can be derived from some (N − 1)-wr-irregular sequence by appropriate insertion of a 0 or 1.
Point (iii) suggests that producing recursive techniques to generate (all) N-wr-irregular sequences for N ≠ 2k may be quite challenging. Below, we give a recursive procedure that is part of a general strategy of building up longer N-wr-irregular sequences from shorter such sequences via concatenation. First, we formalize concatenation by
Definition 4: Given finite sequences a := (a(1), … a(d)) and b := (b(1), … b(e)), the concatenated sequence, of length d + e, is a ∨ b := (a(1), … a(d), b(1), … b(e)).
Given a set of 2k-wr-irregular sequences, Algorithm 1 below generates {m, N}-wr-irregular sequences for 2k < N < 2k+1, for all m < k. Within a general protocol of building up via concatenation, two points are critical to achieving maximality: (i) at least one concatenate should have length 2k (so that slight excesses of particular blocks are not augmented); (ii) final segments of the concatenates must match exactly. To illustrate the need for i, consider z := v ∨ v, for v := {0 0 1 1 1} – z is not even {0, 10}-wr-irregular, with 6 1s and 4 0s. To illustrate ii, let v be as above, with w := {1 1 1 0 0 0 1 0}. Then z := v ∨ w is not {1, 13}-wr-irregular, with 5 (1, 1) occurrences, yet 2 occurrences each of both (1, 0) and (0, 1). However, upon translating w by successive 1-shifts to w′ := {0 0 0 1 0 1 1 1 }, matching a final 3-block to v, we deduce that z′ := v ∨ w′ is {m, 13}-wr-irregular, for all m < 3. More generally, we have
Algorithm 1: Given 2k < N < 2k+1, let t := N − 2k. Choose any t-wr-irregular sequence w. We break the construction into two subcases: (I) t ≥ k; (II) t < k. In the primary case (I), consider the end portion of w, the length k block wend := (w(t − k + 1), w(t − k + 2), … w(t)). Choose any 2k-wr-irregular sequence s. By Theorem 3, s contains one occurrence of wend. Define x := (x(1), x(2), … , x(2k)) as a shift of s, so that the block wend is final in x. By shift-invariance, x is 2k-wr-irregular, and by the above, any length-m block with m ≤ k occurs precisely 2k−m times in x. Consider the length-N sequence u := w ∨ x: a straightforward counting argument then establishes that u is {m, N}-wr-irregular for all m < k.
In Case II, with t < k, a slightly modified construction is required. Given the t-wr-irregular sequence w, let
and let z := the length k segment of the final k digits of y. Choose a 2k-wr-irregular sequence x such that z is final in x, then define u := w ∨ x. A virtually identical counting argument to Case I establishes the result in this case as well.
The output of Algorithm 1 is thus a selective list of highly irregular sequences. We then extract N-wr-irregular sequences from this list by direct evaluation of each sequence for {k, N}-wr-irregularity. This final step provides functional triage; e.g., {1 1 0 1 0 0} ∨ {0 1 0 1 1 1 0 0} is {3, 14}- and thus 14-wr-irregular; whereas {1 1 0 1 0 0} ∨ {0 1 1 1 0 1 0 0} is not {3, 14}-wr-irregular, as some 4-blocks occur twice, others not at all.
Finally, our normal number constructions below require some bounds on the distribution of m-blocks for N-wr-irregular and N-irregular sequences. First, given a sequence u, let Nw(u, v1v2 … vk) := no. of occurrences of the block {v1, v2, … , vk} in u, including wrap-around instances; and let N(u, v1v2 … vk) := no. of occurrences of the block {v1, v2, … , vk}, excluding wrap-around instances. Two coarse inequalities, sufficient for our purposes, are as follows:
Theorem 6. Choose an N-wr-irregular sequence u. Then for any k ≤ [log N] and any k-block {v1, v2, … , vk},
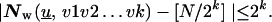 |
2 |
Proof: We need only show that for any given
k, there exists at least one length-N sequence
v satisfying Eq. 2 for all
k-blocks, by the wrap-around version of Theorem
1, in conjunction with the all-sequence minimality imposed by the
wrap-around analog of Eq. 1. We do so constructively. Choose
a 2k-wr-irregular w
with {1 1 … 1} as the initial length k segment. Let
P :=
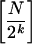 and
let
and
let
. As above, for any P ≥ 1, w*(P) is seen to be {k, P2k}-wr-irregular, indeed exactly equidistributed for all r-blocks, r ≤ k. Now define v := w*(P) ∨ x, where x is a length N − P2k sequence of all 1s. It follows at once that v satisfies Eq. 2, as desired.
Theorem 7. Choose an N-irregular sequence
u. Then for any k ≤
[log N] and any k-block {v1,
v2, … , vk},
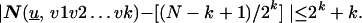
Proof: This estimate follows at once by mimicking the
proof of Theorem 6 (again comparing to
v), in conjunction with two arithmetic
observations. First, |N(u,
v1v2 … vk) −
Nw (u, v1v2 …
vk)| ≤ k − 1. Second,
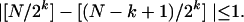
Normal Numbers.
Our objective is to provide explicit rules for concatenating maximally irregular sequences of increasing length such that the limiting infinite sequences are normal numbers. A priori it seems plausible that the length of the ith concatenate should increase very rapidly (e.g., superexponentially) as a function of i (7, 10). However, we demonstrate via a counterexample that concatenating N-wr-irregular sequences with very rapidly growing lengths can lead to sequences where the frequency of occurrences of special blocks of digits is badly skewed over arbitrarily long segments, thus violating normality. Subtle restrictions on growth lengths of concatenates are necessary to ensure that the resulting infinite sequence is a normal number.
A Counterexample: Let Lt(v) denote the length of sequence v. For a concatenated sequence v1 ∨ v2 ∨ … vm, let Lcat(m) = ∑i=1m Lt(vi). Now define v1 = (1, 0, 0, 1). Recursively, starting with v1 ∨ v2 ∨ … vm of length Lcat(m), define sm to be a sequence of 1s of length (Lcat(m))2. Then apply Theorem 4 to obtain vm+1 as a 2(Lcat(m))2-wr-irregular sequence with sm as an initial segment. Finally, define u := limm→∞ v1 ∨ v2 ∨ … vm. Intuitively, in this construction, we are imposing intermediate biasing runs (via the s-blocks) of exponentially increasing length.
Now consider the subsequences u*m := {u(1), u(2), … , u((Lcat(m))2 + Lcat(m))}. Clearly, the fraction of 1s in u*m ≥ Lcat(m)2/(Lcat(m)2 + Lcat(m)), which converges to 1 as m → ∞. Thus u is not a normal number, for if it were, then limm→∞ [fraction of 1s in u*m] = 1/2.
The goal of concatenating maximally irregular sequences to produce normal numbers can be realized by bringing in two additional results. These are as follows:
Theorem 8. Given any positive integer k and any ɛ > 0, there exists Nk,ɛ such that for all N > Nk,ɛ, the N-wr-irregular and N-irregular binary sequences are all (k, ɛ)-normal in the sense of Besicovitch (17).
Theorem 9. Let {an} be a nondecreasing sequence of positive integers having the property that, for any given k and ɛ > 0, all but finitely many an are (k, ɛ)-normal in the base b. If the lengths of the base b representations satisfy nLt(an) = O(∑i=1n Lt(ai)), then the number x = .a1a2a3… is normal in base b.
Observe that in base 2, if we define the binary representations of a1, a2, … as the finite sequences v1, v2, … , then x is just v1 ∨ v2 ∨ … .
Theorem 8, a critical observation central to our constructive approach, provides the essential link between (k, ɛ)-normal integers and N-irregular sequences. Theorem 9 is a minor adaptation of a little known theorem of Hanson (18). It provides necessary restrictions on the lengths of N-irregular sequences vi to ensure that u := limm→∞ v1 ∨ v2 ∨ … vm is normal. To formalize these ideas we first require
Definition 5: (Besicovitch, ref. 17) An integer
t =
aμ-1
aμ-2 …
a1 a0
(aμ-1 ≠ 0),
where the ai are digits of some base b, is
(k, ɛ)-normal in base b for a given
positive integer k and real ɛ > 0, if for every
k-digit sequence
c1c2
… ck, we have
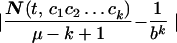 < ɛ, where N(t,
c1c2
… ck) is the number of occurrences of
c1c2
… ck in t.
< ɛ, where N(t,
c1c2
… ck) is the number of occurrences of
c1c2
… ck in t.
Specializing to base 2, we bring in
Proof of Theorem 8: Given k and ɛ, set Nk,ɛ := max(8⋅2k/ɛ, 22k + 1).
wr-Irregular case. For N ≥ Nk,ɛ, choose any N-wr-irregular sequence u and any k-block {v1, v2, … , vk}. Recall the notation N(u, v1v2 … vk) and Nw(u, v1v2 … vk) from Theorems 6 and 7, which we presently abbreviate by N(u), and Nw(u), respectively. Now |N(u)/(N − k + 1) − 1/2k| ≤ |N(u)/(N − k + 1) − Nw(u)/(N − k + 1)| + |Nw(u)/(N − k + 1) − Nw(u)/N| + |Nw(u)/N − 1/2k|. To estimate the first term on the right side of this inequality, since |N(u) − Nw(u)| ≤ k − 1, it follows that |N(u)/(N − k + 1) − Nw(u)/(N − k + 1)| ≤ |(k −1)/(N − k + 1)| ≤ 2k/N ≤ ɛ/4, from the definition of Nk,ɛ. To estimate the second term, since k < log N, by Theorem 6 and Eq. 2, Nw(u) ≤ N/2k + 2k, thus |Nw(u)/(N − k + 1) − Nw(u)/N| ≤ Nw(u)|(k − 1)/[N(N − k + 1)]| ≤ (N/2k + 2k)(2k/N2) ≤ (2N/2k)(2k/N2) = 4k/(N2k) ≤ 2/N ≤ ɛ/4. To estimate the third term, from Eq. 2, |Nw(u)/N − 1/2k| ≤ 2k/N ≤ ɛ/4. Combining these estimates, |N(u)/(N − k + 1) − 1/2k| < ɛ/4 + ɛ/4 + ɛ/4 < ɛ. Thus u is (k, ɛ)-normal in base 2.
Irregular case. For N ≥ Nk,ɛ, choose any N-irregular sequence u and k-block {v1, v2, … , vk}. By Theorem 7, since k < log N, |N(u)/(N − k + 1) − 1/2k| ≤ (2k + k + 1)/(N − k + 1) < (4·2k/N) ≤ ɛ, we conclude that u is (k, ɛ)-normal in base 2.
With this machinery established, we invoke Hanson’s Theorem as adapted to Theorem 9 to immediately deduce
Theorem 10. Define the base 2 sequence u := limm→∞ v1 ∨ v2 ∨ … vm, with Lt(vi) a nondecreasing integer-valued function of i. Let Sn := ∑i=1n Lt(vi). If for all i, (i) vi is either Lt(vi)-irregular or Lt(vi)-wr-irregular, (ii) limi→∞ Lt(vi) → ∞, and (iii) nLt(vn) = O(Sn), then u is normal in base 2.
Theorem 10 provides a means to produce large collections of normal numbers, since diverse classes of functions f(i) := Lt(vi) satisfy the conditions of the theorem. These include all polynomials with nonnegative integer coefficients; f(i) = [A log i], for A > 0; and f(i) = [kiα] for positive k and α. We can extend these classes by observing that if f satisfies condition iii, and if there exist positive c and K such that c ≤ |f(i)/g(i)| ≤ K for all i, then g also must satisfy iii—e.g., if ciα < g(i) < Kiα for all i, where c, K, and α > 0. Basically, functions that violate iii are either globally exponential or have locally, increasingly long exponentially growing segments.
Varieties of Normal Numbers.
The length restrictions imposed by Theorem 10, while ensuring that limiting concatenations are normal numbers, nevertheless allow for considerable variation in sequence structure. We facilitate sequence assessment by introducing the functions defm[u(N)] := max|v|=N ApEn(m, N)(v) − ApEn(m, N)(u(N)). For infinite sequences u these functions measure how close an initial segment, u(N), of length N is to being {m, N}-irregular (or wr-irregular when ApEnw is utilized). Normality reduces to the condition that limN→∞ defm[u(N)] = 0 for all m ≥ 0 (ref. 7). Restricting primary attention herein to m = 0, we can already demonstrate sharp distinctions among normal numbers.
We illustrate this perspective by comparing def0(N) for several sequences. The binary sequences are (i) base 2 expansion of e; (ii) the binary version of Champernowne’s number 0.1234567891011… , denoted by BinChamp := 0.110111001011101111000… ; (iii) a perturbation of BinChamp (denoted as pert-BinChamp) that imposes a bias of excess 1s to BinChamp that decreases sufficiently rapidly with increasing sequence length so that limiting frequencies are unchanged; and (iv) a sequence denoted Seq(FIterLog-3), defined below, where def0[u(N)] is extremely rapidly convergent to 0—i.e., def0[u(N)] ≤ (log log log N)2/4N2 for sufficiently large N. Fig. 1 shows def0[u(N)] vs. N for values of N up to 300,000, with considerable differences among the sequences quite apparent.
Figure 1.

One-dimensional deficit def0(N) from maximal irregularity for base 2 sequence expansions of e and for the binary sequences BinChamp (binary version of 0.1234567… ), pert-BinChamp, and sequence iv := Seq(FIterLog-3), all compared with log log N/N, where this last function is the asymptotic convergence rate of def0 for sequences satisfying the law of the iterated logarithm (LIL).
Further analytic insight is gained by evaluation of asymptotic behavior
of the sequences, and by comparison to the LIL asymptotic rate of
convergence for def0(N). The LIL, an
“almost sure” property of sums of independent, identically
distributed (i.i.d.) binary random variables, interpreted for
individual sequences, requires the following: Let
Xi = 1 if the ith digit is 1, 0
otherwise, and let the partial sums Sn =
∑i=1n
Xi = (no. 1s among the first n
digits). Then lim
supn→∞
(Sn −
n/2)/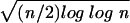 =
1. In ref. 7 we showed that the LIL holds for binary sequences
u if and only if lim
supN→∞
def0[u(N)]/[(log
log N)/N] = 1.
=
1. In ref. 7 we showed that the LIL holds for binary sequences
u if and only if lim
supN→∞
def0[u(N)]/[(log
log N)/N] = 1.
Importantly, sequences ii, iii, and iv, all constructively defined, are normal, yet each has considerably different one-dimensional asymptotic behavior than the LIL mandate (as indicated below). These examples clarify the diversity of possible specifications of what one might mean by “random” (or highly irregular) sequence.
BinChamp is normal (5); yet observe a pronounced bias of excess 1s in BinChamp; e.g., {4, 5, 6, 7}base 2 = {100, 101, 110, 111}. Formally, integers {2k, 2k + 1, … , 2k+1 − 1}base 2 produce 2k segments, each length k + 1, headed by 1, followed, in aggregate, by all possible k-tuples of 1s and 0s. Thus
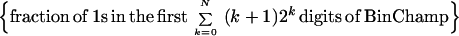 |
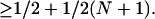 |
3 |
Now recall from ref. 7 the following definition of
excess, for a binary sequence u:
{excess of “0” over “1”}N
(u) = max(0, no. 0s in
u(N)
− no. 1s in
u(N)),
and symmetrically for {excess of “1” over
“0”}N (u).
Let EXCN(u) =
max({excess of “0” over
“1”}N
(u)}, {excess of “1” over
“0”}N(u)}).
In ref. 7, p. 2086, we established an easily derived relationship
between def0 and EXC (for small values of
def0) given by
def0[u(N)]
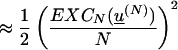 .
Upon translating Eq. 3 to a statement on EXC, we readily
derive that for u := BinChamp, lim
supN→∞
def0[u(N)]
≥ 1/(5 log2N). This convergence rate for
def0(N) thus quantifies the very slow
extent to which the bias of excess 1s in BinChamp decreases toward
asymptotic equidistribution.
.
Upon translating Eq. 3 to a statement on EXC, we readily
derive that for u := BinChamp, lim
supN→∞
def0[u(N)]
≥ 1/(5 log2N). This convergence rate for
def0(N) thus quantifies the very slow
extent to which the bias of excess 1s in BinChamp decreases toward
asymptotic equidistribution.
We now specify sequences iii and iv. This also provides explicit constructions of special classes of normal numbers. We note as well that constructions similar to that of Theorem 11 below, obtained by suitably controlling the length function Lt(vi) in the concatenations of finite maximally wr-irregular sequences, will yield yet further classes of normal numbers with prescribed asymptotic characteristics.
For sequence iii we perturb BinChamp, here denoted as u := (u(1), u(2), …), according to the following algorithm (a specialization of theorem 3 in ref. 7):
Set v(1) = u(1). Given v(1), … , v(N − 1), set v(N) = u(N) if u(N) = 1; set v(N) = 1 if u(N) = 0 and diff1(N − 1)(u, v) ≤ f(N) − 1, where diff1(N)(u, v) := the number of i ≤ N such that u(i) ≠ v(i), with f(N) := [2N √g(N)], for g(N) := N−0.3; otherwise set v(N) = u(N) if u(N) = 0.
Then define pert-BinChamp := v. By theorem 3 of ref. 7, pert-BinChamp is normal, and lim supN→∞ def0[v(N)] > N−0.3, quantifying its very slow convergence of def0 to 0.
Sequence iv is Seq(FIterLog-3), a special case of the general construction in Theorem 11, below. First, we require
Definition 6: Fix n. Define
for
fn(N) := 0 otherwise. Define gn(N) as the greatest even integer ≤ fn(N). Then define FIterLog-n(N) := max(6, gn(N)).
Next, for all i, select a maximally wr-irregular sequence vi of length FIterLog-n(i). Let Seq(FIterLog-n) := limm→∞ wm, where wm = v1 ∨ v2 ∨ … vm. From the construction of FIterLog-n(N), it follows from Theorem 10 that Seq(FIterLog-n) is normal in base 2. We now establish our fine-tuned result:
Theorem 11. Define k(N) := (1/4N2)(FIterLog-n(N))2. Then for u := Seq(FIterLog-n), for all sufficiently large N, def0[u(N)] ≤ k(N).
Proof: Fix N. We will show that for all p ≤ Lt(wN), EXCp(u) ≤ ½(FIterLog-n(N)). Observe that u returns to precise 1-dimensional equidistribution at the cutpoints p(k) := {Lt(wk)} for all k—i.e., for all k, EXCp(k)(u) = 0. This is immediate, since vi is {0, Lt(vi)}-wr-irregular for all i (recalling that FIterLog-n(i) adopts only even values). Therefore maxp≤Lt(wN)EXCp(u) = max1≤i≤N maxp≤Lt(vi)EXCp(vi) ≤ max1≤i≤N max(no. 0s in vi, no. 1s in vi) = ½(FIterLog-n(N)).
Since N < Lt(wN), it then
follows that
EXCN(u) ≤
½(FIterLog-n(N)).
Since u is normal,
limN→∞
def0[u(N)]
= 0, hence for all sufficiently large N,
def0[u(N)]
≤
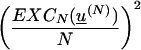 ≤
(1/4N2)(FIterLog-n(N))2
= k(N), which completes the proof.
≤
(1/4N2)(FIterLog-n(N))2
= k(N), which completes the proof.
Thus for any n ≥ 1, for u := Seq(FIterLog-n), lim supN→∞ def0[u(N)] provides a much faster rate of convergence to 0 than that for the LIL of (log log N)/N.
Finally, observe that these
Seq(FIterLog-n)
provide a nearly “best possible” class of normal numbers, insofar
as rapidity of convergence of lim
supN→∞
def0 to 0. By the same argument as in the proof
of theorem 1 of ref. 7, for any binary normal sequence
u, there exists arbitrarily large k
for which
u(2k)
fails to have precisely k 0s and k 1s. For such
k,
EXC2k(u)
≥ 2; since
def0[u(N)]
≥
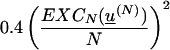 for sufficiently large N, we conclude that
def0[u(N)]
≥ 0.4/N2 for any such
N = 2k—i.e., lim
supN→∞
def0[u(N)]
must infinitely often be at least as large as the order of
1/N2. By comparison, lim
supN→∞
def0[u(N)]
for
Seq(FIterLog-n)
is bounded above by 1/N2 times a
function that can be chosen to increase arbitrarily slowly.
for sufficiently large N, we conclude that
def0[u(N)]
≥ 0.4/N2 for any such
N = 2k—i.e., lim
supN→∞
def0[u(N)]
must infinitely often be at least as large as the order of
1/N2. By comparison, lim
supN→∞
def0[u(N)]
for
Seq(FIterLog-n)
is bounded above by 1/N2 times a
function that can be chosen to increase arbitrarily slowly.
Endnotes.
(i) In a vast preponderance of applications, the requirement of a “random” sequence reduces to (for either finite or infinite sequences) approximate equidistribution of m-blocks for all m. Our primary goal herein, met above, was to produce explicit sets of recipes to realize such sequences. Furthermore, the construction of normal numbers via concatenation of maximally irregular sequences, in conjunction with both the capability to impose length restrictions on the concatenates and the technology to assess resultant sequences via defm[u(N)], provides the basis for understanding irregularity and “randomness” in a previously unaddressed manner. The demonstration of pronounced qualitative differences among normal numbers above reinforces the perspective that grouping all normal numbers into a single asymptotically equidistributed category is often inadequately nonspecific, for both theoretical mathematical and applications-oriented considerations.
As well, a more subtle, yet arbitrary question concerns the choice of a priori constraints beyond normality that one might impose to designate a sequence as “random.” For instance, to interpret a normal sequence as a typical realization of i.i.d. or weakly dependent binary random variables, one might mandate that the sequence satisfy the “almost sure” laws of axiomatic probability theory (19)—e.g., the LIL, and possibly a Gaussian distribution of 1-blocks. However, such mandates lead to conundrums; e.g., via Theorem 11, we now see that sequences satisfying the LIL are, in fact, more regular (less asymptotically equidistributed) than some classes of normal numbers. Additionally, recall that as n → ∞ the proportion of binary sequences of length n that are maximally irregular converges to 0 (7). In contrast, a basic desideratum in Kolmogorov’s algorithmic probability theory (20) is that the set of sequences called “random” should comprise a majority of the possible sequences. Thus the challenge is exposed, namely, how to balance the somewhat conflicting constraints imposed by maximal irregularity, typicality, and satisfaction of almost sure properties, to achieve a single well-defined class of constructable infinite “random” sequences.
(ii) Our explicit construction of normal numbers above is critically dependent on two ideas that had not previously been algorithmically formulated. First, the notion of (k, ɛ) normal number, as put forth by Besicovitch (17), was unaccompanied by any methods to actually produce them. Second, Hanson’s Theorem (18) specifying length restrictions on Lt(vi) to ensure normality in a concatenation limm→∞ v1 ∨ v2 ∨ … vm was not carried further to identify explicitly how to sequentially generate appropriate concatenates.
Among the very few previously constructed normal numbers not indicated above, perhaps most striking are those given by Stoneham (21, 22), who builds up transcendental non-Liouville normal numbers via controlled sums of expansions of reciprocals of powers of ergodic primes. Also notable in this development are some theorems concerning the distribution of residues within the periods of the summands. However, the considerable technologic effort required to achieve these specialized results underscores the need for broadly applicable methods to produce general classes of normal numbers.
(iii) In choosing normal sequences as specified by Definition 6, there is a tradeoff between limiting analytic excellence and appropriateness of application. To vividly clarify this, while Seq(FIterLog-4) produces asymptotically superb one-dimensional equidistribution, by Theorem 11, note that the first 6,000,000 digits of Seq(FIterLog-4) is a single fixed length-6 block concatenated 1,000,000 times, with a glaring and, for most applications, very much undesired periodicity. While the above technology refines the notion of normality, to our sensibilities, the present example highlights that the deficit from maximal equidistribution De[u(N)] := maxm≤mcrit(N)(defm[u(N)]) is a preferred quantity to minimize, compared with def0, in determining “limiting analytic excellence.” For Seq(FIterLog-4), once N were sufficiently large so that mcrit(N) ≥ 5, this sequence would be flagged as suboptimal, based on the lack of near-equidistribution of 6-blocks in long initial segments.
(iv) Symbolic dynamics (the study of maps on the space of infinite, typically binary sequences) has been extremely useful in advancing dynamical systems theory. It would seem natural, and highly worthwhile, to determine relationships between degrees of irregularity and classes of (binary sequence) maps and of dynamical systems. Such relationships may also provide a complementary perspective to and abet understanding of some “pathologies” within celestial mechanics—e.g., the existence of noncollision singularities in the Newtonian 5-body (and n-body) problem—i.e., Painlevé’s conjecture (23). In particular, Xia’s constructive proof of this (24), which critically utilizes symbolic dynamics, bears at least a thematic resemblance to the above counterexample, in which differing subsequences exhibit qualitatively dramatically different behavior, at times showing wild oscillations from equilibrium (equidistribution), at other times settling down to realize arbitrarily close approximation to a collision.
ABBREVIATIONS
- ApEn
approximate entropy
- LIL
law of the iterated logarithm
Footnotes
However, despite the utility seen herein, it would be unwise to employ this choice of mcrit(N) in general statistical analyses of length-N data sets. The “curse of dimensionality” would be manifested in estimations of underlying length log2N joint frequencies, many of which would have 0 or 1 observed occurrences.
References
- 1.Borel E. Rendiconti del circolo matematico di Palermo. 1909;27:247–271. [Google Scholar]
- 2.Franklin J N. Math Comput. 1963;17:28–59. [Google Scholar]
- 3.Knuth D E. Seminumerical Algorithms: The Art of Computer Programming. 2nd Ed. Vol. 2. Reading, MA: Addison–Wesley; 1981. , Chap. 3. [Google Scholar]
- 4.Hardy G H, Wright E M. An Introduction to the Theory of Numbers. 5th Ed. Oxford: Clarendon; 1983. pp. 125–128. [Google Scholar]
- 5.Champernowne D G. J London Math Soc. 1933;8:254–260. [Google Scholar]
- 6.Copeland A H, Erdös P. Bull Amer Math Soc. 1946;52:857–860. [Google Scholar]
- 7.Pincus S, Singer B H. Proc Natl Acad Sci USA. 1996;93:2083–2088. doi: 10.1073/pnas.93.5.2083. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Pincus S M. Proc Natl Acad Sci USA. 1991;88:2297–2301. doi: 10.1073/pnas.88.6.2297. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Pincus S, Kalman R E. Proc Natl Acad Sci USA. 1997;94:3513–3518. doi: 10.1073/pnas.94.8.3513. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Ornstein D S, Weiss B. Ann Probab. 1990;18:905–930. [Google Scholar]
- 11.Beker H, Piper F. Cipher Systems, The Protection of Communications. New York: Wiley; 1982. pp. 169–198. [Google Scholar]
- 12.Golomb S W. Shift Register Sequences. San Francisco: Holden-Day; 1967. [Google Scholar]
- 13.Peterson W, Weldon E. Error-Correcting Codes. 2nd Ed. Cambridge, MA: MIT Press; 1972. [Google Scholar]
- 14.Fredricksen H. SIAM Rev. 1982;24:195–221. [Google Scholar]
- 15.Good I J. J London Math Soc. 1946;21:167–169. [Google Scholar]
- 16.deBruijn N G. Nederl Akad Wetensch Proc. 1946;49:758–764. [Google Scholar]
- 17.Besicovitch A S. Math Z. 1934;39:146–156. [Google Scholar]
- 18.Hanson H A. Can J Math. 1954;6:477–485. [Google Scholar]
- 19.Kolmogorov A N. Grundbegriffe der Wahrscheinlichkeitsrechnung. Berlin: Springer; 1933. [Google Scholar]
- 20.Kolmogorov A N, Uspenskii V A. Theory Probab Its Appl Eng Trans. 1987;32:389–412. [Google Scholar]
- 21.Stoneham R G. Acta Arith. 1973;22:371–389. [Google Scholar]
- 22.Stoneham R G. Acta Arith. 1976;28:349–361. [Google Scholar]
- 23.Painlevé P. Leçons sur la Théorie Analytique des Équations Differentielles. Paris: Hermann; 1897. [Google Scholar]
- 24.Xia Z. Ann Math. 1992;135:411–468. [Google Scholar]